ブラウザでPDFテキストを抽出する「LiteParse for the web」
シモン・ウィルソン氏は、LlamaIndexのオープンソースCLIツール「LiteParse」をブラウザ上で動作するように改造し、PDFからテキストやOCR画像をローカルで抽出するWebデモを提供した。
キーポイント
ブラウザ内完結型PDF解析の実現
Node.js CLIツールだったLiteParseを、PDF.jsとTesseract.jsを活用してブラウザ上で動作するWebアプリへ移植し、ファイルが外部に送信されないプライバシー保護を実現した。
AIモデルに依存しない空間テキスト解析
LLMや生成AIを用いず、マルチカラムや複雑なレイアウトを認識するヒューリスティックアルゴリズム(空間テキスト解析)とOCRエンジンで、PDFの構造化テキスト抽出を高速に行う。
RAGシステム向けの可視化引用機能
抽出テキストに境界ボックス(Bounding Boxes)を付与する「Visual Citations」パターンをサポートし、RAGベースのQ&A回答に対して画像付きの根拠提示を可能にし、信頼性を向上させる。
影響分析・編集コメントを表示
影響分析
本記事は、AIエンジニアリングにおける「データ前処理のローカル化・Web化」というトレンドを具体化するものであり、機密データを扱う企業や個人開発者にとって、安全なPDF解析パイプラインの標準的な選択肢になり得る。また、生成AIに依存しない堅牢なテキスト抽出手法がRAGの信頼性向上に寄与することは、実務的なAIシステム構築において重要な示唆を与える。
編集コメント
CLI依存を解消し、ブラウザ内で完結する実装は、セキュリティ要件が厳しい現場でのAIデータ前処理パイプライン構築に即座に活用できる実用的なアプローチである。
LlamaIndexには、PDFからテキストを抽出するためのNode.js CLIツール(Command Line Interface Tool)を提供する非常に優れたオープンソースプロジェクトLiteParseがあります。私は、Node.jsで動作させるためにLiteParseが使用するほぼ同じライブラリを使用して、ブラウザ上で完全に動作するLiteParseのバージョンを作成しました。
空間テキスト解析(Spatial Text Parsing)
Refreshingly、LiteParseは自身の機能にAIモデル(Artificial Intelligence Models)を使用していません。それは古くからある伝統的なPDF解析(PDF Parsing)であり、テキストそのものではなくテキストの画像を含むPDFに対しては、Tesseract OCR(または他のプラグイン可能なOCRエンジン(Pluggable OCR Engines))にフォールバックします。
LiteParseが解決する難しい問題は、PDFレイアウトの苛立たしいばらつきにもかかわらず、意味のある順序でテキストを抽出することです。彼らはこれを「空間テキスト解析(Spatial Text Parsing)」と呼んでおり、マルチカラムレイアウト(Multi-column Layouts)などの検出に非常に巧妙なヒューリスティック(Heuristics)を使用し、意味のある線形フロー(Linear Flow)でテキストをグループ化して返します。
LiteParseのドキュメントでは、Bounding Boxesを用いたビジュアル引用(Visual Citations with Bounding Boxes)の実装パターンが説明されています。このアイデアは非常に気に入っています:PDFから質問に回答し、その回答に切り抜いて強調表示された画像を添えることができるのは、RAGスタイルのQ&A(Retrieval-Augmented Generation Question & Answer)からの回答の信頼性を高める素晴らしい方法のように感じられます。
LiteParseはエージェント(Agents)が使用するように設計された純粋なCLIツール(Command Line Interface Tool)として提供されています。実行方法は以下の通りです:
npm i -g @llamaindex/liteparse
lit parse document.pdf私はClaudeを使ってその機能を探求し、CLIアプリ(Command Line Interface Application)であり続けることに実質的な理由がないことをすぐに突き止めました。これはPDF.jsとTesseract.jsという2つのライブラリの上に構築されており、これらは過去にブラウザで類似のことを行うために私が使用したものです過去の投稿.
