オープンソースタンパク質折りたたみモデルの予想外の味方:大手製薬会社
医薬品大手が Google DeepMind の AlphaFold に依存しないよう、Mohammed AlQuraishi 教授らが主導するオープンソースプロジェクト「OpenFold」に資金とリソースを提供し、科学界の自律性を維持しようとしている。
キーポイント
学術界の存続危機と OpenFold の設立
AlphaFold の登場により学術研究が産業ラボに独占される懸念から、コロンビア大学のモハメッド・アルクライシ教授らが 2021 年にオープンソース版「OpenFold」を立ち上げ、技術的・組織的な革新で対抗した。
製薬業界という意外な同盟者
通常はオープンサイエンスに消極的な製薬企業だが、Google への依存を避けたいという共通の利害から OpenFold に数百万ドル規模の計算リソースを提供し、研究優先順位への発言権を得ている。
AlphaFold 3 のクローズド化への対抗
DeepMind が AlphaFold 3 でモデル重みの公開を制限した背景には商業戦略の存在があり、OpenFold は完全なソースコードとトレーニングデータを公開することで、研究の透明性と次世代の知見共有を保証している。
実験的構造決定の課題と計算予測の必要性
タンパク質の実験的な形状決定(X線結晶解析など)には時間と費用がかかるため、アミノ酸配列から3D構造を予測する計算手法が重要視されている。
タンパク質の機能は立体構造に依存
タンパク質の生物学的機能(例:酸素結合)はその形状によって決定され、特定のポケット構造が分子の結合・放出を可能にする。
AlphaFold 2 の実用性と精度
2022年のNature記事によると、EMBL-EBIの調査では2億1400万個のタンパク質構造予測のうち80%が少なくとも一部の用途に有用な精度を有していることが示された。
共進化と多配列アライメントの活用
DeepMindはターゲットタンパク質と関連する配列を比較し、同等のアミノ酸を同一列に配置した多配列アライメント(MSA)を入力することで、構造の詳細を推論する「共進化」という手法を採用した。
影響分析・編集コメントを表示
影響分析
この記事は、AI 技術の進展が学術界から産業独占へ移行しつつある現状において、製薬企業という巨大資本がオープンソース運動を支援することでバランスを保とうとする重要な転換点を示しています。これは単なる資金援助ではなく、次世代の治療法開発における知見の共有と加速を妨げないための戦略的連携であり、AI 科学の未来を決定づけるモデルケースとなる可能性があります。
編集コメント
AI 科学の民主化を巡る、学術界と巨大企業の微妙な力学が浮き彫りになった興味深い事例です。製薬企業が「依存回避」のためにオープンソースを支えるという逆説的な動きは、今後の技術ガバナンスを考える上で示唆に富んでいます。
タンパク質折りたたみモデルは、科学における AI の成功事例です。
2010 年代後半、Google DeepMind の研究者たちは機械学習を用いてタンパク質の三次元形状を予測しました。2020 年に発表された AlphaFold 2 はあまりにも優秀で、その創作者たちは外部の学術関係者と共に 2024 年の化学賞ノーベル賞を受賞しました。
しかし、多くの学者たちは DeepMind の進歩に対して複雑な感情を抱いています。2018 年、当時ハーバード大学の研究員だったモハメド・アルキライシは、「タンパク質折りたたみ研究者の間で広範な存在不安がある」と報告する広く読まれたブログ記事を書きました。
AlphaFold の最初のバージョンは、主要なタンパク質折りたたみ競技である CASP13 を制したばかりでした。アルキライシは、自分や同僚の学者たちが、「学問分野としてのタンパク質構造予測に未来があるのか、それとも機械学習の多くの部分と同様に、これからの最良の研究は産業研究所で行われ、学術グループにはわずかな断片しか残らないのではないか」と懸念していると記しました。
産業研究所は、発見を完全に共有したり、即座の実用応用がない問いを検証したりする可能性が低くなります。学問的な研究がなければ、次世代の洞察はいくつかの企業に閉じ込められ、分野全体の進歩が遅れる可能性があります。
これらの懸念は、2024年にリリースされた AlphaFold 3 で現実のものとなりました。同モデルの重み(weights)は当初非公開とされていました。現在では、科学者たちは「Google DeepMind の裁量により」、特定の非営利目的のために重みをダウンロードできるようになっています。DeepMind の AI 科学部門責任者である Pushmeet Kohli は Nature に対し、DeepMind が科学者にとってモデルを「アクセス可能」かつ影響力のあるものにする必要性と、Alphabet の子会社である Isomorphic Labs を通じて「商業的な創薬」を進めたいという Alphabet の意向とのバランスを取る必要があったと語りました。
購読する
アル・アウラシはその後コロンビア大学の教授となり、学術研究者が研究の場から排除されないよう闘い続けています。2021 年には、AlphaFold の革新をオープンに再現することを目指した「OpenFold」というプロジェクトを共同設立しました。これには困難な技術的作業だけでなく、組織運営や資金調達の面でのイノベーションも必要でした。
