Amazon SageMaker AI と vLLM を用いたリアルタイム音声アプリケーションの構築
AWS は Amazon SageMaker AI と vLLM を連携させることで、双方向ストリーミング機能を実装し、従来の遅延問題を解消したリアルタイム音声処理基盤を 2025 年 11 月から提供開始する。
キーポイント
双方向ストリーミングの導入
Amazon SageMaker AI が 2025 年 11 月より、クライアントとモデルコンテナ間での双方向データストリーミングをサポートし、リアルタイム推論の遅延を解消する。
vLLM と Realtime API の連携
vLLM の WebSocket ベースの Realtime API を活用することで、音声入力と文字起こしが同時に流れる低遅延なサービス構築が可能になる。
Mistral AI モデルの実装例
Mistral AI のコンパクトなリアルタイム音声モデル「Voxtral-Mini-4B-Realtime-2602」を SageMaker 上でデプロイする具体的な実装例が提供される。
インフラの統合と管理
SageMaker と vLLM の組み合わせにより、音声 AI アプリケーションに必要な複雑なインフラ構築を一元化し、運用負荷を軽減する。
双方向ストリーミングのラベル設定
Docker イメージに `com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true` ラベルを追加することで、SageMaker AI がコンテナとの WebSocket 接続を確立できるようになります。
WebSocket ブリッジの役割
FastAPI ベースのブリッジアプリが SageMaker のポート(8080)で待機し、vLLM の内部エンドポイント(8081)へ WebSocket 接続を転送して双方向通信を実現します。
非 UTF-8 クライアントへの対応
ブリッジコードには、UTF-8 形式でないクライアントからのデータを受け取った際にデコードして vLLM に送信するフォールバック処理が含まれています。
影響分析・編集コメントを表示
影響分析
この発表は、リアルタイム音声 AI アプリケーションの開発と運用における最大の障壁であった「遅延」と「インフラ構築の複雑さ」を同時に解決する画期的な進展です。AWS と vLLM の強力な連携により、企業は即座に高品質で低遅延の音声エージェントやキャプションサービスを提供できるようになり、業界全体でのリアルタイム AI 応用例が大幅に拡大すると予想されます。
編集コメント
従来のバッチ処理やリクエストレスポンス型推論の限界を打破し、双方向ストリーミングという技術的ブレークスルーを実装環境で提供するのは非常に重要です。特に vLLM のようなオープンソース基盤との親和性が高い点は、開発者の選択肢を広げる意味で大きな価値があります。
音声エージェント、ライブ字幕、コンタクトセンター分析、アクセシビリティツールはすべて、リアルタイムの音声からテキストへの変換に依存しており、アプリケーションがオーディオをストリーミングして入力し、単一の永続的な接続を通じて同時に文字起こしを受け取ります。従来のリクエストレスポンス推論ではここでの要件を満たすことができません。なぜなら、文字起こしは録音されたオーディオ全体を受信するまで開始できないため、これらのワークロードが求めるリアルタイム体験を損なう遅延が生じるからです。
2025 年 11 月より、Amazon SageMaker AI リアルタイム推論のための双方向ストリーミング を使用して、クライアントとモデルコンテナの間でデータを双方向に連続的にストリーミングできるようになります。vLLM では、WebSockets を用いてクライアントとサーバー間の双方向ストリーミングを行う Realtime API を通じて、リアルタイムでオーディオの文字起こしが可能になりました。
本稿では、これらの 2 つの機能を統合します。双方向ストリーミングを備えた vLLM コンテナを使用して、Mistral AI のコンパクトなリアルタイム音声モデルである Voxtral-Mini-4B-Realtime-2602 を SageMaker AI エンドポイントにデプロイする方法を示します。その結果、オーディオが入力され、文字起こしがリアルタイムで返される、完全に管理された音声からテキストへのサービスが実現されます。完全な例は GitHub リポジトリ で確認できます。
音声 AI アプリケーションを実行するために必要な主要機能
