AI ネイティブな開発実践への道
メルカリ NFT チームは、AI-Native 開発において外部の機構よりも自社の価値観に基づく「判断基準」を構築する重要性を説き、Claude Code を活用した PoC の実践とハーネスエンジニアリングの概念を紹介している。
キーポイント
判断基準の優先と機構の外部化
AI に開発を任せる際、正解そのものよりも「何が正しいかの判断基準」を自前で蓄積することが重要であり、技術的な機構は外から調達すべきだと結論づけている。
社内基盤からの脱却による検証
既存の社内基盤に依存せず、あえて前提から組み直すことで AI-Native 開発の本質的な要件や新しいアプローチを検証する Proof of Concept(PoC)として位置付けている。
ハーネスエンジニアリングの実践
Mitchell Hashimoto 氏が提唱する「engineer the harness」の概念に基づき、モデルを制御・観測・保護する外側ハーネス(Guide/Guardrail と Sensor)の設計に注力している。
軽量構成による迅速な適応
Claude Code の進化(プラグインや Agent Teams など)に素早く追随できるよう、CLAUDE.md や rules などの軽量化された構成で試行錯誤し、効果の切り分けを容易にしている。
影響分析・編集コメントを表示
影響分析
この記事は、単なるツール導入の成功談ではなく、AI を開発プロセスに統合する際の戦略的優先順位(判断基準 vs 機構)を明確にした点で業界に示唆を与えるものです。特に、社内基盤への依存を一度断ち切って本質を検証するアプローチや、ハーネスエンジニアリングの実践例は、多くの企業が直面している「AI 開発の壁」を突破するための具体的な指針となります。
編集コメント
「判断基準」の重要性を説く本記事は、AI ツールが普及する中で陥りがちな「技術依存」への警鐘として非常に価値があります。特にハーネスエンジニアリングの実践例は、開発チームがすぐに参照できる具体的なフレームワークとなっています。
こんにちは、becosuke です。メルカリ NFT と、その上で立ち上げている新規サービスの Backend を担当しています。この記事は「Merpay & Mercoin Tech Openness Month 2026」の 20日目の記事です。
この記事では、私たちメルカリ NFT チームがこの4ヶ月ほどで取り組んできた AI-Native な開発について書きます。1月末から、開発のやり方そのものを大きく作り変えてきていて、最終的には人の手をできるだけ介さずにサービスを作り続けられる状態を目指しています。その過程で得た学びを、似たことに取り組もうとしている方に持ち帰ってもらえたらと思っています。
先に結論だけ書いておきます。私たちがリソースを集中させるべきだと判断したのは「正解」そのものではなく、何が正しく何が誤りかの「判断基準」(注1)でした。AI を動かすための機構は、これからどんどん外から手に入るようになります。けれど判断基準だけは、その案件ならではの価値観そのものなので、外注できません。だから私たちは、機構を作ることよりも、その上に載せる判断基準を残すことに時間をかけました。なぜそう考えたのか、そして実際に何をやったのかを、順を追って書いていきます。
この案件の位置付け
私たちは、Non-Fungible Token(NFT)の売買を行うマーケットプレイスである メルカリ NFT を既存サービスとして運営しています。いま新しく立ち上げているのは、この既存の メルカリ NFT のコードベースを土台にした新規サービスです。
この案件には、2つの顔があります。1つは、新しいプロダクトの立ち上げであること。もうひとつは、AI-Native な開発のあり方そのものを試す Proof of Concept(PoC)の場であることです。
メルカリには会社全体として AI-Native 化を進める方針があり、社内基盤もすでにしっかり整っています。その方向性には私たちも強く共感しているのですが、今回はあえて一度そこを離れて、前提から組み直すとどうなるかを試してみることにしました。理由は3つあります。
1つ目は、AI に spec から開発を駆動させるには、その spec を解釈するための価値基準や判断の根拠が前提として必要だと考えたからです。これがいちばん大きな理由でした。社内基盤の上に乗ったとしても、AI が「何を基準に判断すべきか」を持たないうちは自走できません。基盤の良し悪しの問題ではなく、その手前で価値基準と過去の判断の根拠を溜める前工程が、私たちにはまだ必要だったということです。だからまずはそこを溜め込む段階を踏んでから、成熟した先で既存の仕組みに接続する、という順序を選びました。
2 つ目は、既存の正解の上に乗ると、その枠内での最適化しかできないからです。この案件は新しいプロダクトの立ち上げであると同時に AI-Native 開発の PoC(Proof of Concept:概念実証)でもあるので、いったん既成の枠を外して前提から組み直すことに意味があります。AI-Native として本当は何が必要なのかを検証したかったので、別のアプローチで組み立て直すことで見えてくるものを優先しました。社内基盤を使うプロジェクトと、別解を試すプロジェクトが並走すれば、会社全体として AI-Native 開発の幅も広がります。
3 つ目は、Claude Code 本体の進化に身軽についていきたかったからです。Claude Code には plugin や Agent Teams のような、開発の組み立て方そのものに関わる機能追加が数ヶ月単位で入っていて、AI に開発をさせる足場の作り方が次々に変わっていきます。こうした新機能をすぐ取り込めるよう、CLAUDE.md と rules、skill、hooks だけの軽い構成で試したかったという事情もあります。標準機能だけで素朴に組むことで、何が効果を生んでいるのかの切り分けもしやすくなります。
念のため書いておくと、この独自路線は社内基盤と対立するものではありません。あくまで今の段階での選択であって、蓄積が成熟したら、社内基盤の考え方を取り込んだり、逆にこの案件で得たやり方を社内のほかの案件でも使えるようにしたり、という双方向の合流を視野に入れています。
この記事でいちばん伝えたいこと:機構は外から、判断基準は自前で
具体例に入る前に、この記事を貫く中心の考え方から書きます。
AI agent は、モデルと、その周りを取り囲む機構(ハーネス)でできていると言われています(Agent = Model + Harness)。このモデルを取り囲む環境・制約・フィードバックを設計する規律は、2026 年 2 月に Mitchell Hashimoto 氏がブログ (注 2) で "engineer the harness" と名付けて以降、ハーネスエンジニアリングと呼ばれて急速に広まりました。prompt engineering(プロンプトエンジニアリング)から context engineering(コンテキストエンジニアリング)、そして harness engineering(ハーネスエンジニアリング)へ、という発展の系譜です。
ハーネスにはさらに、モデル提供元が出荷する内側ハーネス(Agent SDK など)と、その上に私たちが組み立てる外側ハーネスがあります。Thoughtworks の Birgitta Böckeler は、外側ハーネスを agent の前に指針や制約を渡す Guide / Guardrail(feed-forward:前向きフィード)と、agent の出力を観測してフィードバックを返す Sensor(feedback:後向きフィード)に分けたうえで、ハーネスの議論は禁止やガードレールの側に偏りがちで、観測の側はむしろ手薄になりやすいと指摘しています。
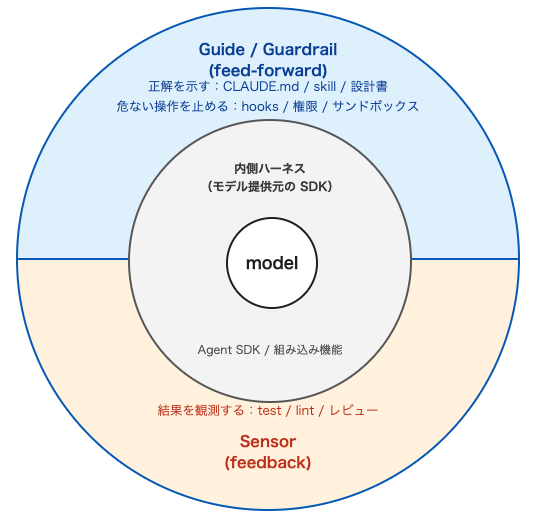
ハーネスには大きく 3 つの役割があります。
- 正解を示すこと
- 結果を観測すること
- 危ない操作を止めること
これらすべては、AI に安心して任せるために欠かせません。私たちはこの偏りに違和感を持ち、3 つの役割を等しく支える機構がどこにあるのかを考えました。
ここで私たちが立てた仮説はこうです。この 3 つを支える機構は、これからプラットフォーム側が整えてくれる。評価ループ(evaluation loop)、hooks、権限のプロンプト、サンドボックスといった機構は、汎用部品として外から提供される方向に向かっている。実際、危ない操作を事前に止める hooks や権限のプロンプトは Claude Code 本体に組み込まれていて、自前で実装するものから既製品として使うものへと、徐々に移ってきています。だとすれば、その機構づくりは私たちのチームでは「できるだけやらない部分」として切り分けてよい、と考えました。
一方で、3 つの役割すべてに共通して必要になるものがあります。何を正解とし、どこからを合格とし、何を危険とするか、それぞれの判断基準です。これは、この案件ならではの価値観そのものなので、外からは提供されません。観測エンジンや停止機構は買えても、その基準は各案件固有の判断の産物で、外注できない。整理すると、三本柱のすべてについて「機構は買える/判断は自前」という構図になります。
機構
判断基準
正解を示す
