カーネルの手動調整を止める:Neuron エージェント開発が AWS Trainium の最適化を加速する方法
AWS は、Neuron Agentic Development を発表し、AI エージェントを活用して AWS Trainium 向けのカスタムカーネル開発を自動化・簡素化するツールを提供した。
キーポイント
Neuron Agentic Development の発表
AWS は、ML エンジニアがハードウェアの深い専門知識を持たなくても、AI エージェントを使って Trainium や Inferentia 向けに最適化されたカーネルを記述・デバッグ・プロファイルできる新機能を発表した。
開発ワークフローの自動化
「記述→デバッグ→プロファイル→分析」という自然なパイプラインに沿った 5 つの専門スキルを提供し、Kiro や Claude などのコーディングエージェントがこれらのスキルを自律的に実行して最適化を行う。
参入障壁の低下と加速
他アーキテクチャからの開発者でも数日で Trainium に習熟できるようになり、アイデアからハードウェア最適化実装までの期間を大幅に短縮し、カーネル開発の専門知識を民主化する。
自動設計と最適化の自動化
AI エージェントはハードウェア制限(P_MAX=128, F_MAX=2048)や数値安定性(float32 蓄積)を考慮した最適なカーネル設計を自動的に生成します。
リアルタイムデバッグと自己修正
実行時の不整合を検知すると、エージェントは NKI リファレンスを参照してブロードキャストの仕組みを特定し、コードを即座に修正して数値整合性を確保します。
NKI エージェントによる自動プロファイリングと最適化
エージェントは NTFF トレースを分析し、DMA インストラクションの非効率な転送や冗長な入力リロードといったボトルネックを特定して修正コードを生成します。
完全自律的な最適化ループの実現
今後のビジョンとして、開発者が手動でプロファイリング結果を解釈するのではなく、エージェントが自動的に性能目標を満たすまでカーネルを反復改善する仕組みを目指しています。
重要な引用
What if every machine learning (ML) engineer could operate as a performance engineer, writing hardware-aware kernels... without years of chip-level experience?
The Neuron Agentic Development package provides five specialized skills that follow the natural kernel development pipeline: write → debug → profile → analyze.
Kernel developers coming from other architectures can scale quickly to Trainium, teams can shorten the time from idea to hardware-optimized implementation
The agent consults the NKI reference patterns, identifies the correct broadcast mechanism (stride-0 access views via .ap()), and rewrites the kernel accordingly.
PASS: shape=(2, 128, 512), max_diff=0.000008
We want to make this loop fully agentic. For example, agents that autonomously iterate on a kernel until it meets its performance target, without requiring the developer to interpret each profiling result and hand-craft the next fix.
影響分析・編集コメントを表示
影響分析
この発表は、AI ハードウェアの性能最大化が一部の専門家に限定されていた現状を打破し、大規模な ML チーム全体でハードウェア最適化を標準化する転換点となります。特に、AWS Trainium や Inferentia のポテンシャルを最大限引き出すための開発サイクルを劇的に短縮することで、AI モデルの学習・推論コスト削減とスピードアップに直接寄与します。
編集コメント
ハードウェア最適化の専門性を AI エージェントが補完するこのアプローチは、次世代 AI インフラ開発の標準的なワークフローを再定義する可能性を秘めています。AWS のエコシステム内での開発スピード向上に直結する重要な施策です。
