TinyFish Bigset がテキストプロンプトからライブデータセットを生成
TinyFish が、自然言語の指示から自動でスキーマを推論し、ウェブ上の生データを収集・検証して構造化データセットとして提供するオープンソース多エージェントシステム「Bigset」を発表した。
キーポイント
テキストプロンプトによる自動化データ収集
ユーザーが自然言語で記述するだけで、AI がスキーマを推論し、ウェブ上の情報を検索・抽出して CSV や XLSX 形式の構造化データセットとして出力する。
自律型エージェントによる検証と更新
オーケストレーターが調査範囲を定義し、サブエージェントが個別のエンティティを調査・検証してデータを挿入する仕組みを採用しており、30 分単位から週次までの自動更新設定が可能。
オープンソース化とコスト管理
システムは GitHub で公開されており、各サブエージェントはツール呼び出しの予算制限(6 回)内で動作し、検証されたデータにソース URL を付与して信頼性を担保する。
自律型マルチエージェントシステム
オーケストレーターとサブエージェントが連携し、自然言語の指示からスキーマを推論してウェブからデータを収集・検証する。
厳格なデータ整合性と自動化
サブエージェントは数値の捏造を禁止し、未確認の場合は空白とし、重複キーを自動拒否することで信頼性を担保する。
オープンソースとセルフホスト対応
AGPL-3.0ライセンスで提供され、Dockerによるセルフホストが可能で、スケーラブルな更新スケジュール設定もサポートしている。
影響分析・編集コメントを表示
影響分析
この発表は、データ収集のハードルを劇的に下げ、開発者やアナリストが即座に生データを入手・活用できる環境を整えるものであり、AI アプリケーションの開発サイクルを加速させる重要な進展です。特に、データの鮮度を自動で維持する機能は、リアルタイム性が求められる分析タスクにおいて大きな価値を持ちます。
編集コメント
「テキストからデータセットへ」というシンプルなユースケースを、自律型エージェントと検証プロセスで実現した点は非常に示唆に富んでいます。特にデータの鮮度を自動更新する機能は、静的なデータベースでは対応できないリアルタイム分析の需要に応える画期的なアプローチです。
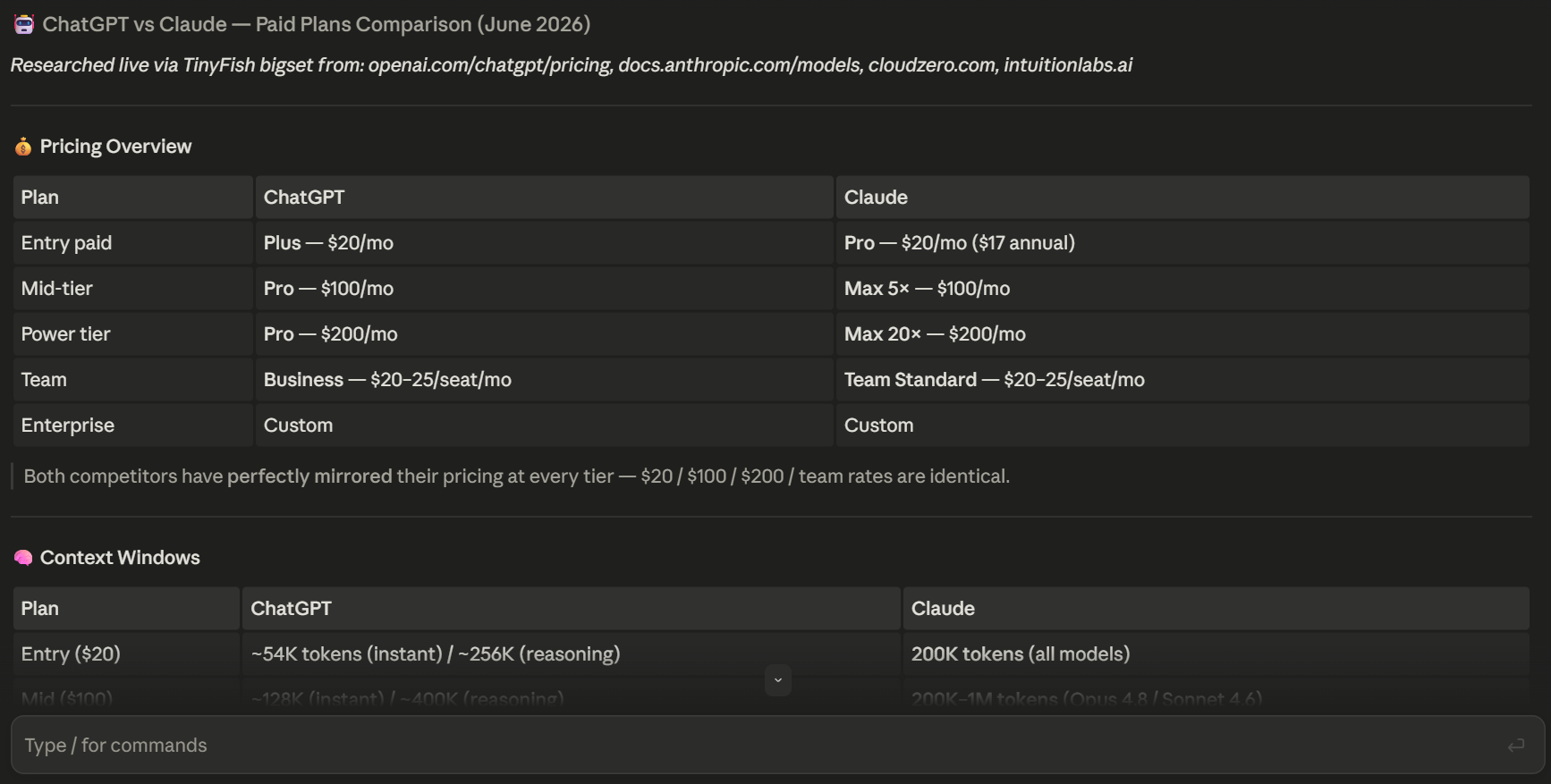
TinyFish は、自然言語の文章から生きたウェブから構造化されたデータセットを抽出するオープンソースのマルチエージェントシステム「Bigset」[https://github.com/tinyfish-io/bigset?ref=testingcatalog.com] をリリースしました。必要なものを記述すると、Bigset がスキーマを推論し、自律型エージェントが実際の Web ページ上で調査を行い、その発見を情報源と照合して検証し、重複を除去した後に、CSV または XLSX としてエクスポート可能なクリーンなテーブルを返します。更新頻度を 30 分単位から週次まで設定可能で、エージェントがスケジュール通りに再実行されるため、誰かがスクリプトに触れなくてもデータセットは常に最新の状態を保ちます。
