Amazon Novaモデル蒸留でビデオ意味検索の意図を最適化
AWSは、Amazon Bedrock上でモデル蒸留を用いて、動画セマンティック検索の意図ルーティングを、コスト95%削減・遅延50%削減しながら高精度を維持する手法を提案した。
キーポイント
動画セマンティック検索における課題
高精度な大規模モデル(Claude Haiku)は遅延(2-4秒、全体の75%)とコストが高く、高速な小規模モデルは複雑な意図ルーティングの知性に欠けるというトレードオフが存在する。
モデル蒸留による解決策
Amazon Bedrockのモデル蒸留機能を用いて、大規模な教師モデル(Amazon Nova Premier)から小規模な生徒モデル(Amazon Nova Micro)へルーティング知性を転移させることで、コストと遅延を大幅に削減する。
実現された性能向上
このアプローチにより、推論コストを95%以上削減し、遅延を50%削減しながら、タスクが要求するニュアンスのあるルーティング品質を維持することに成功した。
実践的な実装プロセス
Jupyterノートブックで、Nova Premierを用いて生成した10,000の合成ラベル付き例によるトレーニングデータの準備から、Amazon S3へのデータセットアップロード、蒸留パイプラインのエンドツーエンドの実行までを解説している。
蒸留ジョブの監視方法
蒸留ジョブは非同期で実行され、Amazon Bedrockコンソールの「Foundation models > Custom models」で進捗を監視できる。プログラムからはget_model_customization_job APIでステータス(Training, Complete, Failed)を確認できる。
トレーニング時間の目安
トレーニング時間はデータセットサイズと選択した学生モデルによって異なる。Nova Microで10,000のラベル付き例の場合、数時間以内に完了することが期待される。
蒸留モデルのデプロイオプション
Amazon Bedrockではカスタムモデルに対して2つのデプロイオプションを提供している。Provisioned Throughputは予測可能な高ボリュームワークロード向け、On-Demand Inferenceは柔軟な従量課金制アクセス向けで、開始時は後者が推奨される。
重要な引用
Rather than choosing between a model that’s fast but too simple or one that’s accurate but too expensive or too slow, we can achieve all three by training a small model to perform the task accurately at much lower latency and cost.
This approach cuts inference cost by over 95% and reduces latency by 50% while maintaining the nuanced routing quality that the task demands.
Amazon Bedrock offers two deployment options for custom models: Provisioned Throughput for predictable, high-volume workloads, and On-Demand Inference for flexible, pay-per-use access with no upfront commitment.
For most teams getting started, on-demand inference is the recommended path. There is no endpoint to provision, no hourly commitment, and no minimum usage requirement.
Once the status shows InService, you can invoke the distilled model exactly as you would any other base model using the standard InvokeModel or Converse API.
You pay only for the tokens you consume at Nova Micro inference rates: $0.000035 per 1,000 input tokens and $0.000140 per 1,000 output tokens.
影響分析・編集コメントを表示
影響分析
この記事は、生成AIの実用化における最大の課題の一つであるコストと遅延を、モデル蒸留という技術で劇的に改善する具体的なAWSのソリューションを示しており、企業が複雑なマルチモーダル検索システムを現実的な予算と応答時間で導入する道筋を提供する。
編集コメント
生成AIの実用段階において、性能と効率性の両立は普遍的な課題。本記事は、AWSが提供するモデル蒸留という具体的な技術ソリューションを通じて、この課題への回答を示した実践的な技術記事である。
- Prepare training data — 10,000 synthetic labeled examples using Nova Premier and upload the dataset to Amazon Simple Storage Service (Amazon S3) in Bedrock distillation format
- Run distillation training job — Configure the job with teacher and student model identifiers and submit via Amazon Bedrock
- Deploy the distilled model — Deploy the custom model using on-demand inference for flexible, pay-per-use access
- Evaluate the distilled model — Compare routing quality against the base Nova Micro and the original Claude Haiku baseline using Amazon Bedrock Model Evaluation
The complete notebook, training data generation script, and evaluation utilities are available in the GitHub repository.
