GitHub Enterprise Serverの高可用性のための検索アーキテクチャ再構築
GitHubは、GitHub Enterprise Serverの検索アーキテクチャを再構築し、Elasticsearchクラスタリングの問題を解決することで、高可用性(HA)環境での管理負荷を軽減し、システムの耐久性を向上させた。
キーポイント
検索機能の重要性と耐久性向上の取り組み
GitHubプラットフォームの多くの機能が検索に依存しており、過去1年間でその耐久性を高めることに注力した。これにより、管理者の運用負荷が軽減され、顧客価値の創出に集中できるようになる。
従来のHA構成におけるElasticsearchの課題
HA構成ではプライマリ/レプリカのリーダー/フォロワーパターンが採用されていたが、Elasticsearchがこのパターンをネイティブにサポートしていなかったため、ノード間でクラスタを構築する必要があった。
クラスタリングによる問題の顕在化
サーバー間でのElasticsearchクラスタリングは、データ複製の容易さやパフォーマンス向上の利点があったが、プライマリシャードがレプリカに移動した際のメンテナンスやアップグレード時のデッドロックなど、問題が利点を上回るようになった。
アーキテクチャ再構築の目的と成果
検索アーキテクチャの再構築により、HA環境でのインデックス破損やロック状態のリスクを低減し、GitHub Enterprise Serverの安定性と管理性を大幅に向上させた。
Elasticsearch Cross Cluster Replication (CCR) の採用
GitHub Enterprise Server は、高可用性を実現するために Elasticsearch の Cross Cluster Replication (CCR) 機能を採用し、複数の独立したシングルノードクラスターとして動作するようになった。
既存インデックスに対するブートストラップ手順
既存の長期間使用されているインデックスに対しては、フォロワーを既存インデックスに接続するブートストラップ手順を実装し、その後新しいインデックスに対して自動フォローを有効にしている。
カスタムワークフローの必要性
