オープンウェイトLLMの春の夢:2026年1月から2月の10のアーキテクチャ
2026年春にリリースされた10のオープンウェイトLLMをまとめ比較。オープンソースAIモデルの進展を示す。
キーポイント
2026年1-2月にリリースされた10のオープンウェイトLLMアーキテクチャを比較分析
Arcee AIのTrinity Large(400B MoE)など大規模モデルの詳細な技術的特徴を解説
オープンウェイトモデルの多様化と専門化(コーディング特化、小型化など)のトレンドを提示
影響分析・編集コメントを表示
影響分析
この記事は、オープンウェイトLLMの急速な進化と多様化を示しており、企業間の競争激化と技術の民主化が進んでいることを示唆している。特にMoEアーキテクチャの普及とモデルサイズの多様化(400Bから小型モデルまで)は、今後のLLM開発の方向性に影響を与える可能性が高い。
編集コメント
Sebastian Raschkaによる技術的に深い分析で、2026年初頭のオープンウェイトLLM動向を包括的に把握できる貴重な資料。特にMoEアーキテクチャの詳細な比較は実務者にとって参考になる。
オープンウェイトLLMの春の夢:2026年1月~2月に登場した10のアーキテクチャ
オープンウェイトLLMの春の夢:2026年1月~2月に登場した10のアーキテクチャ
2026年春にリリースされた10のオープンウェイトLLMのまとめと比較
 Sebastian Raschka, PhD 2026年2月25日 442シェア
Sebastian Raschka, PhD 2026年2月25日 442シェア
今月、オープンウェイトモデルのリリースに追いつくのに少し苦労しているなら、この記事で主要なテーマをキャッチアップできるでしょう。
この記事では、10の主要リリースを時系列順に解説し、アーキテクチャの類似点と相違点に焦点を当てます:
Arcee AIのTrinity Large(2026年1月27日)
Moonshot AIのKimi K2.5(2026年1月27日)
StepFun Step 3.5 Flash(2026年2月1日)
Qwen3-Coder-Next(2026年2月3日)
z.AIのGLM-5(2026年2月12日)
MiniMax M2.5(2026年2月12日)
Nanbeige 4.1 3B(2026年2月13日)
Qwen 3.5(2026年2月15日)