Prepare training data
One of the key reasons we chose モデル蒸留(model distillation) over other customization techniques like 教師ありファインチューニング(supervised fine-tuning, SFT) is that it does not require a fully labeled dataset. With SFT, every training example needs a human-generated response as 正解データ(ground truth). With distillation, you only need prompts. Amazon Bedrock automatically invokes the ティーチャーモデル(teacher model) to generate high-quality responses. It applies データ合成およびデータ拡張技術(data synthesis and augmentation techniques) behind the scenes to produce a diverse training dataset of up to 15,000 prompt-response pairs.
That said, you can optionally provide a labeled dataset if you want more control over the 学習信号(training signal). Each record in the JSONLファイル(JSONL file) follows the bedrock-conversation-2024スキーマ(bedrock-conversation-2024 schema), where the ユーザーロール(user role) (the input prompt) is required, and the アシスタントロール(assistant role) (the desired response) is optional. See the following examples, and reference Prepare your training datasets for distillation for more detail:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [{ "text": "指定された動画検索クエリに対して、視覚・音声・文字起こし・メタデータの重み(合計=1.0)および推論理由をJSON形式で返してください。" }],
"messages": [
{
"role": "user",
"content": [{ "text": "貧困の中で育ったことについて語るオリビア" }]
},
{
"role": "assistant",
"content": [{ "text": " {"visual": 0.2, "audio": 0.1, "transcription": 0.6, "metadata": 0.1, "reasoning": "クエリは音声コンテンツ('語る')に焦点を当てているため、文字起こしが最も重要となります。視覚および音声要素は文脈をサポートする二次的なものであり、メタデータは最小限です。"}"}]
}
]
}
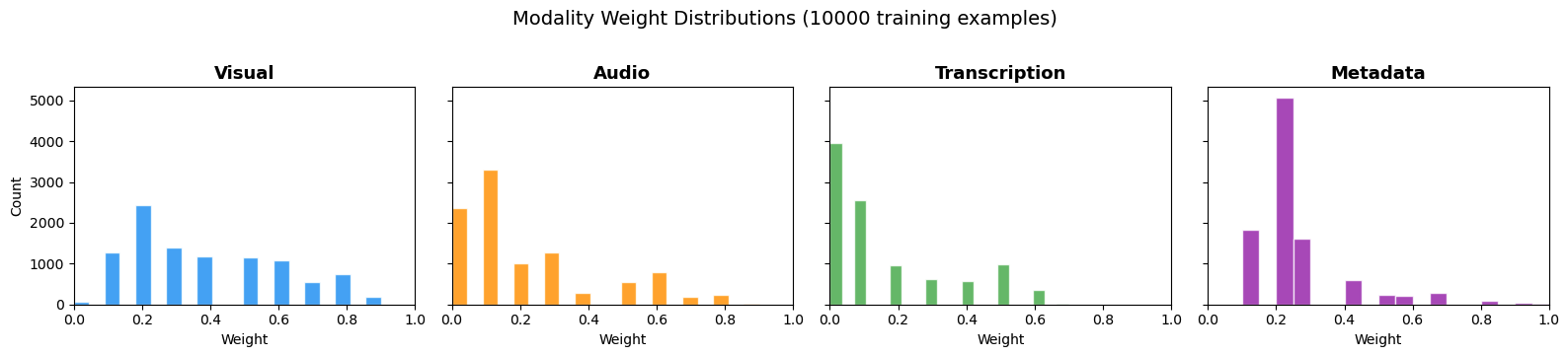
本記事では、Novaファミリーの中で最大かつ最も高性能なNova Premierを使用して、1万件の合成ラベル付き例を作成しました。データは、視覚、音声、文字起こし、メタデータの各信号クエリにわたってバランスの取れた分布で生成されています。この例は、期待される検索入力の全範囲をカバーし、異なる難易度を表し、エッジケースやバリエーションを含み、狭いクエリパターンへの過学習を防ぐものです。以下のチャートは、4つのモーダリティチャンネルにわたる重み分布を示しています。
 image
image
Figure 2: The weight distribution across the 10,000 training examples
追加の例が必要、またはクエリ分布を独自のコンテンツドメインに適応させたい場合は、提供されている generate_training_data.py スクリプトを使用して、Nova Premier でさらに多くのトレーニングデータを合成生成することができます。
Run distillation training job
トレーニングデータをAmazon S3にアップロードしたら、次のステップは蒸留ジョブを送信することです。モデル蒸留(Model Distillation)は、まずプロンプトを使用して教師モデル(Teacher Model)から応答を生成し、その後、そのプロンプトと応答のペアを使用して学生モデル(Student Model)をファインチューニングする手法です。本プロジェクトでは、教師がNova Premier、学生が高速でコスト効率に優れ、高スループット推論(High-Throughput Inference)向けに最適化されたNova Microです。教師のルーティング判断が、学生の動作を形成するトレーニング信号となります。
Amazon Bedrockは、トレーニングオーケストレーション(Training Orchestration)とインフラストラクチャ全体を自動的に管理します。クラスタープロビジョニング(Cluster Provisioning)、ハイパーパラメータ調整(Hyperparameter Tuning)、教師から学生へのモデルパイプラインの設定は不要です。教師モデル、学生モデル、トレーニングデータへのS3パス、および必要な権限を持つAWS Identity and Access Management (IAM) ロールを指定するだけで、Bedrockが残りの処理を行います。以下は、蒸留トレーニングジョブをトリガーするコードスニペットの例です:
import boto3
from datetime import datetime
bedrock_client = boto3.client(service_name="bedrock")
teacher_model = "us.amazon.nova-premier-v1:0"
student_model = "amazon.nova-micro-v1:0:128k"
