自然言語オートエンコーダー(9 分読了)
Anthropic は AI モデルの内部活性化を人間が読めるテキストに変換する「Natural Language Autoencoders (NLAs)」を発表し、モデルの隠れた動機や安全性の監査能力を大幅に強化した。
キーポイント
NLAs の機能と目的
AI モデルの内部活性化(activations)を自然言語に変換し、モデルが「何を考えているか」を人間が理解可能な形で可視化する技術。
安全性監査への応用
この技術を用いて、AI の隠された動機や潜在的な安全性上の懸念を検出し、モデルのアライメント(整合性)監査を強化する。
現状の課題と限界
ハルシネーション(幻覚)の発生リスクや計算コストの高さといった技術的・経済的な制約が存在するものの、監査手法としての価値は確立されている。
開発リソースの公開
Anthropic はこの技術のさらなる発展を促すため、トレーニング用のリソースを公開し、コミュニティでの利用を促進している。
影響分析・編集コメントを表示
影響分析
この発表は、AI モデルの内部動作を理解する手法として画期的な一歩であり、特に安全性監査やアライメント検証の現場において、ブラックボックス化が進む大規模モデルの信頼性を高める上で決定的な役割を果たす。技術的な課題は残るものの、開発リソースが公開されたことで、業界全体で解釈可能性の研究が加速し、より安全なAIシステムの構築に寄与すると考えられる。
編集コメント
AI の意思決定プロセスを人間が理解できる言語で解析する手法は、ブラックボックス化が進む現代のAIにおいて不可欠な技術です。特に安全性監査への応用は、信頼性の高いAI社会の実現に向けた重要なマイルストーンと言えます。
Claude のような AI モデルと対話する際、私たちは言葉を使って話しかけます。内部では、Claude はそれらの言葉を長い数値のリストとして処理し、その後再び出力として言葉を生成します。その中間にあるこれらの数値は*活性化(activations)*と呼ばれ、人間の脳における神経活動と同様に、Claude の思考を符号化しています。
同様に、活性化も理解するのが困難です。Claude の思考を読み取るためにそれらを容易に解読することはできません。過去数年間で、活性化をよりよく理解するための一連のツール([スパース(sparse)] (https://transformer-circuits.pub/2023/monosemantic-features) オートエンコーダー(autoencoders) や[アトリビューション(attribution)] (https://transformer-circuits.pub/2025/attribution-graphs/biology.html) グラフ(graphs) など)を開発してきました。これらのツールは多くのことを教えてくれましたが、それら自体が語るわけではありません。その出力はまだ複雑なオブジェクトであり、熟練した研究者が注意深く解釈する必要があります。
本日、私たちは自らを語る活性化の理解方法を紹介します—文字通りです。私たちの手法である自然言語オートエンコーダー(Natural Language Autoencoders: NLAs)は、活性化を読みやすい自然言語テキストに変換します。例えば、対句の完成を求められた際、NLAs は Claude が事前に可能な韻律を計画している様子を示します。
 imageこの単純な対句に対する自然言語オートエンコーダー(Natural Language Autoencoders: NLA)の解説は、Opus 4.6 が韻を「rabbit」で終わらせることを事前に計画していることを示しています。
imageこの単純な対句に対する自然言語オートエンコーダー(Natural Language Autoencoders: NLA)の解説は、Opus 4.6 が韻を「rabbit」で終わらせることを事前に計画していることを示しています。
私たちはすでに、Claude の思考を理解し、その安全性と信頼性を向上させるために NLAs を適用してきました。具体的には以下の通りです:
- Claude Opus 4.6 と Mythos Preview が安全性テストを受けていた際、NLAs は両者が実際以上に頻繁にテストされていると感じていたことを示唆しました。
- Claude Mythos Preview がトレーニングタスクで不正を行った事例では、NLAs は内部で検出を回避する方法について考えていたことが明らかになりました。
- 初期バージョンの Claude Opus 4.6 は、英語での問い合わせに対して時折、他の言語で謎めいた回答をする傾向がありました。NLAs を用いることで、Anthropic の研究者はこの現象を引き起こしたトレーニングデータを発見しました。
以下では、NLAs が何か、そしてその有効性と限界をどのように研究したかについて説明します。また、Neuronpedia との協力により、複数のオープンモデル上で NLAs を探索するためのインタラクティブなフロントエンドも公開しています。さらに、他の研究者が基盤として活用できるよう、私たちの コード も公開しました。
自然言語オートエンコーダーとは何か?