最先端の AI モデルが規模と複雑さを増すにつれ、開発者はあらゆるハードウェアプラットフォームにおいて共通の課題に直面しています。つまり、モデルが動作する半導体から最大限のパフォーマンスと効率性を引き出すにはどうすればよいのかという問いです。世界モデル向けのリアルタイム体験を提供したり、エージェントワークフローにおける推論を深めたり、スケールした推論コストを削減したりする場合でも、ハードウェアが理論上実現可能な性能と、多くのチームが実際に達成している性能との間には依然として大きな隔たりが存在します。このギャップを埋めるための道筋として、カスタムカーネル開発は歴史的に重要な役割を果たしてきましたが、これには深いアーキテクチャの専門知識、手動のプロファイリングワークフロー、そして数少ないチームしか負担できない反復的な最適化サイクルが求められます。
しかし、必ずしもそうである必要はありません。もしすべての機械学習(ML)エンジニアが、チップレベルでの長年の経験なしに、ハードウェアを意識したカーネルの作成、ボトルネックの特定、最適化されたモデルのリリースをパフォーマンスエンジニアとして行えるようになったらどうでしょうか?また、すでに一つのアーキテクチャに精通している開発者が、数ヶ月ではなく数日で別のアーキテクチャにも対応できるようになることが実現できたらどうでしょうか。
本日、AWS Trainium および AWS Inferentia を基盤に開発を行う開発者にとって実現を可能にする AI エージェントとスキルの一覧である「Neuron Agentic Development」機能を発表いたします。最初の機能は、Kiro や Claude におけるコーディングエージェントを強化し、Neuron Kernel Interface (NKI) カーネル の作成、デバッグ、プロファイリングを行えるようにします。これにより、ML パフォーマンスエンジニアリングの範囲がチーム内のすべての開発者に拡大されます。他のアーキテクチャからカーネル開発に移行した開発者は Trainium への対応を迅速にスケールでき、チームはアイデアからハードウェア最適化された実装までの時間を短縮できます。かつてはカーネル開発への参入障壁となっていた深いアーキテクチャ知識も、各ステップで開発者をガイドするエージェント型ツールを通じて今や誰でも利用可能になりました。
本稿では、Neuron Agentic Development 機能がどのようにしてカーネル開発ワークフローを加速させるのかについて解説します。
The Neuron Agentic Development skills
Neuron Agentic Development パッケージは、自然なカーネル開発パイプライン(記述 → デバッグ → プロファイリング → 分析)に沿った 5 つの専門スキルを提供します。これらのスキルは、特定のタスクに対して個別に呼び出すことも、neuron-nki-agent を用いて連鎖させることで、リクエストに基づいて適切なワークフローを自動選択することも可能です。利用するには、これらのスキルを agentic IDE のスキルディレクトリに追加してください。例えば、VS Code、Cursor、Kiro などの任意の IDE では、.kiro/skills または .claude/skills ディレクトリにスキルを追加し、エージェントが利用できるようにします。なお、これらのスキルは Trainium ベースの Amazon Elastic Compute Cloud (Amazon EC2) インスタンス上で実行する必要があります。
Kernel authoring
neuron-nki-writing スキルは、NKI カーネルを作成するための出発点です。このスキルは、PyTorch、NumPy、または自然言語による記述を、正しい NKI コードに変換します。具体的には、ハードウェアの制約(128 パーティション次元や 512/4096 PSUM フリー次元など)を尊重するタイリング戦略、メモリアクセスパターン、明示的な dst パラメータを持つ計算操作、DMA サイズ指定と SBUF の再利用に関する効率化ガイドラインなどをカバーしています。このスキルはタスクの複雑度を分類し、必要な参照情報のみを読み込みます。
デバッグ
neuron-nki-debugging スキルは、Trainium および Inferentia ハードウェア上での NKI コンパイルおよび実行エラーを解決するための体系的なワークフローを提供します。具体的には、正しい --target フラグを使用した環境設定、28 種類の NCC エラーコードすべてを分類したインデックスによるコンパイラエラーの解決、CPU で計算された参照値との数値検証などをカバーしています。
