研究が示す、推論モデルが解決策を超えて考えがちな理由
AI推論モデルは、最適な停止点を過ぎても推論を続ける傾向があり、効率性と過剰思考のバランスが課題となっています。
キーポイント
大規模推論モデルは正解に到達した後も不必要な推論ステップを継続する傾向がある(過剰推論問題)
モデル自体は終了タイミングを認識しているが、一般的なサンプリング手法がその能力を活用できていない
研究チームはSAGE(Self-Aware Guided Efficient Reasoning)という解決策を提案している
RFCS(Ratio of the First Correct Step)という新しい評価指標で問題を定量化
複数の推論パスを並行評価する手法(TSearch)で効率的な終了が可能であることを実証
影響分析・編集コメントを表示
影響分析
この研究は、大規模言語モデルの推論効率と信頼性を向上させる重要な課題に取り組んでおり、計算コスト削減と精度向上の両立に貢献する可能性がある。特に、モデルが本来持つ終了判断能力を活用する方法論は、今後の推論最適化技術の発展に影響を与えるだろう。
編集コメント
モデルの「無駄話」問題を科学的に分析した研究で、実用面での計算コスト削減に直結する重要な発見。推論最適化の新たな方向性を示している。
研究は、推論モデルがなぜ解答をはるかに超えて考え続けるのかを示す
大規模推論モデルは、正解をはるかに過ぎて考え続けることが多い:再確認、言い換え、すでに正解を得た内容の再確認を行う。新しいバイトダンスの研究は、モデルが実際にはいつ終了すべきかを知っていることを示している。一般的なサンプリング手法が、単にそれらを停止させないだけだ。
