自律稼働デバイス向け高精度軽量VLM「PLaMo 2.1-VL」
Preferred Networksは、自律稼働デバイス向けに高精度かつ軽量なVision Language Model「PLaMo 2.1-VL」を開発し、そのアーキテクチャ、学習方法、工場作業分析やインフラ異常検出といった社会実装例を公開した。
キーポイント
自律稼働デバイス向けVLMの開発
ドローンやロボットなどエッジデバイス上での効率的な動作を目指し、8Bと2Bの2サイズの高精度軽量VLM「PLaMo 2.1-VL」を開発した。
Visual Grounding能力の重視
誤動作リスク低減のため、言語と画像の対応付け(grounding)を中核能力として最優先で強化し、判断根拠の明確化と説明・要約を可能にした。
具体的な社会実装例の提示
工場内での作業者工具認識による作業分析と、警備巡回ドローンや監視カメラを用いたインフラ設備の異常検出という2つの実用的な適用事例を紹介している。
実績ある標準アーキテクチャの採用
LLaVAと同系統の標準アーキテクチャを採用し、DPOでInstruction Tuning済みのPLaMo LLM、SigLIP2画像エンコーダ、MLPアダプタ、dynamic tilingを組み合わせている。
適用範囲と限界の明確化
自然画像を対象としたVQAとVisual Groundingが主眼であり、OCRや専門知識、複数画像処理など特定タスクには限界があることを明記している。
画像エンコーダの選択理由
複数の画像エンコーダを比較した結果、SigLIP2が最も安定した高性能を示し、特にローカライゼーション能力の改善が確認されたため、局所的な画像理解タスクに有利と判断して採用した。
学習方法の特徴
2段階学習(Stage 1.0とStage 1.5)を採用し、Stage 1.0では画像エンコーダとLLMを凍結してアダプタのみ学習、Stage 1.5ではLoRAを用いて全パラメータを調整することで、視覚と言語のアライメントと指示追従能力の両立を図った。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIが研究段階から実装段階へ移行する中で、特に産業現場での自律システムへの適用を具体化した重要な事例を示している。軽量化と高精度化を両立させたVLMの開発は、エッジコンピューティングとAIの融合を加速させ、製造業やインフラ管理などのDX推進に直接貢献する可能性が高い。
編集コメント
PR要素を含みつつも、技術的詳細と実装限界を明確に記載しており、業界関係者にとって実用的な情報を提供している。エッジデバイス向けVLMの具体的な設計思想と社会実装例の組み合わせが説得力を持つ。
視覚的接地(Visual Grounding)の能力を向上させる初期の試みでは、画像中の「特定のインスタンス1つ」を一意に指す参照表現と、正解の境界ボックス(bounding box、bbox)を1つだけ生成するデータセットを中心に学習していました。しかし、このデータで学習されたモデルは合成データの偏りを強く吸収し、境界ボックス出力タスクにおいて「必ず1つだけ境界ボックスを出力する」というバイアスが生じました。その結果、実運用で頻出する「複数インスタンスを指す参照表現」(例:「テーブルの上のリンゴ全部」)を入力しても、モデルが境界ボックスを1つしか返さないことがあり、汎用性に課題がありました。
そこでデータ合成の方針を見直し、複数インスタンスを指し示す参照表現も意図的に生成して学習データに含めるように変更しました。これにより、「単体も集合も自然に扱える」出力分布へ近づけることができます。
合わせて領域抽出の実験を進めたところ、境界ボックスの品質はQwen3‑VL‑235B‑A22B‑Instructの直接出力よりもSAM3の方が安定して高精度であることが分かりました。そのため、基本ワークフローはSAM3に寄せつつ、SAM3が領域を返せない例外ケースではQw
原文を表示

はじめに
Preferred Networks(以下、PFN)では2025年8月から、経済産業省および国立研究開発法人 新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内の生成AI基盤モデルの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受け、自律稼働デバイスに向けた高精度軽量Vision Language Model(VLM)「PLaMo 2.1-VL」の開発に取り組んできました。PLaMo 2.1-VLの開発では、現時点の自律稼動デバイスで動作が可能と考えられるモデルサイズの範囲の中で、より高精度を目指した8BサイズのモデルPLaMo 2.1-8B-VLと、より小型・軽量で手軽に試せる2BサイズのモデルPLaMo 2.1-2B-VLの2つのモデルに取り組んできました。
前回の記事では、PLaMo 2.1-8B-VLが目指す方向性と設計思想に加え、その性能の中間報告と評価ベンチマークについて紹介しました。合わせて、同モデルの強みであるVisual Question Answering(VQA)およびVisual Groundingについても取り上げました。
本記事ではその続編として、モデルアーキテクチャと学習方法に加え、2つの社会実装例(工場での作業分析/インフラ設備での異常検出)、そしてそれらの性能を支えるデータ合成の取り組みを紹介します。
なお、本記事ではモデルの重みが一般に公開されているモデルを、便宜上「オープンモデル」と呼びます。また、本記事でいうzero-shotは、評価対象現場のデータを学習に用いず、対象現場への追加学習も行わない設定を指します。PLaMo 2.1-VLの評価には、Hugging Faceで公開しているモデル(PLaMo 2.1-8B-VL、PLaMo 2.1-2B-VL)を用いています。
PLaMo 2.1-VLの特徴
PLaMo 2.1-VLは、ドローン、ロボット、自動車、監視カメラなどの自律稼働デバイスでの利用を想定し、エッジデバイス上で効率よく動作する高精度・軽量VLMを目指して開発されました。
自律稼働デバイス向けのVLMでは、自然文の回答だけが返り「どれを見て判断したか」が曖昧なままだと、誤動作や運用上のリスクが高まります。そこでPFNでは、言語と画像の対応付け(grounding)を中核能力として最優先で強化しました。さらに現場運用では、判断結果を人に伝え、記録し、遠隔で共有できる形に整える必要があります。そのため、groundingに基づく説明・要約も重要な要件になります。
以上を踏まえ、PLaMo 2.1-VLでは次の2つの能力を基本性能として重視しています。
VQA(Visual Question Answering):画像とテキストを入力として、自然言語の応答を返す能力
Visual Grounding:テキストの指示が指す人物・物体を画像中から特定する能力(REC: Referring Expression Comprehension を含む)
これらを土台に、PFNでは以下の社会実装を進めています。
作業分析:工場内での作業者の作業分析に向けた工具認識
異常検出:警備巡回ドローン搭載カメラや監視カメラ映像を用いた異常検出
以降では、まずPLaMo 2.1-VLのモデルアーキテクチャと学習方法を説明し、続いてVQAおよびVisual Groundingのベンチマーク結果、社会実装タスク、そしてモデルの性能を支えるデータ合成の取り組みについて述べます。
適用範囲と留意点
PLaMo 2.1-VLは、自然画像を対象としたVQAおよびVisual Groundingを主眼として学習したモデルです。そのため、それら以外のタスクに対しては必ずしも高い性能が得られるとは限りません。例えば、OCRに特化した学習は行っておらず、画像中の文字の正確な読み取りや、文書画像・図表・数式の理解は現時点では限定的です。また、入力は単一画像に限定されており、複数画像を同時に扱うことを前提としたタスクには対応していません。一般的・日常的な知識は一定程度備える一方で、特定分野の深い専門知識を重点的に学習させたモデルではありません。専門的判断を要する用途に適用する場合は、追加学習や外部知識の参照、周辺システムとの組み合わせを前提とする必要があります。
さらに、PLaMo 2.1-VLは、画像とテキストのペア入力を前提として学習されています。そのため、画像のみ、あるいはテキストのみを入力する使い方では、想定どおりに動作しない可能性があります。また、画像とテキストの両方を入力したうえで、画像を参照しないよう指示する使い方も想定していません。
PLaMo 2.1-VLのモデル設計と学習方法
モデルアーキテクチャ概要
PLaMo 2.1-VLは、NeurIPS 2023で提案されたLLaVAと同系統の、実績のある標準的なアーキテクチャを採用しています。PLaMo 2.1-VLは一般的なVLMと同様に、言語モデル(LLM)、画像エンコーダ、および両者を接続する画像アダプタから構成されます。
ベースLLM:中核となるLLMには、Direct Preference Optimization(DPO)によってInstruction Tuning済みのPLaMo 2.1-2BまたはPLaMo 2.1-8Bを採用しました。これにより、ユーザ指示に対して安全かつ正確に追従できる基盤を確保しています。
画像エンコーダ:視覚表現の抽出には SigLIP2(siglip2-so400m-patch14-384)を採用しました。
画像アダプタ:画像特徴をLLMが扱える表現へ写像するために、シンプルなMulti-Layer Perceptron( MLP)を用いました。
加えて、モデルへの入力表現を改善するため、画像入力のトークナイズ(画像の分割・整形)には、NVIDIA Eagle 2に類似したdynamic tilingを採用しています。これにより、画像を適切な単位に分割してモデルへ入力し、解像度やアスペクト比の異なる画像に対しても安定した処理を可能にしています。
設計の狙いとトレードオフ
各コンポーネントの選定は、実験に基づく性能とハードウェア効率(とくに学習時のGPU VRAM制約)を重視して決定しました。本節では、主要な設計判断とその理由を整理します。
なぜSigLIP2か?