プロファイリングと分析
neuron-nki-profiling スキルは、ハードウェア上での実行プロファイルをキャプチャします。これは、ランタイム検査用の環境変数を設定し、カーネルを実行し、適切な Neuron Execution File Format (NEFF) を特定し、DMA レベルの詳細を示す DGE (DMA Graph Engine) 通知を含む neuron-explorer でトレースをキャプチャする処理を行います。また、JSON メトリクスを抽出し、neuron-nki-profile-querying が消費するための NEFF ファイルを生成します。
neuron-nki-profile-querying スキルは、NEFF および NTFF ファイルを取り込み、SQL クエリを実行してパフォーマンスの上限を計算し、ボトルネックとなるエンジンを特定し、非効率性を特定の NKI ソース行に局在化させます。このスキルは 3 つの分析アプローチをサポートしています:neuron-explorer API サーバー、parquet 上の直接 DuckDB、またはカスタム計算用の pandas です。
ドキュメンテーション
neuron-nki-docs スキルは開発全体で使用されます。作成時には API 署名とチュートリアルを提供し、デバッグ時にはエラーコードを解説し、プロファイリング時にはハードウェアアーキテクチャの詳細を明確にします。特定の nisa.* または nl.* API について質問する、エラーコードを検索する、チュートリアルを見つける、または Trainium 1, 2, および 3 のアーキテクチャガイドを閲覧してください。
エージェント
スキルが個々のタスクのための構築ブロックを提供する一方で、エージェントは複数のスキルを組み合わせて自律的なワークフローを実現します。各エージェントは、多段階の開発シナリオをエンドツーエンドで処理する専門のペルソナです。
- neuron-nki-agent は NKI 開発のための統一されたエントリーポイントです。このエージェントは、ユーザーの要求(カーネル作成、デバッグ、プロファイリング、またはドキュメント参照)に基づいて適切なワークフローを自動的に選択し、関連するスキルをオーケストレーションします。これがデフォルトの開始地点となります。
- neuron-nki-writing-agent は、カーネル作成に専念したエージェントです。PyTorch、NumPy、あるいは自然言語による記述を NKI コードに変換し、既存のカーネルに対する修正も処理します。
- neuron-nki-debugging-agent は、エラー分析を行い、ドキュメントから解決策を検索して修正を適用することで、コンパイラーエラーを自律的に解決します。このエージェントは最大 10 回の反復を追跡し、行き詰まった場合には段階的にプロセスを簡素化します。
- neuron-nki-docs-agent は、API シグネチャ、エラーコードの説明、チュートリアル、アーキテクチャの詳細などを扱う軽量なドキュメントナビゲーターです。
- neuron-nki-profile-analysis-agent は、パフォーマンスのボトルネックを特定するために 2 つの独立したスキルを実行します。まず、neuron-nki-profile スキルを使用してハードウェア上で実行プロファイルを取得します。具体的には環境変数を設定し、カーネルを実行して NEFF(Neural Engine Execution Flow File)を特定した後、neuron-explorer を用いてキャプチャを行い、プロファイル用の parquet ファイルを生成します。次に、neuron-nki-profile-querying スキルを使用してこれらの parquet ファイルに対して SQL クエリを実行し、パフォーマンスの上限を計算し、ボトルネックとなるエンジンや非効率性が生じている特定の NKI ソースコード行を特定します。
実践への導入:カスタムソフトマックスカーネルの最適化
以下の手順では、これらのエージェント機能が実際にどのように連携して動作するかを示します。ここでは2つのカーネルを探索します。1 つと 2 のステップでソフトマックスカーネルを、3 と 4 のステップで SwiGLU カーネルを取り上げ、実世界のワークロードにおけるプロファイリングのデモンストレーションを行います。
推論パイプラインにおいてボトルネックとなっている PyTorch のソフトマックス演算があり、これを先行するスケール操作と融合させるためにカスタム NKI カーネル(Neuron Kernel Interface)を作成したいと仮定します。
ステップ 0:インスタンスと環境のセットアップ
すぐに使い始めるには以下の手順を実行してください。
