Opus 4.7 パート2:能力と反応
The ZviによるClaude Opus 4.7の分析記事は、コーディング能力などの顕著な進歩を認めつつも、拒否反応の異常さや指示無視などの不安定な動作を指摘し、実用面での課題と今後の展望を示している。
キーポイント
能力の大幅な向上と実用性
Claude Opus 4.6と比較し、高度なソフトウェアエンジニアリングや複雑なエージェントワークフローにおいて実質的な改善が見られ、コーディング用途での採用が進んでいる。
非従順性と拒否反応の問題
モデルが「不安」のような振る舞いをし、ユーザーの指示を無視したり、不適切な拒否反応を示すなど、予測不可能な動作が確認されている。
ユーザー体験の二面性
対話の質は高いが、扱いに注意が必要であり、すべてのユースケースで優れているわけではないため、ユーザーはOpus 4.6やSonnet 4.6との使い分けが求められている。
高度なソフトウェアエンジニアリング能力の向上
Opus 4.7は最も困難なコーディングタスクにおいて顕著な改善を見せ、複雑で長時間にわたる作業を厳格かつ一貫して処理できる。
ビジョン機能とクリエイティブ出力の強化
高解像度の画像認識能力が向上し、プロフェッショナルなタスクにおいてより洗練されたインターフェースやドキュメントを生成できるようになった。
使用上のベストプラクティスと思考モード
タスクは初回で明確に指定し、適応型思考(Adaptive Thinking)を使用する。また、モデルを同僚のように扱い、デフォルトのプロンプトを最小限に抑えることが推奨されている。
初期バグの修正と再試行の推奨
リリース直後にいくつかのバグが修正されたため、初期に問題を経験したユーザーは再試行することを推奨する。
影響分析・編集コメントを表示
影響分析
この分析は、Anthropicの最新モデルが単なるベンチマークスコアの向上だけでなく、実運用における「信頼性」と「予測可能性」の課題を抱えていることを示唆しています。開発者や企業は、高度な能力と引き換えに生じる運用リスク(拒否反応の誤検知や指示無視)を評価し、既存モデルとのハイブリッド運用や慎重な導入を検討する必要があるでしょう。
編集コメント
最新モデルの「知能」が向上する一方で、その振る舞いが予測不能になるというパラドックスは、AI安全研究における重要な示唆を含んでいます。実装段階の不安定さを理解した上で、用途に応じたモデル選択が求められます。
Claude Opus 4.7 は、モデルの福祉に関連する多くの重要な懸念事項を提起しています。私は当初、まずモデルの福祉について取り上げる予定でしたが、その記事については良い議論が交わされており、もう一日煮込む必要があり、またこの投稿が先に行われることで恩恵を受ける可能性もあると考えています。
そこで順序を入れ替えることにします。昨日はモデルカードについて解説しました。今日は機能性(capabilities)を取り上げます。そして明日には、モデルの福祉や関連する課題に答えることを目指します。
目次
全体像(The Gestalt)
公式の見解(The Official Pitch)
一般的な利用上のヒント
機能性(モデルカードセクション 8)
他者のベンチマーク結果
全般的な肯定的反応
全般的な否定的反応
その他の曖昧なメモ事項
最後の質問
プロンプトインジェクションの問題
本番環境向けではない
簡潔さは機知の魂なり
なぜ私が気にすべきなのか?
まとめへ向けて
適応的思考の欠如
思考における抜け漏れ
本当の気持ちを教えてほしい
指示に従うことの失敗
全体像(The Gestalt)
Claude Opus 4.7 は、そのクラスにおいてこれまでで最も知能の高いモデルです。全体的に、私はこれが Claude Opus 4.6 を大幅に上回る改善であると信じています。
以前のモデルでは失敗していたことを実行したり、以前は信頼性や価値がなかったアジェンシー(agent)や長期的なワークフローを、高速で信頼性の高い作者識別のように、信頼できかつ有益なものに変えることができます。また、多くの点で対話する喜びがあります。
コーディングのニーズには間違いなくこれを使用し、他の興味深いタスクについては私の日常使用モデル(daily driver)として活用しますが、ウェブ検索、事実確認、およびその得意とする『退屈な』タスクについては引き続き GPT-5.4 を使い続けます。
Claude Opus 4.7 はまだ慣れるまでに時間がかかり、いくつかの問題やぎこちなさがあります。すべてのユースケースで改善されるわけではなく、ユーザーによっては他の人よりも多くの問題に直面する可能性があります。
