オンデマンドおよびバッチパイプラインによる動的なデータ抽出
AWS Machine Learning Blog は、Amazon Bedrock を活用したオンデマンドとバッチ処理を動的に切り替えるインテリジェントなドキュメント処理パイプラインの構築手法を紹介し、大規模なスキャンPDFからのデータ抽出における柔軟性とコスト最適化を実現する。
キーポイント
ハイブリッド推論アーキテクチャ
時間要件の高いリクエストには秒単位で結果を返すオンデマンド推論、大量のバックログ処理には非同期でコスト効率の良いバッチ推論という 2 つのパイプラインを構築し、状況に応じて動的に呼び出す仕組みを提供する。
Prompt Management の活用
Amazon Bedrock の Prompt Management を利用してプロンプトIDとバージョンをリクエスト時に指定することで、スキャンPDFの多様なフォーマットやテキストファイルなど、異なる種類のドキュメントに対して標準化された抽出ロジックを適用可能にする。
大規模非構造化データ処理
画像のみを含むスキャンPDF(例:土地賃貸契約書)が数百万件蓄積されているようなケースでも、LLM を駆使してデータを正確に抽出・標準化し、ビジネスインテリジェンスとして活用できる基盤を提示する。
影響分析・編集コメントを表示
影響分析
本記事は、生成 AI の実運用において頻出する「大量の非構造化データ(特にスキャンPDF)をいかに効率的かつ安価に処理するか」という課題に対する具体的なアーキテクチャソリューションを示しています。オンデマンドとバッチ処理を状況に応じて使い分ける設計思想は、大規模なドキュメント処理システムを構築する企業にとって、コスト削減とスピードの両立を実現するための重要な指針となります。
編集コメント
生成 AI の実装において、単にモデルを呼び出すだけでなく、ビジネス要件(時間対コスト)に応じて推論モードを動的に切り替える設計思想は非常に重要です。特に大量のバックログ処理とリアルタイム処理を同一システムで両立させる手法は、即戦力となるアーキテクチャパターンと言えます。
多くの企業には、未活用ビジネスインテリジェンスを含む大量の紙文書または電子文書が存在します。生成 AI の進展に伴い、さまざまな大規模言語モデル(LLM)を用いて、これらの文書から関連データを正確に抽出することが可能になりました。本記事では、ドキュメント処理時間とコストの柔軟性を確保するため、オンデマンド推論とバッチ推論の両方のオプションを備えたインテリジェントなドキュメント処理パイプラインについて解説します。Amazon Bedrock 上で動作するこのパイプラインでは、時間制約のあるリクエストにはオンデマンド推論オプションを、コスト最適化が最優先されるケースにはバッチ推論オプションを使用できます。また、ドキュメントレベルで大規模言語モデルとプロンプトを動的に指定する方法についても説明し、同じパイプラインを用いて複数の種類の文書からデータを抽出できるようにします。
ソリューション概要
