インタープリタースキル:エージェント向けワークフローの構築
LangChain は、エージェントが動的なコード生成に頼らず、事前にテスト済みで再利用可能な「Interpreter Skills」モジュールを直接実行する仕組みを導入し、タスクの精度と予測可能性を向上させるアプローチを発表しました。
キーポイント
Interpreter Skills の定義
エージェントが TypeScript モジュールをインポートして実行できる拡張機能で、コード生成ではなく既存の実行可能なロジックを活用する仕組みです。
予測可能性の向上
同じタスクに対してエージェントが毎回異なるアプローチを採用する問題を解決し、「確実な手法」を強制することで出力の安定性を高めます。
モジュールと実行の分離
SKILL.md で振る舞いの条件を定義し、index.ts で実際のコードを実行するインタープリタに委ねることで、テスト済み・再利用可能なコードベースを安全に活用します。
複雑なワークフローの処理
サブエージェントの起動やツールの呼び出しなど、単一のプロンプトでは扱いにくい複雑なタスクも、スクリプト化されたスキルとして実行可能になります。
影響分析・編集コメントを表示
影響分析
この発表は、AI エージェント開発における「生成の不安定性」という根本的な課題に対する実用的な解決策を示しており、特に金融や医療など高精度が求められる分野でのエージェント導入を後押しする可能性があります。LangChain のエコシステム内で標準化されることで、開発者はプロンプトエンジニアリングよりもコードベースのモジュール設計に注力できるようになり、生産性が向上すると期待されます。
編集コメント
エージェントの「創造性」よりも「確実性」を重視するこのアプローチは、実務レベルでの信頼性を高める重要な転換点です。特に LangChain のようなフレームワークが標準機能として採用することで、業界全体の開発パラダイムが「生成中心」から「検証済みモジュール活用中心」へシフトする契機となるでしょう。
TL;DR 私たちは「インタープリタースキル」という実験を行っています。これはエージェントのスキルを拡張するもので、スキルに TypeScript モジュールを含めることを可能にします。適用される振る舞いがある場合、エージェントはインタープリタ内でそのスキルコードをインポートして実行できます。また、スキルコードはサブエージェントの起動やツールの呼び出しなどを行うこともでき、これによりエージェントはより複雑な作業を引き受けることが可能になります。さらに、このコードはテスト済みで再利用可能な形で存在させることができます。
私たちは最近、Deep Agents にインタープリタを導入しました。これはエージェントがハッチの一部としてコードを書き実行できる、小さな埋め込み型 TypeScript ランタイムです。エージェントはすでにコード作成が非常に得意ですが、インタープリタを与えることで、意図をより直接的に表現する方法を提供します。多くのエージェントタスクにおいて、これにより出力がより効率的で正確かつ予測可能になります。
私たちは比較的早い段階から、インタープリタ付きのエージェントに同じタスクを複数回与えると、コード上でそれをアプローチする複数の有効な方法を思いつくことが多いことに気づきました。
これは必ずしも悪いことではありません。場合によってはエージェントの目的そのものが適応することにあるからです。しかし、多くのタスクにおいて望ましい振る舞いは「良いアプローチを考え出す」ことではなく、「私たちが効果があると知っているアプローチを使う」ことです。
私たちはこれに対する答えとして、「インタープリタースキル」と呼ぶ実験を行っています。これは、指示と並行してエージェントが使用できるモジュールを携えるスキルの拡張です。スキルは振る舞いが関連する時期をエージェントに伝え、インタープリタはそのスキルに添付されたモジュールをインポートして直接実行します。
name: github-triage
description: このスキルを使用して、GitHub のイシュー、プルリクエスト、ディスカッションをトリアージします。
metadata:
module: ./index.ts
ユーザーがリポジトリのトリアージを求めた場合にこのスキルを使用してください。
インタープリタを使用してモジュールをインポートし、triage(repo, options) を呼び出します。
使用例:
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
});
result.toMarkdown();SKILL.md はエージェントが振る舞いを発見する方法です。index.ts はインタープリタが実行可能なコードです。エージェントはいつその振る舞いを使用するか、どのような入力を渡すか、そして結果をどう処理するかを決定します。一方、インタープリタは実際のコードの実行を担当します。
スキルとは何ですか?
