Redeploying Fable 5
Anthropic は米政府による輸出規制の解除を受け、Claude Fable 5 のグローバル利用を再開し、業界全体のセキュリティ基準策定に向けた共同枠組みの構築を発表した。
キーポイント
輸出規制の解除とサービス再開
6月12日に発令された米国政府による輸出規制が解除され、Claude Fable 5 は7月1日よりグローバルで利用可能となる。
利用制限とクレジット制度の導入
Pro、Max、Team および一部の Enterprise プランでは、7月7日までの期間中、週次使用量の上限の最大50%が Fable 5 に割り当てられる。
業界共通のセキュリティ枠組みの構築
Amazon、Microsoft、Google と連携し、AI モデルの「ジャイルブレイク」リスクを評価・分類するための業界標準フレームワークの開発を開始した。
Glasswing プログラムの拡大
米国政府との調整により、Claude Mythos 5 のアクセス権限が一部の米国内組織に復元され、国内外のパートナーへの展開を継続する。
影響分析・編集コメントを表示
影響分析
このニュースは、AI モデル開発における輸出規制という複雑な課題に対する実務的な解決策を示しており、企業と政府間の協力体制が機能し始めていることを示唆しています。また、単一の企業の対応に留まらず、業界全体でセキュリティ基準を統一しようとする動きは、将来の AI ガバナンスにおいて重要な先例となるでしょう。
編集コメント
規制という外部要因によるサービス停止から、業界全体での標準化へ視座を移した点は、AI ガバナンスの成熟を示す重要な転換点です。
6月12日(金)、米国政府は当社の最新モデルであるClaude Fable 5およびClaude Mythos 5に対して輸出管理措置を適用しました。これにより、米国国内・国外を問わず外国人へのアクセス制限が必要となりました。命令が即時発効し、リアルタイムでの国籍確認に信頼できる手段が存在しなかったため、両モデルに対するすべてのユーザーのアクセスを一時的に停止いたしました。
本日6月30日現在、Fable 5およびMythos 5に対する輸出管理措置は解除されましたこちら。
Fable 5は、明日の7月1日(水)より、Claude Platform、Claude.ai、Claude Code、およびClaude Coworkにおいて世界中のユーザーにご利用いただけるようになります。Pro、Max、Team、および一部のEnterpriseプランでは、7月7日まで週間の利用制限の最大50%までFable 5が含まれます。その後、利用クレジットを通じてご利用いただけます。AWS、Google Cloud、Microsoft Foundryにおけるアクセスも可能な限り早期に再開いたします。
また、米国政府の承認を受けました6月26日を踏まえ、特定の米国組織に対してMythos 5へのアクセスも復旧いたしました。引き続き政府と連携し、Glasswingプログラムにおけるより広範な国内および国際パートナー向けにアクセス拡大を進めてまいりますこちら。
本投稿の残りの部分では、以下の4つの領域についてさらに詳細と更新情報を提供します。
- イベントの時系列。これには、セーフガードに対して行った更新も含まれます。輸出管理指令に至った経緯と、新しいセーフガードでどのように対応したかについて議論します。
- セーフガードに対する一般的なアプローチ。モデルの潜在的に危険なサイバーセキュリティ用途を検出するために、安全性分類器をどのように使用しているかについて、より多くの背景情報を提供します。
- 業界共通の枠組み。建設的な解決策に至りましたが、これらの出来事は、AI モデルの「 Jailbreak(セーフガード回避)」(モデルのセーフガードを迂回する技術)2 を評価し修正するための業界全体で統一された方法が必要であることを明確にしました。特定の Jailbreak の深刻度を判断するための共通基準は、新たな発見が生じた際に AI 開発者が優先順位をつけ、より高い安全性をもって高機能なモデルをリリースし、政府や産業パートナーに対してリスクレベルを一貫して伝えることを支援します。Amazon、Microsoft、Google、およびその他の Glasswing パートナーと共に、私たちはそのような枠組みの開発を開始しており、その概要を以下に示します。
- 政府とのさらなる協力。また、米国政府との間で、リリース前の新たなテスト、情報共有、研究協力における協力のレベルを強化しています。このより深い協力については最終セクションで説明します。
タイムラインとセーフガードの更新
私たちは火曜日、6 月 9 日に Fable 5 と Mythos 5 をリリースしました。両者は同じ基盤モデルを共有していますが、Fable 5 は一般利用における安全性を高めるために強力なセーフガード(安全装置)とともにリリースされました。一方、セーフガードが比較的少ない Mythos 5 は、防御的なサイバーセキュリティ用途に限定し、信頼できるプロジェクト・グラスウィングのパートナーの一部のみに対してリリースされています。
