Deep Agents に動的サブエージェントを導入
LangChain は、大規模なタスクや複雑なロジックを処理するために、従来のツール呼び出しに代わりエージェントがスクリプトを記述してサブエージェントを動的に制御する「Dynamic Subagents」機能を Deep Agents に導入した。
キーポイント
プログラムによるオーケストレーションの実現
従来のツール呼び出し方式ではなく、エージェントがループや分岐を含むスクリプトを記述し、軽量なインタプリタで実行することで、複雑な制御ロジックを実現する。
大規模処理における確実性の向上
300 ページのドキュメントを例に挙げ、構造化されたループによって全ページを漏れなく処理することを保証し、エージェントの判断ミスによるカバー漏れを防ぐ。
コンテキスト管理とスケーラビリティ
サブエージェントを独立して実行することでメインのコンテキストウィンドウを圧迫せず、数百ものサブエージェントを並列または条件付きで処理する能力を高める。
影響分析・編集コメントを表示
影響分析
この発表は、LLM エージェントが単純なタスク実行から、複雑なビジネスロジックや大規模データ処理を自律的かつ確実に遂行できるレベルへと進化することを示しています。特に、ツール呼び出しの非決定的な性質に起因するエラーリスクをコードベースの制御で排除できる点は、実務での信頼性を劇的に高める重要な転換点となります。
編集コメント
ツール呼び出しの限界を打破し、コード生成能力を活用した動的なエージェント制御への転換は、実用レベルの AI アプリケーション開発において極めて重要なステップです。特に大規模ドキュメント処理など、確実性が求められるユースケースでの採用が期待されます。

エージェントがより野心的なタスクを引き受けるにつれ、以下のような困難に直面しています:
- スケールして確実に作業を完了すること
- 自身のコンテキスト(文脈)を管理すること
私たちはこれらの課題に対処する方法として、動的サブエージェントと呼ばれる形式の実験を行っています。これは、汎用的なツール呼び出しを通じてサブエージェントのタスクを発行するのではなく、エージェントが実行スクリプトを記述してサブエージェントの実行を駆動するというアプローチです。これにより、モデルはループ処理、分岐処理、並列処理など得意とするコードパターンを活用し、タスクに最適なオーケストレーションロジック(調整・制御論)を記述することが可能になります。
なぜ動的サブエージェントなのか?
Deep Agents はすでに サブエージェント をサポートしています。これらはコンテキストを分離し、メインのエージェントが作業の個別単位を委任することを可能にし、中間結果をメインのコンテキストウィンドウから外すことができます。では、なぜ動的サブエージェントが必要なのでしょうか?
通常のサブエージェントは、メインモデルが直接呼び出すことで一度に一つずつ実行されます。これは小規模なスケールでは機能しますが、数百ものサブエージェントを生成する必要がある場合や、オーケストレーションロジックが条件分岐型または多段階である場合には機能しなくなります。
動的サブエージェントはプログラムによるオーケストレーションによってこの問題を解決します。ターンごとのツール呼び出しを行うのではなく、エージェントがサブエージェントの調整と実行を行う短いスクリプトを記述し、それを軽量なインタプリタ上で実行します。
