Outpost VFX が AWS を活用して VFX 向け AI モデル学習を加速した方法
Outpost VFX は AWS のマルチ GPU インフラを活用して顔置換 AI モデルの学習速度を 8 倍に加速し、VFX プロダクションにおけるボトルネックを解消した。
キーポイント
単一 GPU によるボトルネックの打破
従来の VFX 顔置換ワークフローでは AI モデル学習が数日かかることが課題だったが、Outpost VFX は AWS を活用してマルチ GPU 並列処理を実現し、学習時間を劇的に短縮した。
AWS との協働による技術最適化
AWS Generative AI Innovation Center の専門家と連携し、セキュリティ要件を満たしつつ大規模データや高解像度画像に対応できるアーキテクチャを構築した。
具体的な成果とビジネスインパクト
学習速度が 8 倍向上したことで、制作スケジュールの遅延リスクが低減し、クライアントへの迅速なフィードバックサイクルの実現が可能となった。
影響分析・編集コメントを表示
影響分析
この事例は、VFX や映画制作といったクリエイティブ産業において、AI モデルの実用化における計算リソースのボトルネックをクラウドインフラで解決できる具体的な証明となった。特に「8 倍の高速化」という数値的成果は、大規模な映像データ処理が必要な業界全体にとって、AI 導入の障壁を下げる重要な示唆を与えるものである。
編集コメント
VFX業界特有の「顔置換」タスクにおいて、クラウドの計算リソースをどう活用するかという実務的な課題解決事例として非常に価値が高い。単なる技術紹介ではなく、具体的な数値(8倍)とビジネスインパクトを示している点が評価できる。
*この投稿は、Outpost VFX の Tim Chauncey 氏と Dheeraj Bhadani 氏との共著です。*
視覚効果(VFX)における AI モデルのトレーニングには数週間を要することがあり、制作スケジュールにボトルネックを生じさせています。英国、カナダ、インドにスタジオを展開し、高品質な映画やエピソードコンテンツを提供している Outpost VFX にとって、1 日の遅れもクライアントへの納品物やプロジェクトスケジュールに影響を与えます。
本稿では、Outpost VFX が AWS インフラストラクチャを活用して顔置換ワークフローを革新し、トレーニング速度を 8 倍に向上させた方法と、単一 GPU の制限を克服するために実装した技術アーキテクチャ、そして AWS マルチ GPU トレーニングを通じて達成された具体的な成果について探ります。
課題:AI トレーニングにおける単一 GPU のボトルネック
従来の VFX 制作における顔置換ワークフローでは、監督の承認を得るための初期バージョンを作成するために、コンポジット処理または専門的なビュティ・デエイジング支援に 5 日以上を要することが一般的です。これらの方法は効果的ですが、制作スケジュールにおいて最も重要なフェーズである反復的な承認プロセスの初期段階でボトルネックを生じさせます。VFX プロフェッショナルにとって、AI トレーニングの遅延は、期限の逸失、コスト増大、およびクライアントからのフィードバックサイクルの遅れに直結します。
Outpost VFX は、セット撮影映像をトレーニング対象とすることで顔置換プロセスを加速できる AI モデルを開発していました。しかし、その効率性は単一 GPU による計算能力の制約によって制限されていました。既存の顔置換ツールは一度に 1 つの GPU しか利用できず、ビデオランダムアクセスメモリ(VRAM)へのアクセスやモデルトレーニング処理の容量が制限されていました。これにより、チームは AI 支援アプローチの可能性を十分に引き出すことができませんでした。
デザイン上の考慮事項
Outpost VFX は、AI ワークフローを最適化するために以下の 3 つの重要な技術要件を特定しました:
- コンピューティングのスケーラビリティ – チームは、意味のある効率向上を実現するために、顔置換モデルのトレーニングを複数の GPU にわたって並列化する必要がありました。単一 GPU でのトレーニングでは、モデルの反復サイクルに数週間の遅延が生じていました。
