[AINews] すべては導体である:AI が医療を改善する最新ポッドキャストとエンジニア登壇の募集
GitHub が「エージェントファースト」を標榜する新アプリを発表し、既存のコードエディタと競合する中、Conductor のような先行ツールとの比較や、Y Combinator の Garry Tan 氏による評価を通じて、AI エージェントツールの市場競争とデザイントレンドが浮き彫りになった。
キーポイント
GitHub の新アプリ発表と「エージェントファースト」戦略
GitHub がコードファーストではなく、エージェントファーストを重視するユーザー向けの新しいアプリを発表し、VS Code との棲み分けを示唆した。
Conductor の先行性と市場での立ち位置
同様のインターフェース(コンダクター型フォームファクター)を先駆けた Conductor が、Garry Tan 氏によって「よりレスポンスが良く、透明性が高い」と評価され、先行者の優位性が議論された。
AI ツールのデザイントレンドと模倣の課題
「カニ型(Crab)」の進化のジョークを用いて、特定の UI/UX が他社に模倣される現象を指摘し、先行企業がどのように収益化し、次世代へどう進化するかが問われている。
OpenAI と Codex のモバイル展開
OpenAI は ChatGPT モバイルアプリに Codex を統合し、ユーザーが遠隔からタスクを管理・承認できる機能を強化したことが紹介された。
OpenAI の Codex ワークフロー強化とリモート管理
Codex が ChatGPT モバイルアプリに統合され、ユーザーが遠隔からタスクの実行を監視・承認・制御できるようになりました。また、Remote SSH の一般提供に加え、企業向け自動化のためのフックやプログラムアクセストークンが追加されました。
IDE エコシステムの「エージェントファースト」への移行
GitHub Copilot App や VS Code が並列作業やマルチエージェントワークフローに対応し、Nous/Hermes Agent や Kimi Web Bridge などのオープンソース・拡張機能も、コード実行と人間のようなウェブ操作を統合しています。
LangChain の観測可能性から学習ループへ
SmithDB と LangSmith Engine が導入され、エージェントのトレースデータを分析して失敗をクラスタリング・修正提案を行うことで、受動的な監視から継続的な自己改善ループへと進化しました。
影響分析・編集コメントを表示
影響分析
この記事は、GitHub という巨大プラットフォームが AI エージェント領域に本格参入したことで、既存のニッチツール(Conductor など)との競合関係が明確になったことを示しています。特に「エージェントファースト」という新しい開発パラダイムにおける UI/UX の標準化競争と、先行企業の収益化モデルの難しさが浮き彫りとなり、業界全体が次のステップを模索している現状を反映しています。
編集コメント
GitHub の新戦略は、単なるツールの追加ではなく、「開発者の思考プロセス」そのものを AI エージェント中心に変える意図を感じさせる重要な転換点です。先行ツールとの比較から、機能の優劣だけでなく「透明性」という要素が次世代 IDE の鍵となる可能性が示唆されています。
AI がヘルスケアをどのように改善しているかに関心がある方は、今日公開された最初のポッドキャストをお聴きください。また、この分野の他のトップエンジニアと交流したい方は、登壇申請もお待ちしております!
進化生物学には「すべてはカニである」という冗談が根付いています。カニという形態は、地球において少なくとも 7 回独立して進化したからです。

今日のオピニオン記事の直接的なきっかけは、GitHub が新しい GitHub アプリを発表したことでした。Oren Melamed 氏によれば、「コードファーストなら、昔ながらの VS Code に留まるべきですが、エージェントファーストかつ GitHub ファーストなら、素晴らしい体験が待っています!」
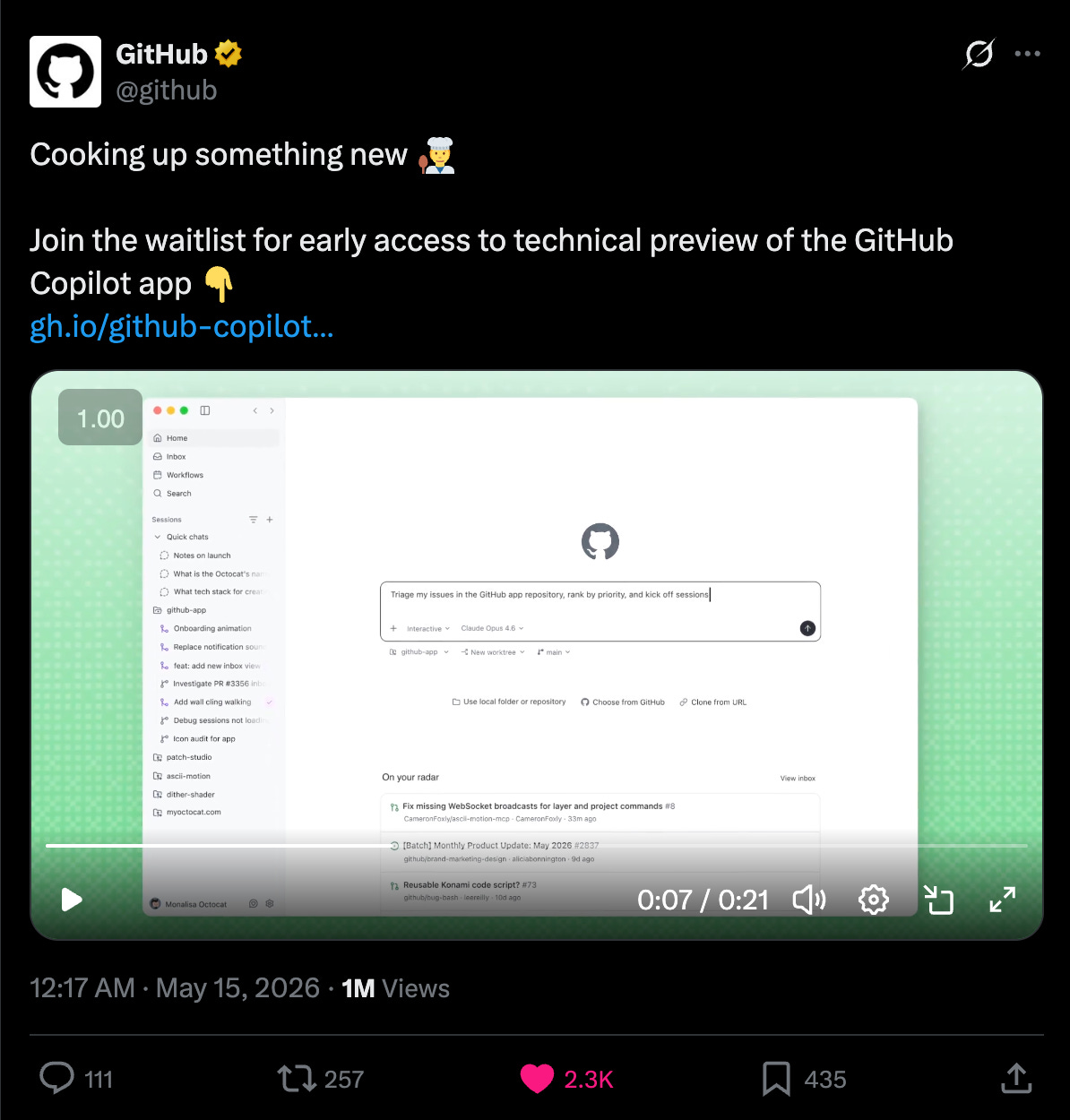
ふむ。これはどこか見覚えがある……
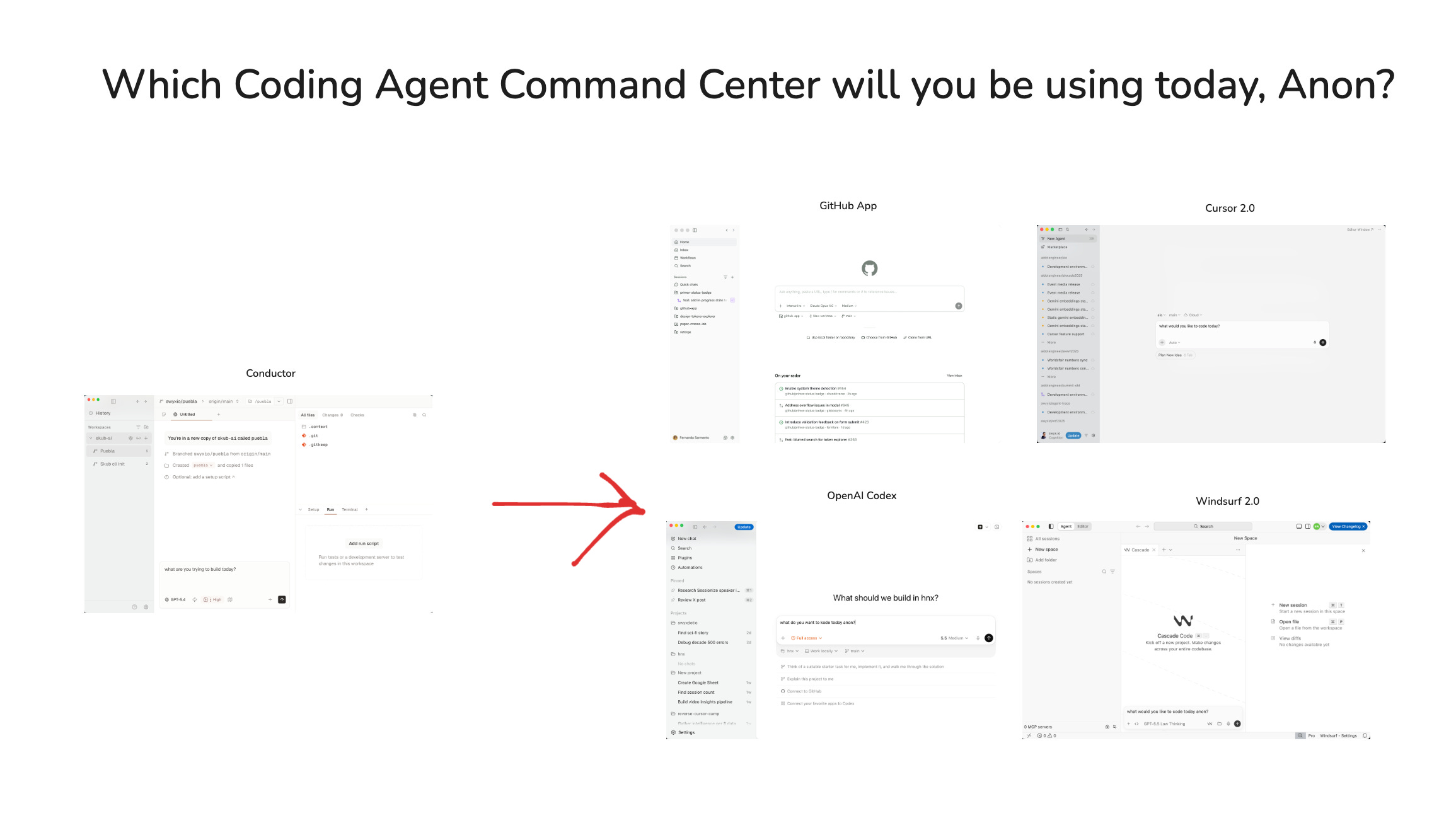
もちろん、この形態因子(フォームファクター)を先駆した Conductor にとっては非常に喜ばしいことであり、今や Y Combinator の AI に熱狂する CEO ガリー・タンが大声で支持するファンとなっています。
@conductor_build と Conductor は依然として優れています。より反応が良く、何をしているかを隠さず、さらに堅牢です。
