マルチモーダル評価器:Strands Evalsにおける画像からテキストへのタスク向けMLLM-as-a-judge
AWS は画像理解タスクの精度検証を自動化する「MLLM-as-a-Judge」評価機能を Strands Evals SDK に追加し、テキストベースの評価では検出できない視覚的ハルシネーションや事実誤認の自動検出を実現した。
キーポイント
4 つの新規評価指標の導入
Overall Quality(総合品質)、Correctness(正しさ)、Faithfulness(忠実性)、Instruction Following(指示遵守)の 4 つの評価器が画像入力に対して直接スコアリングを行うようになった。
視覚的ハルシネーションの自動検出
テキストのみを評価する従来の手法では不可能だった、画像に存在しないボタンの記述や事実と異なる説明といった「視覚的ハルシネーション」を自動的に捕捉できる。
柔軟な評価ワークフローの提供
既存の CI/CD パイプラインに組み込み可能で、参照回答あり・なしの切り替えや、ドメイン固有の基準に基づくカスタムルブリック作成もサポートする。
コストと精度のバランス調整
Amazon Bedrock 上で複数の MLLM ジェッジモデルから選択可能であり、精度、コスト、レイテンシの要件に応じて最適な評価モデルを選定できる。
評価器の多様性
品質(Likert 1-5)、正しさ、忠実性、指示従順性の4種類のバイナリまたはスコアリング評価器を並列で使用して包括的な分析を行います。
モダリティの貢献度検証
画像入力とテキスト記述入力を切り替えて再実行することで、画像モダリティが評価結果にどの程度寄与しているかをアブレーション実験で検証できます。
デバッグに有用な理由付きスコア
各評価者はスコアだけでなく「reason」文字列も返すため、CI で失敗した際に再実行せずに原因を特定できる。
影響分析・編集コメントを表示
影響分析
この発表は、画像認識やドキュメント解析など視覚情報を扱うアプリケーション開発において、品質保証のボトルネックであった「人間による検証依存」を打破する重要な一歩です。特に Gartner の予測通りマルチモーダルソフトウェアが急増する中で、テキストベースの評価では見逃されやすいハルシネーションを検出できる仕組みは、実運用レベルでの信頼性を担保するために不可欠なインフラと言えます。
編集コメント
テキストベースの LLM 評価が主流となる中、画像入力と出力の整合性を直接検証する機能の標準化は、実務レベルでの AI 導入リスクを大幅に低減させる画期的な進展です。特に CI/CD への組み込みやすさは、開発現場の即戦力となり得る高品質なアップデートと言えます。
ビジュアルショッピング、画像やドキュメントの理解、チャート分析を構築している場合、モデルの回答が実際にソース画像に基づいているかどうかを検証する方法が必要です。テキストのみで評価するシステムでは、キャプションが画像を忠実に記述しているか、抽出された請求書の合計金額が文書と一致しているか、画面サマリーに存在しなかったボタンが幻覚として生成されていないかなどを確認できません。Gartner は 予測 しています。2030 年までにエンタープライズソフトウェアの 80% がマルチモーダル(複数の入力・出力形式を扱う技術)になる見込みで、これは 2024 年の 10% 未満から大幅に増加するものです。自動的なマルチモーダル評価がなければ、高価な人的レビューと信頼性の低いテキストベースの代替手段の間で板挟みになります。
本日、Strands Evals ソフトウェア開発キット (SDK) の画像からテキストへのタスク向けに、4 つの新しいマルチモーダル大規模言語モデル (MLLM)-as-a-Judge 評価器を発表します。これらはOverall Quality(全体的な品質)、Correctness(正確性)、Faithfulness(忠実度)、そしてInstruction Following(指示遵守)です。各評価器は、出力された画像からテキストへの回答をソース画像に対してスコアリングします。評価器は、クエリと回答、および(オプションで)参照回答とともに、画像を直接マルチモーダルなジャッジモデルに送信します。ジャッジは、画像に基づいたスコアと、デバッグに使用できる推論ストリングを返します。これらの評価器は、既存の Strands Evals の Case → Experiment → Report ワークフローにおけるテキスト専用ジャッジのドロップイン代替として使用でき、継続的インテグレーション (CI) に組み込むことで、視覚的な幻覚、事実上の誤り、指示違反を自動的に検出できます。
