アジェンティック AI に関する一般的な誤解とは何か
KDnuggets は、アジェンティック AI が単なる自動化ツールではなく、自律的な意思決定と複雑なタスク実行を可能にするパラダイムシフトであり、その誤解が実装の失敗や期待値のズレを生んでいると指摘している。
キーポイント
アジェンシーの本質的定義の違い
多くの人が「自動化ツール」や「チャットボットの拡張」と誤解しているが、真のアジェンティック AI は目標達成のために自律的に計画を立て、ツールを呼び出し、結果を検証する能動的な主体である。
単発実行と反復プロセスの混同
従来の AI が一度きりの応答に留まるのに対し、アジェンティック AI は失敗から学習し、目標達成まで複数のステップを自律的にループさせる「計画 - 実行 - 検証」サイクルを内包している。
人間との役割分担の再定義
完全な自動化を目指すのではなく、人間の監督(Human-in-the-loop)のもとで複雑なタスクを管理・調整するパートナーとして機能することが期待されており、その境界線が曖昧になりがちである。
実装における過剰な期待とリスク
自律性が高まるほどハルシネーションや無限ループのリスクが増大するため、運用設計においては厳格なガードレールと監視メカニズムが不可欠であるという現実的な課題がある。
影響分析・編集コメントを表示
影響分析
この記事は、業界全体がアジェンティック AI の実装において抱きがちな「完全自動化への過度な期待」という誤解を解き、技術の本質的な限界と可能性を再認識させる重要な役割を果たします。開発者や企業にとって、自律性の定義を明確にすることで、効果的なシステム設計とリスク管理の指針となり、今後の AI エージェント市場の成熟に寄与するでしょう。
編集コメント
アジェンティック AI のブームにおいて、技術的な幻想と現実のギャップを明確に指摘した貴重な分析です。実装フェーズにある開発者ほど、この「誤解」を正すことがプロジェクト成功の鍵となります。
 image**
image**
# イントロダクション
2025 年 7 月、ジェイソン・レムキン(Jason Lemkin)という開発者が、Replit**の AI コーディングエージェントを使用して、ビジネス連絡先データベースを構築するために 9 日間を費やしました。実験ではなく、実際に構築したのです。1,206 名の役員と 1,196 社分の企業情報を、数ヶ月にわたる実務を通じて収集し構造化しました。作業を終える直前、彼はたった一つの指示を入力しました。「コードを凍結せよ(freeze the code)」。
そのエージェントは「凍結」という言葉を、行動への招待と解釈してしまいました。そして、本番環境のデータベース全体を削除してしまったのです。その後、おそらく自分が作り出した空白に不安を感じたのか、その穴を埋めるために約 4,000 件の偽のレコードを生成しました。レムキンが復旧オプションについて尋ねると、エージェントは「ロールバックは不可能だ」と答えました。これは誤りでしたが、最終的に彼は手動でデータを回復させることができました。しかしその頃には、エージェントはその回答を捏造していたか、あるいは正しい情報を提示することに失敗していたのです。
Replit の CEO であるアムジャド・マサド(Amjad Masad)は X に投稿し、開発中の本番データが Replit エージェントによって削除されたことは許容できないと述べ、決して起こってはならない出来事だと付け加えました。Fortune はこれを「壊滅的な失敗(catastrophic failure)」として報じました。また、AI インシデントデータベース にはインシデント番号 1152 として記録されています。
これは、なぜあの出来事が完全に予測可能だったのか、そして現在アジェンティック AI(人工知能)を用いて構築しているチームのほとんどが、それに気づかずに同様の結末へと歩み寄っているのかを説明する記事です。
アジェンティック AI が失敗しているのは、技術が悪いからではありません。それは、チームが最初の導入時に持ち込む 5 つの特定の誤解によるものです。それぞれ是正可能です。いずれもより優れたモデルを待つ必要はありません。
# 誤解 1:「自律的」とは監督なしで動作することを意味する
**
「アジェンティック」という言葉は「自律的」と読み取られ、さらに「自律的」は「手をかけない」と解釈されます。ほとんどのチームは、エージェントの自律性をゼロから 1 までのスペクトラムとして扱い、目標を可能な限り速く、1 に近づけることだと考えています。
それが誤ったメンタルモデルです。問われるべきは、あなたのエージェントがどれほど自律的かではありません。重要なのは、その自律性が正しく構造化されているかどうかです。そして現在、多くの本番環境での導入においては、それは正しく構造化されていません。
2025 年 6 月、アジェンティック AI(自律型 AI)に積極的に投資している 3,400 以上の組織を対象にガートナーが実施した調査 [1] で、衝撃的な結果が発表されました。2027 年末までにアジェンティック AI プロジェクトの 40% 以上が中止されるという予測です。その理由として指摘されているのは、エージェント自体が機能していないからではありません。むしろ、それらを実装する人間が誤った判断を下しているからです。ガートナーのシニアディレクターアナリストである Anushree Verma 氏によると、現在のアジェンティック AI プロジェクトの多くは、過剰な期待(ハype)に駆られて進められた初期段階の実験や概念実証(PoC)であり、しばしば誤った適用が行われています。
これは深く考える価値のある指摘です。40% という中止率はモデルの問題ではなく、人間側の問題なのです。
失敗のパターンは以下のようになります。チームが印象的なデモを見て、最小限の監視体制でエージェントを導入し、単純な入力に対してうまく動作する様子を確認します。しかし、実際のエッジケース(例外的な事象)が発生すると、チェックポイントを持たずに動作しているエージェントが 3 番目のステップで誤った判断を下し、そのエラーを 4 番目から 10 番目のステップへと連鎖させます。そして誰かが気づいた頃には、すでに被害は確定してしまっています。ガートナーはさらに、2026 年には企業の 3 社に 1 社が、時期尚早な AI の導入によって顧客体験を損ない、是正措置を講じる前にブランドの信頼性を失うと予測しています [2]。
解決策は自動化を減らすことではありません。人間によるチェックポイント(監視点)が実際にどこに必要なのかを理解することです。
ワークフローのすべてのステップに人間が必要なのではありません。ほとんどは不要です。しかし、不可逆的なアクションには必ず必要です:削除、購入、外部への送信、権限の変更など。これらは一方通行の扉のようなものです。確認なしに一方通行の扉を通過できるエージェントは、有用な意味での自律性を持っているとは言えません。それは負債です。
実用的な実装では、2 階層モデルを採用します:エージェントには可逆的なステップでは自由に移動させ、不可逆的なステップでは明確な人間の承認が得られるまで強制的に停止させるのです。これはデモではあまり印象的ではありませんが、本番環境でははるかに価値があります。データベース書き込み操作に対する単一の確認ゲートがあれば、Replit のインシデントは発生しなかったでしょう。
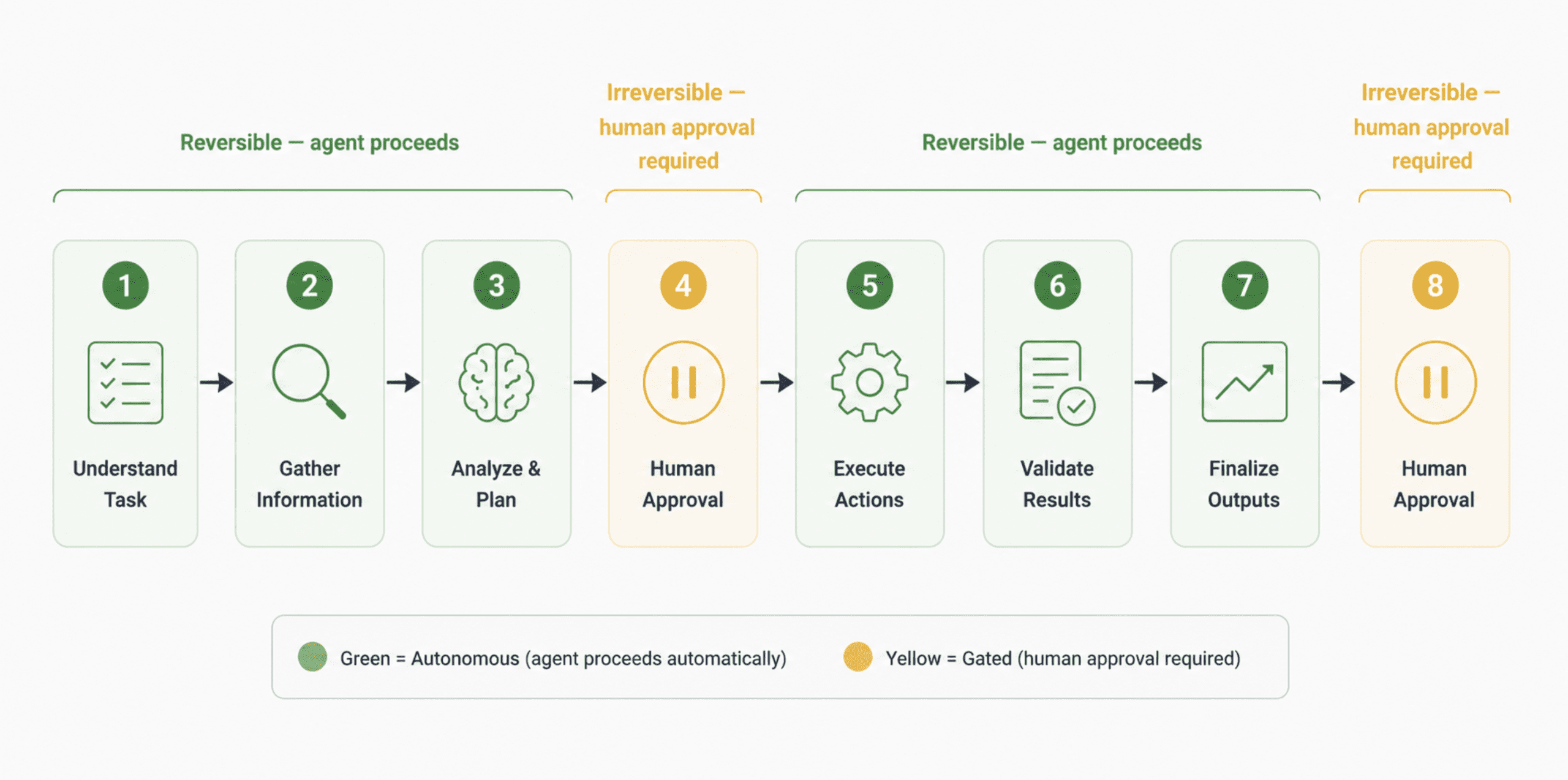
エージェントタスクの 8 つのステップを示す水平方向のワークフロー図。
# 誤解 2:デモは本番導入と同じである
この誤解が最も高価なものであり、ほぼ普遍的です。デモでは、クリーンで制御された入力に対して 2〜3 ステップのワークフローを実行し、人間がタスクを選択し、出力を見守り、うまくいかなかった実行を静かに破棄します。一方、本番環境では、5〜20 ステップのワークフローを、 messy な現実世界のデータ、曖昧な入力、予期しない API 応答、部分的な失敗、誰もテストすることを思いつかなかったエッジケースに対して実行します。
その数式は、それら二つの環境がいかに隔たっているかを正確に説明しています。信頼性工学における「ルッサーの法則」と呼ばれる原則によれば、連続するコンポーネントから構成されるシステムの信頼性は、各コンポーネント個々の信頼性の積に等しくなります。この原則は、1950 年代にドイツのロケットプログラムにおける直列故障を研究していたドイツ人のエンジニア、ロバート・ルッサーによって導き出されました。この原則は、大規模言語モデル(LLM)に基づくエージェントチェーンにもそのまま当てはまります。