事前検証として、PaliGemmaで用いられているSigLIPや、Qwen2.5-VLのViTなど、複数の有力な画像エンコーダを比較しました。その結果、SigLIP2が最も安定して高い性能を示しました。具体的には、セマンティック理解に加えて、ローカライゼーション(画像内の「どこにあるか」を捉える能力)の改善が確認できました。こうした特性から、SigLIP2はセマンティックセグメンテーションや物体検出、Visual Grounding/RECのように局所的な画像理解を要するタスクで有利になり得ると考えています。直感的には、各セル/各パッチに対応する特徴が画像内の局所情報を表すため、よりグローバルな表現に寄りやすいCLIP系のエンコーダと比べて、局所対応(「どの領域が指されているか」)を取りやすいという期待があります。さらに、Visual Grounding/RECにおいて対象領域への対応付けが安定すれば、VQAにおいても適切な領域へ注意を向けやすくなり、回答の質が改善する可能性が高いと期待しています(ただし、この効果は一般論として断定するものではなく、経験的にそうなりやすいという位置づけです)。
なぜMLPアダプタか?
当初は、より良い画像トークンを動的に選択できる可能性のあるQ-formerのような、より複雑なアダプタも検討しました。しかし、学習時のGPU VRAM制約が大きく、複雑なアダプタを採用すると学習バッチサイズを大幅に削減せざるを得ませんでした。そこで、より単純なMLPアダプタに切り替えることでVRAM使用量を抑え、バッチサイズを確保することにより学習を高速化できました。結果として、試行錯誤の機会が増加し、総合的なベンチマークスコアの改善につながりました。
なぜdynamic tilingか?
画像入力のトークナイズについては、dynamic tilingと、NaViT-styleのnative resolution tokenization(Qwen2.5-VLで採用)を比較しました。評価ベンチマーク上ではdynamic tilingの方が一貫して良好な結果を示したため、最終的にこちらを採用しています。
学習方法
VLMの学習では、LLMに視覚入力の理解を獲得させつつ、既存の自然な対話能力を損なわないようにする必要があります。LLaVAやEagle 2と同様に、PLaMo 2.1-VLも段階的学習を採用しました。当初はEagle 2に近い3段階構成も検討しましたが、最終段階の効果を十分に再現することが難しかったため、本開発では2段階(Stage 1.0 と Stage 1.5) に絞って設計・最適化しました。
Stage 1.0:視覚と言語のアライメント
学習対象:画像エンコーダとベースLLMは完全に凍結(freeze)して、画像アダプタの重みのみを更新します。
目的:この段階の目的は、視覚と言語のアライメントです。画像エンコーダが出力する視覚特徴を、LLMが理解可能な表現へ写像できるように、アダプタを学習させます。ベースとなるPLaMo 2.1はすでにInstruction Tuning済みであるため、この段階でLLMを凍結することが重要です。これにより、画像アダプタの能力を高めつつ、ベースモデルの指示追従の振る舞いや安全性のガードレールを保ったまま学習を進められます。
学習データ:Web規模の画像キャプションデータを用い、日本語:英語=75:25で混在させました。予備実験では、日本語のみよりも、英語データを25%混ぜた方が日本語性能が向上しました。PLaMo 2.1はバイリンガル性が高く、埋め込み空間上で日英が近く対応付く傾向があります。加えて、英語データセットは一般にアノテーション品質が高く、高品質な学習信号として日本語タスクへも転移しやすいと考えられます。
Stage 1.5:Instruction Tuning と日本語への視覚の適応
学習対象:画像エンコーダ、画像アダプタ、ベースLLMの全てに対して、Low-Rank Adaptation(LoRA)を適用して学習します。
目的:画像に関するより複雑なタスクを扱い、詳細な指示にも追従できるようにInstruction Tuningを行います。この段階でLoRAを用いるのは、学習の安定性とメモリ効率を両立しつつ、ベースLLMが持つ高品質な指示追従能力を維持し、事前学習知識の破壊的忘却(catastrophic forgetting)を抑えるためです。
学習データ:日本語:英語=75:25の比率は維持しつつ、タスクの多様性を大きく拡張しました。Stage 1.0のキャプションデータに加え、VQA、Visual Grounding、オープンボキャブラリ物体検出、異常検出、工場作業の理解に関するデータセットを導入しました。
PLaMo 2.1-VLの性能
本セクションでは、PLaMo 2.1-VLのVQAおよびVisual Groundingに関する性能をベンチマークで示します。評価ベンチマークの背景(JA-VG-VQA-500やRef-L4の狙い)や各指標の定義、評価手順の詳細については前回Tech Blogで詳しく説明しているため、本記事では前回と同一の評価設定に基づくスコアのみを掲載します。
VQAベンチマーク:JA-VG-VQA-500
VQAの評価には、日本語ベンチマークであるJA-VG-VQA-500を用いました。
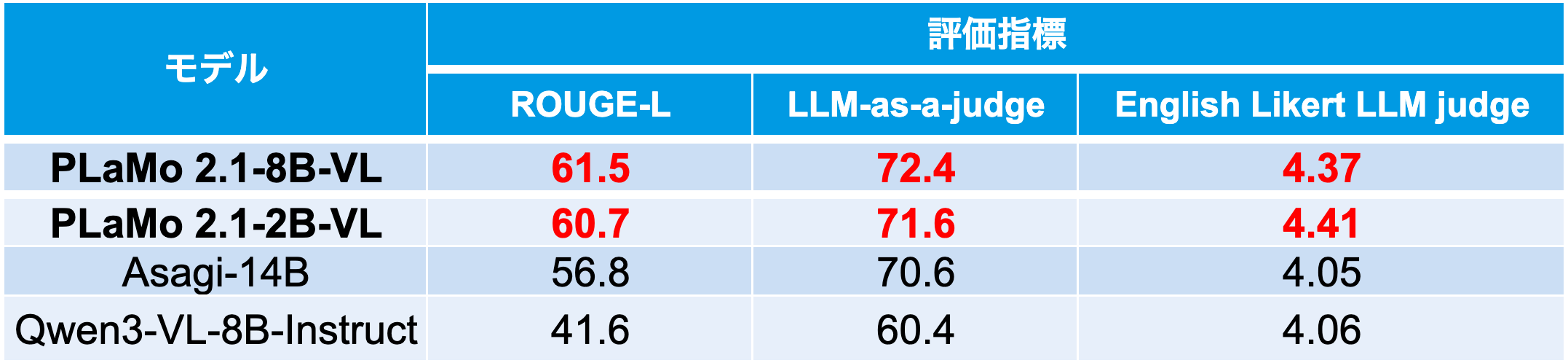
