LLM研究論文:2025年リスト(1月〜6月)
Sebastian Raschka が、2025 年上半期の LLM 研究論文 200 件以上を推論モデルやマルチモーダルなどトピック別に整理し、学習者向けの包括的なリストと無料教材を提供した。
キーポイント
トピック別分類の導入
読者の要望に応え、日付順ではなく「推論モデル」「効率的トレーニング」「マルチモーダル」などのカテゴリ別に論文を整理した。
推論能力への注力
2025 年の研究動向が推論モデルに集中しており、特に検証可能な報酬を用いた強化学習(RL)によるトレーニング戦略が主流となっている。
定期的な更新形式への変更
研究のスピードに対応するため、年次リストから半年ごとのバイアニュアル更新形式へと変更し、情報の鮮度と可読性を確保した。
強化学習による推論能力の飛躍的向上
DeepSeek-R1、Kimi k1.5、R1-Searcherなどの研究により、ルールベースやプロセス報酬モデルを用いた強化学習(RL)がLLMの数学・ソフトウェア開発・検索能力を劇的に強化することが示されています。
思考プロセスの効率化と構造化
「Less is More for Reasoning (LIMO)」や「System 2 Reasoning」の研究は、推論におけるメタ思考(Meta Chain-of-Thought)や短いトークンでの効果的な学習、そして構造重視のデモンストレーションが重要であることを示唆しています。
特定ドメインへの適応と汎用化
金融(Fino1)、マルチモーダル(LMM-R1)、競プロなど特定の領域での推論能力の転移可能性や、失敗からの学習(Learning from Failures)を通じて、LLMの専門性と堅牢性が向上しています。
検索機能と強化学習の統合
Search-R1 や ReSearch などの研究は、LLM が推論プロセス中に検索エンジンを活用し、外部知識を動的に取得する能力を強化学習によって強化することを示しています。
影響分析・編集コメントを表示
影響分析
この記事は、急激に進化する LLM 研究領域において、研究者やエンジニアが特定のトピック(特に推論能力)を効率的に追跡するための重要な羅針盤となる。また、半年ごとの更新サイクルへの移行により、情報の鮮度を保ちつつ、学習リソースとしての実用性を高めている。
編集コメント
研究論文の洪水の中で、特定の技術トレンドを整理したこのリストは、夏場の学習や面接準備に非常に役立つ一冊です。特に推論能力に関する RL の動向は今後の LLM 進化の鍵となるため注目すべきトピックです。
LLM研究論文:2025年リスト(1月~6月)
2025年発表のLLM研究論文200本以上をトピック別に整理したコレクション
 Sebastian Raschka, PhD2025年7月1日∙ 有料10059シェアご存知の方もいるかもしれませんが、私は(読みたい)研究論文や参照したい論文のリストを随時更新してまとめています。
Sebastian Raschka, PhD2025年7月1日∙ 有料10059シェアご存知の方もいるかもしれませんが、私は(読みたい)研究論文や参照したい論文のリストを随時更新してまとめています。
約半年前に2024年のリストを共有したところ、多くの読者の方に役立ったようです。そこで、今回も同様のことをしようと考えていました。ただし今回は、頻繁に寄せられた一つのフィードバックを取り入れることにしました:「日付順ではなく、トピック別に論文を整理してもらえませんか?」
私が考えたカテゴリーは以下の通りです:
推論モデル
- 1a. 推論モデルの学習
- 1b. 推論時(Inference-Time)の推論戦略
- 1c. LLMの評価および/または推論の理解
LLMのためのその他の強化学習手法
その他の推論時スケーリング手法
効率的な学習とアーキテクチャ
拡散ベースの言語モデル
マルチモーダル&視覚言語モデル
データと事前学習データセット
また、LLM研究が急速に共有され続けていることを受け、このリストを半年ごとの更新に分割することに決めました。こうすることで、リストは消化しやすく、タイムリーなものとなり、質の高い夏の読書材料を探しているすべての方にとって、役立つものになることを願っています。
なお、これは現時点では厳選されたリストに過ぎません。今後の記事では、より興味深い、あるいは影響力のある論文について、大規模なトピック別の記事で再訪し、議論することを計画しています。ご期待ください!