LiteParseに純粋なブラウザ版が存在しなかった唯一の理由は、誰もまだそれを作っていなかっただけのことです……
Web向けLiteParseの紹介(Introducing LiteParse for the web)
https://simonw.github.io/liteparse/にアクセスして、ブラウザ上で完全に動作するLiteParseを任意のPDFファイルで試してみてください。以下がその外観です:
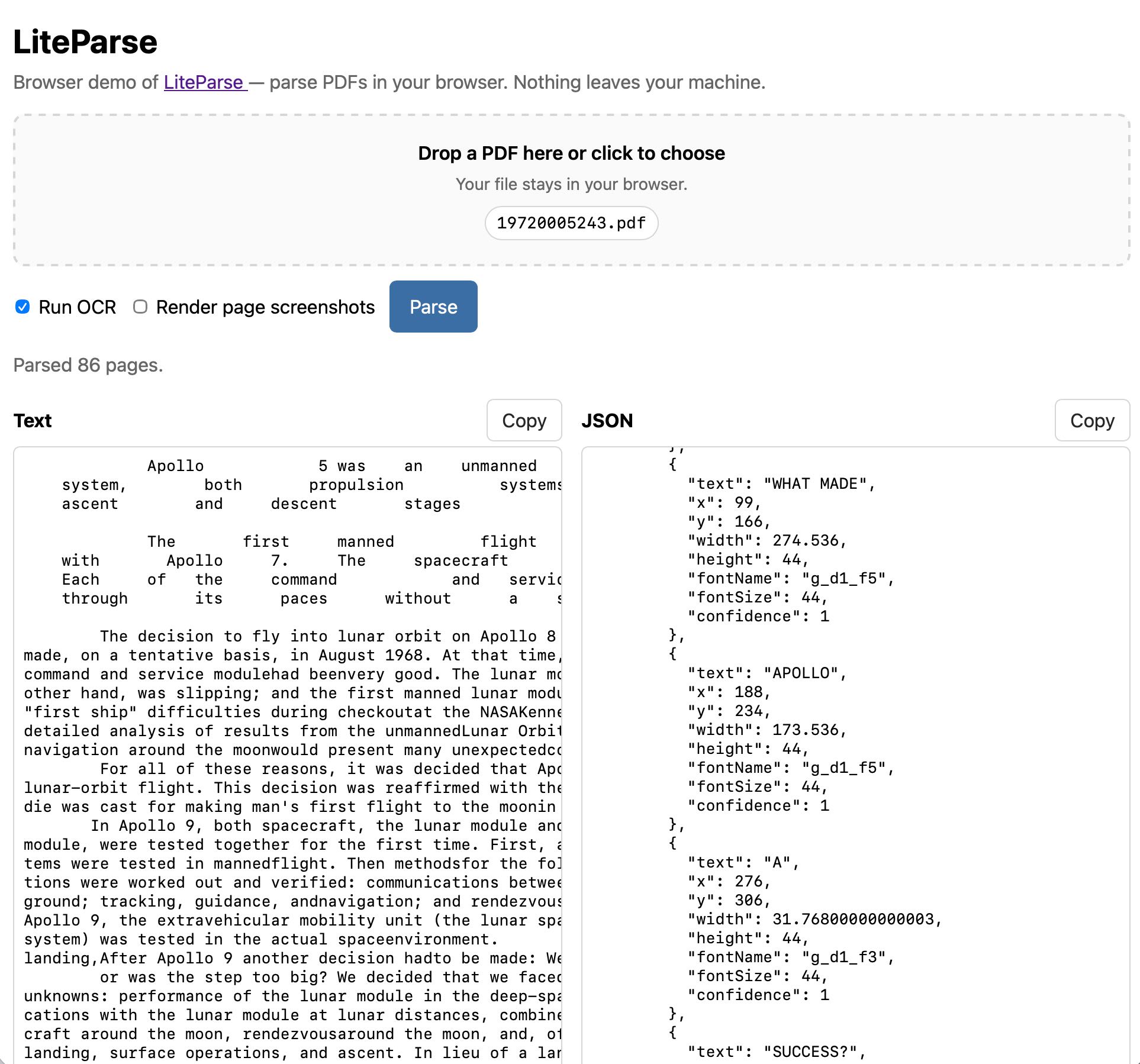
このツールはOCR(Optical Character Recognition)の実行有無に関わらず動作し、オプションでPDFの各ページの画像をページ下部に表示することもできます。
Claude CodeとOpus 4.7を用いた構築(Building it with Claude Code and Opus 4.7)
この構築プロセスは、iPhoneの通常のClaudeアプリで始まりました。私はLiteParseを自分で試したかったので、まずスマートフォンにたまたま保存していたランダムなPDFと、以下のプロンプトをアップロードすることから始めました:
https://github.com/run-llama/liteparseをクローンして、このファイルで試してみてください
最近の通常のClaudeチャットではGitHubから直接クローン可能であり、デフォルトではコンテナ内からインターネットの大部分にアクセスできませんが、PyPI(Python Package Index)やnpm(Node Package Manager)からのパッケージインストールも可能です。
私はスマートフォンで新しいオープンソースソフトウェア(open source software)を試す際、よくこれを使います。ノートパソコンの前に座らなくても、さっと何かを実行・確認できる手軽な方法だからです。
会話の全貌はこちらの共有Claudeトランスクリプトで追うことができます。動作についていくつかのフォローアップ質問をした後、私はこう尋ねました:
このライブラリ(library)はブラウザ(browser)上で動作しますか? 動作可能でしょうか?
返ってきた回答は十分詳細で、実際に動作させる価値があると感じました。そこでノートパソコンを開き、Claude Codeに切り替えました。
GitHub上で元のリポジトリ(repo)をフォークし、ローカルにクローンしました。新しいwebブランチ(web branch)を作成し、Claudeからの最後の回答をnotes.mdという新しいファイルに貼り付けました。その後、Claude Codeにこう指示しました:
これをWebアプリとして動作させてください。index.htmlを読み込んだ際、ユーザーがブラウザ(browser)でPDFを開き、OCRモード(OCR mode)または非OCRモードを選択して実行できるアプリをレンダリングする必要があります。この問題に関する初期調査はnotes.mdを読んでください。その後、詳細な実装計画をplan.mdとして出力してください
このようなプロジェクトでは、常に計画から始めるのが好きです。時にはClaudeの「プランニングモード(planning mode)」を使いますが、今回はリポジトリ内に計画書をアーティファクト(artifact)として残したかったので、plan.mdを直接作成するよう指示しました。
