映像言語モデルに映画の語り方を教える研究
カーネギーメロン大学とハーバード大学の研究者らが、100 人以上の専門クリエイターとの協働を通じて構築した動画キャプションパイプラインの知見を共有し、モデルのスケーリングよりも人間による監督(Human-AI Oversight)の重要性を強調している。
キーポイント
人間による監督の重要性
大規模なデータセットやモデルの単純な拡大ではなく、100 人以上のプロクリエイターが関与する「Human-AI Oversight」の仕組みこそが、高品質な動画言語生成を実現する鍵であると結論づけている。
映画監督のような視点の導入
現在の動画生成モデルは単なる描写に留まらず、ハリウッドの監督のように「シーンの効果」や「視聴者の感情を揺さぶるショット」を意図的に選択・生成できる能力への進化が求められている。
CVPR 2026 の研究成果
本記事は CVPR 2026 でハイライト(Top 3%)に選ばれた論文「Building a Precise Video Language with Human-AI Oversight」に基づいており、その実践的な教訓を共有している。
映画用語の欠如による生成モデルの限界
現在のビジョン・ランゲージモデルは映像技術の専門用語(ショットサイズ、レンズ歪みなど)を体系的に理解しておらず、指示されたカメラワークを実行できない。
既存キャプションデータの二大欠陥
クラウドワーカーによるデータは映画用語が不足しており、AI 生成のデータは流暢だが事実と異なる描写(ハルシネーション)が多いという問題がある。
CHAI パイプラインによる人間と AI の協働
専門家の批評を介してモデルが草案を修正する「批判ベースの人間-AI 監視(Critique-based Human-AI Oversight)」アプローチを採用し、高精度な映像キャプションを作成する。
ボトルネックはモデルの容量而非データ不足
現在のビジョン言語モデルの能力不足や学習動画量の欠如が原因ではなく、既存のキャプションに映画技法を記述するための正確な語彙が含まれていないことが問題の本質です。
影響分析・編集コメントを表示
影響分析
この記事は、動画生成AIの進化において「データ量」や「パラメータ数」への依存から脱却し、「人間の専門知識と監督」をどうシステムに組み込むかが次世代の競争力となることを示唆しています。特に映画制作のような高度な文脈理解や感情表現をAIに実装する際、単なる技術的スケーリングではなく、人間中心のアプローチが不可欠であるという重要な指針を提供しています。
編集コメント
モデルの性能向上にばかり注目が集まりがちですが、この記事は「人間の知見をどうAIに注入するか」という本質的な課題を浮き彫りにしており、開発者にとって非常に示唆に富む内容です。
// スペース調整の修正を注入
jQuery('')
.prop('type', 'text/css')
.html(`
.post-authors {
padding-right: 40px;
}
`)
.appendTo('head');
const authors = [
{ name: "Zhiqiu Lin", affiliations: ["Carnegie Mellon University"] },
{ name: "Chancharik Mitra", affiliations: ["Carnegie Mellon University"] },
{ name: "Siyuan Cen", affiliations: ["Carnegie Mellon University"] },
{ name: "Isaac Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Yuhan Huang", affiliations: ["Carnegie Mellon University"] },
{ name: "Yu Tong Tiffany Ling", affiliations: ["Carnegie Mellon University"] },
{ name: "Hewei Wang", affiliations: ["Carnegie Mellon University"] },
{ name: "Irene Pi", affiliations: ["Carnegie Mellon University"] },
{ name: "Shihang Zhu", affiliations: ["Carnegie Mellon University"] },
{ name: "Ryan Rao", affiliations: ["Carnegie Mellon University"] },
{ name: "George Liu", affiliations: ["Carnegie Mellon University"] },
{ name: "Jiaxi Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Ruojin Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Yili Han", affiliations: ["Carnegie Mellon University"] },
{ name: "Yilun Du", affiliations: ["Harvard University"] },
{ name: "Deva Ramanan", affiliations: ["Carnegie Mellon University"] },
];
jQuery('.post-authors').empty();
jQuery('.affiliations').empty();
jQuery('.post-authors').append('Authors
');
const affiliationMap = {};
let affiliationIndex = 1;
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
// First pass: assign unique affiliation numbers
authors.forEach(author => {
author.affiliations.forEach(affiliation => {
if (!affiliationMap[affiliation]) {
affiliationMap[affiliation] = affiliationIndex++;
}
});
});
// Build author line
const authorsHtml = authors.map((author, index) => {
const affIndices = author.affiliations.map(a => affiliationMap[a]);
const superscriptParts = [...affIndices];
if (author.equalContribution) {
superscriptParts.push('*');
}
const superscript = ${superscriptParts.join(',')};
let separator = '';
if (index > 0) separator = ', ';
return ${separator}${author.name}<sup>${superscript}</sup>;
});
// Build affiliations section
const affiliationHtml = Object.entries(affiliationMap).map(([affiliation, index]) => {
return <div class="affiliation">${index}. ${affiliation}</div>;
}).join('');
// Equal contribution footnote
let equalContributionNote = '';
if (authors.some(a => a.equalContribution)) {
equalContributionNote = '<p><sup>*</sup>Equal contribution</p>';
}
// Render final HTML structure
const outputHtml = `
<div class="author-line">
${authorsHtml.join('')}
</div>
<div class="affiliations">
${affiliationHtml}
</div>
${equalContributionNote}
`;
jQuery('.doi').remove();
A year of building a video caption pipeline with 100+ professional creators, and what it taught us about scaling supervision instead of models.
By Zhiqiu Lin and Chancharik Mitra. Based on our CVPR 2026 work, Building a Precise Video Language with Human-AI Oversight (Highlight, Top 3%).
How close is today's video generator to a Hollywood cinematographer?