音声エージェント、ライブ字幕サービス、またはコンタクトセンター分析パイプラインなど、本番環境向けの音声 AI アプリケーションを構築するには、厳格なレイテンシ要件を満たすために複数のインフラストラクチャコンポーネントが連携して動作する必要があります。Amazon SageMaker AI と vLLM はそれぞれこのスタックの異なる部分を担っており、両者を組み合わせることで、差別化できない重労働を排除するエンドツーエンドのソリューションを提供します。これらのアプリケーションが求める要件と、各コンポーネントがどのように対応するかは以下の通りです:
- 効率的な GPU サービングを備えたリアルタイム音声モデル。あらゆる音声 AI アプリケーションの中核には、オーディオが入力されるたびに逐次的に処理し、録音の完了を待たずにトランスクリプショントークンを生成する音声認識 (ASR) モデルがあります。vLLM はその Realtime API を通じてこれらのモデルを提供します。これは /v1/realtime にネイティブな WebSocket エンドポイントであり、複数の音声モデルをサポートし、ピースワイズ CUDA グラフ実行を適用することで GPU カーネル起動のオーバーヘッドを削減し、ストリーミングトランスクリプション中のトークンあたりのレイテンシを直接低下させます。vLLM はオープンソースであるため、サービング層におけるベンダーロックインなしで、モデル設定、量子化、コンパイル設定を完全に制御できます。
- 双方向ストリーミングインフラストラクチャ。従来のリクエストレスポンス API では、クライアントがサーバーの処理を開始する前にオーディオファイル全体をアップロードする必要があります。音声 AI アプリケーションでは、クライアントがオーディオを入力し、サーバーが同時にトランスクリプションを返す永続的なフルデュプレックス接続が必要です。SageMaker AI はポート 8443 上のネイティブな HTTP/2 双方向ストリーミングでこれを解決し、クライアント側の HTTP/2 イベントストリームプロトコルとコンテナ側の WebSocket の間を自動的にブリッジします。このプロトコル変換層を構築または管理する必要はありません。SageMaker AI がこれを透明性を持って処理します。
- オーディオ処理とエンコーディング。マイクや電話システムからの生オーディオは様々な形式とサンプリングレートで到着します。モデルに到達する前に、リサンプリング(通常は 16 kHz モノ PCM16)、適切なサイズのセグメントへのチャンキング、および送信のための base64 エンコードが必要です。この変換処理はクライアント側のパイプラインが担当し、vLLM の Realtime API がプロトコルを定義します。base64 化された PCM16 チャンクが WebSocket を経由して流入し、トランスクリプショントークンはストリーミングで返されます。SageMaker AI の双方向ストリームは両方向のデータを同時に運搬します。
- コネクション管理とレジリエンス。SageMaker AI は ping/pong 保活フレームを備えた WebSocket 接続を維持し、コンテナのヘルスチェックを行い、Amazon CloudWatch を通じてエンドポイントレベルのモニタリングを提供します。これにより、カスタム計測なしで本番環境での観測性と接続のレジリエンスが実現されます。
要するに、vLLM はネイティブな WebSocket ストリーミングを備えた高性能なオープンソースモデルサービングを提供し、SageMaker AI はプロトコルブリッジ、ヘルスモニタリング、運用ツールを備えた管理されたインフラストラクチャでそれを包み込みます。これらを組み合わせることで、カスタムのストリーミングインフラストラクチャの構築や GPU サーバーの管理なしに、Hugging Face 上の音声モデルから本番環境対応のリアルタイムトランスクリプションサービスへと移行できます。
ソリューションの概要
このウォークスルーを終える頃には、以下ができるようになっています:
- 双方向ストリーミング機能を有効にした SageMaker AI vLLM Deep Learning Container を基盤としたカスタム Docker コンテナ。
- Voxtral-Mini-4B-Realtime-2602 を実行中の SageMaker AI エンドポイント。
- SageMaker AI 双方向ストリーミング SDK を使用して、オーディオファイルをエンドポイントにストリーミングし、リアルタイムで文字起こしを受け取る Python クライアント。
- 話している間の音声をリアルタイムで文字起こしする Gradio ベースのライブマイクデモ。
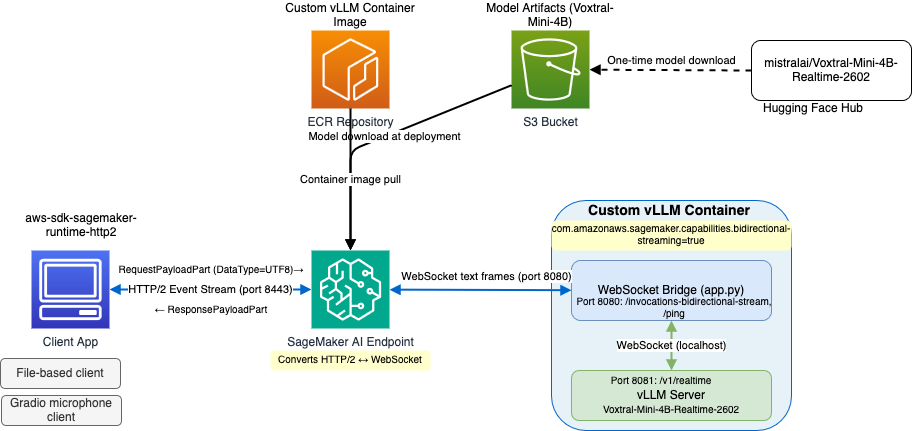
このソリューションは3つのレイヤーを接続します:

クライアントから SageMaker AI へ: アプリケーションは、多重化された双方向ストリーミングをサポートする HTTP/2 を使用してポート 8443 の SageMaker AI ランタイムエンドポイントに接続します。vLLM リアルタイムプロトコルの各 JSON メッセージ(input_audio_buffer.append や transcription.delta など)は、DataType が「UTF8」に設定された RequestPayloadPart 内に送信されます。これにより、SageMaker AI はデータを WebSocket テキストフレームとして転送します。応答メッセージは ResponsePayloadPart イベントとして到着します。
SageMaker AI から Docker コンテナへ: SageMaker AI は自動的に HTTP/2 イベントストリームと WebSocket プロトコルをブリッジします。SageMaker AI が双方向ストリーミングを期待するパスである ws://localhost:8080/invocations-bidirectional-stream に対して、コンテナに WebSocket 接続を確立し、両方向へデータフレームを転送します。クライアントで DataType="UTF8" を設定すると、ブリッジは WebSocket テキストフレームをコンテナに送信します。
Docker コンテナ内: コンテナ内部では、軽量な FastAPI ブリッジ(app.py)がポート 8080 の /invocations-bidirectional-stream で待機しています。SageMaker AI から WebSocket 接続を受け取ると、vLLM の Realtime API(ws://localhost:8081/v1/realtime)に対して第 2 の WebSocket 接続を開き、メッセージを双方向に転送します。このブリッジは、SageMaker AI が期待するパスと vLLM のネイティブエンドポイント間のルート変換を処理し、テキストフレームは変更なしで通過させます。vLLM サーバーはポート 8081 で動作し、デフォルトの /v1/realtime WebSocket エンドポイントで Realtime API を提供します。ソースコードのパッチ適用は不要です。また、ブリッジは /ping ヘルスチェックを vLLM のヘルスエンドポイントにプロキシし、SageMaker AI のホスティング契約を満たします。
Realtime API プロトコル
Realtime API は、WebSocket ベースのストリーミング音声文字起こしを提供し、録音中にリアルタイムで音声からテキストへの変換を可能にします。送信する前に、オーディオは 16 kHz サンプリングレート、モノラルチャンネルの base64 PCM16 (PCM16) 形式でエンコードする必要があります。このプロトコルにおけるメッセージフローは以下の通りです。
- クライアントが ws://host/v1/realtime に接続します。
- サーバーから session.created イベントが送信されます。
- クライアントは任意で、モデルやパラメータを含む session.update を送信できます。
- 準備ができたら、クライアントは input_audio_buffer.commit を送信します。
- クライアントは base64 PCM16 (PCM16) のチャンクを含む input_audio_buffer.append イベントを送信します。
- サーバーから、逐次的なテキストを含む transcription.delta イベントが送信されます。
- サーバーから、最終的な文字起こしと使用統計を含む transcription.done が送信されます。
- 次の発話のためにステップ 5 から繰り返し実行します。
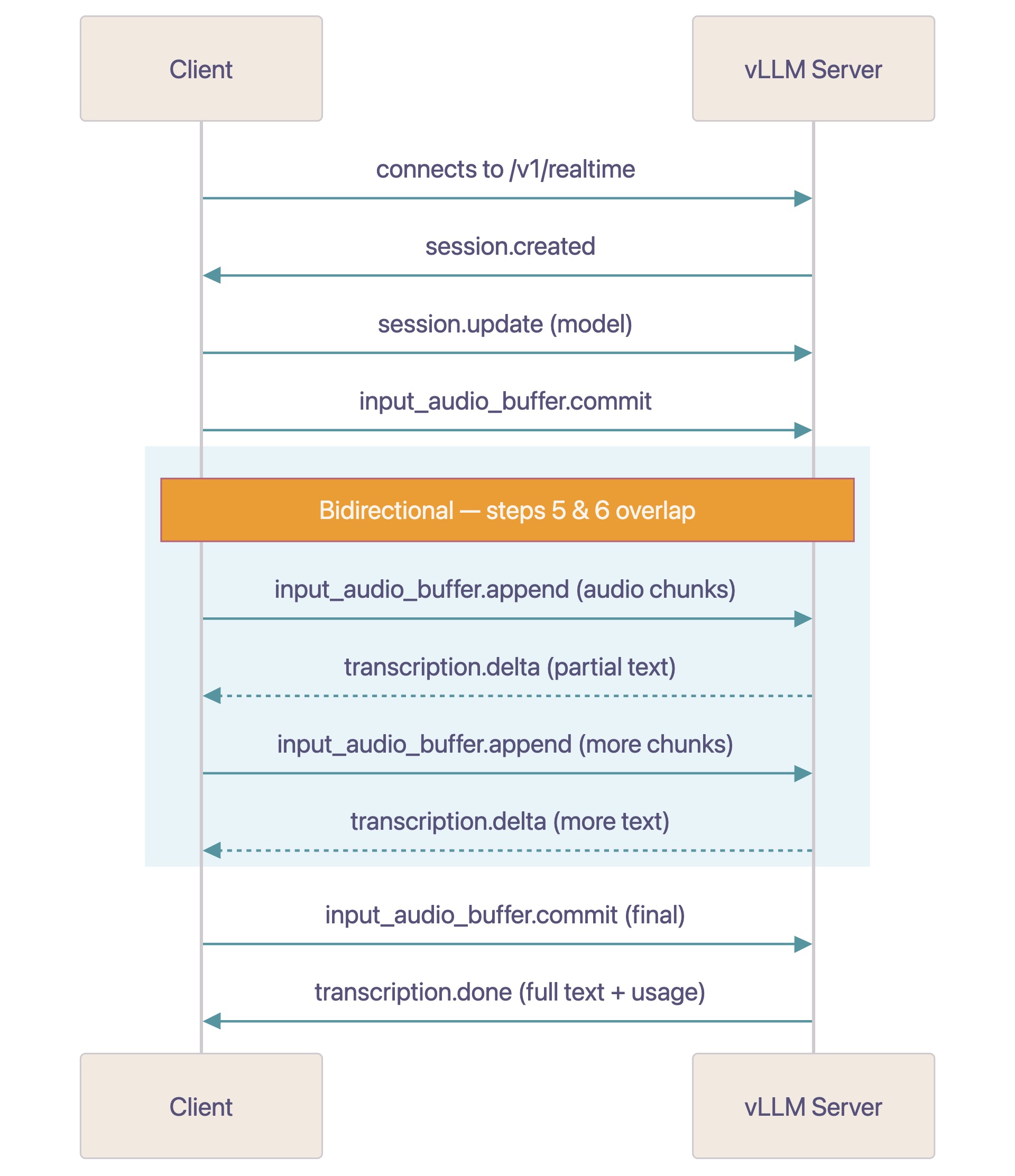
モデルは、十分なオーディオコンテキストが揃った時点で文字起こしを開始し、クライアントが引き続きオーディオチャンクを送信している間も、transcription.delta トークンをストリーミングしてクライアントに返します。結果を受け取るために、すべてのオーディオを送信するまで待つ必要はありません。オプションとして、クライアントは input_audio_buffer.commit を final=True とともに送信して、音声入力が完了したことをシグナルできます。これは、オーディオファイルをストリーミングする場合に有用です。
前提条件
- SageMaker AI の権限を持つ AWS アカウント(双方向ストリーミングには sagemaker:InvokeEndpoint* 権限を含む)。
