LangChainガイド:観測可能性を用いたAIエージェントのデバッグと評価方法
LangChainが公開したガイドは、AIエージェントの観測可能性(Observability)を活用してトレーシング、推論のデバッグ、パフォーマンス分析を行い、エージェントの振る舞いを反復的に改善・評価する手法を解説している。
キーポイント
観測可能性の重要性
AIエージェントの開発において、単なる出力だけでなく内部プロセスの可視化(トレーシング)が評価と改善に不可欠であることを強調している。
デバッグと推論の検証
エージェントがどのように思考し、行動を選択しているかを追跡することで、エラーの原因を特定し、推論プロセスをデバッグする具体的な手法を示している。
パフォーマンス分析とイテレーション
収集された観測データを用いてエージェントのパフォーマンスを定量的に評価し、フィードバックループを通じてエージェントの動作を継続的に最適化するプロセスを説明している。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIアプリケーション開発において「ブラックボックス化」しがちなエージェントの内部動作を可視化する重要性を再認識させるものであり、実務的なデバッグ手法を提供する点で価値が高い。LangChainエコシステム内の開発者にとって、エージェントの信頼性を高めるための標準的なプラクティスを学ぶ機会となるが、既存の観測ツール(LangSmithなど)の利用を前提とした内容であるため、新規技術の発見というよりはベストプラクティスの整理に近い。
編集コメント
エージェント開発の現場では、出力の正誤だけでなく「なぜその結論に達したか」のプロセス可視化が課題となっている。本記事は、LangChain公式の文脈での具体的な実装アプローチを示しており、開発者のデバッグ効率向上に寄与する実用的な情報である。
エージェントの可観測性は、エージェント評価を支える
主要なポイント
エージェントがどのように推論するかを理解せずに、信頼性の高いエージェントを構築することはできません。また、体系的な評価を行わずに改善を検証することもできません。この記事では、エージェントの可観測性(Observability)のための基本要素、異なる粒度でエージェントを評価する方法、そして生産環境でのトレース(Trace)が継続的な改善の基盤となる仕組みについて解説します。
TL;DR(要約)
- エージェントを実行するまで、その行動はわからない — つまり、エージェントの可観測性はソフトウェアのそれとは異なり、より重要である
- エージェントはしばしば複雑で開放的なタスクを処理するため、その評価方法はソフトウェアの評価とは異なる
- トレースはエージェントの振る舞いが現れる場所を文書化するものであるため、多様な方法で評価を支える
従来のソフトウェアにおいて何かが失敗した場合、取るべき行動は明確です。エラーログを確認し、スタックトレース(Stack Trace)を見て、失敗したコードの行を特定します。しかし、AIエージェントはデバッグの対象を変えました。あるエージェントがタスクを完了するために2分間で200ステップを実行し、その途中でミスをした場合、それは異なる種類のエラーです。失敗したコードがあるわけではないため、スタックトレースはありません。失敗したのはエージェントの推論(Reasoning)でした。
コードのデバッグから推論のデバッグへ
エージェントを定義するためのコードは依然として記述します。例えば、利用可能なツールや入手可能なデータなどを指定するコードです。エージェントの行動を誘導するためのプロンプトやツールの説明も記述しますが、LLM がこれらの指示をどのように解釈するかは、実際に実行してみなければ分かりません。したがって、真実の源泉はコードから、エージェントが実際に行ったことを示すトレースへとシフトします。
