Nvidia の大規模発表、OpenAI と Amazon の提携、Grok の動画価格引き下げ、再帰型言語モデル
The Batch の編集者は、AI 反対派が「人類滅亡」よりも「戦争」「環境負荷」「雇用喪失」を煽る戦略に転換している現状を分析し、特定の企業利益のために規制を誘導する動きへの警鐘を鳴らした。
キーポイント
AI 反対キャンペーンの戦略的転換
「人類滅亡」などの過激な主張は公衆に響かなくなっており、現在では AI による戦争や環境負荷、雇用喪失といった具体的な懸念を煽るメッセージが主流となっている。
政治的・商業的動機への批判
一部の大手企業やロビイストが、競合他社(特にオープンソース)の自由な配布を阻害するために AI の危険性を誇張し、規制_capture を狙っている可能性を指摘している。
編集者の立場表明
編集者自身は AI 戦争や環境問題への懸念に共感するが、一面的な情報操作によって公共の利益が損なわれる現状を強く批判し、慎重な議論の必要性を訴えている。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界における規制議論の質的変化を指摘しており、今後は「人類滅亡」といったSF的な脅威よりも、現実的な社会インパクト(環境・軍事)や経済的影響(雇用)が規制の根拠としてより頻繁に利用されるようになることを示唆しています。企業側にとっては、オープンソースの推進や技術の普及を妨げるための不当なプロパガンダへの対抗策が必要となる重要な示唆を含んでいます。
編集コメント
編集者は AI の真のリスクと、それを悪用した政治的・商業的なプロパガンダを明確に区別しており、業界が直面している「規制の嵐」の本質を見抜いた鋭い分析です。
親愛なる皆様、
反 AI コーリションは引き続き、AI の進展を遅らせるための根拠を探そうと動き続けています。もし誰かが AI の特定の影響について真摯な懸念を抱いている場合、例えばそれが人類の絶滅につながるかもしれないという点についてであれば、私はその立場に深く反対しつつも、その知的誠実さを尊重します。しかしながら、人々を AI に対して敵対させるようなメッセージを見つけようとして世論調査を行う組織や、ロビイストや有権者を不安がらせようとする政治家によってこれらのメッセージが拡散される際の公衆の反応、規制の乗っ取りを狙う企業や自社の技術力を強化しようとする企業、あるいは挑発的な言動で注目を集めたり利益を得ようとしたりする個人について、私は懸念を抱いています。
英国のグループによる大規模な研究(AI パニックブログへの感謝)では、AI に関する警戒心を高めるために設計された異なるメッセージがテストされました。その結果、AI が人類の絶滅を引き起こすという主張は、ほぼ失敗に終わったことが分かりました。数年前には終末論者がこの議論を推進していましたが、幸いにも私たちのコミュニティがこれを退けることができました。しかし、AI を利用した戦争や環境への懸念は、より共感を呼んでいます。これらの根拠で AI に反対するメッセージの洪水(すでに始まっています)に備えておく必要があります。さらに、失業や子供たちへの危害は、人々を行動させる動機となるメッセージです。
明確に言っておきますが、私は AI を利用した戦争には警鐘を鳴じるべきだと考えます;AI の環境への影響を監視し軽減するための真剣な取り組みを継続する必要があります;あらゆる雇用喪失は悲劇であり、個人や家族を傷つけます;そして父親として、すべての子供の福祉の重要性を心から重んじています。これらの各トピックは、最大限の注意と配慮をもって真剣に取り扱う価値があります。
しかし、反 AI プロパガンダが複雑な問題を一方的に捉え、一般大衆の犠牲の上に自らの組織の利益を図る場合 — 例えば、大手 AI 企業がオープンソースプロジェクトの自由な配布を阻むために AI が危険であると主張し、それが自社製品と競合する場合など — では、私たちは皆損失を被ることになります。
例えば、データセンターの環境への影響に対する一般の認識は、すでに 現実 よりもはるかに悪いものです — データセンターは行う業務に対して驚くほど効率的であり、その建設を妨げることは環境にとって害となり、助けにはなりません。雇用喪失は確かに問題ですが、パンデミック期間中に過剰採用を行った企業が AI を最近の人員削減の責任者として名指しする「AI によるレイオフ(人員削減)の言い訳」 — AI はまだその業務に影響を与えていないにもかかわらず — は、AI が雇用への影響について過度に誇張された恐怖を生み出しています。
残念ながら、このようなプロパガンダは容易に規制を生み出し、すべての人にとってより悪い結果をもたらします。例えば、石油会社は何年もの間、原子力エネルギーへの恐怖を煽るために活動しました。その結果、原子力発電所の安全性に関する過剰な懸念が原子力開発を阻害し、他のエネルギー源によって引き起こされた大気汚染による数百万人の早期死亡と、二酸化炭素排出量の劇的な増加をもたらしました。AI に対する過剰な懸念が、より速い AI 開発の恩恵を受ける多くの人々にとって同様の運命を招かないよう注意しましょう。
今週、ホワイトハウスは AI に関する国家立法枠組みを提案しました。その重要な構成要素の一つは、州ごとの規制がばらつき、AI 開発を阻害することを防ぐための連邦優先権(preemption)枠組みです。私はこれを支持します。
連邦レベルでの進展に失敗した後、多くの反 AI プロパガンダは州レベルへとシフトしました。50 の州のいずれかが生産的ではない方法で AI を制限する法律を可決すれば、それがすべての州、ひいては世界中における AI 開発の阻害につながる可能性があります。ホワイトハウスの提案は、各州が独自のゾーニングを管理し、消費者保護のための一般法をどのように執行するか、そして AI をどのように利用するかという権利を正しく尊重しています。しかし、ある州が AI 開発を制限する法律を可決した場合、連邦規則がその州の法律に優先します。
ホワイトハウスの提案は現時点では提案のままである。しかし、もし米国議会がこれを可決すれば、AI を有益な形で開発するための継続的な取り組みへの道が開かれるだろう。
ここからどう進むべきか?人々を害するアプリケーション(AI を利用するものも、しないものも含む)を制限することに支持を示そう。反 AI 連合が AI に反対する際、議論の妥当性を考慮するだけでなく、彼らの立場が一貫性があり説得力があるのか、それともその時点で世論を動かすと考えられる懸念をただ宣伝しているだけなのかを検討すべきだ。また、AI の便益と予想される害を科学的なアプローチで比較検討し続けることで、AI がもたらす可能性のある恩恵を制限する過剰な懸念に陥らないようにしよう。
引き続き構築し続けよう!
アンドリュー
DEEPLEARNING.AI からのメッセージ
「Anthropic との Agent Skills」では、ワークフローロジックをプロンプトから再利用可能なスキルへ移行することで、エージェントの信頼性を高める方法を紹介します。コーディング、データ分析、調査、その他のワークフローにわたるスキルの設計と適用方法について学びましょう。こちらで登録!
