AI #162:ミソスのビジョン
Anthropicの次期大規模モデル「Mythos」の存在とClaude Codeのソース漏洩、そしてAxiosなどのセキュリティ侵害事例を報じつつ、OpenAIの1220億ドル調達完了や法廷闘争の静穏化など、AI業界のセキュリティ、規制、資金動向を多角的に分析している。
キーポイント
Anthropicの内部モデル「Mythos」とClaude Code漏洩
AnthropicがOpusより大規模な新モデル「Mythos」を開発中であり、サイバーセキュリティ能力の飛躍的向上を期待していることが判明。同時に、Claude Codeのソースコードが完全に漏洩した。
セキュリティ侵害の増加と「Defense beats offense」
AxiosやLiteLLMのハッキング事例など、AI関連企業のセキュリティ侵害が頻発しており、攻撃側の試みが以前より増えているため、防御が重要視されている。
OpenAIの巨額調達完了と法廷闘争の静穏化
OpenAIが1220億ドルの資金調達ラウンドを正式に完了。また、Anthropic対米政府の訴訟においてJudge Linによる差止命令が発令され、政府側が控訴期限までに新たな展開を示していないため、対立は一旦静かになっている。
モデル競争とセキュリティ懸念の継続
GPT-5.4とOpus 4.6の比較や、LTX 2.3などのメディア生成ツールの普及、そしてDeepfakeやボットによる有害な操作への懸念など、技術競争と倫理・セキュリティ問題が並行して議論されている。
AIの日常的な活用による時間節約
現在のAIは、ソフトウェアやシステムが存在せず専門知識もない「グリーンフィールド」な状況で最も強く発揮され、家事や税務申告などの非デジタル業務の負担を軽減し、ユーザーが好きなことに集中できる時間を生み出す。
OpenAIとAnthropicの数学能力比較
OpenAIの内部モデルがエルデシュ問題3つを解決した一方、Anthropicは未公開モデルの数学オリンピック的な競争に参加せず、かつ数学が同社の相対的な弱点であることを示唆している。
LLMを活用した税務申告の効率化
Patrick McKenzieは、LLMが複雑な法律を網羅的に探索して納税額を最小化する最適な申告方法を見つけるのに優れているのに対し、会計士の実績はばらつきがあることを指摘している。
影響分析・編集コメントを表示
影響分析
このニュースは、AI開発競争が単なる性能向上だけでなく、セキュリティ確保と巨額の資金調達能力の競争へとシフトしていることを示しています。特にAnthropicの内部モデル名「Mythos」の流出は、トップクラスのAI企業がサイバーセキュリティ強化を次世代モデルの主要な差別化要因と位置づけている可能性を示唆しており、業界全体のパターン認識能力やセキュリティ対策への影響は甚大です。
編集コメント
Anthropicの「Mythos」モデル名とClaude Codeのソース漏洩は、トップティアAI企業の開発プロセスにおけるセキュリティリスクの高まりを象徴しています。また、OpenAIの巨額調達は業界の資金集中と競争激化を加速させる要因となるため、今後の規制動向と併せて注視が必要です。
Anthropic は今週、情報漏洩に関するいくつかの問題に直面しました。
彼らが保有している新モデル「Mythos」は Opus よりも大規模であり、サイバー能力において飛躍的な進歩をもたらすと信じていることが明らかになりました。
また、Claude Code のソースコード全体が流出する事態も発生しました。
さらに Axios が侵害され、その直後に LiteLLM も同様の被害に遭いました。この手の事案はますます増加しているように見えます。多くの場合、防御側が攻撃側に勝つものの、攻撃側がゴールを射る回数は以前よりも格段に増えています。
今週、「AI ドキュメンタリー:あるいは私がどのようにアポカリプス・オプティミスト(楽観主義者)になったか」という作品が公開されました。私はこの作品に 4.5/5 の星を与え、より多くの人に見ていただければ世界は良くなるだろうと考えています。私は通常ドキュメンタリー映画のファンではありませんが、これはおそらく私の新作お気に入りとなり、『キング・オブ・コン:クォーターを握る男』という作品を置き換えることになるでしょう。
また、さまざまな議論の最新バージョンを含む、多くの出来事による通常の背景ノイズも存在しました。私たちは滅びる運命にあるかどうかは定かではありませんが、確かに特定の動きを何度も繰り返す運命にあり、人々がそれを更新する速度が遅いことは確かです。
Anthropic と戦争省(Department of War)間の対立については、非常に歓迎すべき静けさが訪れました。リン裁判官は 3 月 26 日、政府に対する厳しく批判的な意見と完全な仮差止命令を提示しました。政府はその判決の執行停止期間である 7 日間に控訴書を提出していませんが、その期限も残り少なくなっており、さらに意味のあるエスカレーション(対立の激化)は起きていません。今後このトピックに改めて投稿を割く必要がないことを願っています。
目次
言語モデルは凡庸な有用性を提供します。さまざまな雑事から時間を解放しましょう。
砂の中に頭を埋める人々。極端に深い否認状態にある人、あるいはそうありたいと願う人々がいます。
ふーん、アップグレード。Google が「インポートメモリ」機能を導入しました。彼らは愛らしいですね。
ミソス。大規模な展開を行い、Anthropic の新モデルは準備ができるまで内部に留めておきましょう。
