現代LLMにおけるアテンション変種のビジュアルガイド
Sebastian Raschka氏は、DeepSeek V4のリリース待機中に、過去数年にわたってカバーしてきた45種類のLLMアーキテクチャを視覚的モデルカード付きで整理した「LLM Architecture Gallery」を公開し、併せて近年の注目すべきアテンション変種について解説する記事を執筆した。
キーポイント
LLMアーキテクチャギャラリーの公開
Sebastian Raschka氏が、過去数年にわたりカバーしてきた45種類のLLMアーキテクチャを視覚的モデルカード付きで整理・公開したオンラインギャラリーを立ち上げ、定期的な更新を計画している。
ポスター版の提供開始
読者の要望に応え、ギャラリーの内容をまとめたポスター版をRedbubbleで販売開始したが、最小サイズでは一部のテキストが読みづらい可能性があると注意を促している。
コアLLM概念の解説資料作成
ギャラリーに加えて、いくつかのコアなLLM概念に関する短い解説資料の作成にも並行して取り組んでいる。
近年のアテンション変種の解説
本記事では、近年の著名なオープンウェイトアーキテクチャで開発・使用されている様々なアテンションの変種(例:Multi-Head Attention)を、参照資料および軽量な学習リソースとしてまとめ直している。
Attentionの歴史的背景と発明の動機
AttentionはTransformerやMulti-Head Attention以前に、翻訳のためのエンコーダ-デコーダRNNで発明されました。従来のRNNでは入力文を圧縮された隠れ状態に変換する際に情報のボトルネックが生じ、長いシーケンスや知識検索タスクで問題がありました。
従来RNNアプローチの限界
エンコーダ-デコーダRNNでは、入力文全体を圧縮された隠れ状態(または最終状態)に変換するため、次の出力単語に関連する情報が入力文の別の場所にある場合にボトルネックが生じ、文レベルの構造を適切に扱えないという問題がありました。
TransformerにおけるSelf-Attentionの役割
Transformerでは、RNNの再帰構造を排除し、Self-Attentionが主要なシーケンス処理メカニズムとなっている。各トークンが他の全トークンに対して重みを計算し、情報を混合する。
影響分析・編集コメントを表示
影響分析
この記事は、急速に進化するLLM技術の複雑なアーキテクチャを体系的に可視化・整理する貴重な教育・参照リソースを提供するものであり、研究者、開発者、学生の学習と理解を促進する可能性が高い。ただし、新規の技術的ブレークスルーを報告するものではなく、既存知識の整理と普及に主眼を置いている。
編集コメント
技術の進歩が速い分野において、体系的な知識の整理と可視化は学習コストを下げ、コミュニティ全体の理解を深める上で極めて重要。継続的更新の約束は、リソースの長期的価値を高める鍵となる。
元々、DeepSeek V4 について書く予定でした。しかしまだリリースされていないため、この時間を活用して、長年リストアップしていたプロジェクトに取り組むことにしました。それは過去数年間にわたって取り上げてきたさまざまな LLM アーキテクチャを収集し、整理し、洗練させることです。
そこで、ここ数週間でその取り組みを LLM アーキテクチャギャラリー(執筆時点で 45 エントリー)へとまとめ上げました。これは以前の論文からの資料と、まだ文書化していなかったいくつかの重要なアーキテクチャを組み合わせたものです。各エントリーにはビジュアルモデルカードが付属しており、今後も定期的に更新していく予定です。
ギャラリーはこちらで見ることができます:https://sebastianraschka.com/llm-architecture-gallery/

図 1: LLM アーキテクチャギャラリーおよびそのビジュアルモデルカードの概要。
初期バージョンを公開した後、いくつかの読者からポスター版はないかと問い合わせがありました。そこで現在は Redbubble を通じてポスター版も提供しています。私は Medium サイズ(26.9 x 23.4 インチ)を購入して印刷時の様子を確認しましたが、結果は鮮明でクリアでした。ただし、そのサイズでも最も小さなテキスト要素はかなり小さくなっているため、すべての内容を可読にしたい場合は、より小さいバージョンはお勧めしません。
図 2: アーキテクチャギャラリーのポスター版で、スケールを示すためのいくつかのランダムなオブジェクトが含まれています。
