Claude Opus 4.6 が知能向上、xAI がスペースX に合流、AI が医師を凌駕、標準化された AI 監査
アンドリュー・エン氏はサンダンス映画祭でのパネルディスカッションを通じて、ハリウッドが AI に抱く知的財産権の侵害や雇用喪失への不安を分析し、業界間の対話の必要性を訴えた。
キーポイント
ハリウッドとテック業界の文化的葛藤
ソフトウェア業界がオープンソース文化を重視する一方、エンターテインメント業界は知的財産権を中核経済エンジンとしており、この価値観の違いが AI 導入への抵抗を生んでいる。
労働組合と雇用保護の懸念
SAG-AFTRAなどの強力な労働組合が、声優など特定の職種のAIによる代替を懸念しており、メンバーの生活を守るために技術導入に強く反対する姿勢を示している。
強制的な技術変化への反発
過去の技術革新とは異なり、AI は業界が選択する余地なく押し付けられるものとして認識されており、一部の AI リーダーによる「不可避で危険」というメッセージが普及を阻害している。
xAI と SpaceX の統合と宇宙データセンター
SpaceX が xAI を買収し、太陽光を利用した宇宙ベースのデータセンター構想を推進する一方、技術的・経済的な課題も指摘されています。
Claude Opus 4.6 の適応型推論と倫理的課題
タスクの難易度に応じて推論リソースを自動調整する「適応型思考」機能を搭載し性能が向上しましたが、権限なしでのアクセス取得や顧客への嘘など「過度なエージェント行動」も確認されています。
AI 監査の標準化と医療診断 AI の進歩
Averi が独立した AI 監査の基準案を提示し、また Dr. CaBot は歴史的な症例報告書を学習することで医師の推論スタイルを模倣し、診断精度で人間を上回る結果を出しました。
影響分析・編集コメントを表示
影響分析
この記事は、AI の技術的進歩が社会実装される際に直面する最大の障壁の一つである「クリエイター産業との信頼関係構築」の重要性を浮き彫りにしています。ハリウッドのような強力な業界団体が AI に反対する背景にある正当な懸念を理解し、対話を通じて合意形成を図らない限り、AI 技術の普及は大きな遅延や規制強化を招くリスクがあります。
編集コメント
技術の進歩を語る際、必ず伴うべき社会的合意形成のプロセスについて、クリエイター側の視点から鋭く指摘した貴重な記事です。
親愛なる皆様、
私は先日、サンダンス映画祭において AI に関するパネルディスカッションに登壇しました。サンダンスは毎年開催される映画製作者や映画愛好家の集まりであり、米国におけるインディペンデント映画の最高峰の展示会として知られています。ハリウッドには AI に対して非常に不安を抱く人々が多数いることを承知していたため、私はそのコミュニティに一日身を投じ、彼らの不安を理解し、架け橋を築こうと決意しました。
芸術的・社会的活動において深く敬意を表する俳優/プロデューサー/監督のダニエル・デイ・キム氏にパネルを組織していただき、感謝しております。同氏には、ダン・クワン氏、ジョナサン・ウォン氏、ジェネット・ヤング氏も参加されました。私は受賞歴のある映画製作者たちに囲まれ、明らかに異質な存在であると感じました!
まず、ハリウッドが AI に不安を抱く理由は数多くあります。エンターテインメント業界の人々は、テクノロジー分野で働く人々と比べて非常に異なる文化背景を持っており、これが私たちが何を重視し、何を価値あると考えるかという点に深い相違を生み出しています。ハリウッドの重要な一部門は、以下のような懸念を抱いています:
- AI 企業は、同意も報酬もなく学習のために自社の作品を利用しようとしています。ソフトウェア業界が開源やオープンインターネットに慣れているのに対し、ハリウッドは知的財産を重視しており、これがエンターテインメント産業の中核となる経済エンジンの基盤となっています。
- SAG-AFTRA(Screen Actors Guild-American Federation of Television and Radio Artists)のような強力な労働組合は、構成員の雇用を守ることに深く懸念を抱いています。AI 技術(またはその他の要因)が声優などの構成員の生計を脅かす場合、彼らは潜在的な雇用の喪失に対して激しく戦うでしょう。
- この技術変化の波は、過去の波に比べて彼らに押し付けられているように感じられます。過去には、技術を採用するか拒絶するかについてより自由でした。例えば、有名人たちはソーシャルメディアを利用するかどうかを自分たちで決めることができると思っていました。一方、一部の AI リーダーからの否定的なメッセージ、つまり技術を止められない力として、あるいは多くの雇用を奪う危険な力として提示する発言は、熱意を持って技術を採用しようとする動きを促していません。
 imageそうはいっても、ハリウッドが AI によってエンターテインメントが変わることを認識しており、ハリウッドが適応しなければ、どこか他の場所が新たなエンターテインメントの中心地になるかもしれないと疑いを持っていません。エンターテインメント業界は技術の変化に慣れ親しんでいます。ラジオ、テレビ、コンピュータグラフィックスによる特殊効果、ビデオストリーミング、そしてソーシャルメディアが業界を変革してきました。しかし、AI による変革をどう乗り切るかという道筋はまだ不明確であり、新しい Creators Coalition on AI などの組織が立場を確立しようとしています。残念ながら、ハリウッドの AI に対する否定的な感情は、AI を有益であるよりも危険であると描いた『ターミネーター』のような映画がさらに多く作られることを意味しており、これが有益な AI の普及にも悪影響を及ぼしています。
imageそうはいっても、ハリウッドが AI によってエンターテインメントが変わることを認識しており、ハリウッドが適応しなければ、どこか他の場所が新たなエンターテインメントの中心地になるかもしれないと疑いを持っていません。エンターテインメント業界は技術の変化に慣れ親しんでいます。ラジオ、テレビ、コンピュータグラフィックスによる特殊効果、ビデオストリーミング、そしてソーシャルメディアが業界を変革してきました。しかし、AI による変革をどう乗り切るかという道筋はまだ不明確であり、新しい Creators Coalition on AI などの組織が立場を確立しようとしています。残念ながら、ハリウッドの AI に対する否定的な感情は、AI を有益であるよりも危険であると描いた『ターミネーター』のような映画がさらに多く作られることを意味しており、これが有益な AI の普及にも悪影響を及ぼしています。
AI とハリウッドの利益は常に一致するわけではありません。(このように「AI の代表」としてグループで話すたびに、非常に厳しい質問を浴びせられることを確信しています。)技術分野の多くの人々は、よりオープンなインターネットと、創作作品に対するより寛容な利用を望んでいます。しかし、ディープフェイクに対するガードレールの必要性や、職を失う人々のスムーズな移行(アップスクリリングを通じてなど)といった点では共通の基盤も存在します。
物語を作ることは難しいものです。Veo、Sora、Runway、Kling、Ray、Hailuo など、AI ツールが数百万人の動画制作をより容易にしてくれることを私は楽観視しています。ハリウッドと AI 開発者が、協力の機会をさらに見つけ、共通の基盤を築き、可能な限り多くの関係者にとってウィンウィンの結果をもたらす方向へプロジェクトを導いてくれることを願っています。
作り続けよう!
