AutoSP の紹介:長文コンテキスト LLM 学習を自動化する新技術
AutoSP は、LLM の超長文脈トレーニングにおけるメモリ不足と複雑な実装課題を解決する自動化コンパイラ技術であり、DeepSpeed との統合により開発者の負担を劇的に軽減する。
キーポイント
長文脈トレーニングのボトルネック解消
100k トークンを超える超長文脈処理における OOM(メモリ不足)問題を、従来の ZeRO/FSDP スケーリングでは解決が困難な状況を打破する。
AutoSP の自動化コンパイラ技術
DeepSpeed 内の DeepCompile エコシステムに統合された AutoSP が、複雑なシーケンス並列化(SP)の実装を自動的に行い、開発者が手動でコードを変更する必要をなくす。
実用性とパフォーマンスの両立
既存の並列戦略との互換性を保ちつつ、多様なハードウェア環境でも高いパフォーマンスを発揮する「性能移植性」をコンパイラレベルで実現している。
AutoSP の導入と機能
DeepSpeed の設定変更と簡単なタグ付けだけで、既存の単一デバイス用トレーニングコードをシーケンス並列化(DeepSpeed-Ulysses)および長文脈最適化に対応させる。
独自の活性化チェックポイント戦略
PyTorch の標準的な手法よりも保守的すぎない「Sequence-aware AC (SAC)」を導入し、長文脈トレーニングにおけるメモリ不足(OOM)を回避しつつ、必要な場合にのみスループット低下を引き起こす。
パフォーマンスと制限
最大学習可能シーケンス長は大幅に向上するが、モデル全体を単一のコンパイル可能なアーティファクトとして扱わなければならず、グラフブレイクはサポートされていない。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の学習コストと実装難易度を下げる重要なインフラ技術の登場を示しており、特に超長文脈処理が必要な研究開発現場において、エンジニアリングリソースの大幅な節約をもたらす可能性があります。AutoSP のような自動化コンパイラが普及すれば、ハードウェアベンダーごとの最適化作業から解放され、より迅速に新しいアーキテクチャやモデルサイズの検証が可能になるでしょう。
編集コメント
長文脈 LLM の実用化において最大の障壁の一つであった「メモリ効率と実装の複雑さ」を、コンパイラレベルでの自動化で解決する画期的なアプローチです。開発者の負担を劇的に減らし、研究サイクルを加速させる可能性を秘めています。
近年、大規模言語モデル(LLM)は、トークン数が 10 万を超えるような極めて長いコンテキストを扱うタスク向けに訓練されるようになっています。このようなトークン数では、ZeRO や FSDP といった従来の訓練手法を用いてデバイス数をスケールさせても、メモリ不足(OOM: out-of-memory)の問題が表面化し始めます。これらの問題を回避するために、シーケンス並列処理(SP: sequence parallelism)という手法が広く用いられています。これは、入力トークンを複数のデバイスに分割することで、GPU 数の増加に伴って長いコンテキストの訓練を可能にする並列訓練技術です。
しかし、SP の実装は非常に困難で知られており、DeepSpeed や HuggingFace といった既存ライブラリに対して侵入的なコード変更が必要です。これらのコード変更には、入力トークンのコンテキスト(および中間活性化)の分割、通信集合(collectives)の挿入、計算と通信の重なり付けが含まれ、これらは順伝播(forward pass)と逆伝播(backwards pass)の両方で行わなければなりません。その結果、長いコンテキスト機能を試したい研究者たちは、そのような機能を実現するためにシステムスタックのエンジニアリングに多大な労力を費やすことになり、異なるハードウェアベンダーごとにこの作業を繰り返さねばなりません。
この複雑さを回避するため、AutoSP を導入します。これは完全自動化されたコンパイラベースのソリューションであり、記述が容易なトレーニングコードを、より長い入力コンテキストで効率的に GPU を使用してトレーニングしつつ、既存のパラレル戦略(ZeRO など)と組み合わせ可能なマルチ GPU シーケンスパラレルコードに変換するものです。これにより、開発者が長文コンテキストトレーニングのためにトレーニングパイプラインを繰り返し修正するという面倒な必要性が不要になります。ユーザーは now AutoSP をインポートし、AutoSP バックエンドを使用して任意のモデルをコンパイルするだけでよく、誰でも長文コンテキストトレーニングのパワーを利用できるようになります。さらに、この技術をコンパイラに埋め込むことで、当社のアプローチはパフォーマンスポータブルとなります:高性能なシーケンスパラレル(Sequence Parallelism)が多様なハードウェア上で実現可能です。
本記事の構成は以下の通りです。(1) AutoSP とモデル科学者が長文コンテキストトレーニングを可能にするための使用方法、(2) AutoSP の主要な設計判断、(3) 使いやすさと影響を示す主要な AutoSP の結果、(4) いくつかの制限事項と AutoSP が実行できないこと。
