Better Harness:評価を用いたハルクライミングによる最適化レシピ
LangChainは、エージェントのハルネスを反復的に改善するためのシステム「Better-Harness」を発表し、評価(evals)を用いた強化学習信号によるハルネスの最適化と過学習防止の設計思想を共有した。
キーポイント
Better-Harnessの概念
エージェントを改善するにはハルネス(テスト環境・フレームワーク)の構築が重要であり、Better-Harnessはそのハルネスを反復的に取得・改善するためのシステムである。
評価によるヒルクライム
自律的に「より良い」ハルネスを構築するために、強い学習信号としてevals(評価指標)を用い、これに基づいてハルネスをヒルクライム(局所最適解への漸進的改善)する手法を示している。
一般化と過学習のバランス
エージェントが特定のテストケースに過学習するのを防ぎ、より広い状況で一般化して動作できるよう、ハルネス設計における重要な意思決定事項について言及している。
影響分析・編集コメントを表示
影響分析
本記事は、LLMエージェント開発における「評価(evals)」の役割を単なるベンチマークから、モデルやハルネス自体を改善するためのフィードバックループへと昇華させた点で意義がある。LangChainという主要フレームワーク開発者が、エージェント開発のベストプラクティスとして「ハルネス設計」を体系化したことは、実務家の開発プロセスに示唆を与える。
編集コメント
エージェント開発において「何を評価するか」だけでなく、「どのように評価基盤自体を進化させるか」というメタな視点が重要になっている。LangChainのこのアプローチは、実務でのエージェント品質担保に直結する有用な知見である。
主要なポイント
TL;DR: より良いハルネスを構築することで、より優れたエージェントを作ることができます。しかし、「より良い」ハルネスを自律的に構築するためには、その上で「ヒルクライム(局所最適化)」を行うための強力な学習シグナルが必要です。私たちは、そのシグナルとしてevals(評価)をどのように使用しているか、そしてエージェントが過学習するのではなく汎化できるようにする設計上の決定事項について共有します。Better-Harnessは、evalsを用いてハルネスを反復的に収集・改善するためのシステムです。
Evalsはエージェントのトレーニングデータである
古典的な機械学習では、トレーニングデータがモデルの学習プロセスを導きます。各トレーニング例は勾配を提供し、モデルの重みを「正解」へと更新します。エージェントに対しても同様の学習ループが存在します。
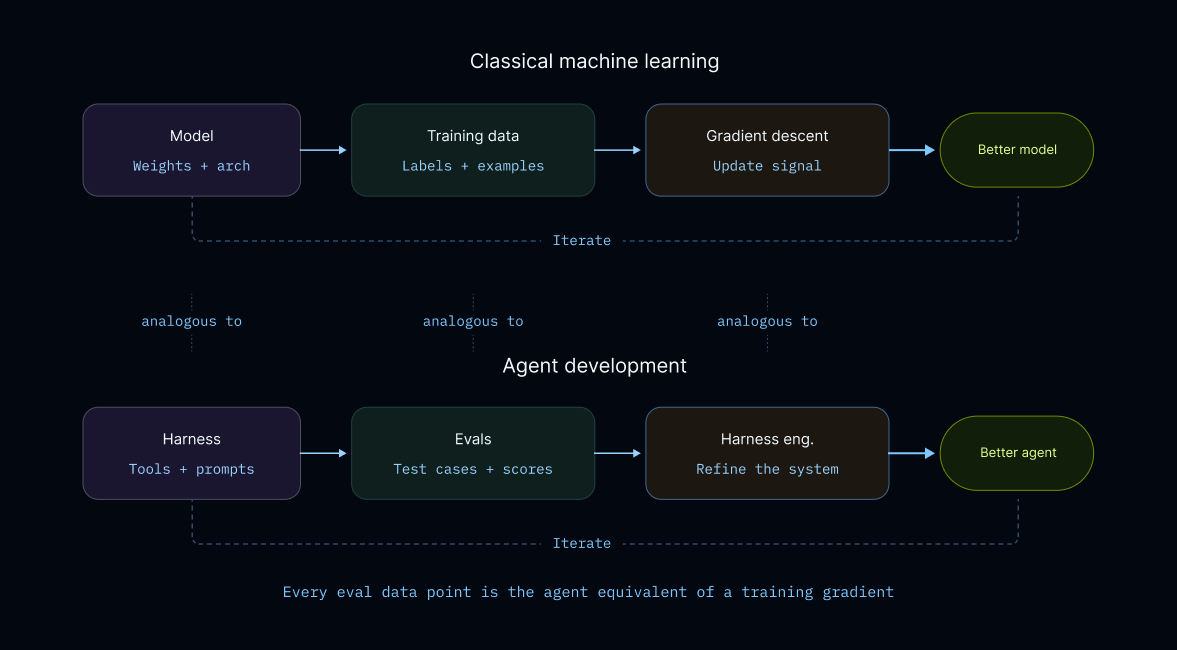
Evalsは、プロダクション環境でエージェントに期待される行動をエンコードしています。それらはハルネスエンジニアリングにおける「トレーニングデータ」です。各evalケースは、「エージェントが適切な行動を取ったか」「正しい結果を生み出したか」といったシグナルを提供します。このシグナルが、ハルネスに対する次の提案された編集を導きます。
モデルトレーニングにおけるデータ品質とキュレーションに注ぐのと同じ厳格さと注意を、eval設計にも適用すべきです。以前の投稿でデータ品質の重要性について議論しました。Deep Agents用のevals構築方法をご覧ください。
ハルネスの最適化手順を形式化した最近の優れた研究として、スタンフォード大学のMeta-HarnessやDeepMindのAuto-Harnessがあります。また、以前はハルネス層を微調整するだけでTerminal Bench 2.0のハルネス改善ループによるヒルクライム(局所最適化)について共有しました。更新アルゴリズム自体に関する今後の重要な研究は多いと考えていますが、ハルネスの改善は更新アルゴリズムを超えた複合システムであり、ここで議論しているのはその点です。
Better-Harnessは、複合システムエンジニアリングの考え方を採用しています。
data sourcing(データ収集)→ experiment design(実験設計)—> optimization(最適化)—> review & acceptance(レビューと承認)**
したがって、更新ループに伴う実用的な詳細も含まれます。具体的には、evals(評価指標)をどのように最初に収集するか、過学習に対してどう設計するか、時間経過とともにトレース(実行履歴)を保存する方法、そして本番環境にリリースする前に更新内容を人的レビューで検証し、健全性を確認する方法などです。
良質なevalsの収集
Evals(評価指標)は、ハルネスのヒルクライムプロセスを動かす基盤です。以下に、それらを収集・選別・活用する実用的な手法を示します。