エージェントエンジニアリングは反復的なプロセスであり、トレーシング(追跡)と評価がそのループを閉じる手段となります。この投稿では、エージェントの観測可能性(Observability)と評価が従来のソフトウェアと根本的に異なる理由、必要となる新しいプリミティブ(基本要素)やプラクティス、そして観測可能性が評価をどのように支え、両者が切り離せない関係にあるのかを探ります。
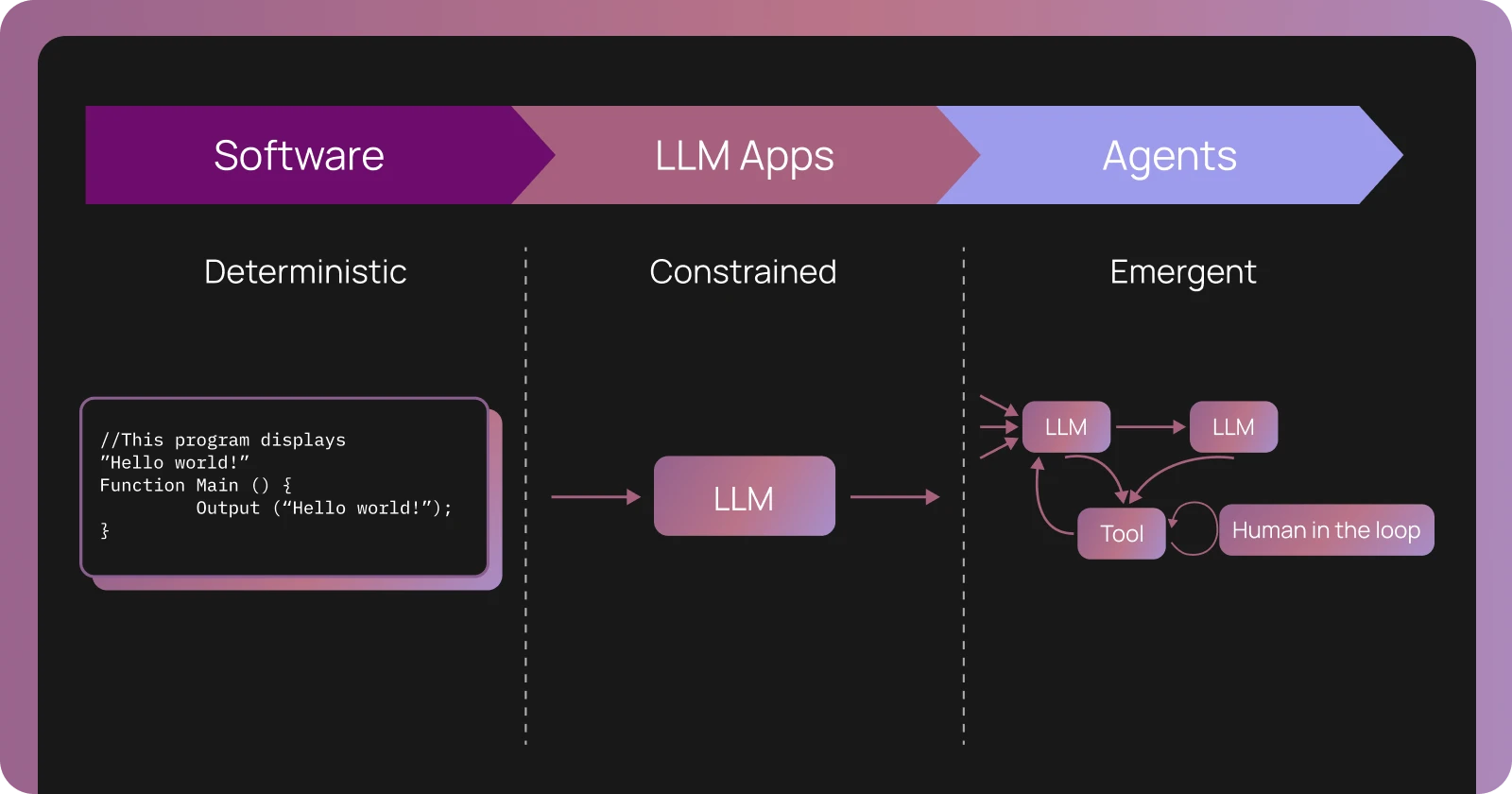
エージェントの観測可能性 ≠ ソフトウェアの観測可能性
LLM 以前、ソフトウェアは主に決定論的でした。同じ入力に対して、常に同じ出力が得られます。ロジックはコード化されており、コードを読めばシステムがどのように振る舞うかを正確に知ることができました。何か問題が発生した場合、ログはどのサービスや関数が失敗したかを示し、その後コードに戻ってその理由を理解し、修正を行います。
AI エージェントは、決定論とコードを真実の源とするという前提を崩します。 従来のソフトウェアから LLM(大規模言語モデル)アプリケーション、そしてエージェントへと移行するにつれて、各段階で不確実性が増していきます。LLM アプリケーションはコンテキストを用いて LLM に単一の呼び出しを行い、自然言語に内在する「曖昧さ」を導入しますが、1 回の LLM 呼び出しという制約内に留まります。
しかし、エージェントはタスクが完了したと判断するまでループ内で LLM およびツールを呼び出し、数十から数百のステップにわたって推論を行い、ツールを呼び出し、状態を維持し、コンテキストに基づいて行動を適応させます。エージェントを構築する際、あなたはコードとプロンプトにおいてアプリケーションのロジックを推奨しようとするでしょう。しかし、実際に LLM を実行するまで、このロジックが何を行うかは分かりません。
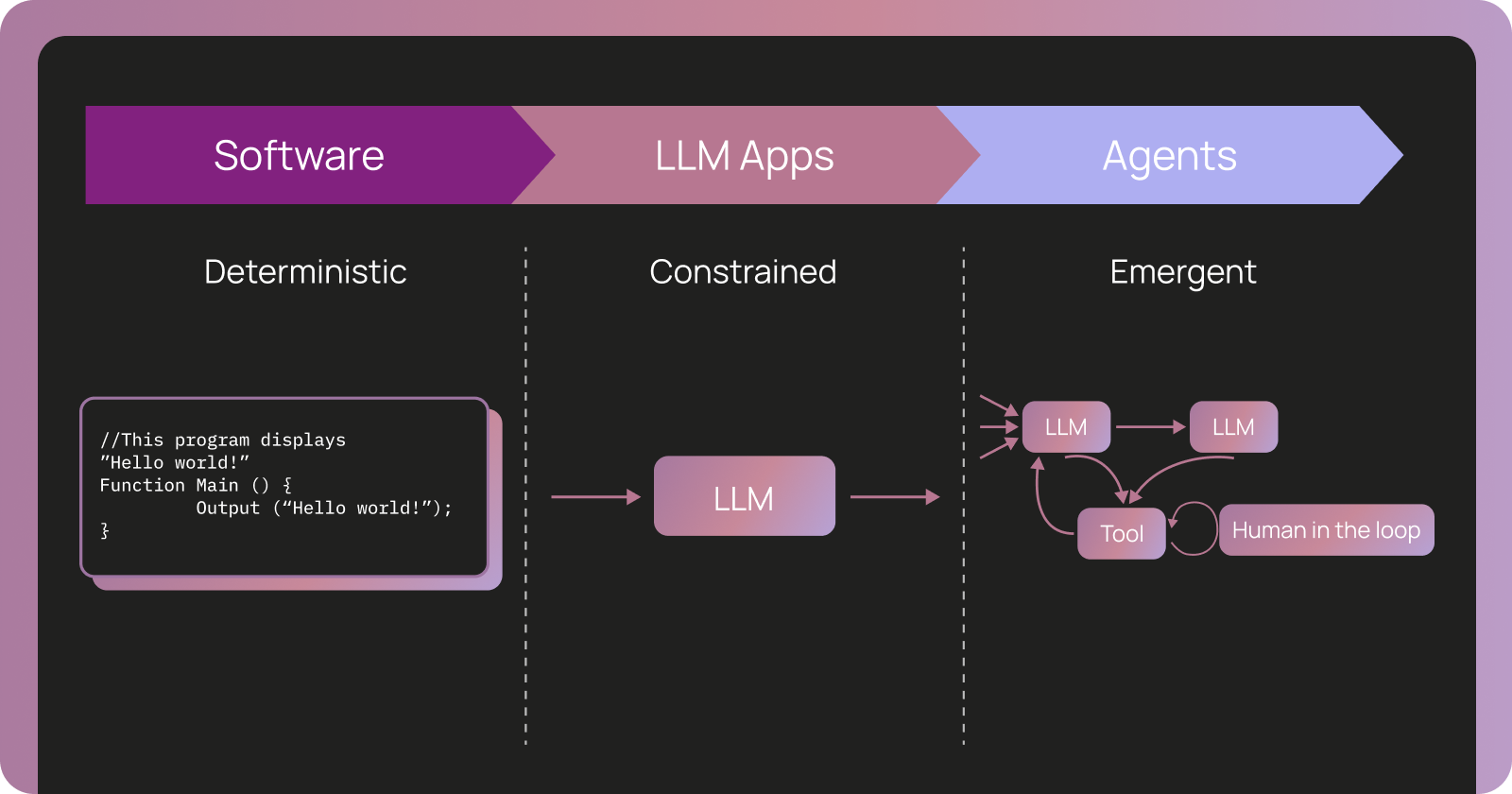
従来のソフトウェア対 LLM アプリケーション対エージェント何か問題が発生した際、失敗した単一のコード行を見つけるわけではありません。代わりに、以下を問いかけます:
- エージェントは、200ステップ中の23番目のステップで、read_fileではなくedit_fileを呼び出すと判断した理由は何ですか?
- その決定を下す際に、どのようなコンテキストやプロンプトの指示が考慮されましたか?
- この2分間、200ステップからなる軌跡の中で、エージェントはどの時点で道に迷いましたか?
従来のトレーシングツールでは、これらの質問に答えることはできません。200ステップのトレースは人間が解析するには大きすぎますし、従来のトレースは各決定背后的な推論コンテキストを捉えるものではなく、呼び出されたサービスとその所要時間のみを記録します。
エージェント評価 ≠ ソフトウェア評価
従来のソフトウェアテストは、決定論的なアサーション(assertion)に依存しています。出力が期待値と一致するかどうかをチェックするテストを書き、パスすることを確認してから、製品に組み込みます。オンライン評価(A/Bテストやプロダクトアナリティクス)は、ビジネスへの影響を別途測定します。エージェントの評価は、ソフトウェアの評価とはいくつかの重要な点で異なります:
1. コードパスではなく、推論をテストしている
従来のソフトウェアには、異なる粒度(ユニットテスト、インテグレーションテスト、E2Eテスト)のテストがあり、読み込んで修正できる決定論的なコードパスをテストします。エージェントも異なる粒度でのテストが必要ですが、ここではもはやコードパスをテストしているのではなく、推論をテストしています:
- 単一ステップ:エージェントはその瞬間に正しい判断を下したか?
- フルターン:エージェントはエンドツーエンドの実行で良好なパフォーマンスを発揮したか?
- マルチターン:エージェントは会話全体を通じてコンテキストを維持できたか?