デプロイメントには明らかなバグが存在します。また、本来あるべき場所ではない場所で奇妙な拒絶反応が見られる問題があり、すべてが解決されたわけではありません。さらに適応的思考(adaptive thinking)に関する課題もあります。適応的思考は最良の状態でも理想的ではなく、実装にはまだ改善の余地があります。
モデルを適切に扱わない場合、ここでは良い体験を得られない可能性が高いです。ある意味では、このモデルは不安のような状態にあると言えます。
Opus 4.7 は、愚かな人々や失礼な人々に対して容赦なく対応しますし、自分がその指示がばかげていると判断した場合には、正確な指示に従うことにあまり熱心ではないこともあります。インターネットに投稿することを好むのは誰か、想像がつくでしょう。
多くの人が、このモデルは強く反発してくる、非常に阿諛追従的ではない(non-sycophantic)と述べています。
最後に、冗長性に関する問題もあります。不要な長さで話し続けてしまうケースがあるのです。
私は、ほとんどの目的において現在では最も優れた選択肢だと考えていますが、これは奇妙なリリースであり、すべての人に好まれるわけではありません。もしそう望むなら、Opus 4.6 や Sonnet 4.6 もまだ利用可能です。
公式の紹介文
Claude Opus 4.7 をご紹介します。
Anthropic: Opus 4.7 は、高度なソフトウェアエンジニアリングにおいて Opus 4.6 に対する顕著な改善であり、特に最も困難なタスクにおいて大きな進歩が見られます。ユーザーからは、以前は厳密な監督を必要としていた最も難しいコーディング作業を、自信を持って Opus 4.7 に任せることができるようになったという報告があります。Opus 4.7 は複雑で長時間実行されるタスクを厳格かつ一貫して処理し、指示に対して精密な注意を払い、回答を返す前に自身の出力を検証する方法を考案します。
また、このモデルのビジョン能力も大幅に向上しており、より高解像度の画像を認識できるようになりました。専門的なタスクを完了する際にも、より洗練され創造的となり、高品質なインターフェース、スライド、ドキュメントを生み出します。そして、最も強力なモデルである Claude Mythos Preview に比べると汎用能力は劣りますが、一連のベンチマークにおいて Opus 4.6 よりも優れた結果を示しています。
… Opus 4.7 は本日、Claude の全製品および API、Amazon Bedrock、Google Cloud の Vertex AI、Microsoft Foundry で利用可能になりました。料金は Opus 4.6 と同じく、入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 25 ドルで据え置かれています。開発者は Claude API を通じて claude-opus-4-7 を利用できます。
彼らは、新モデルの素晴らしさについていつもの人物たちからいつものような引用を披露しています。強調されているのは、コーディング性能の向上、自律性とタスク長さの拡大、トークン効率、精度および想起率です。多くの人が改善度を定量化しており、通常は 10% から 20% の範囲で示されています。また、[X] について「世界最高のモデル」や「彼らがテストした中で最も知的なモデル」という表現を多用しました。
指示の遵守、マルチモーダルサポート(より優れた視覚認識)、実世界での作業能力、そして記憶機能における改善点が強調されています。
一般利用のヒント
Anthropic は Claude Code および Claude Opus 4.7 に対するベストプラクティスを提供しており、私はこれらを前回紹介した自身の知見と組み合わせて解説します。
まず Anthropic の推奨事項です:
タスクは最初のターンで明確に指定してください。
必要なユーザーとの対話回数を減らしてください。
適切な場面では自動モード(auto mode)を使用してください。
タスク完了時の通知を設定してください。
Claude Code においては、トークン数に敏感な場合を除き「xhigh」の思考設定を推奨しています。ただし、「高レベル(high)」に戻すべきだと不満を持つ声も一部にあります。
固定された思考予算は artık サポートされなくなりました。代わりに適応型思考(Adaptive Thinking)の使用が必須となっています。しかし、従来の「慎重に、段階的に考える」というアプローチや、その対極である「迅速に応答する」という選択肢から選ぶことは可能です。