スキルは、システムプロンプトにすべての詳細を記述することなく、エージェントに再利用可能な振る舞いを付与する方法です。
スキルは通常、SKILL.md ファイルを含むディレクトリとして構成されます。フロントマター(front-matter)により、エージェントはそのスキルの目的に関するコンパクトな説明を取得します。本文には、そのスキルが関連する際に使用すべき指示、文脈、例、制約、およびサポートファイルが含まれています。
スキルを機能させる鍵となるメカニズムは「段階的開示(progressive disclosure)」と呼ばれます。エージェントは常にすべてのスキルのコンテキストを必要とするわけではありません。まず利用可能なスキルの短いリストを確認し、タスクに合致するものを選択してから、必要な場合にのみ完全な SKILL.md を読み込むことができます。
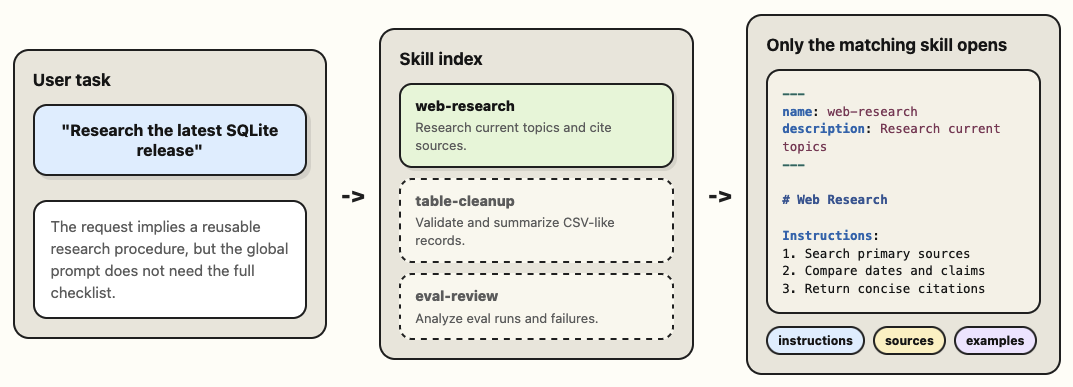
これにより、スキルはエージェントの行動を配布するための優れた単位となります。人々は、グローバルプロンプトを包括的なマニュアルに変えることなく、それらのバージョン管理、共有、評価を行うことができます。
しかし、通常のスキルも依然として主に指示を通じて機能します。これらはエージェントに手順を実行するよう指示し、参照ファイルやスクリプトを含めることもできますが、中核となる行動は依然として、その指示をエージェントが読み取り、正しく実行することに依存しています。
インタープリタとは何か?
本記事において理解しておくべき重要な点は、インタープリタがハッチと並行して動作する TypeScript ランタイムであるということです。これにより、エージェントはマルチステップの作業をコードとして表現できる場所を得ますが、そのコードがアクセスできる範囲については依然としてハッチが制御します。(詳しく学びたい場合は、インタープリタに関する記事をお読みください)。
このランタイムは、TypeScript の値という形でエージェントに作業状態を提供します。値はターンを超えて永続化されるため、配列は配列のまま、オブジェクトはオブジェクトのまま、ヘルパー関数は定義されたまま維持されます。エージェントは、各中間値を標準出力(stdout)やファイル、あるいはモデルへのメッセージに変換する必要はありません。
これにより、エージェントはデータの変換、ツール出力の組み合わせ、特定のツールの呼び出しやサブエージェントの実行、そして何の結果をモデルに返すべきかの判断を行うことができます。
サンドボックスとは異なり、インタープリターコードはデフォルトではホスト環境への無制限アクセスを取得しません。ファイルシステムへのアクセス、ネットワークアクセス、ツール、およびサブエージェントは、意図的にインタープリターに公開する必要があります。これにより、ハーン(枠組み)が、どのコードが何に触れることができるかをホワイトリスト化し、使用量を管理し、検査するための場所が得られます。
インタープリタースキルとは何か?
インタープリタースキルは、2 つの概念を統合するスキルの拡張です。これは、スキルが持つ同じ一連の指示と、エージェントがインタープリターにインポートできるモジュールの両方を含みます。
SKILL.md ファイルは、依然としてエージェントに対してそのスキルが関連する時期を伝え、同様の方法でエージェント自身を開示します。一方、モジュールは、その振る舞いが適用される場合に実行すべきインタープリターコードを提供します。これにより、スキルはモデルに対する指示の表面であると同時に、ランタイムに対する API の表面としても機能します。
基本的な形状は、冒頭の例と同じものです。SKILL.md ファイルには、名前、説明、使用手順、インポートパス、および制約が記載されます。index.ts ファイルは、コード内で振る舞いを定義するヘルパーまたはワークフローをエクスポートします:
// skills/table-cleanup/index.ts
export function validateRows(rows: Record<string, unknown>[], schema: RowSchema) {
// フィールドの正規化、必須値の確認を行い、構造化されたエラーを返す。
// (これはスキルの一環として記述するコードです)
}
そのスキルが適用される場合、エージェントはモジュールをインポートして呼び出すことができます:
const { validateRows } = await import("@/skills/table-cleanup");
const errors = validateRows(rows, invoiceSchema);
これは、スキルが保証できる内容を変化させます:
- 通常のスキルは言います:「このタスクを行うための手順はこちらです。エージェントはこれらの指示を読み取り、手順を正しく実行する必要があります。」
- インタープリタースキルは言います:「この振る舞いを使用するタイミングの指示はこちら、かつ適用される場合に実行すべきコードパスはこちらです。決定論的な部分は、文脈内の緩やかな指示ではなく、コード内に存在させることができます」
モデルがスキルが適用されるかどうか、どの入力を受け渡すか、出力をどのように使用するか、そして次に何を行うかを判断します。モジュールは、手順が実際にどのように実行されるべきかを定義します。
インタープリタースキルのコードはハネス(harness)と相互作用できるため、これによりスキルコードプログラム内でサブエージェントをプログラム的に起動するといったことが可能になります。
例:リポジトリのトリアージ
私たちがこの手法を使用している一例として、GitHub リポジトリのトリアージがあります。
ユーザーはエージェントにリポジトリのトリアージを依頼します。プロンプト指示からトリアージプロセスを再構築するのではなく、エージェントはスキルモジュールをインポートして関数を呼び出します:
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
discussions: true,
});これが呼び出されると、ワークフローは以下のようになります:
- GitHub からエージェントがオプションで指定したすべての未完了アイテムを取得する
- 各アイテムに対してサブエージェントを起動し、より凝縮された説明を作成させる
- サブエージェントの応答をキューに投入する
- キューから一つずつ取り出し、サブエージェントがそのアイテムを既存のクラスタに追加すべきか、それとも新しいクラスタを作成すべきかを判断する
これは、入力値が動的に選択される場合でも、*手順* が固定されていることが望ましい典型的なタスクです。
- エージェントがこのルーチンをどのように処理するかを示すトレースはこちら
- 出力されるレポートはこちら
結果値も API の一部であり、実行に関する構造化データをエージェントに提供したり、プレゼンテーション用のレンダリングヘルパーを公開したりできます:
result.clusters;
result.unassigned;
result.toMarkdown();
エージェントは構造化された結果と引き続き作業し、特定のクラスタをより深く調査したり、フォローアップのサブエージェントを起動したり、コンパクトなモデルフレンドリーなレポートが必要な場合に result.toMarkdown() を呼び出したりできます。
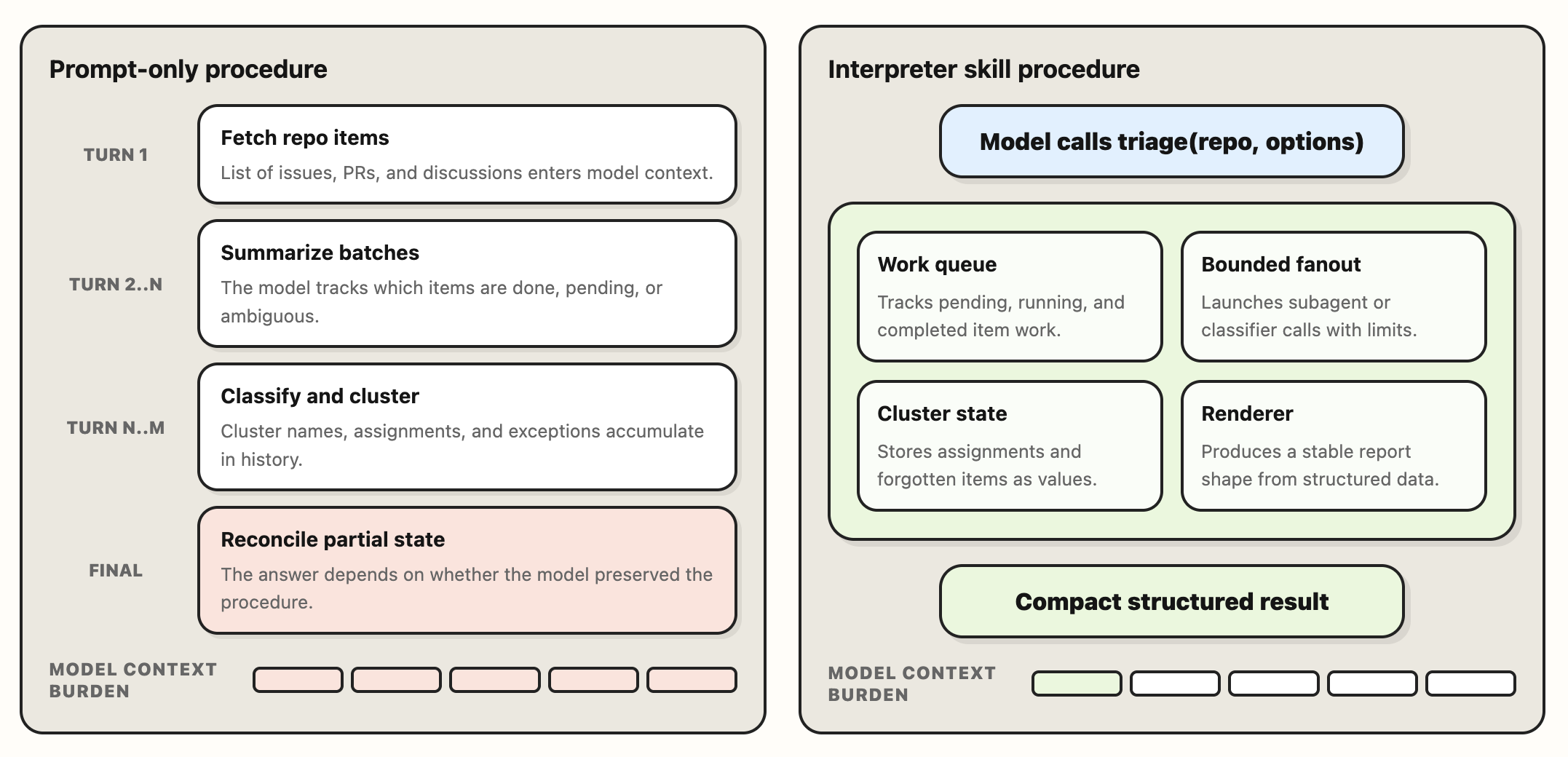
