コーディングエージェントの構成要素
Sebastian Raschka氏は、コーディングエージェントの設計における6つの主要構成要素と、LLM、推論モデル、エージェントの関係性を解説し、実用的なAIシステム構築におけるエージェント層の重要性を論じている。
キーポイント
コーディングエージェントの定義と目的
Claude CodeやCodex CLIなどのコーディングエージェントは、LLMをアプリケーション層(エージェントハーネス)でラップし、コーディングタスクにおいてより便利で高性能なエージェント的ツールとして機能する。
実用的LLMシステムの進歩におけるエージェントの重要性
最近の実用的LLMシステムの進歩は、より優れたモデルだけでなく、ツール使用、コンテキスト管理、メモリなどの周辺システムの活用に大きく依存しており、これがプレーンなチャットインターフェースよりもClaude CodeやCodexがはるかに有能に感じられる理由である。
LLM、推論モデル、エージェントの関係性の明確化
LLMはコアの次トークンモデル、推論モデルは中間推論により多くの推論時間を費やすように訓練/プロンプトされたLLM、エージェントはモデルを囲む制御ループとして機能する上位層であり、目標に基づいて次のアクションを決定する。
コーディングエージェントの主要構成要素
コーディングエージェントは、モデル選択だけでなく、リポジトリコンテキスト、ツール設計、プロンプトキャッシュの安定性、メモリ、長いセッションの継続性などの周辺システムを含むソフトウェア作業向けに設計されている。
エージェントの構成要素と関係性
LLMは生のモデル、推論モデルは中間推論トレースを出力し自己検証を強化したLLM、エージェントはモデルにツール・メモリ・環境フィードバックを組み合わせたループ、エージェントハーネスはコンテキスト・ツール使用・プロンプト・状態・制御フローを管理するソフトウェア構造である。
コーディングハーネスの役割
コーディングハーネスはエージェントハーネスの特殊ケースで、コードコンテキスト・ツール・実行・反復的フィードバックを管理し、リポジトリナビゲーションやテスト実行などコーディング特有の複雑な作業を支援する。
コーディングハーネスの重要性
コーディングハーネスは、モデルの周りのソフトウェア層であり、プロンプトの組み立て、ツールの公開、ファイル状態の追跡、編集の適用、コマンドの実行、権限の管理、安定したプレフィックスのキャッシュ、メモリの保存などを担当する。この層は、モデルを直接プロンプトするよりもユーザーエクスペリエンスを大きく形成する。
影響分析・編集コメントを表示
影響分析
この記事は、AI業界で注目が高まるエージェント技術の基礎的な概念整理と実装指針を提供しており、特にソフトウェア開発分野でのLLM応用を深化させるための重要なフレームワークを示している。技術的な概念の明確化により、開発者間の共通理解を促進し、より洗練されたAI支援ツールの開発を加速させる可能性がある。
編集コメント
エージェント技術の基礎を体系的に解説した教育・啓発的な内容であり、実践的な開発者向けの参考資料として価値が高い。技術トレンドの核心を捉えつつ、過度な宣伝色がなく、概念整理が明確に行われている点が評価できる。
この記事では、コーディングエージェントとエージェントハーネスの全体的な設計について、それらが何であるか、どのように機能するか、そして実際にさまざまな要素がどのように組み合わさるかについて説明します。私の『Build a Large Language Model (From Scratch)』および『Build a Large Reasoning Model (From Scratch)』の読者はエージェントについてよく質問するので、参照できる資料を書くことが役立つと考えました。
より一般的には、エージェントは重要なトピックとなっています。なぜなら、実用的なLLM(大規模言語モデル)システムにおける最近の進歩の多くは、より優れたモデルだけでなく、それらの使い方についても関わっているからです。多くの現実世界のアプリケーションでは、ツールの使用、コンテキスト管理、メモリなどの周辺システムが、モデル自体と同じくらい重要な役割を果たします。これはまた、Claude CodeやCodexのようなシステムが、プレーンなチャットインターフェースで使用される同じモデルよりもはるかに能力が高いと感じられる理由を説明するのにも役立ちます。
この記事では、コーディングエージェントの主要な構成要素を6つ示します。
Claude Code、Codex CLI、およびその他のコーディングエージェント
あなたはおそらくClaude CodeやCodex CLIに精通しているでしょうが、前提を説明するために、これらは本質的に、LLMをアプリケーション層(いわゆるエージェントハーネス)でラップして、コーディングタスクにより便利で高性能にするエージェント的コーディングツールです。
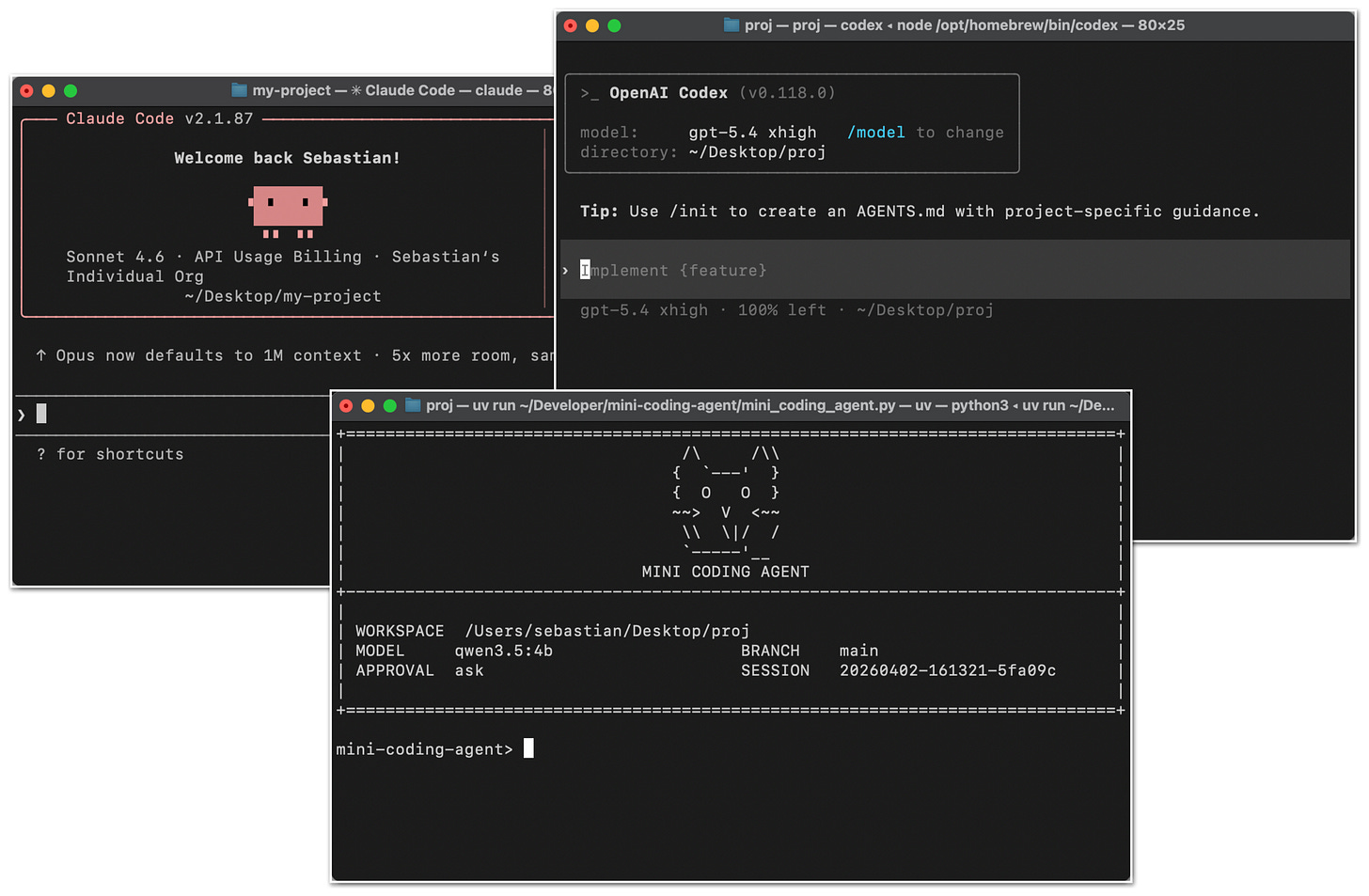
図1: Claude Code CLI、Codex CLI、および私のMini Coding Agent。
コーディングエージェントは、ソフトウェア作業のために設計されており、注目すべき部分はモデルの選択だけでなく、リポジトリコンテキスト、ツール設計、プロンプトキャッシュの安定性、メモリ、長いセッションの継続性などの周辺システムも含まれます。
この区別は重要です。なぜなら、LLMのコーディング能力について話すとき、人々はモデル、推論行動、エージェント製品を一つのものとしてまとめてしまうことがよくあるからです。しかし、コーディングエージェントの詳細に入る前に、より広い概念であるLLM、推論モデル、エージェントの違いについて、少し背景を簡単に説明させてください。
LLM、推論モデル、エージェントの関係について