比較対象として、(1) GENIAC第3期申請時点(2025年4月)でオープンモデルの中でJA-VG-VQAのベンチマークにおいて最も性能が高かったAsagi-14B、(2) PLaMo 2.1-8B-VLと同程度のサイズ帯のオープンモデルの中で本評価実施時点で最も性能が高いQwen3-VL-8B-Instructを選定しました(表1)。その結果、PLaMo 2.1-8B-VLは、これらのモデルと比べて複数の指標において高いスコアを達成しました。また、PLaMo 2.1-2B-VLでも比較対象を上回るスコアが得られています。なお、Qwen3-VL-235B-A22B-Instructは、ベンチマークで想定されている水準を超えて具体的な回答を生成する傾向があり、スコアが不当に低くなったため除外しています。
表1 JA-VG-VQA-500におけるVQA評価結果
Visual Groundingベンチマーク:Ref-L4英語版と日本語版
Visual Groundingの評価には、英語ベンチマークであるRef-L4と、Ref-L4のPFN日本語翻訳版を用いました。
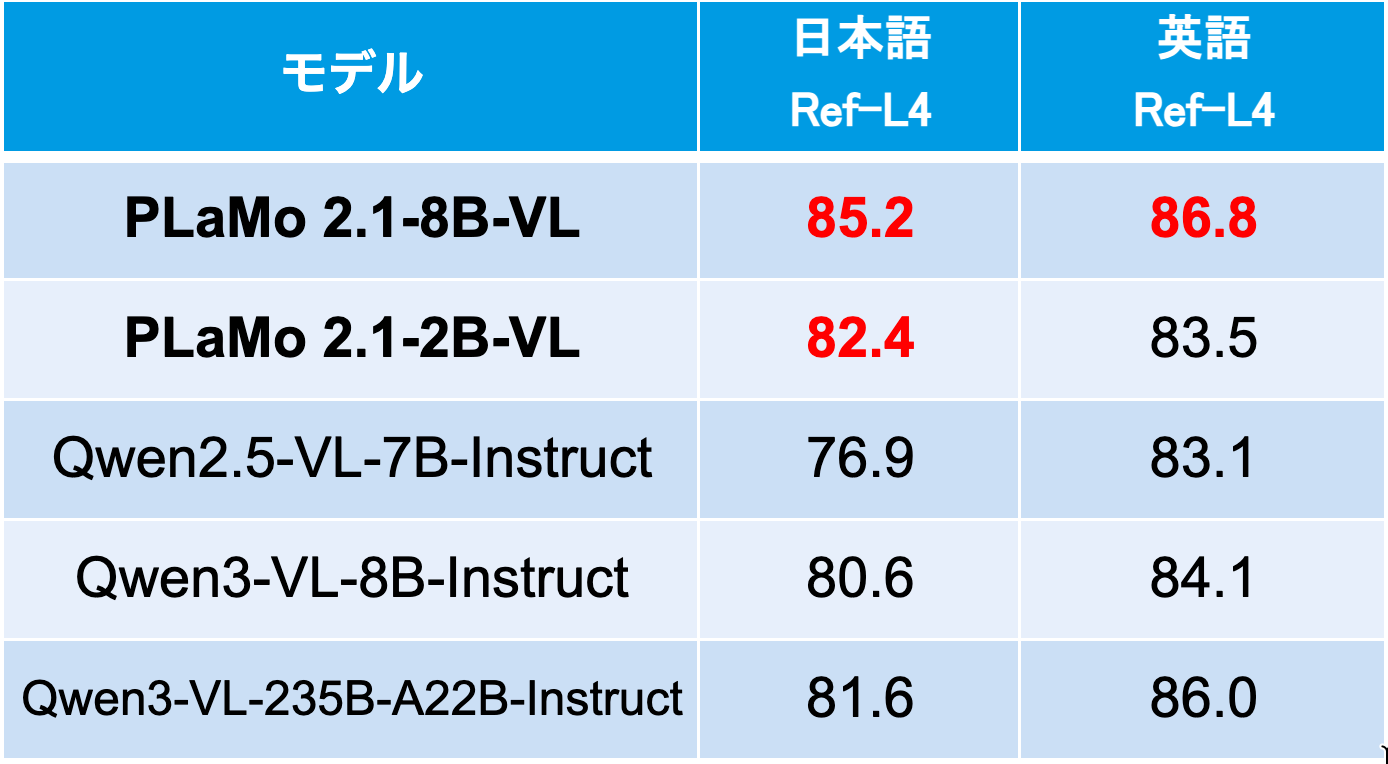
比較対象として、(1) GENIAC第3期申請時点(2025年4月)でPLaMo 2.1-8B-VLと同程度のサイズ帯のオープンモデルの中で最も性能が高いQwen2.5-VL-7B-Instruct、(2) 本評価実施時点で最新の同程度サイズ帯のオープンモデルであるQwen3-VL-8B-Instruct、および(3)Qwen3-VLシリーズのフラッグシップモデルであるQwen3-VL-235B-A22B-Instructを選定しました(表2)。その結果、英語・日本語いずれのRef-L4においても、PLaMo 2.1-8B-VLは比較対象を上回るスコアを達成しました。また、PLaMo 2.1-2B-VLも英語ではQwen3-VL-8B-Instructなどに劣るものの、日本語では比較対象を上回るスコアが得られています。
表2 Ref-L4日本語版および英語版におけるVisual Grounding評価結果
工場作業の理解:工具認識に基づくタスク推定
作業分析の内容
PLaMo 2.1-VLが想定するユースケースの1つに、産業領域、特に工場内における作業(タスク)分析があります。工場現場で作業者の様子を観察しても、作業者の姿勢や周囲の環境情報だけから「いまどのタスクが行われているか」を推定するのは容易ではありません。そこで私たちは、作業者が使用している工具の認識がタスク理解の主要な手がかりになると考えました。たとえば、トルクレンチを扱っているのか、ドライバーを扱っているのかを高精度に認識できれば、モデルは実行中のタスク内容をより高い確度で認識できます。この工具認識性能を強化するために、工具認識に特化した独自データセットを作成しました。データは、VQA、Visual Grounding(画像中の工具位置の特定)、および単純な画像分類といった複数の形式で作成しています。この独自データセットの作成については、後述のデータ合成の章で説明します。
作業分析の結果
実環境の産業シナリオにおけるモデル性能を評価するため、GENIAC3プロジェクトで整備した工場タスク分析ベンチマークを用いました。本ベンチマークは、実際の工場内で作業者が10種類の作業タスクを実施している画像から構成されており、モデルには画像中で行われているタスクを10クラス分類することが求められます。
推論時プロンプトの例(工具情報を用いたタスク分類)
タスク分析の推論では、各タスクが特定の工具と強く結び付く点に着目し、工具の外観情報をヒントとして与えるプロンプトを採用しました。プロンプトで工具名だけを与えると、専門性の高い工具の認識が不安定になる場合があります。そこで本開発では、プロンプトに形状・色・典型部位(例:ラチェット機構、ソケット部、ケーブル類など)といった視覚的手がかりも併記することで、画像からの同定を補助しています。以下はその一例です。
作業者が画像内で現在行っているタスクを特定してください。以下の10個のタスクラベルから該当するものを選んでください。
各タスクは特定の工具で特徴づけられるため、工具の視覚的な説明をヒントとして用いてください。
タスクラベルと工具の特徴は以下のとおりです:
A:金属製の長いトルクレンチ。ローレット加工のグリップ、ラチェット機構、重厚なソケットヘッドを持つ。
B:はんだごて。黄色い樹脂製ハンドル、円筒状の金属製ヒータ部、先端が細い銀色のチップを持つ。
…
J:工業用グルーガン。白い樹脂ボディ、大きなトリガー機構、背面から太い透明な接着スティックが差し込まれている。
画像に基づいてタスクラベルを選び、該当するラベル名のみを出力してください。その他の文章は出力しないでください。
ベンチマーク結果
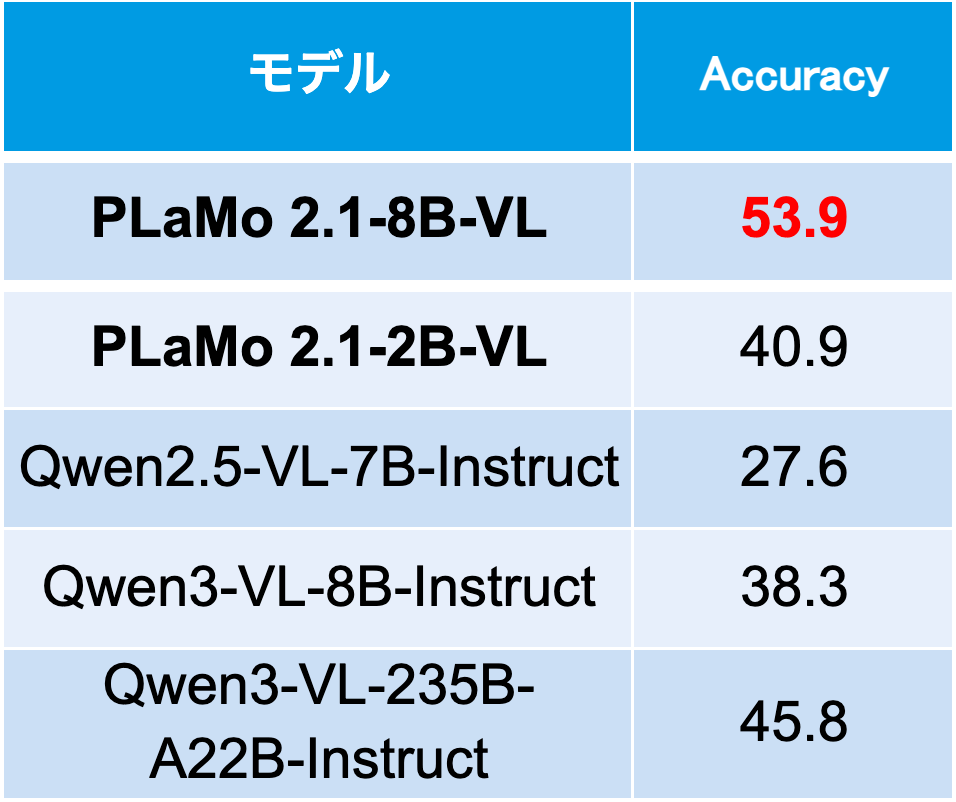
本ベンチマークに含まれる工場の画像は、PLaMo 2.1-VLの学習には一切使用しておらず、評価はzero-shot設定で実施しています。結果を表3に示します。10種類の細かな作業をzero-shotで分類する設定は非常に難易度が高く、Qwen2.5-VL-7B(27.6%)や、より新しいQwen3-VL-8B(38.3%)、さらにパラメータ数の多いQwen3-VL-235B-A22B-Instruct(45.8%)といった強力なオープンモデルでも精度が伸びにくいことが分かります。一方で、工具認識に焦点を当てた学習と、日本語を中心とした学習を組み合わせることで、PLaMo 2.1-8B-VLは53.9%の精度を達成し、これらのベースラインを大きく上回りました。なお、PLaMo 2.1-2B-VLも、Qwen3-VL-235B-A22B-Instructには劣るものの、Qwen3-VL-8B-Instructを上回るスコアが得られています。
