コーディングエージェントには最適条件があり、多くの人はそれを飛ばしている
コーディングエージェント成功の4条件:参照物、自己テスト、設計図、方向性の管理。これらを満たせば品質が向上するが、全てのプロジェクトに適するわけではない。
キーポイント
Coding Agentの成功には「明確な参照物(翻訳型タスク)」「自動化された検証(エージェントループ)」「適切なアーキテクチャ設計(タスク分解)」の3条件が重要
大規模な実プロジェクト(JustHTML移植、vinext開発)でAIによる高品質なコード生成が実証された
人間は方向性の決定とコンテキスト提供に集中し、AIは実行を担当するという協働モデルが有効
テスト駆動開発とAIの組み合わせが自動化フィードバックループを実現する
影響分析・編集コメントを表示
影響分析
この記事はAIコーディングエージェントの実用的な成功条件を具体的な事例で示しており、単なる技術デモを超えた実務応用の可能性を明確にした。特に「翻訳型タスク」という制約付き活用と自動テスト連携による品質保証のアプローチは、AIプログラミングの現実的な導入方法として業界に影響を与える可能性が高い。
編集コメント
AIコーディングの「できること」と「できないこと」の境界線を実例で示した良記事。成功事例の背後にある具体的な条件設定が参考になる。
See all postsPublished on 2026-02-25Coding Agent 有个甜蜜点,多数人直接跳过了
有两个 Vibe Coding 项目让我印象很深。
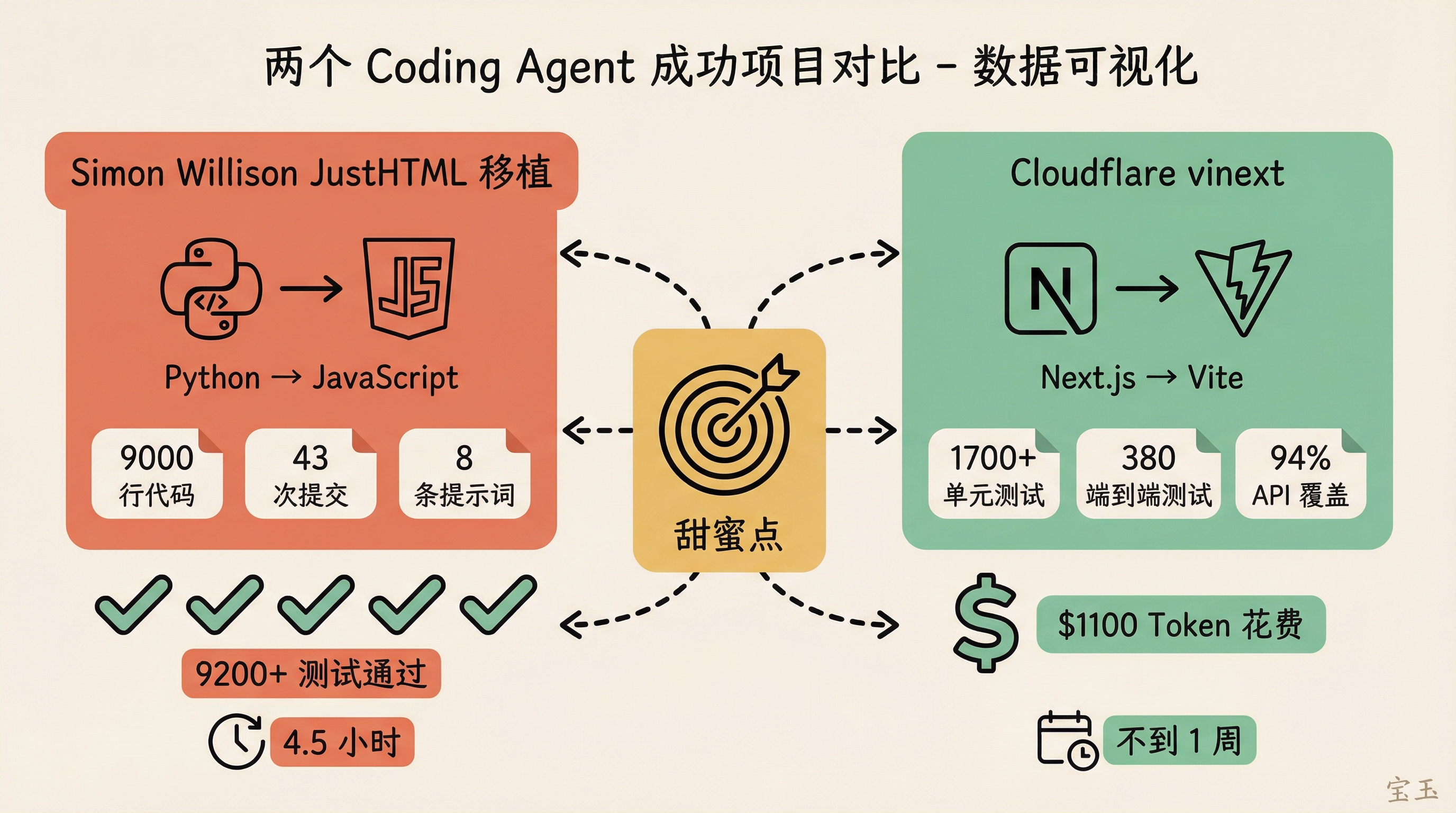
一个是 Simon Willison(Django 框架の共同創設者)が、家族とクリスマスツリーを飾りながら映画を見ている間に、Codex CLI と GPT-5.2 を使い、Emil Stenström の JustHTML(純粋な Python で書かれた HTML パーサーライブラリ)を、依存関係ゼロの純粋な JavaScript 版へ移行しました。9200 以上の html5lib-tests テストケースをパスし、約 9000 行のコードと 43 回のコミットを生み出しています。この過程で彼自身が発したプロンプトはわずか 8 個程度です。
《I ported JustHTML from Python to JavaScript with Codex CLI and GPT-5.2 in 4.5 hours》https://simonwillison.net/2025/Dec/15/porting-justhtml/
もう一つは Cloudflare で、エンジニアマネージャーが AI を率いて、わずか一週間足らずで Vite 上で Next.js の API を再実装し、vinext というプロジェクトを立ち上げました。1700 以上のユニットテストと 380 個の E2E テスト(End-to-End Test)をパスし、Next.js の API の 94% をカバーしています。すでに顧客が本番環境で稼働させています。総コストは約 1100 ドルの Token です。