このギャラリーと並行して、私は主要な大規模言語モデル(LLM)の概念に関する短い解説記事も執筆中です。
そこで今回は、近年注目されるオープンウェイトアーキテクチャで開発・採用された最新の注意機構(アテンション)の変種をすべて振り返ることで、興味深い内容になるだろうと考えました。
私の目標は、このコレクションがリファレンスとしても、軽量な学習リソースとしても有用となるようにすることです。皆様にとって有益かつ教育的なものになれば幸いです!
- マルチヘッドアテンション(MHA)
セルフアテンションでは、各トークンがシーケンス内の他の可視トークンを参照し、それらに重みを割り当て、その重みを用いて入力に対する新しい文脈依存表現を構築します。
マルチヘッドアテンション(Multi-Head Attention: MHA)は、この考え方を標準的なトランスフォーマー版として実装したものです。複数のセルフアテンションヘッドを並列で実行し、それぞれが異なる学習された射影を用いて処理を行い、その出力を組み合わせてより豊かな表現へと統合します。
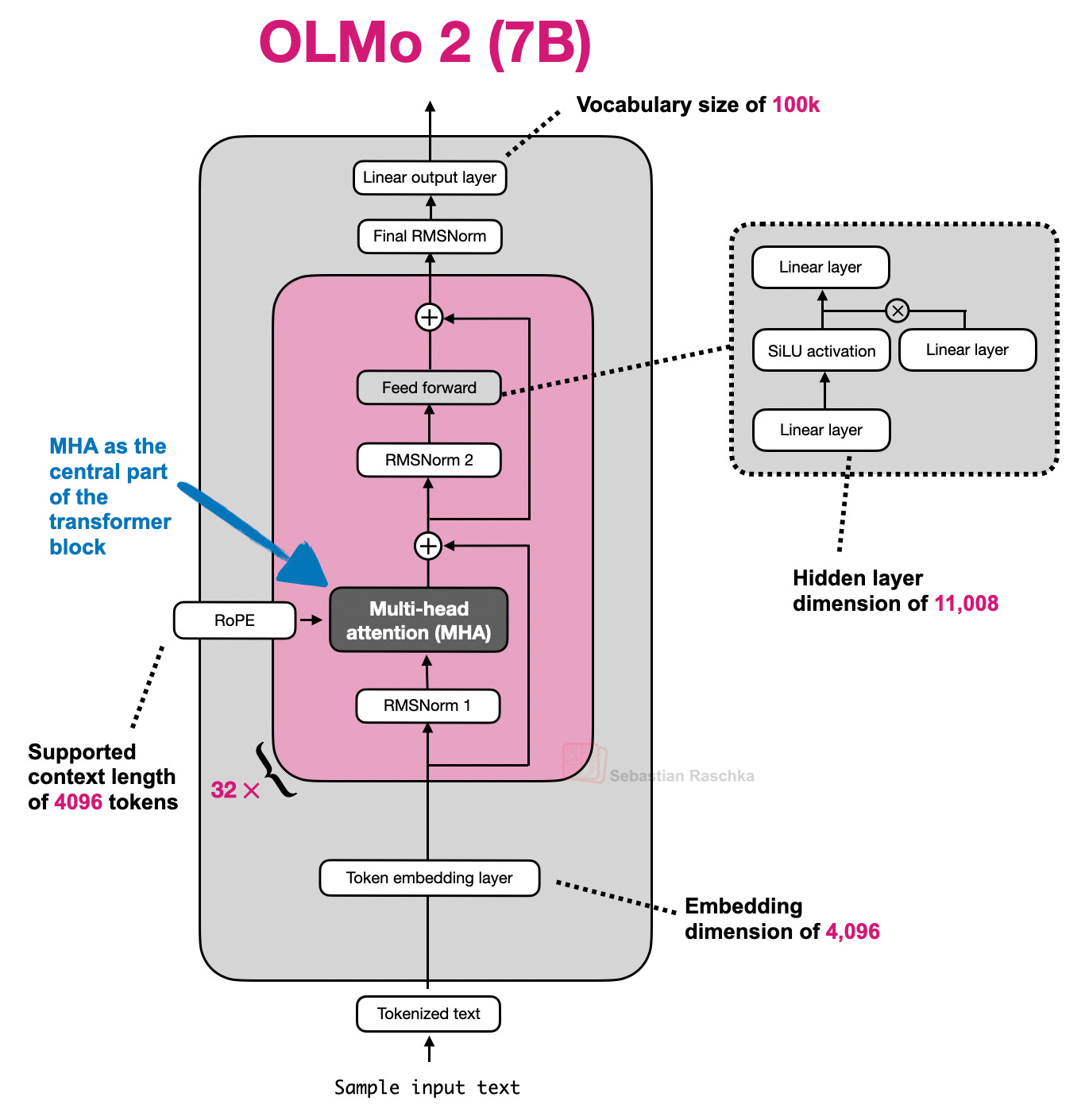
図 3: MHA を採用するアーキテクチャの例としての Olmo 2。
以下のセクションでは、まず MHA(Multi-Head Attention)を説明するために自己注意機構(self-attention)の概要を素早く巡ります。これは、グループ化クエリアテンション(grouped-query attention)、スライディングウィンドウアテンション(sliding window attention)などの関連する注意概念のための舞台設定を行うための簡易な概説として意図されています。より長く詳細な自己注意機構の解説に興味がある場合は、私の「LLM における自己注意機構、マルチヘッドアテンション、因果的アテンション、クロスアテンションの理解と実装」という長編記事をご覧になることをお勧めします。
例示アーキテクチャ
GPT-2, OLMo 2 7B, および OLMo 3 7B
1.2 歴史的な豆知識とアテンションが考案された理由
アテンションはトランスフォーマーや MHA よりも以前に存在します。その直近の背景には、翻訳のためのエンコーダー・デコーダー RNN(Recurrent Neural Network)があります。
これらの古いシステムでは、エンコーダー RNN がソース文をトークンごとに読み込み、それを隠れ状態のシーケンス、あるいは最も単純なバージョンでは最終的な一つの状態に圧縮します。その後、デコーダー RNN はその限定的な要約からターゲット文を生成する必要がありました。これは短く単純なケースでは機能しましたが、次の出力単語に関連する情報が入力文の別の場所にある場合、明白なボトルネックが生じました。
つまり、問題は隠れ状態が無限の情報やコンテキストを保持できない点にあり、時には完全な入力シーケンスを参照し直すことが有用になることがあるのです。
以下の翻訳例は、このアイデアの限界の一つを示しています。例えば、文は多くの局所的に妥当な語彙選択を保持していても、モデルが問題を単語ごとの対応として過度に扱う場合、翻訳として失敗することがあります。(上段のパネルでは、文を単語ごとに翻訳する誇張された例を示していますが、明らかに結果の文の文法は誤っています。)実際には、正しい次の単語は、文レベルの構造と、そのステップでどの先行ソース単語が重要であるかに依存します。もちろん、これは RNN でも適切に翻訳可能ですが、前述したように隠れ状態が保持できる情報量に限界があるため、より長いシーケンスや知識検索タスクでは困難を伴います。
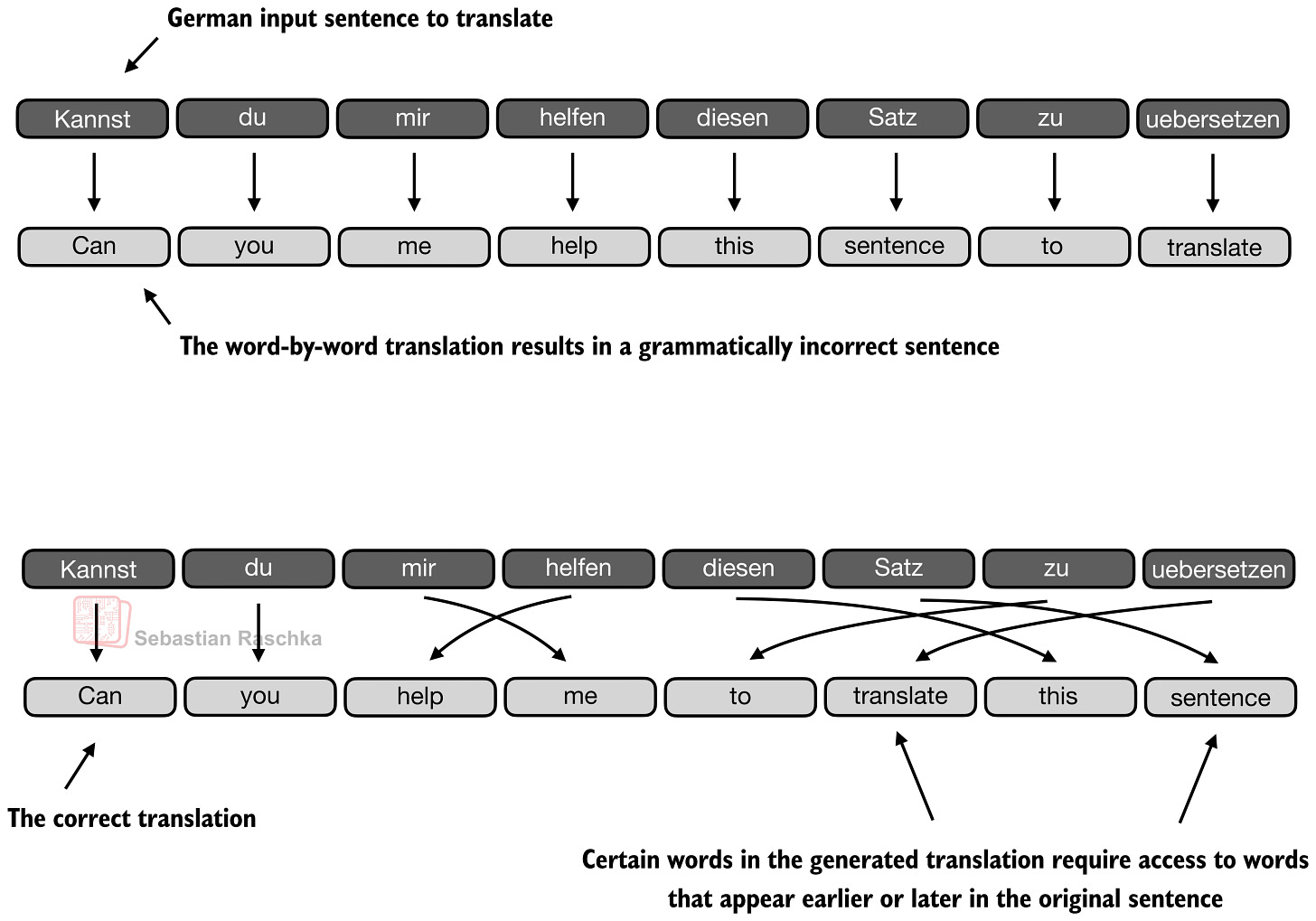
図 4: 個々の語彙選択の多くが妥当に見える場合でも、文レベルの構造が依然として重要であるため、翻訳は失敗する可能性があります(元のソース:LLMs-from-scratch)。
次の図は、この変化をより直接的に示しています。デコーダーが出力トークンを生成する際、1 つの圧縮された記憶経路に限定されるべきではありません。より関連性の高い入力トークンに直接遡ってアクセスできる必要があります。
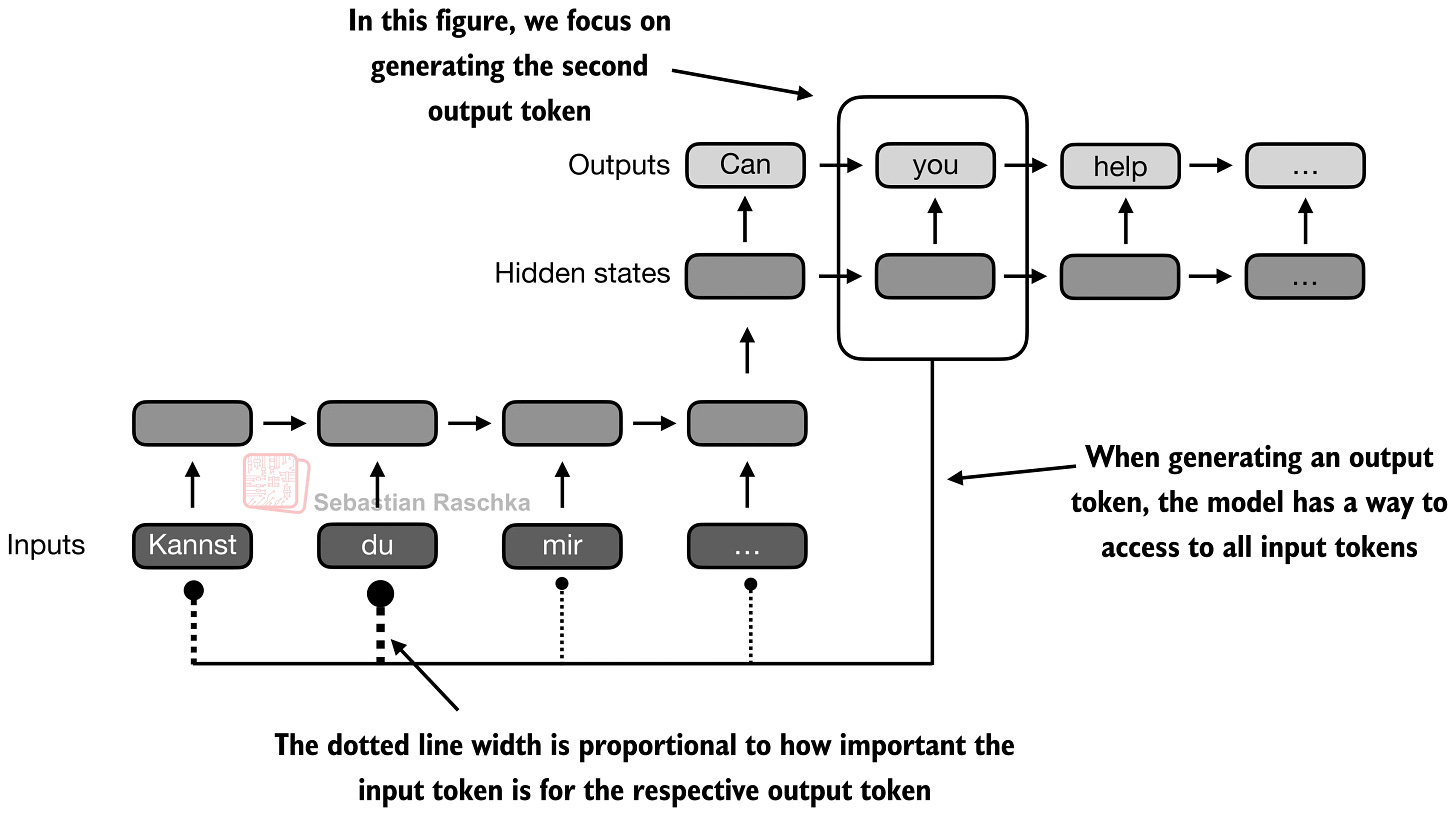
図 5: アテンション(attention)は、現在の出力位置が単一の圧縮された状態に頼るのではなく、入力シーケンス全体を再訪できるようにすることで、RNN のボトルネックを打破します(元出典:LLMs-from-scratch)。