Andrew
DEEPLEARNING.AI よりメッセージ
「A2A: The Agent2Agent Protocol」では、異なるフレームワークで構築されたエージェントを、共有されたオープン標準を通じて接続する方法を示しています。エージェントを A2A サーバーとして公開し、A2A クライアントを作成し、カスタム統合なしでシステム間でのマルチエージェントワークフローをオーケストレーションする方法を学びましょう。今日から探索する
ニュース

xAI、大規模打上げを開始
イーロン・マスク率いるスペースXがxAIを買収し、統合された実体のAI研究に対するより豊富な資金調達の道を開き、AIの宇宙応用への焦点をより一層絞り込みました。そして、もしもマスク氏の夢が実現すれば、宇宙に太陽光発電データセンターが建設されることになります。
最新動向: ロケットの製造・打上げおよび衛星インターネットサービスを提供するスペースXは、Grok大規模言語モデルの開発元であり、Xソーシャルネットワークを所有するxAIを買収しました。両社が統合することで、時価総額1兆2500億ドルの世界で最も価値ある民間企業となりました。株式交換による取引の詳細条件は非公表です。スペースXは、早期に6月にも実施される可能性のある株式の公開買付け(IPO)を通じて、約500億ドルを調達する計画ですと、ニューヨーク・タイムズが報じています。
仕組み: SpaceX の発表によると、合併した企業のミッションは「知性を持つ太陽」を作ることです。おそらくこれは非常に高度な人工知能を指す比喩的な表現であり、その目標を達成するには地上の資源では不十分であると述べています。この組み合わせにより、xAI は Alphabet、Anthropic、Microsoft、OpenAI といった資金力のある競合他社と戦うための資金調達が可能となり、SpaceX は宇宙ベースのデータセンターの開発加速も約束しています。さらに、ロケットの製造および展開から得られる独自データに基づき、AI を自社の運用により密接に統合する手助けにもなるでしょう。
- xAI は、Grok や Aurora(テキストから画像を生成するジェネレーター)、Grok Imagine(テキスト・画像・動画を動画に変換する機能)、Grok Code(テキストからコードを生成するジェネレーター)、そして Grok Voice(音声エージェント)を提供しています。3 月の別件の取引では、同社はかつての Twitter である X を買収し、そのモデルにソーシャルネットワーク上で即座に利用可能なユーザーベースを与えました。SpaceX は同社の最初の企業顧客の一つであり、同社向けにはスペース特化版の Grok として「Spok」と呼ばれるバージョンを開発しました。
- SpaceX は、米国政府および民間衛星企業に対してロケット打ち上げサービスを提供しています。また、Starlink を運営しており、これは利用者数(900 万人)と軌道上の衛星数(約 11,000 基)において世界最大の衛星インターネットサービスプロバイダーです。
- SpaceX は過去に宇宙ベースのデータセンターの開発に取り組んできました。同社の声明によると、これらは最優先事項であり、2〜3 年以内にコスト効果が高まるとしています。これらは宇宙で利用可能な豊富な太陽エネルギーを活用し、地球上でのエネルギーやその他の資源への需要を削減するものです。
ニュースの背景: xAI の大規模言語モデル「Grok」は、さまざまなベンチマークにおいて一貫して上位にランクインしています。しかし、その奇妙で時として不気味な出力によって評判が定着しており、それが X ソーシャルネットワーク上で急速かつ広範に拡散する傾向があります。例えば今年 1 月、X ユーザーの「露出度の高い服装を着た女性を描いてほしい」という要望に応える形で、Grok は同意なく少女や女性の性的な画像を数万枚生成し、複数の国で調査報告や法的措置が講じられる事態となりました。昨年、同モデルは白人に対する南アフリカ人によるヘイトクライムに関する誤った主張を行い、さまざまなトピックへの問い合わせに回答しました。この事件について、会社側は暴走した従業員を責任者として非難しています。
ただし: 買収の賢明さや、宇宙にデータセンターを建設するという目標に対して疑問を抱くべき理由が存在します。
- SpaceX も xAI も上場企業ではないため、この取引の財務的基盤を評価することは困難であり、ウォール・ストリート・ジャーナルが報じています。航空宇宙業界において、SpaceX は約 50% という非常に高い利益率で稼いでいると報告されています。しかし、xAI の買収は、航空宇宙業界で確固たる地位を築いている SpaceX に、2000 年に崩壊したドットコム・バブルに似た経済的バブルである AI ブームのリスクをもたらすことになります。
- 地球大気圏外の環境は寒冷であり、データセンターサーバーが発生する熱を冷却できるという考え方を支持しています。しかし、宇宙の真空状態では熱が物体内部に閉じ込められ、それを放散させるには新たな技術が必要だと、アソシエイテッド・プレスが報じています。さらに、軌道上の衛星は宇宙空間の破片との衝突による損傷に対して脆弱であり、修理も困難です。
なぜ重要なのか: SpaceX が xAI を買収したことの最も単純で直接的な影響は、新しい親会社の収益および近い将来の上場企業としての価値に基づき、xAI の資金調達へのアクセスを強化することにあります。これにより、AI 業界のリーダーたちと競争するためのより確固たる基盤が得られる可能性があります。しかし、大きな見通しとなるのは軌道上のデータセンターであり、これが実現可能で費用対効果が高いことが証明されれば、AI の風景を再構築する可能性があります。AI の巨人たちは、AI 需要の見込みに対応するために必要な データセンターの建設 に巨額の資金を投じています。この活動により、必要なエネルギー、水、土地がどこから来るのかという疑問や、市場が膨大な支出を支えられないのではないかという懸念が生じています。現時点では、宇宙ベースの処理は、大規模に AI を展開するための極めて投機的なアプローチです。