- Docker 環境(Docker が有効化された SageMaker AI Studio、またはローカルマシン)。
- Python 3.12 以上。
- Hugging Face 上の Voxtral-Mini-4B-Realtime-2602 モデルへのアクセス権限。
- 双方向ストリーミング API を呼び出すための aws-sdk-sagemaker-runtime-http2 Python パッケージ。
カスタム vLLM コンテナの構築
SageMaker AI の vLLM Deep Learning Container(深層学習コンテナ)をベースに、3 つの要素を追加します。1 つ目は双方向ストリーミングをサポートする Docker ラベル、2 つ目は SageMaker AI が期待するルートと vLLM のネイティブ API パス間を変換する WebSocket ブリッジ、3 つ目は両方のプロセスを実行するエントリーポイントです。
Dockerfile
FROM public.ecr.aws/deep-learning-containers/vllm:0.17.1-gpu-py312-cu129-ubuntu22.04-sagemaker-v1.0-soci
# SageMaker AI に対して、このコンテナが双方向ストリーミングをサポートしていることを通知
LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true
WORKDIR /opt/ml/code
# ブリッジの依存関係をインストール
COPY requirements.txt .
RUN pip install --upgrade --no-cache-dir -r requirements.txt
# WebSocket ブリッジ:/invocations-bidirectional-stream を /v1/realtime にルーティング
COPY app.py .
COPY sagemaker-entrypoint.sh entrypoint.sh
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
HEALTHCHECK --interval=30s --timeout=10s --start-period=120s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1
Docker ラベル com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true は、このコンテナが双方向ストリーミングをサポートしていることを SageMaker AI に通知するものです。このラベルがない場合、SageMaker AI はコンテナに対して WebSocket 接続を確立しません。
ブッリッジ (app.py) は、ポート 8080 でリスニングする小規模な FastAPI アプリケーションです。これは SageMaker AI 向けのポートであり、WebSocket 接続を vLLM の内部ポート 8081 にある /v1/realtime エンドポイントへ転送します。また、/ping ヘルスチェックも vLLM の /health エンドポイントへプロキシします。
VLLM_WS_URL = "ws://localhost:8081/v1/realtime"
@app.websocket("/invocations-bidirectional-stream")
async def websocket_bridge(sm_ws: WebSocket):
await sm_ws.accept()
async with websockets.connect(VLLM_WS_URL) as vllm_ws:
async def sm_to_vllm():
"""SageMaker AI → vLLM への転送を行う。"""
while True:
message = await sm_ws.receive()
if "text" in message and message["text"]:
await vllm_ws.send(message["text"])
elif "bytes" in message and message["bytes"]:
# UTF-8 非対応クライアント向けのフォールバック
await vllm_ws.send(message["bytes"].decode("utf-8"))
async def vllm_to_sm():
"""Forward vLLM → SageMaker AI."""
