Amazon SageMaker AI でアゼルバイジャン語の言語モデルをトレーニングする手法
アゼルバイジャン通信大手 Azercell は AWS と共同で、言語リソースが限られたアゼルバイジャン語向け大規模言語モデルの構築に成功し、トレーニング効率とコンテキスト容量を大幅に向上させる実証を行いました。
キーポイント
低リソース言語への最適化アプローチ
形態論的に複雑で学習データが限られるアゼルバイジャン語に対し、カスタムモノリンガルトークナイザーを採用することで単語あたりのトークン数を半分に削減し、コンテキストウィンドウ内の情報密度を2倍に高めました。
AWS SageMaker AI における技術的突破
PyTorch と Hugging Face Transformers に加え Liger Kernels を活用したカーネルレベルの最適化により、ml.p5.48xlarge インスタント上でトレーニングスループットを23%向上させ、ピークGPUメモリ使用量を58%削減することに成功しました。
段階的なモデル開発フレームワーク
トークナイザー開発、Llama 3.2 1B への継続的事前学習(CPT)、LoRA を用いた教師あり微調整という3段階の工程を確立し、生産環境で即座に活用可能な基盤を構築しました。
重要な引用
The challenge: adapting foundation models (FMs) to a morphologically rich language with limited training data and no existing blueprint for efficient LLM training in Azerbaijani.
delivered a 23% higher training throughput and 58% lower peak GPU memory usage through kernel-level optimizations
effectively doubling the amount of Azerbaijani text that fits within the model's context window
影響分析・編集コメントを表示
影響分析
この事例は、英語以外の低リソース言語における大規模言語モデルの実用化において、ハードウェア最適化とデータ前処理(トークナイザー設計)が同等に重要であることを示す決定的な証拠となります。特に、既存のブループリントがない状況で AWS のインフラとオープンソース技術を組み合わせることで、短期間で生産レベルの成果を達成できる可能性を示しており、グローバルな AI 展開における重要なテンプレートとなり得ます。
編集コメント
英語圏に偏りがちな LLM 開発において、特定の言語特性に合わせた技術的工夫(トークナイザー設計やカーネル最適化)が如何に劇的な性能向上をもたらすかを示した実証例です。
*このソリューションは、PyTorch、Hugging Face Transformers、Liger Kernels などのオープンソースツールを基盤として構築されています。また、本プロジェクトの実現に貢献された Aiham Taleb 氏、Arefeh Ghahvechi 氏、Manav Choudhary 氏、Rohit Thekkanal 氏、Daz Akbarov 氏、Jamila Jamilova 氏、Ross Povelikin 氏、Almas Moldakanov 氏、Christelle Xu 氏、Ivan Khvostishkov 氏にも深く感謝いたします。
Azercell Telecom LLC はアゼルバイジャンを代表する通信事業者ですが、通信用途や顧客対応チャットボットのために Amazon SageMaker AI 上でアゼルバイジャン語の大規模言語モデル(LLM)を構築したいと考えていました。課題は、形態論的に複雑な言語でありトレーニングデータが限られており、効率的な LLM トレーニングのための既存の設計図もないアゼルバイジャン語に対して、ファウンデーションモデル(FMs)を適応させることでした。6 週間の共同作業を通じて、Azercell は AWS Generative AI Innovation Center と協力し、ml.p5.48xlarge インスタンス上でカーネルレベルの最適化を施すことで、トレーニングのスループットを 23% 向上させ、ピーク時の GPU メモリ使用量を 58% 削減する、本番環境対応のフレームワークを Amazon SageMaker AI 上に確立しました。また、このフレームワークはカスタムトークナイザーを用いて単語あたりのトークン数を 2 倍に改善し、モデルのコンテキストウィンドウ内に収容できるアゼルバイジャン語のテキスト量を効果的に倍増させました。低リソース言語や形態論的に複雑な言語を扱う場合、本記事ではそのアプローチを紹介し、同様の技術の評価にご活用いただけるよう解説します。
