新しいオープンウェイトのリーダー、ビッグ AI の政治的影響力、病気の予測、高速推論
アンドレス・カーペンティエ氏は、AI が職を奪うという懸念に対し、歴史的な技術革新が新たな雇用を生む事例を挙げ、AI によるデジタルサービス需要の拡大とエージェント型ツールの活用が新しい仕事機会を創出する可能性を示唆している。
キーポイント
AI と雇用の歴史的関係性
農業や製造業の雇用減少は、ケア、クリエイティブ、技術、ビジネスサービス分野の成長によって過去150年間で相殺されてきたと指摘し、AI による雇用創出の可能性を歴史的文脈で位置づけている。
エージェント型ツールの実証例
著者自身のプロジェクトである「Agentic Reviewer」が、手動検索を超える膨大なウェブ検索クエリを自動生成し、AI エージェントが人間以上の作業負荷を生み出している具体例を示した。
倫理的責任と機会の両立
AI による生活の脅威に対する社会的な道徳的責任を認めつつも、同時に人々が新たな役割を引き継ぎ成長する機会があるという楽観的な視点を提供している。
GLM-5 がオープンウェイトモデルのリーダーに
Z.ai の「GLM-5」は、推論機能とエージェントタスクにおいて人工知能分析指数で最高スコアを記録し、クローズドな最先端モデルとの差を縮めています。
AI 業界のロビー活動が過去最高に
2025 年に主要テック企業は政治への影響を強めるため 1 億ドル以上を費やし、規制緩和やデータセンター建設支援など自社に有利な政策を推進しました。
エッジデバイス向け高速推論モデルの登場
Liquid AI の「LFM2.5-1.2B-Thinking」は、1GB 未満のメモリで動作しながらも推論速度と精度を両立し、オンデバイスでのエージェント活用を可能にしました。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界における雇用不安という社会的議論に対し、歴史的データと具体的な技術事例(エージェント)を用いて反論・補強する重要な視点を提供しています。特に「Agentic Reviewer」のような自律型ツールの台頭が、単純な代替ではなく新たな需要と業務の拡大を招くことを示唆しており、企業や開発者が AI 導入戦略を考える際の倫理的・経済的枠組みに寄与します。
編集コメント
単なる技術の進歩論ではなく、社会への影響と雇用という人間的な視点をバランスよく扱った良質な分析記事です。特に「AI エージェントが検索クエリを自動化する」という具体例は、抽象的な議論に終始しがちなこのテーマに対して説得力を持たせています。
親愛なる皆様、
AI は新たな雇用機会を生み出すのでしょうか?私の娘のノヴァは猫が大好きで、お気に入りの色は黄色です。彼女の7歳の誕生日には、まず Gemini の Nano Banana を使用してデザインし、その後職人に美味しいスポンジケーキとアイシングを使って作ってもらうことで、猫をテーマにした黄色いケーキを用意しました。このユニークな創作に娘は大満足し、そのプロセスによって職人には追加の仕事が生まれ(私はそれを負担できる特権を持っていると感じています)。
多くの人々が AI による雇用の喪失を心配しています。社会として、生計を立てる手段を奪われた人々をケアする道徳的責任があります。同時に、人々が新しい仕事に就き、責任の範囲を広げるための多くの機会があるとも見ています。
私たちはまだ、AI が多くの新しい雇用を生み出すという道の序盤にいます。AI によって設計されたケーキを焼くことが大規模なビジネスへと成長するかどうかはわかりません。(AI ファンドはこの機会を追及していません。なぜなら、もしそうすれば私が大幅に体重を増やすことになるからです。)しかし、歴史上を通じて、人々が人間の創造性を解き放つ道具を発明したとき、常に大量の新しい意味のある仕事が生まれてきました。例えば、ある研究によると、過去 150 年間にわたり、農業および製造業における雇用減少は、「ケア、クリエイティブ、テクノロジー、ビジネスサービス部門の急速な成長によって完全に相殺されてきた」のです。
AI はまた、多くのデジタルサービスに対する需要も拡大させており、これがこれらのサービスの作成・維持・販売・拡張に関わる人々の仕事量を増やすことにつながります。例えば、私はかつて毎日限られた数のウェブ検索しか行いませんでした。しかし今日では、私のコーディングエージェントが劇的に多い数のウェブ検索を実行しています。例えば、週末のプロジェクトとして始めた後に江一星氏が大幅に改善を手伝った Agentic Reviewer は、自動的に研究論文をレビューします。これは関連する作業を検索するためにウェブ検索 API を使用しており、これにより一日に実行されるウェブ検索クエリの数は、私が手動で入力したことがあった数よりもはるかに多くなります。
 imageAI とソフトウェアの進化は加速し続けており、私たちが構築できるものの機会は毎日増え続けています。私はもはや手書きでコードを書くのをやめました。より議論を呼ぶことですが、生成されたコードを読むのも長らく止めています。ここでは少数派にいると自覚していますが、コーディング構文を直接見なくても、私が欲しいものをほとんど構築できると感じています。そして、私自身はコーディングエージェントを使ってコードを操作することで、より高いレベルの抽象度で動作しています。
imageAI とソフトウェアの進化は加速し続けており、私たちが構築できるものの機会は毎日増え続けています。私はもはや手書きでコードを書くのをやめました。より議論を呼ぶことですが、生成されたコードを読むのも長らく止めています。ここでは少数派にいると自覚していますが、コーディング構文を直接見なくても、私が欲しいものをほとんど構築できると感じています。そして、私自身はコーディングエージェントを使ってコードを操作することで、より高いレベルの抽象度で動作しています。
従来のプログラミング言語である Python や TypeScript は、アセンブリ言語のように、生成されて使用されるが人間が開発者によって直接検証されない道を進むのでしょうか?それとも、モデルが英語のプロンプトから直接バイトコードにコンパイルするようになるのでしょうか?
どちらの道を選んでも、すべての開発者が 10 倍の生産性を持つようになったとしても、開発者の数が 1/10 に減ることはないと思います。なぜなら、カスタムソフトウェアに対する需要には実質的な天井がないからです。むしろ、ソフトウェアを開発する人の数は劇的に増加するでしょう。実際、「X エンジニア」と呼ばれる新しい職種の兆候が見え始めています。例えば、採用エンジニアやマーケティングエンジニアなどです。これらは特定の業務機能 X に所属し、その機能を支援するためのソフトウェアを構築する人々です。
Nova の誕生日ケーキに関する私の経験に基づき、確信していることがあります。AI は私たちにより良い人生をもたらしてくれるのです!