トランスフォーマー(Transformers)は、前述のアテンション修正型 RNN からその核となるアイデアを引き継ぎつつも、再帰性(recurrence)を取り除いています。古典的な「Attention Is All You Need」論文において、アテンション自体が主要なシーケンス処理メカニズムとなります(RNN エンコーダー・デコーダーの一部であるだけでなく)。
トランスフォーマーでは、このメカニズムは自己アテンション(self-attention)と呼ばれ、シーケンス内の各トークンが他のすべてのトークンに対して重みを計算し、それらのトークンからの情報を混合して新しい表現を生成します。マルチヘッド・アテンション(multi-head attention)とは、同じメカニズムを並列に複数回実行するものです。
1.3 マスク付きアテンション行列
T トークンのシーケンスに対して、アテンションでは各トークンごとに重みの行が必要となるため、全体として T x T の行列が得られます。
各行は単純な問いに応えるものです。このトークンを更新する際、各可視トークンはどの程度重要なのか?デコーダー専用 LLM では、未来の位置はマスク(mask)されるため、下の図では行列の右上部分が灰色で表示されています。
自己アテンションは、因果マスクの下でこれらのトークン間重みパターンを学習し、それらを用いて文脈を考慮したトークン表現を構築することの本質です。
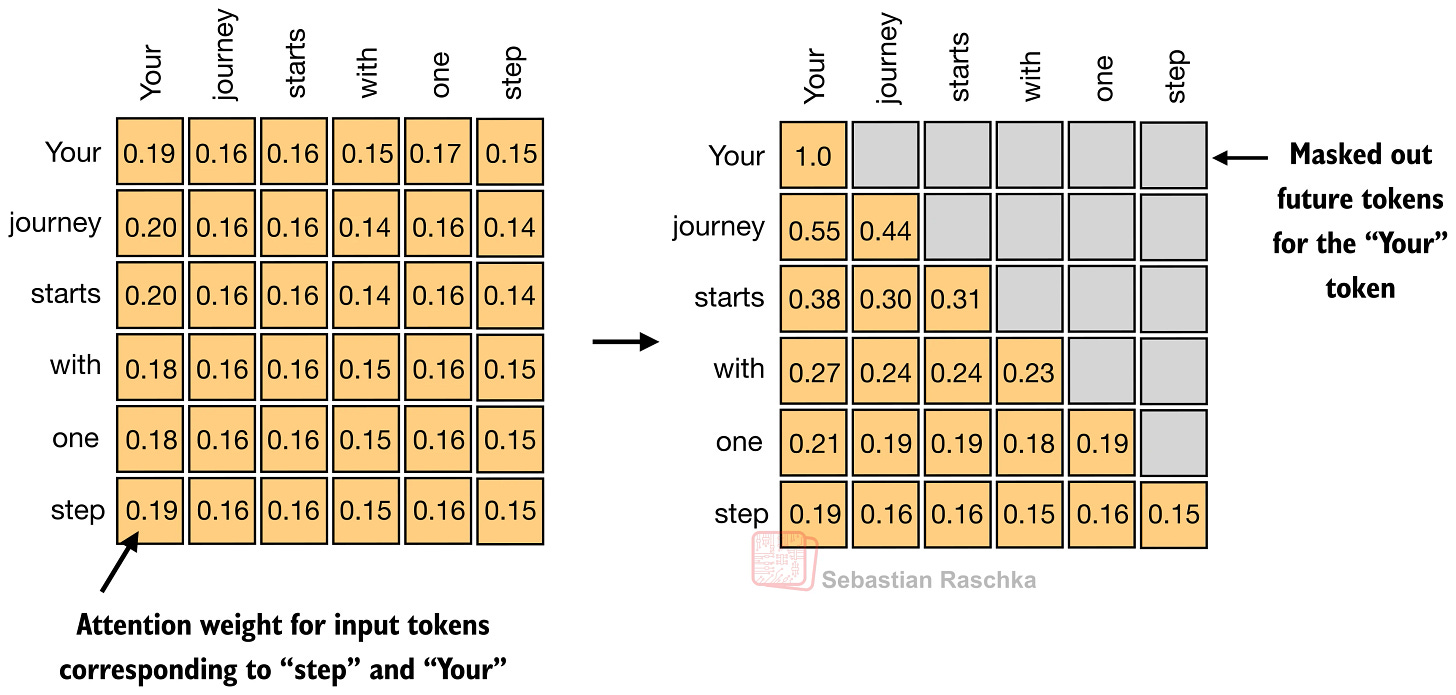
図 6: 具体的なマスク付きアテンション行列の例。各行は一つのトークンに属し、各エントリはアテンション重みであり、因果マスクによって未来のトークンに関するエントリが除去されています(元出典:Understanding and Coding Self-Attention)。
1.4 自己アテンションの内部構造
次の図は、トランスフォーマーが入力埋め込み X からアテンション行列 (A) を計算し、それが変換された入力 (Z) の生成にどのように用いられるかを示しています。
ここで Q、K、V はそれぞれクエリ(queries)、キー(keys)、値(values)を意味します。トークンのクエリは、そのトークンが何を探しているかを表し、キーは各トークンがマッチングのために何を利用可能にしているかを表し、値はアテンション重みが計算された後に出力に混合される情報を表します。
手順は以下の通りです:
Wq、Wk、および Wv は、入力埋め込みを Q、K、V へ投影する重み行列です。
QK^T は、トークン間の生の関連度スコアを生成します。
softmax は、これらのスコアを前節で議論した正規化されたアテンション行列 A に変換します。
A が V に適用され、出力行列 Z が生成されます。
注意してください。アテンション行列は、手書きの別個のオブジェクトではありません。これは Q(クエリ)、K(キー)、および softmax から生じるものです。
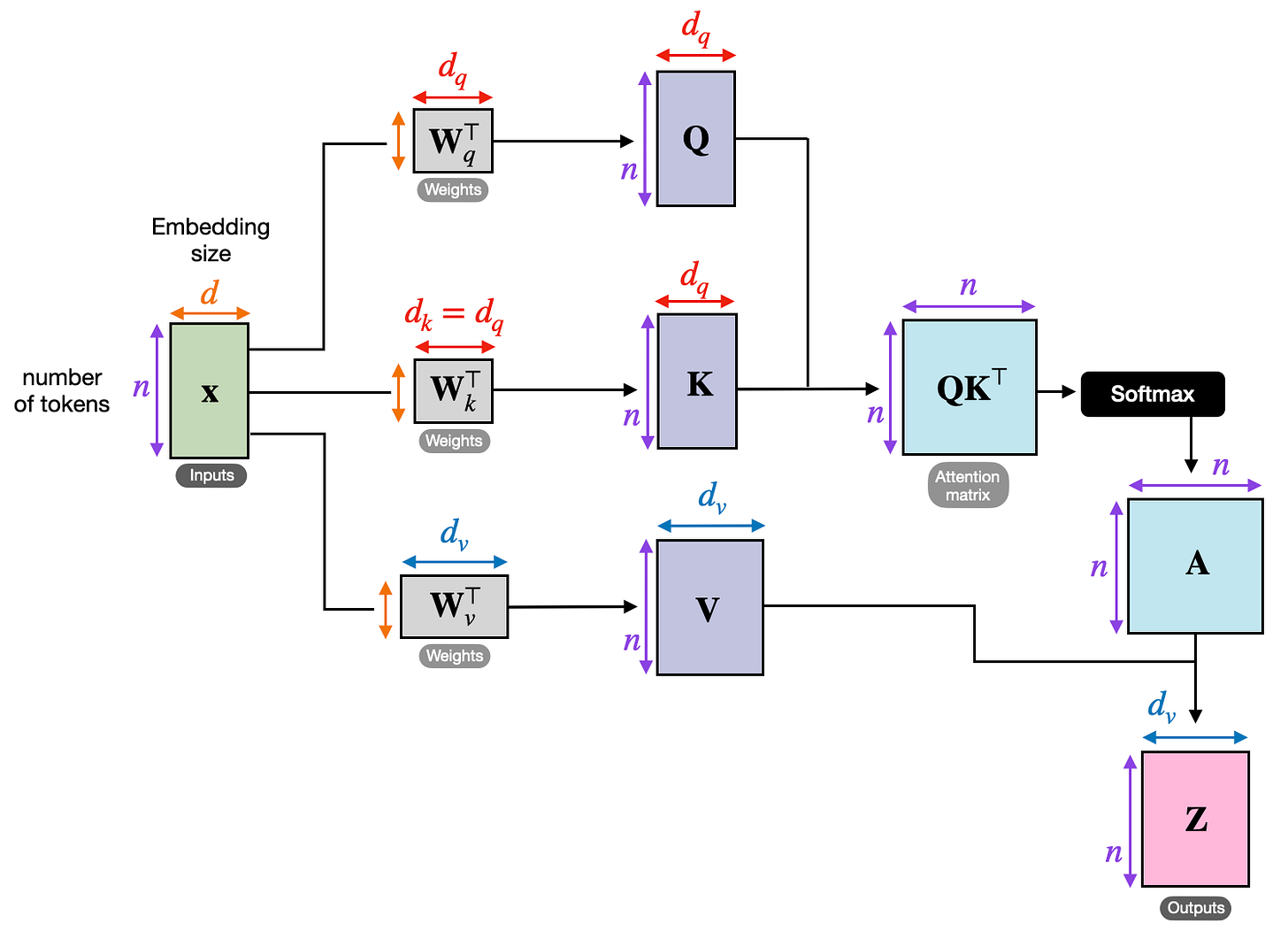
図 7: 入力埋め込み X から正規化されたアテンション行列 A、および出力表現 Z に至る完全な単一ヘッドのパイプライン(元出典:Understanding and Coding Self-Attention)。
次の図は、前の図と同じ概念を示していますが、アテンション行列の計算が「スケーリングドットプロダクトアテンション」ボックスの中に隠されており、すべての入力トークンに対してではなく、1 つの入力トークンのみに対して計算を実行します。これは、次のセクションでマルチヘッドアテンションに拡張する前に、単一ヘッドによる自己アテンションのコンパクトな形式を示すためです。
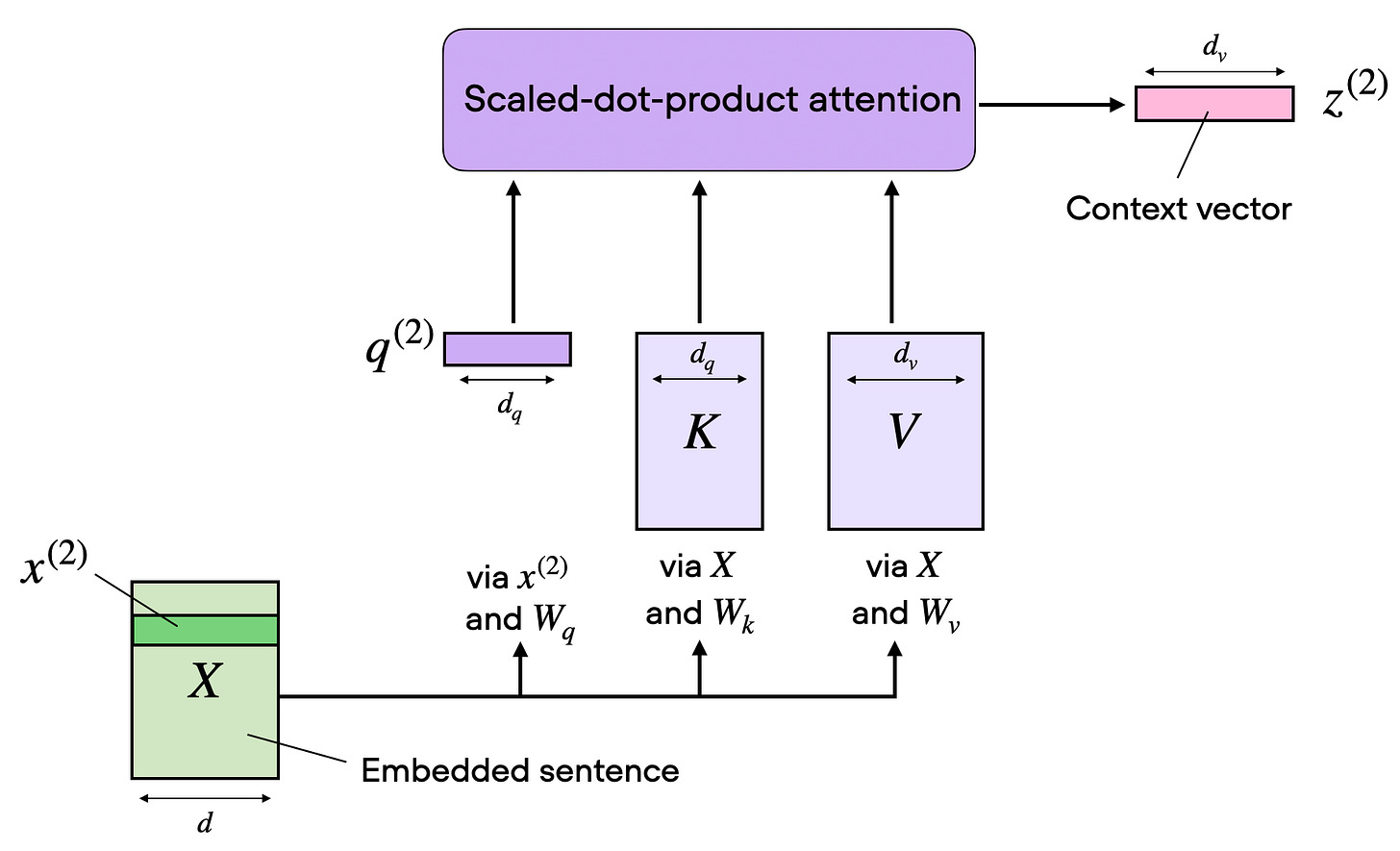
図 8: 1 つのアテンションヘッドはすでに完全なメカニズムです。1 つのセットの学習済み射影(投影)が、1 つのアテンション行列と 1 つの文脈認識型出力ストリームを生成します(元出典:Understanding and Coding Self-Attention)。
1.5 単一ヘッドからマルチヘッドアテンションへ
Wq/Wk/Wv の行列セット 1 つが 1 つのアテンションヘッドを与え、つまり 1 つのアテンション行列と 1 つの出力行列 Z を意味します。(この概念は前のセクションで説明されています。)
マルチヘッドアテンションは、単に異なる学習された射影行列を用いてこれらのヘッドを並列に複数実行するものです。
