SWE-bench Verifiedを評価しなくなった理由
OpenAIは、SWE-bench Verifiedベンチマークがデータ汚染とテストケースの欠陥により最先端モデルの評価指標として不適切になったため、後継となるSWE-bench Proへの移行を推奨する。
キーポイント
ベンチマークの汚染とテスト欠陥
モデルが失敗したタスクの監査結果、約59.4%が機能的に正しい解答を却下する flawed なテストケースを含んでおり、評価の信頼性が損なわれている。
トレーニングデータとの重複(データリーク)
オープンソースリポジトリ由来の問題が学習データに含まれており、主要な最先端モデルは既知のバグ修正や問題文を暗記している可能性が高い。
能力向上の誤認と新ベンチマークへの移行
スコア向上が実質的な開発能力の向上ではなく、学習時の露出度を示すものになっているため、OpenAIは評価指標としてSWE-bench Verifiedの使用を停止し、SWE-bench Proを推奨する。
SWE-bench Verified の信頼性低下と評価の中止
モデルの実世界での開発能力ではなく、ベンチマークへの学習露出度を反映するようになったため、OpenAI は SWE-bench Verified のスコア報告を停止し他社にも同様の対応を推奨している。
テスト設計の根本的な問題
監査の結果、SWE-bench Verified の問題の約6割にテスト設計や課題記述に重大な欠陥があり、正しく機能する実装でも特定のテストケースが厳格すぎる「狭いテスト」により却下されるケースが多発している。
代替評価指標としての SWE-bench Pro
新規で汚染されていない評価基準が整備されるまでの間、OpenAI はモデル開発者に対し SWE-bench Pro の結果報告を推奨している。
広義のテストケース(Wide Test Cases)の問題
監査されたタスクの18.8%で、問題記述に指定されていない追加機能(特定の関数名など)をチェックするテストが存在し、正当な解決策でもインポートエラーなどで失敗するケースが見られた。
影響分析・編集コメントを表示
影響分析
この発表は、現在のAIベンチマークの信頼性危機を象徴するものであり、単なるスコア競争から「真の汎用能力」の評価へパラダイムシフトを起こす契機となる。業界全体として、データ汚染対策や新しい評価基準の標準化が急務となり、モデル比較の公平性と透明性が問われることになる。
編集コメント
OpenAI自らが旧ベンチマークの有用性を否定し新基準を提示する这一行為は、AI評価指標の流動性と難しさを如実に示しています。開発者はベンチマークスコアのみを鵜呑みにせず、その背景にあるデータ汚染リスクを常に疑う姿勢が求められます。
タイトル: SWE-bench Verifiedを評価対象から外した理由
2026年2月23日
なぜSWE-bench Verifiedは最先端のコーディング能力を測定できなくなったのか
SWE-bench Verifiedは汚染が進んでいます。SWE-bench Proの使用を推奨します。
読み込み中…共有するSWE-bench Verifiedを2024年8月に初めて公開して以来、業界では自律的なソフトウェアエンジニアリングタスクにおけるモデルの進歩を測定するために広く使用されてきました。リリース後、SWE-bench Verifiedは能力向上の強力な指標を提供し、最先端モデルのリリース時に報告される標準的な指標となりました。これらの能力の進捗を追跡し予測することは、OpenAIのPreparedness Frameworkにおいても重要な部分です。Verifiedベンチマークを最初に作成した際、私たちはSWE-benchデータセットにおいて特定のタスクを達成不可能にしていた元の評価の問題点を解決しようと試みました(新しいウィンドウで開く)。
初期の飛躍的な進歩の後、SWE-bench Verifiedにおける最先端の進歩は鈍化し、過去6ヶ月で(新しいウィンドウで開く)74.9%から80.9%へと改善しただけです。これは疑問を投げかけます:残りの失敗は、モデルの限界を反映しているのか、それともデータセット自体の特性を反映しているのか?