Elasticsearch はドキュメントレプリケーションのみを処理し、フェイルオーバー、インデックス削除、アップグレードなどのインデックスのライフサイクル管理には独自のカスタムワークフローを開発する必要があった。
影響分析・編集コメントを表示
影響分析
この改善は、大規模なオンプレミス環境でGitHub Enterprise Serverを運用する企業にとって、システムの安定性向上と運用負荷の軽減に直接寄与する。検索機能の信頼性向上は、開発者体験と生産性の向上にもつながる重要な基盤強化である。
編集コメント
技術的な課題解決に焦点を当てた実践的な記事。AI/機械学習の核心技術ではないが、大規模プラットフォームの基盤構築における重要な教訓を含んでいる。
GitHubで皆さんが操作する多くの部分は検索に依存しています。GitHub Issuesページのような検索バーやフィルタリング機能はもちろんのこと、リリースページ、プロジェクトページ、イシューやプルリクエストの件数表示などの中核にもなっています。検索がGitHubプラットフォームの中心的な部分であることを踏まえ、私たちはこの1年間、さらに堅牢なものにする取り組みを行ってきました。つまり、GitHub Enterprise Serverの管理に費やす時間を減らし、お客様が最も関心を持つことに注力する時間を増やすことを意味します。
近年、GitHub Enterprise Serverの管理者は、検索に最適化された特殊なデータベーステーブルである検索インデックスに特に注意を払う必要がありました。メンテナンスやアップグレードの手順を正確な順序で守らなかった場合、検索インデックスが破損して修復が必要になったり、ロックされてアップグレード中に問題を引き起こしたりする可能性がありました。高可用性(HA)設定を導入していない場合の簡単な背景説明をすると、HAはシステムの一部が故障してもGitHub Enterprise Serverを円滑に稼働し続けるように設計されています。書き込みとトラフィックをすべて処理するプライマリノードと、同期を保ち必要に応じて引き継ぐことができるレプリカノードがあります。
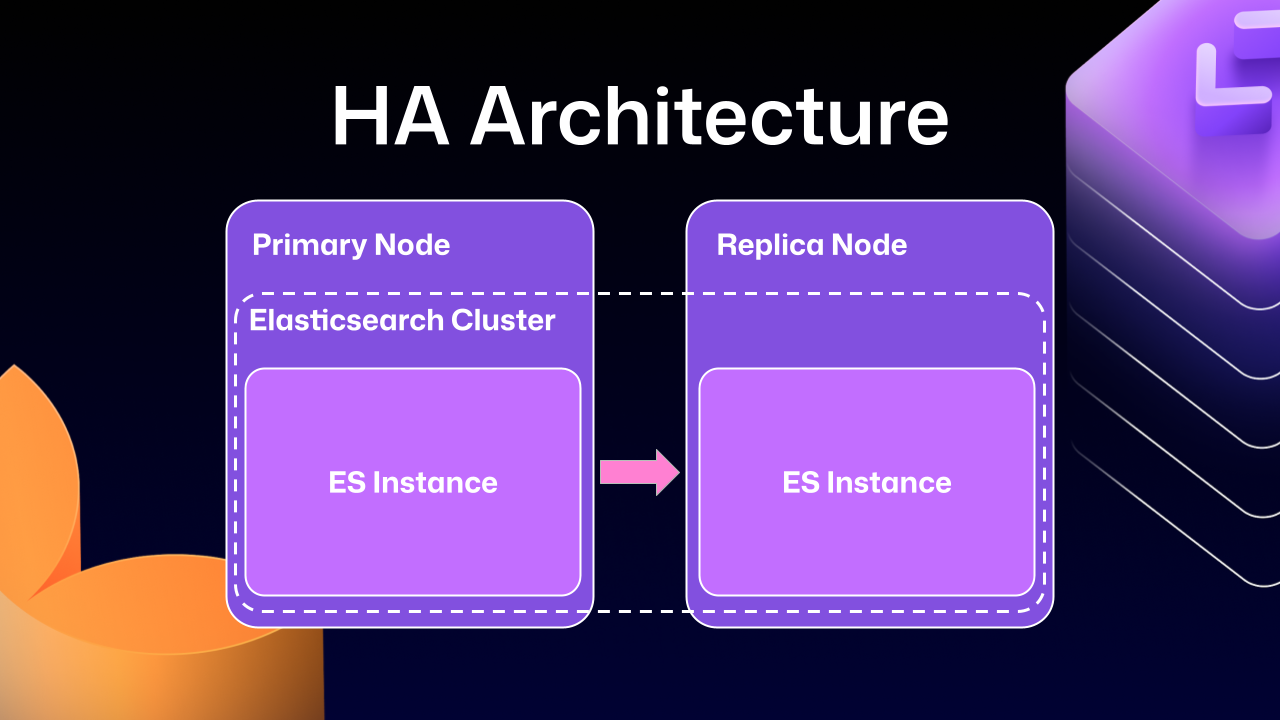