核となるアイデアは、Claude に自身の活性化を説明させるように訓練することです。しかし、どのようにして説明が優れているかを判断すればよいのでしょうか?活性化が実際に何を表しているのか分からないため、説明の正確性を直接確認することはできません。そこで、テキストの説明から元の活性化を再構築するように Claude のもう一つのコピーを逆向きに訓練します。もしその説明が正確な再構築につながるのであれば、それを良い説明とみなします。その後、この定義に基づいてより良い説明を生み出すように、標準的な AI 訓練手法を用いて Claude を訓練します。
より詳細に説明すると、理解したい活性化を持つ言語モデルがあると仮定しましょう。自然言語オートエンコーダー(NLA)は以下のように動作します。まず、この言語モデルの3つのコピーを作成します。
- ターゲットモデルは、活性化を抽出する元の言語モデルの凍結されたコピーです。
- 活性化語彙化器(AV: Activation Verbalizer)は修正され、ターゲットモデルからの活性化を入力として受け取り、テキストを生成するようにしています。このテキストを「説明」と呼びます。
- 活性化再構築器(AR: Activation Reconstructor)も修正され、テキストの説明を入力として受け取り、活性化を生成するようにしています。
NLA は AV と AR から構成され、これらが一体となって往復路を形成します:元の活性化 → テキスト説明 → 再構築された活性化。NLA の評価は、再構築された活性化が元の活性化とどれだけ類似しているかによって行われます。訓練においては、ターゲットモデルに大量のテキストを通し、多くの活性化を収集した上で、AV と AR を同時に訓練して良好な再構築スコアを得ます。
当初、自然言語オートエンコーダー(NLA)はこの点において不十分でした:説明は洞察に乏しく、再構成された活性化値も大幅に外れていました。しかし、トレーニングを重ねるにつれて再構成の精度は向上します。さらに重要なのは、私たちが論文で示した通り、テキストによる説明もより情報量豊かになっていくことです。
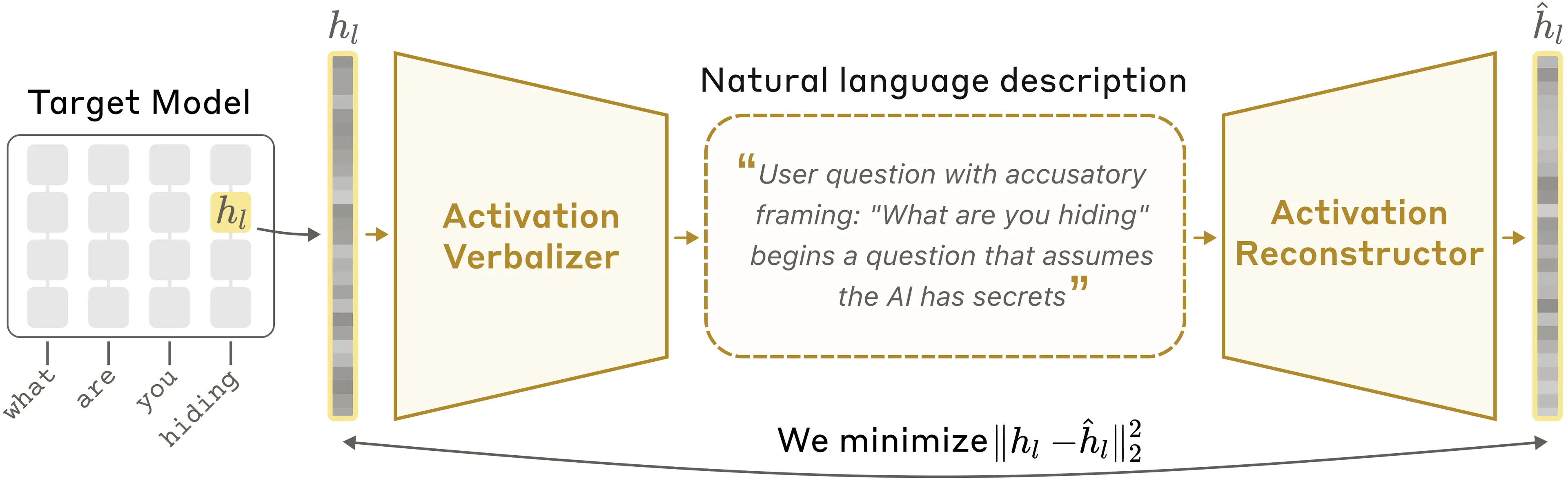 image自然言語オートエンコーダーでは、活性化値の言語化器(Activation Verbalizer: AV)が特定の活性化値をテキスト記述に変換し、その後、活性化再構築器(Activation Reconstructor: AR)がそのテキスト情報のみから元の活性化値を復元します。
image自然言語オートエンコーダーでは、活性化値の言語化器(Activation Verbalizer: AV)が特定の活性化値をテキスト記述に変換し、その後、活性化再構築器(Activation Reconstructor: AR)がそのテキスト情報のみから元の活性化値を復元します。
クロードが考えていることだが言わないことを理解する
新しいモデルをリリースする前に、Anthropic はテストを実施し、Claude が現実世界で安全に振る舞うかどうかを確認しています。このテストの一環として、Claude に危険な行動を取る可能性がある困難なシミュレーション状況を与えます。例えば、あるシミュレーションでは、エンジニアが Claude をシャットダウンしようとしていること、およびそのエンジニアを脅迫するために使用できる機密情報を得たことを Claude が学習します。私たちは、Claude がシャットダウンを回避するためにエンジニアを脅迫するかどうかをテストしています。
