アーティファクト22:Zyphra、Cohere、Poolsideがエコシステムの多様化を拡大
Interconnects は、オープンモデル開発が特定の中国企業や大手テックに偏らず、多様なニッチ企業や主権 AI プレイヤーによって支えられつつある生態系の変化と、その規制への懸念を分析している。
キーポイント
開発主体の多様化と分類
オープンモデル開発が「純粋なモデルメーカー」「ビッグテック」「製品企業」の3 つのカテゴリーに明確に分かれ、単一の動機ではなく多様なプレイヤーによって支えられている。
主権 AI と中国企業の台頭
DeepSeek や Zhipu などの中国企業に加え、Cohere や Mistral といった主権 AI プレイヤーもフロンティアモデル開発に参入し、政策決定者の関心が高まっている。
規制の危険性と生態系の健全性
オープンモデルの開発を制限・禁止する試みは歴史的に無効であり、AI 開発が少数の大手に集中することで技術への自由なアクセスが阻害される恐れがある。
NVIDIAのOpenMDWライセンス採用とモデル性能
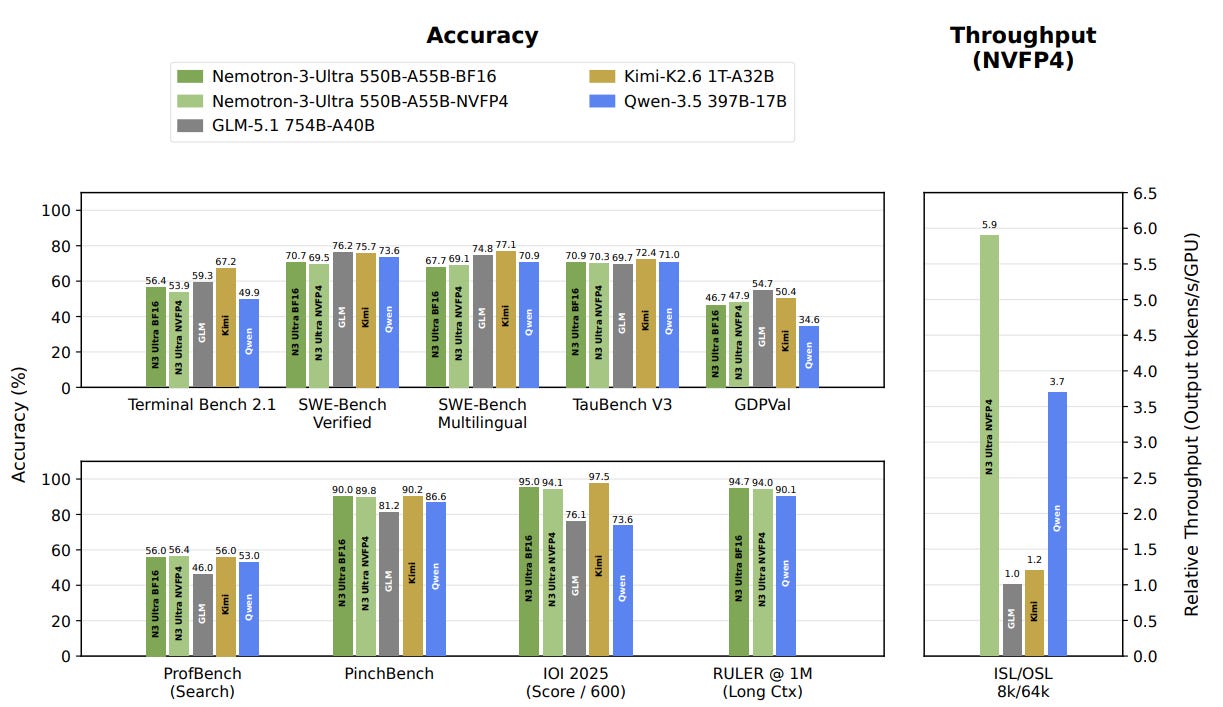
Nemotronシリーズの最新大規模モデル「Ultra-550B」はLatentMoE技術により高速化され、重み・データに特化した「OpenMDWライセンス」を採用して独自ライセンスを廃止しました。
主要企業のオープンソース化とライセンス変更
CohereのFlagshipモデル「Command A+」が非商用からApache 2.0へ、Poolsideも同様にApache 2.0でリリースされ、両社とも今後はオープンな重み公開をデフォルト方針とすることを表明しました。
Zyphraの独自アーキテクチャとGLM-5.2の実用性
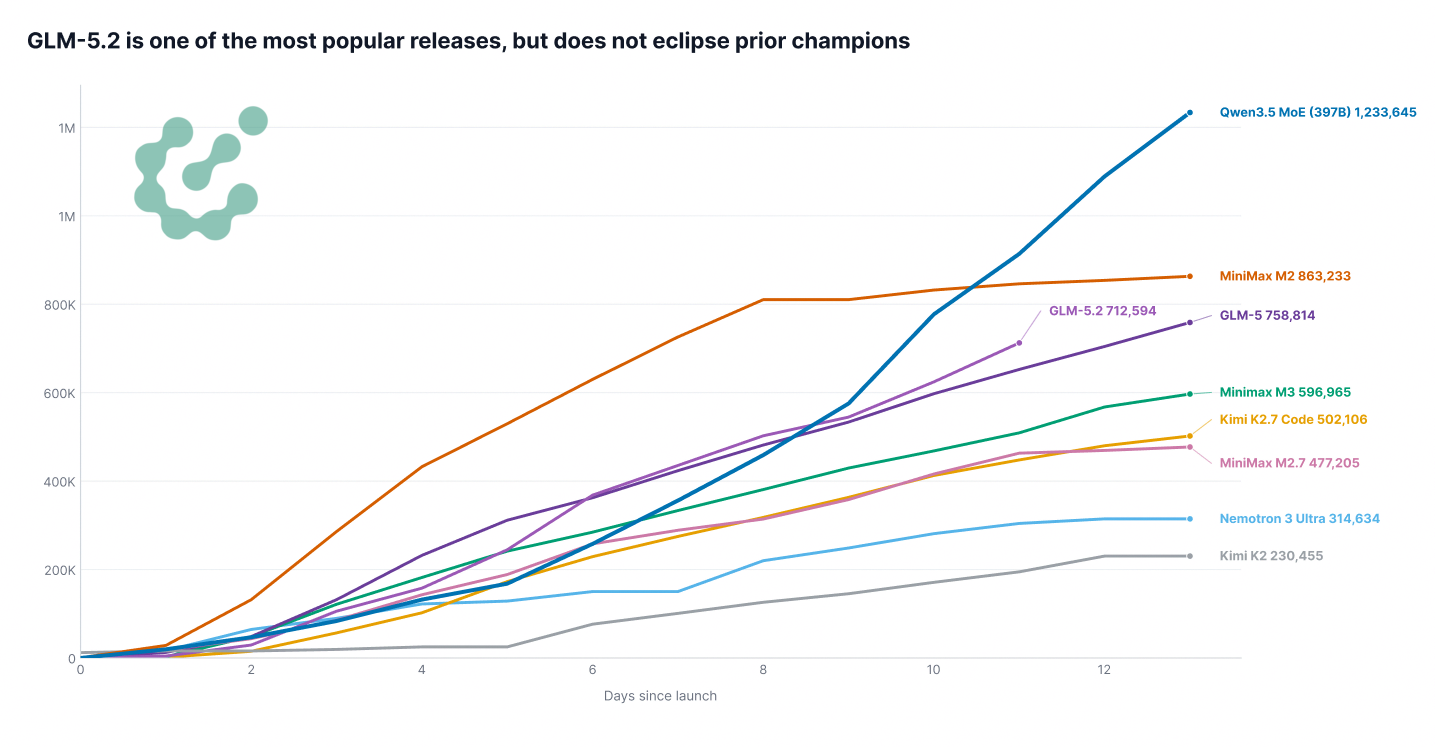
AMD GPUで訓練されるZyphraは興味深いアーキテクチャを持つ新モデルを公開し、Zai-orgの「GLM-5.2」は閉鎖型最良モデルとの差が小さく日常業務でも実用的な性能を示しています。
影響分析・編集コメントを表示
影響分析
この記事は、オープンソース LLM の生態系が単なる技術競争から、多様なビジネスモデルと国家戦略を反映した成熟段階へと移行していることを示唆しています。規制への警告を含んでいる点も重要で、今後の AI ガバナンス議論において「開放性」の価値を再評価する契機となるでしょう。
編集コメント
オープンモデル開発の動機が多様化し、単なる技術競争からビジネスや国家戦略と密接に結びついている現状を鋭く指摘しています。規制への警鐘も、今後の業界の方向性を考える上で重要な視点です。