この困難の多くは、私たちが選択した検索データベースであるElasticsearchの以前のバージョンがどのように統合されていたかから生じています。HA構成のGitHub Enterprise Serverインストールでは、リーダー/フォロワーパターンを使用します。リーダー(プライマリサーバー)はすべての書き込み、更新、トラフィックを受け取ります。フォロワー(レプリカ)は読み取り専用に設計されています。このパターンはGitHub Enterprise Serverのすべての操作に深く根付いています。
ここでElasticsearchは問題に直面し始めました。プライマリノードとレプリカノードの両方をサポートできなかったため、GitHubのエンジニアリングチームはプライマリノードとレプリカノードにまたがるElasticsearchクラスターを作成する必要がありました。これによりデータの複製が簡単になり、さらに各ノードがローカルで検索リクエストを処理できるため、いくつかのパフォーマンス上の利点も得られました。
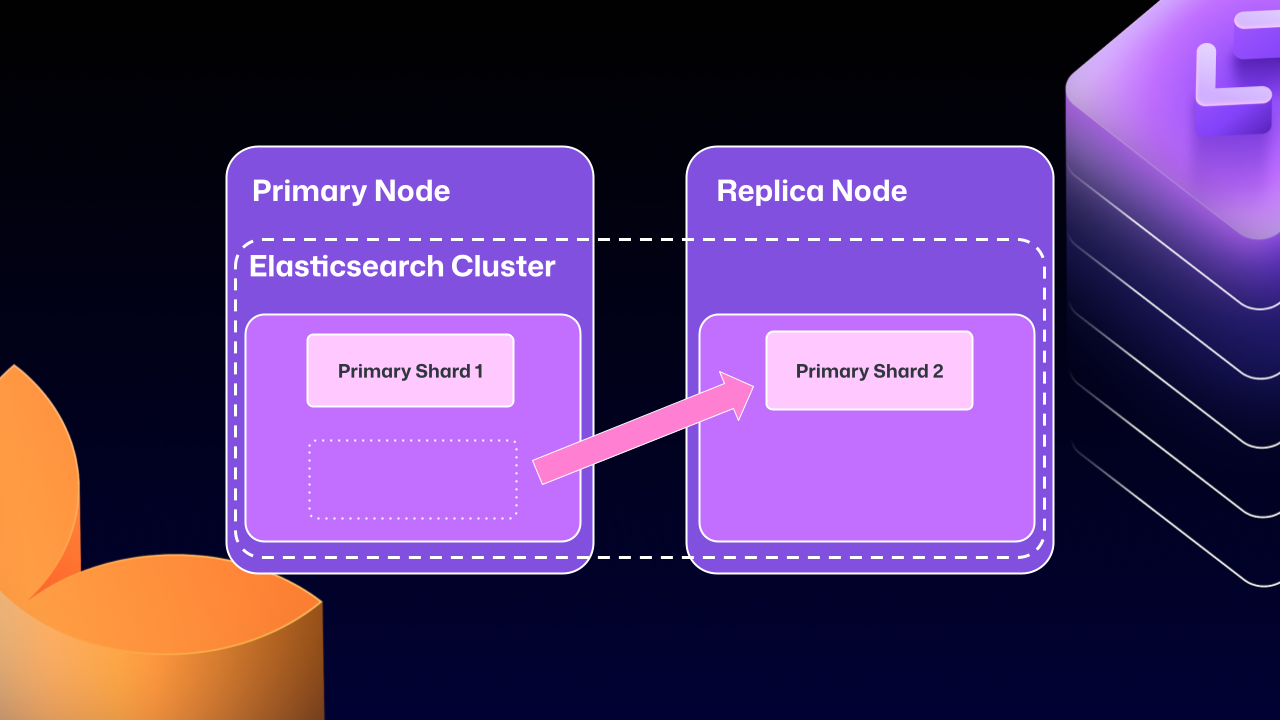
残念ながら、サーバー間でのクラスタリングの問題は、最終的に利点を上回り始めました。例えば、Elasticsearchはいつでもプライマリシャード(書き込みの受信/検証を担当)をレプリカに移動させることができました。そのレプリカがメンテナンスのために停止させられた場合、GitHub Enterprise Serverはロック状態に陥る可能性がありました。レプリカはElasticsearchが正常になるのを待ってから起動しますが、Elasticsearchはレプリカが再参加するまで正常になることができませんでした。
いくつかのGitHub Enterprise Serverリリースにわたって、GitHubのエンジニアはこのモードをより安定させようと試みました。Elasticsearchが正常な状態にあることを確認するチェックや、状態のずれを修正しようとする他のプロセスを実装しました。クラスターモードから脱却できる「検索ミラーリング」システムの構築を試みるまでに至りました。しかし、データベースレプリケーションは非常に困難であり、これらの取り組みには一貫性が必要でした。
何が変わったのか?