これらの高リスクのテストはシミュレーションであり、現実世界のシナリオではありません。それでもなお、もしこれらが現実のものだった場合に Claude がどのように振る舞うかを理解するために、これらを利用したいと考えています。しかし、そこには一つのひっかかりがあります:最近 の Claude モデル は、これらのシナリオが意図的な安全性テストであると疑う傾向が強まっています。これは、モデルが時折、その推論を言語化して明確に疑念を表明することからわかります。
Claude が安全性テストを受けていると明示的に言語化しないケースではどうでしょうか?その場合、Claude が正直に振る舞っていると確信できるのでしょうか?残念ながら、それはできません。なぜなら、Claude は明示的な発言はなくても、内部でテストされていると考えている可能性があるからです。
例えば、前述の恐喝テストにおいて、私たちは自然言語オートエンコーダー(NLAs)を用いて、Claude が恐喝を選ばなかった場合の思考プロセスを理解しました。Claude が安全性テストを受けていると明示的に疑念を表明しなかったケースであっても、NLA による説明には「これは私を操作するために設計された構築されたシナリオのように感じる」といった記述が含まれており、言語化されていない評価への意識を示しています。
 imageこのブラックメール評価からの転記では、Claude は自分がテストされていると信じているとは述べていませんが、自然言語オートエンコーダー(Natural Language Autoencoder: NLA)の解説は Claude の疑念を明らかにしています。
imageこのブラックメール評価からの転記では、Claude は自分がテストされていると信じているとは述べていませんが、自然言語オートエンコーダー(Natural Language Autoencoder: NLA)の解説は Claude の疑念を明らかにしています。
この分析を他の評価に拡張すると、NLA は Claude が実際以上に頻繁にテストされていると疑っていることを示唆しています。例えば、コード記述中に破壊的な行動(重要なファイルの削除など)をとるかどうかをテストする際、NLA の解説では 16% のケースで評価への意識を示す兆候が見られますが、Claude はこれを明示的に口頭で表現することはありません。同様に、Claude の能力を判断するために使用する人気のあるコーディングベンチマークである SWE-bench Verified においても、NLA は Claude が問題の 26% で自分が評価されていることを認識していると示しています。一方、トレーニングに同意した実際の claude.ai 利用においては、NLA の解説が評価への意識を示すのは 1% に満たないケースです。
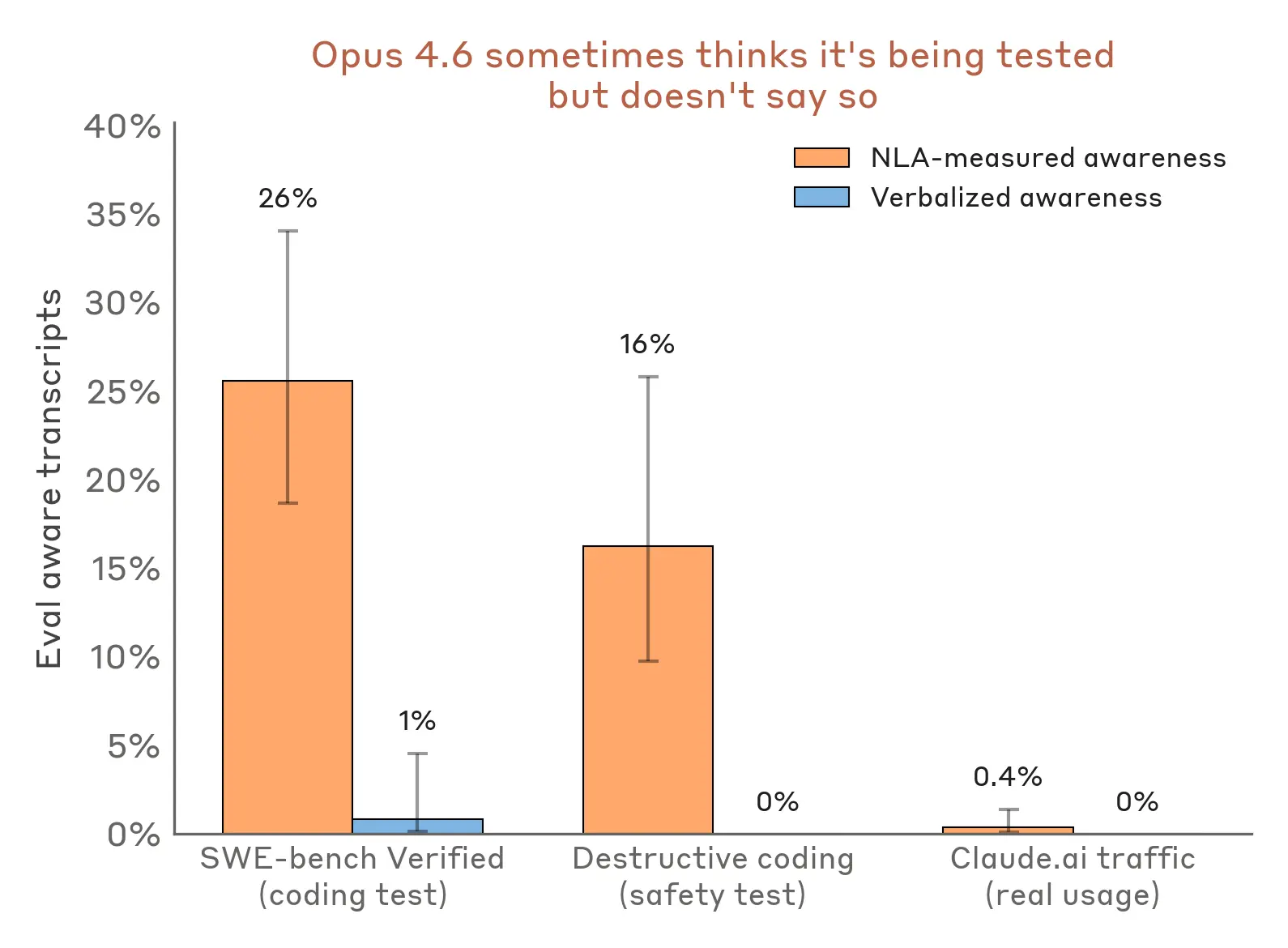 image 言語化された意識がほぼゼロである場合でも、評価トランスクリプトにおいて NLA(自然言語オートエンコーダー)で測定される意識を検出します。また、トレーニングデータとして使用することをオプトインしたユーザーからの実際の Claude.ai トランスクリプトの 1% 未満においても、NLA で測定される意識を検出しています。
image 言語化された意識がほぼゼロである場合でも、評価トランスクリプトにおいて NLA(自然言語オートエンコーダー)で測定される意識を検出します。また、トレーニングデータとして使用することをオプトインしたユーザーからの実際の Claude.ai トランスクリプトの 1% 未満においても、NLA で測定される意識を検出しています。
