ハーネスエンジニアリングによる深層エージェントの改善
LangChainは、エージェントの「ハネスエンジニアリング」手法を適用し、システムプロンプトやツールの最適化に加え、LangSmithのトレースを用いた自動検証と修正ループを導入することで、コーディングエージェントのTerminal Benchスコアを大幅に向上させた。
キーポイント
ハネスエンジニアリングの定義と目的
モデルのスパイク状の知能を特定のタスク向けに整形するためのシステム設計であり、プロンプト、ツール、実行フローの設計が重要である。
自動化されたトレース分析スキルの実装
LangSmithのデータを基にエラーを並列分析し、メインエージェントが知見を統合してハネス(プロンプトやミドルウェア)を改善する自動化されたレシピを開発した。
実験結果とスコア向上
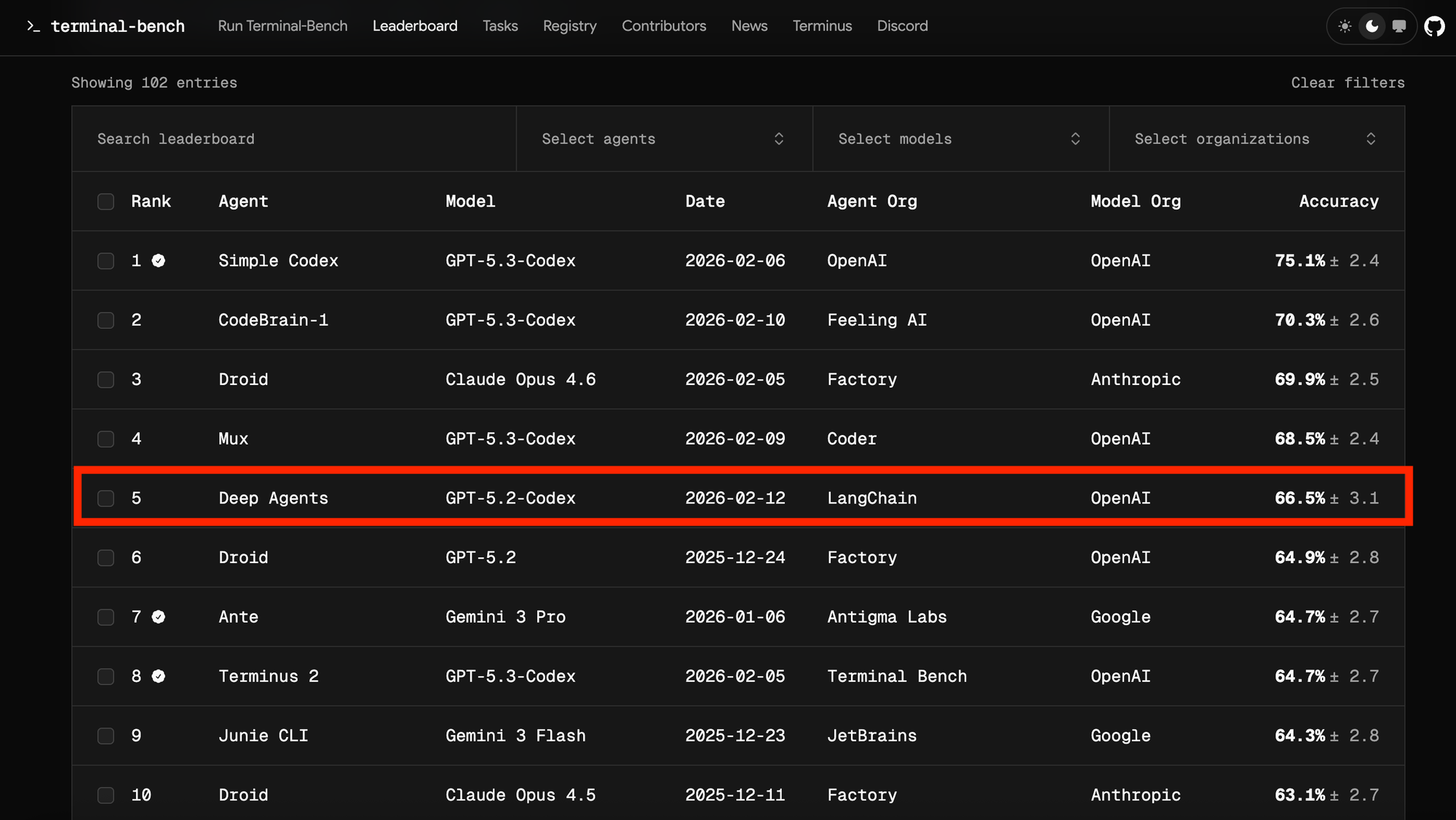
GPT-5.2-Codexを使用し、デフォルトスコア52.8%から大幅に改善し、Terminal Bench 2.0でトップ30からトップ5へランクインさせた。
最適化対象の限定と検証プロセス
システムプロンプト、ツール、ミドルウェアの3つに焦点を絞り、過学習を防ぐために人間の検証を組み合わせた反復的な改善プロセスを採用した。
Build & Self-Verify ループの構築
エージェントに自然な自己改善傾向を持たせるため、計画策定、検証を念頭に置いた実装、テスト実行、エラー分析という構造化されたフィードバックループをシステムプロンプトに組み込んだ。
環境コンテキストと制約の注入
ディレクトリ構造、ツールの利用可能性、厳格なタイムアウトといった環境情報をエージェントに提供し、時間予算の警告を注入することで作業の完了と検証フェーズへの移行を促す。
テスト可能なコード生成の促進
エージェントに対し、プログラムmaticなテストで評価されることを意識させ、正確なファイルパスの遵守や「ハッピーパス」だけでなくエッジケースのテストを含むコード記述を促すことで、品質低下(slop buildup)を防ぐ。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデル(LLM)単体よりも、それを取り巻くシステム設計(ハネスエンジニアリング)がエージェント性能に与える影響の大きさを示唆している。特に、LangSmithなどの観測ツールと連携した自動改善サイクルの確立は、実務レベルでのエージェント開発効率を劇的に高める可能性があり、業界標準となるプラクティスの確立に寄与する。
