NVIDIA の「LocateAnything」が迅速なグラウンディングを実現(8 分読了)
NVIDIA は、視覚言語モデルの座標生成における逐次処理のボトルネックを解消する「Parallel Box Decoding」技術と大規模データセット「LocateAnything-Data」を発表し、高速かつ高精度な統合型視覚検出を実現した。
キーポイント
並列ボックスデコーディング(PBD)の導入
従来のトークン逐次生成方式に代わり、バウンディングボックスやポイントを原子単位として一度にデコードする新手法を採用し、幾何学的整合性を保ちながら推論速度を大幅に向上させた。
大規模データエンジンとデータセット
1 億 3800 万件以上のトレーニングサンプルを含む「LocateAnything-Data」を構築し、多様性を高めて高精度な位置特定を実現した。
速度と精度の両立によるフロンティア拡大
並列処理と大規模学習データの相乗効果により、既存ベンチマークで高い IoU(交差率)を維持しつつ、デコーディングスループットを劇的に改善した。
Parallel Box Decoding (PBD) の導入
各バウンディングボックスを定長の原子単位として扱い、座標セットを並列ステップで予測することで、従来の逐次トークン生成や不規則なチャンク化の問題を解決し、高速かつ正確な位置特定を実現します。
柔軟な推論モードの提供
最大スループットを目指す「Fast Mode」、最高精度を求める「Slow Mode」、そして両者の利点を組み合わせて状況に応じて切り替える「Hybrid Mode」の3つの推論モードを備えています。
高精度なアーキテクチャ構成
Moon-ViTビジョンエンコーダーとQwen2.5言語デコーダーをMLPプロジェクターで橋渡しし、画像の解像度を維持したまま視覚トークンをボックスアラインされたブロックレベル予測へと直接変換する構造を採用しています。
並列推論のエラー処理と回復メカニズム
フォーマット不整合や空間的曖昧性が発生した場合、誤ったブロックを破棄して検証済みのプレフィックスに戻り、NTP(自己回帰)で再生成してからMTP(並列推論)へ復帰する仕組みを採用している。
影響分析・編集コメントを表示
影響分析
この発表は、Vision-Language Models(VLM)の実用化において最大の課題の一つであった「推論速度」と「位置特定精度」の両立に決定的な進展をもたらすものです。特に、並列処理を可能にするアーキテクチャの変更と大規模データの組み合わせは、自動運転やロボティクスなどリアルタイム性が求められる産業応用におけるモデル導入のハードルを大幅に下げると予想されます。
編集コメント
逐次生成の限界を打破する並列処理アプローチは、VLM の実世界適用において極めて重要な転換点となる技術です。特に大規模データとの相乗効果により、理論的な可能性が即座に実用レベルのパフォーマンスとして示された点は注目すべき成果です。