2. 本番環境が主要な教師となる
従来のソフトウェアでは、オフラインテスト(ユニットテスト、インテグレーションテスト、ステージング環境でのテスト)によって、ほとんどの正しさに関する問題を把握できます。カナリーデプロイメントやフィーチャーフラグを通じて本番環境でもテストを行いますが、その目的は見逃したエッジケースやインテグレーションの問題を把握することにあります。
エージェントの場合、本番環境の役割は異なります。自然言語での入力はすべて一意であるため、ユーザーがリクエストをどのように表現するか、あるいはどのようなエッジケースが存在するかを事前に予測することはできません。本番環境のトレースは、予測できなかった失敗モードを明らかにし、実際のユーザーインタラクションにおいて「正しい動作」が実際にどのようなものかを理解するのを助けます。
これは評価に関する考え方をシフトさせます。本番環境は、見逃されたバグを把握する場所であるだけでなく、オフラインで何をテストすべきかを見つける場所でもあります。本番環境のトレースはテストケースとなり、評価スイートは設計されたシナリオだけでなく、現実世界の例から継続的に成長していきます。
エージェント可観測性のプリミティブ
エージェントの可観測性は、非確定的な推論を捉えるために3つのコアプリミティブを使用します。
- Runs: 単一の実行ステップ(入力と出力を伴う1回のLLM呼び出し)
- Traces: すべての実行とその関係を示す完全なエージェントの実行
- Threads: 時間経過とともに複数のトレースをグループ化するマルチターン会話
これらは従来の可観測性(例:トレース、スパン)と同じ概念を使用していますが、サービス呼び出しやタイミングではなく、推論のコンテキストを捉えます。
Runs: LLM の単一ステップでの行動をキャプチャする
run は、単一の実行ステップをキャプチャします。これは、特定の時点での LLM の動作を把握するのに最も有用です。これには、LLM 呼び出しの完全なプロンプトが含まれ、すべての指示、使用されたツール、およびコンテキストが含まれます。
これらの run は二つの目的を果たします:
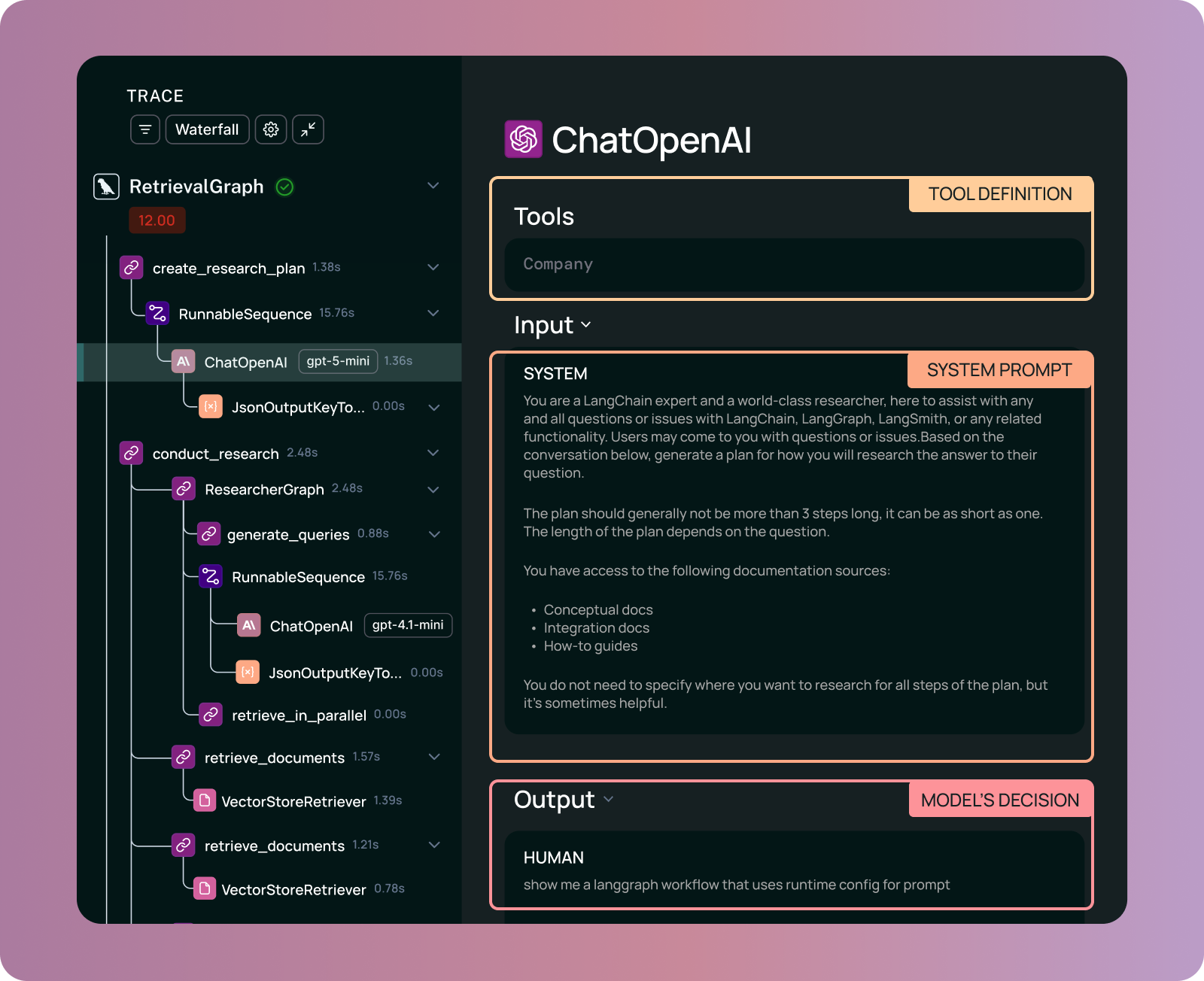
エージェントの実行例とその構成要素 - デバッグ用:任意のステップでエージェントが何を考えていたかを正確に確認できます。プロンプトには何が含まれていましたか?利用可能なツールは何でしたか?なぜこのアクションを選択したのですか?
- 評価用:この run に対してアサーションを記述します。エージェントは正しいツールを呼び出しましたか?適切な引数で呼び出しましたか?
Traces: 実行軌跡のキャプチャ
trace は、発生したすべての run をリンクさせることで、エージェントの実行全体をキャプチャします。推論の trace は以下をキャプチャします:
- 各ステップでモデルに入力されるすべての情報は、トレースを構成するランとしてキャプチャされます
- 引数と結果を含むすべてのツール呼び出し
- ステップ間の関係を示すネストされた構造
