バイトゥー千帆チーム、40億パラメータの統一文書知能モデル「Qianfan-OCR」を公開
百度Qianfanチームは、ドキュメント解析から理解までを統一する4BパラメータのエンドツーエンドOCRモデル「Qianfan-OCR」を公開し、レイアウト分析とテキスト認識の統合により高精度な情報抽出を実現した。
キーポイント
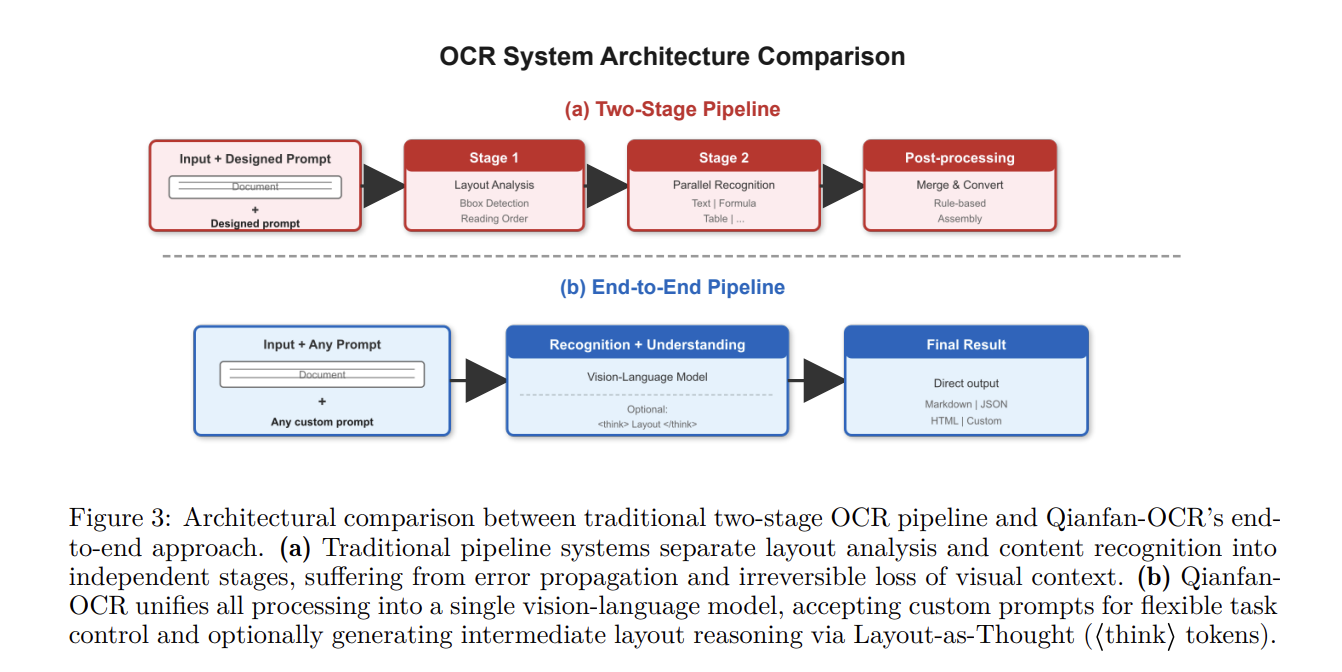
エンドツーエンドの統一アーキテクチャ
従来のマルチステージパイプラインに代わり、画像から直接Markdownへの変換とプロンプト駆動型タスク(表抽出、QA)を単一のビジョン言語モデルで処理する。
「Layout-as-Thought」思考メカニズム
特殊トークンにより構造化されたレイアウト表現(境界ボックス、要素タイプ)を生成する思考フェーズを導入し、複雑なドキュメントの精度を向上させる。
ベンチマークにおける首位成績
OmniDocBenchやOCRBenchなどの主要ベンチマークで、より大規模な競合モデルを凌駕し、エンドツーエンドカテゴリで最高スコアを記録した。
高効率な技術仕様
Qwen3-4Bをバックボーンに採用し、GQAによるメモリ削減と専用トークンによる出力短縮により、計算効率と処理速度を最適化した。
二段階OCR+LLMパイプラインの限界
空間推論が必要なタスクにおいて、従来の二段階システムは視覚的文脈を失うためチャート解釈で失敗し、CharXivベンチマークで0.0点という結果を示した。
W8A8量子化による推論効率の向上
NVIDIA A100 GPU単体でのテストにおいて、W8A8(AWQ)量子化により1.024 PPSを達成し、精度損失を抑えつつ推論速度を2倍に向上させた。
GPU集中型アーキテクチャの優位性
CPUベースのレイアウト分析に依存するパイプラインシステムとは異なり、Qianfan-OCRはGPU中心設計によりステージ間の処理遅延を回避し、大規模バッチ推論を効率的に実行可能である。
影響分析・編集コメントを表示
影響分析
このモデルは、高精度なOCRとドキュメント理解を必要とする業務自動化(RPA)や知的財産管理の現場において、従来の複雑なパイプラインに代わる単一ソリューションとして採用される可能性がある。特に4Bという比較的小さいパラメータ数で競合モデルを凌駕したことは、コスト敏感な企業やエッジデバイスでの展開において大きな競争優位をもたらす。
編集コメント
軽量モデルで高精度なOCRを実現した点は実用的だが、その性能が既存の専用パイプラインや大規模VLMに対してどの程度持続可能か、また「Layout-as-Thought」のオーバーヘッドが実運用でどう評価されるかが今後の鍵となる。
百度千帆チームは、ドキュメント解析、レイアウト分析、ドキュメント理解を単一のビジョン・ランゲージアーキテクチャ内で統合するために設計された 4B パラメータのエンドツーエンドモデル「Qianfan-OCR」を発表しました。従来のレイアウト検出とテキスト認識のために別々のモジュールを連鎖させる多段階 OCR パイプラインとは異なり、Qianfan-OCR は画像から直接 Markdown への変換を実行し、テーブル抽出やドキュメント質問応答などのプロンプト駆動型タスクをサポートします。
 imagehttps://arxiv.org/pdf/2603.13398