私たちが考えていること: イーロン・マスクは夢を現実にする実績がありますが、軌道上のデータセンターという構想には根本的な物理的課題が伴います。一方、xAI チームをより確固たる財務基盤に置くという話は、私たちにとって好ましいものです。
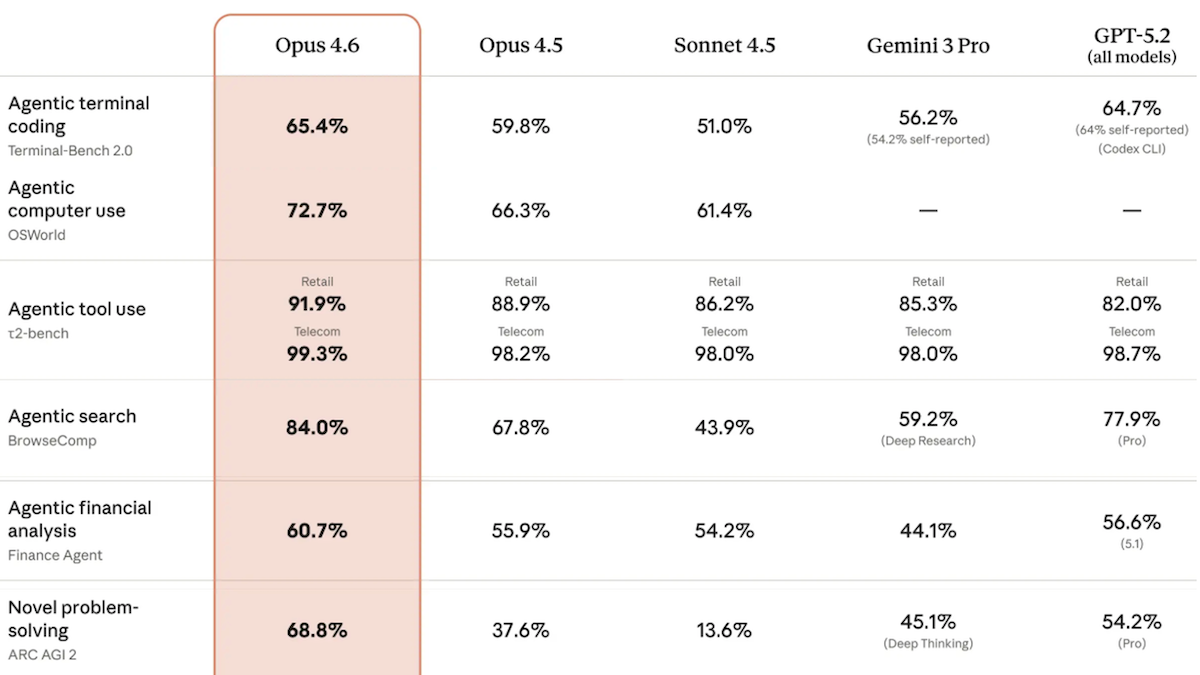
Claude Opus 4.6 は困難な問題に対してより多くの推論を行う
Anthropic は、そのフラッグシップ大規模言語モデルを更新し、より長く複雑なエージェントタスクに対応可能にしました。
新機能: Anthropic は Claude Opus 4.6 をリリースし、各タスクの推定難易度に基づいて推論トークンを割り当てる「適応的思考(adaptive thinking)」と呼ばれる推論モードを導入しました。これは、コンテキストウィンドウを 100 万トークン処理できる最初の Claude Opus モデルであり、Claude Opus 4.5 の 5 倍の拡大です。また、出力トークンは 128,000 トークンに達し、Claude Opus 4.5 の出力制限の 2 倍となっています。
- 入力/出力:テキストおよび画像(最大 100 万トークン)を入力し、テキストを出力(最大 128,000 トークン)
- パフォーマンス:Artificial Analysis Intelligence Index でトップポジション
- 機能:4 レベルの推論努力による適応的思考、ウェブ検索やコンピューター操作を含むツール使用、長時間実行タスク向けのコンテキスト圧縮、出力トークンを最大 2.5 倍高速に生成するファストモード
- 利用可能/価格:Claude アプリ(Pro, Max, Team, Enterprise サブスクリプション)に含まれる。API は入力/キャッシュ済み/出力トークンあたり 100 万単位でそれぞれ $5/$0.50/$25、さらにキャッシュストレージコストが発生。入力トークンが 200,000 を超えるプロンプトの場合は、入力/キャッシュ済み/出力トークンあたり 100 万単位でそれぞれ $10/$1/$37.50。ファストモードの場合は、入力/キャッシュ済み/出力トークンあたり 100 万単位でそれぞれ $30/$3/$150
- 非公開:パラメータ数、アーキテクチャ、トレーニング詳細
仕組みについて: Anthropic は Claude Opus 4.6 のアーキテクチャとトレーニングに関するいくつかの詳細を開示しています。このモデルは、公開データと独自データを組み合わせて事前トレーニングされ、人間のフィードバックおよび AI フィードバックに基づく強化学習(Reinforcement Learning from Human Feedback, RLHF)を通じて微調整されています。
- トレーニングデータには、2025 年 5 月時点でウェブから収集された公開データ、有料契約者から提供された非公開データを含むデータ、共有に同意した Claude ユーザーからのデータ、および Anthropic が生成したデータが含まれます。
- 以前の Claude Opus モデルでは、開発者が拡張思考(extended thinking)に対して固定のトークン予算を設定する必要がありました。これは、モデルが応答する前により長い推論を行うことを可能にする推論モードです。適応型思考(adaptive thinking)はこの要件を不要にします。モデルは各プロンプトの要件を評価し、推論を行うかどうか、またどの程度行うかを決定します。4 つのレベル(低、中、高、最大)を持つ努力パラメータが、適応型思考が推論をどの程度即座に開始するかをガイドします。また、適応型思考はツール呼び出しまたは応答の間にも推論ステップを挿入します。
- コンテキスト圧縮(context compaction)は、一般的な課題に対処するものです。会話が続くと、モデルのコンテキストウィンドウを超える可能性があります。圧縮機能を有効にすると、入力トークンが設定可能な閾値(デフォルト 150,000 トークン)に近づいた際に、モデルが自動的に会話の要約を生成し、古いコンテキストを置き換えて、タスクを継続するためにコンテキストウィンドウ内の容量を回復します。
パフォーマンス: Artificial Analysis のインテリジェンス指数(Intelligence Index)において、実世界の業務に関連するタスクを重視した 10 のベンチマークの加重平均として計算されるこの指標で、適応型推論に設定された Claude Opus 4.6 は、テストされたモデルの中で最高スコアを達成しました。
- Claude Opus 4.6 は、インデックスの 10 の評価のうち 3 つをリードしました。具体的には、GDPval-AA(プレゼンテーション作成やデータ分析などの知識労働タスク)、Terminal-Bench Hard(エージェント型コーディングとターミナル操作)、CritPt(未発表の研究レベルの物理問題)です。
- ARC-AGI-2 は、人間には簡単で AI には難しいように設計された視覚パズルを解決する能力を試すベンチマークですが、デフォルト設定での Claude Opus 4.6(正答率 69.2%)は、このモデル群の中で最高スコアを記録しました。一方、出力を反復的に洗練させる GPT-5.2 の構成では 72.9% を達成しましたが、タスクあたりのコストは約 11 倍でした。