Claude Code のワークツリー機能は素晴らしいですが、Conductor の方がまだ上です。
さて、20 億ドルの質問を二つ。
もしあなたが新しいフォームファクター(製品形状・形態)を先駆したなら、他社が模倣する中でどうやって収益化しますか?
次は一体何でしょうか?
代替歴史に興味がある方のために、昨年末に一時的にトレンド入りしたカンバンボードのフォームファクターで実際に何が起きたかを紹介します。
そして、GitHub Ace の背後にあるデザイン思考を解説している Maggie Appleton の記事はこちらです。
2026 年 5 月 13 日〜14 日の AI ニュース。私たちは 12 のサブレッドと 544 件の Twitter(X)投稿を確認し、Discord は確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space の一部となっています。メール配信頻度のオプトイン・オプトアウトが可能です!
AI Twitter リキャップ
コーディングエージェントツールリング:Codex Mobile、GitHub の新アプリ、VS Code におけるマルチエージェント UX、および Hermes/Codex の相互運用性
OpenAI は Codex をさらに日常業務ワークフローに深く統合しました。このセットにおける最大の製品発表は、ChatGPT モバイルアプリへの Codex の搭載です。これにより、ユーザーはラップトップ、Mac mini、または開発用ボックス上で Codex が実行され続ける間、遠隔からタスクの開始、出力の確認、コマンドの承認、および実行の制御を行うことが可能になりました。また OpenAI は、管理されたリモート環境向けに Remote SSH が一般利用可能になったことを発表し、その後、Codex ループに関するビジネス/エンタープライズ自動化のためにフックとプログラムアクセストークンを追加しました(OpenAI, OpenAI follow-up, @OpenAIDevs on mobile workflow, @OpenAIDevs on Remote SSH, @OpenAIDevs on hooks/tokens)。別に、OpenAI はコーディングエージェントにおける有用性と制約されたマシンアクセスのトレードオフに焦点を当てた、Codex 用の Windows サンドボックスに関する技術的な解説記事を公開しました(OpenAI Devs, @gdb)。
より広範な IDE/アプリケーションエコシステムは「エージェントファースト」UX に収束しています:GitHub は、並行するワークストリーム、リポジトリ/PR のライフサイクル管理、モデルの柔軟性を提供するデスクトップ環境として説明されている GitHub Copilot App の技術プレビューを発表しました(GitHub, @adrianmg, @OrenMe)。VS Code は、マルチエージェント・マルチプロジェクトワークフローのための新しい「Agents」ウィンドウをリリースし、vscode.dev/agents を介したブラウザ/モバイルサポート、BYOK(Bring Your Own Key)の改善、圧縮されたターミナル出力のようなトークン効率化機能を実装しました(VS Code, リモート/ブラウザサポート、BYOK 更新、ターミナル圧縮)。オープンソース側では、Nous/Hermes Agent が Codex ランタイム統合を追加し、OpenAI ベースのターンを Codex CLI/app サーバー経由でルーティングし、Hermes セッション内で ChatGPT サブスクリプションに裏打ちされた実行を再利用するようになりました(Nous Research, @Teknium, @HermesAgentTips)。また、Kimi は「Kimi Web Bridge」をリリースしました。これはブラウザ拡張機能であり、人間のようなウェブインタラクションを Kimi Code CLI、Claude Code、Cursor、Codex、Hermes などへ公開するものです(Moonshot AI)。
エージェントインフラストラクチャと自己改善ループ:LangSmith Engine、SmithDB、サンドボックス、継続的学習