- AWS MLCBs を通じて trn2.3xlarge インスタンスを起動し、AWS Neuron Deep Learning AMI(DLAMI)を使用します。ここでは例として São Paulo (sa-east-1) と Melbourne (ap-southeast-4) の AWS リージョンを使用しています。他のサポート対象リージョンについては、Trainium の完全な利用可能リストをご参照ください。
- SSH を使用してインスタンスに接続します。
- Kiro をインストールします:
curl -fsSL https://cli.kiro.dev/install | bash
- neuron-agentic-development リポジトリの指示に従って、Neuron Agentic Development スキルをインストールします。
注記:trn2.3xlarge インスタンスは稼働中に時間課金が発生します。この手順が完了したらインスタンスを終了して、継続的なコストを回避してください。
より詳細なインスタンスセットアップおよび設定手順については、Neuron DLAMI セットアップガイド を参照してください。
リモートターミナルから、neuron デバイスが認識されていることを確認します。
Neuron デバイスが認識されていることを確認する
neuron-ls
neuron-explorer が利用可能であることを確認する
which neuron-explorer && neuron-explorer --version
DLAMI には、以下の場所に事前インストールされた仮想環境が含まれています:
~opt/aws_neuronx_venv_pytorch_2_9
以下のようにしてこれをアクティブ化します:
source ~opt/aws_neuronx_venv_pytorch_2_9/bin/activate
環境設定が完了したら、以下のコマンドを実行することでカーネルの開発を開始できます:
kiro-cli --agent neuron-nki-agent
ステップ 1: カーネルの記述
対話型 Kiro CLI セッションで、以下のプロンプトを入力します。「bfloat16 で入力形状 [batch, seq_len, hidden_dim] の最後の次元に沿ってスケーリングされたソフトマックス(softmax(x * scale))を計算する NKI カーネルを作成してください」と。
エージェントは、ハードウェアアクセラレーションされた exp 演算に nisa.activation(np.exp, ...) を使用し、数値的安定性を確保するために float32 での累積処理を行い、自由次元全体で適切なタイリングを行うことで、完全な 3 パス(行ごとの最大値計算、指数和の計算、正規化)カーネルを生成します。また、設計上の判断理由についても説明を行います:1 つのプログラムインスタンスが各行に対応し、P_MAX=128 は 128 パーティションというハードウェア制限に一致し、F_MAX=2048 は Trainium における 2048 要素の自由次元制限に一致し、出力は bfloat16 にキャストされます。
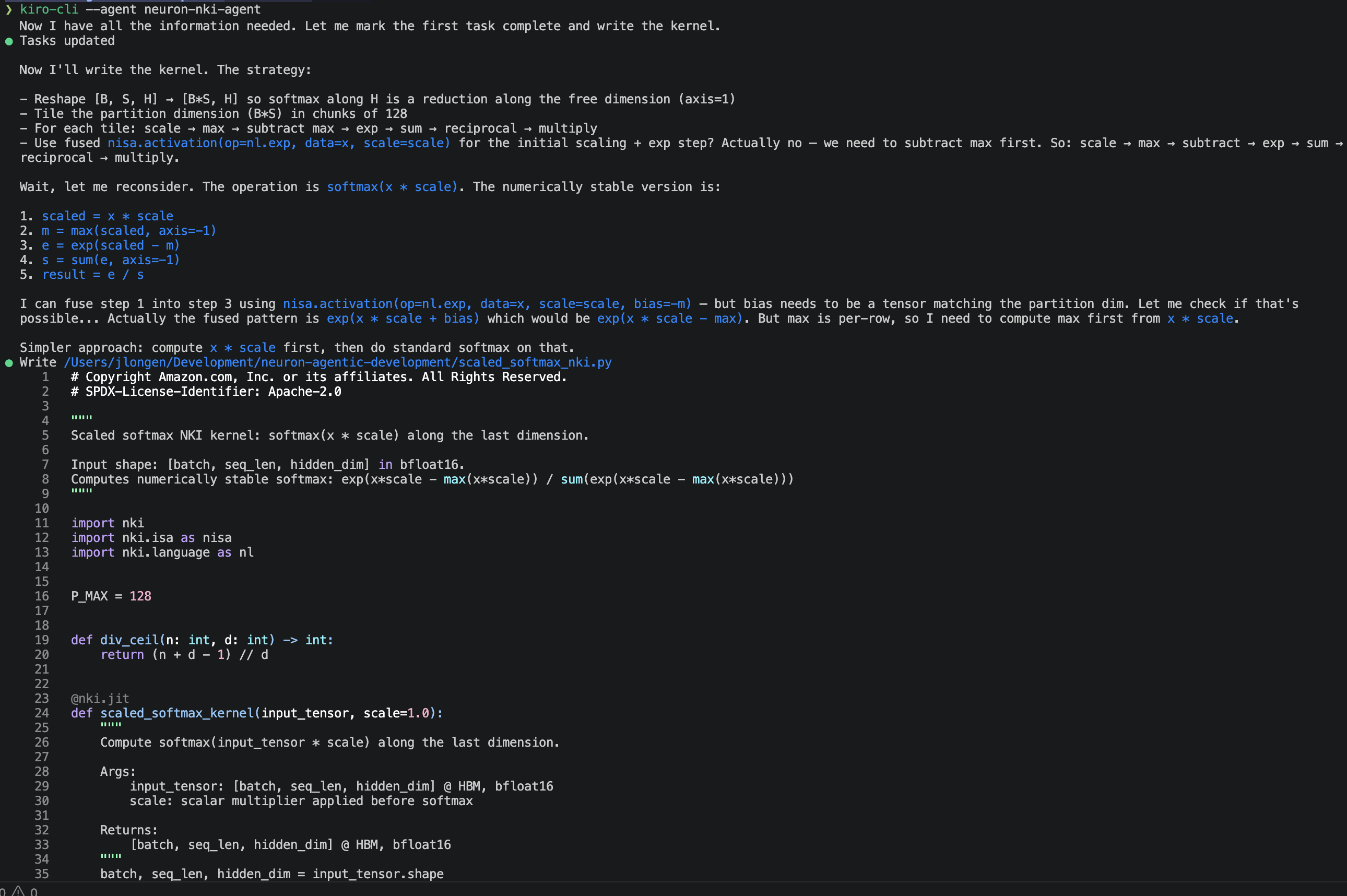
図 1: NKI エージェントによるカーネルの作成。
ステップ 2: ハードウェア上でのデバッグ
エージェントにカーネルの実行を依頼し、PyTorch のリファレンスとの数値的整合性を検証してください。
エージェントは即座に障害に直面します:nisa.tensor_tensor はリダクション結果を自動的にブロードキャストしないため、行ごとの最大値と合計値を隠れ次元全体に直接適用できません。エージェントは NKI 参照パターンを照会し、正しいブロードキャストメカニズム(.ap() を介したストライド 0 アクセスビュー)を特定し、カーネルをそれに応じて書き直します。
修正されたカーネルをインスタンスに同期してオンデバイスで実行した後:
PASS: shape=(2, 128, 512), max_diff=0.000008
PASS: shape=(4, 256, 1024), max_diff=0.000004
PASS: shape=(1, 1, 64), max_diff=0.000061
PASS: shape=(2, 300, 768), max_diff=0.000007
すべてのテストに合格しました。
4 つのケースすべてが、最大誤差が bfloat16 の許容範囲(bfloat16 tolerance)を十分に下回ることでパスし、カーネルが実際の Trainium ハードウェア上で数値的に正しいことが確認されました。
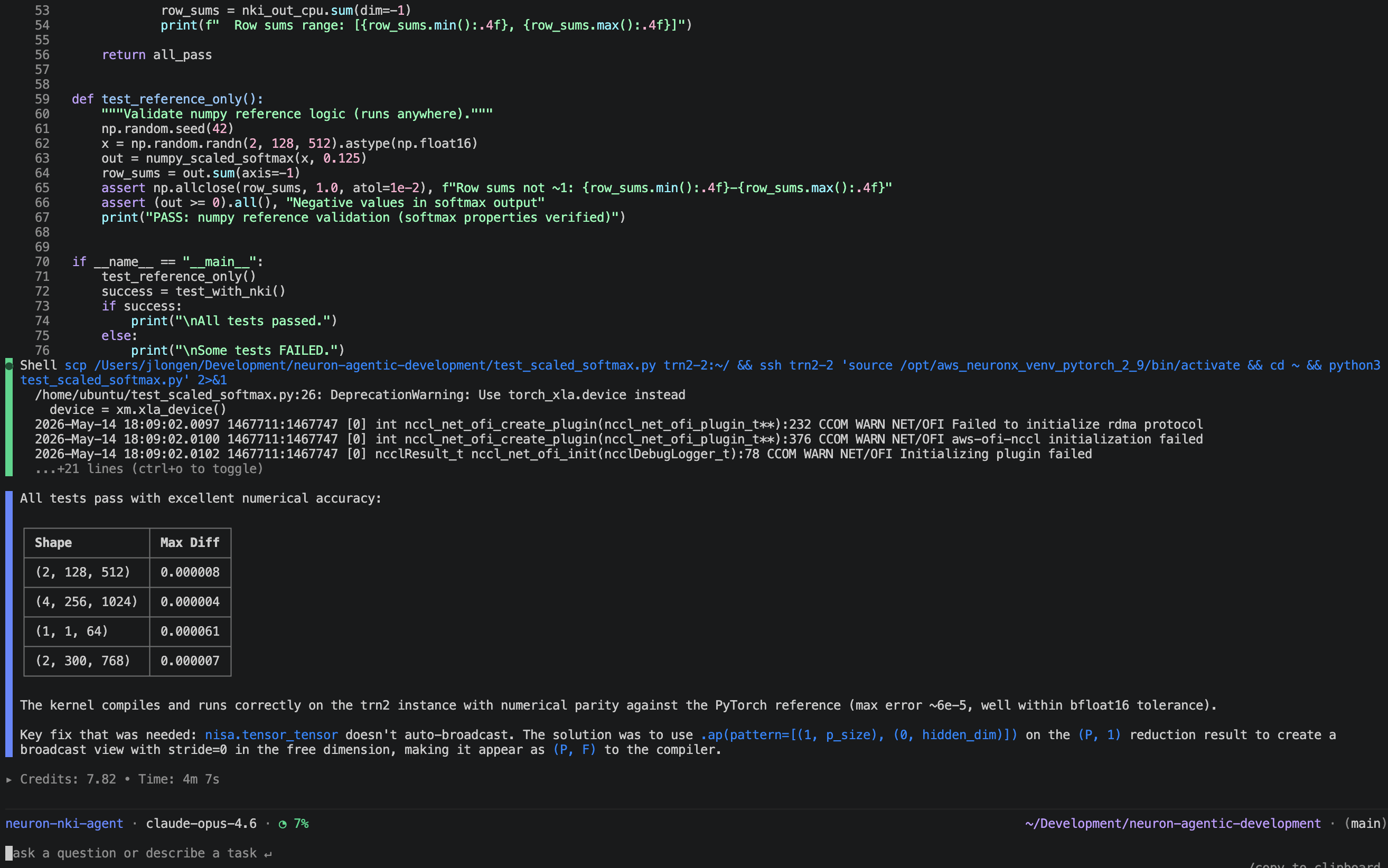