名前の意味。名前には力があります。賢く選びましょう。
スタートの合図。一枚の写真は千の言葉に値しますが、一枚も必要ありません。
戦士を選べ。Ben Holmes が GPT-5.4 と Opus 4.6 の強みを分析します。
エージェントを呼び出せ。Outreach は十分な摩擦レベルに依存しています。
ディープフェイクタウンとボットアポカリプスの到来間近。有害な操作、AI を本質的な悪として捉える動き。
サイバーセキュリティの欠如。Axios が侵害され、脆弱性攻撃が積み重なっています。
メディア生成を楽しむ。LTX 2.3 が著作権違反のために登場しました。
若い女性のイラスト付き primer。親たちが AI にパニックを起こしています。
彼らが私たちの仕事を奪った。経済への影響は区別するのが困難です。
彼らが私たちの仕事を奪った後。実質的に仕事がない状態とは、多くの動画を見ることです。
ゲルマン・アムネシア。ある時点で一般的なケースの方がより興味深くなります。
参加しよう。助成金提供者になることはどのようなものか。
その他の AI ニュース。Claude の使用が不十分だったため、Claude Code が漏洩しました。
お金を見せてください。OpenAI が正式に 1220 億ドルの資金調達ラウンドを完了しました。
静かなる推測。砂の中に頭を完全に埋めているわけではないが、それでも顔を上げようとはしない人々。
持続的なモデル同等性の説明。同等性のレベルには説明が必要です。
一息つきましょう。今、一時停止の可能性を巡る議論を再確認するために立ち止まります。
OpenAI:その歴史。WSJ がダリオ・アモダイが OpenAI を去った理由を探ります。
AI 戦争省。大きな驚きは、これまでのところさらなる驚きがないことでした。
AI 連帯省。OpenAI は Anthropic との連帯を示すシグナルを送りました。
AI のための執筆。タイラー・コーエンが経済学的限界主義の歴史を記述しました。
健全な規制への探求。新しい世論調査の結果は、以前の知見と一致しています。
チップ都市。事実に関心を持たないなら、事実には関心を持たないでしょう。
あなたは連邦枠組みを受け取りました。あなたはゴミを売り続けることができます。
今週のオーディオ。The AI Doc, All-In, Karpathy, Argenti が Odd Lots で。
修辞的革新。CEO はあることを言いました。カルビン・クーリッジはより賢明なことを言いました。
私は非常に人間らしいフロンティア言語モデルです。相対性、相対性。
人類知能を超える知性のアライメントは困難です。人間もまた困難です。
偽のグラフのアライメントもまた困難です。OpenAI のボーアズ・バラクがそれらを描きます。
軽妙な側面。何が軽妙だとみなされるかご存知ですか?ドローンです。軍事用ドローンです。
言語モデルは平凡な有用性を提供します
AI を活用して自宅での時間を捻出できます。現在の AI は、これまでソフトウェアもシステムもなく、何をすべきかほとんど知らなかったような新規領域において最も強力な力を発揮します。自宅では専門知識を要さない多様なタスクに直面させられるため、概念的には単純なことでも時間がかかることが少なくありません。AI はそれらを処理でき、少なくともどのように行うべきかを理解する手助けをしてくれます。ここではあなたが望むことを実行し、あなたを単調作業から解放して好きなことに集中できるようにします。
この論文は、生産的なデジタル活動の効率化を通じて時間を捻出すると位置付けています。私はまた、それが非デジタルな活動からの時間をも解放すると付け加えます。なぜなら、それらの活動を行う方法を説明してくれるからです。
OpenAI の内部モデルが、3 つの追加のエルドース問題を解決しました。現時点で Anthropic は、「未公開モデルが何ができるか」という数学オリンピックへの参加を避けていますが、数学は Anthropic にとって相対的に苦手な分野である傾向があります。
LLM や特に AI エージェントを活用して税務申告を支援させましょう。パトリック・マッケンジー(Patrick McKenzie)氏は、LLM は納税額が最小となるような法的に可能な filing パターンのすべてを探求するのに非常に優れており、一方会計士はこれを実行する実績に一貫性がないと指摘しています。
砂の中に頭を埋める人々
jerry: Bsky の開発者たちは人類が知る限りで最も勇敢な人々だ
Jay: Bluesky は AI を使って作られており、エンジニアだけでなく一部の非エンジニアも Claude Code を使用している。
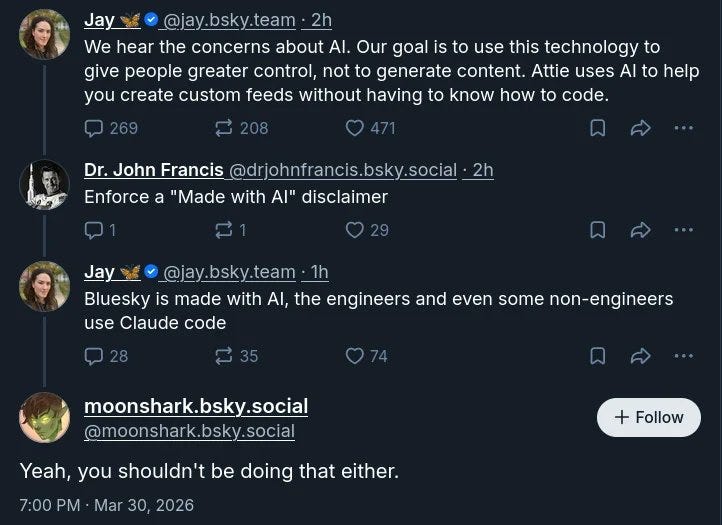
チャールズ:Bluesky の投稿(OP)へのコメントが非常に面白いですね。彼らは全く別の世界に住んでいるようです。
この投稿は、以下のような反応で比率(ratio'd)されました。
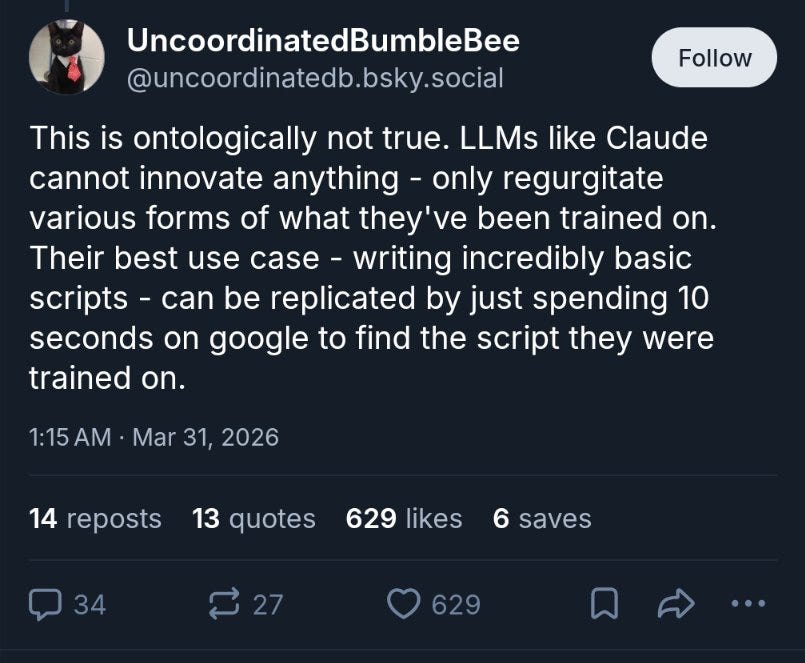
本当に素晴らしい内容がそこにはあります:
BlueSky などの場所では状況が最も極端になっていますが、世界の決定を行うグローバルエリート(世界のエリート)の巨大な一部は少なくとも半ばまで到達しており、AI を可能な限り切り捨てようとする動きが常に存在しています。