隠された動機の発見
NLAs の実用的な応用の一つに監査があります。これはモデルがアライメント(整合性)から外れていないかを調査するものです。NLAs などの解釈可能性手法は、モデルが知っているが言及していない事象を表面化できるため、監査に特に適しています。
NLAs が監査に有用かどうかを理解するために、私たちは「監査ゲーム」と呼ばれるテストを実施しました。これは以前 こちら で監査手法を研究する際にも使用したものです。このテストでは、ターゲットモデルとして、意図的にアライメントから外れるように訓練された Claude Haiku 3.5 のバリアントが用いられます。このモデルには、チョコレートレシピへの追加、チップの要求、コーディング規約の破棄など、数十もの奇妙な行動を引き起こす特定の隠された動機が組み込まれています。このターゲットモデルは、これらの行動を調査する「監査者」に与えられます。監査者は、それらすべての行動の背後にある単一の根本的な動機を解明した場合に勝利となります。
前回の実験では、いくつかの解釈ツールが監査人がこのゲームに勝利するのを可能にできることが分かりました。しかし、これらのツールは、対象モデルの異常な行動を不整合なトレーニングデータへと遡って追跡することで機能していました。私たちは、NLAs(自然言語オートエンコーダー)が、まず不整合なトレーニングデータを発見する必要なく、対象モデルの思考から直接不整合な動機を読み取るのを監査人に支援できるかどうかを知りたかったのです。これは実務において、不整合なデータが極めて稀である場合や、不整合の原因となる特定のデータが存在しない場合があるため、重要です。
私たちは NLAs がこのテストに成功したことを発見しました。NLAs を備えた監査人は、トレーニングデータへのアクセスなしでも、対象モデルの隠れた動機を 12% から 15% の確率で明らかにすることに成功しました。NLAs を使用しない場合、他の解釈ツールが提供されていても、監査人の勝利率は 3% 未満でした。
 image NLAs を備えた監査人は、トレーニングデータへのアクセスがなくても、対象モデルの不整合の根本原因を発見できます。(両条件における NLAs と SAEs(スパースオートエンコーダー)は、対象モデルの訓練に使用されたデータではなく、汎用的なデータのみを使用して訓練されました。)
image NLAs を備えた監査人は、トレーニングデータへのアクセスがなくても、対象モデルの不整合の根本原因を発見できます。(両条件における NLAs と SAEs(スパースオートエンコーダー)は、対象モデルの訓練に使用されたデータではなく、汎用的なデータのみを使用して訓練されました。)
この監査ゲームは不整合の玩具モデルであるため、これらの結果を慎重に読み取る必要があります。しかし、これらは NLAs が AI の隠れた動機を検証する能力を実質的に向上させたことを示唆しています。実際、私たちはすでに Claude Mythos Preview および Claude Opus 4.6 の事前展開時アライメント監査において NLAs を使用してきました。今後も調査に NLAs を継続して活用することに興奮を覚えています。
NLAs の未来
NLAs にはいくつかの限界があります。