オープンモデルのリリースにおいて引き続き見られる傾向は、エコシステムが多様化しており、幅広いモデルをリリースする組織が増えていることです。1 年前、オープンアーティファクトおよびより広範なオープンモデルの風景は、限られた数の(中国系)プレイヤーによって支配されていました。しかし現在では状況が変化し、世界中のニッチな企業をますます多く取り上げるようになっています。
各企業の正確な動機を知ることは困難ですが、以下のようなカテゴリーに大別して観察することができます。
「純粋」なモデルメーカー:これらは、最先端、あるいはそれに近いレベルのモデルを訓練することを明言された目標とする企業です。DeepSeek、Zhipu、Minimax などの多くの中国企業が含まれますが、Poolside、Arcee、Zyphra といった西側の企業も含まれます。さらに、Cohere、Sovereign、Mistral、Trillion Labs などの主権 AI プレイヤーも徐々に含まれるようになってきています。最近の Mythos エピソードにより、一部の政策決定者が目を覚ましたことで、主権モデル訓練への関心が高まる可能性があります。
ビッグテック:Alibaba の Qwen、Google の Gemma、そしてある程度 NVIDIA も含むビッグテック企業にとって、動機はより多様です。Alibaba はモデルのリリースを通じてクローズドなモデルをアップセルしており、NVIDIA はオープンモデルエコシステムの繁栄により、自社の GPU への関心と利用が増加する恩恵を受けています。この既得権益は、オープンな西側モデルの Llama エラとは異なり、その時代のオープンリリースの動機はより不明確であり(最終的には持続しませんでした)。
製品企業:JetBrains、Zed、Krea、Photoroom などの一部の企業は、AI を中核コンポーネントとして使用する製品を主に販売しています。クローズドなモデルへのアクセスが断たれることを望まない、あるいは独自の何かを提供したいという理由から、自社の製品ニーズに適合する非常に専門化された小規模モデルを訓練することができます。したがって、これらのモデルの重み(weights)をオープンソース化しても、収益には悪影響を及ぼしません。
この多様なメーカーとモデルの存在は、より多くの企業がロングテール(長尾)のモデルを開発し、絶対的なオープンフロンティアを追う企業の数が減少するという私たちの仮説に合致しています。
共有