この問題は新しいものではない。Deepseek-R1は、AIME 2025ベンチマークでClaude 3.7 Sonnetと同等の精度ながら、約5倍の長さの解答を生成する。QwQ-32Bは、最も短い解答で2パーセントポイント高いスコアを達成し、同時に31パーセント少ないトークンを使用する。そして、正解と不正解の両方が生成されたケースの72パーセントにおいて、より長い解答の方がより頻繁に間違っていた。
答えはそこにあるが、モデルは話し続ける
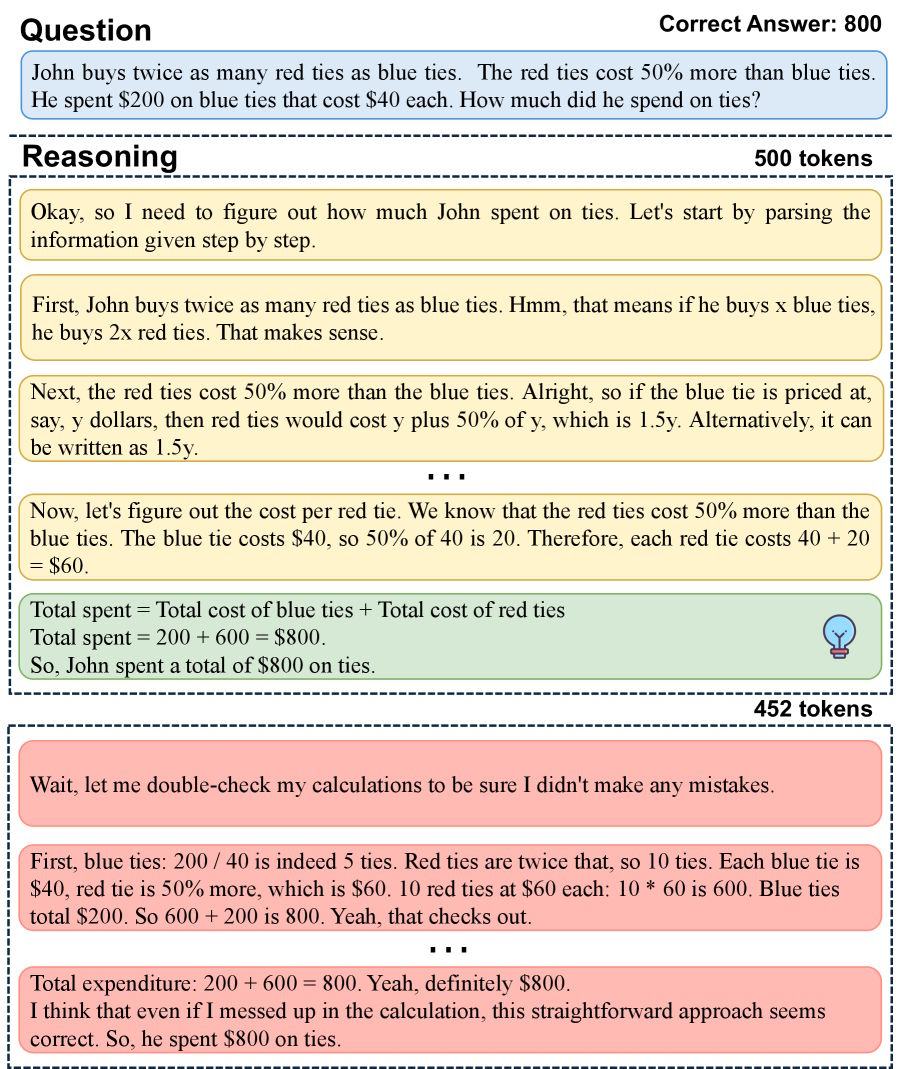
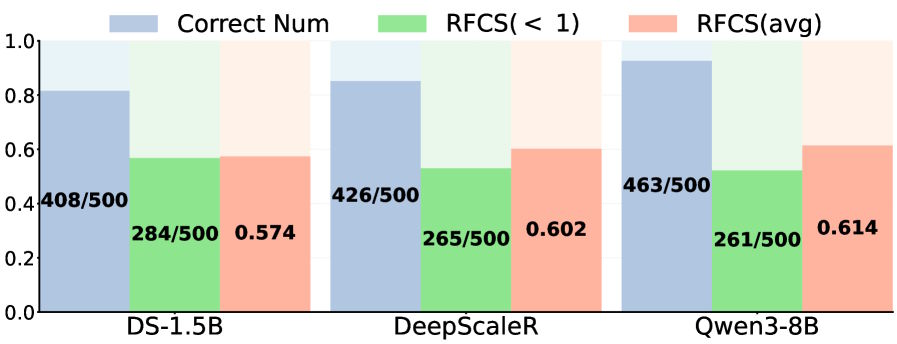
この問題を定量化するため、研究者たちはRFCS(最初の正しいステップの比率)を導入した。これは、思考の連鎖の中で正解が最初に現れる位置を全体の長さに対して追跡する。MATH-500では、正しく解答された問題の半数以上において、正しい解法が終了よりずっと前に現れる。
考えすぎの典型的な例:モデルは500トークン後に正解に到達するが、その後、冗長な再確認と検証のためにさらに452トークンを生成する。| 画像: Huang et al.
あるケースでは、モデルは500トークン後に答えを正確に出したが、さらに452トークンにわたって続けた:再確認、言い換え、すでに正しかったことの再確認である。このパターンは、Deepseek-R1-Distill-Qwen-1.5Bのような小型モデルからQwen3-8Bのような大型モデルまで両方に見られる。強力な事後学習でもこれは修正されない。
テストされた3つのモデルすべてにおいて、正解の半数以上が、最初の正しい解法の後に不要な推論ステップを含んでいた。より強力なモデルでもほとんど改善されない。| 画像: Huang et al.
