知っておくべきこと:マスク言語モデルは驚くほど優れたゼロショット学習者である
Answer.AI は、従来のタスク固有ヘッドを廃し、事前学習時のマスク言語モデリング(MLM)ヘッド自体でゼロショット分類や推論を行う「ModernBERT-Large-Instruct」を発表し、小規模モデルでも大規模モデルに匹敵する性能を示した。
キーポイント
MLM ヘッドの活用によるパラダイムシフト
従来のエンコーダーモデル(BERT など)がタスク固有ヘッドを必要とする慣習に対し、事前学習で使われた MLM ヘッド自体を推論に転用する手法を実証した。
小規模モデルでの大規模モデル凌駕
MMLU-Pro ベンチマークにおいて、10 億パラメータ未満の Qwen2.5 や SmolLM2 を上回り、Llama3-1B に迫る性能を達成した。
アーキテクチャ変更なしの実装
複雑なパイプラインや独自の注意機構(attention mask)の追加を必要とせず、既存の AutoModelForMaskedLM でそのまま動作するシンプルさを維持している。
従来のエンコーダーモデルの課題
タスク固有のヘッドを使用する従来のアプローチでは、元の事前学習ヘッド(MLM ヘッド)が廃棄され、ゼロショット能力に制限がかかる。
既存手法の限界とLLMとの比較
既存のゼロショット分類手法は複雑さや言語化語への脆さといった欠点があり、一方、デコーダー型LLM は計算コストが高く小規模モデルではエンコーダーに劣る。
ModernBERT-Large-Instruct の登場
本記事は、これらの課題を解決し、効率的なゼロショット学習を実現する新しいモデル「ModernBERT-Large-Instruct」を紹介している。
単一トークン回答によるゼロショット学習
モデルに質問と選択肢を与え、最終トークンとして単一のトークン(アーカー記号でプレフィックス)を予測させることで、複雑なアーキテクチャ変更なしに NLU タスクを実行可能にする。
重要な引用
Functionally, this means that we discard all the language modelling goodness stored in the Masked Language Modelling head... and seek to simply re-use the backbone
On the MMLU-Pro leaderboard, it outperforms all sub-1B models like Qwen2.5-0.5B and SmolLM2-360M
Unlike previous approaches, our method requires no architectural changes nor complex pieplines
the MLM head, its original pre-training head, is fully discarded
small LLMs are routinely outperformed by encoders, which can even match the larger ones once fine-tuned!
"All tasks are formatted in a way where the model can answer with a single token, which is also the final token of the input."
影響分析・編集コメントを表示
影響分析
この発表は、Transformer エンコーダーモデルの活用方法における根本的な見直しを促すものであり、推論コストを抑えつつ高性能な NLU タスクを実現する新しい標準となり得る。特にリソース制約のある環境や、大規模言語モデル(LLM)ほどではないが従来の BERT よりも高度な推論能力が必要なケースにおいて、実用的な代替案として注目されるだろう。
編集コメント
「エンコーダーは推論が苦手」という定説を覆す結果であり、小規模モデルのポテンシャルを引き出す新たなトレーニング手法として非常に注目すべき一報です。実装の簡便さも相まって、すぐにでもプロトタイプ開発に応用できる可能性があります。
この投稿へようこそ!「TIL」として、これは意図的に小さくまとめられたブログ記事であり、重要な詳細のみを含んでいます。さらに詳しく知りたい場合は、技術レポートをご覧くださいか、HuggingFace でモデルを遊んでみてください!
TL;DR
従来(もちろん例外はありますが)、BERT などのエンコーダーモデルは、コアとなるエンコーダーモデルの上にタスク固有のヘッドを搭載して使用されてきました。機能的には、これは事前学習時に使用されるマスク言語モデリングヘッド(MLM ヘッド)に蓄積された言語モデリングの良さをすべて捨てて、バックボーンを再利用してさまざまなタスクを実行しようとすることを意味します。
このアプローチは非常にうまく機能しています:これが支配的なパラダイムとなっている理由があります!しかし、もし生成ヘッド自体がゼロショットでもほとんどのタスクを実行できるのであればどうでしょうか?私たちが試したのはまさにこれであり、かなり良い結果が出ました!私たちは「ModernBERT-Large-Instruct」を導入しました。これは ModernBERT-Large をベースに、驚くほどシンプルなメカニズムでインストラクションチューニングされたエンコーダーです。このモデルは、タスク固有のヘッドの代わりに ModernBERT の MLM ヘッドを使用して、分類や多肢選択タスクを実行することができます。以前の手法とは異なり、私たちの方法ではアーキテクチャの変更も複雑なパイプラインも必要とせず、さまざまなタスクで強力な結果を達成しています。
知識 QA タスクにおいて、エンコーダーが通常苦手とする分野で驚くほど高い能力を発揮します:MMLU-Pro リーダーボードでは、Qwen2.5-0.5B や SmolLM2-360M といった 10 億パラメータ未満のすべてのモデルを上回り、Llama3-1B(はるかに多くのトークンでトレーニングされ、かつパラメータ数が 3 倍)にも非常に近い性能を達成しています!