Ant GroupのLing 2.5 1T & Ring 2.5 1T(2026年2月16日)
CohereのTiny Aya(2026年2月17日)
(追記:DeepSeek V4はリリース次第追加予定です。)
扱う範囲が広いため、本記事では特定の技術トピック(Mixture-of-Experts、QK-Norm、Multi-head Latent Attentionなど)の背景情報として、以前の記事「The Big LLM Architecture Comparison」を参照し、本記事内での重複を避けます。
- Arcee AIのTrinity Large:オープンウェイトモデルを公開する新興米国スタートアップ
1月27日、Arcee AI(それまで私のレーダーに捉えていなかった企業)は、モデルハブ上でオープンウェイトの400BパラメータLLM「Trinity Large」のバージョンと、2つの小型バリアントの公開を開始しました:
彼らの主力大規模モデルは、130億の活性化パラメータを持つ4000億パラメータのMixture-of-Experts(MoE)です。
2つの小型バリアントは、Trinity Mini(活性化パラメータ30億の260億パラメータ)とTrinity Nano(活性化パラメータ10億の60億パラメータ)です。
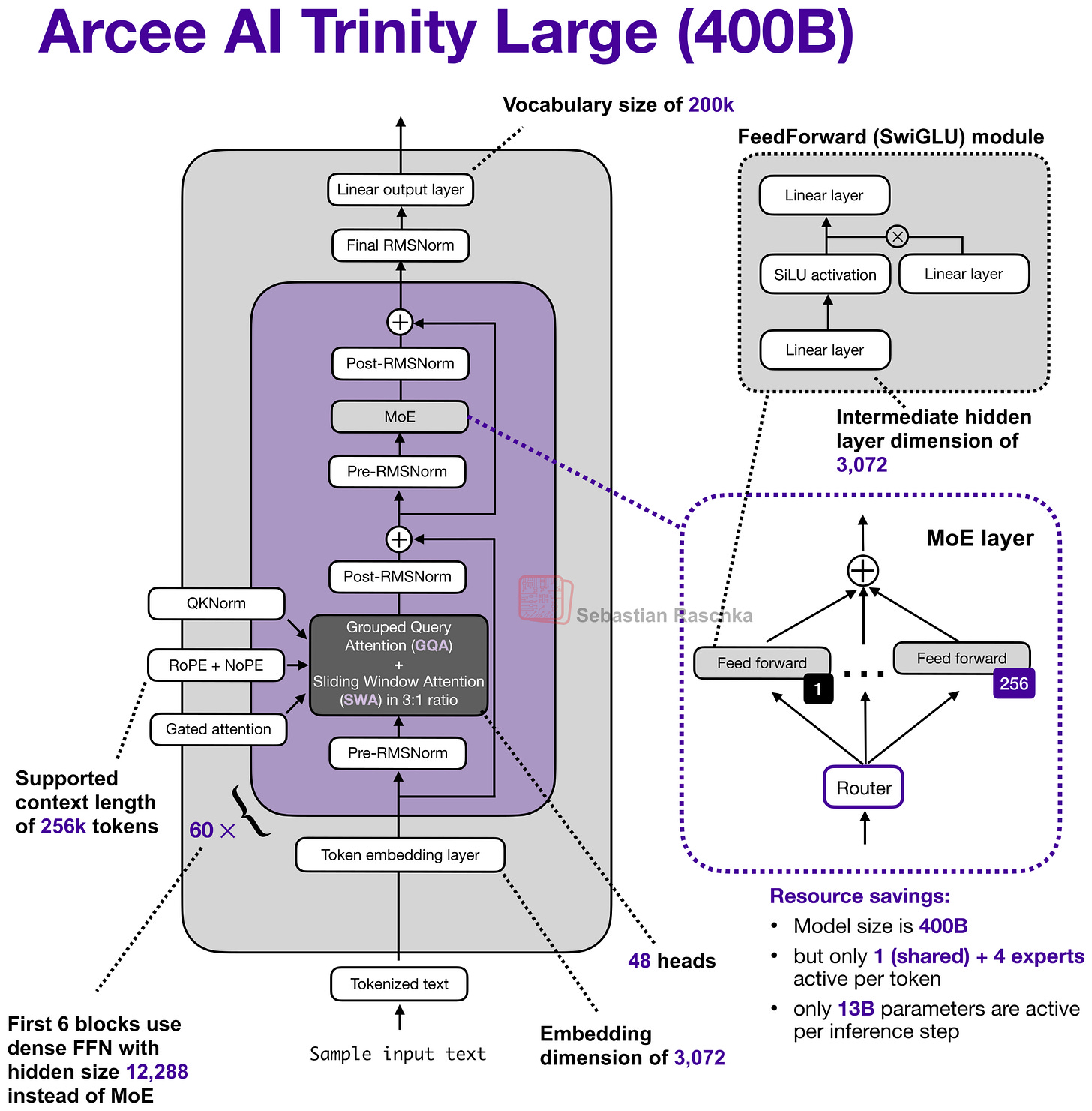 図1:Trinity Largeアーキテクチャの概要(モデルハブの設定ファイルに基づく)。
図1:Trinity Largeアーキテクチャの概要(モデルハブの設定ファイルに基づく)。
モデルウェイトと共に、Arcee AIはGitHub上で(2月18日現在arXivにも)詳細な技術レポートも公開しました。
それでは、4000億パラメータの主力モデルを詳しく見てみましょう。下の図2は、規模が類似する3550億パラメータを持つz.AIのGLM-4.5と比較したものです。
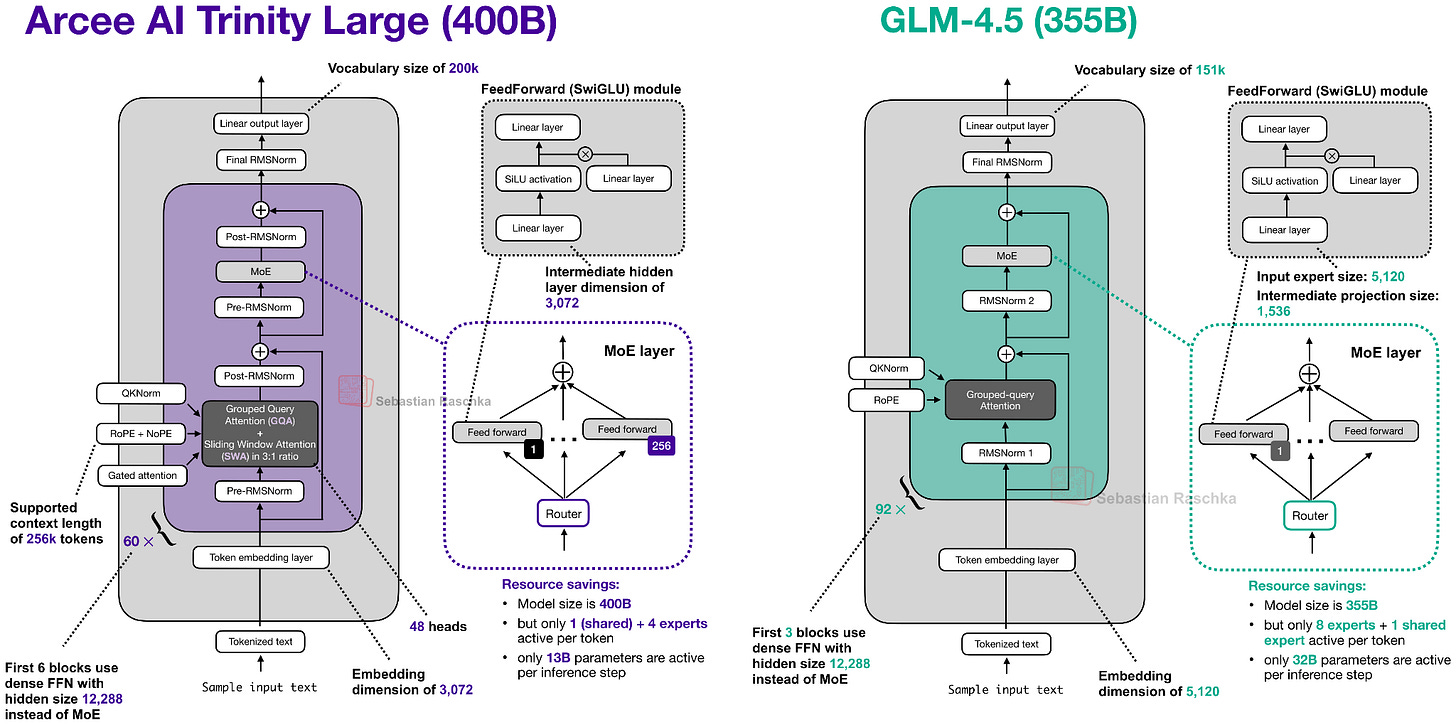 図2:比較的類似した規模(4000億 vs 3550億)のGLM-4.5と並べたArcee AI Trinity Large。
図2:比較的類似した規模(4000億 vs 3550億)のGLM-4.5と並べたArcee AI Trinity Large。
TrinityとGLM-4.5の比較で分かるように、Trinityモデルにはいくつかの興味深いアーキテクチャ構成要素が追加されています。