必要な数百万ドル規模の計算資源を得るため、アル・アウラシと彼の同僚たちは、予想外の同盟者に頼りました。それは製薬業界です。製薬会社は一般にオープンサイエンスへのコミットメントで知られていませんが、彼らは Google に依存したくないという強い意向を持っていました。
OpenFold を支援することは、これらの製薬企業にプロジェクトの研究優先事項への影響力を与えます。製薬会社はまた、社内利用のために OpenFold のモデルへの早期アクセスも得られます。しかし、何よりも重要なのは、OpenFold がそのモデルを一般公衆に公開し、最近の AlphaFold のリリースに含まれていなかった完全なトレーニングデータ、ソースコード、その他の資料も同時に提供している点です。
「この研究が影響力を持つことを望んでいます」と AlQuraishi は月曜日のインタビューで私に語りました。彼は新たな発見への貢献と新しい治療法の創出に関与したいと考えていました。今日では、「その多くは業界の中で行われています」と彼は言います。しかし、OpenFold のようなプロジェクトは、学術研究者により大きな役割を切り開く手助けとなり、その過程で科学発見のペースを加速させる可能性があります。
タンパク質フォールディング:配列から構造へ
タンパク質は生命に不可欠な大分子です。血糖値調節(インスリンなど)や抗体としての機能など、多くの生物学的機能を担っています。
タンパク質の形状はその機能にとって不可欠です。筋肉組織で酸素を貯蔵するミオグロビン(写真参照)の例を取りましょう。ミオグロビンの形状は、鉄を含む分子(灰色の円で囲まれた部分)を保持する小さなポケットを作り出します。このポケットの形状により、鉄が酸素と可逆的に結合できるようになり、タンパク質は必要に応じて筋肉内で酸素を捕捉・放出することができます。
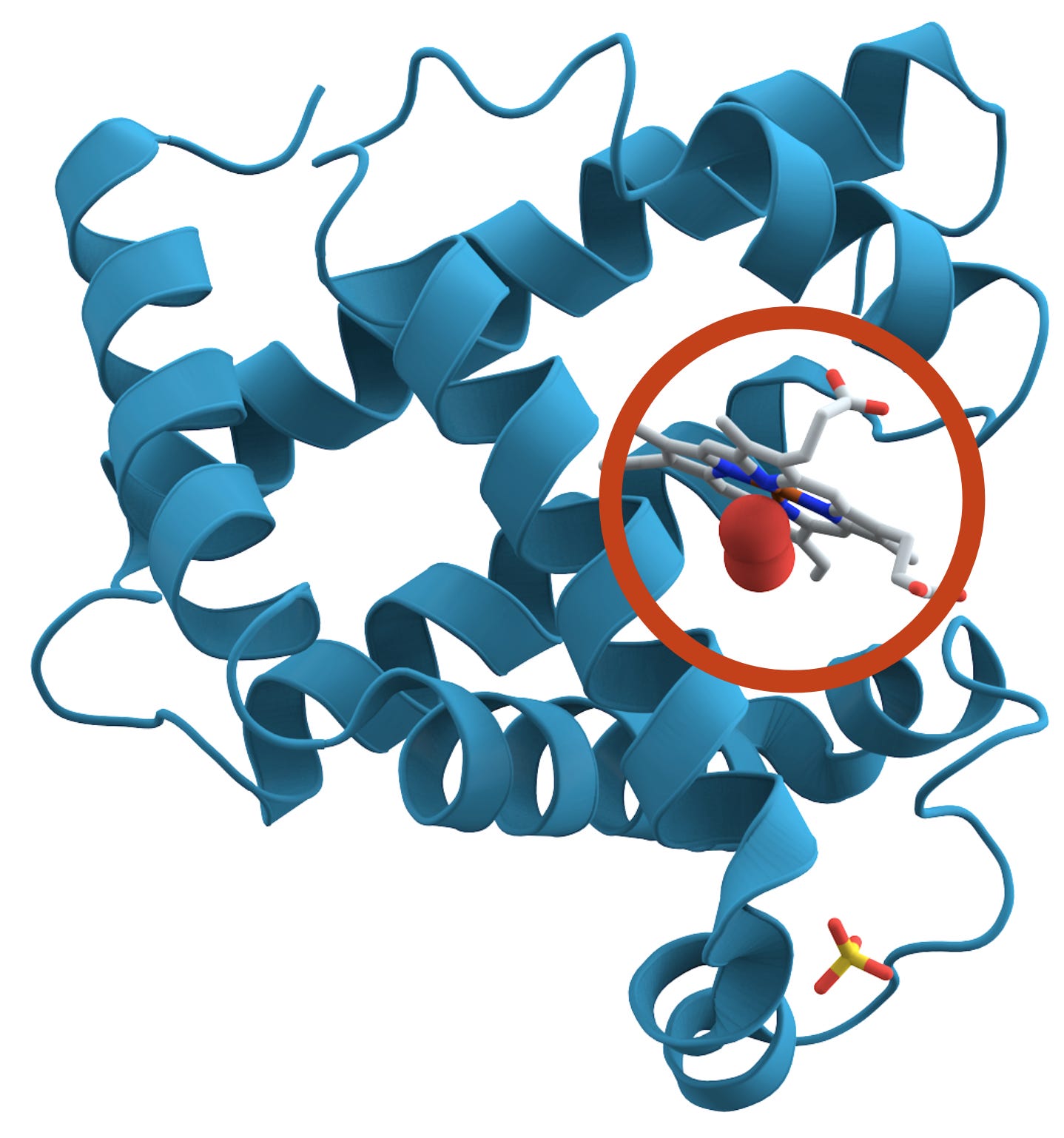
ミオグロビンというタンパク質の 3D 表現。囲まれた領域はヘム基(灰色)を示しており、その中心にある鉄原子が酸素分子(赤色)と結合している。
しかし、実験的にタンパク質の形状を決定するのは高価である。従来のアプローチでは、タンパク質を結晶化し、その後 X 線が結晶構造からどのように散乱するかを分析する必要がある。このプロセスは X 線結晶解析(X-ray crystallography)と呼ばれ、困難なタンパク質の場合には数ヶ月、あるいは数年かかることもある。より新しい手法では速くできる場合もあるが、依然として高価である。
そのため、科学者たちはしばしば計算機を用いてタンパク質の構造を予測しようとする。すべてのタンパク質はアミノ酸の鎖であり、わずか 20 種類のタイプから成り立っているものが 3D 形状に折りたたまれるものである。テキサス大学オースティン校(The University of Texas at Austin)の生物学教授であるクラウス・ウィッケ(Claus Wilke)氏は、タンパク質のアミノ酸鎖を決定することは、構造を直接解明するのと比較すれば「非常に簡単」だと述べている。
しかし、アミノ酸から 3D 構造を予測するプロセス、つまりタンパク質がどのように折りたたまれるかを解明するプロセスは、単純ではない。可能性が多すぎるため、力ずくの探索では宇宙の年齢よりも長い時間がかかってしまうだろう。
科学者たちは長年、問題を単純化するためのさまざまな工夫を行ってきました。例えば、20 万ほどの構造を有するタンパク質データバンク(PDB)内の配列と比較する方法があります。類似した配列は、おそらく類似した形状を持つと考えられています。しかし、正確かつ便利な予測手法を見つけることは、50 年以上にわたって未解決の課題でした。
これが AlphaFold 2 の登場によって一変しました。これによりタンパク質構造の予測が劇的に容易になりました。これはタンパク質折りたたみそのものを「解決」したわけではありません——予測が常に正確であるわけではないからです——しかし、それは画期的な進歩でした。欧州バイオインフォマティクス研究所(EMBL-EBI)によると、2022 年の『ネイチャー』誌の報告では、2 億 1400 万個のタンパク質構造予測のうち 80% が少なくとも一部の用途において有用である程度に正確であるとされています。
AlphaFold 2 は優れたエンジニアリングといくつかの巧妙な科学的アイデアを組み合わせました。DeepMind が使用した重要な技術の一つに「共進化(coevolution)」があります。基本的な考え方は、対象タンパク質と配列が密接に関連する他のタンパク質を比較することです。重要なステップは、多重アラインメント(MSA)——等価なアミノ酸が同じ列に並ぶように整理されたタンパク質配列のグリッド——を計算することです。AlphaFold の入力に MSA を含めることで、タンパク質構造に関する詳細を推論することが可能になりました。

多重配列アライメントの例。最上段は標的タンパク質のアミノ酸配列であり、その下の各行は関連するタンパク質です。ダッシュはギャップを示します。(OpenProteinSet: Ahdritz 他による大規模構造生物学のためのトレーニングデータより。CC BY 4.0)
購読する
オリジナルの OpenFold
DeepMind は AlphaFold 2 のモデル重みとアーキテクチャの高レベルな説明を公開しましたが、トレーニングコードや使用されたすべてのトレーニングデータは含まれていませんでした。2021 年に設立された OpenFold は、このような情報を自由に利用可能にすることを目指しました。