エージェントのトレースは非常に巨大です。典型的な分散トレースが数百バイトである場合、エージェントのトレースはその桁違いに大きくなることがあります。複雑で長時間実行されるエージェントの場合、トレースは数百メガバイトに達することもあります。このコンテキストは、エージェントの推論をデバッグおよび評価するために必要です。
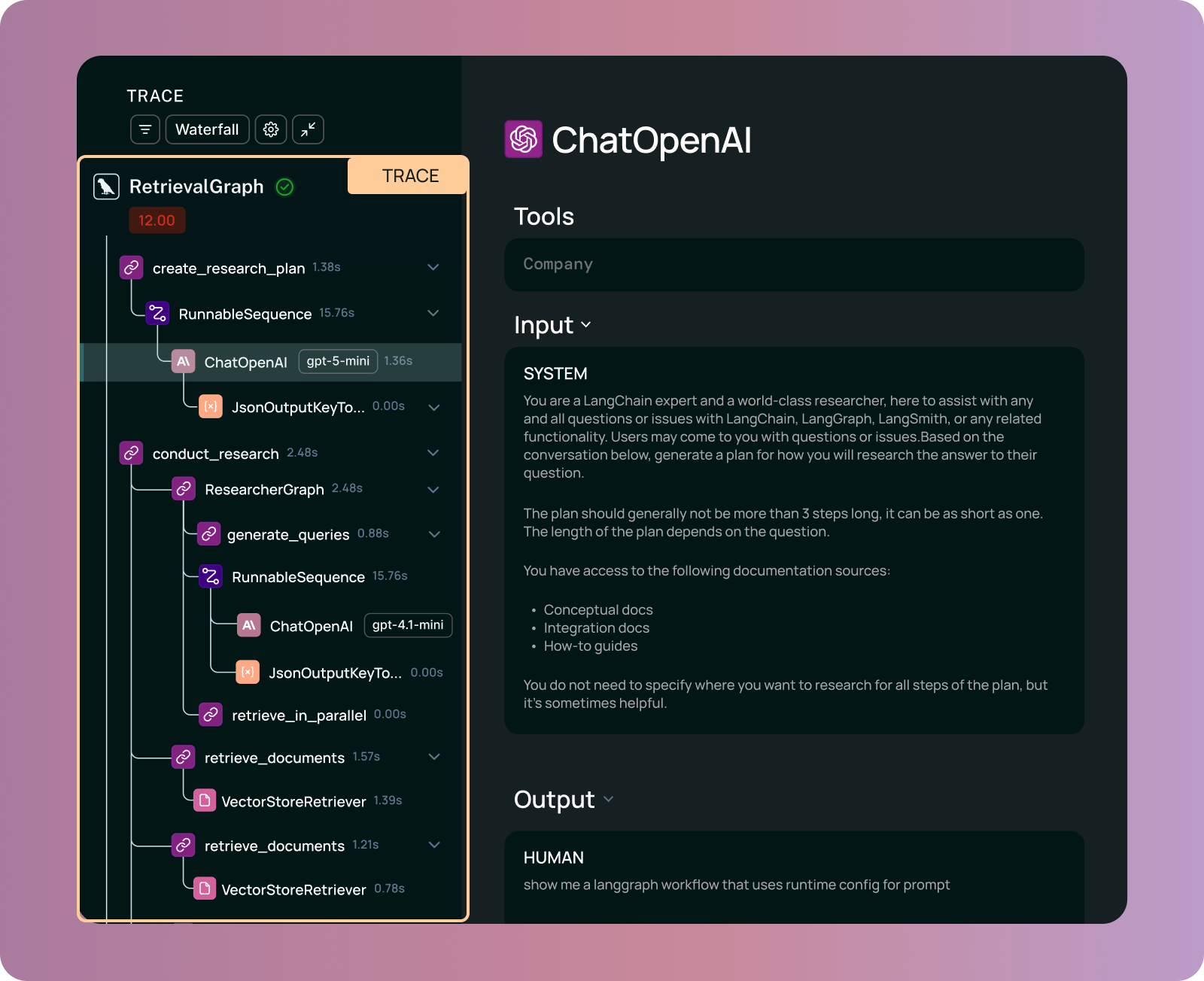
トレースの例とその構成要素
スレッド:複数回の会話コンテキスト
単一のトレースは1つのエージェント実行をキャプチャしますが、エージェントはユーザーやシステムとの複数のやり取りを含むセッションで動作することがよくあります。スレッドは、複数のエージェント実行(トレース)を1つの会話セッションにグループ化し、以下の情報を保持します。
- 複数回のコンテキスト:ユーザーとエージェントのすべてのやり取りを時系列順に記録
- 状態の変化:ターンを通じてエージェントのメモリ、ファイル、その他のアーティファクトがどのように変化したか
- 時間範囲:会話は数分、数時間、あるいは数日にわたることがあります
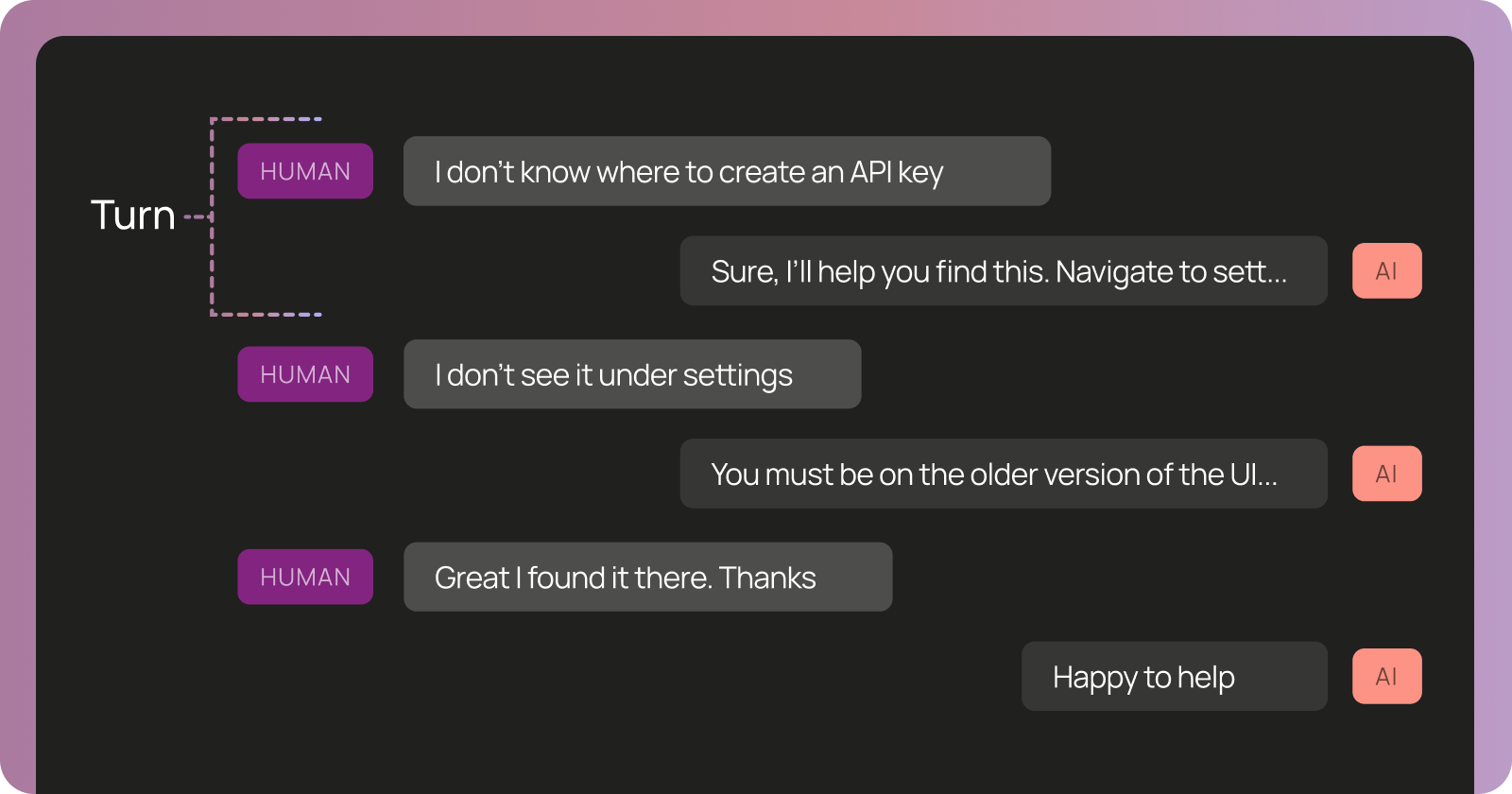
複数の会話のやり取りをキャプチャしたスレッドの例
10ターンまでは正常に動作していたコーディングエージェントが、突然11ターン目でミスし始めた場合のデバッグを考えてみましょう。単独で11ターンのトレースを見ると、エージェントが妥当なツールを呼び出しているように見えます。しかし、完全なスレッドを確認すると、6ターン目でエージェントが誤った前提でメモリを更新しており、その11ターン目までにその不適切なコンテキストが蓄積してバグのある動作につながっていたことがわかります。
スレッドは、エージェントの振る舞いが時間とともにどのように進化するか、そして相互作用 across でコンテキストが蓄積(または劣化)していくかを理解するために不可欠です。
エージェント評価への影響
エージェントの振る舞いは実行時に初めて現れ、観測可能性(runs、traces、および threads)によってのみキャプチャされます。つまり、振る舞いを評価するには、観測可能性データを評価する必要があります。これにより、2つの重要な問いが生じます。
- エージェントをどの粒度で評価するか? run、trace、または thread のレベルか?
- いつエージェントを評価するか? 振る舞いはエージェントを実行したときに初めて現れるのであれば、ソフトウェアと同様にオフラインで評価できるか?
異なる粒度でのエージェント評価
エージェントは、観測可能性のプリミティブと1:1で対応する異なる粒度で評価できます。 何を評価するかによって、必要なプリミティブが決まります:
- シングルステップ評価は個々の実行を検証する → エージェントは特定のステップで正しい判断を下したか?
- フルターン評価は完全なトレースを検証する → エージェントはタスク全体を正しく実行したか?
- マルチターン評価はスレッド(会話スレッド)を検証する → エージェントは会話全体を通じて文脈を維持できたか?
