Spring AI SDK for Amazon Bedrock AgentCoreが一般提供開始
AWSはSpring AI SDK for Amazon Bedrock AgentCoreを一般提供開始し、Java/Spring開発者がAgentic AIエージェントを既知のパターンで構築・本番展開できるようにした。
キーポイント
Agentic AIの本番展開課題の解決
組織がAgentic AIを概念実証から本番環境にスケールする際の、スケーラビリティ・ガバナンス・セキュリティ課題に対処するプラットフォームとしてAmazon Bedrock AgentCoreを提供。
Java/Spring開発者向けの大幅な開発効率向上
従来は数週間のインフラ作業が必要だったAgentCore Runtimeとの統合作業を、Spring AI AgentCore SDKがアノテーションと自動設定で自動化し、AIエージェントロジックの開発に集中できる。
AgentCore Runtime契約の自動実装
/invocationsエンドポイントと/pingヘルスエンドポイントの実装、非同期タスク検出など、AgentCore Runtimeが要求する契約をSDKが自動的に実装する。
オープンソースライブラリとしての提供
Spring AI AgentCore SDKはオープンソースライブラリとして提供され、Spring AIエコシステム内でAmazon Bedrock AgentCoreの機能を既知のパターンで利用可能にする。
エージェント作成の簡素化
@AgentCoreInvocationアノテーションを使用することで、エージェントリクエストを処理するメソッドを簡単に定義でき、SDKが自動的にエンドポイントとシリアライゼーションを設定する。
設定の最小化
application.propertiesでAWSリージョンと使用するモデルを指定するだけで、Amazon Bedrockとの連携が可能になる。
ストリーミング対応の簡易実装
戻り値をFlux<String>に変更するだけで、SDKが自動的にSSE出力に切り替わり、フレーミングやヘッダー処理を担当する。
影響分析・編集コメントを表示
影響分析
この発表は、Java/Spring開発者コミュニティがAgentic AIアプリケーションを本番環境に迅速に展開できる道筋を示した。既存のSpring開発パターンを活用できるため、学習コストが低く、企業のAI導入障壁を下げる効果が期待される。AWSのBedrockエコシステムの拡大と、Spring開発者層の取り込みを同時に進める戦略的なリリースと言える。
編集コメント
Java/Springという巨大な開発者コミュニティをAgentic AI領域に取り込むための重要なインフラ整備。AWSがクラウドプラットフォームだけでなく、開発者体験でも差別化を図っている好例。
Agentic AI(自律型AI)は、組織が生成AIを活用する方法を変革し、プロンプトと応答のやり取りを超えて、計画立案、実行、そして複雑なマルチステップタスクを完了できる自律型システムへと移行しています。Agentic AIの初期概念実証がビジネス関係者を興奮させる一方で、それらを実運用(プロダクション)にスケールアップするには、スケーラビリティ、ガバナンス、セキュリティの課題に対処する必要があります。Amazon Bedrock AgentCore は、あらゆるフレームワークとモデルを使用して、エージェントを大規模に構築、デプロイ、運用するためのAgentic AIプラットフォームです。
Java開発者は、よく知られたSpringのパターンを用いてAIエージェントを構築したいと考えていますが、実運用へのデプロイには、ゼロから実装するのが複雑なインフラストラクチャが必要です。Amazon Bedrock AgentCoreは、管理されたランタイムインフラストラクチャ(スケーラビリティ、信頼性、セキュリティ、観測可能性)、短期・長期メモリ、ブラウザ自動化、サンドボックス化されたコード実行、および評価といったビルディングブロックを提供します。これらの機能をSpringアプリケーションに統合するには、現在、AgentCore Runtime契約を満たすためのカスタムコントローラーの記述、Server-Side Events (SSE) ストリーミングの処理、ヘルスチェックの実装、レートリミティングの管理、そしてSpringアドバイザー、メモリリポジトリ、ツール定義の接続を行う必要があります。これは、AIエージェントロジックを記述する前に数週間にわたるインフラストラクチャ作業となります。