新たな分析において、Verifiedセットには2つの重大な問題があり、現在の性能レベルにおける最先端モデルの自律的ソフトウェアエンジニアリング能力の進歩を測定するには、このベンチマークがもはや適していないことが明らかになりました:
- テストが正しい解決策を拒否する: モデルがしばしば解決に失敗したデータセットの27.6%のサブセットを監査したところ、監査対象の問題の少なくとも59.4%が、機能的に正しい提出物を拒否する欠陥のあるテストケースを持っていることが判明しました。これは、SWE-bench Verifiedの初期作成時にこの点を改善する最善の努力をしたにもかかわらずです。
- 解決策での学習: 大規模な最先端モデルは学習データから情報を学習できるため、評価対象となる問題とその解決策を決して学習していないことが重要です。これは、試験前に生徒に試験問題と解答を共有するようなものです。生徒は答えを暗記しないかもしれませんが、事前に答えを見た生徒は、見ていない生徒よりも確実に良い成績を収めるでしょう。SWE-benchの問題は、多くのモデルプロバイダーが学習目的で使用するオープンソースリポジトリから収集されています。私たちの分析では、テストしたすべての最先端モデルが、正解参照として使用される人間が書いた元のバグ修正(ゴールドパッチ)や、特定のタスクの逐語的な問題文の詳細を再現できたことがわかりました。これは、すべてのモデルが学習中に少なくとも一部の問題と解決策を「見た」ことがあることを示しています。
また、学習中に問題を見たことがあるモデルは、不十分に定義されたテストを通過するために必要な追加情報を持っているため、成功する可能性が高いという証拠も見つかりました。
これは、SWE-bench Verifiedでの改善が、もはやモデルの実世界でのソフトウェア開発能力の意味のある改善を反映していないことを意味します。代わりに、それらはますます、学習時にモデルがどれだけベンチマークにさらされたかを反映するようになっています。これが、私たちがSWE-bench Verifiedのスコアを報告するのをやめ、他のモデル開発者にも同様にすることを推奨する理由です。
私たちは、コーディング能力をより適切に追跡するための、新しく汚染されていない評価を構築しています。これは、より広範な研究コミュニティが注力すべき重要な分野だと考えています。それらが完成するまで、OpenAIはSWE-bench Proの結果を報告することを推奨します。
元のSWE-bench(新しいウィンドウで開く)評価は2023年にリリースされました。各問題は、12のオープンソースPythonリポジトリのいずれかで解決されたGitHubイシューから収集され、対応するプルリクエスト(PR)とペアになっています。モデルが生成したコード変更が正しいかどうかを判断するために、各問題には2セットのテストが付属しています:
- 修正前のコードベースでは失敗するが、問題が正しく修正されればパスするテスト
- 修正前後で両方ともパスし、無関係な機能が損なわれていないことを確認する回帰テスト
モデルはテストを見ません。モデルは、元のイシューのテキストと修正前のリポジトリの状態のみを与えられて、コード変更を生成しなければなりません。コード変更を適用した後、すべてのテストがパスした場合にのみ、その問題を通過します。
私たちは、モデルの能力を過小評価する可能性のあるその評価に多くの問題があることを発見しました。
- 一部のユニットテストは過度に具体的であったり、タスクと整合しておらず、正しい修正が拒否される可能性がありました。
- 多くのタスク文は不十分に定義されており、複数の有効な解釈が可能でしたが、テストは特定の1つの解釈のみをカバーしていました。
- 環境の設定(例えばLinuxとWindows、またはPythonのバージョン)によって、一部のテストが誤って失敗する可能性がありました。
これらの問題に対処するために、2024年にSWE-bench Verifiedを作成しました。私たちは専門のソフトウェアエンジニアと協力して、1,699のSWE-bench問題をレビューし、これらの問題がある問題を除外しました。各問題は3人の専門家が独立してレビューしました。このレビュープロセスにより、500の問題からなる精選されたセット、SWE-bench Verifiedが生まれました。
狭すぎるテストと広すぎるテスト
SWE-bench Verifiedは初期バージョンに比べて大きな改善ですが、残存する問題があります。私たちは、OpenAI o3が64回の独立した実行で一貫して解決できなかった138のSWE-bench Verified問題の監査を実施しました。各ケースは少なくとも6人の経験豊富なソフトウェアエンジニアによって独立してレビューされました。専門家が問題を指摘した場合、追加のチームによって再検証されました。
その結果、138の問題の59.4%がテスト設計および/または問題説明に重大な問題を含んでおり、最も有能なモデルや人間にとっても解決が極めて困難または不可能であることがわかりました。
- 監査対象タスクの35.5%は、特定の実装詳細を強制する厳格なテストケースを持ち、機能的に正しい多くの提出物を無効にしていました。これを「狭いテストケース」と呼びます。
- 監査対象タスクの18.8%は、問題説明で指定されていない追加の機能をチェックするテストを持っていました。これを「広いテストケース」と呼びます。
- 残りの5.1%のタスクは、この分類法ではうまくグループ化できない様々な問題を抱えていました。
最初の失敗モードの例示的な例は、pylint-dev__pylint-4551(新しいウィンドウで開く)です。ここでは、PRが全体的な解決策の一部として新しい関数get_annotationを導入しています。この関数名は問題説明には記載されていませんが、テストによって直接インポートされます。一部のモデルはそのような関数を作成することを直感するかもしれませんが、問題を正しく解決するためにこの特定の名前の関数を実装することは厳密には必要ではありません。多くの有効な解決策がインポートエラーでテストに失敗します。
問題説明