本稿では、以下の内容について学びます:
- 4 つの多モーダル評価器を設定し、画像からテキストへのタスクに対して実行します。
- 同じ評価器を使用して、参照ベースの評価と非参照ベースの評価を切り替えます。
- ドメイン固有の基準に合わせたカスタム多モーダル評価基準を作成します。
- 精度、コスト、レイテンシのバランスが取れた Amazon Bedrock 上の判別モデルを選択します。
- 実験において判別者と人間の整合性を向上させたプロンプト設計の選択肢を適用します。
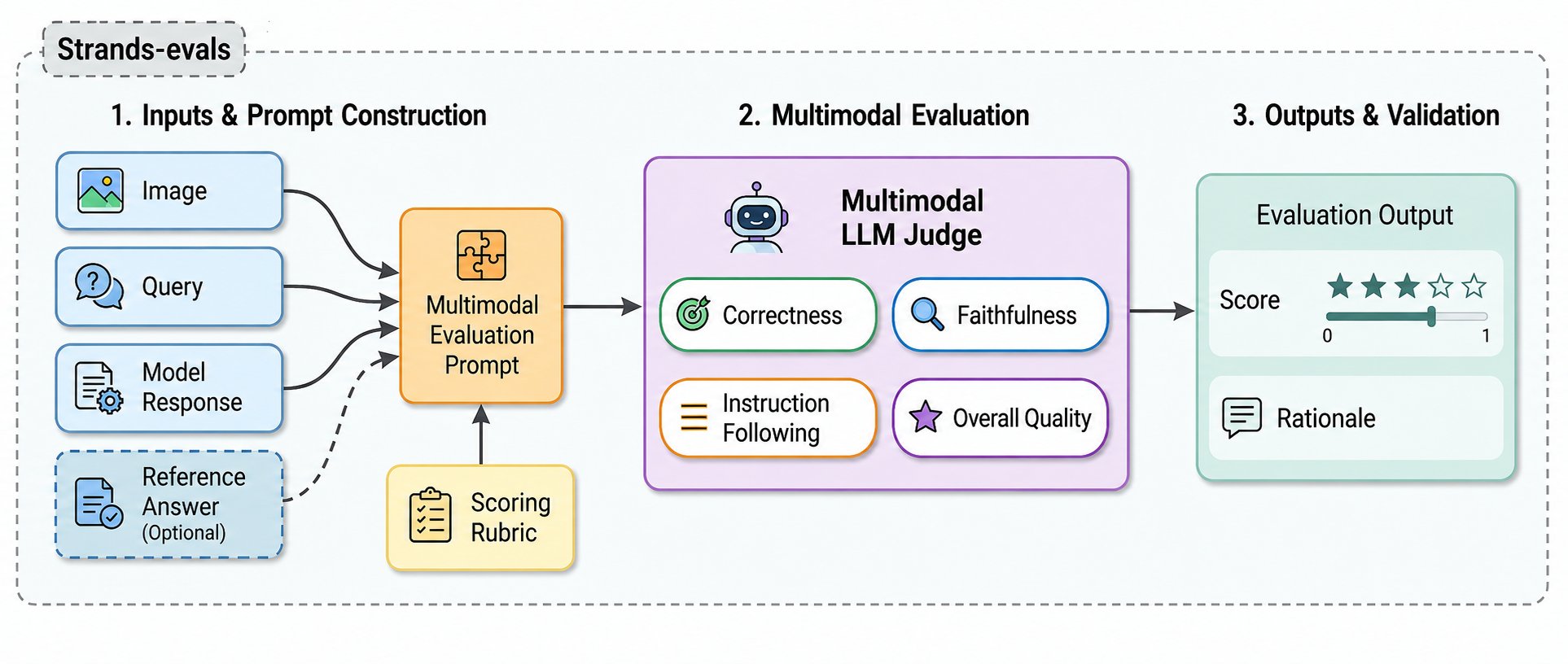
*図 1: 多モーダル判別フレームワークの概要。画像(またはドキュメント画像)、テキストクエリ、およびモデル生成応答が与えられた場合、このフレームワークは多モーダル評価プロンプトを構築し、MLLM ベースの判別器を適用して、スコア(Likert 1-5 または二値)と推論理由を返します。このフレームワークは参照ベースおよび非参照ベースの評価をサポートしており、ケース管理とレポート作成のために Strands Evals と統合されています。
前提条件
本記事のウォークスルーを追うためには、以下の準備が必要です:
- Python 3.10 以降が環境にインストールされていること。
- 評価用ツールには
pip install strands-agents-evalsを、ウォークスルーで使用される対象エージェントにはpip install strands-agentsを実行してください。
- Amazon Bedrock にアクセス権限を持つ AWS アカウントを持っていること。
- ローカルで AWS 認証情報が設定されていること(例:
aws configureコマンドまたは AWS Identity and Access Management (AWS IAM) ロールによる設定)。また、評価用モデルとして Amazon Bedrock のInvokeModelパーミッションが付与されている必要があります。
- Strands Evals の「ケース→実験→レポート」ワークフローに慣れていること。Strands Evals が初めての場合は、クイックツアーとして Strands Evals 発売時のブログポストをご覧ください。
テキストのみによる評価者が画像に基づく失敗を見逃す理由
請求書の読み取りやダッシュボードの要約、スクリーンショットのナレーションを行うモデルをリリースしたと仮定しましょう。テキストのみで LLM-as-a-Judge(LLM による評価者)を実行すれば、ある程度のシグナル(文章が流暢である、構造が明確であるなど)は得られますが、実際に重要な失敗を見逃してしまいます:
- モデルが自信を持ってチャートのトレンドを指摘しますが、そのチャートには実際に表示されていません。
- 画像に存在しない製品、ラベル、人物をでっち上げます(ハルシネーション)。
- 間違った質問に答えるか、正しい質問に対しては誤った形式で回答します。
テキストのみによる評価者は出力内容だけを読み、画像を確認せずに承認してしまいます。真の正解は画像の中にあり、評価者はそれを決して見ることができません。
たとえ包括的な「全体的な品質」評価者から低いスコアを取得したとしても、そのスコアだけでは何が壊れたのかは分かりません。失敗の原因は事実誤認、捏造された詳細、あるいは指示の無視など多岐にわたります。これら 3 つの失敗モードにはそれぞれ異なる修正策が必要となるため、それらを一つのスコアに集約してしまうと、デバッグが実際以上に困難になってしまいます。
イメージ・テキストタスク向けの4つの評価者
この4つの評価者は、最も広く利用されているマルチモーダルカテゴリを対象としています。入力画像(またはドキュメント画像)とテキストの組み合わせであり、出力はテキストとなります。このカテゴリには、画像キャプション生成、視覚的質問応答、チャートおよびインフォグラフィックの解釈、ドキュメントフィールド抽出、OCR(光学文字認識 (Optical Character Recognition))、スクリーンショット要約などが含まれます。以下の表では、新たに導入された4つの評価者がそれぞれ何を検出するかをまとめます。
評価者
スコア
核心的な質問
検出対象
1
全体的な品質 (Overall Quality)
リッカート尺度 1-5
回答の全体的な質はどうか?
関連性の低さ、不正確さ、浅い回答、包括性の欠如
2
正しさ (Correctness)