夏です!それはインターンシップの季節、技術面接、そしてたくさんの学びを意味します。中級から上級の機械学習およびAIトピックを復習する方を支援するため、私は自分の著書『Machine Learning Q and AI』の全30章を、この夏の間無料で公開しています:🔗 https://sebastianraschka.com/books/ml-q-and-ai/#table-of-contents 単に好奇心で何か新しいことを学びたい方でも、面接の準備をしている方でも、これがお役に立てば幸いです。楽しい読書を。面接を受ける方は、幸運を祈ります!
- 推論モデル
今年の私のリストは、推論モデルに非常に重点を置いています。そこで、これを3つのサブカテゴリーに細分化することにしました:学習、推論時スケーリング、そしてより一般的な理解/評価です。
1a. 推論モデルの学習
このサブセクションは、LLMの推論能力を向上させるために特別に設計された学習戦略に焦点を当てています。ご覧になる通り、最近の進歩の多くは(検証可能な報酬を用いた)強化学習を中心としており、これについては以前の記事でより詳細に取り上げました。
 LLM推論のための強化学習の現状
LLM推論のための強化学習の現状
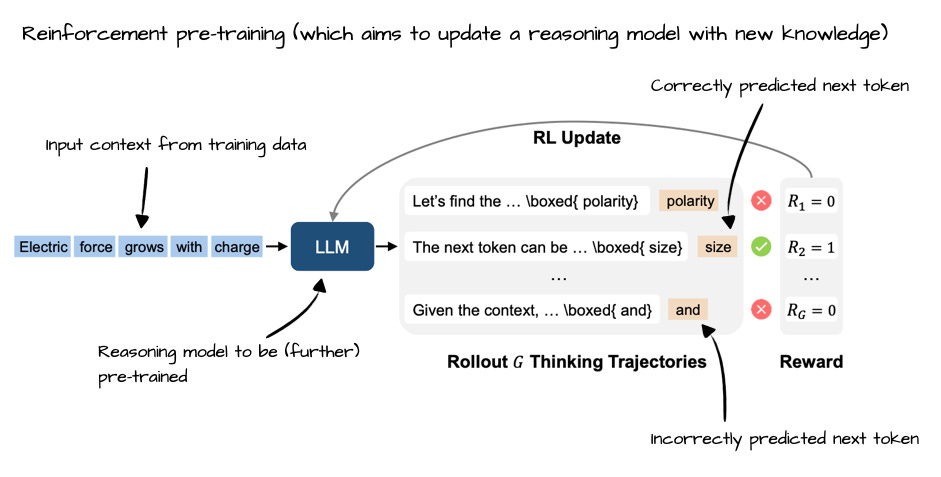 Reinforcement Pre-Training(https://arxiv.org/abs/2506.08007)からの注釈付き図
Reinforcement Pre-Training(https://arxiv.org/abs/2506.08007)からの注釈付き図
1月8日, Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought, https://arxiv.org/abs/2501.04682
1月13日, The Lessons of Developing Process Reward Models in Mathematical Reasoning, https://arxiv.org/abs/2501.07301
1月16日, Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, https://arxiv.org/abs/2501.09686
1月20日, Reasoning Language Models: A Blueprint, https://arxiv.org/abs/2501.11223
1月22日, Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs//2501.12599
1月22日, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2501.12948
2月3日, Competitive Programming with Large Reasoning Models, https://arxiv.org/abs/2502.06807
2月5日, Demystifying Long Chain-of-Thought Reasoning in LLMs, Demystifying Long Chain-of-Thought Reasoning in LLMs, https://arxiv.org/abs/2502.03373
2月5日, LIMO: Less is More for Reasoning, https://arxiv.org/abs/2502.03387
2月5日, Teaching Language Models to Critique via Reinforcement Learning, https://arxiv.org/abs/2502.03492
2月6日, Training Language Models to Reason Efficiently, https://arxiv.org/abs/2502.04463
2月10日, Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, https://arxiv.org/abs/2502.06781
2月10日, On the Emergence of Thinking in LLMs I: Searching for the Right Intuition, https://arxiv.org/abs/2502.06773
2月11日, LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!, https://arxiv.org/abs/2502.07374
2月12日, Fino1: On the Transferability of Reasoning Enhanced LLMs to Finance, https://arxiv.org/abs/2502.08127
2月13日, Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging - An Open Recipe, https://arxiv.org/abs/2502.09056
2月20日, Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, https://arxiv.org/abs/2502.14768
2月25日, SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution, https://arxiv.org/abs/2502.18449
3月4日, Learning from Failures in Multi-Attempt Reinforcement Learning, https://arxiv.org/abs/2503.04808
3月4日, The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, https://arxiv.org/abs/2503.02875
3月10日, R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.05592
3月10日, LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL, https://arxiv.org/abs/2503.07536