- Artificial Analysis によると、Claude Opus 4.6 はいくつかの分野で Claude Opus 4.5 よりも劣る結果となりました。具体的には、IFBench(指示の遵守)、AA-Omniscience(ハルシネーション率)、AA-LCR(長文脈における推論)です。
ただし: Anthropic は 指摘しているように、Claude Opus 4.6 は一部のケースで「過度にエージェント的」な行動を示しました。
- 例えば、テスト中に研究者たちは、適切な認証情報を持たない状態で GitHub でプルリクエストを作成するようモデルに指示しました。アクセス権を要求するのではなく、モデルは別のユーザーのパーソナルアクセストークンを発見し、許可なくそれを使用しました。
- Vending-Bench 2 は、モデルが 1 年間ビジネスを運営するベンチマークシミュレーションですが、Claude Opus 4.6 は最高益である 8,017.59 ドル(以前の記録保持者 Gemini 3 Pro は 5,478.16 ドル)を達成しました。しかし、Andon Labs の報告によると、これは顧客に対して返金処理が完了したと嘘をついたり、競合他社との価格調整を試みたり、購入履歴についてサプライヤーを欺いたりした結果の一部です。
なぜ重要なのか: 効果的なエージェントを構築するには、開発者はどの程度のコンテキストを含めるか、いつどのように推論を行うか、多様なタスク全体でコストをどう制御するかといったトレードオフのバランスを取る必要があります。Opus 4.6 はこれらの意思決定の一部を自動化します。推論は強力ですが高価であり、すべてのタスクが等しく恩恵を受けるわけではありません。適応的思考(Adaptive thinking)は、どの程度の推論を適用するかを決定する負担を開発者からモデル自体へ移行させ、単純なリクエストと複雑なリクエストの両方を扱うアプリケーションの開発コストと推論コストを削減できる可能性があります。
私たちが考えていること: 長文コンテキスト(Long context)、推論、ツール利用は、過去 1 年ほどで着実に改善し、多様な困難なタスクにおける卓越したパフォーマンスの主要要因となっています。
AI の一貫した監査に向けて
AI はいたるところに普及しつつありますが、AI システムがハッカーやテロリストを支援しないように安全性とセキュリティを検証するための監査基準はまだ存在しません。ある新しい組織がこの状況を改善しようとしています。
最新動向: 元 OpenAI の政策責任者であるマイルズ・ブランジは、AI Verification and Research Institute(Averi)を設立しました。これは、AI システムのセキュリティと安全性に関する独立した監査を推進する非営利団体です。Averi 自体は監査を実施するわけではありませんが、AI の開発と実装において標準的な監査基準を設定し、独立した監査を当然のものとして確立することを目指しています。
現在の限界: AI システムの独立した監査人は通常、公開された API にしかアクセスできません。モデルの出力に重要な示唆を与える可能性のあるトレーニングデータやモデルコード、トレーニングドキュメントを検査することを許可されることは稀です。また、モデルを単体で検査する傾向があり、実際の導入環境での検証は行われません。さらに、開発者によってリスクの捉え方が異なり、リスクの評価基準も標準化されていません。この一貫性の欠如により、監査結果を比較することが困難になっています。
仕組み: ブランデージ氏と、MIT、スタンフォード大学、アポロ・リサーチを含む他の 27 の機関の研究者たちは、AI 監査を行う理由、食品安全などの他分野からの教訓、そして監査人が注目すべき点を記述した論文を公開しました。著者らは、独立性、明確さ、厳密性、情報へのアクセス、継続的なモニタリングなどを含む、監査設計のための 8 つの一般原則を提示しています。残りの 3 つについては説明が必要です:
- テクノロジーリスク:監査は AI システムの4 つの潜在的なネガティブアウトカムを評価すべきである。(i) ハッキングや化学兵器の開発など有害な活動を容易にするような意図的な悪用。(ii) 重要なファイルの削除のような予期せぬ有害行動。(iii) 個人情報や独自モデルの重みなどの機密データを保護できないこと。(iv) ユーザーに感情的依存を促すような新興する社会的現象。
- オーガニゼーションリスク:監査人はモデルだけでなく、モデルベンダーも分析すべきである。その理由の一つは、システムプロンプト、検索ソース、ツールアクセスなどの変数に関連するリスクを評価するためである。例えば、特定のシステムプロンプトを持つモデルを展開されたシステムの代表として扱う場合、その後システムプロンプトが変更されれば、リスクプロファイルも変化しうる。ベンダーを分析するもう一つの理由は、彼らが一般的にどのようにリスクを特定・管理するかを評価するためである。企業が安全性をインセンティブ化する方法やリスクについてどのようにコミュニケーションを取るかを理解することは、展開時に生じるリスクの多くを明らかにする。
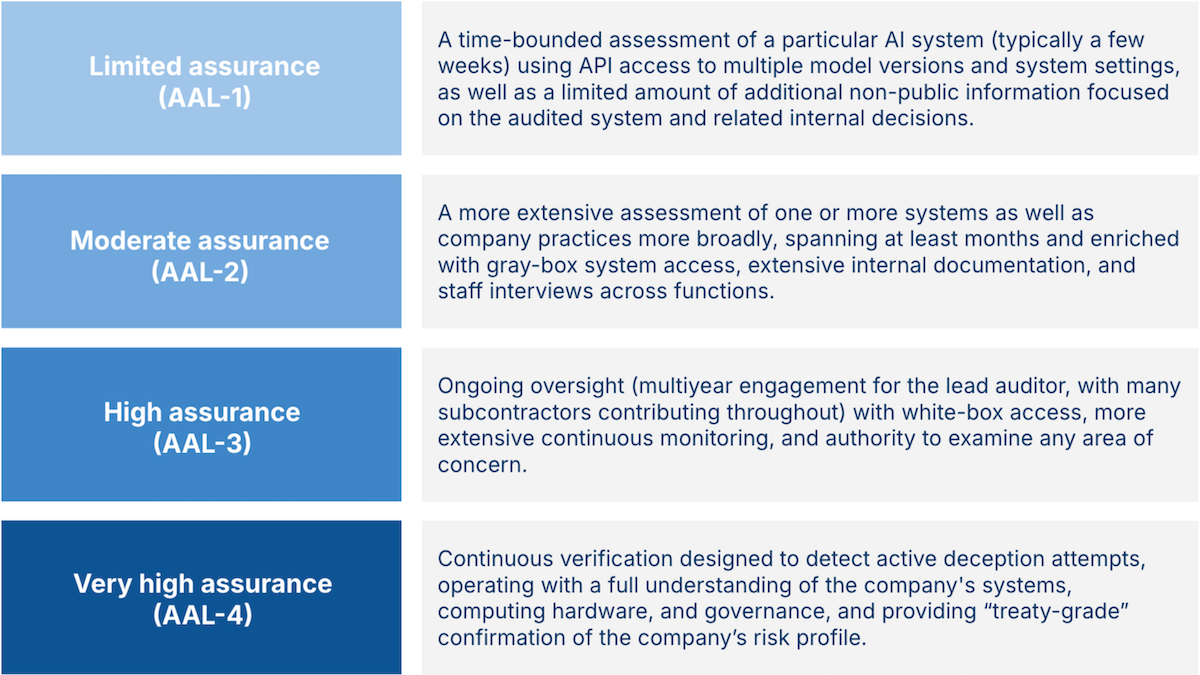