作り続けよう、
Andrew
A MESSAGE FROM DEEPLEARNING.AI
AI Dev 26 × サンフランシスコの最初のスピーカーが公開されました!AI を形成するリーダーたちの話を聞き、ハンズオン技術ワークショップに参加し、実世界システムのライブデモを探検し、新しい AI スタートアップトラックで新興スタートアップを発見してください。ラインナップを確認し、今日チケットを確保する
News
GLM-5 Scales Up
Z.ai は、フラッグシップ大規模言語モデル(LLM)のサイズを倍以上に拡大し、オープンウェイト競合の中で優れたパフォーマンスを実現しました。
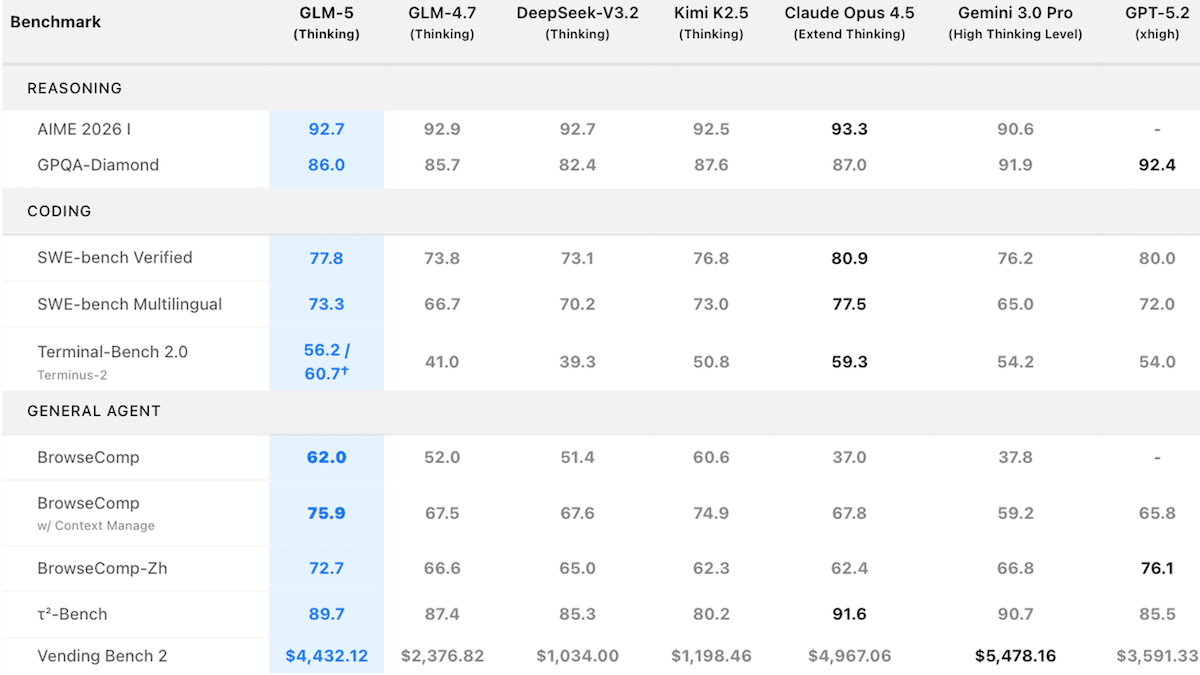
何が新しいか: GLM-5 は、長時間実行されるエージェントタスク向けに設計されています。このモデルは、Artificial Analysis のインテリジェンス指数において、他のオープンウェイトモデルを上回っています。
- 入力/出力:最大 200,000 トークンのテキスト入力、最大 128,000 トークンのテキスト出力
- アーキテクチャ:Mixture-of-experts(専門家混合)トランスフォーマー、7440億パラメータ、トークンあたり 400 億パラメータがアクティブ
- 機能:関数呼び出し、推論、コンテキストキャッシング
- パフォーマンス:Artificial Analysis Intelligence Index、𝜏²-Bench Telecom、Vending Bench 2、Chatbot Arena Code において、オープンウェイトモデルの中で最高性能
- 利用可能状況/価格:Web インターフェースは無料。重み(weights)は Hugging Face で入手可能で、MIT ライセンスの下に商用・非商用の両方で利用可能。API は入力トークンあたり 1.00 ドル、キャッシュ済みトークンあたり 0.20 ドル、出力トークンあたり 3.20 ドル(いずれも百万トークン単位)。コーディングプランは四半期あたり 27 ドルから 216 ドル。
- 非公開:具体的なアーキテクチャ、トレーニングデータ、および手法
仕組みの概要: Z.ai は GLM-5 のアーキテクチャとトレーニングに関するいくつかの詳細を開示しています。
- 同社は GLM-5 を 28.5 トリリオントークンで事前学習し、GLM-4.5 の 23 トリリオントークンから増加させました。
- 事後学習には、Z.ai が起源となった強化学習用のオープンソースソフトウェア「slime」を使用しました。このソフトウェアではデータ生成とトレーニングが独立したプロセスとして行われます。同社によると、このインフラによりトレーニングのスループットが向上し、強化学習中により多くの反復が可能になったとのことです。
- GLM-5 は DeepSeek のスパースアテンション(sparse attention)を採用しており、長いコンテキスト全体を処理するのではなく、入力の中で最も関連性の高い部分のみを処理することで、長文コンテキストにおける計算量を削減しています。
性能: GLM-5 は一部のコーディングやエージェントタスクにおいてオープンウェイトモデル間で最高性能を達成しましたが、全体的には独自開発の最先端モデルには及びませんでした。
- Artificial Analysis のインテリジェンス指数(経済的に有用な作業に焦点を当てた 10 の評価の加重平均)において、推論機能を有効にした GLM-5 (スコア: 50) は、推論機能を有効にした前回のオープンウェイトリーダーである Kimi K2.5 (スコア: 47) を上回りました。しかし、適応型推論に設定された Claude Opus 4.6 (スコア: 53) や xhigh 推論に設定された GPT-5.2 (スコア: 51) には及びませんでした。
- GLM-5 はまた、エージェントタスクにおいても強みを示しました。対話型エージェントが技術サポートシナリオでユーザーと協力する能力をテストする 𝜏²-Bench Telecom では、推論機能ありで 98 パーセント、なしで 97 パーセントを達成し、SOTA (state of the art: 最先端) を記録した Qwen3-Max-Thinking (98.2 パーセント) に次ぐ結果となりました。また、長いコンテキストにおけるエージェントのパフォーマンスを測定するために設計されたシミュレーションビジネスシナリオである Vending-Bench 2 では、GLM-5 は $4,432.12 の成果を上げ、Kimi K2.5 ($1,198.46) を含むテストされたすべてのオープンウェイトモデルを上回りました。
- 人間による審査員がモデル同士を直接比較する Chatbot Code Arena では、GLM-5 (Elo レーティング: 1449) がオープンウェイトモデルの中で 1 位にランクインしました。全体では 6 位で、Claude Opus 4.6 (Elo レーティング: 1567) に次ぎ、Gemini 3 Pro と同点でしたが、Kimi K2.5 (Elo レーティング: 1447) を上回りました。
なぜ重要なのか: Artificial Analysis のインテリジェンス指数において、GLM-5 は Claude Opus 4.6 や GPT-5.2 という独自開発のリーダーモデルにほぼ匹敵する性能を示しました。オープンウェイトモデルと独自開発モデルとの間の格差が縮小していることは、開発者にとって、自社のハードウェア上で修正・実行可能な高性能な選択肢を提供することになります。
私たちが考えていること: オープンウェイト AI の重心は決定的に東へ移りました。ここ最近、中国の開発者たちは GLM 4.5、Kimi K2、Qwen3-VL-235B-A22B、そして Kimi K2.5 など、次々と主要なオープンウェイト大規模言語モデル(LLM)を生み出しています。
Big AI Spends Big on Lobbying
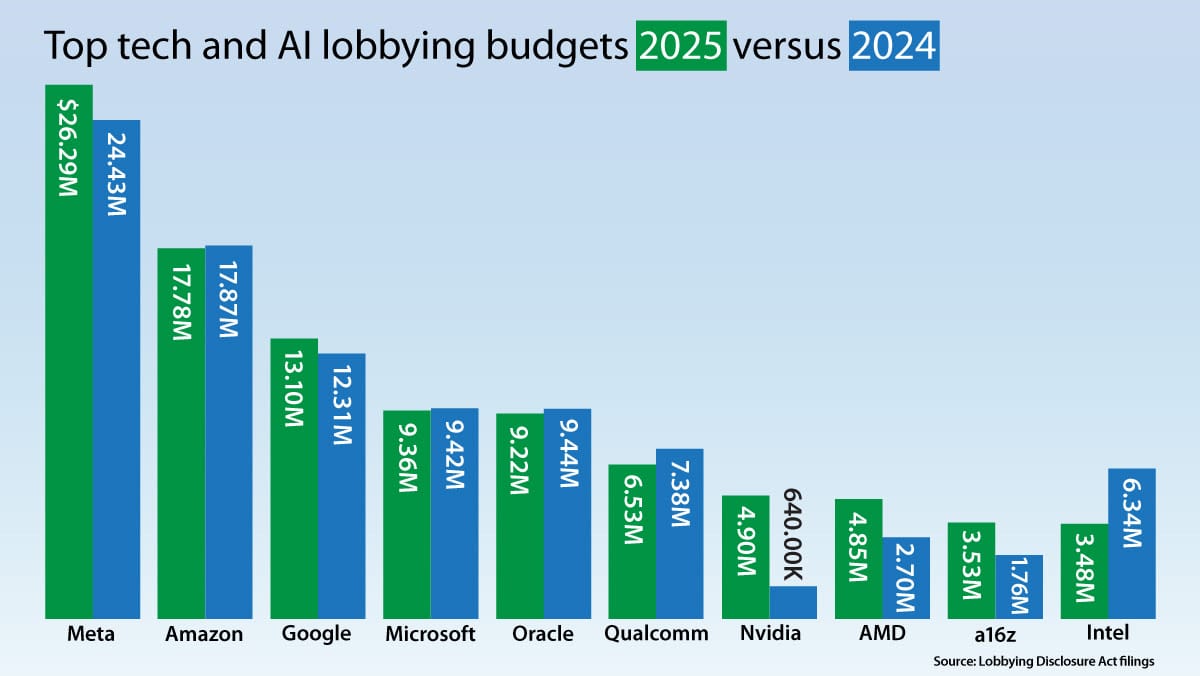
