高度な結合技術:LATERAL 結合、セミ結合、アンチ結合
この記事は、一般的な結合操作では解決が難しいデータ処理課題に対して、LATERAL、Semi、Anti Join という高度な SQL 技術を実用的な例と共に解説している。
キーポイント
LATERAL Joins の役割と活用
FROM クラース内の先行テーブルの列を参照できる LATERAL サブクエリにより、行ごとに集計関数や正規表現処理を実行する高度なデータ操作が可能になる。
Semi Joins と Anti Joins の定義
Semi Join は他テーブルに一致する行を重複なく返す一方、Anti Join は一致しない行のみを抽出するもので、それぞれ存在確認と除外処理に最適化されている。
実務での具体的な適用ケース
配列の展開(unnest)、正規表現による全マッチ抽出、JSON 配列の分割、グループごとの上位 N 件取得など、複雑なデータ加工タスクでこれらの技術が不可欠である。
Google の面接課題事例
テキスト内の特定単語(例:bull, bear)を大文字小文字区別なくカウントし、部分一致(例:bullish)を除外するといった実社会の質問に対する SQL 解決策が提示されている。
LATERAL と正規表現の組み合わせによる単語カウント
FROM クラウスに LATERAL を使用して regexp_matches() を実行し、1 行ごとに複数回マッチする単語を抽出・集計できます。
PostgreSQL の単語境界アンカーの活用
\m と \M を使用することで部分一致(例:bullish)を除外し、完全な単語のみを正確にカウントすることが可能です。
Semi Join の特性と実装方法
左テーブルの行が右テーブルで少なくとも 1 つマッチする場合に返す join で、INNER JOIN と異なり重複が発生しません。EXISTS や IN を使用して実装します。
影響分析・編集コメントを表示
影響分析
この記事は、SQL の基礎的な結合操作を超えた高度なデータ分析スキルを持つエンジニアにとって不可欠な知識を提供しています。特に大規模データ処理や複雑なテキスト解析が必要な現場において、パフォーマンスと可読性を同時に向上させるための具体的なパターンを提示しており、実務の質を高める重要な役割を果たします。
編集コメント
AI モデルの学習や推論におけるデータ前処理工程でも、この高度な SQL パターンは頻繁に必要とされるため、データサイエンティストやエンジニアが押さえておくべき基礎知識です。
**
# イントロダクション
INNER JOIN と LEFT JOIN は、SQL クエリの大部分を処理できます。しかし、より少数のクラスの問題には、他の 結合タイプ が必要です**:集計関数(set-returning function)の結果を行ごとにカウントする、別のテーブルでの存在に基づいて行をフィルタリングする、あるいは別のテーブルで一致しない行を返すといったケースです。
これらをきれいに処理するのが、3 つのあまり一般的ではない結合です。LATERAL 結合(LATERAL join)は、FROM クラース内のサブクエリが、同じ FROM クラース内で先行する列を参照することを可能にします。Semi 結合(Semi join)は、別のテーブルで一致が存在する行を返しますが、その行の重複は発生しません。Anti 結合(Anti join)は、別のテーブルで一致が存在しない行を返します。
これらのパターンを実践的にどのように適用するかを探っていきましょう。
**

FROM クラース内の LATERAL サブクエリは、同じ FROM クラース内の先行するテーブルの列を参照できます。LATERAL を使用しない場合、FROM 内のサブクエリは独立して評価され、それらの列を認識することはできません。
これは、セット返却関数(set-returning function:入力に対して複数の行を返す関数)を呼び出す際に特に重要です。セット返却関数は SELECT リスト内で呼び出すこともできますが、FROM クラース内の外部テーブルの列に対して行ごとに適用するには、LATERAL が必要です。
一般的なケース:**
- 配列カラムに対して unnest() を呼び出し、配列の各要素ごとに 1 行を取得する
- 'g' フラグを指定して regexp_matches() を呼び出し、各行ごとのすべての一致箇所を抽出する
- FROM 句に相関サブクエリを使用して、グループごとの上位 N 件結果を計算する
- 各行の JSON 配列を分割する
// 例:単語出現回数のカウント
この Google の質問 では、contents カラム内の「bull」という単語と「bear」という単語がそれぞれ何回出現しているかを数えるよう求めています。一致は大文字小文字を区別せずに行う必要がありますが、「bullish」や「bearing」のような部分文字列は除外する必要があります。
データ: google_file_store テーブルの内容は以下の通りです:
filename
contents
draft1.txt
The stock exchange predicts a bull market which would make many investors happy.
draft2.txt
The stock exchange predicts a bull market... but analysts warn... we are awaiting a bear market.
final.txt
The stock exchange predicts a bull market... a bear market. As always predicting the future market is uncertain...
