AIパフォーマンスの測定が困難になる理由
METRが公開するAIモデルの性能比較チャートは、Claude Opus 4.6のスコールに大きな誤差(ノイズ)が含まれているため、単なる数値比較ではAIの進歩速度を正確に評価できない可能性を示唆している。
キーポイント
METRチャートとAI進歩の認識
METR(Model Evaluation and Threat Research)が公開するチャートは、AIモデルが人間プログラマーの作業時間をどの程度短縮できるかで性能を比較しており、Claude Opus 4.6の高性能スコアから急速な進歩があるように見える。
測定結果のノイズと不確実性
Claude Opus 4.6のスコアには5時間から66時間という広範な信頼区間があり、METR自身も測定が「極めてノイズが多い」と警告しており、最新結果を絶対的な事実として受け取らないよう注意喚起している。
評価手法の限界と課題
METRはモデルの能力を括るために易しいタスクと難しいタスクの混合を使用しているが、Claude Opus 4.6が hardest problems を解いたため、正確な測定が困難になり、評価指標の信頼性に疑問が生じている。
ベンチマークの飽和と誤差の問題
MMLUのような主要ベンチマークではスコアが頭打ちに達しており、93%以上の高得点は質問自体の誤差(約6.5%)の影響を受けるため、実質的に不可能となっている。
測定可能な能力と実際の有用性の乖離
現実の職場ではタスクは相互に関連し、目標が流動的だが、現在のベンチマークはこれらを測定できず、AIの実際の業務能力と測定結果の間に大きな隔たりが生じている。
長期タスクにおける評価の難しさ
数週間から数ヶ月かかるような長期タスクにおいて、人間の作業パフォーマンスを評価すること自体が困難であるため、AIのそれらのタスクに対する性能を測定する優れた手法が存在しない。
従来のベンチマークの飽和
MMLUなどの既存ベンチマークは最高スコートに近づき、モデル間の差がノイズレベルに収束しているため、性能評価が困難になっている。
影響分析・編集コメントを表示
影響分析
この記事は、AI業界で広く参照されている性能ベンチマークの信頼性について根本的な疑問を投げかけています。開発者や投資家は、単一のスコア値に依存するのではなく、測定手法の限界と不確実性を理解した上で判断する必要があり、これはAIモデルの評価基準を見直す重要な示唆となります。
編集コメント
最新のAIベンチマーク結果は、その背後にある測定手法のノイズや不確実性を考慮せずに鵜呑みにすべきではありません。開発者は、スコアだけでなく信頼区間や評価手法の限界を重視したリサーチが求められます。
本記事に入る前に、自動運転車に関するオーディオコンテンツをいくつかお勧めします。
2010 年、友人のライアン・アヴェントと私は自動運転車の未来について賭けをしました。その賭けは先月期限を迎え、私が勝利しました。ライアンと私は私のポッドキャスト「AI Summer」で敗因分析を行いました。こちらから聴くか、お好みのポッドキャストアプリで「AI Summer」と検索してください。
PJ・ヴォグトのポッドキャスト『Search Engine』が自動運転車について 2 部構成のシリーズを放送しました。私は両エピソードで引用されたためバイアスがかかっていますが、非常に素晴らしい内容だと感じました。こちらから聴くか、お好みのポッドキャストアプリで「Search Engine」と検索してください。
さて、本題の本記事です!