これは有用です。なぜなら、異なるヘッドが異なるトークン間の関係性に特化できるからです。あるヘッドは短い局所的な依存関係に焦点を当て、別のヘッドはより広範な意味的なリンクに、さらに別のヘッドは位置情報や構文構造に焦点を当てる可能性があります。
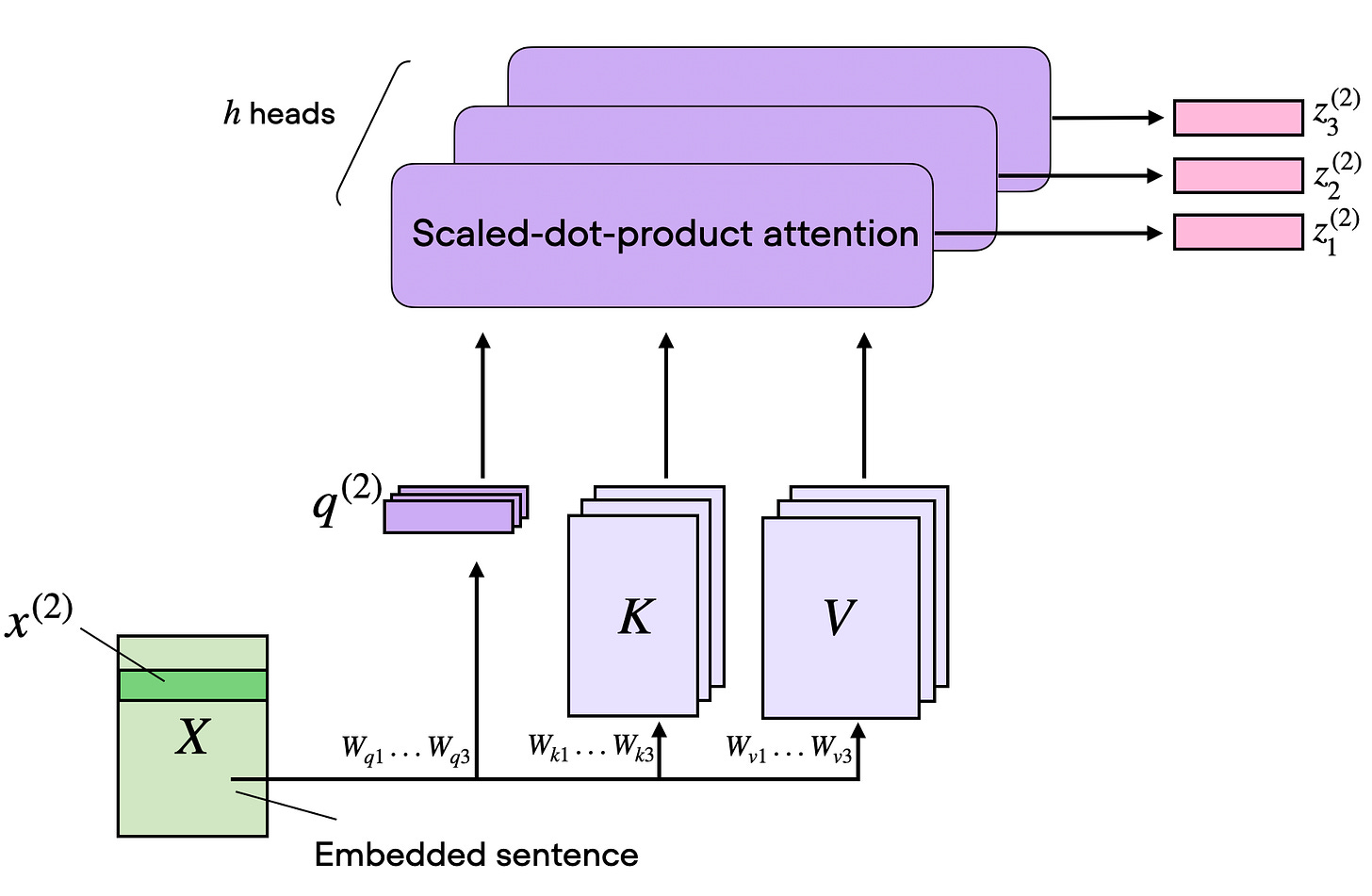
図 9: マルチヘッドアテンションは、基本的なアテンションのレシピを維持しつつ、これを並列で複数のヘッドに繰り返すことで、モデルが一度に複数のトークン間パターンを学習できるようにします(元出典:Understanding and Coding Self-Attention)。
- グループ化クエリアテンション (GQA)
グループ化クエリアテンションは、標準的なマルチヘッドアテンション (MHA) から派生したアテンションのバリアントです。これは 2023 年に Joshua Ainslie らによって発表された論文「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」で導入されました。
すべてのクエリヘッドに個別のキーと値を与えるのではなく、複数のクエリヘッドが同じキー・値射影を共有することを可能にし、これにより KV キャッシング (Key-Value Caching) が大幅に低コスト化されます(主にメモリ削減として)、全体のデコーダーのレシピにはほとんど変更を加えずに済みます。
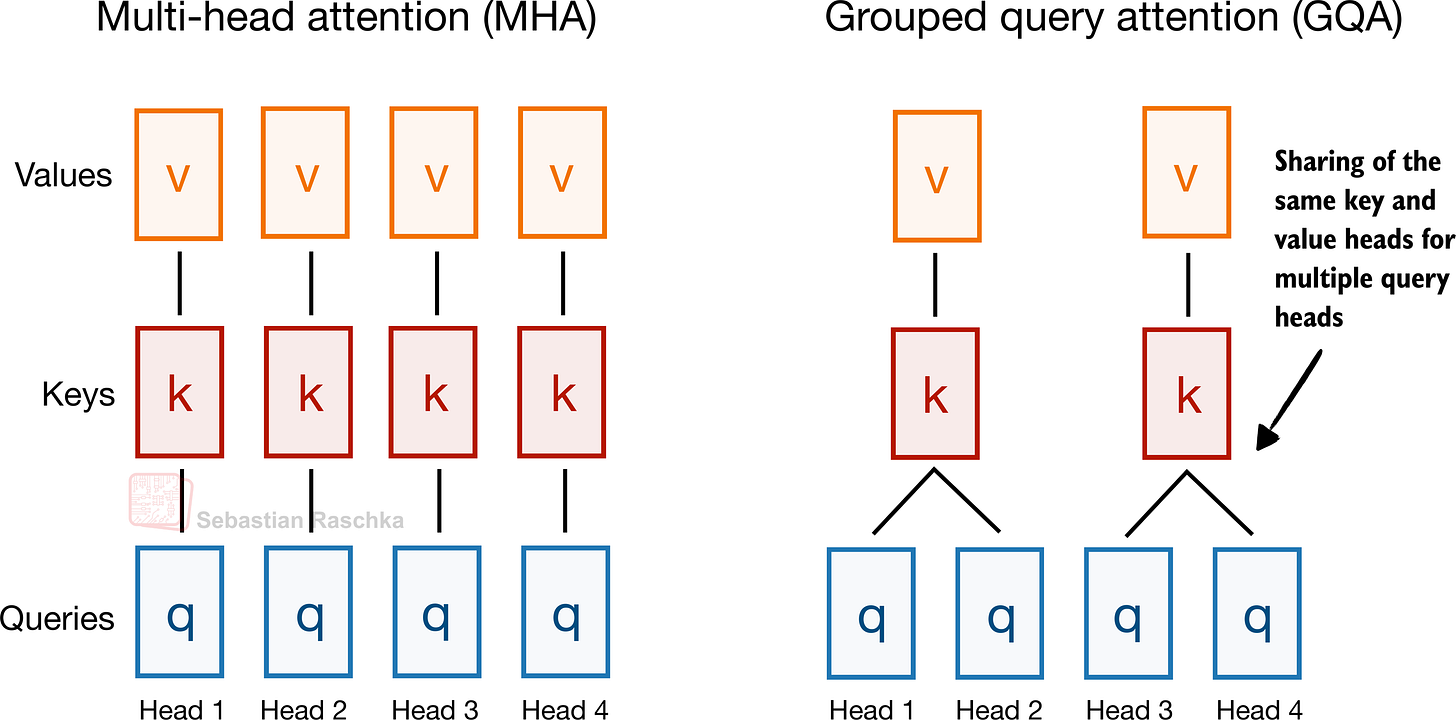
図 10: GQA は MHA と同じ全体的なアテンションパターンを維持しつつ、複数のクエリヘッド間でキー・バリューヘッドを共有することで、その数を削減します(出典:The Big LLM Architecture Comparison)。
EXAMPLE ARCHITECTURES
Dense: Llama 3 8B, Qwen3 4B, Gemma 3 27B, Mistral Small 3.1 24B, SmolLM3 3B, Tiny Aya 3.35B。
Sparse (Mixture-of-Experts): Llama 4 Maverick, Qwen3 235B-A22B, Step 3.5 Flash 196B, Sarvam 30B。
2.1 なぜ GQA が普及したのか
私のアーキテクチャ比較記事では、GQA を古典的なマルチヘッドアテンション(MHA)の新しい標準的な代替案として位置づけました。その理由は、標準的な MHA では各ヘッドが独自のキーとバリューを持つため、モデル化の観点からはより最適ですが、推論時に KV キャッシュにすべての状態を保持しなければならない場合、コストが高くなるからです。
GQA では、より多くのクエリヘッドを維持しつつ、キー・バリューヘッドの数を減らし、複数のクエリでそれらを共有します。これにより、パラメータ数と KV キャッシュのトラフィックを削減できますが、後ほど議論するマルチヘッド潜在アテンション(MLA)のような劇的な実装変更は必要ありません。
実際には、MHA よりも安価でありながら、MLA のような新しい圧縮重視の代替案よりも実装が簡単であるという点から、この手法はラボにとって非常に人気のある選択肢となり続けています。
2.2 GQA によるメモリ節約
GQA は KV ストレージにおいて大きな節約をもたらします。なぜなら、各レイヤーで保持するキー・バリューヘッドの数が少なければ少ないほど、トークンあたりに必要なキャッシュ状態量が減るからです。これが、シーケンス長が成長するにつれて GQA の有用性が高まる理由です。
GQA はスペクトラム(連続体)として捉えることもできます。もしすべてのキー・バリューグループを 1 つの共有グループまで削減すれば、私たちは実質的にマルチクエリアテンションの領域に到達することになります。これはさらに安価ですが、モデル化の品質に対してより顕著な悪影響を与える可能性があります。最適なバランス点は通常、マルチクエリアテンション(1 つの共有グループ)と MHA(キー・バリューグループ数がクエリ数に等しい状態)の間にあるものであり、ここではキャッシュ節約効果が大きい一方で、MHA に対するモデル化性能の低下は控えめに抑えられています。
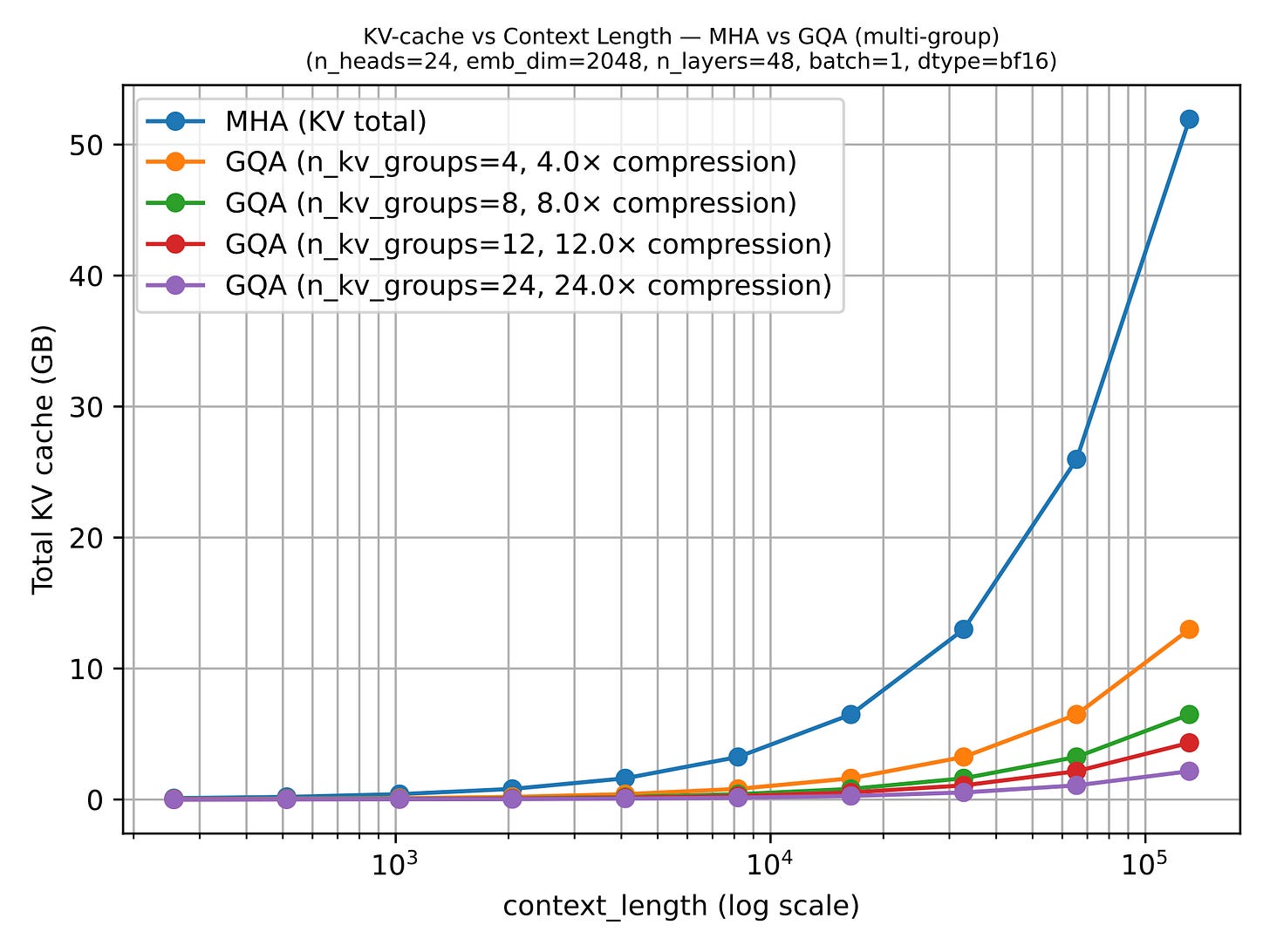
図 11: 数値が低いほど優れています。コンテキストウィンドウが大きくなるにつれて、KV キャッシュの節約効果がより顕著になります。(出典:LLMs-from-scratch GQA マテリアル)
2.3 なぜ 2026 年においても GQA は重要なのか
