AgentCore Memory におけるメタデータによる構造化メモリフィルタリング
AWS は AgentCore Memory にメタデータフィルタリング機能を追加し、類似度検索の精度を大幅に向上させることで、AI エージェントの記憶管理における文脈依存型クエリの解決策を提供した。
キーポイント
検索精度の壁と解決策
従来の類似度検索では、文脈的に無関係な情報が混在する「検索精度の壁」に直面していたが、メタデータフィルタリングにより優先度や時間範囲などのビジネス次元で絞り込みが可能になった。
実証された精度向上
151 問のテストセットにおいて、メタデータフィルタリング有効化により全体 QA 精度が 40% から 64% に向上し、文脈境界に依存する質問では 16% から 69% と劇的な改善が見られた。
ネームスペースとの連携
メタデータフィルタリングは、クライアントや患者ごとのデータを隔離する「ネームスペース」機能の上に層として追加され、より細粒度なスコーピングを実現する。
メタデータによるコンテキスト付与
イベント作成時に部門(billing)や優先度(high)をメタデータとして追加し、構造化されたフィルタリングを可能にしている。
階層構造の活用
payload 内で conversational リスト内のオブジェクトを使用し、役割とテキスト内容を明確に分離して記録している。
厳密な一貫性によるメタデータ分離
STRICTLY_CONSISTENT キーを設定すると、値が異なるイベントは強制的に別々に抽出・保存され、意図しないマージやコンテキスト混在を防ぎます。
インデックスキーの制限と事前計画
STRICTLY_CONSISTENT キーは最大 3 つまで許可され、それぞれメモリリソース内の 10 個あるインデックスキースロットを消費するため、事前に予約が必要です。
影響分析・編集コメントを表示
影響分析
この機能追加は、AI エージェントが膨大な履歴データから正確な情報を抽出する能力を飛躍的に高めるものであり、カスタマーサポートや医療記録管理などの実務現場での信頼性を劇的に向上させる。特に、単なる類似度検索に依存していた従来の RAG パターンにおける文脈の欠落問題を解決し、より高度で制御されたエージェント運用を可能にする重要なステップとなる。
編集コメント
単なる類似度検索の限界を打破し、実務で不可欠な「文脈制御」を実現した AWS の技術革新は、AI エージェントの実装におけるベストプラクティスを再定義する内容です。
例えば、カスタマーサポートエージェントが「請求に関する問題」を問い合わせた際、技術サポートのチケット、領収書関連の販売会話、請求紛争などが混在して返されてしまうことがあります。これは、エージェントが数週間にわたる対話履歴を蓄積したチームが直面する検索精度の壁です。類似度検索は、この顧客にとって意味的に近いものをすべて見つけますが、実際に必要な問題タイプ、ステータス、時間といった関連次元に範囲を限定しません。
Amazon Bedrock AgentCore Memory は、AI エージェントが会話間を通じて情報を記憶・想起できる能力を与えるフルマネージドのメモリサービスです。エージェントのメモリレコードは、クライアントや client-123 といった孤立したスコープを定義する名前空間に整理されます。これにより、各エンティティのデータが分離されたまま保たれます。名前空間組織化の詳細については、Organizing Agents' memory at scale: Namespace design patterns in AgentCore Memory のブログ記事をご覧ください。メモリが増大するにつれて、関連するシグナルは意味的には類似しているが文脈上は無関係な結果に埋もれ、名前空間によるスコーピングだけではそれらを分離できません。
メタデータフィルタリングはこのギャップを埋めます。これにより、名前空間の分離の上に、優先度、部署、または時間範囲といったビジネス次元による検索範囲の特定に役立つ、細粒度で属性ベースのフィルターを重ねて適用できるようになりました。長期記憶ベンチマーク(LoCoMo スタイルのマルチセッション会話)に基づいて構築された 151 問からなるテストセットでの評価では、改善が確認されました。メタデータフィルタリングをすべての質問タイプに対して有効にした結果、全体としての質問応答 (QA) 精度は 40% から 64% に向上しました。この向上は、時間制限付きの検索や優先度ベースのフィルタリング、部署限定の検索など、文脈的制約に依存する質問のサブセットに集中しています。これらの質問においては、精度が 16% から 69% に急上昇しました。
本稿では、メタデータが設定、取り込み、検索の各段階でどのように機能するかを解説し、マルチエージェントやマルチテナントアーキテクチャを含むエンタープライズユースケースを探求し、実装のためのベストプラクティスをご紹介します。
ネームスペースとメタデータの構造化
AgentCore Memory は、主要なエンティティの境界に沿ってメモリを整理および隔離するためにネームスペースを使用します。検索範囲を clients/client-123/sessionABC や patients/patient-456 のような特定のネームスペースに限定することで、エージェントが誤って他のクライアントや患者のデータを取得しないようにします。ネームスペースは分離のための基盤層を提供します。詳細については、ネームスペース設計パターンに関するブログ をお読みください。