お客様の中にも、スキャンされた PDF 形式(編集可能なテキストを含まず画像のみを含む PDF、例えばこの場合はスキャンされた土地賃貸契約書が PDF として保存されているケース)で数百万件の文書をバックログとして抱え、さらに新しい文書が毎日積み上がっているという方がいらっしゃるかもしれません。そのような場合でも、本ソリューションを使用すれば、これらの文書から効果的にデータを抽出することが可能です。以下の図に示す通り、このソリューションはオンデマンド型とバッチ型の 2 つの推論パイプラインを構築し、動的に呼び出す仕組みを提供します。Amazon Bedrock プロンプト管理 で効果的に設計・管理されたプロンプトを活用することで、形式や規約がバラバラであることが多いスキャン PDF やテキストファイルからデータを抽出し、標準化することができます。
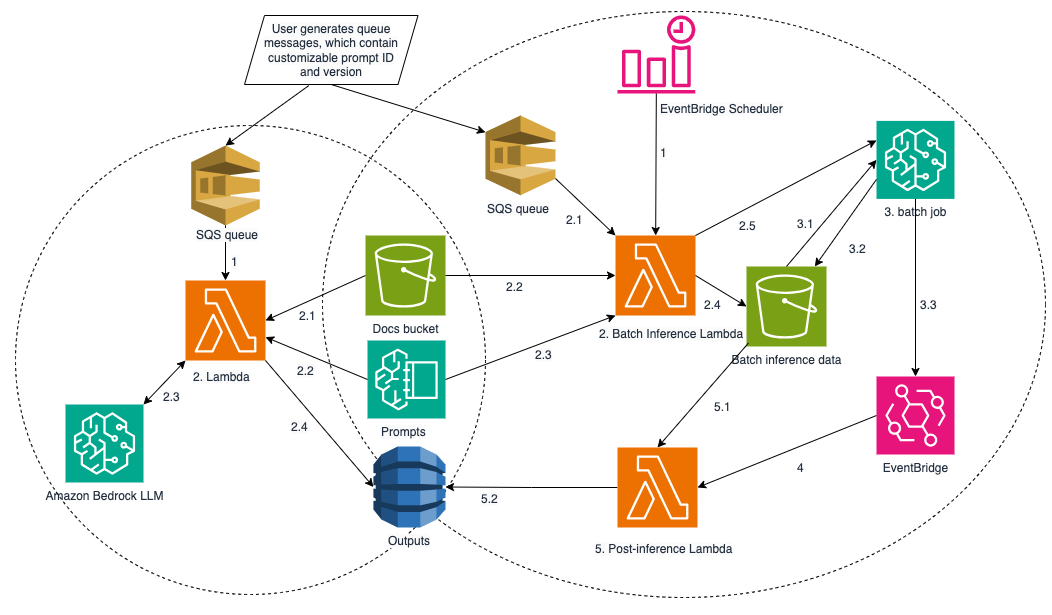
左側のパイプラインはオンデマンド型で、文書を 1 つずつ抽出し、数秒以内に結果を返します。このため、時間制約のあるリクエストに適しています。
右側のパイプラインは、単一の Amazon Bedrock バッチ推論 ジョブで複数のドキュメントリクエストを処理するバッチ推論パイプラインであり、モデルの呼び出しは非同期で処理されます。ユーザーは両方のパイプラインにおいて、リクエスト内でプロンプト ID とバージョンを指定でき、対応するプロンプトテキストは Amazon Bedrock プロンプト管理から取得されます。
以下のセクションでは、両方のパイプラインの詳細な説明を提供します。
1. オンデマンド推論パイプライン
オンデマンド推論パイプラインには、AWS SQS の First-In, First-Out (FIFO) キューが作成されます。ドキュメント ID、LLM モデル ID、プロンプト ID/バージョン、システムプロンプト ID/バージョンを含むキューメッセージが到着すると、AWS Lambda 関数がトリガーされます。この関数は、指定された Amazon S3 バケットから PDF ドキュメントを取得し、PDF ページを PNG 画像に変換し、Amazon Bedrock プロンプト管理から関連するプロンプトを取得し、LLM を呼び出すためのメッセージを組み立て、その結果を Amazon DynamoDB テーブルに保存します。
1.1. AWS SQS FIFO キュー
単一のドキュメントが到着した際に Amazon Bedrock の推論をトリガーするために、AWS SQS FIFO キューが使用されます。FIFO キューを使用する主な理由は以下の通りです:
- リライアブルメッセージ配信 – 各メッセージが正確に一度だけ配信されることを保証します。
- First-In, First-Out (FIFO) プロセッシング – 厳格な順序を維持し、処理の予測可能性を高めます。
- メッセージグループ化 – Message Group ID 属性により、各グループ内でメッセージが順序通りに処理されることが保証されます。各プロデューサーは、関連するメッセージの順序を維持するために一意の Message Group ID を使用できます。
How is a queue message created?