コード: regexp_matches() は一致するたびに 1 行を返します。google_file_store の各行に対してこれを一度実行し、テーブル全体のすべての一致箇所を数えるために、LATERAL を使用して FROM 句に配置します。\m と \M アカーは PostgreSQL の単語境界を示すものであり、これによって「bullish」や「bearing」が除外されます。
SELECT 'bull' AS word,
COUNT(*) AS nentry
FROM google_file_store,
LATERAL regexp_matches(LOWER(contents), '\m(bull)\M', 'g')
UNION ALL
SELECT 'bear' AS word,
COUNT(*) AS nentry
FROM google_file_store,
LATERAL regexp_matches(LOWER(contents), '\m(bear)\M', 'g');
// Output
word
nentry
bull
3
bear
2
# Semi Joins (セミジョイン)
**
セミジョインは、右テーブルに少なくとも1つの一致が存在する左テーブルの行を返すものであり、各左テーブルの行は最大1回しか現れません。INNER JOIN では、右側に複数の一致がある場合、左テーブルの行が重複して表示されます。しかし、セミジョインではそのような重複は発生しません。
2 つの SQL 実装方法:**
- WHERE EXISTS (SELECT 1 FROM ...)
- WHERE col IN (SELECT col FROM ...)
EXISTS はより一般的な形式です。これは、クエリを書き換えることなく、複数列の結合条件や相関サブクエリを処理できるためです。
// Example: Finding High-Value Customers (例:高価値顧客の特定)
この質問 では、$100 以上の注文を少なくとも 1 つ行った顧客を見つけ、その顧客 ID と名前を返すよう求めています。
データ: online_store_customers および online_store_orders のプレビュー:**
customer_id
customer_name
1
Alice Johnson
2
Bob Smith
3
Carol Williams
…
…
10
Jack Anderson
order_id
customer_id
amount
status
101
1
150
paid
102
1
200
paid
103
1
75
paid
...
...
...
...
115
9
450
paid
コード: EXISTS サブクエリは、顧客ごとに $100 を超える注文が存在するかどうかを確認します。SELECT 1 は、EXISTS が行が返ってくるかどうかにのみ関心があり、その中身には関心がないため、この慣習です。
SELECT
c.customer_id,
c.customer_name
FROM online_store_customers c
WHERE EXISTS (
SELECT 1
FROM online_store_orders o
WHERE o.customer_id = c.customer_id
AND o.amount > 100
);
もし INNER JOIN を使用した場合、顧客 1 は一致する注文が 2 つあるため結果に 2 回表示されます。EXISTS は顧客 1 を 1 回のみ返します。
// 出力
customer_id
customer_name
1
Alice Johnson
2
Bob Smith
3
Carol Williams
…
…
9
Ivy Taylor
# アンチジョイン (Anti Joins)
**アンチジョインは、右テーブルに一致する行が存在しない場合、左テーブルから行を返します。これはセミジョインの逆です。
2 つの SQL 実装:**
- LEFT JOIN ... WHERE right_table.col IS NULL
- WHERE NOT EXISTS (SELECT 1 FROM ...)