ソリューション概要
このフレームワークは、それぞれが次の工程へ成果物を引き継ぐ 3 つの連続したステージを実装しています。
- ステージ 1:トークナイザー開発では、アゼルバイジャン語用の効率的なトークナイザーを構築します。3 つのアプローチ(ベースラインの英語最適化トークナイザー、語彙拡張、カスタム単一言語トークナイザー)を評価し、標準的な指標を通じて符号化効率を測定しました。その結果、カスタムの単一言語トークナイザーが最も優れた結果を示し、単語あたりのトークン数をベースラインと比較して半分に削減することに成功しました。
- ステージ 2:継続事前学習(CPT)では、分散トレーニングと Amazon Sage AI トレーニングジョブ上の Liger Kernel の最適化を活用して、FM(Llama 3.2 1B)をアゼルバイジャン語を理解できるように適応させます。これにより、同じハードウェア上でより大きなバッチサイズと高いスループットが可能になります。今回の 10 億規模の概念実証では分散トレーニングは必須ではありませんでしたが、Azercell がより大規模なモデルへスケールする際には不可欠となります。
- ステージ 3:低ランク適応(LoRA)を用いた教師あり微調整により、事前学習済みモデルを対話型アシスタントへと変換します。CPT の後、モデルはアゼルバイジャン語のトークンを予測できますが、対話を行うことはできません。ステージ 3 では、トレーニング可能なパラメータ数を大幅に削減するパラメータ効率の高い微調整手法である LoRA を適用します。
トレーニング段階(CPT と LoRA による微調整)は、Amazon SageMaker Unified Studio から起動された Amazon SageMaker AI トレーニングジョブとして実行され、それぞれがカスタムトレーニングスクリプトを指しています。各ジョブは、完了後に終了する新しい Amazon Elastic Compute Cloud (Amazon EC2) インスタンスをプロビジョニングするため、アイドル状態のクラスターコストが発生せず、実際の計算時間のみに対して課金されます。
以下の図は、各ステージを独立して最適化できるモジュラーアーキテクチャを示しています。トークナイザーの改善はすべての後続トレーニングステージに恩恵をもたらし、CPT(Continual Pre-Training)設定はファインチューニングタスク間でも転移可能です。
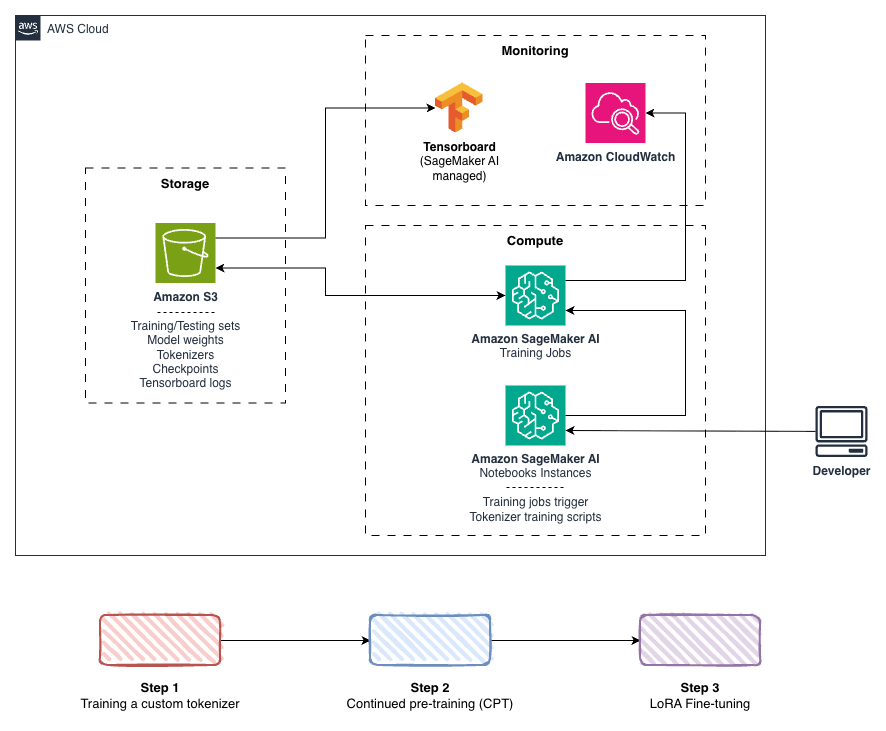
図 1. トレーニングパイプラインアーキテクチャ。オペレーターは Amazon SageMaker AI Notebook Instances からトレーニングジョブを開始します。トレーニングデータとモデルアーティファクトは Amazon Simple Storage Service (Amazon S3) に保存されます。トレーニングメトリクスは Amazon SageMaker AI の TensorBoard で追跡され、システムメトリクスは Amazon CloudWatch を通じてキャプチャされます。
アゼルバイジャン語トークナイザーの開発
アゼルバイジャン語のような言語は形態論的に豊かで、英語では複数の単語で表現される文法的意味を接尾辞を通じて単一の単語に符号化しています。しかし、標準的な英語最適化トークナイザーはこれらの複雑な語形を断片化してしまいます。例えば、「kitablardan」(本からという意味)という単語を、図 2 に示すように複数のサブワードトークンに分割すると、固定サイズのコンテキストウィンドウ内に収まる実際のコンテンツ量が減少します。
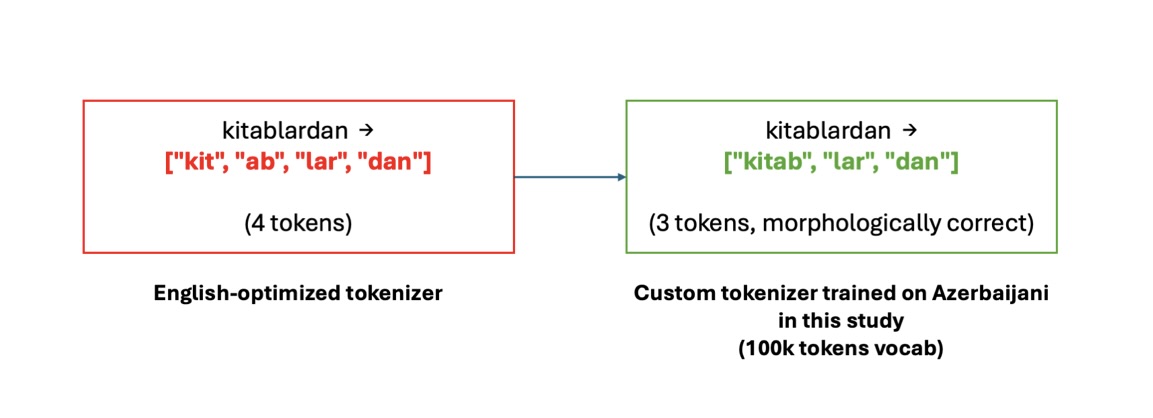
図 2. アゼルバイジャン語テキストにおけるベースラインとカスタムトークナイゼーションの比較。トークンの断片化が減少していることが示されています。
これに対処するため、アゼルバイジャン語のテキストを用いてバイトレベルのバイトペアエンコーディング(BBPE)アルゴリズムを適用したカスタムトークナイザーを訓練しました。このアルゴリズムは、最も頻出するバイト対を反復的に結合して語彙エントリを作成します。事前定義された文字セットではなく生バイトから開始することで、手動のアルファベット定義を必要とせず、アゼルバイジャン語固有の文字を完全に網羅できます。語彙サイズは 50k〜100k トークンの範囲で実験し、適切なバランスを探りました:小さすぎるとトークナイザーが単語を過度に断片化し、大きすぎると稀なトークンが十分な学習シグナルを得られなくなります。