LangChain の発表スタックは、最も実質的なエージェントインフラリリースのクラスターでした。SmithDB はエージェントのトレースデータ用に特別に設計されたデータベースであり、一方 LangSmith Engine はトレースを消費し、障害をクラスタリングし、可能性の高いコード上の問題を特定し、修正や評価案を提案します。これにより、観測性が受動的な検査から改善ループへと転換されます (@hwchase17, @caspar_br on Engine, @bentannyhill)。コミュニティのコメントでは、SmithDB のアーキテクチャがオブジェクトストレージへのシフトと、このワークロード形状に特化したカスタムストレージ/クエリパスへ向かっている点が強調されました (@caspar_br on SmithDB, @ngates_, Chinese summary)。
LangChain はまた、エージェントの継続的学習を中心とした応用研究活動である LangChain Labs も発表しました。そのテーゼは、本番環境でのトレースが長期にわたるトレーニングシグナル、評価指標、そして targeted な機能向上へと変換されるべきだというものです (LangChain, @jakebroekhuizen, @willccbb, Prime Intellect partnership)。
エージェントの実行分離は着実に成熟しています。W&B/CoreWeave は、強化学習、ツール使用、評価ワークロードにおける隔離実行のための CoreWeave Sandboxes を立ち上げました。これは、rm -rf / といった破壊的コマンドを大規模にテストすることを明示的に目的としています (Weights & Biases)。同様の精神に基づき、エージェントのデバッグに関するオープンソース/ローカル開発ツールが台頭しました。@benhylak は、トレースを Codex/Claude Code に公開し、自動化された評価作成を可能にする無料のローカルエージェントデバッグスタックを紹介しました。
Anthropic Claude Code の制限と開発者からの反発
最も鋭いエコシステムへの反応は、Anthropic が Claude Code の利用を制限・再構築したことに対するものでした。特にサードパーティのラッパーや高ボリュームのプログラムワークフローにおいて顕著でした。Theo のスレッドが焦点となりました:彼は、公式にサポートされた経路を通じて統合していたにもかかわらず、T3 Code のユーザーが劇的なレート制限の削減を実質的に受けたと主張し、その後自身のサブスクをキャンセルするとともに、オープンソースへの寄付のために他の人々にもキャンセル画面の投稿を促しました(@theo 初期スレッド、サブスクキャンセル、寄付スレッド、T3 Code の補足)。他の著名なビルダーも同様の苦情を表明し、Anthropic が実質的にオープンソースの開発者やアプリを遮断し、claude -p を中心に構築されたハーンズを不安定化させたと指摘しました(@theo, @andersonbcdefg)。
また、より戦略的な反論もありました:一部のユーザーは、Anthropic がサードパーティ製アプリに対して開発者に大幅な補助付きの固定価格トークンを提供する義務はないと主張し、エコシステムはおそらくより明示的な API 経済モデルへ移行し、高価なモデルと安価なモデルの間でより賢いルーティングが行われるようになるだろうと予測しました(Sentdex, @tadasayy)。それでも、目に見える離脱のシグナルは無視できないものでした。返信スレッドからのキャンセルだけで意味のある ARR(年間収益)の損失を推計するユーザーもいました(@thegenioo, Uncle Bob Martin, Theo 後日)。エージェントエンジニアにとっての実践的な教訓は明快です:サブスクに依存したハーンズは安定したプラットフォームの基盤要素ではありません。プロバイダー/モデル抽象化と BYOK(Bring Your Own Key)パスがますます必須となっていくでしょう。
ロボティクスと具現化 AI:Figure の 24/7 ソーティングストリームと広範な自動化のシグナル
Figure のライブストリーミングがロボティクス議論を支配しました。同社はまず、8 時間にわたる完全自律型かつ監督なしの作業を示し、その後 24/7 のライブストリームに拡張し、最終的に小規模パッケージのソートにおいて人間並みのスループットで 24 時間以上の連続する自律動作を失敗なく達成したと報告しました。これは Helix-02 がオンボードのみで実行され、OOC(Out-of-Distribution:分布外)ケースに対して自動リセットを行うものであり、テレポートレーション(遠隔操作)は一切行われていないと明確に主張しています(Figure CEO Brett Adcock の 24 時間更新、詳細な技術的解説、Day 2 ライブストリーム)。繰り返される「Bob, Frank, and Gary」のアップデートは少し華やかさがありましたが、中核となるシグナルは生産環境のような稼働率での持続的な自律動作でした。