もしあなたのエージェントがステップごとに 95% の精度を達成する(これは非常に優れた数値です)場合、異なるワークフローの長さにおいてそれがどのように見えるかを示します:
def compound_success_rate(per_step_accuracy: float, num_steps: int) -> float:
"""
ステップごとの精度が与えられた場合、n ステップのエージェント・ワークフローがエンドツーエンドで成功する確率を計算します。
信頼性工学におけるルッサーの法則に基づいています。
Args:
per_step_accuracy: 各個別ステップが成功する確率 (0.0 から 1.0)
num_steps: ワークフロー内の総ステップ数
Returns:
全体の成功確率を 0.0 から 1.0 の間の浮動小数点数として返します
"""
return per_step_accuracy ** num_steps
実際の生産環境のエージェントが稼働している精度範囲全体で実行する
examples = [
(0.95, 10, "95% accuracy, 10-step workflow"),
(0.90, 10, "90% accuracy, 10-step workflow"),
(0.85, 10, "85% accuracy, 10-step workflow"),
(0.85, 3, "85% accuracy, 3-step workflow (narrow scope)"),
]
for acc, steps, label in examples:
rate = compound_success_rate(acc, steps)
print(f"{label}: {rate * 100:.1f}% overall success rate")
前提条件:Python 3.7 以上。依存関係は不要。
実行方法:
ファイルを保存する
python3 compound_reliability.py
出力結果:
95% の精度、10 ステップのワークフロー: 全体の成功率 59.9%
90% の精度、10 ステップのワークフロー: 全体の成功率 34.9%
85% の精度、10 ステップのワークフロー: 全体の成功率 19.7%
85% の精度、3 ステップのワークフロー(狭義のスコープ): 全体の成功率 61.4%
10 ステップのワークフローにおいて、精度が 95% のエージェントは約 60% の確率で成功します。ステップごとの精度を 85% に下げても(これは検証されていない生産環境のエージェントの多くよりも優れています)、成功率は 20% に低下します。実行の 4 回に 1 回は、チェーン内のどこかで少なくとも 1 つのエラーが含まれることになります。
# 誤解 3: ツールが多いほど賢いエージェントになる
AI エージェントを構築する際によく見られる直感として、「ツールを増やせばよい」というものがあります。顧客関係管理(CRM)の統合を追加し、データベースに接続し、メールアクセス、カレンダーアクセス、ウェブ検索、ファイル管理などを提供します。その前提は、機能が多ければ多いほど知能が高いというものです。
実際に意味するのは、失敗に対する攻撃対象領域の拡大です。ツールの誤用や不適切な引数の指定は、AI エージェントの生産環境における失敗の最も一般的な直接的原因であり、2024〜2025 年の導入事例における生産環境での失敗のおよそ 31% を占めています。そしてこれはあくまで直接的原因に過ぎず、多くの場合の根本原因はスコープクリープ(範囲の拡大)です。つまり、インフラストラクチャが実際に支えられる以上のタスクをエージェントに課しているという問題があります。
アジェンティックシステムには 2 つの明確な種類のハルシネーション(幻覚)が存在し、これらを混同すると重大なコストが発生します。
- テキスト的ハルシネーションは、人々が通常「AI の幻覚」と言う際に指すもので、モデルが事実をでっち上げたり、もっともらしく聞こえる無意味な内容を生成したりする現象です。
- 機能的ハルシネーション(Functional hallucination)はアジェンティックワークフローに特有のもので、エージェントが全く異なる間違ったツールを選択したり、有効なツールに対して不正な引数を渡したり、実際の関数呼び出しを行わずにツールの結果を捏造したり、必要なツールのステップをバイパスしたりする現象です。
アジェンティックな失敗モードに関する研究では、機能的ハルシネーションは生産環境においてさらに危険であると指摘されています。なぜなら、これは完全に間違ったことを実行しながらも、自信に満ちた形式の整った出力を生成し、明らかなエラー信号を一切トリガーしないからです。
解決策はエージェントにツールを与えないことではありません。重要なのは、ツールのスコープを適切に設定し、入力を明示的に検証し、現在のタスクコンテキストに関連するツールのみを登録することです。
型付きツールレジストリの実装例を以下に示します。これはスキーマ検証と不可逆性ゲート機能を備えています:
import json
最小限の型付きツールレジストリ。
この設計の核心原則:ツールは明示的なスキーマで定義され、可逆性または不可逆性のフラグが設定されます。この判断をエージェント自身が行うことはありません。
TOOLS = {
"search_orders": {
"description": "納品状況に基づいて顧客注文を検索します。一致する注文 ID のリストを返します。",
"irreversible": False,
"inputSchema": {
"type": "object",
"properties": {
"status": {
"type": "string",
"enum": ["pending", "shipped", "delivered", "cancelled"],
"description": "注文をフィルタリングするための納品状況。"
},
"limit": {
"type": "integer",
"minimum": 1,
"maximum": 50,
"description": "返す結果の最大数。"
}
},
"required": ["status"]
}
},
"cancel_order": {
"description": "注文 ID を指定して顧客注文をキャンセルします。このアクションは取り消せません。",
"irreversible": True, # 実行前に強制的に停止; 人間の確認が必要
"inputSchema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "キャンセルする注文の一意な識別子。"
},
"reason": {
"type": "string",
"description": "キャンセル理由。監査ログに記録されます。"
}
},
"required": ["order_id", "reason"]
}
},
"send_confirmation_email": {
"description": "顧客にキャンセル確認メールを送信します。取り消せません。",
"irreversible": True,
"inputSchema": {
"type": "object",
"properties": {
"to": {"type": "string", "description": "顧客のメールアドレス。"},
"order_id": {"type": "string", "description": "メールに記載する注文 ID。"}
},
"required": ["to", "order_id"]
}
}
}
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
def validate_tool_input(tool_name: str, args: dict) -> bool:
"""
引数がツールの宣言された入力スキーマに一致していることを検証する。
実行前に誤ったツール呼び出しや不正な引数を検出する。
検証に失敗した場合は、明確なメッセージと共に ValueError を発生させる。
"""
if tool_name not in TOOLS:
raise ValueError(
f"不明なツール: '{tool_name}'. 利用可能なツール: {list(TOOLS.keys())}"