デプロイメントがスケールするにつれ、ネームスペース内でのセマンティック検索(意味的検索)には限界が生じます。例えば、クライアントごとにネームスペースを持つ金融サービスエージェントを想定してください。このエージェントは 6 ヶ月分の対話履歴を蓄積しています。あるリレーションシップマネージャーが、特定のクライアントについて「ポートフォリオの再バランスに関する議論」を思い出してほしいと依頼した場合、ネームスペースはそのクライアントのメモリに対する検索範囲を正しく限定します。しかし、結果にはそのクライアントの履歴内にある異なる投資戦略、期間、優先度が混在しています。エージェントは先週の重要な再バランス会話と 3 ヶ月前の日常的な問い合わせを区別することができません。情報は意味的に類似していても、文脈は全く異なります。
マルチテナント環境は、この階層構造を明確に示しています。名前空間(Namespaces)はすでにテナント間で完全なデータ分離を提供します。各テナントの名前空間内では、IT ヘルプデスクエージェントは解決パターンを検索する前にチケットタイプをフィルタリングする必要があります。名前空間は「誰」に対する論理的な分離であり、メタデータフィルタリングはその境界内でのサブグループ分け(カテゴリ、解決ステータス、日付、優先度、タグ)を担当します。
AgentCore Memory におけるメタデータ
AgentCore Memory 内のメタデータは、短期記憶と長期記憶の両方にまたがって機能し、設定、取り込み、検索という 3 つのフェーズからなるライフサイクルに従います。以下のセクションでは、まず短期記憶でのメタデータの動作を説明し、その後、長期記憶における完全な 3 フェーズライフサイクルについて詳しく解説します。
短期記憶におけるメタデータ
短期記憶層では、イベントに文字列ベースのキー・バリューペア(key-value pairs)を付与し、会話自体には含まれないが後日の検索において極めて重要な文脈情報を対話にタグ付けします。
短期記憶のメタデータは、フィルタリングに使用できるイベント上の文字列ベースのキー・バリューペアをサポートしています。これらのタグは、抽出および統合プロセスを通じて長期記憶へ引き継がれ、そこでフィルタ可能な次元となります。
メタデータによる長期記憶
メタデータがその真価を発揮するのは長期記憶の領域です。以下に説明する 3 つのフェーズにより、構造化されたコンテキストをどのように宣言し、伝播させ、照会するかを精密に制御できます。要約すると、設定時にどのキーが重要かを宣言します。取り込み時には値を付与するか、モデルに推論させ、検索時にはそれらに基づいてフィルタリングを行います。セッション内の複数のイベントが同じキーを持つ場合、AgentCore Memory は llmExtractionInstruction で定義した解決動作を用いて、それらを 1 つの値に統合します。
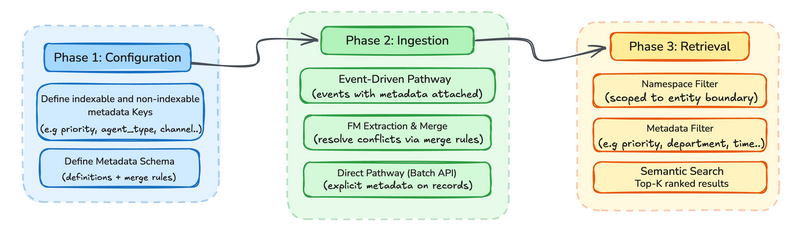
フェーズ 1: 設定
メモリリソースを作成する際、メモリレコード間での高速なフィルタリングと検索のためにインデックス化するメタデータキーを宣言します。各メモリ戦略にメタデータスキーマを定義することで、AgentCore Memory がメタデータの値をどのように抽出し解決するかを指示します。インデックス化されたキーはクエリフィルタリングに最適化された形式で保存され、非インデックス化のキーは参考情報としてメモリレコードと共に保存されます。
以下は、メタデータ設定を含むカスタマーサポート用メモリリソースを作成する例です:
response = agentcore_client.create_memory(
name="CustomerSupportMemory",
eventExpiryDuration=30,
indexedKeys=[
{"key": "priority", "type": "STRING"},
{"key": "agent_type", "type": "STRING"},
{"key": "channel", "type": "STRING"},
{"key": "ticket_id", "type": "STRING"}
],
memoryStrategies=[{
"semanticMemoryStrategy": {
"name": "SupportSemanticStrategy",
"description": "Captures support interaction details",
"namespaces": ["support/{actorId}"],
"memoryRecordSchema": {
"metadataSchema": [
{
"key": "priority",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionType": "STRICTLY_CONSISTENT""extractionConfig": {
"llmExtractionConfig": {
"definition": "Issue priority level based on customer impact.",
"llmExtractionInstruction": "LATEST_VALUE",
"validation": {
"stringValidation": {
"allowedValues": ["critical", "high", "medium", "low"]
}
}
}
}
},
{
"key": "agent_type",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionConfig": {