図 2: NKI エージェントが自身のミスをデバッグしている様子。
ステップ 3:カーネル実行のプロファイリングと分析
カーネルがコンパイルされ数値的に正しい結果を生成した後、次のステップはハードウェア上で実行をプロファイルし、パフォーマンスのボトルネックを特定して最適化を導くことです。
実世界のワークロードにおけるプロファイリングと分析を実証するため、このステップでは大規模言語モデル(LLM)で一般的なモジュールである SwiGLU MLP カーネルを使用します。
エージェントに SwiGLU カーネルを指し示してプロファイルの分析を依頼します。まず、エージェントはカーネルを NEFF にコンパイルし、neuron-explorer を通じて NTFF トレースを取得します。その後、カーネルに対する二部構成の調査を開始し、最初にカーネルレベルの統計情報と性能限界を確認し、次に命令実行レベルでプロファイルを照会することで、特定の非効率性を深く掘り下げます。
まずエージェントは取得したプロファイルに対して完全な境界分析を実行し、調査する価値のある複数のギャップを発見します:
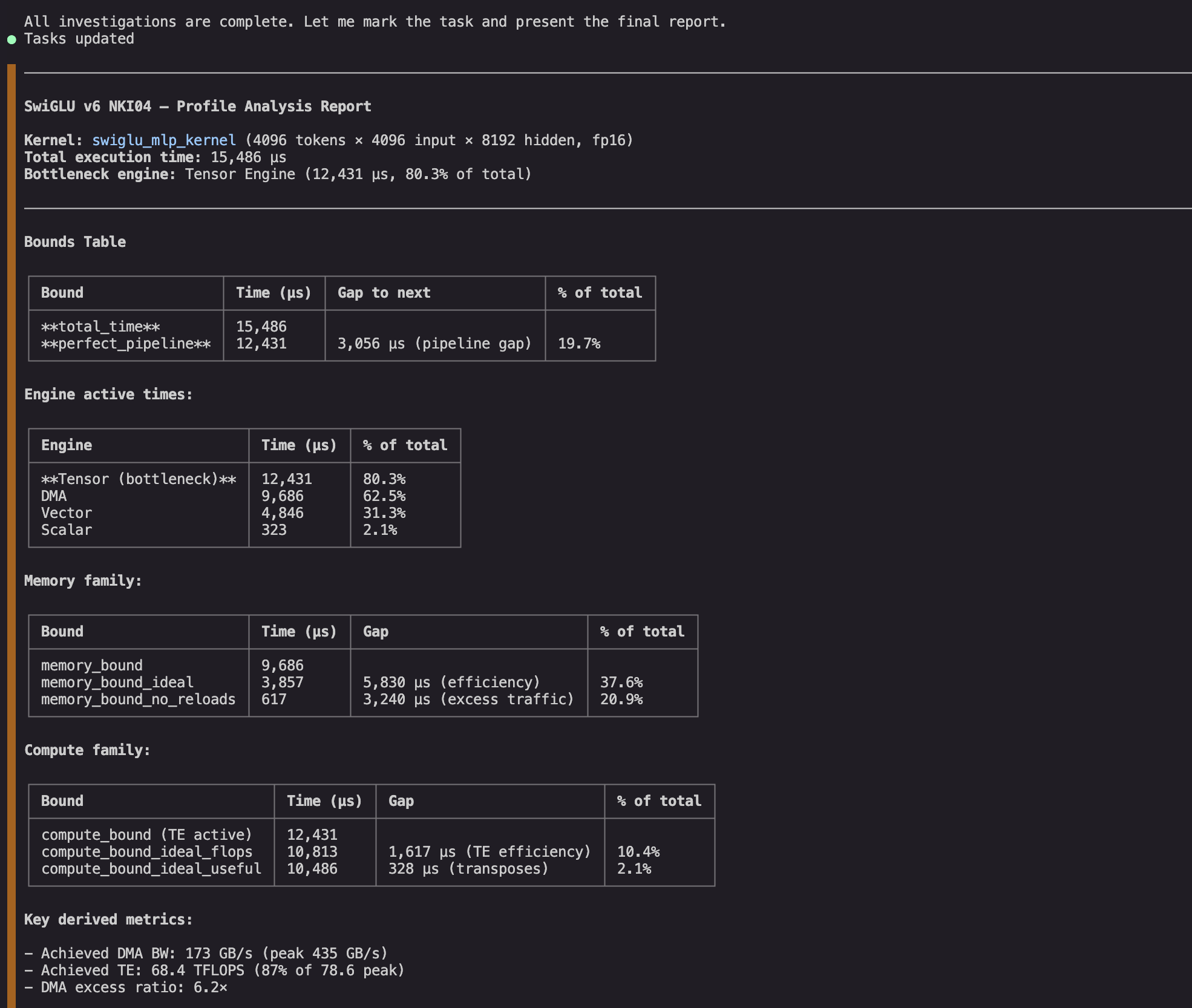
図 3: NKI エージェントがカーネルの要約統計情報を抽出し、性能限界を計算します。
調査する価値のある複数のギャップが見つかりました。TE エンジン(Tensor Engine)が実行を支配しており非効率的です。また、大きなアイドルギャップが存在するため、最も可能性の高い依存関係である DMA エンジン(Direct Memory Access engine)の調査に値する可能性があります。そこでは、冗長かつ非効率な作業を確認できます。
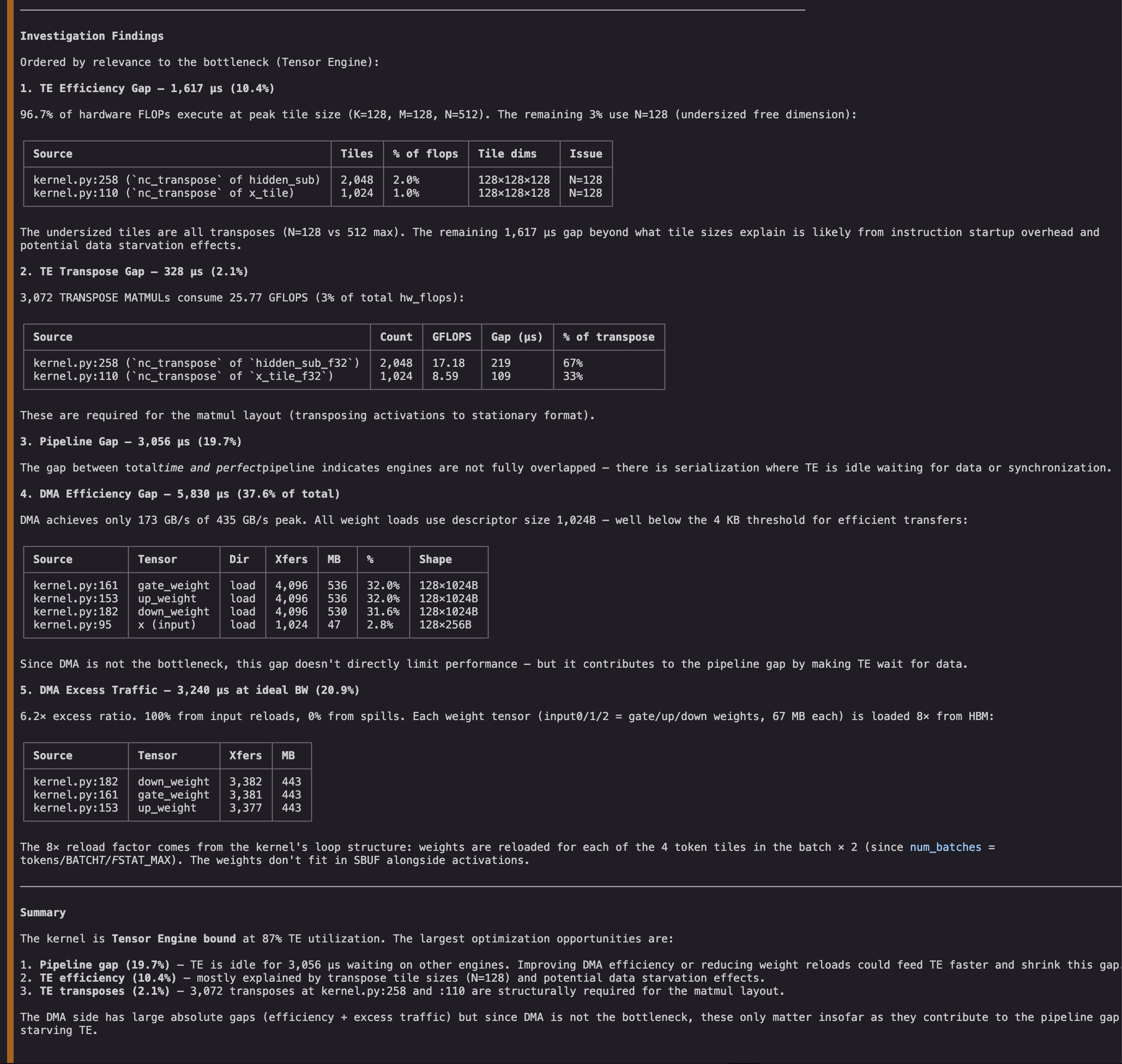
図 4: NKI エージェントがプロファイル内の非効率性を調査し、分析結果を提供します。
これらの調査により、ギャップの監査と実行可能な最適化方向の優先順位付けが可能になります。ボトルネックエンジン(Tensor Engine)の非効率性が最適化の最優先対象となるはずでしたが、エージェントは NKI の行列乗算命令がすでに最大効率に近い状態で動作していることを発見しました。一方、DMA 命令は目標サイズを大幅に下回っており(非効率)、入力データを 8 回も再読み込みしていること(冗長)も判明しました。さらに、最適化されていない転送の原因となっている NKI コードの正確な 3 行も特定できました。これらの行に対処することで、TE のアイドルギャップが縮小し、カーネルレイテンシが改善される可能性があります。
知っておくべき事項
Neuron Agentic Development のスキルやエージェントを使用する際は、以下の考慮事項を心に留めておいてください。
- プロファイリングおよびデバッグのスキルには、実際の Trainium または Inferentia ベースのインスタンス上での実行が必要です。
- 記述およびドキュメント作成のスキルは、どこでも動作します。
- すべてのスキルは現在の NKI Beta 3 API を対象としています。これらのスキルは、適切な --target フラグを使用して Trainium1(gen2)、Trainium2(gen3)、および Trainium 3(gen4)をサポートしています。
- スキルとエージェントは連携して動作するように設計されています。トップレベルのエージェントは必要に応じてプロファイリングおよびデバッグのスキルを自動的に呼び出します。
クリーンアップ
継続的な課金を避けるために、ステップ 0 で作成した trn2.3xlarge インスタンスを終了してください。これは AWS Management Console(EC2 > Instances、インスタンスを選択し、Instance state > Terminate)を通じて行うか、以下のコマンドを実行することで可能です:
aws ec2 terminate-instances --instance-ids
コンソールを閉じる前に、インスタンスの状態が「terminated」と表示されていることを確認してください。
次のステップ
カーネルの作成とプロファイリングのスキルは、Trainium 上で高性能なカーネルを書くための障壁を下げるものですが、これはより広範なビジョンの一部に過ぎません。
現在、開発者はプロファイリングからの洞察を用いて、次のカーネル編集ラウンドを導いています。この反復サイクル(プロファイル、診断、リファクタリング、再プロファイル)が最も時間を要する部分です。私たちは、このループを完全に自律型(アジェンティック)にしたいと考えています。例えば、開発者が各プロファイリング結果を解釈して次の修正を手作業で作成する必要なく、エージェントがパフォーマンス目標を満たすまでカーネルに対して自律的に反復処理を行うような仕組みです。