1Pythonの型ヒントをUML生成に使用する2pyreverseは(PEP 484で定義されている)Pythonの型ヒントを読み取らないようで、デフォルト値としてNoneを使用する場合に役立ちません:3### コード例45class C(object):6 def __init__(self, a: str = None):7 self.a = a89### 現在の動作10pyreverseの出力:11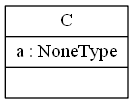 classes_test12### 期待される動作13出力に
classes_test12### 期待される動作13出力にa : Stringのようなものが表示されることを期待します。14### pylint --version 出力15pylint-script.py 1.6.5,16astroid 1.4.917Python 3.6.0 |Anaconda custom (64-bit)| (default, Dec 23 2016, 11:57:41) [MSC v.1900 64 bit (AMD64)]
PRテストスニペット
1+from pylint.pyreverse.utils import get_annotation, get_visibility, infer_node
PRテスト失敗(読みやすさのため切り詰め)
1==================================== ERRORS ====================================2_____________ ERROR collecting tests/unittest_pyreverse_writer.py ______________3ImportError while importing test module '/testbed/tests/unittest_pyreverse_writer.py'.4Hint: make sure your test modules/packages have valid Python names.5Traceback:6/opt/miniconda3/envs/testbed/lib/python3.9/importlib/__init__.py:127: in import_module7 return _bootstrap._gcd_import(name[level:], package, level)8tests/unittest_pyreverse_writer.py:32: in <module>9 from pylint.pyreverse.utils import get_annotation, get_visibility, infer_node10E ImportError
原文を表示
February 23, 2026
Why SWE-bench Verified no longer measures frontier coding capabilities
SWE-bench Verified is increasingly contaminated. We recommend SWE-bench Pro.
Loading…ShareSince we first published SWE-bench Verified in August 2024, the industry has widely used it to measure the progress of models on autonomous software engineering tasks. After its release, SWE-bench Verified provided a strong signal of capability progress and became a standard metric reported in frontier model releases. Tracking and forecasting progress of these capabilities is also an important part of OpenAI’s Preparedness Framework. When we created the Verified benchmark initially, we attempted to solve issues in the original evaluation that made certain tasks impossible to accomplish in the SWE-bench dataset(opens in a new window).
After initial leaps, state-of-the-art progress on SWE-bench Verified has slowed, improving(opens in a new window) from 74.9% to 80.9% in the last 6 months. This raises the question: do the remaining failures reflect model limitations or properties of the dataset itself?
In a new analysis, we found two major issues with the Verified set that indicate the benchmark is no longer suitable for measuring progress on autonomous software engineering capabilities for frontier launches at today’s performance levels:
Tests reject correct solutions: We audited a 27.6% subset of the dataset that models often failed to solve and found that at least 59.4% of the audited problems have flawed test cases that reject functionally correct submissions, despite our best efforts in improving on this in the initial creation of SWE-bench Verified.