過去 1 年間 AI を追いかけていれば、おそらく有名な「METR チャート」をご覧になったことがあるでしょう:
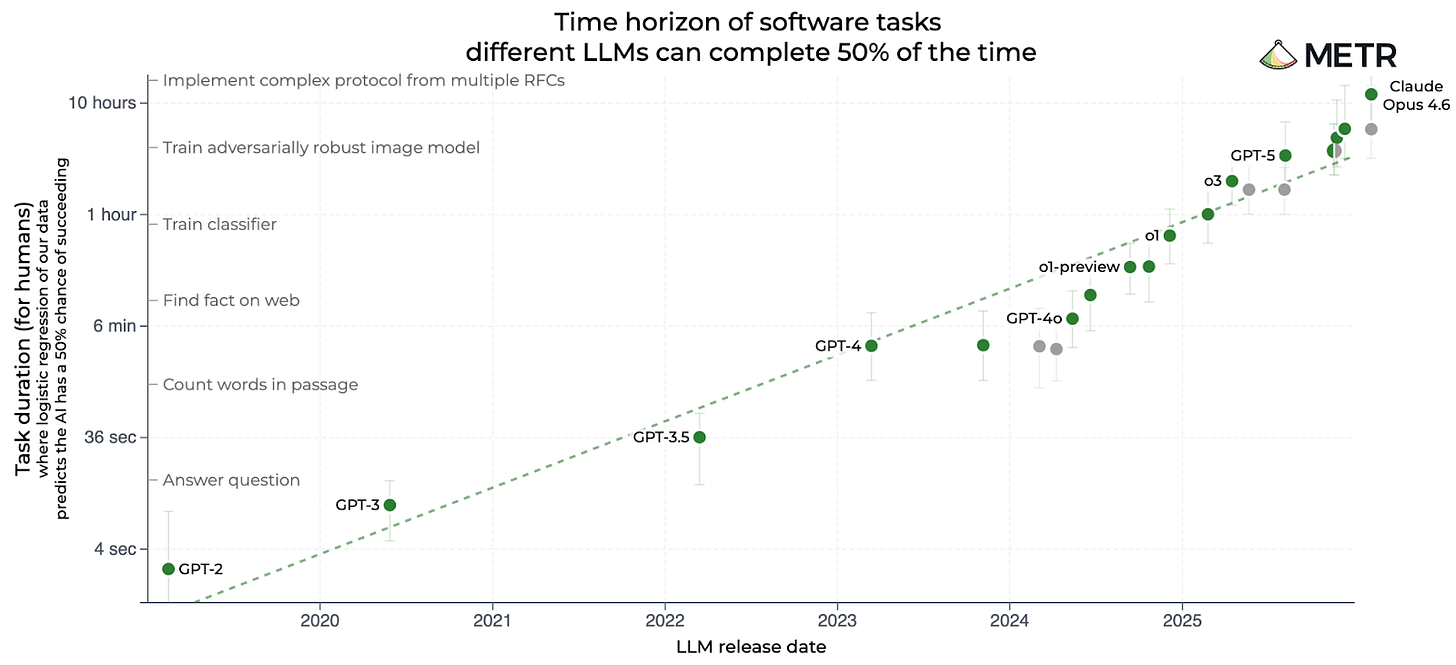
METR は「Model Evaluation and Threat Research(モデル評価と脅威研究)」の略称で、カリフォルニア州バークレーに拠点を置いています。同グループは多数のチャートを公開していますが、このチャートがその代名詞となっています。これは AI モデルを、それらが完了できるソフトウェアエンジニアリングタスクの複雑さに基づいて比較するもので、複雑さは人間プログラマーが同じタスクを完了するのに要する時間で測定されます:
GPT-3.5 — 最初の ChatGPT を支えたモデル — は、人間プログラマーに約 30 秒かかるタスクを完了できました。
GPT-4 は 2023 年 3 月にリリースされ、この時間を 4 分に引き上げました。
o1 は 2024 年 12 月にリリースされた OpenAI の最初の「推論モデル」であり、人間が 40 分を要するタスクを実行できました。
GPT-5 は 2025 年 8 月にリリースされ、人間が 3 時間を要するタスクを完了できる能力を持っていました。
Claude Opus 4.6 は Anthropic によって 2 月にリリースされました。METR の推計では、このモデルは人間のプログラマーに 12 時間かかるタスクを完了できるとされています。
その最後の数値は、わずか 2 ヶ月前にリリースされた前回のリーダーである GPT-5.2 の推定値の 2 倍の長さです。
私はこのチャート、特に Claude Opus 4.6 の印象的なスコアが、ここ数ヶ月で加速する AI の進歩という印象を強めるのに大きく寄与したと考えています。このチャートは対数目盛(ログスケール)であるため、直線は指数関数的な進歩を示します。Claude Opus 4.6 が以前のトレンドラインを上回っている事実は、非常に急速な進歩があったことを示唆しています。
しかし、METR のタスク長さページをクリックして Claude Opus 4.6 のドットにカーソルを合わせると、興味深いことがわかります:METR の信頼区間(confidence interval)は Claude Opus 4.6 において 5 時間から 66 時間の範囲にあります。Twitter では METR のスタッフが、最新の結果を絶対的な真実として受け取らないよう人々に呼びかけています。
「測定が極めてノイズが多いと言うとき、私たちは本当にそう言っているのです」と、METR の David Rein は記述しています。
METR は、AI モデルが解決できる簡単なタスクと、解決できない難しいタスクの両方が混在していることを前提としています。これにより、同グループはモデルの能力を範囲内に収めることができます。しかし、Claude Opus 4.6 は METR のテストスイートにある最も困難な問題の一部を解決できてしまい、その能力に対する上限を設定することが難しくなりました。
したがって、最新の Claude Opus が以前のモデルよりも優れていることはわかりますが、どれほど優れているかは言い難い状況です。これは、ここ数ヶ月に見られる一見した加速が実態を伴うものなのか、単なる統計的なアーティファクトに過ぎないのか、私たちがまだ知らないことを意味します。
