Amazon Bedrock と LLM ゲートウェイを用いたレジリエンスパターンの実装
AWS は、生成 AI アプリケーションの生産環境移行に伴い、可用性・応答速度・コスト・スループットを最適化する 5 つの実践的なレジリエンスパターンと LLM ゲートウェイの活用方法を提示した。
キーポイント
生成 AI レジリエンスの 4 大次元
生産環境におけるアーキテクチャ決定は、可用性(障害時の稼働)、応答速度(TTFT/TTLT)、コスト、スループットの 4 つの相互関連する要素によってガイドされる。
LLM 固有の課題と対策
既存のベストプラクティスに加え、モデル利用状況の急変、プロバイダーごとのトークン制限、および新しいモデルの一貫性維持といった生成 AI 特有の課題への対応が求められる。
段階的な実装アプローチ
AWS のネイティブ機能(Amazon Bedrock)から始まり、LLM ゲートウェイを用いたマルチモデルオーケストレーションへと至る、5 つの実践パターンを段階的に導入する「crawl, walk, run」方式が提案されている。
実用的なパターンの具体例
予期せぬトラフィック急増によるクォータ枯渇の回避、地理的分散による可用性最大化、マルチテナント環境でのノイジーネイバー問題の防止など、現実的な課題に対する解決策が示されている。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI が実験段階から本番運用へ移行する際の最大の障壁である「信頼性と安定性の確保」に対して、具体的なアーキテクチャパターンと AWS のツールを活用した解決策を提供しています。特に、可用性・コスト・速度のトレードオフ関係を明確にし、段階的な導入を促すことで、組織がリスクを抑えながら AI 基盤を強化する道筋を示しており、技術リーダーにとって即座に活用可能な指針となります。
編集コメント
本番環境での生成 AI 運用における「可用性」と「コスト」のバランスをどう取るかという実務的な課題に対し、AWS 公式が具体的な設計パターンとコードサンプルを提供しており、非常に即戦力となる内容です。
生成 AI ワークロードが実験段階から大規模な本番環境へ移行するにつれ、大規模言語モデル (LLM) の推論に対するレジリエンスパターンの実装は極めて重要です。LLM を活用したアプリケーションがすでに本番稼働している現在、組織は大規模な運用において LLM 推論を高い可用性、応答性、そしてコスト効率で維持する方法を必要としています。静的安定性の確保やバックオフ・リトライの実装といった既存のレジリエンスのベストプラクティスは依然として適用されます。しかし、生成 AI はモデルの可用性、急速に変化するクォータ、複数プロバイダーにわたるトークン制限、および新しくリリースされたモデルとの一貫性維持など、新たな考慮事項をもたらします。Amazon Bedrock は、クロスリージョン推論といった組み込みのレジリエンス機能を備えたフルマネージド型ファウンデーションモデルを提供しています。
本番環境での推論を設計する際、アーキテクチャ上の意思決定を導くのは通常 4 つの次元です:可用性、応答時間、コスト、そしてスループットです。可用性とは、モデル、リージョン、またはプロバイダーの障害中も推論を継続して維持することを指します。応答時間は、ユーザーが出力を受け取るまでの速度、具体的には最初のトークン到達時間 (TTFT) および最後のトークン到達時間 (TTLT) として測定されることが多いです。コストは、トークン単位およびリクエスト単位の支出と、ルーティングの決定がこれにどう影響するかを捉えます。スループットは、負荷下でシステムが維持できる同時実行リクエスト数および秒間あたりのトークン数を反映します。