job_name = f"video-search-distillation-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
model_name = "nova-micro-video-router-v1"
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=distillation_role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={"s3Uri": training_s3_uri},
outputDataConfig={"s3Uri": output_s3_uri},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": 1000
}
}
}
)
job_arn = response['jobArn']
ジョブは非同期で実行されます。Amazon BedrockコンソールのFoundation models > Custom models(ファウンデーションモデル > カスタムモデル)で進捗状況を確認するか、プログラム的に監視できます:
status = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job status: {status}") # 学習中、完了、または失敗
学習時間はデータセットのサイズと選択した学生モデル(スチューデントモデル)によって異なります。Nova Microで10,000件のラベル付きサンプルを使用する場合、ジョブは数時間以内に完了する見込みです。
Deploy the distilled model
蒸留ジョブが完了すると、カスタムモデルはAmazon Bedrockアカウント内で利用可能になり、デプロイの準備が整います。Amazon Bedrockはカスタムモデルに対して2つのデプロイオプションを提供します:Provisioned Throughput(プロビジョンドスループット)で予測可能な高ボリュームのワークロードに対応し、On-Demand Inference(オンデマンド推論)で事前のコミットメントなしに柔軟な従量課金アクセスを提供します。
新規で取り組み始めるチームのほとんどにとって、オンデマンド推論が推奨されるパスです。エンドポイントのプロビジョニングは不要で、時間単位のコミットメントや最低利用要件もありません。以下がデプロイコードです:
import uuid
deployment_name = f"nova-micro-video-router-{datetime.now().strftime('%Y-%m-%d')}"
response = bedrock_client.create_custom_model_deployment(
modelDeploymentName=deployment_name,
modelArn=custom_model_arn,
description="Distilled Nova Micro for video search modality weight prediction (4 weights)",
tags=[
{"key": "UseCase", "value": "VideoSearch"},
{"key": "Version", "value": "v2-4weights"},
],
clientRequestToken=f"deployment-{uuid.uuid4()}",
)
deployment_arn = response['modelDeploymentArn']
print(f"Deployment ARN: {deployment_arn}")
ステータスがInService(サービス稼働中)と表示されたら、標準のInvokeModelまたはConverse APIを使用して、他の基本モデル(ベースモデル)と同様に蒸留済みモデルを呼び出すことができます。Nova Microの推論レートに基づき、消費したトークンに対してのみ課金されます:入力1,000トークンあたり$0.000035、出力1,000トークンあたり$0.000140です。
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
custom_model_arn = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn
)['outputModelArn']
response = bedrock_runtime.converse(
modelId=custom_model_arn,
messages=[
{
"role": "user",
"content": [{"text": query}]
}
]
)
routing_weights = json.loads(
response['output']['message']['content']['text']
)
print(routing_weights)
{"visual": 0.7, "audio": 0.1, "transcription": 0.1, "metadata": 0.1}
Evaluate the distilled model
オリジナルのルーターと比較する前に、モデル蒸留(distillation)によってベースモデル(base model)がルーティングタスク(routing task)を遂行する能力が向上したことを検証しておく価値があります。以下の表は、ベースのNova Microと蒸留されたNova Microで同じプロンプトを実行した結果を並べて示しています。
クエリ
蒸留されたNova Micro
ベースのNovaMicro
"CEOが四半期決算について語っている"
{"visual": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "クエリは決算に関する音声コンテンツ(transcription)に焦点を当てていますが、視覚的手がかり(CEOの外見)や音声(トーン/明瞭さ)も重要です..."}
ご要望のCEOが四半期決算について語っている動画検索クエリに関する情報のJSON表現は以下の通りです:
`json{ "video": { "visual": 0.3, "audio": 0.3, "transcription": 0.2, "metadata": 0.1, "reasoning": "視覚コンポーネントにはCEOのpres....
