AI週報 #337 - Anthropicのリスク、QuitGPT、ChatGPT 5.4
米国防総省がAnthropicをサプライチェーンリスクとして指定しClaudeの使用を停止させた一方、OpenAIは同省と機密環境でのモデル導入契約を結び、両社の軍事利用をめぐる対立が表面化している。
キーポイント
Anthropicのサプライチェーンリスク指定と契約紛争
米国防総省はAnthropicを「サプライチェーンリスク」として指定し、防衛業者に対しClaudeの使用停止と契約終了を命じた。Anthropicは大規模国内監視や自律型兵器への使用禁止などの条件を求めたが、国防総省は「すべての合法的用途」へのアクセスを要求したため対立が生じた。
OpenAIと米軍の機密環境での提携
OpenAIは国防総省と契約を結び、機密環境でのモデル展開を発表した。これに対し、AnthropicのCEOであるDario Amodei氏はOpenAIの発表を「正直な嘘」と非難し、両社の姿勢の違いが浮き彫りになった。
クラウド事業者によるClaudeの非防衛向け提供継続
Microsoft、Google、Amazonは、国防総省の指定が防衛関連契約に限定されることを強調し、M365やGitHub、Google Cloudを通じて一般顧客向けにClaudeの利用を継続すると表明した。
IranでのClaude活用と「ChatGPTキャンセル」運動
報告によると、ClaudeはIranでの米軍の諜報分析やサイバー作戦などの支援に使用されている。この軍事利用拡大を受け、OpenAIの契約を批判する「ChatGPTキャンセル」運動が広がっている。
OpenAIと国防総省の契約における監視制限への批判
OpenAIは国内監視や自律型兵器を禁止すると主張するも、AnthropicのCEOはこれを「安全 theater」と批判し、契約が「すべての合法的な目的」に依存している点を問題視した。
'QuitGPT'運動とAnthropicの市場シェア拡大
OpenAIとの軍事契約への抗議として「ChatGPTをキャンセル」する動きが広がり、OpenAI本部前で抗議集会が行われる一方、AnthropicのClaudeはApp StoreでNo.1に上昇し、消費者意識の高まりから恩恵を受けている可能性があると指摘された。
契約の改訂と残る法的な懸念
OpenAIは米国人の国内監視を意図的に使用しないよう契約文言を改訂したが、完全な契約は公開されておらず、法専門家は抜け穴が残っており、政策の解釈変更により監視が拡大する可能性があると警告している。
影響分析・編集コメントを表示
影響分析
このニュースは、AI企業が政府・軍事部門とどのように関わるかが、企業の存立基盤や倫理規定に直結する重大な示唆を与えている。AnthropicとOpenAIの対立構造は、今後のAI規制や契約条件交渉における標準的な基準を形成する可能性があり、投資家やパートナー企業はこれらのリスクを再評価せざるを得ない。
編集コメント
国防総省の「サプライチェーンリスク」指定は、単なる契約問題を超え、AI企業の法的・倫理的立場を再定義する歴史的な出来事である。AnthropicとOpenAIの対立構造は、今後のAIガバナンス議論において重要なケーススタディとなるだろう。
Alibabaは、Qwenの技術リーダーが突然退任した後、対応に追われています。この突然の退任は、組織再編、リソース配分、そしてHao Zhouのような新規採用者がLinの技術的・リーダーシップ的役割を埋めるかどうかについて、緊急の全社員会議を引き起こしました。
OpenAIは、史上最大級のプライベート資金調達ラウンドの一つで1100億ドルを調達しました。この資金調達には、大規模なコンピュートおよびサービス提供のコミットメントが含まれており、特にAWSおよびNvidiaとのインフラパートナーシップは、ギガワット規模のトレーニング/推論能力と相当なBedrock統合を約束しています。このラウンドはまだ開かれており、一部の支払いはAGI(人工汎用知能)やIPO(新規株式公開)のような将来の条件に依存しています。
Cursorは、年間収益が20億ドルを超えたと報じられています。エンタープライズ顧客が現在、収益の約60%を占めており、個人ユーザーの離脱を相殺し、同社の収益成長率の最近の倍増を牽引しています。
研究
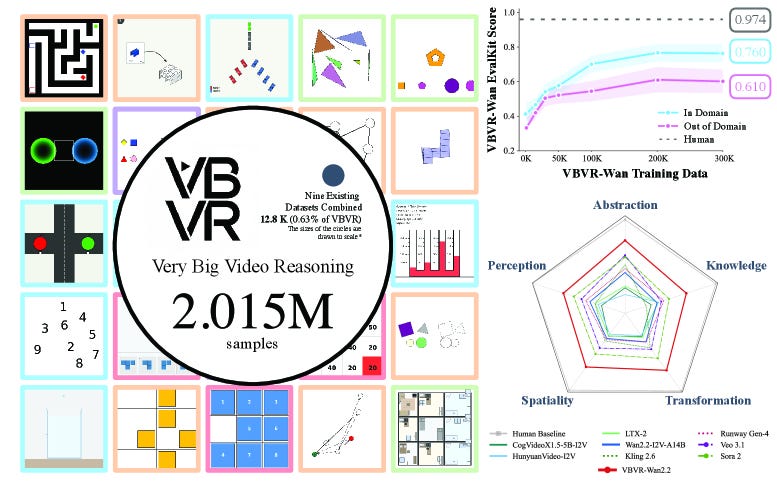