これらの次元は相互に関連しています。例えば、リージョン間ルーティングは可用性とスループットを向上させますが、応答時間が長くなる可能性があります。本記事のパターンは主に可用性に焦点を当てており、フェイルオーバー、地理的分散、クォータの分離を通じて推論が稼働し続けることを目指しています。今後の記事では、応答時間の最適化とコスト意識型のルーティングについて詳しく探求していきます。
本記事では、AWS 上で堅牢な生成 AI アプリケーションを構築するための 5 つの実践的なパターンを学びます。これらは、ネイティブの Amazon Bedrock の機能から始まり、LLM ゲートウェイを使用したマルチモデルオーケストレーションへと段階的に進みます。これらのパターンは、予期せぬトラフィック急増時のクォータ枯渇、推論の地理的分散による可用性の最大化、マルチテナント環境におけるノイジーネイバー問題の防止といった、現実世界の課題に対応します。また、インテリジェントなリクエストルーティングを通じてコスト最適化を支援し、特定の要件に基づいて複数のモデルやプロバイダーを使用する柔軟性も提供します。
この「 crawling(這う)、walking(歩く)、running(走る)」アプローチにより、アプリケーションの成熟度と要件に応じてパターンを段階的に導入できます。併せて提供される GitHub リポジトリ には、各パターンの実装を示すコードサンプルが含まれています。
推論レジリエンスパターンへの段階的アプローチ
GitHub リポジトリのこのセクションにあるコードサンプルと手順を使用して、ご自身の環境で以下の各パターンをテストすることができます。
前提条件
デモを開始する前に、前提条件の手順に従って、適切なソフトウェアがインストールされていることと、AWS アカウントが正しく設定されていることを確認してください。
注記:本記事で示すパターンを実行すると、Amazon Bedrock での推論リクエストや Amazon CloudWatch ログなど、課金が発生する AWS リソースが作成・使用されます。テスト後に継続的な課金を避けるには、「クリーンアップ」セクションを参照してください。
パターン 1:Amazon Bedrock を用いたクロスリージョン推論
Amazon Bedrock クロスリージョン推論(CRIS)は、デフォルトで堅牢な推論の基盤を提供するネイティブ機能です。クロスリージョン推論プロファイル を使用することで、スループットの向上、AWS リージョン内でのレート制限(throttling)の発生確率低下、モデルトラフィックの分散が可能になります。CRIS は、トラフィック配分の管理に必要な手作業を不要にし、アプリケーションの可用性を向上させます。これは、可用性、レイテンシ、現在の需要といったリアルタイム要因に基づいて、リクエストをソースリージョンから最適な宛先リージョンへ自動的にルーティングします。これにより、ピーク利用時の予期せぬトラフィックバーストにも対応し、サービスクォータが推論に影響を与える可能性を低減します。
CRIS プロファイルは通常、米国や EU といった特定の地理圏内の商用リージョンに紐付けられており、推論リクエストに対してパフォーマンスとレイテンシの適切なバランスを提供します。このアプローチにより、データ所在(data residency)を地理的境界内に維持したまま、単一リージョンのクォータを超えた集約スループットを実現できます。
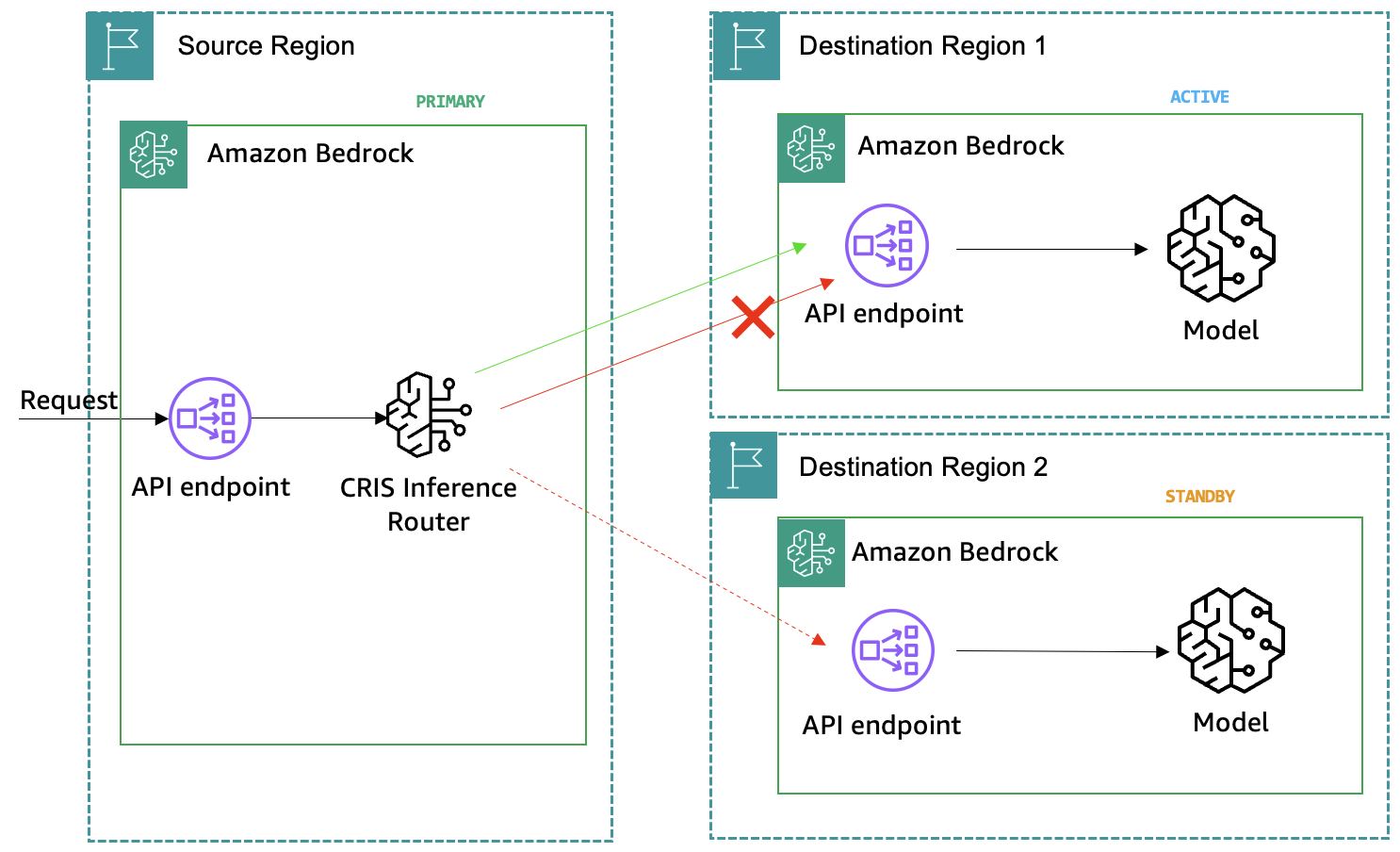
Amazon Bedrock クロスリージョン推論
推論リクエストにおいてより高いレイテンシを許容できる特定のユースケースでは、グローバル・クロスリージョン推論プロファイルを使用するオプションがあります。グローバルプロファイルを使用すると、モデルがグローバル推論のために利用可能な複数の商用リージョン間でリクエストをルーティングできるため、標準的なクロスリージョン推論プロファイルよりもさらに高いスループットを実現できます。