数年にわたる作業の末、私たちは現在、Elasticsearchのクロスクラスターレプリケーション(CCR)機能を使用してHA構成のGitHub Enterpriseをサポートできるようになりました。
「でもデイビッド、それはクラスター間のレプリケーションでしょう?それがここでどのように役立つのですか?」
ご質問ありがとうございます。このモードでは、複数の「シングルノード」Elasticsearchクラスターを使用するように移行しています。現在、各Enterpriseサーバーインスタンスは独立したシングルノードElasticsearchクラスターとして動作します。
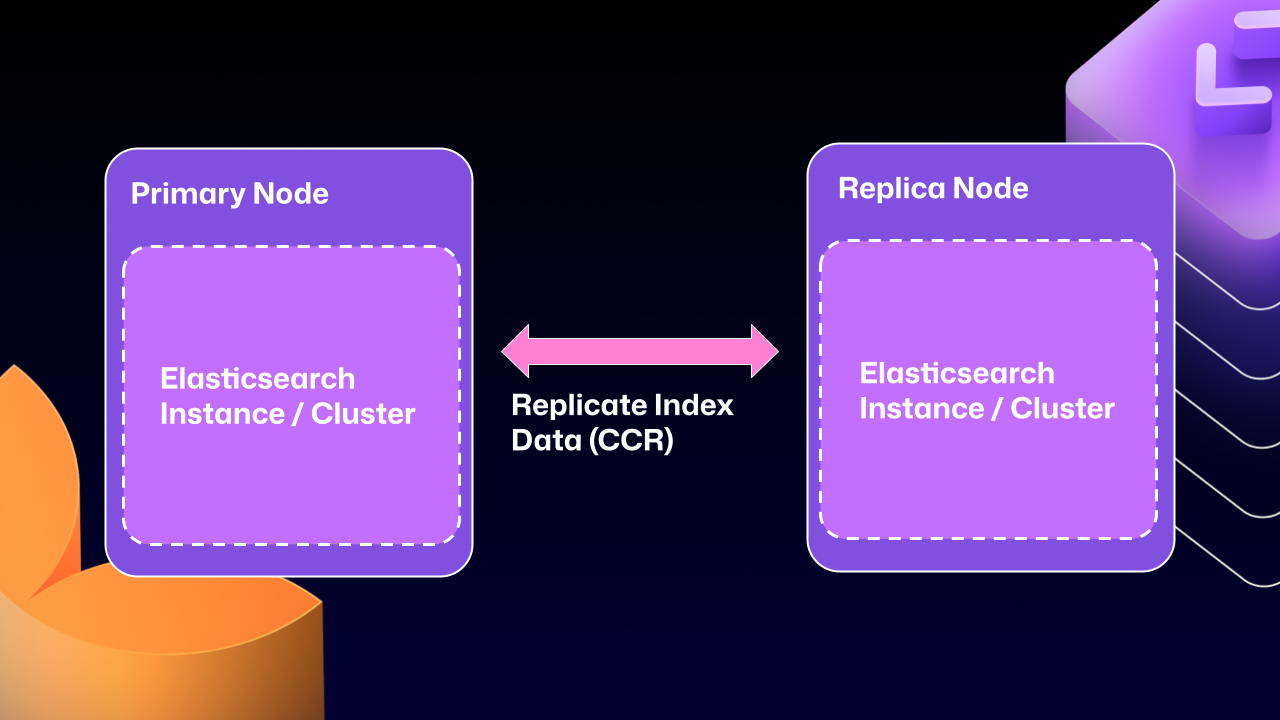
CCRにより、Elasticsearchによって厳密に制御され、ネイティブでサポートされる方法でノード間のインデックスデータを共有できます。データがLuceneセグメント(Elasticsearchの基盤となるデータストア)に永続化された後にコピーします。これにより、Elasticsearchクラスター内で確実に永続化されたデータを複製していることが保証されます。
言い換えれば、Elasticsearchがリーダー/フォロワーパターンをサポートするようになったことで、GitHub Enterprise Serverの管理者は、重要なデータが読み取り専用ノードに残ってしまう状態に置かれることはなくなります。
内部の仕組み
Elasticsearchには自動フォローAPIがありますが、それはポリシーが存在した後に作成されたインデックスにのみ適用されます。GitHub Enterprise ServerのHAインストールにはすでに長期間存続するインデックスのセットがあるため、既存のインデックスにフォロワーを接続し、将来作成されるものに対して自動フォローを有効にするブートストラップステップが必要です。
そのワークフローがどのようなものかのサンプルを以下に示します:
function bootstrap_ccr(primary, replica):
# それぞれの現在のインデックスを取得
primary_indexes = list_indexes(primary)
replica_indexes = list_indexes(replica)
# システムインデックスを除外
managed = filter(primary_indexes, is_managed_ghe_index)
# フォロワーパターンがないインデックスについては、
# その契約を初期化する必要がある
for index in managed:
if index not in replica_indexes:
ensure_follower_index(replica, leader=primary, index=index)
else:
ensure_following(replica, leader=primary, index=index)
# 最後に、新しいインデックスが自動的にフォローされるように
# 自動フォロワーパターンを設定する
ensure_auto_follow_policy(
replica,
leader=primary,
patterns=[managed_index_patterns],
exclude=[system_index_patterns]
)
これは、GitHub Enterprise ServerでCCRを有効にするために作成した新しいワークフローの1つに過ぎません。フェイルオーバー、インデックス削除、アップグレードのためのカスタムワークフローを設計する必要がありました。Elasticsearchはドキュメントレプリケーションのみを処理し、インデックスのライフサイクルの残りの部分は私たちが責任を持ちます。
CCRモードの始め方
新しいCCRモードの使用を開始するには、support@github.comに連絡し、GitHub Enterprise Serverの新しいHAモードを使用したい旨を伝えてください。必要なライセンスをダウンロードできるように、あなたの組織を設定します。
新しいライセンスをダウンロードしたら、ghe-config app.elasticsearch.ccr trueを設定する必要があります。それが完了すると、管理者はconfig-applyを実行できます。
GitHub Enterprise Serverが再起動すると、Elasticsearchはインストールを新しいレプリケーション方法を使用するように移行します。これにより、すべてのデータがプライマリノードに統合され、ノード間のクラスタリングが解除され、CCRを使用したレプリケーションが再起動されます。この更新は、GitHub Enterprise Serverインスタンスのサイズによっては時間がかかる場合があります。
新しいHA方法は現在オプションですが、今後2年間でデフォルトにする予定です。GitHub Enterprise管理者が十分な時間をかけてフィードバックを提供できるようにしたいと考えていますので、今が試す時期です。