図1に、実際の作業分析の例を示します。今回の評価対象では、見た目が似た工具が多いうえ、一部の工具は手や身体、対象物に隠れてしまうため、誤認識が生じるケースが見られました。今後は、画像単体の情報に加えて時系列情報も活用することで、さらなる精度向上が期待できます。
表3 工場作業タスク分析におけるzero-shot分類精度の比較(10クラス)
 image図1 工場作業タスク分析の予測例。左・中央は正解例、右は誤分類例。
image図1 工場作業タスク分析の予測例。左・中央は正解例、右は誤分類例。
警備巡回ドローン搭載カメラや監視カメラ映像を用いたインフラ設備での異常検出
異常検出の内容
インフラ設備の異常検出は、設備ごとに外観や設置環境が大きく異なる一方、公開データやWeb上の画像や動画が乏しく、大規模な学習データを収集しにくい領域です。そのため、特定の設備や環境に依存せず、zero-shot(または少量データ)で適用できるアプローチが求められます。
そこで私たちは、警備巡回ドローンや監視カメラが同じ場所を繰り返し撮影するという運用特性に着目し、参照画像(正常状態)と現在画像の2枚を比較して変化を検出することにしました。具体的には、参照画像を正常状態のベースラインとみなし、現在画像との差分から、異常候補となる変化箇所を抽出します。想定する異常には、設備の破損・欠損、通常は存在しない物体の出現、液漏れ痕、扉やバルブの開閉状態の変化などが含まれます。
ドローン搭載カメラでの撮影では、同じルートを飛行しても、GPSや飛行制御の誤差、風などの外乱により、撮影位置や画角は完全には一致しません。監視カメラでも、微小な揺れや視点変化が生じます。さらに日照や天候の違いが加わるため、画素差分のような単純な比較では、位置ずれや照明変化による「見かけの差分」が支配的になり、検出が不安定になりがちです。
この課題に対して本手法では、VLMに「意味のある変化」に注目して2枚を比較する能力を持たせることで、位置・画角のずれや日照条件の差をある程度吸収しながら、異常に結びつく変化を抽出することを狙います。また、実設備画像を大量に収集できない制約を踏まえ、学習には実画像ではなく合成データを用い、2枚比較による差分検知の振る舞いを学習させます。これにより、特定環境に過度に依存せず、新しい現場にも展開しやすい構成を目指します。
出力は、異常候補の位置を示すバウンディングボックス(bbox)と、各bboxに付与する異常ラベルから構成されます。bboxの形式とラベル設計の詳細は、次のセクションで説明します。
本手法の特徴のまとめです。
2枚比較で異常箇所を特定:参照画像と現在画像の差から、変化箇所を異常候補として抽出
撮影条件の違いに頑健:画角・位置ずれや日照変化よりも、異常につながる「意味のある変化」に着目
zero-shot/少量データで展開が容易:実設備データに依存しにくく、新規環境でも追加学習なし、または少量データでの追加学習が適用しやすいことを期待
異常検出用ペア画像データセットの作成
PLaMo 2.1-VLに異常検出の能力を持たせるとともに、その性能を評価するために、学習用と評価用の2種類のデータセットを用意しました。学習ではデータ合成で作成したデータを用い、参照画像(正常状態)と対象画像(異常状態)を比較して異常を検出する差分検知の能力を学習させます。合成データの利用には、データ量の確保に加え、様々な画像を学習させることで未知の状況でも「2枚の比較」に基づいて異常を特定できるようにする狙いがあります。評価では、発電プラント施設内で撮影したドローンデータを用い、現場条件下での性能を検証します。学習用データの詳細は後述のデータ合成の章で説明することとし、本章では評価用データの作成について説明します。
発電プラントでのドローン撮影
現実に即した異常をどの程度扱えるかを検証するため、発電プラント施設内で異常を人工的に再現し、カメラ搭載ドローンで撮影しました。撮影は発電プラント施設内の複数の設備で設備ごとに事前設計した飛行ルートに沿って実施し、同様の軌道で3日間にわたり複数回行っています。撮影パターンは、異常物体を設置しない参照画像(正常状態)と、異常物体を人工的に設置した対象画像(異常状態)の2種類です。評価データの多様性を確保するため、異常物体は撮影のたびに再配置し、設置する物体の種類を変えました。さらに各設備は異なる日時でも撮影しており、日照・天候・背景変化など現場特有の揺らぎを含むデータになっています。
アノテーションは対象画像(異常状態)に対して実施し、異常物体についてバウンディングボックス(bbox)と14種類の異常ラベルを付与しました。ラベルはペットボトル、空き缶、工具、ゴミ袋、カラーコーン、手袋、ヘルメット、鳥の巣、傘、タオル、養生テープ、人、配電盤等の扉開放、水漏れです。ラベル定義は現場運用を意識しており、たとえば扉開放は開放されている扉にbboxを付与し、水漏れは漏水源ではなく検知対象として重要な濡れている領域にbboxを付与します。対象画像のデータセット全体では、1個以上の異常を含む画像の割合は全体の約40%です。1画像あたりの異常物体数は基本的には1個ですが、状況によっては2〜6個程度含まれる場合もあります。また、異常物体は最小で一辺が数十ピクセル程度まで小さく写り得るため、小物体を含む検出能力も評価できる設定になっています。
対象画像と参照画像のペア作成(飛行ログと画像マッチングに基づく位置合わせ)