代表的な例:300 ページのドキュメントに対してページごとにサブエージェントを 1 つずつ割り当てるケースです。サブエージェントツールを 300 回呼び出すのではなく、エージェントはループを書きます。
const results = await Promise.all(pages.map(page =>
task({ description: Summarize page ${page.number}, subagentType: "summarizer" })
));
これにより、ツール呼び出しベースのオーケストレーションでは確実に提供できない 2 つのことが可能になります。
スケーラブルな確定的カバレッジ。 構造化されていない場合、エージェントは範囲に関する判断を下し、500 項目のうち 75 項目をスクリーニングして完了とみなすことがあります。しかし、ディスパッチループ(配信ループ)ではそうなりません。カバレッジはプロンプトエンジニアリングの問題ではなく、構造的な保証となります。
信頼性の高い複雑なオーケストレーション。 ファンアウト+合成、多段階パイプライン、または条件分岐を扱う場合などにおいて、モデルがツール呼び出しのシーケンスとして再現するよりも、コードとしてオーケストレーションを書く方がはるかに信頼性が高くなります。
これは Claude Code のワークフロー や 再帰型言語モデル (RLMs) の背後にある同じ考え方です。つまり、モデルがコードを書き、そのコードがさらにエージェントをディスパッチするのです。
クイックスタート
動的サブエージェントを使用するには、作業を委譲する subagents と、モデルがオーケストレーションコードの記述と実行を行う安全で軽量なランタイムである code interpreter の 2 つが必要です。Deep Agents には QuickJS をベースにしたオプションのコードインタープリターが含まれています。これを使用するには、QuickJS ミドルウェアパッケージをインストールし、create_deep_agent の middleware 引数に CodeInterpreterMiddleware を渡します。
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware()],
)
Deep Agents には、汎用的な subagent が標準で組み込まれており、ワークフローですぐに使用できる汎用サブエージェントプロファイルが既に用意されています。専門的なワークフローの場合、独自の名称、説明、システムプロンプトを持つ カスタムサブエージェント を設定します。名称と説明は、エージェントがどの役割を担うべきかを判断するための手がかりとなります。
動的サブエージェントを発動させるには、"workflow" という単語を使用してエージェントにプロンプトを入力してください。例:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "Run a workflow that reviews every file in src/routes/ and summarizes the top risks."}]