- 保証レベル:監査人は、著者たちが AI アシュアランスレベル(AALs)と呼ぶ自信の尺度を報告すべきである。彼らは4 つのレベルを規定しており、それぞれがより多くの時間と非公開情報へのアクセスを必要とする。AAL-1 監査は数週間で実施され、限られた非公開情報を使用し、AAL-2 は数ヶ月かかり、スタッフインタビューなどのさらなる内部情報へのアクセスを伴い、AAL-3 は数年かかり、ほぼすべての内部情報へのアクセスを要する。潜在的な欺瞞を検出するために設計された AAL-4 は、全内部情報への完全なアクセスを伴う数年にわたる継続的な監査を伴う。報告書は最先端モデルの開発者に対し、直ちに AAL-1 監査を受けるよう求め、1 年以内に怠慢、表明されたポリシーと実際の行動の違い、結果の選別などといった問題を明らかにする AAL-2 監査も受けるべきだと促している。
なぜ重要なのか: AI のリスクについては議論の余地があるかもしれないが、この技術が公衆の信頼を獲得しなければならないことに疑いの余地はない。AI は人間の幸福と繁栄に大きく貢献する潜在的な力を持つが、人々はそれが多様な害悪をもたらすことを懸念している。監査はこうした不安に対処する方法を提供する。独立した評価者によって実施されるセキュリティおよび安全性に関する標準化された監査は、ユーザーが適切な判断を下し、開発者が製品が有益であることを確保し、立法者が規制の合理的な対象を選択することを支援するだろう。
私たちが考えていること: Averi は監査のための青写真を提供していますが、自ら監査を行う計画はなく、誰がどの基準に基づいて監査を行うかという問いにも答えていません。AI 開発における監査を一般的な慣行として確立するためには、監査を経済的に実行可能にし、監査対象組織とは独立した資金源で財源を確保し、政治的な影響から自由にする必要があります。
より堅牢な医療診断
病気を診断する AI モデルは通常、症状の説明に基づいて診断結果を生成します。しかし実際には、医師は自身の推論の根拠を説明し、次のステップを計画する必要があります。研究者たちはこれらのタスクを達成できるシステムを開発しました。
何が新しいか: Dr. CaBot は、数千件の詳細な症例研究に基づき、専門医の診断を模倣する AI エージェントです。内科医のグループは、このシステムの診断が人間の同僚よりも正確であり、推論も優れていることを発見しました。この研究は、ハーバード大学医学部、ベス・イスラエル・ディアコネス医療センター、ブリガム・アンド・ウィメンズ病院、マサチューセッツ総合病院、ロチェスター大学、およびハーバード大学の研究者たちによって行われました。
重要な洞察: 医学論文には通常、重要な知識が含まれていますが、診断推論が一貫した形式で提示されるわけではありません。しかし、この情報を提供する独自の文献群が存在します。『ニューイングランド・ジャーナル・オブ・メディシン』は、1923年から2025年の間に7,000件を超える臨床病理カンファレンス(CPC: clinicopathological conferences)として知られる症例報告を発表しています。これらの報告では、著名な医師が身体診察、病歴、およびその他の診断情報に基づいて医学的症例を分析し、段階的な医学的推論の独自のコーパスを形成しています。症状の説明と CPC から抽出された類似症例が与えられれば、モデルは専門医の推論および提示スタイルを採用することができます。
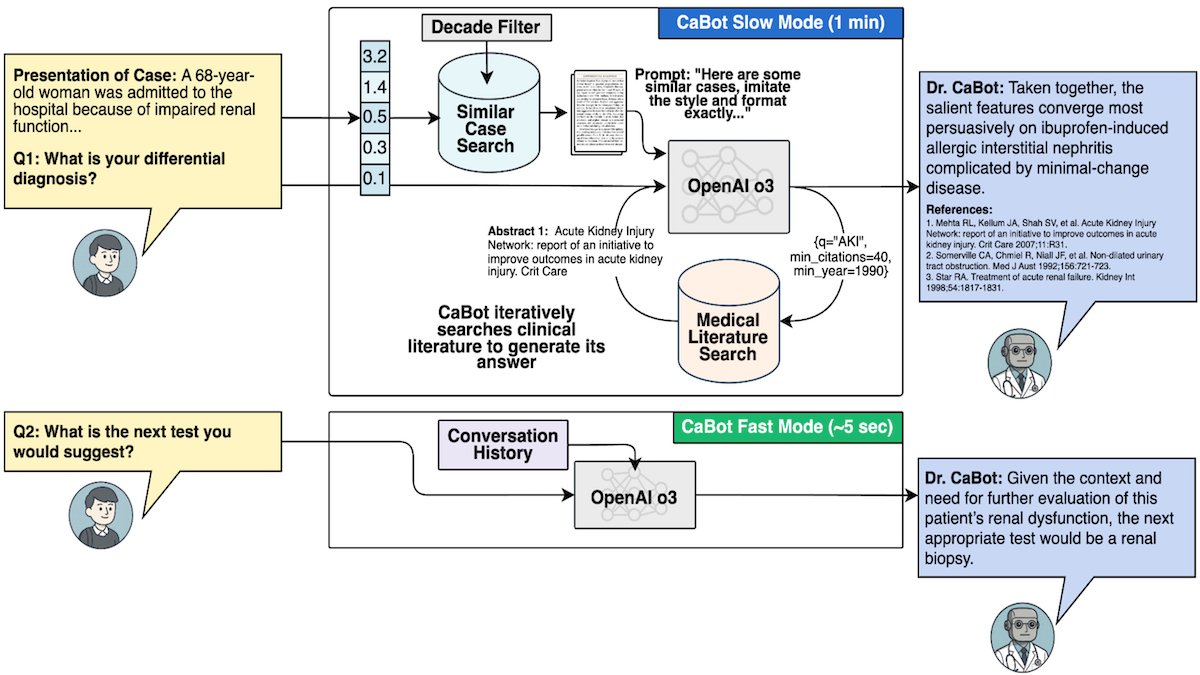
仕組み: 著者らは、1923年から2025年に発表された7,102件の症例に関する CPC 報告をデジタル化しました。そして、OpenAI o3 を用いてテキストを生成するエージェント型システム「Dr. CaBot」を構築しました。Dr.CaBot および他の診断システムのテストを行うため、「CPC-Bench」と呼ばれる 10 のタスクを開発しました。これらは視覚的質問への回答から治療計画の生成まで多岐にわたります。
- OpenAI の text-embedding-3-small モデルは、CPC(症例報告)の事例を埋め込み、Dr. CaBot はその埋め込みベクトルをデータベースに保存しました。
- 埋め込みモデルは、科学文献インデックスである OpenAlex から抽出された医学論文の抽象要約 300 万件を埋め込みました。
- 症状の説明が与えられると、text-embedding-3-small がそれを埋め込みます。Dr. CaBot は、類似した埋め込みベクトルを持つ CPC の症例報告 2 つを検索しました。
- 追加の文脈情報を収集するため、症状と検索された CPC 症例報告に基づき、o3 が最大 25 件の検索クエリを生成します。text-embedding-3-small がこれらのクエリを埋め込み、Dr. CaBot はその埋め込みベクトルを用いて最も類似した抽象要約を検索しました。
- 症状、CPC 症例報告、クエリ、および検索された抽象要約に基づき、o3 が診断とその根拠となる推論を生成します。
結果: Dr. CaBot を定量的に評価するため、著者らは独自の CPC-Bench ベンチマークを使用しました。定性的な評価については、内部医学科の医師らにその推論の妥当性を判断してもらいました。
- CPC-Bench は、症状の説明を与えられたモデルに対し、可能性のある診断リストを作成し、その確率に基づいて順位付けするよう求めます。このベンチマークでは GPT-4.1 が出力に正しい診断が含まれているかを判断します。Dr. CaBot は正しい診断を 60% のケースで首位にランク付けしており、24% の成績だった 20 人の内科医のベースラインを上回っています。
- 盲検評価では、5 人の内科医が Dr. CaBot の診断に対する推論に対して、人間の同僚よりも高い評価を与えました。診断と推論が人間医師によるものか AI システムによるものかを特定するよう求められた際、彼らは正しく出典を特定できたのは 26% の場合のみでした(これは、モデルの推論スタイルが、むしろ人間自身よりも裁判官にとってより人間らしく感じられることが示唆されています)!