これにより、Claudeと計画を反復(イテレーション)で改善できるのも利点です。ClaudeはPDF内の画像のスクリーンショット生成については先送りし、「canvas-encode swap(canvas-encode swap)」をv2に延期することを提案していたことに気づきました。私は以下のようにプロンプトしてそれを修正しました:
計画を更新し、スクリーンショットの機能が動作するように「canvas-encode swap(canvas-encode swap)」を必ず行うと明記してください
いくつかの短いフォローアッププロンプトを経て、以下は実装に十分な強度があると判断したplan.mdです。
私はこうプロンプトしました:
構築してください。
その後は主にClaude Codeに任せておき、他のプロジェクトをいじったり、Duolingoで復習したりしながら、時々進捗を確認しました。
作業中にいくつかのプロンプトをキュー(queue)に追加しました。これらはまだエクスポートされたトランスクリプトには表示されませんが、関連する ~/.claude/projects/ フォルダで rg queue-operation --no-filename | grep enqueue | jq -r '.content' を実行すると抽出できることがわかりました。
主要なフォローアッププロンプトと補足メモは以下の通りです:
- これを実装する際は、Playwright(ブラウザ自動化フレームワーク)とred/green TDD(テスト駆動開発の手法)を使用し、その計画も立ててください - red/green TDDについてはこちらで詳しく書いています。
let's use PDF.js's own renderer (it was messing around with pdfium)
→ PDF.js(PDF表示ライブラリ)の独自レンダラーを使用しましょう(pdfiumとの互換性調整で手間取っていたため)
The final UI should include both the text and the pretty-printed JSON output, both of those in textareas and both with copy-to-clipboard buttons - it should also be mobile friendly - I had a new idea for how the UI should work
→ 最終的なUI(ユーザーインターフェース)には、テキストと整形済みJSON(JavaScript Object Notation)出力の両方を含める必要があります。どちらもtextarea要素で表示し、クリップボードへのコピーボタンも付けます - モバイルフレンドリー(モバイル対応)であることも必須です - UIの動作について新しいアイデアが浮かびました
small commits along the way - see below
→ 作業の過程で小さなコミットを積み重ねてください - 以下参照
Make sure the index.html page includes a link back to https://github.com/run-llama/liteparse near the top of the page - it's important to credit your dependencies in a project like this!