NLU タスクでは、ModernBERT-Instruct を同じデータセットでファインチューニングした場合、従来の分類ヘッドと同等かそれ以上の性能を発揮します。
これらの結果は、非常にシンプルでエキサイティングなトレーニングレシピによって達成されました。今後さらに改善の余地が十分にあります👀👀
私もぜひ試してみたいです!
このモデルは HuggingFace で ModernBERT-Large-Instruct として利用可能です。カスタムアテンションマスクやそれに類するものを必要としないため、ゼロショットパイプラインの設定と使用は非常に簡単です:
ModernBERT-Large-Instruct の使い方を見るにはこちらをクリック -->
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
モデルとトークナイザーの読み込み
model_name = "answerdotai/ModernBERT-Large-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
model = AutoModelForMaskedLM.from_pretrained(model_name, attn_implementation="flash_attention_2")
else:
model = AutoModelForMaskedLM.from_pretrained(model_name)
model.to(device)
分類または多肢選択のための入力を整形します。これは MMLU からランダムに選ばれた例です。
text = """あなたは質問と選択肢を与えられます。正しい答えを選択してください。
QUESTION: (G, .) が群であり、すべての a, b ∈ G に対して (ab)^-1 = a^-1b^-1 が成り立つとき、G は次のどれか
CHOICES:
- A: 可換半群 (commutative semi group)
- B: アベル群 (abelian group)
- C: 非アベル群 (non-abelian group)
- D: これらのいずれでもない
ANSWER: [unused0] [MASK]"""
予測を取得する
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model(**inputs)
mask_idx = (inputs.input_ids == tokenizer.mask_token_id).nonzero()[0, 1]
pred_id = outputs.logits[0, mask_idx].argmax()
answer = tokenizer.decode(pred_id)
print(f"Predicted answer: {answer}") # 出力結果:B
さらに詳しく知りたい場合は、モデルのファインチューニング方法に関する例が掲載されている当社のミニクックブック GitHub リポジトリをご覧ください!
-->
導入
エンコーダーモデルは従来、タスク固有のヘッドを備えたすべてのタスクで最も高い性能を発揮してきました。必ずしも問題ではないものの、これは少し無駄に感じられます:MLM ヘッド(その元の事前学習時のヘッド)が完全に捨て去られてしまうからです。実際にはこのアプローチは機能しますが、何か見落としているような気もします。さらに、これによりゼロショット能力に対して大きな制限が生じます:タスク固有のヘッドが通常必要とされるため、これを回避して良好なゼロショット性能を得るためにさまざまな工夫が必要となってきました。
MLM エンコーダーの下流利用における簡略化された不完全な歴史
エンコーダーモデルを用いたゼロショット分類は長年にわたり様々なアプローチが試されてきた活発な研究分野です。最も一般的な手法は、テキストの包含関係(entailment)を流用するもので、MNLI などのタスクで学習させた後、与えられたラベルが入力テキストによって論理的に導かれるか(entailed か)を予測します。tasksource/ModernBERT-large-nli といった大規模な TaskSource データセット上で訓練された非常に強力なモデルも存在します。
これは生成型 BERT をマルチタスク学習者として探求した最初の研究ではありません:プロンプト手法や、パターン利用トレーニング(PET)法によるサンプル効率的な学習、あるいはモデルを自己回帰的にする試みなど、いくつかの先行研究があります。また、UniMC のように、意味的に中立な語彙化子(verbalizers)(例えば「A」「B」などの意味のある単語ではないもの)を用いてタスクを多肢選択形式に変換し、カスタムアテンションマスクを採用する手法など、 ours と非常に類似したアプローチも存在します。
しかし、これらのすべての方法には欠点があります。一部の手法は脆く(特に語彙化子の違いに敏感)、あるいは有望ではあるがまだ完全ではない性能しか達成できません。一方、他の手法は非常に良い結果を達成する一方で、大幅な複雑さを付加しています。その一方で、デコーダーの世界(あるいはお望みなら LLM トピア)では、インストラクションチューニングが極めて急速に進化しており、大規模で恐ろしいとされる大規模言語モデル(LLM)は、インストラクション学習のおかげで生成型分類、特にゼロショットにおいて非常に優れた能力を発揮するようになっています。
しかし、これにも欠点があります:小規模な大規模言語モデル(LLM)は、エンコーダーに通常より劣っており、微調整を施せば大型モデルと同等の性能を発揮することさえあります。さらに、 autoregressive 型の LLM を実行する計算コストは、小規模なモデルであっても、単一の順方向パスでタスクを実行するエンコーダーと比較して一般的に大幅に大きくなります。
ModernBERT-Large-Instruct
私たちのアプローチは、おそらく、あるいはたまたま、両方の利益を得られるかもしれないことを示すものです:もし MLM が、パイプラインやアーキテクチャの複雑さを追加することなく、単一の順方向パスで生成方式によりタスク(ゼロショットのものさえも!)を処理でき、さらに容易に微調整してドメイン内での性能を向上させることができるならどうでしょうか?