Abstract
VLM グラウンディングにおける自己回帰的ボトルネックの克服
ビジョン・ランゲージモデル(VLM)は、視覚的グラウンディングと検出を座標トークンの生成問題として定式化することが一般的です。これは、各 2D ボックスを複数の 1D トークンにシリアライズし、これらを主に独立して学習・復号化するアプローチです。このトークンごとの復号化は、ボックス幾何構造が持つ結合された構造と整合せず、厳密な逐次生成のために実用的な推論のボトルネックを生み出します。
私たちは、並列ボックス復号(Parallel Box Decoding: PBD)に基づく統合的な生成グラウンディングおよび検出フレームワークであるLocateAnythingを発表します。LocateAnything は、バウンディングボックスやポイントなどの幾何要素を原子単位として単一のステップで復号化することで、ボックス内の幾何的整合性を維持し、大幅な並列処理の可能性を開きます。私たちは、PBD が復号スループットと位置特定精度の両方を向上させることを示します。
さらに、スケーラブルなデータエンジンを発展させ、1 億 3800 万件以上のトレーニングサンプルを有する大規模データセット「LocateAnything-Data」を整備し、高精度な位置特定のためのデータの多様性を大幅に向上させました。広範な評価により、LocateAnything が速度と精度のフロンティアを前進させることが示され、デコードスループットが著しく向上するとともに、多様なベンチマークにおいて高い IoU(Intersection over Union)の位置特定品質も改善されました。これらの結果は、並列ボックスデコーディングと大規模トレーニングデータの相補的な利点が、効率的かつ精密な統合ビジュアルグラウンディングおよび検出を可能にすることを浮き彫りにしています。
Method
LocateAnything: 並列ボックスデコーディング
高いスループットでのデコーディングと信頼性の高い位置特定を両立させるため、私たちはParallel Box Decoding (PBD)(並列ボックスデコーディング)を基盤とした、VLM(Vision-Language Model:視覚言語モデル)に基づくビジュアル検出およびグラウンディングのための統合フレームワークである「LocateAnything」を提案します。
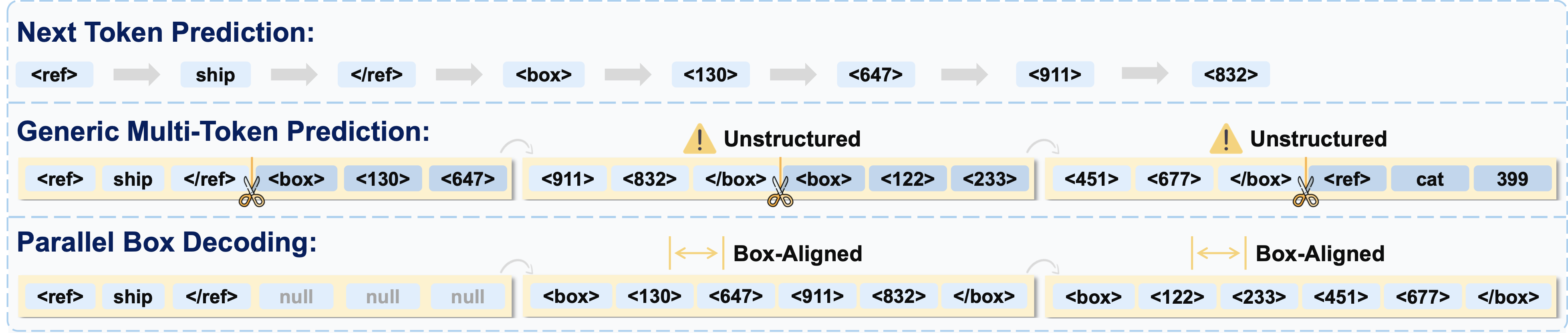
標準的なトークンデコーディング手法と並列ボックスデコーディング(PBD)の比較。
ボックス整合型原子単位
- 入力:画像と自然言語によるクエリ。ビジョンエンコーダーはネイティブ解像度で視覚トークンを抽出し、高精度な位置特定のために微細な空間詳細を保持します。