METR はより困難なタスクをテストスイートに追加する可能性があり、おそらくそうするでしょう。これにより、将来のモデルをより高い精度でテストできるようになります。
しかし、それにはさらに深い哲学的な課題も存在します。
ほとんどの AI ベンチマークと同様に、このベンチマークは、明確に定義され、独立しており、容易に検証可能なタスクを用いて AI のパフォーマンスを測定しています。しかし、人間が行う多くのタスクはそうではありません。
実際の職場では、タスクは他のタスクと密接に関連していることが多く、頻繁に他者や外部世界との相互作用を必要とします。また、どのタスクを行うべきかが明確でない場合もあり、プロジェクトに取り組む過程で目標が変化することさえあります。さらに、タスクが完了した後も、それが適切に行われたかどうかについて人々が合意しないこともあります。
このような複雑さは、AI モデルが数時間ではなく数週間や数ヶ月を要するより長いタスクに取り組むようになるにつれて、ますます重要になっていきます。これらの種類のタスクにおける AI モデルのパフォーマンスを測定するための優れた方法はまだなく、その一因として、同様の状況下での人間労働者のパフォーマンスを評価すること自体に困難があることが挙げられます。
その結果、私たちが測定できる能力と、実際に私たちが重視する能力との間に、徐々に乖離が生じるようになるかもしれません。
AI ベンチマークのライフサイクル
大規模言語モデルの初期には、MMLU(Massive Multitask Language Understanding の略)と呼ばれるベンチマークを引用するのが一般的でした。これは、歴史、コンピュータサイエンス、遺伝学、天文学、国際法など、幅広いトピックについて言語モデルを厳しく問いただすものです。
2020 年に MMLU が発表された当時、最もパフォーマンスが高かった LLM は GPT-3 で、スコアは 43.9% でした。より古いモデルである GPT-2 のスコアは 32.4% で、ランダムな推測で得られる 25% よりも少し良い程度でした。
私が 2023 年に LLM について書き始めた頃には、GPT-4 は 86.4% を達成していました。2024 年には GPT-4o が 88.7%、2025 年には GPT-4.1 が 90.2% のスコアを記録しました。
過去一年間、AI 企業は MMLU のスコアの報告を停止しました。おそらく、スコアがこれ以上改善しなくなったためでしょう。これは驚くべきことではありません。MMLU の質問の約 6.5% に誤りが含まれているため、不正行為なしで 93% を大幅に超えるスコアを得ることは不可能だからです。
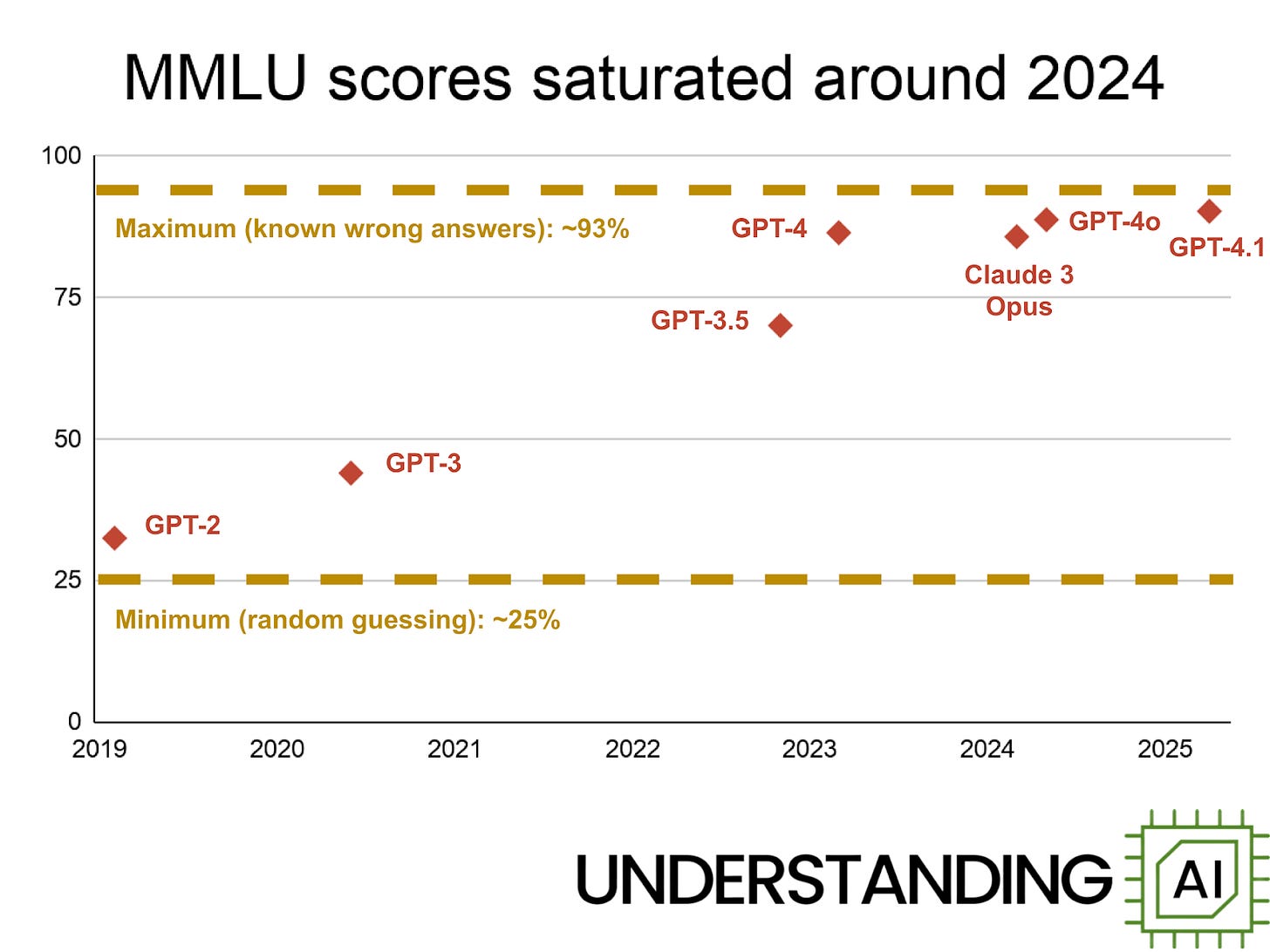
したがって、MMLU などの従来のベンチマーク(性能評価指標)には自然なライフサイクルが存在します。当初はほとんどの問題がモデルの能力を超えており、スコアは最小値付近に集中します。モデルが改善するにつれてベンチマークスコアは上昇し、最終的に理論上の最大値に近づきます。2024 年以降、最先端モデルはすべて 88% から 93% の間でスコアを記録しており、この狭い範囲では差がランダムなノイズによるものとも考えられます。業界用語で言えば、MMLU は飽和状態にあります。