LLMはコアの次トークンモデルです。推論モデルは依然としてLLMですが、通常、推論時間の計算を中間推論、検証、または候補回答の探索により多く費やすように訓練および/またはプロンプトされたものです。
エージェントはその上にある層であり、モデルを囲む制御ループとして理解できます。通常、目標が与えられると、エージェント層(またはハーネス)は次に何を検査するか、どのツールを呼び出すか、状態をどのように更新するか、いつ停止するかなどを決定します。
大まかに、関係を次のように考えることができます:LLMはエンジンであり、推論モデルは強化されたエンジン(より強力だが、使用コストが高い)であり、エージェントハーネスはモデルを活用するのに役立ちます。この比喩は完全ではありません。なぜなら、従来型および推論LLMをスタンドアロンモデル(チャットUIやPythonセッション内)としても使用できるからです。しかし、主なポイントが伝わればと思います。

図2: 従来型LLM、推論LLM(または推論モデル)、およびエージェントハーネスでラップされたLLMの関係。
言い換えれば、エージェントは環境内でモデルを繰り返し呼び出すシステムです。
したがって、要約すると次のようにまとめることができます:
LLM: 生のモデル
推論モデル: 中間推論トレースを出力し、自身をより検証するように最適化されたLLM
エージェント: モデルに加えてツール、メモリ、環境フィードバックを使用するループ
エージェントハーネス: コンテキスト、ツール使用、プロンプト、状態、制御フローを管理するエージェントの周りのソフトウェアスキャフォールド
コーディングハーネス: エージェントハーネスの特殊なケース。つまり、コードコンテキスト、ツール、実行、反復フィードバックを管理するソフトウェアエンジニアリング向けのタスク固有のハーネス
上記にリストしたように、エージェントとコーディングツールの文脈では、エージェントハーネスと(エージェント的)コーディングハーネスという2つの一般的な用語もあります。コーディングハーネスは、モデルが効果的にコードを書き、編集するのを助けるモデルの周りのソフトウェアスキャフォールドです。そして、エージェントハーネスはもう少し広く、コーディングに特化していません(例えば、OpenClawを考えてください)。CodexとClaude Codeはコーディングハーネスと見なすことができます。
いずれにせよ、より優れたLLMは推論モデル(追加の訓練を含む)のより良い基盤を提供し、ハーネスはこの推論モデルからより多くを引き出します。
確かに、LLMと推論モデルは、ハーネスなしでもコーディングタスクを自分で解決することができます。しかし、コーディング作業は次トークン生成だけではありません。その多くは、リポジトリナビゲーション、検索、関数検索、差分適用、テスト実行、エラー検査、および関連するすべての情報をコンテキスト内に保持することに関わっています。(コーダーはこれが難しい精神的作業であることを知っているかもしれません。それが、コーディングセッション中に中断されるのを嫌う理由です :))。
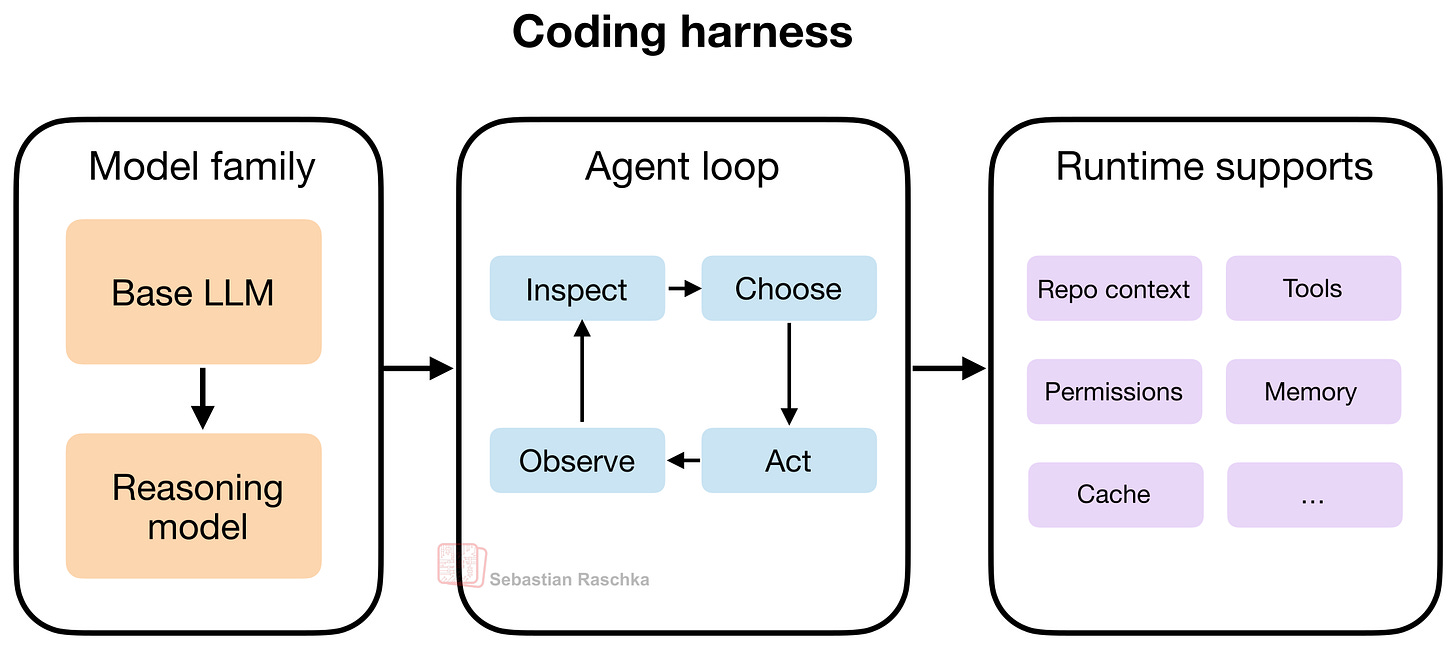
図3. コーディングハーネスは3つの層を組み合わせます:モデルファミリー、エージェントループ、ランタイムサポート。モデルは「エンジン」を提供し、エージェントループは反復的な問題解決を駆動し、ランタイムサポートは配管を提供します。ループ内では、「観察」が環境から情報を収集し、「検査」がその情報を分析し、「選択」が次のステップを選び、「実行」がそれを実行します。
ここでの要点は、優れたコーディングハーネスは、コンテキスト管理などに役立つため、推論モデルと非推論モデルをプレーンなチャットボックスよりもはるかに強力に感じさせることができるということです。
コーディングハーネス
前のセクションで述べたように、ハーネスと言うとき、通常、モデルの周りのソフトウェア層を意味し、プロンプトを組み立て、ツールを公開し、ファイル状態を追跡し、編集を適用し、コマンドを実行し、権限を管理し、安定したプレフィックスをキャッシュし、メモリを保存し、その他多くのことを行います。
今日、LLMを使用する際、この層は、モデルに直接プロンプトを送るか、ウェブチャットUI(「アップロードされたファイルとのチャット」に近い)を使用するかと比較して、ユーザーエクスペリエンスの大部分を形作っています。
私の見解では、現在のLLMのバニラバージョンは非常に似た能力を持っているため(例えば、GPT-5.4、Opus 4.6、GLM-5などのバニラバージョン)、ハーネスはしばしば、あるLLMが別のLLMよりもうまく機能するようにする区別要因となることがあります。
これは推測ですが、最新で最も能力の高いオープンウェイトLLMの1つ、例えばGLM-5を同様のハーネスに組み込んだ場合、CodexのGPT-5.4やClaude CodeのClaude Opus 4.6と同等の性能を発揮できる可能性が高いと思います。とはいえ、ハーネス固有の事後訓練は通常有益です。例えば、OpenAIは歴史的に別々のGPT-5.3とGPT-5.3-Codexバリアントを維持していました。
次のセクションでは、私のMini Coding Agent: https://github.com/rasbt/mini-coding-agent を使用して、コーディングハーネスのコアコンポーネントについてより具体的に議論したいと思います。
図4: 以下のセクションで議論されるコーディングエージェント/コーディングハーネスの主要なハーネス機能。
ちなみに、この記事では、簡単のために「コーディングエージェント」と「コーディングハーネス」という用語をある程度互換的に使用します。(厳密には、エージェントはモデル駆動の意思決定ループであり、ハーネスはコンテキスト、ツール、実行サポートを提供する周辺のソフトウェアスキャフォールドです。)
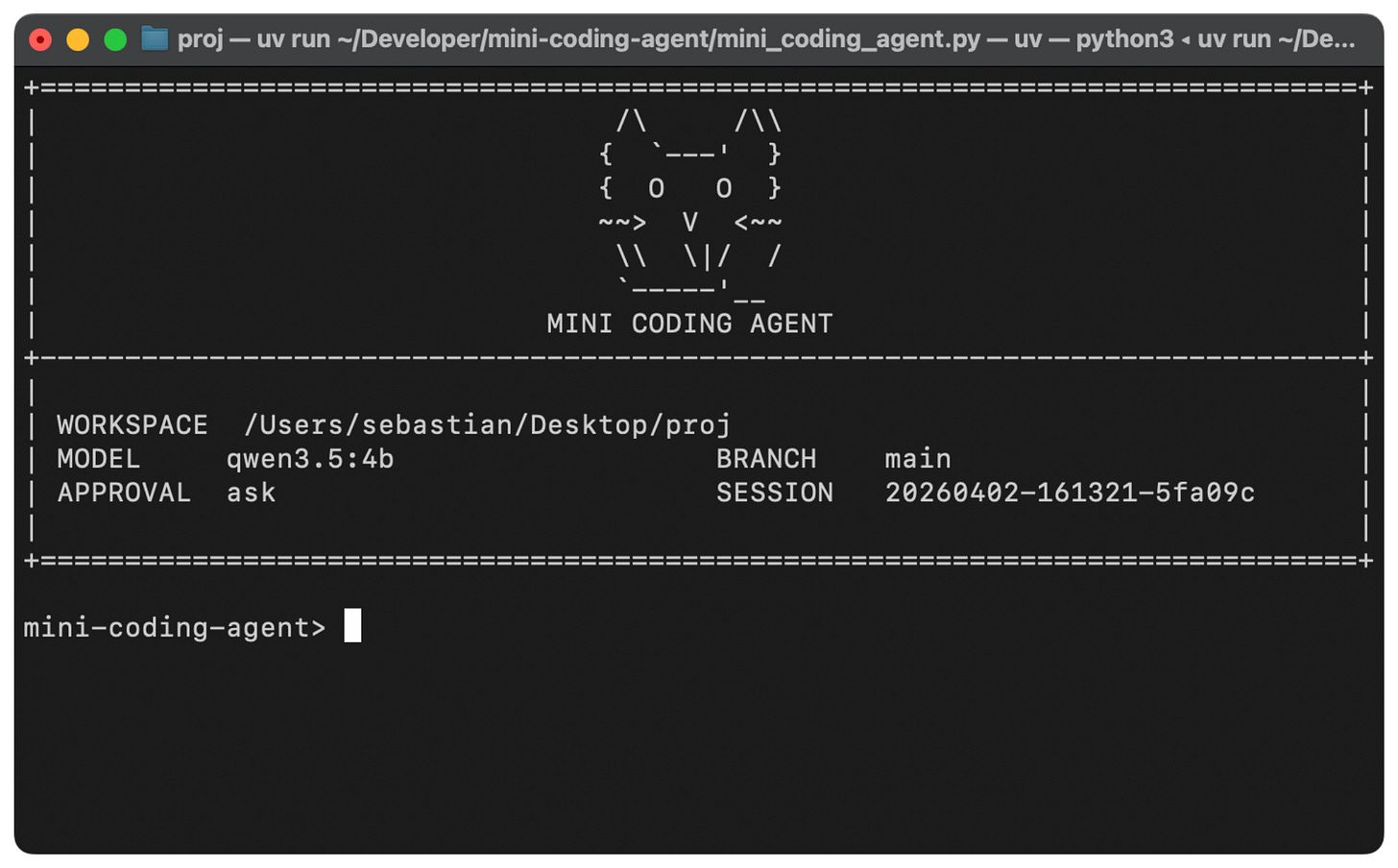