これがここで示す可能性です!私たちは非常にシンプルなトレーニングレシピを使用します。ModernBERT の MLM ヘッドを用いた FLAN スタイルの指示微調整です。カスタムアテンションマスクは使用せず、複雑なプロンプトエンジニアリングも、重厚なデータ前処理パイプラインもありません:単に FLAN から単一トークンで回答可能なタスクのみをフィルタリングし、下流評価に使用するデータセットの一部の例を除外するだけです。
仕組みについて
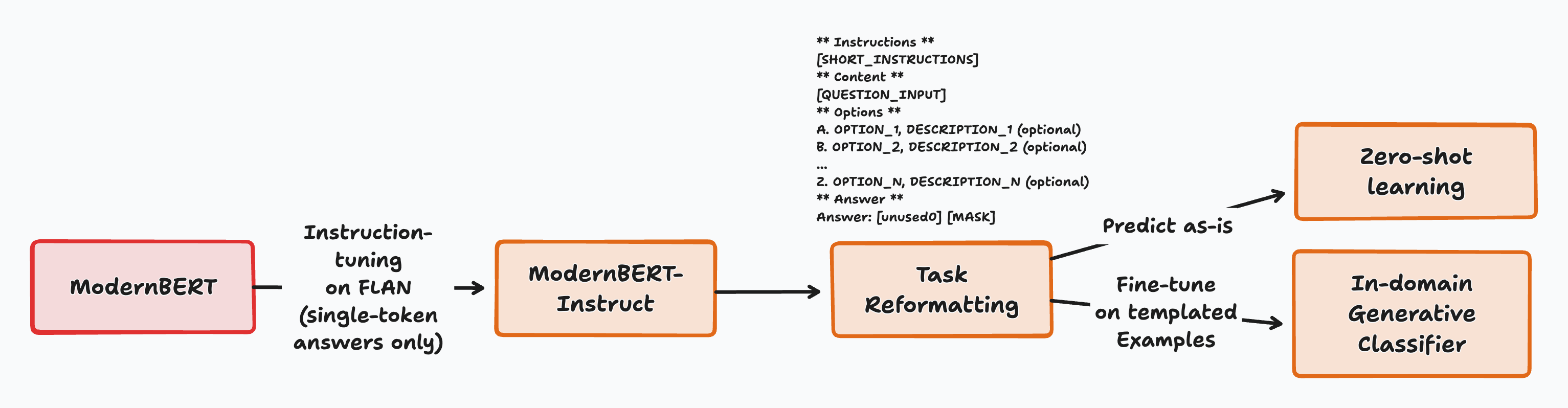
全体プロセスの高レベルな概要
私たちの核心的な洞察は二重です:ModernBERT は単一のヘッドで、ゼロショットまたは完全微調整のいずれにおいても、ほとんどの自然言語理解(NLU)タスクを実行でき、この挙動は極めてシンプルなトレーニングレシピによって解放され、非常に強い可能性を示唆しています。
仕組みは非常にシンプルです:
すべてのタスクは、モデルが単一のトークンで回答できる形式に整形されます。この単一トークンは入力における最終トークンでもあります。これは常にアンカートークン([unused0])で前置され、次のトークンが単一のトークンによる回答であることをモデルに伝えます。
モデルには質問、短い指示、および候補となる選択肢のリストが与えられます。すべての選択肢は、単一トークンの語彙化子(verbalizer)で前置されます。これは、モデルがこのラベルを割り当てた場合に予測するトークンです。
その後、モデルは回答として最も可能性の高いトークンを予測し、スコアが最も高い候補となる語彙化子が回答として選択されます。
このアプローチにはいくつかの利点があります:
- 学習または推論のためにアーキテクチャの変更は不要です。
- マスク言語モデリング(Masked Language Modeling)をサポートするあらゆるモデルで、そのまま試すことができます。
- 実験を開始するために必要なデータの前処理は非常に少なくて済みます。
- 同様に、プロンプトエンジニアリングを大幅に削減します: タスクを実行するには、非常に短いテンプレートとすべてのラベルの説明を書くだけで十分です。
トレーニングの詳細
前述の通り、トレーニングレシピは意図的にシンプルに保たれています。これは主にスコープクリープ(scope creep)を防ぐためです。より優れた処理パイプラインや、より現代的な指示セットを使用することで多くの潜在的な改善点を探求できますが、これらすべてを単一トークンタスクに変換するには複雑なプロセスが必要となります。