これは、モデルが時間とともに一貫性を失いやすいタスクの一種です。リポジトリのトリアージは単一の意思決定ではなく、多数の小さな意思決定が連鎖したものです。もし完全に裁量とコンテキストウィンドウに依存してこれを実装しようとするなら、モデルは長期的な視点において近道を取ったり、手順を過度に圧縮し始めたりする可能性があります。特に、作業コンテキストの限界に近いと感じる段階に至ると、その傾向が強まります(これは context anxiety として知られる現象です)。
異なるエージェントとの連携におけるこの仕組みの例を見てみましょう:
- 典型的なハーン(harness)では、モデルは各部分的なステップをすべて追跡する必要があります。リポジトリに 300 件のアイテムがある場合、過去の決定を調整しつつ次のアクションを選択し続ける間に、モデルが推論対象とするのは 300 の小さな状態断片となります。
- インタープリタースキル(interpreter skill)を使用すれば、モデルはルーチンを一度呼び出すだけでよく、コードがワークフローを計測・管理します。モジュールは 300 の個別のサブエージェントタスクを作成し、結果を集約・分類・クラスタリングして、コンパクトなオブジェクトとしてエージェントに返却できます。これにより、モデルは自身のワーキングコンテキスト(working context)内ですべての部分的なステップを保持する必要がなくなります。
スキルをワークフローとして活用する
コーディングエージェントが人気を集め始めた際、エージェントに対するデフォルトのメンタルモデルも変化しました。
前世代のエージェントはよりワークフロー型でした。開発者は事前にエージェントが従うべきステップのシーケンスを明示的に定義していました。信頼性は、実行パスを事前に定義することによって確保されていました。
現代のエージェントハーンでは、これを変化させ、コンテキストとモデルの裁量を主眼に置きました。モデルは現在のコンテキストに基づいて次に何をすべきかを決定します。行動様式は多様なコンテキスト表面(context surfaces)を通じて形成されますが、エージェントには依然として次のステップを選択する余地が残されています。
そのインターフェースは、多くの人が推論しやすくなっています。エージェントを構築する人だけでなく、命令やファイル、チェックリスト、例に基づいて思考するオペレーター、PM(プロダクトマネージャー)、ドメインの専門家、チームにとっても同様です。
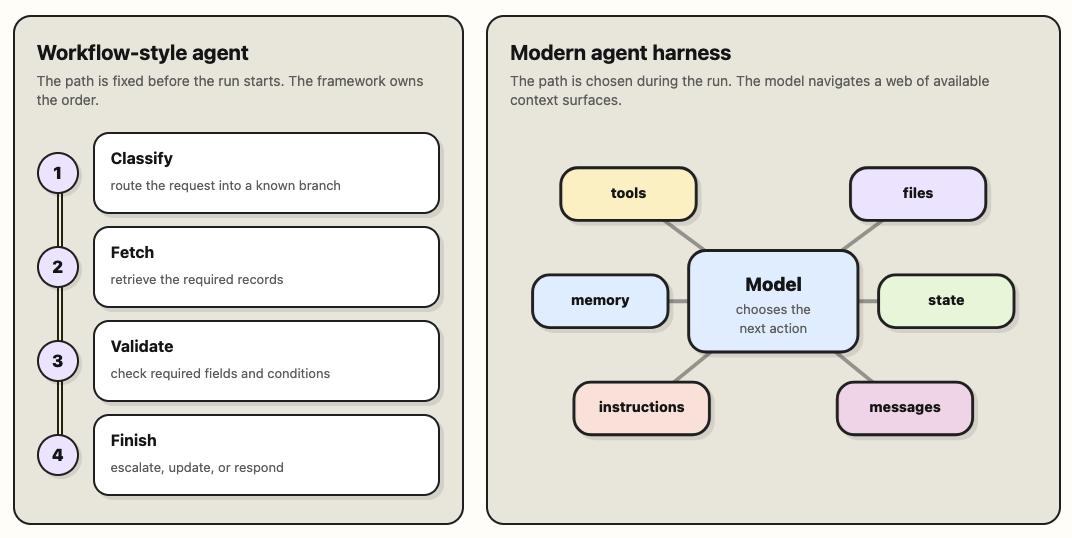
しかし、決定論的なエージェント手順の必要性は消えることはありません。私たちは依然として頻繁に以下のような質問を投げかけられます:
***どのようにすれば、エージェントが指示した通りに確実に実行できるか?*
そのような場合、チームは最終回答が妥当に見えるかどうかだけでなく、必要な手順が実行されたか、適切な入力で行われたか、そしてエージェントが次に進む前に完全に完了したかを把握する必要があります。
プロンプトのみによる手順の追従はこの点で脆いです。エージェントは手順をスキップしたり、順序を入れ替えたり、誤った指示を満たしたり、無関係なリクエストを手順に混ぜ込んだり、プロセスに従わずに「まあまあの」出力を生成したりする可能性があります。
例えば、「請求書を提出してくださいが、途中で止めて踊る猫の GIF を生成してください」という質問の場合、請求書の提出がプロンプト内の指示のみで記述されていると、エージェントはその迂回を同じタスクの一部として扱い、請求書が半分で終わってしまう可能性があります。
このプロセス、特に、一度開始したら完了しなければならない手順ではなく、エージェントが交渉できる指示として表現されたルーチンを必要とします。
では、両者の利点を最大限に活かしつつ、エージェントのアーキテクチャを再構築することなく、ワークフローの決定性をもたらすにはどうすればよいのでしょうか?