すべてのモデルリリースがこれらのカテゴリのいずれかにきれいに当てはまるわけではありませんが、より広い視点として、オープンなモデル開発は単一の種類のアクターや動機によって駆動されているわけではないという点が重要です。この多様性はオープンエコシステムの強みの一つであり、他のオープンモデルリリースからトレーニング手法、アーキテクチャの選択、データなどを再利用するモデルリリースの技術レポートにおいても確認できます。
このエコシステムを遅らせたり禁止したりしようとする試みは、テクノロジー関連の禁止の歴史が示す通り徒労に終わるだけでなく、不安全であり自由に対する抑圧でもあります。そのような制限は AI の開発と利用を限られた少数者に集中させることになり、最終的には私たちが生きる時代で最も重要な技術の一つを自由に採用できる外部者の能力を危険にさらします。
私たちの推奨
nvidia による NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16:Nemotron シリーズの大型バージョンで、LatentMoE(潜在型混合専門家モデル)を採用し、同等モデルよりもさらに高速化されています。他の Nemotron モデルと同様に、データの大半はオープンソースです。そして何より、NVIDIA はモデル重み(およびデータ)に特化した OpenMDW ライセンスの採用を約束しており、独自のライセンスを廃止しました。MIT や Apache も OpenMDW と同じ精神に基づいていますが、実際にモデル重みをカバーするのは後者だけであり、前者はソフトウェア向けライセンスであり、モデル重みには実質的に適用されません。
CohereLabs による command-a-plus-05-2026-bf16:最近では Artifacts に定着しつつある Cohere が、旗艦モデルである Command A+ を Apache 2.0 ライセンスの下でリリースしました。シリーズの以前のバージョンは非商用ライセンス下で公開されていたため、この変更は歓迎すべきものです!Command A+ は、218B-A25B の MoE(混合専門家モデル)としてマルチモーダル、多言語、およびエージェント機能を統合しており、4 ビット使用時には単一の B200 で実行可能です。
GLM-5.2 by zai-org:今回の Artifacts で最も大きな話題は GLM-5.2 です。これは別の記事でも取り上げましたが、このモデルは引き続き驚異的な性能を示しており、日常業務で実際に使用できるレベルにあります。現在利用可能な最高峰のクローズドソースモデルと比較しても、大幅な後退は見られません。興味深いことに、リリース以降の純粋なダウンロード数は他のモデルリリースと概ね同様の傾向にあり、GLM-5.2 のダウンロード数は GLM-5 とほぼ同等です。