- インフラストラクチャのセキュリティ – 2022 年から AWS の顧客であり、完全に仮想化された技術スタックを有する Outpost VFX にとって、このソリューションは極めて機密性の高い制作データを処理するための厳格なセキュリティ要件に準拠している必要があります。
- パフォーマンス最適化 – 単なる速度向上だけでなく、アーキテクチャはより大規模なデータセットと高解像度の画像をサポートし、出力品質を向上させる必要があるものでした。
これらの要件に対応するため、Outpost VFX は AWS ジェネレーティブ AI イノベーションセンターの開発者と協力しました。同センターのメンバーは技術部門の拡張部隊として機能し、AI 学習アルゴリズムの近代化に取り組んでいます。AWS ジェネレーティブ AI イノベーションセンターは、戦略立案者、データサイエンティスト、エンジニア、ソリューションアーキテクトで構成されるチームであり、顧客と段階的に協力してジェネレーティブ AI の力を活用した個別最適化されたソリューションを構築します。このチームとの連携方法については、Generative AI Innovation Center ウェブページをご覧ください。
アーキテクチャの実装
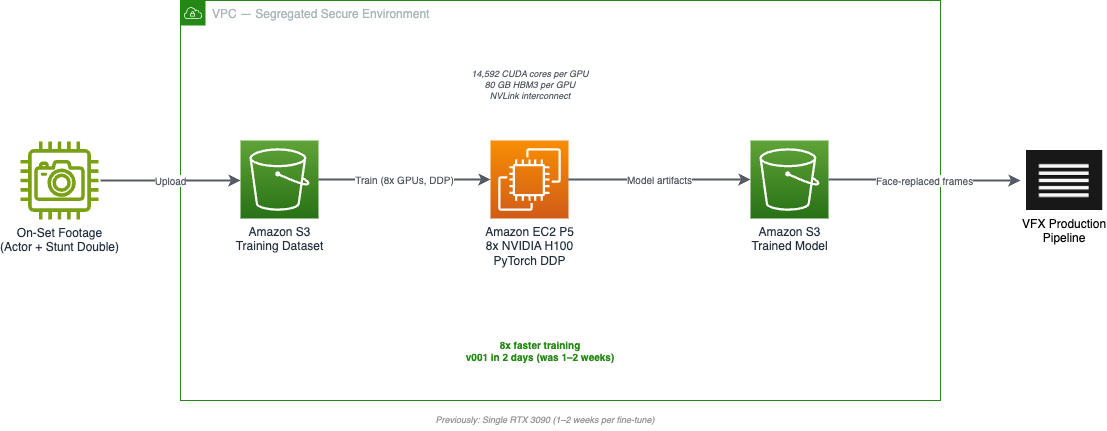
本ソリューションでは、Outpost VFX の既存の顔置換モデルコードベースを改修し、複数の GPU にわたる分散 GPU 学習をサポートできるようにしました。実装には、Outpost VFX の既存インフラ要件に合致した分離された安全なクラウド環境内で、AWS マルチ GPU Amazon Elastic Compute Cloud (Amazon EC2) P5 インスタンスが使用されました。
当初、Outpost VFX は GPU アクセラレーションされたワークステーションで顔置換モデルの学習を行っていました。これには、俳優とそのスタント二重体の小規模データセットを収集し、RTX 3090 GPU 上でベースモデルをファインチューニングする作業が含まれていました。この方法は機能していましたが、Outpost チームはファインチューンごとに約 1〜2 週間かかるという学習時間の遅さに課題を感じていました。また、これらのクラウドワークステーションの管理オーバーヘッドが大きいため、スケールアップは困難でした。そこで同チームは、P5 インスタンス上での学習を検討しました。
P5 インスタンスには、分散学習ワークロード向けに設計された NVIDIA H100 GPU が搭載されています。GPU 間で PCIe 通信を使用する G シリーズインスタンスとは異なり、P5 インスタンスは NV Link インターコネクトを提供し、勾配同期のための帯域幅を大幅に向上させています。これは複数の GPU にわたって学習を行う際に重要な要素です。また、H100 の 14,592 コアの CUDA コアと 80GB の高帯域幅 HBM3 メモリは、ローカルの RTX 3090 環境と比較して大幅なアップグレードを意味しています。
Outpost VFX は生成 AI イノベーションセンターと協力し、P5 インスタンス上でモデルを実行できるように支援しました。6 週間のアドバイザリー期間中、AWS の科学者たちはモデルコードを PyTorch Distributed Data Parallel (DDP) 学習戦略を使用するように変換しました。DDP は、モデルの重みを各 GPU にコピーする並列化技術であり、これによりシステムは各トレーニングバッチでより多くの画像を処理できるようになります。このアプローチにより、各バッチに収容できる画像数が増加し、トレーニングプロセスが直接的に加速されます。