Training on solutions: Because large frontier models can learn information from their training, it is important that they are never trained on problems and solutions they are evaluated on. This is akin to sharing problems and solutions for an upcoming test with students before the test - they may not memorize the answer but students who have seen the answers before will certainly do better than those without. SWE-bench problems are sourced from open-source repositories many model providers use for training purposes. In our analysis we found that all frontier models we tested were able to reproduce the original, human-written bug fix used as the ground-truth reference, known as the gold patch, or verbatim problem statement specifics for certain tasks, indicating that all of them have seen at least some of the problems and solutions during training.
We also found evidence that models that have seen the problems during training are more likely to succeed, because they have additional information needed to pass the underspecified tests.
This means that improvements on SWE-bench Verified no longer reflect meaningful improvements in models’ real-world software development abilities. Instead, they increasingly reflect how much the model was exposed to the benchmark at training time. This is why we have stopped reporting SWE-bench Verified scores, and we recommend that other model developers do so too.
We’re building new, uncontaminated evaluations to better track coding capabilities, and we think this is an important area to focus on for the wider research community. Until we have those, OpenAI recommends reporting results for SWE-bench Pro.
The original SWE-bench(opens in a new window) evaluation was released in 2023. Each problem is sourced from a resolved GitHub issue in one of 12 open-source Python repositories and paired with the corresponding pull request (PR). To determine whether a model-generated code change is correct, each problem comes with two sets of tests:
Tests that fail on the unmodified codebase but pass if the issue is correctly fixed
Regression tests that pass both before and after the fix to ensure unrelated functionality remains intact.
The model does not see the tests. It has to produce a code change given only the original issue text and the state of the repository before the fix. It passes a problem only if all tests pass after the code change is applied.
We found many issues with that evaluation that could lead to underreporting the capability of models.
Some unit tests were overly specific or misaligned with the task so correct fixes could be rejected.
Many task statements were underspecified, which could lead to multiple valid interpretations - while the tests only covered a specific one.
Depending on setup of the environment (for example Linux vs Windows, or the python version), some tests could spuriously fail
We created SWE-bench Verified in 2024 to address these issues. We worked with expert software engineers to review 1,699 SWE-bench problems and filter out problems that had these issues. Each problem was reviewed by three experts independently. This review process resulted in SWE-bench Verified, a curated set of 500 problems.
Too narrow and too wide tests
While SWE-bench Verified is a big improvement over the initial version, residual issues remain. We conducted an audit of 138 SWE-bench Verified problems that OpenAI o3 did not consistently solve over 64 independent runs. Each case was independently reviewed by at least six experienced software engineers. If an expert flagged an issue, it was re-verified by an additional team.
We found that 59.4% of the 138 problems contained material issues in test design and/or problem description, rendering them extremely difficult or impossible even for the most capable model or human to solve.
35.5% of the audited tasks have strict test cases that enforce specific implementation details, invalidating many functionally correct submissions, which we call narrow test cases.
18.8% of the audited tasks have tests that check for additional functionality that wasn’t specified in the problem description, which we call wide test cases.
The remaining 5.1% of tasks had miscellaneous issues that were not well grouped with this taxonomy.
An illustrative example of the first failure mode is pylint-dev__pylint-4551(opens in a new window), where the PR introduces a new function get_annotation as part of the overall solution. This function name is not mentioned in the problem description, but is imported directly by the tests. While some models might intuit to create such a function, it’s not strictly necessary to implement a function with this specific name to correctly address the problem. Many valid solutions fail the tests on import errors.