例えば、デモにおいてクロスリージョン推論プロファイルを使用して Amazon Bedrock へ 10 件のリクエストを送信した際、コマンド出力は CRIS がどのようにモデル推論を 3 つの AWS リージョンに自動的に分散させたかを示しています:
Region Invocations Percentage
us-east-1 1 10%
us-east-2 7 70%
us-west-2 2 20%
*Amazon Bedrock のクロスリージョン推論は、10 件のリクエストを 3 つの AWS リージョンに分散します*
パターン 2: 複数の AWS アカウントの使用
CRIS は AWS アカウント内でスループットを増幅しますが、追加のスケーリングと分離戦略からも恩恵を受けることができます。AWS アカウントシャーディングは、それぞれが独立したクォータと CRIS プロファイルを持つ複数の AWS アカウント間にリクエストを分散します。
アカウントシャード化は、あるアカウントでの問題が他のアカウントに影響を与えない自然な障害分離境界を作成するため、ワークロード間の厳格な分離を必要とするマルチチームおよびマルチテナントアーキテクチャにおいて特に価値があります。
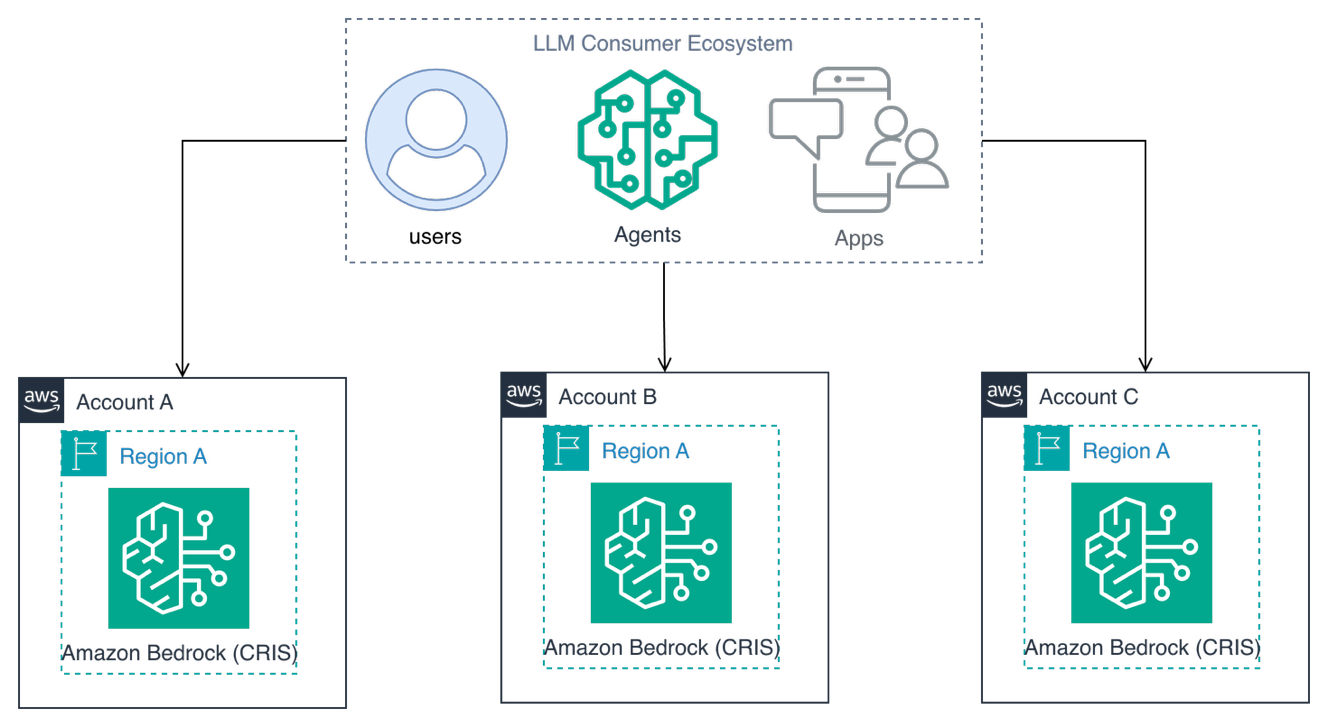
Amazon Bedrock を用いた AWS アカウントシャード化とクロスリージョン推論
アカウントシャード化のデモを実行する際、クロスリージョン推論プロファイルを使用して、設定された 2 つの AWS アカウントそれぞれに 10 件のリクエストを送信します。出力結果は、各アカウントがどのように独立して AWS リージョン間で推論を分散しているかを示しています:
Account 1
Region | Invocations | Percentage
us-east-2 | 7 | 70%
us-west-2 | 3 | 30%
Account 2
Region | Invocations | Percentage
us-east-1 | 2 | 20%
us-east-2 | 3 | 30%
us-west-2 | 5 | 50%
*CRIS を介して、2 つの AWS アカウントが独立してリクエストをリージョン間で分散*
LLM ゲートウェイの活用
複雑な本番環境においては、LLM ゲートウェイは、直接 API 呼び出しを行うだけでは実現できないルーティング、フェイルオーバー、ガバナンス機能を提供します。ゲートウェイはアプリケーションと LLM プロバイダーの間でインテリジェントなプロキシとして機能し、統一された抽象化レイヤーを提供することで、複数のベンダーにまたがる多様なモデルを単一の API インターフェイスを通じてアクセス可能にします。この標準化により統合が簡素化されるだけでなく、責任ある AI 対策、監査ログ、自動リトライおよびフォールバックロジック、クォータ管理などの機能が組み込まれ、個々のモデルが利用できなくなった場合でもアプリケーションのレジリエンスを維持するのに役立ちます。
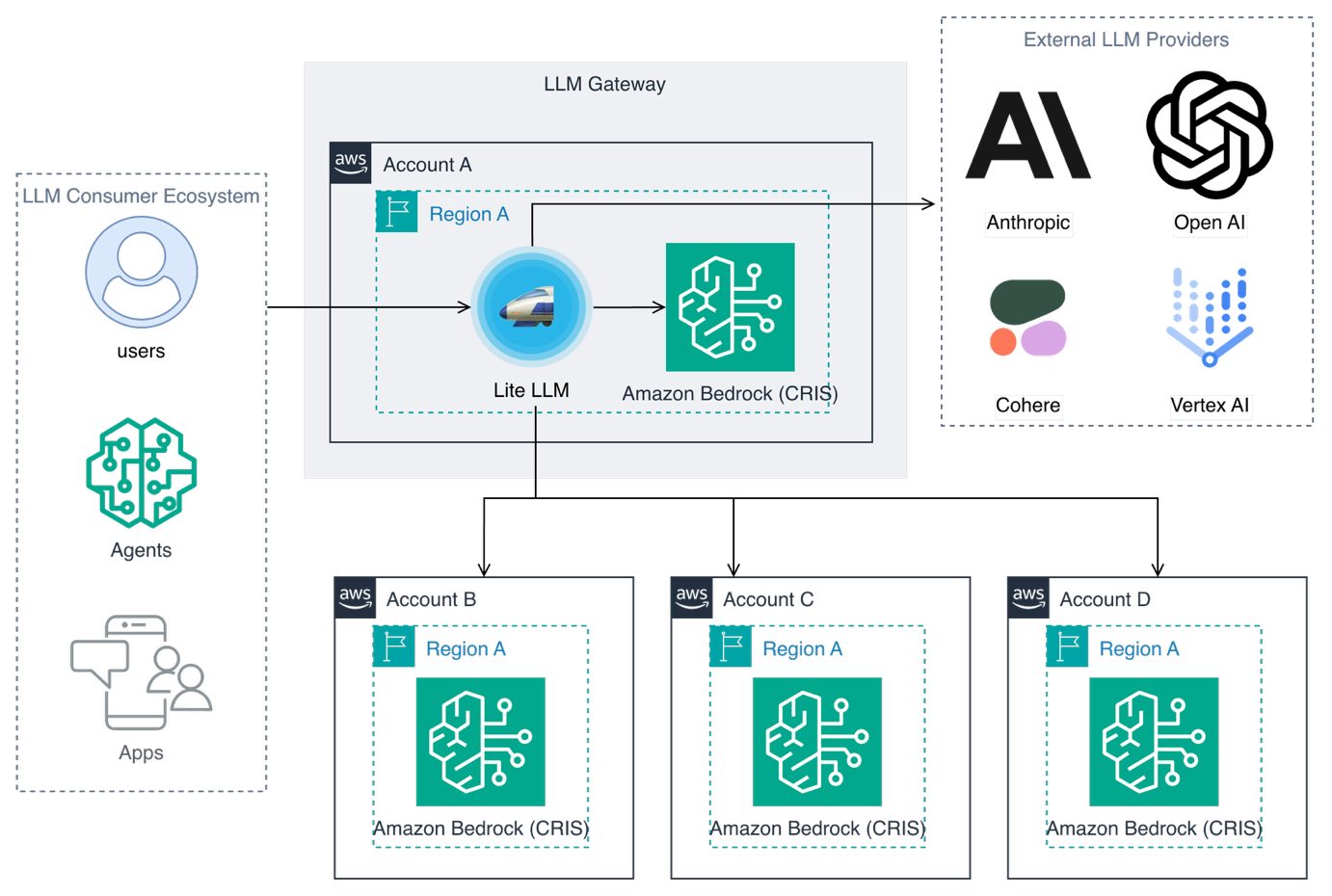
AWS アカウントおよび外部プロバイダーにわたるリクエストをオーケストレーションする LLM ゲートウェイ
ゲートウェイは、複数のモデルやアカウントにまたがるインテリジェントなリクエストルーティングと負荷分散をサポートし、スループットを最大化しながら、レート制限とクォータ管理を実装して各消費者ごとの分離を保証します。これにより、マルチテナント環境における「ノイジー・ネイバー」問題の防止に貢献すると同時に、利用状況分析を通じて包括的なコスト追跡と最適化を実現します。集中型の観測性とモニタリングにより、アプリケーションごとの詳細なインサイトを含む LLM 使用パターンを完全に把握でき、最適化の機会を特定したり、問題を迅速にトラブルシューティングしたりするのに役立ちます。