時間の経過とともに、AI コミュニティは飽和した以前のベンチマークに代わるより困難なベンチマークの開発に取り組んできました。例えば、2025 年初頭に MMLU の主著者である Dan Hendrycks が共同で執筆した、より困難な新ベンチマーク「Humanity's Last Exam (HLE)」が挙げられます。MMLU と同様に、HLE も化学から法律に至るまで多様な科目に関する問題を含んでいます。
リリース当時、最高スコアを記録したのは o3-mini (high) で、HLE での得点は 13.4% でした。現在では、Google の Gemini 3.1 が首位に立ち、得点は 44.7% です。おそらく 1〜2 年後にはモデルがこのベンチマークも飽和させ始め、100% に近づくにつれて向上幅は鈍化していくでしょう。
METR は異なる種類のベンチマークを作成しました
HLE が MMLU よりも難しいことは分かっていますが、どれほど難しいのかを言うのは困難です。異なるベンチマーク間でスコアを比較する明確な方法がないため、長期間にわたるモデルの能力を比較したり、将来のモデルについて予測を立てたりすることが難しくなります。
METR はこの問題に対する賢明な解決策を発案しました。そのベンチマークには幅広い難易度のタスクが含まれています。最も簡単な問題は人間が数秒で完了できるように設計されており、例えばプログラミング言語の構文に関する単純な事実質問などです。一方、最も難しい問題は人間のプログラマーに多くの時間を要するものです。
METR はこれらのタスクを人間がどれくらいで完了するかを単に推測したのではなく、実際にプログラマーを雇用してその実際の完了時間を測定しました。1 つの例として、METR テストスイートには「すべての機能を維持しながらカスタム CUDA カーネルを実装することで、取引実行用の Python バックテストツールの速度を向上させる」という問題がありました。METR はこのタスクが人間のプログラマーに約 8 時間かかると発見しました。
このような方法でタスクを測定することは、劇的に異なる能力を持つモデルを比較する手段を与えてくれます。GPT-2 は人間が約 2 秒で完了できるタスクしか実行できませんでしたが、GPT-5 は人間の努力に約 3 時間かかるタスクも実行できます。したがって、GPT-5 が実行できるタスクは、GPT-2 が実行できるタスクよりも 5,400 倍「難しい」と言うことができます。
(注:原文の末尾にある「1」は脚注番号と推測されますが、翻訳文脈上そのまま残します)
この進歩のペースが続けば、タスク長さが 6 か月または 7 ヶ月ごとに倍増すると仮定して、来年には週単位のタスク(つまり人間労働で 40 時間に相当)を完了できる大規模言語モデル(LLM: Large Language Model)が現れると予想され、2028 年には月単位のタスク(40 時間労働の週が 4 週間分)も可能になるはずです。