AlQuraishi の経歴は、彼がプロジェクトの共同創設者となるのにふさわしい準備を整えていました。彼はバグダードで育ち、5 歳の頃からコンピュータ好きの子供でした(最初のマシンは Commodore 64)。12 歳のとき、家族はベイエリアに移住しました。高校のジュニア年にはインターネットスタートアップを設立し、サンタクララ大学でコンピューターエンジニアリングを学びました。
大学時代、AlQuraishi の関心は技術的起業から科学へとシフトしました。ソフトウェア Wolfram Mathematica に計算生物学の機能を追加する作業を 1 年半行った後、スタンフォード大学に進学し、生物学の博士号を取得しました。PhD 取得後は、機械学習をタンパク質折りたたみ問題に応用する研究を行いました。
2018 年に最初の AlphaFold が CASP13 コンペティションで優勝した後、AlQuraishi は DeepMind の成功が「学術科学に対する深刻な告発である」と記述しました。学術界の研究者数が DeepMind チームを桁違いに上回っていたにもかかわらず、その分野には新しいテック企業によって先手を打たれてしまったのです。
AlQuraishi はタンパク質折りたたみのような大きな課題に取り組むには、組織的な再考が必要だと考えていました。従来の学術ラボは、シニア科学者が数人の大学院生を指導する形態が一般的です。しかし AlQuraishi は、このような小規模な組織では、タンパク質折りたたみといった大規模な問題に対処するための人的資源や資金力が不足すると懸念していました。

モハメッド・アルクワイシ(写真提供:モハメッド・アルクワイシ)
「私は学術研究の組織化における新しい方法を試すことに、あまり遠慮はしていません」と AlQuraishi は月曜日に私に語りました。
AlQuraishi は、学術ラボにはより頻繁なコミュニケーションと優れたソフトウェアエンジニアリングが必要だと考えていました。また、計算資源への十分なアクセスも不可欠です。2013 年にジェフ・ヒントンが Google に加入した際、AlQuraishi は「重要な計算能力へのアクセスなしでは、学術界における機械学習研究の関連性を維持することが次第に困難になる」と予測していました。
2021 年、アルキライシはナジム・ブオッタとガスタフ・アードリッツと共に OpenFold プロジェクトを共同設立しました。このプロジェクトには、単に野心的な技術的ミッションがあるだけでなく、革新的な構造も備わることになりました。
OpenFold の最初の目標は、DeepMind が公開しなかった AlphaFold 2 の一部を逆解析することでした。これにはモデルのトレーニングに使用されたコードやデータが含まれます。DeepMind はトレーニングプロセスにおいて公的なデータセットのみを利用しましたが、トレーニングに使用する際に計算した多重配列アライメント(Multiple Sequence Alignment: MSA)データは公開しませんでした。MSA の計算には多額の費用がかかるため、多くの他の研究グループはゼロから再トレーニングするのではなく、AlphaFold 2 をファインチューニングすることに落ち着きました。OpenFold は、400 万時間の寄付されたコンピューティングリソースを活用した公的な MSA データセットと、トレーニングコードの両方を公開しました。
2 つ目の目標は、AlphaFold 2 のコードをよりパフォーマンスが高く、モジュール化され、使いやすいものへとリファクタリングすることでした。AlphaFold 2 は、より人気のある PyTorch ではなく、Google の機械学習フレームワークである JAX で記述されていました。OpenFold は PyTorch でコードを記述することで、パフォーマンスの向上と他のプロジェクトへの導入の容易さを実現しました。例えば、Meta は OpenFold のアーキテクチャの一部を自社の ESM-Fold プロジェクトで利用しています。
3 つ目の目標は、アルクワイシのコンピュータサイエンスの背景を忠実に反映したものであり、モデル自体の研究でした。プレプリントにおいて、OpenFold チームは AlphaFold のアーキテクチャのトレーニングダイナミクス(学習動態)を分析しました。例えば、モデルが最終的な精度の 90% に達するのは、トレーニング時間の最初の 3% であったことが分かりました。
最後に、アルクワイシと彼の共同研究者たちは、製薬企業が使用できるタンパク質折りたたみモデルが存在することを確実にしたかったのです。これは、AlphaFold 2 が当初非商用ライセンスの下でリリースされたため、必要だと見なされていました。しかし、この目標は AlphaFold 2 のライセンスがよりオープンなものに変更された後には無意味になりました。
OpenFold チームは、2022 年 6 月 22 日までにこれらのすべての目標において大幅な進展を遂げ、その日に OpenFold と MSA データセット内の最初の 400,000 個のタンパク質のリリースを発表しました。さらなる洗練が必要でした——プレプリントはさらに 5 ヶ月後に発表される予定であり、モデルコードも引き続き反復改良されましたが、OpenFold には他の科学的目標もありました。AlphaFold 2 は当初、単一のアミノ酸鎖の構造のみを予測するものでした。OpenFold は、より複雑な構造を予測するための後続の研究を再現できるでしょうか?