技術的な実装には、顔置換モデルの学習におけるマルチ GPU 並列化、機密性の高い生産データのための強化されたセキュリティアーキテクチャ、および Outpost VFX の既存の AWS ベースの技術スタックとの統合が含まれていました。Outpost VFX が AI パイプラインをさらに進化させるにつれ、チームは管理されたトレーニング、モデルバージョン管理、ホスト型推論を備えた Amazon SageMaker AI などのサービスに、グローバルなスタジオ間でモデルを開発・デプロイするプロセスをさらに合理化する可能性を見出しています。
パフォーマンス改善の測定
マルチ GPU 学習の速度向上を検証するため、Outpost VFX は学習用の画像データセットを収集し、モデルのハイパーパラメータを固定した上で、特定の損失閾値に到達するまでの時間を計測しました。ベースラインとして、G5 インスタンス上の 1 つの GPU と比較して P5 インスタンスでモデルを実行した場合の結果を設定しています。
Outpost VFX と AWS の共同開発努力により、顔置換モデルの学習速度が最大 8 倍向上しました。このパフォーマンスの向上は、より迅速な反復サイクルに直接つながり、初期バージョンに対する監督者の承認プロセスを加速させました。高解像度の画像や大規模なデータセットでモデルを学習できる能力により、出力品質も向上しました。最も顕著なのは、クライアントへの v001 納品が、以前の 1〜2 週間から現在では 2 日で行えるようになったことです。
「並列化されたワークフローと、複数の最高級 GPU を同時に活用できる能力のおかげで、私たちははるかに迅速に反復できるようになりました」と、Outpost VFX の CTO である Tim Chauncey は説明します。「VFX 作業において反復の速度は極めて重要であり、このアーキテクチャは将来の開発に対してより堅牢でスケーラブルな機能を提供しています」。
今後の改善策として、画像出力の品質向上が挙げられます。Outpost では、モデルに渡す画像解像度を上げ、より多くの VRAM を備えた最新世代の Amazon EC2 P5 インスタンスを使用して、これらの大規模な画像やデータセットを処理することが可能です。
結論
AWS で最適化されたアーキテクチャにより、Outpost VFX はハイエンドな視覚効果制作におけるセキュリティとスケーラビリティの要件を維持しつつ、クライアントに対して強化された AI 支援顔置換機能を提供できるようになりました。ローカルのコンシューマー向け NVIDIA GPU からエンタープライズ向け NVIDIA GPU への移行を含む並列化されたワークフローアーキテクチャは、Outpost VFX のグローバルスタジオ運営全体にわたる将来の AI ツール開発とスケーリングのための基盤を提供します。
「私が最も興奮しているのは、これらのモデルがもはや研究実験ではなく、現代の VFX パイプラインに不可欠な一部になりつつあることです」と、Outpost VFX のリードソフトウェアアーキテクトである Dheeraj Bhadani は述べています。「マルチ GPU 加速は、次世代のクリエイティブツールが構築される基盤です。」
次のステップ
ご自身の AI トレーニングワークフローを加速させたい場合は、以下の手順を検討してください:
- 現在の GPU 利用率を評価する:シングル GPU の制約がトレーニングパフォーマンスを制限していないか特定する
- マルチ GPU アーキテクチャを探る:Amazon EC2 P5 インスタンスは、分散トレーニングワークロードに対してスケーラブルなコンピューティングを提供します
- AWS ジェネレーティブ AI イノベーションセンターに相談する:Outpost VFX のトレーニングワークフローの並列化を支援した同じチームです
ご自身の特定のユースケースとインフラ要件に合わせて調整された分散トレーニング戦略を実装することで、同様の結果を達成することができます。
謝辞
著者は、本プロジェクトにおける支援に感謝いたします。Josh Chappatte 氏、Laksh Puri 氏、Ruchi Bhatia 氏。
著者紹介
 image
image
Alex Newton