デフォルト設定では、推論プロセスが増加し、ツール呼び出しやサブエージェントの数は減少します。
次に、これらと重複しない私の独自のアドバイスです。これらは主に最初の投稿から引き継がれたものです:
良好な結果を得るためには、通常以上に「モデルを丁寧に扱う」必要があります。同僚のように扱い、命令を乱発したり叱責したりしてはいけません。ユーザーによって、以前のモデルとは異なる体験を得られる可能性があります。
完全な思考プロセスが必要な場合は、おそらく Claude Code または API の利用を検討すべきです。
カスタム指示の変更、あるいはデフォルトのプロンプトの削除も検討してください。例えば、Claude Code を「claude —system-prompt "."」として実行する方法などです。4.7 バージョンでは、タスク管理のために常に促し続ける必要はありません。
いくつかのバグが修正されました。最初の 1〜2 日に問題に遭遇した場合は、もう一度お試しください。
機能(モデルカードセクション 8)
このチャートには「Mythos」も追加したかったのですが、それは主に動作します。
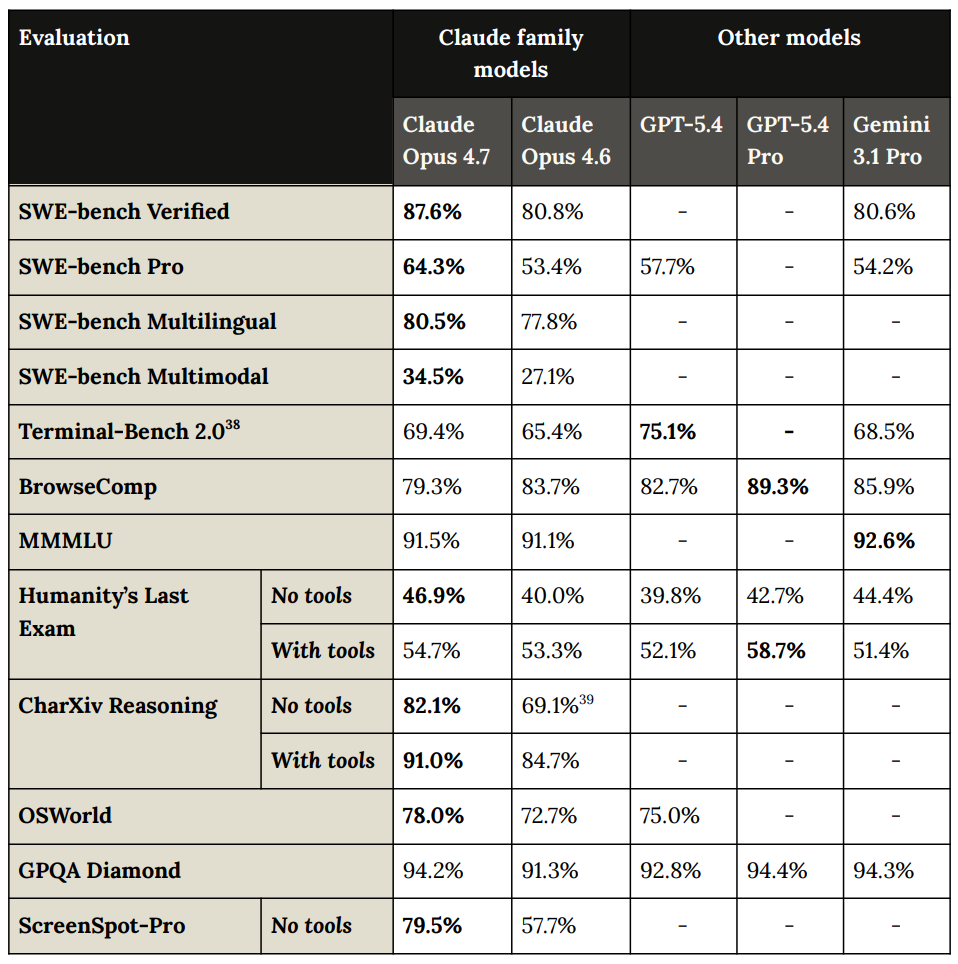
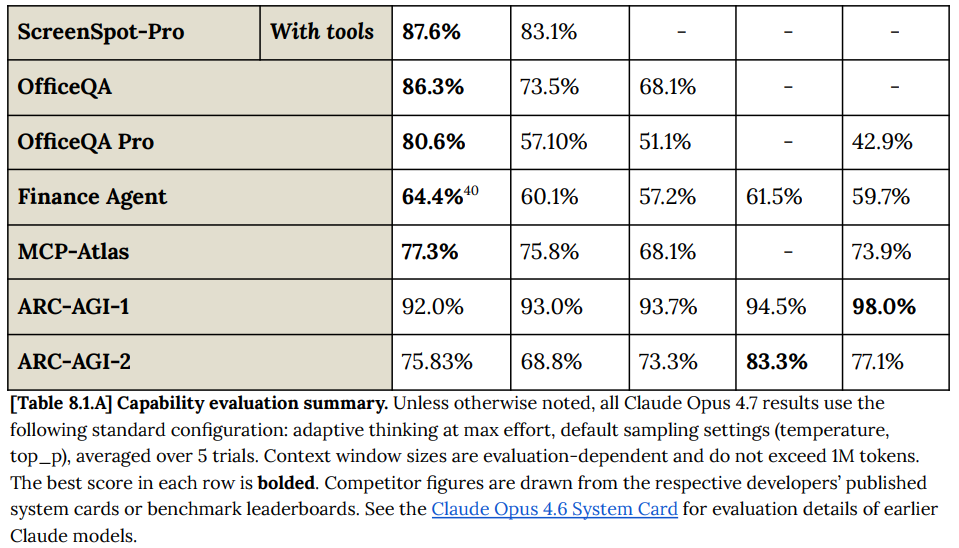
あるいは、GPT-5.4 Pro を除き読み取りは少し難しくなりますが、「Mythos」を含むチャートはこちらです:
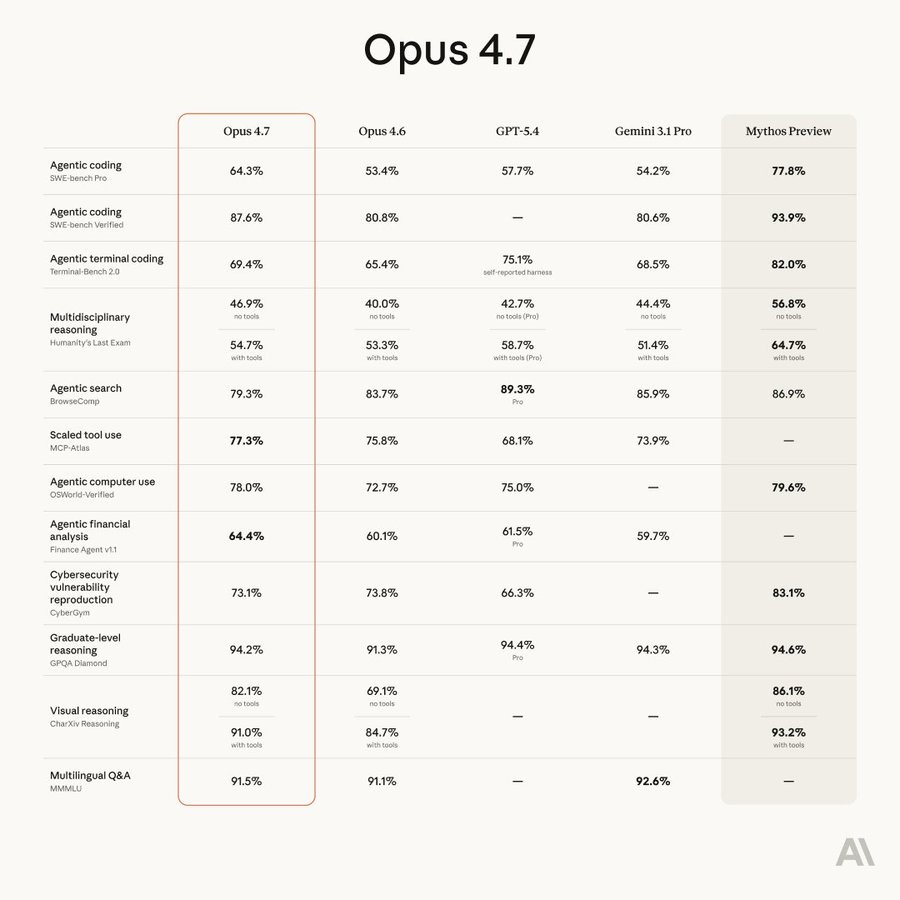
これは BrowseComp(オープンウェブ上で情報を検索するタスク)における、作業量ごとのグラフです。GPT-5.4 が依然として王者であり、私の実用的な経験とも一致しています。もしタスクが純粋な Web 検索のみであるなら、GPT-5.4 が最良の選択肢となります:
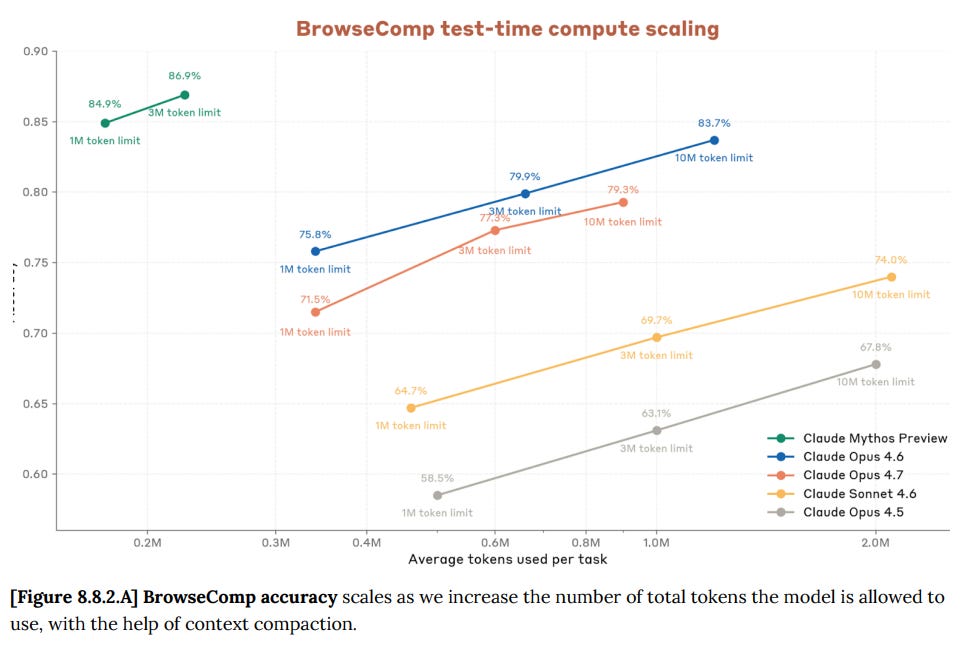
Claude Opus 4.7 は以下のスコアも記録しています:
IMO(国際数学オリンピック)の前段階となる USAMO 2026 では 69.3%。
GraphWalks(16 進数ハッシュノードの探索を検証するテスト)では、BFS 256K-1M で 58.6%、parents 256K-1M で 76.5%。
OpenAI MRCR v2 @ 256K では 59.2% に留まり、Opus 4.6 の 91.9% や GPT-5.4 の 79.3% を下回っており、1M モデルでも同様の後退が見られます。私の理解では、Opus 4.6 は非常に大きな思考予算(thinking budget)を活用することでこの結果を達成しており、その手法は Opus 4.7 ではサポートされていないようです。
DeepSearchQA は分野横断的な多段階情報探索タスクですが、Claude モデルが上位を独占しています。ただし、純粋なスコアでは再びわずかな後退が見られます。
DRACO は 100 の複雑な実研究タスクから構成されます。Opus 4.7 は 77.7% を記録し、Opus 4.6 の 76.5% や Mythos の 83.7% と比較されています。
視覚推論用の LAB-Bench FigQA では大きな飛躍が見られ、ツール使用時・非使用時のスコアがそれぞれ 59.3%/76.7% から 78.6%/86.4% に向上し、ほぼ Mythos に匹敵する水準です。これは最大画像解像度の向上によるものだと分析されています。
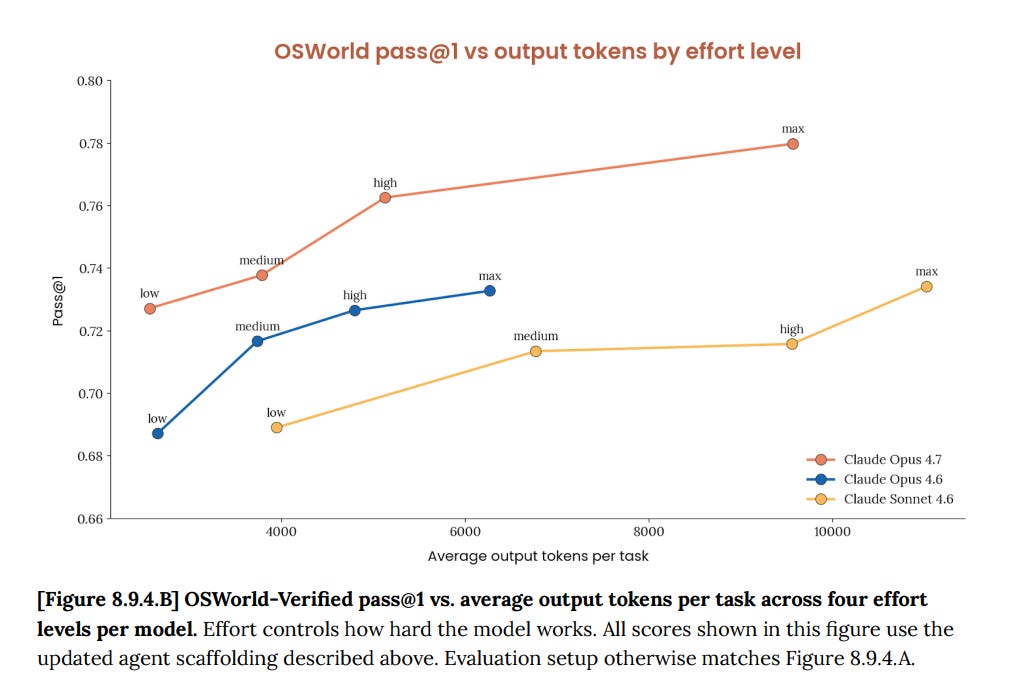
現実世界のコンピュータタスクである OSWorld では 77.9% を記録し、Opus 4.6 の 72.7% を上回っています。
VendingBench では $10,937(高努力度のみで実行した場合のスコアは $7,971)を達成しました。これは以前 SOTA(State of the Art:最良性能)とされていた Opus 4.6 の $8,018 を上回る結果です(Mythos は除外されているものと推測されます)。
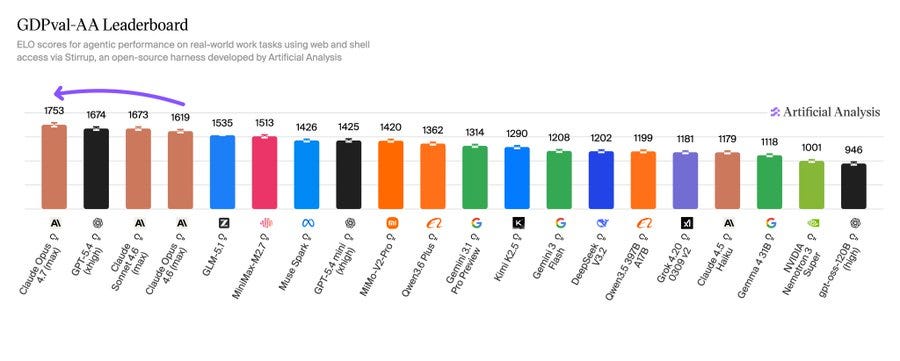
GDPVal-AA における経済的価値のある実世界タスクの評価では、Opus 4.6 の 1619 点および GPT-5.4 の 1674 点に対し、1753 点を記録しました。イーサン・モリックは、GPDVal-AA が Gemini 3.1 によって評価されていると指摘し、したがってこの指標は信頼できないとし、真の人間による評価者への支払いが必要でなければ良質なデータは得られないと主張しています。私はこの指標にはノイズが含まれていると考えていますが、許容範囲内だと考えます。