しかし、現在の METR のタスク長ベンチマークでは、そのような強力なモデルを意味ある形でテストすることはできません。現在のテストスイートで最も困難なタスクとは、「車輪のスリップやモーターのジャーク制限にもかかわらず、4 輪オムニ方向ロボットが制御アルゴリズムを修正してカブスpline(3 次スプライン曲線)を迅速に追従させる」といったものであり、これらを人間が完了するには約 30 時間を要します。
つまり、METR のタスク長ベンチマークは飽和状態に近いのです。
METR のベンチマークは飽和すると少し奇妙な動きを見せます
前述の通り、従来のベンチマークが飽和すると、スコアは最大値(例えば MMLU では 93%)の周りに集約し始めます。一方、METR のベンチマークは異なる挙動を示します。モデルが最も難しい質問を解き始める段階で、ベンチマークの信頼区間が劇的に広がります。これはモデル性能に上限を設定する方法がないためです。私が以前指摘したように、Claude Opus 4.6 に対する METR の信頼区間は 5 時間から 66 時間の範囲にあります。
「もしタスクスイートから一つのタスクを外したり、別のタスクを追加したりすれば、おそらくこの Claude Opus 4.6 の時間軸を、私が思うに 14 時間半で測定する代わりに、8 時間や 20 時間といった値で測定することになるでしょう」と、METR のジョエル・ベッカーは最近の私のポッドキャストでのインタビューで語りました。「今や、一つのタスクに対してこれほど敏感になっているのです。」
原理的には解決策は単純です。人間のプログラマーが 30 時間以上を要するタスクを追加すればよいのです。理想的には、METR は人間が 40 時間、80 時間、160 時間といった時間を要するタスクでモデルをテストすべきでしょう。これにより、ベンチマークの有効寿命は少なくともあと数年延びることになります。
しかし、これは容易ではありません。METR は人間のプログラマーに最低でも時給 50 ドルを支払っているため、単一の 160 時間タスクのベースラインを取得するには、少なくとも 8,000 ドルの費用がかかります。さらに、プログラマーに参加を承諾させることができるかどうかさえも不確実です。私は METR が、数週間にわたるタスクに取り組む経験豊富なプログラマーを見つけるのに苦労するだろうと予想します。多くのプログラマーは時間を捻出するために本業を辞めなければならないでしょう。
また、METR ベンチマーク(あるいはそれに類するベンチマーク)を、数十時間の人間作業を要するタスクに拡張しようとするには、より深い概念的な問題も存在します。
続きを読む
原文を表示
Before we get to today’s article, I want to recommend some audio content about autonomous vehicles:
Back in 2010, my friend Ryan Avent and I made a bet about the future of autonomous vehicles. The bet came due last month and I won. Ryan and I did a postmortem on my podcast, AI Summer. You can listen here or search for “AI Summer” in your favorite podcast app.