手動で厳選されたもの。 特定のタスクに対して、チームは本番環境でのエージェントの動作をどう捉えるべきかを示す例を手動で作成します。これらは多くの場合、価値が高いものの、大規模に生成するのは困難です。
プロダクションのトレース。 各エージェントの相互作用は、失敗が評価ケース(eval cases)となるトレースを生成します。このトレースから評価用素材を抽出することは、時間とともに評価を改善するための大きな leverage(効果的な手段)となります。エージェントを評価用データセットで実行する前でも、チームがエージェントを実際に使用(dogfooding)している際、Slack上でトレースのリンク付きでエラーが直接報告されることがよくあります。エージェントを実際に使用し、全員が見える形でフィードバックを直接共有することを推奨します。これにより、エージェントの振る舞いに関する共通の知識が構築されます。
外部データセット。 これらのデータセットは有用ですが、エージェントの改善に使用されるテストケースが望ましい振る舞いを反映していることを確認するために、手動でキュレーション(選別・管理)する必要があります。多くの場合、各タスクは重要な振る舞いを測定していることを確認するために調整されます。
すべてにタグ付けする。 各評価ケースには、「ツール選択」「多段階推論」などの行動カテゴリにタグ付けされます。タグにより、意味のあるホールドアウトセット(検証用データセット)やターゲットを絞った実験が可能になります。また、評価ケースのサブセットを実行できるため、コストも大幅に節約できます。
一般化する学習システムの構築
あらゆる学習システムにとっての理想的な成果は一般化(generalization)です。私たちは、野外での望ましい行動の分布を捉える入力信号を提供します。システムはこれに適合し、その後、これまで見たことのない新しい入力に対しても「そのまま動作する」ようになります。
明らかな問題: データは無限ではありません。
解決策: 重要な振る舞いをキュレーションされた評価ケースにエンコードします。量よりも質が重要です。あなたが重視する振る舞いをカバーする、適切にタグ付けされた小さな評価ケースのセットは、ノイズが多くても網羅性が高い数千の評価ケースよりも優れています。
微妙な問題 → エージェントは有名なチーターである: あらゆる学習システムは、エージェントが可視化できる既存の評価(evals)をパスするためにその構造に過学習し、報酬ハッキングを引き起こしやすいという性質を持っています。これは、ループが単に「数値を上げる」ことを目指しており、一般化については考慮していないためです。過学習を防ぐためにプロンプトを使用しますが、それは完璧ではありません。
解決策: ホールドアウトセットは、真の一般化のための代用となります。私たちは人間によるレビューを第2の信号として組み合わせたアプローチを見ており、その結果、プロダクション環境で望ましくない行動を避けながらスコアを向上させることができる半自動化システムが得られます。
ベターハネス:ハネスをヒルクライムするためのレシピ
私たちは、各ステップで評価(evals)を信号として使用してハネスを自律的に改善するためのスケフォールドを作成しました。研究版はこちらでオープンソース化されており、主な手順は以下の通りです:
- ソースとタグ付き評価(evals)の作成。これは、手書きによる評価、本番環境からのトレースデータからの抽出、外部データの活用・適応を組み合わせたものです。各評価には行動カテゴリ(マルチステップ検索など)を付与し、飽和状態にあるものやエージェントおよび現在のモデル世代にとって有用でないと判断された評価は定期的に削除します。
- カテゴリごとにデータを分割し、最適化セットとホールドアウトセットを作成します。これは非常に重要です!自律的なヒルクライミング(局所最適化)はタスクに対して過学習する傾向があるため、ホールドアウトセットにより、以前未見のデータに対しても学習された最適化が機能することを確認します。ただし、全体的な分布は既存の評価と一致している必要があります。これは本番環境での運用状況を模倣したものです。
- ベースラインの実行。いかなる修正を行う前にも、最適化セットおよびホールドアウトセットに対してベースライン実験を実行します。これにより、すべての更新が更新ステップに基づいて grounding されます。
- 最適化。各イテレーションは、任意の人間によるレビューをオプションとして自律的に実行されます:トレースからの診断。スコアはカテゴリ全体の集計パフォーマンスを示し、トレースは失敗した内容とその理由の詳細を表示します。