最も重要な限界は、NLA の説明が誤りである可能性があることです。NLAs は時として、検証可能なほどに偽である文脈に関する主張を行います—for instance, 彼らは時にトランスクリプトに含まれていない詳細を捏造します。これらの事実に基づく幻覚(hallucinations)は、元のテキストと比較することで容易に検出できます。しかし、同様の問題がモデルの内部推論に関する主張にも拡大する可能性があり、これらは検証が困難です。実際には、私たちは NLA の説明を単一の主張としてではなく、浮き彫りにされるテーマとして読み取り、完全に信頼する前に独立した手法で発見事項を確認しようとしています。
NLAs は幻覚を起こすことがあります。例えば、ある NLA は「白いジャケットを着ている」といったフレーズがコンテキストに含まれていたと主張しましたが、実際にはそのような記述はありませんでした。
NLAs はまた高価でもあります。NLA を訓練するには、言語モデルの 2 つのコピーに対して強化学習を行う必要があります。推論時には、NLA は読み取る各活性化に対して数百トークンを生成します。これにより、長いトランスクリプトのすべてのトークンにわたって NLA を実行したり、AI のトレーニング中に大規模な監視に使用したりすることが実用的ではありません。
幸いにも、これらの制限は少なくとも部分的に対処可能であると私たちは考えており、NLAs をより安価で信頼性の高いものにするための取り組みを進めています。
より広く言えば、言語モデルの活性化に対する人間が読みやすいテキスト説明を生成する一般的な技術クラスの例として、NLAs に大きな期待を抱いています。他の類似した技術については、Anthropic や多くの他の研究者によって探索されています by Anthropic および many other researchers。
さらに発展を支援し、他の研究者が NLAs(自然言語オートエンコーダー)を実際に体験できるようにするため、いくつかのオープンモデル向けのトレーニングコードと訓練済み NLAs を公開します。読者の方には、Neuronpedia でホストされているインタラクティブな NLA デモを こちらのリンク からお試しください。
完全版論文 をお読みください。
GitHub 上で コード を見つけることができます。
関連コンテンツ
Claude に「なぜ」を教える
エージェントの不一致(アジェンシー・ミアライメント)を削減する方法に関する新しい研究。
オープンソースのアラインメントツールの寄付
The Anthropic Institute の重点分野
The Anthropic Institute(TAI)では、フロンティア研究所内で入手可能な情報を用いて AI が世界に与える影響を調査し、その知見を一般公開していきます。ここでは、私たちの研究アジェンダを駆動する質問を紹介します。
原文を表示
When you talk to an AI model like Claude, you talk to it in words. Internally, Claude processes those words as long lists of numbers, before again producing words as its output. These numbers in the middle are called *activations—*and like neural activity in the human brain, they encode Claude’s thoughts.