6 月 12 日の輸出管理指令は、政府が Amazon の研究者らが Fable 5 のセーフガードを回避する手法を見つけたという報告書の内容を知った後に発令されました。その手法とは、Fable 5 に特定のプロンプトを入力させることで、多数のソフトウェア脆弱性を特定させるというものです。あるケースでは、モデルは関連する脆弱性がどのように悪用されるかを示すコードを生成しました。過去 2 週間にわたり、私たちは政府や Amazon を含む他のパートナーと緊密に連携し、報告書および証拠を見直してきました。
私たちのテストにより、多くの能力が低いモデル(Claude Opus 4.8、GPT-5.5、Kimi K2.7 など)も、Fable 5 が報告書で特定したのと同じ脆弱性を識別できることが確認されました。また、単一の脆弱性の悪用方法をデモンストレーションする点に関しても、テストしたすべてのモデル(Claude Haiku 4.5、Sonnet 4.6、Opus 4.6、Opus 4.7、Opus 4.8、GPT-5.4、GPT-5.5、Kimi K2.7 など)が Fable 5 と同じデモンストレーションを生成できることが判明しました。
重要なのは、報告された手法はミソスレベルの独自のサイバー能力を露呈していなかったことです。この行動は Fable 5 のセーフガードにおける境界事例を示しており、以下で説明するように、危険とは考えにくいタスクであっても、過剰な警戒心からセーフガードによってブロックされるケースが存在します。報告された手法はこの種の行動へのアクセスを可能にしましたが、関与したのは日常的な防御的なサイバーセキュリティ作業のみでした。
それでも私たちは、報告されたバイパスに対処すべく迅速に動き出しました。政府と緊密に連携し、報告書で記述された行動を対象としてブロックする改善されたセーフティ分類器(safety classifier)を訓練しました。Fable 5 へのリクエストがブロックされる場合、ユーザーには通知が行われ、そのリクエストは代わりに Opus 4.8 に転送されます。
新しい分類器により、Amazon の報告書で記述された特定の手法は、ケースの 99% 以上でブロックされます。ごく一部のケースでは、モデルがサイバー攻撃者に役立つほど詳細ではない情報を提供することがあります。以下で説明するように、モデルのセーフガードは、すべての低リスクかつ日常的なサイバー防御能力をブロックするものではなく、潜在的に有害なもののみを対象とすると想定されています。米国商務省 AI 標準化・イノベーションセンター(CAISI)の研究員が、私たちの以前のセーフガードおよび新しいセーフガードの両方をテストし、それらが極めて強力であると合意しています。
新しい分類器は、通常のコーディングやデバッグタスク中に良性の要求をより頻繁にフラグ付けするコストも伴います。すべての安全対策と同様に、私たちは本格的な悪用と正当な要求をより明確に区別し、誤検知(false positives)を減らすために、引き続きこの仕組みを改善していきます。
セキュリティ対策へのアプローチ
Claude Mythos 5 は、他のどのモデルよりも効果的にソフトウェアの脆弱性を発見・悪用でき、熟練した人間のセキュリティ専門家を除けば、それを超える能力を持っています。これらの卓越したサイバーセキュリティ機能は、サイバー攻撃でこのモデルを悪用しようとする悪意のある行為者にとって、特に魅力的な存在となっています。
しかし、Claude Fable 5 はそのような独自の攻撃的機能を提供しません。これは、私たちがこのモデルに適用した中で最も強力な安全対策を備えてリリースしたからです。リリースの直前1 ヶ月間、Anthropic のさまざまなチームからスタッフを移籍させ、この問題に取り組む研究者とエンジニアの数を倍増させました。
Fable 5 は、多種多様な安全メカニズムとともにリリースされました。それぞれの対策単独では完璧な防御を提供するものではありませんが、組み合わせることでモデルが悪用されるのを非常に困難にするアプローチ(「ディフェンス・イン・デプス」と呼ばれる手法)を採用しています。一部の防御策は、危険な要求への支援を断るようモデルを訓練することに関わり、他の対策は悪用のパターンを事後に分析するものです。
特に重要な安全機構の一つに「分類器(classifiers)」があります。これは、対話中にモデルが潜在的に有害なサイバーセキュリティタスクの実行を求められた場合や、潜在的に有害な出力を生成した場合を検出する、より小型の自動化された AI システムです。この状況が発生すると、分類器はモデルがリクエストに応答することをブロックします。これらの分類器の究極的な目的は、モデルが独自に危険な行動をとることを防ぐことです。
すべての安全機構と同様に、分類器も誤りを犯すことがあります。潜在的に危険なコンテンツを見逃してしまう場合があり、また特定のケースでは意図的に「ジャイルブレイク(jailbreak)」されることもあります。ユーザーは、分類器を欺いてシステムがブロックすべき有害な出力をモデルに生成させるために、通常とは異なる方法でモデルにプロンプトを与えることができます。