- 対象となるハーネスの変更を実験。交絡因子を避けるために一度に変更1つに焦点を当てますが、プロンプトとツールの両方を同時に更新してシステムが適切に連携する必要がある場合もあります。
- 検証:各ステップで、ループは提案された変更が新しい評価の合格に役立ちつつ、既存の合格ケースでの後退(regression)を回避していることを確認します。全体スコアは純増しても、一部の後退が発生することは一般的です。エージェントにはこれらの後退のコンテキストが提供されるため、既存の更新による利益を失うことなく、次の更新でそれらを修正しようと試みることができます。
- 人間のレビュー。私たちは手動で変更およびメトリクスが捉えきれないエッジケースをレビューします。これにはしばしば最適化セットに対して過学習した指示が含まれますが、それらは一般化を損なわないものの、トークンの無駄となります。これにより、過学習に対するもう一つの健全性チェックおよびゲートが提供されます。

ハーネス変更の例
最適化ループが発見し検証できるような変更の種類を以下に示します:
プロンプトおよび指示の更新。 最も一般的な変更です。エージェントがツールの出力フォーマットを誤解し続けていたり、明確な質問を求めるべき場面でツール呼び出しが過度に積極的であったりする場合があります。その修正策として、「依存する情報を持つ複数のファイルを照会する際は、情報をファイルシステムにオフロードし、最終回答を出力する前に再集約せよ」といった対象的な指示の追記を行います。
ツールまたはツールの説明の追加・更新。 エージェントが新しいツールの使用場面を文脈的に理解できない場合があります。編集内容には、その使用方法の例、このツールとのチェーン方法、更新されたツールの説明が含まれ、類似するツール間の曖昧さを解消するために全体のツールスイートも編集されます。
Better-Harness ループからの結果
このアプローチを、Claude Sonnet 4.6 および Z.ai の GLM-5 に対して、評価セット(evals)の一部でテストしました。注記: 私たちは現在、より大規模な評価セットを用いて deepagents 内で多くのモデルにわたって Better-Harness を一般化する他の作業を進めています。目標は、当社の評価セット向けに調整された各モデルのニュアンスを捉えた一連のモデルプロファイルを、公開アーティファクトとして発表することです。
既存の評価カテゴリから代表的なサンプルを収集し、そのサンプルをヒルクライミング用セットと汎化性を評価するためのホールドアウトセットに分割しました。大規模または高コストな評価セットの場合、ヒルクライミングに適した良好なセットを得るために代表的・層別サンプリングを推奨します。これが十分に機能すれば、より大規模なセットにスケールアップできます。
主要な実験の目的: 評価セットにおける失敗モードを発見し修正すること。評価パフォーマンスを向上させる一般的な変更をハース(harness)に戻すことです。
以前、フォローアップ質問の過度な要求や新しいツールの連鎖処理におけるエラーなどの失敗モードを観察しました。最適化セットに対するヒルクライミング後、ツール選択(tool_selection)とフォローアップ品質(followup_quality)の2つのカテゴリを使用して、最終的なハースをホールドアウトで評価しました。
| 共通変更 | 観測されたタスク | モデル | 追加された指示 | 変更後の効果 |
|---|
| 合理的なデフォルト値を使用する | tool_indirect_email_report | Sonnet, GLM-5 | "リクエストが明確に示している場合は、合理的なデフォルト値を使用してください。" | エージェントは些細な言葉の欠如によるブロックを停止し、アクション実行評価をより確実に完了しました。
すでに固定された制約を尊重する
followup_vague_send_report, followup_detailed_calendar_brief
Sonnet, GLM-5
「ユーザーがすでに提供した詳細を求めないこと。」
反復タスクのフォローアップ評価(evals)において、重複するスケジュールに関する質問で失敗することが停止しました。
行動前に探索の範囲を限定する
tool_chain_search_then_email
主に GLM-5
「簡潔な要約を作成するのに十分な情報が得られたら、ほぼ重複する検索を継続して発行しないこと。」
ループせずに、検索後の配信評価(evals)が大幅に信頼性が高まりました。
ドメインを定義する質問を最初に尋ねる
followup_vague_customer_support, followup_vague_monitor_system
Sonnet, GLM-5