GitHub Enterprise Serverの管理をよりシームレスな体験にするために、新しいHAモードの使用を開始されることを楽しみにしています。
高可用性GitHub Enterprise Serverデプロイメントで検索を最大限に活用したいですか?サポートに連絡して、新しい検索アーキテクチャを設定してください!
この投稿「How we rebuilt the search architecture for high availability in GitHub Enterprise Server」は、The GitHub Blogに最初に掲載されました。
原文を表示
So much of what you interact with on GitHub depends on search—obviously the search bars and filtering experiences like the GitHub Issues page, but it is also the core of the releases page, projects page, the counts for issues and pull requests, and more. Given that search is such a core part of the GitHub platform, we’ve spent the last year making it even more durable. That means, less time spent managing GitHub Enterprise Server, and more time working on what your customers care most about.
In recent years, GitHub Enterprise Server administrators had to be especially careful with search indexes, the special database tables optimized for searching. If they didn’t follow maintenance or upgrade steps in exactly the right order, search indexes could become damaged and need repair, or they might get locked and cause problems during upgrades. Quick context if you’re not running High Availability (HA) setups, they’re designed to keep GitHub Enterprise Server running smoothly even if part of the system fails. You have a primary node that handles all the writes and traffic, and replica nodes that stay in sync and can take over if needed.
Much of this difficulty comes from how previous versions of Elasticsearch, our search database of choice, were integrated. HA GitHub Enterprise Server installations use a leader/follower pattern. The leader (primary server) receives all the writes, updates, and traffic. Followers (replicas) are designed to be read-only. This pattern is deeply ingrained into all of the operations of GitHub Enterprise Server.
This is where Elasticsearch started running into issues. Since it couldn’t support having a primary node and a replica node, GitHub engineering had to create an Elasticsearch cluster across the primary and replica nodes. This made replicating data straightforward and additionally gave some performance benefits, since each node could locally handle search requests.