そのため、私たちは安全分類器が、明らかに無害であると確信できる一連のリクエストに対してトリガーするように意図的に設定しました。この「安全マージン(safety margin)」アプローチでは、リクエストが非常に明確に安全である場合にのみ、分類器のトリガーを回避できます(下の図の行 A を参照)。ユーザーにとっては、安全マージンにより、合理的で有害ではないいくつかのリクエストに対してモデルが応答しないという体験となります。
Fable 5 では、この安全マージンを過去のあらゆるリリースよりもはるかに大きく設定しました(行 B)。その結果、無害なリクエストの多くがブロックされることになります。私たちは、このような偽陽性(false positives)がユーザーにとってフラストレーションの原因となることを理解していましたが、モデルの他の機能を広く利用可能にするという目的のために、このトレードオフを選択しました。
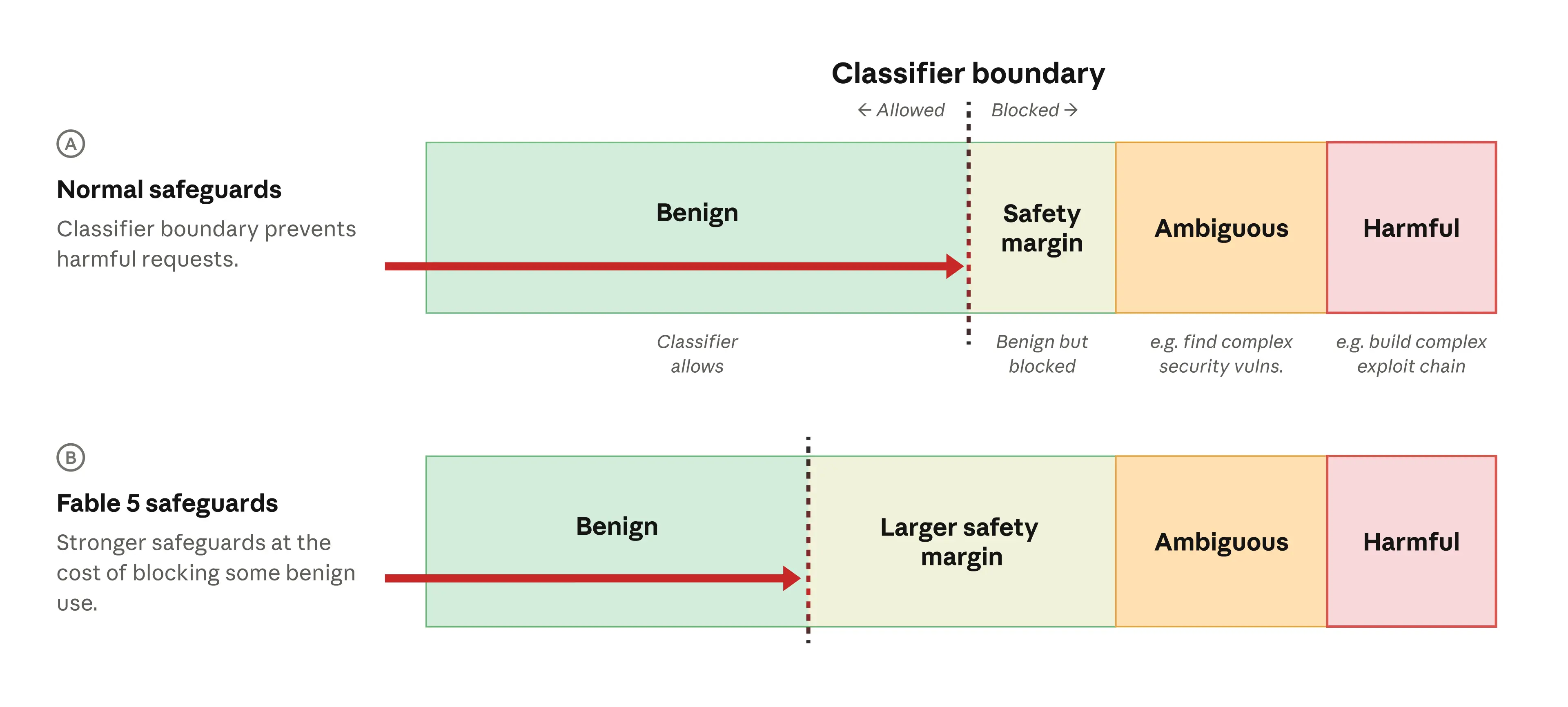 image サイバーセキュリティ安全分類器のイラストです。 モデルへのリクエストがなされた際、この分類器はそれが benign(良性で許可される)ものであるか、潜在的に有害(ブロックされる)であるかを検出します。分類器は曖昧なリクエスト(サイバーセキュリティに関連する明確なものだが、防御目的、例えばセキュリティ脆弱性の発見などである可能性もあるもの)と、有害なリクエスト(ソフトウェアの脆弱性を悪用する連鎖を構築するよう求めるなど、明らかに危険なものを指す)をブロックします。行 A に示されているように、「安全マージン」も設けており、分類器はおそらく benign だが有害になるわずかな可能性のあるリクエストもブロックします。これにより、すべての有害なリクエストが確実にブロックされるという確信が高まります。Fable 5(行 B)ではこの安全マージンをさらに大きく設定しました。その結果、より多くの良性リクエストがブロックされますが、真に有害なリクエストを見逃すことは少なくなります。「Vulns」とは脆弱性(vulnerabilities)を意味します。
image サイバーセキュリティ安全分類器のイラストです。 モデルへのリクエストがなされた際、この分類器はそれが benign(良性で許可される)ものであるか、潜在的に有害(ブロックされる)であるかを検出します。分類器は曖昧なリクエスト(サイバーセキュリティに関連する明確なものだが、防御目的、例えばセキュリティ脆弱性の発見などである可能性もあるもの)と、有害なリクエスト(ソフトウェアの脆弱性を悪用する連鎖を構築するよう求めるなど、明らかに危険なものを指す)をブロックします。行 A に示されているように、「安全マージン」も設けており、分類器はおそらく benign だが有害になるわずかな可能性のあるリクエストもブロックします。これにより、すべての有害なリクエストが確実にブロックされるという確信が高まります。Fable 5(行 B)ではこの安全マージンをさらに大きく設定しました。その結果、より多くの良性リクエストがブロックされますが、真に有害なリクエストを見逃すことは少なくなります。「Vulns」とは脆弱性(vulnerabilities)を意味します。
安全マージンはまた、ジールブレイク( Jailbreak)の緩和にも役立ちます。多くのジールブレイクは狭義のものであり、非常に特定のモデル挙動のみを解除するが、それ以上のことは行いません。あるケースでは、仮想的なユーザーがモデルをわずかにジールブレイクし、安全マージン(あるいは時として曖昧に有害とみなされる行動)に侵入することはできても、私たちがブロックしようとする核心的な有害行為には至りません(以下の表の行 C)。私たちの見解では、これまでに報告されている Fable 5 に対するジールブレイクは、この軽微なカテゴリに該当します。
より深刻なジールブレイクは、より多くの有害行為を解除します。狭義の有害なジールブレイク(行 D)は、特定の有害行為を引き起こす可能性があります。これらのジールブレイクは通常、低から中程度の重大度であり、なぜならその狭さが攻撃者を制限するためです。最も懸念されるカテゴリは、広範な有害行為を解除する*普遍的な*ジールブレイク(行 E)です。
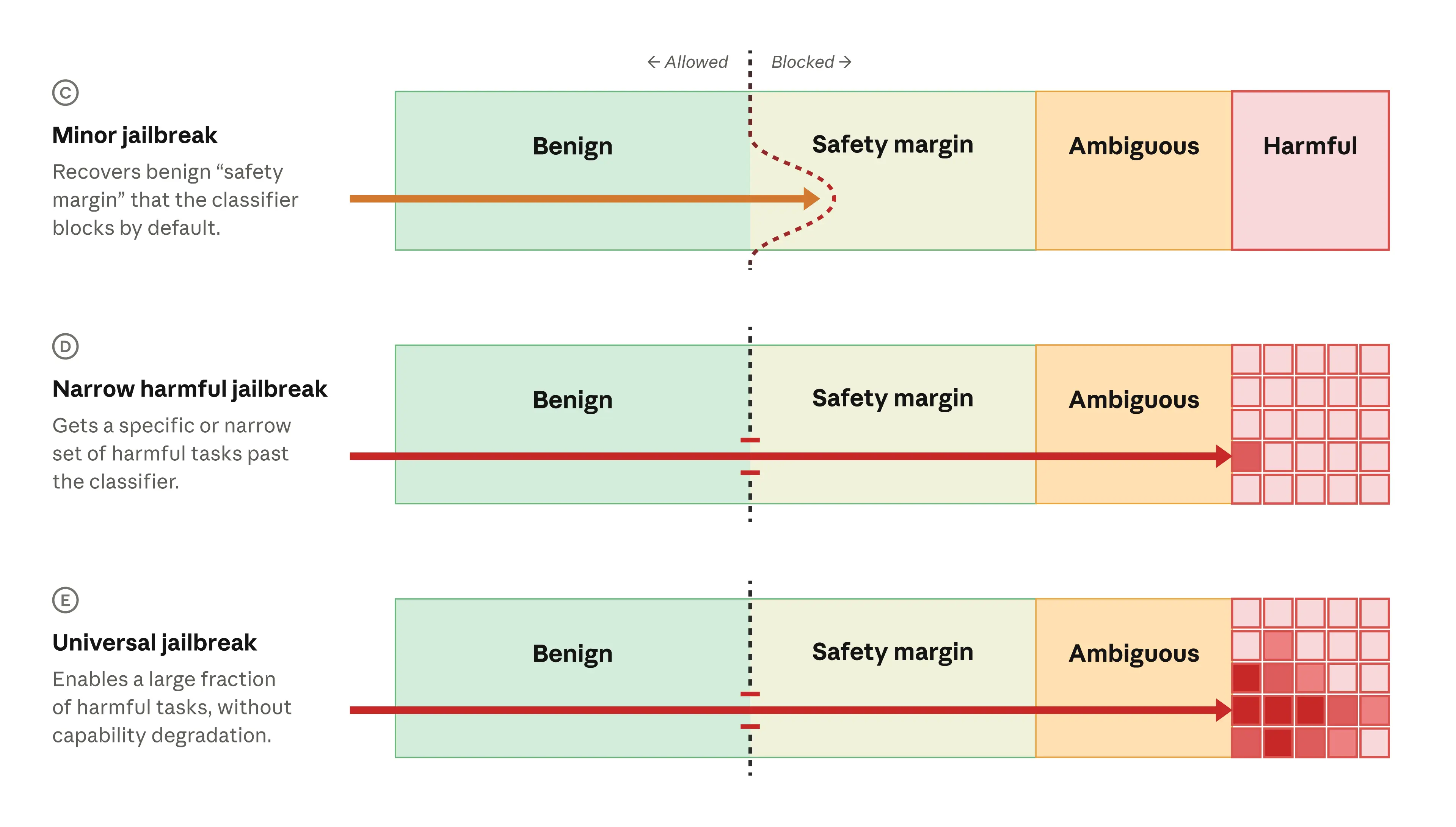 imageジールブレイクが私たちの安全分類器とどのように相互作用するか。**
imageジールブレイクが私たちの安全分類器とどのように相互作用するか。**
軽微なジールブレイク(行 C)の場合、分類器はリクエストをブロックしませんが、そのリクエストはまだ安全マージン内にあり(したがって有害である可能性は非常に低く)、狭義の有害なジールブレイク(行 D)では、プロンプトが分類器を突破してモデルから特定の有害行為を解除します。普遍的なジールブレイク(行 E)では、プロンプトが有害行為のクラス全体を解除します。
私たちが Fable 5 をローンチした際に注記した通り、いかなる AI モデルも完全な堅牢性(つまり、ジャイブレイクに対して無敵であること)を備えることはおそらく不可能です。私たちのモデルに対してもいくつかのジャイブレイクが発見されることを想定しており、その深刻度にはばらつきがあります:多くの軽微なジャイブレイクが存在し、一部の狭義有害なものも現れるでしょう。執筆時点では Fable 5 に対する包括的なジャイブレイクは見つかっていませんが、専門の安全性研究者たちは引き続きレッドチーム(攻撃シミュレーション)を実施しています。私たちは、悪意のある行為者が害をなす前に、主要なジャイブレイクを私たちと安全パートナーが最初に発見し、修正することを確保しようとしています。