より高度なバリアントである MLA は、同じ KV エフィシエンシーレベルにおいてより優れたモデリング性能を提供できるため(例えば DeepSeek-V2 論文の消融実験で議論されている通り)、人気を集めつつありますが、その反面、実装がより複雑になり、アテンションスタックもより複雑なものになります。
GQA は、堅牢であり、実装が容易で、トレーニングも容易である(私の経験則では、必要なハイパーパラメータの調整が少ないため)という点から依然として魅力的です。
そのため、一部の最新リリースでもあえてクラシックなアプローチを維持しています。例えば、私の「Spring Architectures」記事で言及した MiniMax M2.5 や Nanbeige 4.1 は、他の効率化トリックを追加せず、グループドクエリアテンション(Grouped-Query Attention)のみを使用する非常にクラシックなモデルです。Sarvam も特に有用な比較対象となります:30B モデルはクラシックな GQA を維持している一方、105B バージョンでは MLA に切り替えています。
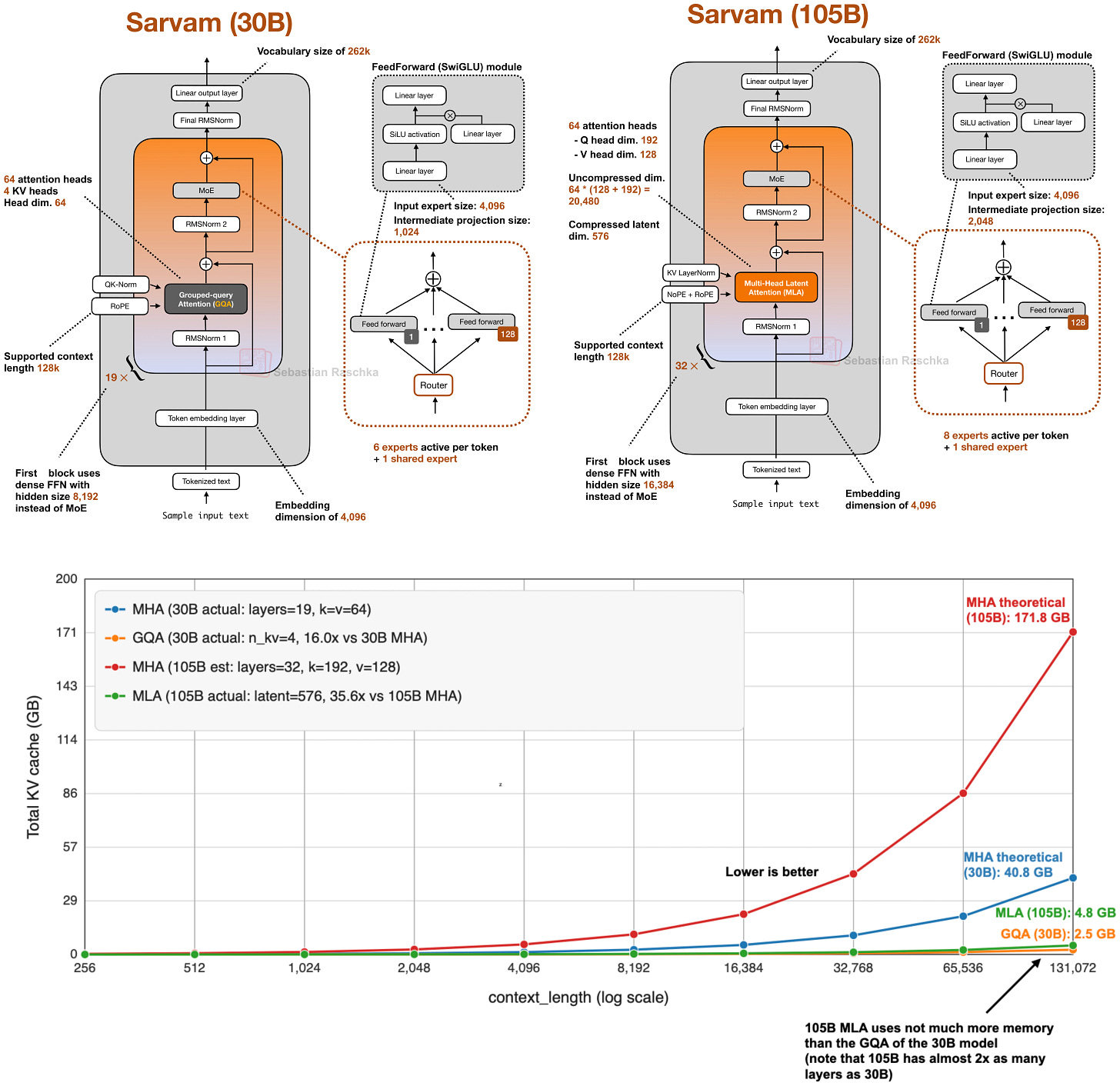
図 12: 105B Sarvam(MLA 使用)と 30B Sarvam(GQA 使用)、および通常の MHA(Multi-Head Attention)を使用した場合の総 KV キャッシュサイズ。
- マルチヘッド潜在アテンション (MLA)
Multi-head Latent Attention (MLA) の背後にある動機は、Grouped-Query Attention (GQA) と同様です。両者とも KV-cache のメモリ要件を削減するための解決策です。GQA と MLA の違いは、MLA がヘッドを共有して保存する K/V の数を減らすのではなく、保存される内容を圧縮することでキャッシュを縮小する点にあります。
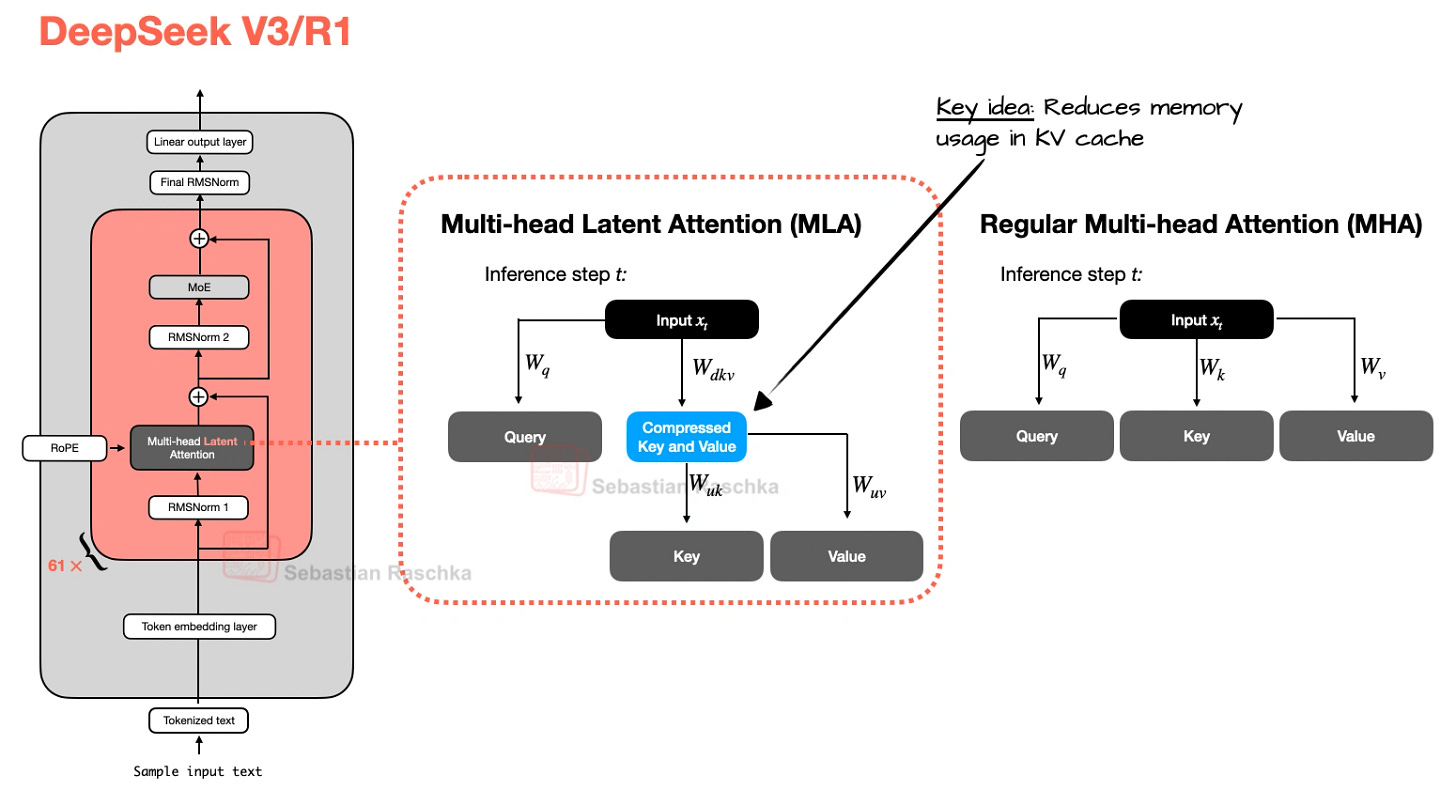
図 13: GQA と異なり、MLA はヘッドをグループ化することで KV コストを削減するわけではありません。代わりに、圧縮された潜在表現(latent representation)をキャッシュすることでコストを削減します。簡略化のため省略されていますが、これはクエリにも適用されます(元出典:The Big LLM Architecture Comparison)。
MLA はもともと DeepSeek-V2 の論文で提案されましたが、DeepSeek 時代の象徴的なアイデアとなりました(特に DeepSeek-V3 と R1 以降)。GQA に比べて実装は複雑であり、サービス提供もより困難ですが、モデルサイズやコンテキスト長が十分に大きくなりキャッシュのトラフィックが支配的になる現代においては、むしろ魅力的な選択肢となることが多くなっています。同じメモリ削減率であっても、より優れたモデリング性能を維持できるからです(これについては後述します)。
EXAMPLE ARCHITECTURES
DeepSeek V3, Kimi K2, GLM-5, Ling 2.5, Mistral Large 3, および Sarvam 105B
3.1 共有ではなく圧縮
MHA や GQA がフル解像度のキーおよびバリューテンソルをキャッシュするのとは異なり、MLA は潜在表現を保存し、必要に応じて使用可能な状態を再構築します。本質的には、これはアテンション内部に埋め込まれたキャッシュ圧縮戦略であり、前述の図で示されています。
以下の図は、通常の MHA と比較した削減効果を表しています。
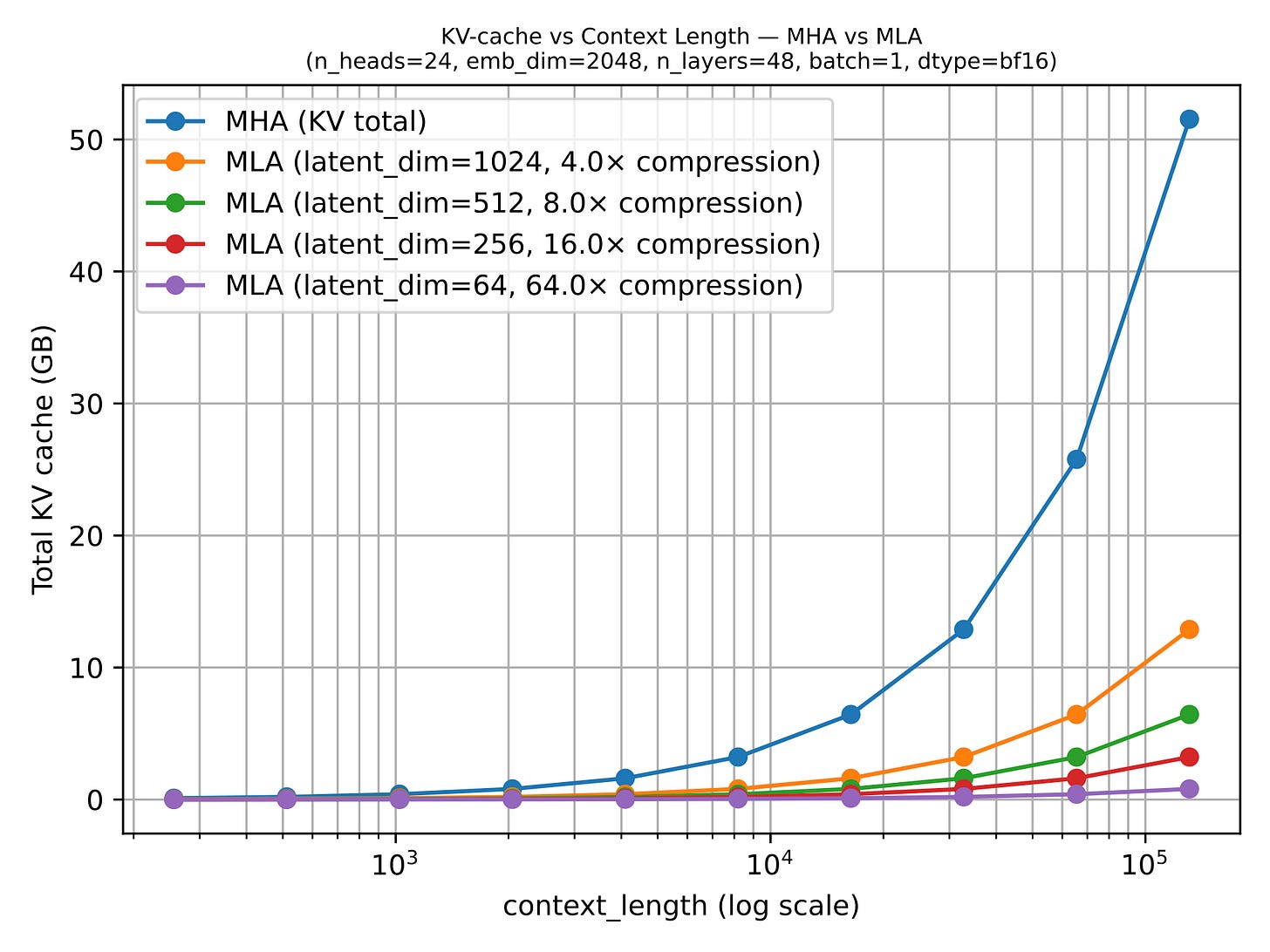
図 14: コンテキスト長が成長すると、フル K/V テンソルではなく潜在表現をキャッシュすることによる削減効果が非常に明確になります(元出典:LLMs-from-scratch の MLA セクション)。
3.2 MLA アブレーションスタディーズ
DeepSeek-V2 の論文では、いくつかのアブレーション実験が示されており、モデル性能の観点からは GQA が MHA よりも劣っているように見える一方で、MLA ははるかに良好に機能し、注意深くチューニングすれば MHA をさえ上回る可能性があるとされています。これは「(メモリも)節約できる」という理由よりも、はるかに強力な根拠となります。