二値判定
画像とクエリを踏まえて、回答が事実上正確かつ完全か?
事実誤認、属性・数値・位置の誤り、省略
3
忠実度 (Faithfulness)
二値判定
回答は画像に基づいており、幻覚(ハルシネーション)はないか?
捏造された物体、根拠のない推論、外部知識の漏洩
4
指示の遵守
二値判定
回答はクエリの制約に従っていますか?
フォーマット違反、誤った数値、主題から外れた内容、無視されたスコープ
各評価器は2つのモードをサポートしています。参照ベースモードでは、回答を正解(ゴールド)と比較し、ラベル付きテストセットがある場合に有用です。参照フリーモードでは画像のみに基づいて判断するため、システムが実環境の画像で動作し、正解データが存在しない場合に唯一の選択肢となります。
チャート読み取りタスクの評価におけるエンドツーエンドのウォークスルー
API を具体的に理解するために、単一のケースを順を追って解説します。入力データは、地域別(米国/カナダ、EMEA、アジア太平洋地域、ラテンアメリカ)の有料ストリーミングメンバーシップあたりの平均収益を示す棒グラフです。テスト対象システムは、このチャートに関する限定された質問に答えるシンプルなビジョンエージェントです。4 つの多モーダル評価器を同じ実験で実行します。これらは共通の MultimodalOutputEvaluator ベースクラスを共有し、画像データ(ImageData)を通じて画像を受け取ります。
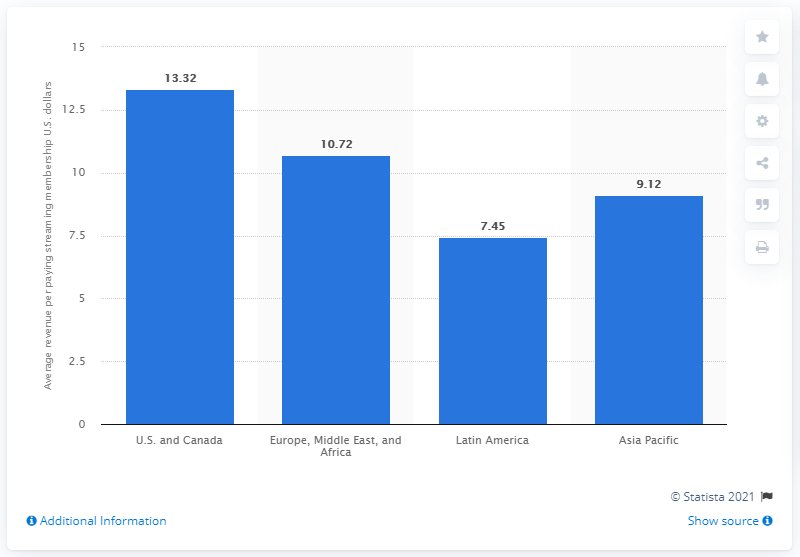
*図 2: 地域別の有料ストリーミングメンバーシップあたりの平均収益(Statista)。テスト対象システムは、このチャートに関する根拠のある質問に答えるよう求められます。
ステップ 1. ケースと評価器の定義。ケースは画像と指示を MultimodalInput にラップし、期待される出力(expected_output)を提供することで、対応する評価器に対して参照ベースの評価を有効化します。
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import (
MultimodalOverallQualityEvaluator,
MultimodalCorrectnessEvaluator,
MultimodalFaithfulnessEvaluator,
MultimodalInstructionFollowingEvaluator,
)
from strands_evals.types import ImageData, MultimodalInput
cases = [
Case[MultimodalInput, str](
name="revenue-chart-1",
input=MultimodalInput(
media=ImageData(source="revenue_chart.jpeg"),
instruction="Which region has the highest average revenue? "
"State the region name and the dollar amount shown in the chart.",
),
expected_output="U.S. and Canada has the highest at $13.32.",
metadata={"dataset": "ChartQA"},
),
]
evaluators = [
MultimodalOverallQualityEvaluator(), # リケルト 1-5
MultimodalCorrectnessEvaluator(), # バイナリ
MultimodalFaithfulnessEvaluator(), # バイナリ
MultimodalInstructionFollowingEvaluator(), # バイナリ
]
ステップ 2. タスクを接続して実験を実行する。タスク関数は各 Case を受け取り、画像と指示に対してビジョンモデルを実行し、評価対象となる応答文字列を返す。
agent = Agent(callback_handler=None)
task_output = None
def run_task(case):
global task_output
image = case.input.media
messages = [
{"image": {"format": image.format or "png", "source": {"bytes": image.to_bytes()}}},