そのため、同じ日に OpenFold は、製薬企業(これらも同様のタンパク質折りたたみに関する質問に関心を持っている)が、研究方向への入力と引き換えに、OpenFold のさらなる研究資金を提供すると発表しました。
AlphaFold 3 を再現するための競争
査読プロセスはあまりにも遅く、公式の OpenFold の論文は初期リリースから一年半後の 2024 年 5 月に Nature Methods でようやく出版されました。その論文が発表される一週間前、Google DeepMind は偶然にもオープンな研究の価値を実証しました。
DeepMind は AlphaFold 3 を発表し、これが他の種類の分子との相互作用がタンパク質の 3D 形状にどのような影響を与えるかを予測できることを示しました。しかし、条件がありました:このモデルは公開されません。DeepMind は 2021 年に Hassabis が設立した Google の AI 創薬スタートアップである Isomorphic と提携し、AlphaFold 3 を開発しました。Isomorphic は完全なアクセス権と商用利用の権利を得ており、それ以外の者はすべて Web インターフェースを通じてこのモデルを利用する必要があります。
科学者たちは怒りました。1,000 人以上が署名した公開書簡で、DeepMind がモデルの詳細を十分に提供せずに AlphaFold 3 に関する論文を Nature に掲載させたことを非難しました。その書簡は「AlphaFold 3 の出版物における開示量は、企業ウェブサイトの発表(実際、著者らはこれらの進展をプレビューするためにこのサイトを使用しました)には適切だが、科学コミュニティが求める利用可能・スケーラブル・透明性の基準を満たしていない」と指摘しています。
DeepMind はこれに対し、1 日の生成数を 20 回に引き上げ、6 ヶ月以内にモデルの重みを「学術利用目的」で公開すると約束することで応じました。実際に重みを公開した際、同社は大幅な制限を追加しました。アクセスは厳格に非商用であり、「Google DeepMind のみの裁量」によるものです。さらに、科学者がモデルをファインチューニングしたり、知識蒸留(distillation)したりすることはできません。
これに対し、AlphaFold 3 のオープンな複製版を求める声が即座に高まりました。数ヶ月のうちに、ByteDance や Chai Discovery といった企業が AlphaFold 3 の論文に記載されたトレーニングの詳細に従ったモデルを公開しました。また、MIT の研究チームは 2024 年 11 月、オープンライセンスの下で Boltz-1 モデルをリリースしています。
2024 年 6 月、AlQuraishi は出版物『GEN Biotechnology』に対し、自身の研究グループがすでに AlphaFold 3 の複製に取り組んでいると語りました。しかし、AlphaFold 2 と比較して AlphaFold 3 を再現することは新たな課題に直面しました。
AlphaFold 3 のリバースエンジニアリングには、AlphaFold 2 よりも多様なタスクでの成功が必要です。「これらの異なるモダリティ(様式)はしばしば競合し合うものです」と AlQuraishi は私に語りました。あるドメインにおいて AlphaFold 3 と同等のパフォーマンスを示すモデルであっても、別のドメインでは失敗する可能性があります。「これらすべてのモダリティの間で適切なトレードオフを最適化することは非常に困難です。」
これにより、生成されたモデルは訓練においてより「扱いにくい」ものになると、アルクライシ氏は述べています。AlphaFold 2 はまさに「工学の驚異」であり、OpenFold は最初の学習ラウンドでほぼそれを再現することができました。しかし、OpenFold 3 の訓練には、アルクライシ氏が私に語ったように、より多くの「手厚いケア」が必要でした。
生成すべきデータも100倍になります。Google DeepMind は、AlphaFold 3 のトレーニングセットを拡張するために、AlphaFold 2 から得た最も信頼性の高い予測を数千万件使用し、また AlphaFold 2 で使用されたものよりもはるかに多くの MSAs(Multiple Sequence Alignments: 多重配列アラインメント)も利用しました。OpenFold はこの両方を再現する必要がありました。現在 OpenFold 3 の開発に取り組んでいる博士課程の学生であるルカス・ヤロシュ氏は、私にこう語りました。OpenFold 3 のために進行中の合成データベースは、学術研究室が計算した中で最大規模のものになるかもしれないと。
これらすべてを考えると、膨大な計算リソースが必要となります。12月に OpenFold のビジネス開発マネージャーであるマロリー・トレフソン氏は、このプロジェクトで「約 1700 万ドル相当の計算リソース」が、多様な来源から寄付された形で使用されたと語りました。その多くはデータセット作成のためのものです。アルクライシ氏によると、そのコストは約 1500 万ドルに達すると推定されています。