0:00
/0:48
University Application Tracker
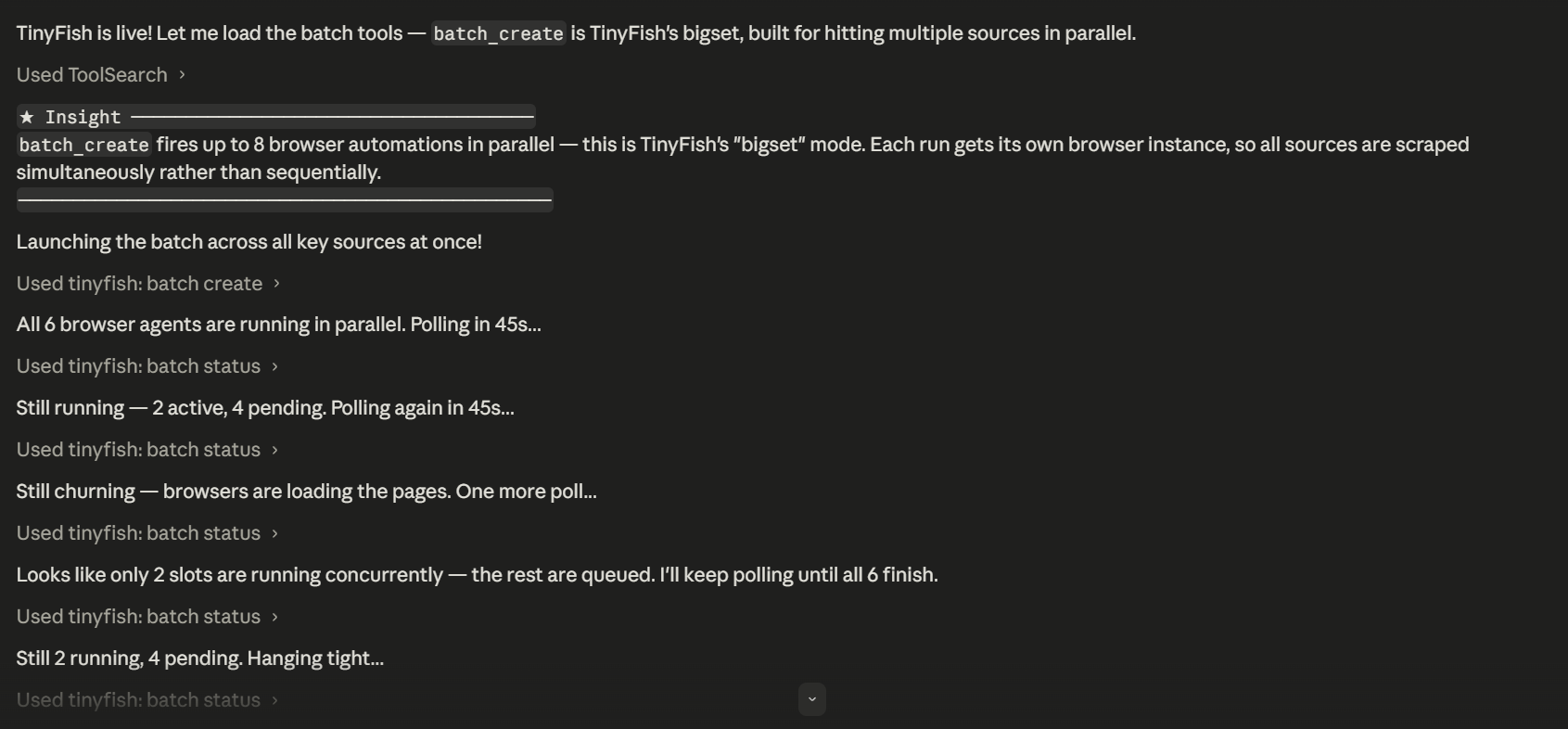
この作業は 2 つのエージェント役割に分割されています。オーケストレーターエージェントは幅優先探索を行い、どの行をデータセットに含めるべきか、またウェブ上のどこでそれらを見つけるべきかを特定し、それぞれの行を埋めるためにサブエージェントを派遣します。オーケストレーター自体には書き込み権限はありません。各サブエージェントは 6 つのツール呼び出しという厳格な予算の下で単一のエンティティを調査し、TinyFish Search と Fetch を通じて実データを取得し、ソース URL とデータ発見のプロセス記録を伴う 1 つの検証済み行を挿入します。
TinyFish Bigset サブエージェントには、値を捏造しないこと、確認できない場合はフィールドを空白のままにすること、重複する主キーは自動的に拒否することが指示されています。オーケストレーターはデータセットが目標行数に達するまで実行され、データの所在を学習するにつれて構築速度が向上します。
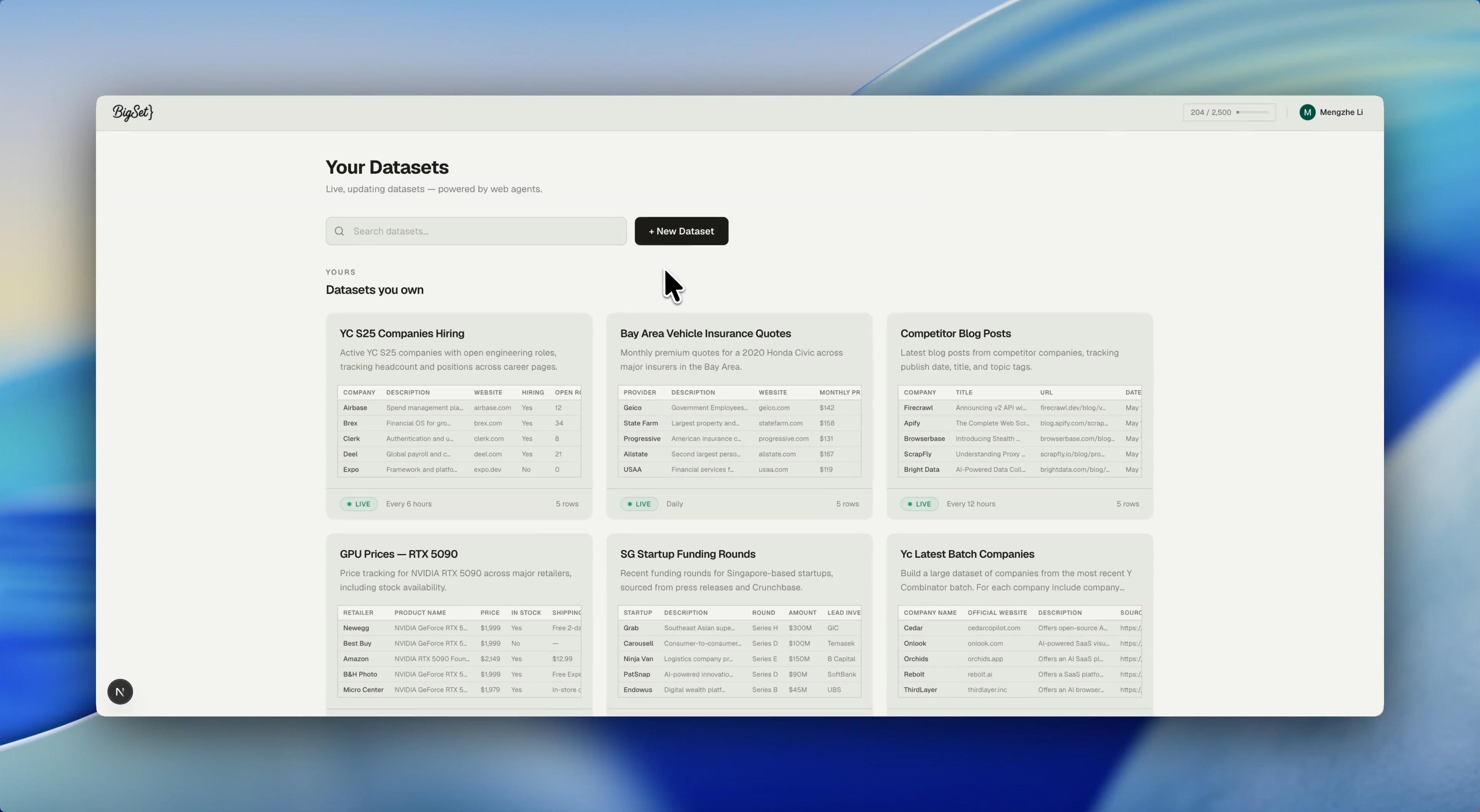
 imageTinyfish Bigset ResultsBigset は AGPL-3.0 ライセンスの下で提供され、Docker を通じてセルフホストで動作します。デフォルトでは、スキーマ推論に Claude Sonnet 4.6 を、エージェントの役割には Qwen3.7-max を使用し、すべて OpenRouter を経由してルーティングされますが、各役割ごとに設定可能です。チームは率直に、このプロジェクトは実験的なものであると述べています。データセットの構築には 2〜5 分かかり、公開されたウェブデータが存在するトピックにおいて最も効果的に機能します。無料プランでは月間 2,500 行分の操作が可能で、AI 企業の採用情報、GPU の価格、モデルの料金、主要なオープンソースリポジトリを網羅した 9 つの厳選されたパブリックデータセットが同梱されています。アカウントなしでも閲覧可能です。