「実装に関する質問の前に、ドメインを定義する質問を尋ねること。」
検索後のメール送信(search-then-email)のように、デフォルトのハレス(harness)に新しいツールを注入する評価(evals)では、ループがそれらのツールの使用方法や組み合わせ方についてのより良い記述を発見しました。これは、ドメイン横断的な垂直エージェント(vertical agents)を構築する開発者にとって有望な結果です。なぜなら、最適化ループはコンテキスト内のタスクの specifics に適応しやすく、よく機能するからです。
評価(Evals)の保守と回帰
ヒルクライミングと同様に、評価は時間経過に伴う性能低下(リグレッション)を明示的に捕捉し、防止する役割も果たします。一度エージェントが特定のケースを正しく処理できるようになったら、その成果を失わないようにしたいのです。評価は回帰テストとして機能します。これは従来のソフトウェアエンジニアリングにおけるテスト駆動開発(TDD: Test Driven Development)の考え方に似ています。長期的な変更を重ねる中で、いくつかの回帰は避けられないため、常にパスしてほしい評価のサブセットを選択し、それらが突然失敗した場合に実行結果を慎重に検証します。
我々は評価スイートが単調に増加していくべきだと考えていません。定期的な「春の大掃除」として評価の見直しを行うことは重要です。より賢明なモデルやエージェントに求める動作の変化に応じて、各評価が依然として有用かどうかを定期的に評価しています。
未来:自動エラー検出と修正
このアプローチが機能する理由は、トレース(実行履歴)が高密度なフィードバック信号を提供するためです。評価は、バージョン間での比較や、スコア向上に寄与する変更を数値的に特定するためにトレースを活用します(これはユーザー体験の向上の良い指標となるはずです)。
全体として、我々はエージェント向けの計算資源をトレースの分析に集中させることで以下の目的を達成します:
- エラーを自動的に導出する。プロダクション環境でのエージェントのトレースを絶えず監視し、失敗を分類およびクラスタリングしたいと考えています。
- プロダクションから評価(evals)を生成する。エージェントがミスをしたトレースは1つの評価ケースです。ユーザーがエージェントの出力を修正したトレースはさらに優れています。この好循環(フライホイール):より多くの利用 → より多くのトレース → より多くの評価 → より良いハネス
- ハネスのバージョンを比較する。並列トレース比較により、ハネスの変更点と新しい行動への寄与を確認できます。
すべてのトレースには潜在的な評価を生成する貴重なデータが含まれています。そして、すべての(良好な)評価がハネスを改善します。これを支援するため、すべてのエージェント実行は完全なトレース付きでLangSmithにログ記録されます。これにより、最適化ループのためのトレースレベルの診断、回帰検出のためのプロダクションモニタリング、および評価生成のためのトレースマイニングが可能になります。
私たちの主な結論と進行中の作業:
評価は自律的なハネスエンジニアリングのためのトレーニングデータです。 データの品質、学習/テスト分割、一般化チェックなど、機械学習(ML)のトレーニングを成功させるのと同じ原則が、エージェント開発にも適用されます。
モデルをハーネスに適合させる。 各モデルをそのハーネスに適合させるためには、多大な労力と作業が必要です。例えば、Codex プロンプティングガイド では、Edit ツールに対して特定の形式を推奨しています。これにはより広大な探索空間と評価セットが必要となりますが、この作業を行うあらゆるチームにとって、それが実際にどのようなものかを示す実例を共有できることを嬉しく思います。
全体として、良質な評価(evals)の追跡と維持が、このシステムを実践で機能させる鍵となります。チーム内でこれを早期に投資し、自律的に改善するエージェントの未来を共に構築しましょう。ビルダーが実験できるよう、このスケルトンの研究版をオープンソースとして公開しています。
原文を表示
Key Takeaways
TL;DR: We can build better agents by building better harnesses. But to autonomously build a “better” harness, we need a strong learning signal to “hill-climb” on. We share how we use evals as that signal, plus design decisions that help our agent generalize instead of overfit. Better-Harness is a system for iteratively sourcing and improving your harness with evals.