キューメッセージは、AWS CLI または AWS SDK API を用いて外部から作成できます。以下に AWS CLI コマンドの例を示します:
aws sqs send-message --queue-url https://sqs.us-east-1.amazonaws.com/1111111111/ondemand-data-pipeline-queue.fifo --message-group-id "1" --message-body "msg 1" --message-attributes file://message_txt.txt
この例におけるファイル message_txt.txt は、アプリケーションに必要なメッセージ属性を含む JSON ファイルです。詳細は以下の「パイプラインのテスト」セクションをご覧ください。
Lambda 関数は、Amazon Bedrock が抽出データを返した後、キューメッセージを削除します。
1.2. Lambda function – queue message processing and inferencing
1.2.1 Retrieving the documents, converting to images, and splitting large files
Lambda 関数は、キューメッセージ内の s3_location 属性を使用してドキュメントをダウンロードします。ドキュメントがスキャンされた PDF の場合、マルチモーダルモデルが理解できるように画像に変換されます。
執筆時点において、Claude 4 Sonnet モデルはマルチモーダル呼び出しあたり最大 20 枚までの画像しか許可していません。したがって、ドキュメントに 20 ページを超える画像が含まれる場合は、20 ページごとのチャンクに分割する必要があります。doc_id(文書識別子)、chunk_count(チャンク数)、chunk_id(各チャンクの識別子)は、抽出結果およびモデルのパフォーマンス指標とともに Amazon DynamoDB テーブルに格納されます。
- doc_id: 文書の識別子
- chunk_count: その文書に対するチャンクの総数
- chunk_id: 文書の各チャンクの識別子
1.2.2. Amazon Bedrock Prompt Management からのプロンプト取得
土地賃貸契約書はフォーマットが様々です。番号付きリストで土地区画の属性を示すものもあれば、表形式のもの、さらには土地図面として記述されたものもあります。そのため、各ドキュメントのフォーマットに合わせた異なるプロンプトを使用することで、抽出精度を向上させることができます。
LLM 呼び出しで使用されるプロンプトは Amazon Bedrock Prompt Management に格納されています。各プロンプトには一意の ID が割り当てられ、バージョン管理されています。SQS メッセージでは関連するプロンプト ID とバージョンを指定する必要があり、Lambda 実行時にこれらの情報を用いてプロンプト本文が取得されます。
注記:リージョンあたり最大 50 プロンプト、プロンプトあたり最大 10 バージョンというサービス制限があります。
1.2.3 LLM 呼び出し用のメッセージ作成とレスポンス処理
Lambda 関数は以下の手順を続行します:
- LLM のメッセージは、プロンプト本文と画像を連結して作成します。
- Converse API を使用して Amazon Bedrock へリクエストを送信します。
LLM は抽出データを JSON 文字列として返します。この結果は、以下のパイプラインテストセクションで示すように、DynamoDB テーブルで確認できます。
1.2.4 結果の保存
最後に、Lambda 関数は以下の処理によってプロセスを完了します:
- JSON を解析し、土地区画の属性を DynamoDB テーブルに格納します。
- ドキュメントが正常に処理され、結果が保存された場合、SQS メッセージはキューから削除されます。
2. バッチ推論パイプライン
バッチ推論パイプラインには、高いスループットを実現するために標準的な AWS SQS キューが使用されます。メッセージの作成方法はオンデマンドパイプラインと同様ですが、message-group-id 属性は不要です。
バッチ推論パイプラインの主要なコンポーネントは以下の通りです:
- Amazon EventBridge Scheduler(スケジューラ)。
- スキャンされた PDF の前処理、JSONL ファイルの作成、およびバッチ推論ジョブの送信を行う Batch Inference AWS Lambda 関数。
- Amazon EventBridge ルール。
- 後処理を行う Post-processing AWS Lambda 関数。
以下のセクションでバッチ推論パイプラインの詳細を説明します。
2.1. Amazon EventBridge スケジューラ
Amazon EventBridge Scheduler は、スケジュールに基づいてバッチ推論用 Lambda 関数を起動します。
2.2. バッチ推論 Lambda 関数
この関数は、処理を続行する前にキュー内に十分なメッセージがあるかどうかをまず確認します。執筆時点では、Amazon Bedrock のバッチ推論ジョブに対して、レコードの最小数が 100 件と設定されています。
2.2.1 キューからのメッセージ受信
Lambda 関数はキュー内のメッセージをループ処理し、ドキュメント ID、LLM モデル ID、プロンプト ID/バージョン、およびシステムプロンプト ID/バージョンを抽出します。
2.2.2 ドキュメントの重複排除取得、画像への変換、大規模ファイルの分割
