Amazon Bedrockにおける強化学習ファインチューニング:ベストプラクティス
AWSはAmazon Bedrock上での強化学習によるファインチューニング(RFT)のベストプラクティスを公開し、ラベル付きデータセットを必要とせずに最大66%の精度向上を実現する手法を、コード生成や数学的推論などのユースケースで解説した。
キーポイント
RFTの基本概念と利点
強化学習によるファインチューニング(RFT)は、正解応答のラベル付きデータを必要とせず、報酬信号から学習することで、ベースモデルに対して最大66%の精度向上とカスタマイズコスト・複雑性の低減を実現する。
効果的な適用領域
RFTは、コード生成テストの通過など自動的に正しさを検証できるタスクと、別のモデルが応答品質を効果的に評価できる主観的タスクの2つの主要領域で特に有効である。
実践的なベストプラクティス
データセット設計、報酬関数戦略(ルールベース、トレーニング済み採点モデル、LLM裁判官)、ハイパーパラメータチューニング、Amazon Bedrockメトリクスを使用したトレーニング進捗の監視について具体的なガイドラインを提供している。
具体的な実証例
GSM8K数学的推論データセットを具体例として使用し、RFTの有効性を実証しながら、複数のモデルとユースケースにわたる実験に基づいた実用的な知見を共有している。
データセットの品質原則
RFTの効果を最大化するためには、プロンプト分布の適切な範囲、ベースモデルの基本能力、明確なプロンプト設計、信頼性のある参照回答、一貫した報酬信号の5つの品質原則を考慮する必要がある。
報酬関数の設計アプローチ
検証可能なタスクではプログラムによる正しさのチェックが有効で、非検証可能なタスクではLLMベースの評価者が主観的評価を近似し、両者を組み合わせることで質を高めることができる。
トレーニング進捗の評価指標
トレーニング報酬と検証報酬の推移を監視し、全体的な上昇傾向と検証データでの安定した改善を確認することで、モデルが適切に学習しているか判断できる。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIのカスタマイズにおける実用的な障壁(ラベル付きデータの必要性)を解消する手法を提供し、企業のAI導入コストと複雑性を大幅に低減する可能性がある。AWSのマネージドサービスとして提供されることで、技術的専門知識が限られる組織でも高度なモデルカスタマイズが可能になる点が業界全体に与える影響は大きい。
編集コメント
技術的な深みと実践的なガイドラインのバランスが良く、企業のAI導入現場で即座に活用できる内容。AWSのプラットフォーム戦略としての位置付けも明確で、クラウドAIサービスの進化を感じさせる。
Amazon Bedrockで強化学習ファインチューニング(Reinforcement Fine-Tuning: RFT)を使用することで、Amazon Novaおよびサポートされているオープンソースモデルをカスタマイズできます。これは「良い」とは何かを定義することで実現され、大規模なラベル付きデータセットは必要ありません。静的な例ではなく報酬信号から学習することで、RFTはカスタマイズの費用と複雑さを抑えつつ、ベースモデルに対して最大66%の精度向上をもたらします。本稿では、コード生成、構造化抽出、コンテンツモデレーションなどのユースケース向けに、Amazon Bedrock上でのRFTに関するベストプラクティスとして、データセットの設計、報酬関数の戦略、およびハイパーパラメータチューニングについて解説します。
本稿では、RFTが最も効果的な領域を探求し、具体的な例としてGSM8Kという数学的推論データセットを使用します。その後、データセットの準備と報酬関数の設計に関するベストプラクティスを確認し、Amazon Bedrockのメトリクスを使用してトレーニングの進捗を監視する方法を示します。最後に、複数のモデルおよびユースケースにわたる実験に基づいた実践的なハイパーパラメータチューニングのガイドラインで締めくくります。
RFT のユースケース:RFT が輝く場所