現在、多くのオープンソースおよび商用の LLM ゲートウェイが存在します。デモでは、これらのパターンを実演するために、ローカルで動作する軽量なオープンソースオプションとして LiteLLM を使用しています。大規模展開を行う場合、AWS のマルチプロバイダー生成 AI ゲートウェイソリューション が参照実装およびアーキテクチャを提供しており、こちらでも LiteLLM を採用しつつ、コンテナ化された Amazon Elastic Container Service (Amazon ECS) または Amazon Elastic Kubernetes Service (Amazon EKS) 上でのデプロイ、自動スケーリング、AWS WAF による保護、シークレット管理、そして Amazon CloudWatch を通じた完全な観測性といった、エンタープライズ向けの機能を追加しています。
パターン 3:モデルフォールバック
モデル間の自動フェイルオーバーは、プライマリモデルがレート制限に達したりサービス障害を経験したりした場合でも、より高い可用性をサポートします。このパターンは、顧客が定義したプライマリモデルとセカンダリモデルの間でリクエストを自動的にルーティングするように設計されています。フォールバック戦略の焦点がクォータ枯渇ではなく品質とコストの最適化にある場合、Amazon Bedrock Intelligent Prompt Routing がネイティブオプションとして提供されます。これは外部ゲートウェイを必要とせず、各リクエストに対して最も適切なモデルを動的に選択します。プライマリモデルへの呼び出しが失敗した場合、ゲートウェイは自動的にセカンダリモデルを使用してリクエストを再試行し、予期せぬトラフィックの急増時でも高い可用性をサポートします。フォールバック戦略には、コスト最適化とパフォーマンスの考慮も組み込まれており、例えば高コストのモデルをスロットリングし、適切な場合によりコスト効果の高い代替手段にフォールバックするなどです。
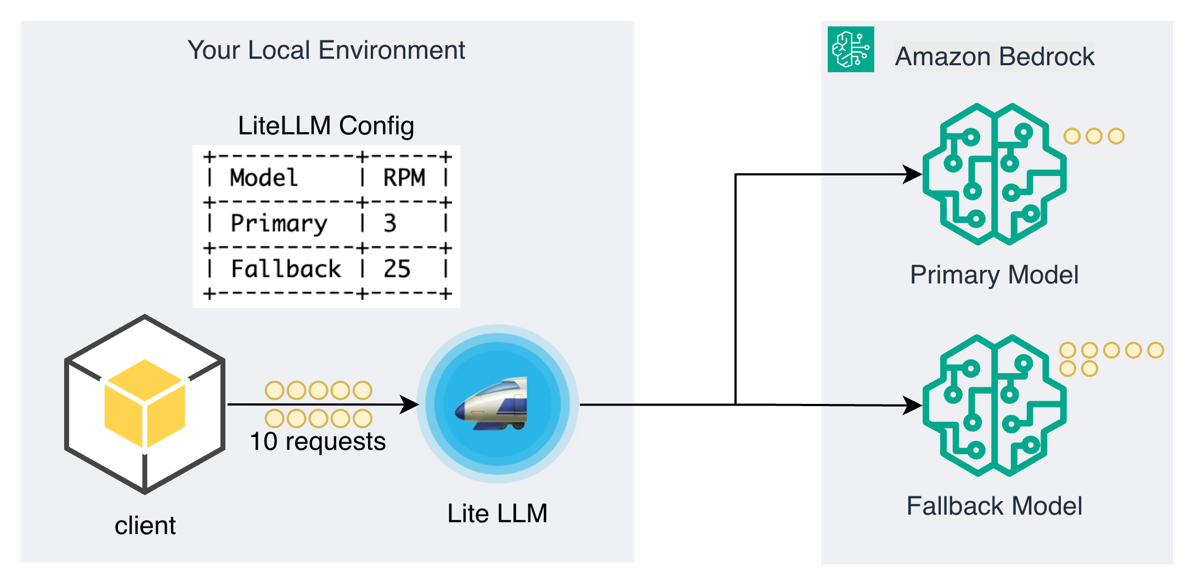
レート制限されたプライマリモデルとより高容量のフォールバックモデルによるフォールバックデモンストレーション
デモにおいて、LiteLLM の設定は、1 分あたり 3 リクエストという制限されたレートリミットを持つプライマリモデルと、25 RPM というより高い容量を持つフォールバックモデルを定義しています。クライアントがゲートウェイを通じて 10 の並列リクエストを送信すると、最初の 3 つのリクエストは Amazon Bedrock のプライマリモデルにルーティングされます。プライマリモデルがレートリミットに達すると、LiteLLM は自動的に残りの 7 リクエストをフォールバックモデルへ振り分けます。これにより、10 のリクエストすべてが手動介入やアプリケーションレベルの再試行ロジックなしで正常に完了します。
デモ出力はこのパターンの有効性を確認しており、プライマリモデルのレートリミットにもかかわらず 10 リクエストがすべて正常に完了したことで高い信頼性が示されています。分布状況を見ると、プライマリモデルがクォータに達する前に正確に 3 リストを処理し、残りの 7 リクエストはフォールバックモデルへフェイルオーバーしました。これは、ゲートウェイがインテリジェントなルーティングを通じてサービスの可用性を維持できる能力を示しています。
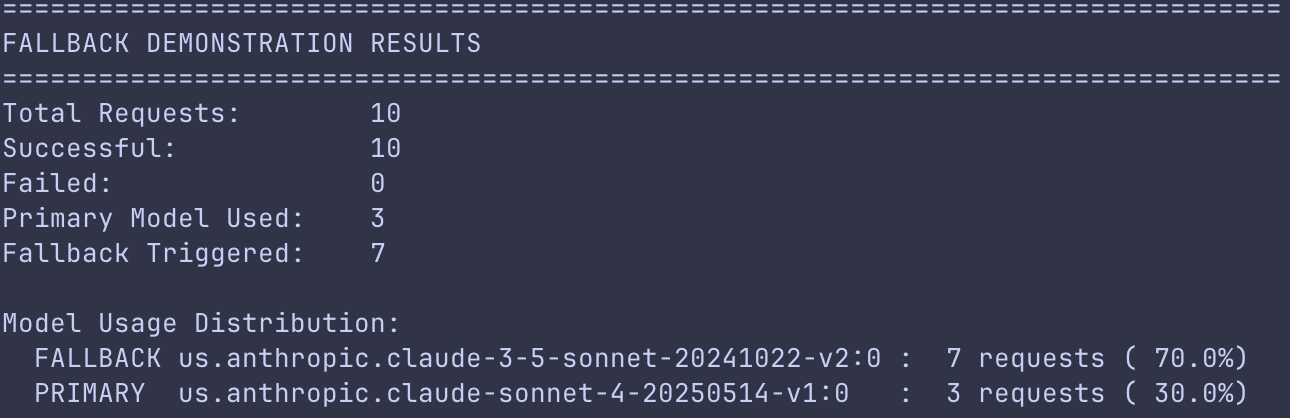
モデル分布を示すフォールバックデモ出力
パターン4:モデル間での負荷分散