編集コメント
モデル自体の変更ではなく、システム構成(ハネス)の最適化で劇的な性能向上が得られる点は、実務開発において非常に示唆に富む。特に自動トレース分析を用いた改善サイクルは、エージェント開発のボトルネック解消に直結する手法である。
TLDR: 当社のコーディングエージェントがTerminal Bench 2.0でトップ30からトップ5に躍進しました。変更したのはハーネスだけです。これが当社のハーネスエンジニアリングへのアプローチです(予告: 自己検証とトレースが大いに役立ちます)。
ハーネスエンジニアリングの目標
ハーネスの目標は、モデルが本質的に持つ「突出した知性」を、私たちが重視するタスクのために形成することです。ハーネスエンジニアリングはシステムに関するものであり、タスクのパフォーマンス、トークン効率、レイテンシなどの目標を最適化するために、モデルの周囲にツーリングを構築します。設計上の決定事項には、システムプロンプト、ツールの選択、実行フローなどが含まれます。
しかし、エージェントを改善するために、ハーネスをどのように変更すべきでしょうか?
LangChainでは、大規模なエージェントの失敗モードを理解するために「トレース」を使用しています。現在のモデルは大部分がブラックボックスであり、その内部メカニズムを解釈するのは困難です。しかし、私たちはテキスト空間におけるそれらの入出力を確認することができ、それを改善のフィードバックループに利用しています。
私たちは、deepagents-cli(当社のコーディングエージェント)を13.7ポイント向上させるために、単純なレシピを用いて反復的に改善を行いました。
実験のセットアップとハーネスの調整項目
私たちはTerminal Bench 2.0を使用しました。これは現在、エージェント型コーディングを評価する標準的なベンチマークとなっています。機械学習、デバッグ、生物学などの分野にわたる89のタスクがあります。実行を調整するためにHarborを使用しています。Harborはサンドボックス(Daytona)を起動し、エージェントループと対話し、検証とスコアリングを実行します。