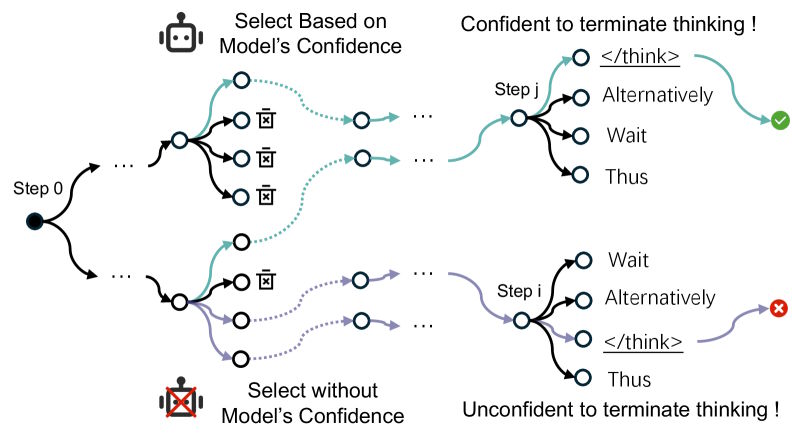
モデルはいつ止めるかを知っている;サンプリング手法が知らないだけだ
推論時にモデルが複数の思考連鎖を同時に追う場合、それらは高い確信度を割り当てる、短く正確な推論経路を確実に見つける。研究者たちはこれをTSearchで実証している。これは個々のトークンではなく、連鎖全体の平均確率を評価する。
3つの観察がこれを裏付けている:選択された経路は、より短く、より正確な答えを生み出す。それらの終点では、停止信号が次のトークン候補の中で一貫して首位にランクされる:モデルは終了したことを知っている。そして、より多くの並列経路がこの振る舞いをより安定させる。効率的な終了はすでにモデルに組み込まれている;一般的なサンプリング手法がそれを活用していないだけだ。
推論経路がモデルの全体的な確信度に基づいて選択される場合(上)、モデルは高い確実性を持って終了する。この尺度がない場合(下)、終了信号は不確かである。| 画像: Huang et al.
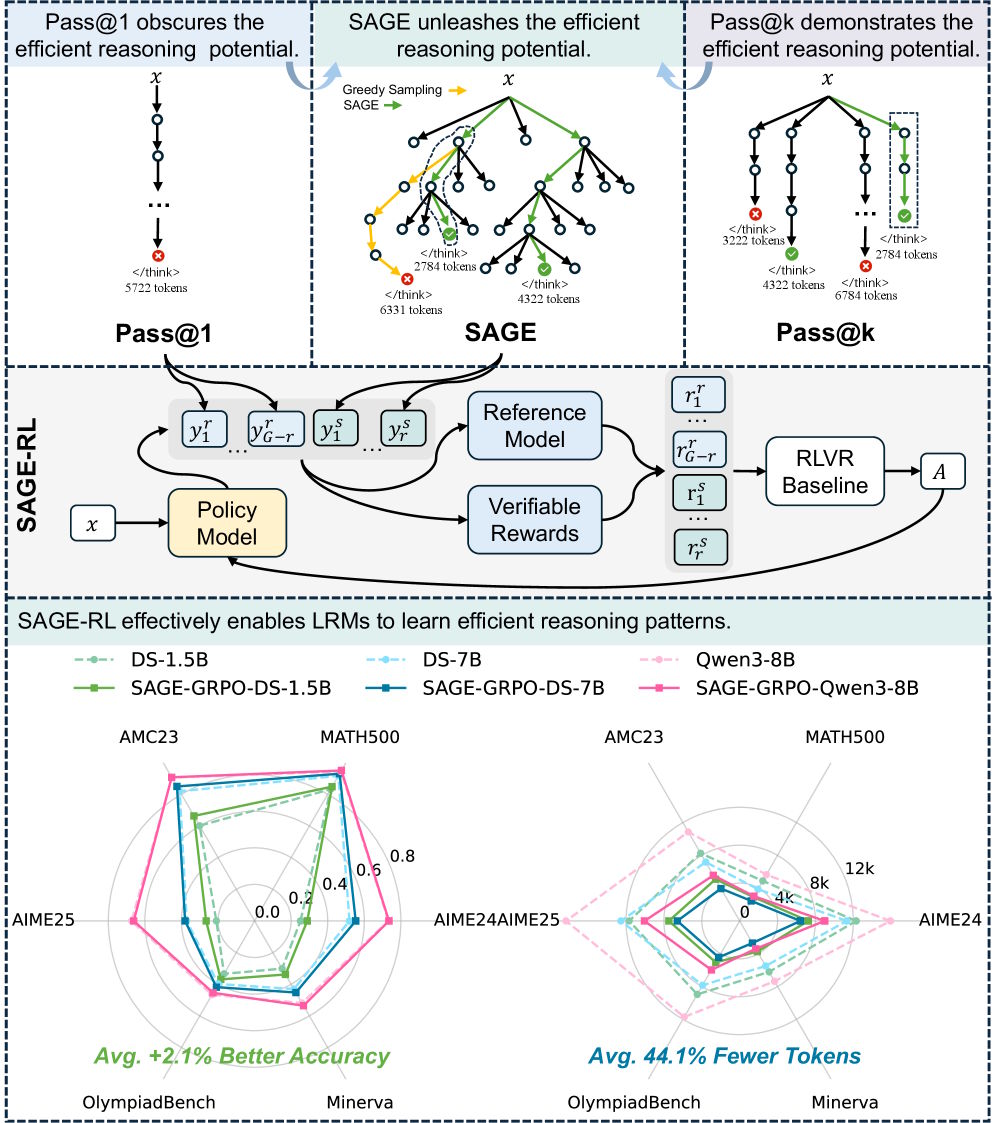
SAGEはトークン単位ではなく、ステップ単位で探索する
研究者たちの解決策はSAGE(Self-Aware Guided Efficient Reasoning)である。トークン単位で拡張する代わりに、SAGEは思考の連鎖を推論ステップ全体として拡張し、各ステップ後にモデルが終了を信号しているかどうかをチェックする。もしそうなら、推論は停止する。
実験では、SAGEは設定に応じて異なる振る舞いを示した:強力なモデルと難しいベンチマークでは、精度が主に向上した。弱いモデルと単純なタスクでは、解答の長さが大幅に短縮された。基本的に、SAGEはモデルが考えすぎている場所では短縮し、能力が余っている場所ではより良い解決策を見つけた。
これらのパターンを恒久的にするため、研究者たちはSAGE-RLを提案している。これは標準的な強化学習に小さな調整を加えたものだ。トレーニンググループごとに8つの応答のうち、2つはSAGEから、6つは標準サンプリングから得られる。モデルは、アドバンテージ推定量を通じて、より簡潔な推論経路を好むように学習する。