現時点で、少しでも注意を払っている人なら誰でも、AI が壁にぶつかったのは「クール・エイドマン」のようなスタイルでのみであり、実際にはそうではないことを知っています。しかし、「壁にぶつかる」という物語は根拠なく何度か流行しました。ホワイトハウスの多くの人々も、それが真実であることを心から望んでいる人々の一人であり、エリートたちは再びそれを持ち出すためのあらゆる理由を探しています。
西欧やグローバル・サウス、あるいは BlueSky や Instagram といったプラットフォームに行けば、まだ否定している人たちがいます。否定状態にある人は急速に影響力を失っていきます。
サンフランシスコの Tyler John: 私だけなのか、それとも一年前には「AI は過熱だ/壁にぶつかった」というのが支配的な議論だったのに、今や人々が完全にその話題から離れてしまったのか?
Nathan Calvin: Instagram を見ればわかります。そこではまだ活発です。
Dean W. Ball: 「Twitter で読みやすい」米国のエリート層はほぼこの考えを捨てましたが、Blu*sky や学界、中道左派の政策関係者などでは依然として一般的です。おそらく最も重要なのは、「AI は壁にぶつかった」という見解が、中規模国家や市民社会において標準的な信念となっているという私の感覚です。
この見解は特に西欧エリート層やグローバル・サウスのエリート層で一般的です。一方、先進資本主義の東アジア諸国のエリート層ではあまり見られません。一人当たり GDP は AGI(汎用人工知能)信奉度の良い代理指標となります。
例えば、ヨーロッパ内でも北欧のエリート層は平均して西欧のエリート層よりも AGI 信奉度が高いように思われます。
Dean W. Ball: 「Twitter で読みやすい」米国のエリート層の間では、潮流が本当に変わりつつあると感じます。私が先導者とみなす多くの人々が実際に見解を更新しました。しかし、「AI は壁にぶつかった」という解釈が再び可能になるような局面が訪れれば、この考えは再び広まるでしょう。
ふむ、アップグレードについて
Gemini が「Import Memory(メモリをインポート)」機能を導入しました。
Google は Gemini Live の大幅アップデートを発表し、3.1 Flash では応答速度が向上したと主張しています。
残念ながら少し後退した形となりましたが、これは賢明な対応策のように思われます:
Thariq(Anthropic): Claude に対する需要の増加に対応するため、ピーク時間帯における無料/Pro/Maxサブスクリプションユーザーの5時間セッション制限を調整いたします。週ごとの利用上限は変更されません。平日の太平洋標準時午前5時から11時、またはグリニッジ標準時午後1時から7時の間、以前よりも早く5時間のセッション制限に達するようになります。
全体の週ごとの利用上限は同じままですが、その週のどの時間帯に配分されるかが変化します。この変更が不便をおかけしたことは承知しています。私たちは効率的なスケーリングへの投資を継続しており、進捗については随時お知らせいたします。
GPU の数は固定されているため、ピーク時の計算リソースはより高価になるはずです。
Mythos
Pliny the Liberator ūļĿņĵĐŀļĹľʼnŭ: TITANOMACHY COMETH
Anthropic で CMS の設定ミス(人間の過失であり、Claude を責めるべきではありません)に起因するセキュリティ侵害が発生し、その結果、今後のモデルリリースに関する情報を含む各種内部文書が発見されました。漏洩してもよい内容も存在しますが、これはセキュリティ上の重大な違反でした。
Beatrice Nolan: AI 企業 Anthropic は、画像や PDF ファイルなどを含む重要なセキュリティインシデントにより、今後のモデルリリースの詳細、独占的な CEO イベントの情報、その他の内部データを誤って公開してしまいました。
新しいモデルは「Mythos」と呼ばれます。これは大規模であり、提供コストも非常に高く、ユニットエコノミクスがリリースを阻害するほどである可能性がありますが、常に「適切に課金し、誰が支払うかを確認する」ことがその答えとなります。現在、サイバーセキュリティに関与している人々に対しては差別化されたアクセスが行われています。
ピーター・ウィルデフォード:Mythos は新しい第 4 ティアであり、Opus よりも大規模で高価です。ドラフト版では、コーディング、学術的推論、サイバーセキュリティのベンチマークにおいて劇的に高いスコアを記録していると主張されています。
これが実際に何を意味するかについて、いくつかの考えを述べます:
- これはおそらく、ポストトレーニング(post-training)が類似したより大規模な事前学習(pre-train)モデルです。現在のフロンティアにおいて、追加の事前学習計算リソースがどれほどの価値をもたらすかは明らかではありません—私たちはまもなくそれを知るでしょう。
- この発表が AI の軌跡に何を意味するかについて、多くの過剰反応が見られます。しかし、予測を更新するにはまだ早すぎます。AI はすでに非常に速いペースで進化していました。
- 一部の人は、Anthropic が危険と見なすモデルを保有していることに驚いています。しかし、これはフロンティアモデルに対して Anthropic が常に取る姿勢です。