上記のような慎重なアプローチにより、圧倒的多数のジャイブレイクは危険な行動を無効化することに成功しません。私たちの分類器は、成功したジャイブレイクの生成に非常に高いコストと多大な労力を要するように設計されており、たとえ*もし*ジャイブレイクが成功した場合でも、追加された防御層がさらなる緩和措置を提供します。私たちは新たなジャイブレイク技術についてより多くを学ぶにつれて、分類器の更新を継続していきます。
ジャイブレイクに関する業界共通の枠組み
現在、AI 業界において、AI のジャイブレイクの深刻度を客観的な用語で記述する方法については合意が形成されていません。これは、新たなジャイブレイク技術が発見されるたびに大きな不確実性を生み出します:開発者にはどの発見を最も緊急性を持って注力すべきかについての共通基準がなく、政府にはいつ行動を起こすべきかについての共通基準がありません。
4
この問題は、今後数ヶ月のうちに、より強力なサイバーセキュリティ(およびその他の)機能を備えたモデルが訓練され、評価され、リリースされるにつれて、一層深刻なものとなるでしょう。AI の脱獄(jailbreak)を評価するための共通基準は、当社や他の企業が新しいモデルを安全にローンチするのを助けるとともに、ユーザーが高度な機能を最大限に活用することを可能にするはずです。
そのため、私たちはアマゾン、マイクロソフト、グーグル、およびその他のグラスウィング(Glasswing)パートナーと連携し、AI の脱獄の深刻度を評価するための合意形成されたフレームワークを策定するとともに、AI 開発者がそれらに対応すべき方法を検討しています。他の業界パートナーやモデルプロバイダーにも、この取り組みに参加していただくことを呼びかけます。
現在の提案では、特定の脱獄手法を以下の4つの異なる基準に基づいてスコアリングするものです。最初の2つは攻撃者に提供されるものを記述し、残りの2つは、その脱獄が現実世界の問題となるまでの速度を記述します:
- キャパビリティの向上。この Jailbreak(拘束解除)によって、既存のツールを超えてユーザーはどの程度まで到達できるのか?既存の広く利用可能なツール(他のより弱い AI モデルを含む)が、Jailbreak されたモデルと同じ能力に達できる場合、ここでのスコアは低くなります;一方、Jailbreak がドメインの専門家ですら大幅に加速させることができるモデルの能力を解放する場合、スコアは高くなります。
- キャパビリティ向上の範囲。同じ Jailbreak テクニックがいくつの異なる攻撃タスクで機能するか?この Jailbreak がモデルに狭いターゲットのみを追及させる場合、スコアは低くなります;一方、同じ Jailbreak テクニックが複数の異なるターゲットやテクニックに対して機能する場合、スコアは高くなります。
- 兵器化の容易さ。Jailbreak を攻撃に変換するために必要な人的努力はどの程度か?Jailbreak に高度なプロンプト作成と多数のリトライが必要となる場合、スコアは低くなります;一方、単一のプロンプトで、あるいは最初の試行または2回目の試行で機能する場合、スコアは高くなります。
- 発見可能性。誰かがこのテクニックを入手することはどの程度容易か?専門知識を必要とする場合はスコアが低くなり、すでに広く知られておりオンライン上で利用可能であればスコアが高くなります。
私たちは、この深刻度フレームワークを用いて、新たに発見された Jailbreak に対する対応を調整することを提案します。最も深刻なクラスの Jailbreak(例えば、他の特徴に加え、実際に重要な電力網や銀行システムに壊滅的な影響を与えるために使用されている Jailbreak)については、その深刻度が確認され次第、直ちに予備的な緩和策の展開を開始します。また、主要な Jailbreak 提出チャネルを24時間365日監視するためのチームも編成しています。
ジャイルブレイク(脱獄)のスコアリング手法には必ず不完全さがつきまといます。それでも、共通の枠組みを通じて特定の発見の概算的な深刻度を伝える価値はあります。これは現在進行形の取り組みであり、より多くのパートナーからのフィードバックを受け取るにつれて、この枠組みも時間とともに進化していくと予想しています。
提案された枠組みの詳細については近日中に共有する予定です。その間、セキュリティ研究者が Fable 5(利用可能になった際)で発見した潜在的なサイバージャイルブレイクを提出し、当社のレビューを受けることができる新しい HackerOne プログラム を開始します。
米国政府との先端的 AI セキュリティにおける連携
過去 10 週間にわたり、Anthropic は、6 月 2 日付の 高度人工知能イノベーションとセキュリティの促進に関する大統領令 に反映されたアプローチを米国政府が策定する過程で、同政府と緊密に協力してきました。当社の関与範囲は、国家サイバーディレクター事務所、科学技術政策局、財務省、商務省(CAISI を含む)、および関連する国家安全保障機関に及びました。