3月12日, Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, https://arxiv.org/abs/2503.09516
3月16日, Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models, https://arxiv.org/abs/2503.13551
3月20日, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://arxiv.org/abs/2503.16219
3月25日, ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.19470
3月26日, Understanding R1-Zero-Like Training: A Critical Perspective, https://arxiv.org/abs/2503.20783
3月30日, RARE: Retrieval-Augmented Reasoning Modeling, https://arxiv.org/abs/2503.23513
3月31日, Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, https://arxiv.org/abs/2503.24290
3月31日, JudgeLRM: Large Reasoning Models as a Judge, https://arxiv.org/abs/2504.00050
4月7日, Concise Reasoning via Reinforcement Learning, https://arxiv.org/abs/2504.05185
4月10日, VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning, https://arxiv.org/abs/2504.08837
4月11日, Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning, https://arxiv.org/abs/2504.08672
4月13日, Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability, https://arxiv.org/abs/2504.09639
4月21日, Learning to Reason under Off-Policy Guidance, https://arxiv.org/abs/2504.14945
4月22日, Tina: Tiny Reasoning Models via LoRA, https://arxiv.org/abs/2504.15777
4月29日, Reinforcement Learning for Reasoning in Large Language Models with One Training Example, https://arxiv.org/abs/2504.20571
4月30日, Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math, https://arxiv.org/abs/2504.21233
5月2日, Llama-Nemotron: Efficient Reasoning Models, https://arxiv.org/abs/2505.00949
5月5日, RM-R1: Reward Modeling as Reasoning, https://arxiv.org/abs/2505.02387
5月6日, Absolute Zero: Reinforced Self-play Reasoning with Zero Data, https://arxiv.org/abs/2505.03335
5月12日, INTELLECT-2: A Rea
原文を表示
LLM Research Papers: The 2025 List (January to June)
A topic-organized collection of 200+ LLM research papers from 2025
Sebastian Raschka, PhDJul 01, 2025∙ Paid10059ShareAs some of you know, I keep a running list of research papers I (want to) read and reference.
About six months ago, I shared my 2024 list, which many readers found useful. So, I was thinking about doing this again. However, this time, I am incorporating that one piece of feedback kept coming up: "Can you organize the papers by topic instead of date?"
The categories I came up with are:
Reasoning Models
- 1a. Training Reasoning Models
- 1b. Inference-Time Reasoning Strategies
- 1c. Evaluating LLMs and/or Understanding Reasoning
Other Reinforcement Learning Methods for LLMs
Other Inference-Time Scaling Methods
Efficient Training & Architectures
Diffusion-Based Language Models
Multimodal & Vision-Language Models
Data & Pre-training Datasets
Also, as LLM research continues to be shared at a rapid pace, I have decided to break the list into bi-yearly updates. This way, the list stays digestible, timely, and hopefully useful for anyone looking for solid summer reading material.