})
コーディングエージェントでの使用
動的サブエージェントを試す最速の方法は、Deep Agent をベースに構築されたターミナル用コーディングエージェントである dcode です。コードインタープリタが有効になっている状態で提供されるため、追加の設定は一切不要で、動的サブエージェントはそのまま利用可能です。
インストール
curl -LsSf https://langch.in/dcode | bash
実行
dcode
動的サブエージェントをトリガーするには、「workflow(ワークフロー)」と指示するだけです。作業そのものを地道に行ったり、ネイティブのタスクツールでサブエージェントのフォークアウトを管理しようとしたりする代わりに、エージェントは組み込みの task() グローバル関数を呼び出すオーケストレーションスクリプトを作成し、コードインタープリタ内で実行します。例えば、「src/ 内のすべてのファイルをレビューして SQL インジェクションを検出する *workflow* を実行してください」と指示します。
サブエージェントが起動すると、dcode はディスパッチごとにフェーズにグループ化された動的サブエージェントパネルでそれらをリアルタイムに表示します。

この機能は dcode で最も手軽に試せますが、ACP(Zed など)を通じてお好みのツールでも利用可能です。
仕組み
エージェントには 評価ツール が与えられます。エージェントは、インタプリタ内で安全に実行される JavaScript を記述します。サブエージェント が設定されている場合、インタプリタはコードからサブエージェントを起動する組み込みのグローバル関数 task() を公開します。現在のタスクに応じてモデルが異なるコード(ループ、分岐、Promise.all など)を記述し、インタプリタがそれを決定論的に実行します。

task() 関数は、説明(description)、サブエージェントタイプ(subagentType)、およびオプションのレスポンススキーマ(responseSchema)を受け取ります。レスポンススキーマが指定された場合、結果はすでに型付けされたオブジェクトとなり、フィルタリングや次のステップへの引き渡しに即座に使用できます。
const result = await task({
description: "Review src/auth/login.ts for security issues.",
subagentType: "reviewer",
responseSchema: {
type: "object",
properties: {
severity: { type: "string", enum: ["high", "medium", "low"] },
issues: { type: "array", items: { type: "string" } },
},
},
});
const critical = result.severity === "high" ? result.issues : [];
critical; // モデルは最後の行を確認します詳細については、ドキュメントの プログラムによるサブエージェント および インタプリタ をご覧ください。
共通のオーケストレーションパターン