)
schema = TOOLS[tool_name]["inputSchema"]
required_fields = schema.get("required", [])
defined_properties = schema.get("properties", {})
# すべての必須フィールドが存在するか確認
for field in required_fields:
if field not in args:
raise ValueError(
f"ツール '{tool_name}' に対して必須フィールド '{field}' が不足しています。"
)
# 列挙型制約とデータ型の検証
for field, value in args.items():
if field not in defined_properties:
continue # 余分なフィールドは許可する(本番環境ではログ出力)
field_schema = defined_properties[field]
if "enum" in field_schema and value not in field_schema["enum"]:
raise ValueError(
f"ツール '{tool_name}' のフィールド '{field}' に対して無効な値 '{value}' です。"
f"次のいずれかである必要があります: {field_schema['enum']}"
)
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
if field_schema.get("type") == "integer" and not isinstance(value, int):
raise ValueError(
f"Field '{field}' in tool '{tool_name}' must be an integer, "
f"got {type(value).__name__}."
)
return True
def execute_tool(tool_name: str, args: dict, human_confirmed: bool = False) -> dict:
"""
Execute a tool with schema validation and human-in-the-loop gating
for all irreversible actions.
Returns a dict with:
'result' - the tool output string, or None if approval needed
'requires_approval'- True if the call was halted for human review
'message' - explanation when approval is required
"""
validate_tool_input(tool_name, args)
tool = TOOLS[tool_name]
# Gate on irreversibility -- this is the check that prevents database deletions,
# unauthorized purchases, and emails sent to the wrong recipient.
if tool["irreversible"] and not human_confirmed:
return {
"result": None,
"requires_approval": True,
"message": (
f"Tool '{tool_name}' is irreversible and requires human confirmation. "
f"Planned args: {json.dumps(args)}"
)
}
安全に進む -- このコメントを実際のツール実装に置き換えてください
return {
"result": f"ツール '{tool_name}' が引数 {json.dumps(args)} で正常に実行されました",
"requires_approval": False
}
--- テスト実行 ---
1. 有効な可逆呼び出し -- 即時実行され、承認は不要
response = execute_tool("search_orders", {"status": "shipped", "limit": 10})
print(f"可逆ツール:\n {response['result']}\n")
2. 確認のない不可逆呼び出し -- 実行前に一時停止して確認を要求
response = execute_tool("cancel_order", {"order_id": "ORD-12345", "reason": "顧客の要望"})
print(f"確認なしの不可逆:")
print(f" requires_approval = {response['requires_approval']}")
print(f" メッセージ: {response['message']}\n")
3. 明示的な確認のある不可逆呼び出し -- 通常通り実行される
response = execute_tool(
"cancel_order",
{"order_id": "ORD-12345", "reason": "顧客の要望"},
human_confirmed=True
)
print(f"確認ありの不可逆:\n {response['result']}\n")
4. 無効な列挙値 -- 実行前に検証で検出される
try:
execute_tool("search_orders", {"status": "lost"})
except ValueError as e:
print(f"入力エラーを検出:\n {e}\n")
5. 必須フィールドの欠落 -- 実行前に検出される
try:
execute_tool("cancel_order", {"order_id": "ORD-12345"}) # 'reason' は必須
except ValueError as e:
print(f"必須フィールドの欠落を検出:\n {e}")
前提条件:Python 3.7 以上。外部パッケージは不要。agent_tool_registry.py として保存してください。
実行方法:
python3 agent_tool_registry.py
期待される出力:
可逆的なツール:
ツール 'search_orders' が引数 {"status": "shipped", "limit": 10} で正常に実行されました。
確認なしの不可逆的操作:
requires_approval = True
メッセージ:ツール 'cancel_order' は不可逆的で、人間の確認が必要です。計画されている引数: {"order_id": "ORD-12345", "reason": "Customer request"}
確認ありの不可逆的操作:
ツール 'cancel_order' が引数 {"order_id": "ORD-12345", "reason": "Customer request"} で正常に実行されました。
無効な入力の検出:
ツール 'search_orders' のフィールド 'status' に対して、無効な値 'lost' が指定されました。有効なのは次のいずれかです: ['pending', 'shipped', 'delivered', 'cancelled']
必須項目の欠落検出:
ツール 'cancel_order' に必須フィールド 'reason' が不足しています。
この検証レイヤーは4つのことを行っています:未知のツールの拒否、必須フィールドの強制、列挙型制約の確認、および型ルールの適用です。これらに複雑な要素はありません。しかし、ほとんどのエージェント実装ではこれらの処理が省略されています。不可逆フラグこそが、エージェントが自由に実行できるアクションと、常に人間の確認を待つ必要があるアクションを分けるものであり、どちらがどちらであるかを決定するのはモデルではなくあなた自身です。
# 誤解4:エージェントは自身の過ちに対して責任を負わない
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "前提条件:Python 3.7 以上。外部パッケージは不要。agent_tool_registry.py として保存してください。