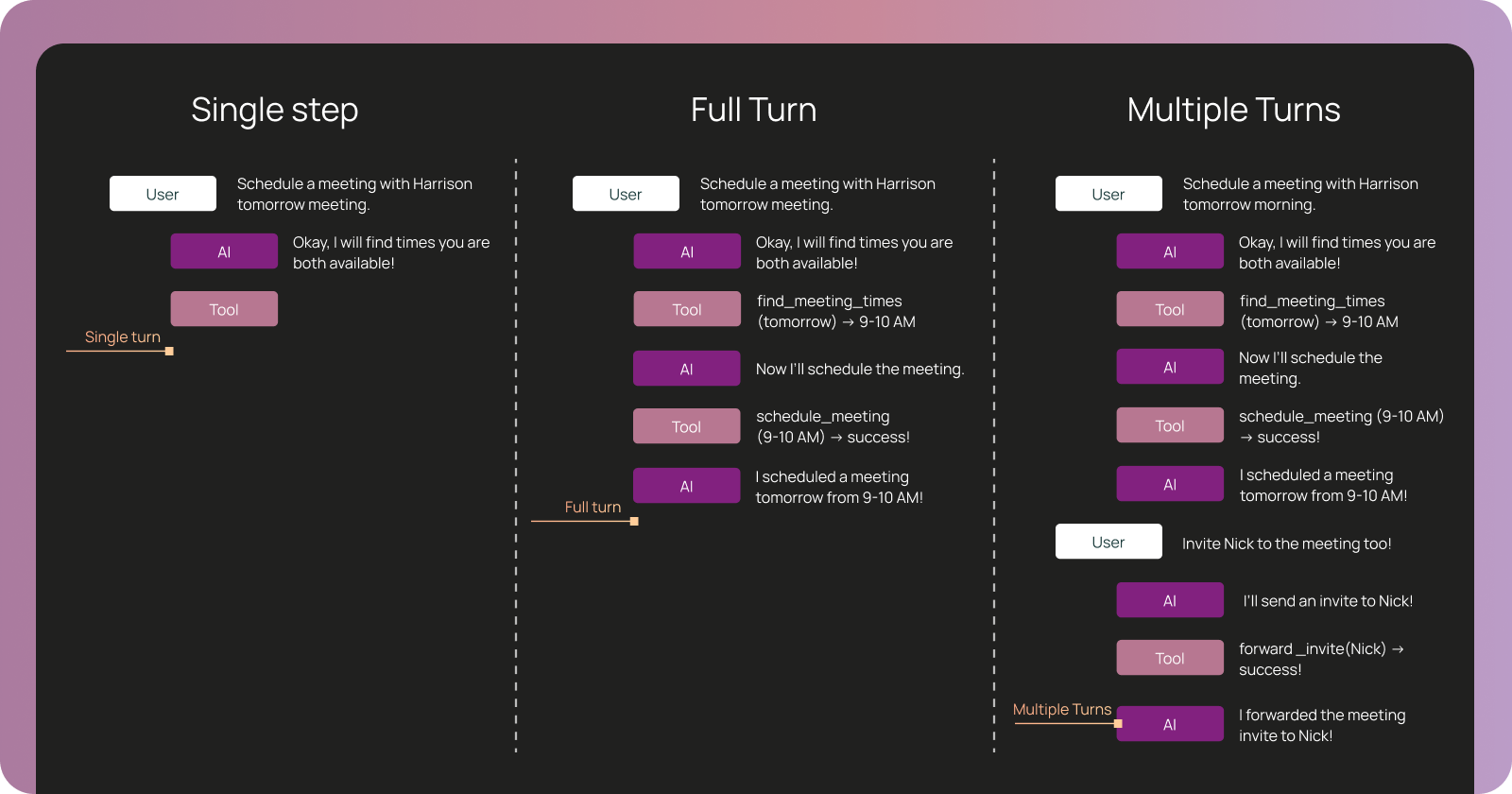
シングルステップ、フルターン、マルチターンの評価パターン
- シングルステップ評価:判断に対するユニットテスト
場合によっては、エージェント全体を実行せずに、特定の判断ポイントを検証する必要があることがあります。特定のシナリオでエージェントが適切なツールを選択したか、あるいは正しい引数を使用したかどうかを確認したい場合などが該当します。

これはエージェントの推論に対するユニットテストのようなものです:特定の状態(会話履歴、利用可能なツール、現在のタスク)を設定し、エージェントを1ステップ実行して、正しい判断を下したことをアサートします。シングルステップ評価は、個々のLLM呼び出し(Large Language Model call)である実行を検証します。
例:カレンダーエージェントのツール選択テスト
スケジューリングエージェントは、会議の予約を行う前に空き時間を見つける必要があります。そのエージェントが、すぐに会議を作成しようとするのではなく、まず空き時間を確認するかどうかを検証したい場合を考えます。
単一ステップのテストは以下の通りです:
- 状態の設定:会話履歴 = ユーザーが「明日の朝、ハリソンとの会議を予約して」と言った、利用可能なツール = [find_meeting_times, schedule_meeting, send_email]
- 1ステップの実行:エージェントが次のアクションを生成
- アサーション:エージェントは schedule_meeting ではなく find_meeting_times を選択した
なぜラン(Runs)が必要なのか:単一ステップのテストは、しばしば本番環境でエラーが発生した実際のケースから派生します。これらのケースを再現するには、そのステップ直前のエージェントの正確な状態が必要です。詳細なランのキャプチャが、この情報を得る唯一の方法です!
単一ステップの評価は効率的であり、個々の意思決定ポイントでの回帰テストを検出できます。実際、エージェントのテストスイートの約半分は、これらの単一ステップテストを使用して、完全なエージェント実行のオーバーヘッドなしで、特定の推論動作を分離して検証しています。
2. フルターン評価:エンドツーエンドのトラジェクトリ評価
一方で、エージェントの実行全体を確認する必要がある場合もあります。フルターン評価はトラジェクトリ(traces)、つまりすべてのランを含む完全なエージェント実行を検証し、複数の次元をテストすることを可能にします:
トラジェクトリ:エージェントは必要なツールを呼び出したか?バグ修正を行うコーディングエージェントの場合、以下のようなアサーションを行います。「エージェントは read_file を呼び出し、次に edit_file を呼び出し、最後に run_tests を実行するべきである。」正確なシーケンスは異なる場合もありますが、特定のツールが呼び出されることが必須です。
最終応答:出力は正しく、有用でしたか?リサーチやコーディングのようなオープンエンドなタスクでは、特定の処理経路よりも最終回答の品質の方が重要になることがよくあります。
状態変化:エージェントは適切な成果物を作成しましたか?コーディングエージェントの場合、作成したファイルを確認し、正しいコードが含まれているかを検証します。メモリ機能を持つエージェントの場合は、適切な情報が保存されたかを確認します。

ユーザーの好み(プリファレンス)を記憶するエージェントのテストには、以下の3つの要素を検証する必要があります:
- 軌跡(Trajectory):エージェントはメモリーファイルに対して
edit_fileを呼び出したか? - 最終応答:エージェントはユーザーに対して更新を確認したか?
- 状態:メモリーファイルには実際にその好み(プリファレンス)が記録されているか?