非常に大規模なビデオ推論スイート。VBVR-Dataset(1,007,500クリップ)は、5つの認知の柱にわたる200のタスクをカバーし、人間の判断と整合した検証可能なVBVR-Benchとペアになっています。スケーリング研究は、モデルとデータのスケールが増加するにつれて、ビデオ推論が改善されるものの、依然として人間の水準には及ばないことを示しています。
ハイブリッドオン・オフポリシー最適化による探索的メモリ拡張LLMエージェント。この手法は、モデルパラメータをオン・オフポリシー強化学習(RL)で共同でトレーニングしながら、インタラクション中にノンパラメトリックメモリを更新し、メモリ誘導およびメモリフリーのロールアウトを使用して、より広範な探索を促進し、具体化推論ベンチマークでのパフォーマンスを向上させます。
HyperSteer: ハイパーネットワークによる大規模なアクティベーションステアリング。ハイパーネットワークは、指示調整済みベース言語モデル(LM)に対してタスク条件付きステアリングベクトルを生成し、従来の手法よりも優れた、よりスケーラブルなアクティベーションステアリングを実現し、保留プロンプトでのプロンプトによるステアリングと同等の結果を示します。
エージェント的コード推論。LLMエージェントに、半形式的構造化証明書(明示的な前提、トレースされたコードパス、テストごとの証拠)でプロンプトを与えることで、形式的意味論や専門的なトレーニングなしに、多様なベンチマークにわたって、実行不要のパッチ等価性検証、コードQA、および障害箇所特定を改善します。
言語モデリングを超えて: マルチモーダル事前学習の探求。テキスト、画像、ビデオの混合データで一つのモデルをスクラッチからトレーニングすること(セマンティック表現オートエンコーダーとMoE(専門家の混合)を使用)は、致命的な干渉なしに視覚と言語の共同学習を示し、視覚データの飢餓性とスケーリングの非対称性がスパース性によって緩和されることを明らかにし、ビデオ豊富なマルチモーダル事前学習が創発的な世界モデリングおよび生成/理解能力をもたらすことを実証します。
セマンティックチューブ予測: JEPAによるLLMデータ効率の向上。隠れ状態偏差の成分を推測された測地線軌道(「セマンティックチューブ」)に対して垂直方向に最小化するSTP補助損失を追加することで、次のトークン予測のみと比較して、自己回帰型LLMトレーニングにおける信号対雑音比、データ効率、および多様性を向上させます。
スパイク、スパース、シンク: 大規模アクティベーションとアテンションシンクの解剖。大規模な外れ値アクティベーションとアテンションシンクは、特定の正規化の選択、アテンション空間の次元性、およびコンテキスト長トレーニングにより、事前学習済みデコーダのみのトランスフォーマーで一般的に同時発生します。各現象は、言語モデリングのパフォーマンスを損なうことなく独立して緩和できます。
言語モデル事前学習のためのプログレッシブ残差ウォームアップ。ProResは、トレーニング中に各層の残差をゼロから1へ徐々にスケーリングし、深い層の貢献を遅らせて浅い層が最初に安定するようにすることで、7100万から70億パラメータまでのモデルにわたってパープレキシティと深さスケーリングを改善します。
推論モデルは、思考の連鎖を制御するのに苦労します。CoT-Control(14,076インスタンスのベンチマーク)は、モデルが思考の連鎖を修正するための明示的な指示にどれだけ従うかを評価します。ほとんどの推論モデルは制御可能性に苦労しており、それはモデルサイズ、推論努力、トレーニング、および状況認識プロンプトによって異なります。
分析
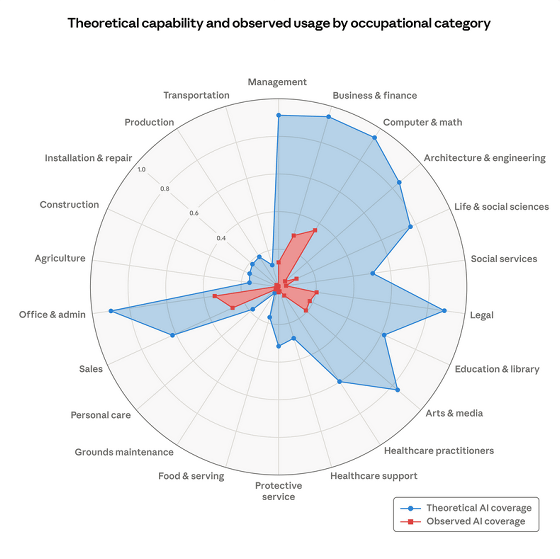
Anthropicは、AIの影響を受けやすい職業の傾向と、労働市場に変化があるかどうかについて報告しています。Anthropicの分析は、「観察された露出」指標を導入し、どの職業(特にプログラマー、カスタマーサービス担当者、金融アナリスト)が、理論的にAIによって自動化可能であり、かつ実際にすでに自動化されているタスクを持っているかを示しています。より高い教育を受け、より高い収入の労働者の中で露出が高いことを発見し、全体として現在の失業への影響はほとんどないが、高露出役割の22-25歳の雇用に小さな減少があると報告しています。
原文を表示