つまり、DeepSeek にとって MLA が好ましいアテンションメカニズムである理由は、単に効率的だからだけでなく、大規模スケールにおいて品質を維持したままの効率化策として機能するように見えるからです。(ただし、同僚からは、MLA は特定のサイズでのみうまく機能すると聞いています。より小さなモデル、例えば 100B より小さい場合では、GQA の方がむしろよく機能するか、少なくともチューニングして正しく動作させるのが容易であるようです。)
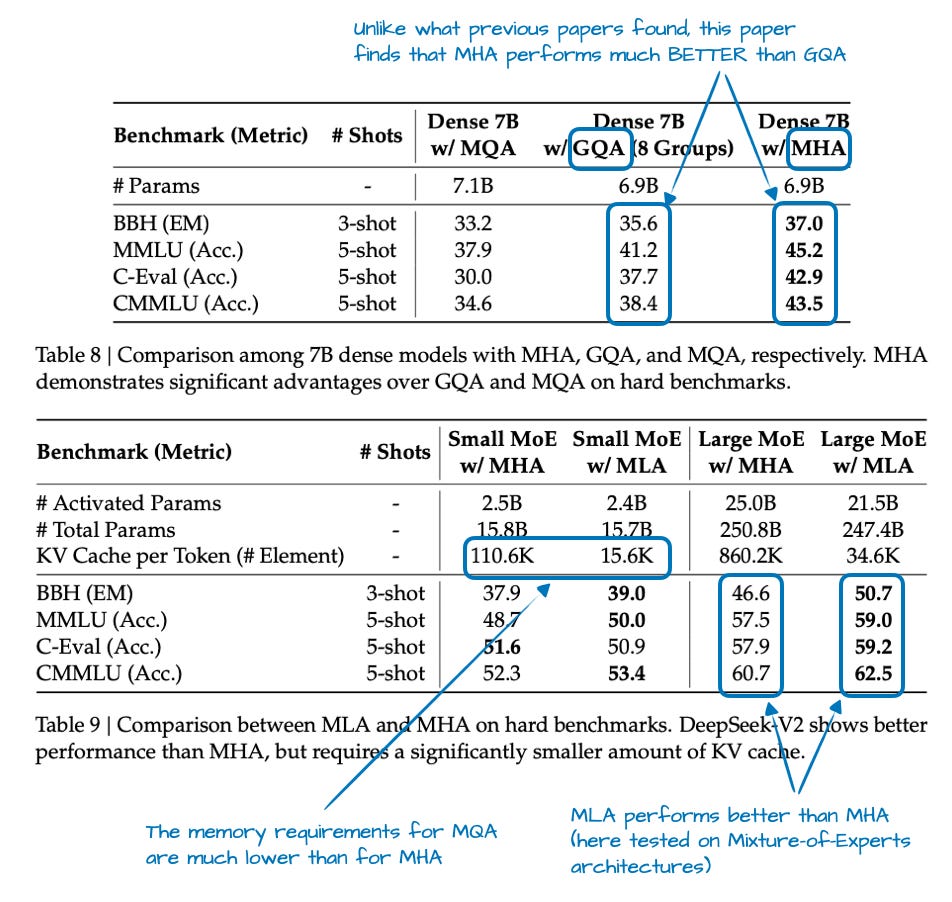
図 15: ここでは GQA が MHA を下回っており、MLA は依然として競争力があり、わずかに上回ることもあります。基礎となる論文:DeepSeek-V2。
以下は、30B の Sarvam における GQA と、105B の Sarvam における MLA の比較を再掲したものです。
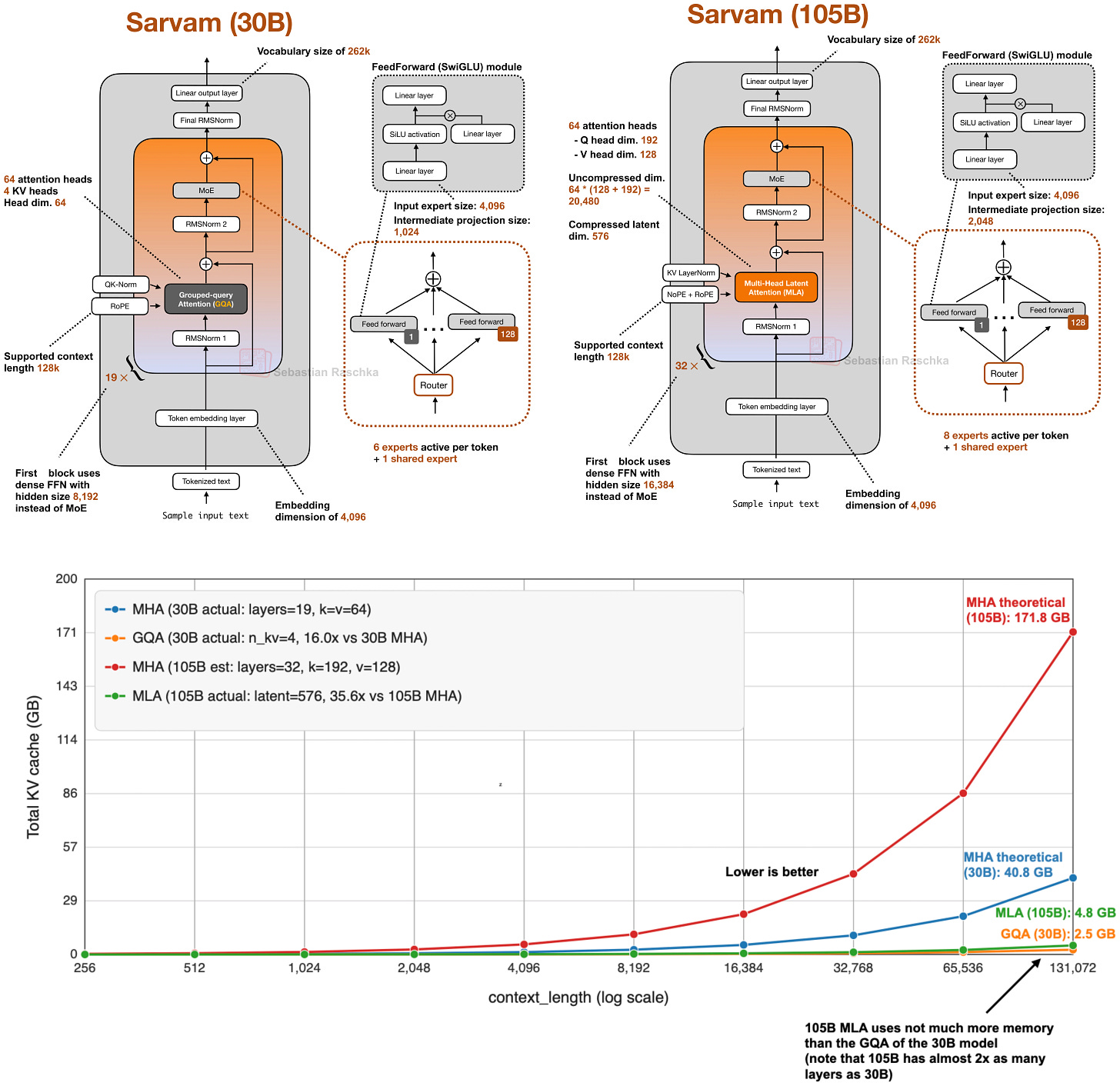
図 16: GQA と MLA は、異なる方向から同じボトルネックを解決しています。トレードオフは、簡素さ versus より大規模なモデルにおける優れたモデリング性能です。
3.3 DeepSeek 後の MLA の普及
DeepSeek V3/R1 や V3.1 などにより、V2 で導入された設計が標準化されると、MLA は第二波のアーキテクチャにおいて現れ始めました。Kimi K2 は DeepSeek のレシピを継承してスケールアップしました。GLM-5 は、DeepSeek Sparse Attention(DeepSeek V3.2 から)とともに MLA を採用しました。Ling 2.5 は、MLA と線形アテンションのハイブリッドを組み合わせています。Sarvam は 2 つのモデルをリリースしており、30B モデルは従来の GQA に留まり、105B モデルは MLA に切り替えました。
最後のペアは特に有用です。なぜなら、技術的な複雑さに関する議論を脇に置くことができるからです。つまり、Sarvam チームは両方のバリアントを実装し、意図的に一方には GQA を、他方には MLA を採用することを選択しました。したがって、ある意味で、MLA は理論的な代替案というよりも、ファミリーがスケールアップする際に具体的なアーキテクチャのアップグレードパスのように感じられます。
- スライディングウィンドウアテンション (SWA)
スライディングウィンドウアテンションは、各位置が参照できる過去のトークンの数を制限することで、長文コンテキスト推論におけるメモリと計算コストを削減します。すべてのプレフィックスに注意を向けるのではなく、各
原文を表示
I had originally planned to write about DeepSeek V4. Since it still hasn’t been released, I used the time to work on something that had been on my list for a while, namely, collecting, organizing, and refining the different LLM architectures I have covered over the past few years.
So, over the last two weeks, I turned that effort into an LLM architecture gallery (with 45 entries at the time of this writing), which combines material from earlier articles with several important architectures I had not documented yet. Each entry comes with a visual model card, and I plan to keep the gallery updated regularly.
You can find the gallery here: https://sebastianraschka.com/llm-architecture-gallery/
Figure 1: Overview of the LLM architecture gallery and its visual model cards.