"山々を背景にした夕焼け"
{"visual": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "クエリは視覚シーン(山々を背景にした夕焼け)に焦点を当てており、音声やトランスクリプションの要素はありません。メタデータには場所や時間に関連するタグが含まれる可能性があります。"}
視覚、音声、トランスクリプション、メタデータの重み(合計=1.0)、および推論を含む「山々を背景にした夕焼け」の動画検索クエリに関するJSON表現は以下の通りです:
`json{ "query": "山々を背景にした夕焼け", "results": [ { "video_id": "123456", "visual": 0.4, "audio": 0.3 ....
ベースモデルは指示と出力形式の両方で一貫性に課題を抱えています。自由テキストの応答、不完全なJSON、数値ではない重み値を生成します。一方、蒸留モデルはルーティングパイプラインが必要とするスキーマに一致する、合計が1.0となる4つの数値重みを持つ整形式のJSONを常に返します。
元のClaude Haikuルーター(Claude Haiku router)との比較では、Nova Premierによって生成された100件のラベル付き例のホールドアウトセットに対して両モデルが評価されます。私たちは、構造化された管理されたワークフローで比較を実行するためにAmazon Bedrock Model Evaluation を使用します。標準的な指標を超えてルーティング品質を評価するため、グラウンドトゥース(ground truth)に対する重みの正確さと推論の品質という2つの次元で各予測をスコアリングするようClaude Sonnetに指示するカスタムのOverallQualityルブリック(OverallQuality rubric)を定義しました。各次元は具体的な5段階の閾値にマッピングされるため、このルブリックは数値のズレと定型化した推論の両方にペナルティを科します。
"rating_scale": [
{"definition": "参照値から0.05以内の重み。推論が具体的で一貫性がある。",
"value": {"floatValue": 5.0}},
{"definition": "参照値から0.10以内の重み。推論が明確でほぼ一貫性がある。",
"value": {"floatValue": 4.0}},
{"definition": "主要なモーダリティが一致。平均エラー 0.15以下。推論が曖昧または一貫性がない。",
"value": {"floatValue": 2.0}},
{"definition": "解析できないJSON、キーの欠落、またはエラー > 0.30。有用な推論なし。",
"value": {"floatValue": 1.0}},
]
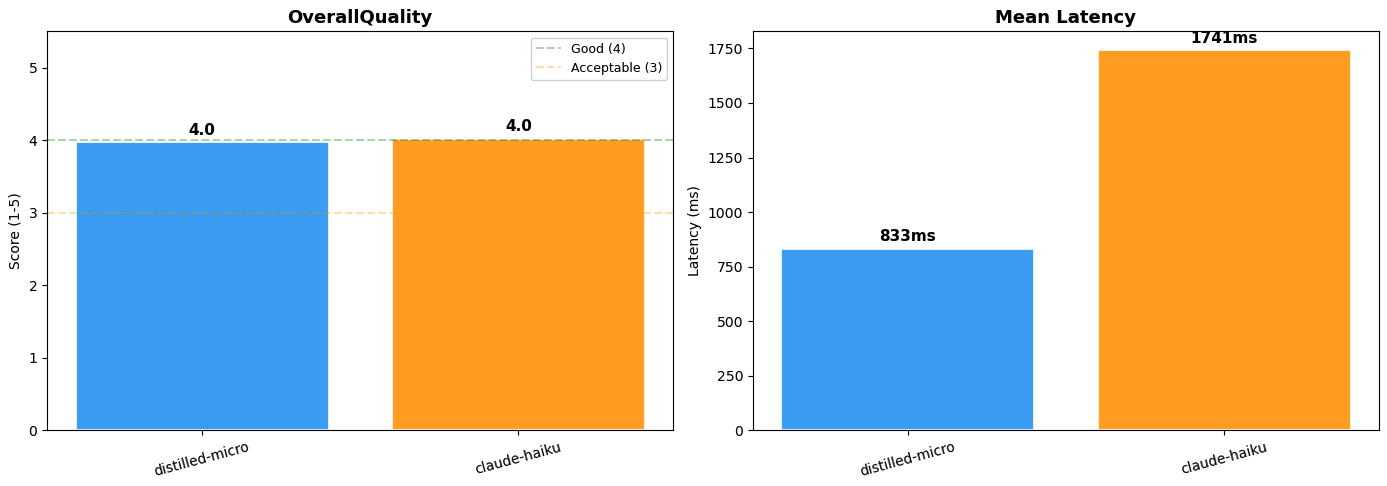