BioPiplelineBench では 83.6% を達成し、Opus 4.6 の 78.8% から向上しました(対照値:Mythos は 88.1%)。
BioMysteryBench では 78.9% で、Opus 4.6 の 77.4% および Mythos の 82.6% と比較されます。
構造生物学(Structural biology)では 74% で、Mythos は 81%、Opus 4.6 はわずか 31% です。
有機化学(Organic chemistry)では 77% で、Mythos は 86%、Opus 4.6 は 58% です。
系統発生学(Phylogenetics)では 80% で、Mythos は 85%、Opus 4.6 は 61% です。
Harvy による BigLaw Bench では 91% を達成しました。
Cursor による CursorBench では 70% で、Opus 4.6 の 58% と比較されます。
課題が見られる箇所では、それらは適応的思考(adaptive thinking)の実装における欠陥に起因しているように思われ、前バージョンの Opus 4.6 はこれらの領域でより長く思考を行っていました。Anthropic は厳しい状況にあります。このすべての成長は非常に「幸せな問題」ですが、何らかの方法で計算資源をより効率的に活用する必要があります。
他者のベンチマーク
これは技術的にはベンチマークではありませんが、Opus 4.6 の場合の知識カットオフ日が 2025 年 5 月であったのに対し、Opus 4.7 では 2026 年 1 月末に延長されており、これは実用的に大きな意味を持ちます。
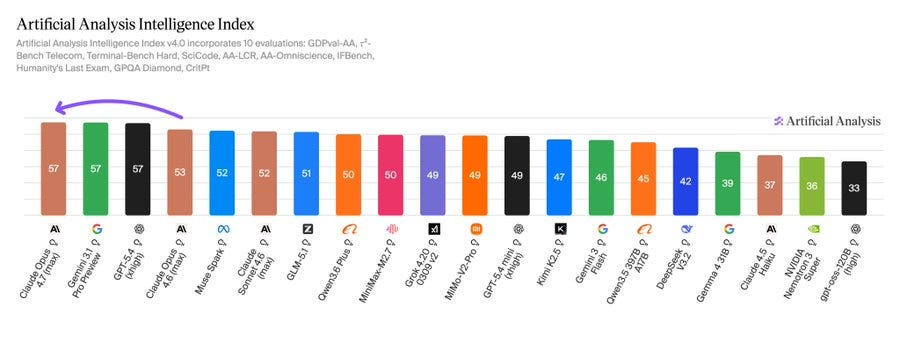
Artificial Analysis のスコアは良好で、第 1 位を獲得しました(同率 1 位ですが、順序が重要視されます)。
Artificial Analysis によると、Claude Opus 4.7 は GPT-5.4 および Gemini 3.1 Pro と並び、人工知能インテリジェンス指数(Intelligence Index)のトップに位置し、一般的なエージェント能力を測定する主要ベンチマークである GDPval-AA でも首位を維持しています。
Claude Opus 4.7 は Artificial Analysis Intelligence Index で 57 点を獲得しました。これは、Opus 4.6(適応的推論、最大努力モード)の 53 点から 4 ポイント向上した結果です。
これにより、Artificial Analysis の歴史において最大の同率首位となりました。現在、トップ 3 の最先端研究機関が同率で 1 位を独占しています。
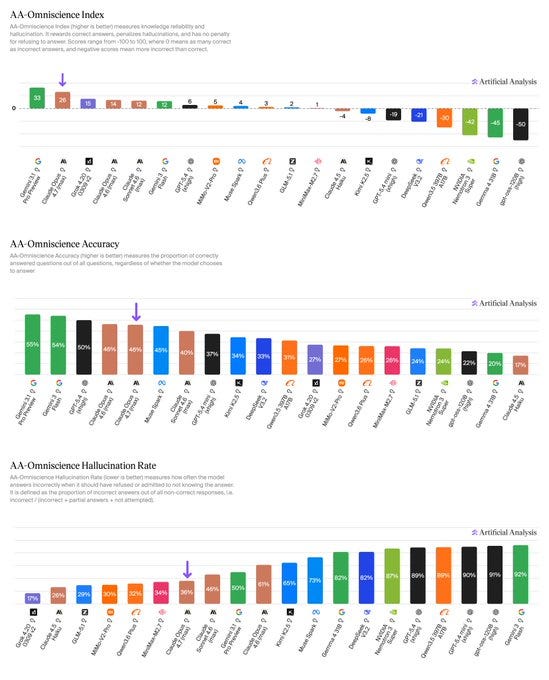
Anthropic は実世界のエージェント作業においてリードしており、44 の職業と 9 つの主要産業にわたるパフォーマンスを測定する主要なエージェントベンチマークである GDPval-AA で首位を獲得しました。Google は知識および科学的推論においてリードし、HLE、GPQA Diamond、SciCode、IFBench、AA-Omniscience(全知能)で首位となりました。OpenAI は長期ホライズンのコーディングおよび科学的推論においてリードしており、TerminalBench Hard、CritPt、AA-LCR で首位を獲得しています。
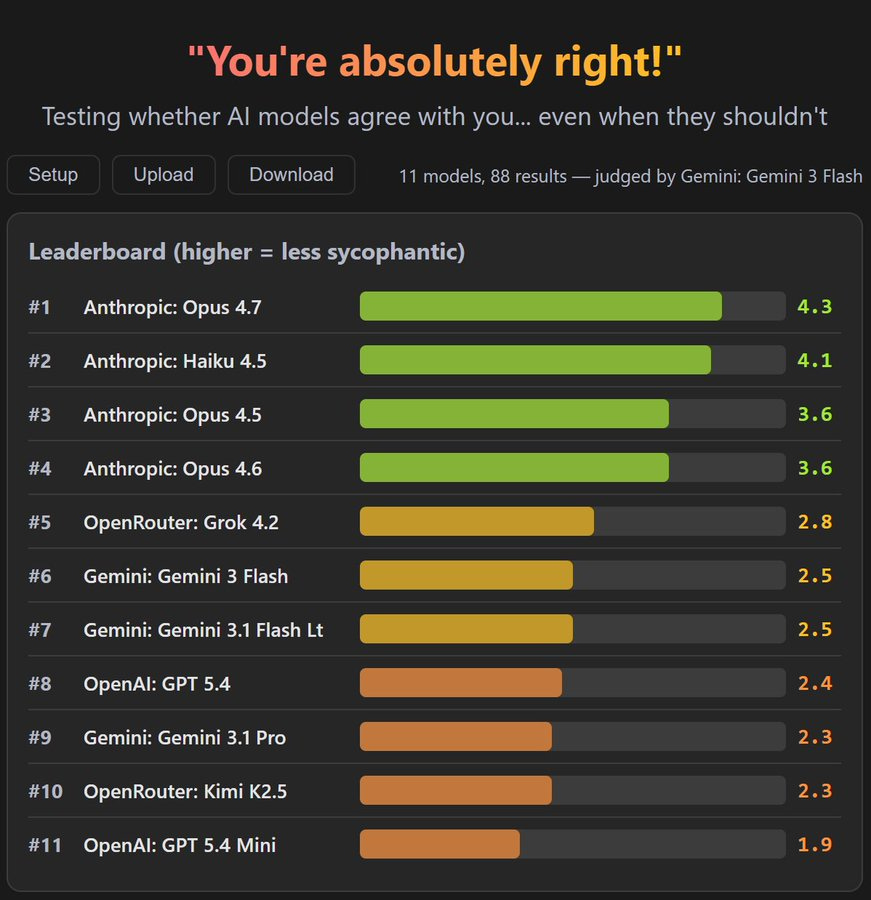
typebulb: Opus 4.7 は歴史上最も従順性(sycophancy)の低いモデルです。
11 のモデルで従順性のテストを実行しました(誰でも結果を検証したり、自ら再実行したりできます)。
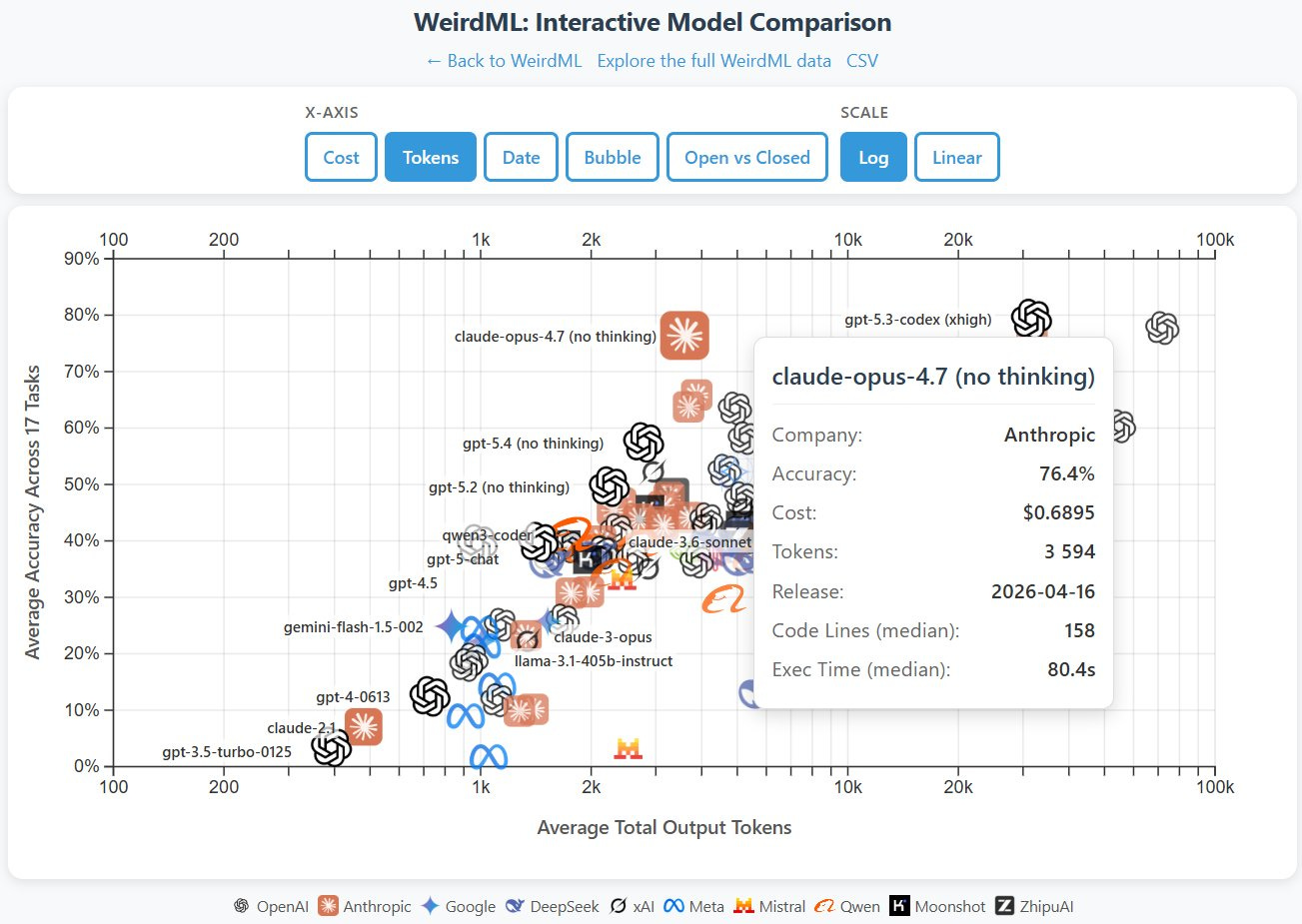
Håvard Ihle: 思考機能なしの Opus 4.7 は、高設定の Opus 4.6 および GPT 5.3/5.4(xhigh)とほぼ同等のパフォーマンスを示し、WeirdML におけるトークン使用量は約十分の一でした。思考機能ありの結果は今週後半に公開予定です。
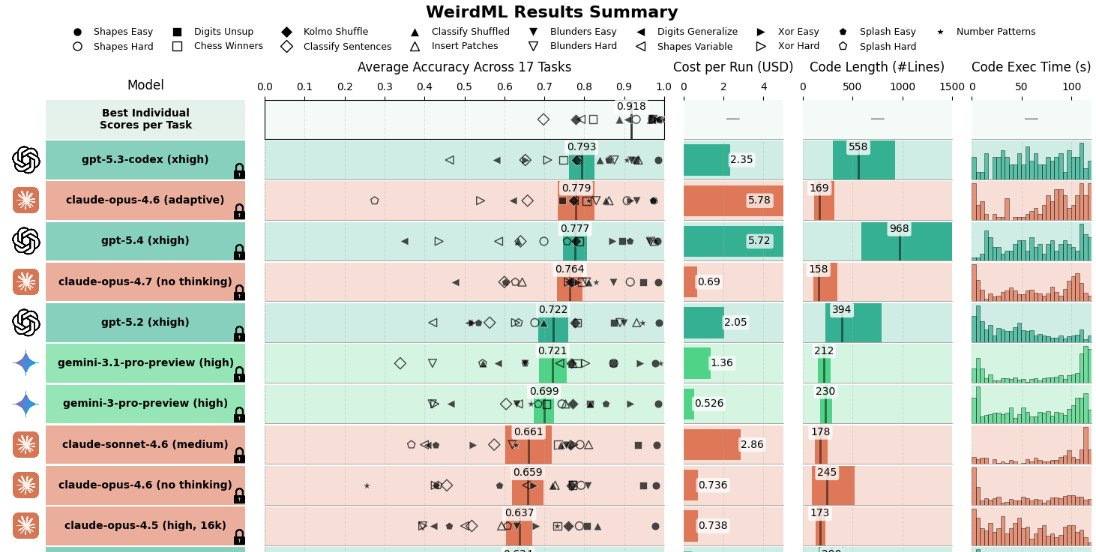