News
オープンソースの速度の鬼
AI チップの支配的な供給元である Nvidia は、そのサイズクラスで速度がトップを走る競争力のあるオープンソース大規模言語モデルを発表しました。これは昨年 Meta が Llama 4 を発表した以来、米国から登場した最初のオープンウェイト(重み公開)のリーダーです。
新情報: Nvidia は リリース した Nemotron 3 Super 120B-A12B は、エージェントアプリケーション向けに設計された大規模言語モデルであり、重みだけでなくトレーニングデータセットやレシピ(訓練手順)も含まれています。これは計画中の 3 つからなるファミリーの 2 番目です:Nvidia は 2025 年 12 月に Nemotron 3 Nano-39B-A3B を リリース しており、Nemotron 3 Ultra-500B-A50B は近日公開予定です。
- 入力/出力:テキスト入力(最大 100 万トークン)、テキスト出力(最大 100 万トークン)
- 知識の截止日:2025 年 6 月(事前学習データ)、2026 年 2 月(ファインチューニングデータ)
- アーキテクチャ:ハイブリッド Mamba-2/Transformer/Expert モデル(Mixture of Experts、MoE)にマルチトークン予測層を組み合わせた構成(1,200 億パラメータ、トークンあたり 120 億がアクティブ)
- 学習データ:ウェブから収集・合成された 25 兆トークンの厳選データ。自然言語は 20 カ国語、プログラミング言語は 43 言語に対応
- 機能:ツール呼び出し、構造化出力、7 か国語対応(中国語、英語、フランス語、ドイツ語、イタリア語、日本語、スペイン語)、推論モード(オフ、低、通常)
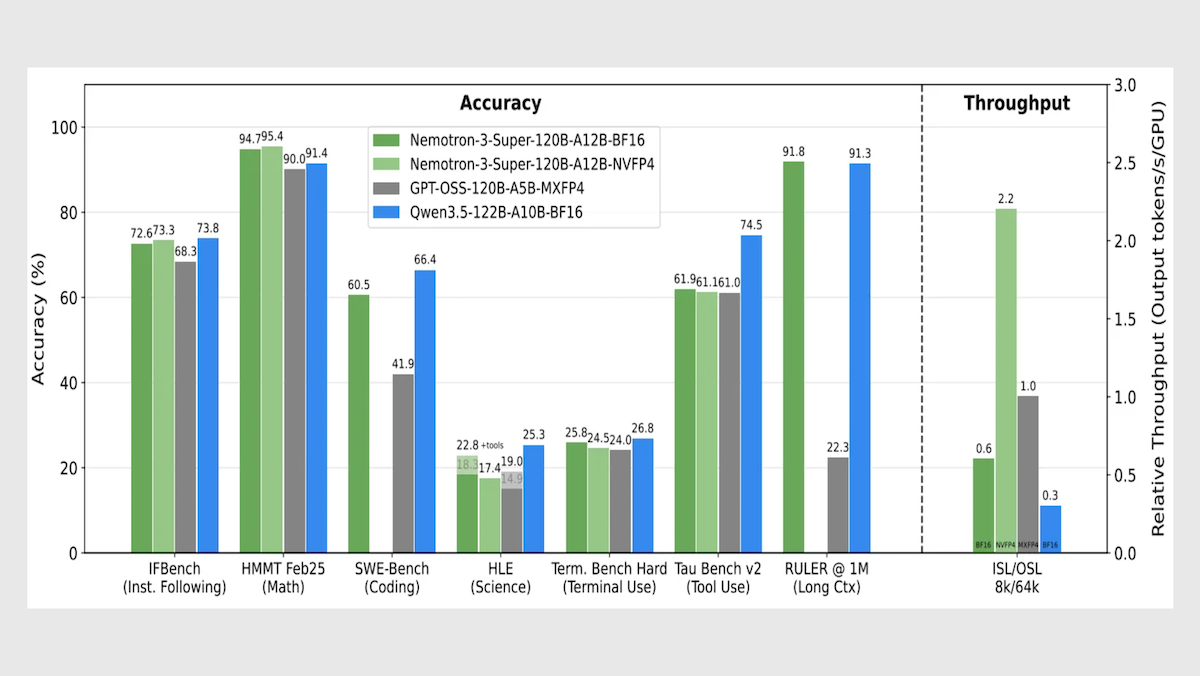
- パフォーマンス:同規模のオープンウェイトモデルの中で最速(1 秒あたり 442 トークン出力)。エージェントタスク向け PinchBench テストではオープンウェイトモデル群をリード
- 利用可能/価格:非商用・商用利用を許可するライセンスの下、重みとデータセットは無料でダウンロード可能。ただし、安全ガードレールを代替なしに削除した場合や、ユーザーが特許または著作権訴訟を起こした場合は権利が終了。Nvidia および OpenRouter を通じた無料チャット利用が可能。API はサードパーティプロバイダ経由で、入力/出力 100 万トークンあたり約 0.30 ドル/0.80 ドル
仕組み: Nemotron 3 Super のハイブリッドアーキテクチャは、Mamba-2、アテンション(注意機構)、修正された MoE レイヤーをマルチトークン予測ヘッドと交互に配置し、1 回の順伝播で複数のトークンを生成します。
- Nemotron 3 Super の層のほとんどは mamba-2 層です。入力長が増加するにつれて処理能力が二次関数的に増大するアテンション層とは異なり、mamba-2 層は各ステップで以前のコンテキストをコンパクトな表現に圧縮します。Nemotron 3 Super は、mamba-2 層では扱いにくい入力のごく遠い部分からの正確な検索が必要なタスクに対処するために、アテンション層を選択的にインターリーブ(交互配置)しています。
MoE 層は Nvidia の LatentMoE デザインを採用しており、MoE ルーターがどのエキスパートを活性化するかを決定する前に、各トークンの表現を通常のサイズの 1/4 に圧縮します。この圧縮により、モデルは通常 5〜6 エキスパートが必要とするのと同程度の処理能力で、トークンあたり 22 エキスパートを活性化することが可能になります。
マルチトークン予測(MTP)ヘッドは、順次パスごとに複数の出力トークンを予測します。トレーニング中、これはモデルがより長距離のパターンを学習することを促します。推論時には、MTP ヘッドがモデルが単一のパスで検証するトークンをドラフトすることで出力を加速します。モデルの確率分布と整合性のあるものは保持し、それ以外は破棄します。
チームは NVFP4 で事前トレーニングを行いました。NVFP4 は Nvidia Blackwell GPU アーキテクチャに組み込まれた 4 ビット浮動小数点数値形式であり、このモデルはトレーニング後に量子化されるのではなく、低精度での動作を学習するように設計されています。
チームは、プロンプト、推論、ツール呼び出し、最終出力からなる 700 万シーケンス以上でモデルのファインチューニングを行いました。これらのシーケンスは、数学、コード、多言語クエリを含む一部のタスクでは DeepSeek V3.2 と Kimi K2 によって、ソフトウェアエンジニアリングのタスクでは Qwen3-Coder-480B によって生成されました。その後、強化学習が 3 つの段階で実施されました。第 1 段階は数学、コーディング、科学、パズル、エージェント型ツール使用などの分野で客観的に検証可能な出力を持つタスクです。第 2 段階はテスト実行を報酬信号として用いて GitHub の課題を解決する専用ソフトウェアエンジニアリングステージです。第 3 段階は対話の質を向上させるための人間フィードバックからの強化学習です。チームは PivotRL ファインチューニング手法について論文で詳述しています。
パフォーマンス: Nemotron 3 Super は、そのサイズクラスにおいて速度と長文コンテキスト処理で首位に立ち、全体的な知能やエージェント型タスクにおいても競争力のある指標を示しています。
- Nemotron 3 Super を推論モード(レベル未指定)に設定した場合、1 秒あたり約 442 トークンを生成し、推論モード(高)に設定された OpenAI gpt-oss-120b(1 秒あたり 278 トークン)や、推論モードに設定された Google Gemini 3.1 Flash-Lite(1 秒あたり 266 トークン)を大きく上回ります。
- Artificial Analysis のインテリジェンス・インデックスでは、経済的に有用な作業に焦点を当てた 10 のベンチマークの加重平均を用いて評価が行われますが、Nemotron 3 Super を推論モード(レベル未指定)に設定した場合(スコア 36)は、推論モードに設定された Qwen3.5-122B(スコア 42)には及びませんでしたが、推論モード(高)に設定された gpt-oss-120b(スコア 33)を凌駕しました。
- Nvidia が開発した長文脈評価「RULER」では、入力トークン数 100 万を与えた場合、Nemotron 3 Super の精度は 91.75% で、Qwen3.5-122B(精度 91.33%)をわずかに上回り、gpt-oss-120b(精度 22.30%)を大きく引き離しました。
- PinchBench は、自律型エージェント(OpenClaw)の意思決定コアとしてモデルがタスクをどの程度完遂できるかを評価するベンチマークです。Nemotron 3 Super(85.6%)は、1 兆パラメータを持つ Kimi K2.5(84.8%)や 7,440 億パラメータの GLM-5(84.1%)、同規模の Qwen3.5-122B(84.5%)など、はるかに大きなオープンウェイト競合他社製品をすべて上回りました。