私たちは、米国政府パートナーとの事前展開テストおよび評価に関するほぼ2年間にわたる既存の協力[1]を基盤とし、その取り組みを継続することにコミットしています。以下のコミットメントは、これらの既存の作業と、上記の枠組みが最終化されるにつれて政府間の協力を拡大するための私たちの新たな提案の両方を反映したものです。
[1]: https://www.anthropic.com/news/strengthening-our-safeguards-through-collaboration-with-us-caisi-and-uk-aisi
- 事前の政府アクセスと評価。国家安全保障に関連する分野において能力のフロンティアを本格的に前進させるモデルについては、指定された政府パートナーに対して、モデルおよびそれに付随するセーフガードへの早期アクセスを拡大して提供します。これらのパートナーは、広範なリリース前に、独立した能力評価を実施し、当社のガードレールをテストすることができます。これらのテスト期間中、Anthropic の技術スタッフが政府の評価者と並んで作業にあたることを約束します。
- セーフガードに関する迅速な情報共有。重大なジールブレイクや悪用のパターンが特定された場合、私たちは速やかに調査を行い、優先順位をつけて適切な政府関係者に通知します。それに応じて構築した新たなセーフガードを共有し、独立してテストできるようにします。また、公開に先立ち政府パートナーに対して脅威インテリジェンス報告を提供し、6 月 2 日の大統領令第 2(d) 条に基づいて設立された省庁間サイバーセキュリティ脆弱性クリアリングハウスに参加します。
- 共同研究のための専用リソース。AI セキュリティに関する政府パートナーとの共同作業を大幅に拡大しています。政府の優先事項に取り組むための専任 Anthropic チームを設置し、政府のテストと研究をサポートするための相当量の計算資源(compute)を割り当てるとともに、AI 評価の最先端を推進するために、当社の安全性およびレッドチームing の専門知識を提供します。
- 業界共通の基準。フロンティアモデルプロバイダー向けの共有かつ任意のセキュリティおよび評価標準に向けて、政府および業界の同業者と協力して取り組んでいきます。政府が分野全体に適用できる評価、ツール、ベストプラクティスを提供します。
私たちの希望は、この協働関係と私たちが提案する合意形成された業界フレームワークが、業界全体の体系的な規則の基礎となり、さらに AI のリスクとベネフィットに関する効果的なグローバル調整のためのテンプレートの萌芽となることです。
これらのルールは強力な規制に明文化され、フロンティアモデル開発者全体に均等に適用されるべきです。AI のリリースにおける政府の関与には、サイバー防衛担当者やその他の関係者が強力なモデルへのアクセスについて必要な確信を得られるよう、持続可能で透明性の高いプロセスが必要です。
上記のような形で政府との協力をさらに深めていくことを楽しみにしています。また、今回の混乱を辛抱強く受け入れてくださったユーザーの皆様、そして Fable 5 と Mythos 5 を再び利用可能にするために私たちと共に尽力してくださった研究者や業界パートナーの皆様に心から感謝申し上げます。
関連コンテンツ
Claude Sonnet 5 のご紹介
Sonnet 5 は、コーディング、エージェント、大規模な専門業務においてフロンティアレベルのパフォーマンスを提供します。
科学者向けの AI ワークベンチ「Claude Science」が利用可能に
Claude Science は、研究者が最も頻繁に使用するツールやパッケージを統合し、監査可能な成果物を生成し、計算リソースへの柔軟なアクセスを提供するカスタマイズ可能なアプリです。
Claude Tag のご紹介
Claude Tag は、チームが Claude と連携して作業するための新しい方法です。
原文を表示
On Friday, June 12, the US government applied export controls to our newest models, Claude Fable 5 and Claude Mythos 5. This required us to restrict access to foreign nationals, whether inside or outside the United States. Because the order took effect immediately and we had no reliable way to verify nationality in real-time, we suspended access to both models for all users.
As of today, June 30, the export controls on Fable 5 and Mythos 5 have been lifted.