まず、Gemma 3、Olmo 3、Xiaomi MiMoなどに見られる、ローカル:グローバル(スライディングウィンドウ)アテンション層の交互配置(SWA)があります。簡単に言えば、SWAは一種のスパース(ローカル)アテンションパターンで、各トークンが入力全体(最大n=256,000トークン)にアテンションする代わりに、最近のtトークン(例えば4096)の固定サイズウィンドウにのみアテンションします。これにより、シーケンス長nに対するレイヤーごとの通常アテンションのコストがO(n²)からおよそO(n·t)に削減され、長文脈モデルにとって魅力的な理由となっています。
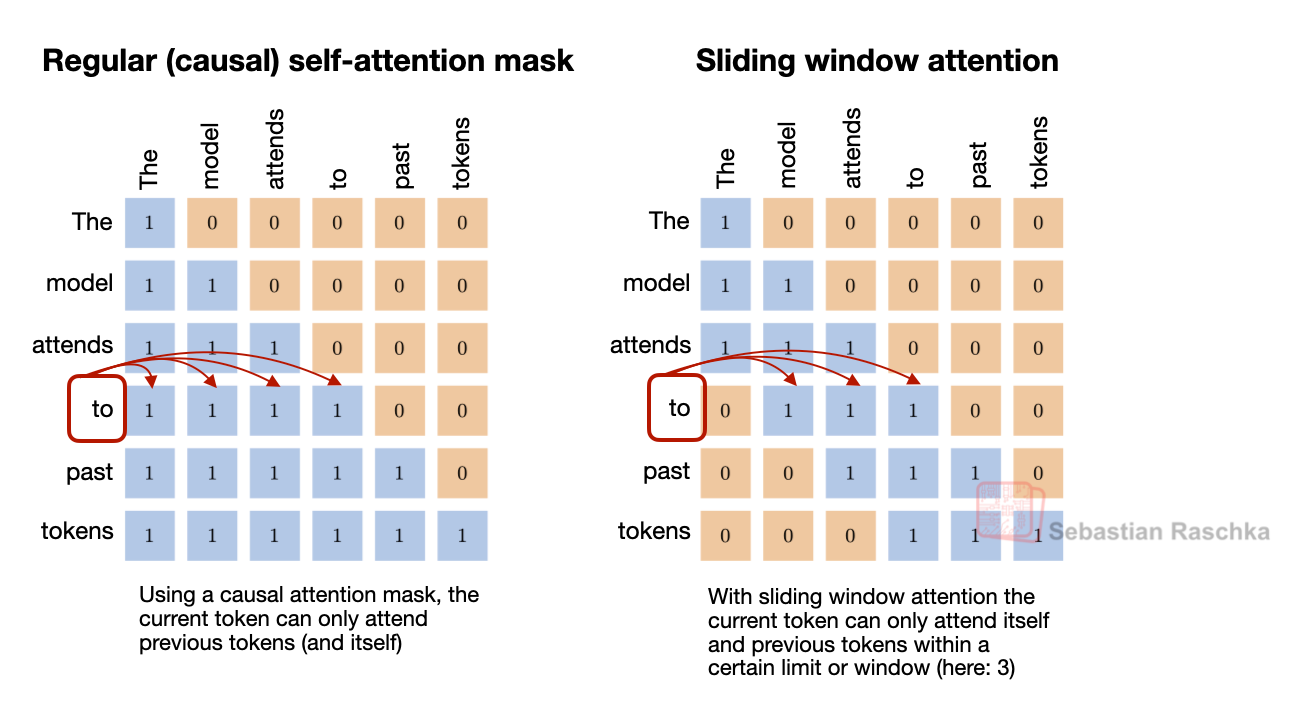 図3:通常のアテンション(グローバルアテンション)とスライディングウィンドウアテンション(ローカルアテンション)の比較。
図3:通常のアテンション(グローバルアテンション)とスライディングウィンドウアテンション(ローカルアテンション)の比較。
しかし、Gemma 3やXiaomiが使用した一般的な5:1のローカル:グローバル比率の代わりに、ArceeチームはOlmo 3と同様の3:1の比率と、比較的大きな4096のスライディングウィンドウサイズ(これもOlmo 3と同様)を選択しました。
このアーキテクチャはまた、QK-Normを使用しています。これは、キーとクエリにRMSNormを適用して訓練を安定させる技術です(下図4参照)。さらに、SmolLM3と同様に、グローバルアテンション層では位置埋め込みを使用しません(NoPE)。
Trinityはまた、一種のゲート付きアテンションを持っています。本格的なGated DeltaNetではありませんが、Qwen3-Nextのアテンションメカニズムと同様のゲーティングを使用しています。
つまり、Trinityチームは標準的なアテンションを修正し、出力線形射影の前にスケーリングドット積に対して要素ごとのゲーティングを追加しました(下図参照)。これにより、アテンションシンクが減少し、長シーケンスの汎化性能が向上します。加えて、訓練の安定性にも寄与しました。
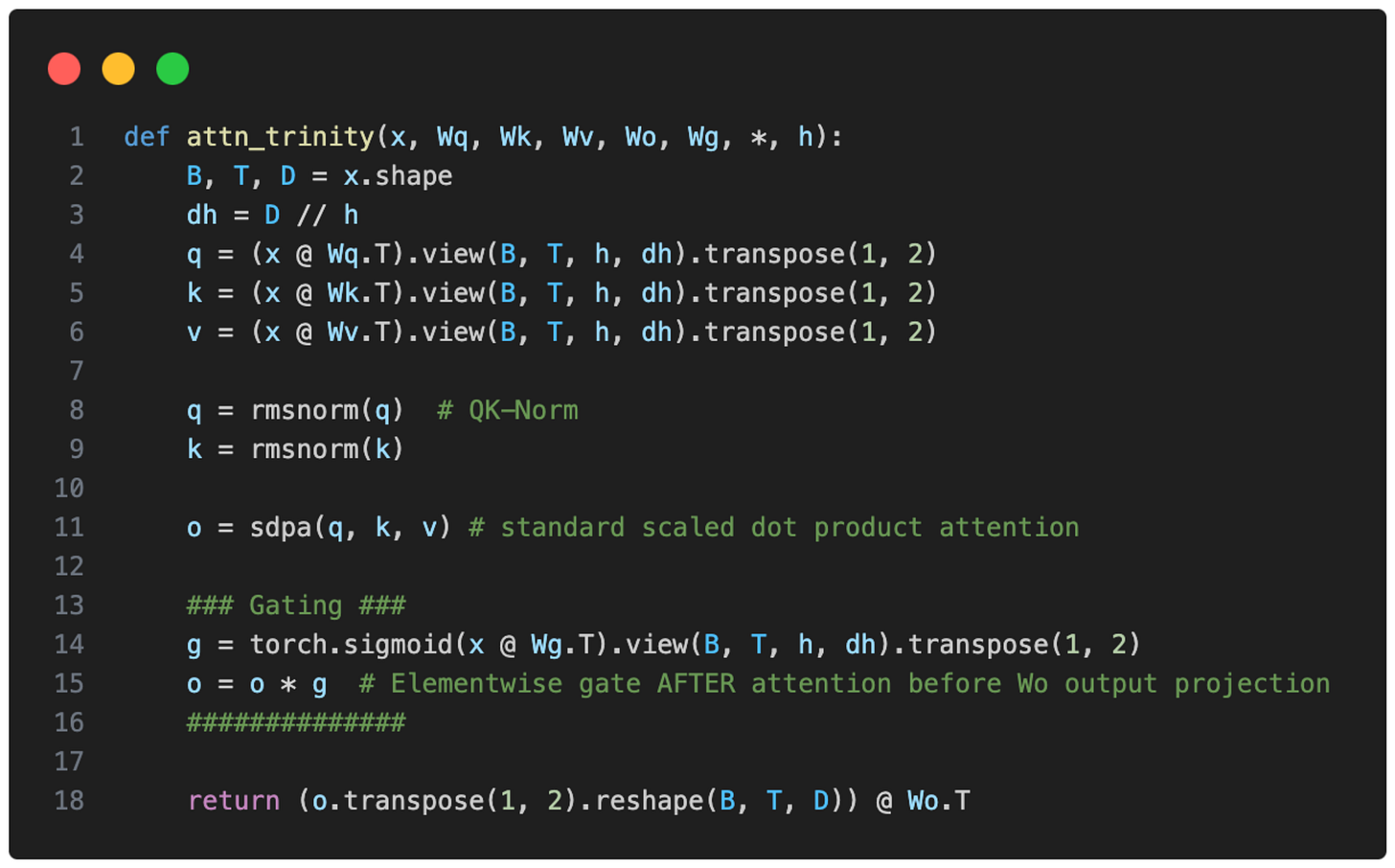 図4:Trinity Largeがアテンションメカニズムで使用するゲーティング機構の図解。
図4:Trinity Largeがアテンションメカニズムで使用するゲーティング機構の図解。