async for msg in vllm_ws:
if isinstance(msg, str):
await sm_ws.send_text(msg)
elif isinstance(msg, bytes):
await sm_ws.send_bytes(msg)
await asyncio.gather(sm_to_vllm(), vllm_to_sm())
クライアントが DataType="UTF8" を設定しているため、SageMaker AI はテキストフレームをブリッジに配信し、それを /v1/realtime で直接 vLLM に転送します。フレームタイプの変換は不要です。sm_to_vllm におけるバイナリからテキストへのデコードは、DataType を設定しないクライアント向けのフォールバック機能です。
SageMaker AI エンドポイントへのデプロイ
私たちは、リクエストを処理する SageMaker AI リアルタイムエンドポイントへデプロイします。
モデル環境の構成とモデルのデプロイ
SM_VLLM_* 環境変数は、vLLM のサーバーパラメータを設定します:
vllm_env = {
"SM_VLLM_MAX_MODEL_LEN": "45000",
"SM_VLLM_COMPILATION_CONFIG": '{"cudagraph_mode": "PIECEWISE"}'
}
Voxtral-Mini-4B は最大 262,144 トークンのコンテキストをサポートします。ここでは MAX_MODEL_LEN=45000 に設定しており、これは約 1 時間の音声(3600 秒 ÷ トークンあたり 0.08 秒)をライブ録音するのに十分な長さです。この値は、想定される音声の再生時間に基づいて調整してください。cudagraph_mode: PIECEWISE を持つ COMPILATION_CONFIG は、推論スループットを向上させるための CUDA グラフ最適化を提供します。
以下のコードスニペットは、SageMaker AI エンドポイントを作成します:
モデルの作成
voxtral_model = Model.create(
model_name=model_name,
primary_container=ContainerDefinition(
image=inference_image,
model_data_source=ModelDataSource(
s3_data_source=S3ModelDataSource(
s3_uri=f"{model_artifact}/",
s3_data_type="S3Prefix",
compression_type="None",
)
),
environment=vllm_env
),
execution_role_arn=role,
)
設定の作成
endpoint_config = EndpointConfig.create(
endpoint_config_name=endpoint_config_name,
production_variants=[
ProductionVariant(
variant_name="AllTraffic",
model_name=model_name,
initial_variant_weight=1.0,
instance_type=instance_type,
initial_instance_count=1,
model_data_download_timeout_in_seconds=health_check_timeout,
)
]
)
エンドポイントの作成
endpoint = Endpoint.create(
endpoint_name=endpoint_name,
endpoint_config_name=endpoint_config_name
)
endpoint.wait_for_status("InService")
Test with bidirectional streaming
エンドポイントが稼働している状態で、aws-sdk-sagemaker-runtime-http2 Python SDK を使用してこれを呼び出します。この SDK は、SageMaker AI ランタイムエンドポイントのポート 8443 上で HTTP/2 イベントストリームを介して通信を行います。
Stream audio and receive transcription
リポジトリには、双方向ストリーミング SDK を SageMakerRealtimeClient クラスでラップした完全なクライアント sagemaker_bidi_client.py が含まれています。transcribe_audio() が実行されると、まずモデルを選択するために session.update イベントを送信し、その後オーディオファイルを 4 KB の PCM16 チャンクとしてストリームします。受信ループはバックグラウンドの asyncio.Task として動作し、メインのコルーチンはオーディオチャンクを送信することで、HTTP/2 ストリームの両方向が同時にアクティブになります。
このオーバーラップを可視化する鍵となる詳細は、各送信後の await asyncio.sleep(chunk_duration) です。これにより、送信速度がリアルタイム再生(16 kHz で 4 KB チャンクあたり約 128 ms)に同期され、イベントループへの制御が譲渡されます。その結果、より多くのオーディオデータが転送されている間に、受信タスクが transcribe.delta イベントを処理する機会が得られます。この yield(制御の譲渡)がない場合、チャンクはモデルが出力を生成できる速度よりも速く送信され、双方向ストリームが存在していても対話が一見逐次的なものに見えてしまいます。
受信側では、ループがイベントタイプに応じて分岐します。通常の ResponseStreamEventPayloadPart イベントには JSON メッセージ(session.created, transcription.delta, transcription.done)が含まれ、ResponseStreamEventModelStreamError や ResponseStreamEventInternalStreamFailure は別個に処理されます。これにより、モデルレベルおよびプラットフォームレベルの障害が明確な診断情報とともに表面化し、ペイロードパスの中で見失われることがなくなります。
クライアントの実行
python sagemaker_bidi_client.py ./audio.wav \
--region us-east-1
オーディオを送信する間、出力ストリームはリアルタイムで転写テキストを流します。オーディオチャンクが背景で継続してストリーミングされる間、デルタトークンは文字単位で表示されます。
Gradio を用いたライブマイクデモ
ファイルベースのクライアントはテストには有用ですが、双方向ストリーミングは生音声において最も低いレイテンシを実現します。リポジトリ には、マイクからの音声をキャプチャして SageMaker AI にリアルタイムでストリーミングする Gradio ベースのマイククライアント (sagemaker_bidi_microphone_client.py) が含まれています:
python sagemaker_bidi_microphone_client.py \
--endpoint-name \
--region us-east-1
このマイククライアントは、ファイルベースのクライアントと同じく DataType="UTF8" 設定と vLLM Realtime API プロトコルを使用します。これは Gradio のストリーミング音声入力を通じてブラウザから音声をキャプチャし、16 kHz PCM16 にリサンプリングしてエンコードします
原文を表示
Voice agents, live captioning, contact center analytics, and accessibility tools all depend on real-time speech-to-text, where your application streams audio in and receives transcription back simultaneously over a single persistent connection. Traditional request-response inference falls short here because transcription cannot begin until the entire audio recording has been received, adding latency that breaks the real-time experience these workloads require.