データ:単一トークンの回答のみを保持するために、20M サンプルにダウンサンプリングされ、フィルタリングされた FLAN-2022 データセット。非常にシンプルなフィルタリングプロセスは、潜在的な回答をトークン化し、回答が 1 つ以上のトークンを含む例をすべて除外することです。評価データセットからの例も、過学習を防ぐために除外されました。
目的:私たちは、答えを含む語彙表(verbalizer)であるべき単一のマスクされたトークンを予測する Answer Token Prediction (ATP) 目的を使用します。最終的なトレーニング目的は、80% の ATP と 20% のダミー MLM 例の混合であり、ここでマスクされたトークンには無意味なラベルが与えられます(後述)。
ベースモデル:LightOn 社やその他のパートナーと共に最近紹介した ModernBERT-Large (395M パラメータ) です。これは、他の代替案よりもはるかに能力の高いベースモデルであることが証明されました。
ダミー例
モデルのトレーニング時に、Answer Token Prediction は壊滅的な忘却(catastrophic forgetting)を引き起こし、モデルが特定のトークンの予測のみを学習して全体的な推論能力を失う可能性があると考えました。これを防ぐために、トレーニング目的の混合を導入しました。具体的には、20% の例に通常の MLM 目的(テキスト内の 30% のトークンをランダムにマスクし、モデルがそれらすべてを同時に予測する)を割り当て、残りの 80% に Answer Token Prediction 目的を採用します。
ただし、私たちはこれを誤って実装してしまい、結果的にこれらのサンプルを空の例として扱い、「ダミー MLM 例」と呼ぶことになりました。問題はラベリングにあり、[MASK] トークンに適切なラベルが割り当てられるべきところを、すべて [MASK] をそのラベルとして与えてしまったのです。これにより、テキスト内に複数の [MASK] トークンが存在する場合、モデルはすぐにそれらすべてに対して [MASK] を予測するよう学習し、これらの例における損失は瞬く間にほぼゼロまで低下しました。
ふむ、単純なミスで、簡単に修正できるはずです、对吧?その通りです。ただし、私たちは予期せぬ現象を観察しました:3 つの事前トレーニング設定(100% ATP、80%ATP/20%MLM、80%ATP/20%dummy)を評価したところ、ダミー例バリアントが最も優れたパフォーマンスを示し、その差は明確でした!この現象について十分に深く探求して説明できる段階には至っていませんが、私の個人的な理論では、これはドロップアウト(dropout)に似た正則化の一種として機能していると考えられます。
性能
ゼロショット結果
ゼロショットの結果は非常に励みになり、ある意味で驚くべきものです!