→ index.htmlページ上部に https://github.com/run-llama/liteparse へのリンクを必ず含めてください - このようなプロジェクトでは依存関係のクレジット表記が重要です!
View on GitHub → is bad copy because that's not the repo with this web app in, it's the web app for the underlying LiteParse library
→ 「View on GitHub →」というコピーは不適切です。このWebアプリが含まれているリポジトリではなく、基盤となるLiteParseライブラリのWebアプリ用だからです
Run OCR should be unchecked by default
→ 「Run OCR」チェックボックスはデフォルトでオフにしてください
When I try to parse a PDF in my browser I see 'Parse failed: undefined is not a function (near '...value of readableStream...') - it was testing with Playwright in Chrome, turned out there was a bug in Safari
→ ブラウザでPDFの解析を試みると、「Parse failed: undefined is not a function (near '...value of readableStream...')」というエラーが表示されます - ChromeでPlaywrightを使用してテストしていましたが、Safariにバグがあることが判明しました
... oh that is in safari but it works in chrome
→ …ああ、それはSafariでの話ですが、Chromeでは正常に動作します
When "Copy" is clicked the text should change to "Copied!" for 1.5s
→ 「Copy」ボタンがクリックされたら、テキストが1.5秒間「Copied!」に変更される必要があります
[Image #1] Style the file input so that long filenames don't break things on Firefox like this - in fact add one of those drag-drop zone UIs which you can also click to select a file - dropping screenshots in of small UI glitches works surprisingly well
→ [Image #1] ファイル入力フィールドをスタイル調整し、Firefoxで長いファイル名がレイアウトを崩さないようにしてください - さらに、クリックしてファイルを選択できるドラッグ&ドロップゾーンUI(ユーザーインターフェース)も追加してください - 小さなUIの不具合スクリーンショットを貼り付けて確認する手法は、予想以上に効果的です
Tweak the drop zone such that the text is vertically centered, right now it is a bit closer to the top
→ ドロップゾーンのテキストが垂直方向で中央に来るように微調整してください。現在は少し上部に寄っています
it breaks in Safari on macOS, works in both Chrome and Firefox. On Safari I see "Parse failed: undefined is not a function (near '...value of readableStream...')" after I click the Parse button, when OCR is not checked - it still wasn't working in Safari...
→ macOS版Safariでは動作が崩れますが、ChromeとFirefoxでは正常に動作します。Safariで「Parse」ボタンをクリックし、OCRチェックがオフの状態で「Parse failed: undefined is not a function (near '...value of readableStream...')」というエラーが表示されます - Safariではまだ動作していませんでした…
works in safari now - but it fixed it pretty quickly once I pointed that out and it got Playwright working with that browser
→ 現在はSafariでも動作するようになりました - ただし、その点を指摘してPlaywrightをそのブラウザで動作させられるようにしたところ、かなり早く修正されました
I've started habitually asking for "small commits along the way" because it makes for code that's easier to understand or review later on, and I have an unproven hunch that it helps the agent work more effectively too - it's yet another encouragement towards planning and taking on one problem at a time.