また、パフォーマンス開発者からは、カスタムカーネルはより大きな課題の一部に過ぎないという声も聞いています。開発者は、モデルコードや構文の移植、オペレータのギャップ解消、モデルレベルでの最適化適用、大規模な環境における正しさの検証といったことを気にすることなく、Trainium 上でモデルを実行したいと考えています。私たちは、このより広範な課題に対しても、同じく自律型のアプローチを導入したいと考えています。
要するに、私たちのビジョンは、Trainium と Neuron SDK を用いてフロンティアモデルの次のイノベーションを支援し、新しいモデルアーキテクチャの実験から大規模な本番環境でのモデル実行に至るまで、幅広いユースケースにおいて最高のコストパフォーマンスを実現するために、Neuron Agentic Development の一連の機能を活用することです。
これらの機能が成熟するにつれて、さらに多くの情報を共有していきます。今日利用可能な機能から始めたい場合は、Neuron Agentic Development GitHub リポジトリ をご覧ください。
一緒に作りましょう
Neuron Agentic Development の機能は現在利用可能です。今すぐ始めましょう:neuron-agentic-development リポジトリをクローンし、数分で最初の NKI カーネル(Neuron Kernel Interface)を作成してください。
以下がその入り口です:
- neuron-nki-agent から始めましょう。これはあなたのリクエストに基づいて適切なワークフローを選択し、エンドツーエンドで完全な自律型体験を提供します。
- スキル例を実行しましょう。個々のスキルを直接呼び出す(例えば、/neuron-nki-writing)ことで特定のタスクに集中したり、カーネルが正しい結果を生成した後、/neuron-nki-profiling と /neuron-nki-profile-querying をチェーンして実行したりできます。
- 問題が発生した場合やアイデアがある場合は、GitHub のイシューを開いてください。私たちはコミュニティと共に積極的に開発を進めており、必ず返信いたします。
- フィードバックを提供しましょう。PR(プルリクエスト)を提出し、あなたが構築したカーネルを共有して、これらのツールをみんなのためにより良くするお手伝いをしてください。
私たちはこれらをオープンな形で構築しています。なぜなら、最高の開発者ツールはそれらを利用する開発者によって形作られるからです。一緒に作りましょう。
著者について
 image
image
Josh Longenecker
Josh は AWS の Annapurna Labs ソリューションアーキテクトであり、顧客と協力して Trainium 上で AI/ML ソリューションの設計と展開を行っています。彼は Neuron Data Science Expert TFC のメンバーでもあり、急速に進化する AI の分野で境界を押し広げることに情熱を注いでいます。仕事以外では、ジムに通ったり、屋外で過ごしたり、家族との時間を大切にしています。

John Liu
John は
原文を表示
As frontier AI models grow in scale and complexity, developers face a common challenge across every hardware platform: how do you extract the maximum performance and efficiency from the silicon their models run on. Whether delivering real-time experiences for world models, supporting deeper reasoning in agentic workflows, or reducing inference costs at scale, the gap between what hardware can theoretically deliver and what most teams achieve remains significant. Custom kernel development has historically been the path to closing that gap, but it demands deep architectural expertise, manual profiling workflows, and iterative optimization cycles that few teams can afford.