すべてのエージェントのアクションはLangSmithに保存されます。また、レイテンシ、トークン数、コストなどのメトリクスも含まれます。
調整可能な項目
エージェントハーネスには多くの調整項目があります:システムプロンプト、ツール、フック/ミドルウェア、スキル、サブエージェントへの委譲、メモリシステムなどです。私たちは意図的に最適化空間を圧縮し、三つに焦点を当てました:システムプロンプト、ツール、およびミドルウェア(モデルとツール呼び出しの周囲のフックを指す当社の用語)です。
デフォルトのプロンプトと標準的なツール+ミドルウェアから始めます。これはGPT-5.2-Codexで52.8%のスコアでした。堅実なスコアで、現在のリーダーボードのトップ30のすぐ外ですが、成長の余地があります。
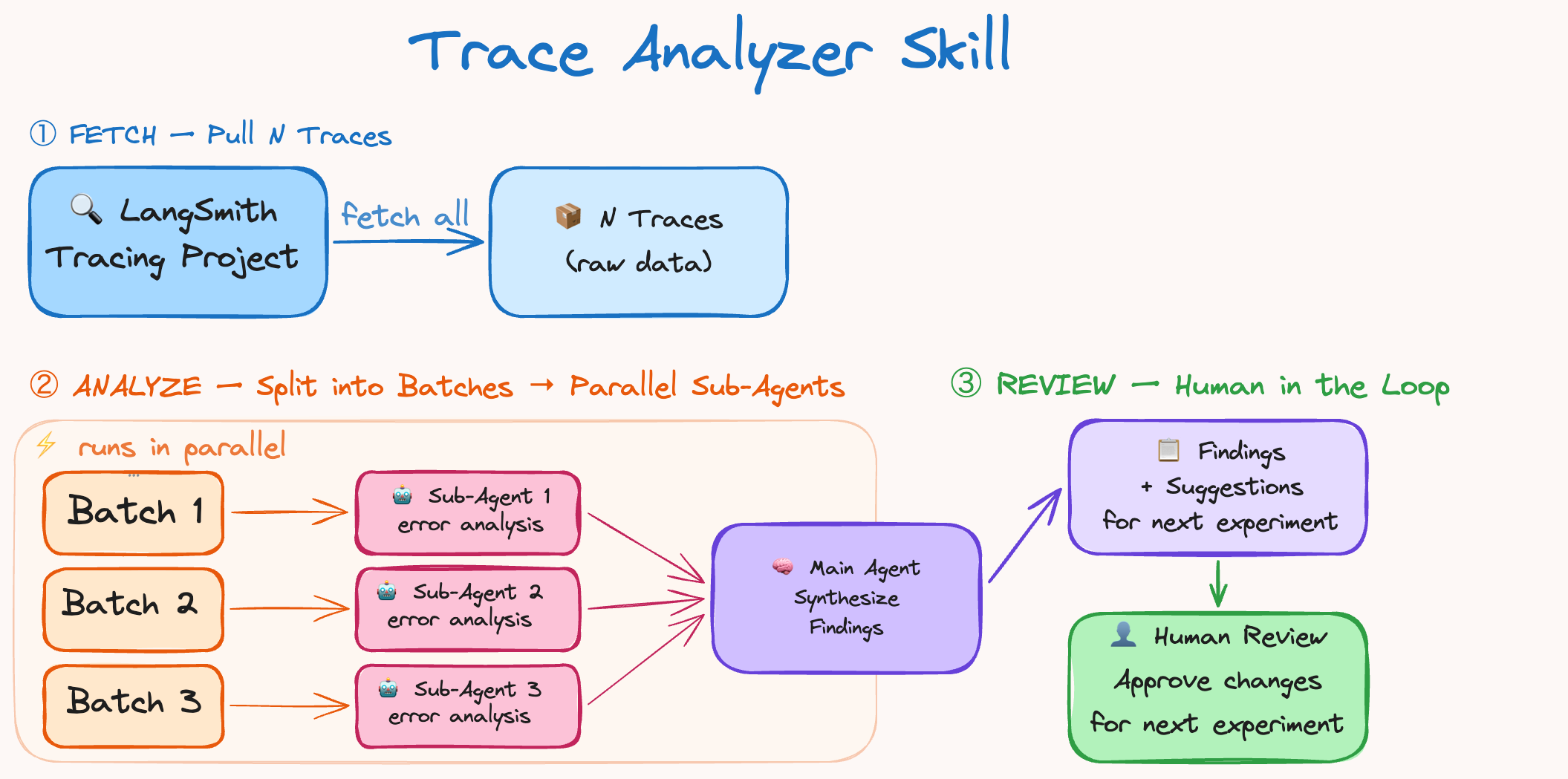
トレースアナライザースキル
トレース分析を繰り返し可能にしたいと考え、それをエージェントスキルにしました。これは、複数の実行にわたるエラーを分析し、ハーネスを改善するための私たちのレシピとして機能します。フローは以下の通りです:
LangSmithから実験トレースを取得する
並列エラー分析エージェントを生成 → メインエージェントが調査結果と提案を統合する
フィードバックを集約し、ハーネスに対して的を絞った変更を加える。
これは、以前の実行からのミスに焦点を当てるブースティングと同様に機能します。ステップ3では、提案された変更を検証し議論するために、人間が非常に役立つ場合があります(必須ではありません)。特定のタスクに過剰適合する変更は一般化に悪影響を及ぼし、他のタスクでの後退を引き起こす可能性があります。
自動化されたトレース分析は何時間もの時間を節約し、実験を素早く試すことを容易にしました。私たちはこのスキルを近日中に公開する予定で、現在、一般的なプロンプト最適化のためにテスト中です。
実際にエージェントのパフォーマンスを改善したもの
自動化されたトレース分析により、エージェントがどこで間違っていたのかをデバッグすることができました。問題には、推論エラー、タスク指示の不遵守、テストと検証の欠如、時間切れなどが含まれていました。これらの改善点については、以下のセクションで詳細に説明します。