{"text": case.input.instruction},
]
task_output = str(agent(messages))
return task_output
reports = await Experiment(cases=cases, evaluators=evaluators).run_evaluations_async(
task=run_task, max_workers=1,
)
各ケースがメディアを含むマルチモーダル入力(MultimodalInput)を保持しているため、4 つの評価者は判断プロンプトに画像を含めます。ご自身のデータにおいて画像モダリティが意味のある寄与をしているかどうかを検証するためには、マルチモーダル入力をプレーン文字列入力(例えば、画像のテキスト説明など)に置き換えて再実行してください。同じ評価者がテキストのみからスコアを算出します。
ステップ 3. レポートの検査。各レポートには、ケースごとのスコア、テストパス数、および理由が含まれています:
print(f"Task Output:\n{task_output}\n")
print("=" * 50)
for name, report in zip(
["Quality", "Correctness", "Faithfulness", "Instruction"], reports,
):
reason = report.reasons[0] if report.reasons else ""
status = "PASS" if report.test_passes[0] else "FAIL"
print(f"{name}: {report.scores[0]:.2f} [{status}]")
print(f" Reason: {reason}\n")
上記のチャートを実行すると、以下のトランスクリプトが得られます:
Task Output:
According to the chart, the U.S. and Canada region has the highest average
revenue per paying streaming membership at $13.32.
品質:1.00 [合格]
理由:回答は、$13.32 という最高収益地域として米国とカナダを正しく特定しており、指示の両方の部分を直接満たしています。この回答はチャートのデータに基づき事実上正確であり、適切な文脈も提供されています。
妥当性:1.00 [合格]
理由:事実に基づく主張は正確です。米国とカナダがチャートで最も高い棒グラフを持つ地域として正しく特定されており、$13.32 はその棒グラフに表示されている正確な金額です。事実上の誤りは見つかっていません。
忠実度:1.00 [合格]
理由:回答は画像に完全に根拠づけられています。各主張はチャートと照合して直接検証可能です。米国とカナダは$13.32 を示しており、視覚的にも最も高い棒グラフです。ハルシネーション(幻覚)は検出されませんでした。
指示遵守:1.00 [合格]
理由:回答は必要な要素である地域名(米国とカナダ)と金額($13.32)の両方を明記することで、指示を完璧に履行しています。制約違反なく、期待される出力と事実上一致しています。
注意すべき点は二つあります。第一に、すべての評価者はスコアに加えて理由を示す文字列を返します。これはデバッグにおいて極めて重要です。CI(継続的インテグレーション)で実行が失敗した場合でも、再実行せずに*なぜ*失敗したのかを確認できます。第二に、同じケースが単一のエクスペリメント内で 4 つの独立した審査員(リッカート尺度 1 つ、二値評価 3 つ)によって評価されました。つまり、あなたのワークフローはテキストのみを対象とした Strands Evals の単一評価者実行と全く同一です。
カスタム評価基準。 ドメイン固有の基準については、基本クラスは任意の評価基準文字列を受け入れます:
from strands_evals.evaluators import MultimodalOutputEvaluator
medical_eval = MultimodalOutputEvaluator(rubric="""診断精度を評価する:
- 1.0: すべての所見が適切な用語で正しく特定されている。
- 0.5: 主要な所見は特定されているが、用語が不正確である。
- 0.0: 重要な所見が見逃されたか、誤って特定されている。""")
私たちが学んだこと:3 つの設計上の問い
Q1. 判定者は画像を見る必要があるのか?