トップテック企業およびAI企業が、政府政策に影響を与えるために 2025 年に支出した金額は 1 億ドルを超え、この水準を突破したのは初めてのことです。
何が起きたか: メタ(Meta)は昨年、政治ロビー活動に 2,629 万ドルを投入し、業界を問わず他のどの企業よりも多額となりました。これはブルームバーグ(Bloomberg)が報じています。その他の巨額の支出者には、アマゾン(1,789 万ドル)、アルファベット(1,310 万ドル)、マイクロソフト(936 万ドル)が含まれ、NVIDIA の比較的控えめな予算も 2024 年の 7 倍となる 490 万ドルに膨らみました。連邦政府がデータセンターの建設支援や、ホワイトハウスによる中国への高度 AI チップ販売禁止令の撤回など、よりテック企業に友好的な政策へと転換したことで、巨額の支出を行った企業たちは報われています。(開示:アンドリュー・ン氏はアマゾンの取締役会に所属しています。)
仕組みについて: 企業によるロビー活動への支出は、通常、政治行動委員会や業界団体を経由した間接的なものを含み、官僚への助言や立法案の起草に充てられます。(支持する候補者の当選を支援するための支出はさらに高額になる可能性があり、メタはこの年、AI に友好的な州の官僚を選出するために 6500 万ドルを割り当てたと、*ニューヨーク・タイムズ*が報道しています。)昨年にロビー活動に最も多くの資金を投じた 10 のテック企業のうち、いくつかは支持するホワイトハウスのプロジェクトや政治団体に寄付を行いました。さらに、一部の企業はトランプ政権と緊密な関係を持つ従業員を採用し、経営陣がホワイトハウス行事に参加することを認めさせ、政権の優先事項への支出を約束しました。
- Meta、Alphabet、Nvidia、AMD、およびベンチャーキャピタル企業である Andreessen Horowitz は 2025 年にロビー活動予算を増額しました。Amazon、Microsoft、Oracle は 2024 年よりわずかに少ない金額を支出しました。Qualcomm と Intel は予算を大幅に削減しました。
- Alphabet、Apple、Meta、Microsoft は、ドナルド・トランプ大統領の優先事項であるホワイトハウス・ボールルームの再建のために資金を寄付することを約束しました。OpenAI のプレジデントである Greg Brockman と彼の妻は合わせて 2500 万ドルを大統領の政治活動委員会に寄付しました。
- Meta は元トランプ顧問を新プレジデント兼副会長として招聘し、元政府高官を法務総括(General Counsel)に昇格させました。OpenAI も元トランプ顧問を招いてグローバルエネルギー政策の統括を任せることにしました。
技術に親和的な政策: 直近の国家 AI ポリシーの変更は、ロビー活動に最も多額の費用を投じた企業の利益と一致するものでした。
- アメリカには AI を明示的に規制する国法は存在しません。しかし、ロビー活動において上位 10 社に入るメタ、OpenAI、アンドリーセン・ホロウィッツは、州レベルでの AI 規制が法律の寄せ集めとなりコンプライアンスを困難にするため、これに反対していました。12 月にはトランプ大統領が、AI を規律する州法を制限することを目的とした行政命令を発令しました。
- 長年にわたり連邦政府は、Nvidia が最も高度な AI チップを中国へ販売することを禁止し、同社に推定 500 億ドルの売上損失をもたらしてきました。これに対し Nvidia はロビー活動予算を 64 万ドルから 490 万ドルへと大幅に増額し、CEO のジェンソン・ファン氏は年内にトランプ大統領と複数回会談しました。大統領は 7 月に禁止令を緩和し、12 月には完全に解除しました。
- OpenAI は 2025 年にロビー活動に約 300 万ドルを費やしており、これは 2024 年の 176 万ドルから増加したものです。同社は AI を処理するための巨大なデータセンター網を構築する「Stargate」と呼ばれる計画に対するホワイトハウスの支援を求めており、CEO のサム・アルトマン氏は就任翌日に大統領と共演し、そのようなデータセンターの立地許可、許認可手続き、資金調達の迅速化に向けた動きを行いました。
- 最初のトランプ政権下では、ホワイトハウスが中国からの輸入品に関税を課しました。これにより、製品の多くを中国で組み立てているアップルに負担が生じました。4 月にはトランプ政権がアップル製品に関税免除措置を講じました。翌年 8 月、アップルは 4 年間で 6000 億ドルを投じて国内製造のための施設を建設することに合意しました。
なぜ重要なのか: テクノロジー企業はロビー活動における最大の支出者ではありません。その地位は医療関連企業にあります。しかし、AI 大手の拡大する取り組みは、規制環境が簡素化される一方で、彼らの権力が内部で強化されることを示唆しています。開発者への影響は概ねポジティブでした。テック巨人によるロビー活動は、州法のはぐれを navigating するという頭痛を軽減するのに役立ったようです。大規模なインフラプロジェクトの構築とチップ輸出規制の緩和に向けた動きは、全体の計算能力とハードウェアの安定性の急増をもたらすことが約束されています。しかし、参加費を支払わない企業にとってはビジネスがより困難になる可能性があります。
私たちが考えていること: 産業が成熟するにつれ、時には技術的実力主義(ベストな技術が勝つ)から、権力関係が少なくとも同程度に重要となる政治的な闘争の場へと移行することがあります。AI 開発者は、善悪にかかわらず、ビッグテックのロビイストによって策定された政策枠組みへとますます誘導される可能性があります。
エッジにおける高速推論
10 億〜20 億パラメータ規模の推論モデルは、通常、実行に 1ギガバイト以上の RAM を必要とします。Liquid AI は、900 メガバイト未満で動作し、驚異的な速度と効率を実現するモデルをリリースしました。
新情報: Liquid AI の LFM2.5-1.2B-Thinking は、小型デバイス上で動作するように設計されています。これは、1 月にデビューしたベースモデル、指令微調整済みモデル、日本語版、ビジョン・ランゲージモデル、オーディオ・ランゲージモデルを含む LFM2.5 の各種バリアントを補完するものです。