Anthropic の ダイナミックワークフロー は、並列エージェント作業のための一連のオーケストレーションパターンを普及させました。これらはオンオフできる機能ではなく、作業から自然に生み出される形状であり、タスクが変化するにつれてエージェントは異なる形状へと移行します。以下の表では、各形状がどの種類の作業に適しているかを対応付けています。
パターン
形状
これを使うべき時
分類して実行
タイプごとにアイテムを専門家にルーティングする
混合された入力には異なる処理が必要
ファンアウトと合成
多くのアイテムに対して並列で同じ作業を行い、その後結合する
独立した単位があり、1 つの統合レポートを作成する場合
敵対的検証
特定し、保持する前に独立して検証する
偽陽性のコストが高い場合
生成とフィルタリング
複数のオプションを生成し、スコア付けして最良のものを選択する
一度に実行するよりも選択肢を探求する方が優れている
トーナメント
直接対決による判定を行い、勝者が次のラウンドへ進む
主観的または相対的な基準がある場合
完了までループ
新しい発見がなくなるまで繰り返し実行する
スコープが不明で、完全性を求める場合
以下では、Deep Agents においてそれぞれがどのように機能するかを、ライブトレースとともに詳しく解説します。また、これら 6 つのパターンを説明する動画も作成しましたので、こちらからご覧ください。
クラス分類して行動
まずアイテムをクラス分類し、その後、各アイテムはその分類に基づいて専門的なサブエージェントによって処理されます。これにより、異なる種類のアイテムに異なる専門知識が必要な混合入力も処理できるようになります。
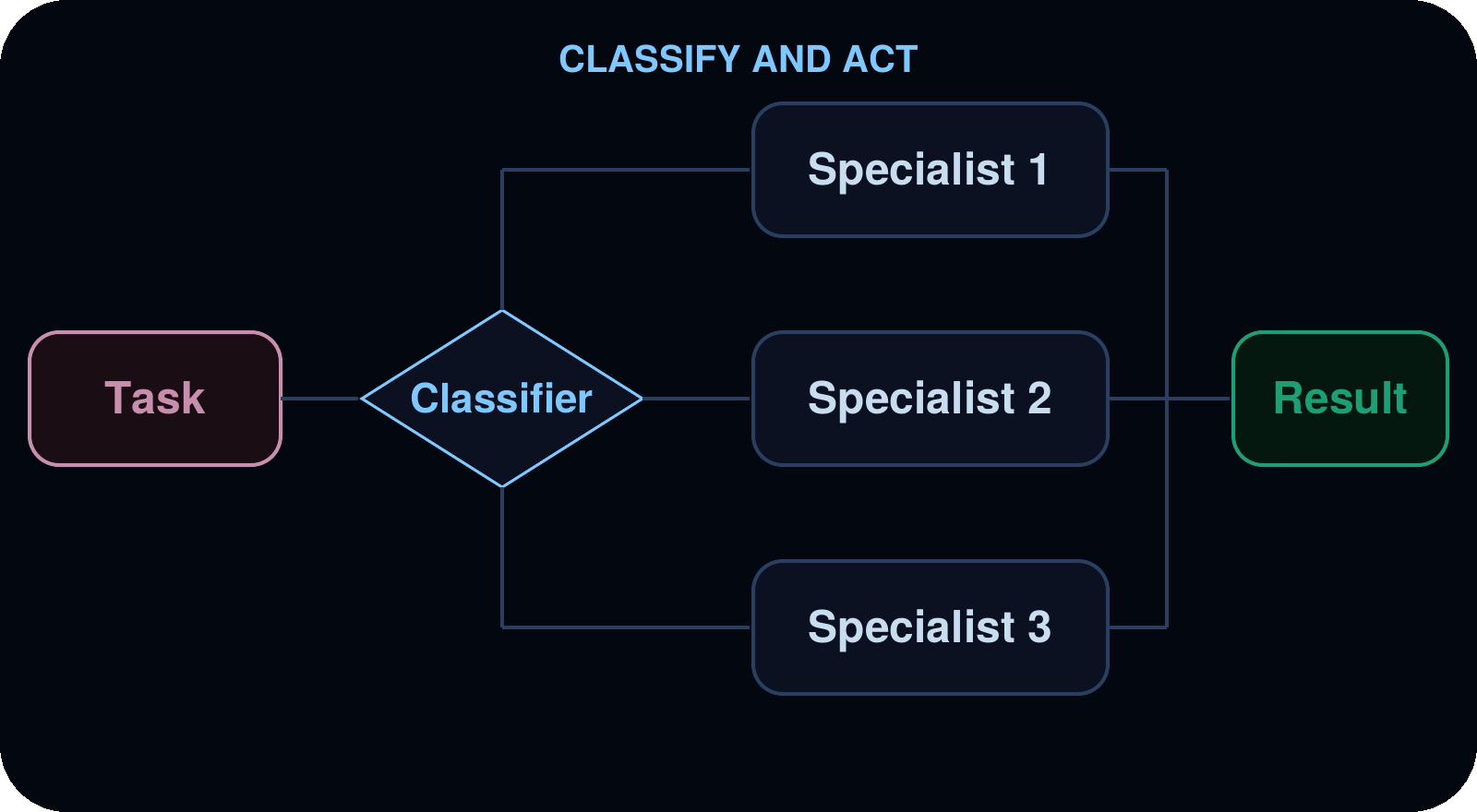
ユースケース: サポートチケット、エラーログ、ユーザーフィードバックのトリアージ、またはタイプに応じて異なる処理が必要なアイテムのバッチ処理。
例: サポートチケットのバックログをトリアージする。エージェントはチケットを読み込み、それぞれを「バグ」「機能リクエスト」「質問」に分類します。バグはバグ調査担当者に、機能リクエストは機能分析担当者に、質問はサポート対応担当者に振り分けられます。結果として、カテゴリ別にグループ化されたサマリーが生成されます。
トレースはこちらで確認できます。
ファンアウトして合成
エージェントは、同じ種類の作業を多数のアイテムに対して並列に実行し、その後その結果を結合します。

ユースケース: ディレクトリ全体にわたるコードレビュー、バッチドキュメントの分析、ログファイルの処理、多数のサービスに対する同一チェックの実行。
例:ソースツリー全体にわたるファイルごとのセキュリティレビュー。エージェントは src/ 配下にあるすべての TypeScript ファイルを特定し、各ファイルに対して並列で 1 つのセキュリティレビュアーを起動します。その後、結果を統合して、重大度評価と変更が必要な行を含む優先順位付けされた単一のレポートを作成します。
トレースはこちら here でご覧ください。
敵対的検証(Adversarial verification)
これは 2 フェーズのパターンです。最初のフェーズで発見事項を生成し、2 つ目のフェーズでは各発見事項を独立した検証者に送り、合意に至った発見事項のみが採用されます。これにより、速度よりも信頼性が重要となる場合に、偽陽性(false positives)を削減できます。