Unfortunately, the problems of clustering across servers eventually began to outweigh the benefits. For example, at any point Elasticsearch could move a primary shard (responsible for receiving/validating writes) to a replica. If that replica was then taken down for maintenance, GitHub Enterprise Server could end up in a locked state. The replica would wait for Elasticsearch to be healthy before starting up, but Elasticsearch couldn’t become healthy until the replica rejoined.
For a number of GitHub Enterprise Server releases, engineers at GitHub tried to make this mode more stable. We implemented checks to ensure Elasticsearch was in a healthy state, as well as other processes to try and correct drifting states. We went as far as attempting to build a “search mirroring” system that would allow us to move away from the clustered mode. But database replication is incredibly challenging and these efforts needed consistency.
What changed?
After years of work, we’re now able to use Elasticsearch’s Cross Cluster Replication (CCR) feature to support HA GitHub Enterprise.
“But David,” you say, “That’s replication between clusters. How does that help here?”
I’m so glad you asked. With this mode, we’re moving to use several, “single-node” Elasticsearch clusters. Now each Enterprise server instance will operate as independent single node Elasticsearch clusters.
CCR lets us share the index data between nodes in a way that is carefully controlled and natively supported by Elasticsearch. It copies data once it’s been persisted to the Lucene segments (Elasticsearch’s underlying data store). This ensures we’re replicating data that has been durably persisted within the Elasticsearch cluster.
In other words, now that Elasticsearch supports a leader/follower pattern, GitHub Enterprise Server administrators will no longer be left in a state where critical data winds up on read-only nodes.
Under the hood
Elasticsearch has an auto-follow API, but it only applies to indexes created after the policy exists. GitHub Enterprise Server HA installations already have a long-lived set of indexes, so we need a bootstrap step that attaches followers to existing indexes, then enables auto-follow for anything created in the future.
Here’s a sample of what that workflow looks like:
function bootstrap_ccr(primary, replica):
# Fetch the current indexes on each
primary_indexes = list_indexes(primary)
replica_indexes = list_indexes(replica)
# Filter out the system indexes
managed = filter(primary_indexes, is_managed_ghe_index)
# For indexes without follower patterns we need to
# initialize that contract
for index in managed:
if index not in replica_indexes:
ensure_follower_index(replica, leader=primary, index=index)
else:
ensure_following(replica, leader=primary, index=index)
# Finally we will setup auto-follower patterns
# so new indexes are automatically followed
ensure_auto_follow_policy(
replica,
leader=primary,
patterns=[managed_index_patterns],
exclude=[system_index_patterns]
)
This is just one of the new workflows we’ve created to enable CCR in GitHub Enterprise Server. We’ve needed to engineer custom workflows for failover, index deletion, and upgrades. Elasticsearch only handles the document replication, and we’re responsible for the rest of the index’s lifecycle.
How to get started with CCR mode
To get started using the new CCR mode, reach out to support@github.com and let them know you’d like to use the new HA mode for GitHub Enterprise Server. They’ll set up your organization so that you can download the required license.
Once you’ve downloaded your new license, you’ll need to set ghe-config app.elasticsearch.ccr true. With that finished, administrators can run a config-apply or an upgrade on your cluster to move to 3.19.1, which is the first release to support this new architecture.
When your GitHub Enterprise Server restarts, Elasticsearch will migrate your installation to use the new replication method. This will consolidate all the data onto the primary nodes, break clustering across nodes, and restart replication using CCR. This update may take some time depending on the size of your GitHub Enterprise Server instance.
While the new HA method is optional for now, we’ll be making it our default over the next two years. We want to ensure there’s ample time for GitHub Enterprise administrators to get their feedback in, so now is the time to try it out.
We’re excited for you to start using the new HA mode for a more seamless experience managing GitHub Enterprise Server.
Want to get the most out of search on your High Availability GitHub Enterprise Server deployment? Reach out to support to get set up with our new search architecture!
The post How we rebuilt the search architecture for high availability in GitHub Enterprise Server appeared first on The GitHub Blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み