ハリウッドの監督たちは、特定のショットを求めます。それはシーンに重みを持たせ、平坦なカバレッジでは生み出せない視聴者に特定の感情を喚起するためです。
お気に入りの動画生成ツール(Veo 3.1、Seedance 2、あるいは最新のオープンソースモデル)を開き、混雑する通りの真ん中に立つ男性のドリーズーム(dolly zoom)を求めてみてください。ヒッチコックが世界が内側へ崩れ落ちるような感覚を生み出すために使用したあのショットです。あるいは、コーヒーカップからその背後にいる女性へと焦点を移すラックフォーカス(rack focus)。これは観客にどこを見るべきかを静かに伝えるタイプのフォーカスプルです。あるいは、虚無を見つめる不安な人物のダッチアングル(Dutch-angle)ショット。これは視聴者を緊張させる傾いたフレームです。
ほとんどの生成モデルは、一般的なドリーイン(dolly-in)に近いものか、焦点が合っていない被写体のスローモーションクリップを返します。出力は視覚的には有能ですが、意図した効果は発揮されません。このモデルは明らかにこれらの技法を含む動画を見ています。ただ、言葉に対してどのように行動すべきかを知らないだけです。
私たちはこれがより広範なギャップの症状だと考えています。映画製作者たちは、ショットサイズ(shot size)、フレーム位置、フォーカスタイプ、レンズ歪み、カメラ高さ、ビデオ速度といった、共有された精密な語彙でコミュニケーションをとります。しかし、現在のビジョンランゲージモデル(VLMs)や、それらを学習させるキャプションデータセットは、ほとんどがそのようではありません。
本稿では、CHAI というキャプション作成パイプラインについて説明します。私たちが過去 1 年間に 100 名以上のプロの動画クリエイターと協力して構築したものです(当用語における「キャプション」とは、字幕トラックではなく、動画の内容・動き・カメラワークを記述する長文で構造化された段落を指します)。この略語は Critique-based Human-AI Oversight(批評に基づく人間と AI の監督)を表しています。既存の動画キャプションデータセットは、通常、ショットを正確に描写するための映画用語を欠いたクラウドワーカーによって作成されるか、あるいは大規模なビジョン・ランゲージモデル(VLM: Vision-Language Model)によって作成されますが、後者の場合、キャプションは流暢で文法やスタイル上の誤りがないものの、動画に含まれていない物体や動きを記述する「幻覚」が頻発します。CHAI の中心的なアイデアはこれら 2 つの要素を組み合わせることです。すなわち、キャプショニングモデル(例:Gemini-2.5-Pro などの大規模なビデオ・ランゲージモデル)が下書きを作成し、訓練された人間がそれに対して批評を行い、モデルはその批評に基づいて修正を行うというプロセスです。
本稿では以下の 4 つの問いについて解説します。
- なぜ VLM は映画用語を用いたプロンプトに苦戦するのか?
- キャプション作成作業を人間とモデルはどのように分担すべきか?
- 人間の批評の質は、モデルが学習できる内容に影響を与えるのか?
- 訓練データにおけるキャプションの質向上は、より優れた動画生成器をもたらすのか?
Figure 1. 現在の動画キャプション化パイプラインの3つの失敗モード(上段、赤)と、それに対する私たちの選択(下段、青):精密な仕様定義、人間と AI の監督ループ、出力単体の比較ではなく明示的な嗜好と批判に基づくトレーニング後の調整。
質問1: なぜ VLM は映画のようなプロンプトに苦戦するのか?
自然な最初の仮説は、これは容量の問題であるというものです。つまり、現在の世代のビジョン・ランゲージモデル(VLM)は単に小さすぎて、コンテキストが不足しているか、あるいは映画のようなプロンプトを処理するために十分な量の動画で事前学習されていないためであり、次世代のモデルがそれを解決するだろう、という考え方です。しかし、2016 年から 2025 年にかけての8つの人気のある動画・テキストデータセット(ActivityNet Captions, MSR-VTT, DREAM-1K, ShareGPT4Video, PerceptionLM など)を監査した結果、ボトルネックは別の場所にあると考えられます。モデルが学習する動画には視覚的コンテンツが含まれており、現代の VLM はそれをよく知覚しています。欠けているのは言語です。これらの動画とペアになったキャプションには、映画技法を記述するために必要な精密な語彙が含まれていません。私たちの実験では、同じデータをより多く用いてモデルを大きくしても、これらの問題はわずかに改善されるだけでした。これらは容量の問題ではなく、注釈付けの方針に関する問題であるように思われます。