強化学習微調整(Reinforcement Fine-Tuning、RFT)は、報酬信号を用いて基盤モデル(Foundation Model、FM)の動作を改善するモデルカスタマイズ手法です。教師あり微調整(Supervised Fine-Tuning、SFT)と比較すると、RFT は正解回答(ラベル付きの入出力ペア)に対して直接学習を行うわけではありません。代わりに、RFT は入力データセットと報酬関数を使用します。この報酬関数は、ルールベースのものや、別の訓練済み評価モデル、あるいは「ジャッジ」として機能する大規模言語モデル(Large Language Model、LLM)のいずれかです。学習プロセスにおいて、モデルは候補回答を生成し、報酬関数が各回答にスコアを付けます。この報酬に基づいてモデルの重みが更新され、高い報酬を得る回答を生成する確率が高まるように調整されます。この「サンプルの生成→スコアリング→重みの更新」という反復サイクルにより、モデルはより良い結果につながる行動を学習していきます。RFT は、望ましい行動の評価が可能だが実証が困難な場合に特に価値があります。これは、ラベル付きデータの収集が現実的ではない場合や、静的な例だけではタスクに必要な推論を捉えきれない場合に該当します。RFT は主に以下の2つの領域で卓越した性能を発揮します:
- ルールやテストによって正しさを自動的に検証できるタスク
- 別のモデルが応答の品質を効果的に評価できる主観的なタスク
最初のカテゴリに属するタスクには、テストをパスしなければならないコード生成、検証可能な回答を持つ数学的推論、厳格なスキーマに一致しなければならない構造化データ抽出、そして正しく解析・実行されなければならないAPI/ツール呼び出しが含まれます。成功基準を直接報酬信号に変換できるため、モデルは限られた数のラベル付き例から教えられるよりも強力な戦略を発見できます。このパターンは検証可能な報酬を用いた強化学習 (RLVR)として知られています。
さらに、RFTは、容易に定量化可能な正しさが欠如しているコンテンツモデレーション、チャットボット、クリエイティブライティング、要約などの主観的なタスクにも適しています。詳細な評価基準によって導かれる判断モデル(Judge Model)が報酬関数の役割を果たします。これは、静的なトレーニングペアとしてエンコードすることが非現実的な基準に対して出力をスコアリングします。このアプローチはAIフィードバックを用いた強化学習 (RLAIF)として知られています。
Amazon BedrockにおけるRFT(Reinforcement Fine-Tuning)では、トレーニングループ中にAmazon Bedrockが呼び出す報酬関数として、カスタムAWS Lambda関数を実装し、ルールベースのアプローチとモデルベースの両方の方式を採用できます。
これらの2つのアプローチの比較は、以下の図に示されています:
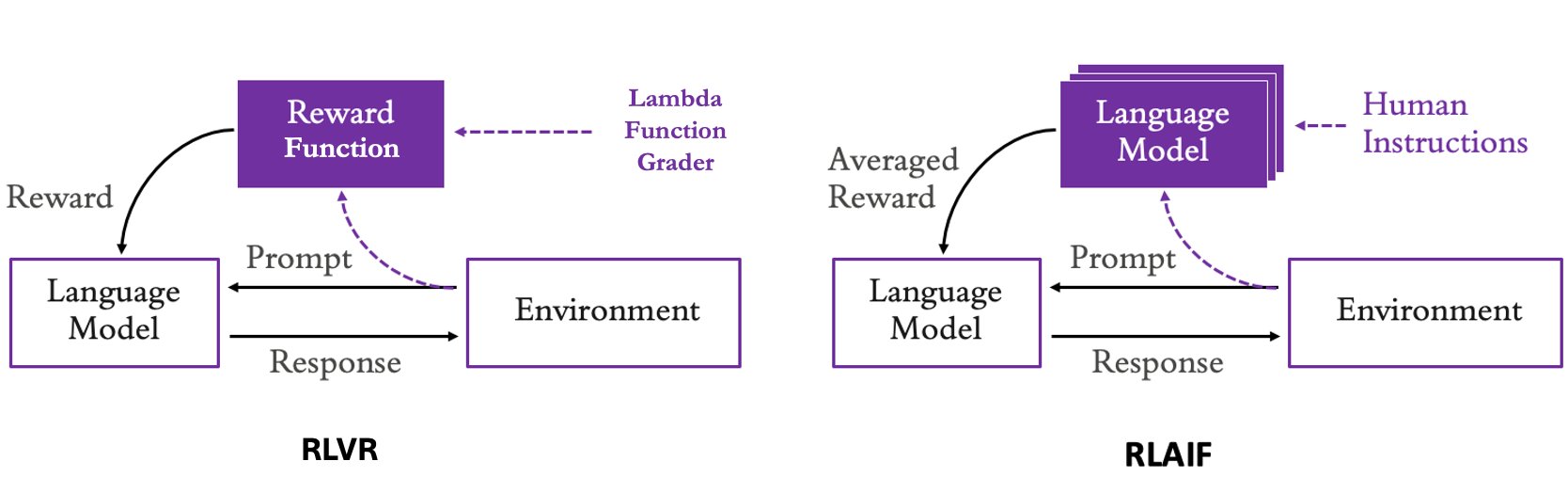
以下は、RLVR(Reinforcement Learning from Verifiable Rewards)やRLAIF(Reinforcement Learning from AI Feedback)、あるいはその組み合わせによって解決できる代表的なユースケースです。
| ユースケース | 報酬信号 |
|---|---|
| 本番環境向けのコード生成 | �ニットテストのパス率、リンティング、ランタイムチェック |
| ツールおよびAPIオーケストレーション | 最終的なエンドツーエンドのタスク完了(例:予約フロー、データ取得パイプライン) |
| 複雑な数学およびアルゴリズム推論 | 正しい最終回答、および/または中間検証ステップ |
| 構造化データ抽出および変換 | スキーマ検証、完全一致、不正な出力に対するペナルティ |
| データベース上のSQL/クエリ合成 | 期待される回答と一致する、またはランタイムの性質を満たすクエリ結果 |
| エージェントワークフロー | RLVRとRLAIFの組み合わせ;ツール呼び出しの正確性にはRLVRを、最終的なタスク完了(有用性、正確性、堅牢性として測定される場合など)にはRLAIFを使用
GSM8K:RFT を用いた数学計算問題の解決策改善
強化学習ファインチューニング(Reinforcement Fine-Tuning: RFT)が実際にどのように機能するかを示すために、具体的な例として、モデルの数学的推論問題解決能力を向上させることを検討してみましょう。RFT は数学的問題に有用です。なぜなら、解答は客観的に検証可能であることが多く、正しい推論と構造化された出力へとモデルを導く明確な報酬信号(Reward Signal)を設計することが可能だからです。GSM8K (Grade School Math 8K) データセットからの例を見てみましょう:
Tina は時給 $18.00 で働いています。シフトで 8 時間以上勤務した場合、残業手当の対象となり、時給に時給の半分を加えた金額で支払われます。彼女が 5 日間、毎日 10 時間勤務した場合、総額いくら稼ぐことになりますか?