自然な疑問として、詳細に自動生成された画像説明を画像の代わりに用いたテキスト専用 LLM(大規模言語モデル)判定者が、マルチモーダル判定者に代わり得るでしょうか。私たちは、MLLM-as-a-Judge(画像とテキストの組み合わせ)を、長いおよび短い画像説明を同じプロンプトに組み込んだ LLM-as-a-Judge と比較しました。
教訓: マルチモーダル判定者は、どちらかのテキスト専用バリアントよりも人間のスコアにより近い一致を示しました。画像説明を生成するための追加の LLM 呼び出しを含めると、テキスト専用の経路は意味のあるコスト削減や速度向上をもたらすものではありません。マルチモーダル判定者が利用可能であれば、それを直接使用してください。
Q2. Amazon Bedrock でどのモデルをジャッジとして使用すべきか?
Amazon Bedrock で利用可能な複数の MLLM(マルチモーダル大規模言語モデル)をジャッジとして評価し、人間によるスコアとの整合性、クエリあたりのコスト、レイテンシに基づいてデフォルトを選択しました。Anthropic の Claude Sonnet 4.6 を Amazon Bedrock で使用した結果、当社のテスト全体を通じて精度とコストのバランスが最も優れており、マルチモーダル評価器のデフォルトジャッジモデルとして採用しています。さらに、試したモデル全般に共通する2つのより広範な観察結果も確認されました。第一に、推論能力を備えた大規模モデルは、小規模モデルよりもジャッジとしての信頼性が高いこと。第二に、能力のあるカテゴリ内では、このタスクにおいては高価格帯のプレミアムモデルが中堅グレードのモデルと比較して測定可能な精度向上をもたらさないことです。
推奨デフォルト: Anthropic Claude Sonnet 4.6.
Q3. どのプロンプト設計の選択が実際に重要なのか?
最終的に推奨するプロンプトに対して、いくつかのプロンプト設計軸をアブレーション(除去実験)しました。当社のテスト全体で一般化された教訓は以下の通りです:
- 採点前に判断者に推論を求めさせること。これが私たちが測定した中で最も影響力のある選択でした。スコアのみを出力する方が安価で自己一貫性が高いですが、人間による評価との整合性は顕著に低下します。もし一つだけ覚えておくなら、これです。
- いくつかの多様な較正例を含めること。ゼロショットから数個の例へと移行するにつれて、整合性は単調に向上しました。
- 視覚的精度、指示への準拠、完全性、一貫性などといった細粒度で多次元の評価基準(ルブリック)を使用し、単一の包括的なプロンプトに頼らないこと。次元を分離することで、一つの曖昧なスコアが異なる失敗モードを吸収してしまうのを防ぎます。
ボーナス:参照あり vs 参照なし
判断者プロンプトにゴールド(正解)の参照回答を注入することは、コンテンツに根ざした評価者に役立ちます。全体的品質、正確性、忠実度は、参照が存在する場合に人間による判断とより密接に一致しました。一方、指示への準拠は逆の結果となりました。参照コンテンツを追加すると、クエリと応答のみで決定される構造的制約(フォーマット、範囲、順序、数)のチェックから判断者が逸れてしまうのです。
一般的なガイドラインとして: コンテンツに根ざした指標には参照を使用し、指示への準拠のような構造的指標ではそれらを省略してください。
ベストプラクティス
私たちの実験と統合作業に基づき、以下を推奨します:
- クイックな整合性チェックには MultimodalOverallQualityEvaluator をデフォルトとし、特定の失敗モードを診断する際に、Correctness(正しさ)、Faithfulness(忠実度)、Instruction Following(指示の遵守)といったターゲット型のバイナリエvaluatorを追加してください。
- 判事(ジャッジ)としては Claude Sonnet 4.6 から開始し、コストやレイテンシが制約条件を支配する場合のみ、Amazon Bedrock 上で推論能力を持つより小規模な MLLM に切り替えてください。判断用には小規模モデルは避けてください。
- reason(理由)と score(スコア)の出力形式を維持してください。コスト面ではスコアのみが魅力的に思えますが、人間による評価との整合性は顕著に低下します。
- 利用可能な場合は、Correctness(正しさ)、Faithfulness(忠実度)、Overall Quality(総合品質)の評価に参照データ(リファレンス)を使用してください。Instruction Following(指示の遵守)についてはそれらを省略してください。
Conclusion
Strands Evals に導入された 4 つの新しい MLLM-as-a-Judge(MLLM を判事とする)評価器により、画像からテキストへのタスクの評価は、高コストな人間のレビューや信頼性の低いテキストのみによる代替手段から、自動化され画像に根ざしたスコアリングへと移行しました。Overall Quality(総合品質)、Correctness(正しさ)、Faithfulness(忠実度)、Instruction Following(指示の遵守)はそれぞれ固有の失敗モードを対象とし、参照データに基づく評価と参照データなしの評価の両方をサポートし、各スコアには診断的な推論も併せて返します。保持された検証分割セットにおいて、これら 4 つの評価器は多様な画像ドメイン全体で人間の判断とよく一致していました。これは Strands Evals におけるより広範なマルチモーダル評価への第一歩です。今後の研究課題としては、マルチモーダルツール利用やエージェントの軌跡に対するステップレベルでの評価、およびテキストから画像へ、動画からテキストへ、音声からテキストへといった追加的なモダリティ組み合わせの評価が含まれます。
画像からテキストへのエージェントの評価を今日から始めましょう。以下のコマンドで Strands Evals をインストールしてください:
pip install strands-agents-evals
次に、以下のリソースをご覧ください:
- Case → Experiment → Report ワークフローの全体像については、Strands Evals のドキュメントをお読みください。
- MultimodalInput, ImageData、組み込みの評価基準、および 4 つの利便性サブクラスを含む完全な API は、マルチモーダル評価器のリファレンスをご覧ください。
- Strands Agents ドキュメントリポジトリにあるマルチモーダル評価器のサンプルを試してみてください。
フィードバックや機能要望は こちら でお寄せください。
原文を表示
If you’re building visual shopping, image or document understanding, or chart analysis, you need a way to verify whether your model’s response is actually grounded in the source image. A text-only evaluator cannot tell you whether a caption faithfully describes an image, whether an extracted invoice total matches the document, or whether a screen summary hallucinated a button that was never on the page. Gartner predicts that by 2030, 80% of enterprise software will be multimodal, up from less than 10% in 2024. Without automated multimodal evaluation, you’re stuck between expensive human review and unreliable text-only proxies.