3 つのパターンが繰り返し現れました:
• 用語の曖昧さ。キャプションでは、ドリーイン(カメラが物理的に前方へ移動する)とズームイン(焦点距離が変化する)を混同したり、魚眼レンズによる歪みを「円形の建物」と記述したりしています。
• 情報の欠落。キャプションはフレーム内のものだけを記述し、それ以外のすべてを省略します:動き、カメラの揺れ、フォーカスの変化、ショットサイズなどです。時間的な要素やカメラに関する情報はすべて削除されてしまいます。
• 主観的な記述。「緊張感に満ちた雰囲気のあるショット」といった記述は、モデルがピクセルに基づいて具体化できる情報を何も提供しません。
自然な次の考えとして、「より慎重なキャプションを書くためにクラウドワーカーを雇えばよいのではないか」というものがあります。私たちは実際に試しましたが、クラウドワーカーも依然としてドリーインとズームインを混同し、ワイドショットを「クローズアップ」と呼び、魚眼レンズの歪みを「丸い建物」と記述していました。「見る」ことと、「どのように記述するかを知る」ことは同じではありません。
Figure 2. クラウドワーカーによる記述と専門家による記述の比較(同一クリップ)。クラウドワーカーは空中からの視点ショット、魚眼レンズ、ドリーズームを認識しています。しかし、モデルがその記述に基づいて行動するために必要な専門用語ではなく、「バードズアイビュー」「円形の建物」「歪み効果」といった日常的な言語に頼ってしまいます。
最終的に成功したのは、この語彙の使用が業務に必須である人々を招き入れたことです:撮影監督、撮影監督(ディレクター・オブ・フォトグラフィ)、モーショングラフィックスデザイナー、VFX アーティスト、ゲームデザイナー、カメラオペレーターです。過去 1 年間、私たちは 100 人以上のこうした協力者と連携し、構造化されたキャプション仕様を構築しました。この仕様には 5 つの側面があります:
• 主題(種類、属性、関係)
• シーン(構図、ダイナミクス、オーバーレイ、視点)
• モーション(被写体の動作、相互作用、グループ活動)
• 空間的(ショットサイズ、フレーム位置、奥行き、空間的な動き)
• カメラ(フォーカスタイプ、被写界深度、安定性、移動、ビデオ速度、レンズ歪み、高さ、アングル)
これら 5 つの側面を合わせると、約 200 の低レベルな視覚プリミティブが含まれ、それぞれに定義と適用時の判断ルールが用意されています。これにより、注釈作成者が用語を独自に作り出すことを防ぎ、注釈作成者は仕様に対してタグ付けするだけで済みます。
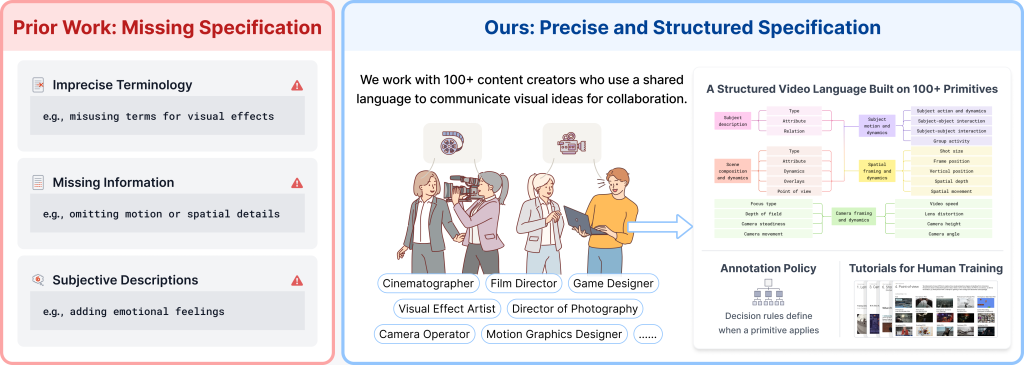 image図 3. 従来のキャプション作成における典型的な問題(左側、赤)と、私たちが到達した解決策(右側、青)。この構造化された分類体系は、撮影監督、撮影監督、VFX アーティスト、モーショングラフィックスデザイナー、ゲームデザイナーと共同で構築され、注釈作成者間で語彙が統一されるよう、注釈ポリシーおよびトレーニングチュートリアルと組み合わされています。
image図 3. 従来のキャプション作成における典型的な問題(左側、赤)と、私たちが到達した解決策(右側、青)。この構造化された分類体系は、撮影監督、撮影監督、VFX アーティスト、モーショングラフィックスデザイナー、ゲームデザイナーと共同で構築され、注釈作成者間で語彙が統一されるよう、注釈ポリシーおよびトレーニングチュートリアルと組み合わされています。
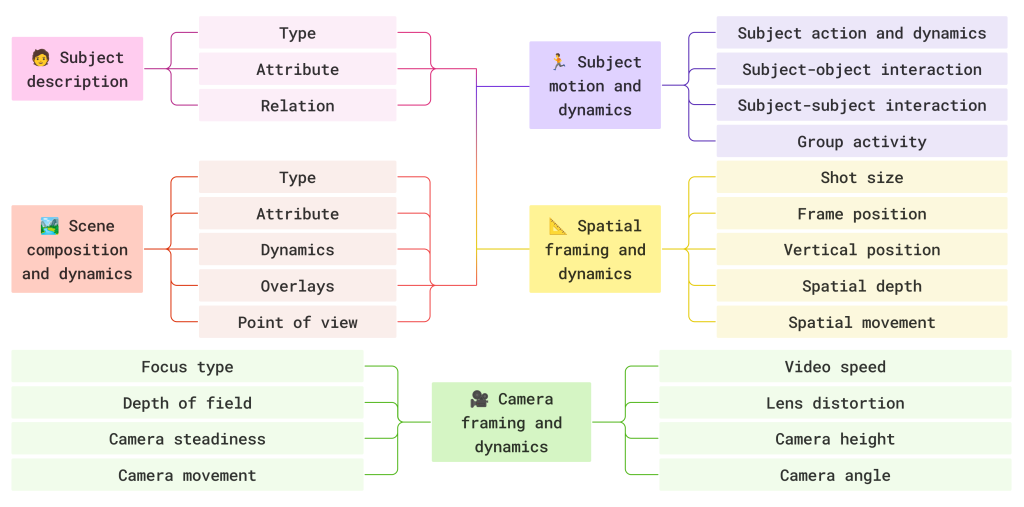 image図 4. 完全な分類体系。5 つの側面があり、それぞれがサブ側面に分解され、各サブ側面は視覚的または運動的なプリミティブのセットに基づいています。
image図 4. 完全な分類体系。5 つの側面があり、それぞれがサブ側面に分解され、各サブ側面は視覚的または運動的なプリミティブのセットに基づいています。
教訓:VLM(Vision-Language Models)は、映画製作者が使用する正確な語彙が含まれていないキャプションで訓練されたことが原因で、映画に関するプロンプトに苦戦します。私たちの実験では、モデルやデータを単にスケールさせるだけではわずかな改善しか得られず、言語を慎重に指定することがはるかに大きな違いをもたらしました。
質問 2:人間とモデルはどのようにしてキャプション作成の仕事を分担すべきか?