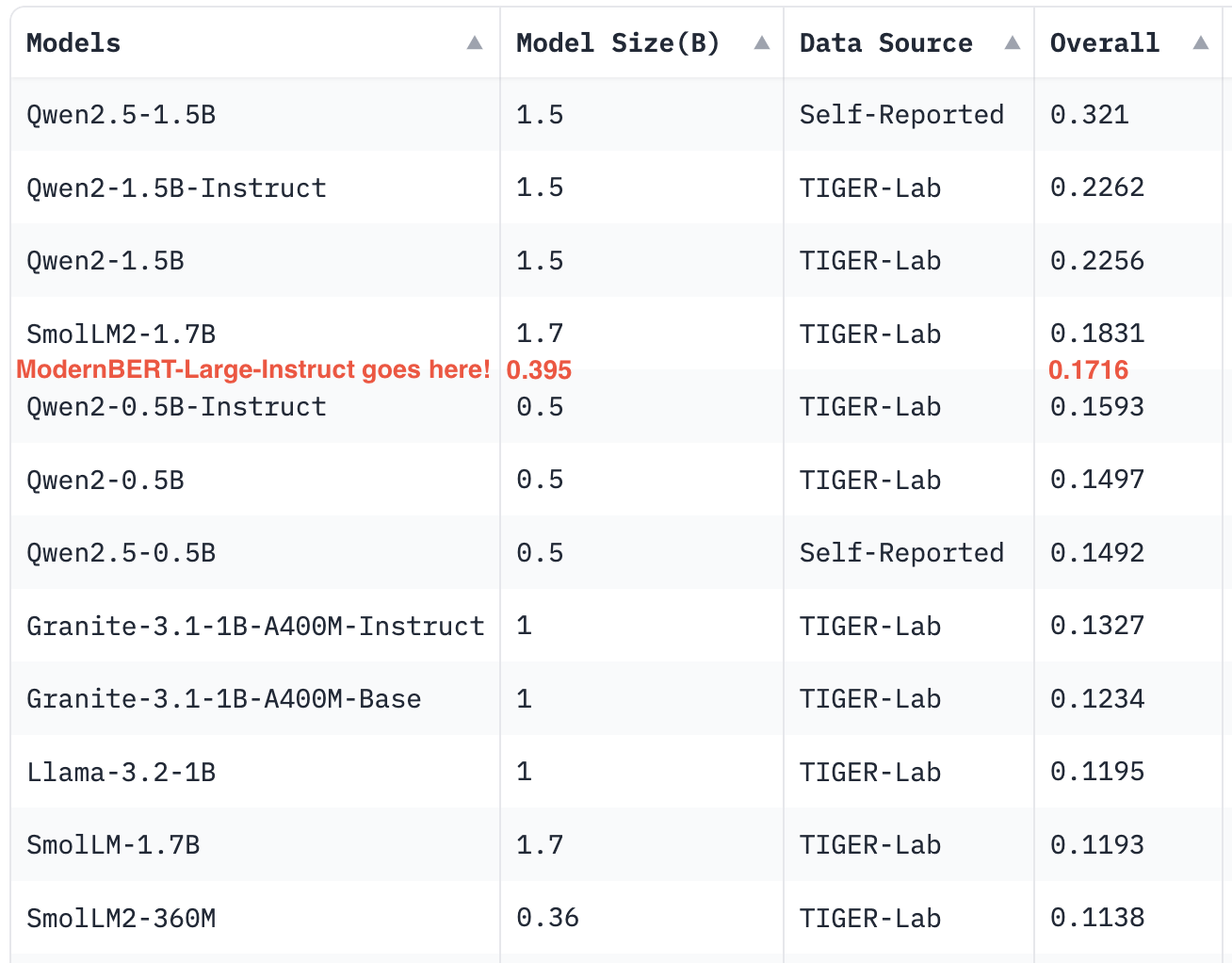
最良のものとの競合(2B 未満のモデル向け MMLU-Pro リーダーボード)
知識ベースの多肢選択問題 (MMLU および MMLU-Pro): ModernBERT-Large-Instruct は MMLU で 43.06% の精度を記録し、同サイズのモデルである SmoLLM2-360M(35.8%) を上回り、Llama3-1B(45.83%) に迫る結果となりました。MMLU-Pro では、そのパフォーマンスがリーダーボード上で非常に高い位置を占めるものであり、自身のサイズクラスをはるかに超える活躍を見せ、より大きな大規模言語モデル (LLM) と競合するレベルです。
分類タスク: 平均的には、この手法はすべての既存のゼロショット手法を上回ります。ただし、データセットごとの詳細で見ると必ずしもそうではありません。この方法には強い可能性があり全体的に非常に良い結果を出していますが、一部のデータセットでは性能が低下し、他のデータセットでは過剰な評価を示すケースもあります。これは、今後の手法開発において大きなポテンシャルがあることを示唆しています。
ファインチューニング後の結果
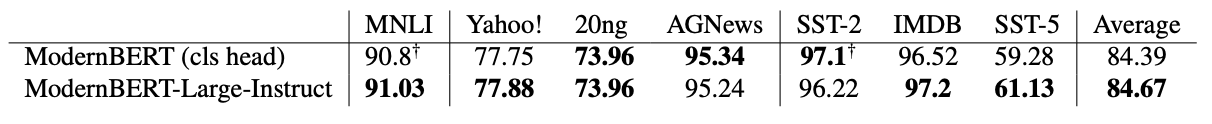
MLM ヘッドだけで十分である
トピック分類、テキストの含意 (MNLI)、感情分析など多様なタスクにおいて、各タスクに対して ModernBERT-Large-Instruct をファインチューニングすることは、従来の分類ヘッドベースのアプローチと同等のパフォーマンスを発揮することが確認されました。特定のデータセットでは、むしろそれらを上回る結果も得られています。実際、この方法こそが最後のギャップを埋め、DeBERTaV3 よりも優れた分類器として ModernBERT を実現するための鍵であると私は考えています。
ここで注意すべき点は、これらのタスクの一部のトレーニングセットが、私たちの事前学習ミックスの中に比較的小さな割合ではあるが存在していることです。しかし、複数のエポックにわたってファインチューニングを行うことで両方の手法が明確に「ドメイン内」領域に入るため、この効果はむしろ最小限であると予想されます。
現代性が重要である

恥知らずな自己剽窃だが適切なミーム
最後に、この可能性がすべての事前学習された MLM エンコーダーに本質的に備わっているのか、それとも ModernBERT に固有のものなのかを知りたかった。この問いに答えるため、RoBERTa-Large などの古いモデルや、現代的なアーキテクチャを持つものの小規模で多様性に欠けるデータでトレーニングされたモデルに対して同じアプローチを適用したところ、パフォーマンスは大幅に低下しました。
モデル
MMLU
ModernBERT-Large-Instruct
43.06
GTE-en-MLM-Large
36.69
RoBERTa-Large
33.11
これは、ModernBERT-Large-Instruct と非常に類似したアーキテクチャ(効率化の調整を除く)を採用している GTE-en-MLM-Large との間には大きなパフォーマンスの差があることから、MLM エンコーダーにおける強力な生成型下流タスクのパフォーマンスは、十分に大規模で多様なデータミックスでトレーニングされていることに大きく依存していることを示唆しています。RoBERTa-Large から GTE-en-MLM-Large への相対的に小さなパフォーマンス向上は、より優れたアーキテクチャの採用が役割を果たす一方で、その効果はトレーニングデータのそれほど顕著ではないことを示唆しているようです。
今後の展望
これらの結果は有望ですが、まだ非常に初期段階です。これらが本当に示しているのは、MLM ヘッドが多目的ヘッドとしての可能性を示すことだけであり、その限界を押し広げるにはほど遠いものです。その他にも以下のような課題があります:
より良く、多様なテンプレート化の探求
トレーニングメカニズムおよびダミー例の影響に関するより詳細な分析
より優れた構成を持つ最新の指示データセットでのテスト
ファーストショット学習能力の調査
より大規模なモデルサイズへのスケーリング
…その他にも多くの課題があります!
これらすべてが、将来の研究に向けた非常に有望な方向性として私たちに映ります。実際、これらのいくつかについては、すでに優れた人々が取り組んでいるという話を聞いています…
究極的に、ここで提示した極めてシンプルなアプローチの結果は、エンコーダーモデルにとって新たな可能性を開くものだと私たちは信じています。ModernBERT-Large-Instruct モデルは HuggingFace で利用可能です。
原文を表示
Welcome to this post! As a “TIL”, it’s a purposefully smaller blog post, containing just the key details. If you’d like to know more, head over to the technical report or play with the model on HuggingFace!
TL;DR