蒸留されたNova Microモデルは、大規模言語モデル(LLM)ジャッジスコアで5段階中4.0を獲得し、遅延時間(latency)が約半分であるにもかかわらず、Claude 4.5 Haikuとほぼ同等のルーティング品質(routing quality)を達成しました。コスト面での優位性も同様に顕著です。オンデマンド課金(on-demand pricing)において事前のコミットメントが不要な状態で、蒸留されたNova Microモデルに切り替えることで、入力トークン(input tokens)と出力トークン(output tokens)の両方で推論コスト(inference costs)を95%以上削減できます。注: LLMジャッジによる評価は非確定的(non-deterministic)な性質を持つため、実行ごとにスコアがわずかに変動する場合があります。
 image
image
Figure 3: モデルパフォーマンス比較(Distilled Nova Micro対Claude 4.5 Haiku)
以下は、並列比較結果のテーブルまとめです:
| 指標 | 蒸留Nova Microモデル | Claude 4.5 Haiku |
|---|---|---|
| LLMジャッジスコア | 4.0 / 5 | 4.0 / 5 |
| 平均遅延時間 | 833ms | 1,741ms |
| 入力トークンコスト | $0.00035 / 1K | $0.80–$1.00 / 1K |
| 出力トークンコスト | $0.000140 / 1K | $4.00–$5.00 / 1K |
原文を表示
Optimizing models for video semantic search requires balancing accuracy, cost, and latency. Faster, smaller models lack routing intelligence, while larger, accurate models add significant latency overhead. In Part 1 of this series, we showed how to build a multimodal video semantic search system on AWS with intelligent intent routing using the Anthropic Claude Haiku model in Amazon Bedrock. While the Haiku model delivers strong accuracy for user search intent, it increases end-to-end search time to 2-4 seconds. This contributes to 75% of the overall latency.