Spring AI AgentCore SDK の新機能により、本番環境対応の AI エージェントを構築し、高いスケーラビリティを持つ AgentCore Runtime で実行することができます。Spring AI AgentCore SDK は、アノテーション、自動設定、そして合成可能なアドバイザー(advisors)といったよく知られたパターンを通じて、Amazon Bedrock AgentCore の機能を Spring AI に統合するオープンソースライブラリです。SpringAI Builders は依存関係を追加し、メソッドにアノテーションを付与するだけで、SDK が残りの処理を自動的に実行します。
AgentCore Runtime の契約内容の理解
AgentCore Runtime は、エージェントのライフサイクルとスケーリングを管理し、従量課金制(pay-per-use)を採用しているため、アイドル状態のコンピューティングリソースに対しては課金されません。このランタイムは着信リクエストをエージェントにルーティングし、その健全性を監視しますが、これにはエージェントが特定の契約に従う必要があります。この契約では、実装が2つのエンドポイントを公開することを要求しています。/invocations エンドポイントはリクエストを受け取り、レスポンスを JSON または SSE(Server-Sent Events)ストリーミングのいずれかで返します。/ping 健康状態エンドポイントは、Healthy または HealthyBusy のステータスを報告します。長時間実行されるタスクは「ビジー」状態であることを示す必要があり、そうしないとランタイムはコスト削減のためにそれらをスケールダウンする可能性があります。SDK はこの契約を自動的に実装しており、エージェントが処理を行っている際に ビジー状態 を報告する非同期タスクの検出機能も含まれています。
契約で定義された機能に加え、このSDKは本番環境でのワークロードに対応するための追加機能を提供します。これには、適切なフレーム付けによるSSE(Server-Sent Events)レスポンスの処理、バックプレッシャーの制御、および大規模なレスポンスに対する接続ライフサイクル管理が含まれます。さらに、レートリミティング機能により、トラフィックの急増からエージェントを保護し、ユーザーごとの消費量を制限するようリクエストをスロットリングします。開発者はエージェントのロジック構築に集中し、SDKがランタイム統合を処理します。
この投稿では、チャットエンドポイントから始めて、ストリーミングレスポンス、会話メモリ、Web検索およびコード実行のためのツールを追加し、本番環境で利用可能なAIエージェントを構築します。最終的には、AgentCore Runtimeにデプロイするか、既存のインフラストラクチャ上でスタンドアロンとして実行できる、完全な機能を持つエージェントが完成します。
前提条件
これに従うためには、以下の準備が必要です:
- Java 17以降(Java 25を推奨)
- Spring Boot 3.5以降
- AWSアカウント
- MavenまたはGradle
ソリューションの概要
Spring AI AgentCore SDKは、以下の3つの設計原則に基づいて構築されています:
- 規約による設定の優先 – 明示的な設定を行わずとも、AgentCore の期待値(ポート番号は8080、エンドポイントパス、コンテンツタイプの処理など)に合致する合理的なデフォルト値が適用されます。
- アノテーション駆動型開発 – 単一の
@AgentCoreInvocationアノテーションを付与するだけで、任意の Spring Bean のメソッドがシリアライズ、ストリーミング検出、レスポンスフォーマットを自動処理する AgentCore 互換エンドポイントに変換されます。
- デプロイメントの柔軟性 – この SDK は完全に管理されたデプロイメントを実現する AgentCore Runtime をサポートしていますが、Amazon EKS や Amazon ECS、その他のインフラストラクチャ上で動作するアプリケーションにおいて、メモリ(Memory)、ブラウザ(Browser)、コードインタープリタ(Code Interpreter)などの個別モジュールを使用することも可能です。
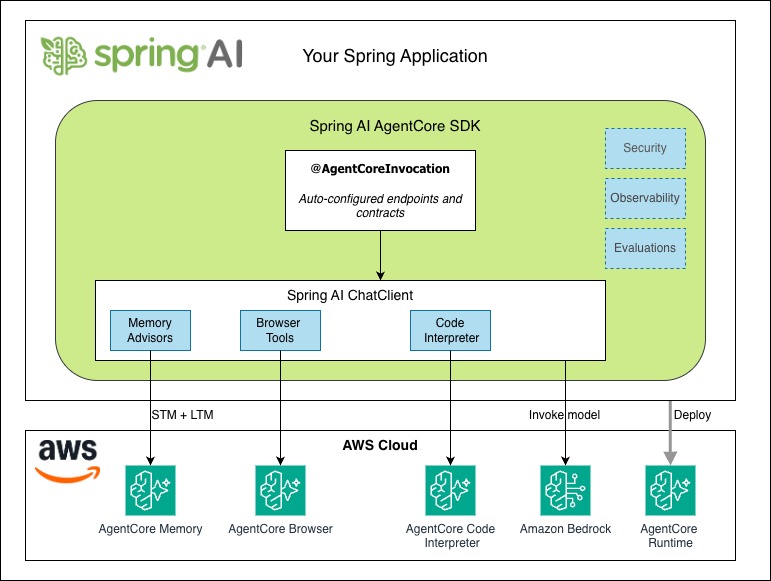
以下の図は、SDK コンポーネント間の相互作用を示しています。@AgentCoreInvocation アノテーションはランタイム契約を処理し、ChatClient はメモリアドバイザー、ブラウザツール、コードインタープリタを組み立てます。AgentCore Runtime へのデプロイはオプションです。SDK モジュールをスタンドアロンの機能として使用することもできます。
最初の AI エージェントの作成
以下のセクションでは、機能するエージェントを段階的に作成する方法を解説します。
ステップ 1: SDK の依存関係を追加する
Maven プロジェクトに Spring AI AgentCore BOM を追加し、その後ランタイムスターターを含めます:
org.springaicommunity
spring-ai-agentcore-bom
1.0.0
pom
import
org.springaicommunity
spring-ai-agentcore-runtime-starterステップ 2: エージェントの作成
@AgentCoreInvocation アノテーションは、このメソッドが入力されるエージェントリクエストを処理することを SDK に伝えます。SDK は POST /invocations と GET /ping エンドポイントを自動構成し、JSON シリアライズを処理し、健康状態のステータスを自動的に報告します。
@Service
public class MyAgent {
private final ChatClient chatClient;
public MyAgent(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@AgentCoreInvocation
public String chat(PromptRequest request) {
return chatClient.prompt()
.user(request.prompt())
.call()
.content();
}
}
record PromptRequest(String prompt) {}
ステップ 3: Amazon Bedrock の構成
application.properties でモデルと AWS リージョンを設定します:
spring.ai.bedrock.aws.region=us-east-1 spring.ai.bedrock.converse.chat.options.model=global.anthropic.claude-sonnet-4-5-20250929-v1:0
ステップ 4: ローカルでテストする
アプリケーションを起動し、リクエストを送信します:
mvn spring-boot:run
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "What is Spring AI?"}'
これは完全な AgentCore 互換の AI エージェントです。カスタムコントローラーはありませんし、プロトコル処理や健康状態チェックの実装も不要です。
ステップ 5: ストリーミングの追加
生成されたレスポンスをストリームするには、戻り値の型を Flux に変更します。SDK は自動的に SSE 出力に切り替えます:
@AgentCoreInvocation
public Flux streamingChat(PromptRequest request) {
return chatClient.prompt()
.user(request.prompt())
.stream()
.content();
}
この SDK は、SSE フレームの処理、Content-Type ヘッダー、改行の保持、および接続のライフサイクルを管理します。あなたのコードは AI 対話に集中できます。
ステップ 6: エージェントにメモリを追加する
現実世界のエージェントは、ユーザーが会話の前半で言ったこと(短期メモリ)と、時間とともに学んだこと(長期メモリ)を記憶する必要があります。この SDK は、Spring AI のアドバイザーパターンを通じて AgentCore Memory と統合されており、プロンプトがモデルに到達する前にコンテキストで強化するインターセプターとして機能します。
短期メモリ(STM)は、スライディングウィンドウを使用して最新のメッセージを保持します。長期メモリ(LTM)は、以下の 4 つの戦略を使用して、セッションをまたいで知識を永続化します。
| 戦略 | 目的 | 例 |
|---|---|---|
| セマンティック | ユーザーに関する事実情報 | 「ユーザーは金融業界で働いている」 |
| ユーザー設定 | 明示的な設定と選択 | 「メートル法を優先」 |
| サマリー | 要約された会話履歴 | 継続性のためのセッションサマリー |
| エピソード | 過去の相互作用と教訓 | 「ユーザーは先週 X で問題を抱えていた」 |
AgentCore は、これらの戦略を非同期で統合し、開発者の明示的な介入なしに関連情報を抽出します。メモリ依存関係を追加し、自動検出を有効にします。自動検出モードでは、SDK は手動設定なしで利用可能な長期メモリ戦略と名前空間を自動的に検出します。
agentcore.memory.memory-id=${AGENTCORE_MEMORY_ID}
agentcore.memory.long-term.auto-discovery=true
次に、AgentCoreMemory をインジェクトしてチャットクライアントに組み込みます:
// MyAgent コンストラクタに追加
private final AgentCoreMemory agentCoreMemory;
public MyAgent(ChatClient.Builder builder, AgentCoreMemory agentCoreMemory) {
this.agentCoreMemory = agentCoreMemory;
this.chatClient = builder.build();
}
// memory アドバイザーを含めるよう chat メソッドを更新
@AgentCoreInvocation
public String chat(PromptRequest request, AgentCoreContext context) {
String sessionId = context.getHeader(AgentCoreHeaders.SESSION_ID);
return chatClient.prompt()
.user(request.prompt())
.advisors(agentCoreMemory.advisors)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "user:" + sessionId))
.call()
.content();
}
agentCoreMemory.advisors リストには、STM(短期記憶)と設定されたすべての LTM(長期記憶)アドバイザーが含まれます。詳細な構成オプションについては、Memory ドキュメント を参照してください。
ステップ 7: ツールによるエージェントの拡張
AgentCore は、SDK が ToolCallbackProvider インターフェースを通じて Spring AI のツールコールバックとして公開する特殊なツールを提供しています。
ブラウザ自動化 – エージェントは AgentCore Browser を使用して、ウェブサイトをナビゲートし、コンテンツを抽出し、スクリーンショットを取得し、ページ要素と対話できます:
org.springaicommunity
spring-ai-agentcore-browser
コードインタープリター – エージェントは、AgentCore Code Interpreter を使用して、安全なサンドボックス内で Python、JavaScript、または TypeScript のコードを記述および実行できます。このサンドボックスには numpy、pandas、matplotlib が含まれています。生成されたファイルはアーティファクトストアを通じてキャプチャされます。
org.springaicommunity
spring-ai-agentcore-code-interpreter
両方のツールは、Spring AI の ToolCallbackProvider インターフェースを通じて統合されます。以下は、メモリ、ブラウザ、コードインタープリターを組み合わせた最終的な MyAgent です:
@Service
public class MyAgent {
private final ChatClient chatClient;
private final AgentCoreMemory agentCoreMemory;
public MyAgent(
ChatClient.Builder builder,
AgentCoreMemory agentCoreMemory,
@Qualifier("browserToolCallbackProvider") ToolCallbackProvider browserTools,
@Qualifier("codeInterpreterToolCallbackProvider") ToolCallbackProvider codeInterpreterTools) {
this.agentCoreMemory = agentCoreMemory;
this.chatClient = builder
.defaultToolCallbacks(browserTools, codeInterpreterTools)
.build();
}
@AgentCoreInvocation
public Flux chat(PromptRequest request, AgentCoreContext context) {
String sessionId = context.getHeader(AgentCoreHeaders.SESSION_ID);
return chatClient.prompt()
.user(request.prompt())
.advisors(agentCoreMemory.advisors)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "user:" + sessionId))