ユースケース: 偽陽性のコストが高いセキュリティ監査、コンプライアンスチェック、発見事項に高い信頼性が求められるあらゆるレビュー。
例:偽陽性が許容されないセキュリティ監査。監査担当者は潜在的な脆弱性を見つけるために広範囲に網羅的に調査し、その後、各発見事項は独立した検証者に引き渡されます。検証者はコードを新たに読み込み、「CONFIRMED(確認済み)」または「REFUTED(反証済み)」の判断を下します。最終レポートに残るのは、確認済みの発見事項のみです。
トレースはこちら here でご覧ください。
生成とフィルタリング
複数のサブエージェントが、同じ問題に対して独立した解決策を生成します。エージェントはコード内でこれらの結果を比較・採点し、最も優れたもののみを残してフィルタリングします。
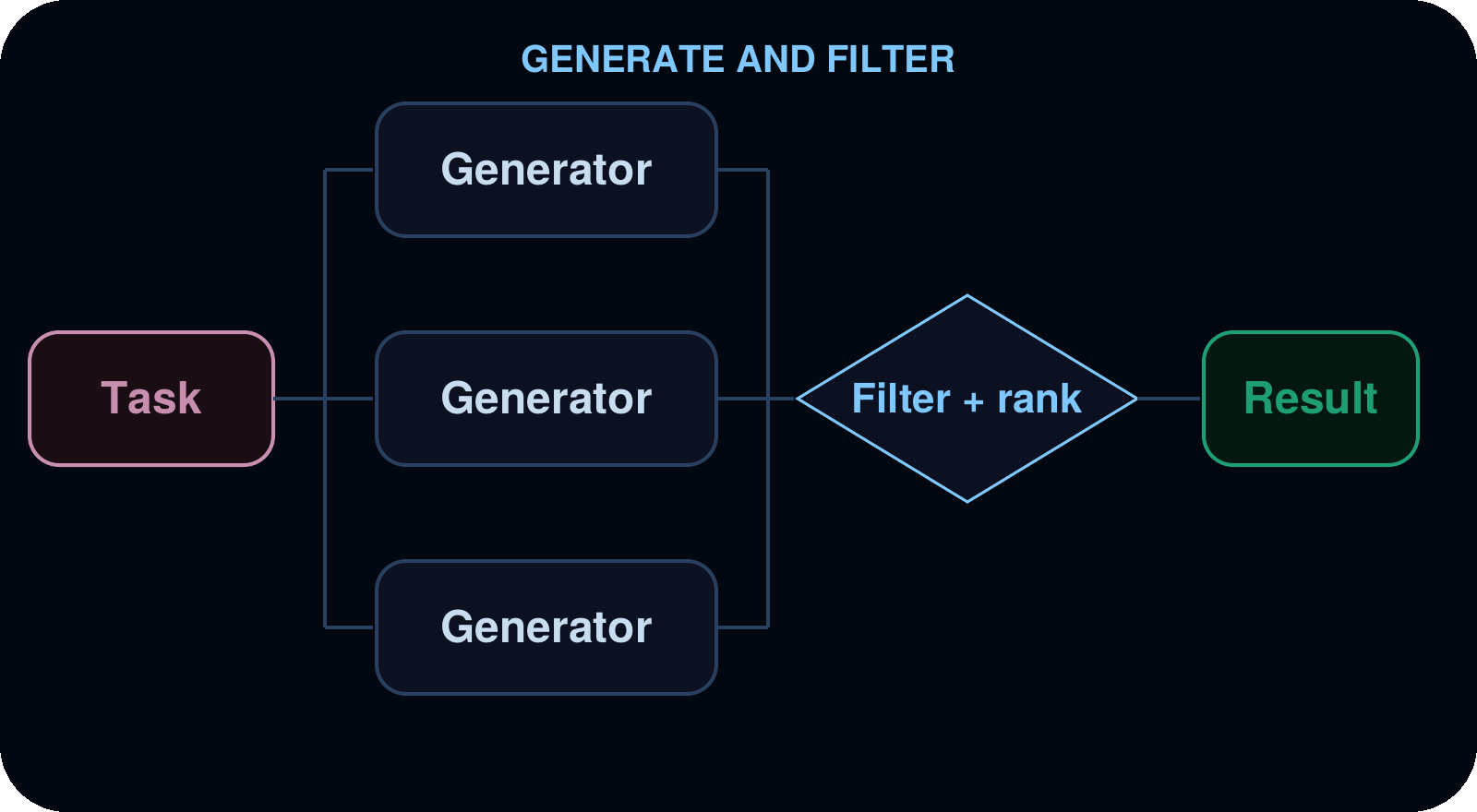
ユースケース: アーキテクチャ提案、リファクタリング戦略、コンテンツのバリエーション、コミットする前に複数の選択肢を検討することでより良い結果が得られるあらゆるタスク。
例:競合するレートリミッター(rate-limiter)のリデザイン案をランク付けしたものです。エージェントにはアーキテクトがおり、rate-limiter.ts の独立した複数リデザインを生成します。それぞれは互いに上書きされないよう個別のファイルに記述されます。その後、バースト時の正しさ、マルチインスタンス対応、複雑さといった観点で採点が行われます。最も強力な案が勝利し、その理由も提示されます。
トレースはこちら here でご覧ください。
トーナメント
バリエーションは、ジャッジサブエージェントによって直接比較され、勝者は敗者淘汰ラウンドを通過して進出します。
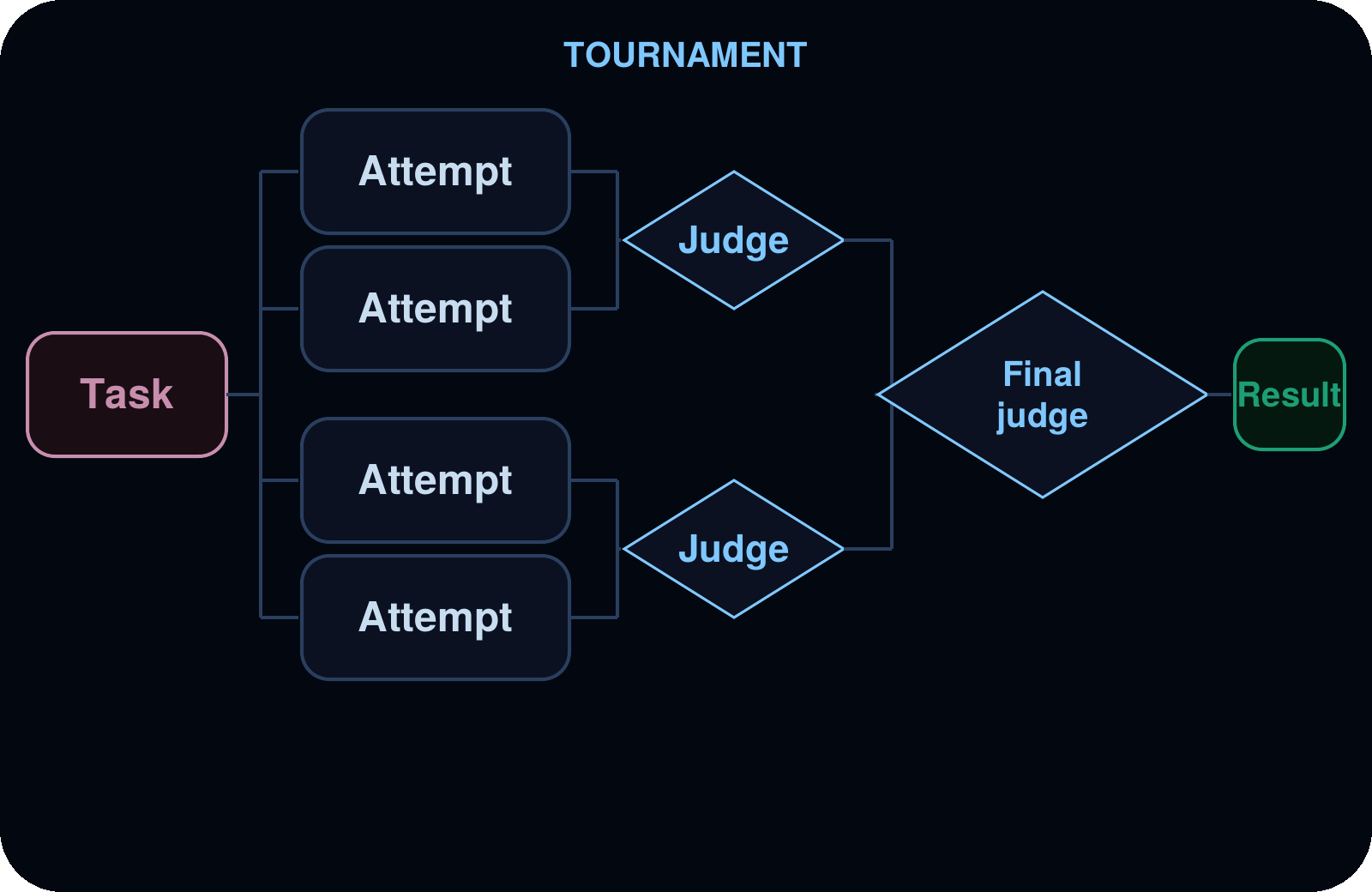
ユースケース: 主観的な基準による最適化、スタイルの選択、競合する実装間の選定。
例:ごちゃごちゃした createOrder ハンドラの書き換えに対するペアワイズブラケット。複数のライターがそれぞれ異なる優先度を持つ候補となる書き換えを生成し、その後ジャッジがそれらを直接比較して勝者をラウンドごとに進め、最終的に一人のチャンピオンが浮き上がるまで続けます。これにはジャッジの推論も返されます。
トレースは こちら でご覧ください。
完了するまでループ
エージェントは、既に見つけた結果と重複排除を行いながら、新しい結果が現れなくなるまでディスカバリーループを実行します。作業の範囲が事前に不明な場合に有用です。
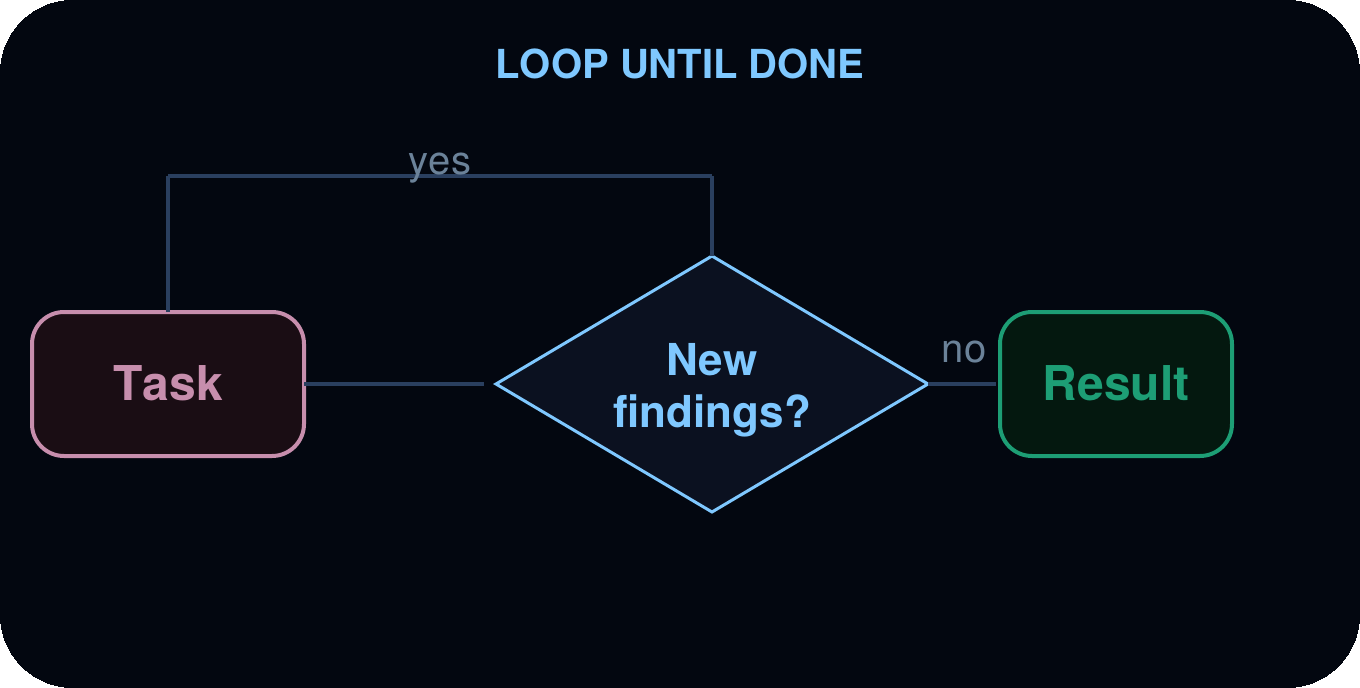
ユースケース: 網羅的な検索、デッドコードの検出、依存関係監査、固定された結果数ではなく完全性を求めるあらゆるスウィープ。
例:パスベースのセキュリティスウィープ。エージェントはスキャンパスを実行し、コード内で発見したものを検査します。そして、前回のパスで新しい問題が表面化した場合にのみ次のパスを開始します。あるパスで新たな発見がない場合に停止します。集約された発見内容と、それまでに要したパス数を報告します。
トレースは こちら でご覧ください。
結論