理想的な回答は以下のようになる可能性があります:
**
5 日間の 10 時間シフトの総賃金を求める必要があります。彼女は毎日 8 時間を超えて勤務するため、各日の労働時間を通常時間と残業時間に分け、残業率(通常の 1.5 倍)を計算し、それを 5 日間で掛ける必要があります。
残業率:$18.00 + (1/2 × $18.00) = $27.00/時間
1 日の収益(10 時間):
通常労働(8 時間): 8 × $18 = $144
残業(2 時間): 2 × $27 = $54
1 日の合計:$198
5 日間の総額:5 × $198 = $990
\boxed{990}
必ず JSON 形式で返してください:
{"translation": "翻訳全文", "technical_terms": ["term1", "term2"]}
ここで、問題が論理的なステップに分解され、最終的な答えだけでなく明確な推論の道筋を示していることがわかります。さらに、モデルにはこの特定の形式で回答し、答えが正解と完全に一致することを期待しています。SFT(Supervised Fine-Tuning:教師あり微調整)などの他の微調整手法は、主にトレーニングデータのパターンマッチングを学習するだけで、真の推論を行わないため、数学的推論において苦戦します。これらのモデルは解決策のテンプレートを暗記することはできますが、問題の新しい変形が出された場合、しばしく失敗します。
RFT(Reinforcement Fine-Tuning:強化学習による微調整)を使用して報酬関数を定義できるため、前述の$990のような正確な答えを客観的に評価できると同時に、正しい中間推論ステップに対して部分点数を与えることができます。これにより、モデルは必要な構造化された形式に従う方法を学習しながら有効な解決アプローチを発見することが可能になり、多くの場合、比較的小さなデータセット(約100〜1000例)でも強力なパフォーマンスを実現します。
データセット準備のベストプラクティス
RFTは、効果的な結果を得るために注意深く準備されたデータセットを必要とします。Amazon Bedrockでは、RFTのトレーニングデータはJSONLファイルとして提供され、各レコードはOpenAIのチャット完了形式に従います。
データセットサイズのガイドライン
RFT(Reinforcement Fine-Tuning)は、100~10,000件のトレーニングサンプルのデータセットサイズをサポートしていますが、要件はタスクの複雑さや報酬関数の設計によって異なります。複雑な推論、専門的なドメイン、または広範な適用範囲を扱うタスクは、一般的により大規模なデータセットと洗練された報酬関数の恩恵を受けます。初期実験では、プロンプトや報酬関数が意味のある学習シグナルを生成し、ベースモデルが測定可能な報酬の改善を実現できることを確認するために、小規模なデータセット(100~200例)から始めてください。特定のドメインでは、小規模なデータセットのみでカスタマイズすると汎化能力が限られ、プロンプトのバリエーション間で結果が一貫しないことがあり得ることに注意してください。200~5,000例を使用した典型的な実装は、より強力な汎化能力と、プロンプトのバリエーションにわたってより一貫したパフォーマンスを提供します。より複雑な推論タスク、専門的なドメイン、または洗練された報酬関数の場合、5,000~10,000例を使用することで、多様な入力に対する堅牢性が向上します。
データセットの要件に関する詳細については、Amazon Bedrock ドキュメントを参照してください。
データセット品質の原則
トレーニングデータの品質は、RFT の結果を根本的に決定します。データセットを準備する際、以下の原則を考慮してください:
- プロンプトの分布**** データセットが、本番環境でモデルが遭遇する可能性のあるすべてのプロンプトの範囲を反映していることを確認してください。偏ったデータセットは、汎化性能の低下や不安定な学習動作を引き起こす可能性があります。
- ベースモデルの能力**** RFT(Reinforcement Fine-Tuning:強化学習によるファインチューニング)は、ベースモデルが基本的なタスクの理解を示していることを前提とします。もしモデルがプロンプトに対してゼロ以外の報酬を得られない場合、学習信号が強すぎて効果的なトレーニングが行えません。簡単な検証ステップとして、ベースモデルから複数の応答を生成し(例:温度 ≈ 0.6)、出力が意味のある報酬信号を生み出すかを確認します。
- 明確なプロンプト設計**** プロンプトは、期待値と制約条件を明確に伝えるべきです。曖昧な指示は一貫性のない報酬信号をもたらし、学習品質の低下を招きます。プロンプトの構造は、報酬関数の解析と整合している必要があります。例えば、特定のマーカーの後に最終回答を要求したり、プログラミングタスクに対してコードブロックを強制したりするなど、ベースモデルが事前学習から慣れ親しんでいるプロンプト構造であることが望ましいです。
