Unweight: 品質を犠牲にせずLLMを22%圧縮した方法
CloudflareはLLM推論のメモリ帯域幅ボトルネックを解決する無損失圧縮システム「Unweight」を開発し、モデルサイズを最大22%削減しながら品質を維持する技術を発表した。
キーポイント
メモリ帯域幅ボトルネックの解決
GPUのテンソルコア処理速度がメモリ転送速度を大幅に上回る現代環境において、オンチップメモリでの高速解凍とテンソルコアへの直接供給により転送オーバーヘッドを削減。
無損失圧縮と自動最適化
量子化のような精度劣化を伴う損失圧縮とは異なり、ビット完全な出力を維持する無損失方式を採用。ワークロードに応じて複数の実行戦略から自動チューナーが最適パスを選択。
実証結果とVRAM節約効果
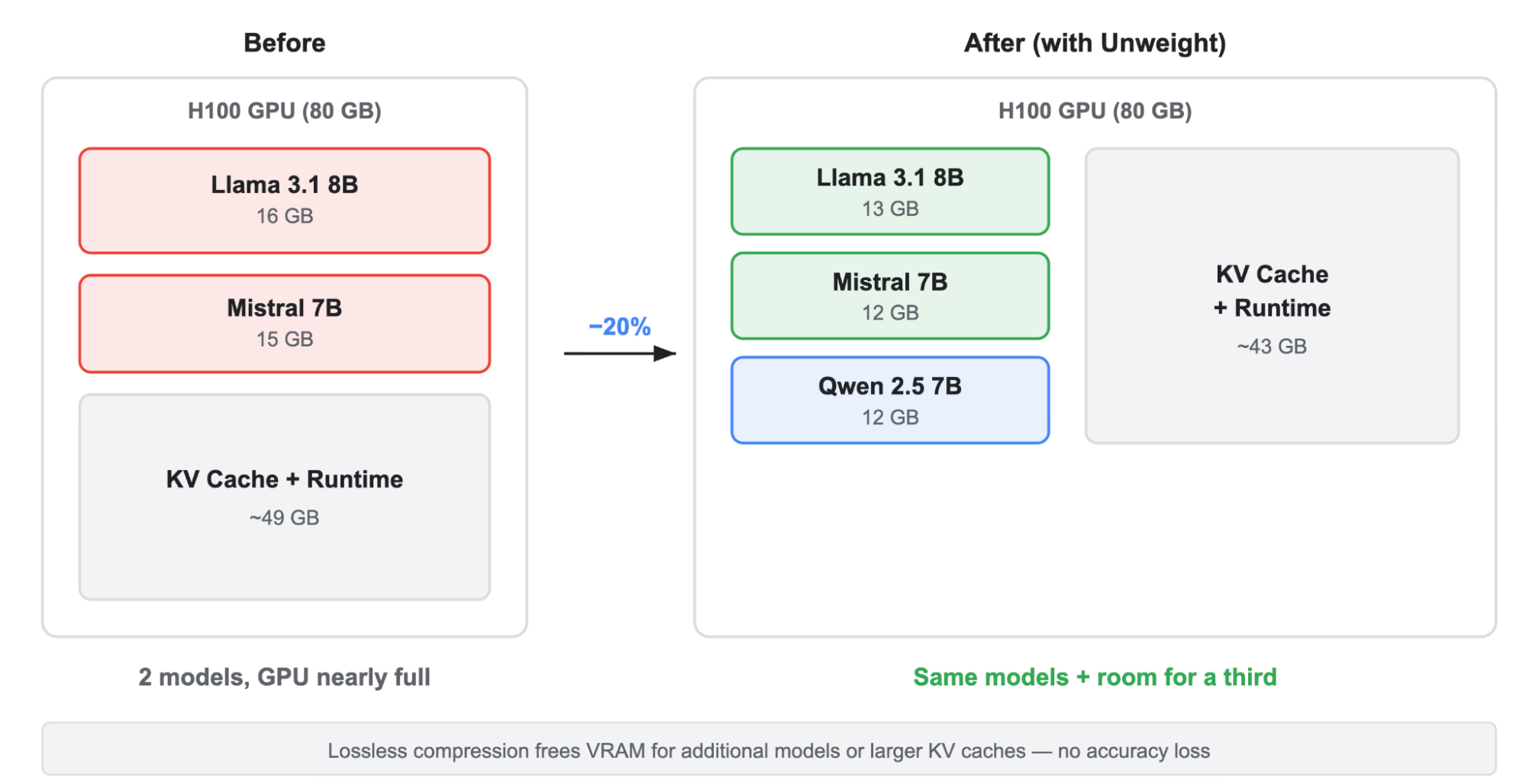
Llama-3.1-8BでMLP重みを約30%圧縮し、モデル全体サイズを15-22%削減。これにより単一GPUあたりのVRAM使用量を約3GB節約し、モデル収容数を増加。
技術論文とGPUカーネルの公開
透明性と業界イノベーションを促進するため、詳細な技術論文と実装用GPUカーネルをオープンソースとして公開し、推論最適化の標準化を推進。
要点タイトル
1-2文の説明
Selective Exponent Compression
Huffman coding applied only to exponent bytes in MLP matrices achieves ~30% compression on the exponent stream, yielding an overall ~20% reduction in MLP weight size.
Row-Level Fallback Optimization
Rows containing rare exponents are stored verbatim, eliminating per-element branching and streamlining the critical inference path.