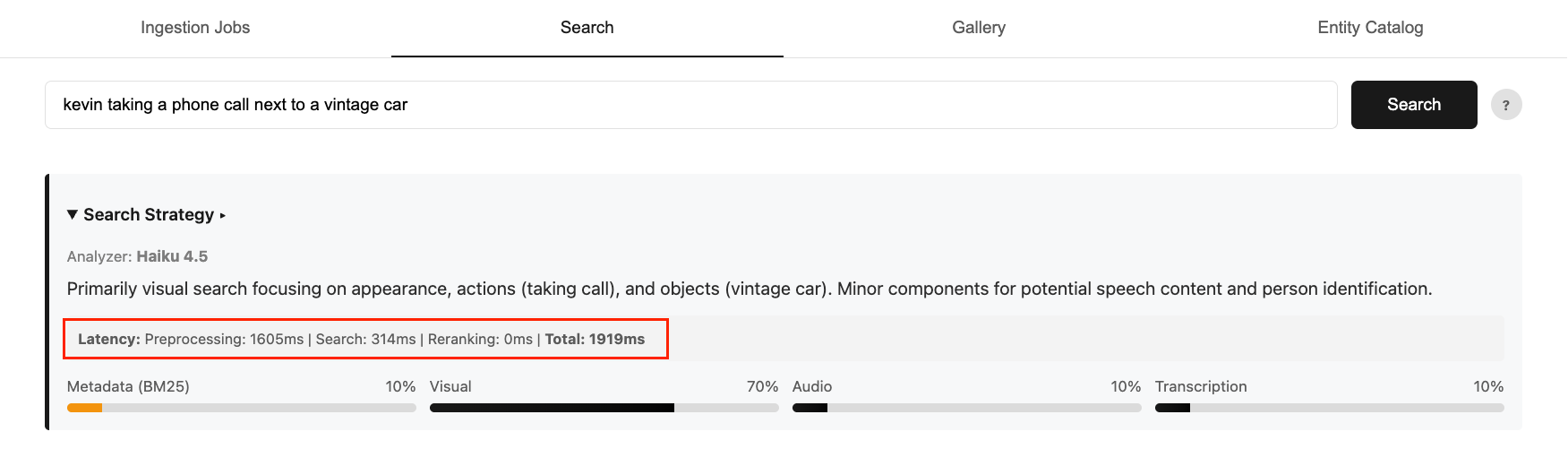
Figure 1: An example end-to-end query latency breakdown
Now consider what happens as the routing logic grows more complex. Enterprise metadata can be far more complex than the five attributes in our example (title, caption, people, genre, and timestamp). Customers may factor in camera angles, mood and sentiment, licensing and rights windows, and more domain-specific taxonomies. More nuanced logic means a more demanding prompt, and a more demanding prompt leads to more expensive and slower responses. This is where model customization comes in. Rather than choosing between a model that’s fast but too simple or one that’s accurate but too expensive or too slow, we can achieve all three by training a small model to perform the task accurately at much lower latency and cost.
In this post, we show you how to use Model Distillation, a model customization technique on Amazon Bedrock, to transfer routing intelligence from a large teacher model (Amazon Nova Premier) into a much smaller student model (Amazon Nova Micro). This approach cuts inference cost by over 95% and reduces latency by 50% while maintaining the nuanced routing quality that the task demands.
Solution overview
We will walk through the full distillation pipeline end to end in a Jupyter notebook. At a high level, the notebook contains the following steps:
- Prepare training data — 10,000 synthetic labeled examples using Nova Premier and upload the dataset to Amazon Simple Storage Service (Amazon S3) in Bedrock distillation format
- Run distillation training job — Configure the job with teacher and student model identifiers and submit via Amazon Bedrock
- Deploy the distilled model — Deploy the custom model using on-demand inference for flexible, pay-per-use access
- Evaluate the distilled model — Compare routing quality against the base Nova Micro and the original Claude Haiku baseline using Amazon Bedrock Model Evaluation
The complete notebook, training data generation script, and evaluation utilities are available in the GitHub repository.
Prepare training data
One of the key reasons we chose model distillation over other customization techniques like supervised fine-tuning (SFT) is that it does not require a fully labeled dataset. With SFT, every training example needs a human-generated response as ground truth. With distillation, you only need prompts. Amazon Bedrock automatically invokes the teacher model to generate high-quality responses. It applies data synthesis and augmentation techniques behind the scenes to produce a diverse training dataset of up to 15,000 prompt-response pairs.