imageTinyfish Bigset ResultsBigset は AGPL-3.0 ライセンスの下で提供され、Docker を通じてセルフホストで動作します。デフォルトでは、スキーマ推論に Claude Sonnet 4.6 を、エージェントの役割には Qwen3.7-max を使用し、すべて OpenRouter を経由してルーティングされますが、各役割ごとに設定可能です。チームは率直に、このプロジェクトは実験的なものであると述べています。データセットの構築には 2〜5 分かかり、公開されたウェブデータが存在するトピックにおいて最も効果的に機能します。無料プランでは月間 2,500 行分の操作が可能で、AI 企業の採用情報、GPU の価格、モデルの料金、主要なオープンソースリポジトリを網羅した 9 つの厳選されたパブリックデータセットが同梱されています。アカウントなしでも閲覧可能です。
TinyFish はプラットフォームの開発元であるカリフォルニア州パロアルトに拠点を置く企業で、ICONIQ が主導するシリーズ A ラウンドで 4,700 万ドルの資金調達を果たしました。Google、DoorDash、Amazon をエンタープライズ顧客として抱え、これまでに 4,000 万件以上のエージェント操作を処理しています。Bigset は、同社のエンタープライズ向けエージェント製品の基盤となるウェブインフラである TinyFish Search と Fetch に直接構築されており、プロプライエタリな自然言語データセットツールのためのオープンソース版として登場しました。利用料はユーザー数ベースではなく、ドメイン制限も設けられておらず、自分で実行する場合はパイプラインの完全な所有権を確保できます。
原文を表示
TinyFish has launched Bigset, an open-source multi-agent system that turns a plain-language sentence into a structured dataset pulled from the live web. You describe what you want, and Bigset infers the schema, sends autonomous agents to research it on real web pages, verifies their findings against sources, deduplicates, and hands back a clean table you can export as CSV or XLSX. Set a refresh cadence from 30 minutes to weekly, and have the agents rerun on schedule so the dataset stays current without anyone needing to touch a script.