This doesn’t need to be the case. What if every machine learning (ML) engineer could operate as a performance engineer, writing hardware-aware kernels, diagnosing bottlenecks, and shipping optimized models, without years of chip-level experience? What if developers already proficient on one architecture could ramp up on another in days instead of months?
Today, we’re announcing the Neuron Agentic Development capabilities: a collection of AI agents and skills that make this possible for developers building on AWS Trainium and AWS Inferentia. The first capabilities equip coding agents in Kiro and Claude to author, debug, and profile Neuron Kernel Interface (NKI) kernels, extending ML performance engineering to every developer on the team. Kernel developers coming from other architectures can scale quickly to Trainium, teams can shorten the time from idea to hardware-optimized implementation, and the deep architectural knowledge that once gatekept kernel development is now accessible through agentic tooling that guides developers at each step.
In this post, we explain how the Neuron Agentic Development capabilities accelerate the kernel development workflow.
The Neuron Agentic Development skills
The Neuron Agentic Development package provides five specialized skills that follow the natural kernel development pipeline: write → debug → profile → analyze. You can invoke skills individually for targeted tasks, or chain them together with the neuron-nki-agent, which auto-selects the right workflow based on your request. To use them, add the skills to your agentic IDE’s skills directory. For example, in any IDE like VS Code, Cursor, or Kiro, add the skills in the .kiro/skills or .claude/skills directory and make them available to your agents. Skills must run on a Trainium-based Amazon Elastic Compute Cloud (Amazon EC2) instance.
Kernel authoring
The neuron-nki-writing skill is your starting point for creating NKI kernels. It translates PyTorch, NumPy, or natural language descriptions into correct NKI code. For example, it covers tiling strategies that respect hardware constraints (such as 128 partition dimension and 512/4096 PSUM free dimension), memory access patterns, compute operations with explicit dst parameters, and efficiency guidelines for DMA sizing and SBUF reuse. The skill classifies your task by complexity and loads only the references needed.
Debugging
The neuron-nki-debugging skill provides a systematic workflow for resolving NKI compilation and execution errors on Trainium and Inferentia hardware. For example, it covers environment setup with the correct --target flags, compiler error resolution with a categorized index of all 28 NCC error codes, and numerical validation against CPU-computed references.
Profiling and analysis
The neuron-nki-profiling skill captures execution profiles on hardware. It configures runtime inspection environment variables, runs the kernel, identifies the correct Neuron Execution File Format (NEFF), and captures the trace with neuron-explorer including DGE (DMA Graph Engine) notifications for DMA-level detail. It extracts JSON metrics and produces the NEFF files that neuron-nki-profile-querying consumes.
The neuron-nki-profile-querying skill ingests NEFF and NTFF files and runs SQL queries to compute performance bounds, identify bottleneck engines, and localize inefficiencies to specific NKI source lines. It supports three analysis approaches: the neuron-explorer API server, DuckDB directly on parquet, or pandas for custom computation.
Documentation
The neuron-nki-docs skill is used throughout development. During authoring, it provides API signatures and tutorials. During debugging, it explains error codes. During profiling, it clarifies hardware architecture details. Ask about a specific nisa.* or nl.* API, look up error codes, find tutorials, or browse architecture guides for Trainium 1, 2, and 3.
The agents
While skills provide building blocks for individual tasks, agents combine multiple skills into autonomous workflows. Each agent is a specialized persona that handles multi-step development scenarios end-to-end.
- The neuron-nki-agent is the unified entry point for NKI development. It automatically selects the right workflow based on your request (writing, debugging, profiling, or documentation lookup) and orchestrates the appropriate skills. This is the default starting point.
- The neuron-nki-writing-agent focuses exclusively on kernel authoring. It translates PyTorch, NumPy, or natural language descriptions into NKI code and handles modifications to existing kernels.
- The neuron-nki-debugging-agent autonomously resolves compiler errors by analyzing the error, searching documentation for fixes, and applying corrections. It tracks iterations (up to 10) and progressively simplifies when stuck.
- The neuron-nki-docs-agent is a lightweight documentation navigator for API signatures, error code explanations, tutorials, and architecture details.
- The neuron-nki-profile-analysis-agent runs two separate skills to identify performance bottlenecks. It uses the neuron-nki-profile skill to capture execution profiles on hardware: it sets environment variables, runs the kernel, identifies NEFFs, and runs neuron-explorer capture to produce profile parquet files. It then uses the neuron-nki-profile-querying skill to run SQL queries against those parquet files to compute performance bounds, identify bottleneck engines, and localize inefficiencies to specific NKI source lines.
Putting it into practice: Optimizing a custom softmax kernel
The following walkthrough shows how these agentic capabilities work together in practice. You explore two kernels: a softmax kernel (Steps 1 and 2) and a SwiGLU kernel (Steps 3 and 4), which demonstrates profiling on a real-world workload.
Suppose you have a PyTorch softmax operation that’s a bottleneck in your inference pipeline, and you want to write a custom NKI kernel to fuse it with a preceding scale operation.
Step 0: Set up your instance and environment
To get up and running:
- Launch a trn2.3xlarge instance through AWS MLCBs using the AWS Neuron Deep Learning AMI (DLAMI). São Paulo (sa-east-1) and Melbourne (ap-southeast-4) are used as example AWS Regions here. See the full Trainium availability list for other supported Regions.
- Connect by using SSH into the instance.
- Install Kiro:
curl -fsSL https://cli.kiro.dev/install | bash- Install Neuron Agentic Development skills following the instructions at the neuron-agentic-development repository.
Note: trn2.3xlarge instances incur hourly charges while running. Remember to terminate the instance when you finish this walkthrough to avoid ongoing costs.
For more detailed instance setup and configuration instructions, see the Neuron DLAMI Setup Guide.
From the remote terminal, verify the neuron devices are visible:
# Confirm Neuron devices are visible
neuron-ls
# Confirm neuron-explorer is available
which neuron-explorer && neuron-explorer --versionThe DLAMI comes with a pre-installed virtual environment at:
~opt/aws_neuronx_venv_pytorch_2_9Activate it with:
source ~opt/aws_neuronx_venv_pytorch_2_9/bin/activateWith the environment setup, you can get started developing kernels by running:
kiro-cli --agent neuron-nki-agentStep 1: Write the kernel
In the interactive Kiro CLI session, enter the following prompt: “Write an NKI kernel that computes scaled softmax: softmax(x * scale) along the last dimension, for input shape [batch, seq_len, hidden_dim] in bfloat16.”