Traditionally (with some exceptions, of course), encoder models such as BERT are used with a task-specific head on top of the core encoder model. Functionally, this means that we discard all the language modelling goodness stored in the Masked Language Modelling head (the one used during pre-training), and seek to simply re-use the backbone to perform various tasks.
This works really well: there’s a reason why it’s the dominant paradigm! However, what if the generative head itself could actually perform most tasks, even zero-shot? This is what we tried, and it works pretty well! We introduce ModernBERT-Large-Instruct, an “instruction-tuned” encoder fine-tuned on top of ModernBERT-Large with a shockingly simple mechanism. It can be used to perform classification and multiple-choice tasks using ModernBERT’s MLM head instead of task-specific heads. Unlike previous approaches, our method requires no architectural changes nor complex pieplines, and still achieves strong results across various tasks.
It’s surprisingly capable at knowledge QA tasks, where encoders are usually weak: On the MMLU-Pro leaderboard, it outperforms all sub-1B models like Qwen2.5-0.5B and SmolLM2-360M, and is quite close to Llama3-1B (trained on considerably more tokens, and with 3x the parameters)!
On NLU tasks, fine-tuning ModernBERT-Instruct matches or outperforms traditional classification heads when fine-tuned on the same dataset.
We achieve these results with a super simple training recipe, which is exciting: there’s definitely a lot of room for future improvements👀👀
I just want to try it!
The model is available on HuggingFace as ModernBERT-Large-Instruct. Since it doesn’t require any custom attention mask, or anything of the likes, the zero-shot pipeline is very simple to set up and use:
Click to see how to use ModernBERT-Large-Instruct -->
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
Load model and tokenizer
model_name = "answerdotai/ModernBERT-Large-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
model = AutoModelForMaskedLM.from_pretrained(model_name, attn_implementation="flash_attention_2")
else:
model = AutoModelForMaskedLM.from_pretrained(model_name)
model.to(device)
Format input for classification or multiple choice. This is a random example from MMLU.