"llmExtractionConfig": {
"definition": "Support agent classification.",
"llmExtractionInstruction": "Prefer the most specialized agent type. Hierarchy: specialist > tier3 > tier2 > tier1 > bot."
}
}
},
{
"key": "sentiment",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionConfig": {
"llmExtractionConfig": {
"definition": " Customer sentiment during the interaction. ",
"llmExtractionInstruction": "Classify the overall customer sentiment based on tone and language used.",
"validation": {
"stringValidation": {
"allowedValues": ["positive", "neutral", "negative", "frustrated"]
}
}
}
}
}
]
}
}
}]
)
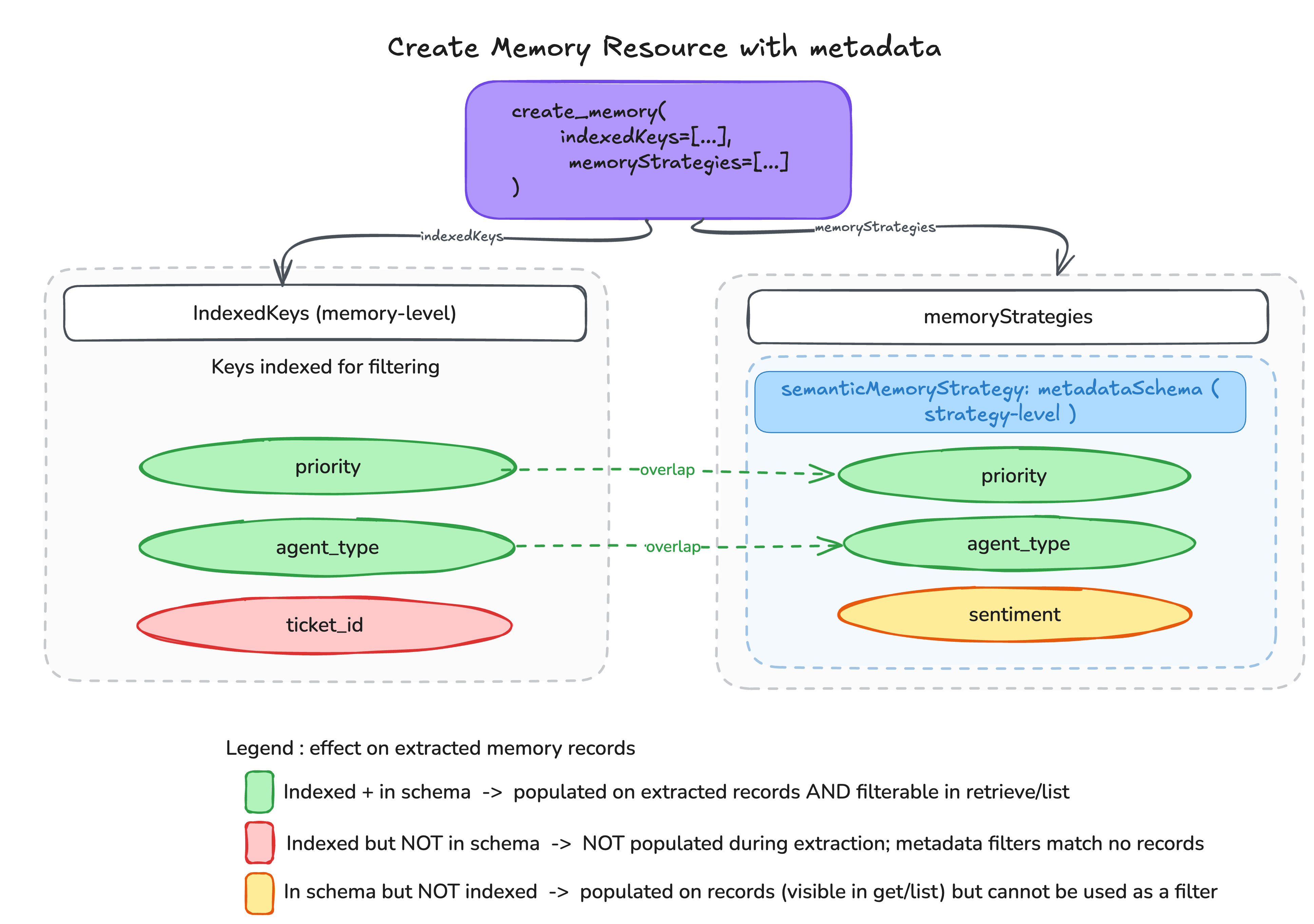
各スキーマエントリの extractionConfig は、メタデータ抽出時に大規模言語モデル(LLM)をガイドします。definition フィールドはそのフィールドが何を表すかを記述し、llmExtractionInstruction は追加の抽出ガイダンスおよび競合解決動作を提供します。組み込みの LATEST_VALUE 演算子は最新性に基づく解決を提供しますが、カスタムの自然言語指示はドメイン固有ロジックを処理します。オプションの validation フィールドは、STRING および STRINGLIST に対する allowedValues、STRINGLIST に対する maxItems、または NUMBER に対する min-max など、抽出された値を制約し、下流のフィルタリングで一貫した値を維持します。前述のコードサンプルで注意すべき点は、sentiment がスキーマで定義されているものの、インデックス付きキーとして宣言されていないことです。したがって、LLM は会話内容からその値を導出し、抽出レコードに埋め込みますが、メタデータフィルタ式で使用することはできません。
ticket_id がメモリレベルでインデックス付きキーとして宣言されているが、戦略の memoryRecordSchema には含まれていない点にも注意してください。このキーは抽出されたメモリエコードには埋め込まれません。抽出後にレコードに現れるのは、戦略の memoryRecordSchema で定義されたキーのみです。スキーマに含まれないインデックス付きキーは、発生源イベントに一致する値が存在する場合でも省略されます。あるキーを抽出レコードに現れさせる必要がある場合は、そのキーには必ずスキーマエントリが必要です。
構成制約の詳細については、AgentCore Memory ドキュメントをご覧ください。設定されたメタデータキーに加えて、メモリ減衰を考慮するための時間的フィルタリング(必要な場合)は、システム生成の dateTimeValue フィールドである x-amz-agentcore-memory-createdAt および x-amz-agentcore-memory-updatedAt を通じて利用可能です。これらは、日時インデックス付きキーを宣言する必要なく、BEFORE および AFTER オペレータをサポートしています。
既知の値に対する厳密な整合性を保つメタデータ
一部のメタデータキーは、部門、コンプライアンスレベル、インタラクションタイプなどの組織分類子です。これらのキーには、呼び出し元アプリケーションがイベント作成時点で既に知っている値が含まれており、結果として生成されるメモリレコードには、提供された通り正確に格納されなければなりません。LLM(大規模言語モデル)による抽出は、これらのキーにおいてばらつきをもたらします:同じ会話から、あるレコードでは「eng」という値が、別のレコードでは「Engineering」という値が生成される可能性がありますし、イベントで提供された値が抽出プロセス中に再推論されることもあります。AgentCore Memory は、この課題に対して STRICTLY_CONSISTENT 抽出タイプという解決策を提供します。これは LLM_INFERRED 抽出タイプのオプションです。キーがこのように設定されている場合、イベント上で提供された値は、抽出および統合の過程で変更されずに伝播し、そのキーについては LLM が参照されることはありません。
"metadataSchema": [
{
"key": "department",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT"
},
{
"key": "priority",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT"
}
{
"key": "topic",
"type": "STRING",
"extractionType": "LLM_INFERRED"
"extractionConfig": {