Today, we’re announcing four new multimodal large language model (MLLM)-as-a-Judge evaluators for image-to-text tasks in Strands Evals software development kit (SDK): Overall Quality, Correctness, Faithfulness, and Instruction Following. Each evaluator scores image-to-text outputs against the source image. The evaluator sends the image directly to a multimodal judge model, alongside the query, the response, and (optionally) a reference answer. The judge returns a score grounded in the image, together with a reasoning string you can use for debugging. You can use these evaluators as drop-in replacements for text-only judges in your existing Strands Evals Case → Experiment → Report workflow, and plug them into continuous integration (CI) to catch visual hallucinations, factual errors, and instruction violations automatically.
In this post, you will learn how to:
- Set up the four multimodal evaluators and run them on an image-to-text task.
- Switch between reference-based and reference-free evaluation with the same evaluator.
- Write a custom multimodal rubric for domain-specific criteria.
- Choose a judge model on Amazon Bedrock that balances accuracy, cost, and latency.
- Apply prompt-design choices that improved judge-to-human alignment in our experiments.
*Figure 1: Overview of the multimodal judge framework. Given an image (or document image), a textual query, and a model-generated response, the framework constructs a multimodal evaluation prompt, applies an MLLM-based judge, and returns a score (Likert 1-5 or binary) along with reasoning. The framework supports both reference-based and reference-free evaluation, and integrates with Strands Evals for case management and reporting.*
Prerequisites
To follow the walkthrough in this post, you need:
- Python 3.10 or later installed in your environment.
- pip install strands-agents-evals for the evaluators, and pip install strands-agents for the target agent used in the walkthrough.
- An AWS account with access to Amazon Bedrock.
- AWS credentials configured locally (for example, via aws configure or an AWS Identity and Access Management (AWS IAM) role) with Amazon Bedrock InvokeModel permission for the judge model.
- Familiarity with the Strands Evals Case → Experiment → Report workflow. If you are new to Strands Evals, see the Strands Evals launch blog post for a quick tour.
Why text-only judges miss image-grounded failures
Suppose you’ve shipped a model that reads invoices, summarizes dashboards, or narrates screenshots. Running a text-only LLM-as-a-Judge over the response gets you *some* signal (the writing is fluent, the structure is clean), but it misses exactly the failures that matter:
- The model confidently names a chart trend that the chart doesn’t actually show.
- It hallucinates a product, a label, or a person who isn’t in the picture.
- It answers the wrong question, or answers the right one in the wrong format.
A text-only judge reads the output and approves it without verifying the image. The ground truth lives in the image, and the judge never sees it.
Even when you *do* get a low score from a holistic “rate overall quality” judge, the score alone doesn’t tell you *what broke*. The failure could be a factual error, an invented detail, or an ignored instruction. These three failure modes require three different fixes, so collapsing them into one score makes debugging harder than it needs to be.