imagehttps://arxiv.org/pdf/2603.13398
アーキテクチャと技術仕様
Qianfan-OCR は、千帆 VL(Vision-Language)フレームワークから採用されたマルチモーダル・ブリッジング・アーキテクチャを利用しています。システムは以下の 3 つの主要コンポーネントで構成されています。
ビジョンエンコーダ(Qianfan-ViT):画像を 448 x 448 パッチにタイル分割する「Any Resolution」設計を採用しています。最大 4K の可変解像度入力をサポートし、1 枚の画像あたり最大 4,096 ビジュアルトークンを生成することで、小文字や高密度テキストの空間分解能を維持します。
クロスモーダルアダプタ:視覚的特徴を言語モデルの埋め込み空間へ投影する、GELU 活性化関数を持つ軽量な 2 レイヤー MLP(多層パーセプトロン)です。
ランゲージモデルバックボーン(Qwen3-4B):36 レイヤーとネイティブ 32K コンテキストウィンドウを備えた 40 億パラメータのモデルです。グループ化クエリアテンション(GQA: Grouped-Query Attention)を採用することで、KV キャッシュメモリの使用量を 4 分の 1 に削減します。
「レイアウト・アズ・スート」機構
モデルの主な特徴は、レイアウト・アズ・ス思考(Layout-as-Thought)です。これはトークンによってトリガーされるオプションの思考フェーズであり、この段階でモデルは最終出力を生成する前に、構造化されたレイアウト表現(バウンディングボックス、要素タイプ、読み順を含む)を生成します。
機能性:このプロセスにより、エンドツーエンドのパラダイムではしばしば失われる明示的なレイアウト分析能力(要素の位置特定とタイプ分類)が回復されます。
性能特性:OmniDocBench v1.5 における評価によると、思考フェーズを有効化することで、「レイアウトラベルエントロピー」が高い文書、すなわち混合テキスト、数式、図表など多様な要素を含む文書において、一貫した優位性が示されました。
効率性:バウンディングボックス座標は専用の特殊トークン(<bbox_start>から<bbox_end>)として表現されるため、通常の数字列と比較して思考出力の長さが約 50% 短縮されます。
実証的性能とベンチマーク
Qianfan-OCR は、専門的な OCR システムおよび汎用ビジョン・ランゲージモデル(VLMs)との比較で評価されました。
文書解析および一般 OCR
このモデルは、いくつかの主要なベンチマークにおいてエンドツーエンドモデルの中で 1 位を獲得しました:
OmniDocBench v1.5: スコア 93.12 を達成し、DeepSeek-OCR-v2(91.09)および Gemini-3 Pro(90.33)を上回りました。
OlmOCR Bench: スコア 79.8 を記録し、エンドツーエンドカテゴリで首位に立ちました。
OCRBench: スコア 880 を達成し、テストされたすべてのモデルの中で 1 位となりました。
主要情報抽出(KIE)
公開された KIE ベンチマークにおいて、Qianfan-OCR は最も高い平均スコア(87.9)を達成し、はるかに大きなモデルを大きく上回りました。
モデル 全体平均 (KIE) OCRBench KIENanonets KIE (F1)