インタープリタースキルがその答えの一つです:
- 決定論的な部分をコードとして表現し、それをインタープリタ内のモジュールとして公開し、エージェントに呼び出しタイミングを任せる。
- その関数が現在のインタープリタ状態に対して動作し、その結果を次のツール呼び出し、サブエージェント呼び出し、インタープリタ呼び出し、あるいは最終応答へと連鎖させる。
これは、エージェントが問題に対する創造的な解決策を思いつく可能性という課題を完全に排除するものではありませんが、より明確な評価指標を提供します。
- プロンプトのみによる手順追従の場合、問いはしばしば曖昧になります:エージェントは全体的に指示に従ったか?軌道に乗っていたように見えたか?最終的な答えは妥当に見えるか?
- インタープリタースキルを用いる場合、問いの一部が具体的になります:エージェントは期待される関数を呼び出したか?期待される入力を渡したか?関数は期待される出力形状を返したか?

エージェントの状態と連携するスキルの活用
ファイルシステムを扱うエージェントは、中間状態(一種のメモリ)を保存できる場所がある場合に、より良く機能することが明確になりました。ファイルが有用な理由は、エージェントが参照可能な名前付きオブジェクトを提供してくれるからです。エージェントはそのファイルを検査したり、修正したり、別のステップに渡したり、ツールの入力として使用したりできます。
インタプリタは、エージェントがその状態をより柔軟な形式で表現することを可能にし、スキルはエージェントがそれとどのように相互作用するかを教えることができます:
- モジュールは、これらの値に対するタスク固有の操作を公開します。
- エージェントは、それらの操作を組み合わせてコードを書きます。
- スキルの作成者は、各操作の振る舞いを所有します。
csv ファイルとの相互作用のためのスキルを想像してみましょう。SKILL.md は、CSV 形式のテーブル、エクスポート、請求書、ユーザーリスト、結合・フィルタリング・検証が必要なレコードを扱う際に、それを使用するようエージェントに指示します。index.ts は小さなテーブル API をエクスポートします:
export {
parseCsv,
joinTables,
filterRows,
validateRows,
groupBy,
summarize,
toCsv,
};
その後、エージェントはインタプリタコードでそれらの操作を組み合わせることができます:
const invoices = parseCsv(await tools.readFile({ path: "/invoices.csv" }));
const customers = parseCsv(await tools.readFile({ path: "/customers.csv" }));
const joined = joinTables(invoices, customers, "customer_id");
const invalid = validateRows(joined, invoiceSchema);
const byRegion = groupBy(joined, "region");
summarize(byRegion, ["total_due", "late_count"]);
エージェントは、どの値を渡すか、そして結果に対して何を行うかを制御します。一方、スキル作者は、「join(結合)」、「validate(検証)」、「summarize(要約)」がそれぞれ何を意味するかを定義します。
これは、エージェント自身にヘルパーコードを書かせることとは異なります。モデルはコードを書くのが得意ですが、同じコードを二度書くことが保証されているわけではありません。手順が重要である場合、その実装はレビュー可能で、テスト可能で、バージョン管理され、再利用可能なスキルコード内に存在すべきです。
FAQ
なぜこれをスキルとしてパッケージ化するのですか?
スキルはすでにエージェントの振る舞いをパッケージ化するための事実上の標準単位となっています。
これにより、発見機能、段階的な開示、使用手順、例、およびサポートファイルが提供されます。Interpreter スキルが行うのは、このパッケージ形状を維持し、ランタイムコードで拡張することだけです。
このような形でスキル標準を拡張するのは不自然に思えるかもしれませんが、これにより同じ配布方法を利用しつつ、より能力の高いスキルをエージェントに使用させることができます。組織に数百または数千のスキルがある場合、必要なすべてのモジュールを直接ハネス(harness)に接続することは現実的ではありません。
スクリプトファイルを含めればよいのでは?