仕様書を作成した後でも、誰が長いキャプションを書くかを決定する必要がありました。明白な選択肢は人間かモデルかの二つですが、それぞれに周知の限界があります。
人間のみでキャプションを作成すると、誤字や文法エラー、イベント順序の不整合が生じます。また疲労もします:仕様書を確認しながら、動画あたり 200〜400 語の注意深い文章を書くのは、疲弊しやすく高価です。
モデルのみでキャプションを作成すると、美しく読めるものの、悲観的な割合のクリップにおいて、存在しない物体や動きを自信を持って記述してしまいます。また、左と右を頻繁に混同します。
パイロット研究で気づいたのは、失敗モードが有用な形で非対称であるということです。今日の LLM は、ほとんどの人間よりも優れた文章を書きます。しかし、特に訓練された人間は、キャプションに「左へ移動」とあるのに被写体が右へ動いているような、ドラフト内の視覚的または運動的なエラーを指摘する点において、LLM よりもはるかに優れています。そこで私たちは、この非対称性を軸にパイプラインを構築しました。モデルが草案を作成し、人間が批判し、モデルが修正するという流れです。これは概念上、要約のための自己批判型モデルとして Saund ers et al. (2022) が提案した手法と似ていますが、長編動画のキャプション付けという文脈で適用されており、依然として人間が困難な部分、つまり実際の映像に対して根拠のあるエラーを検出する役割を担っています。
具体的には、以下のループとなります:
- 素要素。訓練された注釈担当者が、クリップ内に存在する視覚的および運動的な素要素(primitives)にラベル付けを行います。
- プレビューキャプション。モデルは、その素要素に基づき、仕様に従って長いキャプションを生成します。
- 批判。注釈担当者は、動画とプレビューキャプションを見比べ、何が間違っており何を修正すべきかを指摘する批判文を作成します。この批判は正確であること(指摘された箇所が実際に誤りであること)、完全であること(エラーを見逃さないこと)、建設的であること(単に「悪い」と言うのではなく、モデルに対して何をすべきかを示すこと)の 3 つを満たさなければなりません。
- ポストキャプション。モデルは批判文に基づいて草案を修正します。
- 洗練。ポストキャプションがまだ不十分な場合、人間はキャプションを書き直すのではなく、批判文自体を改良します。
レビュー担当者(上位の注釈付け担当者から品質管理役割に昇格した人々)に、すべての批評と投稿キャプションが動画に対して正しいかを確認するよう命じました。これにより、注釈付け担当者はその精度に基づいて評価され、レビュー担当者は発見したミスを指摘することで報酬を得る仕組みとなりました。モデル化が行われる前のデータレベルにおいて、両方の指標——すなわち精密率(誤っていないものを誤りとフラグしないこと)と再現率(誤っているものを見逃さないこと)——がインセンティブとして設計されました。
人間の役割を「作成」から「校閲」へとシフトさせたことは、私たちが過小評価していた副次的なメリットをもたらしました。各動画にかかる認知負荷が大幅に減少し、その結果生じる 200 から 400 語程度のキャプションは、人間単独やモデル単独で生成されるものよりもはるかに正確なものとなりました。
教訓:大規模言語モデル(LLM)と人間には、長編動画のキャプション作成において非対称な強みがあります。一方を他方で置き換えようと試みるのではなく、この非対称性を基にパイプラインを設計することで、双方にとってより良いキャプションが生成され、持続可能な注釈付けプロセスを実現できます。
質問 3:人間の批評の質は、モデルが学習できる内容に影響を与えるか?
本パイプラインでは、各動画に対して(事前キャプション、批評、事後キャプション)というトリプルを生成します。このトリプルは単なる注釈付きキャプション以上の意味を持ち、同時に 3 つの異なるポストトレーニングタスクに対する教師信号として機能します:
• キャプション作成:モデルに長く忠実なキャプションを生成させるよう訓練する。
• リワードモデリング:(事前キャプション、事後キャプション)を(拒否されたペア、好まれたペア)として扱う。
• 批評生成:動画とドラフトが与えられた場合、モデル自身に批評文を書くように訓練する。
Qwen3-VL-8B を、標準的な教師あり微調整(SFT)を用いて 3 つのフォーマットすべてにわたって共同でポストトレーニングしました。また、直接選好最適化(DPO)などの強化学習(RL)手法も試みましたが、完全なトリプレットデータに対する単純な SFT が最も強力であることが分かりました。詳細な数値は論文に記載されていますが、肝心なのは、明示的な選好と批判の信号を追加することで、テストしたすべての手法で性能が向上することです。
批判の質が下流タスクのパフォーマンスに影響するのか、それとも単に「これは間違っている」という信号であれば何でもよいのかについて興味を持ちました。そこでアブレーション実験を行いました:クリーンな CHAI 批判を用い、正確性、再現率、建設性の各プロパティを一度に一つずつ意図的に劣化させ、ポストトレーニングされたキャプション生成モデルが各タスクでどのように振る舞うかを確認しました。
 image図 6. 有用な批判は、正確であること(指摘された箇所が実際に間違っている)、完全であること(存在するエラーをすべて捉えている)、そして建設的であること(単に何が悪いと言うのではなく、何を修正すべきかを示す)の 3 つの条件を満たさなければなりません。これら 3 つはすべて必要であり、どれか一つでも劣化させると下流モデルのパフォーマンスが低下します。
image図 6. 有用な批判は、正確であること(指摘された箇所が実際に間違っている)、完全であること(存在するエラーをすべて捉えている)、そして建設的であること(単に何が悪いと言うのではなく、何を修正すべきかを示す)の 3 つの条件を満たさなければなりません。これら 3 つはすべて必要であり、どれか一つでも劣化させると下流モデルのパフォーマンスが低下します。
各バリアントごとにポストトレーニングされた8B Qwen3-VL の結果を Table 1 に示します。Caption と Critique は、保持された参照キャプションおよび批評に対する BLEU-4 スコアです(0–100 の尺度で参照テキストとの n-gram 重複度を測定する標準的なテキスト生成指標であり、数値が高いほど人間の参照に近くなります)。Reward タスクについては、キャプショナーがポストキャプションをプレキャプションよりも高く評価しているかどうかの二値精度を報告します(確率レベルは 50% です)。すべての項目において、数値が高いほど優れています。
批評バリアント Acc. Rec. Constr. Caption Reward Critique
Blind Gemini-2.5 ——— 10.9 44.5 21.1
Gemini-2.5 ——— 12.7 62.0 26.2
Inaccurate critique ✗ ✓ ✓ 12.1 47.1 21.9
Incomplete critique ✓ ✗ ✓ 12.5 56.6 28.7
Non-constructive critique ✓ ✓ ✗ 13.4 67.2 32.9
CHAI (with QC) ✓ ✓ ✓ 18.2 89.8 41.7
Table 1. 批評を一度に一つの特性ごとに人工的に劣化させた場合のポストトレーニング結果。数値が高いほど優れています。追加的な参照点として、市販モデルに代替して批評を生成させる試みも行いました:(1) Blind Gemini-2.5 は、キャプションテキストのみを用いて Gemini-2.5 に批評を行わせ、動画へのアクセスは行わない(言語事前知識に基づくベースライン);(2) Gemini-2.5 は、同じモデルを用いて完全な動画入力を行います。CHAI (with QC) は、Question 2 から得たピアレビュー品質管理ステップを含む当社のフルパイプラインであり、すなわち批評は正確で、完全かつ建設的なものです。
3 つの点が際立っています:
- 品質はオプションではありません。3 つの特性のいずれかを欠落させると、すべての下流タスクに実質的な悪影響を及ぼします。建設的でない批判(何が悪いのかを説明する必要がないため収集コストが最も低い)は最も害が少ないものの、依然として大きな性能差を残したままです。
- 既存のデータは主に建設的ではありません。Saunders ららの GDC リリースや MM-RLHF などの公開データセットにおける批判を確認しましたが、私たちの定義するところでは半数以上が建設的ではありません(「これは間違っている」という指摘のみで、修正案が示されていない)。これが、これらのデータセットで学習しても性能が十分に発揮されない理由を説明しています。