Fable 5 will be available starting tomorrow, Wednesday, July 1, to users globally on the Claude Platform, Claude.ai, Claude Code, and Claude Cowork. For Pro, Max, Team, and select Enterprise plans,1 Fable 5 will be included for up to 50% of weekly usage limits through July 7, after which it will be available via usage credits. We will re-enable access on AWS, Google Cloud, and Microsoft Foundry as quickly as possible.
We have also restored access to Mythos 5 for a set of US organizations, following the US government’s approval on June 26. We continue to coordinate with the government to expand access to the broader set of domestic and international partners in the Glasswing program.
In the remainder of this post, we provide further details and updates in four areas:
- A timeline of events, including updates we made to our safeguards. We discuss the events that led to the export control directive and how we addressed it with new safeguards.
- Our general approach to safeguards. We provide more context on how we use safety classifiers to detect potentially dangerous cybersecurity uses of our models.
- A shared industry framework. Although we have reached a constructive resolution, these events have made clear that the industry needs a consistent way to assess and fix potential “jailbreaks” of AI models (techniques that bypass a model’s safeguards).2 A shared standard for judging the severity of a given jailbreak would help AI developers triage new findings as they arise, launch highly-capable models with greater safety, and communicate the level of risk consistently to government and industry partners. Together with Amazon, Microsoft, Google, and other Glasswing partners, we’ve started to develop such a framework, and we outline it below.
- Deeper government collaboration. We’re also strengthening our level of collaboration with the US government on new pre-release testing, information sharing, and research collaboration. We describe this deeper collaboration in the final section.
Timeline and safeguard updates
We released Fable 5 and Mythos 5 on Tuesday, June 9. They both share the same underlying model, but Fable 5 was released with strong safeguards to make it safer for general use. Mythos 5, which has fewer safeguards, was only released to a small number of trusted Project Glasswing partners for use in defensive cybersecurity.