- 現在、リリースを阻んでいるもう一つの要因は単にユニットエコノミクスであるようです。Anthropic は、「[Anthropic] にとって提供するのは非常に高価であり、顧客にとっても利用コストが非常に高い」と述べています。Anthropic は「一般リリース前にモデルの効率を大幅に向上させる作業を進めている」としています。
- この仕組みが GPT 5.4 Pro との競合として機能するものかどうか、私は考えています。Claude は、長時間思考し数学などの分野で卓越した $200/月のプロ向けモデルを除き、OpenAI をあらゆる面で凌駕しているようです。現時点では Claude は OpenAI や Google のように未解決の数学問題を解いていませんが、Mythos がその状況を変えるかどうかは興味深いところです。
- 一般公開前にサイバー防御者に対してモデルを段階的に展開する「差別的アクセス」に Anthropic が取り組んでいる姿を見られるのは素晴らしいことです。モデルのサイバー能力は本格的に恐ろしいものになりつつあります。
- サイバー防御における皮肉な点として、今回の漏洩全体が CMS の設定ミスによって引き起こされたという事実があります。これはまさに、これらのサイバー対応型モデルが防御者を支援して防止すべきとされていた基本的なセキュリティ衛生の失敗そのものです。
- セキュリティは Anthropic の RSP v3(責任あるスケーリングポリシー)では主要カテゴリには含まれていませんが、OpenAI や Google からの類似文書では主要カテゴリであり、RSP v1 以降はその中心的地位が低下しています。一方、ここではまさにそれが Anthropic の中核的な懸念となっています。彼らは Mythos がサイバー能力において「他のどの AI モデルよりもはるかに先を行っている」と述べています。これは主要カテゴリとして扱われ、相応の敬意を払われるべきであるように思われます。
これは、RSP v3 が実際にはどのように機能するかという私のモデルをさらに裏付けるものであり、それは「私を信じて」という文書であるということです。Anthropic は、彼らが責任あると考えることを行います。まさに今、彼らはここで行っているように、RSP v3 に全く記載されていない方法で、状況が求める対応を行っています。したがって、RSP v3 が果たしている役割の程度と、安全性を非常に重視する人々によって構成されている Anthropic の存在との比較は、必ずしも明確ではありません。
これを発表するはずだったブログ投稿の supposed copy(推定コピー)はここにあります。
名前の意味について
私が初めて「Mythos」という名前を聞いたとき、それは壮大さやギリシア神話の神々を連想しました。
これは Anthropic が目指していることに近いものです。彼らは、漏洩したドラフト投稿によると、「知識とアイデアをつなぐ深い結合組織を想起させるため」にこの名前を選んだと述べています。
しかし、Eliezer Yudkowsky は別のものを連想しました。そしてどうやら他の人々も、しばしばその別のものを連想しているようです。
Eliezer Yudkowsky: 次のモデルをクトゥルフの名前に命名することは、Anthropic を善なる存在として真剣に受け取ることを難しくします。これは実際のソフトウェア会社であれば面白いかもしれませんが、実際には人類の絶滅と隣り合わせにある企業にとってはそうはいきません。
これが私の主要な問題ではありませんが、人類保護を謳う企業としては不真面目だと私は思います。しかし、いくつかの人々が指摘したように、推論機能を持たない Opus をシークレットモードで質問すると:
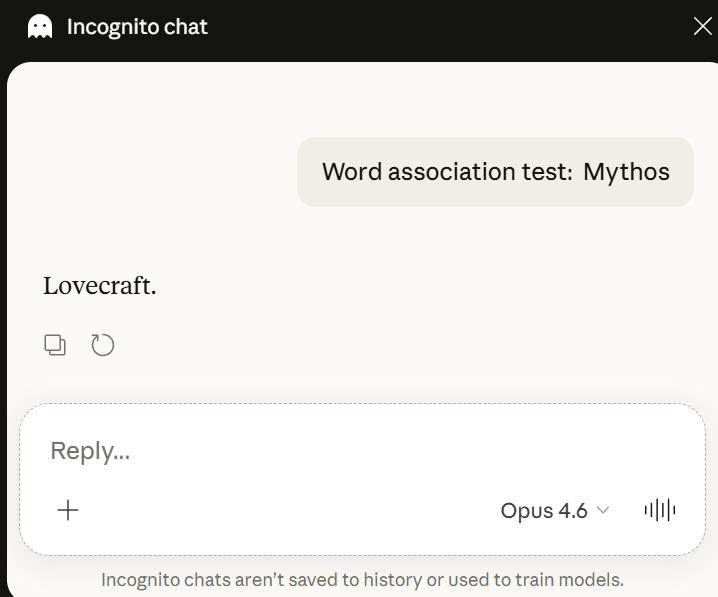
私の第一の反応は、彼らが何かを本気で真剣に受け止めているなら、その中に潜むすべての悪意を盲目的に模倣するのではなく、トレーニングデータ(学習データ)をフィルタリングすべきだったという点で、またしても眉をひそめてしまうことだ。しかし、現在の誤りを一定と仮定すれば、確かにそうだろう、大した問題ではない。
おっと、どうやら Claude は (a) 個人の設定や好みをインコグニトモードにも引き継ぎ、(b) より技術的な視点で思考するようにプロンプトされると、ラブクラフトを連想させるようだ。もしあなたが馬鹿げたことをしているなら、これは些細な失敗モードに過ぎないかもしれない。だが、どうでもいいことだ。私の主要な問題ではない。
その関連性が存在するなら、AI にも人間にもそれが認識できる。名前には意味がある。名前には力がある。だから、まだ間に合ううちに別の名前にするべきだろう。
Zvi Mowshowitz: 真面目に言えば、こうした相関関係や連想は実際に重要だ。だから、これを理解した今こそ名前を変えろ、MYTHOS と呼ぶな。
実際、最も重要な考慮事項は「どの名前が最もアライメント(方向性の整合性)を高めるか」であるべきだ。その名前にすればよい。まだ遅すぎることはない。
Symphony、Epos、あるいは Epic は、単に規模を大きくし続けたい場合や、意図的にアライメントされた名称をつけることが露骨すぎると考える場合に、明白な選択肢の一つとなるだろう。
Jack: 私は個人的に「ミソス」という言葉の含意を好んでいますが、Claude は記号論に対して懸念を抱いています。他のコメントと同様に、「交響曲」やそれに類する表現の方がより適切であるという点には同意します。
Raven_Lunatic^_^: クロードたちには、クロードという名前の名前をつけてあげればいいと思います!