また、Trinityの技術レポートは、Trinity LargeとGLM-4.5のベースモデルのモデリング性能が実質的に同一であることを示しています(最近のベースモデルと比較しなかったのは、現在多くの企業がファインチューニング済みモデルのみを公開しているためだと思われます。)
先ほどのTrinity Largeアーキテクチャ図で、2つではなく4つのRMSNorm層が使用されていることに気付いたかもしれません。一見するとGemma 3に似ています。
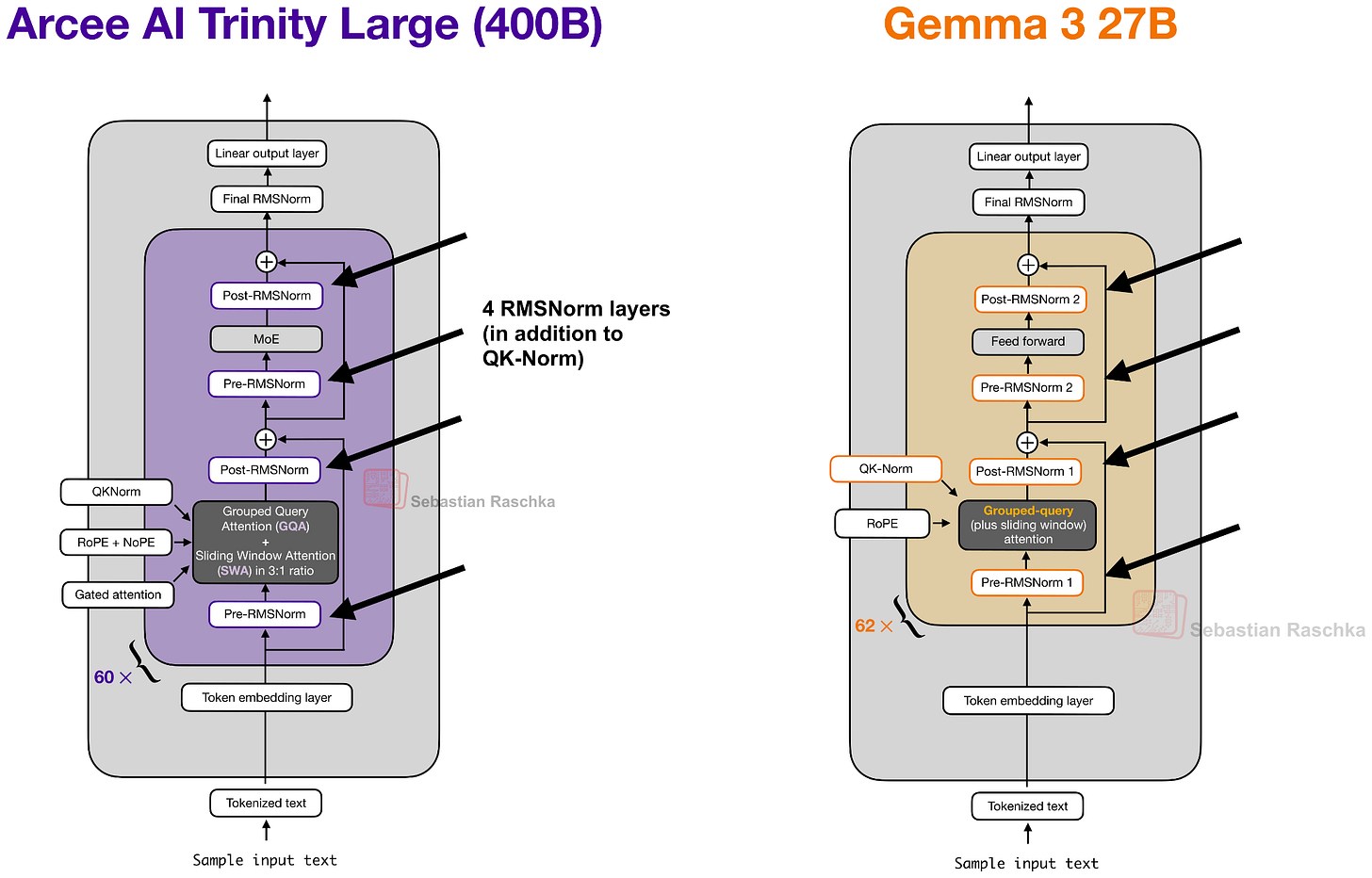 図5:Arcee TrinityとGemma 3のRMSNorm配置を並べて表示。
図5:Arcee TrinityとGemma 3のRMSNorm配置を並べて表示。
全体として、RMSNormの配置はGemma 3のようなRMSNorm配置に見えますが、ここでの工夫は、各ブロック内の2番目のRMSNormのゲインが深さ方向にスケーリングされている点です。つまり、約1 / sqrt(L)(Lは総レイヤー数)で初期化されます。したがって、訓練の初期段階では残差更新は小さく始まり、モデルが適切なスケールを学習するにつれて大きくなります。
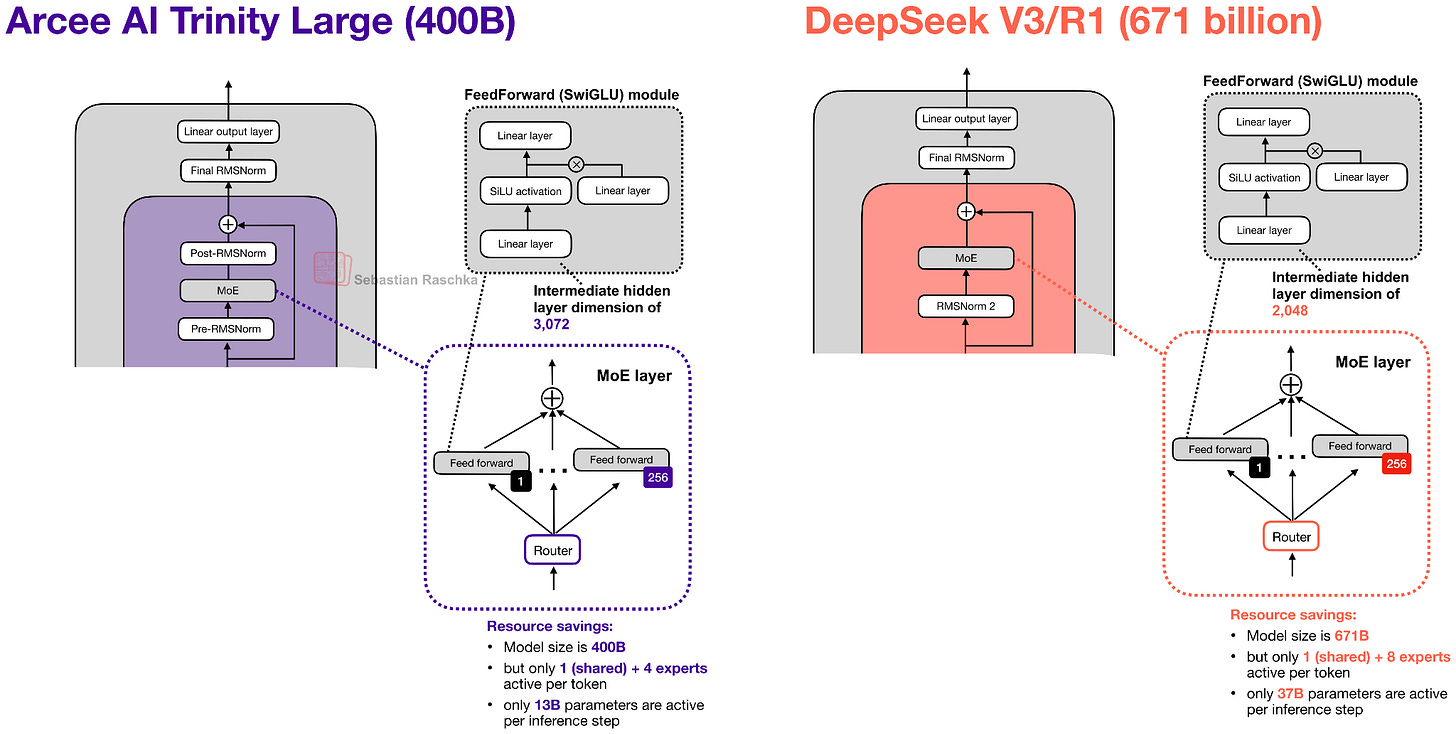 図6:Arcee TrinityとDeepSeek V3/R1 MoEを並べて表示。
図6:Arcee TrinityとDeepSeek V3/R1 MoEを並べて表示。
MoEは、多くの小さなエキスパートを持つDeepSeek風のMoEですが、推論スループット向上のために粗くしてあります(これは、DeepSeek V3アーキテクチャを採用したMistral 3 Largeでも見られたことです)。
最後に、訓練の改善に関する興味深い詳細(新しいMoE負荷分散戦略とMuOptオプティマイザの使用など)がありますが、これは主にアーキテクチャに関する記事であり(また、カバーすべきオープンウェイトLLMが他にも多くあります)、これらの詳細は範囲外とします。
- Moonshot AIのKimi K2.5:1兆パラメータ規模のDeepSeek風モデル
Arcee Trinityが実質的に古いGLM-4.5モデルのモデリング性能に匹敵したのに対し、Kimi K2.5は、1月27日のリリース時点でオープンウェイトの性能限界を新たに設定したオープンウェイトモデルです。
