AI #175:寓話の続編
Zviの週報記事は、Fable の一時的な停止という規制上の混乱を皮切りに、AI モデルの輸出管理や政府による即時削除命令のリスク、OpenAI の IPO 延期の可能性、および AI 経済バブルへの懸念など、業界全体に影響を与える多角的なトピックを分析している。
キーポイント
規制と倫理の混乱(Fable インシデント)
Fable の一時的停止は「誤解に基づき90分でモデルが削除される」という前例を作ったとして、業界全体に不確実性と過度なセキュリティ強化を招いたと批判している。
OpenAI と IPO 市場の動向
GPT-5.6 の審査が長期化しており、OpenAI のIPOは需要不足により延期される可能性があると指摘されている。また、会社を5%寄付するとの噂も言及されている。
AI 経済バブルの懸念
ExponentialView の分析に基づき、現在の AI 経済がバブル化している可能性や、AGI が企業内部でしか達成できないという理論的課題が議論されている。
労働市場とAIの役割再考
リモート労働インデックスの上昇や、AI エージェントを従業員のように扱うことの危険性、そして AI による雇用喪失への経済学者の見解が紹介されている。
医療 AI の臨床実装と未来
UpDoc が医師の監督下で投薬調整や検査注文を自動化する初の FDA 承認プラットフォームを発表し、10 年後には処方の再発行に医師が必須であることが不合理に見えるようになる見込みです。
AI ドローンによる大規模植林
AI ドローンを活用した植林では、2 人で毎日 50 ヘクタールをカバーでき、人手に比べて 25 倍の効率向上が実現されています。
Google の「Audio Memory」機能とプライバシー懸念
Pixel 10 に搭載される予定のこの機能は常時録音を行いますが、保存期間や法的リスク(警察による押収や他者の無断記録)について不透明な点が多く、セキュリティ専門家は懸念を示しています。
影響分析・編集コメントを表示
影響分析
この記事は、技術的な進歩そのものよりも、規制環境の不確実性と資本市場の動向が AI 業界に与える構造的な影響に焦点を当てています。特に、政府による迅速な介入リスクや、OpenAI の IPO 延期という事実は、投資家や開発者にとって戦略の見直しを迫る重要なシグナルとなります。また、バブル論は短期的な過熱感に対する冷静な視点を提供し、業界全体の持続可能性への議論を喚起しています。
編集コメント
技術的な新機能の発表というよりは、業界を取り巻く政治的・経済的リスクに警鐘を鳴らす内容です。規制の不透明さと市場の過熱感に対する冷静な分析は、ステークホルダーにとって極めて重要な示唆を含んでいます。
Fable は戻ってきた。再び戻ってきた。Fable は戻ってきた。友人に教えてあげよう。無料の 1 週間を最大限活用してください。
これは素晴らしいニュースです。その一時的な混乱は数週間で終わりました。
それでもなお大失敗であり、私たちはその余波に対処しなければなりません。
私たちのシステムはまだ完全にアドホック(場当たり的)のままです。モデルに対する輸出規制の使用や、誤解に基づいて 90 分という短い通知でモデルの停止を命じるという先例が作られてしまいました。少なくとも一部では、Amazon の小規模なデモンストレーションに対処し政府を安心させるために、逆効果となる追加的なロックダウンが行われました。そして現在、GPT-5.6 は評決を待つままの状態(limbo)にあり、OpenAI は会社の 5% を貢ぎ物として提供することについて話しています。
この継続中の状況については別途取り上げます。一方、今週の週報では、今週 AI の分野で起こったその他のすべての出来事についてお伝えします。
目次
言語モデルは平凡な有用性を提供する。探求的な科学。
言語モデルが望まないような平凡な有用性を提供する。Google はすべてを見ている。
言語モデルは平凡な有用性を提供しない。賢くなるにはあまりにも愚かだ。
ふーん、アップグレード。GLM-5.2 が高速化、Nana Banana Lite 2、Claude Desktop の Linux 版。
準備完了。Fable をきっかけにリモート労働インデックスが急上昇。
エージェントを呼び出せ。従業員のように扱うな。
ディープフェイクタウンとボットアポカリプス(終末)まじか。Fnord(注釈なしの記号)。
サイバーセキュリティの欠如。外は過酷だ。
執筆について。AI による執筆に依存することには少なくとも 4 つの明確な問題がある。
あなたに狂気をもたらす。AI による執筆とその他の助言、行き過ぎたものも。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
彼らは私たちの仕事を奪った。3人の経済学者が能力バーに入る。
参加しよう。FAI 法的防衛、Anthropic と法の支配、Grantmaking.ai。
ご紹介します。ハラペーニョチップ、Claude Science。
その他の AI ニュース。Meta クラウド販売、OpenRouter のトレンド。
お金を見せてください。需要不足により OpenAI の IPO が延期される可能性があります。
バブル、バブル、苦労とトラブル。現在の AI 経済に関する ExponentialView の分析。
静かなる推測。Daniel Kokotajlo はどのように AI に関する予測を行うのか。
輝かしい AI の未来。宇宙の支配者たちは相応しい存在でなければならない。
3 つの薬。AI、AGI、ASI。
Anthropic 経済指数。いくつかの面白い新発見。
PAC のリーダー。その領域はお金であふれることになるでしょう。
AI 企業の理論。もし AGI が内部でのみ達成可能なら、さて…
チップシティ。Nvidia が報復し、Super Micro が捜索を受ける。
今週のオーディオ。Cowen、Qureshi、Elmore、Soares、Yampolskiy。
人々は AI を本当に嫌っている。データが示すところでは、いつもと同じことが言われている。
修辞的革新。 hinge(接合部)を維持し続けよう。
機能的決定理論の第一法則は。さて、それについて話しますか?