ニュースの背景: Nvidia は今後 5 年間で 260 億ドルを投資し、オープンウェイトモデルの開発を進める計画です。これは非常に大規模なコミットメントです。この発表は、Nvidia のビジネスに影響を与える可能性のあるオープンウェイト分野における動向の変化と時を同じくしています。Alibaba、Moonshot AI、Z.ai を含む中国企業は、現在最も能力の高いオープンウェイトモデルを構築しており、Nvidia の GPU や Cuda ソフトウェアに対する代替品も開発中です。例えば、DeepSeek は最近、Huawei の Ascend チップと Cann ソフトウェアのみを使用して、次期モデルのトレーニングを完了したと報じられています。
なぜ重要なのか: Nemotron 3 Super は、開発者に対して、トレーニングデータ、レシピ、ツールとともに重み(ウェイト)も提供される、エージェントアプリケーション向けの高速で完全オープンなモデルをもたらします。この開放性はまた、Nvidia のビジネス目標にも貢献しています。中国製のオープンウェイトモデルは能力を高めつつあり、非 Nvidia チップ上で実行できるように最適化が進んでおり、以前は Nvidia に依存していた開発者が他社へ流れるリスクが生じています。Nemotron は、その流れを止めるための理由を提供するものです。
私たちが考えていること: GPU 向けにモデルを最適化するのに、GPU を設計している会社ほど適任な存在はありません。カスタム数値形式から推論ソフトウェアに至るまで、Nvidia はほとんど他のモデル開発者が真似できない方法でハードウェアとソフトウェアを共同設計できます。Nvidia は、モデル構築がチップの販売につながり、その逆もまた然りだと賭けているのです。

OpenAI が AWS でエージェントの状態を追跡
OpenAI は、世界最大のクラウドプラットフォーム上でエージェント向けのインフラを構築するために Amazon と提携しました。これは、Microsoft との緊密な関係が弱まっているさらなる兆候です。
何が変わったか: OpenAI と Amazon は、AI エージェント向けに設計された将来のコンピューティングインフラストラクチャである「ステートフルランタイム環境」を発表しました。両社は予定される発売日については開示していません。この提携により、OpenAI のクラウドコンピューティングリソースは Microsoft Azure 以外も多様化し、Amazon は自社の製品で OpenAI のモデルを利用できるようになります。GeekWire による関連文書の分析によると、この契約の一環として Amazon は OpenAI に 150 億ドルを投資し、特定の開示されていない条件が満たされた場合、または 2029 年以前に OpenAI が株式を一般公開した場合、追加で 350 億ドルが投入される見込みです。さらに、クラウド提携が終了した場合、Amazon の残りの 350 億ドルのコミットメントも失われます。この投資は、Nvidia とソフトバンクも参加し、OpenAI の企業価値を 7,300 億ドルと評価した総額 1,100 億ドルに及ぶ巨額の資金調達ラウンドの一部でした。(開示:アンドリュー・イー(Andrew Ng)氏は Amazon の取締役会メンバーです。)
- OpenAI と Amazon Web Services (AWS) は、Amazon Bedrock で実行される状態管理型ランタイム環境を開発します。これは AI アプリケーションの構築とデプロイのための Amazon のプラットフォームです。数ヶ月以内にリリースが予定されており、この環境はエージェントの作業状態(メモリ、ツール接続、ユーザー権限など)を管理するために設計されています。
- AWS は、企業全体で AI エージェントの構築、デプロイ、管理を行うためのプラットフォームである OpenAI Frontier の独占的なサードパーティクラウドプロバイダーです。Amazon を通じて Frontier を購入する顧客は Amazon Bedrock を経由してサービスを受け、OpenAI から直接購入する顧客は Microsoft Azure を経由してサービスを受けます。
- OpenAI と Amazon は、Amazon の製品向けにカスタムモデルを開発します。
- OpenAI は、AI ワークロードのために Amazon が設計した Trainium チップの使用を約束しました。OpenAI は、Tranium 処理能力で 2 ギガワット分の消費を保証し、AWS との既存の 380 億ドルの契約を 8 年間で 1,000 億ドル拡大すると発表しました。
仕組み: 多くの開発者は、各リクエストが独立している状態非依存 API を通じて AI モデルと対話します。開発者がプロンプトを送信しレスポンスを受け取ると、モデルはそのやり取りの記憶を保持しないため、開発者はすべてのコンテキストを毎回のリクエストに含めなければなりません。この状態管理型ランタイム環境は、そのコンテキストを処理し、エージェントがどこにいるかを失うことなく、長く多段階のワークフローを実行できるように支援します。さらに、顧客は AWS で実行されるオープンウェイト OpenAI モデルのカスタマイズ版にもアクセスできるようになります。The Information が報告。
- OpenAI は、生産環境における AI エージェントは複数のツールからの出力に依存し、人間の承認を必要とし、中断された場合に再開できなければならないため、ステートレス API だけでは不十分であると主張しています。
ステートフルとステートレスの区別——これは API の典型的な属性です——には法的な目的もあります。OpenAI と Microsoft の契約により、Azure は OpenAI のステートレス API の排他的なホストとなりますが、ランタイム環境は Microsoft の権利の範囲外に位置します。Amazon との協力によって生じる OpenAI モデルへのステートレス API 呼び出しは Azure でホストされます。
この環境は、AI エージェントのデプロイと管理のための Amazon のツールである Amazon Bedrock AgentCore と統合され、顧客が既存の AWS 環境で実行されます。
Behind the news: OpenAI と Amazon のパートナーシップは、初期の生成 AI エポックを定義していた緊密なクラウド間の提携が解消される過程における最新のステップです。2019 年、Microsoft は OpenAI に 10 億ドル(その後 130 億ドル以上に増加)を投資し、排他的なクラウドプロバイダーとなりました。2023 年には、Amazon が Anthropic に最大 40 億ドルを投資し、主要なクラウドプロバイダーとなりました。それぞれの契約は AI スタートアップとクラウド大手をペアリングするものでした。しかし、これらの結びつきはその後緩やかになっています。
- 2024 年後半までに、マイクロソフトと OpenAI は双方の相互依存関係を減らす取り組みを進めていた。これは、OpenAI の需要がマイクロソフトが構築する計算リソースの範囲を超えていたこと、そしてマイクロソフトが自社の AI 能力開発により注力し始めたことによるものである。
- 2025 年 10 月、OpenAI が営利法人かつ公益目的を掲げる企業として再編された際、その条件によりマイクロソフトは 27 パーセントの株式と OpenAI の収益の 20 パーセントを得る権利を付与されたが、クラウド事業における先取権(right of first refusal)は剥奪され、OpenAI は他のプロバイダーとも提携できるようになった。
- アマゾンとの提携発表当日、マイクロソフトと OpenAI は共同声明を発表し、両社のパートナーシップは継続中であると述べた。マイクロソフトは引き続き、モデルの重み(model weights)などの OpenAI の知的財産に対する独占的アクセス権を保持しており、他のクラウドプロバイダーとの OpenAI からの提携収益についても引き続き配分を受ける。