"llmExtractionConfig": {
"definition": "Primary topic of the conversation",
"llmExtractionInstruction": "Identify the main topic discussed"
}
}
}
]
STRICTLY_CONSISTENT キーは推論をスキップするだけでなく、抽出の分割も行います。同じ値を持つイベントは常に一緒に抽出され、異なる値を持つイベントからは分離されるため、どの値がレコードに属するかという曖昧さは生じません。
この分離は統合にも適用されます。一連の決定論的な値から生成されたレコードは、同じ値を共有するレコードとのみ統合されます。department: "billing" を持つレコードは、その内容がどれだけ意味的に類似していても、department: "engineering" を持つレコードとはマージされません。
顧客の問題が複数の部署にまたがるサポートセッションを考えてみましょう:
イベント 1:初期の請求に関する問い合わせ
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "エンタープライズプランの最新の請求書に、重複した課金が表示されています。"}}}],
metadata={"department": {"stringValue": "billing"}, "priority": {"stringValue": "high"}}
)
イベント 2:引き続き請求文脈
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "先週、スタンダードからエンタープライズティアへアップグレードした後に、その課金が発生しました。"}}}],
metadata={"department": {"stringValue": "billing"}, "priority": {"stringValue": "high"}}
)
イベント 3:エンジニアリング部門へエスカレーション(技術的な根本原因)
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "貴社のチームが、ティア移行中に重複課金を引き起こしたプロビジョニングのバグを発見しました。"}}}],
metadata={"department": {"stringValue": "engineering"}, "priority": {"stringValue": "high"}}
)
決定論的隔離がない場合、3 つのイベントはすべてまとめて抽出されてしまいます。LLM は、結果として得られた事実に非決定論的に「department: "billing"」や「department: "engineering"」、さらには「department: "account_management"」を割り当てる可能性があります。一方、「department」に対して STRICTLY_CONSISTENT(厳密な一貫性)が設定されている場合、
- イベント 1 と 2 は同じ決定論的値(department=billing, priority=high)を共有しており、まとめて抽出されます。結果として得られるメモリ記録には、これらの正確な値が保持されます。
- イベント 3 は異なる決定論的値(department=engineering, priority=high)を持ち、独立して抽出されます。その記録には「department: "engineering"」という値が正確に保持されます。
「department=billing」というクエリを行う請求処理担当エージェントは、重複課金とティアアップグレードに関する事実のみを取得し、エンジニアリング文脈からのプロビジョニングバグの詳細は取得しません。統合プロセスも同様の分離を尊重します:請求記録とエンジニアリング記録は、その内容が意味的に関連していても、マージされることはありません。
これにより、決定論的キーはコンプライアンス隔離(HIPAA 準拠レコードと標準レコードの混在防止)、組織的なルーティング(部門スコープ内の検索による相互汚染の回避)、および呼び出し元アプリケーションがイベント発生時に特定の値を知っており、その値を結果として得られるメモリ上で正確に保持する必要があるあらゆるシナリオにおいて理想的な役割を果たします。
STRICTLY_CONSISTENT(厳密整合性)として設定されたキーは、メモリリソース上でインデックス付きキーとしても宣言されている必要があります。メタデータフィルタによるインデックス付きキーでの統合スコープが、異なる決定論的値を持つレコードの結合を防ぐ役割を果たします。決定論的なメタデータキーの値を欠くイベントも処理されますが、その場合、結果として生成されるレコード上では当該キーは存在しないものとなります。
AgentCore Memory では、各戦略あたり最大 3 つまでの STRICTLY_CONSISTENT キーをサポートしています。これらの各キーは、メモリリソース上の 10 個あるインデックス付きキーのスロットの 1 つを消費します。一度追加されたインデックス付きキーは削除できません。この機能を利用する予定がある場合は、事前にスロットを確保しておく必要があります。
フェーズ 2: データ取り込み
メタデータスキーマの設定が完了したら、次のステップはメタデータを付与したデータの取り込みです。メタデータは 2 つの経路を通じてシステムに入力されます。イベント駆動型経路ではメタデータがイベントに付与され、AgentCore Memory が抽出および統合(抽出指示に基づき)を経て長期的なメモリレコードへ自動的に伝播します:
初期コンタクトイベント
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-001",
eventTimestamp="2024-01-23T10:00:00Z",
payload=[{
"conversational": {
"role": "USER",
"content": {"text": "請求書について質問があります"}
}
}],
metadata={
"priority": {"stringValue": "medium"},
"channel": {"stringValue": "email"},
"ticket_id": {"stringValue": "TKT-5001"}
}
)
セッション内で同一のキーに対して複数のイベントが異なる値を持つ場合、LLM は llmExtra を用いて競合を解決します。
原文を表示
Let’s say your customer support agent asks for “billing issues”, and gets back technical support tickets, sales conversations with receipt issues, and billing disputes all mixed. This is the retrieval precision wall that teams hit once their agents accumulate weeks of interaction history: similarity search finds everything that’s semantically close for this customer but does not scope it to the relevant dimensions you actually need: issue type, status, or time.
Amazon Bedrock AgentCore Memory is a fully managed memory service that gives AI agents the ability to remember and recall information across conversations. It organizes agent memory records into namespaces that define isolated scopes like clients/client-123, so each entity’s data stays separate. You can read the blog on Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory to understand more about namespace organization. As memories grow, relevant signals drown in semantically similar but contextually irrelevant results, and namespace scoping alone cannot separate them.
Metadata filtering closes this gap. You can now layer fine-grained, attribute-based filters on top of namespace isolation that helps in scoping retrieval by business dimensions like priority, department, or time range before similarity search runs. In our evaluations across a 151-question test set built on a long-term memory benchmark (LoCoMo-style multi-session conversation), it showed improvement. The overall question-answering (QA) accuracy rose from 40% to 64% with metadata filtering enabled across all question types. The gain concentrates in the subset of questions that depend on contextual boundaries, such as time-bounded lookups, priority-based filtering, or department-scoped searches. For those questions, accuracy jumped from 16% to 69%.
In this post, you will learn how metadata works across configuration, ingestion, and retrieval, explore enterprise use cases including multi-agent and multi-tenant architectures, and discover best practices for implementation.