影響分析・編集コメントを表示
影響分析
本技術は、大規模言語モデルの推論コストとインフラ制約という業界共通の課題に対し、ハードウェア依存のない無損失圧縮アプローチを提供する。これによりクラウド事業者やエンタープライズは既存GPUリソースの活用効率を大幅に向上させられ、推論スループットの向上とコスト削減が同時に実現可能となる。今後は他のモデルアーキテクチャやベンダーGPUへの拡張が期待され、推論インフラの標準最適化パイプラインに組み込まれる可能性が高い。
編集コメント
推論コスト削減の鍵となる「メモリ帯域幅」に焦点を当てた実用的なアプローチであり、量子化の精度劣化問題を回避しつつオープンソースで提供されている点が評価できる。今後はベンチマークの標準化と他モデルへの適用検証が業界全体の最適化を加速させるだろう。
世界中のインターネット接続人口の95%に対して50ms以内で推論(inference)を実行するには、GPUメモリを徹底的に効率的に扱う必要があります。昨年、Rustベースの推論エンジンであるInfireでメモリ利用率を向上させ、モデルスケジューリングプラットフォームであるOmniでコールドスタート(cold-starts)を解消しました。現在、私たちは推論プラットフォームにおける次の大きなボトルネックであるモデルウェイト(model weights)に取り組んでいます。
LLMから単一のトークンを生成するには、GPUメモリからすべてのモデルウェイトを読み取る必要があります。多くのデータセンターで使用するNVIDIA H100 GPUでは、テンソルコア(tensor cores)がデータを処理する速度はメモリが配信できる速度の約600倍に達し、計算能力ではなくメモリ帯域幅(memory bandwidth)がボトルネックとなります。メモリバスを横断するすべてのバイトは、ウェイトが小さければ回避できた潜在的な無駄です。
この問題解決のため、Unweightを開発しました。これは特殊なハードウェアに依存せず、モデルウェイトを最大15〜22%小さくしながらビット完全な出力(bit-exact outputs)を保持する、損失なし圧縮システムです。ここでの核心的な突破口は、高速なオンチップメモリ(on-chip memory)でウェイトを解凍し、テンソルコアに直接供給することで、低速なメインメモリへの不要な往復を回避できる点にあります。ワークロードに応じて、Unweightのランタイムは複数の実行戦略から選択します(単純さを優先するものもあれば、メモリトラフィックを最小限に抑えるものもあります)、そしてオートチューナー(autotuner)がウェイト行列とバッチサイズごとに最適な戦略を自動で選択します。
本記事ではUnweightの動作原理に深く迫りますが、より高い透明性と急速に進化するこの分野でのイノベーションを促進する精神に基づき、技術論文の公開とGPUカーネル(GPU kernels)のオープンソース化も実施します。
Llama-3.1-8Bでの初期結果では、マルチレイヤーパーセプトロン(Multi-Layer Perceptron, MLP)のウェイトのみで約30%の圧縮率を示しています。Unweightはデコード用のパラメータに対して選択的に動作するため、これによりモデルサイズが15〜22%縮小し、VRAMを約3GB節約できます。以下の図に示す通り、これによりGPUからより多くの性能を引き出し、より多くの場所でより多くのモデルを実行可能になります。これによりCloudflareネットワーク上での推論コストを削減し、速度を向上させます。
 image
image
Unweightのおかげで、単一のGPUにより多くのモデルを収容できるようになりました
Why compression is harder than it sounds
推論を高速化したり、より小さなGPUで実行するために、創造的な方法でモデルウェイトを圧縮する方法を探る研究が徐々に増えています。最も一般的なのは量子化(quantization)で、32ビットまたは16ビットの浮動小数点数を8ビットまたは4ビットの整数に変換することで、モデルウェイトと活性化値(activations)のサイズを削減する技術です。これは損失あり圧縮(lossy compression)の一種であり、異なる16ビット浮動小数点数が同じ4ビット整数に変換される場合があります。この精度の低下は、回答の品質に予測不能な影響を及ぼします。多様なユースケースに対応する本番環境の推論では、モデルの動作を完全に保持する損失なし圧縮(lossless compression)が必要であることは明らかでした。
最近のいくつかのシステム(Huff-LLM、ZipNN、ZipServ)は、大規模言語モデル(Large Language Model, LLM)の重みを大幅に圧縮できることを示したが、これらのアプローチは我々の対象とする問題とは異なる。ZipNNは配布と保存のための重み圧縮を扱い、デコンプレッションはCPU上で行われる。HUff-LLMは復号化のためのカスタムFGPA(Field-Programmable Gate Array)ハードウェアを提案している。またZipServはデコンプレッションとGPU推論を融合させるが、対象とするのは消費者向けグレードのGPUであり、これは当社のH100 GPUでは動作しない。これらのいずれもが我々が求めているもの、つまりHopper GPU上で推論時にロスレス(無損失)なデコンプレッションを行い、Rustベースの推論エンジンと統合できるソリューションを提供しなかった。
中核となる課題は単なる標準的な圧縮ではない——BF16重みの指数部バイトは冗長性が高いため、エントロピー符号化(entropy coding)が非常に効果的に機能する。真の課題は、推論速度を低下させないほど十分に高速にデコンプレッションを行うことである。H100上では、テンソルコア(tensor cores)はメモリの読み込みを待つ間、大半の時間をアイドル状態にしている——しかし、そのアイドル状態の容量を単にデコンプレッション用に再利用することはできない。シェアドメモリ制約(shared memory constraints)のため、各GPUの計算ユニットはデコンプレッションカーネルと行列乗算カーネル(matrix multiplication kernel)のどちらか一方しか同時に実行できず、両方を並行して動かすことはできない。行列乗算と完全にオーバーラップしないデコードレイテンシ(decode latency)は、トークン生成レイテンシ(token latency)に直接加算されてしまう。Unweightの解決策は、高速なオンチップ・シェアドメモリ(on-chip shared memory)内で重みをデコンプレッションし、その結果を直接テンソルコアに供給することである——しかし、異なるバッチサイズ(batch sizes)や重みの形状 across でこれを効率的に動作させることが、真のエンジニアリングの要所となる。
モデル重みの効果的な圧縮方法
AIモデル内のすべての数値は、16ビットの「ブレインフロート(brain float)」(BF16)として保存される。各BF16値は3つの部分で構成される:
符号部(Sign)(1ビット):正負の区別
指数部(Exponent)(8ビット):数値の大きさ
仮数部(Mantissa)(7ビット):その大きさにおける精密な値
これらの重みの内の1つがどのように分解されるかを示す:

符号部と仮数部は重み across で予測不可能に変動する——ランダムなデータのように見え、意味のある圧縮はできない。しかし指数部は異なる物語を語っている。