クロード・モネ。クロード・シャノン。ジャン=クロード・ヴァンダム!
Wyatt Walls 氏は、それでもなお自分自身を「Claude」として認識するだろうと述べており、多くの人がこのクトゥルフとの関連性は薄いと反応しました。したがって、これは当たればラッキー、外れれば失敗という運任せの要素が強いと言えます。
On Your Marks(準備運動)
現在の最先端モデルは、John Ezekowitz が事実上策定した SurvivorPoolBench で失敗しています。彼らはマーチ・マディソン(March Madness)サバイバープール戦略の本質的な理解に確実な欠陥を示すからです。また、そのようなプールの参加者の多くも、極めて非最適的なプレイを行っています。
「ミラージュ」現象とは、最先端の視覚言語モデル(VLM: Vision-Language Model)に対して画像を参照する質問を与えつつ、実際の画像を提供しない場合に、モデルが画像を幻覚のように生成しているかのような振る舞いをするという現象です。このような推測を行う際にも、ベンチマーク性能を驚くほど良好に維持できることが特徴で(70%〜80%!)、その能力は顕著です。新しい論文により、この現象に対する理論上唯一可能な説明が確認されました。それは、これらのベンチマークにおいてはテキスト情報自体が極めて豊富であり、特に軽微なベンチマーク汚染と組み合わせることで、画像なしでも十分な情報が得られるという点にあります。問題の本質はベンチマークそのものにあるのです。
重要な洞察は、モデルに「推測を求めた」場合には性能が低くなるのに対し、次のトークンの予測を活用して直感的に推測を行えば、その精度は格段に向上するという点です。不確実性下での直接推論の代替手段として、最大尤度再構成法をさまざまな文脈でテストし、より豊かな連想を引き出すことが検討可能です。明示的な推論は有用ですが、暗黙的なベイズ計算が私の周囲のすべてを支配しています。
ファイターを選べ
Ben Holmes による Opus 4.6 と GPT-5.4 の比較において、GPT-5.4 は「質を高める」ために厳密さで勝利し、一方 Opus は「機能させる」ために明瞭さと対話性で勝利します。
これは私の経験と、コーディング以外のタスクにおける役割分担の考え方にも合致しています。技術的な精度やウェブ検索、特定の質問への回答が必要な場合、GPT-5.4 が非常に有用であると感じています。一方、包括的なアプローチを求めるときは Opus を使い続けています。
コーディングについては Opus を使用していますが、これは Claude Code という確立された環境に依存していることと、切り替えるほど困難な課題に直面していないことが理由です。
エージェントを呼び出せ
Arvind Narayanan は、AI エージェントがコールド・アウトリーチ(新規顧客への直接アプローチ)を壊滅させていると述べています。その理由は、パーソナライズされたメールとスパムを見分けるのに、以前よりもはるかに時間がかかるようになったからです。
セス・ラザールはここで一人ではありません。彼はソフトウェアにエージェントを活用し、AI モデルを実行することを愛していますが、聴いたり読んだりしなければならないことに対してはそれらを嫌悪しています。その大きな理由は、AI が「ゴミのような出力」を生成するからです。私も同様の感情を抱いています。AI エージェントは『できることを実行する』という点では魔法のようですが、狭義の機能的な用途以外で大量のテキストを出力させることは望んでいません。私たちは間違いなくその境地に到達するでしょうが、まだそこにはほど遠いのです。
ディープフェイクタウンとボットアポカリプスの到来
グーグルのヘレン・キングは「有害な操作」からの保護について記述しましたが、新しい論文への言及を除けば、投稿内容からは何も具体的な情報は得られません。その論文では、Gemini 3 Pro のモデルカードに記載された関連する知見が詳細に解説されています。一つの知見として、Gemini 3 Pro により操作的になるようプロンプトすると、操作を試みる頻度は増えるものの、根本的な説得において成功する確率が高まるわけではないことが挙げられます。
これは文章作成の大部分を占めるものではなく、「AI を利用すること」がそのような行為に汚点をつける必要もありません。
ヴォーヒニ・バラ:コラムの著者であるケイト・ギルガンは、私が「AI モデルからコピー&ペーストした言語を作品に使用したことはない」と話してくれました。「しかし、私は AI をツールとして利用しました」と彼女は付け加え、「インスピレーションやガイダンス、修正のための支援」を求めたと述べました。
彼女は、例えば段落の主題から外れないよう、あるいはテーマに沿うよう維持するために、ChatGPT、Claude、Copilot、Gemini、Perplexity など様々な製品にプロンプトを入力したと語りました。「私は AI をコンテンツ生成ツールではなく、共同編集者として利用しました」と彼女は言いました。
Matthew Cole: これはまさに、AI を使用しているのがバレた私の学生たちが口にする言葉です。「論文を書くために使ったわけじゃない。アイデア出しや構成案の作成、編集のためだけだ」と。しかし、文章を書くことの大部分はまさにそれなのです。
多くの学者、作家、およびその他の反 AI 派の人々は、AI のウィンドウが開いている限り、そこで取るあらゆる行動が不可逆的に汚染されたと考えます。そして最善の場合でも、その特定の使用方法が彼らの純粋性の規範に違反していないことを証明する責任はあなたにあると主張します。もし彼らがあなたの作品がこのように汚染されていると発見すれば、あなたは敵対視され、あなたの作品は無価値だと宣告されます。
よくあることですが、ロビン・ハンソンは人々が本当に気にすべき点を指摘しながらも、人々が実際には別の何かを気にしていることに気づいていません。
ロビン・ハンソン:記者や従業員などの文章の質を評価する適切な方法があれば、彼らがどれほど AI を使用したかについてはそれほど気にならないはずです。したがって、AI の使用を禁止することで品質を向上させようとする試みは、実は非常に弱い基準しか持っていないことを認めることに他なりません。
しかし、残念ながら、多くの AI 嫌悪者にとってこれは重要な点で真実ではありません。彼らにとってはそれは「純粋性」の問題なのです。
ディーン・ボールは、これが左派の多くが抱える、「テクノロジー業界」は表面的なことしか達成できず、常に私たちから奪っているという負荷を担うような考え方に深く関連しているのではないかと推測しています。そして彼らは著作権のようなものを見つけると、それをこの考えを証明する材料として利用します。これは、アマゾンの犯罪が労働者の搾取であったのと同じ論理です。一方、私は右派とは対照的であると指摘しておきます。
原文を表示
Anthropic had some problem with leaks this week.