《How we rebuilt Next.js with AI in one week》https://blog.cloudflare.com/vinext/
この二つのプロジェクトは規模も複雑さも決して低くありませんが、Coding Agent の完成度が驚くほど高いのです。なぜでしょうか?
それは両方とも Coding Agent のコンフォートゾーン、つまり「甜蜜点」を正確に捉えているからです。
明確なリファレンスがある:Agent に「創造」ではなく「翻訳」させる
大規模言語モデル(LLM)が最も得意とすることのひとつは「翻訳」です。自然言語であれプログラミング言語であれ、明確なリファレンスを与えられれば、素早くかつ高品質に処理できます。
Simon のプロジェクトは典型的な翻訳タスクです。すでに Python 版の HTML パーサーライブラリが存在し、API デザインもコードロジックも完成しています。Agent に求められるのは、これらを JavaScript へ「翻訳」することだけです。アーキテクチャをゼロから設計する必要も、製品に関する意思決定をする必要もなく、与えられたものを忠実に書き写せばよいのです。
Cloudflare の vinext プロジェクトはより複雑に見えますが、根底にあるロジックは同じです。Next.js の API は公開されており、ドキュメントも極めて充実しています。Stack Overflow には膨大な Q&A が蓄積されており、これらはすでに大規模言語モデルのトレーニングデータに含まれています。Cloudflare チームは AI に新しいフレームワークを発明させるのではなく、Next.js の仕様書に基づいて Vite 上で再実装させるよう指示したのです。
最初の条件:Agent に明確なリファレンスを与えることです。既存のオープンソースプロジェクトでも、API ドキュメントでも、あなたが以前書いた旧バージョンのコードでも、すべてがリファレンスとして機能します。Agent に「創造」ではなく「翻訳」を任せることで、成功率は格段に高まります。
あなた自身の仕事においても、手を動かす前に一度自問してみてください。「参照できる既存のものはないか?」と。オープンソースの実装、競合他社のコード、あるいは単なる擬似コード(Pseudo-code)であっても、それがあれば Agent のパフォーマンスは一歩跳ね上がります。
自動化された検証:エージェントが自身で正誤を確認できる仕組み
コーディング・エージェントも人間プログラマーと同様、コードを書き終えた後に検証が必要です。違いは、検証に人手を要すると効率が劇的に低下する一方で、エージェント自身がテストを実行し、結果を確認し、バグを修正できれば、高速なループに入り、疲れ知らずに反復改善を行えるようになる点です。