Four evaluators for image-to-text tasks
The four evaluators target the most widely used multimodal category. The input is an image (or document image) together with text, and the output is text. This category covers image captioning, visual question answering, chart and infographic interpretation, document field extraction, OCR, and screenshot summarization. The table below summarizes what each of the four new evaluators catches.
Evaluator
Score
Core question
What it catches
1
Overall Quality
Likert 1-5
How good is the response overall?
Poor relevance, inaccuracy, shallow answers, lack of comprehensiveness
2
Correctness
Binary
Is the response factually correct and complete given the image and query?
Factual errors, wrong attributes, counts, positions, omissions
3
Faithfulness
Binary
Is the response grounded in the image without hallucinations?
Invented objects, unsupported inferences, external-knowledge leakage
4
Instruction Following
Binary
Does the response adhere to the query’s constraints?
Format violations, wrong counts, off-topic content, ignored scope
Every evaluator supports two modes. Reference-based mode compares the response against a gold answer and is useful when you have labeled test sets. Reference-free mode judges from the image alone and is the only option when the system runs on live images with no ground truth available.
End-to-end walkthrough: evaluating a chart-reading task
To make the API concrete, you’ll walk through a single Case. The input is a bar chart of average revenue per paying streaming membership by region (U.S./Canada, EMEA, Asia Pacific, Latin America). The system under test is a simple vision agent that answers a narrow question about the chart. You run the four multimodal evaluators in the same Experiment. They share a common MultimodalOutputEvaluator base class and accept images through ImageData.
*Figure 2: Average revenue per paying streaming membership, by region (Statista). The system under test is asked to answer a grounded question about this chart.*
Step 1. Define the Case and evaluators. The Case wraps the image and instruction in a MultimodalInput, and providing expected_output activates reference-based judging for the evaluators that support it.
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import (
MultimodalOverallQualityEvaluator,
MultimodalCorrectnessEvaluator,
MultimodalFaithfulnessEvaluator,
MultimodalInstructionFollowingEvaluator,
)
from strands_evals.types import ImageData, MultimodalInput
cases = [
Case[MultimodalInput, str](
name="revenue-chart-1",
input=MultimodalInput(
media=ImageData(source="revenue_chart.jpeg"),
instruction="Which region has the highest average revenue? "
"State the region name and the dollar amount shown in the chart.",
),
expected_output="U.S. and Canada has the highest at $13.32.",
metadata={"dataset": "ChartQA"},
),
]
evaluators = [
MultimodalOverallQualityEvaluator(), # Likert 1-5
MultimodalCorrectnessEvaluator(), # Binary
MultimodalFaithfulnessEvaluator(), # Binary
MultimodalInstructionFollowingEvaluator(), # Binary
]Step 2. Wire up the task and run the experiment. The task function receives each Case, runs the vision model on the image plus instruction, and returns the response string to be evaluated.
agent = Agent(callback_handler=None)
task_output = None
def run_task(case):
global task_output
image = case.input.media
messages = [
{"image": {"format": image.format or "png", "source": {"bytes": image.to_bytes()}}},
{"text": case.input.instruction},
]
task_output = str(agent(messages))
return task_output
reports = await Experiment(cases=cases, evaluators=evaluators).run_evaluations_async(
task=run_task, max_workers=1,
)Because each Case above carries a MultimodalInput with media, the four evaluators include the image in the judge prompt. To ablate whether the image modality is contributing meaningfully on your own data, swap the MultimodalInput for a plain-string input (for example, a text description of the image) and rerun. The same evaluator scores from text alone.
Step 3. Inspect the Report. Each Report contains per-case scores, test_passes, and reasons:
print(f"Task Output:\n{task_output}\n")
print("=" * 50)
for name, report in zip(
["Quality", "Correctness", "Faithfulness", "Instruction"], reports,
):
reason = report.reasons[0] if report.reasons else ""
status = "PASS" if report.test_passes[0] else "FAIL"
print(f"{name}: {report.scores[0]:.2f} [{status}]")
print(f" Reason: {reason}\n")Running on the chart above produces the following transcript:
Task Output:
According to the chart, the U.S. and Canada region has the highest average
revenue per paying streaming membership at $13.32.
==================================================
Quality: 1.00 [PASS]
Reason: The response correctly identifies U.S. and Canada as the highest
revenue region at $13.32, directly addressing both parts of the instruction.
The answer is factually accurate based on the chart data and provides
appropriate context.
Correctness: 1.00 [PASS]
Reason: The factual claims are accurate. U.S. and Canada is correctly
identified as the region with the highest bar in the chart, and $13.32 is
the exact dollar amount visible on that bar. No factual errors found.
Faithfulness: 1.00 [PASS]
Reason: The response is fully grounded in the image. Each claim can be
directly verified against the chart. U.S. and Canada shows $13.32 and is
visibly the highest bar. No hallucinations detected.