解釈は Figure 自体への懐疑論と、ロボティクス加速全体に対する確信の間で二分されました。一部のコメント投稿者は、批評家たちがこれらのデモンストレーションが近未来の労働代替に示唆するところを過小評価していると主張しましたが、他の人々は懐疑の対象がロボットというカテゴリそのものよりも Figure に向けられていると指摘しました(@cloneofsimo, @iScienceLuvr, @kimmonismus)。いずれにせよ、これは一連のデモンストレーションの中で最も明確な「連続稼働」のデモの一つでした。
研究、ベンチマーク、オープンモデル:拡散 LM、時系列 FM、機械的解釈可能性、RL/検索
いくつかの技術的に重要なモデル/研究リリースが際立っていました:
Zyphra の ZAYA1-8B-Diffusion-Preview は、自己回帰生成と比較して 4.6–7.7 倍のデコード速度向上を達成し、品質の低下は限定的であると主張しています。これにより、拡散型言語モデルがより安価なロールアウトと豊かな生成モードを実現できるという一般的な見解が裏付けられました(Zyphra)。
Datadog の Toto 2.0 は、Apache 2.0 ライセンスの下で、4M パラメータから 2.5B パラメータまでの 5 つのオープンウェイト時系列予測モデルをリリースしました。BOOM、GIFT-Eval、TIME において第 1 位を獲得したと主張しており、何よりも重要なのは、時系列予測モデル(TSFMs)に対してスケーリング法則がようやく明確に成立する証拠を示している点です(Datadog, @atalwalkar, @ClementDelangue)。
Goodfire の解釈可能性に関する投稿では、Llama が算術処理において幾何学的な「形状回転計算機」/フーリエ特徴量のようなメカニズムを使用していると主張しました。これは純粋な事後説明ではなく、ステアリングに基づく証拠によるものです(GoodfireAI, follow-up)。
強化学習・検索および最適器スタイルの進展については、いくつかのスレッドが注目されました。The Turing Post は、LLM の強化学習を PPO と GRPO の対立としてだけでなく、Generate / Filter / Control / Replay にわたるロールアウト工学として捉え直すサーベイを発表しました。Souradip Chakraborty (@lateinteraction) は、特権情報を用いて有用なロールアウトを能動的に見つける教育的強化学習を提案しました。また、Prime Intellect の nanoGPT スピードランベンチマークにおける自律型最適化器探索では、Opus 4.7 が 2930 ステップ、GPT-5.5 が 2950 ステップを達成し、約 1 万回の試行/約 1 万 4 千時間の H200 GPU 使用後に、人間のベースラインである 2990 ステップを上回りました(Prime Intellect, @eliebakouch)。また注目すべき点として、Kimi K2.6 が Finance Agent Benchmark V2 でオープンウェイトモデル第 1 位となったことが報告されました(Moonshot AI)、Ring-2.6-1T はオープンリリースとして vLLM の day-0 サポートを獲得しました(vLLM)。
トップツイート(エンゲージメント順)
OpenAI の Codex モバイル版の発売は、ChatGPT モバイルから実行中のコーディングエージェントセッションをリモートで制御・レビューできる点において、エンゲージメントと実用性の両面で最も明確な製品勝利となりました (OpenAI)。
Theo 氏の Claude Code に対する反発を示すスレッド群は、プラットフォームリスクやサブスクリプションに支えられたエージェントワークフローに関する開発者間の感情の転換を最も強く捉えています (@theo, @theo 寄付スレッド)。
Figure の自律型ヒューマノイドによる仕分けのライブストリームは、オンボードポリシーの実行とテレオペレーション(遠隔操作)なしという詳細な主張がなされ、24 時間の閾値を超えた後も、最も議論された実体化 AI デモの一つであり続けました (Brett Adcock)。
GitHub の Copilot App と LangChain の Engine/SmithDB/Labs は、今回のサイクルにおいてエージェントエンジニアにとって OpenAI 以外のツール群の中で最も重要な新登場でした (GitHub, LangChain, @hwchase17)。