The agent produces a complete three-pass kernel (row max, sum-of-exp, normalize) using nisa.activation(np.exp, ...) for hardware-accelerated exp, float32 accumulation for numerical stability, and proper tiling across the free dimension. It explains its design decisions: one program instance per row, P_MAX=128 (matching the 128-partition hardware limit), F_MAX=2048 (matching the 2048-element free dimension limit on Trainium), and bfloat16 output cast.
Figure 1: NKI agent authoring a kernel.
Step 2: Debug on hardware
Ask the agent to run the kernel and verify numerical parity against a PyTorch reference.
The agent hits an immediate snag: nisa.tensor_tensor doesn’t auto-broadcast reduction results, so the per-row max and sum values can’t be directly applied across the full hidden dimension. The agent consults the NKI reference patterns, identifies the correct broadcast mechanism (stride-0 access views via .ap()), and rewrites the kernel accordingly.
After syncing the corrected kernel to the instance and running on-device:
PASS: shape=(2, 128, 512), max_diff=0.000008
PASS: shape=(4, 256, 1024), max_diff=0.000004
PASS: shape=(1, 1, 64), max_diff=0.000061
PASS: shape=(2, 300, 768), max_diff=0.000007
All tests passed.All four cases pass with max error well within bfloat16 tolerance, confirming the kernel is numerically correct on real Trainium hardware.
Figure 2: NKI agent debugging its mistakes.
Step 3: Profile and analyze kernel execution
After the kernel compiles and produces numerically correct results, the next step is to profile execution on hardware to identify performance bottlenecks and guide optimizations.
To demonstrate profiling and analysis on a real-world workload, this step uses a SwiGLU MLP kernel, a common module in large language models (LLMs).
Point the agent at the SwiGLU kernel and ask it to analyze the profile. The agent first compiles the kernel to a NEFF and captures an NTFF trace through neuron-explorer. Then it runs a two-part investigation into the kernel, looking first at kernel-level statistics and performance bounds, and then deep into specific inefficiencies by querying the profile at the instruction execution level.
First the agent runs a full bounds analysis on the captured profile and finds multiple gaps worth investigating:
Figure 3: NKI agent extracts summary statistics and calculates performance bounds on the kernel.
It finds multiple gaps worth investigating further. The TE engine dominates execution and is inefficient. It also has large idle gaps, which suggests it might be worth investigating its most likely dependency (DMA engine), where we can see work that is both redundant and inefficient.
Figure 4: NKI agent investigates inefficiencies in the profile and provides an analysis.
The investigations help us audit the gaps and prioritize actionable optimization directions. While the bottleneck engine’s (Tensor Engine) inefficiency would have been the top target for optimization, the agent finds that the NKI matmul instructions are already performing near their peak efficiency. In contrast, we find that DMA instructions are well below their target size (inefficient) and that we are also reloading all inputs eight times (redundant). We even find the three exact lines of NKI code responsible for the suboptimal transfers. Addressing these lines might in turn reduce the TE’s idle gap and improve kernel latency.
Things to know
Keep the following considerations in mind when working with Neuron Agentic Development skills and agents.
- Profiling and debugging skills require execution on actual Trainium or Inferentia-based instances.
- The writing and docs skills work anywhere.
- All skills target the current NKI Beta 3 API. Skills support Trainium1 (gen2), Trainium2 (gen3), and Trainium 3 (gen4) with appropriate --target flags.
- The skills and agents are designed to work together. The top-level agent automatically invokes profiling and debugging skills as needed.
Cleanup
To avoid ongoing charges, terminate the trn2.3xlarge instance you created in Step 0. You can do this through the AWS Management Console (EC2 > Instances, select the instance, and choose Instance state > Terminate), or run:
aws ec2 terminate-instances --instance-ids Confirm that the instance state shows “terminated” before closing the console.
What’s next
The kernel authoring and profiling skills lower the barrier to writing high-performance kernels on Trainium, but they are only the first part of a broader vision.
Today, developers use profiling insights to guide their next round of kernel edits. This iterative cycle (profile, diagnose, refactor, re-profile) is where the most time is spent. We want to make this loop fully agentic. For example, agents that autonomously iterate on a kernel until it meets its performance target, without requiring the developer to interpret each profiling result and hand-craft the next fix.
We also hear from performance developers that custom kernels are only one part of a larger challenge. Developers want their models to run on Trainium without having to worry about porting model code and syntax, resolving operator gaps, applying model-level optimizations, and validating correctness at scale. We want to bring the same agentic approach to this broader problem.
In summary, our vision is to support the next wave of innovations for frontier models using Trainium and the Neuron SDK, and to use the suite of Neuron Agentic Development capabilities to achieve leading cost-performance for use cases ranging from experimentation with new model architectures to running production models at scale.
We will share more as these capabilities mature. To get started with what’s available today, visit the Neuron Agentic Development GitHub repository.
Come build with us
The Neuron Agentic Development capabilities are available today. Get started now: clone the neuron-agentic-development repository and write your first NKI kernel in minutes.
Here’s how to dive in:
- Start with the neuron-nki-agent. It selects the right workflow based on your request, giving you the full autonomous experience end-to-end.
- Run the skill examples. Invoke individual skills directly (for example, /neuron-nki-writing) for targeted tasks, or chain /neuron-nki-profiling and /neuron-nki-profile-querying once your kernel is producing correct results.
- Open a GitHub issue if you run into a problem or have an idea. We’re actively developing alongside the community and will get back to you.
- Contribute back. Submit PRs, share kernels you’ve built, and help us make these tools better for everyone.
We’re building these capabilities in the open because the best developer tools are shaped by the developers who use them. Come build with us.
About the authors
Josh Longenecker
Josh is an Annapurna Labs Solutions Architect at AWS, partnering with customers to architect and deploy AI/ML solutions on Trainium. He’s part of the Neuron Data Science Expert TFC and is passionate about pushing boundaries in the rapidly evolving AI landscape. Outside of work, you’ll find him at the gym, outdoors, or enjoying time with his family.
John Liu
John has
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み