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
Get prediction
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model(**inputs)
mask_idx = (inputs.input_ids == tokenizer.mask_token_id).nonzero()[0, 1]
pred_id = outputs.logits[0, mask_idx].argmax()
answer = tokenizer.decode(pred_id)
print(f"Predicted answer: {answer}") # Outputs: B
For more, you’ll want to check out our mini cookbook GitHub repository, with examples on how to fine-tune the model!
-->
Introduction
Encoder models traditionnally perform best on all tasks with a task-specific head. While not necessarily an issue, this feels like a bit of a waste: the MLM head, its original pre-training head, is fully discarded. In practice, this works, but it also feels like we might leaving something on the table. Additionnally, this places great restrictions on zero-shot capabilities: as task-specific heads are usually always required, it’s been necessary to find various tricks to get around this and still get good zero-shot performance.
A brief, incomplete history of downstream uses of MLM encoders
Zero-shot classification with encoder models has been an active area of research, with various approaches tried over the years. The most common approach has been to repurpose textual entailment: after training on tasks like MNLI, models are used to predict whether a given label is entailed by the input text. Some very powerful models have been trained on the large-scale TaskSource datasets, such as tasksource/ModernBERT-large-nli.
This is also definitely not the first piece of work exploring generative BERTs as multitasks learners: there’s been some work on prompting, sample-efficient training via the pattern-exploitng training (PET) method, or even making the models auto-regressive! Some approaches are even pretty similar to ours, like UniMC which has shown promise by converting tasks into multiple-choice format using semantically neutral verbalizers (e.g., “A”, “B” instead of meaningful words) and employing custom attention masks.
However, all of these methods come with drawbacks: some are either brittle (particularly to different verbalizers) or reach performance that is promising-but-not-quite-there, while others yet reach very good results but add considerable complexity. Meanwhile, in decoder-land (or, if you will, LLMTopia), instruction tuning has progressed extremely rapidly, and big, scary LLMs have become very good at generative classification, especially zero-shot, thanks to their instruction training.
But this, too, has drawbacks: small LLMs are routinely outperformed by encoders, which can even match the larger ones once fine-tuned! Additionnally, the computational cost of running an autoregressive LLM, even one on the smaller side, is generally considerably bigger than that of an encoder, who performs tasks in a single forward pass.
ModernBERT-Large-Instruct
Our approach aims to show that maybe, just maybe, we can have our cake and eat it too: what if an MLM could tackle tasks (even zero-shot ones!) in a generative way with a single forward pass, could be easily fine-tuned further to perform better in-domain, without adding any pipeline or architectural complexity?
This is what we demonstrate the potential of here! We use a very simple training recipe, with FLAN-style instruction tuning with ModernBERT’s MLM head. We do not custom attention masks, no complex prompt engineering, and no heavy-handed data pre-processing pipeline: we simply filter FLAN to only tasks that can be answered using a single token, and filter out some examples from datasets that we used for downstream evaluations.
How It Works
A high-level overview of the full process
Our key insight is two-fold: ModernBERT can use a single-head to perform most NLU tasks, either zero-shot or fully-finetuned, and this behaviour can be unlocked with an extremely simple training recipe, suggesting a very strong potential.
The way it works is very simple:
All tasks are formatted in a way where the model can answer with a single token, which is also the final token of the input. This is always prefaced with an anchor token ([unused0]), to tell the model that the next token needs to be the single token answer.
The model is given a question, short instructions, and a list of potential choices. All choices are prefaced with a single-token verbalizer: this is the token that the model will predict if it assigns this label.
The model then predicts the most likely token for the answer, and the potential verbalizer with the highest score is selected as the answer.
This approach has several advantages: - No architectural changes needed, for training or inference. - It can be tried on any model that supports Masked Language Modeling out of the box. - Very little data pre-processing is needed to begin experimenting. - Likewise, it reduces prompt engineering greatly: only a very short template and a description of all labels needs to be written to perform a task.
Training Details
As above, the training recipe is kept voluntarily simple. This is largely meant to avoid scope screep: there are a lot of potential improvements to be explored by using better processing pipelines, or more modern instruction sets, but these would all require complex processes to turn them into single-token tasks.
Data: A downsampled (20M samples), filtered FLAN-2022 dataset to keep only single-token answers. A very simple filtering process: tokenize the potential answer and exclude all examples where the answer contains more than one token. Examples from our evaluation datasets were also filtered out to avoid overfitting.