Starting November 2025, you can stream data continuously in both directions between your clients and model containers using Amazon SageMaker AI bidirectional streaming for real-time inference. vLLM now lets you transcribe audio in real time through its Realtime API, where you use WebSockets for bidirectional streaming between client and server.
In this post, we bring these two capabilities together. We show how to deploy Voxtral-Mini-4B-Realtime-2602, Mistral AI’s compact real-time speech model, to a SageMaker AI endpoint using a vLLM container with bidirectional streaming. The result is a fully managed, speech-to-text service where audio flows in and transcription flows back in real time. You can follow along with the full example in the GitHub repository.
Key features required to run voice AI applications
Building a production voice AI application whether it’s a voice agent, live captioning service, or contact center analytics pipeline requires several infrastructure components working together with tight latency budgets. Amazon SageMaker AI and vLLM each address distinct parts of this stack, and together they provide an end-to-end solution that eliminates the undifferentiated heavy lifting. Here is what these applications demand and how each component delivers:
- A real-time speech model with efficient GPU serving. At the core of any voice AI application is a speech-to-text (ASR) model that processes audio incrementally, producing transcription tokens as audio arrives rather than waiting for the complete recording. vLLM serves these models through its Realtime API, a native WebSocket endpoint at /v1/realtime that supports multiple speech models, and applies piecewise CUDA graph execution to reduce GPU kernel launch overhead that directly translating to lower per-token latency during streaming transcription. Because vLLM is open source, you retain full control over model configuration, quantization, and compilation settings with no vendor lock-in on the serving layer.
- Bidirectional streaming infrastructure. Traditional request-response APIs force the client to upload the entire audio file before the server begins processing. Voice AI applications require a persistent, full-duplex connection where the client streams audio in and the server streams transcription back simultaneously. SageMaker AI solves this with native HTTP/2 bidirectional streaming on port 8443, automatically bridging between the HTTP/2 event stream protocol on the client side and WebSocket on the container side. You do not need to build or manage this protocol translation layer. SageMaker AI handles it transparently.
- Audio processing and encoding. Raw audio from microphones or telephony systems arrives in various formats and sample rates. Before it reaches the model, it must be resampled (typically to 16 kHz mono PCM16), chunked into appropriately sized segments, and base64-encoded for transmission. The client-side pipeline handles this conversion, while vLLM’s Realtime API defines the protocol: base64 PCM16 chunks flow in via WebSocket, and transcription tokens stream back, with the SageMaker AI bidirectional stream carrying both directions simultaneously.
- Connection management and resilience. SageMaker AI maintains WebSocket connections with ping/pong keepalive frames, health-checks your container, and provides endpoint-level monitoring through Amazon CloudWatch. This gives you production observability and connection resilience without custom instrumentation.
In short, vLLM gives you high-performance, open-source model serving with native WebSocket streaming, while SageMaker AI wraps it in managed infrastructure with protocol bridging, health monitoring, and operational tooling. Together, they let you go from a speech model on Hugging Face to a production-ready, real-time transcription service without building custom streaming infrastructure or managing GPU servers.
Solution overview
By the end of this walkthrough, you will have:
- A custom Docker container built on the SageMaker AI vLLM Deep Learning Container with bidirectional streaming enabled.
- A SageMaker AI endpoint running Voxtral-Mini-4B-Realtime-2602.