動的サブエージェントは、エージェントにより高い自律性と信頼性を付与するための仕組みです。コードがカバレッジと中間コンテキストの処理を担当し、モデル自体は判断を要する重責な作業を引き続き行います。上記のパターンは出発点に過ぎません。実際には、タスクの要件に応じてエージェントがこれらを組み合わせて混合して使用します。
これは再帰型言語モデルのアイデアを最も単純な形にしたものです。コードを書くエージェントがあり、そのコードがさらに多くのエージェントを起動します。これはエージェントが自分自身を再帰的に呼び出す仕組みであり、コンテキストウィンドウによって制限されたり、固定されたワークフローに縛られたりすることはありません。エージェントは問題を可能な限り細分化し、あらゆる形状のピースを組み合わせて再構築できます。上記で強調したオーケストレーションパターンは、実現可能性の初期の兆候ですが、モデルがコード作成をより得意にするにつれて、その上限はさらに高まり続けるでしょう。
動的サブエージェント は、Deep Agents が今日この仕組みを実装したものです。エージェントにコードインタープリターを追加するか、動的サブエージェントがすぐに使える dcode を利用して始めましょう。
関連コンテンツ

Deep Agents
オープンソース
Deep Agents によるプロンプトキャッシング

Alex Olsen
2026 年 6 月 26 日
5 分

Deep Agents
オープンソース
エージェントアーキテクチャ
ループエンジニアリングの芸術

Sydney Runkle
2026 年 6 月 16 日
7 分

オープンソース
エージェントとアプリケーションの間の欠落したリンク

Christian Bromann
2026 年 6 月 10 日
6 分

エージェントが実際に何をしているかを見る
LangSmith は、開発者がエージェントのすべての意思決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるためのエージェントエンジニアリングプラットフォームです。
原文を表示
As agents take on more ambitious tasks, they have a hard time:
- Reliably completing work at scale
- Managing their own context
We’ve been experimenting with how to handle these challenges in the form of what we’re calling dynamic subagents: instead of issuing subagent tasks through generic tool calling, the agent writes a short script that drives subagent execution. This means models can rely on code patterns it’s good at writing (like looping, branching, or concurrency) to write orchestration logic fit to the task.