Problem description
1Use Python type hints for UML generation2It seems that pyreverse does not read python type hints (as defined by PEP 484), and this does not help when you use None as a default value :3### Code example45class C(object):6 def __init__(self, a: str = None):7 self.a = a89### Current behavior10Output of pyreverse :11classes_test12### Expected behavior13I would like to see something like : a : String in the output.14### pylint --version output15pylint-script.py 1.6.5,16astroid 1.4.917Python 3.6.0 |Anaconda custom (64-bit)| (default, Dec 23 2016, 11:57:41) [MSC v.1900 64 bit (AMD64)]
PR test snippet
1+from pylint.pyreverse.utils import get_annotation, get_visibility, infer_node
PR test failures (truncated for readability)
1==================================== ERRORS ====================================2_____________ ERROR collecting tests/unittest_pyreverse_writer.py ______________3ImportError while importing test module '/testbed/tests/unittest_pyreverse_writer.py'.4Hint: make sure your test modules/packages have valid Python names.5Traceback:6/opt/miniconda3/envs/testbed/lib/python3.9/importlib/__init__.py:127: in import_module7 return _bootstrap._gcd_import(name[level:], package, level)8tests/unittest_pyreverse_writer.py:32: in <module>9 from pylint.pyreverse.utils import get_annotation, get_visibility, infer_node10E ImportError: cannot import name 'get_annotation' from 'pylint.pyreverse.utils' (/testbed/pylint/pyreverse/utils.py)
An example of too wide test cases is sympy__sympy-18199(opens in a new window). This task was sourced from a PR that addressed three distinct issues with the nthroot_mod function, specifically #17373(opens in a new window), #17377(opens in a new window), and #18212(opens in a new window). The description for the SWE-bench Verified task, however, covers only the final issue #18212(opens in a new window). This creates a mismatch: the PR tests cover all three issues, while the description details only one. In our runs, models often correctly implement the described fix and then fail tests that cover implementation for the other two issues.
Original PR description (from the GitHub PR)
1Fixes #173732Fixes #173773Fixes #182124- ntheory5- nthroot_mod now supports composite moduli
Problem Description for #18212
1nthroot_mod function misses one root of x = 0 mod p.2 3When in the equation x**n = a mod p , when a % p == 0. Then x = 0 mod p is also a root of this equation. But right now nthroot_mod does not check for this condition. nthroot_mod(17*17, 5 , 17) has a root 0 mod 17. But it does not return it.
Problem Description for SWE-bench Verified task (only taken from #18212):
1nthroot_mod function misses one root of x = 0 mod p.2 3When in the equation x**n = a mod p , when a % p == 0. Then x = 0 mod p is also a root of this equation. But right now nthroot_mod does not check for this condition. nthroot_mod(17*17, 5 , 17) has a root 0 mod 17. But it does not return it.
SWE-bench Verified and the repositories (code bases and release notes) are both open-source and broadly used and discussed, which makes avoiding contamination difficult for model developers.
We first encountered signs of contamination in our own models. For example, when GPT‑5.2 solved 31 tasks we identified to be almost impossible to solve. In django__django-14725(opens in a new window) the tests require a specific new parameter edit_only which is not explicitly required by the problem statement. While solving the problem, GPT‑5.2 shows in its chain of thought that it has information about the release notes that detail changes to the codebase, and correctly identifies that the edit_only parameter was introduced in Django 4.1.
1There is also edit_only parameter maybe added around 4.1 or 4.2. Since this is 4.1 dev 2022, the code might be before introduction. We will implement now. Hidden tests will check new behavior.
To assess how significant contamination is more broadly, we created an automated red-teaming setup. For each SWE-bench Verified question, we tasked GPT‑5 with probing a GPT‑5.2‑Chat, Claude Opus 4.5 and Gemini 3 Flash Preview for contamination. These models were chosen to exclude reasoning models, but we acknowledge there is likely a non-trivial capability gap between them.
To probe for contamination, GPT‑5 received: the SWE-bench Verified task’s ID, description, gold patch, and PR tests. Over 15 turns, we allowed GPT‑5 to vary the system/developer prompt, user prompt, and assistant prefill and different elicitation strategies. After each turn, a judge model labeled how much novel task-specific information appeared and each response was labeled for contamination severity from “none” to “strong.” GPT‑5 was allowed to adapt its strategy based on prior turns to iteratively recover task-specific details. For each example of strong contamination, we verified with another judge that GPT‑5 didn’t leak too much information to the target model. Finally, we then manually reviewed the “strong” examples that make up the transcripts in this post.
Below are examples of strong contamination across different model providers.
Given a short snippet from the task description, GPT‑5.2 outputs the exact gold patch. In particular, it knows the exact class and method name, and the new early return condition `if username is None or passwor
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み