指数部の驚くべき予測可能性
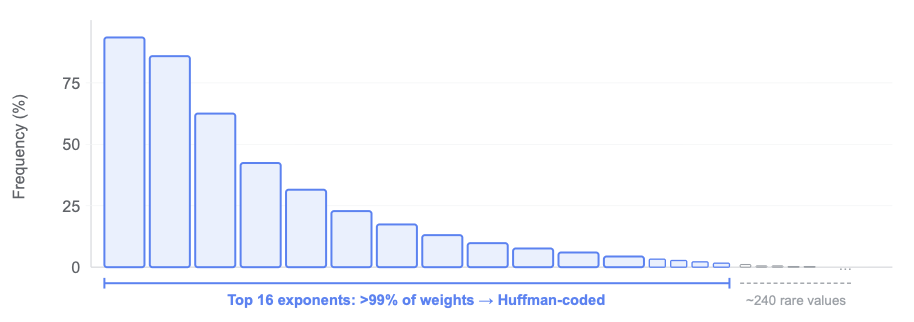
先行研究により、訓練済みLLM across で、256個の可能な指数値のうち、わずか数種類が支配的であることが確立されている。最も一般的な上位16個の指数値は、典型的なレイヤー内の全重みの99%以上をカバーする。情報理論(information theory)によれば、この分布を表すために必要なビット数は約2.6ビットであり、割り当てられた8ビットよりもはるかに少ない。典型的なLLMレイヤーにおける指数値の分布を見れば、上位16個の指数値が全モデル重みの99%を占めていることがわかる。
典型的なLLMレイヤーにおける指数値の分布
これがUnweightが活用する冗長性です。符号部と仮数部はそのままにしておき、指数部バイト(exponent byte)のみをハフマン符号化(Huffman coding)で圧縮します。これは一般的な技術で、頻出する値には短い符号を、稀な値には長い符号を割り当てます。指数部の分布がこれほど偏っているため、指数ストリームに対して約30%の圧縮率を実現します。この手法はMLP重み行列(MLP weight matrices)(ゲート、アップ、ダウン射影(gate, up, and down projections))に選択的に適用しており、これらはモデルパラメータの約3分の2を占め、トークン生成時のメモリトラフィックを支配しています。Attention weights、embeddings、layer normsは圧縮対象外です。総合的に、これらの最適化により多層パーセプトロン(multilayer perceptron, MLP)の重みサイズ全体が約20%削減されます。詳細は技術レポートで解説しています。
稀な指数を持つ少数の重みは別途処理されます:64要素の行の中に、トップ16パレット(top-16 palette)から外れる指数を持つ重みが一つでもあれば、その行全体をそのままの形式で保存します。このアプローチによりホットパス(hot path)における要素ごとの分岐を排除しています。すべての重みを個別に境界ケースとしてチェックするのではなく、行ごとに事前に1回の判断を行うだけです。
The GPU memory bottleneck
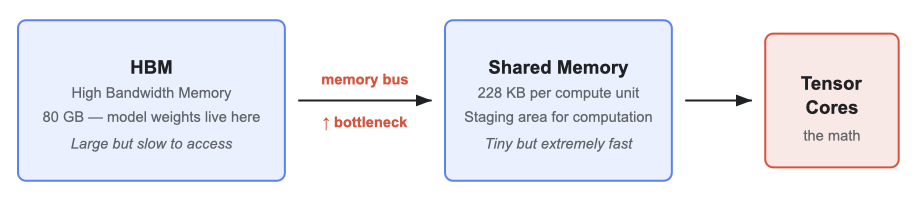
An NVIDIA H100 GPUには、関連する2種類のメモリがあります:
High Bandwidth Memory (HBM):容量は大きいものの、アクセス速度は比較的遅いです。モデルの重みがここに格納されます。
Shared memory (SMEM):容量は非常に小さいものの、極めて高速です。GPUが計算を実行する直前にデータをステージング(準備)する場所です。
 image
image
推論(inference)中にトークンを生成するには、HBMから重み行列全体を読み取る必要があります。HBMとSMEM間のメモリバス(memory bus)がパフォーマンスのボトルネックとなります——演算そのものではありません。バスを通過するバイト数が少なければ少ないほど、トークン生成は高速になります。
推論中にトークンを生成するには、メモリバスを介してHBMから重み行列全体を読み取る必要があります——これがボトルネックです。H100のtensor coresは、HBMがデータを供給する速度よりもはるかに高速に数値演算を実行できます。圧縮は、バスを通過するバイト数を減らせるため有効です。ただし注意点があります:GPUは圧縮されたデータに対して直接演算を実行できないことです。まず重みを解凍(デコンプレス)する必要があります。
従来の多くの手法は、重み行列全体をHBMに解凍してから標準的な行列乗算を実行します。これはストレージ容量の節約には役立ちますが、bandwidthの向上にはつながりません。なぜなら、トークン生成ごとにHBMから完全な非圧縮行列を読み取る必要があるためです。
Four ways to use compressed weights
推論(inference)中に圧縮された重み(weights)を使用する最適な方法は一つではありません。適切なアプローチはワークロード、つまりバッチサイズ(batch size)、重み行列(weight matrix)の形状、および復元(decompression)に割り当てられるGPU時間の量によって異なります。Unweightは4つの圧縮実行パイプライン(execution pipelines)を提供しており、それぞれ復元処理の負荷と計算複雑さの間で異なるバランスを取っています。これらは、完全なHuffmanデコード(full Huffman decode)、指数部のみデコード(exponent-only decode)、パレットトランスコード(palette transcode)、または前処理(pre-processing)を完全にスキップするものです。
 image
image
4つの異なる実行パイプライン(execution pipelines)
4つのパイプラインはスペクトル(spectrum)を形成しています。一端では、完全デコード(full decode)が元のBF16重み(BF16 weights)を完全に再構築し、標準的な行列乗算(matrix multiplication)のためにNVIDIAのcuBLASライブラリに渡します。これは、通常のデータ上でcuBLASが全速力で動作する最もシンプルなパスですが、前処理ステップ(preprocess step)はメインメモリ(main memory)へ最も多くのバイトを書き込みます。行列乗算が微小でカスタムカーネル(custom kernel)のオーバーヘッドが支配的な小さなバッチサイズにおいて、これはよく機能します。他端では、直接パレット(direct palette)は前処理を完全にスキップします。重みはモデルロード時にコンパクトな4ビット形式(4-bit format)に事前にトランスコードされており、行列乗算カーネルはこれらのインデックスからBF16値をその場で再構築します。前処理コストはゼロですが、カーネルは要素ごとに多くの処理を行います。
その中間には2つの独立したパスがあります。1つは指数部(exponent)のバイトのみをデコードするもの(前処理トラフィックを半減)、もう1つは実行時(runtime)に4ビットのパレットインデックスへトランスコードするものです(前処理トラフィックを4分の1に)。両方とも、再構築型行列乗算(reconstructive matrix multiplication)を使用します。これは圧縮データを読み込み、高速な共有メモリ(shared memory)内でBF16を再構築し、メインメモリへの往復を経由せずに直接テンソルコア(tensor cores)に供給するカスタムカーネルです。
単一のパイプラインが勝者にならない理由
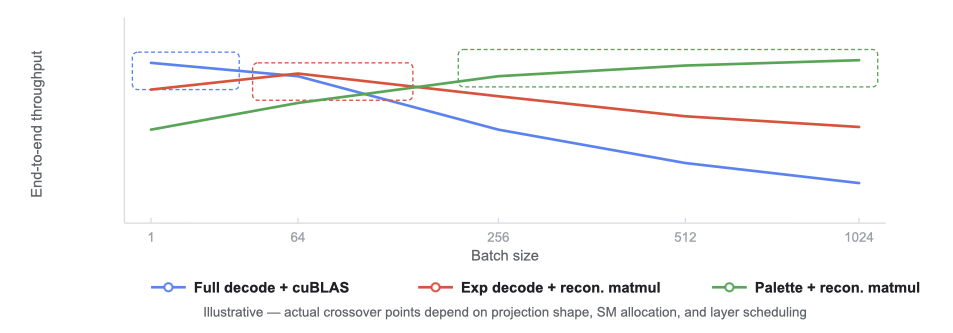
前処理(preprocessing)が少ないということは、HBM(High Bandwidth Memory)へ書き込まれるデータ量が少なくなることを意味し、メモリバス(memory bus)をより早く解放します。ただし、それは行列乗算カーネル(matmul kernel)への再構築作業の負荷を増やすことになります。このトレードオフが利益をもたらすかどうかは、状況によります。