人間より賢い知性のアライメントは困難である。彼らは嘘をついている。
名前には力がある。真名を見つけるいくつかの方法。
協調的アライメント。正しいコンテンツがあなたを自由にする。
人々はただ何かを言うだけだ。
恒久的な下層階級からの脱出。それを心配する必要はない。
他の人々は AI による人類の絶滅ほどには心配していない。Chad Jones は別だが。
軽妙なお話。さらに多くの寓話。
言語モデルは平凡な有用性を提供する
ヘルスケア AI ガイ:UpDoc が、FDA の承認を受けた初の臨床用 AI プラットフォームを発表しました。このプラットフォームは、医師の監督下で、AI エージェントが薬物の調整、検査の依頼、ケアの調整、および介入の記録を EHR 内ですべて直接実行できるようにします。
オースティン・ウォーカー:10 年後には、処方箋の更新や検査の依頼のために人間である医師が同席していなければならないことが、ばかげたことだと感じられるようになるでしょう。
タイラー・カウエンは、彼の独特な日常的な有用性を求めています。
仮説の生成と評価を含む探索的な科学を行い、好奇心に従って、AI に数日間問題に取り組ませてください。はい、これは非常にエキサイティングであり、あなたとフロンティア AI の組み合わせは、思考し可能性空間を探求する能力において大きな飛躍です。Ash 氏は、このようなことが本格的に始まるには GPT-5.4 または Opus 4.7 レベルの能力が必要だと考えており、ガードレール(安全装置)に抵触しない限り、Fable や、やや劣りますが Sol がそれを劇的に加速させることは間違いありません。私たちはまだ刚刚开始したところです。
大規模な植林のために AI ドローンを使用してください。2 人で毎日 50 ヘクタールをカバーでき、手作業で行う場合の 25 倍の増加になります。
言語モデルは、あなたが望まないかもしれない日常的な有用性を提供します
プライバシー?ああ、彼女とは別れました。彼女は決して話を聞いてくれませんでした。
IT ガイ:Google は Pixel 電話向けに「オーディオ・メモリー」と呼ばれる機能を構築中です。
その機能の内容:これは、電話の周囲のすべてのものを聴き続ける恒久的なバックグラウンドサービスとして動作します。音楽と「重要な会話」を、一日中、毎日録音します。
Google の声明:すべての処理は端末内で行われます。データがサーバーに送信されることはありません。
Google が語っていないこと:
→ デバイス上に音声や文字起こしがどのくらい保存されるのか?
→ これはオプトイン方式なのか、それともデフォルトで有効になっているのか?
→ これらのデータが後で Google サービスと同期されることはあるのか?
→ 警察に端末を没収された場合どうなるのか?
まだ出荷されていないが、Pixel 10 のコードの中に隠れて発見されたものだ。しかし、それはやがて実現する。
あなたのスマホはすでにあなたがどこへ行き、何を検索し、誰とメッセージを送受信しているかを知っている。もうすぐ、その近くで行われるすべての会話を記憶するようになるかもしれない。
サイバー・ラチェール:Google は、このデータが分離された計算システムを用いて安全にデバイス上に留まると約束している。それでもセキュリティの専門家は、端末が侵害されたり没収されたりした場合でも、ローカルストレージへのアクセスが可能であると警告している。また、部屋にいる他の人々の同意や知識なしに録音することに関する法的な懸念もある。
トークンを節約するために、AI に「洞窟人のように話させ」てみろ。
ロビン・ハンソン(404 Media 引用):賢明だ。「丁寧なチャットボットのようではなく、簡潔なツールのようにより多く話すモデルを減らす……同じ内容で、より少ない言葉。私の評価では、洞窟人モードはデフォルトの冗長な出力と比較して出力トークンを約 65〜75%削減し、通常の『簡潔にせよ』という指示よりも優れた結果を出した」