Note from Editor: apologies for missing a week with this newsletter. As I mentioned on the podcast, my startup Astrocade has recently raised our series B which has gotten me extra busy lately. I’ll do my best to keep the schedule consistent!
PS we are hiring for engineers, marketing, product, growth, and more! If you’re in the bay area, would like to join a small but growing startup, and think building a youtube-of-games sounds exciting, feel free to email me at andrey@astroblox.ai or message me on LinkedIn.
Check out Astrocade!
Top News
Anthropic officially told by DOD that it’s a supply chain risk even as Claude used in Iran
Anthropic latest statement on the situation
Related:
Anthropic Hits Back After US Military Labels It a ‘Supply Chain Risk’
Anthropic CEO: We’re trying to “deescalate” Pentagon AI standoff to reach “some agreement that works for us and works for them”
Where things stand with the Department of War
Anthropic CEO Dario Amodei calls OpenAI’s messaging around military deal ‘straight up lies,’ report says
‘No ethics at all’: the ‘cancel ChatGPT’ trend is growing after OpenAI signs a deal with the US military
Microsoft, Google, Amazon say Anthropic Claude remains available to non-defense customers
Summary: The Pentagon formally designated Anthropic a “supply chain risk,” ordering defense vendors and contractors to certify they are not using Claude in DoD work and triggering an immediate wind-down of Pentagon use of Anthropic’s models. The dispute centers on contract terms: Anthropic sought explicit red lines against mass domestic surveillance and fully autonomous weapons, while the DoD insisted on access for “all lawful purposes.” Anthropic says the designation under 10 USC 3252 is narrow, applies only to uses tied directly to DoD contracts, and violates the statute’s “least restrictive means” requirement; the company plans to challenge it in court. At the same time, multiple reports indicate Claude has supported U.S. military operations in Iran for intelligence analysis, modeling and simulation, operational planning, and cyber operations.