Why dynamic subagents?
Deep Agents already supports subagents. They isolate context, let the main agent delegate discrete units of work, and keep intermediate results out of the main context window. So why do we need dynamic subagents?
With normal subagents, they are called one at a time, by the main model invoking them directly. That works at small scale. It breaks down when you need to spawn hundreds of subagents, or when the orchestration logic is conditional or multi-phase.
Dynamic subagents solve this with programmatic orchestration. Instead of making tool calls turn-by-turn, the agent writes a short script that orchestrates and calls subagents, and runs it in a lightweight interpreter.
The canonical example: one subagent per page of a 300-page document. Rather than calling the subagent tool 300 times, the agent writes a loop:
const results = await Promise.all(pages.map(page =>
task({ description: Summarize page ${page.number}, subagentType: "summarizer" })
));
`
`This unlocks two things that tool-call-based orchestration can't reliably deliver:
Deterministic coverage at scale. Without structure, agents make judgment calls about scope, screening 75 of 500 items and calling it done. A dispatch loop doesn't. Coverage becomes a structural guarantee, not a prompt engineering problem.
Reliable complex orchestration. Writing orchestration as code is more reliable than having the model reproduce it as a sequence of tool calls, especially for fan-out + synthesis, multi-phase pipelines, or conditional branching.
This is the same idea behind workflows in Claude Code and Recursive Language Models (RLMs): a model writes code, and that code dispatches more agents.
Quickstart
Dynamic subagents require two things: subagents to dispatch work to, and a code interpreter: a secure, lightweight runtime where the model writes and executes orchestration code. Deep Agents includes an optional code interpreter based on QuickJS. To use it, install the QuickJS middleware package, then pass CodeInterpreterMiddleware via the middleware argument on create_deep_agent.
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware()],
)
Deep Agents ships with a general-purpose subagent built in, so there’s already one general subagent profile that can be used in workflows. For specialized workflows, configure custom subagents with their own names, descriptions, and system prompts: the names and descriptions are how the agent knows which role to reach for.
To trigger dynamic subagents, prompt your agent with the word "workflow", like this:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "Run a workflow that reviews every file in src/routes/ and summarizes the top risks."}]
})
Use with a coding agent
The fastest way to try dynamic subagents is with dcode, our terminal coding agent built using a Deep Agent. It ships with the code interpreter enabled, so there's nothing to wire up — dynamic subagents works out of the box.
Install
curl -LsSf https://langch.in/dcode | bash
Run
dcode
To trigger dynamic subagents, just ask for a “workflow”. Instead of grinding through the work itself, or trying to manage subagent fan outs with its native task tool, the agent writes an orchestration script that calls the built-in task() global and executes it in the code interpreter. For example: “run a *workflow* to review every file in src/ for SQL injection.”
As subagents spawn, dcode shows them live in the dynamic subagents panel grouped into phases by dispatch.
You can try this fastest with dcode but you can also use it in your tool of choice via ACP (such as Zed)
How it works
The agent is given an eval tool. It writes JavaScript that executes securely inside the interpreter. When subagents are configured, the interpreter exposes a built-in task() global that dispatches them from code. Based on the task at hand, the model writes different code — a loop, a branch, a Promise.all — and the interpreter runs it deterministically.

task() takes a description, a subagentType, and an optional responseSchema — when provided, the result is already a typed object, ready to filter or pass to the next step.
const result = await task({
description: "Review src/auth/login.ts for security issues.",
subagentType: "reviewer",
responseSchema: {
type: "object",
properties: {
severity: { type: "string", enum: ["high", "medium", "low"] },
issues: { type: "array", items: { type: "string" } },
},
},
});
const critical = result.severity === "high" ? result.issues : [];
critical; // model sees the last line
For more, see Programmatic subagents and Interpreters in the docs.