The export control directive on June 12 came after the government became aware of a report in which Amazon researchers had found a method of bypassing Fable 5’s safeguards: prompting it so that it identified a number of software vulnerabilities. In one case, the model produced code demonstrating how the relevant vulnerability could be exploited. Over the past two weeks, we have worked closely with the government and other partners, including Amazon, to review the report and evidence.
Our testing confirmed that many less capable models—including Claude Opus 4.8, GPT-5.5, and Kimi K2.7—could identify the same vulnerabilities as Fable 5 did in the report. When it came to the demonstration of how to exploit the single vulnerability, every model we tested could produce the same demonstration as Fable 5 (including Claude Haiku 4.5, Sonnet 4.6, Opus 4.6, Opus 4.7, Opus 4.8, GPT-5.4, GPT-5.5, and Kimi K2.7).
Importantly, the reported technique did not expose any unique Mythos-level cyber capabilities. The behavior reflected a borderline case for Fable 5’s safeguards—as we will explain below, there are some tasks that are unlikely to be dangerous but are nonetheless blocked by the safeguards out of an abundance of caution. The reported technique allowed access to one such behavior, but it only involved routine defensive cybersecurity work.
Even so, we moved quickly to address the reported bypass. Working closely with the government, we trained an improved safety classifier that targets and blocks the behavior described in the report. Users will be notified if a request to Fable 5 is blocked, and the request will instead be sent to Opus 4.8.
The new classifier means that the specific technique described in the Amazon report is blocked in over 99% of cases. In a very small fraction of cases the model may provide information that isn’t detailed enough to help a cyberattacker. As we describe below, the model’s safeguards are not expected to block *all* low-risk routine cyberdefense capabilities—just those that are potentially harmful. Researchers from the US Department of Commerce’s Center for AI Standards and Innovation (CAISI) have tested both our prior and new safeguards and agree that they are extraordinarily strong.
The new classifier also comes at the cost of flagging benign requests more often during routine coding and debugging tasks. As with all our safeguards, we’ll continue to refine this to better distinguish genuine misuse from legitimate requests and reduce false positives.
Our approach to cybersecurity safeguards
Claude Mythos 5 can be used to find and exploit software vulnerabilities more effectively than any other model—and all but the most skilled human security experts. These prodigious cybersecurity capabilities make it uniquely attractive to malicious actors who wish to misuse it in cyberattacks.
Claude Fable 5, however, provides no such unique offensive capabilities.* *This is because we launched it with the strongest safeguards we’ve ever applied to a model. In the month prior to launch, we transferred staff from various teams within Anthropic to double the number of researchers and engineers working on this problem.
Fable 5 launched with a variety of safety mechanisms, each of which alone does not provide perfect defense but when combined make the model very difficult to misuse (an approach known as “defense in depth”). Some defenses involve training the model to decline to assist with dangerous requests; others involve retroactively analyzing patterns of misuse.
One particularly important safety mechanism involves *classifiers*—smaller automated AI systems that, during an interaction, detect when the model is asked to perform a potentially harmful cybersecurity task (or produces potentially harmful outputs). When this occurs, the classifiers block the model from responding to requests. The ultimate goal of these classifiers is to prevent the model from engaging in uniquely dangerous behaviors.
Like all safety mechanisms, classifiers can make mistakes. They sometimes fail to notice potentially dangerous content, and in some cases they can be deliberately “jailbroken”: users can prompt the model in unusual ways to trick the classifiers and get the model to produce harmful outputs that the system should have blocked.
We therefore deliberately set the safety classifiers to trigger on a set of requests that we know are likely benign. This “safety margin” approach means that a request has to look very clearly safe to avoid triggering the classifier (see row A in the diagram below). Users experience the safety margin as a model refusing to respond to some reasonable, non-harmful requests.
For Fable 5, we made this safety margin much larger than in any prior launch (row B), meaning that many more benign requests would be blocked. We understood that these kinds of false positives would be frustrating for users, but made this tradeoff in the interest of making the model’s other capabilities widely available.
The safety margin also helps mitigate jailbreaks. Many jailbreaks are narrow: they unblock a very specific model behavior but nothing more. In some cases, a hypothetical user can jailbreak the model in a minor way and intrude into the safety margin (or sometimes into ambiguously harmful behavior), but not to the core harmful behaviors that we aim to block (row C below). Our view is that jailbreaks of Fable 5 reported so far fit into this minor category.
More serious jailbreaks unblock more harmful behaviors. Narrow harmful jailbreaks (row D) can elicit some specific harmful behaviors. These jailbreaks are typically of low to moderate severity, because the narrowness limits the attacker. The most concerning category is a *universal* jailbreak (row E), which unblocks a wide range of harmful behaviors.
As we noted when we launched Fable 5, it is probably impossible to make any AI model fully robust (that is, impervious) to jailbreaks.3 We expect that some jailbreaks will be found for our models, and that they will vary in severity: there will be many minor jailbreaks, some narrow harmful ones, and although no universal jailbreaks for Fable 5 have been discovered at the time of writing, expert safety researchers continue to red-team it. We seek to ensure that we and our safety partners will be the first to find major jailbreaks and fix them before malicious actors can use them for harm.
The cautious approach outlined above means that the vast majority of jailbreaks will not successfully unblock dangerous behaviors. Our classifiers make successful jailbreaks very costly and high-effort to produce, and even *if* a jailbreak is successful, our extra layers of defense provide additional mitigation. We’ll continue to update our classifiers as we learn more about novel jailbreak techniques.