→ 作業の過程で小さなコミットを積むよう習慣的に依頼し始めたのは、後から理解やレビューがしやすいコードになるためです。また、エージェントの作業効率を高めるという確証はないものの直感的にそう思っています - これは計画性を高め、一度に一つの課題に取り組むよう促すもう一つの手段です。
While it was working I decided it would be nice to be able to interact with an in-progress version. I asked a separate Claude Code session against the same directory for tips on how to run it, and it told me to use npx vite. Running that started a development server with live-reloading, which meant I could instantly see the effect of each change it made on disk - and prompt with further requests for tweaks and fixes.
→ 動作している間、進行中のバージョンと対話できるのは良いだろうと考えました。同じディレクトリを対象に別のClaude Codeセッションを立ち上げ、実行方法のヒントを尋ねたところ、「npx vite」を使用するよう指示されました。それを実行するとライブリロード機能付きの開発サーバーが起動し、ディスク上での各変更の効果を即座に確認できました - さらに微調整や修正の依頼をプロンプトとして送ることも可能です。
Towards the end I decided it was going to be good enough to publish. I started a fresh Claude Code instance and told it:
→ 作業の終盤、公開しても問題ないレベルだと判断しました。新しいClaude Codeインスタンスを立ち上げ、以下のように指示しました:
web/フォルダを確認し、このリポジトリに対してGitHub Actions(CI/CD自動化ツール)を設定する。すべてのpush(コミットプッシュ)でテストを実行し、テストが成功すれば、ビルドされたVite(フロントエンドビルドツール)アプリをGitHub Pages(静的サイトホスティングサービス)にデプロイする。デプロイされるアプリケーションのindex.html(インデックスファイル)がweb/index.htmlページになるようにし、GitHub Pages上で正しく動作するようにする。
少しの反復作業を経て、Viteを使用してアプリをビルドし、結果をhttps://simonw.github.io/liteparse/にデプロイするGitHub Actionsのワークフローが完成した。
このような用途にGitHub Pages(静的サイトホスティングサービス)が気に入っているのは、(今回の場合Claudeによって)迅速に設定でき、ゼロコストで必要なビルドステップ(ビルド工程)があれば任意のリポジトリをデプロイ済みのWebアプリに変換できるからだ。秘密のURLのみをセキュリティ対策とすれば、プライベートリポジトリに対しても機能する。
このようなプロジェクトでは、モデル(AIモデル)が「手抜き」をする重大なリスクが常に存在する。主要な機能にTODO(作業予定マーク)とマークして偽装したり、初期要件を無視した近道(ショートカット)を取ったりする可能性がある。
これを防ぐ責任ある方法はすべてのコードをレビューすることだが、このプロジェクトはそういう意図で作ったものではない。そのため代わりに、GPT-5.5(大規模言語モデル)を搭載したOpenAI Codex(コード生成モデル)を起動し(プレビューアクセスを持っていた)、以下のように指示した。
node.jsのCLIツール(コマンドラインインターフェースツール)とweb/バージョンの実行方法の違いを説明してください
返ってきた回答は、Claude Code(AIプログラミングアシスタント)がプロジェクトを脅かすような近道を取っていないという確信を得るのに十分だった。
……それでほぼ完了だ。Claude Codeでの「ビルド」ステップにかかった総時間は59分だった。私はclaude-code-transcripts(会話記録エクスポートツール)を使用して、完全なトランスクリプトの読みやすいバージョンをエクスポートした。これらはこちらで閲覧可能だ(追加のキュー待ちプロンプトは含まれていないが、それらを修正するためのイシューはこちらにある)。
これでもうvibe coding(ノリコーディング)と呼べるのか?