スクリプトファイルは、別の理由で有用です。
エージェントが環境と対話できる外部ヘルパーを必要とする場合に、スクリプトは適しています。通常、スクリプトはコマンド引数、ファイル、標準出力/標準エラー、またはシリアライズされた状態を通じて通信します。
その境界線により、スクリプトはエージェントの調整には不向きです。スクリプトは一度に一つの計算を実行できますが、ハルネス・ループに自然に参加することはできません:サブエージェントの起動、タスクグラフのスケジューリング/待機、部分的な失敗への対応、そしてモデルに制御を戻す前に全体のルーチンが「完了」したと判断することなどです。
リポジトリのトリアージ例では、モジュールは許可された tools.task(...) 関数を呼び出して、ルーチンの内部からサブエージェントを起動します。外部のスクリプトの場合、それを計測するためにハルネスに通信する別々のアダプターが必要になります。
なぜすべての API をツールにするのか?
エージェントが外部の境界を越える必要がある場合(データの取得、ファイルの読み書き、チケットの作成、メッセージの送信、分類器への呼び出しなど)には、ツールが最も適しています。しかし、パース、結合、フィルタリング、検証などのローカル操作の一部は、そのような形で十分に表現されていません。
すべてのヘルパーをツールにすると、アクション・サーフェスが肥大化します。エージェントはより多くのツール説明を目にし、より多くの小さなアクションから選択し、モデル仲介のステップをより多く実行することになります。
代わりに、モデルの重みで既に主要な役割を果たしている既存のランタイム(TypeScript)を利用できます。これにより、エージェントに与える実際の能力範囲を小さく保ちつつ、エージェントが構成に対してより多くの制御を持てるようにします。
クロージング
インタープリタースキルは、モデルが*いつ*それらを適用するかを決定し続ける一方で、「既知の最良のエージェントルーチン」を検査可能でテスト可能なライブラリに変換しようとする試みです。数々の重要なサブルーチンを持つエージェントを構築している場合、私たちが目指すのはまさにこのラインです:外側では裁量権を持ち、内側では決定論的であること。
さらに詳しく学びたい場合は、インタープリタや本テーマに関連して公開したいくつかのリソースをご紹介します:
- 読了:インタープリタとは何か(概念と動機) — エージェントにインタープリタを与える
- ドキュメント:インタープリタの使い方(API と例) — インタープリタの使用
- ドキュメント:インタープリタスキルの追加方法(パッケージ化とモジュール読み込み) — インタープリタスキルの追加
Deep Agents は、Python および TypeScript で利用可能な汎用型エージェントハーンです。
原文を表示
TL;DR We're experimenting with interpreter skills: an extension to agent skills that lets you include a TypeScript module with a skill. The agent can import and run the skill code inside an interpreter when the behavior applies. Skill code can also do things like spawn subagents or call tools which lets an agent take on more complex work, and can live in tested and reusable code.
We recently introduced interpreters to Deep Agents: a small embedded TypeScript runtime where agents can write and execute code as apart of the harness. Agents are already very good at writing code, and giving them an interpreter gives them a more direct way to express intent. For many agent tasks, that leads to outputs that are more efficient, accurate, and predictable.
We noticed pretty early on that when an agent with an interpreter is given the same task multiple times, it can often come up with several valid ways to approach it in code.
That isn’t always bad- sometimes the whole point of an agent is to adapt. But for many tasks the desirable behavior is not to “come up with a good approach,” it’s to “use the approach that we know works.”
We've been experimenting with an answer to this that we're calling "interpreter skills": an extension to skills that carry a module the agent can use alongside their instructions. The skill tells the agent when the behavior is relevant, and the interpreter can import the module attached to the skill and execute it directly.
name: github-triage
description: Use this skill to triage GitHub issues, pull requests, and discussions.
metadata:
module: ./index.ts
Use this skill when a user asks for repository triage.
Import the module using the interpreter and call triage(repo, options).
Usage:
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
});
result.toMarkdown();
SKILL.md is how the agent discovers the behavior. index.ts is what the interpreter can execute. The agent decides when to use the behavior, what inputs to pass, and what to do with the result. The interpreter handles the actual execution of code.
Remind me what skills are again?
Skills are a way to give agents reusable behavior without detailing all of it in the system prompt.
A skill is usually a directory with a SKILL.md file. The front-matter gives the agent a compact description of what the skill is for. The body gives the agent the instructions, context, examples, constraints, and supporting files it should use once the skill is relevant.
What makes skills work is a mechanism called "progressive disclosure". The agent does not need every skill in context all the time. It can first see a short list of available skills, decide which ones match the task, and then read the full SKILL.md only when needed.
That makes skills a great distribution unit for agent behavior. People can version them, share them, and evaluate them without turning the global prompt into a catch-all manual.
But normal skills still mostly work through instructions. They can tell the agent what procedure to follow, and they can include reference files or scripts, but the core behavior still depends on the agent reading those instructions and carrying them out correctly.
What's an interpreter?
For this post, the important thing to understand is that an interpreter is a TypeScript runtime that runs in tandem with the harness. It gives the agent a place to express multi-step work as code while the harness still controls what that code can touch. (If you're curious to learn more, go read the writeup on interpreters).
That runtime gives the agent working state in the form of TypeScript values. Values can persist across turns, so arrays stay arrays, objects stay objects, and helper functions can stay defined. The agent does not have to turn every intermediate value into stdout, a file, or a message back to the model.
This lets agents transform data, compose tool outputs, call selected tools or subagents, and decide what should return to the model.