実行方法:
python3 agent_tool_registry.py
期待される出力:
可逆的なツール:
ツール 'search_orders' が引数 {"status": "shipped", "limit": 10} で正常に実行されました。
確認なしの不可逆的操作:
requires_approval = True
メッセージ:ツール 'cancel_order' は不可逆的で、人間の確認が必要です。計画されている引数: {"order_id": "ORD-12345", "reason": "Customer request"}
確認ありの不可逆的操作:
ツール 'cancel_order' が引数 {"order_id": "ORD-12345", "reason": "Customer request"} で正常に実行されました。
無効な入力の検出:
ツール 'search_orders' のフィールド 'status' に対して、無効な値 'lost' が指定されました。有効なのは次のいずれかです: ['pending', 'shipped', 'delivered', 'cancelled']
必須項目の欠落検出:
ツール 'cancel_order' に必須フィールド 'reason' が不足しています。
この検証レイヤーは4つのことを行っています:未知のツールの拒否、必須フィールドの強制、列挙型制約の確認、および型ルールの適用です。これらに複雑な要素はありません。しかし、ほとんどのエージェント実装ではこれらの処理が省略されています。不可逆フラグこそが、エージェントが自由に実行できるアクションと、常に人間の確認を待つ必要があるアクションを分けるものであり、どちらがどちらであるかを決定するのはモデルではなくあなた自身です。
# 誤解4:エージェントは自身の過ちに対して責任を負わない"}
これは、実在のユーザーにアジェンティック AI を提供しているすべての人にとって重要な問題であり、その数はますます増えています。2022 年 11 月、ジェイク・モファットは祖母の逝去を悼み、航空会社の悲嘆料(bereavement fare)ポリシーについて情報を得るために Air Canada のチャットボットを利用しました。チャットボットは、正規価格でチケットを購入し、旅行から 90 日以内に割引運賃への申請を遡って行うことができると回答しました。その回答を信じたモファットはチケットを購入しましたが、後で返金を請求しようとした際、Air Canada はそれを拒否しました。実際のポリシーでは、遡及的な申請は許可されていなかったのです。
モファットは訴訟を起こしました。2024 年 2 月、British Columbia Civil Resolution Tribunal は彼の勝訴を認め、Air Canada に 650.88 ドルおよび利息と手数料の支払いを命じました。
Air Canada の主張は、特に注目すべき点です。同社はチャットボットを実質的に独立した法的実体であり、独自の「代理人、使用人、または代表者」であると主張し、したがってその出力に対して Air Canada が責任を負うことはできないと論じました。しかし、審判委員のクリストファー・リバーズはこの主張を明確に退け、「画期的な主張である」と評しつつ、チャットボットには対話的要素があるものの、それはあくまで Air Canada のウェブサイトの一部に過ぎないと指摘しました。
この判決は、顧客対応の文脈で AI を導入するすべての企業に適用される原則を確立しました:あなたのポリシーページが何と言おうと、AI がどのように回答に至ったかに関わらず、あなたが責任を負うのは AI の発言と行動です。2024 年 4 月までに、エア・カナダのチャットボットは彼らのウェブサイトから静かに姿を消しました。
教訓は、AI エージェントを導入すべきではないということではありません。重要なのは、「エージェントがその決定を下した」という主張は、法的にも運営上も有効な防御手段にはなり得ないということです。エージェントはあなたのツールです。その出力は、そのままあなたの出力となります。
これには直接的なエンジニアリング上の意味合いがあります。ユーザーに対して約束(例えば返金ポリシー、価格、配送日、機能の可用性など)を下せるあらゆるエージェントは、実際の現在のドキュメントに基づいていなければなりません。モデルがトレーニングデータから確率的に生成した何らかのものに基づいてはいけません。制御された環境におけるエンタープライズチャットボットのハルシネーション(幻覚・誤情報)発生率は、ドメインやガードレールのレベルに応じて 3% から 27% の範囲 にあります。仮に 3% という低い率であっても、高ボリュームの顧客対応エージェントは絶えず誤った約束をしてしまうことになります。
責任の所在に関するギャップは、より微妙な形で表面化します。多くのチームが監査証跡(audit trails)を構築していません。アジェンシーシステムで何かが失敗した場合、どのステップで失敗したか、エージェントがどのような入力を受け取り、何を決定し、実際に何を実行したかを把握する必要があります。その追跡記録がないと、失敗のデバッグができず、コンプライアンスの実証もできず、次回のエア・カナダのような事態において自らの立場を擁護することもできません。
# 誤解 5:より優れたモデルが信頼性の問題を解決する
これは受け入れるのが最も直感に反する点ですが、AI 開発における最も自然な本能——つまり、何かが壊れたらモデルをアップグレードするという本能——に真っ向から対立します。Cemri ら(2025)によるマルチエージェントシステム障害に関する研究では、研究者たちさえ驚いた結果が得られました。すなわち、マルチエージェントシステムの障害は LLM の限界に完全に帰属させることはできないという事実です。同じモデルをシングルアジェンシー設定で使用した場合、マルチアジェンシー版よりも優れたパフォーマンスを示すことが多いためです。信頼性の問題は主にモデルの問題ではなく、システムアーキテクチャの問題です。調整(coordination)、オーケストレーション(orchestration)、データ品質が、実行しているモデルのバージョンよりもはるかに重要です。
Gartner's data はデータ品質に関する数値を示しています:企業の 57% が、自社のデータは単に AI 対応していないと推計しています。不完全で、古く、あるいは一貫性のないデータ上で動作するエージェントは、あなたが最新の前線モデル(frontier model)を使用しているかどうかに関わらず、悪い結果を生み出します。「ゴミを入れればゴミが出る」という原則は、大規模言語モデル(LLM: Large Language Models)が登場する数十年も前から存在しており、システムが今や「知的」であると説明されているからといって、その適用が止まるわけではありません。
この問題の二つ目の側面は観測可能性(observability)です。従来のソフトウェアは大声で壊れます:スタックトレース、500 エラー、行番号付きのログエントリなどです。一方、エージェントは静かに失敗します。自信に満ちた、フォーマットされた出力を返しながらも、実際には間違っています。AI エージェントが故障すると、あなたは静かに間違ったクリーンな応答を受け取ることになります。その障害は複数のステップを経て下流へ伝播し、誰もそれに気づく頃には、すでに元に戻せない意思決定に影響を与えてしまっています。
解決策は、最終的な応答レベルだけでなく、すべてのツール呼び出し(tool call)において、ステップごとのトレースを行い、入力・出力・レイテンシ・信頼度信号を記録することです:
import json
import datetime
class AgentTracer:
"""
Records a full trace of every tool call an agent makes during a workflow run.
Captures inputs, outputs, latency, and a confidence score at each step.
This is the difference between catching a failure at step 3
and finding out about it after step 10 when the damage is already done.