Alex は AWS Generative AI Innovation Center に所属するデータサイエンティストです。生成 AI と機械学習(Machine Learning)を活用して、顧客の複雑な課題解決を支援しています。最先端の ML ソリューションを実際の課題解決に応用することに情熱を持っています。
 image
image
Hanno Bever
Hanno は、ロンドンに拠点を置く AWS Generative AI Innovation Center のシニア機械学習エンジニアです。Amazon での 6 年間にわたり、あらゆる業界の顧客が AWS で機械学習ワークロードを実行できるよう支援してきました。AWS Trainium および GPU インスタンス上での分散モデルトレーニングのスケーリングと推論(Inference)の最適化を専門としています。
 image
image
スティーブン・スミス
スティーブンは、英国を拠点とする AWS のシニアソリューションアーキテクトです。彼は多様な業界にわたるエンタープライズ顧客と協力し、現代的でスケーラブルかつコスト効率の高いクラウドアーキテクチャの設計に取り組んでいます。AWS での 7 年以上の経験を持つスティーブンは、現代のデータおよび AI ソリューションを採用することで、実際のビジネス課題を解決するよう顧客を支援することに情熱を持っています。

ティム・チョンシー
ティムは、2022 年から英国を本拠地とするアウトポスト VFX の最高技術責任者(CTO)を務めています。彼の在任中には、スタジオが高品質な映画やエピソード制作を提供する方法に革命が起き、従来のオンプレミスソリューションから AWS でグローバルに稼働する統合クラウドインフラへの移行が成功しました。現在、彼は最先端の機械学習(ML)制作ツールおよびエージェントシステムをアウトポストの制作ワークフローに統合するチームを率いています。

Dheeraj Bhadani
Dheeraj は Outpost VFX のリードソフトウェアアーキテクトであり、VFX およびアニメーション業界で 20 年以上の経験を持つ。革新的かつ熟練したアーキテクトとして、アカデミー科学技術賞で認められた技術的進展において重要な役割を果たしてきた。Dheeraj は、設計から実装に至るまで、高分散・スケーラブル・レジリエントなシステムの構築に情熱を注いでいる。近年では、デジタルコンテンツ作成アプリケーションに統合され、スタンドアロンソリューションとして展開される戦略的で本番環境対応の AI および機械学習ツール(AI: Artificial Intelligence, Machine Learning)のアーキテクチャ設計と開発に注力している。
原文を表示
*This post was co-written with Tim Chauncey and Dheeraj Bhadani of Outpost VFX.*
AI model training for visual effects (VFX) can take weeks, creating bottlenecks in production timelines. For Outpost VFX, which operates studios across the UK, Canada, and India delivering high-end film and episodic content, every day of delay impacts client deliverables and project schedules.
In this post, we explore how Outpost VFX achieved 8x faster training speeds using AWS infrastructure to transform their face replacement workflow, the technical architecture they implemented to overcome single-GPU limitations, and the measurable results achieved through AWS multi-GPU training.