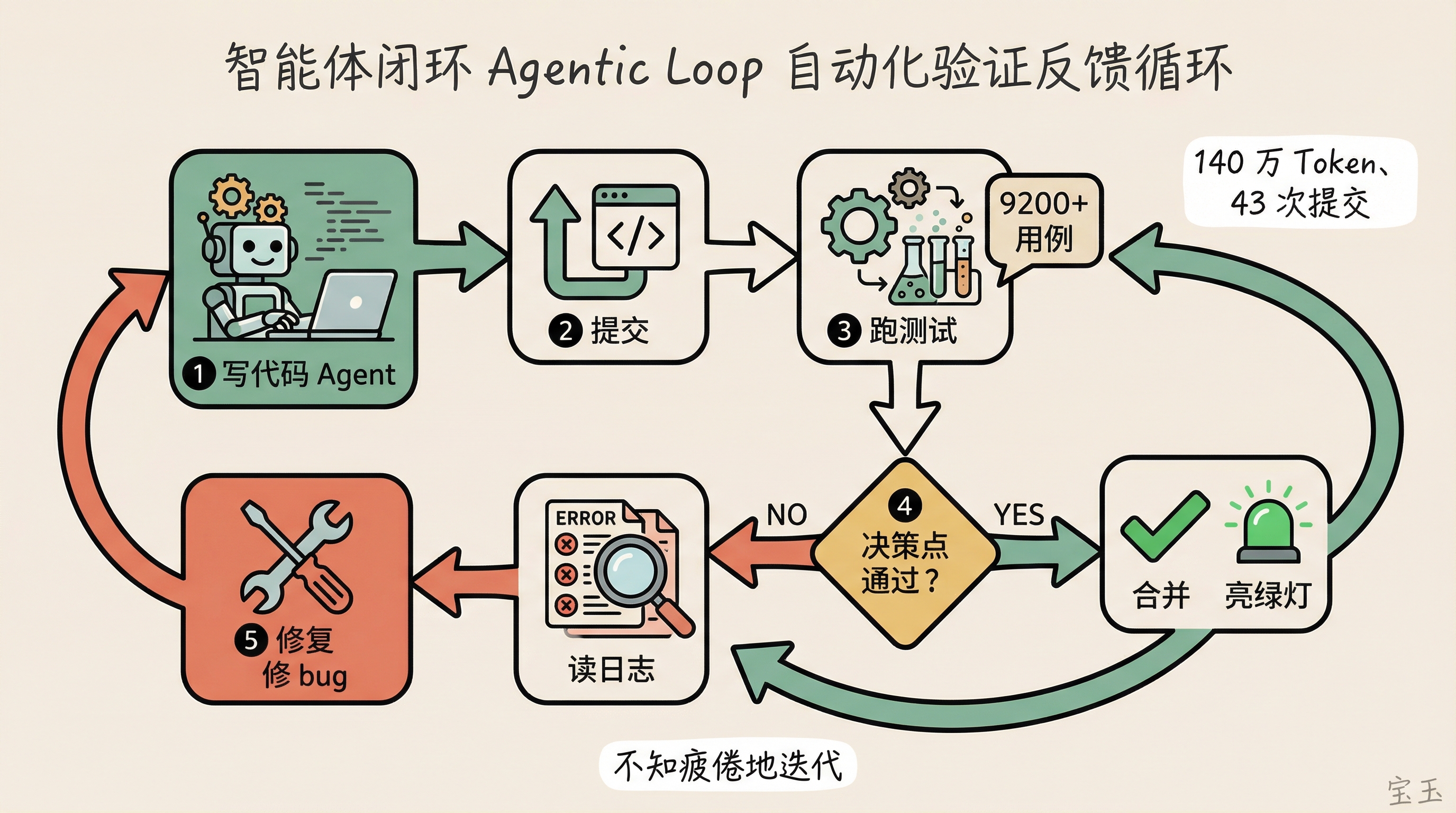
Simon のプロジェクトが成功した背景には、HTML5 標準に「html5lib-tests」と呼ばれるテストスイートが存在することが大きく寄与しています。このテストセットには 9200 以上のケースが含まれており、入力は HTML で、出力は正しい解析構造となります。エージェントに対してどこを間違えたかを教える必要はなく、テストを実行するだけで問題がわかります。Simon が GitHub Actions の設定を終えると、エージェントはこのループに入り、140 万トークン以上を使用し、43 回のコミットを経て、すべてのテストが緑色(合格)になるまで続けました。
Simon はこのプロセスを「デザイン・エージェント・ループ(Designing the Agentic Loop)」と呼び、これが AI のプログラミング能力を引き出すための鍵となるスキルであると指摘しています。
Cloudflare のケースも同様です。Next.js リポジトリには数千ものエンドツーエンドテストが存在し、チームはこれらのテストをそのまま受け入れ基準として採用しました。ワークフローは以下の通りです:タスクを定義し、AI にコードとテストの作成を依頼し、テストを実行します。合格すればマージし、不合格であればエラーメッセージを AI に返して修正させます。ほぼ完全な自動フィードバック・ループが構築されています。
「私のプロジェクトにはそんな完璧なテストスイートはない」とおっしゃるかもしれません。確かに、大多数のプロジェクトにはありません。しかし、この方向性に向かって取り組むことは可能です:
まずテストを記述し、その後に Agent に実装を行わせる(テスト駆動開発と Agent は相性が抜群です)
ブラウザの開発ツールを接続して実行結果を確認できるようにする
少なくとも「npm test」の自動実行を Agent に行わせる
Agent が利用する自動検証ツールの数が増えれば増えるほど、自己修復能力は高まります。
アーキテクチャ・ブループリントの活用:Agent に「作文」ではなく「穴埋め」をさせる
エージェントはコンテキストウィンドウ(文脈の記憶容量)の制限を受けるため、一度に処理できる情報の量には上限があります。複雑なプロジェクトのコードベース全体を丸ごと投げつけても、消化しきれません。また、大規模な機能を最初から最後まで一気に行うよう指示しても、後半になるほど前半の内容を忘れてしまいます。
そのため、アーキテクチャ設計が極めて重要になります。大きなタスクをアーキテクチャに基づいて小さなタスクに分解し、各タスクがエージェントのコンテキストウィンドウ内で完結するように調整することが、熟練者と初心者の間で最も大きな違いの一つです。
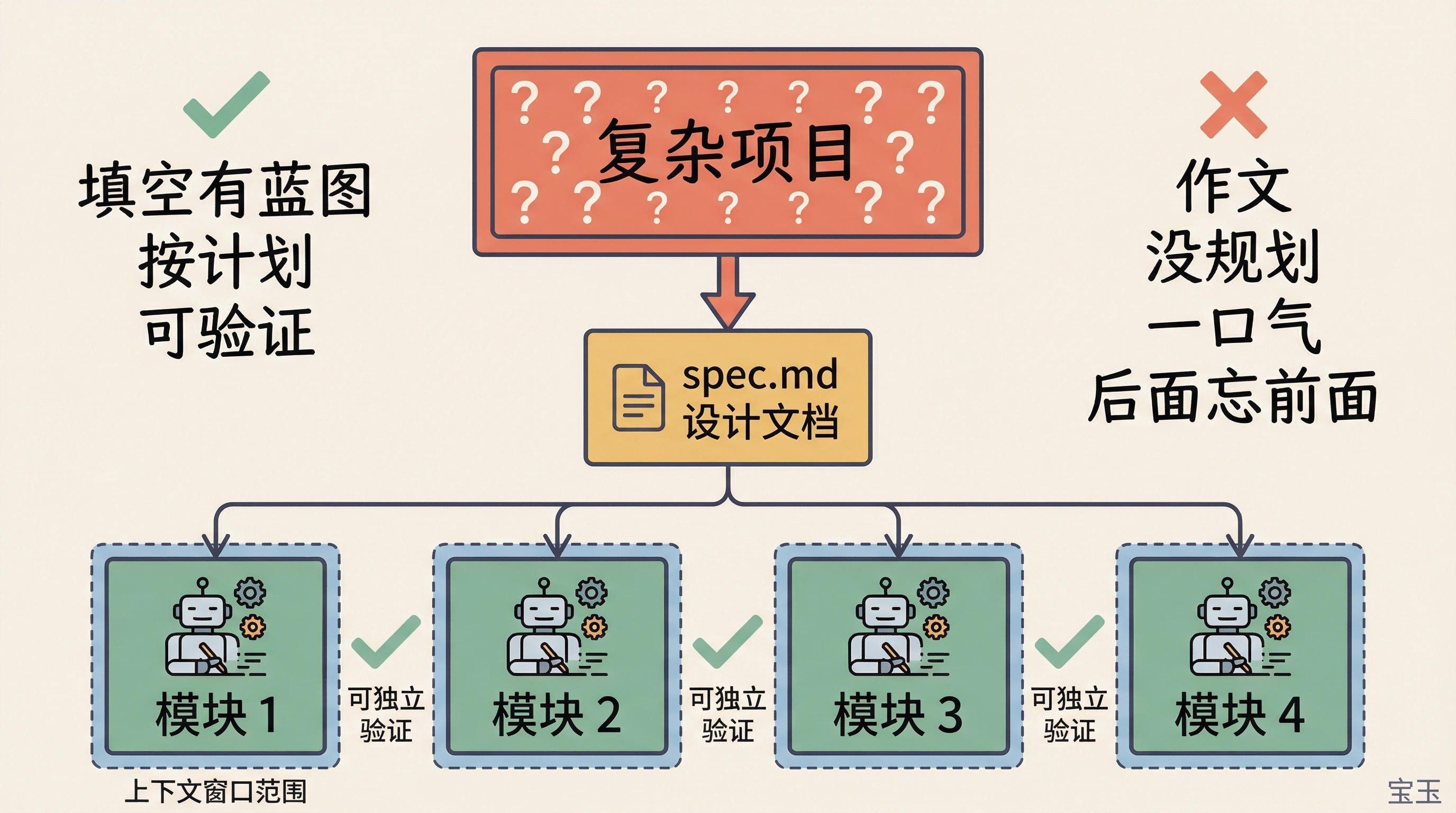