context を供給する足場
何を正解とするか
結果を観測する
評価ループ・eval 基盤(evaluation framework)
どこからを合格とするか
危険を止める
hooks・権限・サンドボックス
何を危険とするか
出どころ
プラットフォームが提供(買える)
案件固有(自前で持つしかない)
なぜ「判断基準」を集めるのか
個別の正解を一つひとつ集めていくより、判断基準を与えるほうが、応用が効きます。1 つの正解は点にすぎませんが、判断基準はその点を生み出す規則です。だから、まだ出会っていない状況に遭遇しても、基準さえあれば AI は自ら考えることができます。
例えばデータの書き換えについて、私たちは「InsertOrUpdate(UPSERT)は使わず、Read で存在を確かめてから INSERT か UPDATE に分岐する」という方針を残しています。UPSERT は全カラムを指定しないと意図しないリセットが起きるためです。この 1 つの方針が、AI が新しい書き込み処理を書くときの指針にもなり、reviewer が UPSERT の紛れ込みを一次チェックする観点にもなります。Anthropic の言葉を借りれば(注 3)、正解を示すというのは「モデルの望ましい挙動を最も生みやすいコンテキストを与えること」で、観測するときの基準もそこから派生します。同じ判断基準が、正解を示す側にも、結果を観測する側にも、両方の基盤になっているわけです。
機構と判断基準には、もうひとつ大事な違いがあります。「寿命」が違うということです。Anthropic 自身も、ハーネスの各構成要素は「いまのモデルにこれができない」という前提のうえに置かれているので、その前提は stress test(ストレステスト)して、要らなくなったら外していく対象だと述べています。(注4)実際、ある世代のモデルで必要だった構成要素が、次の世代では不要になったり、別の組合せに置き換わったりしていく例も出てきています。もちろん、test のようにモデルがどれだけ進化しても外せない観測の機構もあるので、すべての機構が一律に失効していくわけではありません。それでも、機構の側には入れ替わりがある一方で、目標と正しい判断基準を与える側は廃れずに残ります。だからこそ判断基準は、特定のツールの設定ファイルに埋め込むのではなく、自分たちのリポジトリに、可搬な形で持っておくべきだと考えました。
ここからは、この考え方を実際の開発でどう形にしたのか、4 つの具体例と、それによる変化、それらを社内のほかの案件で共有する方法について書いていきます。どの取り組みも、機構を作り込むことよりも、その上流にある判断基準を残すことに重点を置いた話として読んでもらえると、つながりが見えてくると思います。
1. コードの一貫性:言葉の意味や正しいやり方を 1 つに固定する
1 つ目は、コードの一貫性です。
既存のコードベースを途中から AI-Native に切り替えるために、最初にやったことは大量のリファクタリングでした。人間ならあまり気にしないようなちょっとした言葉のゆれが、AI の判断を狂わせてしまうので、意味を 1 つに揃えておく必要があります。同じ概念が場所によって違う名前で呼ばれていたり、書き方が場所ごとに違ったりすると、AI はそのたびに周辺から「この案件ではどう書いているか」を推測することになり、出力がぶれます。
そこで、二段階で揃えました。
まず、同じ言葉が複数の意味を指している状態や、その逆をなくして、「1 つの概念には 1 つの名前、1 つの名前には 1 つの意味」というところまで徹底しました。命名は AI がコードベースの全体像を掴むときに最初に頼る手がかりなので、ここがぶれていると、その先のどんな指示や設計書を渡しても精度が落ちてしまいます (注5)。
次に、正しいやり方が何通りもあるものについて、どれでやるかを決めてルールとして書き残しました。例えばエラーの扱い、ページネーションの実装、enum の持ち方のように、「正解は複数あるが、案件としてはこの形に揃える」というものをルール化しておく。こうしておくと、今後同じような課題にぶつかったとき、AI は解決の方法を迷わず選べます。前の章で書いた「1 つの正解(点)」ではなく「判断基準(規則)」を残す、というのを地でいく作業でした。
この期間、構造を整えながら、差し引きで万単位の行数のコードを減らしました。機能を削ったのではなく、重複や不要な抽象を整理して、同じことをより少ないコードで表すようにした結果です。AI が読まされる量が減り、1 つの概念にあたる場所が一箇所に集まることで、AI に渡す文脈はノイズの少ないものになります。コードベースを整えること、それ自体が、AI のための環境整備の土台になる作業だったと考えています。
2. 判断を残す仕組み:spec / design と RDR / ADR
2 つ目は、判断を残す仕組みです。
私たちは、仕様書(spec)には「いまどうなっているか」だけを書いて、「なぜそう決めたのか」「どの案を捨てたのか」という判断は別のファイルに分けて残しています。判断の経緯を残しておかないと、しばらく経ってから「なぜここをこう決めたんだっけ」と人も agent も何度も悩み直すことになります。一度悩んだことを文字にしておけば、次の人や AI はその上から考え始められます。
設計(design)の判断には、もともと ADR(Architecture Decision Records)という考え方があり、社内基盤でも使われています。私たちはこれを仕様の側にも持ち込んで、なぜその仕様にしたのかという判断を RDR(Requirements Decision Records)という専用のファイルに残す方針にしました。spec 本体は「現時点の仕様」を表し、RDR は「そこに至るまでの判断の積み重ね」を表す、という役割分担です。
ADR や RDR を「どう書くか」「どんなときに新しいレコードを作るか」といった作法は、decision-record という skill にまとめてあります。記録そのものは各案件に固有のものなので持ち運べませんが、「記録の作り方」のほうは共通の手順として配ることができます。
判断の経緯や却下した代替案を本文に混ぜると、「今の仕様はどれか」を読み取りにくくなってしまいます。現時点の要求だけを spec に残し、判断の層を RDR に切り出すことで、レビュー対象をノイズから守っています。
AI 側から見ても、この分離には意味があります。エージェントは普段は現状(spec / design)だけを読み、仕様を変えるときにだけ、紐づく RDR / ADR を必要に応じて引きにいきます。こうすると、AI に渡す context には「いまどうあるか」だけが入り、過去の議論や却下案がノイズとして混ざらない状態を保てます。
Git を origin に、Notion を読む場所に
ドキュメントの原本はすべて Git に置いていて、Notion には自動で同期したコピーを置いて、読む場所やコメントをつける場所として使っています。

Notion をそのまま origin にすると、ドキュメントがチームの同意なしに誰でも編集できる状態になり、設計や実装との整合性が破綻します。逆に Git を origin にすると、Product Manager(PdM)や Designer に GitHub の Pull Request(PR)レビューを強いることになり、レビュー参加の敷居が上がってしまう。そこで、origin は Git に固定したうえで、Notion 側は「読む場所」「コメントをつける場所」と割り切りました。これで、非エンジニアのレビュアーは使い慣れた Notion でレビューに参加できますし、変更履歴は git log に残ります。
Git から Notion への同期は私たちでスクリプトを書いていますが、両者をつなぐ構成自体はありふれたもので、技術的には難しい話ではありません。むしろ難しかったのは、どちらを origin にするかという方針を最初に決めて、運用のなかでぶれずに守ることのほうでした。
レビューを skill に蓄積する
そして、集まったコメントは職種ごとのレビュー用 skill に反映していきます。プロダクトの観点もデザインの観点も、一度もらった指摘によって、次からは AI による一次チェックができるようになります。
コメントを集めるところには、1 つ実装上の落とし穴がありました。Notion のコメントは、解決済み(resolved)にするとコメント API からは取得できなくなります。レビューのコメントは指摘が反映されれば解決済みにしていくものなので、コメント API だけを見ていると、いちばん学びになる「対応済みの指摘」がごっそり抜け落ちてしまう。そこで私たちは、コメントを集めるときはコメント API ではなく履歴 API のほうから取得するようにしています。
例えばプロダクトのレビュー用 skill は、いつも的確な指摘をくれるメンバーのコメントから育てています。他の案件からはなかなかレビューをお願いしづらい立場の方でも、その観点を AI がいつでも一次チェックとして返してくれるようになるので、価値が大きいと感じています。レビューがその場限りで消えずに AI の中へ積み上がっていくのも、判断基準を残すことの 1 つの形です。
spec → design → plan → issue のパイプライン