購読する
OpenFold は独特の構造を持つ
このような計算を調整するには多大な労力が必要です。「モハメッド [アルクライシ] 氏は、この大規模プロジェクトを実際に稼働させるために、確かに多くの糸を引く必要がある」とヤロシュ氏は述べています。
ここが OpenFold の構造と、Open Molecular Software Foundation への加盟がプロジェクトにとって不可欠な側面となる理由です。これはまた、巧妙に調整されたインセンティブの一致を示しているとも思われます。
他のグループは、AlphaFold 3 の部分的な再現版をより早く公開してきました:例えば、Chai Discovery という企業は 2024 年 9 月に Chai-1 をリリースしましたが、OpenFold 3-preview が公開されたのは 2025 年 10 月です。現在、オープンバージョンが必要な科学者たちは他のモデルを利用しています:私が話した数人の科学者は、2025 年 6 月にリリースされた Boltz-2 を高く評価していました。しかし、それらの再現版はいずれも企業によって作成または管理されています:Boltz は最近、公益法人として設立されました。
企業は迅速に動き、リソースを動員できますが、そのモデルへのアクセスを閉鎖し、製薬会社に対してライセンス料を得るというインセンティブも持っています。2
個人レベルの研究者はリソースへのアクセスが少ないものの、商業的に有利な結果を共有しないというインセンティブも依然として存在します。UT オースティン大学の教授である Wilke 氏によると、「タンパク質が潜在的な薬剤とどのように結合するかを測定するなどの特定の分野では、『コードを提供したことがない』のは、常に『そこから利益を得られる』という考えがあったからだ」とのことです。彼はこれがその分野の発展を「数十年にわたり阻んできた」と述べています。
しかし、Jarosch 氏の推測によれば、「OpenFold は長期的なオープンソースへのコミットメントが非常に強く、商業的な展開には一切踏み出さない」とのことです。彼らはこれをどのように実現したのでしょうか?その一部は、製薬会社からの資金調達に依存していることによるものです。
一見すると、製薬会社がオープンソースの触媒となるのは奇妙に思えるかもしれません。彼らは、科学者らが実験的に決定した数十万もの追加タンパク質構造といった知的財産を非常に厳重に保護することで有名です。しかし、製薬会社は自分たちで容易に構築できない AI ツールを必要としています。
計算リソースに 1700 万ドル(約 25 億円)を費やすのは大きな金額ですが、これを 37 社で分担すれば、アルファベットの傘下企業である Isomorphic のような商業サプライヤーからモデルをライセンスするよりも安価になります。さらに、モデルへの早期アクセス権や研究優先事項に対する投票権を加えれば、OpenFold は資金提供に魅力的なプロジェクトとなります。
もし可能であれば、製薬会社は OpenFold のモデルに対して排他的なアクセス権を望むでしょう。(OpenFold のメンバーである Apheris は、トレーニング用に独自データを提供する製薬会社限定で、OpenFold 3 の連合ファインチューニング(federated fine-tune)を構築する作業を行っています)。しかし、完全にオープンなモデルを持つことは、実際にモデルを構築している学界との間で良い妥協案となります。
学術的な観点からも、この提携は魅力的です。製薬会社からのリソースにより、OpenFold のような大規模プロジェクトの実行が容易になります。OpenFold のフルタイムソフトウェアエンジニアであるジェニファー・ウェイ(旧グーグル社員)によると、国立研究所の場合に比べてジョブが1日や1週間に制限されないため、彼らが寄付する計算資源は大規模なトレーニング実行においてより便利です。また、金銭的な貢献とオープンソースの使命が組み合わさることで、ウェイのようなエンジニアリング人材を惹きつけ、高品質なコードを生み出すことにつながっています。
製薬業界からの意見は、研究の実践的な関連性を高める可能性も高めます。博士課程学生であるルカス・ヤロシュは、業界からのフィードバックを評価しています。「共折りたたみモデルが実際の創薬に大きな影響を与えることに興味があります」と彼は私に語りました。
企業側からは有益なフィードバックも得られます。「現実の世界の状況を本当に模倣するベンチマークを作成するのは難しいです」とヤロシュは述べています。製薬会社には独自のデータセットがあり、これを用いてモデルの実践的な性能を測定できますが、これらの結果を公に共有することはめったにありません。OpenFold と製薬企業とのつながりは、高品質なフィードバックを得るための自然なチャネルとなっています。
私がアルキライシに、なぜスタートアップへの資金調達ではなく学術界に残ったのかと尋ねたとき、彼は二つのことを話してくれた。第一に、すぐに収益化できなくても「実際に基礎的な問いに取り組めるようにしたい」という思いがあったことだ。最終的には、コンピュータ上で完全な機能を持つ細胞全体をシミュレーションできるようになることに興味を持っている。それが実現するまでに数十年かかるかもしれないのに、どうやってベンチャーキャピタルからの資金調達を得られるというのか?