- データが適切であれば、8B モデルははるかに大きなクローズドモデルと競合可能です。同じキャプション付け、報酬評価、批判評価のベンチマークにおいて、後から学習された 8B の Qwen3-VL は、報告した指標において GPT-5 や Gemini-3.1-Pro に匹敵し、あるいはそれを超えています。モデルサイズは変更されていませんが、監督信号(supervision signal)が変化しました。
小さなボーナス:同じ報酬モデル(reward model)は推論時にも役立ちます。学習済みの報酬モデルを用いた Best-of-N 復号化では、追加の人間ラベルなしに性能を継続的に向上させることができます。
教訓:批判の形式は単なるスタイルの詳細ではありません。キャプション付け、選好(preferences)、そして批判のすべてに対して共同で後から学習されたモデルは、学習対象となる批判が正確で、完全であり、かつ建設的である場合に、すべての 3 つのタスクにおいて実質的に優れた性能を発揮します。逆に、これらの特性のいずれかが欠如している場合は、実質的に劣った結果となります。
質問 4:トレーニングデータ内のより良いキャプションは、より優れた動画生成器をもたらすのか?
懐疑的な読者は言うかもしれません:これは確かに素晴らしいですが、キャプション作成は、多くの人々が実際に望んでいる生成よりも上位の工程です。そこで、改善されたキャプショナーが下流の動画生成器にどのような影響を与えるかテストしました。私たちは、映画、広告、ミュージックビデオ、ゲームプレイなどからなる大規模なプロフェッショナル動画コーパスを取得し、ポストトレーニング済みの 8B モデルで再キャプション付けを行い、その新しいキャプションを用いて Wan2.2 をファインチューニングしました。
ファインチューニングされたモデルは、市販の生成器が確実に誤る技法に関する詳細なプロンプト(最大約 400 語)に対して動作可能です。
図 7。私たちのポストトレーニング済みキャプショナーによって類似したホールドアウトクリップから生成されたキャプションを起源とする、2 つの長い生成プロンプト(推論時に動画生成器に与えられるテキスト)。右側:ゼロショットの Wan2.2 はプロンプトを緩やかに追従し、ドリーズームが通常のドリーバックになり、等角投影(2.5D)のゲームシーンが汎用的な 3D アークになります。左側:Wan2.2 が私たちのモデルによって再キャプション付けされたトレーニング動画でファインチューニングされた後、同じプロンプトを忠実に追従します。
生成器のアーキテクチャや学習目標を変更したわけではありません。変更されたのは、トレーニングセット内の動画を記述する際に使用される言語のみです。これだけで、既存の生成器に、以前は表現できなかった技法のクラスを教えることができました。
教訓:より正確なキャプション語彙を前段に用いることで、同じモデル構造とトレーニング手順であっても、後段の生成をより制御可能にできる。映画のような表現を制御する際のボトルネックはモデルではなく、監督(指導)にあった。
議論
私たちはこのプロジェクトを開始する際、キャプショナーモデルを訓練することになると考えていました。しかし、結局1年の大半をその周辺パイプラインに費やしました:何をキャプションにするか、誰がそれを書くべきか、誰がチェックすべきか、そしてチェックはどのような形であるべきか。モデルへの貢献は、これらの選択の後に生じるもののように感じられます。
私たちがもっと早く理解しておくべきだった3つのこと:
• スケーリングの前に仕様を明確にすること。ノイズの多いデータでより大きなモデルを訓練しても得られる利益は僅かなものでした。仕様が整った後、小さなモデルですら非常に競争力のあるものになり始めました。
• 「クラウドソーシングすればいい」というのはベースラインではありません;それは異なる問題です。映画技法を正しく注釈付けるには、その分野がすでに使用している語彙が必要です。訓練されていない作業者にその語彙を一から発明させることは、訓練された作業者にそれを適用させることの安価な版ではありません。
• 批評はトレーニングデータであること。今日収集する批評の形式が、明日モデルをいかに効果的に訓練できるかを決定します。単に「いいね/ダメ」という評価のみを記録するデータセットでは、後方学習(post-training)におけるシグナルの多くを見逃しています。
CHAI は、精密なビデオ言語に関するより長期的な取り組みの一部です。最も近い関連プロジェクトは CameraBench(NeurIPS'25 Spotlight)であり、これはカメラ運動に関する私たちの先行ベンチマークで、仕様のカメラ側プリミティブの種となりました。
リソース
私たちは仕様書、トレーニングチュートリアル、注釈プラットフォーム、品質管理フロー、データ、コード、およびモデルを公開します。もしあなたが
原文を表示
// Inject spacing fix
jQuery('')
.prop('type', 'text/css')
.html(`
.post-authors {
padding-right: 40px;
}
`)
.appendTo('head');
const authors = [
{ name: "Zhiqiu Lin", affiliations: ["Carnegie Mellon University"] },
{ name: "Chancharik Mitra", affiliations: ["Carnegie Mellon University"] },
{ name: "Siyuan Cen", affiliations: ["Carnegie Mellon University"] },
{ name: "Isaac Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Yuhan Huang", affiliations: ["Carnegie Mellon University"] },
{ name: "Yu Tong Tiffany Ling", affiliations: ["Carnegie Mellon University"] },
{ name: "Hewei Wang", affiliations: ["Carnegie Mellon University"] },
{ name: "Irene Pi", affiliations: ["Carnegie Mellon University"] },
{ name: "Shihang Zhu", affiliations: ["Carnegie Mellon University"] },
{ name: "Ryan Rao", affiliations: ["Carnegie Mellon University"] },
{ name: "George Liu", affiliations: ["Carnegie Mellon University"] },
{ name: "Jiaxi Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Ruojin Li", affiliations: ["Carnegie Mellon University"] },
{ name: "Yili Han", affiliations: ["Carnegie Mellon University"] },
{ name: "Yilun Du", affiliations: ["Harvard University"] },
{ name: "Deva Ramanan", affiliations: ["Carnegie Mellon University"] },
];
jQuery('.post-authors').empty();
jQuery('.affiliations').empty();
jQuery('.post-authors').append('Authors
');
const affiliationMap = {};
let affiliationIndex = 1;
// First pass: assign unique affiliation numbers
authors.forEach(author => {
author.affiliations.forEach(affiliation => {
if (!affiliationMap[affiliation]) {
affiliationMap[affiliation] = affiliationIndex++;
}
});
});
// Build author line
const authorsHtml = authors.map((author, index) => {
const affIndices = author.affiliations.map(a => affiliationMap[a]);