ここまで書いてきた仕様書や設計書、それにレビューの skill は、つなげて連続的に動かすこともできます。一つひとつを手で進めても十分機能しますが、つなげておくと、仕様書の変更がトリガーとなって実装まで自走させることもできます。
私たちは 3 つのドキュメントを使い分けています。
ドキュメント 役割 対応する skill
spec 仕様書 spec-review
design 設計書 design
plan 手順書 plan
それぞれに専用の skill があって、新しい仕様書が入ってくると、まず spec-review skill がその内容をレビューします。良さそうだと判断されたら、次に design skill で設計書をつくり、そこから plan skill で実装計画を立てます。plan skill は、もともとある plan モードを少し拡張したもので、立てた計画をファイルとしてリポジトリの中に残し、その手順の一つひとつに進捗のチェックがつくようになっています。リポジトリにファイルとして残しておくことで、session をまたいでも、別のメンバーが見ても、その計画と進捗をそのまま読める状態になります。

最後の issue skill だけは少し毛色が違っていて、ドキュメントというより、できあがった計画を実装処理へ渡すための受け渡し役です。issue skill で GitHub issue を用意し、そこに plan ファイルへの参照を入れておくと、GitHub Actions がそれを拾って実装を進め、終わると PR を出してくれます。つまり、仕様書の変更がトリガーとなって、ここまで一気通貫で進められるというわけです。
このパイプラインの土台になっているのは、それぞれの skill のなかに書き留めてきた判断基準です。spec-review が見るべき観点も、design や plan の組み立て方も、すべて私たちが少しずつ言葉にしてきたものです。パイプラインの組み立て自体は Claude Code の標準機能と GitHub Actions の組み合わせなので、目新しさはありません。新しいのは、機構の側ではなく、その上に積み上げた基準のほうです。
3. 検証ループ:推論ではなく、決定論を用意する
3 つ目は、テストの話です。AI に開発を任せるとき、「ちゃんと動いていることをどう確かめるか」は、前章で挙げた三本柱のうち観測の役割にあたります。
ブラウザを動かして操作をひと通り確かめる、通しの End-to-End(E2E)テストを思い浮かべてください。AI にこれをやらせる方法として、Claude のように、その場でブラウザを直接操作してもらうやり方があります。ただし、この方法は毎回 AI の推論が入るので、結果がゆれますし、実行のたびにトークンも消費します。テストの本来の目的は「同じ入力なら同じ結果になること」を確かめることなのに、確かめる側がゆれてしまうと、本末転倒です。
そこで私たちは、AI を活用するのはテストの定義を作るところまでにして、実行のほうは推論を挟まない確定的なやり方にしました。AI に新しい機能の操作手順と期待される結果を書いてもらい、書き終わったら、その後の実行ループからは AI を抜く、という分け方です。こうすると、ゆれる可能性のある推論から決定論に変わって、同じ入力なら必ず同じ結果になります。Continuous Integration(CI)でも手元でも同じスクリプトが同じように走るので、差分が出れば、それは AI のゆらぎではなく、プロダクトに本当の変化があったサインだと、はっきり切り分けられます。
実際に、メルカリ NFT の主要なフローを Playwright で組みました。出品、購入、オファー、承諾、買取、配送といった一連の流れを、売り手と買い手を切り替えながら通しで実行します。これを「regression test を実施して」の一言で AI が全シナリオを走らせる状態にしてあるので、コマンドを覚える必要はありません。
確かめ方そのものを「正解」として固定するというのも、判断基準を残すことの 1 つの形です。AI に任せる範囲を広げるほど、人の代わりに結果を観測する機構は大事になります。そのときに、観測する側まで AI に任せきってしまうと、ゆらぐ判定でゆらぐ実装を確かめるという不安定な構造になってしまいます。確定的に動く部品を観測の側に据えることで、AI に任せる範囲を安心して広げることができるようになりました。
4. 個人情報(PII)の多層防御
4 つ目は、セキュリティ、とくに個人情報の扱いです。社内でも注目されているテーマです。
commit や PR にうっかり個人情報が混入することは、人でも AI でも起こりえます。私たちは commit も PR も、それに Jira チケットの作成も AI にやってもらっているので、AI に開発を広く任せるのであれば、個人情報の保護にも AI を活用するのは自然な流れだと考えました。
そこで、一連の流れに対して個人情報を保護する機構を、三段の防御として載せることにしました。

三段にした意図は、どこか一段が落ちても別の段がカバーする構成にしたかったからです。一段目をすり抜けても二段目で止まり、それも越えてしまったら三段目で後始末できる。完全にミスをなくすことを期待するのではなく、ミスは起こる前提で複数の網を重ねる、というスタンスです。
もうひとつ、skill によるコメントなどで個人情報を引用するときは、先頭の数文字だけ残してあとはマスキングするルールにしています。AI のコメントは、PR の本文に残ったり、コミットメッセージや別ドキュメントに引用されたりと、思わぬ場所に流れていきます。該当箇所が特定できる程度に頭を残してそれ以外を伏せておけば、AI があとでどこかに書き残すときにも、本物の個人情報が混入することはありません。
この例では、機構(hooks や CI のスキャン、復旧手順)も判断基準(何を個人情報とみなすか)も、どちらもプラットフォームでなく私たち側で用意したものです。それでも、機構と判断基準を別物として扱い、判断基準を機構の上流に置く、という構図は変わりません。両者を区別して別々に扱う、という構図自体は崩れないということを、この例はあらためて思い出させてくれました。
どれくらい変わったか
ここまでに紹介した4つの取り組みは、実際にチームの開発にどんな変化をもたらしたのか。指標としては定量的に見られるものと、日々の運用感覚として感じる定性的なものの両面で、いくつかわかりやすい変化が出てきました。
コードの一貫性を整え、開発の効率を上げる skill を入れていった結果、チーム全体の PR の数そのものが増えました。しかも、この案件は1月末にいったん開発チームを解散していて、それ以降はエンジニアが2人、プロダクトとデザインが1人ずつ、という少人数の体制です。チーム全体の流量が増えているうえに人数が少ないので、1 人あたりで見れば何倍にもなっている計算です。
これは AI を導入したから自動的に増えた、というよりは、AI が力を出せるようにコードや判断基準を先に整えてきた結果だと考えています。漫然と AI を導入するだけでは、同じ結果にはならなかったはずです。
もうひとつ、PR の中身についても触れておきます。開発全体の PR 流量が増えている一方で、修正系の PR の割合は抑えられています。新機能や改善の PR の伸びが、修正系の伸びを上回っている、ということです。これは PR の乱造ではなく、品質を上げた上で流量も増えているという、非常に大きな成果だと思っています。
それとは別に、アラートの調査を AI に任せるための skill(監視基盤を直接触れるようにしたもの)も整備しました。アラートの URL を渡すだけで原因を調べて修正までまとめてやってくれるようになりました。日々の運用感覚としても大きい変化でした。
共通と固有を分ける:ほかの案件に持っていくために
ここまで積み上げてきた仕組みは、この案件だけで閉じてしまうのはもったいないので、社内のほかの案件でも使えるようにしておきたいと考えました。そのためにやったのは、どこが共通で、どこがこの案件固有のものかを、はっきり分けておくことです。
この「共通と固有を分ける」やり方は、たった1つの小さな判断から始まりました。社内共通のフレームワークである monorail をアップグレードしたときのことです。monorail のチームは、アップグレードの共通手順を monorail-upgrade という skill で提供してくれています。ただ、私たちの案件には、それだけでは足りない固有の手順がありました。そこで、その名前のうしろに -local をつけた monorail-upgrade-local という skill を作って、固有の手順をそちらに置きました。この小さな切り分けが、いまの形の原型になりました。
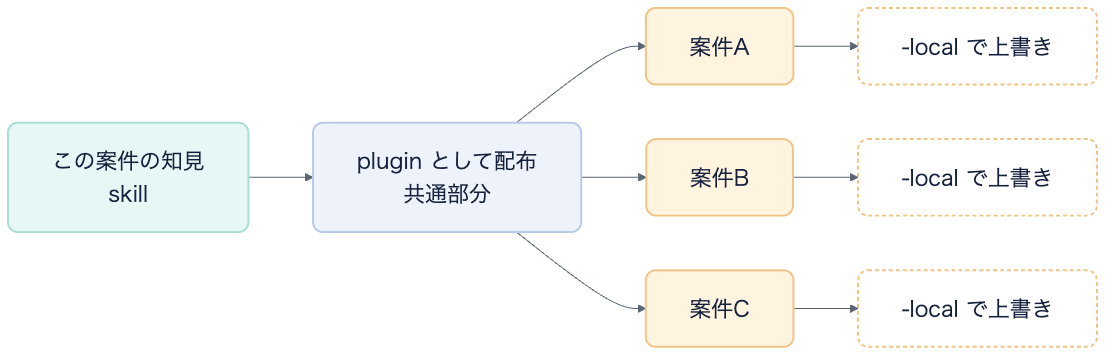
私たちのプロダクトは、Backend と Frontend が別々のリポジトリに分かれていますが、共通で使える skill は、1つの plugin にまとめて配っています。そして、それぞれのリポジトリに固有の部分は、その plugin を上書きする -local な skill に入れています。こうしておくと、片方のリポジトリで skill を改善するともう片方にも横展開しやすくなりますし、skill の名前を見ただけで「どこからが共通で、どこからが案件固有か」が判別できます。