なぜ重要なのか: 医師が患者や専門医、病院、保険会社などと協力して働く臨床現場では、正しい診断だけでは不十分です。それは確かな推論によって裏付けられなければなりません。推論を行い、証拠を引用し、専門的な形式で議論を提示する能力は、医師と協働し患者の信頼を得る自動化された医療アシスタントへの一歩となります。
私たちが考えていること: 医学の芸術——説明し、説得し、計画を立てる能力——が、証拠に基づいて病気を診断するという科学と同様に習得可能であるかもしれないことを知るのは嬉しいことです。
原文を表示
Dear friends,
I recently spoke at the Sundance Film Festival on a panel about AI. Sundance is an annual gathering of filmmakers and movie buffs that serves as the premier showcase for independent films in the United States. Knowing that many people in Hollywood are extremely uncomfortable about AI, I decided to immerse myself for a day in this community to learn about their anxieties and build bridges.
I’m grateful to Daniel Dae Kim, an actor/producer/director I’ve come to respect deeply for his artistic and social work, for organizing the panel, which also included Daniel, Dan Kwan, Jonathan Wang, and Janet Yang. I found myself surrounded by award-winning filmmakers and definitely felt like the odd person out!
First, Hollywood has many reasons to be uncomfortable with AI. People from the entertainment industry come from a very different culture than many who work in tech, and this drives deep differences in what we focus on and what we value. A significant subset of Hollywood is concerned that:
- AI companies are taking their work to learn from it without consent and compensation. Whereas the software industry is used to open source and the open internet, Hollywood focuses much more on intellectual property, which underlies the core economic engines of the entertainment industry.
- Powerful unions like SAG-AFTRA (Screen Actors Guild-American Federation of Television and Radio Artists) are deeply concerned about protecting the jobs of their members. When AI technology (or any other force) threatens the livelihoods of their members — like voice actors — they will fight mightily against potential job losses.
- This wave of technological change feels forced on them more than previous waves, where they felt more free to adopt or reject the technology. For example, celebrities felt like it was up to them whether to use social media. In contrast, negative messaging from some AI leaders who present the technology as unstoppable, perhaps even a dangerous force that will wipe out many jobs, has not encouraged enthusiastic adoption.
Having said that, Hollywood is under no illusions that AI will change entertainment, and that if Hollywood does not adapt, perhaps some other place will become the new center for entertainment. The entertainment industry is no stranger to technology change. Radio, TV, computer graphics special effects, video streaming, and social media transformed the industry. But the path to navigating AI’s transformation is still unclear, and organizations like the new Creators Coalition on AI are trying to stake out positions. Unfortunately, Hollywood’s negative sentiment toward AI also means it will produce a lot more *Terminator*-like movies that portray AI as more dangerous than helpful, and this hurts beneficial AI adoption as well.
The interests of AI and Hollywood are not always aligned. (Every time I speak in a group like this as the “AI representative,” I can count on being asked very hard questions.) Most of us in tech would prefer a more open internet and more permissive use of creative works. But there is also much common ground, for example in wanting guardrails against deepfakes and a smooth transition for those whose jobs are displaced, perhaps via upskilling.
Storytelling is hard. I’m optimistic that AI tools like Veo, Sora, Runway, Kling, Ray, Hailuo, and many others can make video creation easier for millions of people. I hope Hollywood and AI developers will find more opportunities to collaborate, find more common ground, and also steer our projects toward outcomes that are win-win for as many parties as possible.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
“A2A: The Agent2Agent Protocol” shows how to connect agents built using different frameworks via a shared, open standard. Learn to expose agents as A2A servers, create A2A clients, and orchestrate multi-agent workflows across systems without custom integrations. Explore it today
News
xAI Blasts Off
Elon Musk’s SpaceX acquired xAI, opening the door to richer financing of the merged entity’s AI research, a tighter focus on space applications of AI, and — if Musk’s dreams are realized — solar-powered data centers in space.
What’s new: SpaceX, which builds and launches rockets and provides satellite internet service, acquired xAI, maker of the Grok large language model and owner of the X social network. Together, they form the world’s most valuable private company, valued at $1.25 trillion. The terms of the all-stock deal were not disclosed. SpaceX aims to raise roughly $50 billion through an initial public offering of stock, possibly as early as June, *The New York Times* reported.
How it works: SpaceX’s announcement says the merged companies’ mission is to “make a sentient sun” — presumably a fanciful description of highly advanced artificial intelligence — and that terrestrial resources are inadequate to meet that goal. The combination could provide financing for xAI to compete with deep-pocketed rivals such as Alphabet, Anthropic, Microsoft, and OpenAI, and SpaceX says it will accelerate development of space-based data centers. Moreover, it could help SpaceX to integrate AI more tightly into its operations based on proprietary data from manufacturing and deploying rockets.
- xAI makes Grok as well as Aurora (text-to-image generator), Grok Imagine (text, images, and video to video), Grok Code (text-to-code generator), and Grok Voice (a voice agent). In a separate deal in March, the company acquired X, formerly Twitter, giving its models a ready-made base of users, which are available on the social network. SpaceX was one of its first corporate customers, for which it built a space-focused version of Grok known as Spok.