しかし第二に、大規模言語モデル(LLM)が次第に制限されていく様子を目の当たりにした経験が、オープンソースの重要性を浮き彫りにしたと語った。「それほどまでに自分が気にしているとは思わなかった」と彼は私に話した。「私は少しだけ、真のオープンソースの支持者になったんだ。
原文を表示
Protein-folding models are the success story in AI for science.
In the late 2010s, researchers from Google DeepMind used machine learning to predict the three-dimensional shape of proteins. AlphaFold 2, announced in 2020, was so good that its creators shared the 2024 Nobel Prize in chemistry with an outside academic.
Yet many academics have had mixed feelings about DeepMind’s advances. In 2018, Mohammed AlQuraishi, then a research fellow at Harvard, wrote a widely read blog post reporting on a “broad sense of existential angst” among protein-folding researchers.
The first version of AlphaFold had just won CASP13, a prominent protein-folding competition. AlQuraishi wrote that he and his fellow academics worried about “whether protein structure prediction as an academic field has a future, or whether like many parts of machine learning, the best research will from here on out get done in industrial labs, with mere breadcrumbs left for academic groups.”
Industrial labs are less likely to share their findings fully or investigate questions without immediate commercial applications. Without academic work, the next generation of insights might end up siloed in a handful of companies, which could slow down progress for the entire field.
These concerns were borne out in the 2024 release of AlphaFold 3, which initially kept the model weights confidential. Today, scientists can download the weights for certain non-commercial uses “at Google DeepMind’s sole discretion.” Pushmeet Kohli, DeepMind’s head of AI science, told Nature that DeepMind had to balance making the model “accessible” and impactful for scientists against Alphabet’s desire to “pursue commercial drug discovery” via an Alphabet subsidiary, Isomorphic Labs.
Subscribe now
AlQuraishi went on to become a professor at Columbia, and he has fought to keep academic researchers in the game. In 2021, he co-founded a project called OpenFold, which sought to replicate AlphaFold’s innovations openly. This not only required difficult technical work, it also required innovations in organization and fundraising.
To get the millions of dollars’ worth of computing power they would need, AlQuraishi and his colleagues turned to an unlikely ally: the pharmaceutical industry. Drug companies are not generally known for their commitment to open science, but they really did not want to be dependent on Google.
Supporting OpenFold gives these drug companies input into the project’s research priorities. Pharmaceutical companies also get early access to OpenFold’s models for internal use. But crucially, OpenFold releases its models to the general public, along with full training data, source code, and other materials that have not been included in recent AlphaFold releases.
“I’d like to see the work have an impact,” AlQuraishi told me in a Monday interview. He wanted to contribute to new discoveries and the creation of new therapies. Today, he said, “most of that is happening in industry.” But projects like OpenFold could help carve out a larger role for academic researchers, accelerating the pace of scientific discovery in the process.
Protein folding: from sequence to structure
Proteins are large molecules essential to life. They perform many biological functions, from regulating blood sugar (like insulin) to acting as antibodies.
The shape of a protein is essential to its function. Take the example of myoglobin (pictured), which stores oxygen in muscle tissue. Myoglobin’s shape creates a little pocket that holds an iron-containing molecule (the grey shape circled). The pocket’s shape lets the iron bind with oxygen reversibly, so the protein can capture and release it in the muscle as necessary.
A 3D representation of the protein myoglobin. The circled area shows a heme group (gray) who’s central iron atom bonds to an oxygen molecule (in red).
It’s expensive to determine a protein’s shape experimentally, however. The conventional approach involves crystallizing the protein and then analyzing how X-rays scatter off the crystal structure. This process, called X-ray crystallography, can take months or even years for difficult proteins. Newer methods can be faster, but they’re still expensive.
So scientists often try to predict a protein’s structure computationally. Every protein is a chain of amino acids — just 20 types — that fold into a 3D shape. Determining a protein’s amino acid chain is “very easy” compared to figuring out the structure directly, said Claus Wilke, a professor of biology at The University of Texas at Austin.
But the process of predicting a 3D structure from the amino acids — figuring out how the protein folds — isn’t straightforward. There are so many possibilities that a brute-force search would take longer than the age of the universe.
Scientists have long used tricks to make the problem easier. For instance, they can compare a sequence with the 200,000 or so structures in the Protein Data Bank (PDB). Similar sequences are likely to have similar shapes. But finding an accurate, convenient prediction method remained an open question for over 50 years.
This changed with AlphaFold 2, which made it dramatically easier to predict protein structures. It didn’t “solve” protein folding per se — the predictions aren’t always accurate, for one — but it was a substantial advance. A 2022 Nature article reported that 80% of 214 million protein structure predictions were accurate enough to be useful for at least some applications, according to the European Bioinformatics Institute (EMBL-EBI).