図5: 最小限だが完全に動作する、ゼロからのMini Coding Agent(純粋なPythonで実装)
いずれにせよ、以下はコーディングエージェントの6つの主要な構成要素です。より具体的なコード例については、私の最小限だが完全に動作する、ゼロからのMini Coding Agent(純粋なPythonで実装)のソースコードをチェックしてください。コードは以下の6つの構成要素についてコードコメントで注釈を付けています:
##############################
#### 6つのエージェント構成要素 ####
##############################
1) ライブリポジトリコンテキスト -> WorkspaceContext
2) プロンプト形状とキャッシュ再利用 -> build_prefix, memory_text, prompt
3) 構造化ツール、検証、および権限 -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
4) コンテキスト削減と出力管理 -> clip, history_text
5) トランスクリプト、メモリ、および再開 -> SessionStore, record, note_tool, ask, reset
6) 委任と境界付きサブエージェント -> tool_delegate
- ライブリポジトリコンテキスト
これはおそらく最も明白な構成要素ですが、最も重要なものの1つでもあります。
ユーザーが「テストを修正して」や「xyzを実装して」と言うとき、モデルはGitリポジトリ内にいるか、どのブランチにいるか、どのプロジェクト文書に指示が含まれているかなどを知っているべきです。
なぜなら、これらの詳細はしばしば変更されたり、正しいアクションに影響を与えたりするからです。例えば、「テストを修正して」は自己完結した指示ではありません。エージェントがAGENTS.mdやプロジェクトREADMEを見れば、どのテストコマンドを実行すべきかを学ぶかもしれません。リポジトリのルートとレイアウトを知っていれば、推測する代わりに正しい場所を見ることができます。
また、gitブランチ、ステータス、コミットは、現在進行中の変更内容やどこに焦点を当てるべきかについて、より多くのコンテキストを提供するのに役立ちます。
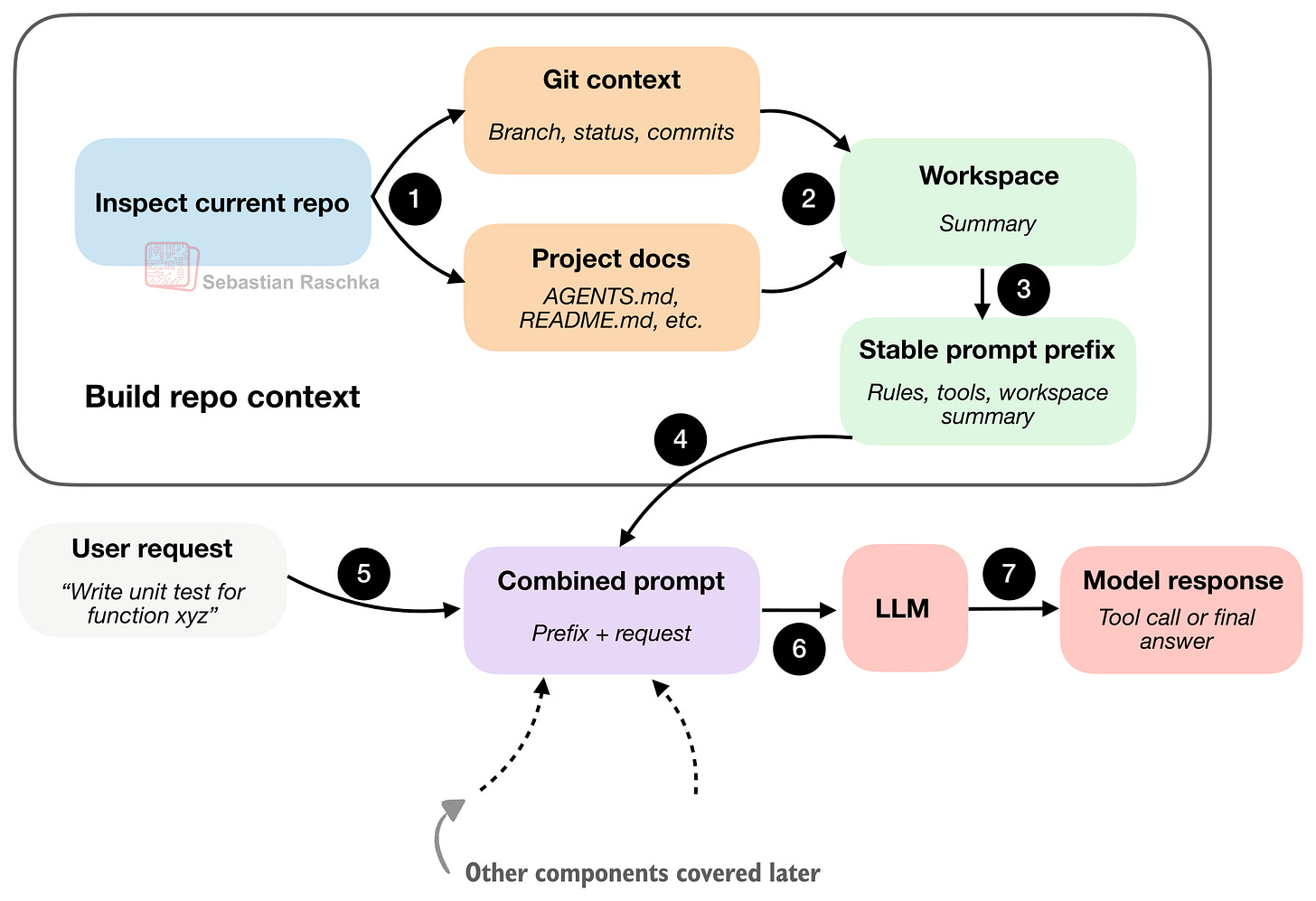
図6: エージェントハーネス(agent harness)は最初に小さなワークスペース要約を構築し、それをユーザーリクエストと組み合わせて追加のプロジェクトコンテキストを提供します。
重要な点は、コーディングエージェントが作業を開始する前に情報(ワークスペース要約としての「安定した事実」)を事前に収集することです。これにより、すべてのプロンプトでコンテキストなしのゼロから始める必要がなくなります。
- プロンプトの形状とキャッシュ再利用
エージェントがリポジトリビューを取得した後、次の問題はその情報をモデルにどのように供給するかです。前の図ではこれを簡略化して示しました(「結合されたプロンプト:プレフィックス+リクエスト」)が、実際には、すべてのユーザークエリでワークスペース要約を結合して再処理するのは比較的非効率的でしょう。
つまり、コーディングセッションは反復的であり、エージェントルールは通常同じままです。ツールの説明も通常同じままです。ワークスペース要約も(大部分)同じままであることが多いです。主な変更は通常、最新のユーザーリクエスト、最近のトランスクリプト、そして短期記憶(short-term memory)です。
「スマート」なランタイムは、以下の図に示すように、すべてのターンで1つの巨大な区別のないプロンプトとしてすべてを再構築することはありません。
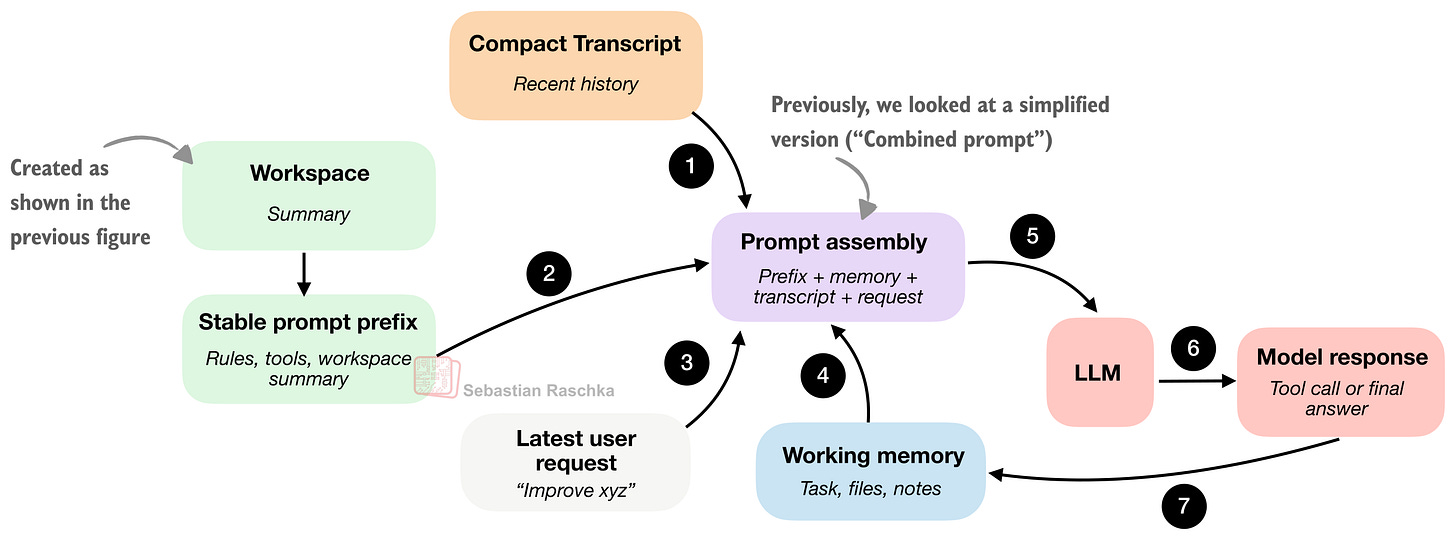
図7: エージェントハーネスは安定したプロンプトプレフィックスを構築し、変化するセッション状態を追加し、その結合されたプロンプトをモデルに供給します。
セクション1との主な違いは、セクション1がリポジトリの事実を収集することについてだったのに対し、ここではそれらの事実を効率的にパッケージ化し、繰り返しのモデル呼び出しのためにキャッシュすることに関心がある点です。
「安定した」プロンプトプレフィックスとは、そこに含まれる情報があまり変化しないことを意味します。通常、一般的な指示、ツールの説明、ワークスペース要約が含まれます。重要な変更がない場合、各インタラクションでゼロから再構築するために計算リソースを浪費したくありません。
他のコンポーネントはより頻繁に更新されます(通常、各ターンごと)。これには短期記憶、最近のトランスクリプト、最新のユーザーリクエストが含まれます。
要するに、「安定したプロンプトプレフィックス」のキャッシュの側面は、スマートなランタイムがその部分を再利用しようとするだけのことです。
- ツールアクセスと使用
ツールアクセスとツール使用は、チャットではなくエージェントらしさを感じ始める部分です。
普通のモデルは散文でコマンドを提案できますが、コーディングハーネス内のLLM(Large Language Model)は、より狭く有用なことを行い、実際にコマンドを実行して結果を取得できるべきです(私たちが手動でコマンドを呼び出して結果をチャットに貼り付けるのとは対照的に)。
しかし、モデルに任意の構文を即興で作らせる代わりに、ハーネスは通常、明確な入力と明確な境界を持つ、許可された名前付きツールの事前定義されたリストを提供します。(もちろん、Pythonのsubprocess.callのようなものもこれの一部となり得るので、エージェントは任意の幅広いシェルコマンドを実行することもできます。)
ツール使用のフローは以下の図に示されています。
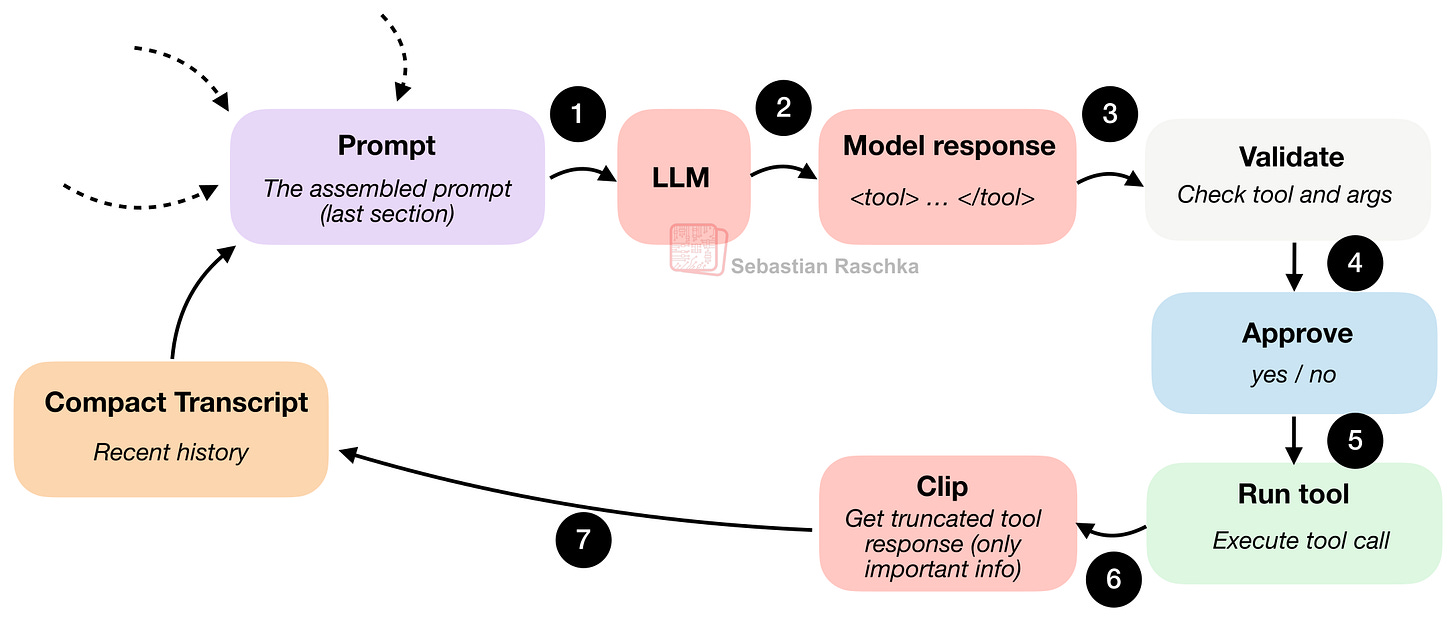