That said, you can optionally provide a labeled dataset if you want more control over the training signal. Each record in the JSONL file follows the bedrock-conversation-2024 schema, where the user role (the input prompt) is required, and the assistant role (the desired response) is optional. See the following examples, and reference Prepare your training datasets for distillation for more detail:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [{ "text": "Return JSON with visual, audio, transcription, metadata weights (sum=1.0) and reasoning for the given video search query." }],
"messages": [
{
"role": "user",
"content": [{ "text": "Olivia talking about growing up in poverty" }]
},
{
"role": "assistant",
"content": [{ "text": " {"visual": 0.2, "audio": 0.1, "transcription": 0.6, "metadata": 0.1, "reasoning": "The query focuses on spoken content ('talking about'), making transcription most important. Visual and audio elements are secondary since they support the context, while metadata is minimal."}"}]
}
]
}For this post, we prepared 10,000 synthetic labeled examples using Nova Premier, the largest and most capable model in the Nova family. The data was generated with a balanced distribution across visual, audio, transcription, and metadata signal queries, The examples cover the full range of expected search inputs, represent different difficulty levels, include edge cases and variations, and prevent overfitting to narrow query patterns. The following chart shows the weight distribution across the four modality channels.
Figure 2: The weight distribution across the 10,000 training examples
If you need additional examples or want to adapt the query distribution to your own content domain, the provided generate_training_data.py script can be used to synthetically generate more training data using Nova Premier.
Run distillation training job
With the training data uploaded to Amazon S3, the next step is to submit the distillation job. Model distillation works by using your prompts to first generate responses from the teacher model. It then uses those prompt-response pairs to fine-tune the student model. In this project, the teacher is Amazon Nova Premier and the student is Amazon Nova Micro, a fast, cost-efficient model optimized for high-throughput inference. The teacher’s routing decisions become the training signal that shapes the student’s behavior.
Amazon Bedrock manages the entire training orchestration and infrastructure automatically. There is no cluster provisioning, no hyperparameter tuning, and no teacher-to-student model pipeline setup required. You specify the teacher model, the student model, the S3 path to your training data, and an AWS Identity and Access Management (IAM) role with the necessary permissions. Bedrock handles the rest. The following is an example code snippet to trigger the distillation training job:
import boto3
from datetime import datetime
bedrock_client = boto3.client(service_name="bedrock")
teacher_model = "us.amazon.nova-premier-v1:0"
student_model = "amazon.nova-micro-v1:0:128k"
job_name = f"video-search-distillation-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
model_name = "nova-micro-video-router-v1"
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=distillation_role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={"s3Uri": training_s3_uri},
outputDataConfig={"s3Uri": output_s3_uri},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": 1000
}
}
}
)
job_arn = response['jobArn']The job runs asynchronously. You can monitor progress in the Amazon Bedrock console under Foundation models > Custom models, or programmatically:
status = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job status: {status}") # Training, Complete, or FailedTraining time varies depending on the dataset size and the student model selected. For 10,000 labeled examples with Nova Micro, expect the job to complete within a few hours.
Deploy the distilled model
Once the distillation job is complete, the custom model is available in your Amazon Bedrock account and ready to deploy. Amazon Bedrock offers two deployment options for custom models: Provisioned Throughput for predictable, high-volume workloads, and On-Demand Inference for flexible, pay-per-use access with no upfront commitment.
For most teams getting started, on-demand inference is the recommended path. There is no endpoint to provision, no hourly commitment, and no minimum usage requirement. The following is the deployment code:
import uuid
deployment_name = f"nova-micro-video-router-{datetime.now().strftime('%Y-%m-%d')}"
response = bedrock_client.create_custom_model_deployment(
modelDeploymentName=deployment_name,
modelArn=custom_model_arn,
description="Distilled Nova Micro for video search modality weight prediction (4 weights)",
tags=[
{"key": "UseCase", "value": "VideoSearch"},
{"key": "Version", "value": "v2-4weights"},
],
clientRequestToken=f"deployment-{uuid.uuid4()}",
)
deployment_arn = response['modelDeploymentArn']
print(f"Deployment ARN: {deployment_arn}")Once the status shows InService, you can invoke the distilled model exactly as you would any other base model using the standard InvokeModel or Converse API. You pay only for the tokens you consume at Nova Micro inference rates: $0.000035 per 1,000 input tokens and $0.000140 per 1,000 output tokens.