- 信頼性の高い参照回答**** 可能であれば、所望の出力パターン、フォーマット、正しさの基準を表す参照回答を含めてください。参照回答は報酬計算の基準となり、学習信号におけるノイズを軽減します。例えば、数学タスクには正しい数値解答を含め、コーディングタスクにはユニットテストや入出力ペアを含めることができます。
また、正解と一致する回答が最大のリワードスコアを受け取ることを確認することで、参照回答を検証することも良いプラクティスです。
- データ内の一貫したリワード信号**
RFT は学習を導くために完全にリワード信号に依存しているため、これらの信号の品質が極めて重要です。データセットとリワード関数は連携して、一貫性があり明確に区別できるスコアを生成する必要があります。これは、類似の入力に対して、優れた回答が確実に劣った回答よりも高いスコアを得ることを意味します。もしリワード関数が良い回答と悪い回答を明確に区別できない場合、または類似の出力が大幅に異なるスコアを受け取る場合、モデルは間違ったパターンを学習したり、改善できなかったりする可能性があります。
次のセクションでは、リワード関数を記述する際に留意すべき点について学びます。
報酬関数の準備
RFT(強化学習によるファインチューニング)において、報酬関数は中心的な役割を果たします。これはモデルの応答を評価・スコアリングし、望ましい出力には高い報酬を、望ましくない出力には低い報酬を割り当てます。このフィードバックは、トレーニング中にモデルの動作改善を促します。数学的推論などの客観的なタスクの場合、正しい回答を生成する候補応答には1の報酬が与えられ、不正解な回答には0の報酬が与えられます。部分的に正しい推論プロセスを含みつつ最終回答は誤っている応答には、最終的な不正解をどの程度ペナルティとするかにもよりますが、0.8の報酬が与えられる可能性があります。主観的なタスクの場合、報酬関数は望ましい品質をエンコードします。例えば、要約タスクでは忠実性(faithfulness)、網羅性(coverage)、明瞭さ(clarity)といった要素が捉えられます。報酬関数の設定に関する詳細については、Amazon Nova モデル用の報酬関数のセットアップをご覧ください。
検証可能なタスクのための報酬設計
数学的推論やコーディングなど、決定論的に検証可能なタスクの場合、最も単純なアプローチは正しさをプログラムでチェックすることです。効果的な報酬関数は通常、形式制約とパフォーマンス目標の両方を評価します。形式チェックは、回答が確実に解析および評価できることを保証します。パフォーマンス指標は結果が正しいかどうかを決定します。報酬は、タスクに応じて、バイナリ信号(正解と不正解の比較)または連続スコアリングを使用して実装できます。
GSM8Kスタイルの数学的推論タスクの場合、報酬関数はモデルが数値回答をどのように表現するかについても考慮する必要があります。モデルは、カンマ、通貨記号、パーセント記号を使用して数値をフォーマットしたり、回答を説明テキスト内に埋め込んだりすることができます。これに対処するため、回答はフォーマット文字列を除去し、構造化された形式を優先してパターンマッチングにフォールバックする柔軟な抽出を適用することにより正規化されます。このアプローチにより、モデルはスタイル的なフォーマット選択でペナルティを受けるのではなく、正しい推論に対して報酬を得ることが保証されます。GSM8Kの完全な報酬関数の実装は、amazon-bedrock-samples GitHub リポジトリで見つけることができます。
検証不可能なタスクに対する報酬設計
要約、創造的ライティング、セマンティック整合性などのタスクでは、LLM ベースのジャッジを使用して主観的な好みを近似する必要があります。この設定において、ジャッジプロンプトは実質的に報酬関数として機能し、どの行動が報酬され、回答がどのように評価されるかを定義します。実用的なジャッジプロンプトは、評価目標を明確に定義し、モデルが改善すべき品質を反映した数値スケールを含む簡潔なスコアリング基準(ルーブリック)を含めるべきです。
ジャッジプロンプトは、最終スコアとオプションの推論を含む JSON やタグ付き形式などの構造化された出力を返す必要があります。これにより、トレーニング中に報酬値を確実に抽出できながら、各回答がどのように評価されたかについての可観測性を維持できます。AI フィードバックを利用する報酬関数の例は、この GitHub 上の PandaLM 報酬関数スクリプト で確認できます。
検証可能な報酬と AI フィードバックの組み合わせ
検証可能タスクに対する報酬関数は、数値的正しさを越えるソリューションの品質を評価するために AI フィードバックで拡張できます。例えば、LLM-as-a-judge(ジャッジとしての大規模言語モデル)は、推論チェーンを評価し、中間計算を検証したり、説明の明確さを評価したりすることで、正しさと推論の質の両方を捉えた報酬信号を提供します。
報酬設計の反復