このやり方は、Claude Code の CLAUDE.md と CLAUDE.local.md の考え方を応用したものです。plugin を案件ごとに上書きする仕組みは、Claude Code に機能として用意されているわけではなく、Feature Request として GitHub に issue が出ている段階です。そこで私たちは、-local という名前のつけ方を決めて、その規約だけで共通と固有の境界を表すことにしました。人によってはすでに自然にやっていることかもしれませんが、これを暗黙のままにせず、命名ルールとして明示しています。
大きな仕組みを最初から設計する必要はありませんでした。小さな判断を、次の人がそのまま使える形で残していけば、それが積み重なって、いつでも広げられる土台になります。
補:個人的な思想
ここからの話は、これまでの章とは少し性質が違います。この案件の特性から導かれた話というよりは、私個人の運用観の話だと思って読んでもらえると、はずれが少ないと思います。同じことをやろうとしている人が、これと違うやり方を選んでもなんら問題ありません。今回の記事に紛れ込ませているのは、この4ヶ月のなかで自分の中にまとまってきた考え方を、せっかくなので書き残しておきたかったからです。
専門知識は skill に集め、agent は薄いラッパーに保つ
Claude Code には、知識や手順をまとめておく skill と、独立した context を持って動かせる subagent という2つの仕組みがあります。コミュニティの best practice を眺めていると、機能領域ごとに専用の subagent を作って、そこに専門知識を持たせていくやり方をよく見かけます。私が選んでいるのはこれとは違うルートで、専門知識は skill にまとめて、agent はそれを呼ぶための薄いラッパーに留める という分け方です。
agent と skill は対立する選択肢ではないと思っています。agent を作ってもよいのですが、agent には「この場面ではこの skill を、次にこの skill を呼ぶ」というルーティング情報だけ書く、と考えています。判断基準や手順、ドメイン知識といった本体は、すべて skill 側に書く。こうしておくと、同じ判断基準が複数の agent に重複して埋め込まれることがなくなりますし、skill を更新すれば、それを呼ぶすべての経路に反映されます。
例えば Anthropic は、長時間動く agent harness の設計について、実装する generator agent とテストする evaluator agent を別の agent として分離することを推奨(注4)しています。生成する agent に自分の仕事を批判させるよりも、別の agent を評価役として厳しくチューンするほうがやりやすい、という理屈です。agent を切るとしたら、こういうメイン context からの隔離と独立した判断、それに伴う権限スコープが単独で必要なときが良さそうです。その場合も専門知識を埋め込まずに、必要な skill 群を呼ぶ薄いラッパーとして組みます。agent の固有価値は隔離・独立した判断・権限スコープであって専門知識そのものではない、というのが私の見立てです。専門知識は skill 側に集めたほうが、再利用しやすく、知識の重複も起こりません。
rewind ではなく、新しい session を fork する
Claude Code には、過去のやり取りを巻き戻して途中の状態から再開できる rewind という機能があります。便利な機能なのですが、私は意識的にあまり使わないようにしています。理由は単純で、rewind は context の rebase に近いところがあって、やってきた流れの一部が history から消える形になるからです。
これは好みの問題で、git の rebase が悪いと言いたいわけではありません。git log がきれいになるメリットと、流れがそのまま残るメリットには、どちらにも価値があると思います。ただ私自身は流れを残しておきたいほうで、後から「あのとき何を試して、何で失敗したか」を辿れるほうに価値を感じます。
やり直したいときは、rewind の代わりに新しい session を fork するようにしています。レビューしたいときも、進捗の区切りごとに分けたいときも、その都度別 session を立てます。session を分けたほうが、それぞれの context を小さく保てるので、結果的に動きも安定すると感じています。
plan ファイルと TODO.local.md が session 間のバトンになる
session を多めに切る運用には、1 つ前提があります。進捗を別 session に渡せる形で残しておく必要があるということです。これを担っているのが plan ファイルと、それからもうひとつ、TODO.local.md というファイルです。
plan ファイルの方は、前章で書いた spec → design → plan → issue のパイプラインで出てくる、あの plan です。手順の一つひとつに進捗のチェックがついていて、ファイルとしてリポジトリに残っているので、別の session を立てても、最後にどこまで終わっていたかをそのファイル 1 枚で引き継げます(注6)。同じことが git worktree を切って並列で動かしているときにも当てはまります。worktree A で進めていた作業を worktree B から続けることもできますし、agent 間でタスクを引き渡すときも、plan ファイルの該当箇所を指せば、お互いのなかで同じ進捗の理解が再現できます。
TODO.local.md の方は、個人レベルの todo を扱うためのファイルです。チケット化するほどではない、あるいはチケット化する前段階のもの、例えば「あとで気が向いたら直したい」「明日の朝いちで手を付ける」といったレベルの個人 todo を、ここに置いています。これを管理するための todo skill も用意していて、追加、完了マーク、一覧表示、コード内 TODO の集約(注7)などができます。チケットほど重くなく、その場の独り言で消えてしまわない、中間地点のタスク管理に意味があります。
plan ファイルと TODO.local.md の 2 つで、チケットに上げるほどではない作業の進捗が、session や worktree、agent をまたいで運べるようになっています。これが、session を多めに切る私の運用を支える土台です。
中心の軸とのつながり
ここまで書いたのは私の運用観なので、章の頭で断ったとおり、違うやり方を選んでもなんら問題ありません。ただ、最初の章で書いた「機構は外から、判断基準は自前で」という軸を頭に置きながら振り返ると、1 つ気付くことがあります。
skill と plan ファイルと TODO.local.md は、判断基準が宿る側にあるということです。判断基準や手順、進捗の文脈を、可搬なファイルとして残しているからです。一方の agent や rewind、session の制御は機構の側で、判断基準そのものを抱え込ませる対象ではない、と私は考えています。
機構と判断基準を分けて、判断基準を機構の上流に置く、という構図を貫こうとすると、自然にこういう運用に寄っていくのではないかと思います。
まとめ
AI を動かす機構はこれからどんどん外から手に入るようになるので、私たちの仕組み化は、その上に載せる判断基準を残すことに集中してきました。
- 何を正解とし、どこからを合格とし、何を危険とするか
- コードの一貫性も、判断の記録も、テストの固定も、個人情報の保護も、すべて「判断基準を、価値観と理由ごと残していく」という同じ考え方でつながっている
- 観測や停止の機構はモデルが進化するにつれて入れ替わったり、外せたりする部分がある。一方、判断基準は廃れにくい資産なので、特定のツールの設定ファイルに埋めるのではなく、自分たちのリポジトリに可搬な形で持っておく
これらが、この 4 ヶ月の試行錯誤から得た学びでした。
結果が出るに越したことはないのですが、まだ誰も正解が分かっていない領域なので、いまは結果そのものよりも、改善していける過程に重きを置く段階だと思っています。同じようなことに取り組んでいる方、真似してみたい方がいれば、ぜひお話ししたいです。最後まで読んでいただき、ありがとうございました。
脚注
注1
ここでいう「判断基準」とは、ドメイン知識と開発ルールを併せたものに近いと、いまは捉えています。ドメイン知識のほうには、その業務を成り立たせるための知識だけでなく、そのドメインで何に重きを置くかという価値観も含まれます。
注2
Mitchell Hashimoto, "My AI Adoption Journey"(2026-02)
https://mitchellh.com/writing/my-ai-adoption-journey
注3
Anthropic, "Effective context engineering for AI agents"(2025-09)
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
注4