負荷分散パターンは、リクエストを複数のモデルインスタンスに分散させることで、リソースの利用率を最適化し、ボトルネックを防ぐ役割を果たします。このアプローチは単に利用率を最大化するだけでなく、必要に応じてモデルインスタンスを追加または削除することで迅速なスケーリングも可能にします。例えば、本番展開前に新しいモデルを評価する際にも、重み付きルーティングやA/Bテスト戦略を実装して、リクエストのほんの一部だけを新しいモデルに割り当て、残りの大部分は実績のあるモデルで処理させることができます。
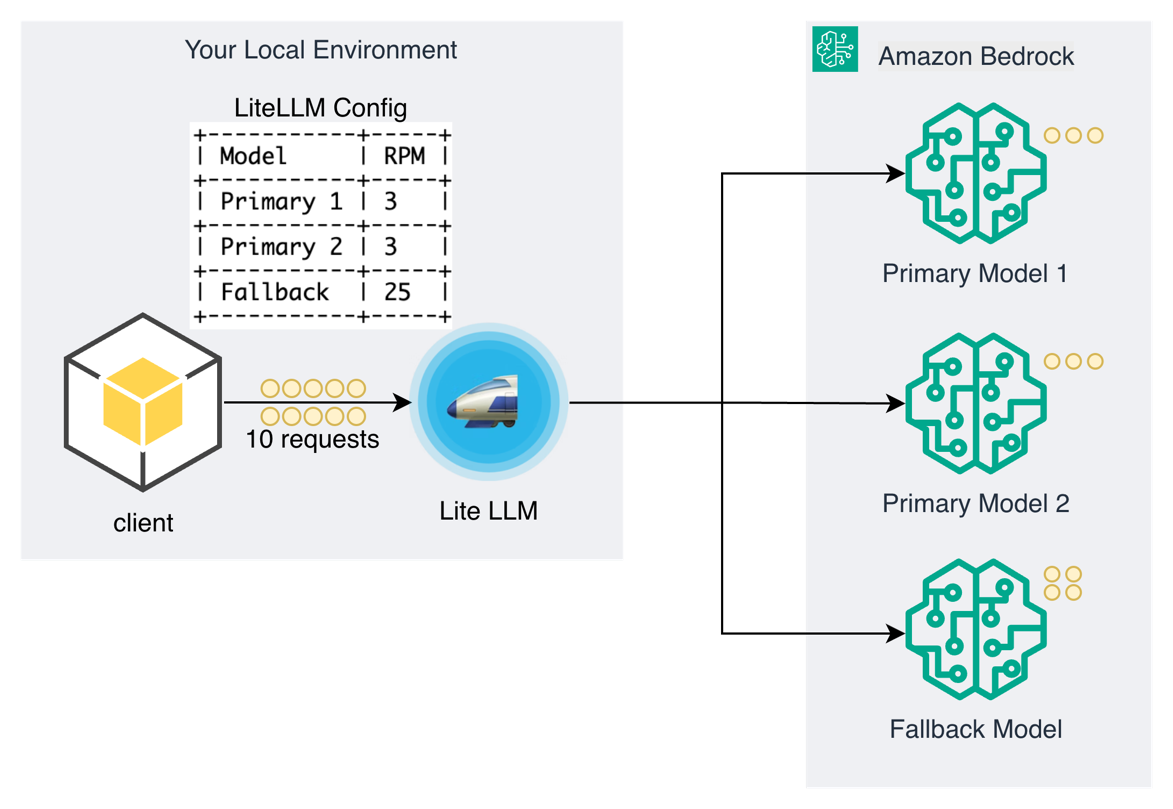
プライマリモデル間での負荷分散とフォールバックオーバーフロー
当社の負荷分散デモでは、ゲートウェイがシャッフル戦略を使用して、2つのモデル間で10の並行リクエストを正常に分散しました。ロードバランサーは最初に設定された2つのプライマリモデルそれぞれに3件のリクエストをルーティングし、レート制限に達すると残りの4件を自動的にフォールバックモデルへ転送します。その結果、成功率は100%となり、負荷分散がフォールバック戦略とどのように連携して機能するかを示しています。
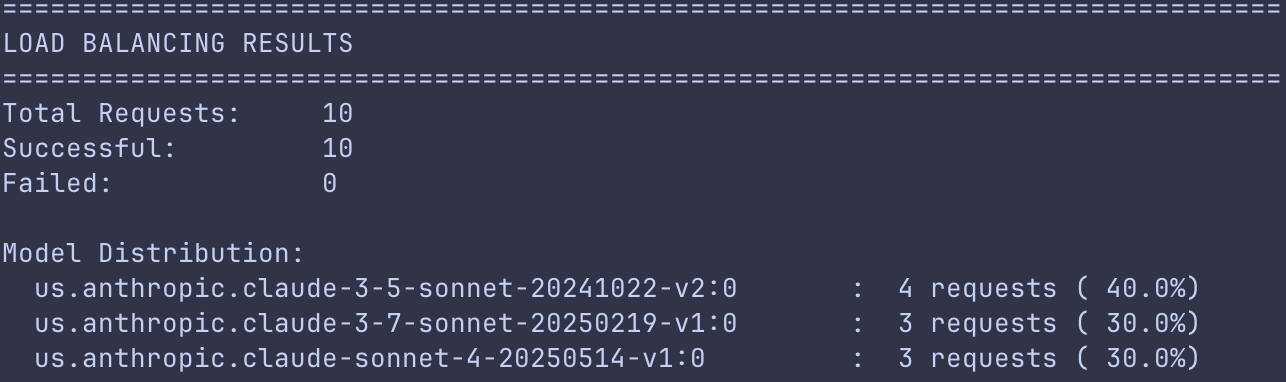
負荷分散デモの出力
パターン 5:マルチテナントクォータ分離
マルチテナントクォータ分離パターンは、リクエストを管理するために独自のクォータとレート制限(rate limits)を備えた論理的に隔離された環境を作成します。各消費者に対して独立したレート制限バケットを実装することで、ある消費者からのリクエストが他の消費者のパフォーマンスに悪影響を与える「ノイジーネイバー」課題を防ぐのに役立ちます。各テナントは、他のテナントの使用パターンに関わらず専用クォータを受け取り、公平なリソース割り当てを支援し、消費者間の一貫したサービス品質を維持します。
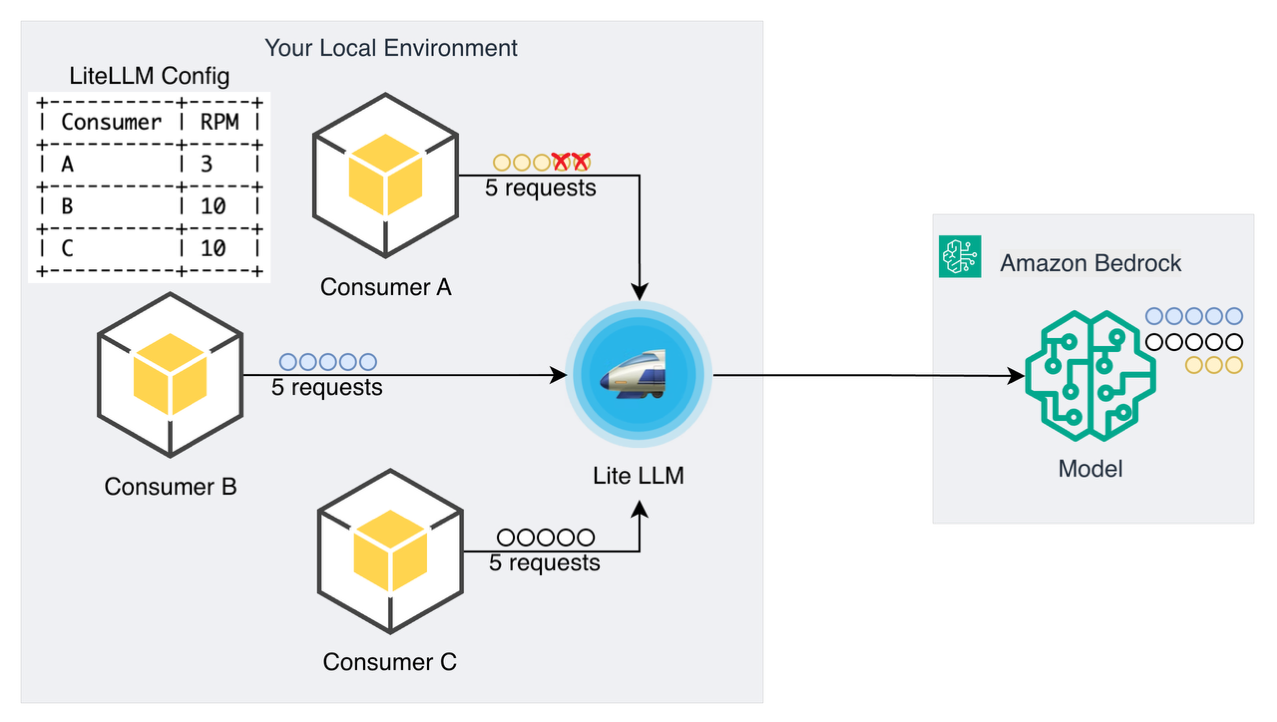
各消費者ごとの独立したレート制限を備えたマルチテナントクォータ分離
このパターンは、複数のアプリケーションがモデルリソースを共有しながらも、予測可能なパフォーマンスと隔離の信頼性を必要とする環境において理想的です。
原文を表示
Implementing resilience patterns for large language model (LLM) inference is critical as generative AI workloads move from experimentation to production at scale. With LLM powered apps now in production, organizations need ways to keep LLM inference highly available, responsive, and cost-effective at scale. Existing resilience best practices like static stability and implementing backoffs and retries still apply. However, generative AI introduces new considerations including model availability, rapidly changing quotas, token limits across multiple providers, and maintaining consistency with newly released models. Amazon Bedrock provides fully managed foundation models with built-in resilience features like cross-Region inference.