両方とも同じ結果を生成します。NOT EXISTS は、最新の PostgreSQL バージョンではより良いクエリプランを生成することが多く、読みやすさの点でも直接的です。LEFT JOIN + IS NULL パターンは古くからあるもので、一致しない行についても右側の列が必要となる場合に有用です。
// 例:4 月に通話のない無料ユーザー
この質問 は、2020 年 4 月に通話をしなかった無料ユーザーを返すよう求めています。
データ: rc_calls と rc_users のプレビュー:**
user_id
call_id
call_date
1218
0
2020-04-19 01:06:00
1554
1
2020-03-01 16:51:00
1857
2
2020-03-29 07:06:00
1525
3
2020-03-07 02:01:00
…
…
…
1910
39
2020-03-11 08:33:00
user_id
status
company_id
1218
free
1
1554
inactive
1
1857
free
2
…
…
…
1884
free
1
コード: 日付フィルタは WHERE 句ではなく ON 句に配置されます。この区別こそが、これをアンチ結合(Anti Join)とする理由です。日付フィルタを WHERE に置くと、LEFT JOIN で NULL が生成された行が削除され、結果としてインナー結合(Inner Join)に戻ってしまいます。一方、フィルタを ON 句に配置することで、条件を満たす 4 月の通話がないフリーユーザーも右側に NULL を持つ行として出力されます。その後、IS NULL チェックによってこれらの行のみが保持されます。
SELECT DISTINCT u.user_id
FROM rc_users u
LEFT JOIN rc_calls c
ON u.user_id = c.user_id
AND c.call_date BETWEEN '2020-04-01' AND '2020-04-30'
WHERE u.status = 'free'
AND c.user_id IS NULL;
// 出力
user_id
1575
1910
# 結論
**
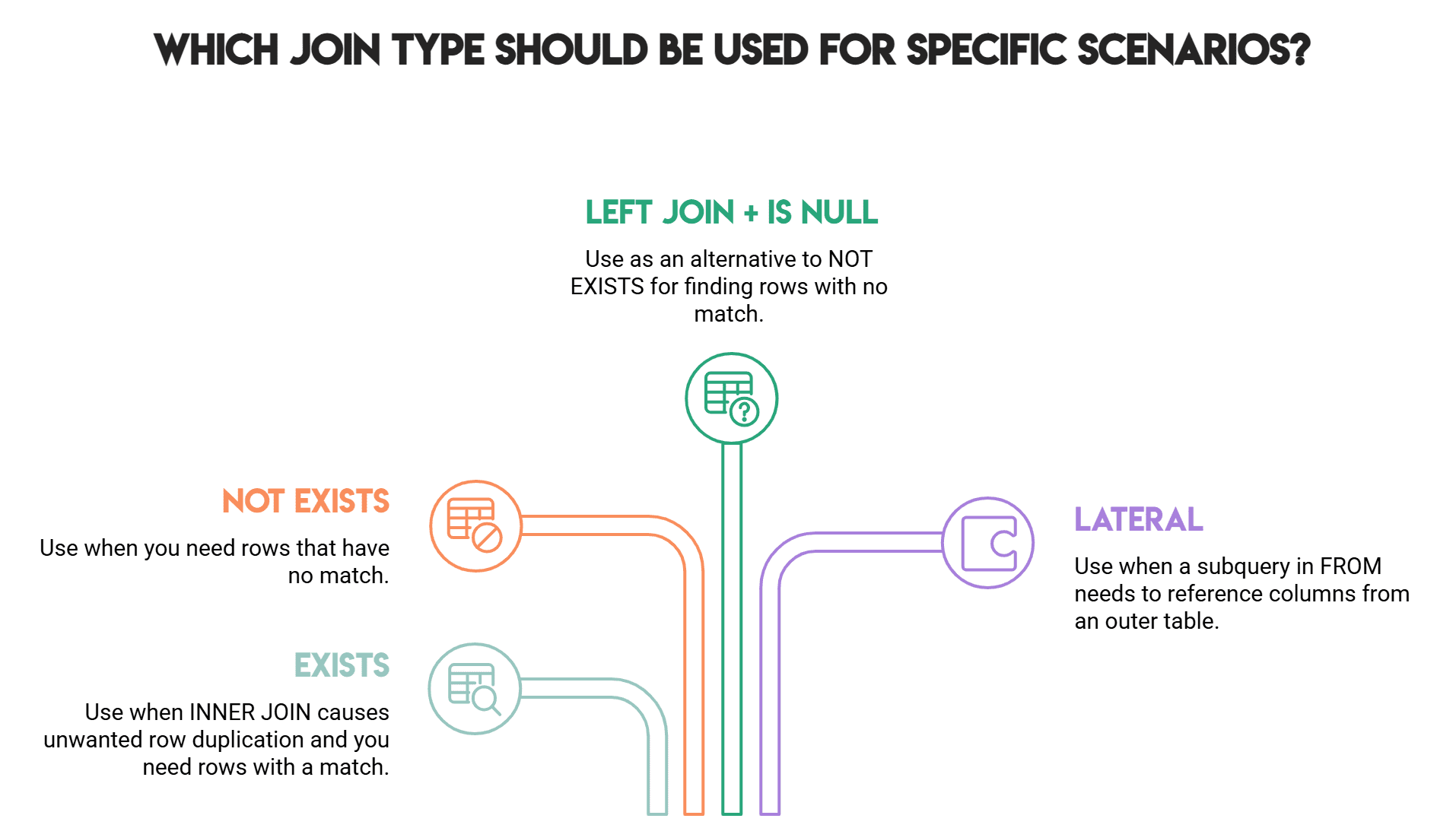
これら 3 つの結合手法は、インナー結合(INNER JOIN)や左結合(LEFT JOIN)が不適切または誤りとなるケースを解決します:**
- LATERAL は、FROM 句内でセット返却関数(set-returning functions)を行ごとに呼び出すための方法です。
- EXISTS を使用すると、重複を引き起こすインナー結合(INNER JOIN)による問題なく、「一致する行」を取得できます。
- NOT EXISTS または LEFT JOIN + IS NULL を組み合わせることで、「一致しない行」をきれいに取得できます。
覚えるべきパターンは短いです。INNER JOIN で望まない行の重複が発生する場合は EXISTS を使い、一致する行がない場合が必要なときは NOT EXISTS または LEFT JOIN + IS NULL を使用します。FROM 句内のサブクエリが外部テーブルの列を参照する必要がある場合は、LATERAL を追加してください。
Nate Rosidi はデータサイエンティストであり、製品戦略に従事しています。また、分析を教える非常勤講師でもあり、一流企業からの実際の面接質問を用いてデータサイエンティストの面接準備をサポートするプラットフォーム「StrataScratch」の創設者です。Nate はキャリア市場における最新動向について執筆し、面接に関するアドバイスを提供し、データサイエンスプロジェクトを紹介し、SQL 関連のあらゆるトピックをカバーしています。
原文を表示

**
# Introduction
INNER JOIN and LEFT JOIN handle most SQL queries. A smaller class of problems needs other join types**: counting set-returning function results row by row, filtering rows by existence in another table, and returning rows that have no match in another table.
Three less-common joins handle these cleanly. LATERAL joins let a subquery in the FROM clause reference columns from earlier in the same FROM clause. Semi joins return rows where a match exists in another table, without duplicating those rows. Anti joins return rows where no match exists.