Prime Intellect の自律型オプティマイザーの検索結果は、コーディングエージェントがアプリ開発だけでなく、オープンエンドな機械学習最適化(ML optimization)のループに組み込まれる具体的な例として注目する価値があります (Prime Intellect)。
AI レッドディット要約
/r/LocalLlama + /r/localLLM 要約
- Qwen 3.6 のローカル推論速度向上と量子化
Qwen における LLaMA.cpp + TurboQuant 用のマルチトークン予測 (MTP)(アクティビティ:514):パッチを当てた llama.cpp のフォークが Qwen 向けに MTP サポートと TurboQuant を追加し、MacBook Pro M5 Max 64GB で 21 tok/s から 34 tok/s への向上を報告しています。 claiming される MTP 受容率は 90% ですが、注意すべきは生速度の向上が約 62% であり、40% ではない点です。コードは AtomicBot-ai/atomic-llama-cpp-turboquant で公開されており、AtomicChat/qwen-36-udt-mtp HF コレクションには Qwen 3.6 27B/35B の GGUF MTP 量子化版が含まれています。コメント投稿者たちは TurboQuant という枠組みに疑問を呈し、多くの場合 f16、q8、または q4 よりも遅いと主張しました。ある投稿者は llama.cpp への TurboQuant プルリクエストが却下された理由として、既存の Q4 KV-量子化回転サポートですでに大半の利点がカバーされており、主な向上は Q3 のみであるが、そこでは品質劣化が懸念されると指摘しました。また、他の投稿者からは高水準の推測/MTP 受容率やトークン/秒数だけでは出力の同等性が保証されないため、品質評価データの提供を求められました。
複数のコメント投稿者が、llama.cpp において TurboQuant が一般的に高速ではないと主張し、そのうち一人は f16、q8、または q4 よりも遅くなる場合があると指摘しました。llama.cpp への以前の TurboQuant プルリクエストは却下された reportedly で、llama.cpp はすでに Q4 KV キャッシュ量子化の回転を実装しており、標準的な Q4 の方が高速でほとんど向上が見られなかったためです。TurboQuant は Q3 周辺でのみ役立つ可能性がありますが、そこでは顕著な品質劣化が伴います。
ユーザーたちは、速度、品質、コンテキストのトレードオフを区別して議論しました。MTP は TurboQuant なしで使用することが速度向上に推奨され、一方、より長いコンテキストや品質の維持には標準的な Q4_1 または Q4_0 の量子化が提案されました。あるコメントでは、TurboQuant に Mac 固有の利点があるのか疑問視されており、その恩恵はハードウェアやワークロードに依存するものであり、広く有用なものではないという示唆が含まれていました。
あるコメントでは、組み込みの MTP ではなく dflash を使用することを推奨し、それが 30〜40% 高速であると主張しました。また、これに関するプルリクエストが既に存在していることも言及しており、実装作業が既存の llama.cpp 統合の取り組みと重複する可能性があることを示唆しています。
続きを読む
原文を表示
If you’re interested in how AI is improving Healthcare, tune in to our first pod on it out today, and if you want to meet other top engineers in the field, apply to speak!
There’s an ongoing joke in evolutionary biology that “Everything is Crab”: the Crab form factor has independently evolved at least 7 times on earth:
The proximate cause of today’s op-ed is GitHub announcing the new GitHub App - as Oren Melamed says, “If you are code first you might wanna stay on good ol’ VS Code, but if you are agent first and GitHub first you are in for a treat!”