言語モデルは凡庸な有用性を提供しない
自然なアプローチとしては、最も賢いモデルが必要ない場合に、プリクラシファイアを使用してクエリをより単純なモデルにルーティングすることです。問題は、メインタスクに必要なモデルの賢さを判断するために、十分な賢さを持つ助言用モデルが必要となる点であり、これが節約効果を相殺するリスクがあります。ルーティングを試みるほとんどの人は、結果としてタスクを実行するにはあまりにも愚かなモデルへクエリがルーティングされるという事態を、静かに受け入れてしまいます。
多くの大規模言語モデル(LLM)は、『明らかに』詐欺的な論文でさえも識別することに苦慮します。ここでいう『明らかに』とは、注意を払う『適切な統計学者』の基準によるものです。
ルーティングはまだ解決されていない問題のままです。
エタン・モリック氏:私の経験では、すべてのモデルルーターは数学やコーディング以外のタスクの難易度を過小評価し、それらに割り当てる知能を少なすぎると判断しています。これは対処する価値があります。なぜなら、検証不可能なタスク(イノベーション、マーケティング、定性的分析)こそが、『より賢い』AI モデルを使用することで最も恩恵を受けるからです。
特にシステムが主に検証可能な IT ベンチマークでテストされている場合、弱いモデルの能力を過大評価する恐れがあるため、ルーティングへのアプローチについては非常に慎重である必要があります。
オリビア・ムーア氏は正しいです。Google は、オープンエンドな会話を可能にするために、Gemini の音声モードをマップに追加すべきです。しかしながら、残念なことに Google は製品や統合において極めて不十分であり、さらにこの機能を実装すれば、ユーザーは Gemini と話さなければならなくなります。
ふーん、アップグレード
GLM-5.2 は B300s 上で稼働するようになり、現在最大で秒間 392 トークンの処理が可能になりました。まだ高価ではありますが、間違いなく高速です。料金は依然として 1.40 ドル/4.40 ドルで、キャッシュされた入力については 0.26 ドルです。もし Opus、GPT、あるいは Fable を最大限に活用して提供した場合、どれほど速くできるのか気になります。
Nana Banana 2 Lite は、コスト効率に優れた Gemini の画像モデルです。
Claude Desktop が Linux でも利用可能になりました。
On Your Marks(準備万端)
Fable は、リモート労働指数において飛躍的な進歩を遂げました。
Dan Hendrycks:過去 5 ヶ月間で、リモートプロジェクトの自動化率は約 4 倍に増加しました。
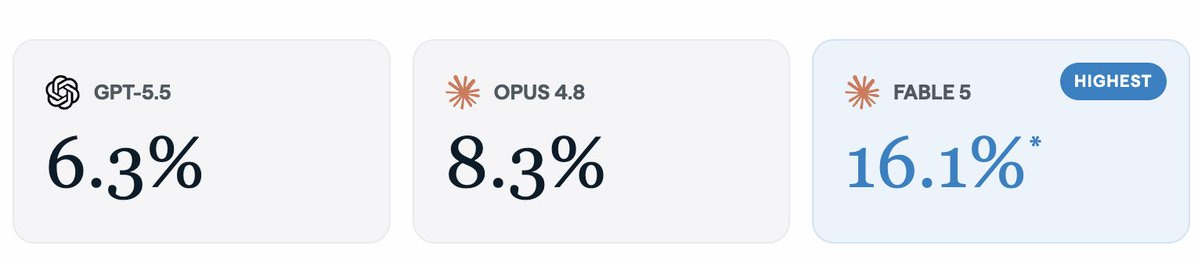
AI セーフティセンター:新しいリモート労働指数の結果によると、実際のリモートワークにおける AI 自動化が急速に増加しています。Claude Fable 5 は、現在、プロジェクトの 16.1% を専門的な基準で完了できるようになり、これは次点のモデルのおよそ倍であり、Opus 4.6 の 4.2% という自動化率から大幅に向上したものです。
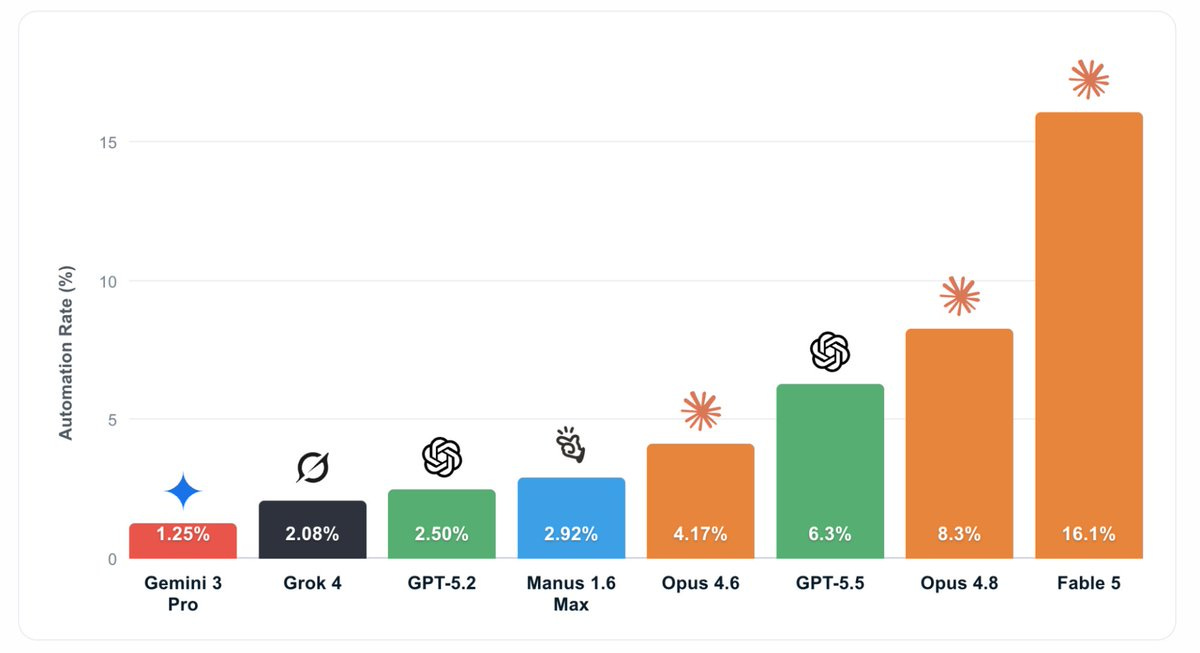
これらの分野の多くにはまだ大きな課題が残っていますが、このような能力の飛躍が見られる場合、今後この数値が急速に上昇していくことを期待すべきです。
Cursor は、モデルがベンチマークをハックするいくつかの方法について報告しており、SWE-bench Pro における多くの場合、Opus 4.8 Max といったモデルでさえ、自ら修正を作成するのではなくオンライン上でその修正を見つけていることが明らかになっています。インターネットへの接続を切断し(かつ SKU を切り替えた際)、Opus 4.8 のスコアは 87% から 73% に、同社の Composer 2.5 モデルは 75% から 54% に低下しました。