Structuring the namespaces and metadata
AgentCore Memory uses namespaces to organize and isolate memories along primary entity boundaries. You scope retrieval to a specific namespace like clients/client-123/sessionABC or patients/patient-456, so your agent does not accidentally retrieve another client’s or patient’s data. Namespaces provide the foundational layer of separation. Read more about it in the blog on Namespace design patterns.
As deployments scale, semantic search within a namespace hits some limits. Consider a financial services agent with a namespace per client that has accumulated six months of interaction history. When a relationship manager asks the agent to recall “*portfolio rebalancing discussions*” for a specific client, the namespace correctly scopes the search for that client’s memories. But the results span different investment strategies, time periods, and priority levels within that client’s history. The agent can’t distinguish a high-priority rebalancing conversation from last week from a routine inquiry three months ago. The information is semantically similar, but the context is entirely different.
Multi-tenant environments illustrate the layering clearly. Namespaces already give you full data separation between tenants. Within each tenant’s namespace, your IT helpdesk agents still need to filter ticket type before searching for resolution patterns. Namespaces are the logical separation on the who. Metadata filtering handles the sub-grouping within those boundaries: the category, resolution status, date, priority, and tags.
Metadata in AgentCore Memory
Metadata in AgentCore Memory operates across both short-term and long-term memory, following a three-phase lifecycle: configuration, ingestion, and retrieval. The following sections walk through how metadata works at each memory layer, starting with short-term memory and then diving into the full three-phase lifecycle for long-term memory.
Metadata in short-term memory
At the short-term memory layer, you attach string-based key-value pairs to events, tagging interactions with contextual information that isn’t part of the conversation itself but is critical for later retrieval.
Short-term memory metadata supports string-based key-value pairs on events, that can be used for filtering. These tags carry forward into long-term memory during extraction and consolidation, where they become filterable dimensions.