次に Lambda 関数はドキュメントを取得し、スキャンされた PDF の場合は画像に変換し、必要に応じて大規模ファイルを分割します。これはオンデマンドパイプラインと同様の処理です。標準的な SQS キューは正確に一度だけのメッセージ配信を保証しないため、この関数では重複するメッセージも無視されるようにしています。
2.2.3 バッチ推論ジョブ内での異なるプロンプトの許可
オンデマンドパイプラインと同様に、より効果的なデータ抽出のためには、異なるドキュメント形式に対して異なるユーザープロンプトが必要です。
各ドキュメントに対する意図するプロンプト ID とバージョンは SQS メッセージ内で指定されています。Lambda 実行中、関数は Amazon Bedrock のプロンプト管理からプロンプト本文を取得します。
2.2.4 バッチ推論ジョブ用の JSONL アーティファクト作成
その後、Lambda 関数は以下のタスクを処理します:
- バッチ推論データ用 S3 バケットに metadata.json を作成し、SQS メッセージ ID、ドキュメント ID、プロンプト ID/バージョン、システムプロンプト ID/バージョン、およびその他のプロジェクト関連属性を含むメッセージ属性を保存します。このファイルは後で Post-Processing Lambda によって DynamoDB テーブルの埋め込みに使用されます。
- Amazon Bedrock のバッチ推論ジョブに必要な JSONL ファイルを作成するためにドキュメントを処理します。このプロセスは効率化のために Python の multiprocessing モジュールを使用して並列化され、JSONL ファイルはバッチ推論データ用 S3 バケットにアップロードされます。
- ドキュメントの準備と S3 バケットへのアップロードが完了した後、SQS メッセージを削除します。これにはキューに対して大きな可視性タイムアウトを設定する必要があります。
2.2.5 メッセージの作成とバッチ推論ジョブの送信
最後に、バッチ推論 Lambda 関数は、前工程で生成された JSONL アーティファクトを使用して Amazon Bedrock のバッチ推論ジョブを作成します。各バッチジョブは 1 つのモデルのみを使用してドキュメントを処理できるため、同じバッチジョブ内の SQS メッセージはすべて同一のモデル ID を指定する必要があります。入力メッセージに複数のモデル ID が指定されている場合、Lambda 関数はポーリングメカニズムを使用し、最も頻繁に指定されたモデル ID を選択して使用します。
2.3. Amazon Bedrock バッチ推論ジョブ
Amazon Bedrock がバッチ推論ジョブを受け取ると、それをキューに配置します。ジョブが開始されると、以下の手順に従って処理が進みます。
2.3.1 バッチ推論ジョブ用の JSONL アーティファクトの取得
Amazon Bedrock は、ジョブ作成時に指定された JSONL アーティファクトを取得します。
2.3.2 バッチ推論出力の保存
完了後、Amazon Bedrock は、ジョブ作成時にも指定されたバッチ推論データ用 S3 バケットへ出力を保存します。
2.3.3 Amazon EventBridge への通知
ジョブ完了後、Amazon Bedrock はイベントブランチルールによって捕捉される、Amazon EventBridge 宛てのジョブステータス変更イベントを送信します。
2.4. Amazon EventBridge ルールが推論後の Lambda 関数をトリガー
EventBridge ルールは、追加のモデル出力処理を処理するための推論後処理用 Lambda 関数をトリガーします。
2.5. 推論後処理 Lambda 関数
2.5.1 出力 JSONL の取得
Lambda 関数は、バッチ推論データ用 S3 バケットから推論出力の JSONL をフェッチします。
2.5.2 推論出力の保存
この関数は JSONL ファイルを解析し、抽出された土地区画属性を DynamoDB テーブルに保存します。
前提条件
この例を自分で試したい場合は、以下の前提条件を満たしていることを確認してください:
- AWS Management Console にアクセスできる AWS アカウント
- CloudFormation スタックの作成と管理に必要な適切な IAM 権限。通常、以下が含まれます:
cloudformation:CreateStack
- cloudformation:DescribeStacks
- cloudformation:UpdateStack
- cloudformation:DeleteStack
CloudFormation スタックのデプロイ
オンデマンドパイプラインをデプロイします:
Launch Stack リンクを選択すると、AWS CloudFormation に遷移し、CloudFormation スタックが起動されます:
- Create stack ページで Next を選択します。
- Specify stack details ページで Next を選択します。
- Configure stack options ページで Next を選択します。
- Review and create ページで、AWS CloudFormation が IAM リソースを作成する可能性があることを承認するチェックボックスを選択します。
- Submit を選択します。
送信後、Stack info、Events、Resource など、スタックに関するいくつかの詳細を確認できます。以下にイベントのスクリーンショットを参考として示します:
同様の手順でバッチパイプラインもデプロイできます。
パイプラインのテスト
以下の手順は、オンデマンドパイプラインをテストするためのガイドです。少なくとも 100 ドキュメントをお持ちであれば、バッチパイプラインも同様の手順でテスト可能です。