const superscriptParts = [...affIndices];
if (author.equalContribution) {
superscriptParts.push('*');
}
const superscript = ${superscriptParts.join(',')};
let separator = '';
if (index Affiliations
');
Object.entries(affiliationMap).forEach(([affiliation, index]) => {
jQuery('.affiliations').append(`${index}${affiliation}
`);
});
// Equal contribution footnote
if (authors.some(a => a.equalContribution)) {
jQuery('.affiliations').append('*Equal contribution
');
}
jQuery('.doi').remove();
A year of building a video caption pipeline with 100+ professional creators, and what it taught us about scaling supervision instead of models.
By Zhiqiu Lin and Chancharik Mitra. Based on our CVPR 2026 work, Building a Precise Video Language with Human-AI Oversight (Highlight, Top 3%).
How close is today's video generator to a Hollywood cinematographer?
Hollywood directors reach for certain shots because they make a scene land. They cue a specific feeling in the viewer that flat coverage cannot. Open your favorite video generator (Veo 3.1, Seedance 2, or any of the latest open-source models) and ask it for a dolly zoom of a man standing in the middle of a bustling street, the way Hitchcock used the shot to make the world feel like it is collapsing inward. Or a rack focus pulling from a coffee cup to the woman behind it, the kind of focus pull that quietly tells the audience where to look. Or a Dutch-angle shot of a nervous person staring into the void, a tilted frame that puts the viewer on edge.
Most generators will hand back something close to a generic dolly-in, or a slow-motion clip with the wrong focal subject. The output is usually visually competent, but it does not do the thing. The model has clearly seen videos that contain these techniques. It just does not know how to act on the words.
We think this is symptomatic of a broader gap. Filmmakers communicate with a shared, precise vocabulary: shot size, frame position, focus type, lens distortion, camera height, video speed. Today's vision-language models (VLMs), and the captioning datasets that feed them, mostly do not.
In this post we describe CHAI, a captioning pipeline (in our usage, a caption is a long, structured paragraph describing a video's content, motion, and camera work — not a subtitle track) that we built over the past year with 100+ professional video creators. The acronym stands for Critique-based Human-AI Oversight. Existing video caption datasets are typically written either by crowdworkers, who lack the cinematic vocabulary to describe a shot precisely, or by large vision-language models, whose captions read smoothly (fluent — no grammatical or stylistic errors) but routinely describe objects and motions that are not in the video (hallucinated). The central idea behind CHAI is to combine the two: the captioner model (e.g., a large video-language model such as Gemini-2.5-Pro) writes the draft, a trained human critiques it, and the model revises against that critique.
This post works through four questions:
- Why do VLMs struggle with cinematic prompts?
- How should humans and models divide the captioning work?
- Does the quality of human critique change what the model can learn?
- Do better captions in the training data give us a better video generator?
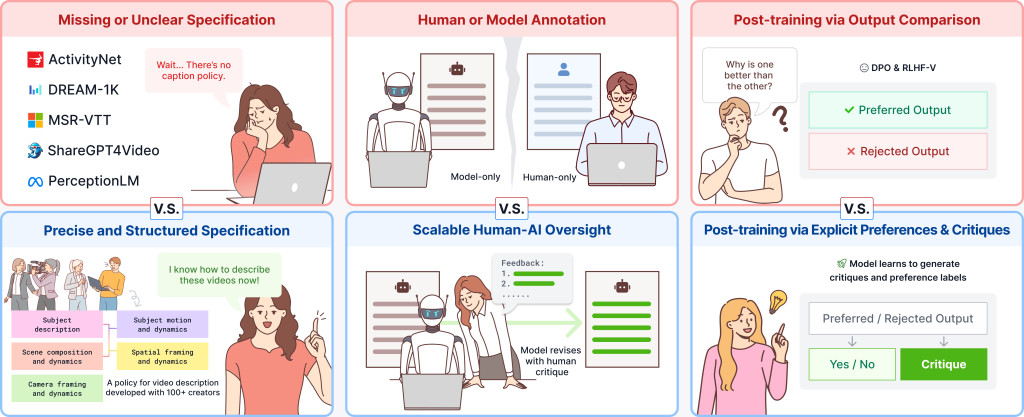 imageFigure 1. Three failure modes of current video captioning pipelines (top, red), and the choices we make in response (bottom, blue): a precise specification, a human-AI oversight loop, and post-training on explicit preferences plus critiques rather than output-only comparisons.
imageFigure 1. Three failure modes of current video captioning pipelines (top, red), and the choices we make in response (bottom, blue): a precise specification, a human-AI oversight loop, and post-training on explicit preferences plus critiques rather than output-only comparisons.