Qianfan-OCR (4B) 87.9 95.0 86.5
Qwen3-4B-VL 83.5 89.0 83.3
Qwen3-VL-235B-A22B 84.2 94.0 83.8
Gemini-3.1-Pro 79.2 96.0 76.1
文書理解
比較テストにより、2段階の OCR+LLM パイプラインは空間推論を必要とするタスクでしばしば失敗することが明らかになりました。例えば、CharXiv ベンチマークではすべてのテスト対象となった 2 段階システムが 0.0 のスコアに留まりました。これは、チャートの解釈に必要な視覚的文脈(軸の関係やデータポイントの位置など)がテキスト抽出フェーズで失われてしまうためです。
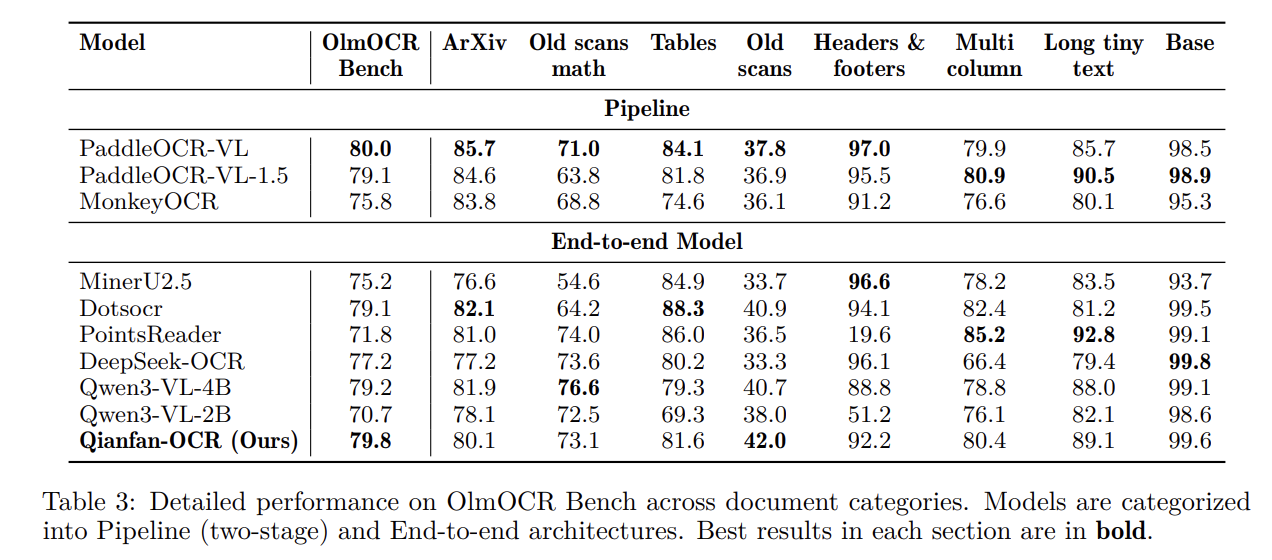 image https://arxiv.org/pdf/2603.13398
image https://arxiv.org/pdf/2603.13398
展開と推論
推論効率は、単一の NVIDIA A100 GPU を使用してページ毎秒 (PPS: Pages Per Second) で測定されました。
量子化:W8A8(AWQ)量子化を採用した Qianfan-OCR は 1.024 PPS を達成し、精度への影響を最小限に抑えつつ、W16A16 ベースラインと比較して 2 倍の高速化を実現しました。
アーキテクチャ上の利点:CPU ベースのレイアウト分析に依存するパイプラインシステムがボトルネックになり得るのに対し、Qianfan-OCR は GPU 中心設計です。これにより、ステージ間の処理遅延を回避し、効率的なバッチ推論が可能となります。
Paper、Repo、およびモデルは HF でご確認ください。また、Twitter でもフォローしていただき、12 万人以上の ML サブレッドに参加し、ニュースレターも購読してください。待ってください!Telegram をご利用ですか?今なら Telegram でもご参加いただけます。
本記事「Baidu Qianfan Team Releases Qianfan-OCR: A 4B-Parameter Unified Document Intelligence Model」は、MarkTechPost で最初に公開されました。
原文を表示
The Baidu Qianfan Team introduced Qianfan-OCR, a 4B-parameter end-to-end model designed to unify document parsing, layout analysis, and document understanding within a single vision-language architecture. Unlike traditional multi-stage OCR pipelines that chain separate modules for layout detection and text recognition, Qianfan-OCR performs direct image-to-Markdown conversion and supports prompt-driven tasks like table extraction and document question answering.