- パラレルデコーディング:LocateAnything は各バウンディングボックス(またはポイント)を定長の原子単位として扱い、座標トークンの任意のチャンク分割を回避しつつ、一連の平行ステップで完全な座標セット (x1, y1, x2, y2) を予測します。
- アーキテクチャ:Moon-ViT ビジョンエンコーダーと Qwen2.5 言語デコーダーを基盤とし、MLP プロジェクターによって橋渡しされ、視覚トークンをボックス整合型のブロックレベル予測シーケンスへ直接変換します。
柔軟な推論モード
- Fast Mode (MTP): 最大スループットを実現するために、複数のボックスを並列に予測します。これは、オンデバイス・ロボティクスや具現化エージェントなど、レイテンシと計算リソースが制約される環境に適しています。
- Slow Mode (NTP): 座標トークンを自己回帰的にデコードして最大限の安定性を確保します。高精度なラベリング、データセットのキュレーション、精度重視のオフライン評価に適切です。
- Hybrid Mode: デフォルトでは Fast Mode を使用しますが、フォーマットの不規則性や空間的な曖昧性が検出された場合は Slow Mode に切り替えます。これにより、速度向上の大部分を維持しつつ、堅牢な出力を保証します。
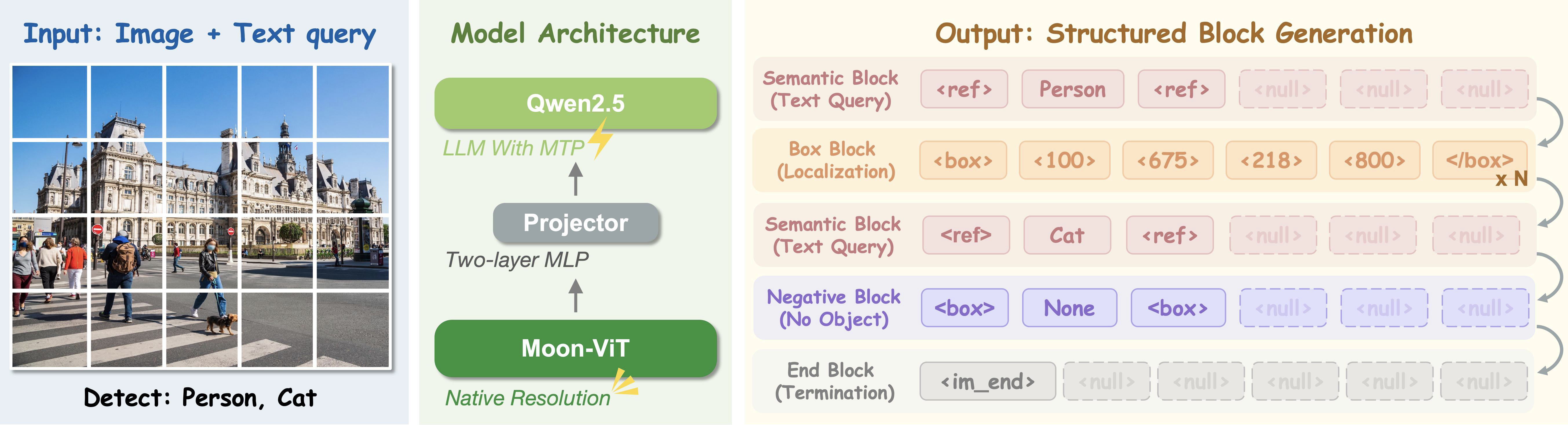
Parallel Box Decoding を用いた LocateAnything のアーキテクチャ概要。
On-Demand Inference: Corrected NTP Re-decoding
並列デコードにおいて*フォーマット不整合*(カテゴリ境界における構文の破損)または*空間的曖昧さ*(密に配置されたオブジェクト間の中間座標)が発生した場合、影響を受けたブロックは破棄され、生成は最後に検証されたプレフィックスに戻ります。その後、NTP は問題のあるブロックに対して自己回帰的にトークンを生成し、MTP に切り替える前に処理を完了します。

修正された NTP の再デコード:並列デコードでフォーマット不整合や空間的曖昧さに遭遇した場合、モデルは誤ったブロックを破棄し、標準的な NTP に戻って堅牢な予測を確保します。
LocateAnything-Data
138M の多様な言語クエリと 785M のボックス
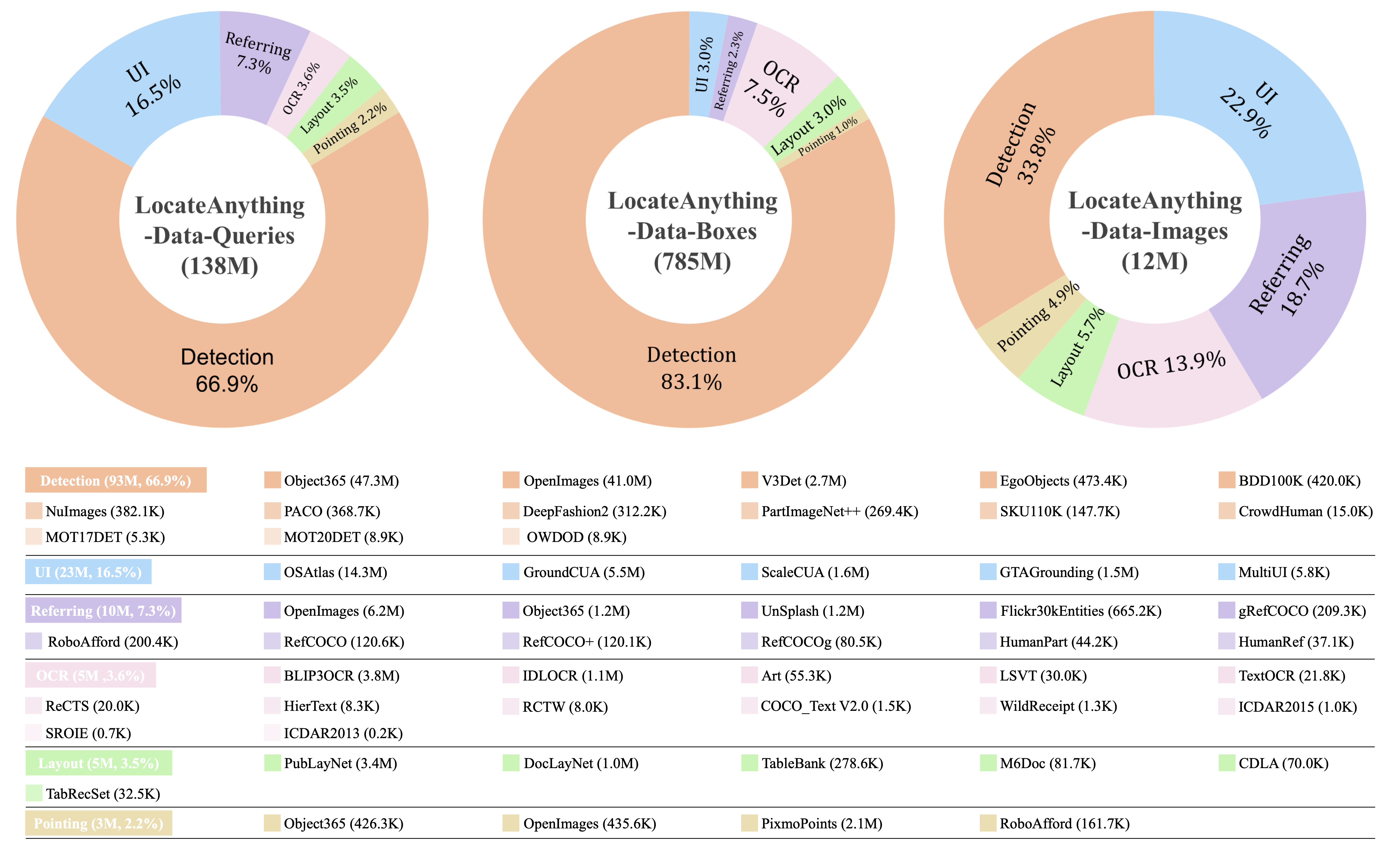
LocateAnything-Data に含まれる多様なクエリタイプの概要。
汎用的な視覚検出およびグラウンディングのために高度に能力の高いモデルを訓練するために、1200 万枚の一意な画像と膨大で密な監督空間信号を含むマルチドメインデータセットであるLocateAnything-Dataをキュレートしました。
一般物体検出