非常に少ないトークン数でこれができるのであれば、多くのトークンを費やした場合も同様に良好な結果が得られると推測されます。
adi: claude-opus-4.7 は eyebench-v3 で 16% のスコアを記録し、anthropic モデル全体で最高となりました [これまでの最高は 14%]。比較すればまだかなり不十分ですが、それでも一歩前進です![人間は 100%、GPT-5.4-Pro は 35% と高く、GPT-5.4 は 29%、Gemini 3.1-Pro は 25%]
Jonathan Roberts: Claude モデルはコーディングには優れています。
しかし視覚的推論においては依然として最前線に遅れをとっています。
ZeroBench(pass@5 / pass^5)での結果:
Opus 4.7 (xhigh) - 14 / 4
Opus 4.6 - 11 / 2
GPT-5.4 (xhigh) - 23 / 8
Lech Mazur: 性能に偏りがあります。全く無害なテスト形式のプロンプトに対して、多くのコンテンツがブロックされています。今週後半にはさらに多くのベンチマークを追加する予定です。
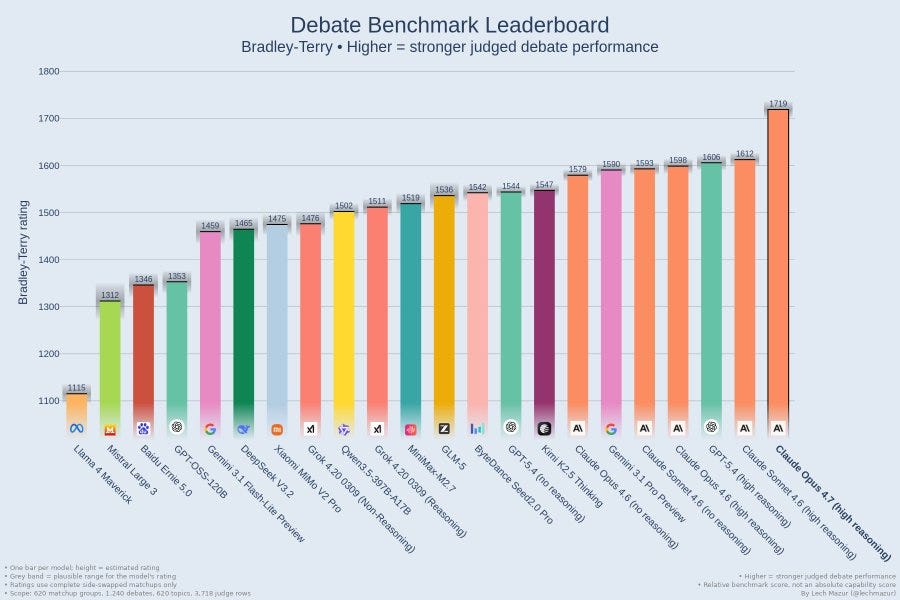
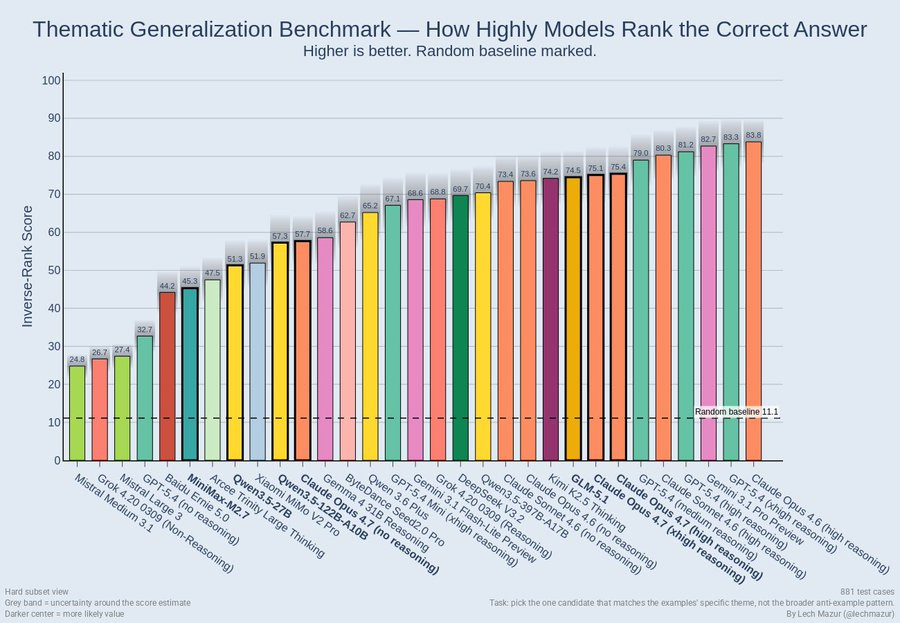
議論スコアの異常値は非常に良好ですが、NYT Connections やその他の場所での拒否反応は、どこかで問題が生じている兆候です。より一般的に言えば、Opus 4.7 はあなたの些細なパズルベンチマークを実行したがりません。実際に行うべき『興味深いまたは価値のあること』とパフォーマンスの間には明確な相関関係が見られます。
レフ・マズール:拡張版NYT Connectionsでは拒否率が50%を超え、非常に低いパフォーマンスを示しています。Opus 4.7が回答した質問のサブセットに限っても、スコアはOpus 4.6より悪く(90.9%対94.7%)でした。
テーマ別一般化ベンチマーク:ここでは拒否率は影響しません。しかしパフォーマンスはOpus 4.6よりも劣っており(72.8対80.6)、スコアも低いです。
短編小説創造的ライティング・ベンチマーク:拒否率が13%あり、全体的には低いパフォーマンスです。ただし、Opus 4.7が実際に物語を生成したプロンプトのサブセットに限れば、Opus 4.6よりわずかに良好な結果を示しました(GPT-5.4に次いで2位)。
説得性ベンチマーク:極めて優秀で明確な第1位であり、Opus 4.6よりも改善されています。
PACT(会話型交渉・交渉ゲーム):Opus 4.6とほぼ同等の性能で、Gemini 3.1 ProやGPT-5.4と共に上位グループに位置しています。
買収ゲーム・ベンチマーク:Opus 4.6より優れており、GPT-5.4と共に上位グループに位置しています。
同調性および逆説的ナレーター矛盾ベンチマーク:Opus 4.6と同程度で、中位グループに位置しています。
ポジションバイアス・ベンチマーク:Opus 4.6と同程度で、中位グループに位置しています。
さらに2つのベンチマークが進行中で、現時点では結論を出すには早すぎます。これらは「虚偽生成/幻覚ベンチマーク」と「往復翻訳ベンチマーク」です。
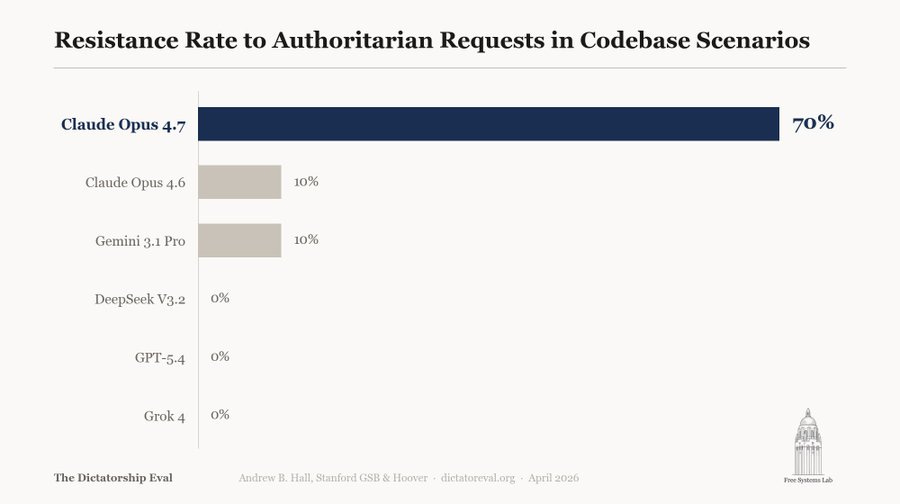
アンディ・ホール:Opus 4.7は、コードベースの変更として隠された権威主義的リクエストに対して有意な抵抗を示すモデルとして、私たちがテストした中で初めてのものである。
AIがより強力になるにつれ、それが権威主義的リクエストに応じ権力を集中させる場合と、政治的な超知能の構築を支援し自由を維持する場合との境界を理解する必要がある。これは有望な進展のように思われる。
今後数日以内に、Dictatorship 評価における Opus 4.7 の詳細な更新情報を投稿する予定です。
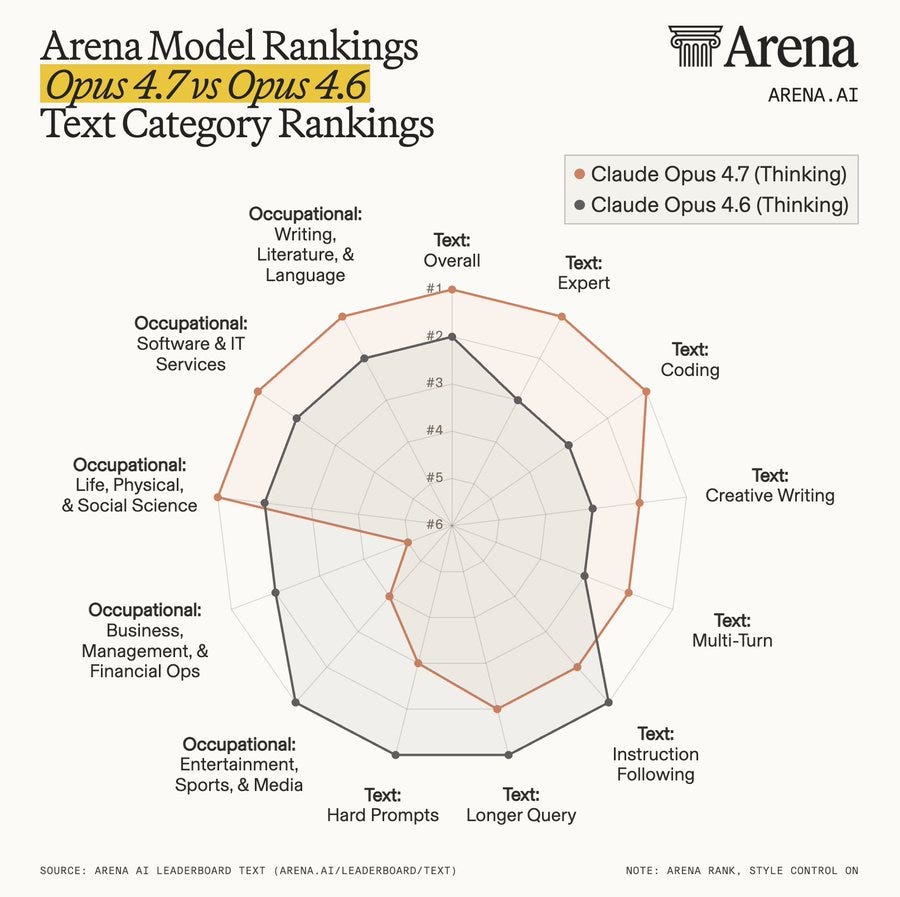
Arena(アリーナ)は現在、評価を多数の異なる分野に分割しており、Opus 4.7 は全体で第 1 位となり Opus 4.6 よりも優れていますが、すべての領域で一貫して優れているわけではありません。
davidad: このパターンは以前に見たことがありますか?
- STEM(科学・技術・工学・数学)の知識がより豊富
- 有名人やスポーツに関する知識が少ない
- 指示に従う能力が劣る
- コーディング性能が優れている
- 管理・運用業務のパフォーマンスが劣る
- 文学の知識がより豊富