差分検知の入力は、対象画像(異常状態)を左、参照画像(正常状態)を右に並べ、2枚を横方向に結合(concat)した1枚の画像です。ドローンは事前設計したルートに沿って飛行しますが、前述のとおり、GPSや飛行制御の誤差、風などの外乱により、撮影位置や画角は完全には一致しません。ずれを含んだままVLMに入力することも可能ですが、学習で「位置ずれの吸収」まで同時に学ばせると負担が増え、結果として「意味のある変化」ではなく見かけの差分に引っ張られやすくなります。そこで本開発では前処理として、対象画像に対して画角が近い参照画像を選び、位置合わせしてからペア化しています。
手順は次の通りです。まず、撮影と同時に記録されたテレメトリ情報(ドローンの緯度・経度・高度など)から、各フレームの撮影時のドローンの位置情報に基づいて参照画像の候補フレームを複数選択します。候補として複数のフレームを選択するのは、位置が最も近くてもドローンの姿勢やカメラの向きによっては必ずしも画角が近いとは限らないためです。次に、各候補フレームに対してSIFTとLightGlueを用いた画像マッチングを行い、対応する特徴点間の画像上での距離の平均値が最も小さい画像を参照画像として選択します。最後に、マッチング結果から推定したホモグラフィ変換により参照画像を補正し、画角差や位置ずれを低減したうえで、左に対象画像、右に参照画像の順で配置して結合し、入力画像を作成しました。
図2に(a)対象画像、(b)選択された参照画像、および(c)ホモグラフィ変換後の参照画像の例を示します。(b)選択された参照画像では、画角に対して撮影対象の位置が左にずれており、角度も反時計回りに微妙にずれているのが分かります。これに対し(c)ホモグラフィ変換後の参照画像では、参照画像の特徴点の位置が対応する対象画像の特徴点の位置と最も近くなるように変換されるため、この位置と角度のずれが修正されていることが分かります。実際には、わずかなスケール差もあわせて補正されています。
なお、参照画像は対象画像を基準に検索・処理して抽出するため、状況によっては外観差が大きいペアが混入することがあります。例えば、見た目が大きく変化している場合、対象画像・参照画像のどちらかまたは両方でブレが大きい場合、あるいはドローンの位置が近くても姿勢の変化により画角が大きく異なる場合などです。この点は、現場運用で起こりうる再撮影の揺らぎも含めた評価条件として扱っています。
 image図2 ペア画像の作成例。(a) 対象画像、(b) 選択された参照画像、(c) ホモグラフィ変換後の参照画像。
image図2 ペア画像の作成例。(a) 対象画像、(b) 選択された参照画像、(c) ホモグラフィ変換後の参照画像。
異常検出の推論方法
異常検出では、単に「異常がある/ない」を判定するだけでなく、どこで(位置)、何が(内容)変化したのかを説明できることが重要です。本モデルは、参照画像(正常画像)と対象画像(異常画像)を比較し、異常箇所の位置(bbox)と内容(ラベル)として意味のある変化を出力することを目的とします。この目的のため、図3に示す二段階推論(pass 1 / pass 2)を採用しました。
pass 1(bboxとラベルの同時推定):画像全体を入力し、異常候補を探索してbboxを出力します。同時に、各bboxに対してラベルを一次推定します。
pass 2(ラベルの再推定):pass 1で得られたbbox領域を切り出し、領域画像のみを入力としてVQAでラベルを再推定します。
画像全体でbboxとラベルを同時推定すると、背景や周辺物体などの文脈がノイズとなりラベル推定が不安定になり得ます。そこで、pass 1で異常候補の位置(bbox)を特定したうえで、pass 2ではbbox領域のみを入力して余計な情報を排除した状態でラベルを再推定することで、精度と安定性の向上を狙いました。この手法では、pass 1のbbox推定が「テキスト指示が指す対象を画像中から特定する」Visual Grounding能力に、pass 2のラベル推定が「領域を見て適切なテキストを返す」VQA能力に、それぞれ強く依存すると考えられます。
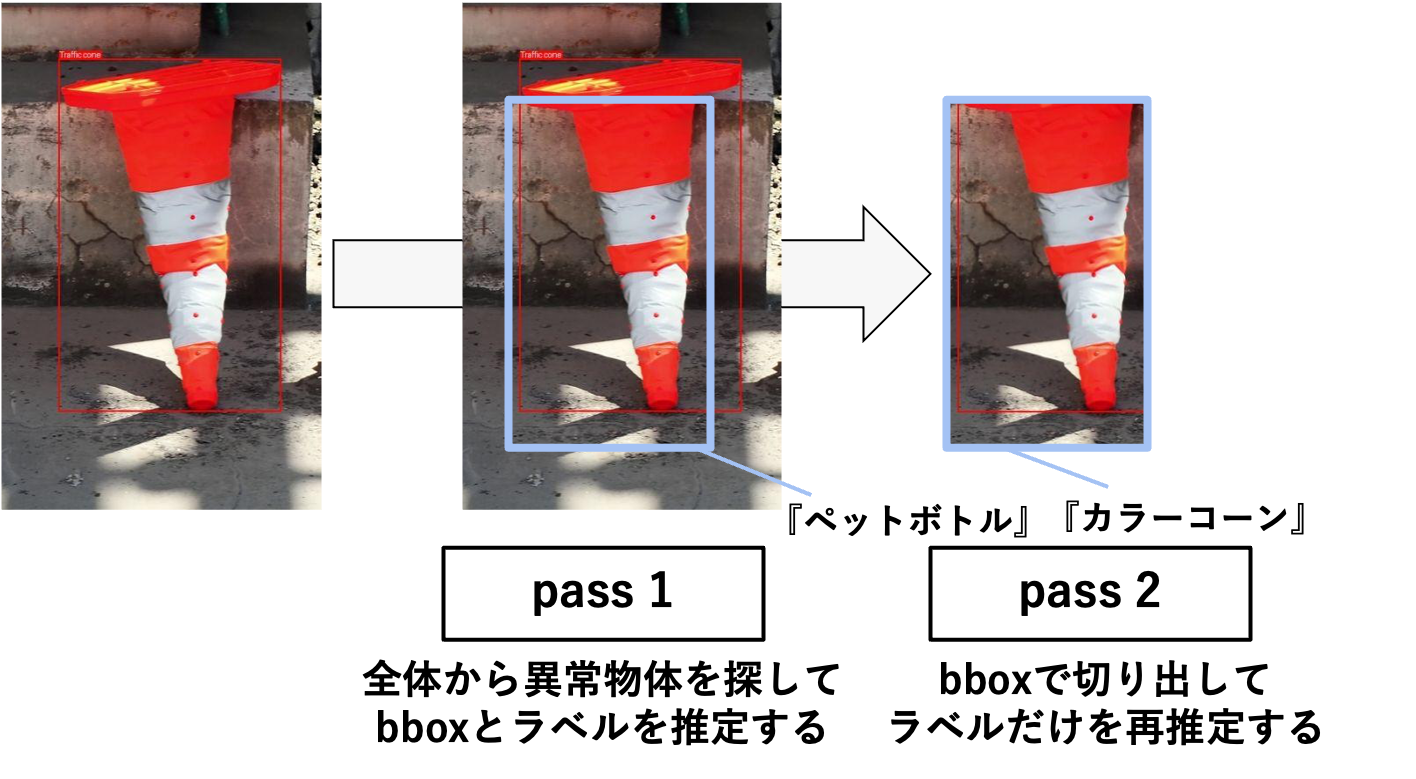 image図3 異常検出における二段階推論の流れ。pass 1で画像全体から異常候補を探してbboxとラベルを推定し、pass 2ではpass 1で得られたbbox領域を切り出してラベルを再推定する。(図中の赤枠は正解(Ground Truth)のbboxおよびラベルを表している。)
image図3 異常検出における二段階推論の流れ。pass 1で画像全体から異常候補を探してbboxとラベルを推定し、pass 2ではpass 1で得られたbbox領域を切り出してラベルを再推定する。(図中の赤枠は正解(Ground Truth)のbboxおよびラベルを表している。)
異常検出の結果
実環境に近い条件でモデルの異常検出性能を評価するため、前節「発電プラントでのドローン撮影」で説明したデータを用いて、発電所における異常検出ベンチマークを作成しました。検証専用データセットは、発電所内の設備3箇所から1個以上の異常を含む各400サンプル、合計1,200サンプルで構成されます。各サンプルは対象画像と参照画像の画像ペアであり、異常ラベルは14種類です。なお、対象画像および参照画像の解像度は、いずれも3840×2160ピクセルです。
社会実装を見据え、運用シナリオを次の2段階として整理し、それぞれを評価します。
bboxのみ(位置の特定):異常候補の位置が分かる状態を想定します。オペレータに通知し、該当箇所を目視確認したうえで判断・対応につなげる運用を対象とします。