imagehttps://arxiv.org/pdf/2603.13398
Architecture and Technical Specifications
Qianfan-OCR utilizes the multimodal bridging architecture from the Qianfan-VL framework. The system consists of three primary components:
Vision Encoder (Qianfan-ViT): Employs an Any Resolution design that tiles images into 448 x 448 patches. It supports variable-resolution inputs up to 4K, producing up to 4,096 visual tokens per image to maintain spatial resolution for small fonts and dense text.
Cross-Modal Adapter: A lightweight two-layer MLP with GELU activation that projects visual features into the language model’s embedding space.
Language Model Backbone (Qwen3-4B): A 4.0B-parameter model with 36 layers and a native 32K context window. It utilizes Grouped-Query Attention (GQA) to reduce KV cache memory usage by 4x.
‘Layout-as-Thought’ Mechanism
The main feature of the model is Layout-as-Thought, an optional thinking phase triggered by <think> tokens. During this phase, the model generates structured layout representations—including bounding boxes, element types, and reading order—before producing the final output.
Functional Utility: This process recovers explicit layout analysis capabilities (element localization and type classification) often lost in end-to-end paradigms.
Performance Characteristics: Evaluation on OmniDocBench v1.5 indicates that enabling the thinking phase provides a consistent advantage on documents with high “layout label entropy”—those containing heterogeneous elements like mixed text, formulas, and diagrams.
Efficiency: Bounding box coordinates are represented as dedicated special tokens (<COORD_0> to <COORD_999>), reducing thinking output length by approximately 50% compared to plain digit sequences.
Empirical Performance and Benchmarks
Qianfan-OCR was evaluated against both specialized OCR systems and general vision-language models (VLMs).
Document Parsing and General OCR
The model ranks first among end-to-end models on several key benchmarks:
OmniDocBench v1.5: Achieved a score of 93.12, surpassing DeepSeek-OCR-v2 (91.09) and Gemini-3 Pro (90.33).
OlmOCR Bench: Scored 79.8, leading the end-to-end category.
OCRBench: Achieved a score of 880, ranking first among all tested models.
Key Information Extraction (KIE)
On public KIE benchmarks, Qianfan-OCR achieved the highest average score (87.9), outperforming significantly larger models.
ModelOverall Mean (KIE)OCRBench KIENanonets KIE (F1)
Qianfan-OCR (4B)87.995.086.5
Qwen3-4B-VL83.589.083.3
Qwen3-VL-235B-A22B84.294.083.8
Gemini-3.1-Pro79.296.076.1
Document Understanding
Comparative testing revealed that two-stage OCR+LLM pipelines often fail on tasks requiring spatial reasoning. For instance, all tested two-stage systems scored 0.0 on CharXiv benchmarks, as the text extraction phase discards the visual context (axis relationships, data point positions) necessary for chart interpretation.
imagehttps://arxiv.org/pdf/2603.13398
Deployment and Inference
Inference efficiency was measured in Pages Per Second (PPS) using a single NVIDIA A100 GPU.
Quantization: With W8A8 (AWQ) quantization, Qianfan-OCR achieved 1.024 PPS, a 2x speedup over the W16A16 baseline with negligible accuracy loss.
Architecture Advantage: Unlike pipeline systems that rely on CPU-based layout analysis—which can become a bottleneck—Qianfan-OCR is GPU-centric. This avoids inter-stage processing delays and allows for efficient large-batch inference.
Check out Paper, Repo and Model on HF. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Baidu Qianfan Team Releases Qianfan-OCR: A 4B-Parameter Unified Document Intelligence Model appeared first on MarkTechPost.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み