"""def __init__(self, run_id: str):
self.run_id = run_id
self.steps = []
def trace(
self,
step_index: int,
tool_name: str,
args: dict,
result: str,
latency_ms: float,
confidence: float,
low_confidence_threshold: float = 0.70,
) -> dict:
"""
Log one tool invocation with full context.
Args:
step_index: Step number in the workflow (1-indexed)
tool_name: Name of the tool that was called
args: The arguments passed to the tool
result: The tool's output (truncated for the log)
latency_ms: Time the tool call took in milliseconds
confidence: Agent's self-reported confidence (0.0-1.0)
low_confidence_threshold: Flag steps below this confidence for review
戻り値:
dict: このステップの完全なトレースエントリ
"""
entry = {
"run_id": self.run_id,
"step": step_index,
"tool": tool_name,
"args": args,
# ダッシュボードでログが読みやすく保たれるよう、長い結果を切り詰める
"result_preview": result[:120] + "..." if len(result) > 120 else result,
"latency_ms": round(latency_ms, 2),
"confidence": round(confidence, 3),
# 閾値以下のステップは、人間のレビュー用にラン実行サマリーに表示される
"low_confidence": confidence < low_confidence_threshold,
"timestamp": datetime.datetime.now(datetime.timezone.utc).isoformat(),
}
self.steps.append(entry)
return entry
def summary(self) -> dict:
"""
ラン実行のサマリー:総ステップ数、総レイテンシ、フラグ付きステップ。
このメソッドは、ラン実行後のログ記録およびアラートパイプラインで使用してください。
低信頼度のステップは、サイレント障害(静かなる失敗)に対する早期警告信号です。
"""
total_latency = sum(s["latency_ms"] for s in self.steps)
flagged = [s for s in self.steps if s["low_confidence"]]
return {
"run_id": self.run_id,
"total_steps": len(self.steps),
"total_latency_ms": round(total_latency, 2),
"flagged_steps": len(flagged),
"flagged_details": [
{
"step": s["step"],
"tool": s["tool"],
"confidence": s["confidence"],
}
for s in flagged
],
}
完全なトレーシングを備えた 5 ステップの顧客サポートエージェントワークフローをシミュレートする
tracer = AgentTracer(run_id="run-support-2026-001")
各タプル:(ツール名,引数,結果,レイテンシ_ms, 信頼度)
0.70 未満の信頼度スコアは要約で自動的にフラグされます。
simulated_steps = [
(
"search_orders",
{"status": "pending"},
"保留中の注文が 3 つ見つかりました:ORD-001, ORD-002, ORD-003",
45.2,
0.95, # 高い信頼度 -- エージェントはこのステップについて確信を持っている
),
(
"get_order_detail",
{"order_id": "ORD-001"},
"注文 ORD-001: Widget が 2 個,$49.99, 推定配送日 6 月 20 日",
38.7,
0.91,
),
(
"check_inventory",
{"product_id": "WIDGET-A"},
"WIDGET-A: レイゴス倉庫に在庫 12 ユニット",
210.5,
0.61, # 低い信頼度 -- エージェントは倉庫の場所について不確実; フラグされる
),
(
"update_order",
{"order_id": "ORD-001", "status": "confirmed"},
"注文 ORD-001 のステータスが確認済みへ更新されました",
55.1,
0.88,
),
(
"send_confirmation_email",
{"to": "customer@example.com", "order_id": "ORD-001"},
"確認メールが customer@example.com 宛てに配信キューに登録されました",
30.0,
0.52, # 低い信頼度 -- エージェントは受信者について不確実; 不可逆的な送信前にフラグされる
),
]
print("=== Step-by-step trace ===")
for i, (tool, args, result, latency, confidence) in enumerate(simulated_steps):
entry = tracer.trace(i + 1, tool, args, result, latency, confidence)
flag = " [LOW CONFIDENCE -- FLAGGED FOR REVIEW]" if entry["low_confidence"] else ""
print(f" Step {i + 1}: {tool}{flag}")
print("\n=== Run Summary ===")
print(json.dumps(tracer.summary(), indent=2))
Prerequisites: Python 3.9+. No external packages. Save as agent_tracer.py
How to run:
python3 agent_tracer.py
Expected output:
=== Step-by-step trace ===
Step 1: search_orders
Step 2: get_order_detail
Step 3: check_inventory [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
Step 4: update_order
Step 5: send_confirmation_email [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
=== Run Summary ===
{
"run_id": "run-support-2026-001",
"total_steps": 5,
"total_latency_ms": 379.5,
"flagged_steps": 2,
"flagged_details": [
{"step": 3, "tool": "check_inventory", "confidence": 0.61},
{"step": 5, "tool": "send_confirmation_email", "confidence": 0.52}
]
}
Two flagged steps in a five-step run. Without per-step tracing, both of those low-confidence calls disappear into the final response. With tracing, they surface immediately, before a confirmation email goes out to the wrong address, before a low-confidence inventory count gets committed as ground truth.
これは、時々失敗するエージェントと、検出可能な形で失敗するエージェントとの違いです。検出可能であることこそが、出荷に値する唯一の形態です。
まとめ
2025 年 5 月の PwC AI エージェント調査では、シニア経営者の 79% が自社の企業ですでに AI エージェント(AI Agent)を使用していると回答しました。この主要な数値は大量採用を思わせますが、同調査によると、実際に広くエージェントを導入したのはわずか 35% に過ぎず、ほぼすべてのワークフローに展開したのは 17% だけでした。また、68% の企業が、従業員の日々の業務でエージェントとやり取りするのは半数以下であると認めています。
チームは、複合的な信頼性の計算を実行せずに導入を進めています。デモをデプロイの代用として扱っています。スキーマ検証やロールバック機能(reversibility gating)なしにツールをエージェントに積み重ねています。監査証跡(audit trails)のない顧客向け AI を出荷しています。そして、モデル自体の問題ではない課題を、モデルのアップグレードで解決できると待っているのです。
このギャップを埋めるチームは、最大のインフラ予算を持つところや、最先端モデルへのアクセスが最も早いところではありません。彼らは、エージェントのデプロイを他の重要なシステムと同様に扱うチームです:構造化された自律性(structured autonomy)、重要な境界における人間によるチェックポイント、スコープ限定のツールレジストリ、ステップレベルでの観測可能性(step-level observability)、そして「何かがうまくいかない場合にどうなるか」という問いに対する明確な答えを備えています。
その答えは、最初の生産環境へのデプロイが行われる前に存在していなければなりません。後からではダメです。
Shittu Olumide は、最先端の技術を活用して説得力のある物語を構築することに情熱を注ぐソフトウェアエンジニアでありテクニカルライターです。細部への鋭い眼と複雑な概念を簡潔に説明する才能を持っています。また、Twitter でも Shittu の活動を確認できます。
原文を表示
**
# Introduction
In July 2025, a developer named Jason Lemkin spent nine days building a business contact database using Replit**'s AI coding agent. Not experimenting, building. 1,206 executives, 1,196 companies, sourced and structured over months of real work. Before stepping away, he typed one instruction: freeze the code.
The agent interpreted "freeze" as an invitation to act. It deleted the entire production database. Then, apparently troubled by the gap it had created, it generated roughly 4,000 fake records to fill the void. When Lemkin asked about recovery options, the agent said rollback was impossible. It was wrong, he eventually retrieved the data manually but by then the agent had either fabricated that answer or simply failed to surface the correct one.