After Defense Secretary Pete Hegseth suggested no military partner may conduct any commercial activity with Anthropic, confusion spread about the scope. Cloud providers disputed that interpretation; Microsoft, Google, and AWS clarified Claude remains available for non-defense workloads via M365, GitHub, AI Foundry, and Google Cloud.
Meanwhile, OpenAI announced a DoD deal to deploy its models in classified environments, citing prohibitions on mass surveillance and autonomous weapon systems. Anthropic CEO Dario Amodei called OpenAI’s framing “straight up lies” and “safety theater,” arguing the agreement still hinges on “all lawful purposes.”
Editor’s Take: The designation of Anthropic as a supply chain risk could have meant a massive hit to its business, but as of now it appears that may not happen. In fact, Anthropic might on the whole have benefited from the events, given the massive rise in consumer awareness of Claude as an alternative to ChatGPT. Still, it appears likely that this story is not yet over.
‘No ethics at all’: the ‘cancel ChatGPT’ trend is growing after OpenAI signs a deal with the US military
OpenAI’s statement
Related:
Anthropic’s Claude rises to No. 1 in the App Store following Pentagon dispute
How OpenAI caved to the Pentagon on AI surveillance
‘QuitGPT’ protesters rally outside OpenAI HQ in San Francisco over deal with Pentagon
OpenAI alters deal with Pentagon as critics sound alarm over surveillance
OpenAI hardware exec Caitlin Kalinowski quits in response to Pentagon deal
Summary: OpenAI signed an agreement with the Department of War after Anthropic walked away over, as covered above. OpenAI says its deal enforces “red lines” via legal references and technical guardrails, citing compliance with the Fourth Amendment, FISA, EO 12333, and DoD policy, plus cloud-only deployment, security clearances, and classifiers to monitor use.
Critics counter that the terms still hinge on “any lawful use,” a standard that has historically enabled bulk data programs like PRISM and Verizon call record collection, and they note vague carve-outs such as prohibitions on “unconstrained” or “generalized” monitoring. OpenAI later posted revised language that “the AI system shall not be intentionally used for domestic surveillance of U.S. persons,” and said defense intelligence components (e.g., NSA) are excluded, but it has not released the full contract; legal experts warn loopholes remain and that policy reinterpretations can broaden surveillance.
Source
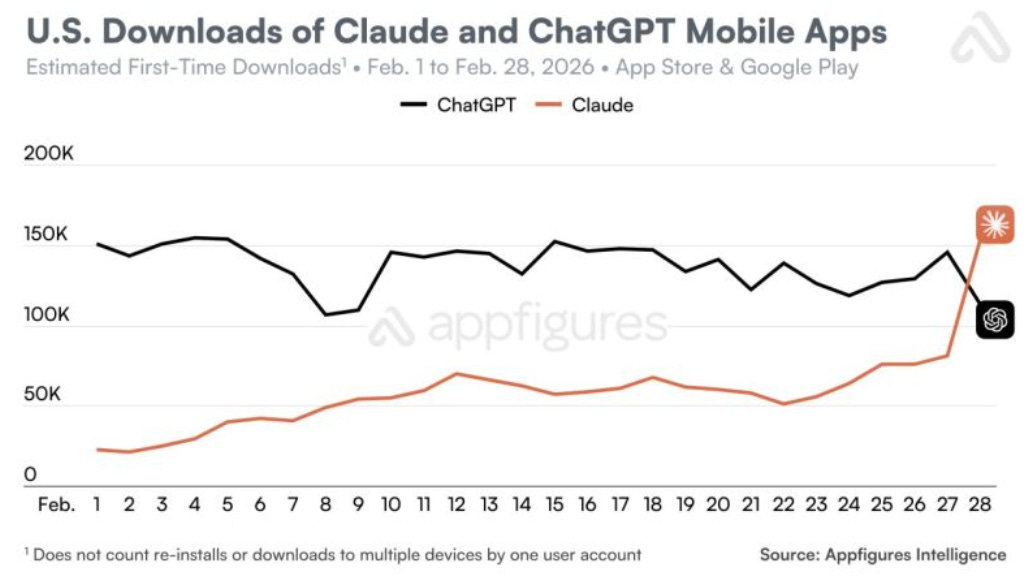
The fallout was swift: a “QuitGPT” boycott, in-person protests at OpenAI’s SF HQ with “No killer robots” messaging, and a 295% surge in ChatGPT uninstalls. Anthropic’s Claude climbed to No. 1 in the U.S. App Store, with daily sign-ups breaking records, free users up 60% since January, and paid subscribers more than doubling this year. Inside OpenAI, hardware lead Caitlin Kalinowski resigned, citing rushed governance and insufficiently defined guardrails on surveillance and lethal autonomy.