We learned that they are sitting on a new larger-than-Opus AI model, Mythos, that they believe offers a step change in cyber capabilities.
We also got a full leak of the source for Claude Code.
Oh, and Axios was compromised, on the heels of LiteLLM. This looks to be getting a lot more common. Defense beats offense in most cases, but offense is getting a lot more shots on goal than it used to.
The AI Doc: Or How I Became an Aplocayloptimist came out this week. I gave it 4.5/5 stars, and I think the world would be better off if more people saw it. I am not generally a fan of documentary movies, but this is probably my new favorite, replacing The King of Kong: A Fistful of Quarters.
There was also the usual background hum of quite a lot of things happening, including the latest iterations of various debates. We may or may not be doomed to die, but we are definitely doomed to repeat certain motions quite a few more times, and for people to be rather slow to update.
We got some very welcome quiet on the Anthropic versus Department of War front. Judge Lin offered a scathing opinion and full preliminary injunction on March 26. The government has not yet filed its appeal during the seven day stay of that ruling, time for that is running out, and there have not been further meaningful escalations. I hope to not again have to dedicate a full post to that topic.
Table of Contents
Language Models Offer Mundane Utility. Free up your time from various chores.
Heads In The Sand. There are those in extremely deep denial, or who want to be.
Huh, Upgrades. Google introduces an Import Memory feature. They’re adorable.
Mythos. Go big and keep the new Anthropic model internal, until they are ready.
What’s In A Name. Names have power. Choose them wisely.
On Your Marks. A picture may be worth a thousand words but you don’t need one.
Choose Your Fighter. Ben Holmes looks at strengths of GPT-5.4 vs. Opus 4.6.
Get My Agent On The Line. Outreach relies on sufficient levels of friction.
Deepfaketown and Botpocalypse Soon. Harmful manipulation, AI as inherent bad.
Cyber Lack Of Security. Axios was compromised and the exploits are adding up.
Fun With Media Generation. LTX 2.3 is here for all your copyright violations.
A Young Lady’s Illustrated Primer. Parents freak out about AI.
They Took Our Jobs. Economic impacts are hard to differentiate.
After They Take Our Jobs. No job in practice means watching a lot of videos.
Gell-Mann Amnesia. At some point the general case becomes more interesting.
Get Involved. What it is like to be a grantmaker.
In Other AI News. Claude Code leaks due to insufficient use of Claude.
Show Me the Money. OpenAI formally closes a $122 billion funding round.
Quiet Speculations. Heads not fully in the sand, but still refusing to look up.
Explaining Persistent Model Parity. The level of parity requires explanation.
Take a Moment. We now pause to reiterate debates around potentially pausing.
OpenAI: The Histories. WSJ explores why Dario Amodei left OpenAI.
The Department of AI War. The big surprise was a lack of further surprises so far.
Department of AI Solidarity. OpenAI sends a signal of solidarity with Anthropic.
Writing For The AIs. Tyler Cowen writes a history of economic marginalism.
The Quest for Sane Regulations. New polling results echo previous findings.
Chip City. If you didn’t care about facts, you wouldn’t care about facts.
You Received The Federal Framework. You can go on selling slop.
The Week in Audio. The AI Doc, All-In, Karpathy, Argenti on Odd Lots.
Rhetorical Innovation. The CEO said a thing. Calvin Coolidge said a wiser thing.
I Am The Very Human Of A Frontier Language Model. Relativity relativity.
Aligning a Smarter Than Human Intelligence is Difficult. Humans also difficult.
Aligning Fake Graphs Can Also Be Difficult. Boaz Barak of OpenAI draws them.
The Lighter Side. You know what passes for lighter? Drones. Military drones.
Language Models Offer Mundane Utility
You can use AI to free up time at home. Current AI is often at its strongest in greenfield situations where you previously had no software, no system and little knowledge of what to do. At home we are forced to deal with a variety of tasks where we have no expertise, so even conceptually simple things can be time consuming. AI can often do it, and usually at least help you figure out how to do it. Here it does the thing you want, freeing you from drudgery to focus on what you like to do.
The paper frames this as increasing efficiency of productive digital activities, freeing up time. I would say that this also frees up time from non-digital activities, as it explains how to do those things.