AutoSP の使い方
AutoSP の重要な設計哲学は、複数の GPU をプログラミングする際の複雑さのほとんどをユーザーから抽象化し、シンプルさを保つことにあります。これを実現するために、AutoSP は DeepCompile 内に実装されています。これは DeepSpeed 内のコンパイラエコシステムであり、深層ニューラルネットワークのトレーニングに対して多様な最適化をプログラム可能にします。これにより、DeepSpeed を使用するあらゆるユーザーが、ほとんど手間をかけずにシーケンス並列処理(Sequence Parallelism)を自動的に有効にできます。次に例を見てみましょう。
DeepSpeed の設定をインスタンス化します。
8 つの GPU を使用し、2 つのデータ並列(DP)ランクと 4 つのシーケンス並列(SP)ランクがあると仮定します。
config = {
"train_micro_batch_size_per_gpu": 1,
"train_batch_size": 2,
"steps_per_print": 1,
"optimiser": {
"type": "Adam",
"params": {
"lr": 1e-4
}
},
"zero_optimization": {
"stage": 1, # AutoSP は ZeRO 0/1 と相互運用します。
},
# DeepCompile をオンにし、AutoSP パスをトリガーするように設定するだけです。
"compile": {
"deepcompile": True,
"passes": ["autosp"]
},
"sequence_parallel_size": 4,
"gradient_clipping": 1.0,
}
モデルで DeepSpeed を初期化します。
model, _, _ = deepspeed.initialize(config=config,model=model)
モデルをコンパイルし、自動的に AutoSP パスを適用します。
model.compile(compile_kwargs={"dynamic": True})
for idx, batch in enumerate(train_loader):
# Custom function that we expose within:
# deepspeed/compile/passes/sp_compile.
inputs, labels, positions, mask = prepare_auto_sp_inputs(batch)
loss = model(
input_ids=inputs,
labels=labels,
position_ids=positions,
attention_mask=mask
)
... # Backwards pass, optimiser step etc...
上記の例から分かるように、ユーザーは単一デバイス上で動作する既存のトレーニングコードを引き続き使用し、以下の手順を実行します。(1) DeepSpeed で公開されている prepare_autosp_input ユーティリティ関数を使用して、AutoSP 内のプログラム解析で利用するための入力トークン、アテンションマスク、位置 ID に軽量なタグ付けを行います。(2) DeepSpeed の設定を調整して DeepCompile を有効にし、「passes」フラグを「autosp」に指定します。残りの処理は、モデルのコンパイル時に呼び出される AutoSP コンパイラパスによって自動的に処理され、他の長文脈トレーニング最適化と並列してシーケンス並列化が自動的に有効化されます。AutoSP はさらに ZeRO stage 1 ともデフォルトで自動連携し、DeepSpeed 設定において AutoSP フラグと共に ZeRO-1 フラグを設定するだけで、両方の戦略を組み合わせることができます。
AutoSP コンパイラパス
AutoSP はユーザーコードを変換してより長い文脈でのトレーニングを可能にするため、ここでは AutoSP の主要な設計ポイントとコード変換の内容、および透明性を保つためのユーザーへの影響について簡単に解説します。
シーケンシャル並列化コード変換。AutoSP は自動的にシングル GPU コードをマルチ GPU 用のシーケンシャル並列化(Sequence Parallelism、以下 SP)コードに変換します。AutoSP がコードを変換する具体的な SP ストラテジーは DeepSpeed-Ulysses です。他のストラテジー(例:RingAttention)と比較して DeepSpeed-Ulysses に焦点を当てているのは、NVLink ネットワークトポロジやファットツリーネットワークにおいて、GPU 数が増加しても通信オーバーヘッドが一定に保たれるためです。ただし、DeepSpeed-Ulysses はモデル内のヘッド数(7-8B モデルでは 32)まで SP サイズを拡張できるという点に限界があります。