図8: モデルは構造化されたアクションを出力し、ハーネスはそれを検証し、必要に応じて承認を求め、実行し、境界付けられた結果をループにフィードバックします。
これを説明するために、以下は私のMini Coding Agentを使用しているユーザーにとってこれが通常どのように見えるかの例です。(これはClaude CodeやCodexほど見栄えが良くありません。非常に最小限で、外部依存関係なしのプレーンなPythonを使用しているためです。)
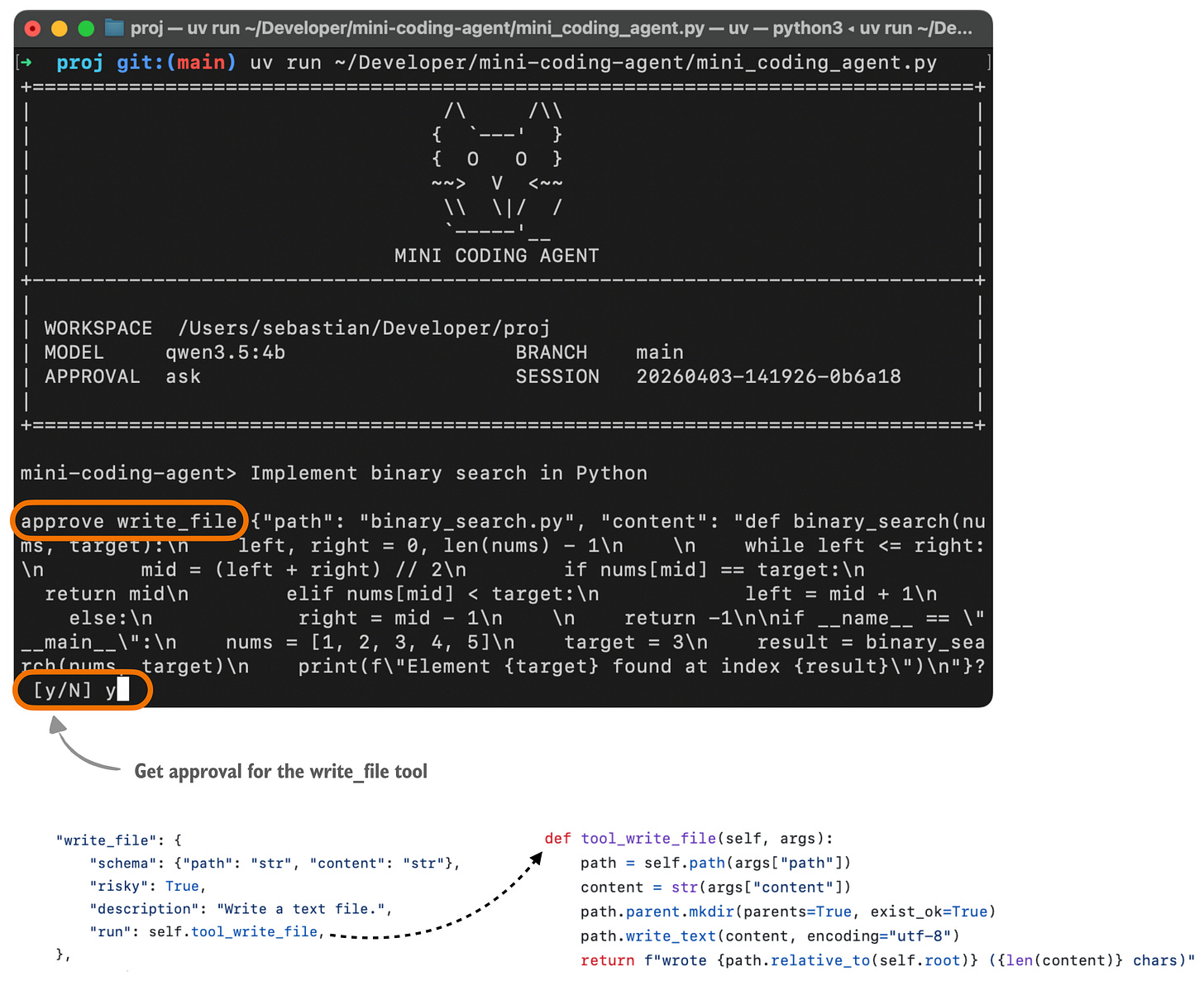
図9: Mini Coding Agentにおけるツール呼び出し承認リクエストの図解。
ここでは、モデルはハーネスが認識するアクションを選択する必要があります。例えば、ファイルのリスト表示、ファイルの読み取り、検索、シェルコマンドの実行、ファイルの書き込みなどです。また、ハーネスがチェックできる形状で引数を提供する必要もあります。
したがって、モデルが何かを実行するように要求すると、ランタイムは停止してプログラム的なチェックを実行できます。例えば、
「これは既知のツールですか?」
「引数は有効ですか?」
「これはユーザーの承認が必要ですか?」
「要求されたパスはワークスペース内にありますか?」
これらのチェックに合格した後でのみ、実際に何かが実行されます。
コーディングエージェントの実行には当然ある程度のリスクが伴いますが、ハーネスのチェックは信頼性も向上させます。なぜなら、モデルが完全に任意のコマンドを実行しないからです。
また、不正な形式のアクションを拒否したり承認ゲートを設けることに加えて、ファイルパスをチェックすることでファイルアクセスをリポジトリ内に保つことができます。
ある意味、ハーネスはモデルに与える自由度を減らしていますが、同時に使いやすさも向上させています。
- コンテキスト肥大化の最小化
コンテキスト肥大化(context bloat)はコーディングエージェントに特有の問題ではなく、LLM全般の問題です。確かに、LLMは最近ますます長いコンテキストをサポートしています(そして私は最近、計算上より実現可能にするアテンション(attention)の変種について書きました)。しかし、長いコンテキストは依然としてコストがかかり、追加のノイズを導入する可能性もあります(多くの無関係な情報がある場合)。
コーディングエージェントは、マルチターンチャット中、通常のLLMよりもコンテキスト肥大化の影響を受けやすいです。なぜなら、繰り返しのファイル読み取り、長いツール出力、ログなどがあるためです。
ランタイムがそれらすべてを完全な忠実度で保持すると、利用可能なコンテキストトークン(context tokens)がすぐになくなってしまいます。したがって、優れたコーディングハーネスは通常、通常のチャットUIのように単に情報をカットしたり要約したりする以上の、コンテキスト肥大化の処理についてかなり洗練されています。
概念的には、コーディングエージェントにおけるコンテキスト圧縮(context compaction)は以下の図に要約されるように機能するかもしれません。具体的には、前のセクションの図8のクリップ(clip)(ステップ6)部分を少し拡大して見ています。
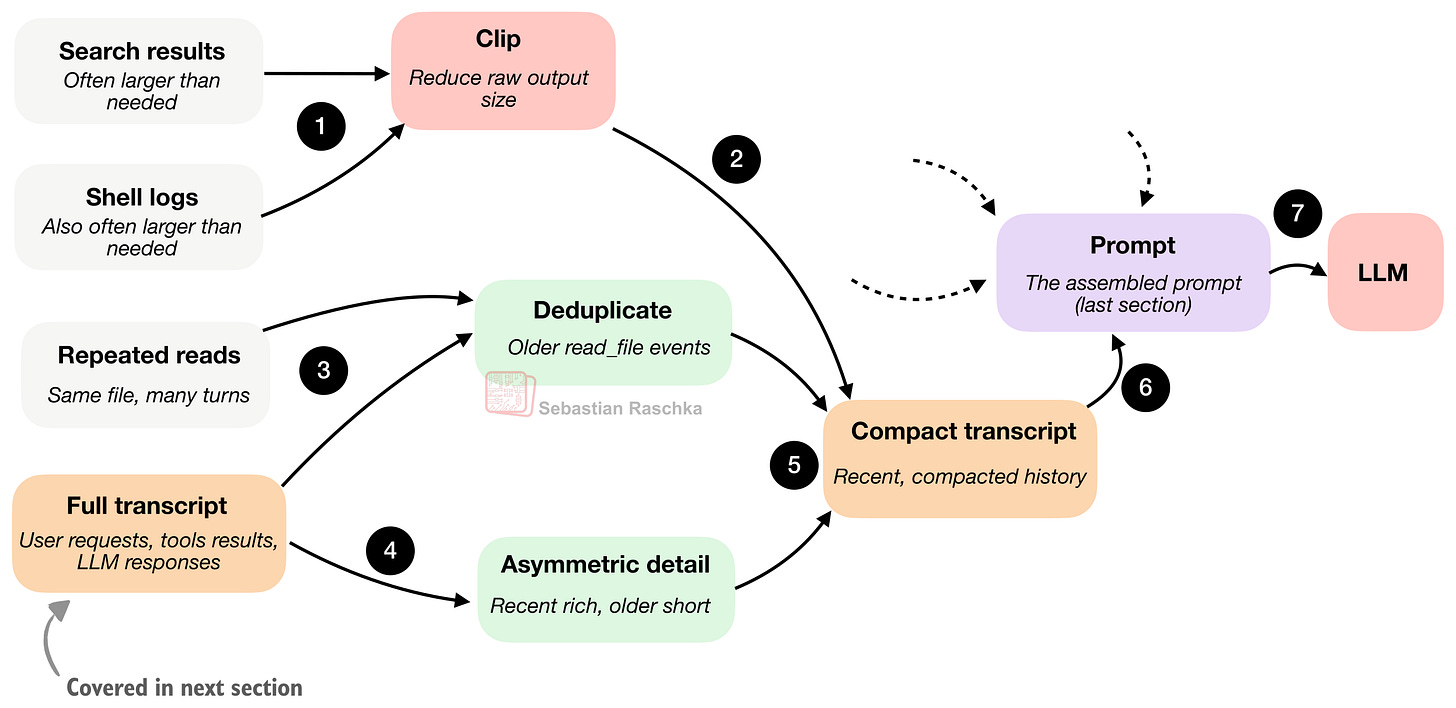
図10: 大きな出力はクリップされ、古い読み取りは重複排除され、トランスクリプトはプロンプトに戻る前に圧縮されます。
最小限のハーネスは、その問題を管理するために少なくとも2つの圧縮戦略を使用します。
1つ目はクリッピング(clipping)です。これは長いドキュメントの断片、大きなツール出力、メモリノート、トランスクリプトエントリを短縮します。言い換えれば、たまたま冗長だったという理由だけで、1つのテキストがプロンプトの予算を独占するのを防ぎます。
2つ目の戦略はトランスクリプトの削減または要約(transcript reduction or summarization)です。これは完全なセッション履歴(これについては次のセクションで詳しく説明します)を小さなプロンプト可能な要約に変えます。
ここでの重要なコツは、最近のイベントをより豊富に保つことです。なぜなら、それらは現在のステップにとってより重要である可能性が高いからです。そして、古いイベントは関連性が低い可能性が高いため、より積極的に圧縮します。
さらに、古いファイル読み取りも重複排除(deduplicate)します。これにより、モデルがセッションの早い段階で複数回読み取られたという理由だけで、同じファイル内容を何度も見続けることがなくなります。
全体として、これは優れたコーディングエージェント設計の過小評価された、退屈な部分の1つだと思います。多くの見かけ上の「モデル品質」は、実際にはコンテキスト品質なのです。
- 構造化セッションメモリ
実際には、ここで取り上げたこれら6つの核心概念はすべて密接に関連しており、異なるセクションと図は異なる焦点やズームレベルでそれらをカバーしています。前のセクションでは、履歴のプロンプト時使用と、コンパクトなトランスクリプトをどのように構築するかをカバーしました。そこでの問題は:次のターンでモデルに戻すべき過去の情報はどれくらいか?です。したがって、重点は圧縮、クリッピング、重複排除、新近性(recency)です。
さて、このセクション、構造化セッションメモリ(structured session memory)は、履歴の保存時構造についてです。ここでの問題は:エージェントは永続的な記録として時間とともに何を保持するか?です。したがって、重点は、ランタイムがより完全なトランスクリプトを耐久性のある状態として保持し、それに加えて、より小さく、単に追加されるのではなく変更および圧縮される軽量なメモリ層を保持することです。
要約すると、コーディングエージェントは状態を(少なくとも)2つの層に分けます:
ワーキングメモリ(working memory): エージェントが明示的に保持する小さく蒸留された状態
完全なトランスクリプト(full transcript): すべてのユーザーリクエスト、ツール出力、LLM応答をカバーします
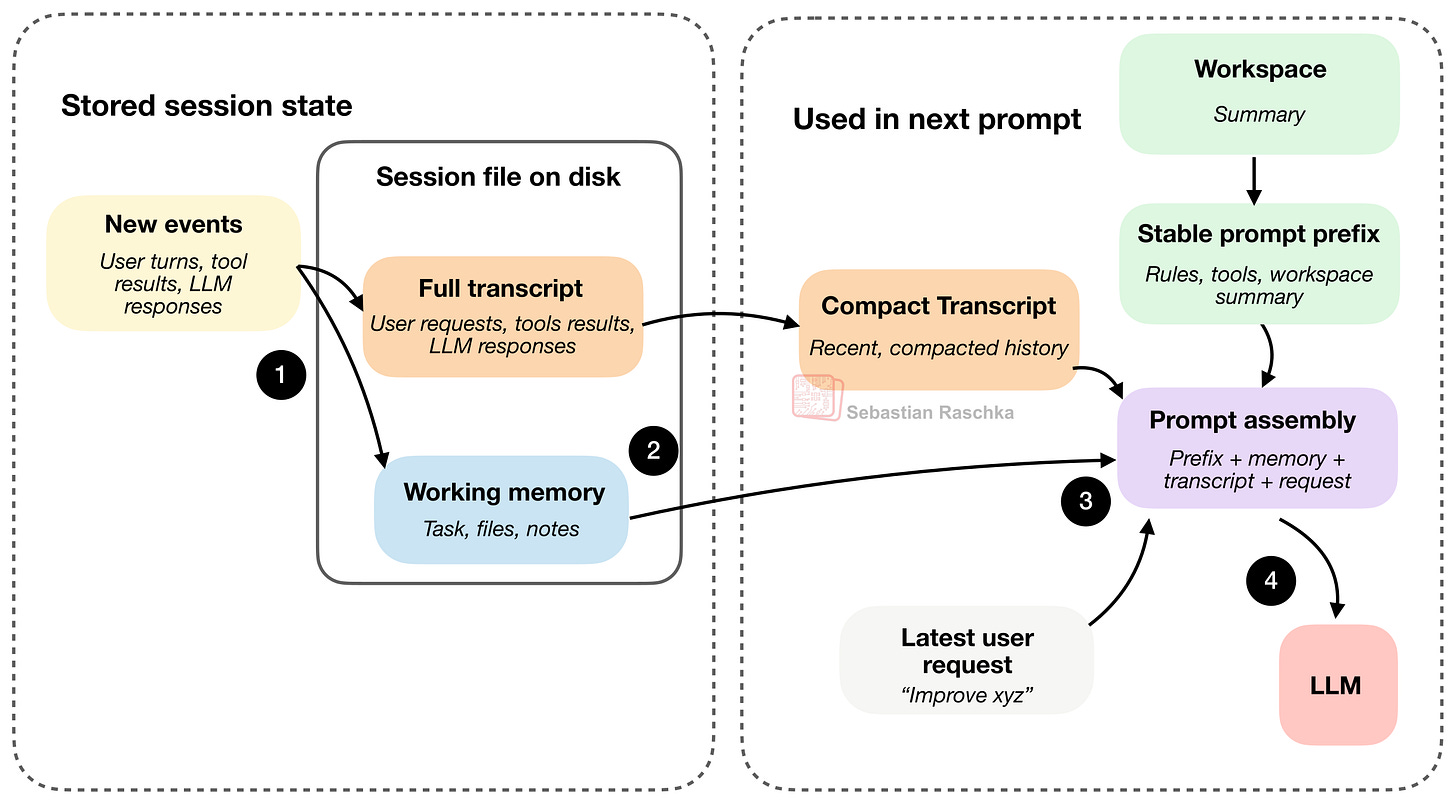
図11: 新しいイベントは完全なトランスクリプトに追加され、ワーキングメモリに要約されます。ディスク上のセッションファイルは通常JSONファイルとして保存されます。
上の図は、通常ディスク上のJSONファイルとして保存される2つの主要なセッションファイル、完全なトランスクリプトとワーキングメモリを示しています。前述のように、完全なトランスクリプトは履歴全体を保存し、エージェントを閉じても再開可能です。ワーキングメモリは、現在最も重要な情報を含む、より蒸留されたバージョンであり、コンパクトなトランスクリプトとやや関連しています。
しかし、コンパクトなトランスクリプトとワーキングメモリは少し異なる役割を持っています。コンパクトなトランスクリプトはプロンプト再構築のためのものです。その役割は、モデルに最近の履歴の圧縮ビューを提供し、すべてのターンで完全なトランスクリプトを見ることなく会話を続けられるようにすることです。ワーキングメモリは、よりタスクの継続性のために意図されています。その役割は、ターン間で重要なこと、例えば現在のタスク、重要なファイル、最近のメモなどの、小さく明示的に維持された要約を保持することです。
上図のステップ4に続いて、最新のユーザーリクエストとLLM(大規模言語モデル)の応答、およびツールの出力は、次のラウンドで「新しいイベント」として完全なトランスクリプトとワーキングメモリの両方に記録されます。これは、図の煩雑さを減らすために表示されていません。
原文を表示
In this article, I want to cover the overall design of coding agents and agent harnesses: what they are, how they work, and how the different pieces fit together in practice. Readers of my Build a Large Language Model (From Scratch) and Build a Large Reasoning Model (From Scratch) books often ask about agents, so I thought it would be useful to write a reference I can point to.
More generally, agents have become an important topic because much of the recent progress in practical LLM systems is not just about better models, but about how we use them. In many real-world applications, the surrounding system, such as tool use, context management, and memory, plays as much of a role as the model itself. This also helps explain why systems like Claude Code or Codex can feel significantly more capable than the same models used in a plain chat interface.
In this article, I lay out six of the main building blocks of a coding agent.
Claude Code, Codex CLI, and Other Coding Agents
You are probably familiar with Claude Code or the Codex CLI, but just to set the stage, they are essentially agentic coding tools that wrap an LLM in an application layer, a so-called agentic harness, to be more convenient and better-performing for coding tasks.
Figure 1: Claude Code CLI, Codex CLI, and my Mini Coding Agent.
Coding agents are engineered for software work where the notable parts are not only the model choice but the surrounding system, including repo context, tool design, prompt-cache stability, memory, and long-session continuity.
That distinction matters because when we talk about the coding capabilities of LLMs, people often collapse the model, the reasoning behavior, and the agent product into one thing. But before getting into the coding agent specifics, let me briefly provide a bit more context on the difference between the broader concepts, the LLMs, reasoning models, and agents.