Common Orchestration Patterns
Anthropic's dynamic workflows popularized a set of orchestration patterns for parallel agent work. They aren’t features you turn on. They’re shapes that naturally fall out of the work, and the agent settles into a different one as the task changes. The table below maps each shape to the kind of work it fits.
Pattern
Shape
Reach for it when
Classify and act
Route each item to a specialist by type
Mixed inputs need different handling
Fanout and synthesize
Same work across many items in parallel, then combine
Independent units, one combined report
Adversarial verification
Find, then independently verify before keeping
False positives are costly
Generate and filter
Produce several options, score, keep the best
Exploring options beats one-shot
Tournament
Head-to-head judging, winners advance
Subjective or relative criteria
Loop until done
Repeat passes until one turns up nothing new
Scope is unknown, you want completeness
Below we’ll dive into how each one works in Deep Agents, with live traces. We also put together a video explaining these six patterns, which you can check out here.
Classify and act
Items are classified first, then each item is handled by a specialized subagent based on its classification. This lets you process mixed inputs where different items need different expertise.
Use cases: Triaging support tickets, error logs, user feedback, or any batch of items that need different handling depending on their type.
Example: triaging a support-ticket backlog. The agent reads the tickets and classifies each as a bug, feature request, or question. Bugs to a bug-investigator, feature requests to a feature-analyst, and questions to a support-responder. The result is a summary grouped by category.
View the trace here.
Fanout and synthesize
The agent dispatches the same kind of work across many items in parallel, then combines the results.
Use cases: Code review across a directory, analyzing a batch of documents, processing log files, running the same check across many services.
Example: a per-file security review across a source tree. The agent discovers every TypeScript file under src/ and dispatches one security-reviewer per file in parallel. It then merges the results into a single prioritized report with severity ratings and the lines that need to change.
View the trace here.
Adversarial verification
A two-pass pattern. The first pass produces findings. The second pass sends each finding to independent verifiers, and only findings that survive agreement are kept. This reduces false positives when confidence matters more than speed.
Use cases: Security audits where false positives are costly, compliance checks, any review where you need high confidence in findings.
Example: a security audit where false positives are unacceptable. An auditor casts a wide net for potential vulnerabilities, then each finding is handed to an independent verifier that reads the code fresh and returns a CONFIRMED or REFUTED verdict. Only confirmed findings survive into the final report.
View the trace here.
Generate and filter
Multiple subagents generate independent solutions to the same problem. The agent compares, scores, and filters the results in code, keeping only the best.
Use cases: Architecture proposals, refactoring strategies, content variations, any task where exploring multiple options before committing produces a better outcome.
Example: competing rate-limiter redesigns, ranked. The agent has an architect to produce several independent redesigns of rate-limiter.ts, each written to its own file so they don’t overwrite each other. It then scores them on correctness under burst, multi-instance support, and complexity. The strongest one wins, with a rationale for why.
View the trace here.
Tournament
Variations are compared head-to-head by a judge subagent, with winners advancing through elimination rounds.
Use cases: Optimization under subjective criteria, style selection, choosing between competing implementations.
Example: a pairwise bracket over rewrites of a messy createOrder handler. Several writers each produce a candidate rewrites with different priorities, then a judge compares them head-to-head, advancing winners round-by-round until one champion stands out. It comes back with the judge’s reasoning.
View the trace here.
Loop until done
The agent runs a discovery loop, deduplicating against what it has already found, until no new results appear. Useful when the scope of the work is not known upfront.
Use cases: Exhaustive search, dead code detection, dependency audits, any sweep where you want completeness rather than a fixed number of results.
Example: a pass-based security sweep. The agent runs a scan pass, inspects what it found in code, and only starts another pass if the previous one surfaced new issues. It stops when a pass turns up nothing new. It reports the consolidated findings and how many passes it took.
View the trace here.
Conclusion
Dynamic subagents are how you give agents more autonomy and increased reliability. The code handles coverage and intermediate context, and the model still does the judgement-heavy work. The above patterns above are a starting point. In practice, agents compose and mix them based on what the task demands.
This is the Recursive Language Model idea in its simplest form. An agent that writes code, and that code dispatches more agents. It’s an agent calling itself recursively and it isn’t capped by a context window or boxed into a fixed workflow. An agent can break the problem down as far as it goes and reassemble the pieces in whatever shape fits. The orchestration patterns highlighted above are early glimpses of what is possible but the ceiling will only continue to rise as models get better at writing code.
Dynamic subagents are how Deep Agents puts this in your hands today. Get started by adding a code interpreter to your agent, or reach for dcode where dynamic subagents works out of the box.
Related content
Deep Agents
Open Source
Prompt Caching with Deep Agents
Alex Olsen
June 26, 2026
5
min
Deep Agents
Open Source
Agent Architecture
The Art of Loop Engineering
Sydney Runkle
June 16, 2026
7
min
Open Source
The Missing Link Between Agents and Applications
Christian Bromann
June 10, 2026
6
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み