ウィンドサーフアリーナモードリーダーボード:人々が求めるのはスピード
Windsurf Blog は、アリーナモードの初期リーダーボード結果を発表し、ユーザーがコード生成速度を最も重視しているという予想外の傾向を示した。
キーポイント
速度への強い要望
リーダーボードの結果分析から、ユーザーは機能の多様性よりも、AI が回答するまでの「速度」を最優先事項としていることが明らかになった。
予想外の結果
開発チームが想定していた評価基準とは異なり、スピード感がユーザー体験において決定的な要素となっていることが浮き彫りとなった。
今後の開発指針への影響
このフィードバックは、Windsurf の次期アップデートやモデル最適化において、応答速度の向上を最優先課題とする方向性を示唆している。
影響分析・編集コメントを表示
影響分析
このニュースは、AI エディタ市場における競争優位性が「機能の多さ」から「レスポンスの速さ」へとシフトしつつあることを示唆しています。開発チームはユーザーの真のニーズを再認識し、次期バージョンで速度最適化にリソースを集中させる可能性が高く、業界全体のパフォーマンス基準の見直しを促す一因となるでしょう。
編集コメント
機能追加に目が行きがちだが、この結果は「速さ」こそが AI ツールの生命線であることを再認識させる重要なデータです。開発チームの柔軟な対応が今後の製品評価を分ける鍵となりそうです。
私たちが Wave 14 アップデート で予告した通り、本日 Windsurf Arena Mode リーダーボードの初期結果を発表します:https://windsurf.com/leaderboard
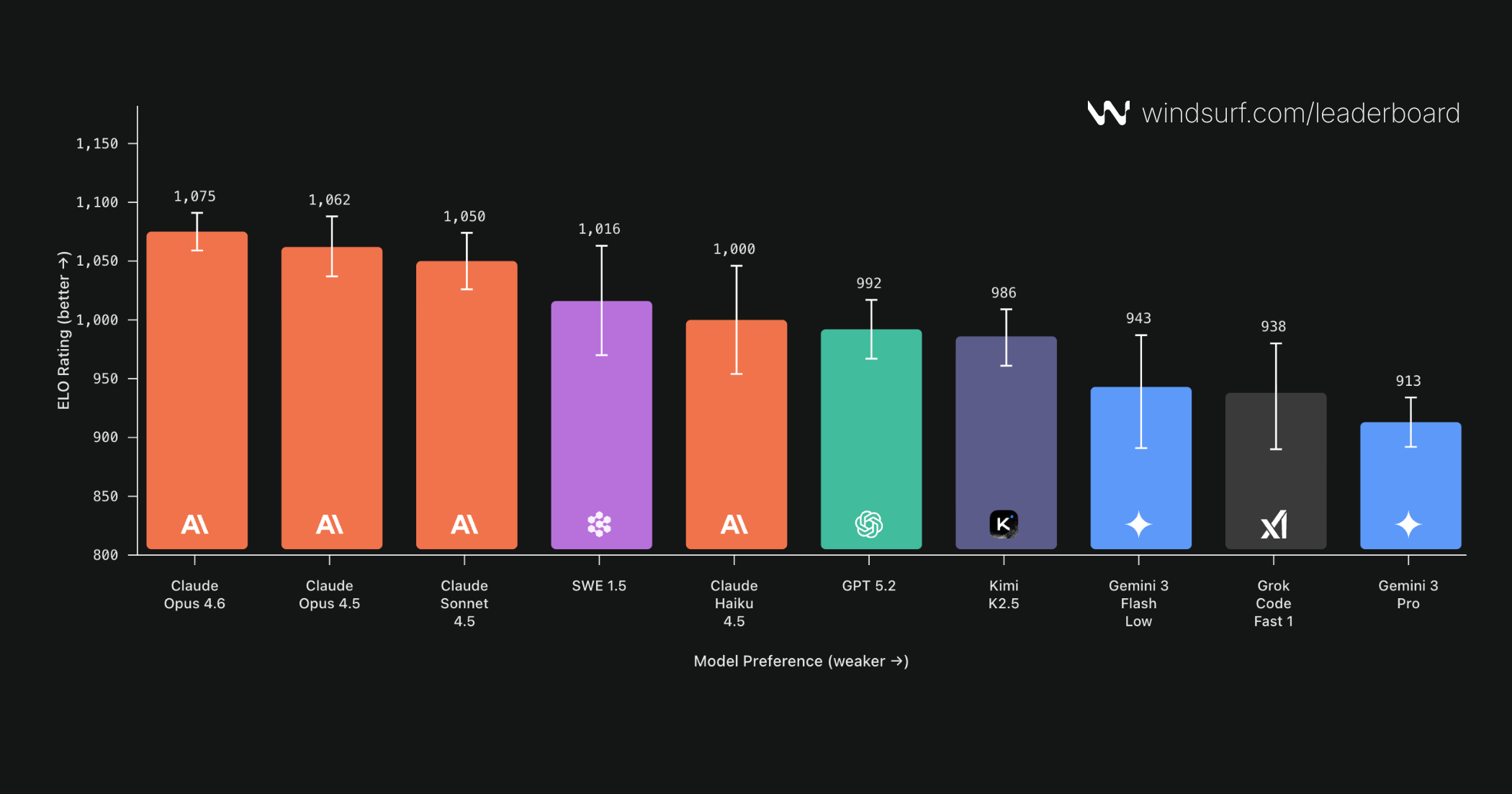
Arena Mode の紹介で述べた通り、従来の Web ベースのアリーナと同じ結果を期待しないでください。実際、初期ランキングにはいくつかの驚くべき結果があります。Arena Mode は、CopilotArena が史上初であることに敬意を表しつつも、大規模に数百万人のユーザー向けに展開された初の製品内アリーナであり、意図的な設計上の違いがあります:
- IDE 内で実行されるため、Arena Mode は現代の IDE エージェントが利用されるすべての機能(コードベースへの質問応答、バグ発見、ターミナルコマンドの実行、MCP と Skills の活用など)を直接テストするという点で、タスク配分が完全に異なります。平均会話長は 3〜6 ターンであり、雰囲気重視の捨ててしまうフロントエンド専用アプリ作成といった「バイブコーディング」への比重は大幅に低くなっています。
- ユーザー層と対象オーディエンスも異なります(定量化は困難ですが、Web ベースのアリーナ利用者と製品内アリーナ利用者の重複部分は小さいと考えています)。
- 最も重要なのは、当社の Arena Mode が「速くて十分」というモデルを罰しない点です。まだタスクやユーザーの構成比を公開していないため、この最後の点がリーダーボードの結果を理解する上で最も重要なポイントとなります。
従来のアリーナは出力品質のみを評価することに焦点を当てているため、完全に盲検化された実験設計を提供するために、遅い方のモデルが完了するまで速いモデルの結果を保留します。Cognition では、速度と品質のトレードオフに関心があり、Windsurf をAI を活用してユーザーをフロー状態に保ち、半同期の死の谷から逃がすことに注力しています。そのため、Arena Mode では、モデルが最初に完了し、かつ十分であれば投票が可能となります。
言い換えれば、私たちはモデルに、思考の各トークンを重要視させるよう強制しています。多くの学術的評価では、レイテンシやトークンコストを考慮しておらず、一部のモデルが同僚よりも最大 10 倍も非効率的な思考(up to 10x more inefficient thinking)を行うことで、わずかに高い出力品質を達成し、意図的または無意識にシステムを操作できてしまいます。これは発表された結果には素晴らしいことですが、ユーザーにとっては望ましくありません。
1 週間で 40,000 票を集めた私たちの結果は、業界で主張されている事象(例えば、Claude Opus 4.6 が統計的有意性を持って Opus 4.5 を上回るなど)を独立して裏付けています。しかし、おそらくより注目すべきは、私たちがデータで見つけた「番狂わせ」であり、これらはそのまま報告します:
- Gemini 3 Flash と Grok Code Fast の両方が Gemini 3 Pro を上回りました
- Claude Haiku 4.5 が GPT 5.2 に勝利しました
- Kimi K2.5 は Claude Sonnet 4.5 を下回りませんでした
- 最後に、当社の SWE 1.5 が Claude Haiku を上回りました。
当社の最高ランクのモデルは、速度と品質の両方で完璧な成績を収めています。 テストでは、Claude Opus 4.6 がより多くの思考時間を要する小規模モデルを上回るケースが複数回ありました。しかし、タスクの大きなセクション、おそらく大多数のタスクにおいて、最初の回答が十分良好で速度が決定的要因となったか、あるいは低速なモデルの回答が、小規模/高速モデルによる勝利から生じる Elo 値の低下を相殺する十分な品質を提供していなかったかのいずれかが見られました。その結果、「Gemini 3 Pro Low が High を上回る」「GPT 5.2 Low が Medium を上回る」といった「奇妙な」結果が生まれました。結果について慎重に検討し、再確認を行った際、当社のプロダクトマネージャーである Theo は単にこう結論付けました:「人々は速度を求めている」。
自社のモデルが当社のリーダーボードで特に有利に評価されている様子が、どのように見えるかはご存知の通りです。とりわけ「Speed」タブに切り替えた際にはその傾向が顕著になりますが、この速度に関する詳細は 私たちの SWE-1.5 記事 で解説しています。私たちは Arena.ai の 公開されたアリーナランク手法 を採用しており、信頼区間も公表済みです。そのため、ランキングがさらに変動する余地は十分にあります。実際、Arena.ai の CEO であるアナスタシオス氏と会話を行いました。彼は「Cognition がアリーナランク手法を活用してリーダーボードを構築していることを嬉しく思います。今後も一流のリーダーボードが登場することを期待しています」と述べてくれました。私たちは私たちのアプローチと結果に自信を持っており、これ以上の解説を加えずにそのまま公開することで、皆様にご自身で判断していただくことにしました。