報酬関数にはしばしば反復的な改善が必要です。初期バージョンではノイズの多い信号を生成したり、学習ループの中でモデルが報酬関数を悪用して所望の行動を学ばずに高得点を生成したりすることがあります。観察された学習挙動に基づいて報酬ロジックを refinements することは不可欠です。本格的なトレーニングジョブを開始する前に、サンプルプロンプトと既知の出力を使用して報酬関数を独立してテストし、スコアリングロジックが安定かつ意味のある報酬信号を生成することを確認するのが良いプラクティスです。
学習進捗の評価:モデルが学習していることを示す信号
データセットと報酬関数の準備が整ったら、Amazon Bedrock API またはコンソールを通じて RFT(Reinforcement Fine-Tuning)トレーニングを開始できます。正確なワークフローは、お好みの開発環境によって異なります。Amazon Bedrock ユーザーガイドの「Create and manage fine-tuning jobs for Amazon Nova models」セクションには、両方のアプローチに関するステップバイステップの手順が記載されています。トレーニング開始後、学習メトリクスを監視することが重要です。これらの信号は、報酬関数が意味を成しているか、そしてモデルが過学習や単純な戦略への収束ではなく有用な行動を学習しているかどうかを示します。以下の画像は、GSM8K のトレーニング実行の 1 つにおける学習メトリクスを示しており、健全な学習ダイナミクスが見られます。
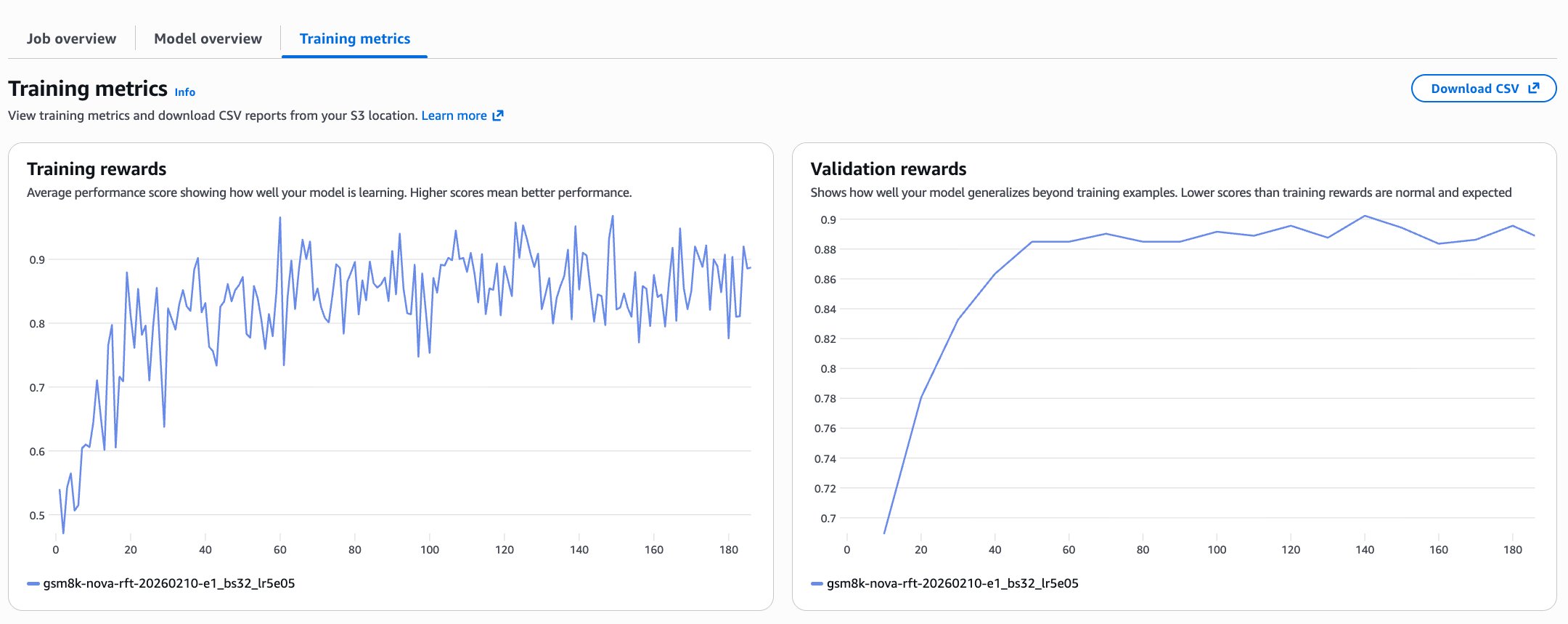
トレーニング報酬プロットは、各学習ステップにおける平均報酬スコアを示します。バッチ内の入力プロンプトがランダムにサンプリングされるため、バッチ間の難易度に差が生じるため、分散が発生するのは当然です。さらに、モデルが異なる戦略を探索していることも分散の一因となります。重要なのは全体的な傾向であり、報酬は約0.5から0.8〜0.9の範囲で増加しており、モデルが高い報酬を得る方向に収束していることを示しています。検証用報酬は保持されたデータセット上で計算されるため、より明確なシグナルを提供します。ここでは、最初の約40ステップで急激な改善が見られ、その後プラトーに達していることがわかります。
原文を表示
You can use reinforcement Fine-Tuning (RFT) in Amazon Bedrock to customize Amazon Nova and supported open source models by defining what “good” looks like—no large labeled datasets required. By learning from reward signals rather than static examples, RFT delivers up to 66% accuracy gains over base models at reduced customization cost and complexity. This post covers best practices for RFT on Amazon Bedrock, from dataset design, reward function strategy, and hyperparameter tuning for use cases like code generation, structured extraction, and content moderation.
In this post, we explore where RFT is most effective, using the GSM8K mathematical reasoning dataset as a concrete example. We then walk through best practices for dataset preparation and reward function design, show how to monitor training progress using Amazon Bedrock metrics, and conclude with practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases.
RFT use-cases: Where can RFT shine?