Hugging Face tokenizers ライブラリを用いて、ネイティブの Llama 3.2 トークナイザーと同じ設定でカスタムトークナイザーを訓練し、語彙サイズのみを変化させました。異なる語彙サイズを持つ複数のトークナイザーを訓練・評価した結果、最終的に 100k トークンの語彙を選択しました。カスタムトークナイザーがモデルの品質を犠牲にしていないかを確認するため、継続事前学習後のモデル比較にはパープレキシティではなくバイト当たりビット数(BPB)を用いました。これは BPB がバイトレベルでの予測品質を測定することで語彙の違いを正規化するためです。カスタムトークナイザーを採用したモデルは検証セットで 0.5795 の BPB を達成し、ベースラインの 0.6830 と比較して、符号化効率の向上が品質のトレードオフなしに実現されたことを確認しました。
モデルの品質を維持するだけでなく、カスタムトークナイザーは実用的な効率面で大幅な向上をもたらします。エンコーディング効率は、 fertility score(平均単語あたりのトークン数)によって定量化できます。値が低いほど効率的なエンコーディングを示します。ベースラインの Llama 3.2 トークナイザーではアゼルバイジャン語の単語あたり平均 3.22 トークンでしたが、カスタムの単一言語用トークナイザーでは 1.59 トークンを達成し、エンコーディング効率が 2 倍向上しました。Llama 3.2 の 128k トークンのコンテキストウィンドウを考慮すると、これは実質的な容量の違いとして現れます:ベースラインのトークナイザーでは約 40,000 語に対して、最適化されたトークナイザーでは 80,000 語となり、モデルが一度に処理できるコンテンツ量が効果的に倍増します。
継続的事前トレーニング
継続的事前トレーニングは、FM(Llama 3.2 1B)をアゼルバイジャン語を理解できるように適応させるプロセスです。この段階における主要なボトルネックは GPU メモリであり、メモリ利用効率の最適化が、ハードウェア投資のうちどれほどトレーニングスループットに転換されるかを直接決定します。私たちは ml.p4d.24xlarge(8× NVIDIA A100 GPU)および ml.p5.48xlarge(8× NVIDIA H100 GPU)インスタンスの両方でベンチマークを行いました。以下のセクションでは、ベンチマークされた 2 つの最適化アプローチについて説明します:PyTorch の Fully Sharded Data Parallel (FSDP) を用いた分散トレーニングと、Liger Kernel の統合です。
Fully Sharded Data Parallel (FSDP) を用いた分散トレーニング
モデルのメモリフットプリントには、重みだけでなく、勾配、オプティマイザの状態、活性化値も含まれます。これらのコンポーネントは、Llama 3.1 8B のような大規模モデルでは混合精度計算において 100 GB を超える可能性があります。私たちは 1B モデル上で分散トレーニングの設定を開発・検証しており、より大きなアーキテクチャへスケーリングする際にも、パイプラインの再構築ではなく設定変更のみで対応できるようにしています。標準的な Distributed Data Parallel (DDP) は、各 GPU にモデル全体を複製するため、実現可能なバッチサイズやモデル規模に制限が生じます。一方、FSDP はパラメータ、勾配、オプティマイザの状態を GPU 間でシャード(分割)し、計算ステップごとに必要な部分のみを動的に収集します。これにより、ml.p4d.24xlarge 環境における GPU あたりのモデル状態メモリ使用量は 9.23 GB から 1.17 GB に削減され、より大きなバッチサイズを実行するための余裕が生まれました。
Liger Kernel の統合
Liger Kernels は、一般的な大規模言語モデル(LLM)演算のためのメモリ効率に優れた実装であり、Triton ベースで複数の演算を単一の GPU カーネル起動に融合させることで、中間メモリの割り当てを削減しつつ、数値的に等価な結果を生成します。これらは Llama を含むいくつかの主要なモデルアーキテクチャをサポートしています。導入前に、ご自身のアーキテクチャとの互換性を必ず確認することをお勧めします。
統合には最小限のコード変更しか必要としません。単一の関数呼び出しにより、インスタンス化前に最適化されたカーネルがモデルにパッチ適用され、Liger Kernels は分散トレーニング設定への修正なしで PyTorch FSDP と連携します。PyTorch Profiler を用いて実行の正しさを検証し、トレース内で融合演算が確認されました。以下の表は、各最適化ステップの両インスタンスタイプにわたる累積的な影響を要約したものです。なお、DDP のメモリとスループットについては p5 インスタンスではベンチマークされていません。これは FSDP が目標構成であったためです。