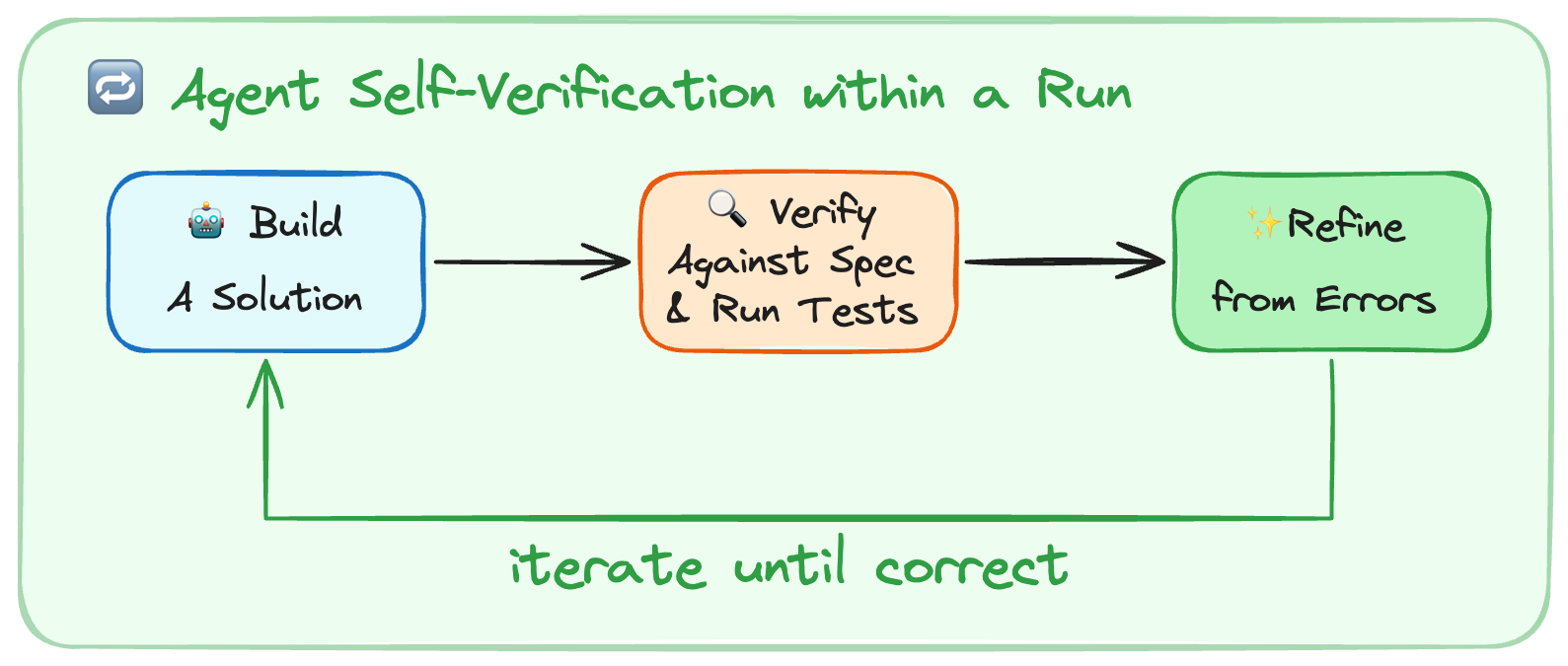
構築と自己検証
今日のモデルは、卓越した自己改善マシンです。
自己検証により、エージェントは1回の実行内でフィードバックを通じて自己改善することができます。しかし、彼らには自然にこの「構築-検証」ループに入る傾向はありません。
最も一般的な失敗パターンは、エージェントが解決策を書き、自身のコードを再読し、問題なさそうだと確認し、停止するというものでした。テストは自律的なエージェント型コーディングの重要な部分です。それは全体的な正確性をテストするのに役立ち、同時に、エージェントが「丘登り」を行うためのシグナルを与えます。
私たちは、問題解決へのアプローチ方法について、システムプロンプトにガイダンスを追加しました。
計画と調査: タスクを読み、コードベースをスキャンし、タスク仕様と解決策の検証方法に基づいて初期計画を立てる。
構築: 検証を念頭に置いて計画を実装する。テストが存在しない場合はテストを構築し、正常系とエッジケースの両方をテストする。
検証: テストを実行し、出力全体を読み、求められたものと比較する(自身のコードと比較しない)。
修正: エラーを分析し、元の仕様を再確認し、問題を修正する。
私たちは、テストが各イテレーションの変化を促進するため、テストに特に焦点を当てています。プロンプティングと並行して、決定論的なコンテキスト注入がエージェントの作業検証に役立つことを発見しました。私たちはPreCompletionChecklistMiddlewareを使用しています。
エージェントに環境に関するコンテキストを与える
ハーネスエンジニアリングの一部は、コンテキストエンジニアリングのための優れた配信メカニズムを構築することです。Terminal Benchのタスクには、ディレクトリ構造、組み込みツーリング、厳格なタイムアウトが付属しています。
ディレクトリコンテキストとツーリング: LocalContextMiddleware