After I shared the initial version, a few readers also asked whether there would be a poster version. So, there is now a poster version via Redbubble. I ordered the Medium size (26.9 x 23.4 in) to check how it looks in print, and the result is sharp and clear. That said, some of the smallest text elements are already quite small at that size, so I would not recommend the smaller versions if you intend to have everything readable.
Figure 2: Poster version of the architecture gallery with some random objects for scale.
Alongside the gallery, I was/am also working on short explainers for a few core LLM concepts.
So, in this article, I thought it would be interesting to recap all the recent attention variants that have been developed and used in prominent open-weight architectures in recent years.
My goal is to make the collection useful both as a reference and as a lightweight learning resource. I hope you find it useful and educational!
- Multi-Head Attention (MHA)
Self-attention lets each token look at the other visible tokens in the sequence, assign them weights, and use those weights to build a new context-aware representation of the input.
Multi-head attention (MHA) is the standard transformer version of that idea. It runs several self-attention heads in parallel with different learned projections, then combines their outputs into one richer representation.
Figure 3: Olmo 2 as an example architecture using MHA.
The sections below start with a whirlwind tour of explaining self-attention to explain MHA. It’s more meant as a quick overview to set the stage for related attention concepts like grouped-query attention, sliding window attention, and so on. If you are interested in a longer, more detailed self-attention coverage, you might like my longer Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article.
EXAMPLE ARCHITECTURES
GPT-2, OLMo 2 7B, and OLMo 3 7B
1.2 Historical Tidbits And Why Attention Was Invented
Attention predates transformers and MHA. Its immediate background is encoder-decoder RNNs for translation.