- 入力/出力:テキスト入力(最大 32,768 トークン)、テキスト出力
- アーキテクチャ:ハイブリッド型トランスフォーマー・畳み込みニューラルネットワーク、11.7 億パラメータ
- パフォーマンス:ほとんどの推論ベンチマークにおいて Qwen3-1.7B と同等かそれ以上の性能を発揮しつつ、実行速度は約 2 倍、必要なメモリ量も少なく、生成される出力トークン数も削減
- 機能:推論、ツール利用、8 か国語対応(英語、アラビア語、中国語、フランス語、ドイツ語、日本語、韓国語、スペイン語)
- 提供状況:無料の Web ユーザーインターフェースを提供。重みはダウンロード可能で、年間収益が 1,000 万ドル以下の組織に対して非商用・商用の両方でライセンス供与
- 非公表事項:トレーニングデータ
仕組み: アーキテクチャでは、アテンション層と畳み込み層を組み合わせ、新しいトークンが入力された際、アテンションが全入力シーケンスを対象とするのに対し、畳み込み層は隣接するトークンのグループのみを処理するため、計算量とメモリ使用量を削減できる。小規模モデルでは、連続するドメインで学習を進める過程で忘却などの問題が発生することがある。この課題に対処するため、チームは LFM2.5-12B-Thinking を段階的に訓練した。
- チームは、モデルを28兆トークンで事前学習しました。これは以前のバージョンの10兆トークンから増加した数値です。
- 中間トレーニング段階において、段階的な推論データが導入されました。この段階は事前学習の後に位置し、通常は中規模のデータセットを使用して、微調整前の段階で特定のスキルを鋭敏化するために用いられます。
- その後、合成された推論データを用いた教師あり微調整が続けられました。
- 強化学習(RL)フェーズでは、チームは推論、数学、ツール使用など異なるドメインに特化したモデルの25バージョンを作成し、それらを単一のモデルに統合しました。(著者たちはモデル統合の方法については記述していません。)例えば、ツール使用における RL 訓練の後、ツール使用版と数学版を統合することで、劣化してしまった数学能力を回復させました。
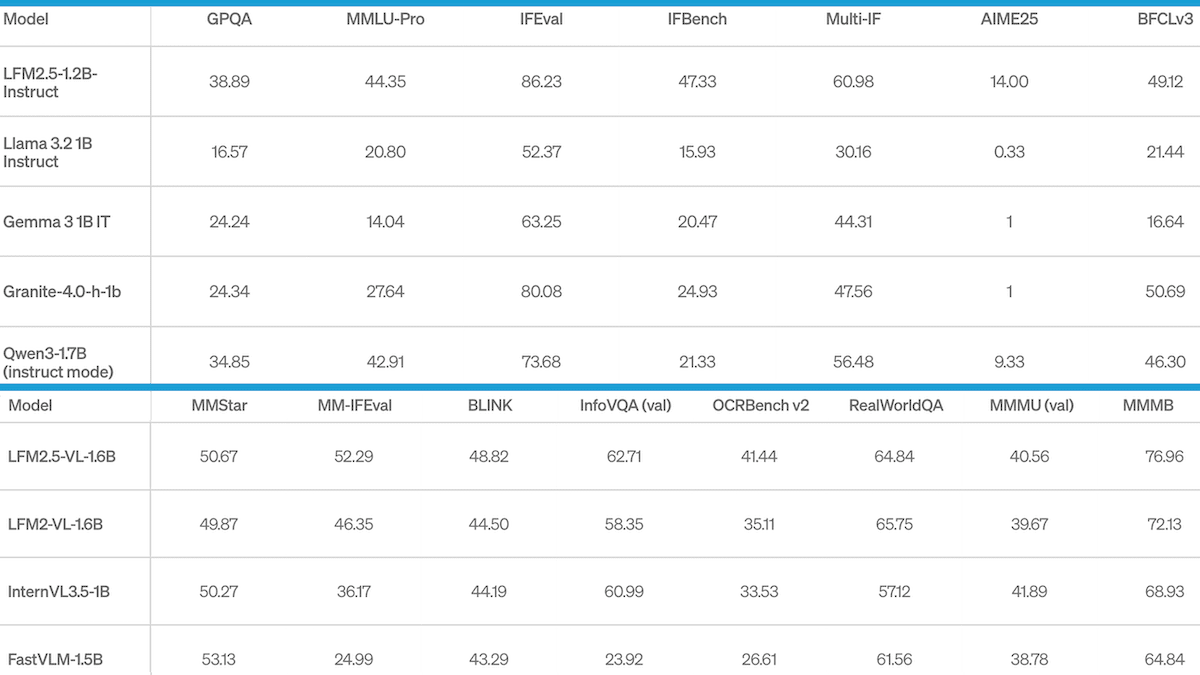
結果: Artificial Analysis のインテリジェンス指数(10 のベンチマークの加重平均)において、LFM2.5-1.2B-Thinking は、思考モードでの Qwen3-1.7B を含む、同サイズおよびより大きなサイズのモデルと同等の性能を示しました。
- Liquid AI が実施したテストでは、LFM2.5-1.2B-Thinking は思考モードにおいて GPQA Diamond、IFEval、IFBench、Multi-IF、GSM8K、MATH-500、BFCLv3 において Qwen3-1.7B を上回るか同等の性能を示しました。一方、MMLU-Pro と AIME 2025 では同モデルを下回りました。
- 上記すべてのベンチマークにおいて、LFM2.5-1.2B-Thinking は Google Gemma 3 1B IT、IBM Granite-4.0-1B、IBM Granite-4.0-H-1B(ハイブリッド型トランスフォーマー/Mamba アーキテクチャ)、および Meta Llama 3.2 1B Instruct を上回りました。
- Liquid AI の推論速度に関するテストでは、LFM2.5-1.2B-Thinking が首位となりました。CPU(Samsung Galaxy S25 Ultra および AMD Ryzen AI Max+ 395)上で実行した場合、思考モードなしの Qwen3-1.7B と比較して出力トークンの生成速度が約 2 倍速く、かつメモリ使用量は約 45% 少ないものでした。
ただし: 小規模モデルはハルシネーション(幻覚)に弱く、この点において LFM2.5-1.2B-Thinking は競合他社モデルを下回っています。
- Artificial Analytics の AA-Omniscience テストは、ハルシネーション(幻覚)に対してペナルティを課し、モデルを -100 から 100 のスケールで評価します。数値が高いほど優れています。LFM2.5-1.2B-Thinking は思考モードで -83 を記録し、Qwen3-1.7B(思考モード:-78)や LFM2.5-1.2B-Instruct(-75)に次ぐ結果でした。一方、Qwen3-8B の思考モードは -66、DeepSeek v3.2 の思考モードは -23 を達成しました。
- その結果、Liquid AI はこのモデルを「エージェントタスク、データ抽出、RAG(Retrieval-Augmented Generation:検索強化生成)」に使用することを推奨し、「知識集約型タスクやプログラミング」には使用しないよう警告しています。
なぜ重要なのか: LFM2.5-1.2B-Thinking は、ツール呼び出しの調整やデータ抽出、ローカルデータベースへの問い合わせを行うオンデバイスエージェントを駆動するのに適しています。これらのエージェントは、外部情報を取得する可能性が高いため、百科事典的な知識よりも指示に従う能力が求められます。また、長いリクエストチェーンを処理するための速度と、他のアプリケーションに余裕を持たせるための小さなメモリフットプリントもメリットとなります。
私たちが考えていること: 多くの開発者がモデルに最大限の知能を詰め込もうとする中、LFM2.5-1.2B は知能、推論速度、およびメモリ要件の間でバランスの取れた選択となっています。
睡眠信号が病気を予測する
不眠症は、心臓疾患や精神障害、その他多くの病気の前兆となることがよくあります。研究者たちは、睡眠研究で収集されたデータを用いてこれらの状態を検出しました。