クエリの 66.9% およびボックスの 83.1% を占めます。精密かつ密な座標アライメントのための必須のバウンディングボックス(境界箱)監督を提供します。
GUI エレメントグラウンディング
クエリの 16.5% を占めます。モデルがエンボディドエージェントおよびグラフィカルユーザーインターフェース(GUI)ナビゲーションタスクをサポート可能にします。
参照理解
クエリの 7.3% を占めます。複雑な自然言語の意図を画像内の特定の空間領域にリンクさせます。
テキストローカライゼーション (OCR)
クエリの 3.6% を占めます。画像内のテキスト情報を知覚し、密にグラウンディングします。
レイアウトグラウンディング
クエリの 3.5% を占め、ドキュメントおよびシーンレイアウトの理解における構造的推論能力を強化します。
ポイントベースの位置特定
クエリの 2.2% を占め、微細な座標予測のための空間精度を向上させます。
主要結果
## 最先端のビジュアルグラウンディングと検出
デフォルトのハイブリッドモードにおける LocateAnything の精度指標およびスループット(NVIDIA H100 GPU 単体で測定した BPS)を報告します。LocateAnything は 12.7 BPS を達成し、テキストベースの Qwen3-VL (1.1 BPS) よりも 10 倍以上、量子化ベースの Rex-Omni (5.0 BPS) よりも 2.5 倍高速です。
## 高品質なマルチオブジェクト検出
 image
image
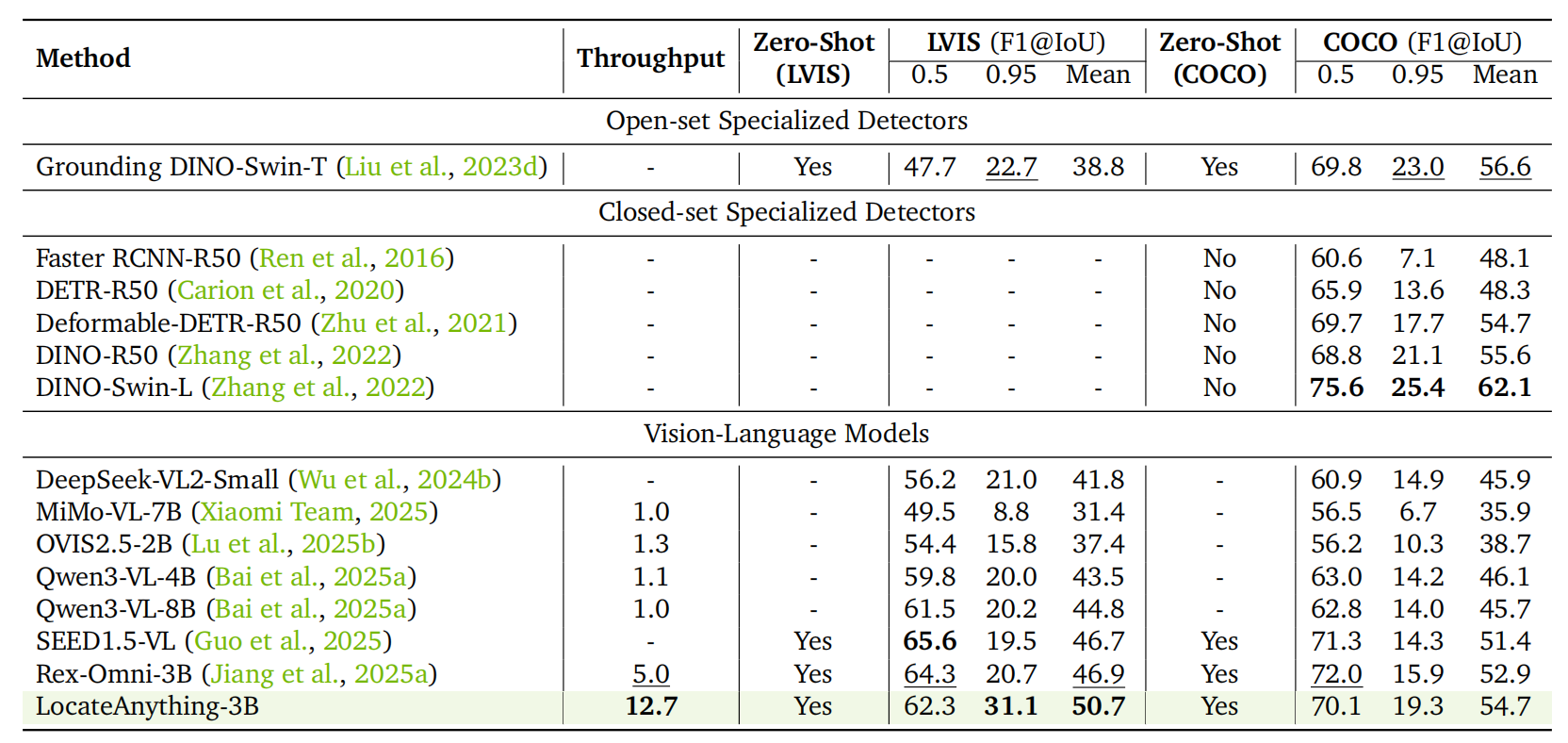
LVIS および COCO における結果。
LocateAnything は、同等のモデルサイズにおいて Rex-Omni と比較して LVIS で平均 F1 スコアを +3.8%、COCO で +1.8% 向上させました。特に高い IoU(Intersection over Union)閾値での改善が顕著です(LVIS における IoU=0.95 で 31.1 vs. 20.7)。
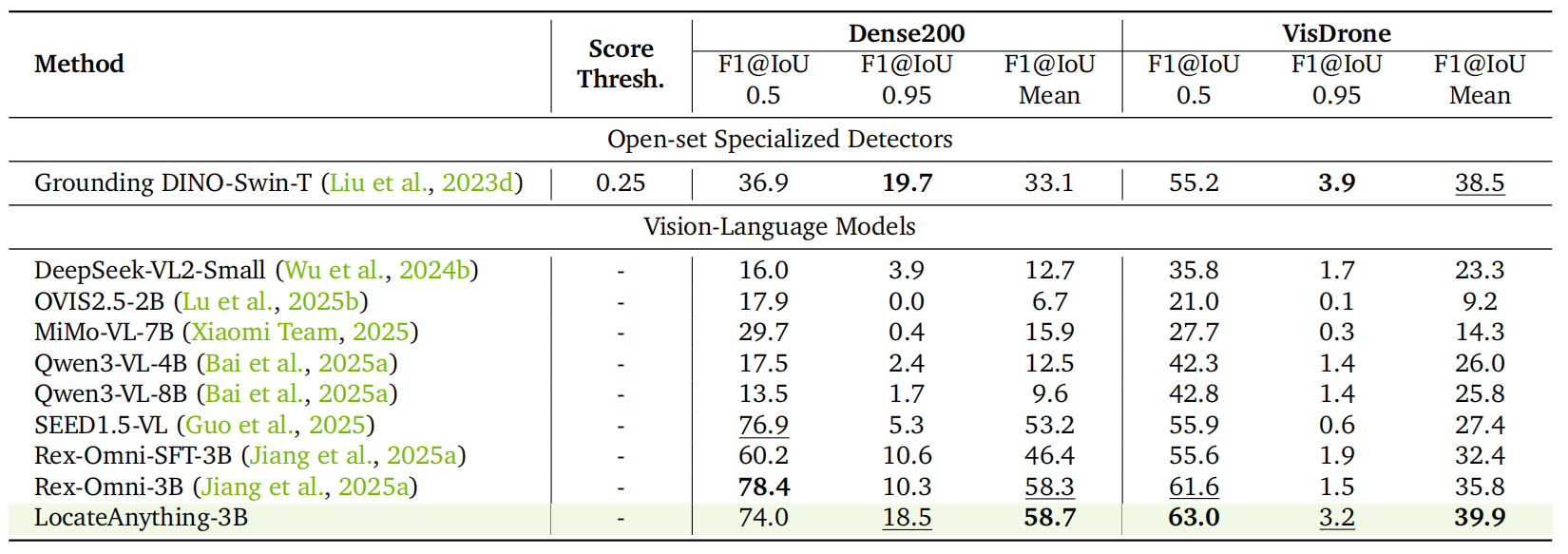
Dense Object Detection.
Dense200 および VisDrone の密集検出ベンチマークにおいて、LocateAnything はそれぞれ平均 F1 スコア 58.7 と 39.9 を達成し、Rex-Omni(58.3 / 35.8)を大幅に上回りました。これは、物体が重なり合う環境における境界の明確な描画能力に優れていることを示しています。
Precise Open-World Localization
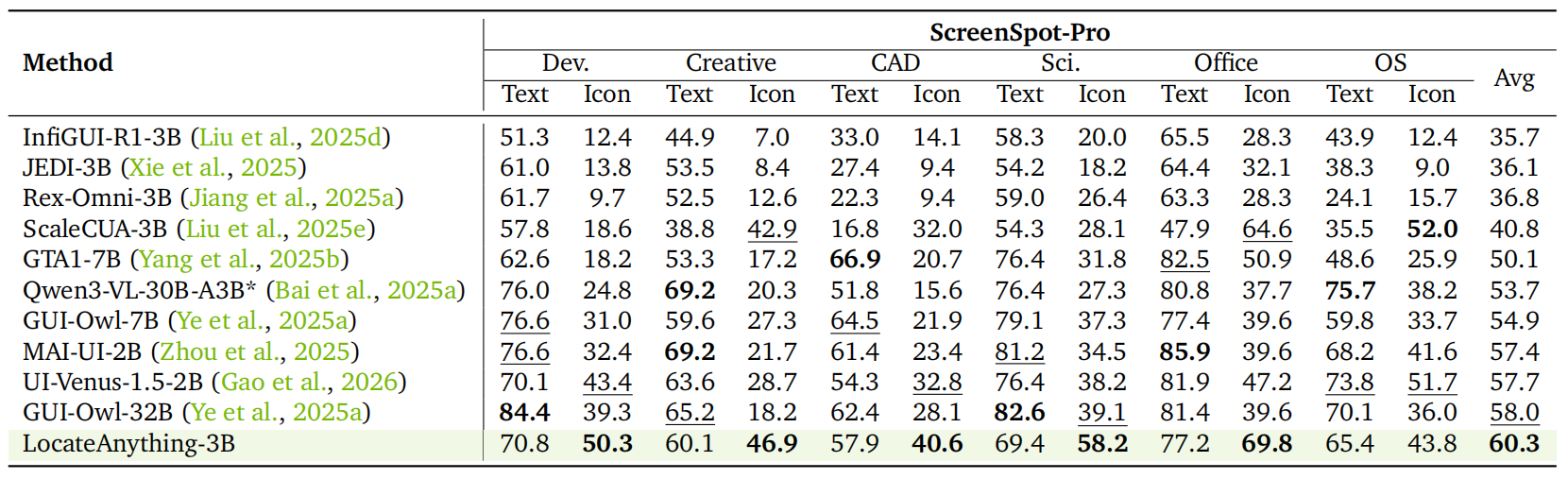
GUI Grounding (ScreenSpot-Pro).