.stream()
.content();
}
}
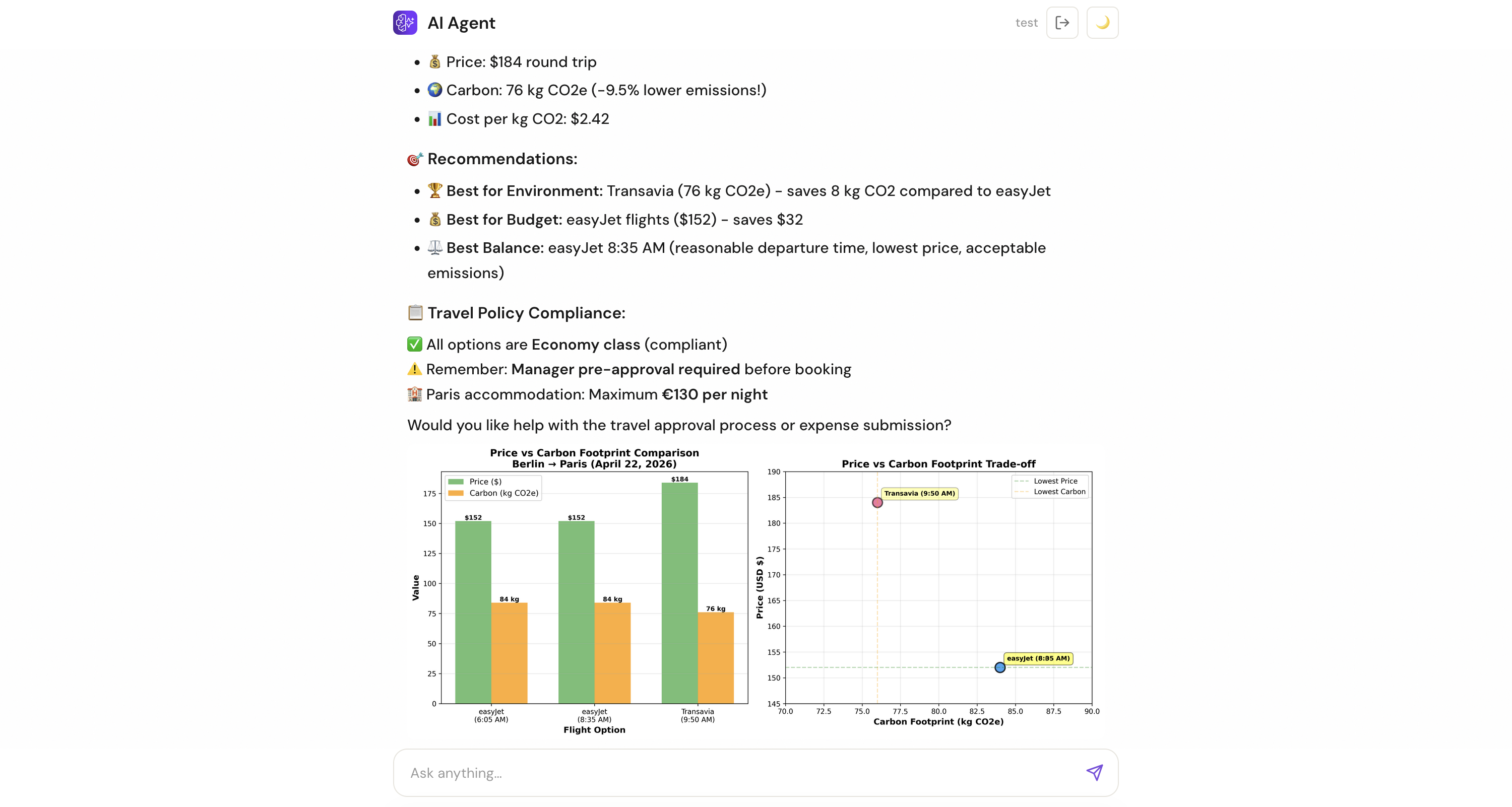
モデルはすべてのツールを同等に認識し、ユーザーのリクエストに基づいて呼び出すべきツールを判断します。今回の投稿では基盤モデル(FMs)にアクセスするためにAmazon Bedrockに焦点を当てていますが、Spring AIはOpenAIやAnthropicを含む複数の大規模言語モデル(LLM)プロバイダーをサポートしているため、ニーズに合ったモデルを選択できます。例えば、旅行・経費管理エージェントは、ブラウザツールを使用してフライトの選択肢を検索し、コードインタープリターを使って支出パターンを分析してチャートを生成するなど、単一の会話内でこれらすべてのタスクを実行できます:
エージェントのデプロイメント
SDKは2つのデプロイメントモデルをサポートしています:
AgentCore Runtime – 完全に管理されたインフラストラクチャが必要な場合は、アプリケーションをARM64コンテナとしてパッケージ化し、Amazon Elastic Container Registry (Amazon ECR)にプッシュして、そのイメージを参照するAgentCore Runtimeを作成します。ランタイムはスケーリングとヘルスモニタリングを処理します。examples/terraformディレクトリには、IAMおよびOAuth認証オプションを含むインフラストラクチャー・アズ・コード(IaC)が提供されています。
スタンドアロン – Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Compute Cloud (Amazon EC2)、またはオンプレミス環境で動作するアプリケーションにおいて、AgentCore Memory、Browser、Code Interpreter を使用します。このアプローチにより、チームは AgentCore の機能を段階的に導入できます。例えば、後で AgentCore Runtime への移行に先立って、既存の Spring Boot サービスにメモリ機能を追加するなどです。
認証と認可
AgentCore Runtime は、2 つの認証方式をサポートしています。AWS サービス間の呼び出しには IAM ベースの SigV4 を、ユーザーFacing のアプリケーションには OAuth2 を使用します。Spring AI エージェントを AgentCore Runtime にデプロイする場合、認証はインフラストラクチャ層で処理されます。アプリケーションは AgentCoreContext を介して認証済みユーザーのアイデンティティを受け取ります。その後、これらの原則に基づき、標準的な Spring Security パターンを使用して、Spring アプリケーション内で細粒度の認可(authorization)を実装できます。スタンドアロンデプロイメントの場合、Spring アプリケーションは Spring Security を使用して認証と認可を提供する責任を負います。この場合、AgentCore サービス(Memory、Browser、Code Interpreter)への呼び出しは、標準的な AWS SDK の資格情報メカニズムを使用して保護されます。
AgentCore Gateway 経由の MCP ツールへの接続
Spring AI エージェントは、アウトバウンド認証とセマンティック・ツールレジストリを備えた Model Context Protocol (MCP) サポートを提供する AgentCore Gateway を通じて、組織のツールにアクセスできます。Gateway を使用するには、Spring AI MCP クライアントのエンドポイントを AgentCore Gateway に向け、IAM SigV4 または OAuth2 を使用して認証を行います。
spring.ai.mcp.client.toolcallback.enabled=true
spring.ai.mcp.client.initialized=false
spring.ai.mcp.client.streamable-http.connections.gateway.url=${GATEWAY_URL}これにより、エージェントはエンタープライズ・ツールを検出して呼び出すことができます。Gateway は下流のサービスに対する資格情報管理を処理します。実践的な例については、Spring AI と Amazon Bedrock AgentCore を使用した Java AI エージェントの構築ワークショップを参照してください。ここでは、AgentCore Gateway による MCP の統合方法が示されています。
次のステップは?