何が新しいか: SleepFM は、睡眠中のバイタルサイン(生体指標)に基づいて、アルツハイマー病、パーキンソン病、前立腺がん、脳卒中、うっ血性心不全など多くの疾患を分類するシステムであり、症状が現れる最大 6 年前から検出可能です。ラハル・タパとマグヌス・ルード・キャーは、スタンフォード大学、デンマーク睡眠医学センター、デンマーク工科大学、BioSerenity、ハーバード医科大学、コペンハーゲン大学の同僚たちと共同で研究を行いました。
- 入力/出力:睡眠の一夜分の録音データを入力し、疾病分類を出力
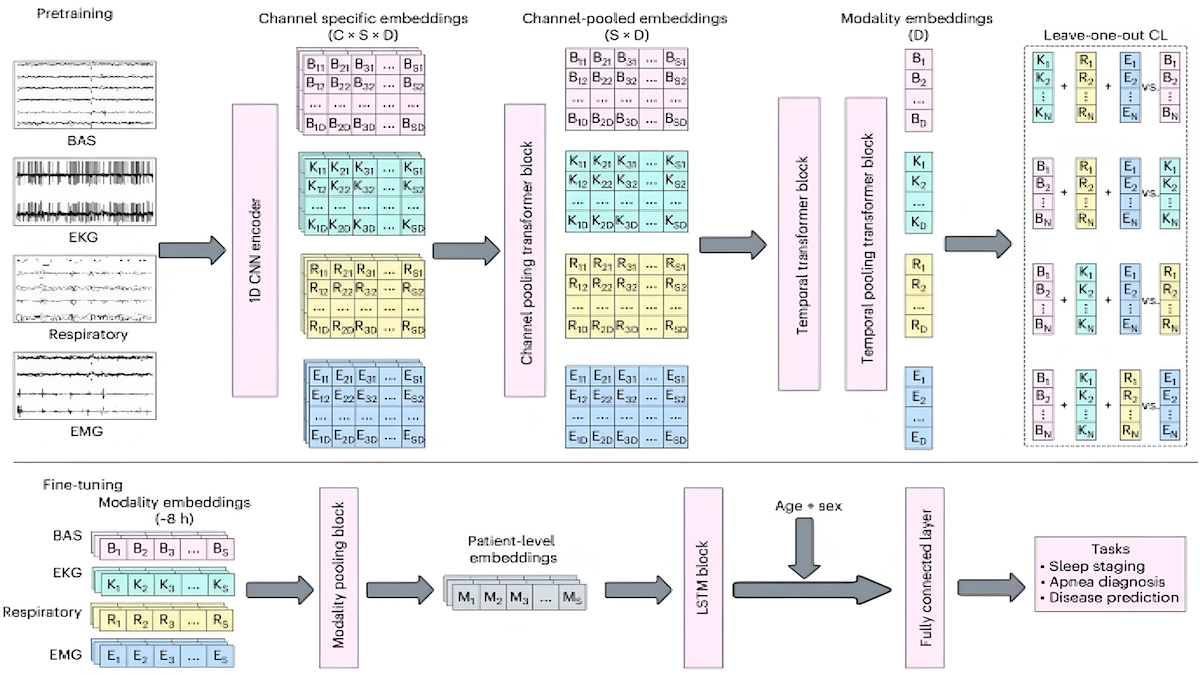
- アーキテクチャ:畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)エンコーダ、トランスフォーマー、LSTM
- パフォーマンス:130 以上の病態を正確に分類可能。これには、6 年以内に心不全や脳卒中を発症するリスクも含まれる。
- 利用状況:重み(weights)、トレーニングコード、推論コードは商用・非商用のいずれでもダウンロード可能。データセットの一部は非商用利用に限って公開されている。
仕組み: SleepFM は、畳み込みニューラルネットワーク(CNN)、トランスフォーマー、LSTM から構成される。著者らはこのシステムを 2 つの段階で訓練した:(i) 睡眠データのパターンをエンコードすること、および (ii) 疾病を分類すること。訓練データには、約 58.5 万時間の睡眠研究録音が含まれており、各患者の年齢と性別に加え、脳・心臓・呼吸器系(気流、いびき、血中酸素濃度)および脚筋の活動信号が含まれていた。データは主に proprietary(独自所有)であったが、一部は公開 データセット も含まれていた。
- 著者らは CNN とトランスフォーマーを共同で訓練しました。5 分間の録音データを与えられた際、CNN は各信号タイプの埋め込み(embeddings)を生成するよう学習し、一方トランスフォーマーは時間軸にわたる同一信号タイプ内の関係を捉えるためにこれらの埋め込みを修正しました。CNN とトランスフォーマーは、同時に記録された睡眠録音に対して類似の埋め込みを、そうでない録音に対して異なる埋め込みを生成するよう促されました。
- 著者らは LSTM を追加し、9 時間の睡眠データおよび被験者の年齢と性別を与えられて個別に訓練し、1,000 種類以上の疾患を分類できるようにしました。
結果: 著者らは SleepFM の性能を、事前学習を行っていない同一システムおよび人口統計情報のみで訓練されたバニラニューラルネットワークとの比較により評価しました。
- 14 の一般的な疾患カテゴリー全体において、SleepFM は真陽性対偽陽性の指標である曲線下面積(AUC)で高い値を達成しました(陽性とは記録から 6 年以内にその状態が発生したことを意味し、数値が高いほど優れています)。例えば、外傷後ストレス障害の分類においては SleepFM が AUC 0.75 を達成しましたが、事前学習を行わない同一システムでは AUC 0.64 にとどまりました。
- 公開睡眠データセット SHHS における心房細動の予測において、SleepFM は AUC 0.81 を達成しました。一方、その目的のためにのみ訓練された先行研究では AUC 0.82 を記録しています。
なぜ重要なのか: AI の微妙なパターンを認識する能力は、医療およびそれ以外の分野で驚くべき可能性を秘めています。この応用においては、深刻な疾患の早期警告を提供し、人々が病気が発症する前に予防措置を講じることを可能にします。
私たちが考えていること: この論文を読み終えた今、私たちは完全に目覚めきっています!
原文を表示
Dear friends,
Will AI create new job opportunities? My daughter Nova loves cats, and her favorite color is yellow. For her 7th birthday, we got a cat-themed cake in yellow by first using Gemini’s Nano Banana to design it, and then asking a baker to create it using delicious sponge cake and icing. My daughter was delighted by this unique creation, and the process created additional work for the baker (which I feel privileged to have been able to afford).
Many people are worried about AI taking peoples’ jobs. As a society we have a moral responsibility to take care of people whose livelihoods are harmed. At the same time, I see many opportunities for people to take on new jobs and grow their areas of responsibility.
We are still early on the path of AI generating a lot of new jobs. I don't know if baking AI-designed cakes will grow into a large business. (AI Fund is not pursuing this opportunity, because if we do, I will gain a lot of weight.) But throughout history, when people have invented tools that unleashed human creativity, large amounts of new and meaningful work have resulted. For instance, according to one study, over the past 150 years, falling employment in agriculture and manufacturing has been “more than offset by rapid growth in the caring, creative, technology, and business services sectors.”