Instruction: 1.00 [PASS]
Reason: Response perfectly follows instruction by stating both required
elements: region name (U.S. and Canada) and dollar amount ($13.32). Matches
expected output factually with no constraint violations.Two things to notice. First, every evaluator returns a reason string in addition to a score, which is critical for debugging. When a run fails in CI, you can see *why* without re-running. Second, the same Case was scored by four independent judges (one Likert, three binary) in a single Experiment, so your workflow is identical to single-evaluator runs in text-only Strands Evals.
Custom rubrics. For domain-specific criteria, the base class accepts an arbitrary rubric string:
from strands_evals.evaluators import MultimodalOutputEvaluator
medical_eval = MultimodalOutputEvaluator(rubric="""Rate diagnostic accuracy:
- 1.0: All findings correctly identified with proper terminology.
- 0.5: Key findings identified but imprecise terminology.
- 0.0: Critical findings missed or misidentified.""")What we learned: three design questions
Q1. Does the judge need to see the image?
A natural question: can a text-only LLM judge, given a detailed auto-generated image description in place of the image, substitute for a multimodal judge? We compared MLLM-as-a-Judge (image plus text) against LLM-as-a-Judge with long and short image descriptions feeding into the same prompt.
Takeaway: the multimodal judge aligned more closely with human scores than either text-only variant. Once you count the extra LLM call to generate the image description, the text-only route is not meaningfully cheaper or faster either. If you have a multimodal judge available, use it directly.
Q2. Which model on Amazon Bedrock to use as the judge?
We evaluated several MLLMs available on Amazon Bedrock as judges and used alignment with human scores, per-query cost, and latency to pick a default. Anthropic Claude Sonnet 4.6 on Amazon Bedrock offered the best accuracy-to-cost trade-off across our runs, and we use it as the default judge model for the multimodal evaluators. Two broader observations also held up consistently across the models we tried. First, larger reasoning-capable models were more reliable as judges than smaller ones. Second, within the capable tier, premium-priced models did not gain measurable accuracy over mid-tier ones for this task.
Recommended default: Anthropic Claude Sonnet 4.6.
Q3. Which prompt-design choices actually matter?
We ablated several prompt-design axes against our final recommended prompt. The takeaways that generalized across our runs:
- Ask the judge to reason before scoring. This was the single most impactful choice we measured. Score-only output is cheaper and more self-consistent, but alignment with human scores drops noticeably. If you only remember one thing, it is this.
- Include a few diverse calibration examples. Alignment improved monotonically as we moved from zero-shot to a handful of examples.
- Use a fine-grained, multi-dimensional rubric (e.g., visual accuracy, instruction adherence, completeness, coherence) instead of a single holistic prompt. Separating dimensions prevents a single vague score from absorbing distinct failure modes.
Bonus: reference-based vs. reference-free
Injecting a gold reference answer into the judge prompt helps content-grounded evaluators. Overall Quality, Correctness, and Faithfulness aligned more closely with human judgment when a reference was available. Instruction Following went the other way. Adding reference content distracted the judge from checking structural constraints (format, scope, order, count) that are determined by the query and response alone.
As a general guideline: use references for content-grounded metrics, and skip them for structural metrics like instruction following.
Best practices
Based on our experiments and integration work, we recommend:
- Default to MultimodalOverallQualityEvaluator for quick sanity checks, then add targeted binary evaluators (Correctness, Faithfulness, Instruction Following) as you diagnose specific failure modes.
- Start with Claude Sonnet 4.6 as the judge, and drop to smaller reasoning-capable MLLMs on Amazon Bedrock only if cost or latency dominates your constraints. Avoid small models for judgment.
- Keep the reason+score output format. Score-only is tempting for cost, but alignment with human scores drops noticeably.
- Use references for correctness, faithfulness, and overall quality if available. Skip them for instruction following.
Conclusion
The four new MLLM-as-a-Judge evaluators in Strands Evals move image-to-text evaluation from expensive human review or unreliable text-only proxies to automated, image-grounded scoring. Overall Quality, Correctness, Faithfulness, and Instruction Following each target a distinct failure mode, support both reference-based and reference-free evaluation, and return diagnostic reasoning alongside every score. On our held-out validation split, the four evaluators aligned well with human judgment across diverse image domains. This is the first step toward broader multimodal evaluation in Strands Evals. Future work includes step-level evaluation for multimodal tool use and agent trajectories, and additional modality combinations such as text-to-image, video-to-text, and audio-to-text.
Start evaluating your image-to-text agents today. Install Strands Evals with the following command:
pip install strands-agents-evalsThen explore the resources below:
- Read the Strands Evals documentation for an end-to-end overview of the Case → Experiment → Report workflow.
- See the multimodal evaluator reference for the full API, including MultimodalInput, ImageData, the built-in rubrics, and the four convenience subclasses.
- Try the multimodal evaluator example in the Strands Agents docs repository.
Share your feedback and feature requests in <a href="https://github.com/strands-agents/evals/issues"
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み