Anthropic, "Harness design for long-running application development"(2026-03, Prithvi Rajasekaran)
https://www.anthropic.com/engineering/harness-design-long-running-apps
注5
これは人間も間違える原因になるので、AI を使わないとしても徹底したほうが良いと思っています。今回は AI-Native の話なので、本筋ではありませんが。
注6
Justin Young, "Effective harnesses for long-running agents"(2025-11)
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
session をまたぐ継続性を artifact(この場合はテキストファイル)で確保するという趣旨が該当します。
注7
これは案件内で共通のものなので TODO.md にまとめられています。IDE を常に開いていた頃なら、こういった TODO は自動的に収集してきてくれましたが、最近は Claude Code だけで済んでしまうので、こういったものが必要になりました。
原文を表示
こんにちは becosuke です。メルカリ NFT と、その上で立ち上げている新規サービスの Backend を担当しています。この記事は「Merpay & Mercoin Tech Openness Month 2026」の 20日目の記事です。
この記事では、私たちメルカリ NFT チームがこの4ヶ月ほどで取り組んできた AI-Native な開発について書きます。1月末から、開発のやり方そのものを大きく作り変えてきていて、最終的には人の手をできるだけ介さずにサービスを作り続けられる状態を目指しています。その過程で得た学びを、似たことに取り組もうとしている方に持ち帰ってもらえたらと思っています。
先に結論だけ書いておきます。私たちがリソースを集中させるべきだと判断したのは「正解」そのものではなく、何が正しく何が誤りかの「判断基準」(注1)でした。AI を動かすための機構は、これからどんどん外から手に入るようになります。けれど判断基準だけは、その案件ならではの価値観そのものなので、外注できません。だから私たちは、機構を作ることよりも、その上に載せる判断基準を残すことに時間をかけました。なぜそう考えたのか、そして実際に何をやったのかを、順を追って書いていきます。
この案件の位置付け
私たちは、Non-Fungible Token(NFT)の売買を行うマーケットプレイスである メルカリ NFT を既存サービスとして運営しています。いま新しく立ち上げているのは、この既存の メルカリ NFT のコードベースを土台にした新規サービスです。
この案件には、2つの顔があります。1つは、新しいプロダクトの立ち上げであること。もうひとつは、AI-Native な開発のあり方そのものを試す Proof of Concept(PoC)の場であることです。
メルカリには会社全体として AI-Native 化を進める方針があり、社内基盤もすでにしっかり整っています。その方向性には私たちも強く共感しているのですが、今回はあえて一度そこを離れて、前提から組み直すとどうなるかを試してみることにしました。理由は3つあります。
1つ目は、AI に spec から開発を駆動させるには、その spec を解釈するための価値基準や判断の根拠が前提として必要だと考えたからです。これがいちばん大きな理由でした。社内基盤の上に乗ったとしても、AI が「何を基準に判断すべきか」を持たないうちは自走できません。基盤の良し悪しの問題ではなく、その手前で価値基準と過去の判断の根拠を溜める前工程が、私たちにはまだ必要だったということです。だからまずはそこを溜め込む段階を踏んでから、成熟した先で既存の仕組みに接続する、という順序を選びました。
2つ目は、既存の正解の上に乗ると、その枠内での最適化しかできないからです。この案件は新しいプロダクトの立ち上げであると同時に AI-Native 開発の PoC でもあるので、いったん既成の枠を外して前提から組み直すことに意味があります。AI-Native として本当は何が必要なのかを検証したかったので、別のアプローチで組み立て直すことで見えてくるものを優先しました。社内基盤を使うプロジェクトと、別解を試すプロジェクトが並走すれば、会社全体として AI-Native 開発の幅も広がります。
3つ目は、Claude Code 本体の進化に身軽についていきたかったからです。Claude Code には plugin や Agent Teams のような、開発の組み立て方そのものに関わる機能追加が数ヶ月単位で入っていて、AI に開発をさせる足場の作り方が次々に変わっていきます。こうした新機能をすぐ取り込めるよう、CLAUDE.md と rules、skill、hooks だけの軽い構成で試したかったという事情もあります。標準機能だけで素朴に組むことで、何が効果を生んでいるのかの切り分けもしやすくなります。
念のため書いておくと、この独自路線は社内基盤と対立するものではありません。あくまで今の段階での選択であって、蓄積が成熟したら、社内基盤の考え方を取り込んだり、逆にこの案件で得たやり方を社内のほかの案件でも使えるようにしたり、という双方向の合流を視野に入れています。
この記事でいちばん伝えたいこと:機構は外から、判断基準は自前で
具体例に入る前に、この記事を貫く中心の考え方から書きます。
AI agent は、モデルと、その周りを取り囲む機構(ハーネス)でできていると言われています(Agent = Model + Harness)。このモデルを取り囲む環境・制約・フィードバックを設計する規律は、2026年2月に Mitchell Hashimoto 氏がブログ(注2)で "engineer the harness" と名付けて以降、ハーネスエンジニアリングと呼ばれて急速に広まりました。prompt engineering から context engineering、そして harness engineering へ、という発展の系譜です。
ハーネスにはさらに、モデル提供元が出荷する内側ハーネス(Agent SDK など)と、その上に私たちが組み立てる外側ハーネスがあります。Thoughtworks の Birgitta Böckeler は、外側ハーネスを agent の前に指針や制約を渡す Guide / Guardrail(feed-forward)と、agent の出力を観測してフィードバックを返す Sensor(feedback)に分けたうえで、ハーネスの議論は禁止やガードレールの側に偏りがちで、観測の側はむしろ手薄になりやすいと指摘しています。
ハーネスには大きく3つの役割があります。
- 正解を示す こと
- 結果を観測する こと
- 危ない操作を止める こと
このどれもが、AI に安心して任せるために欠かせません。私たちはこの偏りに違和感を持ち、3つの役割を等しく支える機構がどこにあるのかを考えました。
ここで私たちが立てた仮説はこうです。この3つを支える機構は、これからプラットフォーム側が整えてくれる。評価ループ、hooks、権限のプロンプト、サンドボックスといった機構は、汎用部品として外から提供される方向に向かっている。実際、危ない操作を事前に止める hooks や権限のプロンプトは Claude Code 本体に組み込まれていて、自前で実装するものから既製品として使うものへと、徐々に移ってきています。だとすれば、その機構づくりは私たちのチームでは「できるだけやらない部分」として切り分けてよい、と考えました。
一方で、3つの役割すべてに共通して必要になるものがあります。何を正解とし、どこからを合格とし、何を危険とするか、それぞれの判断基準です。これは、この案件ならではの価値観そのものなので、外からは提供されません。観測エンジンや停止機構は買えても、その基準は各案件固有の判断の産物で、外注できない。整理すると、三本柱のすべてについて「機構は買える/判断は自前」という構図になります。
機構
判断基準
正解を示す
context を供給する足場
何を正解とするか
結果を観測する
評価ループ・eval 基盤
どこからを合格とするか
危険を止める
hooks・権限・サンドボックス
何を危険とするか
出どころ
プラットフォームが提供(買える)
案件固有(自前で持つしかない)
なぜ「判断基準」を集めるのか
個別の正解を一つひとつ集めていくより、判断基準を与えるほうが、応用が効きます。1つの正解は点にすぎませんが、判断基準はその点を生み出す規則です。だから、まだ出会っていない状況に遭遇しても、基準さえあれば AI は自ら考えることができます。
例えばデータの書き換えについて、私たちは「InsertOrUpdate(UPSERT)は使わず、Read で存在を確かめてから INSERT か UPDATE に分岐する」という方針を残しています。UPSERT は全カラムを指定しないと意図しないリセットが起きるためです。この1つの方針が、AI が新しい書き込み処理を書くときの指針にもなり、reviewer が UPSERT の紛れ込みを一次チェックする観点にもなります。Anthropic の言葉を借りれば(注3)、正解を示すというのは「モデルの望ましい挙動を最も生みやすいコンテキストを与えること」で、観測するときの基準もそこから派生します。同じ判断基準が、正解を示す側にも、結果を観測する側にも、両方の基盤になっているわけです。