Let's explore how to apply these patterns in practice.
**
A LATERAL subquery in the FROM clause can reference columns from preceding tables in the same FROM clause. Without LATERAL, a subquery in FROM is evaluated independently and cannot see those columns.
This matters most when calling a set-returning function (one that returns multiple rows per input). Set-returning functions can be called in the SELECT list, but to apply them row-by-row to a column from an outer table inside the FROM clause, LATERAL is required.
Common cases:**
- Calling unnest() on an array column to get one row per array element
- Calling regexp_matches() with the 'g' flag to extract every match per row
- Computing a top-N-per-group result with a correlated subquery in FROM
- Splitting JSON arrays per row
// Example: Counting Word Occurrences
This Google question asks us to count how many times the words "bull" and "bear" appear in a contents column. Matches must be case-insensitive, and substrings like bullish or bearing should be excluded.
Data: the google_file_store table is:**
filename
contents
draft1.txt
The stock exchange predicts a bull market which would make many investors happy.
draft2.txt
The stock exchange predicts a bull market... but analysts warn... we are awaiting a bear market.
final.txt
The stock exchange predicts a bull market... a bear market. As always predicting the future market is uncertain...
Code: regexp_matches() returns one row per match. To run it once per row of google_file_store and count all matches across the table, we put it in the FROM clause with LATERAL. The \m and \M anchors are PostgreSQL** word boundaries, which is what excludes "bullish" and "bearing".
SELECT 'bull' AS word,
COUNT(*) AS nentry
FROM google_file_store,
LATERAL regexp_matches(LOWER(contents), '\m(bull)\M', 'g')
UNION ALL
SELECT 'bear' AS word,
COUNT(*) AS nentry
FROM google_file_store,
LATERAL regexp_matches(LOWER(contents), '\m(bear)\M', 'g');// Output
word
nentry
bull
3
bear
2
# Semi Joins
**
A semi join returns rows from the left table where at least one match exists in the right table, with each left-table row appearing at most once. INNER JOIN duplicates left-table rows when the right side has multiple matches. Semi joins do not.
Two SQL implementations:**
- WHERE EXISTS (SELECT 1 FROM ...)