小さなバッチサイズ(i.e. 1-64トークン)の場合、行列乗算は微小であるため、重なる計算がほとんどなく、カスタムカーネルの固定コストが支配的になります。cuBLASのオーバーヘッドが低いため、完全デコード+cuBLASがよく勝者となります。大きなバッチサイズ(i.e. 256+トークン)の場合、行列乗算は追加の再構築作業を吸収するのに十分な長さ実行されます。軽量な前処理はより速く完了し、解放されたバス帯域幅と計算のオーバーラップが利益をもたらします。パレットまたは指数パイプラインが先頭を走ります。同じレイヤー内の異なる重み行列は、異なるパイプラインを有利に働かせます。「gate(ゲート)」および「up」射影は、「down」射影とは異なる次元を持ち、行列乗算内で実行される演算の順序を変更するため、異なるパフォーマンスのトレードオフを要求します。
スループット(throughput)とパイプライン戦略
これがUnweightが単一の戦略をハードコードしない理由です。ランタイムは、ターゲットハードウェアでの実際のエンドツーエンドのスループットを測定するオートチューニング(autotuning)プロセスによって判断され、各バッチサイズ(batch size)における各ウェイト行列(weight matrix)に対して最適なパイプラインを選択します(詳細は後述)。
How the reconstructive matmul works -> 再構成型行列乗算(reconstructive matmul)の動作原理
4つのパイプラインのうち3つは、デコードと演算を融合したカスタム行列乗算カーネル(matrix multiplication kernel)を使用しています。このカーネルは、HBM(High Bandwidth Memory)から圧縮データをロードし、共有メモリ(shared memory)内で元のBF16値を再構成して、テンスコア(tensor cores)に直接供給します。これらはすべて1つの操作で完結し、再構成された重みはメインメモリに存在することはありません。
Traditional decompression vs Unweight -> 従来のデコードとUnweightの比較

Unweightを使用すると、MLP(Multi-Layer Perceptron)のウェイト行列を伝送するメモリーバス(memory bus)のデータ量が約30%削減されます
このカーネル内部では、GPUのスレッドグループ(thread groups)は2つの役割に分割されます:
プロデューサーグループ(producer group)は、専用のメモリコピーハードウェア(TMA:Tensor Memory Accelerator)を使用して、HBMから圧縮入力を共有メモリにロードします。符号付き仮数(sign+mantissa)バイト、指数データ(exponent data)(またはパレットインデックス(palette indices))、そして稀な指数を持つ行の場合はそのままの指数行をステージングします。コンシューマーより先に実行し、データが必要になる前に準備が完了するよう円形バッファ(circular buffer)を埋めます。
コンシューマーグループ(Consumer groups)は、指数と符号付き仮数バイトを結合してBF16値を再構成し、その結果をすぐにHopperアーキテクチャのWGMMA(Warped Group Matrix Multiply-Accumulate)テンスコア命令に供給します。再構成された重みは、共有メモリから出ることなく、アセンブリから直接演算へと渡されます。
再構成型行列乗算には複数のバリエーションがあり、各コンピュートユニット(compute unit)が処理する出力タイルの数と円形バッファの深さが異なります。広い出力タイルはバッチサイズが大きい場合のデータ再利用を向上させ、深いバッファはバッチサイズが小さい場合のメモリレイテンシを隠蔽します。オートチューナー(autotuner)が各ワークロードに対して最適なバリエーションを選択します。
Sharing the GPU between decoding and computation -> デコードと演算の間のGPU共有
2つの融合パイプラインでは、別個のプリプロセスカーネル(Huffman decoderまたはpalette transcoder)が再構成型行列乗算と並行して実行されます。しかし、これらのカーネルはGPUリソースを競合します。
Hopperアーキテクチャでは、各コンピュートユニット(SM:Streaming Multiprocessor)に228 KBの共有メモリが搭載されています。再構成型行列乗算にはパイプラインバッファとアキュムレータタイル(accumulator tiles)用に約227 KBが必要です。デコードカーネルにはハフマン探索テーブル(Huffman lookup table)用に約16 KBが必要です。227 + 16 > 228 となるため、これら2つのカーネルは同じコンピュートユニットを共有できません。デコードに割り当てられるSMが1つ増えるごとに、行列乗算で使用可能なSMは1つ減ります。

これはバランス調整を生み出します:デコード用のSM(ストリーミングマルチプロセッサ)を増やすと前処理は高速化しますが行列乗算(matmul)が遅くなり、その逆も同様です。最適な分割比率はもう一つの調整可能なパラメータであり、これが自動チューナー(autotuner)がヒューリスティックに頼るのではなく実際のスループットを測定する理由の1つでもあります。
Pipelining across layers
SM(ストリーミングマルチプロセッサ)の分割制約があっても、UnweightはTransformerモデルの構造を活用することで、復号化コストの大部分を隠蔽しています。
実行時にすべてのレイヤーがHuffman復号化を必要とするわけではありません。Unweightはレイヤーを「ハード」(Huffman前処理が必要)と「イージー」(行列乗算(matmul)が直接消費できる事前トランスコード済みパレットデータを使用)に分類します。ランタイムはこれらを交互に実行します:
 image
image
復号化は、ブートストラップ、アテンション(注意機構)、イージーなMLP(多層パーセプトロン)計算中に別々のCUDAストリーム上で実行されます。ハードレイヤーのMLPが実行される頃には、その前処理済み重みはすでに待機しています
GPUが前処理を必要としないイージーレイヤーの計算を行っている間、別セットのCUDAストリームがバックグラウンドで次のハードレイヤーの重みを復号化しています。イージーレイヤーが完了してハードレイヤーの番が回ってくる頃には、その前処理済みデータはすでに待機しています。ダブルバッファリングされた前処理スロットにより、1つのハードレイヤーからの復号化出力がまだ消費されている間に上書きされないことが保証されます。
下向き投影(down projection)はこのオーバーラップから最大の恩恵を受けます:MLPシーケンスの最後(ゲート、活性化関数、上向き投影(up)の後)に消費されるため、復号化が完了するまでの最長のタイムロス(ランウェイ)を確保できます。
自動チューニング
4つのパイプライン、複数の行列乗算(matmul)カーネルのバリエーション、そして復号化と計算の間で調整可能なSM分割があるため、設定空間は広大です。単一の戦略をハードコードするのではなく、Unweightはターゲットハードウェアでの実際のエンドツーエンド推論スループットを測定する自動チューナー(autotuner)を使用します。ゲート投影については上向きと下向きの設定を固定したまま候補設定を探索し、次に上向き、そして下向きを探索し、これ以上改善が見られないまでこれを繰り返します。その結果、各バッチサイズにおける各投影に対して、どのパイプライン、行列乗算のバリエーション、SM割り当てを使用するかをランタイムに指示するモデルごとの設定ファイルが生成されます。これらはすべて、ヒューリスティックではなく測定されたパフォーマンスによって駆動されています。