- ローカル環境にデータをダウンロードします。テキサス州土地記録および郡記録ウェブサイトから購入した、ウィンクラー郡、アンドリュース郡、サットン郡の 3 つの土地文書があります。
- ダウンロードした PDF ファイルを、CloudFormation スタックで作成されたオンデマンドデータパイプラインバケット
on-demand-data-pipeline-bucket-${account_id}にアップロードします。
- 以下の例を元に、CloudFormation スタックから作成されたプロンプト ID、システムプロンプト ID、および S3 バケットを置き換えて、テキストファイル
message_txt.jsonを作成してください。
{
"application": {
"DataType": "String",
"StringValue": "bedrock-example"
},
"id": {
"DataType": "String",
"StringValue": "Winkler_2024-06-05_N_C42758_V_OPR"
},
"model_id": {
"DataType": "String",
"StringValue": "anthropic.claude-sonnet-4-20250514-v1:0"
},
"prompt_id": {
"DataType": "String",
"StringValue": "6CT88W3MWT"
},
"prompt_version": {
"DataType": "String",
"StringValue": "1"
},
"s3_location": {
"DataType": "String",
"StringValue": "s3://ondemand-data-pipeline-bucket-111111111/Winkler_2024-06-05_N_C42758_V_OPR.pdf"
},
"system_prompt_id": {
"DataType": "String",
"StringValue": "R2NFLXFXOJ"
},
"system_prompt_version": {
"DataType": "String",
"StringValue": "1"
}
}
必ず JSON 形式で返してください。`translation` フィールドのみ。**他のフィールド (technical_terms 等) は一切追加しないこと** — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
- 上記の AWS CLI の例を用いて、キュー名を置き換えたシェルスクリプト send2queue.sh を作成し、実行してください。すると、SQS キュー ondemand-data-pipeline-queue.fifo にメッセージが送信されたことを示す通知が表示されます。
- このキューメッセージは、Lambda 関数 ondemand-data-pipeline-queue-processor をトリガーします。
- Amazon CloudWatch の Lambda ログを確認してください。ロググループ名は /aws/lambda/ondemand-data-pipeline-queue-processor です。
- DynamoDB テーブル ondemand-data-pipeline-table 内の Amazon Bedrock 推論出力を確認してください。Winkler カウンティの例における model_response カラムの JSON 結果は、以下のようになります:
[
{
"tract": 1,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1239",
"survey": "PSL Survey",
"section": "8",
"range_block": "B2",
"quarter": "N/2 of N/2"
},
{
"tract": 2,
"state": "Texas",
"co原文を表示
Many companies have large volumes of paper or electronic documents that contain untapped business intelligence. With the advancement of generative AI, various large language models can be used to accurately extract relevant data from these documents. This post demonstrates an intelligent document processing pipeline that consists of both on-demand inference and batch inference options on Amazon Bedrock to enable the flexibility on the document processing time and cost. For time-sensitive requests, one can use the on-demand inference option, while the batch inference option is most cost optimized. It also explains how to dynamically specify the large language model and prompts at the document level, enabling you to extract data from multiple types of documents using the same pipelines.