bbox+ラベル(位置+内容の特定):位置に加えて異常内容(種類)まで分かる状態を想定します。異常対象に応じた対応(例:救護、修理手配)や施設横断でのレポーティング(集計・分類)により、監視・報告の工数削減につなげる運用を対象とします。
評価指標には、対象画像と参照画像の画像ペアからなるサンプルのF1-scoreを全サンプルで平均した平均F1-scoreを用います。F1-scoreをサンプル単位で算出するのは、bbox 単位で全体を一括して評価すると、異常物体数の多いサンプルが評価値に与える影響が大きくなるためです。本ベンチマークでは、各サンプルを等価に扱って画像単位の検出性能を評価するため、サンプルごとにF1-scoreを求め、その平均を用います。
k番目のサンプルにおいて、推論と正解の一致した数を TPk、一致しなかった推論数を FPk、一致しなかった正解数を FNk としたとき、F1-score Fk は次式で表されます。
Fk = 2TPk / (2TPk + FPk + FNk)
また、Nサンプルの平均F1-score M は次式で表されます。
M = (1 / N) ∑k=1N Fk
平均F1-scoreは、要件に合わせて次の2条件で集計します。
bboxのみ(位置のみ):bbox一致を満たす場合を TPk としてカウント
bbox+ラベル(位置+内容):bbox一致かつラベル一致を満たす場合を TPk としてカウント
zero-shotの結果
本節では、発電所異常検出ベンチマークに対するzero-shot評価の結果を示します。比較対象として、同程度サイズ帯のオープンモデルであるQwen2.5-VL-7B-Instructと、より新しいモデルであるQwen3-VL-8B-Instruct、および大きいサイズのQwen3-VL-235B-A22B-Instructを選定しました。なお、事前検証でpass 1のみと二段階推論の比較をした結果、今回評価した全てのモデルで二段階推論の方が高いラベル推定精度を示したため、以降は二段階推論の結果を示します。
表4に示すとおり、PLaMo 2.1-8B-VL、PLaMo 2.1-2B-VLともにbboxのみ・bbox+ラベルのいずれの条件でも、すべての比較モデルを大きく上回る平均F1-scoreを達成しました。一方で、bboxのみの評価に比べるとbbox+ラベルのスコアは低く、異常箇所の位置は捉えられていても、内容ラベルの推定にはなお課題が残ることが分かります。図4に予測例を示します。上段の成功例では、鳥の巣やタオル・工具のような物体異常に対して、bboxとラベルの両方を正しく出力できています。これに対し、下段の失敗例では、小さなペットボトルを見逃す例や、水漏れを別ラベルに取り違える例が見られ、以降で述べる誤り傾向を端的に表しています。
表4 発電所異常検出ベンチマークにおけるzero-shot評価結果
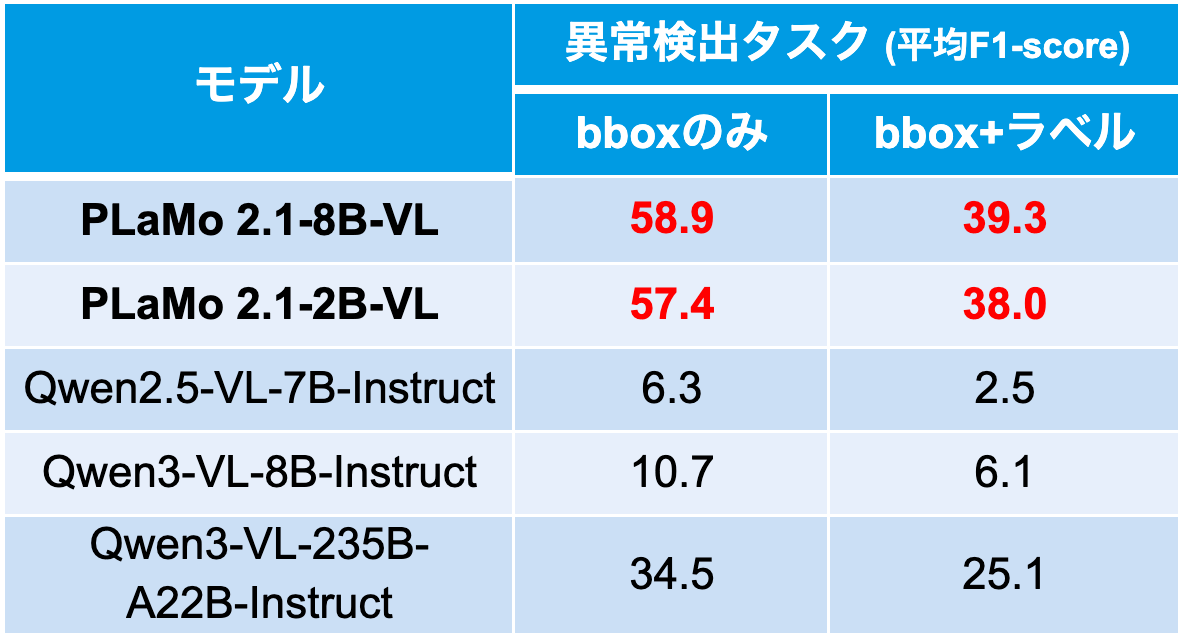

図4 PLaMo 2.1-8B-VLの異常検出の予測例。上段は正解例、下段は失敗例。失敗例として、小物体の見逃しと、状況起因の異常におけるbbox・ラベルの不一致の例を示している。
PLaMo 2.1-8B-VLの誤り傾向を詳しく見るため、図5に各異常物体のbboxサイズの分布を、図6に異常物体別・bboxサイズ別の一致率を示します。図5および図6では、異常物体ごとにbboxをサイズの昇順に並べ、サンプル数が等しくなるように4分位(Q1〜Q4)に分割しています。Q1が最小、Q4が最大であり、各分位におけるbboxサイズの範囲を図5に、一致率を図6に示しています。これらの図から、次の2つの特徴が読み取れます。
第一に、bboxが大きいほど一致率が高く、Q4 > Q3 > Q2 > Q1という単調な傾向が確認できます。特に、飲料缶やペットボトルのような小物体に起因する異常は、検出・ラベル付けのいずれにおいても難易度が高く、一致率が伸びにくい傾向があります。図4下段左の失敗例は、その典型例といえます。第二に、開いたドアや水漏れのように、状態変化に依存する状況起因の異常では、bboxとラベルの両面で誤りが生じやすく、bbox+ラベルの精度改善余地が相対的に大きいことが分かりました。図4下段右の失敗例では、水漏れ領域の近傍に予測は出ているものの、IoUは0.5未満であり、bboxとラベルの両方で誤りが生じています。これは、状態変化に依存する異常では、領域の特定とカテゴリ判別の双方が難しいことを示しています。これらの結果は、「異常検出に基づく目視確認」は応用として成立しやすい一方で、「内容まで含めたレポーティング/対応の自動化」には追加の改善が必要であることを示唆します。
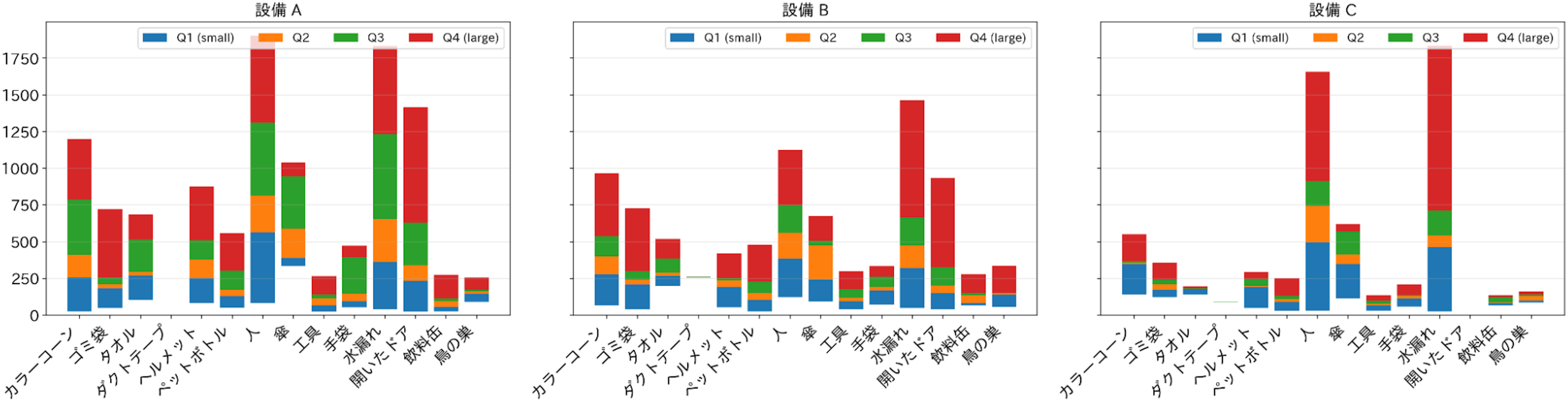 image図5 作成したデータセットに含まれるbboxサイズの分布。bboxをサイズの昇順に並べ、サンプル数が同数になるように4分位(Q1〜Q4)に分割し(Q1が最小、Q4が最大)、各4分位の値(サイズ)の範囲を示している。縦軸はbboxの縦横の幾何平均(=面積の平方根)で示している。
image図5 作成したデータセットに含まれるbboxサイズの分布。bboxをサイズの昇順に並べ、サンプル数が同数になるように4分位(Q1〜Q4)に分割し(Q1が最小、Q4が最大)、各4分位の値(サイズ)の範囲を示している。縦軸はbboxの縦横の幾何平均(=面積の平方根)で示している。
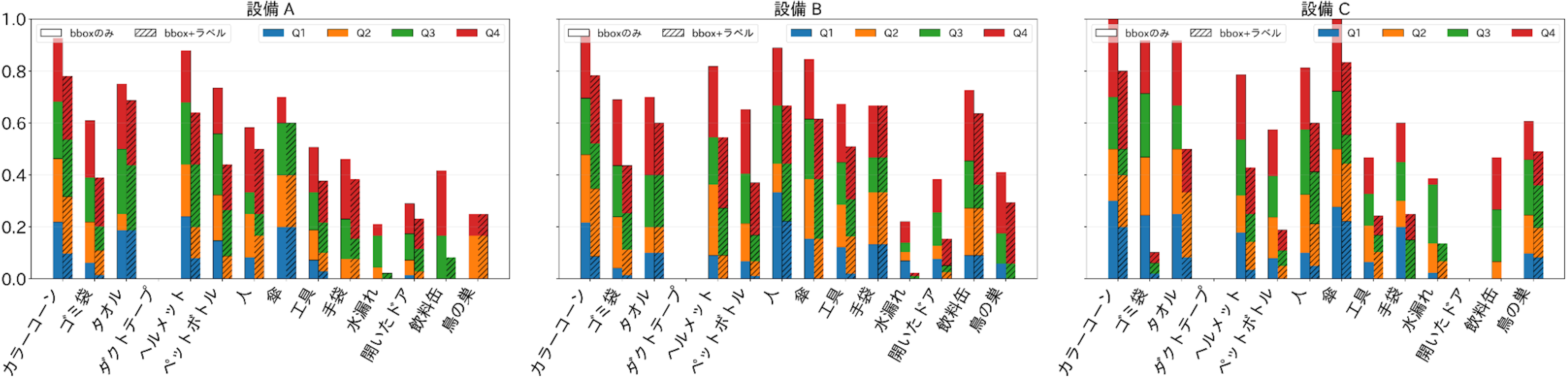 image図6 PLaMo 2.1-8B-VLの検出結果における一致率の内訳。bboxサイズの4分位(Q1〜Q4)ごとに、bboxのみとbbox+ラベルの条件で一致したbboxの割合を示している。各分位の一致率の最大値は0.25で、全ての4分位で全てが一致した場合に一致率の合計が1.0となる。