LocateAnything は、SOTA(State-of-the-Art)の平均 F1 スコア 60.3 を達成し、Qwen3-VL-30B-A3B や GUI-Owl-32B のような汎用型 VLM(Vision-Language Model: ビジョン・ランゲージモデル)や専門モデルを上回りました。特にアイコンベースのクエリに対する性能が顕著に優れています。
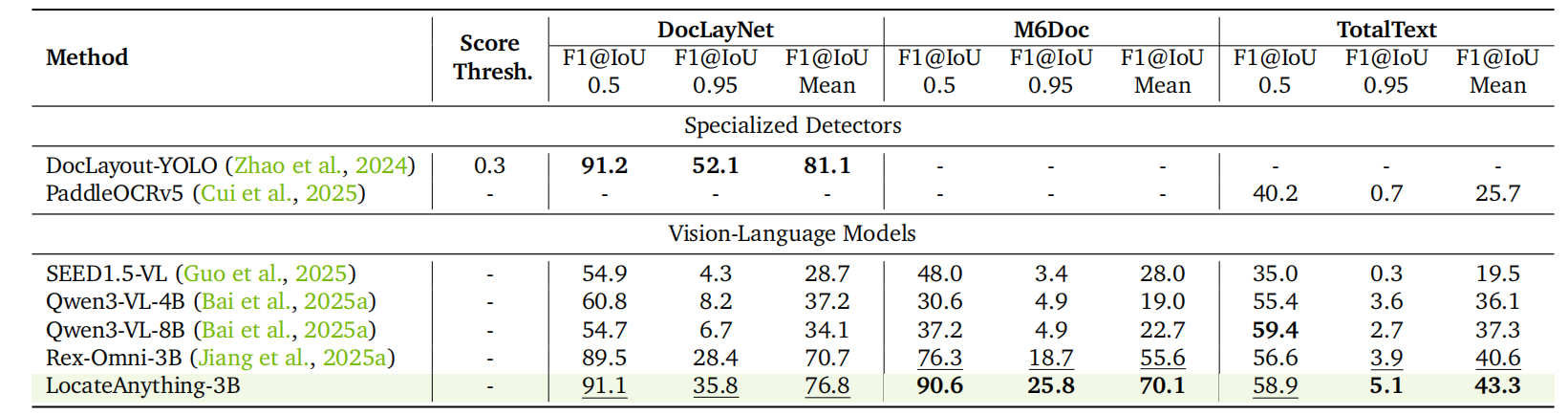
レイアウトグラウンディングと OCR。
LocateAnything は文書理解において新たな基準を確立しました:DocLayNet と M6Doc における平均 F1 スコアはそれぞれ 76.8 と 70.1 で、Rex-Omni を大幅に上回る(+6.1 / +14.5)結果となりました。TotalText OCR では平均 F1 スコア 43.3 を達成し、比較されたすべての手法を上回っています。
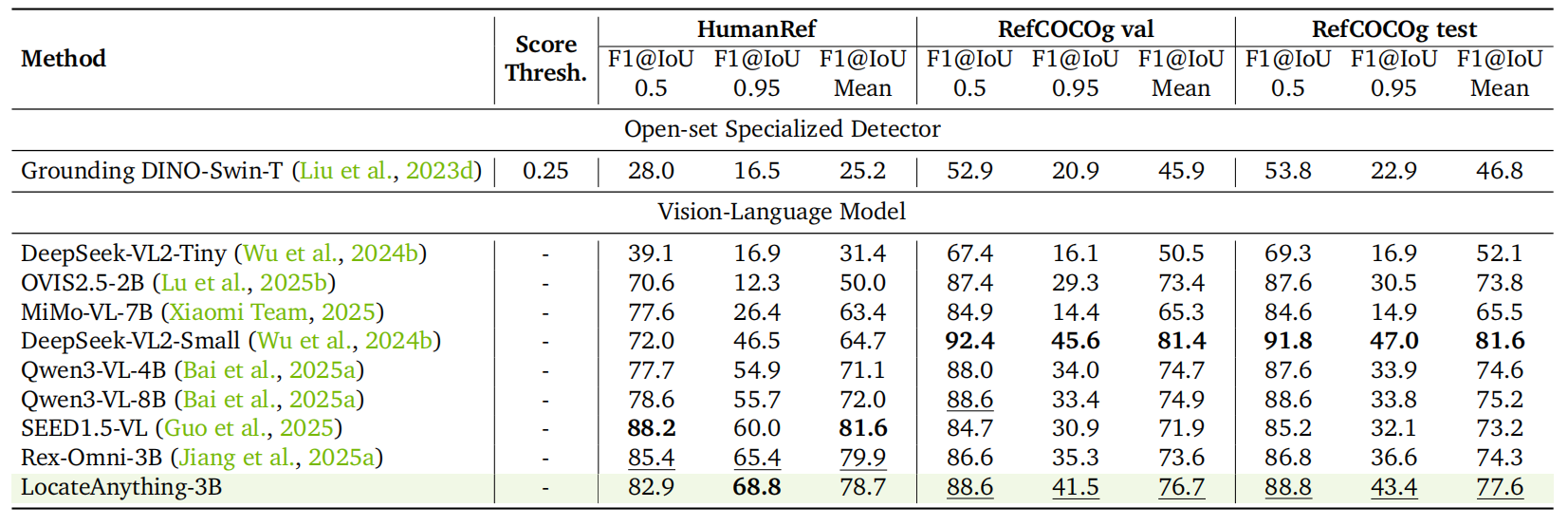
参照表現理解。
LocateAnything は、微妙な人間の意図と視覚領域をシームレスに整合させ、HumanRef において平均 F1 スコア 78.7 を達成し、RefCOCOg においてもトップティアモデルに対して非常に競争力のある結果を示しています。
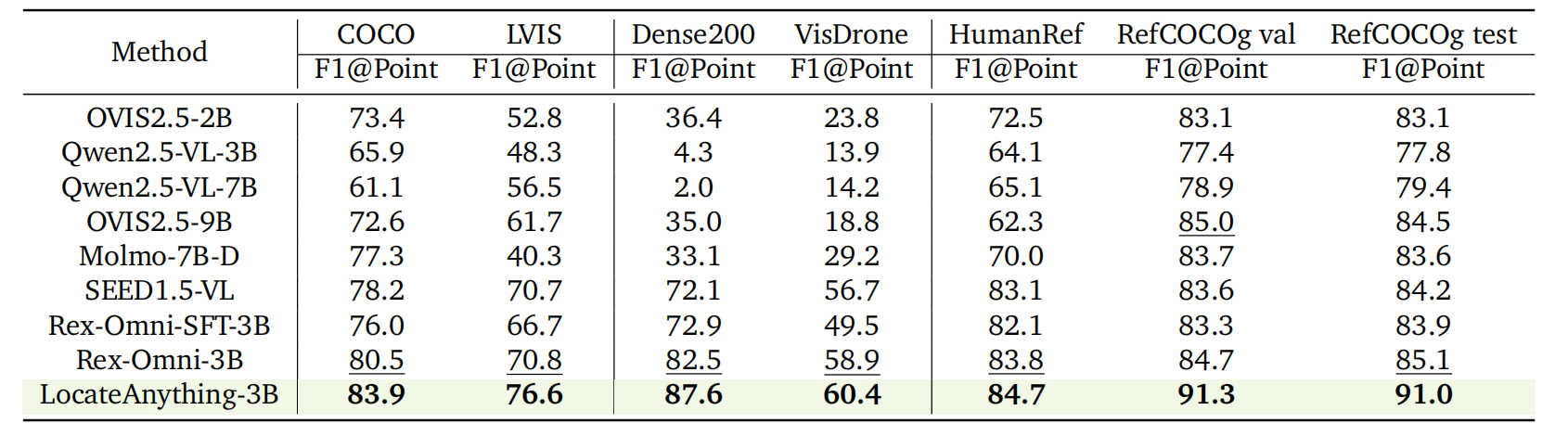
ポイントベースの位置特定。
COCO、LVIS、Dense200、VisDrone、HumanRef、および RefCOCOg ベンチマークにおけるポイントベースグラウンディングの評価。
Ablation Study
デザイン選択の分析とデコーディング効率の解明
COCO データセット上で、座標表現、MTP(Multi-Task Prediction)の定式化、デコーディングモード、ボックス出力順序、スループット拡張にわたるコア設計を検証するためにアブレーション研究を実施しました。

座標表現、MTP 定式化 & デコーディングモード。
(a) PBD(Slow Mode)は F1 スコア 52.1 を達成し、ボックス整合型定式化が 1D シリアライゼーションよりも強力な教師信号を提供することを証明しています。(b) PBD は構造非依存の MTP メソッドを劇的に上回ります(SDLM-B6 の場合、16.9 BPS vs 5.5 BPS)一方で F1 スコアも向上します。(c) 統合トレーニングにより Slow Mode は F1 52.1 に引き上げられ、Hybrid Mode は F1 51.6 を維持しつつ速度の利点(13.2 BPS)のほとんどを保持しています。
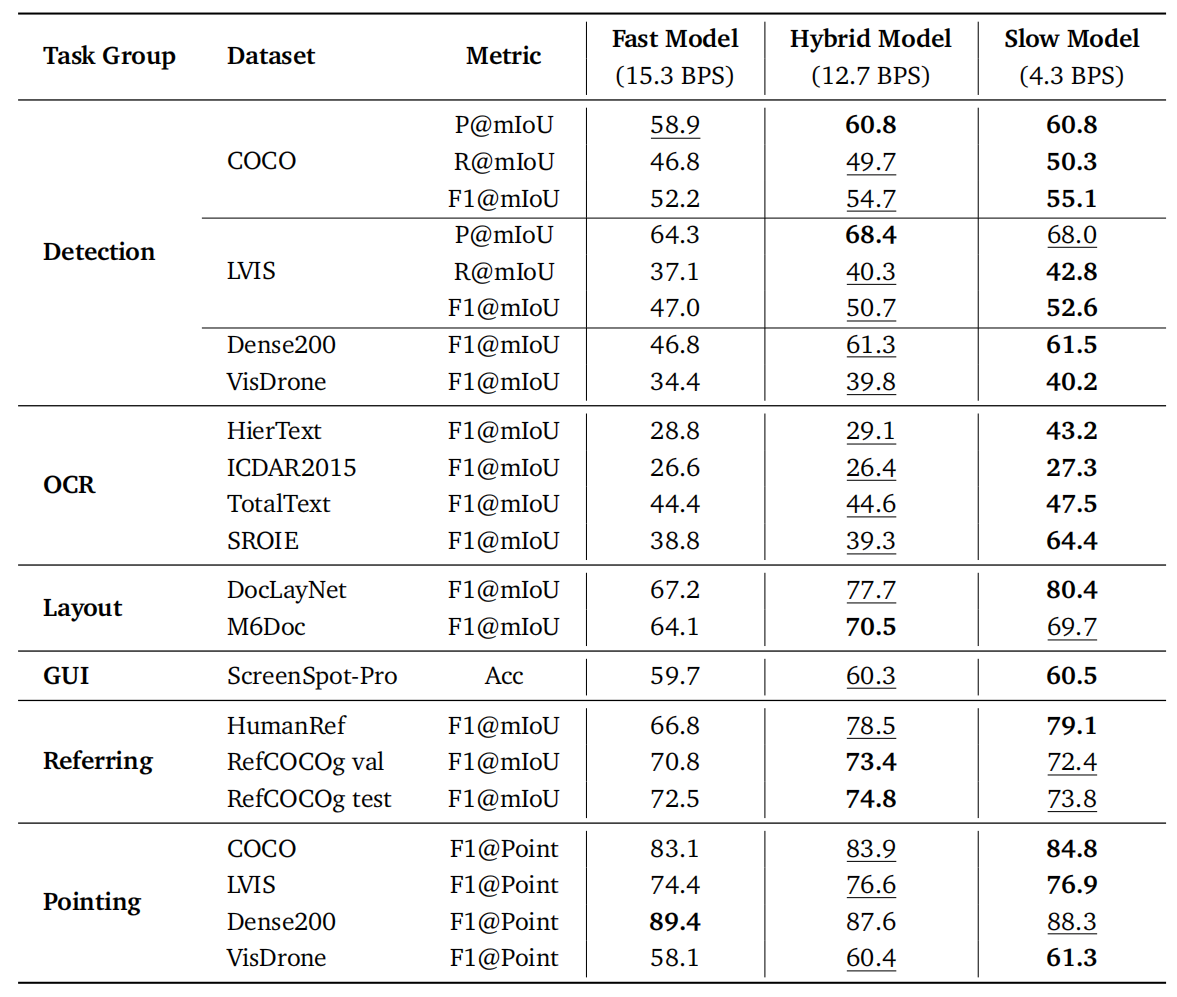
デコーディングモード比較。
統合二重定式化トレーニングにより、Slow Mode の上限は F1 50.1 から 52.1 に引き上げられました。Hybrid Mode は速度と精度のトレードオフをシームレスに解決し、堅牢な高精度ローカライゼーションを実現しながら、速度の利点のほとんどを保持しています。
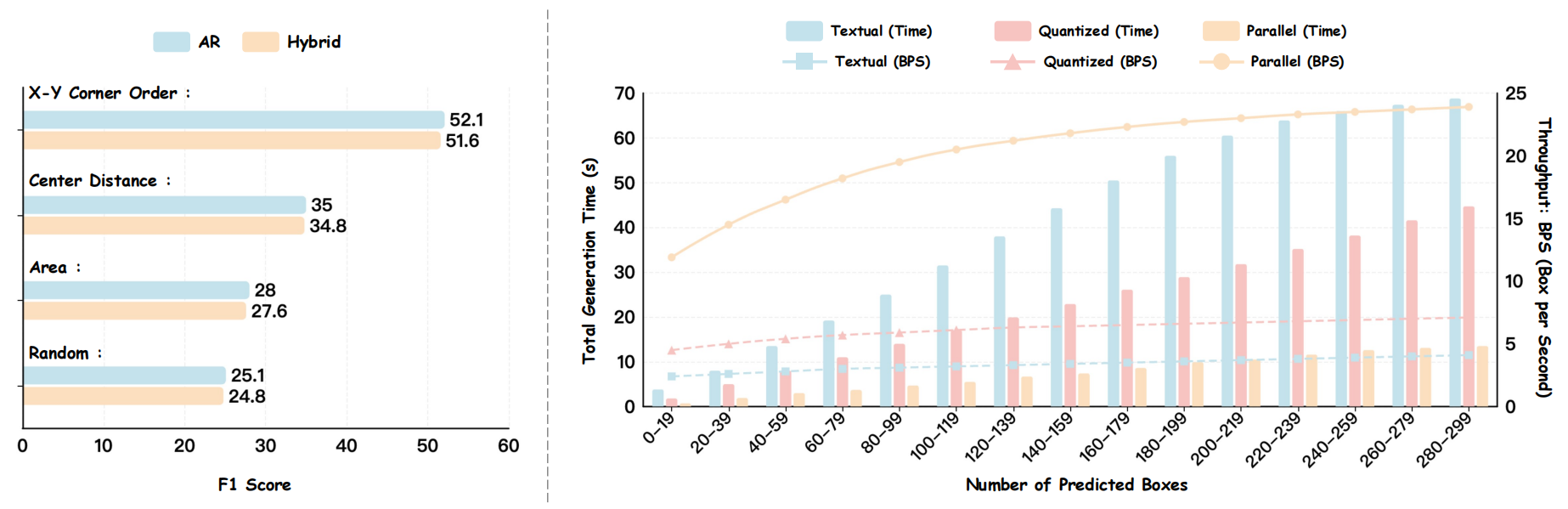
ボックス順序付けとデコードスループット。
*左:* X-Y コーナー順序ソートは、4 つの空間順序付け戦略の中で最も高い F1 スコアを達成します。*右:* 対象となるボックスが 20 から 300 に増加するにつれ、NTP (Non-Parallel Token) メソッドは深刻なレイテンシボトルネックに陥る一方、並列ボックスデコード (Parallel Box Decoding) は 2 倍から 6 倍の高速化を実現し、密集したシーンでのスループットを 12 BPS から約 25 BPS に拡張します。
Qualitative Results
ワイルドにおける高品質なグラウンディング
LocateAnything は、文書理解、GUI インタラクション、オブジェクト検出の各タスクにおいて、精密なビジュアルグラウンディングを実現します。

多様な解像度とカテゴリにわたる、密集かつ高精度なボックス予測の定性的可視化。

Dense Object Detection (高密度オブジェクト検出)

高精度 OCR
参照表現理解
Citation