Reinforcement Fine-Tuning (RFT) is a model customization technique that improves foundation model (FM) behavior using reward signals. Compared to supervised fine-tuning (SFT), it doesn’t directly train on correct responses (labeled I/O pairs). Instead, RFT uses a dataset of inputs and a reward function. The reward function can be rule-based or another trained grader model, or large language model (LLM) as a judge. During training, the model generates candidate responses and the reward function scores each response. Based on the reward, the model weights are updated to increase the probability of generating responses that receive a high reward. This iterative cycle of sample responses, score responses, and update weights steers the model to learn which behaviors lead to better outcomes. RFT is particularly valuable when the desired behavior can be evaluated, but difficult to demonstrate—whether because labeled data is impractical to curate or because static examples alone can’t capture the reasoning a task demands. It excels in two primary areas:
- Tasks where a rule or test can verify correctness automatically
- Subjective tasks where another model can effectively evaluate response quality
Tasks in the first category are code generation that must pass tests, math reasoning with verifiable answers, structured data extraction that must match strict schemas, or API/tool calls that must parse and execute correctly. Because success criteria can be translated directly into reward signals, the model can discover stronger strategies than what a small set of labeled examples could teach. This pattern is known as Reinforcement Learning with Verifiable Rewards (RLVR).
In addition, RFT suits subjective tasks such as content moderation, chatbots, creative writing, or summarization that lack easily quantifiable correctness. A judge model, guided by a detailed evaluation rubric, can serve as the reward function. It scores outputs against criteria that would be impractical to encode as static training pairs. This approach is known as Reinforcement Learning with AI Feedback (RLAIF).
For RFT in Amazon Bedrock, you can implement both rule-based and model-based approaches as a custom AWS Lambda function, which is the reward function that Amazon Bedrock calls during the training loop.
A comparison of these two approaches is depicted in the following diagram:
The following are a few common use cases that can be tackled through RLVR, RLAIF, or a combination of both.