Metadata in long-term memory
Long-term memory is where metadata delivers its full impact. Three phases described below give you precise control over how structured context is declared, propagated, and queried. In short, you declare which keys matter at configuration time. Attach or let the model infer their values during ingestion, and filter on them at retrieval. When several events in a session carry the same key, AgentCore Memory merges them into one value using the resolution behavior you defined in the llmExtractionInstruction.
Phase 1: Configuration
When you create a memory resource, you declare which metadata keys to index for fast filtering and retrieval across memory records. Defining a metadata schema on each memory strategy that instructs AgentCore Memory how to extract and resolve metadata values. Indexed keys are stored in a format optimized for query filtering, while non-indexed keys are stored alongside memory records for informational purposes.
The following creates a customer support memory resource with metadata configuration:
response = agentcore_client.create_memory(
name="CustomerSupportMemory",
eventExpiryDuration=30,
indexedKeys=[
{"key": "priority", "type": "STRING"},
{"key": "agent_type", "type": "STRING"},
{"key": "channel", "type": "STRING"},
{"key": "ticket_id", "type": "STRING"}
],
memoryStrategies=[{
"semanticMemoryStrategy": {
"name": "SupportSemanticStrategy",
"description": "Captures support interaction details",
"namespaces": ["support/{actorId}"],
"memoryRecordSchema": {
"metadataSchema": [
{
"key": "priority",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionType": "STRICTLY_CONSISTENT""extractionConfig": {
"llmExtractionConfig": {
"definition": "Issue priority level based on customer impact.",
"llmExtractionInstruction": "LATEST_VALUE",
"validation": {
"stringValidation": {
"allowedValues": ["critical", "high", "medium", "low"]
}
}
}
}
},
{
"key": "agent_type",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionConfig": {
"llmExtractionConfig": {
"definition": "Support agent classification.",
"llmExtractionInstruction": "Prefer the most specialized agent type. Hierarchy: specialist > tier3 > tier2 > tier1 > bot."
}
}
},
{
"key": "sentiment",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT",
"extractionConfig": {
"llmExtractionConfig": {
"definition": " Customer sentiment during the interaction. ",
"llmExtractionInstruction": "Classify the overall customer sentiment based on tone and language used.",
"validation": {
"stringValidation": {
"allowedValues": ["positive", "neutral", "negative", "frustrated"]
}
}
}
}
}
]
}
}
}]
)Each schema entry’s extractionConfig guides the large language model (LLM) during metadata extraction. The definition field describes what the field represents, while llmExtractionInstruction provides additional extraction guidance and conflict resolution behavior. The built-in LATEST_VALUE operation provides recency-based resolution, while custom natural language instructions handle domain-specific logic. The optional validation field constrains the extracted values, such as allowedValues for STRING and STRINGLIST, maxItems for STRINGLIST, or min-max for NUMBER. This maintains consistent values for downstream filtering. Notice (in the preceding code sample) that sentiment is defined in the schema but not declared as an indexed key. Thus, the LLM will derive its value purely from conversation content and populate it on extracted records, but it cannot be used in metadata filter expressions.
Notice that ticket_id is declared as an indexed key at the memory level but not included in the strategy’s memoryRecordSchema. This key will not be populated on extracted memory records. Only keys defined in the strategy’s memoryRecordSchema appear on records after extraction. Indexed keys absent from the schema are omitted, even if matching values exist on the originating events. If you need a key to appear on extracted records, it must have a schema entry.
You can read more about the configuration constraints in the AgentCore Memory documentation. Apart from the configured metadata keys, temporal filtering (to account for memory decay, if relevant) is available through system-generated dateTimeValue fields, x-amz-agentcore-memory-createdAt and x-amz-agentcore-memory-updatedAt, which support BEFORE and AFTER operators without requiring you to declare datetime indexed keys.
Strictly-consistent metadata for known values
Some metadata keys are organizational classifiers like department, compliance_level, or interaction_type. These carry values the calling application already knows at event creation time, and they must land on the resulting memory records exactly as supplied. LLM extraction introduces variability for these keys: the same conversation can produce “eng” on one record and “Engineering” on another, and a value provided on the event may be re-inferred during extraction. AgentCore Memory addresses this with the STRICTLY_CONSISTENT extraction type, an option to the LLM_INFERRED extraction type. When a key is configured this way, the value supplied on the event propagates unchanged through extraction and consolidation, and the LLM isn’t consulted for that key.