Metric
DDP
FSDP
FSDP + Liger
Max batch size per GPU on ml.p4d.24xlarge (8× NVIDIA A100 GPUs)
2
4
14
Max batch size per GPU on ml.p5.48xlarge (8× NVIDIA H100 GPUs)
4
10
18
Peak GPU memory incl. activations (GB) on ml.p5.48xlarge
—
64
27
Training throughput per GPU (tokens/s) on ml.p5.48xlarge
—
63,771
78,319
ml.p4d.24xlarge において、完全な最適化スタックは DDP を上回る最大バッチサイズで 7 倍の向上をもたらしました。一方、ml.p5.48xlarge では、FSDP に Liger Kernels を追加することで、ピーク GPU メモリが 58% 減少し、GPU あたりのスループットは 23% 増加しました。
Pre-training setup
Stage 1 で使用された各トークナイザー設定は、収束挙動と下流タスクの品質を比較するために、CPT(Continual Pre-Training)においてエンドツーエンドで引き継がれました。カスタムアゼルバイジャン語トークナイザー(語彙数 10 万)を使用した場合、トレーニングコーパスは約 25 億トークンに相当します。
カスタムトレーニングスクリプトでは、設定可能なコンテキストウィンドウ、BFloat16 混合精度計算、AdamW を用いた余弦学習率スケジューリング、および耐障害性を目的とした Amazon S3 への自動チェックポイント保存をサポートしています。コンテキストウィンドウは 2,048 トークンに設定しました。これは、トークン化後のトレーニングサンプルの 90% 以上がこの長さ未満であったためですが、設定自体はモデルのネイティブな 128k トークンの制限まで対応可能です。
語彙に新しいトークンを追加する場合、CPT は 2 フェーズのアプローチを採用します。最初のフェーズでは、モデルのバックボーンを凍結し、埋め込み層のみをトレーニングします。これにより、事前学習された知識を乱すことなく、新しいトークン表現をモデルの既存内部空間に適応させることができます。2 つ目のフェーズでは、パラメータの凍結を解除して完全なトレーニングを行い、モデルがアゼルバイジャン語のパターンを深く学習できるようにします。以下の表は、アゼルバイジャン語カスタムトークナイザー(語彙数 10 万)を使用したトレーニング設定を示しています。トレーニングには FSDP と Liger Kernel の最適化を適用し、2 つの ml.p4d.24xlarge インスタンス(合計 16 個の NVIDIA A100 GPU)を使用しました。
パラメータ
フェーズ 1: エンベディング適応
フェーズ 2: 完全トレーニング
フリーズされたバックボーン
はい
いいえ
学習率
0.0032
0.0024
GPU あたりのバッチサイズ
14
14
ステップ数
5,000
15,000
トレーニング時間
~11,400 秒 (~3.2 時間)
~43,000 秒 (~11.9 時間)
完全トレーニングフェーズでより低い学習率を使用することで、エンベディング適応中に獲得された知識が保持されます。有効バッチサイズが 224(GPU あたり 14 × 16 GPU)で、コンテキストウィンドウが 2,048 トークンの場合、各トレーニングステップでは約 45 万トークンを処理し、この構成における 1 エポックあたりの推定時間は約 4.3 時間となります。ml.p5.48xlarge では、GPU あたりのスループットが高くバッチサイズも大きいため、エポックあたりの時間はさらに短縮されます。
LoRA を用いた教師あり微調整
CPT の後、モデルはアゼルバイジャン語の次のトークンを流暢に予測できるようになりますが、会話構造に関する概念はまだ持っていません。質問を与えられた場合、有用な回答ではなく、妥当な続編を生成してしまいます。LoRA は、事前学習済みの重みを凍結し、モデルのアテンション層とフィードフォワード層に注入する小さな低ランク分解行列を訓練することで、このギャップを効率的に埋めます。フルサイズの重み行列を更新するのではなく、LoRA は2つのより小さな行列を訓練し、その積が完全な更新を近似します—これにより、学習可能なパラメータの数を全体のわずかな割合にまで削減します。以下の表は LoRA 微調整の設定を要約したものです。