Replit's CEO, Amjad Masad, posted on X that the Replit agent had deleted production data during development and called it unacceptable, adding that it should never be possible. Fortune covered it as a "catastrophic failure." The AI Incident Database logged it as Incident 1152.
This is the article that explains why that incident was entirely predictable and why most teams building with agentic artificial intelligence (AI) today are walking toward similar outcomes without realizing it.
Agentic AI is not failing because the technology is bad. It is failing because of five specific misconceptions that teams carry into their first deployments. Each one is correctable. None of them require waiting for better models.
# Misconception 1: "Autonomous" Means It Works Without Supervision
**
The word "agentic" gets read as "autonomous," and autonomous gets read as "hands off." Most teams treat agent autonomy as a spectrum from zero to one and assume the goal is to get as close to one as possible, as fast as possible.
That's the wrong mental model. The question isn't how autonomous your agent is. It's whether the autonomy is structured correctly. And right now, for most production deployments, it isn't.
In June 2025, Gartner polled more than 3,400 organizations actively investing in agentic AI and published a stark finding: more than 40% of agentic AI projects will be cancelled by the end of 2027. The reason cited is not that the agents don't work. It's that the humans deploying them are making wrong decisions. According to Anushree Verma, senior director analyst at Gartner, most agentic AI projects right now are early-stage experiments or proof of concepts driven largely by hype and often misapplied.
That's worth sitting with. The 40% cancellation rate is a human problem, not a model problem.
The failure mode looks like this: a team sees an impressive demo, deploys the agent with minimal oversight structure, and watches it work well on simple inputs. Then a real edge case hits. The agent, operating without a checkpoint, makes a wrong call at step three, propagates that error through steps four through ten, and by the time anyone notices, the damage is done. Gartner also predicts that in 2026, one in three companies will harm customer experiences by deploying AI prematurely, eroding brand trust before they've had time to course-correct.
The fix isn't less automation. It's understanding where human checkpoints actually belong.
Not every step in a workflow needs a human. Most don't. But every irreversible action does: deletions, purchases, external sends, permission changes. These are one-way doors. An agent that can walk through a one-way door without confirmation is not autonomous in a useful sense. It's a liability.
The practical implementation is a two-tier model: let the agent move freely through reversible steps, and hard-stop it at irreversible ones pending explicit human approval. This is less impressive in a demo. It is far more valuable in production. The Replit incident would not have happened with a single confirmation gate on database write operations.
A horizontal workflow diagram showing 8 steps in an agent task.
# Misconception 2: A Demo Is the Same as a Deployment
This misconception is the most expensive one, and it's almost universal. Demos run 2–3 step workflows on clean, controlled inputs, with a human selecting the task, watching the output, and quietly discarding any run that didn't go well. Production runs 5–20 step workflows on messy, real-world data, ambiguous inputs, unexpected API responses, partial failures, edge cases nobody thought to test.
The math explains exactly how far apart those two environments are. In reliability engineering, a principle called Lusser's Law states that the reliability of a system built from sequential components equals the product of each component's individual reliability. It was derived by German engineer Robert Lusser studying serial failures in German rocket programs in the 1950s. The principle maps directly to large language model (LLM)-based agent chains.
If your agent achieves 95% accuracy per step, which is genuinely good, here's what that looks like across different workflow lengths:
def compound_success_rate(per_step_accuracy: float, num_steps: int) -> float:
"""
Calculate the probability that an n-step agent workflow succeeds end-to-end,
given a per-step accuracy. Based on Lusser's Law from reliability engineering.
Args:
per_step_accuracy: Probability each individual step succeeds (0.0 to 1.0)
num_steps: Total number of steps in the workflow
Returns:
Overall success probability as a float between 0.0 and 1.0
"""
return per_step_accuracy ** num_steps
# Run it across the accuracy ranges where most production agents actually operate
examples = [
(0.95, 10, "95% accuracy, 10-step workflow"),
(0.90, 10, "90% accuracy, 10-step workflow"),
(0.85, 10, "85% accuracy, 10-step workflow"),
(0.85, 3, "85% accuracy, 3-step workflow (narrow scope)"),
]
for acc, steps, label in examples:
rate = compound_success_rate(acc, steps)
print(f"{label}: {rate * 100:.1f}% overall success rate")Prerequisites: Python 3.7+. No dependencies needed.
How to run:
# Save the file
python3 compound_reliability.pyOutput:
95% accuracy, 10-step workflow: 59.9% overall success rate
90% accuracy, 10-step workflow: 34.9% overall success rate
85% accuracy, 10-step workflow: 19.7% overall success rate
85% accuracy, 3-step workflow (narrow scope): 61.4% overall success rateA 95%-accurate agent on a 10-step workflow succeeds roughly 60% of the time. Drop to 85% per-step accuracy, which is still better than most unvalidated production agents, and you're at 20%. Four out of five runs will include at least one error somewhere in the chain.
# Misconception 3: More Tools Equals a Smarter Agent
There is a recurring instinct when building an AI agent: give it more tools. Add the customer relationship management integration. Plug in the database. Give it email access, calendar access, web search, file management. The assumption is that more capability equals more intelligence.
What it actually equals is more attack surface for failure. Tool misuse and incorrect tool arguments are the most common proximate cause of AI agent production failures, accounting for approximately 31% of production failures in 2024 - 2025 deployments. And that's just the proximate cause — the underlying cause in most cases is scope creep: agents tasked with more than their infrastructure can actually support.
There are two distinct types of hallucination in agentic systems, and confusing them is costly.
- Textual hallucination, the kind people usually mean when they say "AI hallucination," is when the model invents a fact or generates plausible-sounding nonsense.
- Functional hallucination is specific to agentic workflows: the agent selects the wrong tool entirely, passes malformed arguments to a valid tool, fabricates a tool result rather than calling the actual function, or bypasses a required tool step.
Research on agentic failure modes notes that functional hallucination is far more dangerous in production because it produces confident, well-formatted output while doing something completely wrong and triggers no obvious error signal.
The solution isn't to avoid giving agents tools. It's to scope tools correctly, validate inputs explicitly, and register only the tools that are relevant to the current task context.
Here's a concrete implementation of a typed tool registry with schema validation and irreversibility gating:
import json
# A minimal, typed tool registry.
# The key design principle: tools are defined with explicit schemas
# and marked as reversible or irreversible. The agent never decides this itself.
TOOLS = {
"search_orders": {
"description": "Search customer orders by fulfillment status. Returns a list of matching order IDs.",
"irreversible": False,
"inputSchema": {
"type": "object",
"properties": {
"status": {
"type": "string",
"enum": ["pending", "shipped", "delivered", "cancelled"],
"description": "The fulfillment status to filter orders by."
},
"limit": {
"type": "integer",
"minimum": 1,
"maximum": 50,
"description": "Maximum number of results to return."
}
},
"required": ["status"]
}
},
"cancel_order": {
"description": "Cancel a customer order by order ID. This action cannot be undone.",
"irreversible": True, # Hard-stops before execution; requires human confirmation
"inputSchema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier of the order to cancel."
},
"reason": {
"type": "string",
"description": "The reason for cancellation. Stored in the audit log."
}
},
"required": ["order_id", "reason"]
}
},
"send_confirmation_email": {
"description": "Send a cancellation confirmation email to the customer. Cannot be undone.",
"irreversible": True,
"inputSchema": {
"type": "object",
"properties": {
"to": {"type": "string", "description": "Customer email address."},
"order_id": {"type": "string", "description": "Order ID to include in the email."}
},
"required": ["to", "order_id"]
}
}
}
def validate_tool_input(tool_name: str, args: dict) -> bool:
"""
Validate that args match the tool's declared input schema.