Simon のアプローチは賢明です。彼の最初のプロンプトは AI にコードを書かせるのではなく、Python プロジェクトを読み込んだ後に JavaScript 版の設計ドキュメント(spec.md)を作成させるというものでした。
Cloudflare チームのアプローチはより体系的です。エンジニアリングマネージャーがまず Claude と数時間にわたりアーキテクチャ案を繰り返し議論し、全体像であるブループリントを確定させた上で、モジュールごとにタスクを分割しました。各タスクの境界が明確なため、AI は一つのモジュールを書き終えるたびに独立してテストでき、プロジェクト全体の完成を待たずに検証が可能です。
アーキテクチャの専門家でなくてもこの作業は可能です。たとえ AI と 10〜30 分ほど話し合い、実行計画を立ててもらい、その計画に従って段階的に進めるだけでも、結果は格段に良くなります。「設計してから実装する」という原則は人間プログラマーにも適用されますが、Agent にとってはより一層重要なルールです。
誰かが方向性をコントロールする:エージェントが実行し、人間が意思決定する
Cloudflare のブログにはこんな一節があります。
AI に良い方向性、良い文脈、そして適切なガードレールを与えれば、高い生産性が得られます。しかし、ハンドルは人間の手に握らせておく必要があります。
AI には頭を悩ませる特徴が一つあります。それは、見た目は完全に正しくても実際には動作しないコードを書きがちだということです。構文に問題はなく、論理も一見通じているのに、実行すると正しくないのです。このような「高信頼度の誤り」を見抜くためには、現時点では人間による判断が必要です。
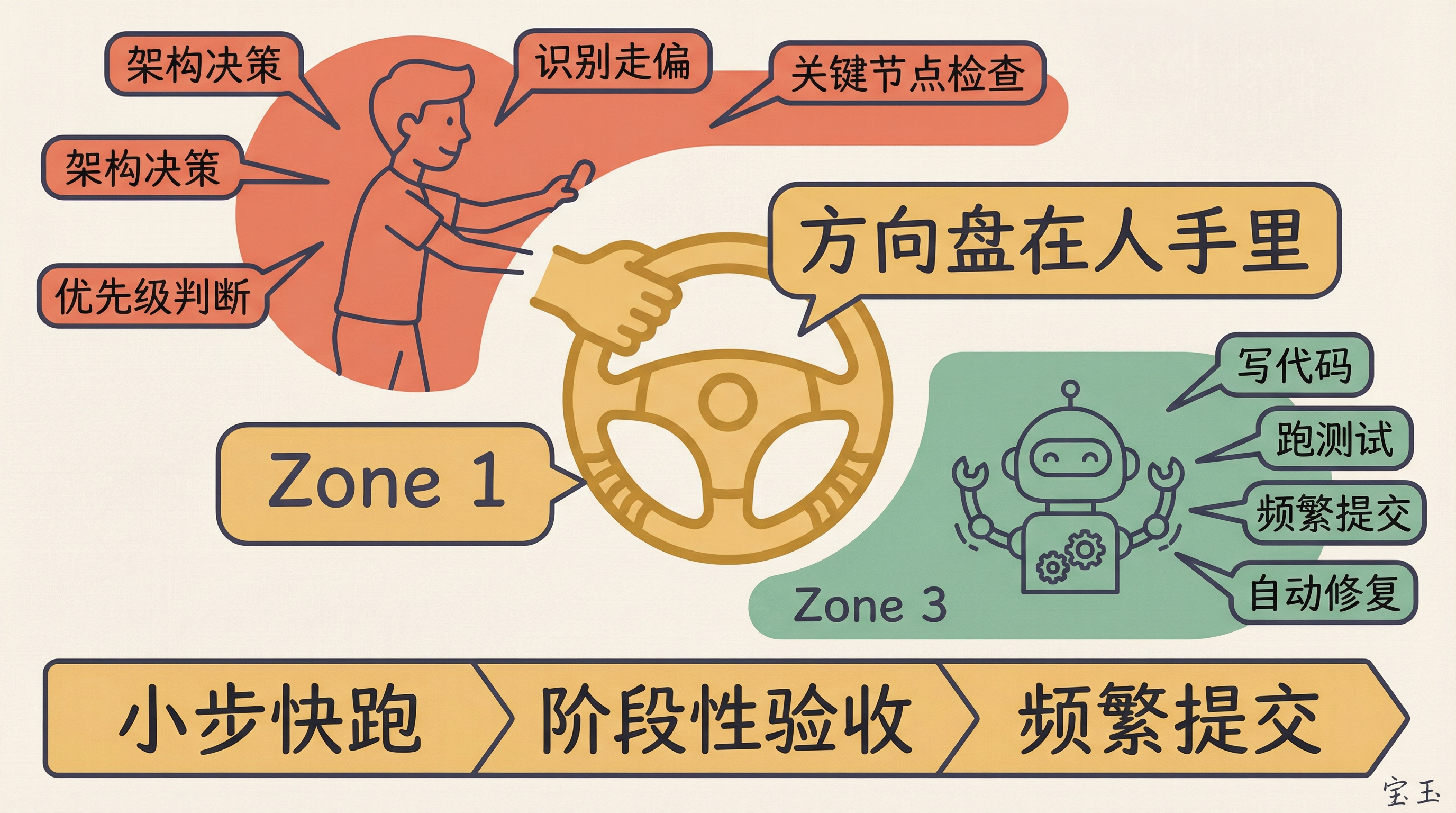
Simon はエージェントに対して「頻繁にコミットしてプッシュする(commit and push often)」よう指示しました。これにより、彼はスマートフォンで GitHub のコミット履歴を閲覧するだけで進捗を追跡できます。Cloudflare チームもコードレビューの一部を AI エージェントに任せていますが、アーキテクチャの意思決定、優先順位の判断、そして AI が逸脱したことを検知することについては、依然として人間がコントロールしています。
この二つのプロジェクトを担当しているのは初心者ではありません。Simon は Django の共同創設者であり、Cloudflare 側の担当者はエンジニアリングマネージャーです。彼らは大きな問題を AI が処理できる小さなタスクに分解する方法を知っており、いつ介入すべきか、いつ手を離すべきかも理解しています。
あなたが彼らと同じような達人である必要はありませんし、エージェントが書くコードのすべての行を監視する必要もありません。しかし、重要な局面で方向性が正しいかどうかを確認する必要があります。エージェントに大きすぎるタスクを与えて自分自身は去ってしまうと、通常良い結果は得られません。小刻みに進め、段階的に検証するというのが、現在最も信頼できる協働方式です。