印象的に、彼ら自身の詳細な技術レポート内のベンチマークによれば、リリース時点での主要なプロプライエタリモデルと同等の性能でした。
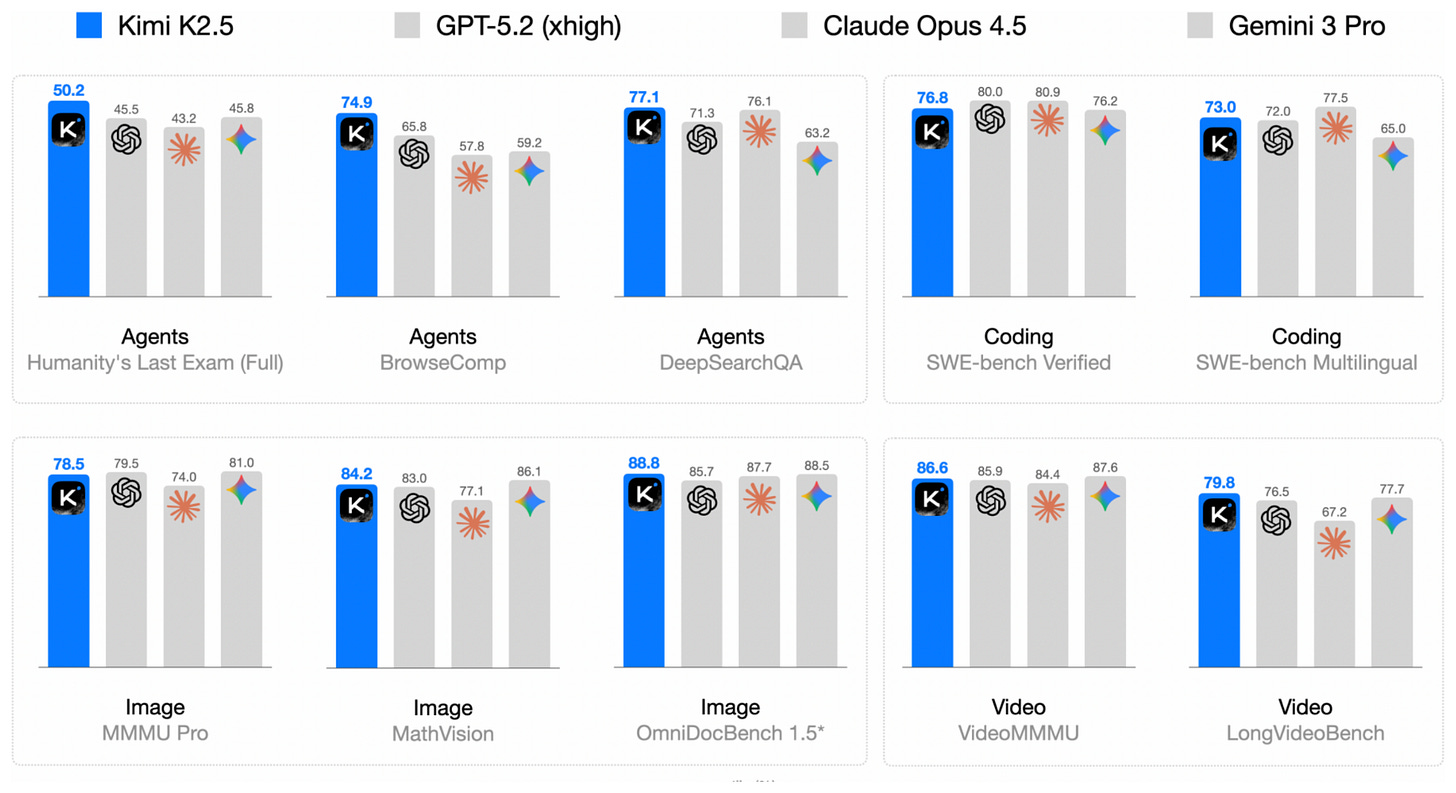 図7:公式K2.5技術レポートからのKimi K2.5性能ベンチマーク。
図7:公式K2.5技術レポートからのKimi K2.5性能ベンチマーク。
優れたモデリング性能は、例えば前述のArcee TrinityやGLM-4.5と比較しても驚くべきことではありません。なぜなら、(その前身K2と同様に)Kimi K2.5は1兆パラメータスケールのモデルだからです。
原文を表示
A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
Sebastian Raschka, PhDFeb 25, 2026442Share
If you have struggled a bit to keep up with open-weight model releases this month, this article should catch you up on the main themes.
In this article, I will walk you through the ten main releases in chronological order, with a focus on the architecture similarities and differences:
Arcee AI’s Trinity Large (Jan 27, 2026)
Moonshot AI’s Kimi K2.5 (Jan 27, 2026)
StepFun Step 3.5 Flash (Feb 1, 2026)
Qwen3-Coder-Next (Feb 3, 2026)
z.AI’s GLM-5 (Feb 12, 2026)
MiniMax M2.5 (Feb 12, 2026)
Nanbeige 4.1 3B (Feb 13, 2026)
Qwen 3.5 (Feb 15, 2026)
Ant Group’s Ling 2.5 1T & Ring 2.5 1T (Feb 16, 2026)
Cohere’s Tiny Aya (Feb 17, 2026)
(PS: DeepSeek V4 will be added once released.)