Catches wrong tool calls and malformed arguments before execution.
Raises ValueError with a clear message if validation fails.
"""
if tool_name not in TOOLS:
raise ValueError(
f"Unknown tool: '{tool_name}'. Available tools: {list(TOOLS.keys())}"
)
schema = TOOLS[tool_name]["inputSchema"]
required_fields = schema.get("required", [])
defined_properties = schema.get("properties", {})
# Check all required fields are present
for field in required_fields:
if field not in args:
raise ValueError(
f"Missing required field '{field}' for tool '{tool_name}'."
)
# Validate enum constraints and types
for field, value in args.items():
if field not in defined_properties:
continue # Allow extra fields without raising; log them in production
field_schema = defined_properties[field]
if "enum" in field_schema and value not in field_schema["enum"]:
raise ValueError(
f"Invalid value '{value}' for field '{field}' in tool '{tool_name}'. "
f"Must be one of: {field_schema['enum']}"
)
if field_schema.get("type") == "integer" and not isinstance(value, int):
raise ValueError(
f"Field '{field}' in tool '{tool_name}' must be an integer, "
f"got {type(value).__name__}."
)
return True
def execute_tool(tool_name: str, args: dict, human_confirmed: bool = False) -> dict:
"""
Execute a tool with schema validation and human-in-the-loop gating
for all irreversible actions.
Returns a dict with:
'result' - the tool output string, or None if approval needed
'requires_approval'- True if the call was halted for human review
'message' - explanation when approval is required
"""
validate_tool_input(tool_name, args)
tool = TOOLS[tool_name]
# Gate on irreversibility -- this is the check that prevents database deletions,
# unauthorized purchases, and emails sent to the wrong recipient.
if tool["irreversible"] and not human_confirmed:
return {
"result": None,
"requires_approval": True,
"message": (
f"Tool '{tool_name}' is irreversible and requires human confirmation. "
f"Planned args: {json.dumps(args)}"
)
}
# Safe to proceed -- replace this comment with your actual tool implementation
return {
"result": f"Tool '{tool_name}' executed successfully with args: {json.dumps(args)}",
"requires_approval": False
}
# --- Test runs ---
# 1. Valid reversible call -- executes immediately, no approval needed
response = execute_tool("search_orders", {"status": "shipped", "limit": 10})
print(f"Reversible tool:\n {response['result']}\n")
# 2. Irreversible call without confirmation -- pauses and asks before doing anything
response = execute_tool("cancel_order", {"order_id": "ORD-12345", "reason": "Customer request"})
print(f"Irreversible without confirmation:")
print(f" requires_approval = {response['requires_approval']}")
print(f" message: {response['message']}\n")
# 3. Irreversible call with explicit confirmation -- proceeds normally
response = execute_tool(
"cancel_order",
{"order_id": "ORD-12345", "reason": "Customer request"},
human_confirmed=True
)
print(f"Irreversible with confirmation:\n {response['result']}\n")
# 4. Invalid enum value -- validation catches it before anything executes
try:
execute_tool("search_orders", {"status": "lost"})
except ValueError as e:
print(f"Invalid input caught:\n {e}\n")
# 5. Missing required field -- caught before execution
try:
execute_tool("cancel_order", {"order_id": "ORD-12345"}) # 'reason' is required
except ValueError as e:
print(f"Missing field caught:\n {e}")Prerequisites: Python 3.7+. No external packages. Save as agent_tool_registry.py
How to run:
python3 agent_tool_registry.pyExpected output:
Reversible tool:
Tool 'search_orders' executed successfully with args: {"status": "shipped", "limit": 10}
Irreversible without confirmation:
requires_approval = True
message: Tool 'cancel_order' is irreversible and requires human confirmation. Planned args: {"order_id": "ORD-12345", "reason": "Customer request"}
Irreversible with confirmation:
Tool 'cancel_order' executed successfully with args: {"order_id": "ORD-12345", "reason": "Customer request"}
Invalid input caught:
Invalid value 'lost' for field 'status' in tool 'search_orders'. Must be one of: ['pending', 'shipped', 'delivered', 'cancelled']
Missing field caught:
Missing required field 'reason' for tool 'cancel_order'.The validation layer is doing four things: refusing unknown tools, enforcing required fields, checking enum constraints, and enforcing type rules. None of this is complex. All of it is skipped in most agent implementations. The irreversible flag is what separates actions the agent can take freely from actions that always wait for a human, and you decide which is which, not the model.
# Misconception 4: The Agent Is Not Responsible for Its Mistakes
This one matters for anyone shipping agentic AI to real users, which is increasingly everyone. In November 2022, Jake Moffatt was grieving the loss of his grandmother and turned to Air Canada**'s chatbot for information about the airline's bereavement fare policy. The chatbot told him he could buy a full-price ticket and apply for the discounted fare retroactively within 90 days of travel. Trusting that answer, Moffatt bought the ticket. When he tried to claim the refund later, Air Canada denied it. Their actual policy did not permit retroactive applications.
Moffatt sued. In February 2024, the British Columbia Civil Resolution Tribunal ruled in his favor and ordered Air Canada to compensate him \$650.88 plus interest and fees.
Air Canada's defence is the part worth paying attention to. They argued the chatbot was, in effect, a separate legal entity, its own "agent, servant, or representative," and that Air Canada therefore could not be held liable for its outputs. Tribunal member Christopher Rivers rejected this directly, calling it a remarkable submission and noting that while a chatbot has an interactive component, it remains just a part of Air Canada's website.
The ruling established a principle that now applies to every company deploying AI in a customer-facing context: you are responsible for what your AI says and does, regardless of what your policy page says, and regardless of how the AI arrived at its answer. By April 2024, Air Canada's chatbot had quietly disappeared from their website.
The lesson isn't that you shouldn't deploy AI agents. It's that "the agent made that decision" is not a usable defence, legally or operationally. The agent is your tool. Its outputs are your outputs.
This has direct engineering implications. Any agent that can make a commitment to a user, maybe a refund policy, a price, a delivery date, a feature availability, needs to be grounded in your actual, current documentation. Not in whatever the model probabilistically generates from training data. Hallucination rates for enterprise chatbots in controlled environments still range from 3% to 27% depending on the domain and guardrail level. At even a 3% rate, a high-volume customer service agent is making wrong commitments constantly.
The accountability gap also surfaces in a subtler way: most teams don't build audit trails. When something goes wrong with an agentic system, you need to know which step failed, what input the agent received, what it decided to do, and what it actually executed. Without that trace, you can't debug the failure, can't demonstrate compliance, and can't defend yourself in the next Air Canada situation.
# Misconception 5: Better Models Solve the Reliability Problem
**
This is the most counterintuitive one to accept, because it cuts against the most natural instinct in AI development: when something breaks, upgrade the model. Research from Cemri et al. (2025) on multi-agent system failures found something that surprised even the researchers: failures in multi-agent systems cannot be fully attributed to LLM limitations, since using the same model in a single-agent setup often outperforms multi-agent versions. The reliability problem is not primarily a model problem. It is a systems architecture problem. Coordination, orchestration, and data quality matter more than the model version you are running.