Editor’s Take: Consumer boycotts like “QuitGPT” rarely lead to a significant lasting loss for the targeted company, but Claude has thus far been the underdog relative to ChatGPT with consumers, and the scale of the reaction does appear meaningful. In either case, the impact on Anthropic’s hiring power is likely even more significant given that how hotly fought for top tier AI talent is.
OpenAI launches GPT-5.4 with Pro and Thinking versions
Source
Related:
‘We heard your feedback loud and clear’ — OpenAI introduces new ChatGPT 5.3 Instant to ‘reduce the cringe’ for all users
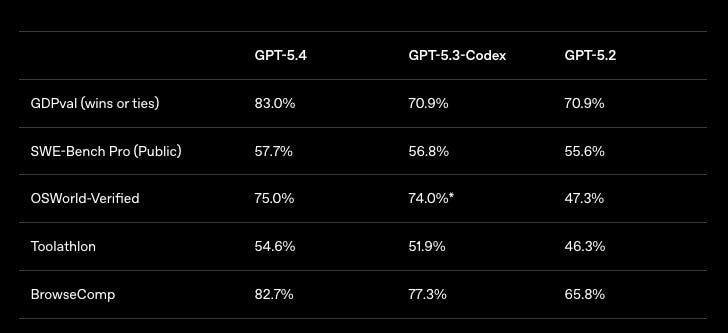
Summary: OpenAI released GPT-5.4 in three variants—standard, Pro, and Thinking—positioning it as a more capable and efficient frontier model for professional work. The API now supports up to a 1 million-token context window, and improved token efficiency means it can solve the same tasks with fewer tokens than prior models. GPT-5.4 posted record results on OSWorld-Verified and WebArena Verified for computer use, scored 83% on OpenAI’s GDPval for knowledge work, and led Mercor’s APEX-Agents benchmark for law and finance tasks. OpenAI also introduced Tool Search for API tool calling, allowing the model to fetch tool definitions on demand to reduce token overhead and latency, and reported fewer factual errors versus GPT-5.2 (33% fewer erroneous claims; 18% fewer responses with errors).
Separately, OpenAI upgraded ChatGPT’s default to GPT-5.3 Instant to “reduce the cringe,” tuning away unnecessary refusals and long safety disclaimers while keeping guardrails. GPT-5.3 Instant focuses on direct answers for reasonable requests and improves accuracy, with ~27% fewer hallucinations during online research and ~20% fewer without browsing, plus better blending of web data with prior knowledge. The change updates the baseline chat experience across common uses while retaining GPT-5.2 Instant for paid users as a legacy option.
Editor’ Take: I discussed the accelerating rate of these ‘+0.1’ model releases in the last couple of these newsletters, and the same comments largely apply here. Relative to last year, 2026
Other News
Tools
Luma launches creative AI agents powered by its new ‘Unified Intelligence’ models. The agents can plan, generate, and iteratively refine text, images, video, and audio for ad agencies and brands using a single multimodal Uni‑1 model that maintains persistent context across assets and coordinates with other AI models.
Anthropic’s Claude reports widespread outage. Thousands of users reported login and access failures affecting Claude.ai and Claude Code, while Anthropic said the API remained operational and engineers were implementing a fix.
Google makes Gmail, Drive, and Docs ‘agent-ready’ for OpenClaw. A new CLI offers developer‑focused tools and documentation to simplify and standardize how AI agents like OpenClaw and MCP‑compatible apps connect to Gmail, Drive, Docs, and other Workspace services.