より長いコンテキストでのトレーニングのための活性化チェックポイント。AutoSP は、長文コンテキストモデリング向けに特別に設計されたカスタム活性化チェックポイント (AC) 戦略も適用しています。AC は計算コストの低い演算子の中間活性化を解放し、必要な勾配を計算するために逆伝播パスで必要に応じて再計算を行います。PyTorch-2.0 では、自動化された最大フロー最小カットに基づく AC の定式化 が導入されていますが、長文コンテキストモデリングにおいては過度に保守的であることが判明しました。そこで我々は、長文コンテキストトレーニングを対象とした新たな AC 戦略として、独特な長文コンテキストの FLOP(浮動小数点演算数) ダイナミクスを活用する「シーケンス認識型 AC (SAC)」を導入しました。(AutoSP のデフォルト設定で) トリガーされると、これはトレーニングのスループットをわずかに低下させます。しかし、これなしでは長いコンテキストでのトレーニングは不可能となるため、ユーザーは OOM(メモリ不足) が発生する構成に対してのみ、このパスを選択的にオンにすることができます。
実モデルにおける AutoSP の評価
AutoSP の実用性を示すために、異なるサイズのモデルに対して NVIDIA GPU で性能を評価し、使いやすさがランタイムパフォーマンスにほとんどあるいは全くコストをかけないことを示します。8 個の A100-80Gb SXM ノード上で、さまざまな Llama 3.1 モデルをベンチマークしました。PyTorch 2.7 と CUDA 12.8 を使用し、AutoSP を以下の torch コンパイル済み手書きベースラインと比較します:RingFlashAttention、DeepSpeed-Ulysses、および ZeRO-3。主要な結果を以下にまとめます。
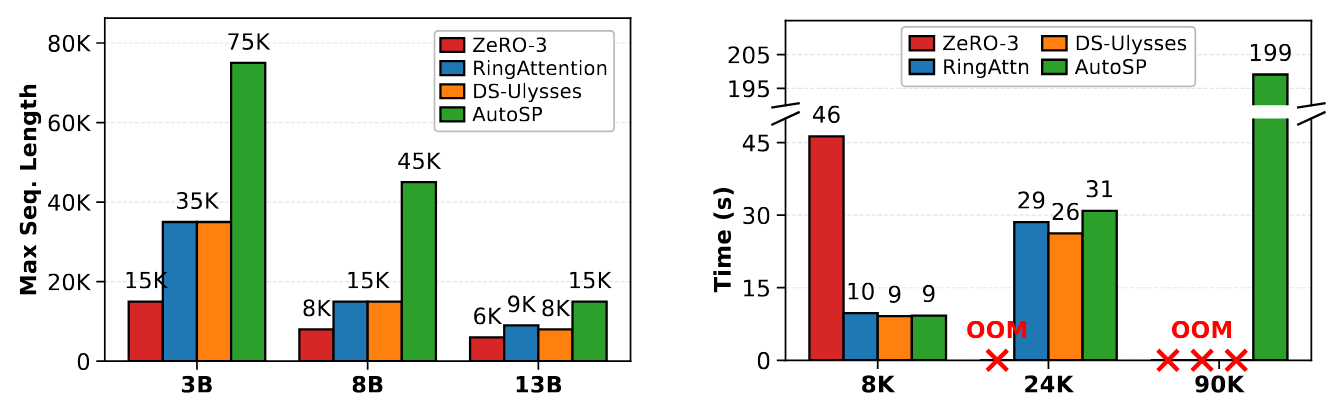
AutoSP は、同じリソース条件下で最大学習可能シーケンス長を増加させるだけでなく(左図 – 高いほど良い)、これらの利点はランタイムパフォーマンスにほとんどコストをかけないことも示されています(右図 – 低いほど良い)。
制限事項
AutoSP には2つの主要な制限があります。第一に、ユーザーはトランスフォーマーを単一のコンパイル可能なアーティファクトとして強制的にコンパイルする必要があります。場合によっては、PyTorch ユーザーが多数の関数を個別にコンパイルしてそれらを1つのモデルに結合することがありますが、これは AutoSP では許可されていません。入力シーケンスを正しくシャードし、この情報をグラフ全体に伝播させるためには、モデル全体をコンパイルして確認する必要があるためです。第二に、コンパイル可能なアーティファクト内のグラフブレイクはすべて禁止されています。これにより情報の分析と伝播が複雑化するため、AutoSP をグラフブレイク耐性のあるものへと拡張することは今後の研究課題として残します。
結論
AutoSP を使用すると、ユーザーは任意のトランスフォーマー学習コードにシーケンス並列化を容易に追加し、長期コンテキスト学習を強化するためのカスタム AC 戦略を実装できます。DeepSpeed との統合により、設定ファイルを変更するだけで、既存の DeepSpeed 学習コードを使用してより長いコンテキストで学習することが可能になります。実際のモデルワークロード(例:Llama 3.1 8B)で試せるエンドツーエンドのサンプルを こちら に用意しています。長期コンテキスト学習がいかに容易になったか、ぜひお試しください。
原文を表示
Increasingly, Large-Language-Models (LLMs) are being trained for extremely long-context tasks, where token counts can exceed 100k+. At these token counts, out-of-memory (OOM) issues start to surface, even when scaling device counts using conventional training techniques such as ZeRO/FSDP. To circumvent these issues, sequence parallelism (SP): partitioning the input tokens across devices to enable long-context training with increasing GPU counts, is a commonly used parallel training technique.