Question 1: Why do VLMs struggle with cinematic prompts?
A natural first hypothesis is that this is a capacity problem — that the current generation of vision-language models is simply too small, has too little context, or has not been pretrained on enough video to handle cinematic prompts, and that the next generation will solve it. But after auditing eight popular video-text datasets from 2016 to 2025 (ActivityNet Captions, MSR-VTT, DREAM-1K, ShareGPT4Video, PerceptionLM, and others), we think the bottleneck is somewhere else. The visual content is in the videos these models train on, and modern VLMs perceive it well. What is missing is the language: the captions paired with those videos do not contain the precise vocabulary needed to describe cinematic technique. In our experiments, training larger models on more of the same data only marginally improved these issues. They appear to be problems of annotation policy, not of capacity.
Three patterns showed up over and over:
• Imprecise terminology. Captions conflate dolly-in (the camera physically moves forward) with zoom-in (the focal length changes), or describe a fisheye distortion as "circular building."
• Missing information. Captions describe what is in the frame and skip everything else: motion, camera shake, focus changes, shot size. Anything temporal, anything about the camera, gets dropped.
• Subjective descriptions. "An atmospheric shot full of tension" tells a model nothing it can ground in pixels.
A natural next thought: just hire crowdworkers to write more careful captions. We tried that. Crowdworkers still confused dolly-in with zoom-in, called wide shots "close-ups," and described fisheye distortion as "a round building." Seeing is not the same as knowing how to describe.
Figure 2. Crowdworker vs. expert descriptions for the same clips. Crowdworkers see the aerial-view shot, the fisheye lens, and the dolly zoom. They just reach for everyday language ("bird's-eye view," "circular building," "warping effect") instead of the technical vocabulary the model would need to act on the description.
What worked, eventually, was bringing in people whose job requires this vocabulary: cinematographers, directors of photography, motion graphics designers, VFX artists, game designers, camera operators. Over the past year, we built a structured caption specification with 100+ such collaborators. The specification has five aspects:
• Subject (type, attribute, relations)
• Scene (composition, dynamics, overlays, point of view)
• Motion (subject actions, interactions, group activity)
• Spatial (shot size, frame position, depth, spatial movement)
• Camera (focus type, depth of field, steadiness, movement, video speed, lens distortion, height, angle)
All five aspects together involve roughly 200 low-level visual primitives, every one with a definition and a decision rule for when it applies. This prevents annotators from freelancing terminology, as all they have to do is tag against the spec.
imageFigure 3. Typical issues with prior captioning work (left, red) and what we converged on (right, blue). The structured taxonomy was built collaboratively with cinematographers, directors of photography, VFX artists, motion graphics designers, and game designers, and is paired with an annotation policy and training tutorials so the vocabulary stays consistent across annotators.
imageFigure 4. The full taxonomy. Five aspects, each decomposed into sub-aspects, each grounded in a set of visual or motion primitives.
Takeaway: VLMs struggle with cinematic prompts because the captions they were trained on do not contain the precise vocabulary professionals use. In our experiments, scaling models or data alone gave only marginal gains; specifying the language carefully made a much bigger difference.
Question 2: How should humans and models divide the captioning work?
Once we made the spec, we still had to decide who would write the long captions. The two obvious choices, humans or models, each come with well-known limitations.
Humans alone produce captions with typos, grammatical errors, and inconsistent event ordering. They also fatigue: 200 to 400 words of careful prose per video, while looking up the spec, is exhausting and expensive.
Models alone produce captions that read beautifully but that, on a depressing fraction of clips, confidently describe objects and motions that are not there. They also frequently mix up left and right.
What we noticed in pilot studies is that the failure modes are asymmetric in a useful way. Today's LLMs write better prose than most humans. But humans, especially trained ones, are much better than LLMs at noticing visual or motion errors in a draft, the kind where the caption says "moving left" but the subject is moving right. So we built the pipeline around that asymmetry. The model drafts, the human critiques, the model revises. This is conceptually similar to Saunders et al. (2022)'s self-critiquing models for summarization, but applied to long-form video captioning where the human still does the hard part: catching grounded errors against the actual video.
Concretely, the loop:
- Primitives. A trained annotator labels which visual and motion primitives are present in the clip.
- Pre-caption. The model generates a long caption from those primitives, following the spec.
- Critique. An annotator reads the pre-caption against the video and writes a critique pointing out what is wrong and what should change. The critique has to be accurate (the things it flags are wrong), complete (it does not miss errors), and constructive (it tells the model what to do, not just that something is bad).
- Post-caption. The model revises its draft using the critique.
- Refinement. If the post-caption is still off, the human refines the critique rather than rewriting the caption.
We tasked reviewers (top-performing annotators promoted to a quality-control role) with checking every critique and post-caption against the video. This way annotators were scored based on their accuracy, while reviewers earned rewards for catching the mistakes they found. Both precision (do not flag things that are not wrong) and recall (do not miss things that are wrong) were incentivized at the data level, before any modeling happened.
Shifting the human's job from writing to proofreading has a side benefit we underestimated: each video takes far less cognitive effort, and the resulting 200 to 400 word captions end up more accurate than what either humans or models produce alone.
Takeaway: LLMs and humans have asymmetric strengths in long-form video captioning. Designing the pipeline around that asymmetry, rather than trying to replace one with the other, gives both better captions and a more sustainable annotation process.