興味深いのは、どのモデルも勝率が 80% を超えることがないという点です。私たちのテストでは、特定のタスクにおいて、ランキングが低いモデルでも SOTA(State-of-the-Art:最先端)モデルに勝利するケースが見つかりました。アリーナモードが成熟するにつれて、これらの事例をより詳細に研究することに興奮しています。明らかにタスクの多様性を理解し、まだ限界がある領域を把握することが、次世代のコーディングモデルを構築するすべての人にとって有益です。
定性的にも、モデル内での盲検テストを有効にしたことで、モデルに対する印象は変化しています。CTO のスティーブンが述べたように、「アリーナモードは、公開評価では感じられないモデル間の違いについて何かを感じさせてくれます。どのモデルが最良かという意見形成には通常、確認バイアスが強く働きますが、アリーナモードは評価において客観性と功績主義を強制します」。
アリーナモードのリーダーボードは、コミュニティへの文献貢献です。GPT-5.3-Codex のローンチ結果を間もなく更新し、より先端的な評価を通じてコミュニティに引き続き貢献していく所存です。
原文を表示
As previewed in our Wave 14 update, we are releasing the initial results of the Windsurf Arena Mode leaderboard today: https://windsurf.com/leaderboard
As we mentioned in the Arena Mode introduction, you should not expect the same results as traditional web-based arenas, and indeed there are some shockers in the early rankings. Arena Mode is the first in-product Arena deployed at scale to millions of users (due credit to CopilotArena for being first ever), with conscious design differences:
- It is run inside the IDE, meaning Arena Mode has a completely different task distribution as it directly tests models on everything a modern IDE agent would be used for, including codebase Q&A, bugfinding, running terminal commands, leveraging MCPs and Skills, with an average conversation length of 3-6 turns, and a much lower emphasis on vibe coding throwaway frontend-only apps.
- It has a different userbase and audience (hard to quantify, but we think the Venn diagram overlap of web-based arena vs in-product arena users is small)
- Most importantly, our Arena Mode does not penalize fast models for being “fast but good enough”.
Since we don’t yet publish task and user breakdowns, this last point is the most important one to understand our leaderboard results.
Traditional arenas are focused on evaluating output quality alone, and therefore hold back fast model results until the slower of the two models complete, so as to offer a fully blinded experiment design. At Cognition, we are interested in the tradeoff of speed vs quality, and focus Windsurf on using AI to keep you in flow and out of the Semi-Async Valley of Death. So Arena Mode lets you vote on a model if it completed first and was good enough.
Put another way, we force models to make every thinking token count. Most academic evals do not take latency or token cost into perspective, allowing some models to intentionally or unintentionally game the system by having up to 10x more inefficient thinking than peers to achieve marginally higher output quality. This is great for published results, and not great for users.