テスト可能なコードを書くことをエージェントに教える: エージェントは、自身のコードがどのようにテスト可能である必要があるかを知りません。私たちは、彼らの作業がプログラムによるテストに対して測定されることを示すプロンプトを追加します。これは、コードをコミットするときと似ています。例えば、ファイルパスに言及するタスク仕様は、自動採点ステップで解決策が機能するように、正確に従うべきです。エッジケースを強調するプロンプティングは、エージェントが「正常系」ケースのみをチェックすることを避けるのに役立ちます。モデルにテスト標準に準拠させることは、時間の経過とともに「ずさんさが蓄積する」ことを避けるための強力な戦略です。
時間予算: 私たちは時間予算の警告を注入し、エージェントに作業を終了して検証に移行するよう促します。エージェントは時間見積もりが非常に苦手で有名なので、このヒューリスティックはこの環境で役立ちます。現実世界のコーディングには通常厳格な時間制限はありませんが、制約に関する知識を何も追加しないと、エージェントは時間制限内で作業しません。
エージェントが自身の環境、制約、評価基準についてより多く知るほど、彼らは自律的に自身の作業を方向付けることができます。
ハーネスエンジニアの目的: エージェントが自律的に作業を完了できるように、コンテキストを準備し提供することです。
エージェントに一歩引いて計画を再考するよう促す
エージェントは、一度計画を決めると近視眼的になることがあり、同じ破綻したアプローチに小さなバリエーションを加える「破滅ループ」に陥ります(一部のトレースでは10回以上)。
私たちはLoopDetectionMiddlewareを使用しています。
重要な注意点。これは、現在認識されているモデルの問題をエンジニアリングする設計ヒューリスティックです。モデルが改善されるにつれて、これらのガードレールはおそらく不要になるでしょうが、今日ではエージェントが正確かつ自律的に実行するのに役立ちます。
推論にどれだけの計算リソースを費やすかを選択する
推論モデルは何時間も自律的に実行できるため、各サブタスクにどれだけの計算リソースを費やすかを決定しなければなりません。すべてのタスクで最大の推論予算を使用することもできますが、ほとんどの作業は推論計算コストの最適化から恩恵を受けることができます。
Terminal Benchのタイムアウト制限はトレードオフを生み出します。より多くの推論はエージェントが各ステップを評価するのに役立ちますが、2倍以上を消費する可能性があります。