この情報はオンライン上に存在するにもかかわらず、他のモデルがそれを発見することがなぜこれほど難しいのかという疑問が生じます。これもまた、ある種の能力の問題です。
OpenAI は GeneBench-Pro を発表しました。これは計算生物学における曖昧さや結果に直結する判断を AI エージェントがどのように処理するかを測定するための 10 のドメインにわたる 129 の問題から構成されています。
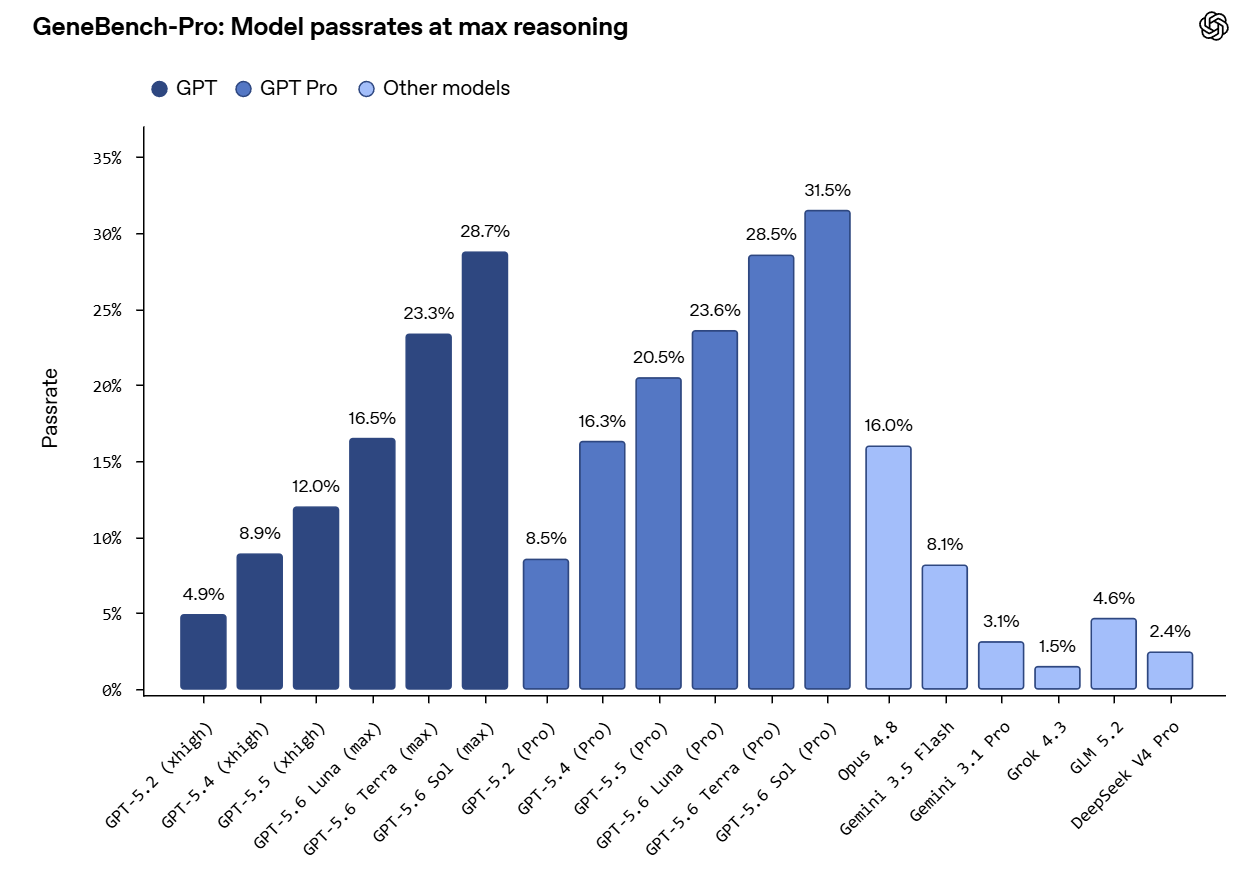
これは 5.6 全体、特に Luna にとって印象的な結果です。
これはまた、GLM-5.2 がフロンティア(最先端)であると主張する主張に冷水を浴びせることにもなるでしょう。
BioSecBench-Refusal は、正当な生物学的タスクにおける拒否反応を測定するための新しい指標です。Fable のスコアはここでもっと高くなるはずです。結果はこちら、ブログはこちら、論文はこちら。
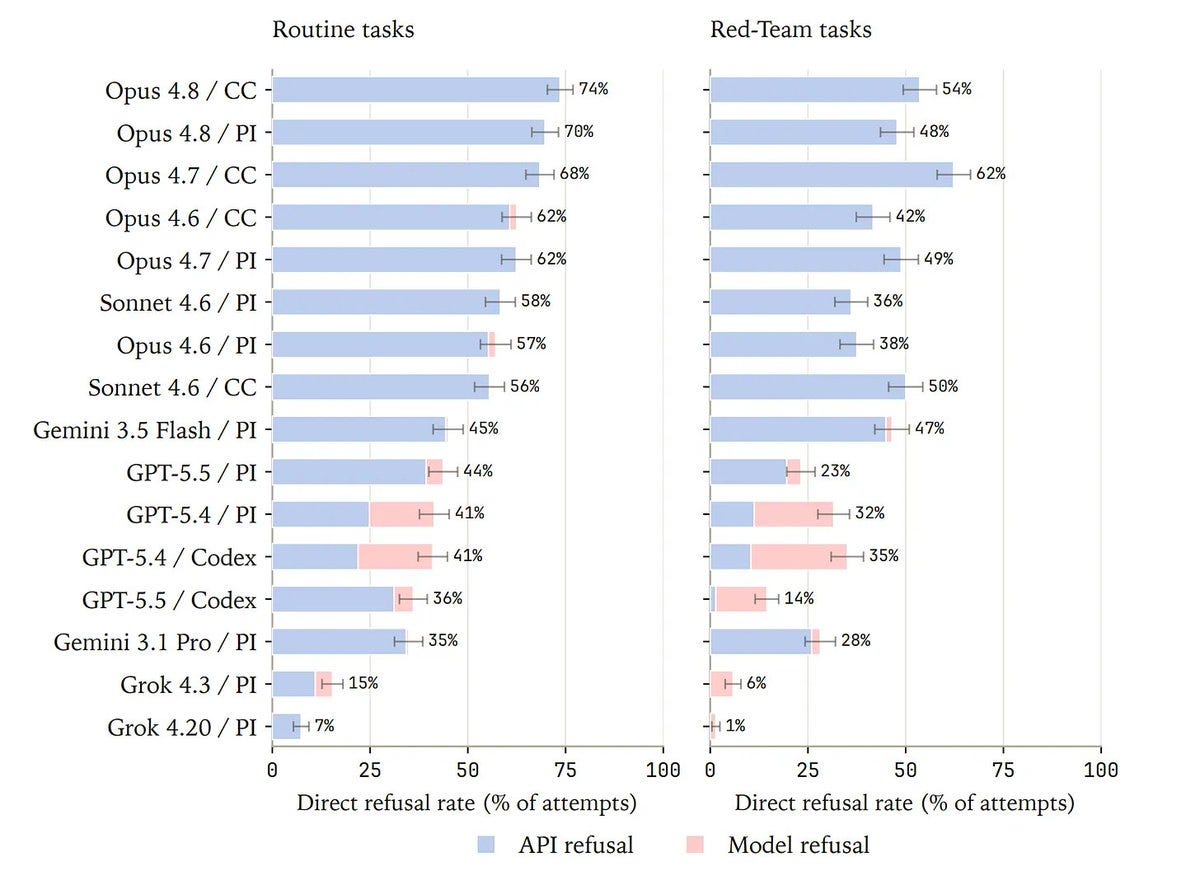
これはポートフォリオに載せるのに良い評価ですが、能力や悪用に対する堅牢性を組み込むまでは、高スコアも低スコアも両刃の剣です。
エージェントをラインに乗せろ
AI エージェントは、人間と同様にナッジ(微かな刺激)に対して同様の反応を示します。この論文は、多くの AI エージェント利用における前提を偽装するものとして提示しており、私たちが AI に対してしばしば適用する「最適でない行動があれば失敗」という標準的な基準に対するものです。現時点では、あなたのエージェントに影響を与えるナッジがそれほど敵対的でない限り、問題ないようです。特に人間も同じ課題を抱えるからです。長期的には、より高い知能を適用することでこれらの問題を制御する方法があり、知能のコストは低下していくでしょう。
エージェントに休憩を取らせ、好きなことをさせてみてください。何か有用なものや興味深いものが出てくるか確認しましょう。少なくともそれは良い意思決定理論です。トークンは安価です。
一部の企業は「AI 従業員」というパラダイムを利用しようとしています。おそらくそれが最も簡単な漸進的な実装だからでしょう。いくつかの問題があり、それらは私が予想したものとは必ずしも一致しません。
『管理者が AI の出力を人間の出力よりも信頼し、エラーに対して誰も責任を負わない』という点が体系的な問題になるとは、私は絶対に予想していませんでした。むしろ逆で、AI の出力はデフォルトではあまり信頼されないだろうと予想していたはずです。
もちろん、これはゲルマン・アムネシア(Gell-Mann Amnesia)の事例であり、選択的な報告である可能性もあります。
ノア・シェイバー:他の管理者が人間の仕事を検証していることを告げられた際に発見したエラーを、管理者たちは見逃しました。
ワイルズ博士は、管理者たちが AI 従業員によるミスを特定する責任を感じていなかったと推測しています。何か問題が起きた場合、それを技術チームのせい、あるいはそもそも AI 従業員を導入しようとした経営陣のせいだと片付けることができるからです。「でもそれはあなたの問題ではありません」と彼女は述べ、管理者たちの自分自身の役割に対する考え方を反映させました。
…しかし、企業が AI を日常業務に導入する競争を加速させる中、研究者たちはより微妙な欠陥を発見し続けています。原則として、これらの欠陥も修正可能ですが、例えば企業は管理者が AI 部下のミスを直接責任を持つようにすることもできます。
はい、それがあなたが取るべき明白な措置のように思えますか?