機構と判断基準には、もうひとつ大事な違いがあります。「寿命」が違うということです。Anthropic 自身も、ハーネスの各構成要素は「いまのモデルにこれができない」という前提のうえに置かれているので、その前提は stress test して、要らなくなったら外していく対象だと述べています。(注4)実際、ある世代のモデルで必要だった構成要素が、次の世代では不要になったり、別の組合せに置き換わったりしていく例も出てきています。もちろん、test のようにモデルがどれだけ進化しても外せない観測の機構もあるので、すべての機構が一律に失効していくわけではありません。それでも、機構の側には入れ替わりがある一方で、目標と正しい判断基準を与える側は廃れずに残ります。だからこそ判断基準は、特定のツールの設定ファイルに埋め込むのではなく、自分たちのリポジトリに、可搬な形で持っておくべきだと考えました。
ここからは、この考え方を実際の開発でどう形にしたのか、4つの具体例と、それによる変化、それらを社内のほかの案件で共有する方法について書いていきます。どの取り組みも、機構を作り込むことよりも、その上流にある判断基準を残すことに重点を置いた話として読んでもらえると、つながりが見えてくると思います。
1. コードの一貫性:言葉の意味や正しいやり方を1つに固定する
1つ目は、コードの一貫性です。
既存のコードベースを途中から AI-Native に切り替えるために、最初にやったことは大量のリファクタリングでした。人間ならあまり気にしないようなちょっとした言葉のゆれが、AI の判断を狂わせてしまうので、意味を1つに揃えておく必要があります。同じ概念が場所によって違う名前で呼ばれていたり、書き方が場所ごとに違ったりすると、AI はそのたびに周辺から「この案件ではどう書いているか」を推測することになり、出力がぶれます。
そこで、二段階で揃えました。
まず、同じ言葉が複数の意味を指している状態や、その逆をなくして、「1つの概念には1つの名前、1つの名前には1つの意味」というところまで徹底しました。命名は AI がコードベースの全体像を掴むときに最初に頼る手がかりなので、ここがぶれていると、その先のどんな指示や設計書を渡しても精度が落ちてしまいます(注5)。
次に、正しいやり方が何通りもあるものについて、どれでやるかを決めてルールとして書き残しました。例えばエラーの扱い、ページネーションの実装、enum の持ち方のように、「正解は複数あるが、案件としてはこの形に揃える」というものをルール化しておく。こうしておくと、今後同じような課題にぶつかったとき、AI は解決の方法を迷わず選べます。前の章で書いた「1つの正解(点)」ではなく「判断基準(規則)」を残す、というのを地でいく作業でした。
この期間、構造を整えながら、差し引きで万単位の行数のコードを減らしました。機能を削ったのではなく、重複や不要な抽象を整理して、同じことをより少ないコードで表すようにした結果です。AI が読まされる量が減り、1つの概念にあたる場所が一箇所に集まることで、AI に渡す文脈はノイズの少ないものになります。コードベースを整えること、それ自体が、AI のための環境整備の土台になる作業だったと考えています。
2. 判断を残す仕組み:spec / design と RDR / ADR
2つ目は、判断を残す仕組みです。
私たちは、仕様書(spec)には「いまどうなっているか」だけを書いて、「なぜそう決めたのか」「どの案を捨てたのか」という判断は別のファイルに分けて残しています。判断の経緯を残しておかないと、しばらく経ってから「なぜここをこう決めたんだっけ」と人も agent も何度も悩み直すことになります。一度悩んだことを文字にしておけば、次の人や AI はその上から考え始められます。
設計(design)の判断には、もともと ADR(Architecture Decision Records)という考え方があり、社内基盤でも使われています。私たちはこれを仕様の側にも持ち込んで、なぜその仕様にしたのかという判断を RDR(Requirements Decision Records)という専用のファイルに残す方針にしました。spec 本体は「現時点の仕様」を表し、RDR は「そこに至るまでの判断の積み重ね」を表す、という役割分担です。
ADR や RDR を「どう書くか」「どんなときに新しいレコードを作るか」といった作法は、decision-record という skill にまとめてあります。記録そのものは各案件に固有のものなので持ち運べませんが、「記録の作り方」のほうは共通の手順として配ることができます。
判断の経緯や却下した代替案を本文に混ぜると、「今の仕様はどれか」を読み取りにくくなってしまいます。現時点の要求だけを spec に残し、判断の層を RDR に切り出すことで、レビュー対象をノイズから守っています。
AI 側から見ても、この分離には意味があります。エージェントは普段は現状(spec / design)だけを読み、仕様を変えるときにだけ、紐づく RDR / ADR を必要に応じて引きにいきます。こうすると、AI に渡す context には「いまどうあるか」だけが入り、過去の議論や却下案がノイズとして混ざらない状態を保てます。
Git を origin に、Notion を読む場所に
ドキュメントの原本はすべて Git に置いていて、Notion には自動で同期したコピーを置いて、読む場所やコメントをつける場所として使っています。
Notion をそのまま origin にすると、ドキュメントがチームの同意なしに誰でも編集できる状態になり、設計や実装との整合性が破綻します。逆に Git を origin にすると、Product Manager(PdM)や Designer に GitHub の Pull Request(PR)レビューを強いることになり、レビュー参加の敷居が上がってしまう。そこで、origin は Git に固定したうえで、Notion 側は「読む場所」「コメントをつける場所」と割り切りました。これで、非エンジニアのレビュアーは使い慣れた Notion でレビューに参加できますし、変更履歴は git log に残ります。
Git から Notion への同期は私たちでスクリプトを書いていますが、両者をつなぐ構成自体はありふれたもので、技術的には難しい話ではありません。むしろ難しかったのは、どちらを origin にするかという方針を最初に決めて、運用のなかでぶれずに守ることのほうでした。
レビューを skill に蓄積する
そして、集まったコメントは職種ごとのレビュー用 skill に反映していきます。プロダクトの観点もデザインの観点も、一度もらった指摘によって、次からは AI による一次チェックができるようになります。
コメントを集めるところには、1つ実装上の落とし穴がありました。Notion のコメントは、解決済み(resolved)にするとコメント API からは取得できなくなります。レビューのコメントは指摘が反映されれば解決済みにしていくものなので、コメント API だけを見ていると、いちばん学びになる「対応済みの指摘」がごっそり抜け落ちてしまう。そこで私たちは、コメントを集めるときはコメント API ではなく履歴 API のほうから取得するようにしています。
例えばプロダクトのレビュー用 skill は、いつも的確な指摘をくれるメンバーのコメントから育てています。他の案件からはなかなかレビューをお願いしづらい立場の方でも、その観点を AI がいつでも一次チェックとして返してくれるようになるので、価値が大きいと感じています。レビューがその場限りで消えずに AI の中へ積み上がっていくのも、判断基準を残すことの1つの形です。
spec → design → plan → issue のパイプライン
ここまで書いてきた仕様書や設計書、それにレビューの skill は、つなげて連続的に動かすこともできます。一つひとつを手で進めても十分機能しますが、つなげておくと、仕様書の変更がトリガーとなって実装まで自走させることもできます。
私たちは3つのドキュメントを使い分けています。
ドキュメント
役割
対応する skill
spec
仕様書
spec-review
design
設計書
design
plan
手順書
plan
それぞれに専用の skill があって、新しい仕様書が入ってくると、まず spec-review skill がその内容をレビューします。良さそうだと判断されたら、次に design skill で設計書をつくり、そこから plan skill で実装計画を立てます。plan skill は、もともとある plan モードを少し拡張したもので、立てた計画をファイルとしてリポジトリの中に残し、その手順の一つひとつに進捗のチェックがつくようになっています。リポジトリにファイルとして残しておくことで、session をまたいでも、別のメンバーが見ても、その計画と進捗をそのまま読める状態になります。