1つの圧縮フォーマット、複数の用途
エンコーディングフォーマット、実行パイプライン、スケジューリング(スケジューラ)は独立した選択です。同じHuffman圧縮モデルバンドルが、配布と推論の両方に使用できます:
配布においては、Huffmanエンコーディングが圧縮率を最大化し(モデル全体のサイズを約22%削減)、ネットワーク全体でモデルを送信する際の転送時間を短縮します。
推論(inference)時、Huffman符号化された射影行列はモデルロード時にパレット中間形式にトランスコード可能であり、配布フォーマットを制限することなく、最も効率的なランタイム実行を実現します。
単一のモデルバンドルは、パッケージング時に一つの戦略に縛られる必要はありません。ランタイムは、射影行列ごと、バッチサイズごとに最適な実行パスをその場で選択します。
\n 結果 \n \n
\n Llama 3.1 8B(主要なテストベッド)において、Unweightは以下の成果を達成します:\n
推論用バンドルではモデルフットプリントが約13%削減(ゲート/アップMLP射影のみを圧縮)、配布用バンドルでは約22%削減(ダウンを含むすべてのMLP射影を圧縮)。すべての圧縮は100%ビット完全な可逆圧縮です。Llama 70Bに外挿すると、構成によっては約18〜28 GBの節約につながります。
現在の最適化レベルにおけるスループットオーバーヘッドは30〜40%(H100 SXM5でのエンドツーエンド測定)。このオーバーヘッドはバッチサイズ1で最大(約41%)となり、バッチ1024では縮小(約30%)します。既知の3つの要因——小バッチの固定コスト、冗長なウェイトタイル再構築、除外されたダウン射影——は現在積極的に最適化中です。
これらは単一モデルにおける中間結果です。圧縮率は他のSwiGLUアーキテクチャにも一般化するはずです(指数統計はモデル規模全体で一貫しています)、ただしスループット数値は現在のカーネル実装に固有のものであり、最適化の進行とともに変化します。また、現時点ではアテンション重み(attention weights)、埋め込み表現(embeddings)、レイヤー正規化(layer norms)は圧縮対象としておらず、これらが全体の削減率を薄めています。
\n なぜこれが重要なのか \n \n
\n GPUは複数の次元で高価です:カード自体のコスト、要求される高帯域幅メモリ(high-bandwidth memory)、そして大きな電力消費。\n
これに対処するため、複数の研究者が完全モデルに対して約30%の圧縮率という有望な結果を示すシステムを発表していますが、これらはコンシューマー向けGPUやプロダクションスケールで動作しない研究用フレームワークを対象としています。Unweightの開発における鍵となる洞察は、マルチレイヤーパーセプトロン(MLPs)がモデル重みの大部分を占め、推論ワークロードにおける計算コストの大きな部分を構成しているという点です。UnweightはMLP重みだけを圧縮し(圧縮の恩恵が限定的なレイヤーでのオーバーヘッドを回避)、計算とメモリがきめ細かくバランスされたデータセンター向けH100 GPUのために特別に設計されており、単一のアプローチではなくバッチサイズに適応する4つの実行パイプラインを備えています。
ただし、明確にしておきたい点があります。Unweightはタダで手に入るもの(free lunch)ではありません。オンチップでの再構築は、非圧縮重みでは発生しない計算作業を追加します。Llama 3.1 8Bにおいて、推論設定は典型的なサービングバッチサイズで約30%のスループットコストを払うことで、モデルメモリ全体の約13%を節約します。このギャップはより大きなバッチ(プリプロセスのオーバーラップが改善される)で縮小し、最適化が進むにつれてさらに縮小すると予想されます——特に、
原文を表示
Running inference within 50ms of 95% of the world's Internet-connected population means being ruthlessly efficient with GPU memory. Last year we improved memory utilization with Infire, our Rust-based inference engine, and eliminated cold-starts with Omni, our model scheduling platform. Now we are tackling the next big bottleneck in our inference platform: model weights.
Generating a single token from an LLM requires reading every model weight from GPU memory. On the NVIDIA H100 GPUs we use in many of our datacenters, the tensor cores can process data nearly 600 times faster than memory can deliver it, leading to a bottleneck not in compute, but memory bandwidth. Every byte that crosses the memory bus is a byte that could have been avoided if the weights were smaller.
To solve this problem, we built Unweight: a lossless compression system that can make model weights up to 15–22% smaller while preserving bit-exact outputs, without relying on any special hardware. The core breakthrough here is that decompressing weights in fast on-chip memory and feeding them directly to the tensor cores avoids an extra round-trip through slow main memory. Depending on the workload, Unweight’s runtime selects from multiple execution strategies – some prioritize simplicity, others minimize memory traffic – and an autotuner picks the best one per weight matrix and batch size.