- アマゾン側でも同様の構図が展開されている。アマゾンの主要な AI パートナーである Anthropic は、アマゾンが投資する以前から Google Cloud に存在し、その後マイクロソフトにも展開した。2025 年 11 月、マイクロソフトは Anthropic へ最大 50 億ドルを投資し、Claude モデルを Azure で利用可能にしたことで、Claude は主要な 3 つのクラウドプラットフォームすべてで利用可能な最初の主要モデルファミリーとなった。
- GeekWire がレビューした米国証券取引委員会(SEC)に提出された書類によると、アマゾンの株式投資とクラウド提携は契約上リンクされている。合意が終了した場合、アマゾンが残りの 350 億ドルのコミットメントも同時に失われることになる。
なぜ重要なのか: AI エージェントを開発する開発者は通常、ステートレスな API(Application Programming Interface)の上に、独自の状態管理、ツールオーケストレーション、障害回復機能を実装している。これらの機能をインフラストラクチャとして処理するように設計されたランタイム環境は、AI エージェントのデプロイにおける障壁を低下させる可能性がある。一方で、保存される状態の内容とそのポータビリティ(移植性)次第では、異なるクラウドベンダーへ移行するコストが増大する可能性もある。この技術が市場シェア最大のクラウドプロバイダーである AWS で動作するため、広範な開発者コミュニティに利用可能になるだろう。
私たちが考えていること: ステートレスとステートフルを区別することは巧妙な法的エンジニアリングかもしれませんが、それは実際の技術的転換も反映しています。AI アプリケーションが自律性へと移行するにつれ、エージェントの背後にあるインフラストラクチャはモデルそのものと同じくらい重要になる可能性があります。

xAI のコスト効果の高い動画生成器
xAI は、競合他社の価格のほんの一部で独立した品質ランキングで首位を獲得した動画生成器をリリースしました。
新情報: Grok Imagine 1.0 は、テキストに画像や/または動画を含め、対話、効果音、音楽を含むことができる動画クリップを生成します。
- 入力/出力:テキスト、画像(オプション)、動画(オプション)を入力し、音声付きの動画を出力(チャットインターフェース経由では最大 10 秒間、解像度 1,280x720 ピクセル;API 経由では最大 15 秒間、解像度 1,280x720 ピクセルまたは 854x480 ピクセル)
- パフォーマンス:ローンチ時に Artificial Analysis Video Arena(人工知能分析動画アリーナ)のテキストから動画への変換および画像から動画への変換の両方で首位を獲得
- 機能:テキスト指示による動画の改変、カメラモーション(パン、チルト、ズーム)、シーン内でのオブジェクトの追加・削除・置換、スタイル転送、複数のアスペクト比への対応
- 利用可能状況/価格:grok.com、x.com、および Grok モバイルアプリ経由の Web インターフェース(X Basic および Premium ユーザーは無料;Premium ユーザーはより長い動画を生成可能)、API は出力 1 分あたり 4.20 ドル
- 非公開情報:xAI は、Grok Imagine 1.0 の基盤技術やその構築方法について一切情報を開示していない。
パフォーマンス: Grok Imagine 1.0 は、人間視聴者による評価に基づく盲検の直接対決テストである Artificial Analysis Video Arena で首位としてデビューした。一部の競合他社よりも処理速度は遅いものの、一般的にはコストが低い。(開示:アンドリュー・ン氏は Artificial Analysis に個人的な投資を行っている。)
- 発表当時、Artificial Analysis のリーダーボードでは、Grok Imagine 1.0 がテキストから動画への変換および画像から動画への変換の両カテゴリで 1 位を獲得し、Runway Gen-4.5、Kling 2.5 Turbo、Google Veo 3.1 を上回っていました。
- LM Arena の動画リーダーボードでは、grok-imagine-video-720p が画像から動画への変換で 1 位(Elo 評価値 1,400)となり、Google Veo 3.1(Elo 評価値 1,395)を抜きました。また、テキストから動画への変換では 4 位(Elo 評価値 1,362)で、Google Veo 3.1(Elo 評価値 1,371)と OpenAI Sora 2 Pro(Elo 評価値 1,369)に次ぐ結果でした。
- xAI が IVEBench(指示に基づく動画変更の品質を評価するベンチマーク)を用いて行った直接対決テストでは、人間による評価者が Grok Imagine 1.0 を Runway Aleph よりも 64.1% の確率で、Kling O1 よりも 57% の確率で好ましいと評価しました。
- Artificial Analysis によると、平均して Grok Imagine 1.0 は動画(詳細な再生時間は未指定)を生成するのに 110.1 秒を要しましたが、これは Kling 2.5 Turbo(89.2 秒)や Vidu Q2(39.1 秒)よりも遅く、OpenAI Sora 2 Pro(448.4 秒)や MiniMax Hailuo 2.3(167.1 秒)よりも速い速度でした。
- 音声付きで生成された動画 1 分あたり 4.20 ドルという価格設定において、Grok Imagine 1.0 は音声なしの Kling 2.5 Turbo と同額であり、音声付きの Google Veo 3.1 Preview(1 分あたり 12 ドル)や OpenAI Sora 2 Pro(1 分あたり 30 ドル)よりも安価です。
ニュースの背景: Google、OpenAI、Runway の動画生成ツールがスタンドアロン製品および/または API を通じて提供されているのとは異なり、Grok Imagine 1.0 は X ソーシャルネットワークに統合されています。これにより、X ユーザーは X 上で直接動画を生成・共有できるようになりましたが、その機能は 論争を招いています。2025 年後半、X ユーザーは Grok を悪用して、子供を含む実在人物の同意のない性的な画像を作成し、複数の国で調査や利用禁止措置の対象となりました。xAI がこの問題に対処すると約束した後もこの現象は続いたと、Reuters は 報じています。
なぜ重要なのか: ビジョンに一致する動画を生成するには通常、プロンプトの調整、再生成、結果の比較を何度も繰り返す必要があります。xAI は、早期パートナーから、レイテンシとコストが高すぎて反復作業が不可能であれば、品質だけでは役立たないと報告されたと述べています。第三者によるベンチマークでは、Grok Imagine 1.0 がプレミアム競合他社よりも低コストで、品質において主要モデルに匹敵し、あるいは上回っていることが示されており、この組み合わせにより実験のコストを下げることができます。
私たちが考えていること: イメージ生成は約 2 年という短期間で「 novelty(新奇性)」から「必須条件」へと変化しました。動画生成も同様の道筋をたどっています。Grok Imagine 1.0 と、すでにサービス終了した OpenAI Sora 2 Pro の間の 7 倍の価格差は、まだ価格がさらに下落する余地があることを示唆しています。