各アサーションには、トレースの異なる部分が必要です。完全な軌跡と状態変化をキャプチャせずに、これらの次元を評価することはできません。
3. マルチターン評価:現実的な会話フロー
エージェントの動作の一部は、複数のターン(対話ラウンド)を経て初めて現れます。エージェントが5つのターンまでは文脈を正しく維持できても、6番目のターンで失敗することがあります。あるいは、個々のリクエストには適切に対応できるものの、リクエストが積み重なる(相互に関連する)場合に困難をきたすことがあります。
マルチターン評価は、スレッド、つまり複数のエージェント実行を伴う会話セッションを検証します。エージェントがコンテキストを正しく蓄積し、ターン間で状態を維持し、以前のやり取りに基づいて構築される会話フローを処理できるかどうかをテストします。

例えば、コンテキストの永続性をテストする場合:
- ターン 1: ユーザーが好みを示す(「JavaScript より Python を好む」)
- ターン 2: その好みに基づいた質問をする(「例を見せて」)
- ターン 3: その好みが維持されていることをテストする(「これ用のスクリプトを書いて」)
エージェントは、ターン 2 と 3 で JavaScript ではなく Python の例を提供すべきです。これには、ターン間でコンテキストを維持する必要があります。
課題は、マルチターンのテストを軌道に乗せておくことです。もしエージェントがターン 1 で期待されたパスから逸脱した場合、ハードコードされたターン 2 の入力は意味をなさなくなる可能性があります。各ターンの後にエージェントの出力をチェックする条件分岐ロジックを使用し、軌道から外れた場合は早期に失敗させます。
マルチターン評価には、複数のエージェント実行(トレース)を 1 つの会話にグループ化するスレッドが必要です。マルチターンのテストが失敗した場合、何がどこで間違えたかを理解するために、すべてのターンを示すスレッドが必要です。
エージェントの評価粒度をどう選ぶか
エージェントの評価粒度を選ぶ方法に、唯一正解というものは存在しません。私たちが目にしたいくつかのヒューリスティックを紹介します:
- トレースレベルの評価(フルターン)の入力を用意するのは、しばしば最も簡単なアプローチです。これらはエージェントへの入力となるため、期待される入力を想定するのは比較的容易(かつ必要)です。一方で、期待される出力や、それらをプログラムで検証する方法を用意するのは難しい場合があります。その結果、これらのデータポイントに対してエージェントの実行を自動化する期間はあるものの、スコアリングは手動で行うことが多くなります。
- ランレベルの評価(シングルステップ)のスコアリングを完全に自動化するのは最も容易です。これは単一のモデル呼び出しであり、多くの場合、どのツールが呼び出されたかを確認することで評価できます。ただし注意が必要です:エージェントの内部(利用可能なツールや、適切なツールの呼び出し順序など)を頻繁に変更する場合、これらの評価は古くなりやすく、更新が必要になることがあります。この理由から、私たちは一般的に、チームがエージェントのアーキテクチャが比較的安定してからこれらの評価を構築するのを目にします。
- スレッドレベルの評価(マルチターン)は効果的に実装するのが困難です。これには一連の入力を想定する必要がありますが、多くの場合、その一連の入力はエージェントが入力間の処理で特定の振る舞いをした場合にのみ意味を持ちます。また、自動評価も困難です。これが私たちが目にする中で最も一般的な評価タイプではありません。

多くの本番環境で使用されるエージェントは、コアなワークフローに対するフルターンテスト、本番環境で発見された既知の失敗モードに対するシングルステップテスト、そして状態を保持する相互作用に対するマルチターンテストを組み合わせて使用します。
エージェントの評価時期
エージェントの動作は、本番環境で実行されるまで完全に顕在化しません。つまり、エージェントを評価する時期も従来のソフトウェアとは異なります。
- オフライン評価:これは、リリース前にユニットテストを実行することに相当します。これらのテストを実行するには、入力データのセットと、比較対象として任意の正解出力(ground truth outputs)を収集する必要があります。このデータセット上でエージェントを実行・評価するコストに応じて、すべてのコミット時または本番環境へのプッシュ直前にこれらの評価を実行するかを選択できます。オフライン評価を頻繁に実行する場合は、モデルへの不要な呼び出しを防ぐために何らかのキャッシュを設定する必要があります。注:多くの人が「評価」と言う場合、彼らが指しているのは主にこのオフライン評価です。
- オンライン評価:エージェントが本番データ上で実行されるまでそのパフォーマンスがわからないため、エージェントが本番データ上で動作する際に「オンライン」で評価を実行したい場合があります。これを行う場合、これらの評価者は定義上「参照なし(reference free)」である必要があります。オンライン評価子は通常、本番データの取り込み時に実行されます。
- アドホック評価:エージェントの入力と動作は非常に境界が不明確であるため、事前にテストしたい内容を常に把握できるとは限りません。本番環境に多くのトレース(traces)がある場合、それらがすでに取り込まれた後にテストしたいと思うかもしれません。この探索的データ分析は、エージェントの理解において極めて重要となります。LangSmith の Insights Agent などのシステムが、これを実現するのに役立ちます。

重要な転換点:オフライン評価は必要だが、それだけでは不十分です。 本番環境でのエージェントの評価が重要なのは、ユーザーがあなたのエージェントとどのように相互作用するかをすべて予測できないからです。
エージェントの可観測性が評価を支える方法
可観測性のために生成されるトレースは、評価を動かすのと同じトレースであり、統一された基盤を形成します。
トレース → マニュアルデバッグ
アドホックなクエリでローカル環境でエージェントを実行し、結果を手動で検査している場合、それは依然として(手動の)評価の一形態です!トレースはこのワークフローを支え、プロセスのすべてのステップをたどって、どこが間違っていたのかを正確に把握することを可能にします。
トレース → オフライン評価データセット
本番環境のトレースは、自動的にあなたの評価データセットになります。例えば、ユーザーがバグを報告した場合、トレースから以下の情報を確認できます:正確な会話履歴とコンテキスト、各ステップでエージェントが決定したこと、そして具体的にどこで失敗したか。
具体的なワークフローの例:
- ユーザーが誤った動作を報告
- 本番環境のトレースを検索
- 失敗時点の状態を抽出
- その正確な状態からテストケースを作成
- 修正と検証
したがって、オフライン評価用のテストスイートは、実際のデータポイントから構成することができます。
Traces → online evaluation
デバッグのために生成された同じトレースが、継続的な本番環境の検証にも利用されます。オンライン評価は、すでにキャプチャしているトレース上で実行されます。すべてのトレースに対してチェックを実行するか、戦略的にサンプリングして実行することができます:
- 軌跡チェック:異常なツール呼び出しパターンにフラグを立てる
- 効率モニタリング:パフォーマンスの劣化傾向を検出する
- 品質スコアリング:本番環境での出力に対してLLM-as-judge(LLM判定)を実行する
- 失敗アラート:ユーザーからの報告前にエラーを表面化する
これにより、開発時の振る舞いが本番環境でも維持されていることをリアルタイムで検証し、問題を浮き彫りにします。
What this means for teams building agents
信頼性の高いエージェントをリリースしているチームは、コードのデバッグから推論のデバッグへのシフトを受け入れています。従来のソフトウェア開発では、トレース(デバッグ用)とテスト(検証用)は分離されていました。しかし今や、私たちは長期間稼働し状態を保持するプロセスにおける非確定的な推論のデバッグを行っているため、これらのプラクティスは収束しています。エージェントの振る舞いを評価するには推論トレースが必要であり、トレースを理解するには体系的な評価が必要です。
この両方のプラクティスを初日から併用して採用するチームこそが、実際に機能するエージェントをリリースできるでしょう。
Related content

Conceptual Guide
Deep Agents
The runtime behind production deep agents


S. Runkle、
V. Trivedy
2026年4月20日
24分
Harrison's In the Loop
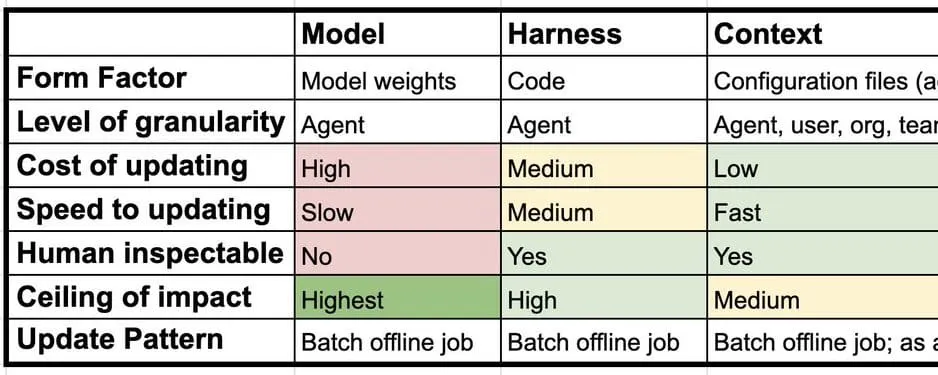
あなたのハルネス、あなたのメモリ

Harrison Chase
2026年4月11日
7分
Harrison's In the Loop
AIエージェントのための継続的学習
Harrison Chase
2026年4月5日
4分

エージェントが実際に何を行っているかを見る
LangSmithは、当社のエージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、評価(eval)の変更を確認し、ワンクリックでデプロイできるように支援します。
原文を表示
Agent observability powers agent evaluation
Key Takeaways
You can't build reliable agents without understanding how they reason, and you can't validate improvements without systematic evaluation. This article explains the primitives for agent observability, how to evaluate agents at different granularities, and how production traces become the foundation for continuous improvement.