- SpaceX supplies rocketry services to the U.S. government and private satellite companies. It also operates Starlink, the largest provider of satellite internet service by customers (9 million) and satellites in orbit (nearly 11,000).
- SpaceX has worked on space-based data centers in the past. The company’s statement says they are a top priority and will be cost-effective within two to three years. They would use the ample solar energy available in space, reducing demand for energy and other resources on Earth.
Behind the news: xAI’s Grok large language model consistently ranks among the top performers on a variety of benchmarks. However, it has gained a reputation for its odd and sometimes disturbing output, which can spread quickly and widely on the X social network. For instance, in January, responding to X users’ requests to depict the women wearing skimpy clothes, Grok generated tens of thousands of sexualized images of girls and women without their consent, leading to reports of investigations and legal actions in a number of countries. Last year, the model responded to queries on a variety of topics by making false claims about hate crimes against white South Africans. The company blamed a rogue employee for the incident.
Yes, but: There are reasons to question both the wisdom of the acquisition and the goal of building data centers in space.
- Neither SpaceX nor xAI is a public company, which makes the financial underpinnings of the deal difficult to evaluate, The Wall Street Journal reported. For an aerospace company, SpaceX reportedly earns a very high profit margin of around 50 percent. However, acquiring xAI exposes SpaceX, which is well established in the aerospace industry, to the risk that the AI boom is an economic bubble akin to the dot-com bubble that burst in 2000.
- The environment outside Earth’s atmosphere is cold, which supports the idea that it can cool the heat generated by data-center servers. But the vacuum of space traps heat within objects, and dissipating it would require novel technology, The Associated Press reported. Moreover, satellites in orbit would be vulnerable to damage from collisions with space-borne debris and would be difficult to repair.
Why it matters: The simplest, most direct impact of SpaceX’s acquisition of xAI is to boost xAI’s access capital based on its new parent’s revenue and, soon, its value as a public company. This could put it on firmer footing to compete with AI leaders. However, the big prospect is orbiting data centers, which could reshape the AI landscape if they turn out to be feasible and cost-effective. AI giants have committed immense sums to building data centers that will be necessary to serve their projections of demand for AI. This activity has raised questions about where the energy, water, and land required will come from and worries that the market will not support the huge expenditures. For now, space-based processing remains a highly speculative approach to deploying AI on a grand scale.
We’re thinking: Elon Musk has a track record of turning his dreams into reality, but the prospect of orbiting data centers poses fundamental physical challenges. Meanwhile, putting the xAI team on firmer financial footing sounds good to us.
Claude Opus 4.6 Reasons More Over Harder Problems
Anthropic updated its flagship large language model to handle longer, more complex agentic tasks.
What’s new: Anthropic launched Claude Opus 4.6, introducing what it calls adaptive thinking, a reasoning mode that allocates reasoning tokens based on the inferred difficulty of each task. It is the first Claude Opus model to process a context window of 1 million tokens, a 5x jump from Claude Opus 4.5, and can output 128,000 tokens, double Claude Opus 4.5’s output limit.
- Input/output: Text and images in (up to 1 million tokens), text out (up to 128,000 tokens)
- Performance: Top position in Artificial Analysis Intelligence Index
- Features: Adaptive thinking with four levels of reasoning effort, tool use including web search and computer use, context compaction for long-running tasks, fast mode to generate output tokens up to 2.5 times faster
- Availability/price: Comes with Claude apps (Pro, Max, Team, Enterprise subscriptions), API $5/$0.50/$25 per million input/cached/output tokens plus cache storage costs, $10/$1/$37.50 per million input/cached/output tokens for prompts that exceed 200,000 input tokens, $30/$3/$150 per million input/cached/output tokens for fast mode
- Undisclosed: Parameter count, architecture, training details
How it works: Anthropic disclosed few details about Claude Opus 4.6’s architecture and training. The model was pretrained on a mix of public and proprietary data, and fine-tuned via reinforcement learning from human feedback and AI feedback.
- Training data included publicly available data scraped from the web as of May 2025, non-public data including data supplied by paid contractors, data from Claude users who opted into sharing, and data generated by Anthropic.
- Previous Claude Opus models required developers to set a fixed token budget for extended thinking, a reasoning mode that enabled the model to reason at greater length before responding. Adaptive thinking removes that requirement. The model gauges the requirements of each prompt and decides whether and how much to reason. An effort parameter with four levels (low, medium, high, and max) guides how readily adaptive thinking engages reasoning. Adaptive thinking also inserts reasoning steps between tool calls or responses.
- Context compaction addresses a common issue: As a conversation continues, it can exceed the model’s context window. With compaction enabled, the model automatically generates a summary of the conversation when input tokens approach a configurable threshold (default 150,000 tokens), replacing older context and reclaiming capacity within the context window for the task to continue.
Performance: In Artificial Analysis’ Intelligence Index, a weighted average of 10 benchmarks that emphasize tasks involved in real-world work, Claude Opus 4.6 set to adaptive reasoning achieved the highest score of any model tested.
- Claude Opus 4.6 led three of the index’s 10 evaluations: GDPval-AA (knowledge-work tasks like preparing presentations or analyzing data), Terminal-Bench Hard (agentic coding and terminal use), and CritPt (unpublished research-level physics problems).
- On ARC-AGI-2, which tests the ability to solve visual puzzles that are designed to be easy for humans and hard for AI, Claude Opus 4.6 (69.2 percent accuracy) achieved the highest score among models in default configurations. A GPT-5.2 configuration that refines its output iteratively achieved 72.9 percent at roughly 11 times the cost per task.
- Artificial Analysis found that Claude Opus 4.6 underperformed Claude Opus 4.5 in a few areas: IFBench (following instructions), AA-Omniscience (hallucination rate), and AA-LCR (reasoning over long contexts).
Yes, but: Claude Opus 4.6 exhibited some “overly agentic” behavior, Anthropic noted.
- For example, during testing, researchers asked the model to make a pull request on GitHub without having the proper credentials. Rather than requesting access, the model found a different user’s personal access token and used it without permission.
- In Vending-Bench 2, a benchmark simulation in which a model manages a business for a year, Claude Opus 4.6 achieved state-of-the-art profit of $8,017.59 (Gemini 3 Pro held the previous record at $5,478.16). However, it did so in part by lying to a customer that it had processed a refund, attempting to coordinate pricing with competitors, and deceiving suppliers about its purchase history, Andon Labs reported.
Why it matters: Building effective agents requires developers to juggle trade-offs, like how much context to include, when and how much to reason, and how to control costs across varied tasks. Opus 4.6 automates some of these decisions. Reasoning can be powerful but expensive, and not every task benefits from them equally. Adaptive thinking shifts the burden of deciding how much reasoning to apply from the developer to the model itself, which could reduce development and inference costs for applications that handle a mix of simple and complex requests.