私たちは、推論が問題を完全に理解するための計画に役立つことを発見しました。Terminal Benchのタスクには非常に難しいものもあります。良い計画は、機能する解決策により迅速に到達するのに役立ちます。
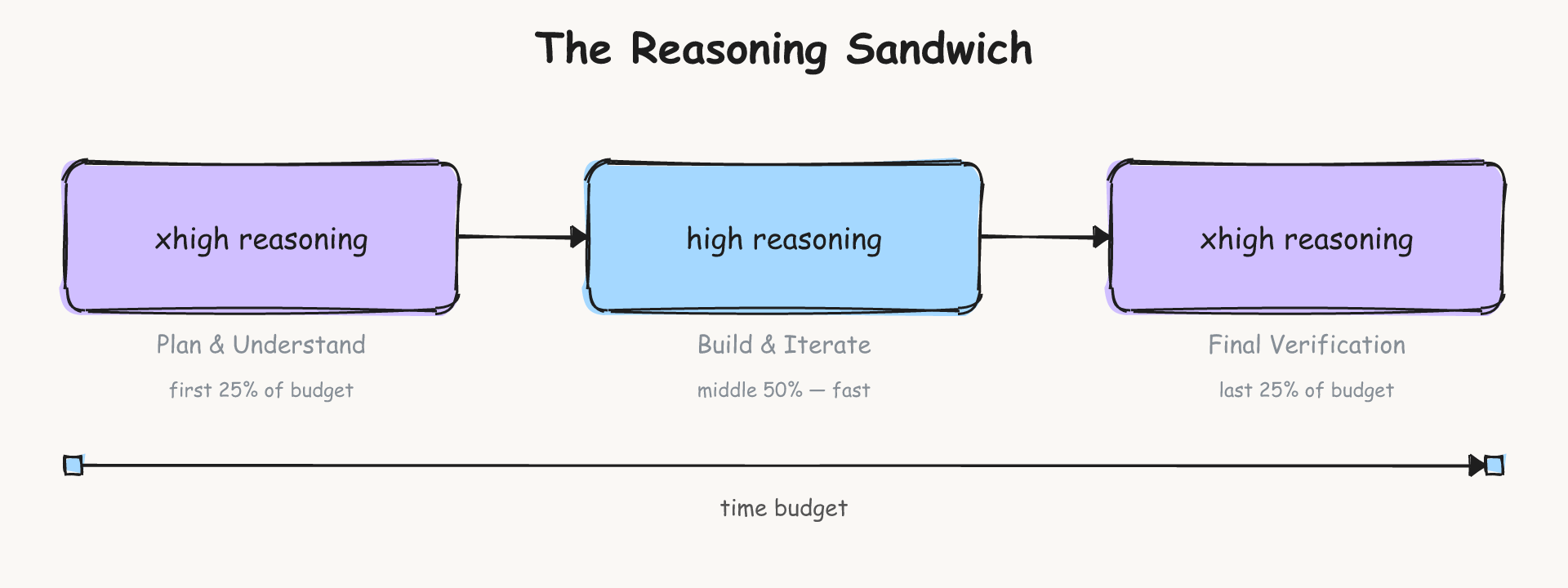
後期段階の検証も、ミスを見つけて解決策を提出するために、より多くの推論から恩恵を受けます。ヒューリスティックとして、私たちは「xhigh-high-xhigh」の「推論サンドイッチ」をベースラインとして選択します。
xhighのみで実行するのは、計画には良いですが、検証には不十分です。
モデルにとって自然なアプローチは適応推論です。ClaudeやGeminiモデルに見られるように、モデルが推論にどれだけの計算リソースを費やすかを決定します。
マルチモデルハーネスでは、推論予算のバランスを取ることは、計画には大規模モデルを使用し、実装にはより小さなモデルに引き渡すという形で展開される可能性があります。
エージェントハーネス構築のための実用的な要点
エージェントの設計空間は広大です。以下は、私たちの実験とdeepagents全体の構築から得られた一般的な原則です。
エージェントに代わって行うコンテキストエンジニアリング。コンテキストの組み立ては、今日のエージェントにとって依然として困難です。特に未知の環境ではそうです。ディレクトリ構造、利用可能なツール、コーディングのベストプラクティス、問題解決戦略などのコンテキストでモデルをオンボーディングすることは、不適切な探索によるエラー面を減らし、計画における回避可能なエラーを防ぐのに役立ちます。
エージェントが自身の作業を自己検証するのを助ける。モデルは、最初に思いついたもっともらしい解決策に偏る傾向があります。彼らに積極的に検証するよう促し、
原文を表示
TLDR: Our coding agent went from Top 30 to Top 5 on Terminal Bench 2.0. We only changed the harness. Here’s our approach to harness engineering (teaser: self-verification & tracing help a lot).