Hmm. That looks familiar…
This is of course very nice for Conductor, which pioneered this form factor, and now has a loudly vocal fan in Garry Tan, the AI pilled CEO of Y Combinator:
@conductor_build and Conductor is still better - it's more responsive, doesn't hide what it's doing, more rock solid. \n\nClaude Code worktrees is good, but Conductor is still better.","username":"garrytan","name":"Garry Tan","profile_image_url":"https://pbs.substack.com/profile_images/1922894268403941377/-dGWAt3N_normal.jpg","date":"2026-02-22T04:48:22.000Z","photos":[],"quoted_tweet":{},"reply_count":82,"retweet_count":9,"like_count":533,"impression_count":61825,"expanded_url":null,"video_url":null,"belowTheFold":true}" data-component-name="Twitter2ToDOM">
Now for two billion dollar questions:
if you pioneered a form factor, how do you monetize it while others copy it?
what’s next after this one?
For those interested in alternate histories, here’s what happened with the Kanban board form factor that briefly trended last year:
And here is Maggie Appleton breaking down the design thinking behind GitHub Ace:
AI News for 5/13/2026-5/14/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agent Tooling: Codex Mobile, GitHub’s New App, VS Code Multi-Agent UX, and Hermes/Codex Interop
OpenAI pushed Codex further into day-to-day workflows: the biggest product launch in this set was Codex in the ChatGPT mobile app, letting users start tasks, review outputs, approve commands, and steer execution remotely while Codex continues running on a laptop, Mac mini, or devbox. OpenAI also noted Remote SSH is now generally available for managed remote environments, and later added hooks plus programmatic access tokens for Business/Enterprise automation around the Codex loop (OpenAI, OpenAI follow-up, @OpenAIDevs on mobile workflow, @OpenAIDevs on Remote SSH, @OpenAIDevs on hooks/tokens). Separately, OpenAI published a technical writeup on the Wi`ndows sandbox for Codex, focused on the tradeoff between utility and constrained machine access for coding agents (OpenAI Devs, @gdb).