- A Python client that streams audio files to the endpoint and receives transcription in real time using the SageMaker AI bidirectional streaming SDK.
- A Gradio-based live microphone demo that transcribes speech as you talk.
The solution connects three layers:
Client to SageMaker AI: Your application connects to the SageMaker AI runtime endpoint on port 8443 using HTTP/2, which supports multiplexed, bidirectional streaming. Each JSON message in the vLLM Realtime protocol (such as input_audio_buffer.append or transcription.delta) is sent inside a RequestPayloadPart with DataType set to “UTF8”. This tells SageMaker AI to forward the data as a WebSocket text frame. Response messages arrive as ResponsePayloadPart events.
SageMaker AI to Docker Container: SageMaker AI automatically bridges the HTTP/2 event stream and WebSocket protocols. It establishes a WebSocket connection to the container at ws://localhost:8080/invocations-bidirectional-stream, the path SageMaker AI expects bidirectional streaming and forwards data frames in both directions. When you set DataType="UTF8" in your client, the bridge sends WebSocket text frames to the container.
Docker Container: Inside the container, a lightweight FastAPI bridge (app.py) listens on port 8080 at /invocations-bidirectional-stream. When it receives a WebSocket connection from SageMaker AI, it opens a second WebSocket connection to vLLM’s Realtime API at ws://localhost:8081/v1/realtime and forwards messages bidirectionally. The bridge handles the route translation between SageMaker AI expected path and vLLM’s native endpoint, while text frames pass through unchanged. The vLLM server runs on port 8081 and serves its Realtime API at the default /v1/realtime WebSocket endpoint, without requiring you to patch source code. The bridge also proxies /ping health checks to vLLM’s health endpoint, satisfying the SageMaker AI hosting contract.
The Realtime API protocol
The Realtime API provides WebSocket-based streaming audio transcription, allowing real-time speech-to-text as audio is being recorded. You must encode your audio as base64 PCM16 at 16 kHz sample rate, mono channel, before sending it. The message flow in the protocol is as follows:
- Client connects to ws://host/v1/realtime.
- Server sends session.created event.
- Client optionally sends session.update with model/params.
- Client sends input_audio_buffer.commit when ready to send audio.
- Client sends input_audio_buffer.append events with base64 PCM16 chunks.
- Server sends transcription.delta events with incremental text.
- Server sends transcription.done with final transcription and usage stats.
- Repeat from step 5 for next utterance.
The model begins transcribing as soon as it has enough audio context, streaming transcription.delta tokens back to the client while the client continues sending audio chunks. You do not need to wait until you’ve sent the entire audio before receiving results. Optionally, client can send input_audio_buffer.commit with final=True to signal audio input is finished, which is useful when streaming audio files.
Prerequisites
- An AWS account with SageMaker AI permissions (including sagemaker:InvokeEndpoint* for bidirectional streaming).
- Docker environment (SageMaker AI Studio with Docker enabled, or a local machine).
- Python 3.12+.
- Access to the Voxtral-Mini-4B-Realtime-2602 model on Hugging Face.
- The aws-sdk-sagemaker-runtime-http2 Python package for invoking the bidirectional streaming API.
Build the custom vLLM container
We start with the SageMaker AI vLLM Deep Learning Container and add three things: the bidirectional streaming Docker label, a WebSocket bridge that translates between SageMaker AI expected routes and vLLM’s native API paths, and an entrypoint that runs both processes.
Dockerfile
FROM public.ecr.aws/deep-learning-containers/vllm:0.17.1-gpu-py312-cu129-ubuntu22.04-sagemaker-v1.0-soci
# Tell SageMaker AI this container supports bidirectional streaming
LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true
WORKDIR /opt/ml/code
# Install bridge dependencies
COPY requirements.txt .
RUN pip install --upgrade --no-cache-dir -r requirements.txt
# WebSocket bridge: routes /invocations-bidirectional-stream → /v1/realtime
COPY app.py .
COPY sagemaker-entrypoint.sh entrypoint.sh
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
HEALTHCHECK --interval=30s --timeout=10s --start-period=120s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1The Docker label com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true signals to SageMaker AI that this container supports bidirectional streaming. Without this label, SageMaker AI will not establish WebSocket connections to the container.
The bridge (app.py) is a small FastAPI application that listens on port 8080, the SageMaker AI-facing port and forwards WebSocket connections to vLLM’s /v1/realtime endpoint on internal port 8081. It also proxies /ping health checks to vLLM’s /health.