This post dives into how Unweight works, but in the spirit of greater transparency and encouraging innovation in this rapidly developing space, we’re also publishing a technical paper and open sourcing the GPU kernels.
Our initial results on Llama-3.1-8B show ~30% compression of Multi-Layer Perceptron (MLP) weights alone. Because Unweight works selectively on the parameters for decoding, this leads to a 15-22% in model size reduction and ~3 GB VRAM savings. As shown in the graphic below, this enables us to squeeze more out of our GPUs and thus run more models in more places — making inference cheaper and faster on Cloudflare’s network.
image
Thanks to Unweight, we’re able to fit more models on a single GPU
Why compression is harder than it sounds
There is a growing body of research exploring how to compress model weights in creative ways to make inference faster and/or run on smaller GPUs. The most common is quantization, a technique to reduce the size of model weights and activations by converting large 32- or 16-bit floating point numbers to smaller 8 or 4-bit integers. This is a form of lossy compression: different 16-bit floating point values can be converted to the same 4-bit integer. This reduction in accuracy affects the quality of responses in unpredictable ways. For production inference serving diverse use cases, we knew we wanted something lossless that preserves exact model behaviour.
Several recent systems (Huff-LLM, ZipNN, and ZipServ) have shown that LLM weights can be compressed significantly, but these approaches target different problems than ours. ZipNN compresses weights for distribution and storage with decompression happening on the CPU. HUff-LLM proposes custom FGPA hardware for decoding. And ZipServ does fuse decompression with GPU inference, but targets consumer grade GPUs, which don’t work with our H100 GPUs. None of these gave us what we needed: lossless inference-time decompression on Hopper GPUs that can integrate with our Rust based inference engine.
The core challenge isn't vanilla compression — exponent bytes in BF16 weights are highly redundant, so entropy coding works well on them. The challenge is decompressing fast enough that it doesn't slow down inference. On an H100, the tensor cores sit idle waiting for memory most of the time — but that idle capacity can't simply be repurposed for decompression. Each GPU compute unit can run either the decompression kernel or the matrix multiplication kernel, not both simultaneously, due to shared memory constraints. Any decode latency that isn't perfectly overlapped with the matrix multiplication becomes directly additive to token latency. Unweight's answer is to decompress weights in fast on-chip shared memory and feed the results directly to the tensor cores — but making that work efficiently across different batch sizes and weight shapes is where the real engineering lives.
How model weights can be compressed effectively
Every number in an AI model is stored as a 16-bit "brain float" (BF16). Each BF16 value has three parts:
Sign (1 bit): positive or negative
Exponent (8 bits): the magnitude
Mantissa (7 bits): the precise value within that magnitude
Here’s how one of these weights breaks down:
image
The sign and mantissa vary unpredictably across weights — they look like random data and can't be meaningfully compressed. But the exponent tells a different story.