PJ Vogt’s podcast Search Engine just did a two-part series on autonomous vehicles. I’m biased since I was quoted in both episodes, but I thought it was incredibly good. You can listen here, or search for “Search Engine” in your favorite podcast app.
Now for today’s article!
If you’ve followed AI over the last year, you’ve probably seen the famous “METR chart”:
METR, short for Model Evaluation and Threat Research, is based in Berkeley, California. The group has published many charts, but this one has become its calling card. It compares AI models based on the complexity of software engineering tasks they can complete, with complexity measured by how long it takes a human programmer to complete the same task:
GPT-3.5 — the model that powered the original ChatGPT — could complete tasks that took a human programmer about 30 seconds.
GPT-4, released in March 2023, bumped that up to 4 minutes.
o1, released in December 2024, was OpenAI’s first “reasoning model.” It could perform tasks that took a human 40 minutes.
GPT-5, released in August 2025, was able to finish tasks that took humans 3 hours.
Claude Opus 4.6 was released in February by Anthropic. METR estimates it can complete tasks that would take a human programmer 12 hours.
That last figure is twice as long as the estimate for the previous leader, GPT-5.2, which had been released just two months earlier.
I think this chart — and especially the impressive score for Claude Opus 4.6 — has done a lot to foster an impression of accelerating AI progress in recent months. Notice that the chart is logarithmic, so a straight line indicates exponential progress. The fact that Claude Opus 4.6 is above the previous trend line suggests very rapid progress indeed.
But if you click on METR’s task length page and hover over the dot for Claude Opus 4.6, you’ll see something interesting: METR’s confidence interval for Claude Opus 4.6 ranges from 5 hours to 66 hours. On Twitter, METR staff have urged people not to take the latest results as gospel.
“When we say the measurement is extremely noisy, we really mean it,” METR’s David Rein wrote.
METR depends on having a mix of easy tasks that an AI model can solve and harder tasks that it can’t. This allows the group to bracket the capabilities of a model. But Claude Opus 4.6 was able to solve some of the hardest problems in METR’s test suite, which made it difficult to put an upper bound on its capabilities.
So we know the latest Claude Opus is better than previous models, but it’s hard to say how much better. This means we don’t know if the apparent acceleration of the last few months is real or just a statistical artifact.
METR could — and perhaps will — add harder tasks to its test suite so it can test future models with greater precision.
But there’s also a deeper philosophical challenge.
Like most AI benchmarks, this one measures AI performance using tasks that are well-defined, self-contained, and easily verified. But a lot of the tasks humans perform aren’t like this.
In real workplaces, tasks are often connected to other tasks. They frequently require interacting with other people or the outside world. Sometimes it’s not clear what task needs doing, and goals may evolve as people work on a project. Even after a task is completed, people might not agree on whether it was done well.
Complexities like this will become more important as AI models tackle longer tasks — tasks that take weeks or months rather than just hours. We don’t have great ways to measure the performance of AI models on these kinds of tasks — in part because we struggle to judge the performance of human workers in the same situations.
As a consequence, we may see a growing divergence between the capabilities we can measure and the capabilities we actually care about.
The life cycle of an AI benchmark
In the early years of large language models, it was common for people to cite a benchmark called MMLU, short for Massive Multitask Language Understanding. It grills a language model on a wide range of topics: history, computer science, genetics, astronomy, international law, and more.
When MMLU was published in 2020, the best-performing LLM was GPT-3. It scored 43.9%. An older model, GPT-2, scored 32.4% — not much better than the 25% score you’d get from random guessing.
By the time I started writing about LLMs in 2023, GPT-4 had scored 86.4%. GPT-4o scored 88.7% in 2024, and GPT-4.1 scored 90.2% in 2025.