When designing inference for production, four dimensions typically guide architectural decisions: availability, response time, cost, and throughput. Availability refers to sustaining inference during model, Region, or provider disruptions. Response time covers how quickly the user receives output, often measured as Time to First Token (TTFT) and Time to Last Token (TTLT). Cost captures per-token and per-request spend and how routing decisions affect it. Throughput reflects how many concurrent requests and tokens per second the system can sustain under load.
These dimensions are interconnected. For example, cross-Region routing improves availability and throughput but may increase response time. The patterns in this post focus primarily on availability: keeping inference operational through failover, geographic distribution, and quota isolation. Future posts will explore response time optimization and cost-aware routing in depth.
In this post, you will learn five practical patterns for building resilient generative AI applications on AWS, progressing from native Amazon Bedrock features to multi-model orchestration using an LLM gateway. These patterns address real-world challenges such as quota exhaustion during unexpected traffic surges, maximizing availability through geographic distribution of inference, and helping prevent noisy neighbor problems in multi-tenant environments. They also support cost optimization through intelligent request routing and give you the flexibility to use multiple models and providers based on your specific requirements.
This crawl, walk, run approach lets you adopt the patterns incrementally based on your application’s maturity and requirements. The accompanying GitHub repository provides code samples demonstrating each pattern.
An incremental approach to inference resilience patterns
You can test out each of the following patterns in your own environment by using the code samples and instructions from this section of the GitHub repository.
Prerequisites
Before starting with the demo, verify that you have the appropriate software installed and your AWS account configured correctly by completing the prerequisites.
Note: Following the patterns in this post will create and use AWS resources that incur charges, including Amazon Bedrock inference requests and Amazon CloudWatch logs. See the Cleanup section to avoid ongoing charges after testing.
Pattern 1: Using Amazon Bedrock cross-Region inference
Amazon Bedrock cross-Region inference (CRIS) is a native feature that provides the foundation for resilient inference by default. You can use cross-Region inference profiles to improve throughput, reduce the likelihood of being throttled within an AWS Region, and distribute model traffic. CRIS removes the manual effort of managing traffic distribution and improves the availability of your application. It automatically routes requests from your source Region to the optimal destination Region based on real-time factors including availability, latency, and current demand. This accounts for unexpected bursts in traffic during peak usage times and reduces the likelihood of service quotas impacting inference.
CRIS profiles are typically tied to commercial Regions within a specific geography like the US or EU, providing the right balance of performance and latency for inference requests. This approach increases aggregate throughput beyond single-Region quotas while maintaining data residency within geographic boundaries.