これら四つの条件は、決して高邁な理論ではありません。振り返ればすべて常識に過ぎません:参照があること、自己検証が可能であること、計画があること、そして人間による管理があること。しかし、まさにそれらがあまりにも常識的であるがゆえに、多くの人がエージェントを使用する際にこれらの条件を無視してしまいます。
Cloudflare チーム自身は言っています。数ヶ月前まではこれを行なうことはできなかったと。それはモデルの能力がどれほど向上したからというだけでなく、正しい方法を見つけたからです。
Coding Agent の適正領域(sweet spot)がどこにあるかを知った今、意識的に自分のプロジェクトをその方向へ近づけることができます:
まず、着手する前に参照となるプロジェクトやコードがあるか確認しましょう。焦ってエージェントにゼロから書かせようとしてはいけません。類似のオープンソース実装がないか、既存の API 仕様はないか、参考になるコードライブラリはないか探してみましょう。エージェントに参照物を与えることは、単なる要件記述を与えるよりもはるかに効果的です。
エージェントに自動検証機能を備えさせましょう。手動テストはエージェントの効率における最大のボトルネックです。検証プロセスを自動化尽可能にしましょう:ユニットテスト、インテグレーションテスト、Lint(コード品質チェック)、型チェック、さらにはブラウザの自動化テストまで。エージェントが自ら実行し、結果を確認し、自ら修正できるようにします。Cloudflare は agent-browser を用いてブラウザ側のレンダリングとインタラクションを検証していますが、このアプローチは非常に参考になります。
実装の前に設計をしましょう。エージェントに作業させる前に、アーキテクチャを明確にし、タスクを適切に分割してください。各タスクの範囲は、エージェントのコンテキストウィンドウ(記憶容量)に収まるほど小さく、かつ有意義なモジュールを生み出すのに十分な大きさである必要があります。このタスク分割能力こそが、達人と初心者の分水嶺です。
フィードバックループを構築しましょう。Simon の手法は典型的です:CI(継続的インテグレーション)を設定し、コミットするたびに自動的にテストを実行します。エージェントがコードを書き、コミットし、CI でエラーが発生し、エージェントがログを読み、修正し、再度コミットします。人間は重要な局面でのみ介入すれば十分です。このループが回れば、エージェントの生産性は、あなたがそこに座って一行ずつコードをレビューするよりも遥かに上回るでしょう。
いつエージェントが機能しないかを知りましょう。すべてのプロジェクトが適正領域にあるわけではありません。明確な規範がない探索的なプロジェクト、ドメイン知識を大量に必要とするビジネスロジック、複雑な人間関係のコミュニケーションを要する要件整理などは、エージェントには苦手です。境界線を見極め、強みを活用することも同様に重要です。