With 40,000 votes gathered in a week, our results independently validate things that are claimed in the industry, for example, Claude Opus 4.6 beats Opus 4.5 with statistical significance. However, likely more noteworthy are “upsets” that we are finding in our data that we will just directly report:
- Both Gemini 3 Flash and Grok Code Fast beat Gemini 3 Pro
- Claude Haiku 4.5 beats GPT 5.2
- Kimi K2.5 does NOT beat Claude Sonnet 4.5
- last but not least, our SWE 1.5 beats Claude Haiku.
Our highest ranked models ace both speed and quality. In our testing we had multiple times where Claude Opus 4.6 beat smaller models that thought more. But for a large section of tasks, perhaps the majority of tasks, we found either that the first result was good enough that speed became the deciding factor, or that slower model answers didn't provide enough quality to outweigh the drop in Elo from small/fast model wins... leading to "weird" results like Gemini 3 Pro Low beating High and GPT 5.2 Low beating Medium. As we stressed over our results and doublechecked them, our PM Theo simply ended up concluding: "the people want speed".
We know how it looks to have our house model show up so favorably in our own leaderboard, especially once you flip over to the Speed tab — the speed of which is explained in our SWE-1.5 post. We use Arena.ai's published arena-rank methodology and have published our confidence intervals and so there is room for rankings to shift still. In fact we did chat with Anastasios, CEO of Arena.ai, who reached out to say: "We're happy to see Cognition leveraging the Arena Rank methodology to drive their leaderboard and look forward to more best in class leaderboards to come." We are confident in our approach and results, and are publishing them as-is so that you can judge for yourself without further commentary from us.
What's interesting is that no one model has even a >80% win rate. In our testing we found selected tasks where even lower ranking models can beat the SOTA model. We're excited to study these in greater detail as Arena Mode matures. Clearly understanding task diversity and where the frontier still falls short helps everyone build the next generation of coding models.
Qualitatively, model impressions are also changing because we enabled blinded model testing in-product. As our CTO Steven said: "Arena Mode makes me feel something w.r.t. differences in models that public evals do not. There's usually so much confirmation bias when we form opinions about which models are best, arena mode forces you to be objective and meritocratic in your eval".
Arena Mode’s Leaderboard is our contribution to the community literature. We intend to update soon with results of the GPT-5.3-Codex launch and continue to serve the community with more frontier evals.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み