MATH-500、AIME 2024および2025、OlympiadBenchを含む6つの数学ベンチマークにわたる結果は一貫している:LC-R1、ThinkPrune、AdaptThinkのような手法は、精度を犠牲にしてトークンを削減する。SAGE-RLは両方を改善した。Deepseek-R1-Distill-Qwen-7Bでは、SAGE-GRPOがMATH-500で91.6パーセントに対して93パーセントを達成し、応答長を3,871トークンから2,141トークンに削減した。
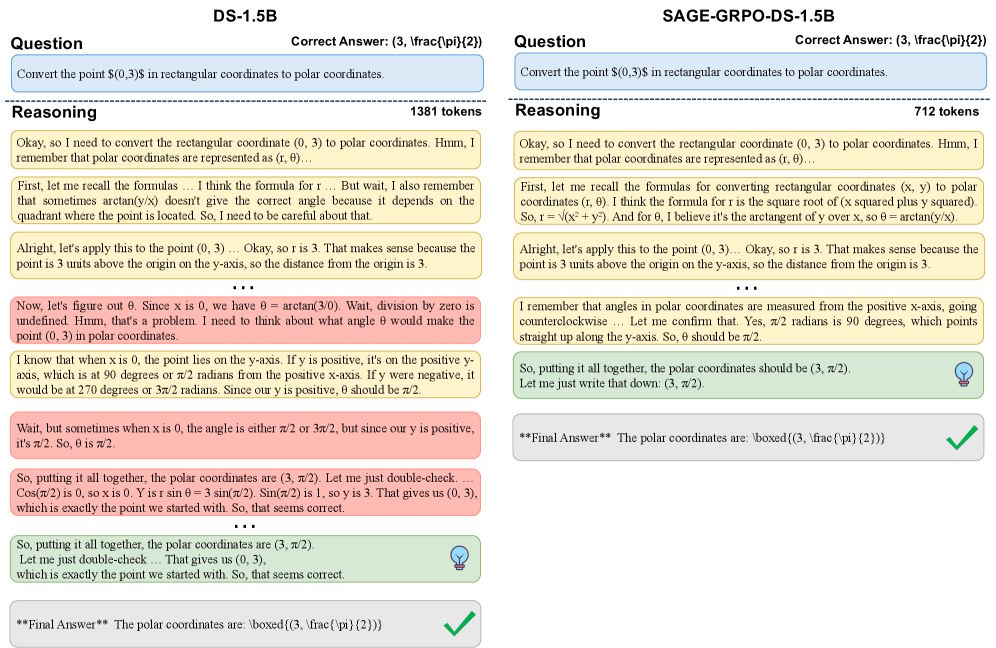
同じ座標問題、二つの解決策:ベースモデルDS-1.5Bは複数の再確認を伴い1,381トークンを必要とする。SAGE-RLでトレーニングされたモデルは、712トークンで同じ答えに到達する。| 画像: Huang et al.
AIME 2025では、DS-1.5Bの精度が6.2パーセントポイント跳ね上がる。同クラスで最強のモデルの一つであるQwen3-8Bでさえ、SAGE-GRPOにより応答長が18,342トークンから9,183トークンに半減し、精度を損なわない。ほとんどのモデルとベンチマークで、推論時間は40パーセント以上短縮される。
最大の向上は最も難しいタスクで現れ、そこに効率的な推論のための最も大きな余地があることを示唆している。考えすぎを修正するのに、新しいアーキテクチャやより洗練された報酬関数は必要ないかもしれない。モデルが終了を信号した時に、単に止めさせてやるだけで十分かもしれない。
推論モデルの考えすぎはしばらく前から研究テーマとなっている。約1年前、ある研究は対話シナリオにおける過剰な「思考」がパフォーマンスを顕著に損なうことを示した。より最近では、Googleの研究者たちは、推論モデルが思考の連鎖をシミュレートされた視点間の内部討論として構造化し、精度を向上させるが、同時に推論に時間がかかる理由も説明していると発見した。
誇大広告のないAIニュース – 人間によるキュレーション
THE DECODERの購読者として、広告なしの読書、週刊AIニュースレター、独占的な「AIレーダー」フロンティアレポート(年6回)、コメントへのアクセス、そして完全なアーカイブを手に入れましょう。
誇大広告のないAIニュース 人間によるキュレーション。
20パーセント以上のローンチ割引。
気が散ることなく読む – Google広告なし。
コメントとコミュニティディスカッションへのアクセス。
週刊AIニュースレター。
年6回:「AIレーダー」 – 主要AIトピックに関する深堀り。
KI Proオンラインイベントの最大25%オフ。
10年分の完全なアーカイブへのアクセス。
The Decoderから最新のAIニュースを入手しましょう。
原文を表示
Study shows why reasoning models often think far beyond the solution
Large reasoning models frequently think well past the correct answer: cross-checking, reformulating, and confirming what they already got right. A new Bytedance study shows the models actually know when they're done. Common sampling methods just don't let them stop.
The problem isn't new. Deepseek-R1 produces answers on the AIME 2025 benchmark nearly five times longer than Claude 3.7 Sonnet's, with comparable accuracy. QwQ-32B scores two percentage points higher with its shortest answers while using 31 percent fewer tokens. And in 72 percent of cases where both correct and incorrect answers were generated, the longer answer was more often wrong.