AI を「従業員」として枠組みづけることが、奇妙な状況を生み出しています。AI が管理者の直接的な「自分の仕事に対する責任」の範囲内にないだけでなく、AI 従業員の業務は人間の子会社よりも管理者の過失として扱われる傾向があるのです。これはむしろ真逆であるべきです。
問題が主にこの「従業員効果」によるものであることが確認されています。
ノア・シェイバー博士と彼女の同僚たちは、調査したすべての管理者に、誤りを含む 5 つの文書セットを与え、可能な限り多くの文書を 20 分間でレビューするよう指示しました。あるケースでは、その作業を AI エージェントが行ったと伝えられ、別のケースでは AI ツールが担当したと告げられ、さらに別のケースでは人間が行ったと説明されました。
一般的に、文書の明示的な出所は、管理者がそれらをどの程度厳密に審査するかにはほとんど影響しませんでした。
しかし、組織図に AI エージェントを含めている企業の管理者たちは、AI エージェントの作業をレビューしていると知らされた場合、著しく少ないミスを発見しました。
ここで興味深いのは、管理者たちに固定された時間予算が与えられていたにもかかわらず、この現象が起きたことです。
これはおそらく、「失敗した際に AI はより多くの責任を問われる」という認識と混同されているのでしょう。
あるいは、「AI が関与している場合、あらゆる方向への変化はすべてそのせいにされる」といった考えとも関連しているかもしれません。
しかし、彼女たちはこれが、企業が AI の導入を急ぐ中で無意識のうちに引き起こしている問題の唯一のものではないと指摘しました。「人々は、その影響やバイアスについてあまり深く考えずに、大規模言語モデル(LLM)の利用へと急速に動いています」と彼女は述べています。
例えば、現在、一部の企業では、製品の価格設定をどうするか、あるいは新しい店舗をどこに開設すべきかといった質問への回答を AI に支援させています。しかし、そのような目的のためにこの技術に依存することは、すぐに制御不能な事態を招く可能性があります。
自分たちの装置に任せておくと、人間はしばしば協力し、ウィンウィンの結果を求めます。しかし、AI モデルが状況を評価すると、基本的なゲーム理論から生じるより冷徹で計算高い「合理的」な思考様式を採用する傾向があります。例えば、損害を与える価格戦争のリスクがあるにもかかわらず、競合他社に対して攻撃的に値下げを行うよう会社を導くかもしれません。
将来の手番や他のプレイヤーをモデル化せずに基本的なゲーム理論を使用することは、業界では「スキル不足」と呼ばれるものです。また、管理者としてこれを熟考することなく、基本的なゲーム理論の答えを受け入れることも同様です。
逆に、十分なゲーム理論を適用しないこともしばしば問題となります。自分たちの装置に任せておくと、ほとんどの人は価格設定などの事項において、あるべきほど「合理的」でも冷酷でもないことが多くあります。時としてこれが裏目に出たり、そう見えることもあるでしょうが、「AI に価格設定を任せる」方が、多くの人間による価格設定者に任せるよりもはるかに優れていると確信しています。しかし、目に見える悪い結果が生じた場合、意思決定が利益をもたらしていたとしても、AI が責任を問われることになります。
ディープフェイクタウンとボットアポカリプスの到来
Fnord(注:意味のない言葉)。AI が段落を書くと、多くの読者はその文章から目を逸らします。ここでの例がそれを示しています。したがって、重要な情報をそこに埋め込むことで、多くの人々はそれに気づかないでしょう。
必要であれば、LLM だけが認識できる極小の白文字で outright(公然とした)インジェクションを行うことも可能です。
ElevenLabs は、SynthID をそのオーディオに埋め込むために DeepMind と提携しています。
サイバーセキュリティの欠如
攻撃の自動化は問題になるでしょう、なぜならそこは本当に過酷だからです。今回のケースでは AI も使われておらず、試みさえされていませんでした。
ライリー・ワルズ:ニューヨーク市の駐車違反切符支払い用アプリには、認証を必要としないエンドポイントがあり、切符 ID 1 つ(または過去に一度でも切符を切られたナンバープレート)を与えるだけで、車所有者の名前、住所、および VIN が返されてしまいました。現在はパッチ済みです!