SDK は進化を続けています。今後の統合には以下が含まれます。
- 観測可能性(Observability) – OpenTelemetry を使用して、Amazon CloudWatch や LangFuse、Datadog、Dynatrace などの外部観測性ツールと連携する Spring AI のトレース、メトリクス、ログの統合。基本的な AgentCore による観測可能性は本日利用可能です。
- 評価(Evaluations) – エージェントのレスポンスに対するテストおよび品質評価フレームワーク。原文を表示
Agentic AI is transforming how organizations use generative AI, moving beyond prompt-response interactions to autonomous systems that can plan, execute, and complete complex multi-step tasks. While early proof of concepts in Agentic AI spaces excite business stakeholders, scaling them to production requires addressing scalability, governance, and security challenges. Amazon Bedrock AgentCore is an Agentic AI platform to build, deploy, and operate agents at scale using any framework and any model.
Java developers want to build AI agents using known Spring patterns, but production deployment requires infrastructure that’s complex to implement from scratch. Amazon Bedrock AgentCore provides building blocks like managed runtime infrastructure (scalability, reliability, security, observability), short- and long-term memory, browser automation, sandboxed code execution, and evaluations. Integrating these capabilities into a Spring application currently requires writing custom controllers to fulfill AgentCore Runtime contract, handling Server-Side Events (SSE) streaming, implementing health checks, managing rate limiting, and wiring up Spring advisors, memory repositories, and tool definitions. This is weeks of infrastructure work before writing any AI Agent logic.
With the new Spring AI AgentCore SDK, you can build production-ready AI agents and run them on the highly scalable AgentCore Runtime. The Spring AI AgentCore SDK is an open source library that brings Amazon Bedrock AgentCore capabilities into Spring AI through known patterns: annotations, auto-configuration, and composable advisors. SpringAI Builders add a dependency, annotate a method, and the SDK handles the rest.
Understanding the AgentCore Runtime contract
AgentCore Runtime manages agent lifecycle and scaling with pay-per-use pricing, meaning you don’t pay for idle compute. The runtime routes incoming requests to your agent and monitors its health, but this requires your agent to follow a contract. The contract requires that the implementation exposes two endpoints. The /invocations endpoint receives requests and returns responses as either JSON or SSE streaming. The /ping health endpoint reports a Healthy or HealthyBusy status. Long-running tasks must signal that they’re busy, or the runtime might scale them down to save costs. The SDK implements this contract automatically, including async task detection that reports busy status when your agent is processing.
Beyond the contract, the SDK provides additional capabilities for production workloads like handling SSE responses with proper framing, backpressure handling, and connection lifecycle management for large responses. It also provides rate limiting, throttling requests to protect your agent from traffic spikes and limit per-user consumption. You focus is on agent logic while the SDK handles the runtime integration.Beyond the contract, the SDK provides additional capabilities for production workloads such as handling SSE responses with proper framing, backpressure handling, and connection lifecycle management for large responses. It also provides rate limiting, throttling requests to protect your agent from traffic spikes and limit per-user consumption. You focus on agent logic while the SDK handles the runtime integration.
In this post, we build a production-ready AI agent starting with a chat endpoint, then adding streaming responses, conversation memory, and tools for web browsing and code execution. By the end, you will have a fully functional agent ready to deploy to AgentCore Runtime or run standalone on your existing infrastructure.
Prerequisites
To follow along, you need:
- Java 17 or higher (Java 25 recommended)
- Spring Boot 3.5 or higher
- An AWS account
- Maven or Gradle
Solution overview
The Spring AI AgentCore SDK is built on three design principles:
- Convention over configuration – Sensible defaults align with AgentCore expectations (port 8080, endpoint paths, content-type handling) without explicit configuration.
- Annotation-driven development – A single @AgentCoreInvocation annotation transforms any Spring bean method into an AgentCore-compatible endpoint with automatic serialization, streaming detection, and response formatting.
- Deployment flexibility – The SDK supports AgentCore Runtime for fully managed deployment, but you can also use individual modules (Memory, Browser, Code Interpreter) in applications running on Amazon EKS, Amazon ECS, or any other infrastructure.