最後の issue skill だけは少し毛色が違っていて、ドキュメントというより、できあがった計画を実装処理へ渡すための受け渡し役です。issue skill で GitHub issue を用意し、そこに plan ファイルへの参照を入れておくと、GitHub Actions がそれを拾って実装を進め、終わると PR を出してくれます。つまり、仕様書の変更がトリガーとなって、ここまで一気通貫で進められるというわけです。
このパイプラインの土台になっているのは、それぞれの skill のなかに書き留めてきた判断基準です。spec-review が見るべき観点も、design や plan の組み立て方も、すべて私たちが少しずつ言葉にしてきたものです。パイプラインの組み立て自体は Claude Code の標準機能と GitHub Actions の組み合わせなので、目新しさはありません。新しいのは、機構の側ではなく、その上に積み上げた基準のほうです。
3. 検証ループ:推論ではなく、決定論を用意する
3つ目は、テストの話です。AI に開発を任せるとき、「ちゃんと動いていることをどう確かめるか」は、前章で挙げた三本柱のうち観測の役割にあたります。
ブラウザを動かして操作をひと通り確かめる、通しの End-to-End(E2E)テストを思い浮かべてください。AI にこれをやらせる方法として、Claude のように、その場でブラウザを直接操作してもらうやり方があります。ただし、この方法は毎回 AI の推論が入るので、結果がゆれますし、実行のたびにトークンも消費します。テストの本来の目的は「同じ入力なら同じ結果になること」を確かめることなのに、確かめる側がゆれてしまうと、本末転倒です。
そこで私たちは、AI を活用するのはテストの定義を作るところまでにして、実行のほうは推論を挟まない確定的なやり方にしました。AI に新しい機能の操作手順と期待される結果を書いてもらい、書き終わったら、その後の実行ループからは AI を抜く、という分け方です。こうすると、ゆれる可能性のある推論から決定論に変わって、同じ入力なら必ず同じ結果になります。Continuous Integration(CI)でも手元でも同じスクリプトが同じように走るので、差分が出れば、それは AI のゆらぎではなく、プロダクトに本当の変化があったサインだと、はっきり切り分けられます。
実際に、メルカリ NFT の主要なフローを Playwright で組みました。出品、購入、オファー、承諾、買取、配送といった一連の流れを、売り手と買い手を切り替えながら通しで実行します。これを「regression test を実施して」の一言で AI が全シナリオを走らせる状態にしてあるので、コマンドを覚える必要はありません。
確かめ方そのものを「正解」として固定するというのも、判断基準を残すことの1つの形です。AI に任せる範囲を広げるほど、人の代わりに結果を観測する機構は大事になります。そのときに、観測する側まで AI に任せきってしまうと、ゆらぐ判定でゆらぐ実装を確かめるという不安定な構造になってしまいます。確定的に動く部品を観測の側に据えることで、AI に任せる範囲を安心して広げることができるようになりました。
4. 個人情報(PII)の多層防御
4つ目は、セキュリティ、とくに個人情報の扱いです。社内でも注目されているテーマです。
commit や PR にうっかり個人情報が混入することは、人でも AI でも起こりえます。私たちは commit も PR も、それに Jira チケットの作成も AI にやってもらっているので、AI に開発を広く任せるのであれば、個人情報の保護にも AI を活用するのは自然な流れだと考えました。
そこで、一連の流れに対して個人情報を保護する機構を、三段の防御として載せることにしました。
三段にした意図は、どこか一段が落ちても別の段がカバーする構成にしたかったからです。一段目をすり抜けても二段目で止まり、それも越えてしまったら三段目で後始末できる。完全にミスをなくすことを期待するのではなく、ミスは起こる前提で複数の網を重ねる、というスタンスです。
もうひとつ、skill によるコメントなどで個人情報を引用するときは、先頭の数文字だけ残してあとはマスキングするルールにしています。AI のコメントは、PR の本文に残ったり、コミットメッセージや別ドキュメントに引用されたりと、思わぬ場所に流れていきます。該当箇所が特定できる程度に頭を残してそれ以外を伏せておけば、AI があとでどこかに書き残すときにも、本物の個人情報が混入することはありません。
この例では、機構(hooks や CI のスキャン、復旧手順)も判断基準(何を個人情報とみなすか)も、どちらもプラットフォームでなく私たち側で用意したものです。それでも、機構と判断基準を別物として扱い、判断基準を機構の上流に置く、という構図は変わりません。両者を区別して別々に扱う、という構図自体は崩れないということを、この例はあらためて思い出させてくれました。
どれくらい変わったか
ここまでに紹介した4つの取り組みは、実際にチームの開発にどんな変化をもたらしたのか。指標としては定量的に見られるものと、日々の運用感覚として感じる定性的なものの両面で、いくつかわかりやすい変化が出てきました。
コードの一貫性を整え、開発の効率を上げる skill を入れていった結果、チーム全体の PR の数そのものが増えました。しかも、この案件は1月末にいったん開発チームを解散していて、それ以降はエンジニアが2人、プロダクトとデザインが1人ずつ、という少人数の体制です。チーム全体の流量が増えているうえに人数が少ないので、1人あたりで見れば何倍にもなっている計算です。
これは AI を導入したから自動的に増えた、というよりは、AI が力を出せるようにコードや判断基準を先に整えてきた結果だと考えています。漫然と AI を導入するだけでは、同じ結果にはならなかったはずです。
もうひとつ、PR の中身についても触れておきます。開発全体の PR 流量が増えている一方で、修正系の PR の割合は抑えられています。新機能や改善の PR の伸びが、修正系の伸びを上回っている、ということです。これは PR の乱造ではなく、品質を上げた上で流量も増えているという、非常に大きな成果だと思っています。
それとは別に、アラートの調査を AI に任せるための skill(監視基盤を直接触れるようにしたもの)も整備しました。アラートの URL を渡すだけで原因を調べて修正までまとめてやってくれるようになりました。日々の運用感覚としても大きい変化でした。
共通と固有を分ける:ほかの案件に持っていくために
ここまで積み上げてきた仕組みは、この案件だけで閉じてしまうのはもったいないので、社内のほかの案件でも使えるようにしておきたいと考えました。そのためにやったのは、どこが共通で、どこがこの案件固有のものかを、はっきり分けておくことです。
この「共通と固有を分ける」やり方は、たった1つの小さな判断から始まりました。社内共通のフレームワークである monorail をアップグレードしたときのことです。monorail のチームは、アップグレードの共通手順を monorail-upgrade という skill で提供してくれています。ただ、私たちの案件には、それだけでは足りない固有の手順がありました。そこで、その名前のうしろに -local をつけた monorail-upgrade-local という skill を作って、固有の手順をそちらに置きました。この小さな切り分けが、いまの形の原型になりました。
私たちのプロダクトは、Backend と Frontend が別々のリポジトリに分かれていますが、共通で使える skill は、1つの plugin にまとめて配っています。そして、それぞれのリポジトリに固有の部分は、その plugin を上書きする -local な skill に入れています。こうしておくと、片方のリポジトリで skill を改善するともう片方にも横展開しやすくなりますし、skill の名前を見ただけで「どこからが共通で、どこからが案件固有か」が判別できます。
このやり方は、Claude Code の CLAUDE.md と CLAUDE.local.md の考え方を応用したものです。plugin を案件ごとに上書きする仕組みは、Claude Code に機能として用意されているわけではなく、Feature Request として GitHub に issue が出ている段階です。そこで私たちは、-local という名前のつけ方を決めて、その規約だけで共通と固有の境界を表すことにしました。人によってはすでに自然にやっていることかもしれませんが、これを暗黙のままにせず、命名ルールとして明示しています。
大きな仕組みを最初から設計する必要はありませんでした。小さな判断を、次の人がそのまま使える形で残していけば、それが積み重なって、いつでも広げられる土台になります。
補:個人的な思想
ここからの話は、これまでの章とは少し性質が違います。この案件の特性から導かれた話というよりは、私個人の運用観の話だと思って読んでもらえると、はずれが少ないと思います。同じことをやろうとしている人が、これと違うやり方を選んでもなんら問題ありません。今回の記事に紛れ込ませているのは、この4ヶ月のなかで自分の中にまとまってきた考え方を、せっかくなので書き残しておきたかったからです。