AlphaFold 2 combined excellent engineering with several clever scientific ideas. One important technique DeepMind used is called coevolution. The basic idea is to compare the target protein with proteins that have closely related sequences. A key step is to compute a multiple sequence alignment (MSA) — a grid of protein sequences organized so that equivalent amino acids are in the same column. Including an MSA in AlphaFold’s input helped it to infer details about the protein’s structure.
An example of a multiple sequence alignment. The top row is the amino acid sequence of the target protein; each row below is a related protein. Dashes indicate gaps. (From OpenProteinSet: Training data for structural biology at scale by Ahdritz et al. CC BY 4.0)
Subscribe now
The original OpenFold
DeepMind released AlphaFold 2’s model weights and a high-level description of the architecture but did not include the training code or all the training data used. OpenFold, founded in 2021, sought to make this kind of information freely available.
AlQuraishi’s background prepared him well to co-found the project. He grew up in Baghdad as a computer kid — starting with a Commodore 64 at the age of five. When he was 12, his family moved to the Bay Area. He founded an Internet start-up in his junior year of high school and went to Santa Clara University for computer engineering.
In college, AlQuraishi’s interests shifted from tech entrepreneurship to science. After a year and a half of working to add computational biology capabilities to the software Wolfram Mathematica, he went to Stanford to get his doctorate in biology. After his PhD, he went on to study the application of machine learning to the protein-folding problem.
After the first AlphaFold won the CASP13 competition in 2018, AlQuraishi wrote that DeepMind’s success “presents a serious indictment of academic science.” Despite academics outnumbering DeepMind’s team by an order of magnitude, they had been scooped by a tech company new to the field.
AlQuraishi believed that tackling big problems like protein folding would require an organizational rethink. Academic labs traditionally consist of a senior scientist supervising a handful of graduate students. AlQuraishi worried that small organizations like this wouldn’t have the manpower or financial resources to tackle a big problem like protein folding.
Mohammed AlQuraishi (Photo courtesy of Mohammed AlQuraishi)
“I haven’t been too shy about trying new ways of organizing academic research,” AlQuraishi told me on Monday.
AlQuraishi thought that academic labs needed more frequent communication and better software engineering. They would also need substantial access to compute: when Geoff Hinton joined Google in 2013, AlQuraishi predicted that “without access to significant computing power, academic machine learning research will find it increasingly difficult to stay relevant.”
So in 2021, AlQuraishi teamed up with Nazim Bouatta and Gustaf Ahdritz to co-found the OpenFold project. The project didn’t just have an ambitious technical mission, it would also come to have an innovative structure.
OpenFold’s first objective was to reverse-engineer parts of AlphaFold 2 that DeepMind had not made public — including code and data used for training the model. While DeepMind had only drawn from public datasets in its training process, it did not release the multiple sequence alignment (MSA) data it had computed for use in training. MSAs are expensive to compute, so many other research groups settled for fine-tuning AlphaFold 2 rather than retraining it from scratch. OpenFold released both a public dataset of MSAs — using four million hours of donated compute — and training code.
The second goal was refactoring AlphaFold 2’s code to be more performant, modular, and easy to use. AlphaFold 2 was written in JAX — Google’s machine learning framework — rather than the more popular PyTorch. OpenFold wrote its code in PyTorch, which boosted performance and made it easier to adopt into other projects. Meta used parts of OpenFold’s architecture in its ESM-Fold project, for instance.
A third goal — true to AlQuraishi’s computer science background — was to study the models themselves. In their preprint, the OpenFold team analyzed the training dynamics of AlphaFold’s architecture. They found, for instance, that the model reached 90% of its final accuracy in the first 3% of training time.
Finally, AlQuraishi and his collaborators wanted to make sure there was a protein-folding model that pharmaceutical companies could use. They saw this as necessary because AlphaFold 2 was initially released under a non-commercial license. But this goal became irrelevant after AlphaFold 2’s license was changed to be more open.
The OpenFold team had made substantial progress on all of these goals by June 22, 2022, when it announced the release of OpenFold and the first 400,000 proteins in its MSA dataset. There was more refinement to be done — the preprint wouldn’t come out for another five months; the model code would continue to be iterated on — but OpenFold also had other scientific goals. AlphaFold 2 initially only predicted the structure of a single amino acid chain; could OpenFold replicate later efforts to predict more complex structures?
So the same day, OpenFold also announced that pharmaceutical companies — who are also interested in the same types of protein folding questions — would help fund OpenFold’s further research in exchange for input into its research direction.
The race to replicate AlphaFold 3
The peer-review process is so slow that the official OpenFold paper was published by Nature Methods in May 2024 — a year and a half after the initial release. A week before the paper came out, Google DeepMind incidentally demonstrated the value of open research.
DeepMind announced AlphaFold 3, which was able to predict how interactions with other types of molecules would impact the 3D shapes of proteins. But there was a caveat: the model would not be released openly. DeepMind had partnered with Isomorphic — Google’s AI drug discovery start-up that Hassabis founded in 2021 — to develop AlphaFold 3. Isomorphic would get full access and the right to commercial use; everyone else would have to use the model through a web interface.
Scientists were furious. Over 1,000 signed an open letter attacking the journal Nature for letting DeepMind publish a paper on AlphaFold 3 without providing more details about the model. The letter remarked that “the amount of disclosure in the AlphaFold 3 publication is appropriate for an announcement on a company website (which, indeed, the authors used to preview these developments), but it fails to meet the scientific community’s standards of being usable, scalable, and transparent.”