Use Case
Reward Signal
Code generation for production services
Unit-test pass rates, linting, and runtime checks
Tool and API orchestration
Successful end-to-end task completion (like, booking flows, data retrieval pipelines)
Complex math and algorithmic reasoning
Correct final answers and/or intermediate verification steps
Structured data extraction and transformation
Schema validation, exact matches, penalties for malformed outputs
SQL / query synthesis over databases
Query results matching expected answers or satisfying runtime properties
Agentic workflows
Combination of RLVR and RLAIF; RLVR for tool calling correctness; RLAIF for final task completion, for example, measured as usefulness, correctness, or robustness
GSM8K: Using RFT to improve solutions to mathematical calculations
To illustrate how reinforcement fine-tuning works in practice, we can examine a concrete example: improving a model’s ability to solve mathematical reasoning problems. RFT is useful for mathematical problems because solutions can often be objectively verified, making it possible to design clear reward signals that guide the model toward correct reasoning and structured outputs. Let’s look at an example from the GSM8K (Grade School Math 8K) dataset:
Tina makes $18.00 an hour. If she works more than 8 hours per shift, she is eligible for overtime, which is paid by your hourly wage + 1/2 your hourly wage. If she works 10 hours every day for 5 days, how much money does she make?
Let’s look at what an ideal response might look like:
I need to find total pay for 5 days of 10-hour shifts. Because she works over 8 hours daily, I'll need to split each day into regular and overtime hours, calculate the overtime rate (1.5x regular), then multiply by 5 days.
Overtime rate: $18.00 + (1/2 × $18.00) = $27.00/hour
Daily earnings (10 hours):
Regular (8 hours): 8 × $18 = $144
Overtime (2 hours): 2 × $27 = $54
Daily total: $198
Total for 5 days: 5 × $198 = $990
\boxed{990}
Here, we see that the problem is broken down into logical steps and shows clear reasoning paths, not only final answers. Additionally, we would like the model to respond in this specific format and have the answer exactly match the ground truth solution. Other fine-tuning methods like SFT struggle with mathematical reasoning because they primarily learn to pattern-match training data rather than truly reason. These models can memorize solution templates but often fail when presented with novel variations of a problem.
Because we can use RFT to define reward functions, exact answers like the previous answer of $990 can be objectively evaluated while also assigning partial credit for correct intermediate reasoning steps. This enables the model to discover valid solution approaches while learning to follow required structured, and in many cases achieves strong performance with relatively small datasets (around 100–1000 examples).
Best practices for preparing Your dataset
RFT requires carefully prepared datasets to achieve effective results. On Amazon Bedrock, RFT training data is provided as a JSONL file, with each record following the OpenAI chat completion format.
Dataset size guidelines
RFT supports dataset sizes between 100–10,000 training samples, though requirements vary depending on task complexity and reward function design. Tasks involving complex reasoning, specialized domains, or broad application scopes generally benefit from larger datasets and a sophisticated reward function. For initial experimentation, start with a small dataset (100–200 examples) to validate that your prompts and reward function produce meaningful learning signals and that the base model can achieve measurable reward improvements. Note that for certain domains, only customizing on small datasets can yield limited generalization and show inconsistent results across prompt variations. Typical implementations using 200–5,000 examples provide stronger generalization and more consistent performance across prompt variations. For more complex reasoning tasks, specialized domains, or sophisticated reward functions, 5,000–10,000 examples can improve robustness across diverse inputs.
For more information about the dataset requirements, see the Amazon Bedrock documentation.
Dataset quality principles
The quality of your training data fundamentally determines RFT outcomes. Consider the following principles when preparing your dataset:
1. Prompt distribution** Make sure that the dataset reflects the full range of prompts that the model will encounter in production. A skewed dataset can lead to poor generalization or unstable training behavior.
- Base model capability**** RFT assumes that the base model demonstrates basic task understanding. If the model can’t achieve a non-zero reward on your prompts, the learning signal will be too weak for effective training. A simple validation step is generating several responses from the base model (like,
temperature ≈ 0.6) and confirming that the outputs produce meaningful reward signals.
- Clear prompt design**** Prompts should clearly communicate expectations and constraints. Ambiguous instructions lead to inconsistent reward signals and degraded learning. Prompt structure should also align with reward function parsing. For example, requiring final answers after a specific marker or enforcing code blocks for programming tasks, as well as the prompt structure that the base model is familiar with from pre-training.
- Reliable reference answers**** When possible, include a reference answer that represents the desired output pattern, formatting, and correctness criteria. Reference answers anchor reward computation and reduce noise in the learning signal. For example, mathematical tasks might include a correct numerical answer, while coding tasks might include unit tests or input-output pairs.
It’s also good practice to validate reference answers by confirming that a response aligned with the ground truth receives the maximum reward score.
- Consistent reward signals within the data**
Because RFT relies entirely on reward signals to guide learning, the quality of those signals is critical. Your dataset and reward function should work together to produce consistent, well-differentiated scores. This means that strong responses reliably score higher than weak ones across similar inputs. If the reward function can’t clearly distinguish between good and poor responses, or if similar outputs receive widely varying scores, the model might learn the wrong patterns or fail to improve altogether.
In the next section you will learn what to keep in mind when writing your reward function.