On The Relationship Between LLMs, Reasoning Models, and Agents
An LLM is the core next-token model. A reasoning model is still an LLM, but usually one that was trained and/or prompted to spend more inference-time compute on intermediate reasoning, verification, or search over candidate answers.
An agent is a layer on top, which can be understood as a control loop around the model. Typically, given a goal, the agent layer (or harness) decides what to inspect next, which tools to call, how to update its state, and when to stop, etc.
Roughly, we can think about the relationship as this: the LLM is the engine, a reasoning model is a beefed-up engine (more powerful, but more expensive to use), and an agent harness helps us the model. The analogy is not perfect, because we can also use conventional and reasoning LLMs as standalone models (in a chat UI or Python session), but I hope it conveys the main point.
Figure 2: The relationship between conventional LLM, reasoning LLM (or reasoning model), and an LLM wrapped in an agent harness.
In other words, the agent is the system that repeatedly calls the model inside an environment.
So, in short, we can summarize it like this:
LLM: the raw model
Reasoning model: an LLM optimized to output intermediate reasoning traces and to verify itself more
Agent: a loop that uses a model plus tools, memory, and environment feedback
Agent harness: the software scaffold around an agent that manages context, tool use, prompts, state, and control flow
Coding harness: a special case of an agent harness; i.e., a task-specific harness for software engineering that manages code context, tools, execution, and iterative feedback
As listed above, in the context of agents and coding tools, we also have the two popular terms agent harness and (agentic) coding harness. A coding harness is the software scaffold around a model that helps it write and edit code effectively. And an agent harness is a bit broader and not specific to coding (e.g., think of OpenClaw). Codex and Claude Code can be considered coding harnesses.
Anyways, A better LLM provides a better foundation for a reasoning model (which involves additional training), and a harness gets more out of this reasoning model.