However, implementing SP is notoriously difficult, requiring invasive code changes to existing libraries such as DeepSpeed or HuggingFace. These code changes often involve partitioning input token contexts (and intermediate activations), inserting communication collectives, and overlapping communication with computation, all of which must be done for both the forward and backwards pass. This results in researchers who want to experiment with long context capabilities spending significant effort on engineering the system’s stack to enable such capability, repeating this effort for different hardware vendors.
To avoid this complexity, we introduce AutoSP: a fully automated compiler-based solution that automatically converts easy-to-write training code to multi-GPU sequence parallel code that efficiently uses GPUs to train on longer input contexts while composing with existing parallel strategies (such as ZeRO). This avoids the cumbersome need for developers to repeatedly modify training pipelines for long-context training. Users can now simply import AutoSP and compile arbitrary models using the AutoSP backend, giving the power of long-context training to anyone. Moreover, by embedding this technology into the compiler, our approach is performance-portable: highly performant SP can be realised on diverse hardware.
We structure this post as follows: (1) AutoSP and how model scientists can use it to enable long-context training, (2) Key design decisions of AutoSP, (3) key AutoSP results, demonstrating its ease-of-use and impact, (4) some limitations and things AutoSP cannot do.
AutoSP Usage
A key design philosophy of AutoSP is simplicity in abstracting most of the complexity in programming multiple GPUs from users. To do this, we implement AutoSP within DeepCompile: a compiler ecosystem within DeepSpeed to programmatically enable diverse optimisations for deep neural network training. With this, any user who uses DeepSpeed can automatically enable Sequence Parallelism with almost zero hassle. We take a look at an example next.
# We instantiate a deepspeed config.
# Assume 8 GPUs with 2 DP ranks and 4 SP ranks.
config = {
"train_micro_batch_size_per_gpu": 1,
"train_batch_size": 2,
"steps_per_print": 1,
"optimiser": {
"type": "Adam",
"params": {
"lr": 1e-4
}
},
"zero_optimization": {
"stage": 1, # AutoSP interoperates with ZeRO 0/1.