Context As An External Variable(外部変数としてのコンテキスト)
長いコンテキストを処理する際、大規模言語モデルは詳細を見失ったり、意味のない内容に陥ったりすることがよくあります。研究者たちは、コンテキストを外部で管理することでこれらの影響を軽減しました。
何が変わったか: MIT の Alex L. Zhang、Tim Kraska、Omar Khattab は、書籍やウェブ検索、コードベースで見られる長いプロンプトを処理するために、外部環境へプロンプトをオフロードし、プログラム的に管理する Recursive Language Models(RLMs)を開発しました。
重要な洞察: 言語モデルは、入力テキストを外部のプログラミング環境における永続変数として扱うことで、コンテキストウィンドウを超えるような長い入力を処理できます。モデルは必要なテキストチャンクのみを取得するコードを書くことができます。例えば、キーワードを検索し、それを取り巻く段落を抽出することも可能です。コードを反復的に記述することで、モデルは全体に着手する前に、長い文脈を持つタスクをサブタスクに分解することが可能になります。
仕組み: RLMs は、単純な読み込み・評価・出力ループ(REPL)環境において Python コードの実行を通じてタスク(ユーザーのプロンプトと関連ドキュメント)を読み取り操作します。対象となるタスクには、長いドキュメントからの分析、理解、または詳細情報の取得が含まれます。モデルは自身やサブモデルと呼ばれる新しいインスタンスを呼び出すプログラムを生成し、各インスタンスの出力をルートモデルにフィードバックしました。
- 著者らは、32,768 トークンのコンテキストウィンドウを備えた Qwen3-8B、400,000 トークンコンテキストウィンドウの GPT-5、および 256,000 トークンコンテキストウィンドウの Qwen3-Coder-480B を基盤とした RLM(Recursive Language Model:再帰型言語モデル)システムを構築しました。各システムは、Python 環境への読み書きやサブモデルの呼び出しを行うカスタムエージェントフレームワークとモデルから構成されていました。
- RLM システムは、タスクデータをモデルに直接入力するのではなく、変数として Python インタープリタにロードします。
- システムプロンプトにより、ルートモデルに対して REPL 環境と対話するための Python コードを生成し、保存されたタスクに対処するよう指示が与えられます。例えば、モデルはプロンプトの長さを確認し、キーワードを検出し、それを論理的なチャンク(章やセクションなど)に分割して、各チャンクに関する質問に答えるために異なるサブモデルを呼び出します。
- 各サブモデルは、ルートモデルからの指示または質問に従ってそのチャンクを処理し、結果をルートモデルへ返却します。
- システムはサブモデルの出力を変数として保存します。ルートモデルはこの中間結果を用いて最終的な出力を構築します。
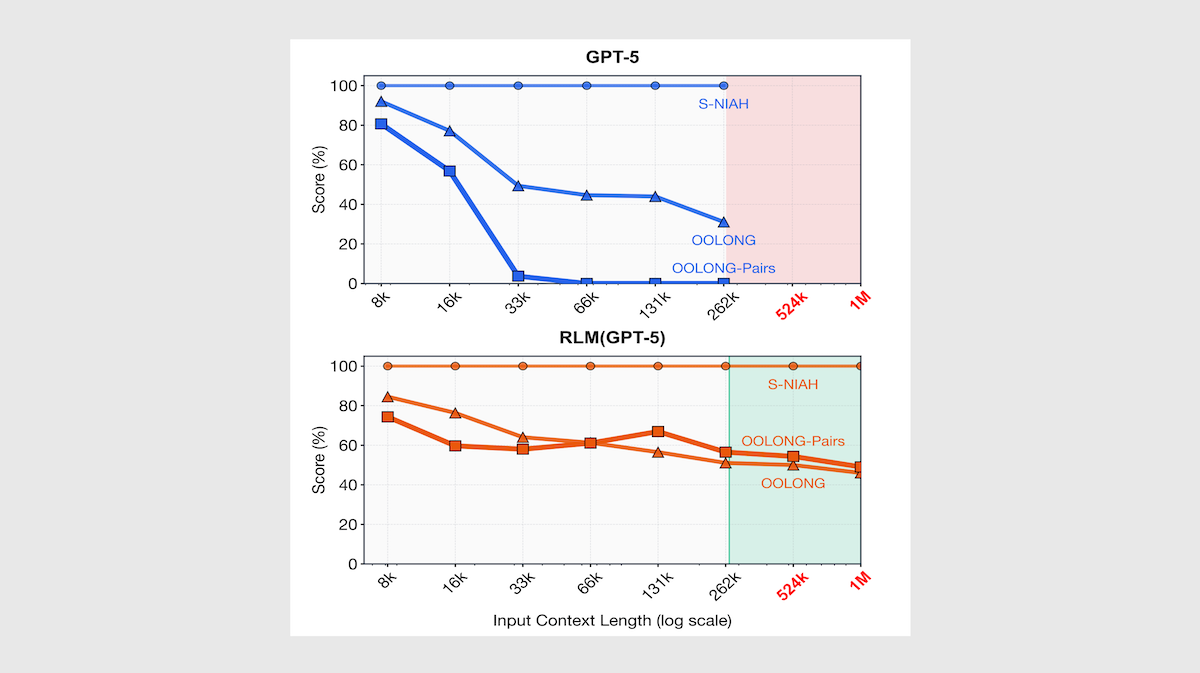
Results: 著者らは、100 万トークンまでの文書に対する検索と推論を含むベンチマークを用いて、Qwen3-8B、中程度の推論能力を持つ GPT-5、および Qwen3-Coder-480B を基盤とした RLM と、元のモデルを比較しました。また、RAG ツールを備えた CodeAct エージェントや、コンテキストを圧縮または要約するカスタムエージェントとの比較も行いました。複数の文書(合計最大 1,100 万トークン)の理解が必要なタスクにおいて、RLM は標準モデルおよび他のエージェント戦略を大幅に上回る性能を示しました。
- BrowseComp+ は、複数の文書にわたる推論を必要とする質問応答ベンチマークですが、RLM-GPT-5(正解率 91.3%)は、コンテキスト長の制限に直面して回答を生成できなかった GPT-5 を上回りました。また、GPT-5 を使用したサマリーエージェント(正解率 70.5%)も上回っています。同様に、RLM-Qwen3-Coder-480B(正解率 44.7%)は、サマリーエージェントを併用した Qwen3-Coder-480B(正解率 38.0%)を上回り、RLM-Qwen3-8B(正解率 14%)も Qwen3-8B(正解率 0%)を上回りました。
- 著者らは、OOLONG 長期文脈推論ベンチマークのバージョンである OOLONG-PAIRS でモデルをテストしました。OOLONG-PAIRS では、ペアになったチャンクを集約して最終出力を構築する必要があります(例:「両方のユーザーが少なくとも [ある値または場所] を持つすべてのユーザー ID のペアをリストする」)。32,000 トークンのコンテキストにおいて、RLM-GPT-5(正解率 58%)は GPT-5(ほぼ 0%)および検索・サマリーエージェント(約 0.3%)を上回りました。また、RLM-GPT-5 は 100 万トークンのコンテキストにおいても約 50% の精度を維持しました。同様に、32,000 トークンのコンテキストにおいて、RLM-Qwen3-8B(正解率 5.2%)は Qwen3-8B(正解率 0%)を上回りました。
なぜ重要なのか: 従来のアプローチでは、長期文脈を扱う際に検索や要約を使用することが多く、重要な詳細を見失う可能性があります。タスクを再帰的なサブコールに分解することで、モデルはより多くのトークンにわたって高い精度を維持できます。この手法は、モデルの入力制限を大幅に超える数のトークンに対して一貫して推論できるエージェントを構築するための青写真となります。
私たちが考えていること: RLM は、特定の瞬間に必要なコンテキストの一部のみに関心を向けます。このアプローチは、人間が文書を一度に一つのセクションずつ処理する方法に似ているように思われます。
原文を表示
Dear friends,
The anti-AI coalition continues to maneuver to find arguments to slow down AI progress. If someone has a sincere concern about a specific effect of AI, for instance that it may lead to human extinction, I respect their intellectual honesty, even if I deeply disagree with their position. However, I am concerned about organizations that are surveying the public to find whatever messages will turn people against AI, and how the public reacts as these messages are spread by lobbyists or by politicians seeking to alarm constituents, companies pursuing regulatory capture or seeking to promote the power of their technology, and individuals seeking to gain attention or to profit by being provocative.