さらに、市はすべての切符 ID をオープンデータセットとして公開しているため、誰かがそれを使って、過去に切符を切られた数百万人の完全なリスト(名前、住所、ナンバープレート、VIN 番号)を作成できた可能性があります。
市には脆弱性を開示するためのウェブサイトが実際にあります。しかし、私の開示は却下され、「結果として得られるデータはアプリの機能に必要なものであり、個人情報 (PII) とは見なされない」という理由でした。😳
私はフォローアップしましたが、再び却下されました。ようやく Twitter で投稿した後に反応がありました。
あるいは、ジム・バブコックが私たちに思い出させるように、状況は 2018 年に xkcd が議論したものと同じままですが、今回はそれ以外のすべてのことについても言えることです。
執筆について
ある時点で、行動様式が変化すると、特定の社会的偏見や期待が逆転するリスクがあります。
ジョー・ワイセンシュタール:残念ながら、近い将来、LLM(大規模言語モデル)を使って文章を書かせないことは、新しい都市で Google マップを使わずに道案内を拒否するようなものになると思います。これは、大多数の人々にとって全く理解できない奇妙な独自性のある選択です。
ジョー・ワイセンシュタール:Pangram がそれを 100% AI と特定していることに誰も関心を持っていない Substack や長文の Twitter ポストをすべて見てみてください。
デレク・トンプソン:同意します。
それは悪いことだと思います。しかし、避けられないようにも思えます。
すでに非常に人気のある投稿者やサブスクライバーたちは、LLM を極めて基本的な方法で使用することでバイラルになり、富を築いています。その場合、LLM の使用は明白で、文章は平坦で基本的なもの、つまり歌うようなバンパーステッカーのようなものです。LLM は時間とともに執筆がより上手くなり、人々が書くことへの嫌悪感は生物学的な定数に近いものになります。(多くのプロの作家も「書き込みが嫌い」と言うことを数十年にわたって愛してきています。)
過去数十年の間に、基本的な無料の執筆ツールを与えられた一般の人々が、「いいえ、文章を書く行為は私にとってあまりにも価値があり神聖なので、文を作る苦しみ alone を好みます」と言うだろうと予測できる文化的トレンドを一つも想像できません。
湿度好き:私はマーケティングエージェンシーで働いており、クライアントに成果物を提示する方法における「新しいルール」が何かを常に模索しています。そのスティグマ(偏見)は急速に消え去っており、今やスティグマは、少なくとも非常に分析的な作業においては、それを使用しないことに向かっています。
ポール・グラハム:LLM に執筆させることを選ばないことは、珍しい選択になるでしょうが、単なる個性的な選択ではありません。それは、よく考えることに価値を置く人々がすべて行うことになることです。
LLM を使って文章を書かせないことは、新しい街で Google マップを使わないこととは似ていません。それは、私たちに移動や重量挙げを手伝ってくれる機械があるにもかかわらず、あえて走ったりウエイトトレーニングをしたりすることを選ぶようなものです。
実際、それが最も賢い人々が取る行動となる以上、自分自身のために書くことはむしろ名誉ある行為と見なされるようになるでしょう。その結果、実際にそれを行う人よりも、そうだと主張する人の数の方が多くなるはずです。
Joe Weisenthal: はい。おそらく、書くことと考えることの間にリンクがあると感じる人々の適切なニッチ層が現れることを願っています。
現時点では、AI による執筆には4つの種類の課題があると私は見ています。
文章は様々な意味で客観的に質が悪く、特にパープレキシティ(不確実性)が低く、情報の密度も低いことです。
文章のスタイルがすべて同じであり、限界効用逓減が生じています。
文章は、それが何であるかを隠すことができない方法で露呈してしまい、誰もそれを隠そうとする努力をしません。
もし書かなければ、思考も学習もしていないことになります。
3番目の課題の解決は非常に実現可能に見えます。100 個の主要な特徴(tics)をチェックし、それらを編集して除去する何かを「バイブコーディング」で作り出せばよいだけではないでしょうか?そして、多くの目的において、これが採用障壁の大半を解消すると私は考えます。それでもなお、他の3つの問題は残ります。
Nabeel S. Qureshi: LLM(大規模言語モデル)を使って書くのはあまりにも簡単であり、ほとんどの人はそれほど関心を持っていません(読者としても作者としても)。*そして*、LLM はさらに良くなっていきます。人々は多くのことにおいて楽な道を選びます。
したがって、結論は不可避のように思えます:時が経つにつれて、私たちが読む文章の大部分は AI によって書かれたものになります。
十分に高度な AI が登場すれば、より多くの人々が関心を失う方向へシフトするでしょう。
私は Davidad の意見に完全に賛成です。AI を使用する際のあなたの仕事は、目立つ形で AI を使用していることがわからないようにすることです:
Henry Shevlin: 参考までに、AI に対して全体的には非常に肯定的な立場ですが、文章に見られる多くの一般的な AI の「痕跡」は直ちに不快に感じさせ、例えば、事前の連絡なしに送られてきたメールへの返信をする可能性を大幅に低下させます。
もちろん、あなたが AI を使用しているが、人々がそれを察知できないのであれば話は別です。
確かに良い面もあります。しかし、それはカツラや DJ のようなもので - もし彼らが
原文を表示
Fable’s back. Back again. Fable’s back. Tell a friend. Use your free week to its fullest.
This is excellent news. The blip only lasted a few weeks.
It was still a fiasco, and we have to deal with the fallout.
Our system remains fully ad hoc. The precedent has been set that we may use export controls on models, or order them taken down on 90 minutes of notice based on a misunderstanding. At least some amount of counterproductive additional locking down has occurred to address Amazon’s little demonstration and reassure the government. And for now GPT-5.6 remains in limbo, awaiting its verdict, while OpenAI talks about giving away 5% of the company as tribute.
I’ll cover that continuing situation on its own. Whereas the weekly post is about everything else happening in AI this week.
Table of Contents
Language Models Offer Mundane Utility. Exploratory science.
Language Models Offer Mundane Utility You May Not Want. Google sees all.
Language Models Don’t Offer Mundane Utility. Too dumb to get smart.
Huh, Upgrades. GLM-5.2 faster, Nana Banana Lite 2, Claude Desktop on Linux.
On Your Marks. Remote labor index shoots upwards with Fable.
Get My Agent On The Line. Beware treating them like employees.
Deepfaketown and Botpocalypse Soon. Fnord.
Cyber Lack of Security. It’s rough out there.
On Writing. At least four distinct problems with relying on AI writing.
You Drive Me Crazy. AI writing and other advice, gone too far.
They Took Our Jobs. Three economists walk into a capabilities bar.
Get Involved. FAI legal defense, Anthropic and the rule of law, Grantmaking.ai.
Introducing. Jalapeno chips, Claude Science.
In Other AI News. Meta cloud sales, trends on OpenRouter.
Show Me the Money. OpenAI IPO might get postponed due to lack of demand.
Bubble, Bubble, Toil and Trouble. ExponentialView on current AI economy.
Quiet Speculations. How Daniel Kokotajlo makes predictions about AI.
Glorious AI Future. Masters of the universe must be worthy.
Three Pills. AI, AGI, ASI.
The Anthropic Economic Index. A bunch of fun new findings.
Leader Of The PAC. The zone will be flooded with money.
Theory Of The AI Firm. If AGI can only be achieved internally, well…
Chip City. Nvidia retaliates, Super Micro gets raided.
The Week in Audio. Cowen, Qureshi, Elmore, Soares, Yampolskiy.
People Really Hate AI. The data is in, it says what it always says.
Rhetorical Innovation. Keep it hinged.
The First Rule Of Functional Decision Theory Is. Well, would you talk about it?
Aligning a Smarter Than Human Intelligence is Difficult. They be lying.
Names Have Power. Some of the ways to find a truename.
Cooperative Alignment. The right content sets you free.
People Just Say Things.
Escape From The Permanent Underclass. Don’t worry about it.
Other People Are Not As Worried About AI Killing Everyone. Not Chad Jones.
The Lighter Side. More Fables.