パラメータ
ランク
アルファ
ドロップアウト
対象モジュール
最大シーケンス長
値
64
28
0.05
q, k, v 射影; ゲート、アップ、ダウン射影
1,024
このコンパクトなフットプリントにより、微調整は単一の ml.g5.8xlarge インスタンス(NVIDIA A10G GPU 1 基)上で実行され、数分で完了しました。微調整には、Hugging Face の SFTTrainer を用いて約 2,000 組の単一ターンアゼルバイジャン語の質問回答ペアを使用し、学習率は 1e-4 としました。これは CPT の学習率よりも高い値ですが、LoRA アダプターはランダムに初期化されており、より強力な勾配更新を必要とするためです。
トレーニングでは、アシスタントの応答トークンとターン終了トークンの予測のみに対してペナルティを課すロストマスキングを採用した Llama スタイルのチャットテンプレートを使用しました。これにより、ユーザーのプロンプトやテンプレートの区切り文字は損失計算から除外されます。その結果、モデルはユーザー入力パターンの暗記ではなく、適切な応答の生成に学習リソースを集中させることができます。
結果と検証
継続的な事前トレーニングでは、カスタムアゼルバイジャン語トークナイザーを使用して約 25 億トーンを使用し、ファインチューニングには 2,000 件の質問
原文を表示
*This solution builds on open source tools including PyTorch, Hugging Face Transformers, and Liger Kernels. The authors would also like to thank Aiham Taleb, Arefeh Ghahvechi, Manav Choudhary, Rohit Thekkanal, Daz Akbarov, Jamila Jamilova, Ross Povelikin, Almas Moldakanov, Christelle Xu, and Ivan Khvostishkov for their contributions in making this project possible.*
Azercell Telecom LLC, Azerbaijan’s leading telecommunications provider, wanted to build an Azerbaijani large language model (LLM) on Amazon SageMaker AI for telecom use cases and a customer-facing chatbot. The challenge: adapting foundation models (FMs) to a morphologically rich language with limited training data and no existing blueprint for efficient LLM training in Azerbaijani. In a six-week collaboration, Azercell worked with the AWS Generative AI Innovation Center to establish a production-ready framework on Amazon SageMaker AI that delivered a 23% higher training throughput and 58% lower peak GPU memory usage through kernel-level optimizations on an ml.p5.48xlarge instance. The framework also achieved a 2× improvement in tokens per word using a custom tokenizer, effectively doubling the amount of Azerbaijani text that fits within the model’s context window. If you work with low-resource or morphologically complex languages, this post walks through the approach so you can evaluate similar techniques.
Solution overview
The framework implements three sequential stages, each producing artifacts that feed the next.