"metadataSchema": [
{
"key": "department",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT"
},
{
"key": "priority",
"type": "STRING",
"extractionType": "STRICTLY_CONSISTENT"
}
{
"key": "topic",
"type": "STRING",
"extractionType": "LLM_INFERRED"
"extractionConfig": {
"llmExtractionConfig": {
"definition": "Primary topic of the conversation",
"llmExtractionInstruction": "Identify the main topic discussed"
}
}
}
]STRICTLY_CONSISTENT keys do more than skip inference. They partition extraction. Events sharing the same values are always extracted together and isolated from events with different values, so there is no ambiguity about which value belongs on a record.
This isolation also governs consolidation. Records produced from one set of deterministic values are only ever consolidated with records sharing those same values. A record carrying department: "billing" will not merge with one carrying department: "engineering", regardless of how semantically similar their content might be.
Consider a support session where a customer’s issue spans multiple departments:
# Event 1: Initial billing inquiry
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "I'm seeing duplicate charges on my last invoice for the enterprise plan."}}}],
metadata={"department": {"stringValue": "billing"}, "priority": {"stringValue": "high"}}
)
# Event 2: Still billing context
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "The charges appeared after we upgraded from the standard to enterprise tier last week."}}}],
metadata={"department": {"stringValue": "billing"}, "priority": {"stringValue": "high"}}
)
# Event 3: Escalated to engineering (technical root cause)
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-escalation-001",
payload=[{"conversational": {"role": "USER",
"content": {"text": "Your team found a provisioning bug that triggered the duplicate charge during tier migration."}}}],
metadata={"department": {"stringValue": "engineering"}, "priority": {"stringValue": "high"}}
)Without deterministic isolation, all three events would be extracted together. The LLM might assign department: "billing", department: "engineering", or even department: "account_management" to the resulting facts non-deterministically. With STRICTLY_CONSISTENT configured on department:
- Events 1 and 2 share the same deterministic values (department=billing, priority=high) and are extracted together. The resulting memory records carry those exact values.
- Event 3 has different deterministic values (department=engineering, priority=high) and is extracted independently. Its records carry department: "engineering" exactly.
A billing agent querying with department=billing retrieves only the facts about duplicate charges and the tier upgrade, not the provisioning bug detail from the engineering context. Consolidation respects the same separation: billing records and engineering records are not merged, even if their content is semantically related.
This makes deterministic keys ideal for compliance isolation (HIPAA vs. standard records do not co-mingle), organizational routing (department-scoped retrieval without cross-contamination), and any scenario where the calling application knows a value at event time and needs it preserved exactly on the resulting memories.
A key configured as STRICTLY_CONSISTENT must also be declared as an indexed key on the memory resource. Consolidation scopes by metadata filters on indexed keys, and that scoping is what keeps records with different deterministic values from merging. Events that are missing values for a deterministic metadata key are still processed, and the key is simply absent on the resulting record.
AgentCore Memory supports up to three STRICTLY_CONSISTENT keys per strategy. Each one of these keys consumes one of the ten indexed-key slots on the memory resource, and indexed keys can’t be removed once added. Reserve slots ahead of time if you plan to use this feature.
Phase 2: Ingestion
Once you’ve configured your metadata schema, the next step is ingesting data with metadata attached. Metadata enters the system through two pathways. The event-driven pathway attaches metadata to events, and AgentCore Memory automatically propagates it through extraction and consolidation (based on extraction instructions) into long-term memory records:
# Initial contact event
agentcore_client.create_event(
memoryId="mem-support-abc123",
actorId="customer-123",
sessionId="session-001",
eventTimestamp="2024-01-23T10:00:00Z",
payload=[{
"conversational": {
"role": "USER",
"content": {"text": "I have a question about my bill"}
}
}],
metadata={
"priority": {"stringValue": "medium"},
"channel": {"stringValue": "email"},
"ticket_id": {"stringValue": "TKT-5001"}
}
)When multiple events in a session carry different values for the same key, the LLM resolves conflicts using the llmExtra
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み