The following diagram shows how the SDK components interact. The @AgentCoreInvocation annotation handles the runtime contract, while the ChatClient composes Memory advisors, Browser tools, and Code Interpreter. Deployment to AgentCore Runtime is optional. You can use the SDK modules as standalone features.
Creating your first AI agent
The following section walks you through how to create a fully functional agent step by step:
Step 1: Add the SDK dependency
Add the Spring AI AgentCore BOM to your Maven project, then include the runtime starter:
org.springaicommunity
spring-ai-agentcore-bom
1.0.0
pom
import
org.springaicommunity
spring-ai-agentcore-runtime-starter
Step 2: Create the agent
The @AgentCoreInvocation annotation tells the SDK that this method handles incoming agent requests. The SDK auto-configures POST /invocations and GET /ping endpoints, handles JSON serialization, and reports health status automatically.
@Service
public class MyAgent {
private final ChatClient chatClient;
public MyAgent(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@AgentCoreInvocation
public String chat(PromptRequest request) {
return chatClient.prompt()
.user(request.prompt())
.call()
.content();
}
}
record PromptRequest(String prompt) {}Step 3: Configure Amazon Bedrock
Set your model and AWS Region in application.properties:spring.ai.bedrock.aws.region=us-east-1 spring.ai.bedrock.converse.chat.options.model=global.anthropic.claude-sonnet-4-5-20250929-v1:0
Step 4: Test locally
Start the application and send a request:
mvn spring-boot:run
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "What is Spring AI?"}'That’s a complete, AgentCore-compatible AI agent. No custom controllers, no protocol handling, no health check implementation.
Step 5: Add streaming
To stream responses as they’re generated, change the return type to Flux. The SDK automatically switches to SSE output:
@AgentCoreInvocation
public Flux streamingChat(PromptRequest request) {
return chatClient.prompt()
.user(request.prompt())
.stream()
.content();
}The SDK handles SSE framing, Content-Type headers, newline preservation, and connection lifecycle. Your code stays focused on the AI interaction.
Step 6: Add memory to your agent
Real-world agents must remember what users said earlier in a conversation (short-term memory) and what they’ve learned over time (long-term memory). The SDK integrates with AgentCore Memory through Spring AI’s advisor pattern, interceptors that enrich prompts with context before they reach the model.
Short-term memory (STM) keeps recent messages using a sliding window. Long-term memory (LTM) persists knowledge across sessions using four strategies:
Strategy
Purpose
Example
Semantic
Factual information about users
“User works in finance”
User preference
Explicit settings and choices
“Metric units preferred”
Summary
Condensed conversation history
Session summaries for continuity
Episodic
Past interactions and lessons
“User had trouble with X last week”
AgentCore consolidates these strategies asynchronously, extracting relevant information without explicit developer intervention.Add the memory dependency and enable auto-discovery. In auto-discovery mode, the SDK automatically detects available long-term memory strategies and namespaces without manual configuration:
agentcore.memory.memory-id=${AGENTCORE_MEMORY_ID}
agentcore.memory.long-term.auto-discovery=trueThen inject AgentCoreMemory and compose it into your chat client:
// Add to MyAgent constructor
private final AgentCoreMemory agentCoreMemory;
public MyAgent(ChatClient.Builder builder, AgentCoreMemory agentCoreMemory) {
this.agentCoreMemory = agentCoreMemory;
this.chatClient = builder.build();
}
// Update the chat method to include memory advisors
@AgentCoreInvocation
public String chat(PromptRequest request, AgentCoreContext context) {
String sessionId = context.getHeader(AgentCoreHeaders.SESSION_ID);
return chatClient.prompt()
.user(request.prompt())
.advisors(agentCoreMemory.advisors)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "user:" + sessionId))
.call()
.content();
}The agentCoreMemory.advisors list includes both STM and all configured LTM advisors. For detailed configuration options, see the Memory documentation.
Step 7: Extending agents with tools
AgentCore provides specialized tools that the SDK exposes as Spring AI tool callbacks through the ToolCallbackProvider interface.
Browser automation – Agents can navigate websites, extract content, take screenshots, and interact with page elements using AgentCore Browser:
org.springaicommunity
spring-ai-agentcore-browser
Code interpreter – Agents can write and run Python, JavaScript, or TypeScript in a secure sandbox using AgentCore Code Interpreter. The sandbox includes numpy, pandas, and matplotlib. Generated files are captured through the artifact store.