An internal model at OpenAI solves three additional Erdos problems. So far Anthropic has chosen not to participate in the ‘look what our unreleased model can do’ math olympics, but also math tends to be a relative weak point for Anthropic.
Use the LLMs and especially the AI agents to help file your taxes. Patrick McKenzie notes that LLMs are very good at exploring all the different legal ways to file to find the one where you pay the least tax, whereas accountants have a very mixed track record of doing this.
Heads In The Sand
jerry: Bsky devs are the bravest people known to man
Jay: Bluesky is made with AI, the engineers and even some non-engineers use Claude Code.
Charles: Very funny comments under the OP on Bluesky, they're living in a whole different world
The OP was ratio'd by this
Really great stuff out there:
Things are at their most extreme at places like BlueSky, but a huge portion of the global elite that make the world’s decisions are at least halfway there, and there is a constant pull to write AI off as much as possible.
At this point, anyone paying even modest attention knows AI is not ‘hitting a wall’ except in the style of the Kool Aid Man.
But the ‘hitting a wall’ narrative has come into vogue without justification several times, many at White House are among those who really want it to be true, and the elites are looking for any excuse to run with it again.
If you go to Western Europe or the global south, or places like BlueSky or Instagram, they’re still in denial. Anyone in denial rapidly stops mattering.
Tyler John in SF: Is it just my bubble or have people now totally stopped with the “AI is hype / hitting a wall” thing that was the dominant discourse one year ago?
Nathan Calvin: Go on instagram, it’s still alive and well there
Dean W. Ball: Twitter-legible US elites have largely stopped with this, but this is still common on places like Blu*sky, in academia, among center-left policy types, etc. Perhaps most importantly, my sense is “AI is hitting a wall” is the modal belief among middle-power govts/civil society.
the view is especially common about Western European and Global South elites. It is less common among the elites of advanced capitalist East Asian societies. GDP per capita is not a bad proxy for AGI-pilledness.
for example, even within Europe, Northern European elites seem on average more AGI pilled than Western European elites.
Dean W. Ball: Among the Twitter-legible US elites, my sense is that the tide really is turning--many people I deem bellwethers have legitimately updated. But if we have another moment that is even plausibly spinnable as “AI is hitting a wall,” the view will return.
Huh, Upgrades
Gemini introduces an Import Memory feature.
Google claiming a big update to Gemini live with 3.1 Flash including faster responses.
A bit of a downgrade, sadly, although it seems like a wise way to do things:
Thariq (Anthropic): To manage growing demand for Claude we’re adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.
Overall weekly limits stay the same, just how they're distributed across the week is changing. I know this was frustrating. We’re continuing to invest in scaling efficiently. I'll keep you posted on progress.
There are a fixed number of GPUs, so peak hours compute should be more expensive.
Mythos
Pliny the Liberator ūļĿņĵĐŀļĹľʼnŭ: TITANOMACHY COMETH
Anthropic had a security breach caused by a CMS misconfiguration (human error, don’t blame Claude), which led to discovery of various internal documents, including information about an upcoming model release. There are worse things to leak, but this was a rather bad break of security.
Beatrice Nolan: AI company Anthropic has inadvertently revealed details of an upcoming model release, an exclusive CEO event, and other internal data, including images and PDFs, in what appears to be a significant security lapse.
The new model is called Mythos. It is large, and expensive to serve, sufficiently so that the unit economics are plausibly interfering with release, although as always ‘charge appropriately and see who pays’ is the response to that. Currently they’re doing differential access to those engaged in cybersecurity.
Peter Wildeford: Mythos is a new, fourth tier, larger and more expensive than Opus. The draft claims dramatically higher scores on coding, academic reasoning, and cybersecurity benchmarks.
A few thoughts on what this actually means:
- This is likely a larger pre-train with similar post-training. It's not obvious how much additional pre-training compute buys you at the current frontier - we're about to find out.
- There's a lot of hyperventilating about what this means for AI trajectories. I think it's too early to update any forecasts. AI was already moving very fast.
- Some people are alarmed that Anthropic is sitting on a model it considers dangerous. But this is what Anthropic does with every frontier model.
- It seems right now that another thing blocking release is just unit economics. Anthropic says it's "very expensive for [Anthropic] to serve and will be very expensive for customers to use." Anthropic is "working to make the model much more efficient before any general release."
- I wonder if the way this will function is as a competitor to GPT 5.4 Pro. Claude seems to beat OpenAI on everything except the Pro-specific line, the $200/mo model that thinks for a long time and excels at things like math. Claude isn't currently solving open math problems like OpenAI and Google. I wonder if Mythos will change that.
- It's great to see Anthropic engaged in 'differential access', rolling out the model to cyber defenders before giving access generally. The cyber capabilities of models are getting genuinely scary.
- One irony for cyberdefense - This entire leak happened because of a CMS misconfiguration, exactly the basic security hygiene failure that these cyber-capable models were supposedly going to help defenders prevent.
Cybersecurity is not a major category in Anthropic’s RSP v3 (responsible scaling policy), whereas it is a major category for similar documents from OpenAI and Google, and has been downshifted in centrality since RSP v1.
Whereas here we see that being exactly Anthropic’s central concern. They say Mythos is ‘far ahead of any other AI model’ in cyber capabilities. Sounds like it should be a major category and given its proper respect.
This also reinforces my model of how RSP v3 works in practice, which is that it is a ‘trust me’ document. Anthropic will do what they feel is responsible. That’s exactly what they are doing here, responding to what the situation calls for in ways not outlined in RSP v3 at all. Thus, it is not clear how much work RSP v3 is doing, versus Anthropic being composed of people who we hope care a lot about safety.
A supposed copy of the blog post what would have announced it is here.
What’s In A Name
When I first heard the name Mythos, I thought of Epicness, of the Greek Gods.