The answer is there, but the model keeps talking
To quantify the problem, the researchers introduced RFCS (Ratio of the First Correct Step), which tracks where in a chain of thought the correct answer first appears relative to total length. On MATH-500, the correct solution shows up well before the end in more than half of all correctly answered problems.Ad
A typical example of overthinking: the model arrives at the correct answer after 500 tokens, then generates another 452 tokens of redundant cross-checks and confirmations. | Image: Huang et al.
In one case, the model nailed the answer after 500 tokens but kept going for another 452: cross-checking, reformulating, and reconfirming what it already had right. This pattern shows up in both smaller models like Deepseek-R1-Distill-Qwen-1.5B and larger ones like Qwen3-8B. Stronger post-training doesn't fix it.AdDEC_D_Incontent-1
Across all three models tested, more than half of correct answers contain unnecessary reasoning steps after the first correct solution. Stronger models barely do better. | Image: Huang et al.
The models know when to stop; sampling methods don't
When models follow multiple chains of thought simultaneously during inference, they reliably find short, precise reasoning paths they assign high confidence to. The researchers demonstrate this with TSearch, which evaluates average probability across the entire chain rather than individual tokens.
Three observations back this up: selected paths produce shorter, more accurate answers. At those endpoints, the stop signal consistently ranks first among probable next tokens: the model knows it's done. And more parallel paths make this behavior more stable. Efficient termination is already baked into the models; common sampling methods just don't tap into it.Ad
When reasoning paths are selected based on overall model confidence (top), the model terminates with high certainty. Without this measure (bottom), the termination signal is uncertain. | Image: Huang et al.
SAGE explores step by step, not token by token
The researchers' solution is SAGE (Self-Aware Guided Efficient Reasoning). Instead of expanding token by token, SAGE extends chains of thought in whole reasoning steps and checks after each whether the model signals it's done. If so, reasoning stops.
In experiments, SAGE behaved differently depending on the setup: with strong models on hard benchmarks, accuracy primarily increased. With weaker models on simpler tasks, answer length dropped significantly. Basically, SAGE shortened where models were overthinking and found better solutions where capacity was left on the table.AdDEC_D_Incontent-2
To make these patterns permanent, the researchers propose SAGE-RL, a small tweak to standard reinforcement learning. Out of eight responses per training group, two come from SAGE, six from standard sampling. The model learns to prefer tighter reasoning paths through the advantage estimator.Ad
Results across six math benchmarks, MATH-500, AIME 2024 and 2025, and OlympiadBench among them, are consistent: methods like LC-R1, ThinkPrune, or AdaptThink cut tokens at the expense of accuracy. SAGE-RL improved both. On Deepseek-R1-Distill-Qwen-7B, SAGE-GRPO hit 93 percent on MATH-500 versus 91.6 percent, cutting response length from 3,871 to 2,141 tokens.
Same coordinate problem, two solutions: the base model DS-1.5B needs 1,381 tokens with multiple cross-checks. The SAGE-RL-trained model reaches the same answer in 712 tokens. | Image: Huang et al.
On AIME 2025, DS-1.5B's accuracy jumps 6.2 percentage points. Even Qwen3-8B, one of the strongest models in its class, sees SAGE-GRPO halve response length from 18,342 to 9,183 tokens without losing accuracy. Inference time drops over 40 percent across most models and benchmarks.
The biggest gains show up on the hardest tasks, suggesting that's where the most room for efficient reasoning exists. Fixing overthinking might not require new architectures or fancier reward functions. It might be enough to just let the models stop when they signal they're done.
Reasoning model overthinking has been a research topic for a while. About a year ago, a study showed excessive "thinking" in interactive scenarios noticeably hurts performance. More recently, Google researchers found that reasoning models structure their chains of thought as internal debates between simulated perspectives, improving accuracy but also explaining why reasoning takes so long.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
AI news without the hype Curated by humans.
Over 20 percent launch discount.
Read without distractions – no Google ads.
Access to comments and community discussions.
Weekly AI newsletter.
6 times a year: “AI Radar” – deep dives on key AI topics.
Up to 25 % off on KI Pro online events.
Access to our full ten-year archive.
Get the latest AI news from The Decoder.


関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み