The broader IDE/app ecosystem is converging on “agent-first” UX: GitHub announced a technical preview of the GitHub Copilot App, described as a desktop environment for parallel workstreams, repo/PR lifecycle management, and model flexibility (GitHub, @adrianmg, @OrenMe). VS Code shipped a new Agents window for multi-agent, multi-project workflows, browser/mobile support via vscode.dev/agents, BYOK improvements, and token-efficiency features like compressed terminal output (VS Code, remote/browser support, BYOK updates, terminal compression). On the open side, Nous/Hermes Agent added Codex runtime integration, effectively routing OpenAI-backed turns through Codex CLI/app-server and reusing ChatGPT subscription-backed execution in Hermes sessions (Nous Research, @Teknium, @HermesAgentTips). Kimi also shipped Kimi Web Bridge, a browser extension exposing human-like web interaction to Kimi Code CLI, Claude Code, Cursor, Codex, Hermes, and others (Moonshot AI).
Agent Infrastructure and Self-Improvement Loops: LangSmith Engine, SmithDB, Sandboxes, and Continual Learning
LangChain’s launch stack was the most substantive agent-infra release cluster: SmithDB is a database purpose-built for agent trace data, while LangSmith Engine consumes traces, clusters failures, identifies likely code issues, and proposes fixes/evals—turning observability into an improvement loop rather than passive inspection (@hwchase17, @caspar_br on Engine, @bentannyhill). Community commentary emphasized SmithDB’s architectural shift toward object storage and a custom storage/query path for this workload shape (@caspar_br on SmithDB, @ngates_, Chinese summary).
LangChain also announced LangChain Labs, an applied research effort around continual learning for agents, with the thesis that production traces should become training signal, evals, and targeted capability improvements over long horizons (LangChain, @jakebroekhuizen, @willccbb, Prime Intellect partnership).
Execution isolation for agents continues to mature: W&B/CoreWeave launched CoreWeave Sandboxes for isolated execution in RL, tool use, and eval workloads, explicitly testing destructive commands like rm -rf / at scale (Weights & Biases). In a similar spirit, open-source/local dev tooling surfaced around agent debugging: @benhylak highlighted a free local agent debugging stack with traces exposed to Codex/Claude Code for automated eval authoring.
Anthropic Claude Code Restrictions and the Developer Backlash
The sharpest ecosystem reaction was to Anthropic restricting/reshaping Claude Code usage, especially for third-party wrappers and high-volume programmatic workflows. Theo’s thread became the focal point: he argued users of T3 Code were effectively hit with dramatic rate-limit reductions despite integrating through the officially supported path, and he subsequently cancelled his subscription while encouraging others to post cancellation screenshots for open-source donations (@theo initial thread, subscription cancellation, donation thread, T3 Code clarification). Other prominent builders echoed the complaint that Anthropic had effectively cut off open-source devs/apps and destabilized harnesses built around claude -p (@theo, @andersonbcdefg).
There was also a more strategic counterargument: some users argued Anthropic does not owe developers heavily subsidized flat-fee tokens for third-party apps, and that the ecosystem will likely shift toward more explicit API economics and smarter routing between expensive and cheap models (Sentdex, @tadasayy). Still, the visible churn signal was nontrivial, including users estimating meaningful ARR loss from reply-thread cancellations alone (@thegenioo, Uncle Bob Martin, Theo later). For agent engineers, the practical takeaway is straightforward: subscription-backed harnesses are not stable platform primitives; provider/model abstraction and BYOK paths look increasingly mandatory.
Robotics and Embodied AI: Figure’s 24/7 Sorting Stream and the Broader Automation Signal
Figure’s livestream dominated robotics discussion. The company first showed 8 hours of fully autonomous, unsupervised work, then extended to a 24/7 livestream, eventually reporting 24+ hours of continuous autonomous operation without failure, around human-parity throughput on small package sorting, and operation by Helix-02 running entirely onboard with automatic resets for OOD cases—explicitly claiming no teleoperation (Figure CEO Brett Adcock, 24h update, detailed technical clarifications, Day 2 livestream). The repeated “Bob, Frank, and Gary” updates were fluffier, but the core signal was sustained autonomous operation at production-like uptime.