},
# Simply turn on deepcompile and set
# the AutoSP pass to be triggered on.
"compile": {
"deepcompile": True,
"passes": ["autosp"]
},
"sequence_parallel_size": 4,
"gradient_clipping": 1.0,
}
# Initialise deepspeed with model.
model, _, _ = deepspeed.initialize(config=config,model=model)
# Compiles model and automatically applies AutoSP passes.
model.compile(compile_kwargs={"dynamic": True})
for idx, batch in enumerate(train_loader):
# Custom function that we expose within:
# deepspeed/compile/passes/sp_compile.
inputs, labels, positions, mask = prepare_auto_sp_inputs(batch)
loss = model(
input_ids=inputs,
labels=labels,
position_ids=positions,
attention_mask=mask
)
... # Backwards pass, optimiser step etc...
As seen in the example above, users take existing training code that runs on a single device and do the following: (1) use the prepare_autosp_input utility function (exposed in DeepSpeed) for lightweight tagging of input tokens, attention masks and position ids for use in program analysis within AutoSP. (2) Adjust the DeepSpeed config to turn DeepCompile on, specifying the “passes” flag to “autosp”. The rest is handled through the AutoSP compiler passes, called when compiling the model, which automatically enable sequence-parallelism alongside other long-context training optimisations. AutoSP additionally automatically composes with ZeRO stage 1 out of the box, simply set the ZeRO-1 flag in DeepSpeed alongside the AutoSP flags to combine both strategies.
AutoSP Compiler Passes
Since AutoSP transforms user code to enable longer-context training, we briefly cover the key design points of AutoSP and code transformations, as well as its consequences to users for transparency.
Sequence Parallelism Code Transformations. AutoSP automatically converts single-GPU code to multi-GPU sequence parallel (SP) code. The specific SP strategy AutoSP converts code into is DeepSpeed-Ulysses. We specifically focus on DeepSpeed-Ulysses over other strategies (e.g. RingAttention) as its communication overhead stays constant with increasing GPU counts on NVLink network topologies or fat-tree networks. However, DeepSpeed-Ulysses only enables scaling the SP-size to the number of heads in a model (32 in 7-8B models).
Activation Checkpointing for longer-context training. AutoSP additionally applies a custom activation-checkpointing (AC) strategy curated for long-context modelling. AC releases intermediate activations of cheap-to-compute operators, recomputing them in the backwards pass as required to compute relevant gradients. PyTorch-2.0 introduces an automated max-flow min-cut based AC formulation, but we find this to be overly conservative for long-context modelling. We accordingly introduce a novel AC strategy targeted for long-context training: Sequence-aware AC (SAC), which exploits unique long-context FLOP dynamics. When triggered on (the default setting in AutoSP), this marginally reduces training throughput. However, without it, training on longer contexts is infeasible, so the user can selectively choose to turn this pass on only for configurations that OOM.
Evaluating AutoSP on Real Models
To demonstrate AutoSP’s viability, we evaluate its performance on models of varying sizes on NVIDIA GPUs to show that its ease of use comes at little to no cost to runtime performance. We benchmark different Llama 3.1 models on an 8 A100-80Gb SXM node. We use PyTorch 2.7 with CUDA 12.8, comparing AutoSP to torch-compiled hand-written baselines of: RingFlashAttention, DeepSpeed-Ulysses, and ZeRO-3. We summarise key results in the figure below:
Not only can AutoSP increase the maximum trainable sequence length given the same resources (left figure – higher is better), but also these benefits come at little cost to runtime performance (right figure – lower is better).
Limitations
There are two key limitations of AutoSP. First, we require that the user forcefully compile a transformer as a single compilable artifact. Occasionally, PyTorch users may compile many functions individually and stitch them together into one model. This is disallowed in AutoSP as we need to compile and see the entire model to correctly shard input sequences and propagate this information throughout the entire graph. Second, we disallow any graph breaks in compilable artifacts. This complicates analysis and propagation of information, and we leave extending AutoSP to be graph-break resilient to future research.
Conclusion
AutoSP enables users to easily extend arbitrary transformer training code to enable Sequence Parallelism, with a custom AC strategy for enhanced long-context training. Integration with DeepSpeed allows users to easily use existing DeepSpeed training code to train on longer contexts by simply changing a config file. We have prepared end-to-end examples for users to play around with on real model workloads (e.g. Llama 3.1 8B) here. Give it a try to see how easy long context training has become.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み