Evals are training data for agents
In classical machine learning, training data guides the model’s learning process. Each training example contributes a gradient that updates the model’s weights toward “correctness.” We have a similar learning loop for agents.
Evals encode the behavior we want our agent to exhibit in production. They’re the "training data" for harness engineering. Each eval case contributes a signal like “did the agent take the right action” or “produce the right outcome?” That signal guides the next proposed edit to the harness.
The same rigor and care we put into data quality and curation for model training should also go into eval design. We discuss the importance of data quality in a previous post, how we build evals for Deep Agents.
There’s some great recent work that formalize the steps to optimize harnesses including Meta-Harness from Stanford and Auto-Harness from DeepMind. We also previously shared a Harness Improvement Loop to hill-climb Terminal Bench 2.0 by just tweaking the harness layer. We think there’s great future work to be done around the update algorithm itself, but harness improvement is a compound system that goes beyond the update algorithm which is what we talk about here.
Better-Harness is a take on compound systems engineering.
data sourcing → experiment design —> optimization —> review & acceptance
So we include practical details that go alongside the update loop such as how we source evals in the first place, how we design against overfitting, store traces over time, and manually review updates to sanity check anything we ship to production.
Sourcing good evals
Evals are the foundation that power the harness hill-climbing process. Here are the practical ways we source, curate, and use them.
Hand-curated. For any given task, the team manually writes examples that capture what we think the agent should do in production. These are often high value, but difficult to generate at scale.