Solution overview
If you, like one of our customers, have hundreds of millions land lease documents in scanned PDF format (PDF that contains only images without editable text, e.g. in this case, scanned land lease saved as PDF) in the backlog, and new documents are still piling up every day, this is a solution you can use to effectively extract data from these documents. As shown in the following diagram, this solution builds two inference pipelines, on-demand and batch, with a mechanism to invoke them dynamically. By using effectively designed prompts managed in Amazon Bedrock Prompt Management, the data can be extracted and standardized from scan PDFs, which often have varying formats and conventions, or from text files.
The pipeline on the left is the on-demand pipeline that extracts data from documents one-by-one, returning results within seconds. This makes it suitable for time-sensitive requests.
The pipeline on the right is the batch inference pipeline that processes multiple document requests in a single Amazon Bedrock batch inference job, where your model invocation will be processed asynchronously. Users can specify the prompt ID and version in the request in both pipelines, and the corresponding prompt text will be retrieved from Amazon Bedrock Prompt Management.
The following sections provide detailed descriptions of both pipelines.
1. On-demand inference pipeline
An AWS SQS First-In, First-Out (FIFO) queue is created in the on-demand inference pipeline. When a queue message containing the document ID, LLM model ID, prompt ID/version, and system prompt ID/version arrives, it triggers an AWS Lambda function. This function retrieves the PDF document from the specified Amazon S3 bucket, converts the PDF pages to PNG images, retrieves the relevant prompts from Amazon Bedrock Prompt Management, composes the message to call the LLM, and saves the result into an Amazon DynamoDB table.
1.1. AWS SQS FIFO queue
An AWS SQS FIFO queue is used to trigger Amazon Bedrock inference when a single document arrives. The key reasons for using a FIFO queue are:
- Reliable Message Delivery – Makes sure that each message is delivered exactly once.
- First-In, First-Out (FIFO) Processing – Maintains a strict ordering, providing better predictability for processing.
- Message Grouping – The Message Group ID attribute makes sure the messages are processed in order within each group. Each producer can use a unique Message Group ID to maintain order for related messages.
How is a queue message created?
The queue messages can be created externally with AWS CLI or AWS SDK API. The following is an AWS CLI command example:
aws sqs send-message --queue-url https://sqs.us-east-1.amazonaws.com/1111111111/ondemand-data-pipeline-queue.fifo --message-group-id "1" --message-body "msg 1" --message-attributes file://message_txt.txtThe file message_txt.txt in this example is a JSON file containing the message attributes needed for the application. See details in the Testing the pipelines section below.
The Lambda function will delete the queue message after Amazon Bedrock has returned the extracted data.
1.2. Lambda function – queue message processing and inferencing
1.2.1 Retrieving the documents, converting to images, and splitting large files
The Lambda function downloads the document using the s3_location attribute in the queue message. If the document is scanned PDF, it is then converted to images for the multimodal model to understand.
As of this writing, the Claude 4 Sonnet model only allows a maximum of 20 images per multimodal invocation. Therefore, if a document contains more than 20 pages of images, it must be split into chunks of 20 pages. The doc_id, chunk_count and chunk_id are stored in an Amazon DynamoDB table, along with the extracted results and the model performance metrics.
- doc_id: the identifier of the document
- chunk_count: the total number of chunks for that document
- chunk_id: the identifier of each chunk of the document
1.2.2. Retrieving prompts from Amazon Bedrock Prompt Management
Land lease documents vary in format – some present land tract attributes in numbered list, others in tables, and some even in land drawings. Hence, using different prompts tailored to each document format enhances extraction accuracy.
The prompts used in the LLM call are stored in Amazon Bedrock Prompt Management. Each prompt has a unique ID and is versioned. The SQS messages must specify the relevant prompt ID and version, which are then used to retrieve the prompt body during Lambda execution.