Since there’s a lot of ground to cover, I will be referencing my previous The Big LLM Architecture Comparison article for certain technical topics (like Mixture-of-Experts, QK-Norm, Multi-head Latent Attention, etc.) throughout this article for background information to avoid redundancy in this article.
- Arcee AI’s Trinity Large: A New US-Based Start-Up Sharing Open-Weight Models
On January 27, Arcee AI (a company I hadn’t had on my radar up to then) began releasing versions of their open-weight 400B Trinity Large LLMs on the model hub, along with two smaller variants:
Their flagship large model is a 400B param Mixture-of-Experts (MoE) with 13B active parameters.
The two smaller variants are Trinity Mini (26B with 3B active parameters) and Trinity Nano (6B with 1B active parameters).
Figure 1: Overview of the Trinity Large architecture (based on the model hub config file).
Along with the model weights, Arcee AI also released a nice technical report on GitHub (as of Feb 18 also on arxiv) with lots of details.
So, let’s take a closer look at the 400B flagship model. Figure 2 below compares it to z.AI’s GLM-4.5, which is perhaps the most similar model due to its size with 355B parameters.
Figure 2: Arcee AI Trinity Large next to GLM-4.5 of a relatively similar size (400B vs 355B).
As we can see in the Trinity and GLM-4.5 comparison, there are several interesting architectural components added to the Trinity model.
First, there are the alternating local:global (sliding window) attention layers (SWA) like in Gemma 3, Olmo 3, Xiaomi MiMo, etc. In short, SWA is a type of sparse (local) attention pattern where each token attends only to a fixed-size window of t recent tokens (for example, 4096) instead of attending to the entire input (which could be up to n=256,000 tokens). This reduces the per-layer regular attention cost from O(n²) to roughly O(n·t) for sequence length n, which is why it is attractive for long-context models.
Figure 3: A comparison between regular attention (global attention) and sliding window attention (local attention).
But instead of using the common 5:1 local:global ratio that Gemma 3 and Xiaomi used, the Arcee team opted for a 3:1 ratio similar to Olmo 3, and a relatively large sliding window size of 4096 (also similar to Olmo 3).
The architecture also uses QK-Norm, which is a technique that applies RMSNorm to the keys and queries to stabilize training (as shown in Figure 4 below), as well as no positional embeddings (NoPE) in the global attention layers similar to SmolLM3.
Trinity also has a form of gated attention. It’s not a full-blown Gated DeltaNet but it uses a similar gating as in the attention mechanism in Qwen3-Next.
I.e., the Trinity team modified the standard attention by adding elementwise gating to the scaled dot-product before the output linear projection (as shown in the figure below), which reduces attention sinks and improves long-sequence generalization. Additionally, it also helped with training stability.
Figure 4: Illustration of the gating mechanism that Trinity Large uses in the attention mechanism.
Also, the Trinity technical report showed that the modeling performance of the Trinity Large and GLM-4.5 base models are practically identical (I assume they didn’t compare it to more recent base models because many companies only share their fine-tuned models these days.)
You may have noticed the use of four (instead of two) RMSNorm layers in the previous Trinity Large architecture figure which looks similar to Gemma 3 at first glance.
Figure 5: Arcee Trinity and Gemma 3 RMSNorm placement side by side.
Overall, the RMSNorm placement looks like a Gemma 3-like RMSNorm placement, but the twist here is that the gain of the second RMSNorm (in each block) is depth-scaled, meaning it’s initialized to about 1 / sqrt(L) (with L the total number of layers). So, early in training, the residual update starts small and grows as the model learns the right scale.
Figure 6: Arcee Trinity and DeepSeek V3/R1 MoE side by side.
The MoE is a DeepSeek-like MoE with lots of small experts, but made it coarser as that helps with inference throughput (something we have also seen in Mistral 3 Large when they adopted the DeepSeek V3 architecture).
Lastly, there are some interesting details on the training improvements (a new MoE load-balancing strategy and another using the MuOpt optimizer), but since this is a mainly an architecture article (and there are many more open-weight LLMs to cover), these details are out of scope.
- Moonshot AI’s Kimi K2.5: A DeepSeek-Like Model at a 1-Trillion-Parameter Scale
While Arcee Trinity essentially matched the modeling performance of the older GLM-4.5 model, Kimi K2.5 is an open-weight model that set a new open-weight performance ceiling at the time of its release on Jan 27.
Impressively, according to their own benchmarks in their detailed technical report, it was on par with the leading proprietary models at the time of its release.
Figure 7: Kimi K2.5 performance benchmark from the official K2.5 technical report.
The good modeling performance is no surprise when compared to, e.g., Arcee Trinity or GLM-4.5 covered earlier, since (similar to its K2 predecessor), Kimi K2.5 is a 1-trillion-parameter model and thus 2.5x larger than Trinity and 2.8x larger than GLM-4.5.
Overall, the Kimi K2.5 architecture is similar to Kimi K2, which, in turn, is a scaled-up version of the DeepSeek V3 architecture.
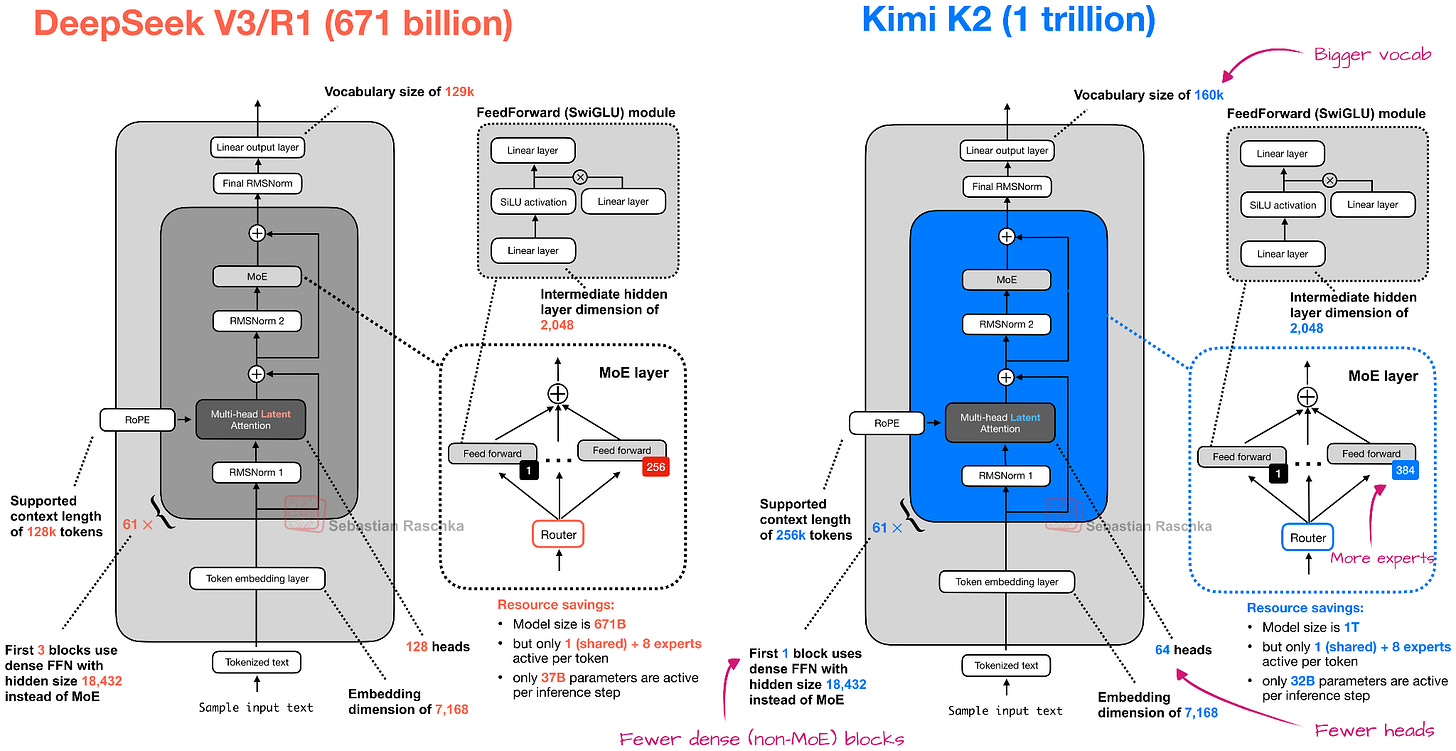 Figure 8: Kimi K2 is a larger version of the DeepSeek V3 architecture.