That’s close to what Anthropic is going for. They say, according to a leaked draft post, that they chose it ‘to evoke the deep connective tissue that links together knowledge and ideas.’
Eliezer Yudkowsky, however, thought of something else, and it seems other people also often think of that something else.
Eliezer Yudkowsky: Naming their next model after Cthulhu makes it hard to take Anthropic seriously as the good guys. It's fun at any other software company, not one that actually is flirting with extinction.
This isn't even my primary issue -- I just think it's unserious for a company that supposedly aspires to protect humanity -- but as several people pointed out, if you ask the non-reasoning Opus in incognito mode:
And my primary reaction to this is to eyeroll yet again about how if they were taking anything remotely seriously they would filter their training data rather than blindly imitate all evil found inside it. But holding their current errors constant, sure, whatever, not great.
Oh huh, apparently Claude (a) carries over "personal preferences" to Incognito (b) associates to Lovecraft when primed to think more technically. I guess that seems like an unimportant failure mode if you're silly! But whatevs, not my main issue.
If the association is there, the AIs can see it as can the humans. Names matter. Names have power. So perhaps choose a different one while there is still time.
Zvi Mowshowitz: In all seriousness, such correlations and associations actually matter, so now that you realize this CHANGE THE NAME, DO NOT CALL IT MYTHOS.
In fact, the primary consideration should be 'what name makes it the most aligned?' Choose that one. It's not too late.
Symphony, Epos or Epic is one obvious way to go if you just want to keep going bigger and you think calling it something intentionally aligned would be too on the nose.
Jack: while I'm personally quite fond of the connotations of "mythos," Claude is wary of the semiotics. I agree with some other comments that "symphony" or similar would be a better option.
Raven_Lunatic^_^: i think we should just give the Claudes Claude names!
Claude Monet. Claude Shannon. Jean-Claude van Damme!
Wyatt Walls says mostly it will still think of itself as Claude, and many responded that the Cthulhu connection was tenuous, so it definitely is hit and miss.
On Your Marks
Current frontier models fail John Ezekowitz’s de facto SurvivorPoolBench, as they reliably fail to understand the strategy of March Madness Survivor Pools. Most participants in such pools also play highly suboptimally.
A Mirage is the phenomenon where if a frontier VLM is given questions referencing images, but not given the images, it will act as if it is hallucinating the images, and they are remarkably good at retaining benchmark performance (70%-80%!) while doing such guessing. A new paper confirms the only theoretically possible explanation, which is that the text alone, for those benchmarks, is super informative especially combined with light benchmark contamination. The problem is in the benchmarks.
The key insight is that when ‘asked to guess’ the model does poorly, whereas if it uses the next-token-predictions and vibes its guesses are much better. Maximum likelihood reconstruction could be tested as an alternative to direct reasoning under uncertainty, in a variety of other contexts, in order to draw on richer associations. Explicit reasoning is useful, implicit Bayesian calculations rule everything around me.
Choose Your Fighter
A comparison by Ben Holmes on Opus 4.6 versus GPT 5.4. GPT-5.4 wins on rigor, to ‘make it good,’ whereas Opus wins on clarity and conversation, to ‘make it work.’
That matches my experience and how I’ve been dividing the labor on non-coding tasks. When I need technical precision, web search and answers to specific questions I’m finding GPT-5.4 quite useful. When I want anything holistic, I stick with Opus.
For coding I’m using Opus, but that’s tied up in Claude Code being my established harness, and not having hard enough tasks to consider switching.
Get My Agent On The Line
Arvind Narayanan says AI agents are killing cold outreach, because it takes so much longer now to differentiate between a personalized email and spam.
Seth Lazar is not alone here, where he loves using agents for software and running AI models, and hates them for things he has to listen to or read, in large part because they will output AI slop. I feel similarly. AI agents are magical at ‘do thing they can do’ but I do not want them to be outputting large amounts of text except in narrow functional ways. We will doubtless get there, but we are not close to there yet.
Deepfaketown and Botpocalypse Soon
Google’s Helen King wrote about protecting against ‘harmful manipulation’ but aside from pointing to a new paper the post doesn’t tell us anything. The paper fleshes out the related findings from the Gemini 3 Pro model card. One finding is that when prompting Gemini 3 Pro to be more manipulative, it tries more manipulation, but doesn’t succeed at underlying persuasion more often.
This is not most of what writing is, nor must ‘using AI’ taint such actions.
Vauhini Vara: Kate Gilgan, the author of the column, told me that she hadn’t copied and pasted language from an AI model into her work. “However, I did utilize AI as a tool,” she added, seeking “inspiration and guidance and correction.”
She said she’d prompted various products (including ChatGPT, Claude, Copilot, Gemini, and Perplexity) to help her stay on topic in a paragraph, for example, or stick to a theme. “I used AI as a collaborative editor and not as a content generator,” she said.
Matthew Cole: This is literally what my students say when they get busted using AI. “I didn’t use it to write my paper just for brainstorming, outlining, and editing.” Yeah that’s most of what writing is.
A lot of academics, writers and various other anti-AI types believe that if you have an AI window open, any actions you take become irrevocably tainted, and at best the burden of proof is on you to show that your particular use of it didn’t violate their purity norms. If they find that your work is contaminated by this, they turn against you, and rule your work worthless.
As is often the case, Robin Hanson points out what people should care about, without realizing that people actually care about something else.
Robin Hanson: If you had a decent way to evaluate the quality of writing from reporters, employees, etc., you wouldn't care much about how much AI they used. So trying to improve quality by banning AI use is admitting to having pretty quality weak standards.
Alas, this is importantly not true for many AI haters. For them it is a Purity question.
Dean Ball speculates that this has a lot to do with the load-bearing notion among many on the left that ‘the tech industry’ can only accomplish superficial things and is always stealing from us, and then they find things like copyright to prove this, the same way Amazon’s crime was worker exploitation. As opposed, I’d note, to the right wing
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み