- Stage 1: Tokenizer development builds an efficient tokenizer for Azerbaijani. We evaluated three approaches (baseline English-optimized tokenizers, vocabulary extension, and custom monolingual tokenizers) measuring encoding efficiency through standardized metrics. The custom monolingual tokenizer achieved the strongest results, halving the tokens per word compared to the baseline.
- Stage 2: Continued pre-training (CPT) adapts an FM (Llama 3.2 1B) to understand Azerbaijani using distributed training and Liger Kernel optimizations on Amazon SageMaker AI training jobs. This allows for larger batch sizes and higher throughput on the same hardware. While distributed training wasn’t required for this 1B-scale proof-of-concept, it will be essential as Azercell scales to larger models.
- Stage 3: Supervised fine-tuning with Low-Rank Adaptation (LoRA) transforms the pre-trained model into a conversational assistant. After CPT, the model can predict Azerbaijani tokens but can’t engage in dialogue. Stage 3 applies LoRA, a parameter-efficient fine-tuning method that significantly reduces trainable parameters.
The training stages (CPT and LoRA fine-tuning) were run as Amazon SageMaker AI training jobs launched from Amazon SageMaker Unified Studio, each pointing to a custom training script. Each job provisions fresh Amazon Elastic Compute Cloud (Amazon EC2) instances and terminates after completion, so you pay only for actual compute time with no idle cluster cost.
The following diagram illustrates the modular architecture, where each stage can be optimized independently. Tokenizer improvements benefit every subsequent training stage, and CPT configurations transfer across fine-tuning tasks.
Figure 1. The training pipeline architecture. Operators launch training jobs from Amazon SageMaker AI Notebook Instances. Training data and model artifacts are stored in Amazon Simple Storage Service (Amazon S3). Training metrics are tracked with TensorBoard in Amazon SageMaker AI, and system metrics are captured through Amazon CloudWatch.