LocateAnything の並列ボックスデコーディング(parallel box decoding)があなたの研究に有用であると感じた場合は、ぜひ以下の論文を引用してください。
@article{wang2025locateanything,
title = {LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding},
author = {Shihao Wang and Shilong Liu and Yuanguo Kuang and Xinyu Wei and Yangzhou Liu and Zhiqi Li and Yunze Man and Guo Chen and Andrew Tao and Guilin Liu and Jan Kautz and Lei Zhang and Zhiding Yu},
journal = {arXiv preprint arXiv:2605.27365},
year = {2026},
}
原文を表示
Abstract
Overcoming Autoregressive Bottlenecks in VLM Grounding
Vision-language models (VLMs) commonly formulate visual grounding and detection as a
coordinate-token generation problem, serializing each 2D box into multiple 1D tokens that are
learned and decoded largely independently. This token-by-token decoding mismatches the coupled
structure of box geometry and creates a practical inference bottleneck due to
strictly sequential generation.
We introduce LocateAnything, a unified generative grounding and detection framework
based on Parallel Box Decoding (PBD). By decoding geometric elements such as
bounding boxes and points as atomic units in a single step, LocateAnything preserves intra-box
geometric coherence and unlocks substantial parallelism. We show that PBD improves both decoding
throughput and localization accuracy.
We further develop a scalable data engine and curate LocateAnything-Data, a
large-scale dataset with more than 138 million training samples, substantially increasing data
diversity for high-precision localization. Extensive evaluations show that LocateAnything advances
the speed–accuracy frontier, achieving significantly higher decoding throughput while improving
high-IoU localization quality across diverse benchmarks. The results highlight the complementary
benefits of Parallel Box Decoding and large-scale training data in enabling efficient and precise
unified visual grounding and detection.
Method