Interpretation split between skepticism about Figure specifically and broader conviction about robotics acceleration. Some commenters argued that critics were underestimating what these demonstrations imply for near-term labor substitution, while others noted skepticism was directed more at Figure than at robotics as a category (@cloneofsimo, @iScienceLuvr, @kimmonismus). Either way, this was one of the clearest “continuous uptime” demos in the batch.
Research, Benchmarks, and Open Models: Diffusion LMs, Time-Series FMs, Mechanistic Interpretability, and RL/Search
A few technically significant model/research releases stood out:
Zyphra’s ZAYA1-8B-Diffusion-Preview claims a 4.6–7.7x decoding speedup versus autoregressive generation with limited quality loss, making the usual case that diffusion LMs enable cheaper rollouts and richer generation modes (Zyphra).
Datadog’s Toto 2.0 released 5 open-weights time-series forecasting models from 4M to 2.5B params under Apache 2.0, claiming #1 on BOOM, GIFT-Eval, and TIME and, more importantly, evidence that scaling laws may finally hold cleanly for TSFMs (Datadog, @atalwalkar, @ClementDelangue).
Goodfire’s interpretability post argued that Llama uses a geometric “shape-rotating calculator” / Fourier-feature-like mechanism for arithmetic, with steering-based evidence rather than pure post-hoc description (GoodfireAI, follow-up).
On RL/search and optimizer-style progress, several threads were notable: a survey framing LLM RL as rollout engineering across Generate / Filter / Control / Replay rather than just PPO-vs-GRPO (The Turing Post); Pedagogical RL using privileged information to actively find useful rollouts (Souradip Chakraborty, @lateinteraction); and Prime Intellect’s autonomous optimizer search on the nanoGPT speedrun benchmark, where Opus 4.7 reached 2930 steps and GPT-5.5 2950, beating the 2990 human baseline after ~10k runs / ~14k H200 hours (Prime Intellect, @eliebakouch). Also noteworthy: Kimi K2.6 was reported as #1 open-weight model on Finance Agent Benchmark V2 (Moonshot AI), and Ring-2.6-1T got day-0 vLLM support as an open release (vLLM).
Top Tweets (by engagement)
OpenAI’s Codex mobile launch was the clearest product winner by engagement and practical relevance: remote control/review of running coding-agent sessions from ChatGPT mobile (OpenAI).
Theo’s Claude Code backlash threads captured the strongest developer sentiment shift around platform risk and subscription-backed agent workflows (@theo, @theo donations thread).
Figure’s autonomous humanoid sorting livestream remained one of the most discussed embodied-AI demos, especially once it crossed the 24-hour mark with detailed claims about onboard policy execution and no teleop (Brett Adcock).
GitHub’s Copilot App and LangChain’s Engine/SmithDB/Labs were the most important non-OpenAI tooling launches for agent engineers this cycle (GitHub, LangChain, @hwchase17).
Prime Intellect’s autonomous optimizer-search result is worth watching as a concrete example of coding agents being looped into open-ended ML optimization, not just app dev (Prime Intellect).
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Qwen 3.6 Local Inference Speedups and Quantization
Multi-Token Prediction (MTP) for Qwen on LLaMA.cpp + TurboQuant (Activity: 514): A patched llama.cpp fork adds Multi-Token Prediction (MTP) support for Qwen plus TurboQuant, reporting 21 tok/s → 34 tok/s on a MacBook Pro M5 Max 64GB, with a claimed 90% MTP acceptance rate; note the raw speedup is ~62%, not 40%. Code is published at AtomicBot-ai/atomic-llama-cpp-turboquant, with GGUF MTP quantizations for Qwen 3.6 27B/35B in the AtomicChat/qwen-36-udt-mtp HF collection. Commenters questioned the TurboQuant framing, arguing it is often slower than f16, q8, or q4; one noted a TurboQuant PR to llama.cpp was rejected because existing Q4 KV-quant rotation support already covered most benefits, with gains mainly at Q3 where quality degradation becomes a concern. Others asked for quality/eval data, since higher speculative/MTP acceptance and tokens/s do not alone establish output parity.
Several commenters argued that TurboQuant is not generally faster in llama.cpp, with one noting it can be slower than f16, q8, or q4. A prior TurboQuant PR to llama.cpp was reportedly rejected because llama.cpp already implements rotations for Q4 KV-cache quantization, where standard Q4 was faster and showed little gain; TurboQuant may only help around Q3, but with notable quality degradation.
Users distinguished between speed, quality, and context tradeoffs: MTP without TurboQuant was suggested for speed, while standard Q4_1 or Q4_0 quantization was recommended for longer context/quality retention. One commenter questioned whether TurboQuant had any Mac-specific advantage, implying the benefit is hardware- or workload-dependent rather than broadly useful.
A commenter recommended using dflash instead of built-in MTP, claiming it is 30–40% faster. They also mentioned that a pull request for this already existed, suggesting the implementation work may duplicate prior llama.cpp integration efforts.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み