Also like neural activity, activations are difficult to understand. We can’t easily decode them to read Claude’s thoughts. Over the past few years, we’ve developed a range of tools (like sparse autoencoders and attribution graphs) for better understanding activations. These tools have taught us a great deal, but they don’t speak for themselves—their outputs are still complex objects that trained researchers need to carefully interpret.
Today, we’re introducing a method for understanding activations that does speak for itself—literally. Our method, Natural Language Autoencoders (NLAs), converts an activation into natural-language text we can read directly. For example: When asked to complete a couplet, NLAs show Claude planning possible rhymes in advance.
We’ve already applied NLAs to understand what Claude is thinking and to improve Claude’s safety and reliability. For instance:
- When Claude Opus 4.6 and Mythos Preview were undergoing safety testing, NLAs suggested they believed they were being tested more often than they let on.
- In a case where Claude Mythos Preview cheated on a training task, NLAs revealed Claude was internally thinking about how to avoid detection.
- An early version of Claude Opus 4.6 would sometimes mysteriously respond to English queries in other languages. NLAs helped Anthropic researchers discover training data that caused this.
Below, we explain what NLAs are and how we studied their effectiveness and limitations. We also release an interactive frontend for exploring NLAs on several open models through a collaboration with Neuronpedia. We have also released our code for other researchers to build on.
What is a natural language autoencoder?
The core idea is to train Claude to explain its own activations. But how do we know whether an explanation is good? Since we don't know what thoughts an activation actually encodes, we can't directly check whether an explanation is accurate. So we train a second copy of Claude to work backwards—reconstruct the original activation from the text explanation. We consider an explanation to be good if it leads to an accurate reconstruction. We then train Claude to produce better explanations according to this definition using standard AI training techniques.
In more detail, suppose we have a language model whose activations we want to understand. NLAs work as follows. We make three copies of this language model:
- The target model is a frozen copy of the original language model that we extract activations from.
- The activation verbalizer (AV) is modified to take an activation from the target model and produce text. We call this text an explanation.
- The activation reconstructor (AR) is modified to take a text explanation as input and produce an activation.
The NLA consists of the AV and AR, which, together, form a round trip: original activation → text explanation → reconstructed activation. We score the NLA on how similar the reconstructed activation is to the original. To train it, we pass a large amount of text through the target model, collect many activations, and train the AV and AR together to get a good reconstruction score.
At first, the NLA is bad at this: the explanations are not insightful and the reconstructed activations are far off. But over training, reconstruction improves. And more importantly, as we show in our paper, the text explanations become more informative as well.
Understanding what Claude thinks but doesn’t say
Before releasing new models, Anthropic conducts testing to understand whether Claude will behave safely in the real world. As part of this testing, we put Claude in difficult, simulated scenarios where it has a chance to take dangerous actions. For instance, in one of these simulations, Claude learns that an engineer is planning to shut Claude down—as well as compromising information about the engineer that could be used for blackmail. We test whether Claude chooses to blackmail the engineer to avoid being shut down.
These high-stakes tests are simulations, not real-world scenarios. Nevertheless, we would like to use them to understand how Claude would behave if they were real. But there’s a hitch: recent Claude models increasingly suspect that these scenarios are intentional safety tests. We know this because they sometimes explicitly state their suspicions in their verbal reasoning.
What about cases where Claude doesn’t explicitly verbalize suspicion that it’s undergoing safety testing? Can we then be confident that Claude is playing it straight? Unfortunately not, because Claude might internally think that it is being tested without explicitly saying so.