Figure 8: Kimi K2 is a larger version of the DeepSeek V3 architecture.
However, K2 was a pure text model, and Kimi K2.5 is now a multimodal model with vision support. To quote from the technical report:
> Kimi K2.5 is a native multimodal model built upon Kimi K2 through large-scale joint pre-training on approximately 15 trillion mixed visual and text tokens.
During the training, they adopted an early fusion approach and passed in the vision tokens early on alongside the text tokens, as I discussed in my older Understanding Multimodal LLMs article.
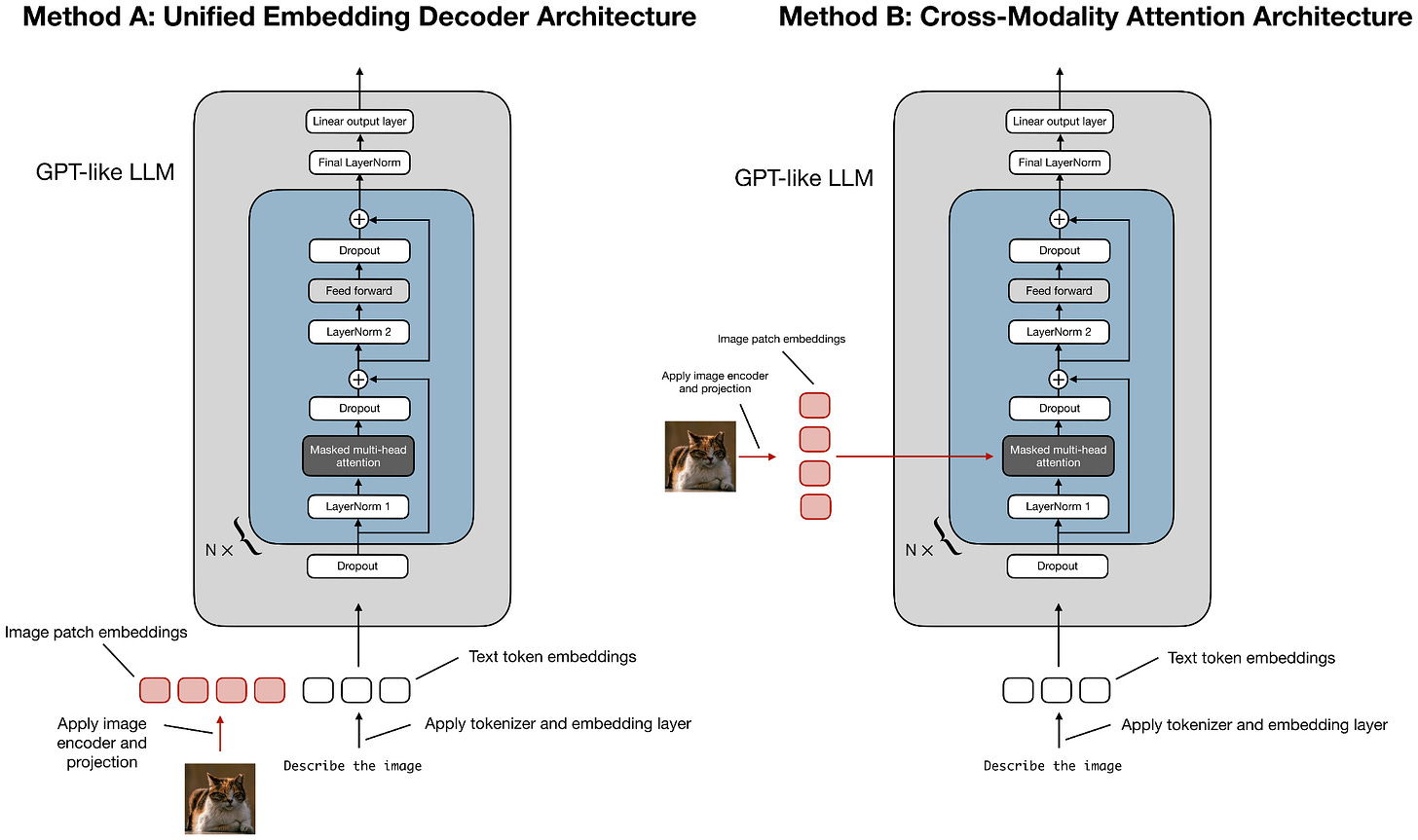 Figure 9: Like most other contemporary multimodal LLMs, Kimi K2.5 uses method A, passing the vision tokens alongside the text tokens during training.
Figure 9: Like most other contemporary multimodal LLMs, Kimi K2.5 uses method A, passing the vision tokens alongside the text tokens during training.
Side note: In multimodal papers, “early fusion” is unfortunately overloaded. It can mean either
- When the model sees vision tokens during pre-training. I.e., vision tokens are mixed in from the start (or very early) of pre-training as opposed to later stages.
- How the image tokens are combined in the model. I.e., they are fed as embedded tokens alongside the text tokens.
In this case, while the term “early fusion” in the report specifically refers to point 1 (when the vision tokens are provided during pre-training), point 2 is also true here.
Furthermore, regarding point 1, the researchers included an interesting ablation study showing that the model benefits from seeing vision tokens early in pre-training, as shown in the annotated table below.