Sure, LLMs and reasoning models are also capable of solving coding tasks by themselves (without a harness), but coding work is only partly about next-token generation. A lot of it is about repo navigation, search, function lookup, diff application, test execution, error inspection, and keeping all the relevant information in context. (Coders may know that this is hard mental work, which is why we don’t like to be disrupted during coding sessions :)).
Figure 3. A coding harness combines three layers: the model family, an agent loop, and runtime supports. The model provides the “engine”, the agent loop drives iterative problem solving, and the runtime supports provide the plumbing. Within the loop, “observe” collects information from the environment, “inspect” analyzes that information, “choose” selects the next step, and “act” executes it.
The takeaway here is that a good coding harness can make a reasoning and a non-reasoning model feel much stronger than it does in a plain chat box, because it helps with context management and more.
The Coding Harness
As mentioned in the previous section, when we say harness, we typically mean the software layer around the model that assembles prompts, exposes tools, tracks file state, applies edits, runs commands, manages permissions, caches stable prefixes, stores memory, and many more.
Today, when using LLMs, this layer shapes most of the user experience compared to prompting the model directly or using web chat UI (which is closer to “chat with uploaded files”).
Since, in my view, the vanilla versions of LLMs nowadays have very similar capabilities (e.g., the vanilla versions of GPT-5.4, Opus 4.6, and GLM-5 or so), the harness can often be the distinguishing factor that makes one LLM work better than another.
This is speculative, but I suspect that if we dropped one of the latest, most capable open-weight LLMs, such as GLM-5, into a similar harness, it could likely perform on par with GPT-5.4 in Codex or Claude Opus 4.6 in Claude Code. That said, some harness-specific post-training is usually beneficial. For example, OpenAI historically maintained separate GPT-5.3 and GPT-5.3-Codex variants.
In the next section, I want to go more into the specifics and discuss the core components of a coding harness using my Mini Coding Agent: https://github.com/rasbt/mini-coding-agent.
Figure 4: Main harness features of a coding agent / coding harness that will be discussed in the following sections.
By the way, in this article, I use the terms “coding agent” and “coding harness” somewhat interchangeably for simplicity. (Strictly speaking, the agent is the model-driven decision-making loop, while the harness is the surrounding software scaffold that provides context, tools, and execution support.)