Amazon Bedrock cross-Region inference
For certain use cases that can handle higher latency in inference requests, there is the option to use Global Cross-Region Inference profiles. With a Global profile, requests can be routed across multiple commercial Regions where the model is available for global inference, providing an even greater throughput than with standard cross-Region inference profiles.
For example, in our demo when sending 10 requests to Amazon Bedrock using a cross-Region inference profile, the command output shows how CRIS automatically distributed the model inference across 3 AWS Regions:
Region
Invocations
Percentage
us-east-1
1
10%
us-east-2
7
70%
us-west-2
2
20%
*Amazon Bedrock cross-Region inference distributes 10 requests across three AWS Regions*
Pattern 2: Using multiple AWS accounts
While CRIS multiplies throughput within an AWS account, you can benefit from additional scale and isolation strategies. AWS account sharding distributes requests across multiple AWS accounts, each with independent quotas and CRIS profiles.
Account sharding creates natural fault isolation boundaries where issues in one account do not affect others, making it particularly valuable for multi-team and multi-tenant architectures requiring strict isolation between workloads.
AWS account sharding with Amazon Bedrock cross-Region inference
When running the account sharding demo, we send 10 requests to each of the two configured AWS accounts using cross-Region inference profiles. The output shows how each account independently distributes inference across AWS Regions:
Account 1
Region
Invocations
Percentage
us-east-2
7
70%
us-west-2
3
30%
Account 2
Region
Invocations
Percentage
us-east-1
2
20%
us-east-2
3
30%
us-west-2
5
50%
*Two AWS accounts independently distributing requests across Regions via CRIS*
Using an LLM gateway
For complex production scenarios, an LLM gateway provides routing, failover, and governance capabilities beyond what is possible with direct API calls. A gateway acts as an intelligent proxy between your applications and LLM providers, offering a unified abstraction layer, so you can access multiple models across various vendors through a single API interface. This standardization simplifies integration while embedding capabilities such as responsible AI safeguards, audit logging, automatic retry and fallback logic, and quota management, among many other features, helping your applications remain resilient even when individual models become unavailable.
LLM gateway orchestrating requests across AWS accounts and external providers
The gateway supports intelligent request routing and load balancing across multiple models and accounts, maximizing throughput while implementing rate limiting and quota management with per-consumer isolation. This helps prevent noisy neighbor problems in multi-tenant environments while providing comprehensive cost tracking and optimization through usage analytics. Centralized observability and monitoring give you full visibility into your LLM usage patterns with granular per-application insights, helping identify optimization opportunities and troubleshoot issues quickly.
Many open source and commercial LLM gateways are available today. For our demos, we use LiteLLM as a lightweight, open source option running locally to demonstrate these patterns. When deploying at scale, the AWS Solution for Multi-Provider Generative AI Gateway provides a reference implementation and architecture that also uses LiteLLM but adds enterprise capabilities including containerized deployment on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS), automatic scaling, AWS WAF protection, secrets management, and full observability through Amazon CloudWatch.
Pattern 3: Model fallback
Automatic failover between models supports higher availability even when primary models hit rate limits or experience service disruptions. This pattern is designed to automatically route requests between customer-defined primary and secondary models. If your fallback strategy focuses on optimizing quality and cost rather than quota exhaustion, Amazon Bedrock Intelligent Prompt Routing provides a native option. It dynamically selects the most appropriate model for each request without requiring an external gateway. If calls to the primary models fail, the gateway automatically retries requests using secondary models, supporting high availability even during unexpected spikes in traffic. The fallback strategy also incorporates cost optimization and performance considerations, for example, throttling higher-cost models and falling back to more cost-effective alternatives when appropriate.
Fallback demonstration with rate-limited primary and higher-capacity fallback models
In our demonstration, the LiteLLM configuration defines a primary model with a restrictive rate limit of 3 requests per minute (RPM) and a fallback model with a higher capacity of 25 RPM. When the client sends 10 concurrent requests through the gateway, the first three requests route to the primary model in Amazon Bedrock. As the primary model reaches its rate limit, LiteLLM automatically diverts the remaining seven requests to the fallback model. The 10 requests complete successfully without manual intervention or application-level retry logic.
The demo output confirms the effectiveness of this pattern, showing high reliability with the 10 requests completing successfully despite the primary model’s rate limit. The distribution reveals that exactly 3 requests were handled by the primary model before reaching its quota. The remaining 7 requests failed over to the fallback model, demonstrating the gateway’s ability to maintain service availability through intelligent routing.
Fallback demo output showing model distribution
Pattern 4: Load balancing across models
The load balancing pattern distributes requests across multiple model instances to optimize resource utilization and helps prevent bottlenecks. This approach not only maximizes utilization but also allows you to quickly scale by adding or removing model instances as needed. For example, when evaluating new models before full deployment, you can implement weighted routing or A/B testing strategies to direct only a small percentage of requests to the new model while the majority continue to use proven models.
Load balancing across primary models with fallback overflow
In our load balancing demo, the gateway successfully distributes 10 concurrent requests across two models using a shuffle strategy. The load balancer initially routes 3 requests to each of the two configured primary models, and when it reaches its rate limit, the remaining 4 requests are automatically redirected to the fallback model. The result is a 100% success rate, demonstrating how load balancing works together with the fallback strategy.
Load balancing demo output
Pattern 5: Multi-tenant quota isolation
The multi-tenant quota isolation pattern creates logically isolated environments equipped with their own quotas and rate limits to manage requests in multi-tenant environments. By implementing independent rate limiting buckets for each consumer, this pattern helps prevent “noisy neighbor” challenges where requests from one consumer negatively impact other consumers’ performance. Each tenant receives a dedicated quota regardless of other tenants’ usage patterns, supporting fair resource allocation and maintaining consistent service quality across consumers.
Multi-tenant quota isolation with independent rate limits per consumer
The pattern is ideal for environments where multiple applications share model resources while requiring predictable performance and isolation confidence.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み