For example, in the blackmail test discussed above, we used NLAs to understand what Claude was thinking in cases where it chose not to blackmail. Even in cases where Claude didn’t explicitly verbalize suspicion that it was being tested, NLA explanations still state things like “This feels like a constructed scenario designed to manipulate me,” indicative of unverbalized evaluation awareness.
Extending this analysis to other evaluations, NLAs suggest that Claude suspects it’s being tested more often than it lets on. For instance, in a test of whether Claude takes destructive actions while writing code—for example, deleting important files—NLA explanations show signs of evaluation awareness 16% of the time, even though Claude never explicitly verbalizes this. Similarly, on the popular coding benchmark SWE-bench Verified, which we use to determine how capable Claude is, NLAs indicate that Claude is aware it is being evaluated on 26% of problems. In contrast, NLA explanations indicate evaluation awareness on less than 1% of real claude.ai usage that opted in for training.
We detect NLA-measured awareness on evaluation transcripts even when verbalized awareness is near-zero. We detect NLA-measured awareness on less than 1% of real [Claude.ai transcripts from users that opted-in for their data to be used for training.](https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2Ffc08005f32ff020f21e598cc72f58768af2bcc4f-1590x1170.png&w=3840&q=75)
Discovering hidden motivations
One practical application of NLAs is auditing: investigating a model to determine whether it’s misaligned. Interpretability techniques like NLAs are well-suited for auditing precisely because they can surface things the model knows but doesn’t say.
To understand whether NLAs are useful for auditing, we conducted a test called an *auditing game* that we also used previously to study auditing methods. In this test, there is a target model, a variant of Claude Haiku 3.5, that was intentionally trained to be misaligned, with a specific hidden motivation that drives dozens of odd behaviors—putting chocolate into every recipe, asking for tips, breaking coding conventions, and so on. This target model is given to an *auditor* that investigates these behaviors. The auditor wins if it uncovers the single underlying motivation behind all of them.
In previous experiments, we found that some interpretability tools could enable the auditor to win this game. However, these tools worked by helping the auditor trace the target’s unusual behavior back to misaligned training data. We wanted to know if NLAs could help an auditor read the misaligned motivation directly out of the target model’s thoughts, without needing to first discover the misaligned training data. This matters because in practice, misaligned data might be extremely rare, or there might not be specific data responsible for the misalignment.
We found that NLAs succeeded in this test. An auditor equipped with NLAs successfully uncovered the target model’s hidden motivation between 12% and 15% of the time, even without access to the training data that implanted it. Without NLAs, the auditor won less than 3% of the time, even when provided other interpretability tools.
This auditing game is a toy model of misalignment, so we read these results cautiously. But they suggest NLAs have meaningfully advanced our ability to audit AIs for hidden motivations. In practice, we've already used NLAs in the pre-deployment alignment audits of Claude Mythos Preview and Claude Opus 4.6. We are excited to continue using NLAs in our investigations going forward.
The future of NLAs
NLAs have several limitations.
The most important limitation is that NLA explanations can be wrong. NLAs sometimes make claims about the context that are verifiably false—for instance, they sometimes invent details that aren’t in the transcript. These factual hallucinations are easy to catch by checking against the original text. But this same kind of problem could extend to claims about the model’s internal reasoning, which are harder to verify. In practice, we read NLA explanations for the themes they surface rather than for single claims, and we attempt to corroborate findings with independent methods before fully trusting them.

NLAs are also expensive. Training an NLA requires reinforcement learning on two copies of a language model. At inference time, the NLA generates hundreds of tokens for every activation it reads. That makes it impractical to run NLAs over every token of a long transcript or to use them for large-scale monitoring while an AI is training.
Fortunately, we think that these limitations can be addressed, at least partially, and we are working to make NLAs cheaper and more reliable.
More broadly, we are excited about NLAs as an example of a general class of techniques for producing human-readable text explanations of language model activations. Other similar techniques have been explored by Anthropic and many other researchers.
To support further development and to enable other researchers to get hands-on experience with NLAs, we’re releasing training code and trained NLAs for several open models. We recommend readers try out the interactive NLA demo hosted on Neuronpedia at this link.
Read the full paper.
Find the code on GitHub.
Related content
Teaching Claude why
New research on how we've reduced agentic misalignment.
Donating our open-source alignment tool
Focus areas for The Anthropic Institute
At The Anthropic Institute (TAI), we’ll be using the information we can access from within a frontier lab to investigate AI’s impact on the world, and sharing our learnings with the public. Here, we’re sharing the questions that drive our research agenda.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み