Question 3: Does the quality of human critique change what the model can learn?
The pipeline produces a triple for every video: (pre-caption, critique, post-caption). That triple is more than just an annotated caption. It is supervision for three different post-training tasks at once:
• Captioning. Train the model to produce long, faithful captions.
• Reward modeling. Treat (pre-caption, post-caption) as a (rejected, preferred) pair.
• Critique generation. Train the model to write the critique itself, given the video and the draft.
We post-trained Qwen3-VL-8B on all three formats jointly using standard supervised fine-tuning (SFT). We also tried reinforcement learning (RL) methods like Direct Preference Optimization (DPO), but found that simple SFT on the full triplet data is the strongest. The detailed numbers are in the paper; the headline is that adding explicit preference and critique signals improves every method we tested.
We were curious whether the quality of the critique mattered to downstream performance, or whether any "this is wrong" signal would do. So we ran an ablation: take a clean CHAI critique, deliberately degrade one property at a time (accuracy, recall, constructiveness), and see how the post-trained captioner performs on each task.
imageFigure 6. A useful critique has to be accurate (the things it flags are actually wrong), complete (it catches the errors that are there), and constructive (it says what should change, not just that something is bad). All three are needed; degrading any one hurts the downstream model.
Results for an 8B Qwen3-VL post-trained on each variant are presented in Table 1. Caption and Critique are BLEU-4 scores (a standard text-generation metric measuring n-gram overlap with reference text on a 0–100 scale; higher means closer to the human reference) against held-out reference captions and critiques. For the Reward task, we report binary accuracy on whether the captioner scores the post-caption higher than the pre-caption (chance = 50). Higher is better on all three.
Critique variantAcc.Rec.Constr.CaptionRewardCritique
Blind Gemini-2.5———10.944.521.1
Gemini-2.5———12.762.026.2
Inaccurate critique✗✓✓12.147.121.9
Incomplete critique✓✗✓12.556.628.7
Non-constructive critique✓✓✗13.467.232.9
CHAI (with QC)✓✓✓18.289.841.7
Table 1. Post-training results when the critique is artificially degraded along one property at a time. Higher is better. As additional reference points, we also tried having off-the-shelf models generate the critiques in place of our human-AI pipeline: (1) Blind Gemini-2.5 uses Gemini-2.5 to critique with the caption text only and no video access (a language-prior baseline); (2) Gemini-2.5 uses the same model with full video input. CHAI (with QC) is our full pipeline including the peer-review quality-control step from Question 2 — i.e., the critiques are accurate, complete, and constructive.
Three things stand out:
- Quality is not optional. Dropping any one of the three properties materially hurts every downstream task. Non-constructive critiques (the cheapest to collect, since you do not have to say what is wrong) hurt the least but still leave a large gap.
- Existing data is mostly non-constructive. We checked the critiques in publicly released datasets like Saunders et al.'s GDC release and MM-RLHF. More than half are non-constructive in our sense ("this is wrong" with no suggested fix). That helps explain why training on those datasets leaves performance on the table.
- An 8B model can be competitive with much larger closed models when the data is right. On the same captioning, reward, and critique benchmarks, the post-trained 8B Qwen3-VL matches or exceeds GPT-5 and Gemini-3.1-Pro on the metrics we report. The model size has not changed; the supervision signal has.
A small bonus: the same reward model also helps at inference time. Best-of-N decoding with the trained reward model continues to improve performance with no additional human labels.
Takeaway: The form of the critique is not a stylistic detail. A model jointly post-trained on captions, preferences, and critiques performs materially better on all three tasks when the critiques it is trained on are accurate, complete, and constructive — and materially worse when any one of those properties is missing.
Question 4: Do better captions in the training data give us a better video generator?
A skeptical reader might say: this is all very nice, but captioning is upstream of what most people actually want, which is generation. So we tested whether the improved captioner moves the needle on a downstream video generator. We took a large corpus of professional video (films, ads, music videos, gameplay), re-captioned it with the post-trained 8B model, and used those new captions to fine-tune Wan2.2.
The fine-tuned model can act on detailed prompts (up to roughly 400 words) for techniques that off-the-shelf generators reliably get wrong:
Figure 7. Two long generation prompts (the text fed to the video generator at inference time) that originated as captions produced by our post-trained captioner on similar held-out clips. Right: zero-shot Wan2.2 follows the prompt loosely, with a dolly zoom becoming a normal dolly-back and an isometric (2.5D) game scene becoming a generic 3D arc. Left: after Wan2.2 is fine-tuned on training videos re-captioned by our model, it follows the same prompt faithfully.
We did not change the generator architecture or training objective. The only thing that changed was the language used to describe the videos in the training set. That was enough to teach an existing generator a class of techniques it previously could not articulate.
Takeaway: A more precise caption vocabulary upstream translates into more controllable generation downstream, with the same model architecture and training recipe. The bottleneck for cinematic control was in the supervision, not the model.
Discussion
We started this project assuming we were going to train a captioner model. We ended up spending most of the year on the pipeline around it: what to write captions about, who should write them, who should check them, and what the checks should look like. The model contributions feel almost downstream of those choices.
Three things we wish we had appreciated earlier:
• Specification before scale. Training larger models on noisier data gave only marginal gains. Once the spec was in place, smaller models started looking very competitive.
• "Crowdsource it" is not a baseline; it is a different problem. Annotating cinematic technique correctly requires the same vocabulary the field already uses. Asking untrained workers to invent that vocabulary on the fly is not the cheap version of asking trained workers to apply it.
• Critiques are training data. The form of the critique we collect today decides how effectively models can be trained tomorrow. Datasets that record only thumbs-up / thumbs-down are leaving a lot of post-training signal on the table.
CHAI is one piece of a longer effort on precise video language. The closest companion is CameraBench (NeurIPS’25 Spotlight), our earlier benchmark on camera motion, which seeded the camera-side primitives in the spec.
Resources
We are releasing the specification, training tutorials, annotation platform, quality-control flow, data, code, and models. If you are work
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み