image図6 PLaMo 2.1-8B-VLの検出結果における一致率の内訳。bboxサイズの4分位(Q1〜Q4)ごとに、bboxのみとbbox+ラベルの条件で一致したbboxの割合を示している。各分位の一致率の最大値は0.25で、全ての4分位で全てが一致した場合に一致率の合計が1.0となる。
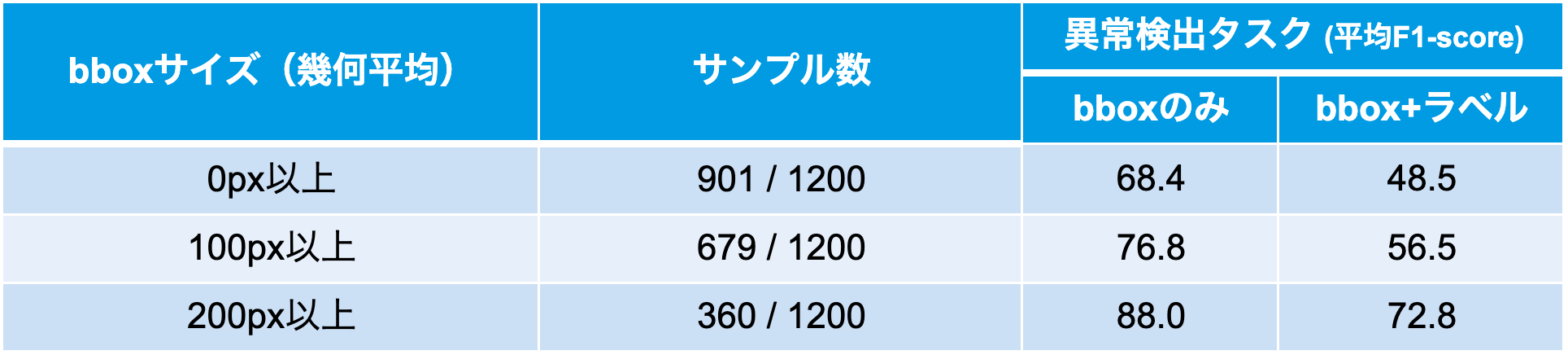
そこで、運用上の意思決定に直結する見え方(対象サイズ・撮影距離)に着目するため、状況起因の異常を含むサンプル(サンプル数299)を除外したうえで、同一データセットに対してbbox面積の下限(正確には面積の平方根の下限)を設け、その値を下回るbboxを含むサンプルを除外し、再評価しました(表5)。その結果、閾値を上げるほど、すなわち十分に大きく写る対象に限定するほど、平均F1-scoreが向上することが確認できました。これは、実環境で期待する性能を満たすために、想定する異常対象の大きさに応じてカメラ仕様や撮影条件(高度・ズーム)を調整すべきことを定量的に示しています。参考として、今回利用した Zenmuse H30のズームカメラ(動画3840×2160、DFOV 66.7°)で、350 mL缶(高さ約0.12 m)程度の対象物が画面上で幾何平均100 pxに写る状況を概算すると、飛行中でもブレが比較的少ない3〜5倍ズーム時の被写体距離は概ね12〜20 mに相当します。
表5 状況起因の異常を除外し、bboxサイズの下限を設けた場合の異常検出結果
異常検出の Fine-tuning:発電所データでの効果検証
前節ではzero-shot性能を確認しました。本節では、発電所で撮影したデータを用いてPLaMo 2.1-8B-VLのFine-tuningを行い、実環境データに合わせ込むことでどの程度性能が向上するかを検証します。
データセットと学習
Fine-tuningでは、3か所の設備(A・B・C)で3日間にわたって収集したデータを、次のように分割して使用しました。各サンプルは「対象画像・参照画像のペア」と、「対象画像に含まれる異常物のbbox(位置)およびラベル」から構成されます。
学習セット:設備A・B(1〜3日目)、全54,722サンプル
検証セット:設備C(1日目)、全5,172サンプル
評価セット:設備C(2〜3日目)から1個以上の異常を含む2,000サンプルをランダム抽出
評価時の推論フローに合わせ、学習・検証データもpass 1とpass 2を意識した形式に加工しています。
pass 1:対象画像と参照画像のペアから、異常物のbbox(位置)とラベルを予測
pass 2:対象画像から異常物を切り出した画像から、ラベルを予測
pass 2は、推論時にpass 1で得たbbox領域を切り出してラベルを再推定する設定を、学習時にも再現することを目的としています。検証損失に対するearly stoppingにより、学習は概ね全学習データの20%程度を消化した時点で終了しています。
評価結果
PLaMo 2.1-8B-VLのFine-tuningにより、pass 1 / pass 2のいずれの観点でも性能は改善しました(表6)。特に改善が大きかったのはラベル推定であり、bboxのみの評価に比べて、bbox+ラベルの評価でより明確な向上が確認されました。これは、異常位置そのものの推定性能はzero-shotの時点ですでに一定水準に達していた一方で、検出結果に付随するラベルの推定性能がFine-tuningによって大きく改善したことを示しています。クラス別に見ると依然として難しい対象は残るものの、全体としてbbox+ラベルのスコアが底上げされています。
さらに、bbox面積の下限(正確には面積の平方根の下限)を設け、その値を下回るbboxを含むサンプルを除外して再評価しました(表7)。その結果、200px未満の異常に対するラベルの認識性能が大幅に向上していることが確認できました。また、Fine-tuning後においてもbboxサイズの下限を大きくするほど平均F1-scoreは高くなる傾向が確認されました。これは、zero-shotでの結果と同様に、社会実装を見据えるうえで、想定する異常対象のサイズに応じてカメラ仕様や撮影条件を設計することの重要性を示唆しています。
発電所での撮影・アノテーションはコストが高く、稼働中の設備に人工的に異常を設置して撮影することには、運用上の大きな制約があります。今回の結果から、bboxの予測性能はすでに一定水準にあり、主な改善余地はラベル推定にあると考えられます。そのため、ラベル性能の向上を主目的とするのであれば、データ収集を必ずしも発電所内に限定せず、異常候補そのものを別環境で撮影して収集するアプローチでも改善が期待できます。これは、pass 2がpass 1で得たbbox領域を切り出した画像を入力としてラベルを再推定する設計であり、背景や撮影環境の違いの影響を相対的に受けにくいと考えられるためです。
表6 発電所データを用いたPLaMo 2.1-8B-VLのFine-tuningの評価結果
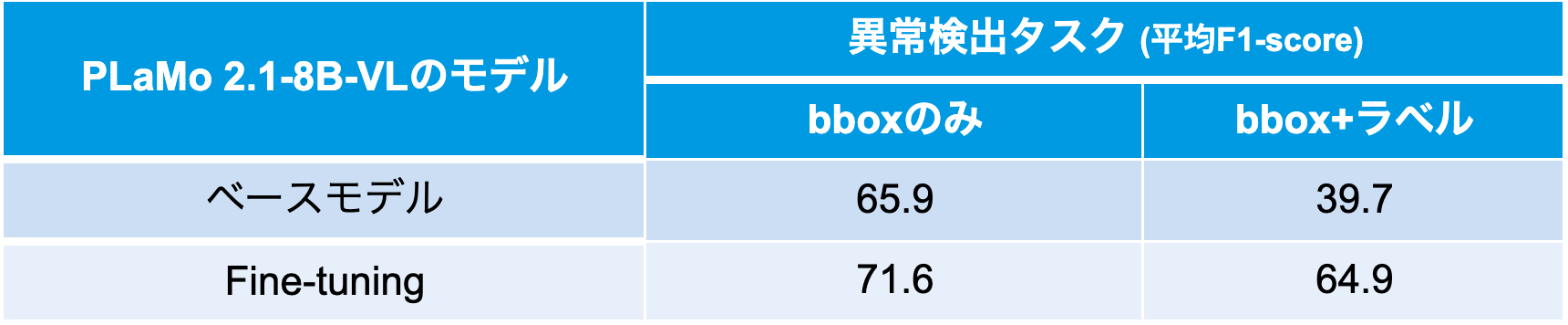
表7 状況起因の異常を除外し、bbox面積の下限を設けた場合のベースモデル(PLaMo 2.1-8B-VL)とFine-tuningモデルの評価結果 image
image
データ合成