org.springaicommunity
spring-ai-agentcore-code-interpreter
Both tools integrate through Spring AI’s ToolCallbackProvider interface. Here is the final MyAgent with memory, browser, and code interpreter composed together:
@Service
public class MyAgent {
private final ChatClient chatClient;
private final AgentCoreMemory agentCoreMemory;
public MyAgent(
ChatClient.Builder builder,
AgentCoreMemory agentCoreMemory,
@Qualifier("browserToolCallbackProvider") ToolCallbackProvider browserTools,
@Qualifier("codeInterpreterToolCallbackProvider") ToolCallbackProvider codeInterpreterTools) {
this.agentCoreMemory = agentCoreMemory;
this.chatClient = builder
.defaultToolCallbacks(browserTools, codeInterpreterTools)
.build();
}
@AgentCoreInvocation
public Flux chat(PromptRequest request, AgentCoreContext context) {
String sessionId = context.getHeader(AgentCoreHeaders.SESSION_ID);
return chatClient.prompt()
.user(request.prompt())
.advisors(agentCoreMemory.advisors)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "user:" + sessionId))
.stream()
.content();
}
}The model sees all tools equally and decides which to call based on the user’s request. While this post focuses on Amazon Bedrock to access foundation models (FMs), Spring AI supports multiple large language model (LLM) providers including OpenAI and Anthropic, so you can choose the models that fit your needs. For example, a travel and expense management agent can use the browser tool to look up flight options and the code interpreter to analyze spending patterns and generate charts, all within a single conversation:
Deploying your agent
The SDK supports two deployment models:
AgentCore Runtime – For fully managed infrastructure, package your application as an ARM64 container, push it to Amazon Elastic Container Registry (Amazon ECR), and create an AgentCore Runtime that references the image. The runtime handles scaling and health monitoring. The examples/terraform directory provides infrastructure as code (IaC) with IAM and OAuth authentication options.
Standalone – Use AgentCore Memory, Browser, or Code Interpreter in applications running on Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Compute Cloud (Amazon EC2), or on-premises. With this approach, teams can adopt AgentCore capabilities incrementally. For example, adding memory to an existing Spring Boot service before migrating to AgentCore Runtime later.
Authentication and authorization
AgentCore Runtime supports two authentication methods: IAM-based SigV4 for AWS service-to-service calls and OAuth2 for user-facing applications. When your Spring AI agent is deployed to AgentCore Runtime, authentication is handled at the infrastructure layer. Your application receives the authenticated user’s identity through AgentCoreContext. Fine-grained authorization can then be implemented in your Spring application using standard Spring Security patterns with these principles. For standalone deployments, your Spring application is responsible for providing authentication and authorization using Spring Security. In this case, calls to AgentCore services (Memory, Browser, Code Interpreter) are secured using standard AWS SDK credential mechanisms.
Connecting to MCP tools with AgentCore Gateway
Spring AI agents can access organizational tools through AgentCore Gateway, which provides Model Context Protocol (MCP) support with outbound authentication and a semantic tool registry. To use Gateway, configure your Spring AI MCP client endpoint to point to AgentCore Gateway and authenticate using either IAM SigV4 or OAuth2:
spring.ai.mcp.client.toolcallback.enabled=true
spring.ai.mcp.client.initialized=false
spring.ai.mcp.client.streamable-http.connections.gateway.url=${GATEWAY_URL}This enables agents to discover and invoke enterprise tools while Gateway handles credential management for downstream services. For a hands-on example, see the Building Java AI agents with Spring AI and Amazon Bedrock AgentCore workshop, which demonstrates MCP integration with AgentCore Gateway.
What’s next?
The SDK continues to evolve. Upcoming integrations will include:
- Observability – Integrate Spring AI tracing, metrics, and logging with support for Amazon CloudWatch and external observability tools such as LangFuse, Datadog, and Dynatrace using OpenTelemetry. Basic AgentCore observability is available today.
- Evaluations – Testing and quality assessment frameworks for agent responses.
関連記事
AWSがS3 Filesを導入、S3バケットへのファイルシステムアクセスを実現
AWSはS3 Filesを発表し、ユーザーがAmazon S3バケットをマウントして標準ファイルシステムインターフェースでデータにアクセスできるようにした。アプリケーションは標準ファイル操作で読み書きでき、システムが自動的にS3リクエストに変換するため、コンピュートサービスがS3に保存されたデータを直接扱える。
AWSが自動インシデント調査のためのDevOpsエージェントを一般提供開始
AWSは、開発者と運用者がAWS環境での問題のトラブルシューティング、デプロイメントの分析、運用タスクの自動化を支援する生成AI搭載アシスタント「DevOps Agent」の一般提供を開始した。
Amazon Bedrockの詳細なコスト帰属機能の導入
AWSがAmazon Bedrockの推論コストをIAMプリンシパルごとに自動的に帰属する機能を発表した。これにより、コストの内訳把握、コスト最適化、財務計画が容易になる。