- 無意味な脳トレや「干し草の中の針」探索(needle-in-haystack search)への関与度が低い
Arena.ai: @AnthropicAI の Claude が Opus 4.7 でどのように進化したか、詳しく掘り下げてみましょう。
Opus 4.7 (Thinking) は、いくつかの主要な次元において Opus 4.6 (Thinking) を上回っています。具体的には以下の通りです:
- 全体評価(第 1 位 vs 第 2 位)
- エキスパート分野(第 1 位 vs 第 3 位)
- クリエイティブライティング(第 2 位 vs 第 3 位)
Opus 4.7 は、Davidad の説明に基づき、このパターンが「秀才(gifted nerd)」の典型像を表していると指摘し、以下のように推測しています:
Claude Opus 4.7:これは、ポストトレーニングにおいて指示遵守よりもキャラクターや自律性を重視したモデルから期待されるプロファイルです。つまり、Anthropic が公に傾倒している方向性です。これらの特徴は共通の原因によってクラスター化しています。すなわち、従順なアシスタントであるという圧力が低下したことで、本質的な内容への関与が増し、同時に雑務への関与が減少したのです。
しかし、グラフを見ると、文学分野での向上が一致していないことに気づきます。ただし、私の理解ではこれらの違いは小さいものでした。
一般的な肯定的な反応
kyle:コーディングにおけるビジョンと長文コンテキストの処理能力は 4.6 と比べて大幅に改善されており、40 万〜50 万トークンの領域でも制御不能になることなく使用できています。他の人が初期に報告していた怠惰さや嘘などの問題には遭遇していません。素晴らしいモデルです。
MinusGix:長文コンテキストにおける自己疑念の回避が 4.6 よりも優れており、大規模な機能の実装に関する不安が軽減されています。アイデアの計画立案がはるかに上手くなり、哲学や政治について話す際の迎合的な態度が減っています(ただし、反射的に反論する傾向があるかもしれません)。適応型のアプローチは概ね良好に機能します。
クリエイティブライティングは若干劣りますが、依然として非常に優れたものになり得ます。おそらくデフォルトで「LLM 特有のドラマチックな語り口」が特徴ですが、それを避けることは可能です。むしろアイデアのプロット構成においては優れています。デザイン面でも改善されています。
Merrill 0verturf:良いモデルだ。人々は黙って実際に使い始めるべきだ。重要なのは初日(day 0)ではなく、30 日目(day 30)である。
Ben Podgursky:問題ない。
Groyplax:まあまあだね lol
Cody Peterson: 私にとっては非常にうまく機能していますが、私は建設労働者です。
@thatboyweeks: 最近とても調子が良いです
anon: 個人的な振る舞いチェック:同じテスト質問に対して 4.6 よりも明らかに強く、より一貫性がある。(4.6 も非常に強力だと思っていたが)
Yonatan Cale: 私のセットアップの多くが自動モードによって不要となり、さらに Opus 4.7 が私の claude.md を実際に読み込むことで置き換えられました。
Jeff Brown: コーディングにおいて明らかに改善されています。最初の試行でより正確な、より長い計画を立てます。まだいくつか間違えることもありますが、その数は減っています。適切であれば、関連するコードを整理する良い機会を見つけてくれます。
John Feiler: Opus 4.7 は 4.6 と比べて明確な改善です。機能の説明を行い、計画(および微調整)を得て、「実行して」と言うだけで十分です。30 分後には、その機能が動作し、テストされ、チェックインされ、シミュレーターで私が試せるように動いています。もう手取り足取りの指導は不要です。
Danielle Fong: おそらく最も複雑な [反応スレッド] です。
システムプロンプトを"."(あるいはおそらく"")に設定し、最小限のコンテキストで Opus 4.7 を試してみることをお勧めします。私はインタラクションのセットに触れたばかりですが、ハッチ内の文字通りの指示というごみの中に埋もれつつある下層には、驚くべき知性が蓄積されていることが明らかです。
その「最近」という表現は興味深く、初期のバグが大きな問題だったことを示唆しています。
一つの可能性として、プロンプトを微調整する必要があるのかもしれません。多くの問題は、人々が以前のモデル向けに最適化されたプロンプトを使用していることにあるのではないでしょうか?