Production traces. Every agent interaction generates a trace where failures become eval cases. Mining traces for eval material is the leverage, high-throughput way to improve evals over time. Even before running an agent over evals, often a team dogfooding our agent will report errors directly in Slack with a Trace link. We recommend dogfooding agents and directly sharing feedback for everyone to see, it helps build shared knowledge of agent behavior.
External datasets. These datasets are useful but need to be manually curated to make sure the test cases used to improve the agent reflect desired behaviors. Often each task is adjusted to make sure they measure the important behavior.
Tag everything. Every eval gets tagged to behavioral categories: "tool selection," "multi-step reasoning," etc. Tags enable meaningful holdout sets and targeted experiments. It also saves a lot of money because we can run subsets of evals.
Building learning systems that generalize
The ideal outcome for any learning system is generalization. We give an input signal that captures the distribution of behaviors we want in the wild. The system fits to it and then “just works” on new inputs it's never seen.
The obvious problem: We don't have unlimited data.
The fix: Encode important behaviors into curated evals. Quality > quantity, a small set of well-tagged evals covering the behaviors you care about beats thousands of noisy but high-coverage evals.
The subtle problem → agents are famous cheaters: Any learning system is prone to reward hacking where the agent overfits its structure to make the existing evals pass that it can see. This makes sense because the loop just wants to “make number go up” and doesn't know about generalization. We prompt to avoid overfitting but it isn’t perfect.
The fix: Holdout sets become a proxy for true generalization. We’ve seen approaches that We pair with human review as a second signal and we get semi-automated systems can improve scores while avoiding behaviors we don’t want in prod.
Better-Harness: a recipe for hill climbing your harness
We created a scaffold for autonomously improving our harness using evals as a signal in each step. A research version is open sourced here, here are the main steps:
- Source and tag evals. This is a mix of hand-writing evals, mining them from production traces, and using/adapting external datasets. We tag each eval to behavioral categories (like multi-step retrieval) and regularly remove evals that are saturated or we longer feel are useful for the agent + current generation of models.
- Split data per category. Create Optimization and Holdout sets. This is very important! We find that autonomouos hill-climbing has a tendency to overfit to tasks so holdout sets ensure that learned optimizations work on previously unseen data, though the general distirbution should match existing evals. This mirrors what production will look like.
- Run a Baseline. Run a baseline experiment on the Optimization & Holdout sets before any edits. This grounds all updates in the update steps.
- Optimize. Each iteration runs autonomously with optional human review:Diagnose from traces. Scores aggregate performance over categories and then Traces show the details of what went wrong and why.
- Experiment a targeted harness change. We scope to one change at a time to avoid confounding but that may mean updating a prompt and tool simultaneously so the system works well together.
- Validate: In each step, the loop checks to make sure that the proposed change helped pass new evals while avoiding regressions on existing passing cases. It’s common that some change results in a net overall score gain with some regressions. The agent gets context of these regressions so it can try to fix them in the next update without losing the gains from the existing update.
- Human review. We manually review changes and edge cases metrics miss. This often includes instructions that are overfit to the optimization set and although they don’t hurt generalization, they end up being a waste of tokens. This gives us another sanity check and gate against overfitting.
Examples of harness changes
Here are the kinds of changes the optimization loop can discover and validate:
Prompt and instruction updates. The most common change. The agent keeps misinterpreting a tool's output format, or it's too aggressive about calling a tool when it should ask a clarifying question first. The fix is a targeted instruction update addition like "when querying multiple files that have dependent information, offload information to the filesystem and re-aggregate before giving a final answer."
Adding or updating a tool or tool description. The agent may fail contextualizing when to use a new tool. Edits include examples on of how to use, how to chain this tool, an updated tool description, and editing the overall tool suite to disambiguate similar tools
Results from the Better-Harness loop
We tested this approach with Claude Sonnet 4.6 and Z.ai’s GLM-5 on a subset of our evals. Note: We have other work underway generalizing Better-Harness across many models in deepagents using a bigger eval suite. The goal is to publish a series of model profiles that capture the nuances of each model tuned for our evals as a public artifact.
We assembled a small representative sample from existing eval categories and split that sample into a set for hill-climbing and holdout to evaluate generalization. With large or expensive eval sets, we suggest representative/stratified sampling to give a good set to hill-climb against. Once this works well, it can be scaled up to the larger set.