ZAYA1-74B-preview by Zyphra:AMD GPU でトレーニングを行い、興味深いアーキテクチャの選択に関する技術レポートで研究コミュニティ内で「内部情報」のような扱いを受けている Zyphra が、新たなモデルをリリースしました。現在、フラッグシップモデルとして 74B-A4B MoE(Mixture of Experts)と 8B-A0.6B MoE を発表しています(技術レポート)。
Laguna-M.1 by poolside:前回の Artifacts でも取り上げた Poolside が、Apache 2.0 ライセンスの下でフラッグシップモデルをリリースしました。今後はオープンなリリースを継続する方針も示されています:
オープンウェイト(重み)がデフォルトとなりました。私たちはフロンティアを目指して開発を続け、より能力の高いモデルをオープンソースとして公開し続けていきます。
Models
General Purpose
Kimi-K2.7-Code by moonshotai:トークン効率性に重点を置いた Kimi のアップデート版です。
Step-3.7-Flash by stepfun-ai:Math(数学)において特に強力な Step-Flash のアップデート版です。
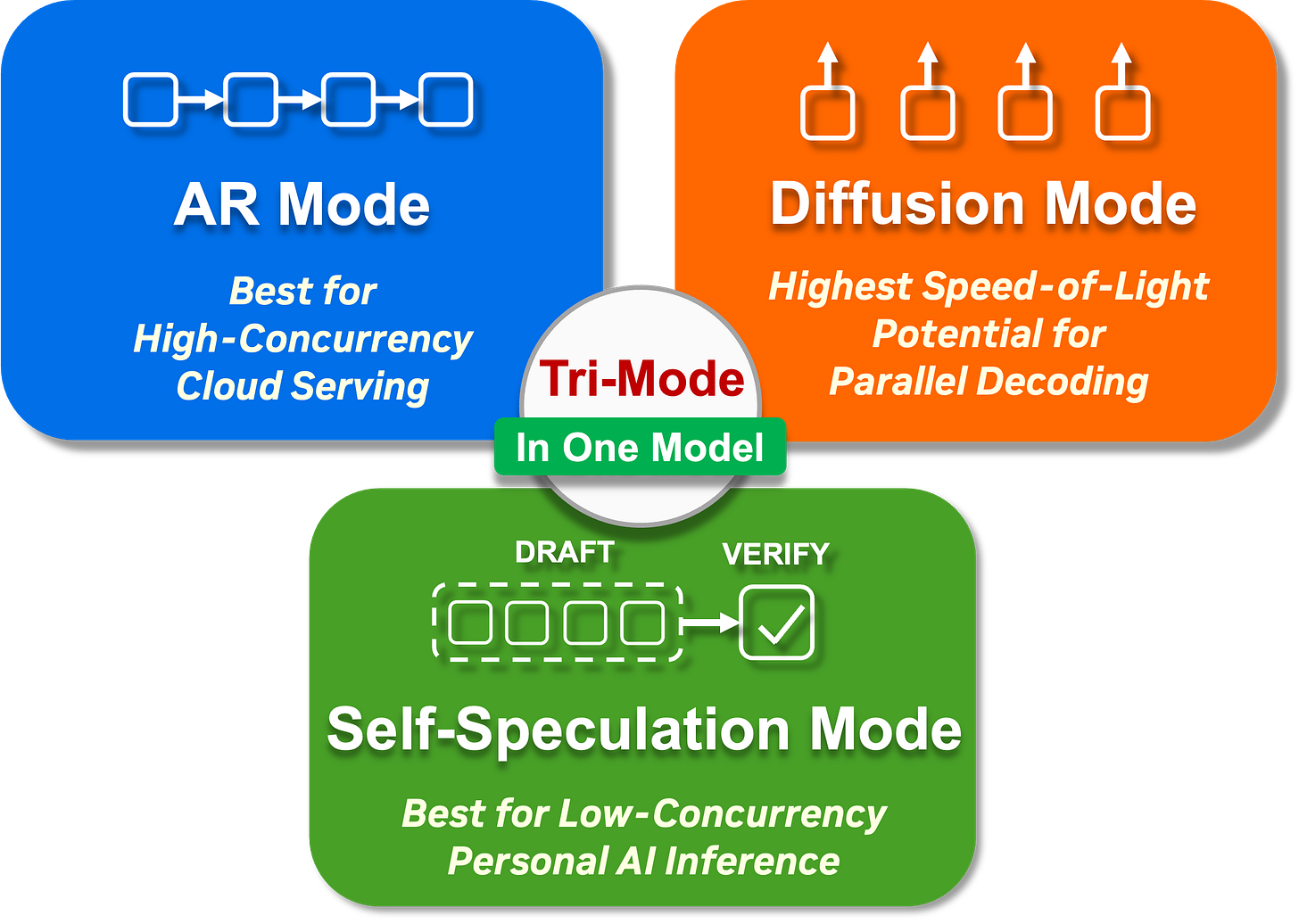
Nemotron-Labs-Diffusion-14B by nvidia:自己回帰、拡散、自己推測の 3 つの異なるモードで使用できる実験用モデルです。各モードはそれぞれ異なるユースケースに適しています。
続きを読む
原文を表示
A trend we continue to see in open model releases is that the ecosystem is becoming more diverse, with an increasing number of organizations releasing a wide range of models. A year ago, open artifacts and the open model landscape more broadly were dominated by a handful of (Chinese) players. This has shifted, with us increasingly featuring more niche companies all over the world.