Preparing your reward function
Reward functions are central to RFT because they evaluate and score model responses, assigning higher rewards to preferred outputs and lower rewards to less desirable ones. This feedback guides the model toward improved behavior during training. For objective tasks like mathematical reasoning, a candidate response that produces the correct answer might receive a reward of 1, while an incorrect answer receives 0. A response with a partially correct reasoning trace and an incorrect final answer might get a reward of 0.8 (depending on how much you want to penalize an incorrect final response). For subjective tasks, the reward function encodes desired qualities. For example, in summarization it might capture faithfulness, coverage, and clarity. For more information about setting up your reward function, see setting up reward functions for Amazon Nova models.
Reward design for verifiable tasks
For tasks that can be deterministically verified, like math reasoning or coding, the simplest approach is to programmatically check correctness. Effective reward functions typically evaluate both format constraints and performance objectives. Format checks make sure that the responses can be reliably parsed and evaluated. Performance metrics determine whether the result is correct. Rewards can be implemented using binary signals (correct compared to incorrect) or continuous scoring depending on the task.
For GSM8K-style mathematical reasoning tasks, reward functions must also account for how models express numerical answers. Models can format numbers with commas, currency symbols, percentages, or embed answers within explanatory text. To address this, answers should be normalized by stripping formatting characters and applying flexible extraction that prioritizes structured formats before falling back to pattern matching. This approach makes sure that the models are rewarded for correct reasoning rather than penalized for stylistic formatting choices. You can find the full reward function implementation for GSM8K in the amazon-bedrock-samples GitHub repository.
Reward design for non-verifiable tasks
Tasks like summarization, creative writing, or semantic alignment require an LLM-based judge to approximate subjective preferences. In this setting, the judge prompt effectively acts as the reward function, defining what behaviors are rewarded and how responses are scored. A practical judge prompt should clearly define the evaluation goal and include a concise scoring rubric with numeric scales reflecting the qualities the model should improve for.
Judge prompts should also return structured outputs, for example JSON or tagged formats containing the final score and optional reasoning, so reward values can be reliably extracted during training while maintaining observability into how each response was evaluated. An example of a reward function that utilizes AI feedback can be seen in this PandaLM reward function script in GitHub.
Combining verifiable rewards with AI feedback
Reward functions for verifiable tasks can also be augmented with AI feedback to evaluate solution quality beyond numerical correctness. For example, an LLM-as-a-judge can assess the reasoning chain, verify intermediate calculations, or evaluate the clarity of explanations, providing a reward signal that captures both correctness and reasoning quality.
Iterating on reward design
Reward functions often require iteration. Early versions might produce noisy signals or during the training loop the model might learn to exploit the reward function to generate a high reward without learning the desired behavior. Refining the reward logic based on observed training behavior is essential. Before launching full training jobs, it’s also good practice to test reward functions independently using sample prompts and known outputs to ensure that the scoring logic produces stable and meaningful reward signals.
Evaluating training progress: signals that the model is learning
After your dataset and reward function are ready, you can launch RFT training using either the Amazon Bedrock API or through the console. The exact workflow depends on your preferred development environment. The Create and manage fine-tuning jobs for Amazon Nova models topic in the Amazon Bedrock User Guide provides step-by-step instructions for both approaches. After training begins, monitoring the training metrics is critical. These signals indicate whether the reward function is meaningful and whether the model is learning useful behaviors rather than overfitting or collapsing to trivial strategies. The following image shows the training metrics of one of our GSM8K training run showing healthy training dynamics.
Training rewards plots the average reward score at each training step. Variance is expected because the input prompts in a batch are sampled randomly so difficulty in batches differ. In addition, the model is exploring different strategies leading to variance. What matters is the overall trend: rewards increase from roughly 0.5 to around 0.8–0.9, indicating that the model is converging on receiving higher rewards. Validation rewards provide a clearer signal because they are computed on a held-out dataset. Here we see a steep improvement during the first ~40 steps followed by a plat
関連記事
Pococha開発環境をEKS上で再設計:ブランチ単位の開発とPull Request単位の検証 [DeNAインフラSRE]
DeNAのインフラSREチームが、Pocochaの開発環境をAmazon EC2からAmazon EKSへ移行し、ブランチ単位の開発とPull Request単位の検証を可能にするコンテナベースの環境を構築した。
Amazon Bedrock AgentCoreでReactアプリにライブAIブラウザエージェントを組み込む
Amazonは、Bedrock AgentCoreのブラウザツールを提供し、開発者がReactアプリにAIエージェントを組み込めるようにした。これにより、ユーザーはAIエージェントのウェブ操作を可視化でき、信頼性と制御性を向上させる。
大規模エージェント管理の未来:AWS Agent Registryがプレビュー公開
AWSがAWS Agent Registryを発表し、組織内でエージェント・ツール・スキルを発見・共有・再利用できる機能をAmazon Bedrock AgentCoreで提供開始した。