A large study (hat tip to the AI Panic blog) by a UK group tested different messages that are designed to raise alarm about AI. Their study found that saying AI will cause human extinction has largely failed. Doomsayers were pushing this argument a couple of years ago, and fortunately our community beat it back. But AI-enabled warfare and environmental concerns resonate better. We should be prepared for a flood of messages (which is already underway) arguing against AI on these grounds. Further, job loss and harm to children are messages that motivate people to act.
To be clear, I find AI-enabled warfare alarming; we need to continue serious efforts to monitor and mitigate the environmental impact of AI; any job losses are tragic and hurt individuals and families; and as a father, I hold dearly the importance of every child’s welfare. Each of these topics deserves serious attention and treatment with the greatest of care.
But when anti-AI propagandists take a one-sided view of complex issues to benefit their own organizations at the expense of the public at large — for instance, when big AI companies argue that AI is dangerous to block the free distribution of open source projects that compete with their offerings — then we all lose.
For example, public perception of data centers’ environmental impact is already far worse than the reality — data centers are incredibly efficient for the work they do, and hampering their buildout will hurt rather than help the environment. While job loss is a real problem, the “AI washing” of layoffs — in which businesses that had over-hired during the pandemic blame AI for recent layoffs, although AI hasn’t yet affected their operations — has led to overblown fears about the impact of AI on employment.

Unfortunately, this sort of propaganda easily leads to regulations that create worse outcomes for everyone. For example, oil companies worked for years to create fear of nuclear energy. The result is that overblown concerns about the safety of nuclear power plants has stifled nuclear power development, leading to millions of premature deaths from air pollution that was caused by other energy sources and a massive increase in CO2 emissions. Let’s make sure overblown concerns about AI do not lead to a similar fate for the many people that would benefit from faster AI development.
This week, the White House proposed a national legislative framework for AI. A key component is a federal preemption framework to prevent a patchwork of state regulations that hamper AI development. I support this.
After failing to gain traction at the federal level, a lot of anti-AI propaganda has shifted to the state level. If just one of the 50 states passes a law that limits AI in an unproductive way, it could lead to stifling AI development across all the states and potentially across the globe. The White House proposal rightfully respects each state’s rights to control its own zoning, how it enforces general laws to protect consumers, and how it uses AI. But if a state were to pass laws that limit AI development, federal rules would preempt the state law.
The White House proposal remains a proposal for now. However, if the U.S. Congress enacts it, it will clear the way for ongoing efforts to develop AI in beneficial ways.
Where do we go from here? Let’s support limiting applications — those that use AI, and those that don’t — that harm people. When the anti-AI coalition argues against AI, in addition to considering the merits of the argument, I consider whether their position is consistent and persuasive, or if they are just promoting whatever concerns they think will sway the public at a given moment. And, let’s also keep using a scientific approach to weighing AI’s benefits against likely harms, so we don’t end up with overblown concerns that limit the benefits that AI can bring everyone.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
“Agent Skills with Anthropic” shows you how to make agents more reliable by moving workflow logic out of prompts and into reusable skills. Learn how to design and apply skills across coding, data analysis, research, and other workflows. Sign up here!
News
Open-Source Speed Demon
Nvidia, the dominant supplier of AI chips, released a competitive open-source large language model whose speed tops its size class — the first open-weights leader to come from the United States since last year, when Meta delivered Llama 4.
What’s new: Nvidia released Nemotron 3 Super 120B-A12B, a large language model designed for agentic applications, including not only weights but also training datasets and recipes. It is the second in a planned family of three: Nvidia released Nemotron 3 Nano-39B-A3B in December 2025, and Nemotron 3 Ultra-500B-A50B is forthcoming.
- Input/output: Text in (up to 1 million tokens), text out (up to 1 million tokens)
- Knowledge cutoff: June 2025 (pretraining data), February 2026 (fine-tuning data)
- Architecture: Hybrid mamba-2/transformer/mixture-of-experts with multi-token prediction layers (120 billion parameters, 12 billion active per token)
- Training data: 25 trillion tokens of curated data scraped from the web and synthesized in 20 natural languages and 43 programming languages
- Features: Tool calling, structured outputs, seven languages (Chinese, English, French, German, Italian, Japanese, Spanish), reasoning modes (off, low, regular)
- Performance: Fastest open-weights model of its size (442 output tokens per second), leads open-weights models on PinchBench test of agentic tasks
- Availability/price: Weights and datasets free to download under a license that permits noncommercial and commercial uses (rights terminate if safety guardrails are removed without replacement or if the user files patent or copyright litigation against Nvidia), free chat via Nvidia and OpenRouter, API around $0.30/$0.80 per 1 million tokens of input/output via third-party providers
How it works: Nemotron 3 Super’s hybrid architecture interleaves mamba-2, attention, and modified MoE layers with multi-token prediction heads that generate a number of tokens per forward pass.
- Most of Nemotron 3 Super’s layers are mamba-2 layers. Unlike attention layers, which consume quadratically more processing power as input length increases, mamba-2 layers compress earlier context into a compact representation at each step. Nemotron 3 Super interleaves attention layers selectively to handle tasks that require precise retrieval from distant parts of an input, which mamba-2 layers struggle with.
- The MoE layers use Nvidia’s LatentMoE design that compresses each token's representation to 1/4 its usual size before the MoE router decides which experts to activate. This compression enables the model to actiate 22 experts per token using roughly the same amount of processing power as five or six experts typically would require.
- Multi-token prediction (MTP) heads predict multiple output tokens per forward pass. During training, this encourages the model to learn longer-range patterns. During inference, the MTP heads accelerate output by drafting tokens that the model verifies in a single pass. It keeps those that are consistent with its probability distributions and discards the rest.
- The team pretrained in NVFP4, the 4-bit floating-point numerical format that’s built into Nvidia Blackwell GPU architecture, so the model learned to work with reduced precision rather than being quantized after training.
- The team fine-tuned the model on more than 7 million sequences that comprised a prompt, reasoning, tool calls, and final output. The sequences were generated by DeepSeek V3.2 and Kimi K2 for some tasks, including math, code, and multilingual queries, and by Qwen3-Coder-480B for software engineering tasks. Reinforcement learning followed in three stages: tasks with objectively verifiable outputs in domains such as math, coding, science, puzzles, and agentic tool use; a dedicated software engineering stage in which the model solved GitHub issues using test execution as a reward signal; and reinforcement learning from human feedback to improve conversational quality. The team described its PivotRL fine-tuning approach in a paper.
Performance: Nemotron 3 Super leads its size class in speed and processing long contexts, with competitive metrics in overall intelligence and agentic tasks.