専門知識は skill に集め、agent は薄いラッパーに保つ
Claude Code には、知識や手順をまとめておく skill と、独立した context を持って動かせる subagent という2つの仕組みがあります。コミュニティの best practice を眺めていると、機能領域ごとに専用の subagent を作って、そこに専門知識を持たせていくやり方をよく見かけます。私が選んでいるのはこれとは違うルートで、専門知識は skill にまとめて、agent はそれを呼ぶための薄いラッパーに留める という分け方です。
agent と skill は対立する選択肢ではないと思っています。agent を作ってもよいのですが、agent には「この場面ではこの skill を、次にこの skill を呼ぶ」というルーティング情報だけ書く、と考えています。判断基準や手順、ドメイン知識といった本体は、すべて skill 側に書く。こうしておくと、同じ判断基準が複数の agent に重複して埋め込まれることがなくなりますし、skill を更新すれば、それを呼ぶすべての経路に反映されます。
例えば Anthropic は、長時間動く agent harness の設計について、実装する generator agent とテストする evaluator agent を別の agent として分離することを推奨(注4)しています。生成する agent に自分の仕事を批判させるよりも、別の agent を評価役として厳しくチューンするほうがやりやすい、という理屈です。agent を切るとしたら、こういうメイン context からの隔離と独立した判断、それに伴う権限スコープが単独で必要なときが良さそうです。その場合も専門知識を埋め込まずに、必要な skill 群を呼ぶ薄いラッパーとして組みます。agent の固有価値は隔離・独立した判断・権限スコープであって専門知識そのものではない、というのが私の見立てです。専門知識は skill 側に集めたほうが、再利用しやすく、知識の重複も起こりません。
rewind ではなく、新しい session を fork する
Claude Code には、過去のやり取りを巻き戻して途中の状態から再開できる rewind という機能があります。便利な機能なのですが、私は意識的にあまり使わないようにしています。理由は単純で、rewind は context の rebase に近いところがあって、やってきた流れの一部が history から消える形になるからです。
これは好みの問題で、git の rebase が悪いと言いたいわけではありません。git log がきれいになるメリットと、流れがそのまま残るメリットには、どちらにも価値があると思います。ただ私自身は流れを残しておきたいほうで、後から「あのとき何を試して、何で失敗したか」を辿れるほうに価値を感じます。
やり直したいときは、rewind の代わりに新しい session を fork するようにしています。レビューしたいときも、進捗の区切りごとに分けたいときも、その都度別 session を立てます。session を分けたほうが、それぞれの context を小さく保てるので、結果的に動きも安定すると感じています。
plan ファイルと TODO.local.md が session 間のバトンになる
session を多めに切る運用には、1つ前提があります。進捗を別 session に渡せる形で残しておく必要があるということです。これを担っているのが plan ファイルと、それからもうひとつ、TODO.local.md というファイルです。
plan ファイルのほうは、前章で書いた spec → design → plan → issue のパイプラインで出てくる、あの plan です。手順の一つひとつに進捗のチェックがついていて、ファイルとしてリポジトリに残っているので、別の session を立てても、最後にどこまで終わっていたかをそのファイル 1 枚で引き継げます(注6)。同じことが git worktree を切って並列で動かしているときにも当てはまります。worktree A で進めていた作業を worktree B から続けることもできますし、agent 間でタスクを引き渡すときも、plan ファイルの該当箇所を指せば、お互いのなかで同じ進捗の理解が再現できます。
TODO.local.md のほうは、個人レベルの todo を扱うためのファイルです。チケット化するほどではない、あるいはチケット化する前段階のもの、例えば「あとで気が向いたら直したい」「明日の朝いちで手を付ける」といったレベルの個人 todo を、ここに置いています。これを管理するための todo skill も用意していて、追加、完了マーク、一覧表示、コード内 TODO の集約(注7)などができます。チケットほど重くなく、その場の独り言で消えてしまわない、中間地点のタスク管理に意味があります。
plan ファイルと TODO.local.md の2つで、チケットに上げるほどではない作業の進捗が、session や worktree、agent をまたいで運べるようになっています。これが、session を多めに切る私の運用を支える土台です。
中心の軸とのつながり
ここまで書いたのは私の運用観なので、章の頭で断ったとおり、違うやり方を選んでもなんら問題ありません。ただ、最初の章で書いた「機構は外から、判断基準は自前で」という軸を頭に置きながら振り返ると、1つ気付くことがあります。
skill と plan ファイルと TODO.local.md は、判断基準が宿る側にあるということです。判断基準や手順、進捗の文脈を、可搬なファイルとして残しているからです。一方の agent や rewind、session の制御は機構の側で、判断基準そのものを抱え込ませる対象ではない、と私は考えています。
機構と判断基準を分けて、判断基準を機構の上流に置く、という構図を貫こうとすると、自然にこういう運用に寄っていくのではないかと思います。
まとめ
AI を動かす機構はこれからどんどん外から手に入るようになるので、私たちの仕組み化は、その上に載せる判断基準を残すことに集中してきました。
- 何を正解とし、どこからを合格とし、何を危険とするか
- コードの一貫性も、判断の記録も、テストの固定も、個人情報の保護も、すべて「判断基準を、価値観と理由ごと残していく」という同じ考え方でつながっている
- 観測や停止の機構はモデルが進化するにつれて入れ替わったり、外せたりする部分がある。一方、判断基準は廃れにくい資産なので、特定のツールの設定ファイルに埋めるのではなく、自分たちのリポジトリに可搬な形で持っておく
これらが、この4ヶ月の試行錯誤から得た学びでした。
結果が出るに越したことはないのですが、まだ誰も正解が分かっていない領域なので、いまは結果そのものよりも、改善していける過程に重きを置く段階だと思っています。同じようなことに取り組んでいる方、真似してみたい方がいれば、ぜひお話ししたいです。最後まで読んでいただき、ありがとうございました。
脚注
注1
ここでいう「判断基準」とは、ドメイン知識と開発ルールを併せたものに近いと、いまは捉えています。ドメイン知識のほうには、その業務を成り立たせるための知識だけでなく、そのドメインで何に重きを置くかという価値観も含まれます。
注2
Mitchell Hashimoto, "My AI Adoption Journey"(2026-02)
https://mitchellh.com/writing/my-ai-adoption-journey
注3
Anthropic, "Effective context engineering for AI agents"(2025-09)
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
注4
Anthropic, "Harness design for long-running application development"(2026-03, Prithvi Rajasekaran)
https://www.anthropic.com/engineering/harness-design-long-running-apps
注5
これは人間も間違える原因になるので、AI を使わないとしても徹底したほうが良いと思っています。今回は AI-Native の話なので、本筋ではありませんが。
注6
Justin Young, "Effective harnesses for long-running agents"(2025-11)
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
session をまたぐ継続性を artifact(この場合はテキストファイル)で確保するという趣旨が該当します。
注7
これは案件内で共通のものなので TODO.md にまとめられています。IDE を常に開いていた頃なら、こういった TODO は自動的に収集してきてくれましたが、最近は Claude Code だけで済んでしまうので、こういったものが必要になりました。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み