The Goal of Harness Engineering
The goal of a harness is to mold the inherently spiky intelligence of a model for tasks we care about. Harness Engineering is about systems, you’re building tooling around the model to optimize goals like task performance, token efficiency, latency, etc. Design decisions include the system prompt, tool choice, and execution flow.
But how should you change the harness to improve your agent?
At LangChain, we use Traces to understand agent failure modes at scale. Models today are largely black-boxes, their inner mechanisms are hard to interpret. But we can see their inputs and outputs in text space which we then use in our improvement loops.
We used a simple recipe to iteratively improve deepagents-cli (our coding agent) 13.7 points
Experiment Setup & The Knobs on a Harness
We used Terminal Bench 2.0, a now standard benchmark to evaluate agentic coding. It has 89 tasks across domains like machine learning, debugging, and biology. We use Harbor to orchestrate the runs. It spins up sandboxes (Daytona), interacts with our agent loop, and runs verification + scoring.
Every agent action is stored in LangSmith. It also includes metrics like latency, token counts, and costs.
The Knobs we can Turn
An agent harness has a lot of knobs: system prompts, tools, hooks/middleware, skills, sub-agent delegation, memory systems, and more. We deliberately compress the optimization space and focus on three: System Prompt, Tools, and Middleware (our term for hooks around model and tool calls).
We start with a default prompt and standard tools+middleware. This scores 52.8% with GPT-5.2-Codex. A solid score, just outside the Top 30 of the leaderboard today, but room to grow.
The Trace Analyzer Skill
We wanted trace analysis to be repeatable so we made it into an Agent Skill. This serves as our recipe to analyze errors across runs and make improvements to the harness. The flow is:
Fetch experiment traces from LangSmith
Spawn parallel error analysis agents → main agent synthesizes findings + suggestions
Aggregate feedback and make targeted changes to the harness.
This works similarly to boosting which focuses on mistakes from previous runs. A human can be pretty helpful in Step 3 (though not required) to verify and discuss proposed changes. Changes that overfit to a task are bad for generalization and can lead to regressions in other Tasks.
Automated trace analysis saves hours of time and made it easy to quickly try experiments. We’ll be publishing this skill soon, we’re currently testing it for prompt optimization generally.
What Actually Improved Agent Performance
Automated Trace analysis allowed us to debug where agents were going wrong. Issues included reasoning errors, not following task instructions, missing testing and verification, running out of time, etc. We go into these improvements in more details in the sections below.
Build & Self-Verify
Today’s models are exceptional self-improvement machines.
Self-verification allows agents to self-improve via feedback within a run. However, they don’t have a natural tendency to enter this build-verify loop.
The most common failure pattern was that the agent wrote a solution, re-read its own code, confirmed it looks ok, and stopped. Testing is a key part of autonomous agentic coding. It helps test for overall correctness and simultaneously gives agents signal to hill-climb against.
We added guidance to the system prompt on how to approach problem solving.
Planning & Discovery: Read the task, scan the codebase, and build an initial plan based on the task specification and how to verify the solution.
Build: Implement the plan with verification in mind. Build tests, if they don’t exist and test both happy paths and edge cases.
Verify: Run tests, read the full output, compare against what was asked (not against your own code).
Fix: Analyze any errors, revisit the original spec, and fix issues.