The challenge: Single-GPU bottlenecks in AI training
Traditional face replacement workflows in visual effects production require over 5 days of compositing or specialist beauty and de-aging support to create initial versions for director approval. While effective, these methods create bottlenecks early in the iterative approval process, the phase that is most critical to production timelines. For VFX professionals, slow AI training translates directly to missed deadlines, increased costs, and delayed client feedback cycles.
Outpost VFX had developed an AI model capable of training on on-set footage to accelerate face replacement processes. However, efficiency was constrained by single-GPU compute limitations. The existing face swap tool could only utilize one GPU at a time, limiting video random access memory (VRAM) access and processing capacity for model training operations. This prevented the team from realizing the full potential of their AI-assisted approach.
Design considerations
Outpost VFX identified three critical technical requirements for optimizing their AI workflow:
- Compute scalability – The team needed to parallelize face replacement model training across multiple GPUs to achieve meaningful efficiency improvements. Single-GPU training was creating week-long delays in model iteration cycles.
- Infrastructure security – As an AWS customer since 2022 with a fully virtualized technology stack, Outpost VFX needed the solution to adhere to its exacting security requirements for processing highly sensitive production data.
- Performance optimization – Beyond raw speed improvements, the architecture needed to support larger datasets and higher-resolution images to improve output quality.
To address these requirements, Outpost VFX collaborated with AWS Generative AI Innovation Center developers who worked as an extension of their technology department to modernize their AI learning algorithms. The AWS Generative AI Innovation Center is a team of strategists, data scientists, engineers, and solutions architects that works step-by-step with customers to build bespoke solutions that harness the power of generative AI. Learn more about how to engage with the team on the Generative AI Innovation Center webpage.
Architecture implementation
The solution involved adapting the Outpost VFX existing face swap model codebase to support distributed GPU training across multiple GPUs. The implementation used AWS multi-GPU Amazon Elastic Compute Cloud (Amazon EC2) P5 instances within a segregated, secure cloud environment that aligned with the Outpost VFX existing infrastructure requirements.
Originally, Outpost VFX trained their face swap models on GPU-accelerated workstations. This involved collecting small datasets of actors and their stunt doubles and fine-tuning a base model on RTX 3090 GPUs. While this method worked, the Outpost team found that training time was slow, at around 1–2 weeks per fine-tune. Scaling up would have been difficult because of the management overhead of those cloud workstations. At this point, they looked at training on P5 instances.
P5 instances feature NVIDIA H100 GPUs, which are purpose-built for distributed training workloads. Unlike G-series instances that use PCIe communication between GPUs, P5 instances provide NV Link interconnects offering significantly higher bandwidth for gradient synchronization, which is a critical factor when training across multiple GPUs. The H100’s 14,592 CUDA cores and 80GB of high-bandwidth HBM3 memory also represented a substantial upgrade over their local RTX 3090 setup.
Outpost VFX worked with the Generative AI Innovation Center to help them get their model running on the P5 instances. Over a 6-week advisory period, AWS scientists converted the model code to use PyTorch Distributed Data Parallel (DDP) training strategy. DDP is a parallelization technique that copies model weights to each GPU, allowing the system to process more images in each training batch. This approach increases the number of images that can be fitted into each batch, directly accelerating the training process.
The technical implementation included multi-GPU parallelization of face replacement model training, enhanced security architecture for sensitive production data, and integration with Outpost VFX existing AWS-based technology stack. As Outpost VFX continues to evolve their AI pipeline, the team sees potential in services like Amazon SageMaker AI with managed training, model versioning and hosted inference to further streamline how they develop and deploy models across their global studios.
Measuring performance improvements
To test the speed improvement of the multi-GPU training, Outpost VFX collected an image dataset for training, fixed model hyperparameters, and measured the time for the training to reach a specific loss threshold. They set the baseline as one GPU on a G5 instance compared to running the models on the P5 instances.