原文を表示
See all postsPublished on 2026-02-25Coding Agent 有个甜蜜点,多数人直接跳过了
有两个 Vibe Coding 项目让我印象很深。
一个是 Simon Willison(Django 框架的联合创始人),他一边陪家人装饰圣诞树、看电影,一边用 Codex CLI + GPT-5.2,把 Emil Stenström 的 JustHTML(一个纯 Python 的 HTML 解析库)迁移成了纯 JS、零依赖的版本,跑过了 9200 多个 html5lib-tests 用例,产出大约 9000 行代码、43 次提交。整个过程他自己只发了 8 条左右的提示词。
《I ported JustHTML from Python to JavaScript with Codex CLI and GPT-5.2 in 4.5 hours》https://simonwillison.net/2025/Dec/15/porting-justhtml/
另一个是 Cloudflare,一个工程经理带着 AI,用不到一周时间,在 Vite 上重新实现了 Next.js 的 API,做出了 vinext 这个项目。1700 多个单元测试、380 个端到端测试、覆盖 Next.js 94% 的 API,已经有客户跑在生产环境了。总花费大约 1100 美元的 Token。
《How we rebuilt Next.js with AI in one week》https://blog.cloudflare.com/vinext/
这两个项目的规模和复杂度都不低,但 Coding Agent 的完成质量出奇地好。为什么?
因为它们都精准命中了 Coding Agent 的舒适区——或者说甜蜜点。
有明确的参照物:让 Agent“翻译”而不是“创造”
大语言模型最擅长的事情之一是“翻译”,无论是自然语言还是编程语言。给它一个明确的参照物,它能做到又快又好。
Simon 的项目就是典型的翻译型任务。已经有一个写好的 Python 版 HTML 解析库,API 设计是现成的,代码逻辑是现成的,Agent 要做的就是把这些“翻译”成 JavaScript。不需要凭空设计架构,不需要做产品决策,照着画就行。
Cloudflare 的 vinext 项目看起来更复杂,但底层逻辑一样。Next.js 的 API 是公开的、文档极其完善,Stack Overflow 上积累了海量问答,这些内容早就进了大模型的训练数据。Cloudflare 团队不是让 AI 发明一个新框架,而是让它照着 Next.js 的规格说明书,在 Vite 上重新实现一遍。
第一个条件:给 Agent 一个明确的参照物。 不管是一个已有的开源项目、一份 API 文档、还是你之前写过的旧版本代码,都可以当参照物。让 Agent 做翻译而不是创造,成功率会高很多。