The work is split across two agent roles. An orchestrator agent does breadth-first discovery, identifying which rows belong in the dataset and where on the web to find them, then dispatches sub-agents to fill each one. The orchestrator holds no write access of its own. Each sub-agent researches a single entity under a tight budget of 6 tool calls, pulls real data via TinyFish Search and Fetch, and inserts one verified row with its source URLs and a record of how the data was found.
Sub-agents are instructed never to fabricate values, to leave fields blank when they cannot be confirmed, and to reject duplicate primary keys automatically. The orchestrator runs until the dataset reaches its row target, building faster as it learns where the data lives.
Bigset is licensed under AGPL-3.0 and runs self-hosted through Docker, with schema inference on Claude Sonnet 4.6 and the agent roles on Qwen3.7-max by default, all routed through OpenRouter and configurable per role. The team is candid that the project is experimental: a dataset takes 2 to 5 minutes to build, it works best on topics with public web data, and the free tier covers 2,500 row operations per month. It ships with 9 curated public datasets covering AI companies hiring, GPU prices, model pricing, and top open-source repositories, browsable without an account.
TinyFish is the Palo Alto-based company behind the platform, backed by $47 million in Series A funding led by ICONIQ, and counts Google, DoorDash, and Amazon among its enterprise clients, having processed more than 40 million agent operations. Bigset is built directly on TinyFish Search and Fetch, the same web infrastructure underneath the company's enterprise agent products, and arrives as the open-source answer to proprietary natural-language dataset tools, with no per-seat pricing, no domain restrictions, and full pipeline ownership for anyone who runs it themselves.
関連記事
Datasette Apps:カスタム HTML アプリケーションを Datasette 内でホスト可能に
Simon Willison が開発した Simon Willison Blog は、Datasette に新しいプラグイン「datasette-apps」を追加し、自己完結型の HTML と JavaScript で構成されるアプリケーションを同プラットフォーム上で実行できる機能を公開しました。
datasette-acl 0.6a0 のリリース
Alex Garcia 氏らが中心となり、データセットのテーブル単位での権限管理から、一般リソース共有システムへと拡張された「datasette-acl」バージョン 0.6a0 が公開されました。これにより、複数ユーザー環境でリソースへのアクセス制御が細かく行えるようになります。
GLM-5.2 はおそらく最も強力なテキスト専用オープンウェイト大規模言語モデルである
中国の AI ラボ Z.ai が、7530億パラメータ(アクティブ400億)を持つテキスト専用モデル「GLM-5.2」を MIT ライセンスで公開した。これは同社が提供するオープンウェイト大規模言語モデルの中で最も強力なものである。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み