私はvibe coding(ノリコーディング)の元の定義に関しては非常に厳格な主義者だ。vibe codingとは、AIを使ってコードを書く支援を受けるすべての状況を指すのではなく、書かれたコードを一切レビューしたり気にしたりせずにAIを使うことを意味する。
私自身の定義によれば、このLiteParse for the webプロジェクトは、これ以上ないほど純粋なvibe codingだ!私はこのプロジェクトのために書かれたHTML(ハイパーテキストマークアップ言語)とTypeScript(JavaScriptのスーパーセット)のコードを*一行も*確認していない。実際、この文を書いている最中に、JavaScriptかTypeScriptのどちらを使っているのか確認しに行ったほどだ。
しかし不思議なことに、他の多くのvibe codingプロジェクトと比べて、これは私にはそれほど「ノリで書かれた」感じはしない:
- GitHub Pages でホストされるブラウザ内静的ウェブアプリケーションとして、バグが発生した場合の影響範囲(ブラスト半径)はほぼゼロです:あなたのPDFで動作するか、しないかのどちらかです。
プライベートなデータは一切外部に送信されません。すべての処理はブラウザ内で行われるため、セキュリティ監査(security audit)は不要です。実行中にネットワークパネル(network panel)を一度確認しましたが、PDFの解析中は追加のリクエストは一切行われていません。
それでも、このようにモデルを使用するには、多くのエンジニアリングの経験と知識が必要でした。LiteParse をブラウザ内で直接実行できるようにポート(移植)することが、プロジェクトの残りの部分にとって重要であるという認識が不可欠でした。
最も重要なのは、私はこのプロジェクトに私の評判を賭けて他の人に試すことをお勧めできることです。私のバイブコーディング(vibe coding)ツールとは異なり、これに大幅な追加のエンジニアリング時間を費やすことが、意味のあるほど優れた初期リリースにつながるとは思えません。今のままで十分です!
私は 元リポジトリ に対して PR(プルリクエスト)をオープンしていません。LiteParse チームとまだ議論していないためです。私は イシューの作成 を行いましたが、彼らが私のバイブコーディング実装をより公式なプロジェクトの起点として使用したい場合は、自由に利用してください。
タグ: javascript, ocr(光学文字認識), pdf, projects, ai(人工知能), generative-ai(生成AI), llms(大規模言語モデル), vibe-coding(バイブコーディング), coding-agents(コーディングエージェント), claude-code, agentic-engineering(エージェント型エンジニアリング)
原文を表示
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
Spatial text parsing
Refreshingly, LiteParse doesn't use AI models to do what it does: it's good old-fashioned PDF parsing, falling back to Tesseract OCR (or other pluggable OCR engines) for PDFs that contain images of text rather than the text itself.
The hard problem that LiteParse solves is extracting text in a sensible order despite the infuriating vagaries of PDF layouts. They describe this as "spatial text parsing" - they use some very clever heuristics to detect things like multi-column layouts and group and return the text in a sensible linear flow.
The LiteParse documentation describes a pattern for implementing Visual Citations with Bounding Boxes. I really like this idea: being able to answer questions from a PDF and accompany those answers with cropped, highlighted images feels like a great way of increasing the credibility of answers from RAG-style Q&A.
LiteParse is provided as a pure CLI tool, designed to be used by agents. You run it like this:
npm i -g @llamaindex/liteparse
lit parse document.pdf
I explored its capabilities with Claude and quickly determined that there was no real reason it had to stay a CLI app: it's built on top of PDF.js and Tesseract.js, two libraries I've used for something similar in a browser in the past.
The only reason LiteParse didn't have a pure browser-based version is that nobody had built one yet...
Introducing LiteParse for the web
Visit https://simonw.github.io/liteparse/ to try out LiteParse against any PDF file, running entirely in your browser. Here's what that looks like:
The tool can work with or without running OCR, and can optionally display images for every page in the PDF further down the page.