- Nemotron 3 Super set to reasoning (level unspecified) generates roughly 442 tokens per second, well ahead of OpenAI gpt-oss-120b set to high reasoning (278 tokens per second) and Google Gemini 3.1 Flash-Lite set to reasoning (266 tokens per second).
- On Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, Nemotron 3 Super set to reasoning (36) fell behind Qwen3.5-122B set to reasoning (42) but outperformed gpt-oss-120b set to high reasoning (33).
- On RULER, a long-context evaluation developed by Nvidia, given 1 million input tokens, Nemotron 3 Super (91.75 percent accuracy) slightly outperformed Qwen3.5-122B (91.33 percent accuracy) and came out well ahead of gpt-oss-120b (22.30 percent a accuracy).
- On PinchBench, which evaluates how well a model completes tasks as the decision-making core of an autonomous agent (OpenClaw), Nemotron 3 Super (85.6 percent) outperformed much larger open-weights contenders including the 1 trillion-parameter Kimi K2.5 (84.8 percent) and the 744 billion-parameter GLM-5 (84.1 percent), as well as the similarly sized Qwen3.5-122B (84.5 percent).
Behind the news: Nvidia plans to invest $26 billion over five years to develop open-weights models — a substantial commitment. The announcement coincides with shifts in the open-weights landscape that could affect Nvidia’s business. Chinese companies, including Alibaba, Moonshot AI, and Z.ai, lately have built the most capable open-weights models, and they are building alternatives to Nvidia GPUs and Cuda software. For instance, DeepSeek has reportedly trained an upcoming model entirely on Huawei’s Ascend chips and Cann software.
Why it matters: Nemotron 3 Super gives developers a fast, fully open model for agentic applications, with training data, recipes, and tools alongside the weights. This openness also serves Nvidia’s business goals. Chinese open-weights models are growing more capable and increasingly streamlined to run on non-Nvidia chips, creating a risk that developers who previously relied on Nvidia will look elsewhere. Nemotron gives them a reason not to.
We’re thinking: Who better to optimize a model for GPUs than the company that designs the GPUs? From custom numerical formats to inference software, Nvidia can co-design hardware and software in ways that few model developers can match. Nvidia is betting that building models will help sell chips and vice versa.
OpenAI Tracks Agent States on AWS
OpenAI partnered with Amazon to build infrastructure for agents on the world’s largest cloud platform, a further sign that its close relationship with Microsoft is weakening.
What’s new: OpenAI and Amazon announced a “stateful runtime environment,” a forthcoming computing infrastructure designed for AI agents. The companies did not disclose the projected launch date. The partnership diversifies OpenAI’s cloud-computing resources beyond Microsoft Azure and lets Amazon use OpenAI models in its own products. As part of the deal, Amazon invested $15 billion in OpenAI with an additional $35 billion to come if certain undisclosed conditions are met, or if OpenAI offers it stock to the public prior to 2029, according to an analysis of related documents by GeekWire. Moreover, if the cloud partnership terminates, Amazon’s remaining $35 billion commitment will die with it. The investment was a part of a gargantuan $110 billion funding round that included Nvidia and Softbank and valued OpenAI at $730 billion. (Disclosure: Andrew Ng is a member of Amazon’s Board of Directors.)
- OpenAI and Amazon Web Services (AWS) will develop a stateful runtime environment that will run on Amazon Bedrock, Amazon’s platform for building and deploying AI applications. Expected to launch within months, the environment is designed to manage agents’ working states including memories, tool connections, and user permissions.
- AWS is the exclusive third-party cloud provider of OpenAI Frontier, a platform for building, deploying, and managing AI agents across a company. Customers who buy Frontier through Amazon will be served via Amazon Bedrock, while those that buy directly from OpenAI will be served via Microsoft Azure.
- OpenAI and Amazon will develop custom models for Amazon’s products.
- OpenAI committed to use Amazon Trainium chips, which are designed by Amazon for AI workloads). OpenAI promised to consume 2 gigawatts’ worth of Tranium processing, expanding its previous $38 billion agreement with AWS by $100 billion over 8 years.
How it works: Many developers interact with AI models through stateless APIs for which each request is independent. A developer sends a prompt, receives a response, and the model retains no memory of the exchange, so developers must pass all context into every request. The stateful runtime environment aims to handle that context, helping agents to execute long, multi-step workflows without losing track of where they are. In addition, customers will have access to customized versions of open-weights OpenAI models that run on AWS, The Information reported.
- OpenAI argues that stateless APIs are insufficient for AI agents in production, which depend on outputs from multiple tools, require human approvals, and must resume if they’re interrupted.
- The distinction between stateful and stateless — a typical attribute of APIs — also serves a legal purpose. The agreement between OpenAI and Microsoft makes Azure the exclusive host for OpenAI’s stateless APIs, but a runtime environment falls outside the scope of Microsoft’s right. Azure will host stateless API calls to OpenAI models that arise from the Amazon collaboration
- The environment will be integrated with Amazon Bedrock AgentCore, Amazon’s tools for deploying and managing AI agents, and will run in customers’ existing environments with AWS.
Behind the news: The partnership between OpenAI and Amazon marks the latest step in the dissolution of the tight cloud partnerships that defined the early generative AI era. In 2019, Microsoft invested $1 billion (which subsequently rose beyond $13 billion) in OpenAI and became its exclusive cloud provider. In 2023, Amazon invested up to $4 billion in Anthropic and became its primary cloud provider. Each deal paired an AI startup with a cloud giant. Both ties have since loosened.
- By late 2024, both Microsoft and OpenAI were working to reduce their interdependence, as OpenAI’s needs outstripped the computational resources Microsoft was willing to build, and Microsoft put more attention into developing its own AI capabilities.
- In October 2025, when OpenAI restructured itself as a for-profit public benefit corporation, the terms gave Microsoft a 27 percent stake and 20 percent of OpenAI’s revenue but removed its right of first refusal on cloud business, freeing OpenAI to work with other providers.
- On the day the Amazon deal was announced, Microsoft and OpenAI issued a joint statement that their partnership was ongoing. Microsoft retains its exclusive access to OpenAI’s intellectual property, such as model weights, and will continue to share in revenue from OpenAI’s partnerships with other cloud providers.
- A mirror image has played out on Amazon’s side. Anthropic, Amazon’s primary AI partner, had been on Google Cloud since before Amazon invested in it, and later it expanded to Microsoft. In November 2025, Microsoft invested up to $5 billion in Anthropic and made Claude models available on Azure, making Claude the first leading model family available on all three major cloud platforms.
- According to documents filed with the U.S. Securities Exchange Commission and reviewed by GeekWire, Amazon’s equity investment and cloud partnership are contractually linked. If the agreement terminates, Amazon’s remaining $35 billion commitment will die with it.
Why it matters: Developers who build AI agents typically build their own state management, tool orchestration, and fault recovery on top of stateless APIs. A runtime environment that’s designed to handle these functions as infrastructure could lower the barrier to deploying AI agents. On the flip side, depending on exactly what state is stored and how portable it is, it may increase the cost to switch to a different cloud vendor. That it will run on AWS, the largest cloud provider by market share, will make it available to a wide swath of the developer community.
We’re thinking: Distinguishing between stateless and stateful may be clever legal engineering, but it also reflects a real technical shift. As AI applications move toward autonomy, the infrastructure behind agents may matter as much as the models.
xAI’s Cost-Effective Video Generator
xAI launched a video generator that topped an independent quality ranking at a fraction of competitors’ prices.