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
custom_model_arn = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn
)['outputModelArn']
response = bedrock_runtime.converse(
modelId=custom_model_arn,
messages=[
{
"role": "user",
"content": [{"text": query}]
}
]
)
routing_weights = json.loads(
response['output']['message']['content']['text']
)
print(routing_weights)
# {"visual": 0.7, "audio": 0.1, "transcription": 0.1, "metadata": 0.1}Evaluate the distilled model
Before comparing against the original router, it is worth validating that distillation improved the base model’s ability to follow the routing task. The following table shows the same prompt run through base Nova Micro and the distilled Nova Micro side by side.
Query
Distilled Nova Micro
Base Nova Micro
"CEO discussing quarterly earnings "
{"visual": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "The query focuses on spoken content (transcription) about earnings, but visual cues (CEO's appearance) and audio (tone/clarity) are also important..."}
Here’s a JSON representation of the information you requested for a video search query about a CEO discussing quarterly earnings:
``json{ "video": { "visual": 0.3, "audio": 0.3, "transcription": 0.2, "metadata": 0.1, "reasoning": "The visual component includes the CEO's pres....</code></p></td>
</tr>
<tr>
<td style="padding: 10px;border: 1px solid #dddddd"><code>"sunset over mountains"</code></td>
<td style="padding: 10px;border: 1px solid #dddddd"><code>{"visual": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "The query focuses on a visual scene (sunset over mountains), with no audio or transcription elements. Metadata might include location or time-related tags."}</code></td>
<td style="padding: 10px;border: 1px solid #dddddd"> <p>Here’s a JSON representation for a video search query “sunset over mountains” that includes visual, audio, transcription, metadata weights (sum=1.0), and reasoning:</p> <p><code>`json{ "query": "sunset over mountains", "results": [ { "video_id": "123456", "visual": 0.4, "audio": 0.3 ....`
The base model struggles with both instructions and output format consistency. It produces free-text responses, incomplete JSON, and non-numeric weight values. The distilled model consistently returns well-formed JSON with four numeric weights that sum to 1.0, matching the schema required by the routing pipeline.
Comparing against the original Claude Haiku router, both models are evaluated against a held-out set of 100 labeled examples generated by Nova Premier. We use Amazon Bedrock Model Evaluation to run the comparison in a structured, managed workflow. To assess routing quality beyond standard metrics, we defined a custom OverallQuality rubric (see the following code block) that instructs Claude Sonnet to score each prediction on two dimensions: weight accuracy against ground truth and reasoning quality. Each dimension maps to a concrete 5-point threshold, so the rubric penalizes both numerical drift and generic boilerplate reasoning.
"rating_scale": [
{"definition": "Weights within 0.05 of reference. Reasoning is specific and consistent.",
"value": {"floatValue": 5.0}},
{"definition": "Weights within 0.10 of reference. Reasoning is clear and mostly consistent.",
"value": {"floatValue": 4.0}},
{"definition": "Dominant modality matches. Avg error 0.15. Reasoning vague or inconsistent.",
"value": {"floatValue": 2.0}},
{"definition": "Unparseable JSON, missing keys, or error > 0.30. No useful reasoning.",
"value": {"floatValue": 1.0}},
]The distilled Nova Micro model achieved a large language model (LLM)-as-judge score of 4.0 out of 5, near-identical routing quality to Claude 4.5 Haiku at roughly half the latency (833ms vs. 1,741ms). The cost advantage is equally significant. Switching to the distilled Nova Micro model reduces inference costs by over 95% on both input and output tokens, with no upfront commitments under on-demand pricing. Note: LLM-as-judge evaluation is non-deterministic. Scores may vary slightly across runs.
Figure 3: Model performance comparison (Distilled Nova Micro vs. Claude 4.5 Haiku)
The following is a table summary of side-by-side results:
Metric
Distilled Nova Micro
Claude 4.5 Haiku
LLM-as-judge Score
4.0 / 5
4.0 / 5
Mean Latency
833ms
1,741ms
Input Token Cost
$0.000035 / 1K
$0.80–$1.00 / 1K
Output Token Cost
$0.000140 / 1K
$4.00–$5.00 / 1K
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み