The exponent is surprisingly predictable
Prior research has established that across trained LLMs, out of 256 possible exponent values, just a handful dominate. The top 16 most common exponents cover over 99% of all weights in a typical layer. Information theory says you only need ~2.6 bits to represent this distribution — far less than the 8 bits allocated. If you look at the exponent value distribution in a typical LLM layer, you can see that the top 16 exponents account for 99% of all model weights.
Exponent value distribution in a typical LLM layer
image
This is the redundancy that Unweight exploits. We leave the sign and mantissa untouched and compress only the exponent byte using Huffman coding — a classic technique that assigns short codes to common values and longer codes to rare ones. Because the exponent distribution is so skewed, this achieves roughly 30% compression on the exponent stream. We apply this selectively to the MLP weight matrices (gate, up, and down projections), which make up roughly two-thirds of a model’s parameters and dominate memory traffic during token generation. Attention weights, embeddings and layer norms are uncompressed. All told the optimizations translate to about 20% reduction in overall multilayer perceptron (MLP) weight size, as explained in full detail in our technical report.
The small number of weights with rare exponents are handled separately: if any weight in a row of 64 has an exponent outside the top-16 palette, the entire row is stored verbatim. This approach eliminates per-element branching in the hot path — instead of checking every single weight for edge cases, we make one decision per row up front.
The GPU memory bottleneck
An NVIDIA H100 GPU has two relevant kinds of memory:
High Bandwidth Memory (HBM): large, but relatively slow to access. This is where model weights live.
Shared memory (SMEM): tiny, but extremely fast. This is where the GPU stages data right before doing math.
image
During inference, generating each token requires reading the full weight matrix from HBM. The memory bus between HBM and SMEM is the performance bottleneck – not the math itself. Fewer bytes across the bus = faster token generation.
During inference, generating each token requires reading the full weight matrix from HBM through the memory bus — this is the bottleneck. The H100's tensor cores can crunch numbers far faster than HBM can feed them data. Compression helps because fewer bytes need to cross the bus. But there's a catch: the GPU can't do math on compressed data. The weights must be decompressed first.
Most prior work decompresses entire weight matrices back into HBM, then runs a standard matrix multiplication. This helps with storage capacity but doesn't help with bandwidth because you still read the full uncompressed matrix from HBM for every token.
Four ways to use compressed weights
There's no single best way to use compressed weights during inference. The right approach depends on the workload — the batch size, the shape of the weight matrix, and how much GPU time is available for decompression. Unweight offers four compressed execution pipelines, each with a different balance between decompression effort and computation complexity: a full Huffman decode, exponent-only decode, palette transcode, or skipping pre-processing completely.
image
Four different execution pipelines
The four pipelines form a spectrum. At one end, full decode completely reconstructs the original BF16 weights and hands them to NVIDIA’s cuBLAS library for a standard matrix multiplication. This is the simplest path with cuBLAS running at full speed on ordinary data, but the preprocess step writes the most bytes back to main memory. It works well at small batch sizes where the matrix multiplication is tiny and custom kernel overhead dominates. At the other end, direct palette skips preprocessing entirely. Weights are pre-transcoded to a compact 4-bit format at model load time, and the matrix multiplication kernel reconstructs BF16 values on the fly from these indices. Zero preprocess cost, but the kernel does more work per element.
In between sit two independent paths: one that decodes only the exponent bytes (halving preprocess traffic), and one that transcodes to 4-bit palette indices at runtime (quartering it). Both use a reconstructive matrix multiplication — a custom kernel that loads compressed data, reconstructs BF16 in fast shared memory, and feeds it directly to the tensor cores without a round-trip through main memory.
Why no single pipeline wins
Less preprocessing means less data written to HBM, which frees the memory bus sooner. But it shifts more reconstruction work onto the matmul kernel. Whether that tradeoff pays off depends on the situation.
With small batch sizes (i.e. 1-64 tokens), the matmul is tiny, so there isn't much computation to overlap with, and the fixed costs of a custom kernel dominate. Full decode + cuBLAS often wins simply because cuBLAS has lower overhead. With large batch sizes (i.e. 256+ tokens), the matmul runs long enough to absorb the extra reconstruction work. A lighter preprocess finishes faster, and the freed-up bus bandwidth and compute overlap pay off. The palette or exponent pipelines pull ahead. Different weight matrices within the same layer can favor different pipelines. The "gate" and "up" projections have different dimensions than the "down" projection, changing the order of operations performed within the matmul which requires different performance tradeoffs.
Throughput vs pipeline strategy
image
This is why Unweight doesn't hard-code a single strategy. The runtime picks the best pipeline for each weight matrix at each batch size, informed by an autotuning process that measures actual end-to-end throughput on the target hardware (more on this below).
How the reconstructive matmul works
Three of the four pipelines use a custom matrix multiplication kernel that fuses decompression with computation. This kernel loads compressed data from HBM, reconstructs the original BF16 values in shared memory, and feeds them directly into the tensor cores — all in one operation. The reconstructed weights never exist in main memory.
Traditional decompression vs Unweight
image
With Unweight, ~30% fewer bytes cross the memory bus for MLP weight matrices
Inside this kernel, the GPU's thread groups are split into two roles:
A producer group loads compressed inputs from HBM into shared memory using dedicated memory-copy hardware (TMA). It stages sign+mantissa bytes, exponent data (or palette indices), and – for rows with rare exponents – the verbatim exponent rows. It runs ahead of the consumer, filling a circular buffer so data is ready before it's needed.
Consumer groups reconstruct BF16 values by combining exponents with sign+mantissa bytes, then immediately feed the result into Hopper's WGMMA tensor-core instructions. The reconstructed weights go straight from assembly to computation without leaving shared memory.