Building it with Claude Code and Opus 4.7
The process of building this started in the regular Claude app on my iPhone. I wanted to try out LiteParse myself, so I started by uploading a random PDF I happened to have on my phone along with this prompt:
Clone https://github.com/run-llama/liteparse and try it against this file
Regular Claude chat can clone directly from GitHub these days, and while by default it can't access most of the internet from its container it can also install packages from PyPI and npm.
I often use this to try out new pieces of open source software on my phone - it's a quick way to exercise something without having to sit down with my laptop.
You can follow my full conversation in this shared Claude transcript. I asked a few follow-up questions about how it worked, and then asked:
Does this library run in a browser? Could it?
This gave me a thorough enough answer that I was convinced it was worth trying getting that to work for real. I opened up my laptop and switched to Claude Code.
I forked the original repo on GitHub, cloned a local copy, started a new web branch and pasted that last reply from Claude into a new file called notes.md. Then I told Claude Code:
Get this working as a web app. index.html, when loaded, should render an app that lets users open a PDF in their browser and select OCR or non-OCR mode and have this run. Read notes.md for initial research on this problem, then write out plan.md with your detailed implementation plan
I always like to start with a plan for this kind of project. Sometimes I'll use Claude's "planning mode", but in this case I knew I'd want the plan as an artifact in the repository so I told it to write plan.md directly.
This also means I can iterate on the plan with Claude. I noticed that Claude had decided to punt on generating screenshots of images in the PDF, and suggested we defer a "canvas-encode swap" to v2. I fixed that by prompting:
Update the plan to say we WILL do the canvas-encode swap so the screenshots thing works
After a few short follow-up prompts, here's the plan.md I thought was strong enough to implement.
I prompted:
build it.
And then mostly left Claude Code to its own devices, tinkered with some other projects, caught up on Duolingo and occasionally checked in to see how it was doing.
I added a few prompts to the queue as I was working. Those don't yet show up in my exported transcript, but it turns out running rg queue-operation --no-filename | grep enqueue | jq -r '.content' in the relevant ~/.claude/projects/ folder extracts them.
Here are the key follow-up prompts with some notes:
- When you implement this use playwright and red/green TDD, plan that too - I've written more about red/green TDD here.
- let's use PDF.js's own renderer (it was messing around with pdfium)
- The final UI should include both the text and the pretty-printed JSON output, both of those in textareas and both with copy-to-clipboard buttons - it should also be mobile friendly - I had a new idea for how the UI should work
- small commits along the way - see below
- Make sure the index.html page includes a link back to https://github.com/run-llama/liteparse near the top of the page - it's important to credit your dependencies in a project like this!
- View on GitHub → is bad copy because that's not the repo with this web app in, it's the web app for the underlying LiteParse library
- Run OCR should be unchecked by default
- When I try to parse a PDF in my browser I see 'Parse failed: undefined is not a function (near '...value of readableStream...') - it was testing with Playwright in Chrome, turned out there was a bug in Safari
- ... oh that is in safari but it works in chrome
- When "Copy" is clicked the text should change to "Copied!" for 1.5s
- [Image #1] Style the file input so that long filenames don't break things on Firefox like this - in fact add one of those drag-drop zone UIs which you can also click to select a file - dropping screenshots in of small UI glitches works surprisingly well
- Tweak the drop zone such that the text is vertically centered, right now it is a bit closer to the top
- it breaks in Safari on macOS, works in both Chrome and Firefox. On Safari I see "Parse failed: undefined is not a function (near '...value of readableStream...')" after I click the Parse button, when OCR is not checked - it still wasn't working in Safari...
- works in safari now - but it fixed it pretty quickly once I pointed that out and it got Playwright working with that browser
I've started habitually asking for "small commits along the way" because it makes for code that's easier to understand or review later on, and I have an unproven hunch that it helps the agent work more effectively too - it's yet another encouragement towards planning and taking on one problem at a time.
While it was working I decided it would be nice to be able to interact with an in-progress version. I asked a separate Claude Code session against the same directory for tips on how to run it, and it told me to use npx vite. Running that started a development server with live-reloading, which meant I could instantly see the effect of each change it made on disk - and prompt with further requests for tweaks and fixes.