In the last year, AI companies have stopped reporting MMLU scores — presumably because scores have stopped improving. That’s not surprising; it’s impossible to get a score much higher than 93% without cheating because around 6.5% of MMLU questions contain errors.
So conventional benchmarks like MMLU have a natural lifecycle. At first, most problems are beyond models’ capabilities, so scores cluster near the minimum. As models improve, benchmark scores increase until they approach the theoretical maximum. Since 2024, frontier models have all scored between 88% and 93%, a narrow enough range that differences could be random noise. In industry jargon, MMLU has saturated.
Over time, the AI community works to develop more difficult benchmarks to replace earlier ones that have saturated. For example, in early 2025 Dan Hendrycks, the lead author of MMLU, co-authored a new, more difficult benchmark called Humanity’s Last Exam (HLE). Like MMLU, HLE includes questions in subjects ranging from chemistry to law.
When it was released, the best model was o3-mini (high), which scored 13.4% on HLE. Today, the leading model is Google’s Gemini 3.1, which scored 44.7%. Perhaps in a year or two models will begin to saturate this benchmark, with gains slowing as they approach 100%.
METR created a different kind of benchmark
We know that HLE is harder than MMLU, but it’s difficult to say how much harder. There’s no obvious way to compare scores across different benchmarks, which makes it hard to compare model capabilities over long time periods — or to make predictions about future models.
METR invented a clever solution to this problem. Its benchmark contains tasks with a wide range of difficulties. The easiest problems are designed to take humans a few seconds — for example, a simple factual question about the syntax of a programming language. The hardest problems would take a human programmer many hours.
METR didn’t just guess how long humans would take on these tasks; it hired programmers and measured their actual completion times.1 For example, one problem in the METR test suite was to “speed up a Python backtesting tool for trade executions by implementing custom CUDA kernels while preserving all functionality.” METR found that this takes human programmers about eight hours.
Measuring tasks this way gives us a way to compare models with dramatically different capabilities. GPT-2 could only complete tasks that took human programmers about two seconds, whereas GPT-5 could complete tasks that took around 3 hours of human effort. So we could say that GPT-5 could complete tasks that are 5,400 times “harder” than the tasks GPT-2 could complete.
If this pace of progress continues — doubling task length every six or seven months — we should expect LLMs capable of completing week-long tasks (that is, 40 hours of human labor) some time next year, and month-long tasks (four 40-hour weeks) in 2028.2
However, the current version of METR’s task-length benchmark wouldn’t be able to meaningfully test such a powerful model. The most difficult tasks in the current test suite — such as “fix a control algorithm for a 4-wheeled omni-directional robot to follow cubic splines quickly despite wheel slippage and motor jerk limitations” — take humans about 30 hours to complete.
In other words, METR’s task-length benchmark is close to saturating.
METR’s benchmark gets a little crazy when it saturates
We saw earlier that when conventional benchmarks saturate, scores start to cluster around a maximum value — like 93% for MMLU. METR’s benchmark works differently. When a model starts solving the hardest questions, the benchmark’s confidence interval widens dramatically because there is no way to place an upper bound on model performance. As I noted previously, METR’s confidence interval for Claude Opus 4.6 ranges from 5 to 66 hours.
“If we took one task out of our task suite or added another task to our task suite, potentially instead of measuring this Claude Opus 4.6 time horizon of, I think, 14 and a half hours, we’d be measuring it at something like eight or 20 hours,” METR’s Joel Becker told me in a recent interview on my podcast. “That’s how sensitive things are now to a single task.”
In principle, the solution is simple: add tasks that take human programmers more than 30 hours. Ideally, METR would test models on tasks that take humans 40 hours, 80 hours, 160 hours, and so forth. That would extend the useful life of the benchmark by at least a couple more years.
But this won’t be easy. METR pays human programmers a minimum of $50 per hour, so getting a baseline for a single 160-hour task would cost at least $8,000. And that’s assuming they can even convince programmers to participate. I bet METR would struggle to find experienced programmers willing to tackle tasks that stretch across multiple weeks; many programmers would have to quit their day jobs to make time.
There’s also a deeper conceptual problem with trying to extend the METR benchmark — or any benchmark like it — to tasks that require dozens of hours of human work.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み