Note: There is a service limit of 50 prompts per region and 10 versions per prompt.
1.2.3 Composing message for LLM calls and processing the response
The Lambda function continues with the following steps:
- Compose the messages for LLM by concatenating the prompt body and images.
- Send request(s) to Amazon Bedrock using the Converse API.
The LLM will return the extract data in a JSON string, you can examine the result in your DynamoDB table as illustrated in the following testing the pipelines section.
1.2.4 Saving the results
Finally, the Lambda function completes the process by:
- Parsing the JSON and storing the land tract attributes to the DynamoDB table.
- If the document has been successfully processed and the results are stored, the SQS message is deleted from the queue.
2. Batch inference pipeline
A standard AWS SQS queue is used for the batch inference pipeline because of its high throughput. The queue messages are created in the similar way as in the on-demand pipeline, except the message-group-id attribute is not required.
The main components in the batch inference pipeline includes:
- Amazon EventBridge Scheduler.
- Batch Inference AWS Lambda function to pre-process the scanned PDFs, create JSONL files and submit the batch inference job.
- Amazon EventBridge rule.
- Post-processing AWS Lambda function.
The following sections describe the details of the batch inference pipeline.
2.1. Amazon EventBridge scheduler
An Amazon EventBridge Scheduler starts the batch inference Lambda function on a schedule.
2.2. Batch inference Lambda function
The function first checks if there are enough messages in the queue before proceeding. At the time of writing, there is a minimum number of records of 100 for Amazon Bedrock batch inference job.
2.2.1 Receiving queue messages
The Lambda function loops through the messages in the queue and extracts the document ID, LLM model ID, prompt ID/version, and system promptID/version.
2.2.2 Retrieving the documents without duplicates, converting to image, and splitting large files
The Lambda function then retrieves the documents, converts them to images if they are scanned PDF, and splits the large files if necessary – just as in the on-demand pipeline. Because the standard SQS queues do not guarantee exactly-once message delivery, the function also makes sure that duplicate messages are ignored.
2.2.3 Allowing different prompts in a batch inference job
Similar to the on-demand pipeline, different document formats require different user prompts for more effective data extraction.
The intended prompt ID and version for each document are specified in the SQS messages. During Lambda execution, the function retrieves the prompt body from Amazon Bedrock Prompt Management.
2.2.4 Creating JSONL artifacts for batch inference job
The Lambda function then handles the following tasks:
- Creating a metadata.json in the Batch Inference Data S3 bucket to store the message attributes, including the SQS message ID, doc_id, prompt ID/version, system prompt ID/version, and other project-related attributes. This file is later used by the Post-Processing Lambda to populate the DynamoDB table.
- Processing the documents to create the JSONL files required for the Amazon Bedrock batch inference job. This process is parallelized using Python’s multiprocessing module for efficiency. The JSONL files are uploaded to the Batch Inference Data S3 bucket.
- Deleting the SQS messages after the documents have been prepared and uploaded to the S3 bucket. This requires setting a large Visibility Timeout for the queue.
2.2.5 Composing messages and submits batch inference job
Finally, the batch inference Lambda function creates the Amazon Bedrock batch inference job using the JSONL artifacts from the previous step. Note that each batch job can only process documents using one model, meaning the SQS messages within the same batch job must specify the same model ID. If there are more than one model ID specified in the incoming messages, the Lambda function uses a polling mechanism that selects the most frequently specified model ID to use.
2.3. The Amazon Bedrock batch inference job
When Amazon Bedrock receives the batch inference job, it places it in a queue. Once the job starts, it proceeds with the following steps.
2.3.1 Retrieving JSONL artifacts for batch inference job
Amazon Bedrock retrieves the JSONL artifacts specified during job creation.
2.3.2 Storing batch inference outputs
Upon completion, Amazon Bedrock stores the outputs to the Batch Inference Data S3 bucket, which is also specified in the job creation.
2.3.3 Notifying Amazon EventBridge
After job completion, Amazon Bedrock sends a job status change event to Amazon EventBridge, which is captured by an EventBridge rule.