AI is also growing the demand for many digital services, which can translate into more work for people creating, maintaining, selling, and expanding upon these services. For example, I used to carry out a limited number of web searches every day. Today, my coding agents carry out dramatically more web searches. For example, the Agentic Reviewer, which I started as a weekend project and Yixing Jiang then helped make much better, automatically reviews research articles. It uses a web search API to search for related work, and this generates a vastly larger number of web search queries a day than I have ever entered by hand.
The evolution of AI and software continues to accelerate, and the set of opportunities for things we can build still grows every day. I’ve stopped writing code by hand. More controversially, I’ve long stopped reading generated code. I realize I’m in the minority here, but I feel like I can get built most of what I want without having to look directly at coding syntax, and I operate at a higher level of abstraction using coding agents to manipulate code for me. Will conventional programming languages like Python and TypeScript go the way of assembly — where it gets generated and used, but without direct examination by a human developer — or will models compile directly from English prompts to byte code?
Either way, if every developer becomes 10x more productive, I don't think we’ll end up with 1/10th as many developers, because the demand for custom software has no practical ceiling. Instead, the number of people who develop software will grow massively. In fact, I’m seeing early signs of “X Engineer” jobs, such as Recruiting Engineer or Marketing Engineer, which are people who sit in a certain business function X to create software for that function.
One thing I’m convinced of based on my experience with Nova’s birthday cake: AI will allow us to have a batter life!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI
The first speakers for AI Dev 26 × San Francisco are live! Hear from leaders shaping AI, join hands-on technical workshops, explore live demos of real-world systems, and discover emerging startups in our new AI Startup Track. View the lineup and secure your ticket today
News
GLM-5 Scales Up
Z.ai more than doubled the size of its flagship large language model to deliver outstanding performance among open-weights competitors.
What’s new: GLM-5 is designed for long-running agentic tasks. It tops other open-weights models in Artificial Analysis’ Intelligence Index.