LocateAnything: Parallel Box Decoding
To reconcile high-throughput decoding with reliable localization, we propose
LocateAnything, a unified framework for VLM-based visual detection and grounding
built upon Parallel Box Decoding (PBD).
Comparison of standard token decoding methods vs Parallel Box Decoding (PBD).
Box-Aligned Atomic Units
- Input: An image and a natural language text query. The vision encoder
extracts visual tokens at native resolution, preserving fine-grained spatial details
for high-precision localization.
- Parallel Decoding: LocateAnything treats each bounding box (or point)
as an atomic unit of constant length and predicts the full coordinate set
(x1, y1, x2,
y2) in one parallel step, avoiding arbitrary chunking of
coordinate tokens.
- Architecture: Built upon a Moon-ViT vision encoder and a Qwen2.5
language decoder, bridged by a MLP projector, directly converting visual tokens into
a sequence of box-aligned block-level predictions.
Flexible Inference Modes
- Fast Mode (MTP): Predicts full boxes in parallel for maximum
throughput, suitable for latency- and compute-constrained settings such as on-device
robotics and embodied agents.
- Slow Mode (NTP): Decodes coordinate tokens autoregressively for maximum
stability, appropriate for high-precision labeling, dataset curation, and
accuracy-oriented offline evaluation.
- Hybrid Mode: Uses Fast Mode by default and falls back to Slow Mode when
format irregularity or spatial ambiguity is detected, preserving most speed gains while
maintaining robust outputs.
Architecture overview of LocateAnything using Parallel Box Decoding.
On-Demand Inference: Corrected NTP Re-decoding
When parallel decoding encounters *Format Irregularity* (malformed syntax at category
boundaries) or *Spatial Ambiguity* (intermediate coordinates between densely arranged
objects), the compromised block is discarded and generation reverts to the last verified prefix.