在你自己的工作中,动手之前先问一句:有没有现成的东西可以参考?一个开源实现、一段竞品代码、甚至一份伪代码,都能让 Agent 的表现跨一个台阶。
有自动化验证:让 Agent 能自己验证对不对
Coding Agent 和人类程序员一样,写完代码需要验证。区别在于:如果验证必须靠人工,效率就会断崖式下降;但如果 Agent 能自己跑测试、自己看结果、自己修 bug,它就能进入一个高速循环,不知疲倦地迭代下去。
Simon 的项目能成功,很大程度上因为 HTML5 标准有一套叫 html5lib-tests 的测试集,9200 多个用例,输入是 HTML,输出是正确的解析结构。Agent 不需要你告诉它哪里写错了,它跑一遍测试就知道。Simon 把 GitHub Actions 配好之后,Agent 就进入了这个循环,用了 140 多万个 Token,提交了 43 次,直到所有测试亮绿灯。
Simon 把这个过程叫做 “设计智能体闭环”(Designing the Agentic Loop),他认为这是释放 AI 编程潜力的关键技能。
Cloudflare 那边也一样。Next.js 仓库里有几千个端到端测试,团队直接把这些测试搬过来当验收标准。工作流程就是:定义任务,让 AI 写代码和测试,跑测试,过了就合并,没过就把报错扔回给 AI 让它改。几乎全自动的反馈闭环。
你可能会说:我的项目哪有这么完美的测试套件。确实,大多数项目没有。但你可以往这个方向靠:
先写测试再让 Agent 写实现(测试驱动开发和 Agent 是天然搭配)
给它接上浏览器开发工具让它能看到运行结果
哪怕只是让 Agent 能自动跑一个 npm test
给 Agent 的自动验证工具越多,它能自我修复的能力就越强。
有架构蓝图:让 Agent”填空”而不是”作文”
Agent 受上下文窗口的限制,一次任务能处理的信息量是有上限的。你把一个复杂项目的整个代码库扔给它,它消化不了。你让它从头到尾一口气做完一个大功能,它做到后面就忘了前面。
所以架构设计特别重要。把大任务按架构拆成小任务,每个任务刚好在 Agent 的上下文窗口内能完成,这是高手和新手使用 Agent 最大的区别之一。
Simon 的做法很聪明。他的第一条提示词不是让 AI 写代码,而是让它读完 Python 项目后写一份 JavaScript 版本的设计文档(spec.md
Cloudflare 团队的做法更系统。工程经理先花了几个小时和 Claude 反复讨论架构方案,定好整体蓝图,然后按模块拆任务。每个任务的边界清晰,AI 写完一个模块就能独立测试,不用等整个项目做完才能验证。
你不需要是架构大师才能做这件事。哪怕是花 10 到 30 分钟和 AI 聊一下你打算怎么做,让它帮你列个实现计划,再按计划分步执行,效果都会好很多。先设计再实现,这个道理对人类程序员适用,对 Agent 同样适用,甚至更适用。
有人把控方向:Agent 执行,人来决策
Cloudflare 的博客里有一句话:
给 AI 好的方向、好的上下文、好的护栏,它就能高产;但方向盘必须在人手里。
AI 有一个让人头疼的特点:它经常写出看起来完全正确、但实际行为不对的代码。语法没问题,逻辑看着也通顺,跑起来就是不对。识别这种“高置信度的错误”,目前还是需要人来做。
Simon 让 Agent“commit and push often”(频繁提交代码),这样他在手机上刷 GitHub 提交记录就能追踪进度。Cloudflare 团队把代码审查也交给了 AI Agent,但架构决策、优先级判断、识别 AI 走偏了,这些仍然由人来把控。
这两个项目的操作者都不是新手。Simon 是 Django 的联合创始人,Cloudflare 那位是工程经理。他们知道怎么把一个大问题拆成 AI 能消化的小问题,知道什么时候该介入,什么时候该放手。
你不需要是他们那样的高手,不需要盯着 Agent 写的每一行代码,但也需要在关键节点检查方向对不对。给 Agent 一个太大的任务然后自己走开,通常不会有好结果。小步快跑、阶段性验收,是目前最靠谱的协作方式。
这四个条件不是什么高深的理论,回头看都是常识:有参考、能自测、有规划、有人管。但正是因为它们太像常识,很多人在使用 Agent 时直接跳过了。
Cloudflare 团队自己说,几个月前这事还做不了,不完全是因为模型变强了多少,而是他们找到了正确的方法。
既然知道了 Coding Agent 的舒适区在哪,就可以有意识地把自己的项目往这个方向靠:
先看看有没有参考项目/代码再动手。 别急着让 Agent 从零开始写。看看有没有类似的开源实现、有没有现成的 API 规范、有没有可以参考的代码库。给 Agent 一个参照物,比给它一段需求描述有效得多。
给 Agent 配上自动验证的能力。 手动测试是 Agent 效率的最大瓶颈。尽量把验证环节自动化:单元测试、集成测试、Lint、类型检查,甚至浏览器自动化测试。让 Agent 能自己跑、自己看结果、自己改。Cloudflare 用了 agent-browser 来验证浏览器端的渲染和交互,这种思路很值得借鉴。
先设计后实现。 在让 Agent 动手之前,先把架构想清楚、任务拆好。每个任务的范围要小到 Agent 的上下文窗口能装下,大到足够产出一个有意义的模块。这个拆分能力本身就是高手和新手的分水岭。
建立反馈闭环。 Simon 的做法很典型:配好 CI,每次提交自动跑测试。Agent 写代码、提交、CI 报错、Agent 读日志、修复、再提交。人只需要在关键节点介入。这个闭环跑起来之后,Agent 的产出效率会远超你坐在那里一行行审代码。
知道什么时候 Agent 不行。 不是所有项目都在舒适区里。没有明确规范的探索性项目、需要大量领域知识的业务逻辑、涉及复杂人际沟通的需求梳理,这些 Agent 做不好。识别边界和利用优势同样重要。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み