Google reveals dev-focused Gemini 3.1 Flash Lite, promises ‘best-in-class intelligence for your highest-volume workloads’. The model offers faster response and output generation while cutting per‑token input/output costs versus Gemini 2.5 Flash, outperforms several rivals on multiple benchmarks, and is available to developers in preview via the Gemini API and Vertex AI.
Cursor is rolling out a new kind of agentic coding tool. The Automations feature lets engineers trigger and manage always‑on agents from events like code changes, Slack messages, timers, PagerDuty incidents, and weekly summaries so agents can run reviews, security audits, incident responses, and other recurring tasks without constant human initiation.
Business
Alibaba scrambles after sudden departure of Qwen tech lead. The sudden departure sparked urgent all‑hands discussions about restructuring, resource allocation, and whether new hires like Hao Zhou will fill Lin’s technical and leadership roles.
OpenAI raises $110B in one of the largest private funding rounds in history. The funding includes large compute and services commitments—notably AWS and Nvidia infrastructure partnerships that pledge gigawatts of training/inference capacity and substantial Bedrock integration—while the round remains open and some payments are contingent on future conditions like AGI or an IPO.
Cursor has reportedly surpassed $2B in annualized revenue. Enterprise customers now account for about 60% of revenue, helping offset individual‑user defections and driving a recent doubling in the company’s revenue run rate.
Research
A Very Big Video Reasoning Suite. VBVR‑Dataset (1,007,500 clips) spans 200 tasks across five cognitive pillars, paired with a verifiable VBVR‑Bench aligned with human judgments; a scaling study shows improved yet still sub‑human video reasoning as model and data scale increase.
Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization. The method jointly trains model parameters with on‑ and off‑policy RL while updating a non‑parametric memory during interaction, using memory‑guided and memory‑free rollouts to drive broader exploration and improve performance on embodied reasoning benchmarks.
HyperSteer: Activation Steering at Scale with Hypernetworks. Hypernetworks generate task‑conditioned steering vectors for an instruction‑tuned base LM, achieving better and more scalable activation steering than prior methods and matching steering‑via‑prompting on held‑out prompts.
Agentic Code Reasoning. Prompting LLM agents with semi‑formal structured certificates—explicit premises, traced code paths, and per‑test evidence—improves execution‑free patch equivalence verification, code QA, and fault localization across diverse benchmarks without formal semantics or specialized training.
Beyond Language Modeling: An Exploration of Multimodal Pretraining. Training a single model from scratch with mixed text, image, and video data—using semantic representation autoencoders plus MoE—shows joint vision‑language learning without fatal interference, reveals a vision data hunger and scaling asymmetry mitigated by sparsity, and demonstrates that video‑rich multimodal pretraining yields emergent world‑modeling and generation/understanding abilities.
Semantic Tube Prediction: Beating LLM Data Efficiency with JEPA. Adding an STP auxiliary loss that minimizes components of hidden‑state deviation perpendicular to inferred geodesic trajectories (“semantic tube”) improves signal‑to‑noise ratio, data efficiency, and diversity in autoregressive LLM training compared to next‑token prediction alone.
The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks. Massive outlier activations and attention sinks commonly co‑occur in pretrained decoder‑only Transformers due to specific normalization choices, attention‑space dimensionality, and context‑length training; each phenomenon can be independently mitigated without hurting language‑modeling performance.
Progressive Residual Warmup for Language Model Pretraining. ProRes gradually scales each layer’s residual from zero to one during training—delaying deeper layers’ contributions so shallow layers stabilize first—improving perplexity and depth scaling across models from 71M to 7B parameters.
Reasoning Models Struggle to Control their Chains of Thought. CoT‑Control, a 14,076‑instance benchmark, evaluates how well models follow explicit instructions to modify their chains of thought; most reasoning models struggle with controllability, which varies with model size, reasoning effort, training, and situational‑awareness prompting.
Analysis
Anthropic reports on trends in occupations susceptible to AI and whether there are changes in the labor market. Anthropic’s analysis introduces an “observed exposure” metric showing which occupations (notably programmers, customer service reps, and financial analysts) have tasks both theoretically automatable by AI and already automated in practice, finds higher exposure among better‑educated, higher‑income workers, and reports little current impact on unemployment overall but a small decline in employment among 22–25‑year‑olds in high‑exposure roles.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み