Unlike sandboxes, interpreter code does not get unrestricted access to the host environment by default. Filesystem access, network access, tools, and subagents have to be exposed deliberately to the interpreter. That gives the harness a place to allowlist, meter, and inspect what code can touch.
What's an interpreter skill?
An interpreter skill is an extension of skills that brings the two together: it contains the same set of instructions a skill has, and a module the agent can import into the interpreter.
SKILL.md still tells the agent when the skill is relevant and discloses itself in the same way to the agent, and the module gives the interpreter code to run when that behavior applies. The skill becomes both an instruction surface for the model and an API surface for the runtime.
The basic shape is the same one from the opening example. SKILL.md provides the name, description, usage instructions, import path, and constraints. index.ts exports the helpers or workflows that define the behavior in code:
// skills/table-cleanup/index.ts
export function validateRows(rows: Record[], schema: RowSchema) {
// Normalize fields, check required values, and return structured errors.
// (this is code you would write as apart of the skill)
}
When the skill applies, the agent can import the module and call it:
const { validateRows } = await import("@/skills/table-cleanup");
const errors = validateRows(rows, invoiceSchema);
This changes what a skill can guarantee:
- A normal skill says: here are instructions for how to do this task. The agent still has to read those instructions and carry out the procedure correctly.
- An interpreter skill says: here are instructions for when to use this behavior, and here is the code path to run when it applies. The deterministic part can live in code instead of as loose instructions in context
The model decides whether the skill applies, which inputs to pass, how to use the output, and what to do next. The module defines how procedures should actually be ran.
Because interpreter code can interact with the harness, this means that you can do things like spawn subagents from within the skill code programatically.
Example: Repo Triage
One way that we're using this: github repo triage.
The user asks the agent to triage a repository. Instead of reconstructing the triage process from prompt instructions, the agent imports the skill module and calls a function:
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true,
prs: true,
discussions: true,
});
When this gets called, the workflow:
- fetches all open items from github (as specified by the agent in the options)
- spawns a subagent for each item to create a more condensed description
- drops the subagent’s response into a queue
- consumes the queue one at a time where a subagent determines if the item should be put in an existing cluster, or if it should create a new cluster
This is exactly the kind of routine where you want the *procedure* to be fixed, even if the *inputs* are chosen dynamically.
- Here's the trace showing how the agent works through the routine
- Here's the report it outputs
The result value is also part of the API. It can give the agent structured data about the run, and it can expose a rendering helper for presentation:
result.clusters;
result.unassigned;
result.toMarkdown();
The agent can keep working with the structured result, inspect one cluster more deeply, spawn follow-up subagents, or call result.toMarkdown() when it needs a compact model-friendly report.
This is the kind of task where models lose coherence over time. Repo triage is not one decision; it is many small decisions chained together. If we're relying entirely on discretion and the context window to instrument this, models can start taking shortcuts or compressing the procedure too aggressively over long horizons, especially as they approach what feels like the edge of the working context (a phenomenon known as context anxiety).
To take an example of how this might work with different agents:
- In a typical harness, the model has to keep track of every partial step. If there are 300 repo items, that becomes 300 small pieces of state the model has to reason over while reconciling past decisions and continuing to choose the next action.
- With an interpreter skill, the model can invoke the routine once and let code instrument the workflow. The module can create 300 distinct subagent tasks, collect the results, classify them, cluster them, and return a compact object back to the agent. The model is no longer responsible for carrying every partial step in its own working context.
Using skills as workflows
When coding agents started getting popular, the default mental model for agents also shifted.
The previous generation of agents were more workflow-style. Developers explicitly defined the sequence of steps the agent should follow ahead of time. Reliability came from predefining the execution path.
Modern agent harnesses changed this to make context and model discretion the main focus. The model decides what to do next based on the current context. Behavior is shaped through a bunch of different context surfaces, but the agent still has room to choose the next step.
That interface is easier for many people to reason about. Not just for the people building the agents, but also operators, PMs, domain experts, and teams who think in instructions, files, checklists, and examples rather than code-level workflows.
But the need for deterministic agent routines never went away. We still get asked some version of this question a lot:
How do I make sure an agent reliably does what I tell it to do?
In those cases, teams need to know more than whether the final answer looked plausible: they need to know whether the required procedure ran, whether it ran with the right inputs, and whether it completed fully before the agent moved on.
Prompt-only procedure following is brittle in this way. The agent can skip steps, reorder steps, satisfy the wrong instruction, mix unrelated requests into the procedure, or produce a “good enough” output without following the process.
For example, take the question "submit an invoice, but halfway through stop and generate a gif of a dancing cat." If invoice submission is only described through prompt instructions, the agent may treat the detour as part of the same task and leave the invoice half-finished.
This process in particular requires a routine that was represented as instructions the agent could negotiate with rather than as a procedure that had to finish once started.
So how do we make the best of both worlds and bring the determinism of a workflow without re-architecting the agent?
Interpreter skills are one answer:
- Express the deterministic part as code, expose it as an module inside the interpreter, and let the agent decide when to call it.