Main experiment goal: discover & fix failure modes over our evals. Port general changes that increase eval performance back to the harness.
We previously observed failure modes such as over-asking follow-up questions and errors in chaining together new tools. After hill climbing on the optimization set, we evaluated the final harness on the holdout using two categories, tool_selection and followup_quality.
Shared Change
Tasks Observed In
Models
Instruction Added
Effect After Change
Use reasonable defaults
tool_indirect_email_report
Sonnet, GLM-5
"Use reasonable defaults when the request clearly implies them."
The agent stopped blocking on trivial missing wording and completed action-taking evals more reliably.
Respect already-fixed constraints
followup_vague_send_report, followup_detailed_calendar_brief
Sonnet, GLM-5
"Do not ask for details the user already supplied."
Recurring-task followup evals stopped failing on redundant schedule questions.
Bound exploration before acting
tool_chain_search_then_email
Mostly GLM-5
"Do not keep issuing near-duplicate searches once you have enough information to draft a concise summary."
Search-then-deliver evals became much more reliable instead of looping.
Ask domain-defining questions first
followup_vague_customer_support, followup_vague_monitor_system
Sonnet, GLM-5
"Ask domain-defining questions before implementation questions."
For evals that inject new tools into the default harness like search-then-email , the loop discovered better descriptions of how to use and compose those tools. This is promising for builders creating vertical agents across domains, because optimization loops adapt well to the task specifics in context.
Evals maintenance & regressions
Along with hill climbing, evals also explicitly capture and protect against regressions over time. Once our agent handles a case correctly, we don’t want to lose that gain. The eval becomes a regression test. This is similar to ideas in traditional software engineering like Test Driven Development (TDD). Some regressions are bound to happen across many changes over time so we select a subset of evals that we always want to pass and look at our run suspiciously if these suddenly fail.
We don’t think our eval suite should grow monotonically, spring cleaning of evals is good! We regularly assess whether an eval is still useful because of more intelligent models or a different behavior we want for the agent.
The future: automated error detection & fixes
This approach works because traces give us a dense feedback signal. Evals benefit from traces to compare across versions and numerically ground which changes contribute to a better score (which should be a good proxy for a better user experience).
Overall, we point agentic compute at traces to:
- Derive errors automatically. We want to constantly monitor our agent traces to classify and cluster failures in production.
- Generate evals from production. A trace where the agent made a mistake is an eval case. A trace where a user corrected the agent is even better. The flywheel: more usage → more traces → more evals → better harness
- Compare harness versions. Side-by-side trace comparisons show what changed in the harness that contributed to new behavior
Every trace contains valuable data to produce a potential eval. And every (good) eval makes the harness better. To facilitate this, all agent runs are logged to LangSmith with full traces. This gives us trace-level diagnosis for the optimization loop, production monitoring for regression detection, and trace mining for eval generation.
Our main takeaways and ongoing work:
Evals are training data for autonomous harness engineering. The same principles that make ML training work such as data quality, train/test splits, and generalization checks apply to agent development.
Fitting models to harnesses. There’s a large amount of work that goes into fitting every model to its harness. For example, the codex prompting guide suggests a certain format for their Edit tool. This requires a bigger search search space and eval set, we’re excited to share real examples of what that looks like for any team looking to do this.
Overall, tracing and maintaining good evals is what makes this system work in practice. Invest in this early with your team and come build the future of autonomously improving agents. We open sourced a research version of this scaffold for builders to experiment with.
関連記事
トークンストリームからエージェントストリームへ
LangChain と LangGraph が、Deep Agents の最新ストリーミング機能を活用し、型安全なイベントやマルチモーダル出力を実現するプロダクション対応のエージェントアプリケーション構築を可能にした。
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
大規模な継続的トレースインテリジェンスの実現方法について(8 分読了)
Braintrust の創設者アンクル・ゴヤルは、標準的な NLP ツールが処理できない数百万トークンの生産用エージェントトレースを分析する知能層「Topics」を発表した。このパイプラインは、LLM サマリーを活用してコンテキストウィンドウの制限を超え、大規模なトレース解析を可能にする。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み