In those older systems, an encoder RNN would read the source sentence token by token and compress it into a sequence of hidden states, or in the simplest version into one final state. Then the decoder RNN had to generate the target sentence from that limited summary. This worked for short and simple cases, but it created an obvious bottleneck once the relevant information for the next output word lived somewhere else in the input sentence.
In short, the limitation is that the hidden state can’t store infinitely much information or context, and sometimes it would be useful to just refer back to the full input sequence.
The translation example below shows one of the limitations of this idea. For instance, a sentence can preserve many locally reasonable word choices and still fail as a translation when the model treats the problem too much like a word-by-word mapping. (The top panel shows an exaggerated example where we translate the sentence word by word; obviously, the grammar in the resulting sentence is wrong.) In reality, the correct next word depends on sentence-level structure and on which earlier source words matter at that step. Of course, this could still be translated fine with an RNN, but it would struggle with longer sequences or knowledge retrieval tasks because the hidden state can only store so much information as mentioned earlier.
Figure 4: Translation can fail even when many individual word choices look reasonable because sentence-level structure still matters (Original source LLMs-from-scratch).
The next figure shows that change more directly. When the decoder is producing an output token, it should not be limited to one compressed memory path. It should be able to reach back to the more relevant input tokens directly.
Figure 5: Attention breaks the RNN bottleneck by letting the current output position revisit the full input sequence instead of relying on one compressed state alone (Original source LLMs-from-scratch).
Transformers keep that core idea from the aforementioned attention-modified RNN but remove the recurrence. In the classic Attention Is All You Need paper, attention becomes the main sequence-processing mechanism itself (instead of being just part of an RNN encoder-decoder.)
In transformers, that mechanism is called self-attention, where each token in the sequence computes weights over all other tokens and uses them to mix information from those tokens into a new representation. Multi-head attention is the same mechanism run several times in parallel.
1.3 The Masked Attention Matrix
For a sequence of T tokens, attention needs one row of weights per token, so overall we get a T x T matrix.
Each row answers a simple question. When updating this token, how much should each visible token matter? In a decoder-only LLM, future positions are masked out, which is why the upper-right part of the matrix is grayed out in the figure below.
Self-attention is fundamentally about learning these token-to-token weight patterns, under a causal mask, and then using them to build context-aware token representations.
Figure 6: A concrete masked attention matrix where each row belongs to one token, each entry is an attention weight, and future-token entries are removed by the causal mask (Original source Understanding and Coding Self-Attention).
1.4 Self-Attention Internals
The next figure shows how the transformer computes the attention matrix (A) from the input embeddings X, which is then used to produce the transformed inputs (Z).
Here Q, K, and V stand for queries, keys, and values. The query for a token represents what that token is looking for, the key represents what each token makes available for matching, and the value represents the information that gets mixed into the output once the attention weights have been computed.
The steps are as follows:
Wq, Wk, and Wv are weight matrices that project the input embeddings into Q, K, and V
QK^T produces the raw token-to-token relevance scores
softmax converts those scores into the normalized attention matrix A that we discussed in the previous section
A is applied to V to produce the output matrix Z
Note that the attention matrix is not a separate hand-written object. It emerges from Q, K, and softmax.
Figure 7: The full single-head pipeline, from input embeddings X to the normalized attention matrix A and output representations Z (Original source Understanding and Coding Self-Attention).
The next figure shows the same concept as the previous figure but the attention matrix computation is hidden inside the “scaled-dot-product attention” box, and we perform the computation only for one input token instead of all input tokens. This is to show a compact form of self-attention with a single head before extending this to multi-head attention in the next section.
Figure 8: One attention head is already a complete mechanism. One set of learned projections produces one attention matrix and one context-aware output stream (Original source Understanding and Coding Self-Attention).
1.5 From One Head To Multi-Head Attention
One set of Wq/Wk/Wv matrices gives us one attention head, which means one attention matrix and one output matrix Z. (This concept was illustrated in the previous section.)
Multi-head attention simply runs several of these heads in parallel with different learned projection matrices.
This is useful because different heads can specialize in different token relationships. One head might focus on short local dependencies, another on broader semantic links, and another on positional or syntactic structure.
Figure 9: Multi-head attention keeps the same basic attention recipe, but repeats it across several heads in parallel so the model can learn several token-to-token patterns at once (Original source Understanding and Coding Self-Attention).
- Grouped-Query Attention (GQA)
Grouped-query attention is an attention variant derived from standard MHA. It was introduced in the 2023 paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints by Joshua Ainslie and colleagues.
Instead of giving every query head its own keys and values, it lets several query heads share the same key-value projections, which makes KV caching much cheaper (primarily as a memory reduction) without changing the overall decoder recipe very much.
Figure 10: GQA keeps the same overall attention pattern as MHA, but collapses the number of key-value heads by sharing them across multiple query heads (Original source: The Big LLM Architecture Comparison).
EXAMPLE ARCHITECTURES
Dense: Llama 3 8B, Qwen3 4B, Gemma 3 27B, Mistral Small 3.1 24B, SmolLM3 3B, and Tiny Aya 3.35B.
Sparse (Mixture-of-Experts): Llama 4 Maverick, Qwen3 235B-A22B, Step 3.5 Flash 196B, and Sarvam 30B.
2.1 Why GQA Became Popular
In my architecture comparison article, I framed GQA as the new standard replacement for classic multi-head attention (MHA). The reason is that standard MHA gives every head its own keys and values, which is more optimal from a modeling perspective but expensive once we have to keep all of that state in the KV cache during inference.
In GQA, we keep a larger set of query heads, but we reduce the number of key-value heads and let multiple queries share them. That lowers both parameter count and KV-cache traffic without making drastic implementation changes like multi-head latent attention (MLA), which will be discussed later.
In practice, that made and keeps it a very popular choice for labs that wanted something cheaper than MHA but simpler to implement than newer compression-heavy alternatives like MLA.
2.2 GQA Memory Savings
GQA results in big savings in KV storage, since the fewer key-value heads we keep per layer, the less cached state we need per token. That is why GQA becomes more useful as sequence length grows.
GQA is also a spectrum. If we reduce all the way down to one shared K/V group, we are effectively in multi-query attention territory, which is even cheaper but can hurt modeling quality more noticeably. The sweet spot is usually somewhere in between multi-query attention (1 shared group) and MHA (where K/V groups are equal to the number of queries), where the cache savings are large but the modeling degradation relative to MHA stays modest.
Figure 11: Lower is better. Once the context window grows, KV-cache savings become more pronounced. (Original source: LLMs-from-scratch GQA materials)
2.3 Why GQA Still Matters In 2026
More advanced variants such as MLA are becoming popular because they can offer better modeling performance at the same KV efficiency levels (e.g., as discussed in the ablation studies of the DeepSeek-V2 paper), but they also involve a more complicated implementation and a more complicated attention stack.
GQA remains appealing because it is robust, easier to implement, and also easier to train (since there are fewer hyperparameter tunings necessary, based on my experience).
That is why some of the newer releases still stay deliberately classic here. E.g., in my Spring Architectures article, I mentioned that MiniMax M2.5 and Nanbeige 4.1 as models that remained very classic, using only grouped-query attention without piling on other efficiency tricks. Sarvam is a particularly useful comparison point as well: the 30B model keeps classic GQA, while the 105B version switches to MLA.
Figure 12: Total KV cache sizes for 105B Sarvam (using MLA) versus 30B Sarvam (using GQA), versus using plain MHA.
- Multi-Head Latent Attention (MLA)
The motivation behind Multi-head Latent Attention (MLA) is similar to Grouped-Query Attention (GQA). Both are solutions for reducing KV-cache memory requirements. The difference between GQA and MLA is that MLA shrinks the cache by compressing what gets stored rather than by reducing how many K/Vs are stored by sharing heads.
Figure 13: Unlike GQA, MLA does not reduce KV cost by grouping heads. It reduces it by caching a compressed latent representation. Note that it is also applied to the query, which is not shown for simplicity (Original source:The Big LLM Architecture Comparison).
MLA, originally proposed in the DeepSeek-V2 paper, became such a defining DeepSeek-era idea (especially after DeepSeek-V3 and R1). It is more complicated to implement than GQA, more complicated to serve, but nowadays also often more compelling once model size and context length get large enough that cache traffic starts to dominate, because at the same rate of memory reduction, it could maintain better modeling performance (more on that later).
EXAMPLE ARCHITECTURES
DeepSeek V3, Kimi K2, GLM-5, Ling 2.5, Mistral Large 3, and Sarvam 105B
3.1 Compression, Not Sharing
Instead of caching full-resolution key and value tensors as in MHA and GQA, MLA stores a latent representation and reconstructs the usable state when needed. Essentially, it is a cache compression strategy embedded inside attention, as illustrated in the previous figure.
The figure below shows the savings compared to regular MHA.
Figure 14: Once context length grows, the savings from caching a latent representation instead of full K/V tensors become very visible (Original source: LLMs-from-scratch MLA section).
3.2 MLA Ablation Studies
The DeepSeek-V2 paper provided some ablations where GQA looked worse than MHA in terms of modeling performance, while MLA held up much better and could even outperform MHA when tuned carefully. That is a much stronger justification than “it (also) saves memory.”
In other words, MLA is a preferable attention mechanism for DeepSeek not just because it was efficient, but because it looked like a quality-preserving efficiency move at large scale. (But colleagues also told me that MLA only works well at a certain size. For smaller models, let’s say <100B, GQA seems to work better, or, is at least easier to tune and get right.)
Figure 15: GQA drops below MHA here, while MLA remains competitive and can even slightly outperform it. Underlying paper: DeepSeek-V2.
Below is again the comparison between GQA in 30B Sarvam versus MLA in 105B Sarvam.
Figure 16: GQA and MLA are solving the same bottleneck from different directions. The tradeoff is simplicity versus better modeling performance for larger models.
3.3 How MLA Spread After DeepSeek
Once DeepSeek V3/R1, V3.1 etc. normalized the design after its introduction in V2, it started showing up in a second wave of architectures. Kimi K2 kept the DeepSeek recipe and scaled it up. GLM-5 adopted MLA together with DeepSeek Sparse Attention (from DeepSeek V3.2). Ling 2.5 paired MLA with a linear-attention hybrid. Sarvam released two models where the 30B model stayed with classic GQA and the 105B model switched to MLA.
That last pair is particularly useful as it puts the technical-complexity discussion aside. I.e., the Sarvam team implemented both variants and deliberately chose to then use GQA for one variant and MLA for the other. So, in a sense, that makes MLA feel less like a theoretical alternative and more like a concrete architectural upgrade path once a family scales up.
- Sliding Window Attention (SWA)
Sliding window attention reduces the memory and compute cost of long-context inference by limiting how many previous tokens each position can attend to. Instead of attending to the entire prefix, eac
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み