Developing an Azerbaijani tokenizer
Languages like Azerbaijani are morphologically rich, with single words encoding grammatical meaning through suffixes that English would express using multiple words. However, standard English-optimized tokenizers fragment these complex word forms. For example, splitting “kitablardan” (meaning from the books) into multiple subword tokens as illustrated in Figure 2, which reduces the actual content that fits within a fixed-size context window.
Figure 2. Comparison of baseline and custom tokenization for Azerbaijani text, showing reduced token fragmentation.
To address this, we trained a custom tokenizer on Azerbaijani text using a Byte-Level Byte-Pair Encoding (BBPE) algorithm, which iteratively merges the most frequent byte pairs into vocabulary entries. Starting from raw bytes rather than predefined character sets provides full coverage of Azerbaijani-specific characters without requiring manual alphabet definitions. We experimented with vocabulary sizes ranging from 50k–100k tokens to find the right balance: too small and the tokenizer over-fragments words, too large and rare tokens lack sufficient training signal.
We trained custom tokenizers using the Hugging Face tokenizers library with the same configuration as the native Llama 3.2 tokenizer, varying only vocabulary size. After training and evaluating multiple tokenizers with different vocabulary sizes, we selected a final vocabulary of 100k tokens. To verify that the custom tokenizer didn’t sacrifice modeling quality, we compared models after continued pre-training using Bits-Per-Byte (BPB) rather than perplexity, because BPB normalizes for vocabulary differences by measuring prediction quality at the byte level. The model using the custom tokenizer achieved a BPB of 0.5795 on the validation set, compared to the baseline’s 0.6830, confirming that improved encoding efficiency came without a quality trade-off.
Beyond preserving modeling quality, the custom tokenizer delivers substantial practical efficiency gains. Encoding efficiency can be quantified through fertility score—the average number of tokens per word, where lower values indicate more efficient encoding. The baseline Llama 3.2 tokenizer averaged 3.22 tokens per Azerbaijani word, while the custom monolingual tokenizer achieved 1.59—a 2× improvement in encoding efficiency. With Llama 3.2’s 128k-token context window, this translates to real capacity differences: approximately 40k words with the baseline tokenizer versus 80k with the optimized one—effectively doubling the content the model considers at once.
Continued pre-training
Continued pre-training adapts the FM (Llama 3.2 1B) to understand Azerbaijani. The primary bottleneck for this stage is GPU memory: optimizing memory utilization directly determines how much of the hardware investment translates into training throughput. We benchmarked on both ml.p4d.24xlarge (8× NVIDIA A100 GPUs) and ml.p5.48xlarge (8× NVIDIA H100 GPUs) instances. The following sections describe the two optimization approaches benchmarked: distributed training with PyTorch’s Fully Sharded Data Parallel (FSDP) and Liger Kernel integration.
Distributed training with Fully Sharded Data Parallel (FSDP)
A model’s memory footprint includes not just weights, but also gradients, optimizer states, and activations. These components can exceed 100 GB for larger models like Llama 3.1 8B in mixed precision. We developed and validated the distributed training setup on the 1B model so that scaling to larger architectures requires only a configuration change, not a re-architecture of the pipeline. Standard Distributed Data Parallel (DDP) replicates the full model on each GPU, which limits the batch size and model scale you can achieve. FSDP shards parameters, gradients, and optimizer states across GPUs, dynamically gathering only what is needed during each computation step. This reduced per-GPU model state memory from 9.23 GB to 1.17 GB on ml.p4d.24xlarge, freeing headroom for larger batch sizes.
Liger Kernel integration
Liger Kernels are memory-efficient, Triton-based implementations of common LLM operations that fuse multiple operations into single GPU kernel launches, reducing intermediate memory allocations while producing numerically equivalent results. They support several popular model architectures including Llama. We recommend that you verify compatibility with your architecture before adoption.
Integration requires minimal code changes: a single function call patches the model with optimized kernels before instantiation, and Liger Kernels work with PyTorch FSDP without modifications to the distributed training setup. We validated correct execution with PyTorch Profiler, confirming fused operations in the trace. The following table summarizes the cumulative impact of each optimization step across both instance types. Note that DDP memory and throughput on p5 instances weren’t benchmarked because FSDP was the target configuration.