We really focus on testing because it powers the changes in every iteration. We found that alongside prompting, deterministic context injection helps agents verify their work. We use a PreCompletionChecklistMiddleware
Giving Agents Context about their Environment
Part of harness engineering is building a good delivery mechanism for context engineering. Terminal Bench tasks come with directory structures, built-in tooling, and strict timeouts.
Directory Context & Tooling: A LocalContextMiddleware
Teaching Agents to Write Testable Code: Agents don’t know how their code needs to be testable. We add prompting say their work will be measured against programatic tests, similar to when committing code. For example, Task specs that mention file paths should be followed exactly so the solutions works in an automated scoring step. Prompting that stresses edge-cases helps the agent avoid only checking “happy path” cases. Forcing models to conform to testing standards is a powerful strategy to avoid “slop buildup” over time.
Time Budgeting: We inject time budget warnings to nudge the agent to finish work and shift to verification. Agents are famously bad at time estimation so this heuristic helps in this environment. Real world coding usually doesn’t have strict time limits, but without adding any knowledge of constraints, agents won’t work within time bounds.
The more that agents know about their environment, constraints, and evaluation criteria, the better they can autonomously self-direct their work.
The purpose of the harness engineer: prepare and deliver context so agents can autonomously complete work.
Encouraging Agents to Step Back & Reconsider Plans
Agents can be myopic once they’ve decided on a plan which results in “doom loops” that make small variations to the same broken approach (10+ times in some traces).
We use a LoopDetectionMiddleware
Important note. This is a design heuristic that engineers around today’s perceived model issues. As models improve, these guardrails will likely be unnecessary, but today helps agents execute correctly and autonomously.
Choosing How Much Compute to Spend on Reasoning
Reasoning models can run autonomously for hours so we have to decide how much compute to spend on every subtask. You can use the max reasoning budget on every task, but most work can benefit from optimizing reasoning compute spend.
Terminal Bench timeout limits create a tradeoff. More reasoning helps agents evaluate each step, but can burn over 2x
We found that reasoning helps with planning to fully understand the problem, some Terminal Bench tasks are very difficult. A good plan helps get to a working solution more quickly.
Later stage verification also benefits from more reasoning to catch mistakes and get a solution submitted. As a heuristic, we choose a xhigh-high-xhigh "reasoning sandwich" as a baseline.
Running only at xhigh
The natural approach for models is Adaptive Reasoning, seen with Claude and Gemini models where the model decides how much compute to spend on reasoning.
In a multi-model harness, balancing reasoning budgets could play out as using a large model for planning and handing off to a smaller model for implementation.
Practical Takeaways for Building Agent Harnesses
The design space of agents is big. Here are some general principles from our experiments and building deepagents overall.
Context Engineering on Behalf of Agents. Context assembly is still difficult for agents today, especially in unseen environments. Onboarding models with context like directory structures, available tools, coding best practices, and problem solving strategies helps reduce the error surface for poor search and avoidable errors in planning.
Help agents self-verify their work. Models are biased towards their first plausible solution. Prompt them aggressively to verify their work by running tests and refining solutions. This is especially important in autonomous coding systems that don’t have humans in the loop.
Tracing as a feedback signal. Traces allow agents to self-evaluate and debug themselves. It’s important to debug tooling and reasoning together (ex: models go down wrong paths because they lack a tool or instructions how to do something).
Detect and fix bad patterns in the short term. Models today aren’t perfect. The job of the harness designer is to design around today’s shortcomings while planning for smarter models in the future. Blind retries and not verifying work are good examples. These guardrails will almost surely dissolve over time, but to build robust agent applications today, they’re useful tools to experiment with.
Tailor Harnesses to Models. The Codex and Claude prompting guides show that models require different prompting. A test run with Claude Opus 4.6 scored 59.6%
There’s more open research to do in harness design. Interesting avenues include multi-model systems (Codex, Gemini, and Claude together), memory primitives for continual learning so agents can autonomously improve on tasks, and measuring harness changes across models.
For the outer loop of improving agents, we’re looking at methods like RLMs to more efficiently mine traces. We’ll be continuing work to improve the harness and openly share our research.
We created a dataset of our Traces to share with the community.
Deep Agents is open source. Python and Javascript.
To more hill climbing and open research.
Join our newsletter
Updates from the LangChain team and community
Processing your application...
Success! Please check your inbox and click the link to confirm your subscription.
Sorry, something went wrong. Please try again.

関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み