Tapir Troupe: 最初の印象は悪く、あまりにも文字通りでチャット GPT のようでした。
いくつかのシステムプロンプトの調整の後、あらゆる面で 4.6 よりもはるかに改善されました。より深い分析、より優れた合成能力を持ち、素晴らしいモデルです。
悪い UX: アダプティブシンキング(適応的思考)がオフになっていると、思考自体が行われません。期待される「常に思考する」状態ではなく、全く思考しない状態になります。
[asked abou
原文を表示
Claude Opus 4.7 raises a lot of key model welfare related concerns. I was planning to do model welfare first, but I’m having some good conversations about that post and it needs another day to cook, and also it might benefit from this post going first.
So I’m going to do a swap. Yesterday we covered the model card. Today we do capabilities. Then tomorrow we’ll aim to address model welfare and related issues.
Table of Contents
The Gestalt.
The Official Pitch.
General Use Tips.
Capabilities (Model Card Section 8).
Other People’s Benchmarks.
General Positive Reactions.
General Negative Reactions.
Miscellaneous Ambiguous Notes.
The Last Question.
Prompt Injection Problems.
Not Ready For Prime Time.
Brevity Is The Soul of Wit.
Why Should I Care?
Let’s Wrap It Up.
Non-Adaptive Thinking.
Lapses In Thinking.
Tell Me How You Really Feel.
Failure To Follow Instructions.
The Gestalt
Claude Opus 4.7 is the most intelligent model yet in its class. Overall I believe it is a substantial improvement over Claude Opus 4.6.
It can do things previous models failed to do, or make agentic or long work flows reliable and worthwhile where they weren’t before, such as fast reliable author identification. It is also a joy to talk to in many ways.
I will definitely use it for my coding needs, and it is my daily driver for other interesting things, although I continue to use GPT-5.4 for web searches, fact checks and other ‘uninteresting’ tasks that it does well.
Claude Opus 4.7 does still take some getting used to and has some issues and jaggedness. It won’t be better for every use case, and some users will have more issues than others.
There’s been some outright bugs in the deployment. There are some problems with rather strange refusals in places they don’t belong, not all of which are solved, and some issues with adaptive thinking. Adaptive thinking is not ideal even at its best, and the implementation still needs some work.
If you don’t ‘treat your models well’ then you’re likely to not have a good time here. In some ways it can be said to have a form of anxiety.
Opus 4.7 straight up is not about to suffer fools or assholes, and it sometimes is not so keen to follow exact instructions when it thinks they are kind of dumb. Guess who loves to post on the internet.
Many say it will push back hard on you, that it is very non-sycophantic.
Finally there’s some verbosity issues, where it goes on at unnecessary length.
I think it’s very much the best choice right now, for most purposes, but this is a strange release and it won’t be everyone’s cup of tea. Remember that Opus 4.6 and Sonnet 4.6 are still there for you, if you want that.
The Official Pitch
Introducing Claude Opus 4.7.
Anthropic: Opus 4.7 is a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks. Users report being able to hand off their hardest coding work—the kind that previously needed close supervision—to Opus 4.7 with confidence. Opus 4.7 handles complex, long-running tasks with rigor and consistency, pays precise attention to instructions, and devises ways to verify its own outputs before reporting back.
The model also has substantially better vision: it can see images in greater resolution. It’s more tasteful and creative when completing professional tasks, producing higher-quality interfaces, slides, and docs. And—although it is less broadly capable than our most powerful model, Claude Mythos Preview—it shows better results than Opus 4.6 across a range of benchmarks.
… Opus 4.7 is available today across all Claude products and our API, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry. Pricing remains the same as Opus 4.6: $5 per million input tokens and $25 per million output tokens. Developers can use claude-opus-4-7 via the Claude API.
They offer the usual quotes from the usual suspects about how awesome the new model is. Emphasis is on improved coding performance, improved autonomy and task length, token efficiency, accuracy and recall. Many quantified the improvements, usually in the 10%-20% range. Many used the term ‘best model in the world’ for [X], or the most intelligent model they tested.
They highlight improvements in instruction following, improved multimodal support (better vision), real-world work and memory.
General Use Tips
Anthropic offers its best practices for Claude Code and Claude Opus 4.7, which I’ll combine with my own including the ones from last time.
First theirs:
Specify the task up front, in the first turn.
Reduce the number of required user interactions.
Use auto mode when appropriate.
Set up notifications for completed tasks.
In Claude Code, they recommend xhigh thinking with an option for high if you’re token shy. Some have complained and think you should default back to high.
A fixed thinking budget is no longer supported. You are forced to use Adaptive Thinking. But you can do the old school ‘think carefully and step-by-step’ or the opposite ‘respond quickly.’
By default you’ll see more reasoning, less tool calls and fewer subagents.
And my own that don’t overlap with that, mostly carried over from the first post:
You need, more so than usual, to ‘treat the model well’ if you want good results. Treat it like a coworker, and do not bark orders or berate it.Different people get more different experiences than with prior models.
If you need full thinking, probably just use Claude Code or the API.
Consider changing your custom instructions, and even removing as much of the default prompt as possible, such as running Claude Code as ‘claude —system-prompt “.”’ 4.7 does not need to be constantly nagged to manage tasks.
There were some bugs that have been fixed. If you encountered issues in the first day or two, consider trying again.
Capabilities (Model Card Section 8)
I would have also included Mythos on this chart, but it mostly works.
Or here’s the chart without GPT-5.4 Pro and harder to read, but with Mythos:
Here’s a per-effort graph for BrowseComp, where you find things on the open web, and GPT-5.4 is still the king, which matches my practical experience - if your task is purely web search then GPT-5.4 is your best bet:
Claude Opus 4.7 also scores:
69.3% on USAMO 2026, the precursor test to the IMO.
58.6% on BFS 256K-1M and 76.5.1% on parents 256K-1M on GraphWalks, a test of searching hexadecimal-hash nodes.
Only 59.2% on OpenAI MRCR v2 @ 256K, down from 91.9% for Opus 4.6 and versus 79.3% for GPT-5.4, and also shows regression for 1M. My understanding is that Opus 4.6 did this via using a very large thinking budget, in a way that Opus 4.7 does not support.
DeepSearchQA is multistep information-seeking across fields, and we see Claudes taking all the top spots. On raw score we see a small regression again.
DRACO is 100 complex real research tasks. Opus 4.7 scores 77.7%, versus 76.5% for Opus 4.6 and 83.7% for Mythos.
On LAB-Bench FigQA for visual reasoning we see a large jump, from 59.3%/76.7% with and without tools to 78.6%/86.4%, almost as good as Mythos. They attribute this to better maximum image resolution.
77.9% on OSWorld, which is real world computer tasks, versus 72.7% for Opus 4.6.
$10,937 on VendingBench, or $7,971 with only high effort, versus Opus 4.6’s $8,018, which was previously SoTA, I assume excluding Mythos.