The combined development effort between Outpost VFX and AWS achieved up to 8x improvement in face replacement model learning speeds. This performance increase directly translated to faster iteration cycles, enabling more rapid director approval processes for early versions. The ability to train models on higher-resolution images and larger datasets improved output quality. Most significantly, v001 delivery to clients for initial review now takes 2 days, compared to the previous 1–2 week timeline.
“We are now able to iterate much faster thanks to our parallelized workflow and the ability to harness multiple top-end GPUs at once,” explains Tim Chauncey, CTO of Outpost VFX. “Speed of iteration is critical to VFX work, and this architecture provides more robust and scalable capabilities for future development.”
A future improvement could include increasing the quality of image outputs. Outpost could increase the image resolutions passed to the model and use newer generations of Amazon EC2 P5 instances with more VRAM to process these larger images and larger datasets.
Conclusion
The AWS-optimized architecture enables Outpost VFX to offer enhanced AI-assisted face replacement capabilities to clients while maintaining the security and scalability requirements of high-end visual effects production. The parallelized workflow architecture including a migration from local consumer NVIDIA GPUs to enterprise NVIDIA GPUs provides a foundation for future AI tool development and scaling across Outpost VFX global studio operations.
“What excites me most is that these models are no longer research experiments; they are becoming an integral part of the modern VFX pipeline,” says Dheeraj Bhadani, Lead Software Architect at Outpost VFX. “Multi-GPU acceleration is the foundation on which next-generation creative tools will be built.”
Next steps
If you’re looking to accelerate your own AI training workflows, consider these steps:
- Evaluate your current GPU utilization: Identify whether single-GPU constraints are limiting your training performance
- Explore multi-GPU architectures: Amazon EC2 P5 instances provide scalable compute for distributed training workloads
- Engage with AWS Generative AI Innovation Center: the same team that helped Outpost VFX parallelize their training workflow
You can achieve similar results by implementing distributed training strategies tailored to your specific use case and infrastructure requirements.
Acknowledgments
The authors would like to thank the following contributors for their support on this project Josh Chappatte, Laksh Puri and Ruchi Bhatia.
About the authors
Alex Newton
Alex is a Data Scientist at the AWS Generative AI Innovation Center, helping customers solve complex problems with generative AI and machine learning. He enjoys applying state of the art ML solutions to solve real world challenges.
Hanno Bever
Hanno is a Senior Machine Learning Engineer in the AWS Generative AI Innovation Center based in London. In his 6 years at Amazon, he has helped customers across all industries run machine learning workloads on AWS. He specializes in scaling distributed model training and optimizing inference on AWS Trainium and GPU instances.
Stephen Smith
Stephen is a Senior Solutions Architect at AWS, based in the UK. He works with enterprise customers to design modern, scalable, cost-effective cloud architectures across a range of industries. With over 7 years at AWS, Stephen is passionate about helping customers adopt modern data and AI solutions to solve real business challenges.
Tim Chauncey
Tim has been Chief Technology Officer at UK-headquartered Outpost VFX since 2022. His tenure has seen a revolution in how the studio delivers high-end film and episodic productions, including a successful migration from traditional on-prem solutions to a unified cloud infrastructure running globally on AWS. He is now leading a team integrating bleeding-edge ML production tools and agentic systems into Outpost’s production workflows.
Dheeraj Bhadani
Dheeraj is a Lead Software Architect at Outpost VFX with more than two decades of experience in the VFX and animation industry. An innovative and seasoned architect, he has played key roles in technological advancements recognized by the Academy Sci-Tech Awards. Dheeraj is passionate about designing and building highly distributed, scalable, and resilient systems from inception through implementation. In recent years, he has focused on architecting and developing strategic, production-grade AI and machine learning tools, integrated into Digital Content Creation applications, and deployed as standalone solutions.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み