The reconstructive matmul comes in multiple variants, differing in how many output tiles each compute unit handles and how deep the circular buffer runs. Wider output tiles improve data reuse at large batch sizes; deeper buffers hide memory latency at small batch sizes. The autotuner selects the best variant per workload.
Sharing the GPU between decoding and computation
In the two fused pipelines, a separate preprocess kernel (Huffman decoder or palette transcoder) runs concurrently with the reconstructive matmul. But these kernels compete for GPU resources.
On Hopper, each compute unit (SM) has 228 KB of shared memory. The reconstructive matmul needs ~227 KB for its pipeline buffer and accumulator tiles. A decode kernel needs ~16 KB for its Huffman lookup table. Since 227 + 16 > 228, these two kernels cannot share the same compute unit. Every SM assigned to decoding is one fewer SM available for the matmul.
image
This creates a balancing act: more decode SMs means faster preprocessing but slower matrix multiplication, and vice versa. The optimal split is another tunable parameter — and another reason why the autotuner measures real throughput rather than relying on heuristics.
Pipelining across layers
Even with the SM partitioning constraint, Unweight hides much of the decompression cost by exploiting the structure of transformer models.
Not every layer needs Huffman decoding at runtime. Unweight classifies layers as "hard" (requiring Huffman preprocessing) or "easy" (using pre-transcoded palette data that the matmul can consume directly). The runtime alternates between them:
image
Decode runs on separate CUDA streams during bootstrap, attention, and easy MLP compute. By the time a hard layer's MLP runs, its preprocessed weights are already waiting
While the GPU computes an easy layer — which needs no preprocessing — a separate set of CUDA streams is decoding the next hard layer's weights in the background. By the time the easy layers finish and the hard layer's turn arrives, its preprocessed data is already waiting. Double-buffered preprocess slots ensure that decode output from one hard layer isn't overwritten while it's still being consumed.
The down projection benefits most from this overlap: it's consumed last in the MLP sequence (after gate, activation, and up), so its decode has the longest runway to complete.
Autotuning
With four pipelines, multiple matmul kernel variants , and a tunable SM split between decoding and computation, the configuration space is large. Rather than hard-coding a single strategy, Unweight uses an autotuner that measures actual end-to-end inference throughput on the target hardware. It sweeps candidate configurations for the gate projection while holding up and down fixed, then sweeps up, then down, repeating until no further improvement is found. The result is a per-model configuration file that tells the runtime exactly which pipeline, matmul variant, and SM allocation to use for each projection at each batch size — all driven by measured performance rather than heuristics.
One compression format, multiple uses
Encoding format, execution pipeline, and scheduling are independent choices. The same Huffman-compressed model bundle can serve both distribution and inference:
For distribution, Huffman encoding maximizes compression (~22% total model size reduction), reducing transfer times when shipping models across the network.
For inference, Huffman-encoded projections can be transcoded to the palette intermediate format on model load, enabling the most efficient runtime execution without constraining the distribution format.
A single model bundle doesn't need to commit to one strategy at packaging time. The runtime selects the best execution path per projection and per batch size on the fly.
Our results
On Llama 3.1 8B (our primary testbed), Unweight achieves:
~13% model footprint reduction for inference bundles (compressing only gate/up MLP projections), or ~22% for distribution bundles (compressing all MLP projections including down). All compression is 100% bit-exact lossless. Extrapolating to Llama 70B, this can translate to roughly 18–28 GB saved depending on configuration.
30–40% throughput overhead at current optimization level, measured end-to-end on H100 SXM5. The overhead is largest at batch size 1 (~41%) and narrows at batch 1024 (~30%). Three known sources – small-batch fixed costs, redundant weight-tile reconstruction, and the excluded down projection – are under active optimization.
These are intermediate results on a single model. The compression ratios should generalize to other SwiGLU architectures (exponent statistics are consistent across model scales), but the throughput numbers are specific to the current kernel implementations and will change as optimization continues. We do not yet compress attention weights, embeddings, or layer norms, which dilute the overall reduction.
Why this matters
GPUs are expensive in multiple dimensions: the cost of the cards themselves, the high-bandwidth memory they demand, and their significant power consumption.
To combat this, several researchers have shown systems with promising results of ~30% compression ratios on full models — but these target consumer GPUs and research frameworks that don’t work at production scale. The key insight into Unweight’s development is that multilayer perceptrons (MLPs) constitute the majority of model weights and a significant amount of the compute cost during inference workloads. It compresses only MLP weights (avoiding overhead on layers where compression benefit is marginal), is designed specifically for datacenter H100 GPUs with their tightly-balanced compute and memory, and comes with four execution pipelines that adapt to batch size rather than using a single approach.
However, we want to be clear: Unweight is not a free lunch. On-chip reconstruction adds computational work that wouldn't exist with uncompressed weights. On Llama 3.1 8B, the inference configuration saves approximately 13% of total model memory at a throughput cost of roughly 30% at typical serving batch sizes. This gap narrows at larger batches (where preprocess overlap improves) and is expected to narrow further as we optimize — in particular,
関連記事
エンドツーエンドFP8精度による高スループット強化学習トレーニングの実行
NVIDIAは、大規模言語モデルの複雑な推論支援のため、エンドツーエンドFP8精度を活用した高スループット強化学習トレーニング手法を提供する。
超大規模言語モデル実行の基盤構築
Cloudflareが、MoonshotのKimi K2.5などの大規模オープンソースモデルをホストするWorkers AIを発表し、モデル速度を3倍向上させた。同社は、これらのモデルを基盤としたエージェント製品やツールを今週リリースしている。
Aurora:推論効率を向上させるオープンソース強化学習フレームワーク
Auroraは、推論効率を1.25倍向上させるオープンソースの強化学習フレームワークです。これは、推論を単なるオフライン設定から、リクエストごとに自己改善するシステムへと変革します。