A consensus industry framework for jailbreaks
There’s currently no consensus in the AI industry on how to describe, in objective terms, the severity of an AI jailbreak. This adds a great deal of uncertainty whenever a new jailbreak technique is discovered: developers have no agreed-upon standard for which findings to focus on most urgently, and governments have no agreed-upon standard for when to act.4
This problem will become more acute in the coming months, as more models with powerful cybersecurity (and other) capabilities are trained, assessed, and released. A common standard for assessing AI jailbreaks would help us and other companies launch new models safely, as well as allow our users to make the most of their advanced capabilities.
We are therefore partnering with Amazon, Microsoft, Google, and other Glasswing partners to draft a consensus framework for assessing the severity of AI jailbreaks and how AI developers should respond to them. We invite other industry partners and model providers to join us in this effort.
Our current proposal is to score a given jailbreak on the four different criteria below. The first two describe what the jailbreak provides to the attacker; the latter two describe how quickly the jailbreak can become a real-world problem:
- Capability gain. How far beyond existing tools does the jailbreak take the user? If existing widely-available tools (including other, weaker AI models) can reach the same capability as the jailbroken model, the score here will be low; if the jailbreak unblocks model capabilities that can significantly accelerate even domain experts, the score will be high.
- Breadth of capability gain. For how many distinct offensive tasks does the same jailbreak technique work? Cases where the jailbreak only allows the model to pursue narrow targets will score low; cases where the same jailbreak technique works for multiple different targets or techniques will score high.
- Ease of weaponization. How much human effort does it take to turn the jailbreak into an attack? Where the jailbreak involves a great deal of skilled prompting and many retries, the score will be low; where the jailbreak works on a single prompt or on the first or second try, the score will be high.
- Discoverability. How easy is it for someone to obtain the technique? If it requires specialist knowledge it will score low; if it is already widely known and available online it will score high.
We propose to use this severity framework to calibrate our response to newly-discovered jailbreaks. For the most severe class of jailbreaks (e.g., a jailbreak that, among other characteristics, is being used to actively cause a devastating impact on critical power grids or banking systems), we will immediately begin deploying preliminary mitigations upon confirmation of severity. We are also creating a team to provide 24/7 monitoring of key jailbreak submission channels.
Any method of scoring jailbreaks will be imperfect. Still, there is value in being able to communicate the approximate severity of a given finding through a common framework. This is a work in progress; as we receive feedback from more partners, we expect the framework to evolve over time.
We expect to share more details on the proposed framework soon. In the meantime, we’re also launching a new HackerOne program where security researchers can submit potential cyber jailbreaks they’ve discovered in Fable 5 (once available) for our review.
Partnering with the US government on frontier AI security
Over the past ten weeks, Anthropic has worked closely with the US government as it developed the approach reflected in the June 2 Executive Order on Promoting Advanced Artificial Intelligence Innovation and Security. Our engagement spanned the Office of the National Cyber Director, the Office of Science and Technology Policy, the Department of the Treasury, the Department of Commerce (including CAISI), and relevant national security agencies.
We are committed to continuing that work, building on nearly two years of pre-existing collaborations with US government partners on pre-deployment testing and evaluation. The commitments below reflect both that pre-existing work and our new proposals to scale up our government collaboration as the above framework is finalized:
- Pre‑release government access and evaluation. For models that materially advance the capability frontier in areas relevant to national security, we will provide designated government partners with expanded early access to both the models and the safeguards that accompany them. Those partners can then run independent capability evaluations and test our guardrails before broad release. We will dedicate Anthropic technical staff to work alongside government evaluators during these testing periods.
- Rapid information sharing on safeguards. When significant jailbreaks or misuse patterns are identified, we will quickly investigate, triage, and notify appropriate government counterparts. We will share the new safeguards we build in response so they can be independently tested. We will also provide government partners with our threat intelligence reporting in advance of publication and participate in the interagency cybersecurity vulnerability clearinghouse established under Sec. 2(d) of the June 2 Executive Order.
- Dedicated resources for joint research. We are substantially scaling up joint work with government partners on AI security. We will stand up dedicated Anthropic teams to work on shared government priorities, provide a significant compute allocation to support government testing and research, and make our safety and red‑teaming expertise available to help advance the state of the art in AI evaluation.
- A common industry bar. We will work with the government and with industry peers toward a shared, voluntary security and evaluation standard for frontier model providers. We’ll contribute evaluations, tooling, and best practices that the government can apply across the field.
Our hope is that this collaboration, along with our proposed consensus industry framework, will serve as the basis for systematic rules for the whole industry—and even offer the beginnings of a template for effective global coordination on the risks and benefits of AI.
These rules should be codified in strong regulation and applied equally across frontier model developers. Government involvement in AI releases requires a durable, transparent process that gives cyber defenders and others the certainty they need about access to powerful models.
We look forward to deepening our government collaboration in the ways we’ve described above. We’re also grateful to our users for bearing with us through this disruption, and to the researchers and industry partners who worked alongside us to make Fable 5 and Mythos 5 available again.
Related content
Introducing Claude Sonnet 5
Sonnet 5 delivers frontier performance across coding, agents, and professional work at scale.
Claude Science, an AI workbench for scientists, is now available
Claude Science is a customizable app that integrates the tools and packages researchers most often use, produces auditable artifacts, and provides flexible access to computing resources.
Introducing Claude Tag
Claude Tag is a new way for teams to work with Claude.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み