- Input/output: Text in (up to 200,000 tokens), text out (up to 128,000 tokens)
- Architecture: Mixture-of-experts transformer, 744 billion parameters, 40 billion active parameters per token
- Features: Function calling, reasoning, context caching
- Performance: Best among open-weights models on Artificial Analysis Intelligence Index, 𝜏²-Bench Telecom, Vending Bench 2, and Chatbot Arena Code
- Availability/price: Web interface free, weights available via Hugging Face for commercial and noncommercial uses under MIT license, API $1.00/$0.20/$3.20 per million input/cached/output tokens, coding plans $27 to $216 per quarter
- Undisclosed: Specific architecture, training data, and method
How it works: Z.ai disclosed few details about the GLM-5’s architecture and training.
- The company pretrained GLM-5 on 28.5 trillion tokens, up from the 23 trillion tokens for GLM-4.5.
- For post-training, the company used slime, open-source software for reinforcement learning, originated by Z.ai, in which data generation and training are independent processes. The company says this infrastructure improved training throughput, enabling more iterations during reinforcement learning.
- GLM-5 uses DeepSeek sparse attention, which reduces computation over long contexts by processing only the most relevant portions of long inputs rather than attending to every token.
Performance: GLM-5 achieved the highest performance among open-weights models in some coding and agentic tasks but generally trailed proprietary frontier models.
- On Artificial Analysis’ Intelligence Index, a weighted average of 10 evaluations that focus on economically useful work, GLM-5 with reasoning enabled (50) surpassed the previous open-weights leader, Kimi K2.5 set to reasoning (47). It trailed Claude Opus 4.6 set to adaptive reasoning (53) and GPT-5.2 set to xhigh reasoning (51).
- GLM-5 also showed strength in agentic tasks. On 𝜏²-Bench Telecom, which tests the ability of conversational agents to collaborate with users in technical support scenarios, GLM-5 achieved 98 percent (with reasoning) and 97 percent (without reasoning), while Qwen3-Max-Thinking (98.2 percent) set the state of the art. On Vending-Bench 2, a simulated business scenario designed to measure agentic performance over long contexts, GLM-5 ($4,432.12) outperformed all open-weights models tested including Kimi K2.5 ($1,198.46).
- In the Chatbot Code Arena, where human judges compare models head-to-head, GLM-5 (1449 Elo) ranked first among open-weights models. It ranked sixth overall, trailing Claude Opus 4.6 (1567 Elo), tied with Gemini 3 Pro, and outperforming Kimi K2.5 (1447 Elo).
Why it matters: On Artificial Analysis’ Intelligence Index, GLM-5 nearly matches proprietary leaders Claude Opus 4.6 and GPT-5.2. The shrinking gaps between open-weights and proprietary models give developers high-performance options to modify and/or run on their own hardware.
We’re thinking: The center of gravity in open-weights AI has shifted decisively eastward. Developers in China have been responsible for a succession of leading open-weights large language models lately, including GLM 4.5, Kimi K2, Qwen3-VL-235B-A22B, and Kimi K2.5.
Big AI Spends Big on Lobbying
Top tech and AI companies spent more than $100 million to influence government policy in 2025, the first time they exceeded that figure.
What happened: Meta put $26.29 million into political lobbying last year, more than any other company in any industry, *Bloomberg* reported. Other big spenders include Amazon ($17.89 million), Alphabet ($13.10 million), and Microsoft ($9.36 million), and Nvidia’s relatively modest budget ballooned to $4.9 million, seven times its size in 2024. Big spenders have been rewarded as the federal government shifted toward more tech-friendly policies, notably support for building data centers and a reversal of the White House’s ban on selling advanced AI chips to China. (Disclosure: Andrew Ng serves on Amazon’s board of directors.)
How it works: Corporate spending on lobbying typically goes into advising officials and drafting legislative proposals, often indirectly through political action committees and industry groups. (Spending to elect favored candidates can be even higher; Meta has allocated $65 million to elect AI-friendly state officials this year, *The New York Times* reported.) Of the 10 tech companies that spent the most on lobbying last year, several donated to favored White House projects and political organizations. In addition, some companies hired employees who have close relationships with the Trump administration, had their executives attend White House events, and committed to spending on administration priorities.
- Meta, Alphabet, Nvidia, AMD, and venture capital firm Andreessen Horowitz raised their lobbying budgets in 2025. Amazon, Microsoft, and Oracle spent slightly less than in 2024. Qualcomm and Intel cut their budgets substantially.
- Alphabet, Apple, Meta, and Microsoft pledged to donate funds to rebuild the White House ballroom, a priority of President Trump’s. OpenAI President Greg Brockman and his wife together gave $25 million to the President’s political action committee.
- Meta recruited a former Trump adviser as its new president and vice chairman and promoted a former administration official to be its general counsel. OpenAI hired another former Trump adviser to lead its global energy policy.
Tech-friendly policies: Recent changes in national AI policy mirrored the interests of companies that spent the most on lobbying.
- No national laws explicitly regulate AI in the United States. However, Meta, OpenAI, and Andreessen Horowitz, all of which are among the top-10 tech companies in terms of lobbying, opposed state-level regulation of AI because they would create a patchwork of laws that would make compliance difficult. In December, President Trump issued an executive order that aims to limit state laws that govern AI.
- For years, the federal government has blocked Nvidia from selling its most advanced AI chips to China, depriving the company of an estimated $50 billion in sales. Nvidia increased its lobbying budget to $4.9 million from $640,000, and CEO Jensen Huang met with President Trump a number of times over the year. The president relaxed the ban in July and lifted it in December.
- OpenAI, which spent nearly $3 million on lobbying in 2025, up from $1.76 million in 2024, seeks White House support for its plan, known as Stargate, to build an immense network of data centers to process AI. CEO Sam Altman appeared with President Trump the day after his inauguration as the president moved to expedite siting, permitting, and funding of such data centers.
- During the first Trump administration, the White House had imposed tariffs on goods imported from China. This placed a burden on Apple, which assembles its products largely in China. In April, the Trump Administration exempted Apple products from tariffs. The following August, Apple agreed to spend $600 billion over four years to build facilities for domestic manufacturing of its products.
Why it matters: Tech companies aren’t the biggest spenders on lobbying. That distinction belongs to healthcare companies. Yet the AI giants’ escalating efforts portend a streamlined regulatory environment while consolidating their power within it. The impact on developers has been largely positive. Lobbying by tech giants appears to have helped alleviate the headache of navigating a patchwork of state laws. The push to build massive infrastructure projects and relax restrictions on chip exports promises a surge in overall compute capacity and hardware stability. However, doing business may become harder for companies that don’t pay to play.
We’re thinking: As industries mature, sometimes they shift from technical meritocracies in which the best tech wins to political arenas in which power dynamics matter at least as much. AI developers increasingly may be channeled into policy frameworks developed by big-tech lobbyists, for better or worse.
Faster Reasoning at the Edge
Reasoning models in the 1 to 2 billion-parameter range typically require more than 1 gigabyte of RAM to run. Liquid AI released one that runs in less than 900 megabytes, and does it with exceptional speed and efficiency.