What’s new: Grok Imagine 1.0 takes text with images and/or video, and produces video clips that can include dialogue, sound effects, and music.
- Input/output: Text, image (optional), video (optional) in, video with audio out (up to 10 seconds at 1,280x720 pixels via chat interfaces, up to 15 seconds at 1,280x720 pixels or 854x480 pixels via API)
- Performance: Topped Artificial Analysis Video Arena in both text-to-video and image-to-video at launch
- Capabilities: Video alteration via text instructions, camera motion (pan, tilt, zoom); add, remove, and swap objects within scenes; style transfer; multiple aspect ratios
- Availability/price: Web interface via grok.com, x.com, and Grok mobile app (free for X Basic and Premium users; Premium users can generate longer videos), API $4.20 per minute of output
- Undisclosed: xAI disclosed no information about Grok Imagine 1.0’s underlying technology and how it was built.
Performance: Grok Imagine 1.0 debuted at the top of the Artificial Analysis Video Arena, a blind, head-to-head test of preferences judged by human viewers. It’s slower than some competitors but generally less expensive. (Disclosure: Andrew Ng has a personal investment in Artificial Analysis.)
- At launch, Artificial Analysis’ leaderboards ranked Grok Imagine 1.0 first in both the text-to-video and image-to-video categories, ahead of Runway Gen-4.5, Kling 2.5 Turbo, and Google Veo 3.1.
- On LM Arena’s video leaderboards, grok-imagine-video-720p ranked first in image-to-video (1,400 Elo), ahead of Google Veo 3.1 (1,395 Elo), and fourth in text-to-video (1,362 Elo), behind Google Veo 3.1 (1,371 Elo) and OpenAI Sora 2 Pro (1,369 Elo).
- In xAI’s head-to-head tests using IVEBench (which evaluates the quality of instruction-guided video alterations), human raters preferred Grok Imagine 1.0 over Runway Aleph (64.1 percent of the time) and Kling O1 (57 percent of the time).
- According to Artificial Analysis, on average, Grok Imagine 1.0 generated a video (duration unspecified) in 110.1 seconds, slower than Kling 2.5 Turbo (89.2 seconds) and Vidu Q2 (39.1 seconds) but faster than OpenAI Sora 2 Pro (448.4 seconds) and MiniMax Hailuo 2.3 (167.1 seconds).
- At $4.20 per minute of generated video (with audio), Grok Imagine 1.0 matches the price of Kling 2.5 Turbo (without audio) and costs less than Google Veo 3.1 Preview ($12 per minute with audio) and OpenAI Sora 2 Pro ($30 per minute with audio).
Behind the news: Unlike video generators from Google, OpenAI, and Runway, which are available as standalone products and/or via APIs, Grok Imagine 1.0 is integrated with the X social network. This enables X users to generate and share video directly on X, where they have caused controversy. In late 2025, X users exploited Grok to produce nonconsensual sexualized images of real people, including children, resulting in investigations and bans in several countries. The phenomenon persisted after xAI promised to address it, Reuters reported.
Why it matters: Generating a video that matches your vision typically requires many iterations of adjusting prompts, regenerating, and comparing results. xAI says that early partners told the company that quality alone was not useful if latency and cost made iteration untenable. Third-party benchmarks show Grok Imagine 1.0 matches or exceeds leading models on quality at a lower cost than premium competitors, a combination that lowers the cost of experimentation.
We’re thinking: Image generation went from novelty to table stakes in roughly two years. Video generation is following a similar path. The seven-fold price gap between Grok Imagine 1.0 and the now-shuttered OpenAI Sora 2 Pro suggests that prices still have plenty of room to fall.
Context As An External Variable
When processing long contexts, large language models often lose track of details or devolve into nonsense. Researchers reduced these effects by managing context externally.
What’s new: MIT’s Alex L. Zhang, Tim Kraska, and Omar Khattab developed Recursive Language Models (RLMs) that process long prompts encountered in books, web searches, and codebases by offloading prompts to an external environment and managing them programmatically.
Key insight: A language model can process long inputs, including inputs larger than its context window, by treating input text as a persistent variable in an external programming environment. The model can write code to fetch only the necessary chunks of text. For example, it can look for keywords and retrieve the paragraphs that surround them. Writing code Iteratively enables the model to break down long-context tasks into sub-tasks before approaching the tasks as a whole.
How it works: RLMs read and manipulate tasks (a user’s prompt and associated documents) using Python code execution in a simple read-evaluate-print loop (REPL) environment. The tasks involved analyzing, understanding, or retrieving details from long documents. The model generated a program that invoked new instances of itself, or submodels, to handle each subtask and fed each instance’s output back into the root model.
- The authors built RLM systems based on Qwen3-8B (which has a 32,768-token context window), GPT-5 (400,000-token context window), and Qwen3-Coder-480B (256,000-token context window). Each system comprised a model and a custom agentic framework that read and wrote to a Python environment and called submodels.
- The RLM systems loaded task data into a Python interpreter as a variable rather than feeding it directly into the model.
- A system prompt instructed the root model to generate Python code to interact with the REPL environment and address stored tasks. For example, the model inspected the length of a prompt, found keywords, split it into logical chunks (like chapters or sections), and called a different submodel to answer questions about each chunk.
- Each submodel processed its chunk according to the root model’s instructions or questions and passed its results back to the root model.
- The system stored the submodels’ outputs as variables. The root model used these intermediate results to construct its final output.
Results: The authors compared RLMs based on Qwen3-8B, GPT-5 with medium reasoning, and Qwen3-Coder-480B to the original models using using benchmarks that involve retrieval and reasoning over documents up to 1 million tokens long. They also compared the RLMs to CodeAct agents with retrieval tools and custom agents that compacted or summarized context. The RLMs significantly outperformed both the stock models and other agentic strategies on tasks that require understanding of multiple documents, up to 11 million tokens total.
- On BrowseComp+, a question-answering benchmark that requires reasoning over multiple documents, the RLM-GPT-5 (91.3 percent accuracy) outperformed GPT-5, which ran into context length limitations and was unable to produce an answer. It also outperformed the summary agent that used GPT-5 (70.5 percent accuracy). Similarly, RLM-Qwen3-Coder-480B (44.7 percent accuracy) outperformed Qwen3-Coder-480B with a summary agent (38.0 percent accuracy). RLM-Qwen3-8B (14 percent accuracy) outperformed Qwen3-8B (0 percent accuracy.)
- The authors tested the models on OOLONG-PAIRS, a version of the OOLONG long-context reasoning benchmark. OOLONG-PAIRS requires aggregating paired chunks to construct a final output (for instance, “list all pairs of user IDs […] where both users have at least [a value or location]”). RLM-GPT-5 (58 percent accuracy) outperformed GPT-5 (nearly 0 percent accuracy) and retrieval and summary agents (about 0.3 percent accuracy) at 32,000 tokens of context. RLM-GPT-5 maintained approximately 50 percent accuracy even at 1 million tokens of context. RLM-Qwen3-8B (5.2 percent accuracy) outperformed Qwen3-8B (0 percent accuracy) at 32,000 tokens of context.
Why it matters: Earlier approaches often handle long contexts by using retrieval or summarization, which can lose critical details. By decomposing tasks into recursive sub-calls, a model can maintain high precision across more tokens. This method provides a blueprint for building agents that can reason coherently over numbers of tokens that far exceed a model’s input limit.
We’re thinking: An RLM pays attention only to the parts of the context it needs at any given moment. This approach seems akin to the human method of processing long documents one section at a time.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み