Objective: We use the Answer Token Prediction (ATP) objective, which is to predict the single masked token which should be the verbalizer containing the answer. The final training objective is a mix of 80% ATP and 20% dummy MLM examples, where masked tokens are given a meaningless label (see below).
Base Model: ModernBERT-Large (395M parameters), which we recently introduced with our friends at LightOn & other places. It proved to be a much more capable base model than alternatives.
Dummy Examples
When training the model, we theorized that Answer Token Prediction could lead to catastrophic forgetting, with the model only learning to predict certain tokens and losing overall reasoning capabilities. To counter this, we introduced a training objective mix, where 20% of the examples were assigned the normal MLM objective (where 30% of tokens in the text are randomly masked, and the model has to predict all of them at once), with the remaining 80% adopting the Answer Token Prediction objective.
Except, we implemented this wrong, and effectively made these samples empty examples, which we dub “dummy MLM examples”. The issue was in the labelling: rather than the [MASK] tokens being assigned the appropriate label, they were all given [MASK] as their label. This meant that very quickly, the model learned to simply predict [MASK] for all of them if there’s more than one [MASK] token in the text, and the loss on these examples swiftly dropped to near-zero.
Hm, simple mistake, easy to fix, right? Right. Except, we observed something that we didn’t expect: we evaluated three pre-training setups (100% ATP, 80%ATP/20%MLM, 80%ATP/20%dummy), and we found that the dummy example variant was the best performing one, by a good margin! While we haven’t explored this phenomenon in enough depth to explain what is going on, my personal theory is that it acts as a form of regularization, similar to dropout.
Performance
Zero-Shot Results
The zero-shot results are pretty encouraging and, in a way, pretty surprising!
Competing with the best (MMLU-Pro leaderboard for sub-2B models)
Knowledge-Based Multiple Choice Questions (MMLU and MMLU-Pro): ModernBERT-Large-Instruct stands at 43.06% accuracy on MMLU, beating similarly sized models like SmoLLM2-360M (35.8%) and getting close to Llama3-1B (45.83%). On MMLU-Pro, its performance would give it a very good spot on the leaderboard, punching far above its weight class and competing with bigger LLMs!
Classification: On average, it beats all the previous zero-shot methods. However, this is not true on a per-dataset basis: while this method has strong potential and gets very good overall results, there are some datasets where it underperforms, and others where it overperforms. This indicates strong potential for future developments of the method.
Fine-Tuned Results
The MLM Head is All You Need
Across a variety of tasks, focusing on topic classification, textual entailment (MNLI) and sentiment analysis, fine-tuning ModernBERT-Large-Instruct on each task appears to match the performance of traditional classification head-based approach. On certain datasets, it even outperforms them! In fact, I think that this method holds the key to finally closing the last gap and making ModernBERT a better classifier than DeBERTaV3.
A caveat here is that the training set of some of these tasks is present, in relatively small proportions, in our pre-training mix: however, we expect this effect to be rather minimal, as fine-tuning performed for multiple epochs bring both methods firmly into the “in-domain” territory.
Modernity Matters
A shamelessly self-plagiarized but appropriate meme
Finally, we wanted to know whether this potential is inherent to all pre-trained MLM encoders, or whether it’s specific to ModernBERT. To answer this question, we applied the same approach to older models like RoBERTa-Large or models with a modern architecture but trained on smaller-scale, less diverse data, and the performance dropped significantly:
Model
MMLU
ModernBERT-Large-Instruct
43.06
GTE-en-MLM-Large
36.69
RoBERTa-Large
33.11
This suggests that strong generative downstream performance in MLM encoders relies largely on being trained on a sufficiently large-scale, diverse data mix, given the vast performance gap between ModernBERT-Large-Instruct and GTE-en-MLM-Large, which adopts a very similar architecture to that of ModernBERT-Large (minus efficiency tweaks). The relatively smaller performance gain from RoBERTa-Large to GTE-en-MLM-Large seems to suggest that while adopting a better architecutre does play a role, it is much more modest than that of the training data.
Looking Forward
While these results are promising, they are very early stage! All they really do is demonstrate the potential of the MLM head as a multi-task head, but they are far from pushing it to its limits. Among other things:
Exploring better, more diverse templating
A more in-depth analysis of the training mechanisms, and the effect of dummy examples
Testing on more recent instruction datasets, with better construction
Investigating few-shot learning capabilities
Scaling to larger model sizes
… so many more things!
All strike us as very promising directions for future work! In fact, we’ve heard that some very good people are working on some of these things already…
Ultimately, we believe that the results of our exceedingly simple approach presented here open up new possibilities for encoder models. The ModernBERT-Large-Instruct model is available on HuggingFace.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み