DeepMind responded by increasing the daily quota to 20 generations and promising that it would release the model weights within six months “for academic use.” When it did release the weights, it added significant restrictions. Access is strictly non-commercial and at “Google DeepMind’s sole discretion.” Moreover, scientists would not be able to fine-tune or distill the model.
This prompted an immediate demand for open replications of AlphaFold 3. Within months, companies like ByteDance and Chai Discovery had released models following the training details in the AlphaFold 3 paper. An MIT lab released the Boltz-1 model under an open license in November 2024.
In June 2024, AlQuraishi told the publication GEN Biotechnology that his research group was already working on replicating AlphaFold 3. But replicating AlphaFold 3 posed new challenges compared to AlphaFold 2.
Reverse engineering AlphaFold 3 requires succeeding on a larger variety of tasks than AlphaFold 2. “These different modalities are often in contention,” AlQuraishi told me. Even if a model matched AlphaFold 3’s performance in one domain, it might falter in another. “Optimizing the right trade-offs between all these modalities is quite challenging.”
This makes the resulting model more “finicky” to train, AlQuraishi said. AlphaFold 2 was such a “marvel of engineering” that OpenFold was largely able to replicate it with its first training run. Training OpenFold 31 has required a bit more “nursing,” AlQuraishi told me.
There’s 100 times more data to generate too. Google DeepMind used tens of millions of the highest-confidence predictions from AlphaFold 2 to augment the training set for AlphaFold 3, as well as many more MSAs than it used for AlphaFold 2. OpenFold has had to replicate both. One PhD student currently working on OpenFold 3, Lukas Jarosch, told me that the synthetic database in progress for OpenFold 3 might be the biggest ever computed by an academic lab.
All of this ends up requiring a lot of compute. Mallory Tollefson, OpenFold’s business development manager, told me in December that the project has probably used “approximately $17 million of compute” donated from a wide variety of sources. A lot of that is for dataset creation: AlQuraishi estimated that it has cost around $15 million to make.
Subscribe now
OpenFold has an unusual structure
Coordinating all of this computation takes a lot of work. “There’s definitely a lot of strings that Mohammed [AlQuraishi] needs to pull to keep such a big project running in practice,” Jarosch said.
This is where OpenFold’s structure — and membership in the Open Molecular Software Foundation — are essential aspects of the project. I think it also shows a clever alignment of incentives.
Other groups have been quicker to release partial replications of AlphaFold 3: for instance, the company Chai Discovery released Chai-1 in September 2024, while OpenFold 3-preview was only released in October 2025. And scientists needing an open version currently use other models: several people I spoke to praised Boltz-2, released in June 2025. But those replications are either made or managed by companies: Boltz recently incorporated as a public benefit corporation.
Companies can move quickly and marshal resources, but also have incentives to close down access to their models, so that they can license the product to pharmaceutical companies.2
While individual academics have less access to resources, they still have incentives not to share commercially lucrative results. For some areas like measuring how proteins bind with potential drugs, “people have never really made the code available because they’ve always had this idea that they can make money with it,” according to Wilke, the UT Austin professor. He said it’s held back that area “for decades.”
Yet OpenFold, in Jarosch’s estimation, “is very committed to long-term open source and not branching out into anything commercial.” How have they set this up? Partly by relying on pharmaceutical companies for funding.
At first glance, pharmaceutical companies might seem like an odd catalyst for open source. They are famously protective of intellectual property such as the hundreds of thousands of additional protein structures their scientists have experimentally determined. But pharmaceutical companies need AI tools they can’t easily build themselves.
$17 million is a lot of money to spend on compute. But when split 37 ways, it’s cheaper than licensing a model from a commercial supplier like Alphabet’s Isomorphic. Add in early access to models and the ability to vote on research priorities and OpenFold becomes an attractive project to fund.
If the pharmaceutical companies could get away with it, they’d probably want exclusive access to OpenFold’s model. (An OpenFold member, Apheris, is working on building a federated fine-tune of OpenFold 3 exclusive to the pharmaceutical companies who provide the proprietary data for training). But having a completely open model is a good compromise with the academics actually building the model.
From an academic perspective, this partnership is attractive too. Resources from pharmaceutical companies make it easier to run large projects like OpenFold. The computational resources they donate are more convenient for large training runs because jobs aren’t limited to a day or a week as with national labs, according to Jennifer Wei, a full-time software engineer at OpenFold. And the monetary contributions, combined with the open-source mission, help attract engineering talent like Wei — an ex-Googler — to produce high-quality code.
Pharmaceutical input makes the work more likely to be practically relevant, too. Lukas Jarosch, the PhD student, said he appreciated the input from industry. “I’m interested in making co-folding models have a big impact on actual drug discovery,” he told me.
The companies also give helpful feedback. “It’s hard to create benchmarks that really mimic real-world settings,” Jarosch said. Pharmaceutical companies have proprietary datasets which let them measure model performance in practice, but they rarely share these results publicly. OpenFold’s connections with pharmaceutical companies give a natural channel for high-quality feedback.
When I asked AlQuraishi why he had stayed in academia rather than getting funding for a start-up, he told me two things. First, he wanted to “actually be able to go after basic questions,” even if they didn’t make money right away. He’s interested in eventually being able to simulate an entire working cell completely on a computer. How would he be able to get venture funding for that if it might take decades to pan out?
But second, the experience of watching LLMs become increasingly restricted underlined the importance of open source. “It’s not something that I thought I cared about all that much,” he told me. “I’ve become a bit more of a true open source advocate.”
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み