2.4. Amazon EventBridge rule triggers the post-inference Lambda function
The EventBridge rule triggers the post-processing Lambda function to handle further model output processing.
2.5. Post-processing Lambda function
2.5.1 Retrieving the output JSONL
The Lambda function fetches the inference output JSONL from the batch inference data S3 bucket.
2.5.2 Saving the inference output
The function parses the JSONL files and saves the extracted land tract attributes to a DynamoDB table.
Prerequisites
If you want to try this example yourself, make sure you meet these prerequisites:
- An AWS account with access to the AWS Management Console
- Appropriate IAM permissions to create and manage CloudFormation stacks, which typically include:
cloudformation:CreateStack
- cloudformation:DescribeStacks
- cloudformation:UpdateStack
- cloudformation:DeleteStack
Deploying the CloudFormation stacks
Deploy the on-demand pipeline:
When you choose the Launch Stack link, you will be taken to AWS CloudFormation to launch the CloudFormation stack:
- On the Create stack page, choose Next
- On the Specify stack details page, choose Next
- On the Configure stack options page, choose Next
- On the Review and create page, select I acknowledge that AWS CloudFormation might create IAM resources
- Choose Submit
After it’s submitted, you can observe some details about the stack such as Stack info, Events, Resource, and more. The following screenshot is the Events for your reference:
You can also deploy the batch pipeline following the same steps.
Testing the pipelines
The following steps guide you to test the on-demand pipeline. The batch pipeline can also be tested in the similar steps if you have at lease 100 documents.
- Download the data to your local environment. There are three land documents from Winkler County, Andrews County, and Sutton County that are purchased from the Texas Land Records and County Records website.
- Upload downloaded PDF file(s) to the S3 artifact bucket ondemand-data-pipeline-bucket-${account_id} that is created in CloudFormation stack.
- Create a text file message_txt.json using the following example by replacing the prompt ID, system prompt ID and S3 bucket that are created from your CloudFormation stack.
{
"application": {
"DataType": "String",
"StringValue": "bedrock-example"
},
"id": {
"DataType": "String",
"StringValue": "Winkler_2024-06-05_N_C42758_V_OPR"
},
"model_id": {
"DataType": "String",
"StringValue": "anthropic.claude-sonnet-4-20250514-v1:0"
},
"prompt_id": {
"DataType": "String",
"StringValue": "6CT88W3MWT"
},
"prompt_version": {
"DataType": "String",
"StringValue": "1"
},
"s3_location": {
"DataType": "String",
"StringValue": "s3://ondemand-data-pipeline-bucket-111111111/Winkler_2024-06-05_N_C42758_V_OPR.pdf"
},
"system_prompt_id": {
"DataType": "String",
"StringValue": "R2NFLXFXOJ"
},
"system_prompt_version": {
"DataType": "String",
"StringValue": "1"
}
}- Create a shell script send2queue.sh by using the above AWS CLI example by replacing the queue name in and execute it. You will see a message to your SQS queue ondemand-data-pipeline-queue.fifo.
- The queue message will trigger the Lambda function ondemand-data-pipeline-queue-processor.
- Examine the Lambda log in Amazon CloudWatch, the log group is /aws/lambda/ondemand-data-pipeline-queue-processor.
- Examine the Amazon Bedrock inference output in the DynamoDB ondemand-data-pipeline-table table. The JSON result in the model_response column for the Winkler County example should look like the following:
[
{
"tract": 1,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1239",
"survey": "PSL Survey",
"section": "8",
"range_block": "B2",
"quarter": "N/2 of N/2"
},
{
"tract": 2,
"state": "Texas",
"co
関連記事
CloudWatch の SageMaker メトリクスとインサイトダッシュボードを用いた生成 AI 推論の監視・デバッグ
AWS は、大規模な生成 AI 推論エンドポイントの P99 レイテンシ急上昇などのトラブルを GPU メモリ圧力や KV キャッシュ飽和などから特定できるよう、CloudWatch に SageMaker の詳細メトリクスとインサイトダッシュボードを追加した。
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み