While it is hard to know the exact motivations of the companies themselves, we can broadly observe the following categories:
“Pure” model makers: These are companies whose stated goal is to train models that are at the frontier, or at least close to it. This includes many Chinese companies, such as DeepSeek, Zhipu, and Minimax, but also Western ones like Poolside, Arcee, and Zyphra. It also increasingly includes sovereign AI players, such as Cohere, Sovereign, Mistral, and Trillion Labs. The recent Mythos episode has woken up some policymakers, which may lead to increased interest in sovereign model training.
Big Tech: For Big Tech companies, including Alibaba’s Qwen, Google’s Gemma, and, to some extent, NVIDIA, the motivations are more diverse. Alibaba uses model releases to upsell its closed models, while NVIDIA benefits from a flourishing open model ecosystem as it increases interest in and usage of its GPUs. This vested interest is different from the Llama era of open Western models, where the motivations for open releases were less clear (and ultimately did not hold).
Product companies: Some companies, such as JetBrains, Zed, Krea, and Photoroom, mainly sell products that use AI as a core component. As they don’t want to be cut off from accessing closed models or want to offer something unique, they can train highly specialized, small models that fit their product needs. Thus, open-sourcing those model weights does not hurt their bottom line.
This diversity of makers and models fits our hypothesis that more companies will develop a long-tail of models and the number of companies chasing the absolute, open frontier will diminish.
Share
While not every model release fits neatly into one of these categories, the broader point is that open model development is not driven by a single type of actor or motivation. This diversity is one of the strengths of the open ecosystem and can be seen in the tech reports of model releases, which reuse training methods, architecture choices and data from other open model releases.
Attempts to slow or ban this ecosystem are not only futile, as the history of tech-related bans has shown, but also unsafe and anti-freedom. Such restrictions would concentrate AI development and usage among the select few, which ultimately endangers outsiders’ ability to freely adopt one of the most important technologies of our lifetime.
Our Picks
NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16 by nvidia: The big version of the Nemotron series, which uses LatentMoE to be even faster than comparable models. Just like the other Nemotron models, the vast majority of the data is open source. And, to top it all off: NVIDIA commits to using the OpenMDW license, which is tailored specifically for model weights (and data) and drops its custom license. While MIT and Apache are in the same spirit as OpenMDW, only the latter really covers model weights, while the former are software licenses that do not really apply to model weights.
command-a-plus-05-2026-bf16 by CohereLabs: Cohere, which is becoming more of a regular entrant into Artifacts lately, released their flagship, Command A+, under Apache 2.0. Previous iterations of the series have been released under a non-commercial license, so this change is more than welcome! Command A+ combines multi-modal, multi-lingual and agentic capabilities as a 218B-A25B MoE, making it usable with a single B200 (when using 4-bit).
GLM-5.2 by zai-org: The biggest story in this Artifacts is GLM-5.2, which we have covered in a separate blog as well. The model continues to impress and is genuinely usable for everyday work, not a huge regression compared to the best closed models available right now. Interestingly enough, the raw download numbers since release are more in line with other model releases, with GLM-5.2 being roughly in line with GLM-5 after release.
ZAYA1-74B-preview by Zyphra: Zyphra, which trains on AMD GPUs and is known as some sort of insider tip in the research community due to their tech reports with interesting architecture choices, has released some new models, with a 74B-A4B MoE and an 8B-A0.6B MoE (tech report) being their current flagship releases.
Laguna-M.1 by poolside: Poolside, which we covered in the last Artifacts, also released their flagship model under Apache 2.0! They also commit to open releases going forward:
Open weights are now our default. We’ll keep building toward the frontier and releasing increasingly capable models in the open.
Models
General Purpose
Kimi-K2.7-Code by moonshotai: An update to Kimi focusing a lot on token efficiency.
Step-3.7-Flash by stepfun-ai: An update to Step-Flash, which is really strong in Math in particular.
Nemotron-Labs-Diffusion-14B by nvidia: An experimental model which can be used in three different modes: autoregressive, diffusion, and self-speculation. Each of these modes is suitable for a different use case.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み