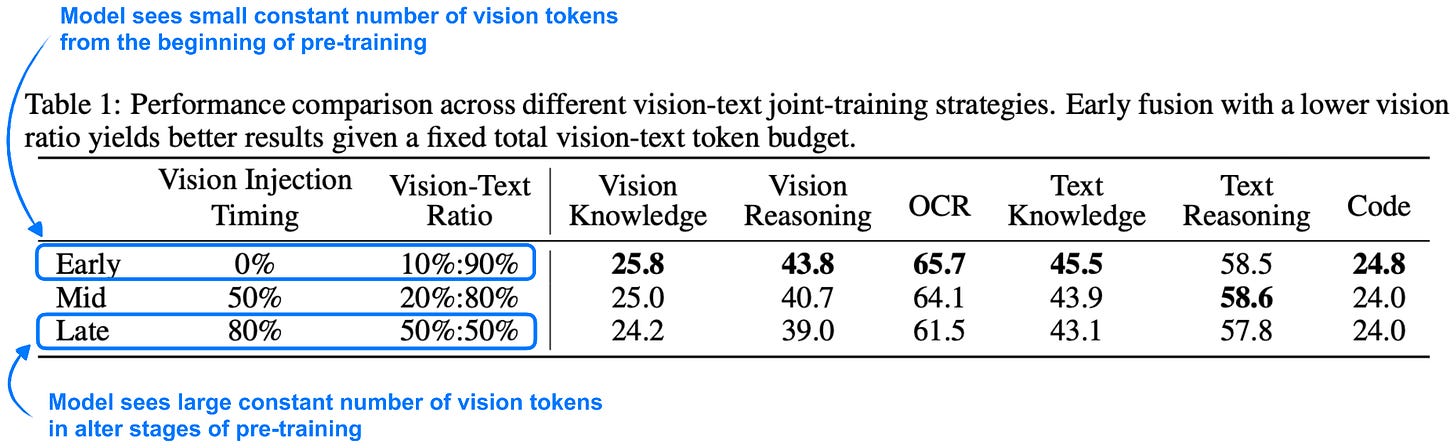 Figure 10: Given a fixed number of vision tokens during training, the model performance benefits if the model is shown a smaller number of vision tokens early on during pre-training (as opposed to adding a higher number of vision tokens later on). Annotated table from the Kimi K2.5 technical report.
Figure 10: Given a fixed number of vision tokens during training, the model performance benefits if the model is shown a smaller number of vision tokens early on during pre-training (as opposed to adding a higher number of vision tokens later on). Annotated table from the Kimi K2.5 technical report.
- StepFun’s Step 3.5 Flash: Good Performance at Great Tokens/Sec Throughput
I have to admit that I haven’t had the Step models on my radar yet. This one caught my attention due to its interesting size, detailed technical report, and fast tokens/sec performance.
Step 3.5 Flash is a 196B parameter model that is more than 3x smaller than the recent DeepSeek V3.2 model (671B) while being slightly ahead in modeling performance benchmarks. According to the Step team, Step 3.5 Flash has a 100 tokens/sec throughput at a 128k context length, whereas DeepSeek V3.2 has only a 33 tokens/sec throughput on Hopper GPUs, according to the data on the Step model hub page.
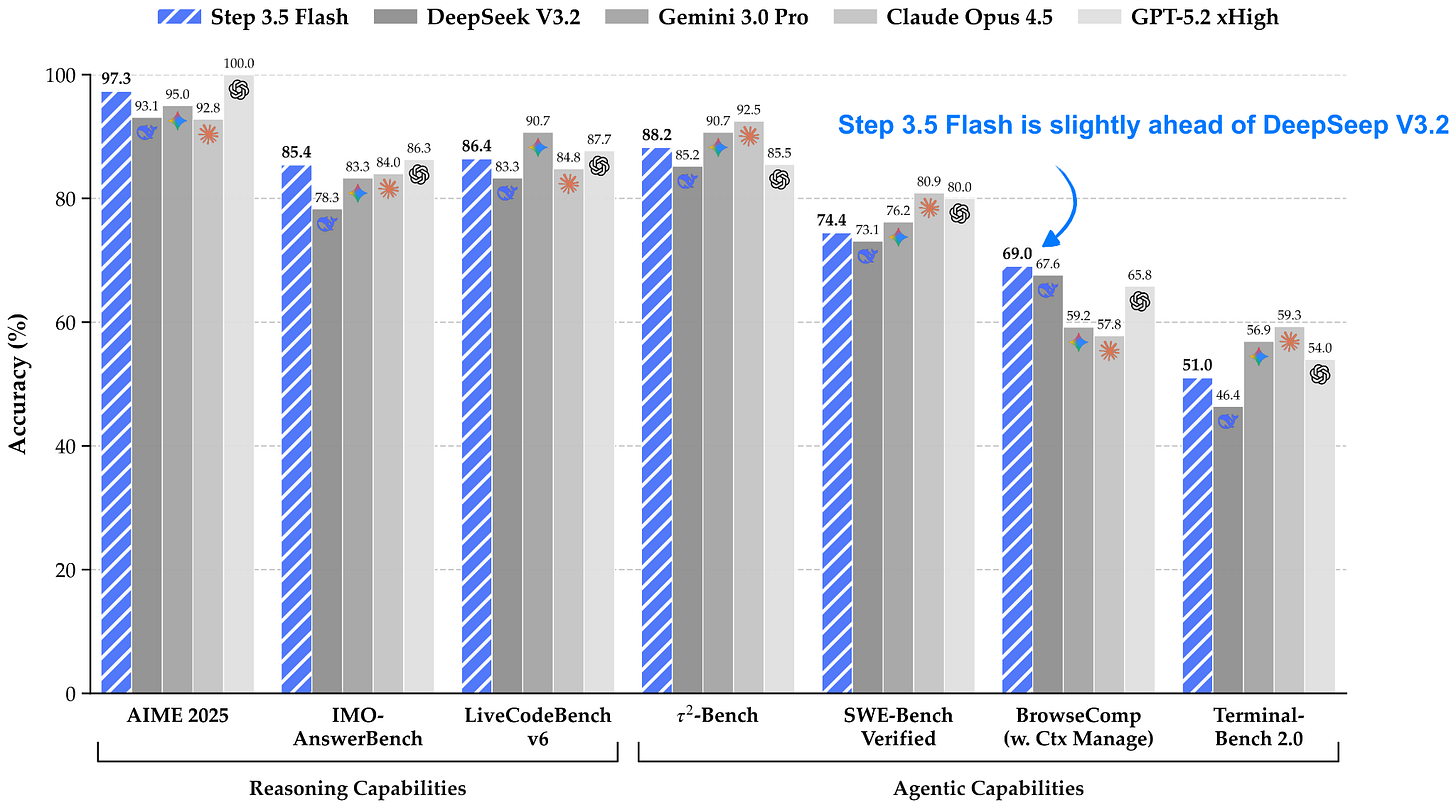 Figure 11: Step 3.5 Flash benchmark from the Step technical report.
Figure 11: Step 3.5 Flash benchmark from the Step technical report.
One reason for this higher performance is the model’s smaller size (196B-parameter MoE with 11B parameters active per token versus 671B-parameter MoE with 37B parameters active), as shown in the figure below.
![](https://substackcdn.com/image/fetch/$s_!S2GJ!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み