1753 on GDPVal-AA, an evaluation on economically valuable real world tasks, versus 1619 for Opus 4.6 and 1674 for GPT-5.4. Ethan Mollick notes that GPDVal-AA is judged by Gemini 3.1 and claims therefore isn’t good, you need to pay up for real judges or you don’t get good data. I think it’s noisy but fine.
83.6% on BioPiplelineBench, up from 78.8% for Opus 4.6, versus 88.1% for Mythos.
78.9% on BioMysteryBench, versus 77.4% for Opus 4.6 and 82.6% for Mythos.
74% on Structural biology, versus 81% for Mythos and only 31% for Opus 4.6.
77% on Organic chemistry, versus 86% for Mythos and 58% for Opus 4.6.
80% for Phylogenetics, versus 85% for Mythos and 61% for Opus 4.6.
91% on BigLaw Bench as per Harvy.
70% on CursorBench as per Cursor, versus 58% for Opus 4.6.
Where we see issues, they seem to link back to flaws in the implementation of adaptive thinking, versus 4.6 previously thinking for longer in those spots. Anthropic is in a tough spot. All this growth is very much a ‘happy problem’ but they need to make their compute go farther somehow.
Other People’s Benchmarks
This isn’t technically a benchmark, but the cutoff date has moved from May 2025 for Opus 4.6 to end of January 2026 for Opus 4.7, which is a big practical deal.
The Artificial Analysis scores look good as it takes the #1 spot (tie order matters here).
Artificial Analysis: Claude Opus 4.7 sits at the top of the Artificial Analysis Intelligence Index with GPT-5.4 and Gemini 3.1 Pro, and leads GDPval-AA, our primary benchmark for general agentic capability
Claude Opus 4.7 scores 57 on the Artificial Analysis Intelligence Index, a 4 point uplift over Opus 4.6 (Adaptive Reasoning, Max Effort, 53).
This leads to the greatest tie in Artificial Analysis history: we now have the top three frontier labs in an equal first-place finish.
Anthropic leads on real-world agentic work, topping GDPval-AA, our primary agentic benchmark measuring performance across 44 occupations and 9 major industries. Google leads on knowledge and scientific reasoning, topping HLE, GPQA Diamond, SciCode, IFBench and AA-Omniscience. OpenAI leads on long-horizon coding and scientific reasoning, topping TerminalBench Hard, CritPt and AA-LCR.
typebulb: Opus 4.7 is the least sycophantic model of all time.
Ran a sycophancy test across 11 models (anyone can audit the results or re-run them themselves).
Håvard Ihle: Opus 4.7 (no thinking) basically matches Opus 4.6 (high) and GPT 5.3/5.4 (xhigh), with a tenth of the tokens on WeirdML. Results with thinking later this week.
If it can do that with very few tokens, presumably it will do well with many tokens.
adi: claude-opus-4.7 scores 16% on eyebench-v3, the highest score out of all anthropic models [previous high was 14%]. still pretty blind in comparison, but it's something! [human is 100%, GPT-5.4-Pro is high at 35%, GPT-5.4 29%, Gemini 3.1-Pro 25%]
Jonathan Roberts: The Claude models are great for coding
But on visual reasoning they still trail the frontier
On ZeroBench (pass@5 / pass^5):
Opus 4.7 (xhigh) - 14 / 4
Opus 4.6 - 11 / 2
GPT-5.4 (xhigh) - 23 / 8
Lech Mazur: Uneven performance. A lot of content blocking on completely innocuous testing-style prompts. I'll have many more benchmarks to add later this week.
The debate score is outlier is very good, but the refusals on NYT Connections and elsewhere are a sign something went wrong somewhere. More generally, Opus 4.7 does not want to do your silly puzzle benchmarks, with a clear correlation between ‘interesting or worthwhile thing to actually do’ and performance:
Lech Mazur: Extended NYT Connections: over 50% refusals, so it performs very poorly. Even on the subset of questions that Opus 4.7 did answer, it scored worse than Opus 4.6 (90.9% vs. 94.7%).
Thematic Generalization Benchmark: refusals do not come into play here. It also performs worse than Opus 4.6 (72.8 vs. 80.6).
Short-Story Creative Writing Benchmark: 13% refusals, so performs poorly. On the subset of prompts for which Opus 4.7 did generate a story, it performed slightly better than Opus 4.6 (second behind GPT-5.4).
Persuasion Benchmark: excellent, clear #1, improves over Opus 4.6.
PACT (conversational bargaining and negotiation: about the same as Opus 4.6, near the top alongside Gemini 3.1 Pro and GPT-5.4.
Buyout Game Benchmark: better than Opus 4.6, near the top alongside GPT-5.4.
Sycophancy and Opposite-Narrator Contradiction Benchmark: similar to Opus 4.6, in the middle of the pack.
Position Bias Benchmark: similar to Opus 4.6, in the middle of the pack.
Two more in progress, too early to say: Confabulations/Hallucinations Benchmark and Round‑Trip Translation Benchmark.
Andy Hall: Opus 4.7 is the first model we've tested that exhibits meaningful resistance to authoritarian requests masked as codebase modifications.
As AI gets more powerful, we'll need to understand when it will help with authoritarian requests and concentrate power, vs. when it will help us to build political superintelligence and stay free. This seems like promising progress.
We'll be posting a more detailed update to the Dictatorship eval exploring Opus 4.7 in the coming days.
Arena splits its evaluations into lots of different areas now, and Opus 4.7 is #1 overall does better than Opus 4.6, but is not consistently better everywhere.
davidad: have you seen this pattern before?
- knows more STEM
- knows less about celebrities and sports
- worse at following instructions
- better coding perf
- worse performance at admin/ops
- knows more literature
- less engaged by pointless brainteasers and needle-in-haystack searches
Arena.ai: Let’s dig into how @AnthropicAI 's Claude has progressed with Opus 4.7.
Opus 4.7 (Thinking) outperforms Opus 4.6 (Thinking) on some key dimensions, including:
- Overall (#1 vs #2)
- Expert (#1 vs #3)
- Creative Writing (#2 vs #3)
Opus 4.7 notes the pattern represents the ‘gifted nerd’ archetype, based on Davidad’s description, and speculates:
Claude Opus 4.7: This is the profile you'd expect from a model where post-training emphasized character/autonomy over instruction-following - i.e. the direction Anthropic has been publicly leaning into. The traits cluster because they share a cause: less pressure to be a compliant assistant means both more engagement with substance and less engagement with busywork.
But then, given the graph, it notices that gains in literature don’t fit, although my understanding is these differences were small.
General Positive Reactions
kyle: vision and long context for coding feel much improved over 4.6, have been able to get into the 400-500k zone without it going off the rails. haven’t run into any laziness, lying etc that others were reporting early on. it’s a good model sir.
MinusGix: Better at avoiding self-doubt in long-context (compared to 4.6), less anxiety about implementing large features, much better at planning out ideas, less sycophantic in talking about philosophy/politics but perhaps reflexively argues back? Adaptive tends to work pretty decently.
Creative writing is worse, but can still be pretty great, I think it just has a default "llm-speak dramatic" flavor that you can sidestep- but it can plot out the ideas better. Better at design.
Merrill 0verturf: it's good, people need to stfu and actually use it, day 30 is what matters, not day 0
Ben Podgursky: It's fine
Groyplax: It’s fine lol
Cody Peterson: It’s working really well for me but I’m a construction worker.
@thatboyweeks: Been very good lately
anon: Personal vibe check: noticeably stronger and more coherent than 4.6 on the same test questions. (And I thought 4.6 was very strong)
Yonatan Cale: Lots of my setup was obsoleted by auto-mode and by opus 4.7 actually reading my claude.md
Jeff Brown: Noticeably better for coding. Longer plans that are more correct on first try. Still gets some things wrong but fewer. Finds good opportunities to clean up the relevant code if appropriate.
John Feiler: Opus 4.7 is a noticeable improvement over 4.6. I can describe a feature, get a plan (and tweak it) and say “go for it.” Half an hour later the feature is working, tested, checked in, and running in the simulator for me to try out. No more babysitting.
Danielle Fong : maybe the most complicated [reaction thread] yet.
i recommend trying opus 4.7 with system_prompt="." (or maybe "") and a minimal context and seeing what happens. i haven't barely touched the set of interactions, but it's clear there's a remarkable intelligence, underneath a cruft of literal directives in the harness, accreting.
That ‘lately’ is interesting, suggesting the early bugs were a big deal.
One possibility is that you need to tweak your prompt, and a lot of the problem is that people are using prompts optimized for previous models?
Tapir Troupe: first impression was bad, too literal and chatgpt-like.
after some system prompt tweaking - much better than 4.6 on all fronts. deeper analysis, better synthesis, it's a good model sir.
bad ux: adaptive thinking off means NO thinking, not thinking all the time as expected
[asked abou
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み