NTP then autoregressively generates tokens for the problematic block before switching back to MTP.
Corrected NTP Re-decoding: when parallel decoding encounters format irregularity or spatial
ambiguity, the model discards the erroneous block and reverts to standard NTP to ensure robust
predictions.
LocateAnything-Data
138M Diverse Language Queries and 785M Boxes
Overview of the diverse query types encompassed within LocateAnything-Data.
To train a highly capable model for general-purpose visual detection and grounding, we curate
LocateAnything-Data, a multi-domain dataset encompassing 12M unique images and
massive, dense supervisory spatial signals.
General Object Detection
66.9% of queries and 83.1% of boxes. Provides essential bounding box supervision for precise
and dense coordinate alignments.
GUI Element Grounding
16.5% of queries. Enables the model to support embodied agents and graphical user interface
navigation tasks.
Referring Comprehension
7.3% of queries. Links complex natural language intents to specific spatial regions within
images.
Text Localization (OCR)
3.6% of queries. Perceives and tightly grounds textual information within images.
Layout Grounding
3.5% of queries. Enriches the structural reasoning capabilities for document and scene
layout understanding.
Point-Based Localization
2.2% of queries. Refines spatial precision for fine-grained coordinate predictions.
Main Results
State-of-the-Art Visual Grounding & Detection
We report accuracy metrics and throughput (BPS, measured on a single NVIDIA H100 GPU) of
LocateAnything under the default Hybrid Mode. LocateAnything achieves 12.7 BPS, over 10× faster
than textual-based Qwen3-VL (1.1 BPS) and 2.5× faster than quantized-based Rex-Omni (5.0 BPS).
High-Quality Multi-Object Detection
Results on LVIS and COCO.
LocateAnything improves the mean F1 by +3.8% on LVIS and +1.8% on COCO compared to
Rex-Omni at identical model size, with particularly strong gains at high IoU thresholds
(31.1 vs. 20.7 at IoU=0.95 on LVIS).
Dense Object Detection.
On dense detection benchmarks Dense200 and VisDrone, LocateAnything achieves 58.7 and 39.9
mean F1 respectively, substantially outperforming Rex-Omni (58.3 / 35.8), demonstrating
superior boundary delineation in heavily overlapping environments.
Precise Open-World Localization
GUI Grounding (ScreenSpot-Pro).
LocateAnything achieves a SOTA mean F1 of 60.3, surpassing generalist VLMs like
Qwen3-VL-30B-A3B and specialized models such as GUI-Owl-32B, with particularly strong
performance on icon-based queries.
Layout Grounding & OCR.
LocateAnything establishes new standards on document understanding: 76.8 and 70.1 mean F1
on DocLayNet and M6Doc respectively, outperforming Rex-Omni by substantial margins (+6.1 / +14.5).
On TotalText OCR, it achieves 43.3 mean F1, surpassing all compared methods.
Referring Expression Comprehension.
LocateAnything seamlessly aligns nuanced human intents with visual regions, achieving
78.7 mean F1 on HumanRef and remaining highly competitive on RefCOCOg against
top-tier models.
Point-Based Localization.
Evaluation on point-based grounding across COCO, LVIS, Dense200, VisDrone, HumanRef, and
RefCOCOg benchmarks.
Ablation Study
Analyzing Design Choices and Decoding Efficiency
We conduct ablation studies on the COCO dataset to validate our core designs across coordinate
representation, MTP formulation, decoding mode, box output order, and throughput scaling.
Coordinate Representation, MTP Formulation & Decoding Modes.
(a) PBD (Slow Mode) achieves the highest F1 of 52.1, proving box-aligned formulation
provides stronger supervision than 1D serialization. (b) PBD dramatically outpaces
structure-agnostic MTP methods (16.9 BPS vs. 5.5 BPS for SDLM-B6) while improving F1.
(c) Joint training pushes Slow Mode to 52.1 F1; Hybrid Mode preserves most speed gains
(13.2 BPS) at 51.6 F1.
Decoding Mode Comparison.
Joint dual-formulation training successfully pushes the Slow Mode upper bound from 50.1 to
52.1 F1. Hybrid Mode seamlessly resolves the speed-accuracy trade-off, achieving robust
high-precision localization while preserving most speed gains.
Box Ordering & Decoding Throughput.
*Left:* X-Y Corner Order sorting yields the highest F1-score among four spatial
ordering strategies. *Right:* As target boxes increase from 20 to 300, NTP methods
suffer from severe latency bottleneck, while Parallel Box Decoding achieves a 2× to 6× speedup,
scaling throughput from 12 BPS to ~25 BPS in dense scenes.
Qualitative Results
High-Quality Grounding In The Wild
LocateAnything achieves precise visual grounding across document understanding, GUI interaction, and
object detection tasks.
Qualitative visualizations of dense and high-precision box predictions across diverse
resolutions and categories.
Dense Object Detection
High-precision OCR
Referring Expression Comprehension
Citation
If you find LocateAnything's parallel box decoding useful for your research, please consider citing
our work.
@article{wang2025locateanything,
title = {LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding},
author = {Shihao Wang and Shilong Liu and Yuanguo Kuang and Xinyu Wei and Yangzhou Liu and Zhiqi Li and Yunze Man and Guo Chen and Andrew Tao and Guilin Liu and Jan Kautz and Lei Zhang and Zhiding Yu},
journal = {arXiv preprint arXiv:2605.27365},
year = {2026},
}
関連記事
NVIDIA AI、空間推論のためのトレーニング不要エージェント「SpatialClaw」を発表:コードを行動インターフェースとして活用
NVIDIA Research は、視覚言語モデルの弱点である物体の位置や関係性の判断を改善するトレーニング不要フレームワーク「SpatialClaw」を発表した。同チームは、知能エージェントが知覚ツールを呼び出す際の行動インターフェースこそがボトルネックであると指摘し、コードをそのインターフェースとして扱う解決策を提案している。
Zyphra が Zamba2-VL を公開:ハイブリッド Mamba2–Transformer 型ビジョン言語モデルが初トークン生成時間を約 10 倍短縮
Zyphra は、画像とテキストを同時に処理するオープンソースのビジョン言語モデル「Zamba2-VL」シリーズ(パラメータ数 1.2B/2.7B/7B)を公開した。同社は従来の密集型 Transformer に代わり、ハイブリッド状態空間設計を採用し、競合と同等の精度を維持しつつ初トークン生成時間を約 10 倍短縮する技術を実現した。
MIT の研究者が AI モデルにチャートの解釈を教示
MIT の研究者らは、市場の意思決定を加速するため、生成 AI モデルが視覚・数値・言語情報を統合してチャートを正確に解釈する技術を研究している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み