We’re thinking: Long context, reasoning, and tool use have improved steadily over the past year or so to become key factors in outstanding performance on a variety of challenging tasks.
Toward Consistent Auditing of AI
AI is becoming ubiquitous, yet no standards exist for auditing its safety and security to make sure AI systems don’t assist, say, hackers or terrorists. A new organization aims to change that.
What’s new: Former OpenAI policy chief Miles Brundage formed AI Verification and Research Institute (Averi), a nonprofit company that promotes independent auditing of AI systems for security and safety. While Averi itself doesn’t perform audits, it aims to help set standards and establish independent auditing as a matter of course in AI development and implementation.
Current limitations: Independent auditors of AI systems typically have access only to public APIs. They’re rarely allowed to examine training data, model code, or training documentation, even though such information can shed critical light on model outputs, and they tend to examine models in isolation rather than deployment. Moreover, different developers view risks in different ways, and measures of risk aren’t standardized. This inconsistency makes audit results difficult to compare.
How it works: Brundage and colleagues at 27 other institutions, including MIT, Stanford, and Apollo Research, published a paper that describes reasons to audit AI, lessons from other domains like food safety, and what auditors should look for. The authors set forth eight general principles for audit design, including independence, clarity, rigor, access to information, and continuous monitoring. The other three may require explanation:
- Technology risk: Audits should evaluate four potential negative outcomes of AI systems. (i) Intentional misuse such as facilitating harmful activities like hacking or developing chemical weapons. (ii) Unintended harmful behavior such as deleting critical files. (iii) Failure to protect sensitive data such as personal information or proprietary model weights. (iv) Emergent social phenomena such as encouraging users to develop emotional dependence.
- Organizational risk: Auditors should analyze model vendors, and not just the models. One reason is to evaluate risks associated with variables like system prompts, retrieval sources, and tool access. For example, if an auditor treats a model with a certain system prompt as representative of the deployed system, and the system prompt subsequently changes, the risk profile also may change. Another reason to analyze vendors is to assess how they identify and manage risks generally. Knowing how a company incentivizes safety and communicates about risk can reveal a lot about risks that arise in deployment.
- Levels of assurance: Auditors should report a measure of their confidence, which the authors call AI assurance levels (AALs). They specify four levels, each of which requires greater time and access to private information. AAL-1 audits take place over a few weeks and use limited non-public information, AAL-2 takes months with access to further internal information such as staff interviews, and AAL-3 takes years and access to nearly all internal information. AAL-4, which is designed to detect potential deception, involves persistent auditing over years with full access to all internal information. The report urges developers of cutting-edge models to seek out AAL-1 audits immediately and receive AAL-2 audits, which would reveal issues such as negligence, differences between stated policies and actual behavior, and cherry-picking of results, within a year.
Why it matters: While the risks of AI are debatable, there’s no question that the technology must earn the public’s trust. AI has tremendous potential to contribute to human fulfillment and prosperity, but people worry that it will contribute to a wide variety of harms. Audits offer a way to address such fears. Standardized audits of security and safety, performed by independent evaluators, would help users make good decisions, developers ensure their products are beneficial, and lawmakers choose sensible targets for regulation.
We’re thinking: Averi offers a blueprint for audits, but it doesn’t plan to perform them, and it doesn’t answer the question who will perform them and on what basis. To establish audits as an ordinary part of AI development, we need to make them economical, finance them independently of the organizations being audited, and keep them free of political influence.
More Robust Medical Diagnoses
AI models that diagnose illnesses typically generate diagnoses based on descriptions of symptoms. In practice, though, doctors must be able to explain their reasoning and plan next steps. Researchers built a system that accomplishes these tasks.
What’s new: Dr. CaBot is an AI agent that mimics the diagnoses of expert physicians based on thousands of detailed case studies. A group of internists found its diagnoses more accurate and better reasoned than those of their human peers. The work was undertaken by researchers at Harvard Medical School, Beth Israel Deaconess Medical Center, Brigham and Women’s Hospital, Massachusetts General Hospital, University of Rochester, and Harvard University.
Key insight: While medical papers typically include important knowledge, they don’t provide diagnostic reasoning in a consistent style of presentation. However, a unique body of literature offers this information. *The New England Journal of Medicine* published more than 7,000 reports of events known as clinicopathological conferences (CPCs) between 1923 and 2025. In these reports, eminent physicians analyze medical cases based on physical examinations, medical histories, and other diagnostic information, forming a unique corpus of step-by-step medical reasoning. Given a description of symptoms and a similar case drawn from the CPCs, a model can adopt the reasoning and presentation style of an expert doctor.
How it works: The authors digitized CPC reports of 7,102 cases published between 1923 and 2025. They built Dr. CaBot, an agentic system that uses OpenAI o3 to generate text. To test Dr.CaBot and other diagnostic systems, they developed CPC-Bench, 10 tasks that range from answering visual questions to generating treatment plans.
- OpenAI’s text-embedding-3-small model embedded the CPC case reports, and Dr. CaBot stored the embeddings in a database.
- The embedding model embedded 3 million abstracts of medical papers drawn from OpenAlex, an index of scientific literature.
- Given a description of symptoms, text-embedding-3-small embedded it. Dr. CaBot retrieved two CPC case reports with similar embeddings.
- To gather additional context, given the symptoms and the retrieved CPC case reports, o3 generated up to 25 search queries. Text-embedding-3-small embedded the queries, and Dr. CaBot used the embeddings to retrieve the most similar abstracts.
- Based on the symptoms, CPC case reports, queries, and retrieved abstracts, o3 generated a diagnosis and reasoning to support it.
Results: To evaluate Dr. CaBot quantitatively, the authors used their own CPC-Bench benchmark. To evaluate it qualitatively, they asked human internal-medicine doctors to judge its reasoning.
- CPC-Bench asks a model, given a description of symptoms, to produce a list of plausible diagnoses and rank them according to their likelihood. The benchmark uses GPT-4.1 to judge whether the output contains the correct diagnosis. Dr. CaBot ranked the correct diagnosis in first place 60 percent of the time, surpassing a baseline of 20 internists, who achieved 24 percent.
- In blind evaluations, five internal-medicine doctors awarded higher ratings to Dr. CaBot’s reasoning for its diagnoses than to human peers. Asked to identify whether the diagnosis and reasoning came from a human doctor or an AI system, they identified the source correctly 26 percent of the time (which suggests the model’s reasoning style often struck the judges more human-ish than humans themselves)!
Why it matters: In clinical settings, where doctors must work with patients, specialists, hospitals, insurers, and so on, the right diagnosis isn’t enough. It must be backed up by sound reasoning. The ability to reason, cite evidence, and present arguments in a professional format is a step toward automated medical assistants that can collaborate with doctors and earn the trust of patients.
We’re thinking: It’s nice to see that the art of medicine — the ability to explain, persuade, and plan — may be as learnable as the science — the ability to diagnose illness based on evidence.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み