VLLM_WS_URL = "ws://localhost:8081/v1/realtime"
@app.websocket("/invocations-bidirectional-stream")
async def websocket_bridge(sm_ws: WebSocket):
await sm_ws.accept()
async with websockets.connect(VLLM_WS_URL) as vllm_ws:
async def sm_to_vllm():
"""Forward SageMaker AI → vLLM."""
while True:
message = await sm_ws.receive()
if "text" in message and message["text"]:
await vllm_ws.send(message["text"])
elif "bytes" in message and message["bytes"]:
# Fallback for non-UTF8 clients
await vllm_ws.send(message["bytes"].decode("utf-8"))
async def vllm_to_sm():
"""Forward vLLM → SageMaker AI."""
async for msg in vllm_ws:
if isinstance(msg, str):
await sm_ws.send_text(msg)
elif isinstance(msg, bytes):
await sm_ws.send_bytes(msg)
await asyncio.gather(sm_to_vllm(), vllm_to_sm())Because the client sets DataType="UTF8", SageMaker AI delivers text frames to the bridge, which forwards them directly to vLLM at /v1/realtime, no frame-type conversion is needed. The binary-to-text decoding in sm_to_vllm is a fallback for clients that do not set DataType.
Deploy to a SageMaker AI endpoint
We deploy to a SageMaker AI real-time endpoint, which will serve our requests.
Configure the model environment and deploy the model
The SM_VLLM_* environment variables configure vLLM’s server parameters:
vllm_env = {
"SM_VLLM_MAX_MODEL_LEN": "45000",
"SM_VLLM_COMPILATION_CONFIG": '{"cudagraph_mode": "PIECEWISE"}'
}Voxtral-Mini-4B supports up to 262,144 tokens of context. We set MAX_MODEL_LEN=45000 here, which is sufficient to live-record approximately one hour of audio (3600 seconds / 0.08 seconds per token). Adjust this value based on your expected audio duration. The COMPILATION_CONFIG with cudagraph_mode: PIECEWISE provides CUDA graph optimization for improved inference throughput.
The following code snippet creates the SageMaker AI endpoint:
# Create model
voxtral_model = Model.create(
model_name=model_name,
primary_container=ContainerDefinition(
image=inference_image,
model_data_source=ModelDataSource(
s3_data_source=S3ModelDataSource(
s3_uri=f"{model_artifact}/",
s3_data_type="S3Prefix",
compression_type="None",
)
),
environment=vllm_env
),
execution_role_arn=role,
)
# Create config
endpoint_config = EndpointConfig.create(
endpoint_config_name=endpoint_config_name,
production_variants=[
ProductionVariant(
variant_name="AllTraffic",
model_name=model_name,
initial_variant_weight=1.0,
instance_type=instance_type,
initial_instance_count=1,
model_data_download_timeout_in_seconds=health_check_timeout,
)
]
)
# Create endpoint
endpoint = Endpoint.create(
endpoint_name=endpoint_name,
endpoint_config_name=endpoint_config_name
)
endpoint.wait_for_status("InService")Test with bidirectional streaming
With the endpoint running, we invoke it using the aws-sdk-sagemaker-runtime-http2 Python SDK. This SDK communicates over HTTP/2 event streams on port 8443 of the SageMaker AI runtime endpoint.
Stream audio and receive transcription
The repository includes a complete client sagemaker_bidi_client.py that wraps the bidirectional streaming SDK in a SageMakerRealtimeClient class. When transcribe_audio() runs, it first sends a session.update event to select the model, then streams the audio file in 4 KB PCM16 chunks. The receive loop runs as a background asyncio.Task, while the main coroutine sends audio chunks so that both directions of the HTTP/2 stream are active simultaneously.
The key detail that makes this overlap observable is the await asyncio.sleep(chunk_duration) after each send. It paces transmission to match real-time playback (~128 ms per 4 KB chunk at 16 kHz) and yields control to the event loop, giving the receive task a chance to process transcription.delta events while more audio is still on the way. Without that yield, chunks would transmit faster than the model can produce output and the interaction would look sequential even though the underlying stream is bidirectional. On the receive side, the loop dispatches on event type: normal ResponseStreamEventPayloadPart events carry JSON messages (session.created, transcription.delta, transcription.done), while ResponseStreamEventModelStreamError and ResponseStreamEventInternalStreamFailure are handled separately so that model-level and platform-level failures surface with clear diagnostics instead of getting lost in the payload path.
Running the client
python sagemaker_bidi_client.py ./audio.wav \
--region us-east-1The output streams transcription text in real time as the audio is sent. Delta tokens appear character by character while audio chunks continue streaming in the background.
Live microphone demo with Gradio
The file-based client is useful for testing, but bidirectional streaming delivers its lowest latency with live audio. The repository includes a Gradio-based microphone client (sagemaker_bidi_microphone_client.py) that captures audio from your microphone and streams it to SageMaker AI in real time:
python sagemaker_bidi_microphone_client.py \
--endpoint-name \
--region us-east-1The microphone client uses the same DataType="UTF8" setting and vLLM Realtime API protocol as the file-based client. It captures audio from the browser via the streaming audio input from Gradio, resamples to 16 kHz PCM16, encodes
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み