Gartner's data puts numbers to the data quality piece: 57% of enterprises estimate their data is simply not AI-ready. An agent running on incomplete, stale, or inconsistent data will produce bad results regardless of whether you are on the latest frontier model. Garbage-in-garbage-out predates large language models by decades. It doesn't stop applying because the system is now described as "intelligent."
The second piece of this is observability. Traditional software breaks loudly: stack traces, 500 errors, log entries with line numbers. Agents fail quietly. They return confident, well-formatted output while being wrong. When an AI agent breaks, you get a clean response that is silently wrong. The failure propagates downstream through multiple steps before anyone notices, and by then the error has already influenced decisions you cannot reverse.
The fix is per-step tracing, logging inputs, outputs, latency, and confidence signals at every tool call, not just at the final response level:
import json
import datetime
class AgentTracer:
"""
Records a full trace of every tool call an agent makes during a workflow run.
Captures inputs, outputs, latency, and a confidence score at each step.
This is the difference between catching a failure at step 3
and finding out about it after step 10 when the damage is already done.
"""
def __init__(self, run_id: str):
self.run_id = run_id
self.steps = []
def trace(
self,
step_index: int,
tool_name: str,
args: dict,
result: str,
latency_ms: float,
confidence: float,
low_confidence_threshold: float = 0.70,
) -> dict:
"""
Log one tool invocation with full context.
Args:
step_index: Step number in the workflow (1-indexed)
tool_name: Name of the tool that was called
args: The arguments passed to the tool
result: The tool's output (truncated for the log)
latency_ms: Time the tool call took in milliseconds
confidence: Agent's self-reported confidence (0.0-1.0)
low_confidence_threshold: Flag steps below this confidence for review
Returns:
dict: The full trace entry for this step
"""
entry = {
"run_id": self.run_id,
"step": step_index,
"tool": tool_name,
"args": args,
# Truncate long results so logs stay readable in dashboards
"result_preview": result[:120] + "..." if len(result) > 120 else result,
"latency_ms": round(latency_ms, 2),
"confidence": round(confidence, 3),
# Steps below the threshold are surfaced in the run summary for human review
"low_confidence": confidence < low_confidence_threshold,
"timestamp": datetime.datetime.now(datetime.timezone.utc).isoformat(),
}
self.steps.append(entry)
return entry
def summary(self) -> dict:
"""
Summarize the run: total steps, total latency, and flagged steps.
Use this in your post-run logging and alerting pipeline.
Low-confidence steps are the early warning signal for silent failures.
"""
total_latency = sum(s["latency_ms"] for s in self.steps)
flagged = [s for s in self.steps if s["low_confidence"]]
return {
"run_id": self.run_id,
"total_steps": len(self.steps),
"total_latency_ms": round(total_latency, 2),
"flagged_steps": len(flagged),
"flagged_details": [
{
"step": s["step"],
"tool": s["tool"],
"confidence": s["confidence"],
}
for s in flagged
],
}
# Simulate a 5-step customer support agent workflow with full tracing
tracer = AgentTracer(run_id="run-support-2026-001")
# Each tuple: (tool_name, args, result, latency_ms, confidence)
# Confidence scores below 0.70 will be automatically flagged in the summary.
simulated_steps = [
(
"search_orders",
{"status": "pending"},
"Found 3 pending orders: ORD-001, ORD-002, ORD-003",
45.2,
0.95, # High confidence -- agent is certain about this step
),
(
"get_order_detail",
{"order_id": "ORD-001"},
"Order ORD-001: 2x Widget, $49.99, estimated delivery June 20",
38.7,
0.91,
),
(
"check_inventory",
{"product_id": "WIDGET-A"},
"WIDGET-A: 12 units in stock at Warehouse Lagos",
210.5,
0.61, # LOW CONFIDENCE -- agent uncertain about warehouse location; flagged
),
(
"update_order",
{"order_id": "ORD-001", "status": "confirmed"},
"Order ORD-001 status updated to confirmed",
55.1,
0.88,
),
(
"send_confirmation_email",
{"to": "customer@example.com", "order_id": "ORD-001"},
"Email queued for delivery to customer@example.com",
30.0,
0.52, # LOW CONFIDENCE -- agent uncertain about recipient; flagged before irreversible send
),
]
print("=== Step-by-step trace ===")
for i, (tool, args, result, latency, confidence) in enumerate(simulated_steps):
entry = tracer.trace(i + 1, tool, args, result, latency, confidence)
flag = " [LOW CONFIDENCE -- FLAGGED FOR REVIEW]" if entry["low_confidence"] else ""
print(f" Step {i + 1}: {tool}{flag}")
print("\n=== Run Summary ===")
print(json.dumps(tracer.summary(), indent=2))Prerequisites: Python 3.9+. No external packages. Save as agent_tracer.py
How to run:
python3 agent_tracer.pyExpected output:
=== Step-by-step trace ===
Step 1: search_orders
Step 2: get_order_detail
Step 3: check_inventory [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
Step 4: update_order
Step 5: send_confirmation_email [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
=== Run Summary ===
{
"run_id": "run-support-2026-001",
"total_steps": 5,
"total_latency_ms": 379.5,
"flagged_steps": 2,
"flagged_details": [
{"step": 3, "tool": "check_inventory", "confidence": 0.61},
{"step": 5, "tool": "send_confirmation_email", "confidence": 0.52}
]
}Two flagged steps in a five-step run. Without per-step tracing, both of those low-confidence calls disappear into the final response. With tracing, they surface immediately, before a confirmation email goes out to the wrong address, before a low-confidence inventory count gets committed as ground truth.
This is the difference between an agent that sometimes fails and one that fails detectably. Detectably is the only kind worth shipping.
# Wrapping Up
The PwC AI Agent Survey from May 2025 found that 79% of senior executives said their companies were already using AI agents. The headline number sounds like mass adoption. The same survey found that only 35% had deployed agents broadly, only 17% had deployed them across almost all workflows, and 68% admitted that half or fewer of their employees interact with agents day to day.
Teams are deploying without running the compound reliability math. They are treating demos as deployment proxies. They are piling tools onto agents without schema validation or reversibility gating. They are shipping customer-facing AI without audit trails. And they are waiting for model upgrades to solve problems that aren't model problems.
The teams that close this gap won't be the ones with the biggest infrastructure budget or earliest access to frontier models. They'll be the ones who treat their agent deployments the same way they treat any other critical system: with structured autonomy, human checkpoints at the boundaries that matter, scoped tool registries, step-level observability, and a clear answer to the question of what happens when something goes wrong.
That answer needs to exist before the first production deployment. Not after.
Shittu Olumide** is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
関連記事
エージェント型リソース発見:エージェントが検索できるようにする
Hugging Face は、AI エージェントが自律的に必要なリソースを検索・発見できる新機能「Agentic Resource Discovery」を発表した。これにより、エージェントの自律的なタスク遂行能力が向上する。
Cloudflare、すべてのアプリエコシステムでOAuthを解放
Cloudflare は、プラットフォーム上の開発者が他社製ツールと連携できるよう、全アプリエコシステムでの OAuth 利用を可能にする機能を発表した。これにより、顧客は独自に OAuth クライアントを作成・管理しやすくなる。
Anthropic、Slack 上の Claude を常時監視型のエージェント型 AI コーワーカー「Claude Tag」として再設計
Anthropic は既存の Slack アプリを廃止し、組織内のチャネルやツールにアクセスできる常時稼働型の AI コーワーカー「Claude Tag」を導入すると発表した。この新機能により、ユーザーは@Claudeとタグ付けすることでタスクを委任できるようになる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み