- WHERE col IN (SELECT col FROM ...)
EXISTS is the more general form because it handles multi-column join conditions and correlated subqueries without rewriting the query.
// Example: Finding High-Value Customers
This question asks us to find customers who have placed at least one order over $100 and return their customer ID and name.
Data: Previews of online_store_customers and online_store_orders:**
customer_id
customer_name
1
Alice Johnson
2
Bob Smith
3
Carol Williams
…
…
10
Jack Anderson
order_id
customer_id
amount
status
101
1
150
paid
102
1
200
paid
103
1
75
paid
...
...
...
...
115
9
450
paid
Code**: The EXISTS subquery checks, per customer, whether any order over $100 exists. SELECT 1 is the convention because EXISTS only cares whether any row comes back, not what is in it.
SELECT
c.customer_id,
c.customer_name
FROM online_store_customers c
WHERE EXISTS (
SELECT 1
FROM online_store_orders o
WHERE o.customer_id = c.customer_id
AND o.amount > 100
);If we used INNER JOIN instead, customer 1 would appear twice in the result because two orders match. EXISTS returns customer 1 once.
// Output
customer_id
customer_name
1
Alice Johnson
2
Bob Smith
3
Carol Williams
…
…
9
Ivy Taylor
# Anti Joins
**
An anti join returns rows from the left table where no match exists in the right table. It is the inverse of a semi join.
Two SQL implementations:**
- LEFT JOIN ... WHERE right_table.col IS NULL
- WHERE NOT EXISTS (SELECT 1 FROM ...)
Both produce the same result. NOT EXISTS often produces a better query plan in modern PostgreSQL versions and reads more directly. The LEFT JOIN + IS NULL pattern is older and useful when you also need columns from the right side for non-matching rows.
// Example: Free Users With No April Calls
This question asks us to return free users who did not make any calls in April 2020.
Data: Previews of rc_calls and rc_users:**
user_id
call_id
call_date
1218
0
2020-04-19 01:06:00
1554
1
2020-03-01 16:51:00
1857
2
2020-03-29 07:06:00
1525
3
2020-03-07 02:01:00
…
…
…
1910
39
2020-03-11 08:33:00
user_id
status
company_id
1218
free
1
1554
inactive
1
1857
free
2
…
…
…
1884
free
1
Code**: The date filter sits in the ON clause, not WHERE. That distinction is what makes this an anti join. Putting the date filter in WHERE would drop rows where the LEFT JOIN produced NULLs, collapsing it back to an INNER JOIN. With the filter in ON, free users with no qualifying April call still produce a row, with NULLs on the right side, and the IS NULL check keeps only those rows.
SELECT DISTINCT u.user_id
FROM rc_users u
LEFT JOIN rc_calls c
ON u.user_id = c.user_id
AND c.call_date BETWEEN '2020-04-01' AND '2020-04-30'
WHERE u.status = 'free'
AND c.user_id IS NULL;// Output
user_id
1575
1910
# Conclusion
**
These three joins solve cases where INNER JOIN and LEFT JOIN are awkward or wrong:**
- LATERAL is the way to call set-returning functions row by row inside FROM.
- EXISTS gives you "rows with a match" without the duplication that INNER JOIN causes.
- NOT EXISTS or LEFT JOIN + IS NULL gives you "rows with no match" cleanly.
The pattern to remember is short. When INNER JOIN duplicates rows you don't want, use EXISTS. When you need rows that have no match, use NOT EXISTS or LEFT JOIN + IS NULL. When a subquery in FROM needs to reference columns from an outer table, add LATERAL.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.
関連記事
データサイエンティストが知っておくべき実用的な SQL の技
KDnuggets は、データサイエンティストが効率的にデータを処理するために役立つ実践的な SQL のテクニックを紹介している。
SQLite 3.53.0 のリリース
SQLite がバージョン3.53.0を公開。ALTER TABLEでNOT NULLやCHECK制約の追加・削除が可能になり、ユーザー向けおよび内部の改善が多数含まれる。
Datasette Apps:カスタム HTML アプリケーションを Datasette 内でホスト可能に
Simon Willison が開発した Simon Willison Blog は、Datasette に新しいプラグイン「datasette-apps」を追加し、自己完結型の HTML と JavaScript で構成されるアプリケーションを同プラットフォーム上で実行できる機能を公開しました。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み