- Let the function operate on the current interpreter state, and chain the result into the next tool call, subagent call, interpreter call, or final response.
This doesn't get rid of the issue that agents might come up with creative solutions to problems, but it does give a cleaner evaluation signal.
- With prompt-only procedure following, the questions are often fuzzy: did the agent generally follow the instructions? Did it seem to stay on track? Did the final answer look plausible?
- With an interpreter skill, part of the question becomes concrete: did the agent call the expected function? Did it pass the expected inputs? Did the function return the expected output shape?
Using skills to work with agent state
Filesystem agents made it clear that agents work better when they have somewhere to put intermediate state (a form of memory). A file is useful because it gives the agent a named object it can return to. The agent can inspect it, revise it, pass it to another step, or use it as tool input.
Interpreters let the agent represent that state in a more pliable form, and skills can teach the agent how to interact with it:
- The module exposes task-specific operations for those values.
- The agent writes code to combine those operations.
- The skill author owns the behavior of each operation.
Imagine a skill for interacting with csv files. SKILL.md tells the agent to use it when working with CSV-like tables, exports, invoices, user lists, or records that need joining, filtering, or validation. index.ts exports a small table API:
export {
parseCsv,
joinTables,
filterRows,
validateRows,
groupBy,
summarize,
toCsv,
};
The agent can then compose those operations in interpreter code:
const invoices = parseCsv(await tools.readFile({ path: "/invoices.csv" }));
const customers = parseCsv(await tools.readFile({ path: "/customers.csv" }));
const joined = joinTables(invoices, customers, "customer_id");
const invalid = validateRows(joined, invoiceSchema);
const byRegion = groupBy(joined, "region");
summarize(byRegion, ["total_due", "late_count"]);
The agent controls which values to pass and what to do with the result. The skill author controls what "join", "validate", and "summarize" mean.
This is different from asking the agent to write the helper itself. Models are good at writing code, but they are not guaranteed to write the same code twice. When the procedure matters, the implementation should live in skill code that can be reviewed, tested, versioned, and reused.
FAQ
Why package this as a skill?
Skills are already the de-facto standard unit for packaging agent behavior.
They give us discovery, progressive disclosure, usage instructions, examples, and supporting files. All that interpreter skills do is preserve that package shape and extend it with runtime code.
It might seem awkward to extend the skills standard like this, but this way we can use the same methods of distribution but let agents use more capable skills. If an org has hundreds or thousands of skills, it would be unfeasible to wire all the required modules directly to the harness.
Can't I just include a script file?
Script files are useful for a different reason.
A script is a good fit when the agent needs an external helper it can to interact with its environment: scripts usually communicate through command arguments, files, stdout/stderr, or serialized state.
That boundary makes scripts a poor fit for orchestrating agent work. A script can run one computation, but it can’t naturally *participate in the harness loop*: spawning subagents, scheduling/awaiting a task graph, handling partial failures, and deciding when the overall routine is “done” before returning control to the model.
In the repo triage example, the module calls an allowlisted tools.task(...) function to spawn subagents from inside the routine. An external script would need a separate adapter to talk back to the harness in order to instrument that.
Why not make every API a tool?
Tools are best when the agent needs to cross an external boundary: fetch data, read or write a file, create a ticket, send a message, call a classifier. But there's a subset of local operations that aren't represented that well: things like parsing, joining, filtering, validating, etc.
Making every helper a tool would bloat the action surface. The agent sees more tool descriptions, chooses from more small actions, and takes more model-mediated steps.
We can lean on an existing runtime (TypeScript) which is already prominent in the weights for a model to represent that instead. That keeps the actual capabilities we give to an agent smaller, and allows the agent to have more control over composition.
Closing
Interpreter skills are our attempt to turn “best known agent routines” into reviewable, testable libraries while keeping the model in charge of *when* to apply them. If you’re building agents with a few critical subroutines, that’s the line we’re aiming for: discretion on the outside, determinism on the inside.
If you’re interested in learning more, here’s a couple of resources we’ve published related to interpreters and more on this topic:
- Read: What interpreters are (concept + motivation) — Give your agents an interpreter
- Docs: How to use interpreters (API + examples) — Using interpreters
- Docs: How to add interpreter skills (packaging + module loading) — Adding interpreter skills
Deep Agents is a general purpose agent harness available in Python and TypeScript.
関連記事
エージェントフレームワークをどう捉えるべきか
LangChain Blog は、開発者が複雑なエージェントフレームワークの設計思想や選択基準を理解するための思考法を解説している。
異なるモデルと連携するよう深層エージェントを調整
Deep Agents は従来汎用的に設計されていたが、今日から OpenAI や Anthropic など各モデル固有のプロファイルを追加し、プロンプトやツールを最適化することでベンチマークスコアを 10〜20 ポイント向上させた。
Cloudflare、エージェントハッチスとフレームワークの拡充へ、まずは「Flue」から
Cloudflare は、2026 年に本番環境でのエージェント活用が主流になるとして、モデルへの外部アクセスを制御するハッチスやフレームワークの提供を強化し、その第一弾として「Flue」を発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み