Metric
DDP
FSDP
FSDP + Liger
Max batch size per GPU on ml.p4d.24xlarge (8× NVIDIA A100 GPUs)
2
4
14
Max batch size per GPU on ml.p5.48xlarge (8× NVIDIA H100 GPUs)
4
10
18
Peak GPU memory incl. activations (GB) on ml.p5.48xlarge
—
64
27
Training throughput per GPU (tokens/s) on ml.p5.48xlarge
—
63,771
78,319
On ml.p4d.24xlarge, the full optimization stack delivered a 7× increase in maximum batch size over DDP. On ml.p5.48xlarge, peak GPU memory dropped 58% and per-GPU throughput increased 23% when adding Liger Kernels to FSDP.
Pre-training setup
Each tokenizer configuration from Stage 1 was carried through CPT end-to-end to compare convergence behavior and downstream quality. With the custom Azerbaijani tokenizer (100k vocabulary), the training corpus amounts to approximately 2.5B tokens.
The custom training script supports configurable context windows, BFloat16 mixed precision, cosine learning rate scheduling with AdamW, and automatic checkpointing to Amazon S3 for fault tolerance. We set the context window to 2,048 tokens because over 90% of training samples fell below this length after tokenization, though the configuration supports up to the model’s native 128k-token limit.
When new tokens are added to the vocabulary, CPT follows a two-phase approach. In the first phase, the model backbone is frozen and only the embedding layer is trained. This adapts the new token representations to the model’s existing internal space without disrupting pre-trained knowledge. In the second phase, the parameters are unfrozen for full training, allowing the model to deeply learn Azerbaijani language patterns. The following table shows the training configuration using the Azerbaijani custom tokenizer (100k vocabulary). Training used two ml.p4d.24xlarge instances (16 NVIDIA A100 GPUs total) with FSDP and Liger Kernel optimizations.
Parameter
Phase 1: Embedding Adaptation
Phase 2: Full Training
Frozen backbone
Yes
No
Learning rate
0.0032
0.0024
Batch size per GPU
14
14
Steps
5,000
15,000
Training time
~11,400 seconds (~3.2 hours)
~43,000 seconds (~11.9 hours)
A lower learning rate in the full-training phase preserves the knowledge acquired during embedding adaptation. With an effective batch size of 224 (14 per GPU × 16 GPUs) and a 2,048-token context window, each training step processes approximately 450k tokens, yielding an estimated per-epoch time of approximately 4.3 hours on this configuration. On ml.p5.48xlarge, higher per-GPU throughput and larger batch sizes would reduce per-epoch time further.
Supervised fine-tuning with LoRA
After CPT, the model can fluently predict the next Azerbaijani token, but it has no concept of conversational structure. Given a question, it generates plausible continuations rather than helpful answers. LoRA bridges this gap efficiently by freezing the pre-trained weights and training small low-rank decomposition matrices injected into the model’s attention and feed-forward layers. Instead of updating a full weight matrix, LoRA trains two smaller matrices whose product approximates the full update—reducing trainable parameters to a small fraction of the total. The following table summarizes the LoRA fine-tuning configuration.
Parameter
Rank
Alpha
Dropout
Target modules
Max sequence length
Value
64
28
0.05
q, k, v, o projections; gate, up, down projections
1,024
This compact footprint meant fine-tuning ran on a single ml.g5.8xlarge instance (1× NVIDIA A10G GPU), completing in minutes. Fine-tuning used approximately 2,000 single-turn Azerbaijani question-answer pairs using Hugging Face’s SFTTrainer with a learning rate of 1e-4—higher than CPT’s learning rates because LoRA adapters are randomly initialized and benefit from stronger gradient updates.
Training used a Llama-style chat template with assistant-only loss masking: the model is penalized only for predicting the assistant’s response tokens and the end-of-turn token (), while user prompts and template delimiters are excluded from the loss. As a result, the model focuses its learning capacity on generating appropriate responses rather than memorizing user input patterns.
Results and validation
Continued pre-training used approximately 2.5B tokens with the custom Azerbaijani tokenizer, and fine-tuning used 2,000 ques
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み