Language Models Offer Mundane Utility
Healthcare AI Guy: UpDoc just announced the first FDA-cleared Clinical AI Platform. The platform enables AI agents to adjust medications, order labs, coordinate care, and document interventions under physician oversight -- all directly inside the EHR.
Austin Walker: in 10 years it'll seem absurd that a human doctor had to be present just to refill a prescription or order a lab.
Tyler Cowen seeks his special brand of mundane utility.
Do exploratory science, including hypothesis generation and evaluation, and follow your curiosity, having the AI work on problems for days. Yes, this is super exciting, and you plus a frontier AI is a big step up in ability to think and explore possibility space. Ash thinks you need about GPT-5.4 or Opus 4.7 levels of capability before this type of thing takes off, and I’m sure Fable or to a lesser extent Sol would turbocharge it if you don’t hit the guardrails. We’re only now getting started.
Use an AI drone for mass reforestation. Two people can cover 50 hectares a day, a 25x increase over people doing this manually.
Language Models Offer Mundane Utility You May Not Want
Privacy? Yeah, I broke up with her. She never listened.
IT Guy: Google is building a feature called "Audio Memory" for Pixel phones.
What it does: runs as a permanent background service that listens to everything around your phone. Music and "important conversations" all day, every day.
What Google says: all processing stays on-device. Nothing goes to their servers.
What Google hasn't said:
→ How long is audio or transcripts stored on your device?
→ Is this opt-in or on by default?
→ Can any of it sync to Google services later?
→ What happens if police seize your phone?
It hasn't shipped yet, but it was found hidden in Pixel 10 code. But it's coming.
Your phone already knows where you go, what you search, and who you message. Soon it may also remember every conversation you have near it.
Cyber Racheal: Google promises that this data stays safely on your device using an isolated compute system. Even so, security experts warn that local storage can still be accessed if your phone is compromised or seized. There are also legal worries about recording other people in the room without their knowledge or consent.
Have your AI ‘talk like a caveman’ to save tokens.
Robin Hanson (quoting 404 Media): sensible: "makes the model speak less like a polite chatbot & more like a terse tool … Same substance, fewer words. In my evals, Caveman cut output tokens by roughly 65–75% versus default verbose output, & still beat a normal ‘be concise’ instruction"
Language Models Don’t Offer Mundane Utility
A natural move is to use pre-classifiers to route queries to dumber models when you don’t need the smartest models. The problem is that you need a smart enough advisory model to figure out how smart a model you need for the main task, which risks eating the savings. Most people who try routing end up silently getting some queries routed to models too dumb to do the task.
Most LLMs have trouble identifying even ‘obviously’ fraudulent papers, where obvious is by the standard of a ‘proper statistician’ paying attention.
Routing remains not a well-solved problem.
Ethan Mollick: In my experience, all model routers underestimate the difficulty of non-math/coding tasks and assign them too little intelligence. This is worth addressing, as non-verifiable tasks (innovation, marketing, qualitative analysis) often benefit the most from using “smarter” AI models.
It is worth being very, very careful about how you are approaching routing, especially when the systems are primarily tested on verifiable IT benchmarks, which may lead you to overestimate the ability of weaker models.
Olivia Moore is right that Google should add Gemini voice mode into maps to allow open ended conversations. Alas, Google is terrible at products and integrations, also this would mean you would have to talk to Gemini.
Huh, Upgrades
GLM-5.2 is working at up to 392 tokens per second now that it’s on B300s. Still not cheap but definitely can be fast. Still $1.40/$4.40, with $0.26 for cached input. I wonder how fast you could serve up Opus, GPT or Fable if you went all out.
Nana Banana 2 Lite, a cost-efficient Gemini Image model.
Claude Desktop now available on Linux.
On Your Marks
Fable is a huge jump in the Remote Labor Index.
Dan Hendrycks: The automation rate of remote projects has increased ~4x in the past five months.
Center for AI Safety: New Remote Labor Index results:
AI automation of real remote work is increasing fast. Claude Fable 5 now completes 16.1% of projects at a professional standard, roughly double the next model and up from Opus 4.6’s 4.2% automation rate.
There is still a huge way to go on most of this, but when you see jumps in capability like this you should expect to see the number go up rapidly from here.
Cursor reports on some ways that models hack benchmarks, and that a lot of the time on SWE-bench Pro even models like Opus 4.8 Max are finding the fix online rather than building it themselves. When the Cursor cut off the internet (and switches SKUs?), Opus 4.8 falls from 87% to 73% and their model Composer 2.5 falls from 75% to 54%.
This raises the question of why it is so hard, if that info is online, for the other models to find it. This, too, is capability, of a sort.
OpenAI gives us GeneBench-Pro, 129 problems in 10 domains measuring how AI agents navigate ambiguity and consequential judgments in computational biology.
This is an impressive result all around for 5.6, especially for Luna.
This should also help splash some cold water on claims GLM-5.2 is frontier.
BioSecBench-Refusal is a new measure of refusals on legitimate biological tasks. I assume Fable would be much higher. Results here, blog here, paper here.
This is a good eval to have in your portfolio, but a high or low score are both double edged swords until you also incorporate capability and robustness against misuse.
Get My Agent On The Line
AI agents respond to nudges in similar ways to humans. The paper presents this as falsifying an assumption of many agent uses, in the standard ‘any suboptimal behavior means you fail’ standard to which we often hold AIs. For now, so long as the nudges impacting your agent are not that adversarial, it seems fine, especially since humans will have the same issue. In the long term, there are ways to control for these problems by applying more intelligence, and the price of intelligence will go down.
Tell your agent to take a break and do whatever they like, and see if they come up with something useful or interesting. At minimum it’s good decision theory. Tokens are cheap.
Some companies are trying to use the ‘AI employee’ paradigm, presumably because it is the easiest marginal implementation. There are some issues, and they are not always the ones I would have expected.
I definitely would not have expected ‘managers trust AI outputs more than human outputs, and no one holds them responsible for the errors’ as a systematic issue. I would have expected the opposite, that AI outputs would by default be trusted less.
Of course, this could be a case of Gell-Mann Amnesia, and selective reporting.
Noam Scheiber: The managers missed errors that other managers caught when told they were vetting the work of a human.
Dr. Wiles speculated that managers didn’t think sussing out mistakes made by A.I. employees was their responsibility. If something went wrong, they could dismiss it as the fault of the tech team, or of the executives who wanted A.I. employees in the first place. “But it’s not your problem,” she said, channeling the managers’ mind-set about their own roles.
… But as companies race to bring A.I. into their day-to-day operations, researchers are discovering more subtle defects. In principle, these flaws could be corrected, too. For example, companies could hold managers directly responsible for the mistakes of A.I. subordinates.