What’s new: Liquid AI’s LFM2.5-1.2B-Thinking is designed to run on small devices. It complements base, instruction-tuned, Japanese, vision-language, and audio-language LFM2.5 variants, which debuted in January.
- Input/output: Text in (up to 32,768 tokens), text out.
- Architecture: Hybrid transformer-convolutional neural network, 1.17 billion parameters
- Performance: Matched or exceeded Qwen3-1.7B on most reasoning benchmarks while running twice as fast, requiring less memory, and generating fewer output tokens
- Features: Reasoning, tool use, eight languages (English, Arabic, Chinese, French, German, Japanese, Korean, Spanish)
- Availability: Free web user interface, weights available for download and licensed for noncommercial and commercial uses to organizations up to $10 million annual revenue
- Undisclosed: Training data
How it works: The architecture mixes attention layers with convolutional layers which, given a new token, process only an adjacent group of tokens — rather than the entire input sequence, as attention does — and thus use less computation and memory. Small models can develop issues such as forgetting as they’re trained on successive domains. To overcome such problems, the team trained LFM2.5-12B-Thinking in phases.
- The team pretrained the model on 28 trillion tokens, up from 10 trillion for earlier variants.
- They introduced step-by-step reasoning data during mid-training, a phase after pretraining that typically uses mid-size datasets to sharpen distinct skills prior to fine-tuning.
- They continued with supervised fine-tuning on synthetic reasoning data.
- During the reinforcement-learning (RL) phase, the team produced 25 versions of the model specialized for different domains such as reasoning, mathematics, and tool use and merged them into a single model. (The authors don’t describe the model-merging method.) For example, after RL training in tool use, they merged the tool-use version with a math version to restore any degraded math capacity.
Results: On Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks, LFM2.5-1.2B-Thinking matched models of similar size and larger size including Qwen3-1.7B in thinking mode.
- In tests performed by Liquid AI, LFM2.5-1.2B-Thinking outperformed or matched Qwen3-1.7B in thinking mode on GPQA Diamond, IFEval, IFBench, Multi-IF, GSM8K, MATH-500, BFCLv3. It underperformed that model on MMLU-Pro and AIME 2025.
- On all benchmarks mentioned above, LFM2.5-1.2B-Thinking outperformed Google Gemma 3 1B IT, IBM Granite-4.0-1B, IBM Granite-4.0-H-1B (a hybrid transformer/mamba architecture), and Meta Llama 3.2 1B Instruct.
- On Liquid AI’s tests of inference speed, LFM2.5-1.2B-Thinking leading. Running on CPUs (Samsung Galaxy S25 Ultra and AMD Ryzen AI Max+ 395), it generated output tokens roughly twice as fast as Qwen3-1.7B (without thinking mode) while using around 45 percent less memory.
Yes, but: Small models struggle with hallucinations, and LFM2.5-1.2B-Thinking underperforms competing models in this regard.
- Artificial Analytics’ AA-Omniscience test penalizes hallucinations to evaluate models on a scale between 100 and -100, higher is better. LFM2.5-1.2B-Thinking (-83) came in behind Qwen3-1.7B in thinking mode (-78) and LFM2.5-1.2B-Instruct (-75). In contrast, Qwen3-8B in thinking mode achieved -66 and DeepSeek v3.2 in thinking mode achieved -23.
- Consequently, Liquid AI recommends using the model for “agentic tasks, data extraction, and RAG” and against using it for “knowledge-intensive tasks and programming.”
Why it matters: LFM2.5-1.2B-Thinking is well suited to drive on-device agents that orchestrate tool calls, extract data, or query local databases. Such agents need the ability to follow instructions more than encyclopedic knowledge, since they’re likely to fetch external information. They also benefit from speed to handle lengthy chains of requests and a small memory footprint that leaves room for other applications.
We’re thinking: While many developers try to pack the most intelligence into their models, LFM2.5-1.2B strikes a balance between intelligence, inference speed, and memory requirements.
Sleep Signals Predict Illness
Difficulty sleeping often precedes heart disease, psychiatric disorders, and many other illnesses. Researchers used data gathered during sleep studies to detect such conditions.
What’s new: SleepFM is a system that classifies Alzheimer’s, Parkinson’s, prostate cancer, stroke, congestive heart failure, and many other conditions based on a person’s vital signs while asleep — as much as 6 years before they show symptoms. Rahul Thapa and Magnus Ruud Kjaer worked with colleagues at Stanford University, Danish Center for Sleep Medicine, Technical University of Denmark, BioSerenity, Harvard Medical School, and University of Copenhagen.
- Input/output: Recordings of one night of sleep in, disease classifications out
- Architecture: Convolutional neural network encoder, transformer, LSTM
- Performance: Can accurately classify over 130 conditions, including experiencing congestive heart failure or stroke within six years.
- Availability: Weights, training code, and inference code are available for download for commercial and noncommercial uses. Part of the dataset is available for noncommercial use.
How it works: SleepFM comprises a convolutional neural network (CNN), transformer, and LSTM. The authors trained the system in two stages: (i) to encode patterns in sleep data and (ii) to classify diseases. The training data comprised roughly 585,000 hours of sleep-study recordings that included, in addition to each patient’s age and sex, signals of activity in the brain, heart, respiratory system (airflow, snoring, and blood oxygen level), and leg muscles. The data was mostly proprietary but included public datasets.
- The authors trained the CNN and transformer together. Given 5 minutes of recordings, the CNN learned to produce embeddings of each type of signal, while the transformer modified the embeddings to capture relationships within a signal type across time. The CNN and transformer were encouraged to produce similar embeddings of sleep recordings that were made at the same time and different embeddings of recordings that weren’t.
- The authors added the LSTM and separately trained it, given 9 hours of sleep data as well as the subject’s age and sex, to classify more than 1,000 diseases.
Results: The authors compared SleepFM’s performance on a proprietary test set to the same system without pretraining and a vanilla neural network that was trained on only demographic information.
- Across 14 general categories of disease, SleepFM achieved a higher area under the curve (AUC), a measure of true versus false positives (positive meaning the condition occurred within six years of the recording), higher is better. For example, classifying post-traumatic stress disorder, SleepFM achieved 0.75 AUC, while the same system without pretraining achieved 0.64 AUC.
- Predicting Atrial Fibrillation in the public sleep dataset SHHS, SleepFM achieved 0.81 AUC, while earlier work trained solely for that purpose achieved 0.82 AUC.
Why it matters: AI’s ability to recognize subtle patterns has amazing potential in medicine and beyond. In this application, it could provide early warning of serious diseases, enabling people to take steps to prevent illness before it develops.
We’re thinking: We’re wide awake after reading this paper!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み