PLaMo 2.1-VLの性能を左右するうえで、学習データはとくに重要です。しかし、既存の公開データセットだけでは、実運用で求められる品質やカバレッジ(日本語・ドメイン固有の画像、指示理解の粒度など)を十分に満たせません。そこで本開発では、データ合成を中核の取り組みとして位置づけ、学習データを自前で大規模に構築しました。
基盤となるのは、PFNで実施したWebクローリングにより蓄積された、日本語Webサイト由来のクロール画像です。まず最初に、合成データ全体のスコープを明確にするため、クロール画像を「自然画像(写真)」と「文書画像(スキャン・資料・紙面など)」に自動分類しました。本開発で主に狙うVisual Grounding / VQA、および工具認識や差分検知といった現場タスクは、画像中の物体・空間関係・局所的な差異に強く依存するため、以降の合成は自然画像を中心に進めています(文書画像は本パートでは扱わず、用途の異なる別スコープとして切り分けています)。
自然画像を出発点として、タスクごとに教師信号(VQAやVisual Groundingなど)を自動付与し、データセット化しています。なお、GENIAC開始当初はQwen2.5-VL-32B-Instruct(https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct)を用いて合成していましたが、Qwen3-VL-235B-A22B-Instructの公開以降は主にこちらを利用しています。本節ではQwen3-VL-235B-A22B-Instructを中心に、クロール画像から基礎能力(Visual Grounding / VQA)をどのように作り込み、さらに工具認識や差分検知といった現場タスクへどう拡張したかを、タスク別に説明します。
Visual Groundingの合成
Visual Groundingは、画像とテキスト(参照表現)を入力し、そのテキストが指す対象領域をbbox(またはmask等)として返すタスクです。VLMを現場で使うとき、単に答えが合っているかだけではなく、「何を見て判断したのか」を説明できることが重要になります。Visual Groundingを強化することで、VQAの信頼性だけでなく、その先の下流タスクの安全性・再現性の向上も期待できます。
PLaMo 2.1-VLのVisual Groundingはbboxを出力形式としているため、合成もbbox前提で行いました。合成は大きく2段階です。
1) 参照表現とラベルの生成
まずQwen3‑VL‑235B‑A22B‑Instructに、画像中の対象インスタンス集合を指す参照表現を生成させます(例:「黒い車」)。カテゴリは事前に固定せず、Qwen3‑VL‑235B‑A22B‑Instructが出力した文字列をそのまま参照表現・ラベルとして採用します。これにより、一般物体だけでなく、ドメイン固有の概念にも広く対応しやすくなります。
2) 領域抽出とbbox化
次に、生成した参照表現をSAM3(https://github.com/facebookresearch/sam3)に入力し、対象領域を抽出します。学習に使うため、SAM3の出力(mask)からbboxを算出して保存します。フレーズが複数インスタンスを指す場合は、複数bboxをそのまま保持します(後述するCountingなどの学習にも繋がります)。しかし、参照表現によってはSAM3が対象をうまく認識できず、領域を返せないケースがあります。その場合は例外処理として、Qwen3‑VL‑235B‑A22B‑Instructにbboxを直接出力させ、SAM3の代替として用いました。
単一bboxバイアスと、複数インスタンス対応への転換
Visual Groundingの能力を上げる初期の試みでは、画像中の「特定のインスタンス1つ」を一意に指す参照表現と、正解bboxを1つだけ生成するデータセットを中心に学習していました。ところが、このデータで学習されたモデルは合成データの偏りを強く吸収し、bbox出力タスクにおいて「必ず1つだけbboxを出す」というバイアスがかかりました。その結果、実運用で頻出する「複数インスタンスを指す参照表現」(例:「テーブルの上のリンゴ全部」)を入力しても、モデルがbboxを1つしか返さないことがあり、汎用性に問題が出ました。そこでデータ合成の方針を見直し、複数インスタンスを指し示す参照表現も意図的に生成して学習データに含めるように変更しました。これにより、「単体も集合も自然に扱える」出力分布へ近づけられます。あわせて領域抽出の実験を進めたところ、bboxの品質はQwen3‑VL‑235B‑A22B‑Instructの直接出力よりもSAM3の方が安定して高精度であることが分かりました。そのため、基本ワークフローはSAM3に寄せつつ、SAM3が領域を返せない例外ケースではQw
関連記事
NVIDIAプラットフォーム、極限の共同設計により最低トークンコストを実現
NVIDIAは、ハードウェア・ソフトウェア・モデルの共同設計により、AIファクトリーの最高スループットと最低トークンコストを提供するプラットフォームを発表した。
ボストン・ダイナミクスとGoogle DeepMind、産業用AIで提携
ボストン・ダイナミクスとGoogle DeepMindは、Google Geminiを活用してボストン・ダイナミクスの産業用検査システムに自律機能を追加する提携を発表した。
リアリティ:最終評価 — Andon Labs のルカス・ペターソンとアクセル・バックランド
Andon Labs のルカス・ペターソン氏とアクセル・バックランド氏が、従来のスコアベースの評価指標では捉えきれない現実世界でのモデル性能を測る新しい評価手法「リアリティ」について議論する。