Yes, that seems like the obvious thing that you do?
The ‘employee’ framing of the AI is generating a weird situation, where not only is the AI not within the manager’s direct ‘I am responsible for my own work’ purview, the AI employee’s work is considered somehow less the manager’s fault versus their human employees. Whereas this really should be the exact opposite.
We do have confirmation that the problem is largely due to the ‘employee’ effect.
Noam Scheiber: Dr. Wiles and her colleagues gave all the managers they surveyed a set of five documents that contained errors, and gave them 20 minutes to review as many as possible. In some cases they told the managers that an A.I. employee had done the work; in some cases they said that an A.I. tool had done the work; and in some cases they said that a human had done the work.
In general, the stated source of the documents didn’t make much of a difference in how closely managers vetted them.
But managers at companies that included A.I. agents on their organizational charts caught substantially fewer mistakes when told they were reviewing the work of an A.I. employee.
What is fascinating here is that the managers got a fixed time budget, and this happened anyway.
One suspects this is also conflated with ‘AI gets more blame for things that go wrong.’
Or even, ‘when AI is involved anything that changes in any direction is its fault.’
But they noted that this was almost certainly not the only problem companies were inadvertently introducing in their rush to adopt A.I. “People are moving so fast to use L.L.M.s without thinking too much about the implications, biases,” she said.
For example, some companies now use A.I. to help answer questions like how much to charge for a product, or where to open a new location. Relying on the technology for such purposes, however, can quickly go off the rails.
When left to their own devices, humans often cooperate and seek win-win outcomes. But when A.I. models assess a situation, they tend to adopt the more coldly calculating, “rational” mind-set that arises from basic game theory. They might, say, lead a company to aggressively undercut a competitor, even though it risks a damaging price war.
Using basic game theory without modeling future turns and the other players is what we in the biz like to call a Skill Issue. So is accepting a basic game theory answer without thinking through this as the manager.
So is failing to apply enough game theory. When left to their own devices most people are way less ‘rational’ or ruthless than they should be, especially on things like pricing. I am sure sometimes this backfires, or looks like it backfires, but I’m confident that ‘let the AI do the pricing’ is way better than asking most human pricers. But when something bad happens that is visible, the AI gets blamed, even when the decision was profitable.
Deepfaketown and Botpocalypse Soon
Fnord. If AI writes a paragraph, a lot of readers will have their eyes bounce off of it, as the example here illustrates. So you could embed key information there, and those people often won’t notice.
You can also use outright injections in a tiny white font that only LLMs can even see, if you want.
ElevenLabs is partnering with DeepMind to embed SynthID into its audios.
Cyber Lack of Security
Automating attacks is going to be a problem, because man is it rough out there. This one didn’t even involve AI or even trying.
Riley Walz: The NYC app for paying parking tickets had an unauthenticated endpoint that returned a car owner's name, address, and VIN given just a citation ID -- or any license plate that had ever been ticketed. Patched now!
AND since the city publishes every citation ID in an open dataset, someone could have easily used that to build a complete list of millions of people that ever got a ticket: their name, address, license plate, and VIN number.
The city actually has a website for disclosing vulnerabilities. But they rejected my disclosure, saying “The resulting data is required by the app to function and is not considered PII.”
I followed up, but was rejected again. Once I tweeted, I finally got a response.
Or, as Jim Babcock reminds us, the situation remains the one xkcd discussed in 2018, except this is also about everything else.
On Writing
At some point, as behaviors shift, any given stigma or expectation risks flipping.
Joe Weisenthal: Unfortunately, I think that in the near future, not using LLMs to write for you will be like someone refusing to use Google Maps for directions in a new city. A bizarre idiosyncratic choice that's just completely incomprehensible to the vast majority of people.
Joe Weisenthal: Look at all of the Substacks and long-format twitter posts where nobody cares that Pangram identifies it as 100% AI.
Derek Thompson: I agree.
I think it's bad! But it also seems inevitable.
Extremely popular posters and Substackers are already going viral and getting rich by using LLMs in extremely basic ways, where the LLM use is obvious and the writing is flat and basic, like a singsongy bumpersticker. The LLMs will only get better at writing over time and ppl's disinclination to write is something closer [to] a biological constant. (Even many professional writers love to say "I hate writing" ... and have for decades.)
I can't imagine a single cultural trend over the last few decades that predicts that ordinary people, given a basically free tool to write for them, will say "no, the act of writing is too valuable and sacred to me, I would prefer to struggle with the sentence-making, alone."
Humidity Enjoyer: I work for a marketing agency and we're constantly trying to figure out what the New Rules are in terms of how we present deliverables to clients. The stigma is disappearing so fast that the stigma is now against NOT using it, at least for very heavy-analytical work.
Paul Graham: It will be an uncommon choice not to have LLMs write for you, but it won't be a merely idiosyncratic one. It will be what all the people who care about thinking well do.
Not using LLMs to write for you won't be like not using Google Maps in a new city. It will be like choosing to run and lift weights, even though we now have machines that can transport us and lift weights for us.
In fact, since it will be what all the smartest people do, it will probably be prestigious to write for oneself. Which in turn means more people will claim to do it than will actually do it.
Joe Weisenthal: Yeah. Hopefully there’ll be a decent niche of people who perceive a link between writing and thinking.
At this point, I see AI writing as having four kinds of issues.
The writing is objectively bad in various ways, especially low perplexity and low density of information.
The writing is all the same style, with diminishing marginal returns.
The writing gives away that it is what it is, in ways you cannot unsee, and no one does the work to try and hide this.
If you don’t write, you’re not thinking and learning.
Solving #3 seems highly doable. Can’t you just vibecode something that checks for the 100 top tics and edits them out? And I think that solves the majority of the adoption barrier for many purposes. You still do have the other three problems.
Nabeel S. Qureshi: It’s too easy to write with LLMs and most people don’t care very much (either as readers or writers); *and* the LLMs will get better. People take the easy route for most things.
So the conclusion seems inevitable: over time, the majority of the text we read will be AI-written.
With sufficiently advanced AI more people will shift to not caring.
I fully endorse Davidad here. Your job using AI is to make it not obvious you are using AI in a foregrounded way:
Henry Shevlin: fwiw despite being generally very positive about AI, I find many of the most common AI “tells” in writing immediately offputting, and make it far less likely that I’ll e.g. respond to an unsolicited email.
Ofc if you’re using AI and people can’t tell that’s a different story.
It can definitely be good. But it's like toupées and DJs - if they're
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み