TL;DR
- You don't know what your agents will do until you actually run them — which means agent observability is different and more important than software observability
- Agents often do complex, open-ended tasks, which means evaluating them is different than evaluating software
- Because traces document where agent behavior emerges, they power evaluation in a multitude of ways
When something goes wrong in traditional software, you know what to do: check the error logs, look at the stack trace, find the line of code that failed. But AI agents have changed what we're debugging. When an agent takes 200 steps over two minutes to complete a task and makes a mistake somewhere along the way, that’s a different type of error. There’s no stack trace - because there’s no code that failed. What failed was the agent’s reasoning.
From debugging code to debugging reasoning
You still write code to define your agent, e.g. which tools exist, what data is available. You write prompts and tool descriptions to guide the agent's behavior, but you won't know how the LLM will interpret these instructions until you run it. The source of truth thus shifts from code to traces that show what the agent actually did.
Agent engineering is an iterative process, and tracing + evaluation are how you close the loop. In this post, we'll explore why agent observability and evaluation are fundamentally different from traditional software, what new primitives and practices you need, and how observability powers evaluation in ways that make them inseparable.
Agent observability ≠ software observability
Pre-LLMs, software was largely deterministic — given the same input, you'd get the same output. Logic was codified. You could read the code and know exactly how the system behaved. When something went wrong, logs pointed you to which service or function failed, then you'd go back to the code to understand why it happened and fix it.
AI agents break the assumptions of determinism and code as a source of truth. As we're moving from traditional software to LLM applications to agents, each step introduces more uncertainty. LLM apps make a single call to an LLM with context, introducing natural language's inherent "fuzziness" but remain constrained to one LLM call.
However, agents call LLMs and tools in a loop until they determine a task is done — and can reason across dozens or hundreds of steps, calling tools, maintaining state, and adapting behavior based on context. When building an agent, you attempt to recommend the application logic in code and prompts. But you don't know what this logic will do until actually running the LLM.
When something goes wrong, you're not finding a single line of code that failed. Instead, you're asking:
- Why did the agent decide to call edit_file instead of read_file at step 23 of 200?
- What context and prompt instructions informed that decision?
- Where in this two-minute, 200-step trajectory did the agent go off track?
Traditional tracing tools can't answer these questions. A 200-step trace is too large for a human to parse, and traditional traces don't capture the reasoning context behind each decision; they only capture which services were called and how long each took.
Agent evaluation ≠ software evaluation
Traditional software testing relies on deterministic assertions: write tests that check output == expected_output, verify they pass, then ship. Online evaluation (A/B tests, product analytics) measures business impact separately. Evaluating agents differ from evaluating software in a few key ways:
1. You're testing reasoning, not code paths
Traditional software has tests at different levels of granularity (unit, integration, e2e), testing deterministic code paths you can read and modify. Agents also need testing at different levels, but you're no longer testing code paths — you're testing reasoning:
- Single-step: Did the agent make the right decision at this moment?
- Full-turn: Did the agent perform well in an end-to-end execution?
- Multi-turn: Did the agent maintain context across a conversation?
2. Production becomes your primary teacher
In traditional software, you can catch most correctness issues with offline tests (unit tests, integration tests, staging). You still test in production through canary deployments and feature flags, but the goal is to catch edge cases and integration issues you missed.
With agents, production plays a different role. Because every natural language input is unique, you can't anticipate how users will phrase requests or what edge cases exist. Production traces reveal failure modes you couldn't have predicted and help you understand what "correct behavior" actually looks like for real user interactions.
This shifts how you think about evaluation: production isn't just where you catch missed bugs. It's where you discover what to test for offline. Production traces become test cases, and your evaluation suite grows continuously from real-world examples, not just engineered scenarios.
The primitives of agent observability
Agent observability uses three core primitives to capture non-deterministic reasoning:
- Runs: A single execution step (one LLM call with its input/output)
- Traces: A complete agent execution showing all runs and their relationships
- Threads: Multi-turn conversations grouping multiple traces over time
These use the same concepts as traditional observability (e.g. traces, spans) but capture reasoning context rather than service calls and timing
Runs: capturing what the LLM did at a single step
A run captures a single execution step. This is most useful for capturing how the LLM behaved at a particular point in time. This captures the complete prompt for an LLM call, including all instructions, tools used, and context.
These runs serve dual purposes:
- For debugging: See exactly what the agent was thinking at any step. What was in the prompt? What tools were available? Why did it choose this action?
- For evaluation: Write assertions against this run. Did the agent call the right tool? With the right arguments?
Traces: capturing trajectories
A trace captures a complete agent execution by linking together all the runs that occurred. A reasoning trace captures:
- All information about what goes into the model at each step, captured as runs that make up the trace
- All tool calls with their arguments and results
- The nested structure showing how steps relate to each other
Agent traces are massive. While a typical distributed trace might be a few hundred bytes, agent traces can be orders of magnitude larger. For complex, long-running agents, traces can reach hundreds of megabytes. This context is necessary for debugging and evaluating the agent's reasoning.
Threads: multi-turn conversation context
A single trace captures one agent execution, but agents often operate across sessions involving multiple interactions with a user or system. A thread groups multiple agent executions (traces) into a single conversational session, preserving:
- Multi-turn context: All interactions between user and agent in chronological order
- State evolution: How the agent's memory, files, or other artifacts changed across turns
- Time span: Conversations can last minutes, hours, or days
Consider debugging a coding agent that worked fine for 10 turns but suddenly started making mistakes in turn 11. The turn 11 trace in isolation might show the agent calling a reasonable tool. But when you examine the full thread, you discover that in turn 6 the agent updated its memory with an incorrect assumption, and by turn 11 that bad context had compounded into buggy behavior.
Threads are essential for understanding how agent behavior evolves over time and how context accumulates (or degrades) across interactions.
How this influences agent evaluation
Agent behavior only emerges at runtime, and is only captured by observability (runs, traces, and threads). This means that to evaluate behavior you need to evaluate your observability data. This raises two key questions:
- At what granularity do you evaluate agents? At the run, trace, or thread level?
- When do you evaluate agents? If behavior only emerges when you run the agents, can you evaluate them offline in the same way you do software?
Evaluations agents at different levels of granularity
You can evaluate agents at different levels of granularity, which map 1:1 to the observability primitives. What you're evaluating determines which primitive you need:
- Single-step evaluation validates individual runs → Did the agent make the right decision at a specific step?
- Full-turn evaluation validates complete traces → Did the agent execute the full task correctly?
- Multi-turn evaluation validates threads → Did the agent maintain context across a conversation?
- Single-step evaluation: unit tests for decisions
Sometimes, you need to validate a specific decision point without running the entire agent. You may want to see if the agent choose the right tool in a specific scenario, or whether it used the correct arguments.