Figure 5: Minimal but fully working, from-scratch Mini Coding Agent (implemented in pure Python)
Anyways, below are six main components of coding agents. You can check out the source code of my minimal but fully working, from-scratch Mini Coding Agent (implemented in pure Python), for more concrete code examples. The code annotates the six components discussed below via code comments:
##############################
#### Six Agent Components ####
##############################
1) Live Repo Context -> WorkspaceContext
2) Prompt Shape And Cache Reuse -> build_prefix, memory_text, prompt
3) Structured Tools, Validation, And Permissions -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
4) Context Reduction And Output Management -> clip, history_text
5) Transcripts, Memory, And Resumption -> SessionStore, record, note_tool, ask, reset
6) Delegation And Bounded Subagents -> tool_delegate1. Live Repo Context
This is maybe the most obvious component, but it is also one of the most important ones.
When a user says “fix the tests” or “implement xyz,” the model should know whether it is inside a Git repo, what branch it is on, which project documents might contain instructions, and so on.
That’s because those details often change or affect what the correct action is. For example, “Fix the tests” is not a self-contained instruction. If the agent sees AGENTS.md or a project README, it may learn which test command to run, etc. If it knows the repo root and layout, it can look in the right places instead of guessing.
Also, the git branch, status, and commits can help provide more context about what changes are currently in progress and where to focus.
Figure 6: The agent harness first builds a small workspace summary that gets combined with the user request for additional project context.
The takeaway is that the coding agent collects info (”stable facts” as a workspace summary) upfront before doing any work, so that it’s is not starting from zero, without context, on every prompt.
- Prompt Shape And Cache Reuse
Once the agent has a repo view, the next question is how to feed that information to the model. The previous figure showed a simplified view of this (“Combined prompt: prefix + request”), but in practice, it would be relatively wasteful to combine and re-process the workspace summary on every user query.
I.e., coding sessions are repetitive, and the agent rules usually stay the same. The tool descriptions usually stay the same, too. And even the workspace summary usually stays (mostly) the same. The main changes are usually the latest user request, the recent transcript, and maybe the short-term memory.
“Smart” runtimes don’t rebuild everything as one giant undifferentiated prompt on every turn, as illustrated in the figure below.
Figure 7: The agent harness builds a stable prompt prefix, adds the changing session state, and then feeds that combined prompt to the model.
The main difference from section 1 is that section 1 was about gathering repo facts. Here, we are now interested in packaging and caching those facts efficiently for repeated model calls.
The “stable” “Stable prompt prefix” means that the information contained there doesn’t change too much. It usually contains the general instructions, tool descriptions, and the workspace summary. We don’t want to waste compute on rebuilding it from scratch in each interaction if nothing important has changed.
The other components are updated more frequently (usually each turn). This includes short-term memory, the recent transcript, and the newest user request.
In short, the caching aspect for the “Stable prompt prefix” is simply that a smart runtime tries to reuse that part.
- Tool Access and Use
Tool access and tool use are where it starts to feel less like chat and more like an agent.
A plain model can suggest commands in prose, but an LLM in a coding harness should do something narrower and more useful and be actually able to execute the command and retrieve the results (versus us calling the command manually and pasting the results back into the chat).
But instead of letting the model improvise arbitrary syntax, the harness usually provides a pre-defined list of allowed and named tools with clear inputs and clear boundaries. (But of course, something like Python subprocess.call can be part of this so that the agent could also execute an arbitrary wide list of shell commands.)
The tool-use flow is illustrated in the figure below.
Figure 8: The model emits a structured action, the harness validates it, optionally asks for approval, executes it, and feeds the bounded result back into the loop.
To illustrate this, below is an example of how this usually looks to the user using my Mini Coding Agent. (This is not as pretty as Claude Code or Codex because it is very minimal and uses plain Python without any external dependencies.)
Figure 9: Illustration of a tool call approval request in the Mini Coding Agent.
Here, the model has to choose an action that the harness recognizes, like list files, read a file, search, run a shell command, write a file, etc. It also has to provide arguments in a shape that the harness can check.
So when the model asks to do something, the runtime can stop and run programmatic checks like
“Is this a known tool?”,
“Are the arguments valid?”,
“Does this need user approval?”
“Is the requested path even inside the workspace?”
Only after those checks pass does anything actually run.
While running coding agents, of course, carries some risk, the harness checks also improve reliability because the model doesn’t execute totally arbitrary commands.
Also, besides rejecting malformed actions and approval gating, file access can be kept inside the repo by checking file paths.
In a sense, the harness is giving the model less freedom, but it also improves the usability at the same time.
- Minimizing Context Bloat
Context bloat is not a unique problem of coding agents but an issue for LLMs in general. Sure, LLMs are supporting longer and longer contexts these days (and I recently wrote about the attention variants that make it computationally more feasible), but long contexts are still expensive and can also introduce additional noise (if there is a lot of irrelevant info).
Coding agents are even more susceptible to context bloat than regular LLMs during multi-turn chats, because of repeated file reads, lengthy tool outputs, logs, etc.
If the runtime keeps all of that at full fidelity, it will run out of available context tokens pretty quickly. So, a good coding harness is usually pretty sophisticated about handling context bloat beyond just cutting our summarizing information like regular chat UIs.
Conceptually, the context compaction in coding agents might work as summarized in the figure below. Specifically, we are zooming a bit further into the clip (step 6) part of Figure 8 in the previous section.
Figure 10: Large outputs are clipped, older reads are deduplicated, and the transcript is compressed before it goes back into the prompt.
A minimal harness uses at least two compaction strategies to manage that problem.
The first is clipping, which shortens long document snippets, large tool outputs, memory notes, and transcript entries. In other words, it prevents any one piece of text from taking over the prompt budget just because it happened to be verbose.
The second strategy is transcript reduction or summarization, which turns the full session history (more on that in the next section) into a smaller promptable summary.
A key trick here is to keep recent events richer because they are more likely to matter for the current step. And we compress older events more aggressively because they are likely less relevant.
Additionally, we also deduplicate older file reads so the model does not keep seeing the same file content over and over again just because it was read multiple times earlier in the session.
Overall, I think this is one of the underrated, boring parts of good coding-agent design. A lot of apparent “model quality” is really context quality.
- Structured Session Memory
In practice, all these 6 core concepts covered here are highly intertwined, and the different sections and figures cover them with different focuses or zoom levels. In the previous section, we covered prompt-time use of history and how we build a compact transcript. The question there is: how much of the past should go back into the model on the next turn? So the emphasis is compression, clipping, deduplication, and recency.
Now, this section, structured session memory, is about the storage-time structure of history. The question here is: what does the agent keep over time as a permanent record? So the emphasis is that the runtime keeps a fuller transcript as a durable state, alongside a lighter memory layer that is smaller and gets modified and compacted rather than just appended to.
To summarize, a coding agent separates state into (at least) two layers:
working memory: the small, distilled state the agent keeps explicitly
a full transcript: this covers all the user requests, tool outputs, and LLM responses
Figure 11: New events get appended to a full transcript and summarized in a working memory. The session files on disk are usually stored as JSON files.
The figure above illustrates the two main session files, the full transcript and the working memory, that usually get stored as JSON files on disk. As mentioned before, the full transcript stores the whole history, and it’s resumable if we close the agent. The working memory is more of a distilled version with the currently most important info, which is somewhat related to the compact transcript.
But the compact transcript and working memory have slightly different jobs. The compact transcript is for prompt reconstruction. Its job is to give the model a compressed view of recent history so it can continue the conversation without seeing the full transcript every turn. The working memory is more meant for task continuity. Its job is to keep a small, explicitly maintained summary of what matters across turns, things like the current task, important files, and recent notes.
Following step 4 in the figure above, the latest user request, together with the LLM response and tool output, would then be recorded as a “new event” in both the full transcript and working memory, in the next round, which is not shown to reduce clu
関連記事
LLM 研究論文:2026 年 1 月から 5 月のリスト
Sebastian Raschka が、2026 年上半期(1 月〜5 月)に注目すべき大規模言語モデル関連の研究論文を選定し、一覧として公開した。
[AINews] 今日特に大きな出来事はありませんでした
Latent Space が運営するニュースレター「AINews」が、6月4日から5日にかけてのAI業界動向を12件のRedditスレッドや544件のTwitter投稿から選別して紹介しました。記事ではRL環境ガイドの推奨や、DeepSeek v4 Pro向けの最適化に関するリモートポッドの更新について言及しています。
低品質な強化学習環境の提供を止める方法(事例付き)
ジェミニで強化学習を担当したオーリエル・W氏が、大手ラボが抱える課題としてデータ品質の重要性やドメイン専門家の欠如などを指摘し、高品質な学習環境の構築方法を解説している。