Towards the end I decided it was going to be good enough to publish. I started a fresh Claude Code instance and told it:
Look at the web/ folder - set up GitHub actions for this repo such that any push runs the tests, and if the tests pass it then does a GitHub Pages deploy of the built vite app such that the web/index.html page is the index.html page for the thing that is deployed and it works on GitHub Pages
After a bit more iteration here's the GitHub Actions workflow that builds the app using Vite and deploys the result to https://simonw.github.io/liteparse/.
I love GitHub Pages for this kind of thing because it can be quickly configured (by Claude, in this case) to turn any repository into a deployed web-app, at zero cost and with whatever build step is necessary. It even works against private repos, if you don't mind your only security being a secret URL.
With this kind of project there's always a major risk that the model might "cheat" - mark key features as "TODO" and fake them, or take shortcuts that ignore the initial requirements.
The responsible way to prevent this is to review all of the code... but this wasn't intended as that kind of project, so instead I fired up OpenAI Codex with GPT-5.5 (I had preview access) and told it:
Describe the difference between how the node.js CLI tool runs and how the web/ version runs
The answer I got back was enough to give me confidence that Claude hadn't taken any project-threatening shortcuts.
... and that was about it. Total time in Claude Code for that "build it" step was 59 minutes. I used my claude-code-transcripts tool to export a readable version of the full transcript which you can view here, albeit without those additional queued prompts (here's my issue to fix that).
Is this even vibe coding any more?
I'm a pedantic stickler when it comes to the original definition of vibe coding - vibe coding does *not* mean any time you use AI to help you write code, it's when you use AI without reviewing or caring about the code that's written at all.
By my own definition, this LiteParse for the web project is about as pure vibe coding as you can get! I have not looked at a *single line* of the HTML and TypeScript written for this project - in fact while writing this sentence I had to go and check if it had used JavaScript or TypeScript.
Yet somehow this one doesn't feel as vibe coded to me as many of my other vibe coded projects:
- As a static in-browser web application hosted on GitHub Pages the blast radius for any bugs is almost non-existent: it either works for your PDF or doesn't.
- No private data is transferred anywhere - all processing happens in your browser - so a security audit is unnecessary. I've glanced once at the network panel while it's running and no additional requests are made when a PDF is being parsed.
- There was still a whole lot of engineering experience and knowledge required to use the models in this way. Identifying that porting LiteParse to run directly in a browser was critical to the rest of the project.
Most importantly, I'm happy to attach my reputation to this project and recommend that other people try it out. Unlike most of my vibe coded tools I'm not convinced that spending significant additional engineering time on this would have resulted in a meaningfully better initial release. It's fine as it is!
I haven't opened a PR against the origin repository because I've not discussed it with the LiteParse team. I've opened an issue, and if they want my vibe coded implementation as a starting point for something more official they're welcome to take it.
Tags: javascript, ocr, pdf, projects, ai, generative-ai, llms, vibe-coding, coding-agents, claude-code, agentic-engineering
関連記事
Microsoft Build でサティア・ナデラ氏と「No Priors」が共演、フロンティア知能プラットフォームを強調
マイクロソフトのサティア・ナデラ最高経営責任者が、AI 専門ポッドキャスト「Latent Space」と「No Priors」の共同特別番組に登場し、同社をフロンティア知能プラットフォームとして位置づける方針を表明した。
正解はデータセットではなくプロセスである
Amazon Science は、AI の主要な課題がモデル構築だけでなく、主張を裏付ける文献と照合できる評価システムの構築にあると指摘し、既存の事実確認ツールの限界について論じている。
エージェント・ハーネスにおけるメモリ状態の現状(12 分読)
Mem0 が Claude Code や Codex など主要な AI エージェントを調査した結果、すべての実装で境界欠陥が確認され、57-71% のユーザー間データ混在が発生していることが判明しました。