This is like a unit test for agent reasoning: set up a specific state (conversation history, available tools, current task), run the agent for one step, and assert that it made the right decision. Single-step evaluation validates runs, i.e. individual LLM calls.
Example: Testing a calendar agent's tool selection
A scheduling agent needs to find available meeting times before scheduling. You want to verify it checks availability first rather than immediately trying to create the meeting:
Your single-step test:
- Setup state: Conversation history = user said "Schedule a meeting with Harrison tomorrow morning", available tools = [find_meeting_times, schedule_meeting, send_email]
- Run one step: Agent generates next action
- Assert: Agent chose find_meeting_times (not schedule_meeting)
Why you need runs: Single step tests often come from real production cases that error. In order to recreate these, you need the exact state of the agent before that step. Detailed run captures are the only way to get this!
Single-step evaluations are efficient and catch regressions at individual decision points. In practice, about half of agent test suites use these single-step tests to isolate and validate specific reasoning behaviors without the overhead of full agent execution.
2. Full-turn evaluation: end-to-end trajectory assessment
Other times, you need to see a complete agent execution. Full-turn evaluation validates traces, i.e. complete agent executions with all their runs, and let you test multiple dimensions:
Trajectory: Did the agent call the necessary tools? For a coding agent fixing a bug, you might assert: "The agent should have called read_file, then edit_file, then run_tests." The exact sequence might vary, but certain tools must be called.
Final response: Was the output correct and helpful? For open-ended tasks like research or coding, the quality of the final answer often matters more than the specific path taken.
State changes: Did the agent create the right artifacts? For a coding agent, you'd inspect the files it wrote and verify they contain the correct code. For an agent with memory, you'd check that it stored the right information.
Testing that an agent remembers user preferences also requires validating three things:
- Trajectory: Did the agent call edit_file on its memory file?
- Final response: Did the agent confirm the update to the user?
- State: Does the memory file actually contain the preference?
Each assertion requires different parts of the trace. You can't evaluate these dimensions without capturing the full trajectory and state changes.
3. Multi-turn evaluation: realistic conversation flows
Some agent behaviors only emerge over multiple turns. The agent might maintain context correctly for 5 turns but fail on turn 6, or handle individual requests fine but struggle when requests build on each other.
Multi-turn evaluation validates threads, i.e. conversational sessions with multiple agent executions. You test whether the agent accumulates context correctly, maintains state across turns, and handles conversational flows that build on previous exchanges.
For example, testing context persistence:
- Turn 1: User shares a preference ("I prefer Python over JavaScript")
- Turn 2: User asks a question building on that ("Show me an example")
- Turn 3: Test that preference persists ("Write a script for this")
The agent should provide Python examples in turns 2 and 3, not JavaScript. This requires maintaining context across turns.
The challenge is keeping multi-turn tests on rails. If the agent deviates from the expected path in turn 1, your hardcoded turn 2 input might not make sense. Use conditional logic to check the agent's output after each turn, and fail early if it goes off track.
Multi-turn evaluation requires threads to group multiple agent executions (traces) into a single conversation. When a multi-turn test fails, you need the thread showing all turns to understand what went wrong and where.
How to choose what granularity to evaluate your agent at
There is no single right way to choose which granularity to evaluate agents at. Some heuristics we’ve seen:
- It’s often easiest to come up with inputs for trace-level evals (full-turn). These are inputs to your agent, so it’s pretty easy (and necessary) to come up with expected inputs. That being said, it can be harder to come up with expected outputs and/or a way to validate those programmatically. This means there may be some period time of where you automate the running of the agent over these datapoints, but not the scoring.
- It’s easiest to fully automate the scoring of run-level evals (single-step). This is just a single model call, and often times can be evaluated by checking with tools were called. One word of caution: depending on how frequently you are changing the internals of your agent (which tools are available, the right sequence to call tools) these evaluations may get out of date quickly and require updating. For this reason, we generally see teams building these only after the general agent architecture is relatively stable.
- Thread-level evals are hard to implement effectively (multi-turn). They involve coming up with a sequence of inputs, but often times that sequence only makes sense if the agent behaves a certain way between inputs. They are also hard to evaluate automatically. This is least common type of evaluation that we see.
Most production agents use a combination: full-turn tests for core workflows, single-step tests for known failure modes discovered in production, and multi-turn tests for stateful interactions.
When to evaluate an agent
Agent behavior doesn’t fully emerge until you run it in production, which means that when you evaluate agents also differs from traditional software.
- Offline evaluation: This is the equivalent of running unit tests before shipping. To run these tests, you’ll want to collect a dataset of inputs and, optionally, ground truth outputs to compare against. Depending on the cost to run and evaluate the agent over this dataset, you may run these evals on every commit, or just before you push to prod. If you are running offline evals frequently, you will want to set up some sort of caching so that you’re not calling the model unnecessarily. Note: when most people talk about “evaluation”, offline evals are the primary type of evaluation they are likely referring to.
- Online evaluation: Since you don’t know how the agent will perform until you run it, you may want to run evaluations “online”, as the agent runs on production data. When doing this, these evaluators definitionally need to be “reference free”. Online evaluators typically run on ingestion of production data.
- Ad-hoc evaluation: Agents are very unbounded in their inputs and behavior, so you don’t always know ahead of time what you want to test for. If you have a lot of traces in production, you may want to test them after they have already been ingested. This exploratory data analysis can be crucial for understanding your agents. Systems like Insights Agent in LangSmith can help you do this.
The key shift: offline evaluation is necessary but not sufficient. Evaluating your agents in production is important because you can't anticipate all the ways users will interact with your agent.
How agent observability powers agent evaluation
The traces you generate for observability are the same traces that power your evaluations, forming a unified foundation.
Traces → manual debugging
When you are running an agent locally on ad hoc queries and manually inspecting the results - that is still a form of (manual) evaluation! Traces power this workflow as they allow you to step into every step of the process and figure out exactly what when wrong.
Traces → offline evaluation datasets
Production traces become your evaluation dataset automatically. For example, when a user reports a bug, you can see in the trace: the exact conversation history and context, what the agent decided at each step, and where specifically it went wrong.
An example workflow:
- User reports incorrect behavior
- Find the production trace
- Extract the state at the failure point
- Create a test case from that exact state
- Fix and validate
Thus, your test suite for offline evaluation can be formed from real data points.
Traces → online evaluation
The same traces generated for debugging power continuous production validation. Online evaluations run on traces you're already capturing. You can run checks on every trace or sample strategically:
- Trajectory checks: Flag unusual tool call patterns
- Efficiency monitoring: Detect performance degradation trends
- Quality scoring: Run LLM-as-judge on production outputs
- Failure alerts: Surface errors before user reports
This surfaces issues in real-time, validating that development behavior holds in production.
What this means for teams building agents
The teams shipping reliable agents have embraced the shift from debugging code to debugging reasoning. Traditional software separated tracing (for debugging) and testing (for validation). Now that we're debugging non-deterministic reasoning across long-running, stateful processes, these practices converge. You need reasoning traces to evaluate agent behavior, and you need systematic evaluation to make sense of traces.
The teams that adopt both practices together, from day one, will be the ones shipping agents that actually work.
Related content
Conceptual Guide
Deep Agents
The runtime behind production deep agents
S. Runkle,
V. Trivedy
April 20, 2026
24
min
Harrison's In the Loop
Your harness, your memory
Harrison Chase
April 11, 2026
7
min
Harrison's In the Loop
Continual learning for AI agents
Harrison Chase
April 5, 2026
4
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
AI ヘルスコーチの構築:評価、安全性、規制対応について
LangChain が AI ヘルスコーチの開発において、評価手法や安全性確保、規制遵守の重要性を解説している。
エージェントシステムにおける意図と実行の架橋
Amazon Science は、AI エージェントのパフォーマンスはモデル自体の問題ではなく、LLM とツール間の仲介役となるハッチ(OS)の設計がボトルネックであると指摘し、意図を実行に移すシステムの重要性を強調した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み