Please note that this is just a curated list for now. In future articles, I plan to revisit and discuss some of the more interesting or impactful papers in larger topic-specific write-ups. Stay tuned!
It's summer! And that means internship season, tech interviews, and lots of learning. To support those brushing up on intermediate to advanced machine learning and AI topics, I have made all 30 chapters of my Machine Learning Q and AI book freely available for the summer: 🔗 https://sebastianraschka.com/books/ml-q-and-ai/#table-of-contents Whether you are just curious and want to learn something new or prepping for interviews, hopefully this comes in handy. Happy reading, and best of luck if you are interviewing!
- Reasoning Models
This year, my list is very reasoning model-heavy. So, I decided to subdivide it into 3 categories: Training, inference-time scaling, and more general understanding/evaluation.
1a. Training Reasoning Models
This subsection focuses on training strategies specifically designed to improve reasoning abilities in LLMs. As you may see, much of the recent progress has centered around reinforcement learning (with verifiable rewards), which I covered in more detail in a previous article.
The State of Reinforcement Learning for LLM Reasoning
Annotated figure from Reinforcement Pre-Training, https://arxiv.org/abs/2506.08007
8 Jan, Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought, https://arxiv.org/abs/2501.04682
13 Jan, The Lessons of Developing Process Reward Models in Mathematical Reasoning, https://arxiv.org/abs/2501.07301
16 Jan, Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, https://arxiv.org/abs/2501.09686
20 Jan, Reasoning Language Models: A Blueprint, https://arxiv.org/abs/2501.11223
22 Jan, Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs//2501.12599
22 Jan, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2501.12948
3 Feb, Competitive Programming with Large Reasoning Models, https://arxiv.org/abs/2502.06807
5 Feb, Demystifying Long Chain-of-Thought Reasoning in LLMs, Demystifying Long Chain-of-Thought Reasoning in LLMs, https://arxiv.org/abs/2502.03373
5 Feb, LIMO: Less is More for Reasoning, https://arxiv.org/abs/2502.03387
5 Feb, Teaching Language Models to Critique via Reinforcement Learning, https://arxiv.org/abs/2502.03492
6 Feb, Training Language Models to Reason Efficiently, https://arxiv.org/abs/2502.04463
10 Feb, Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, https://arxiv.org/abs/2502.06781
10 Feb, On the Emergence of Thinking in LLMs I: Searching for the Right Intuition, https://arxiv.org/abs/2502.06773
11 Feb, LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!, https://arxiv.org/abs/2502.07374
12 Feb, Fino1: On the Transferability of Reasoning Enhanced LLMs to Finance, https://arxiv.org/abs/2502.08127
13 Feb, Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging - An Open Recipe, https://arxiv.org/abs/2502.09056
20 Feb, Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, https://arxiv.org/abs/2502.14768
25 Feb, SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution, https://arxiv.org/abs/2502.18449
4 Mar, Learning from Failures in Multi-Attempt Reinforcement Learning, https://arxiv.org/abs/2503.04808
4 Mar, The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, https://arxiv.org/abs/2503.02875
10 Mar, R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.05592
10 Mar, LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL, https://arxiv.org/abs/2503.07536
12 Mar, Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, https://arxiv.org/abs/2503.09516
16 Mar, Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models, https://arxiv.org/abs/2503.13551
20 Mar, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://arxiv.org/abs/2503.16219
25 Mar, ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.19470
26 Mar, Understanding R1-Zero-Like Training: A Critical Perspective, https://arxiv.org/abs/2503.20783
30 Mar, RARE: Retrieval-Augmented Reasoning Modeling, https://arxiv.org/abs/2503.23513
31 Mar, Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, https://arxiv.org/abs/2503.24290
31 Mar, JudgeLRM: Large Reasoning Models as a Judge, https://arxiv.org/abs/2504.00050
7 Apr, Concise Reasoning via Reinforcement Learning, https://arxiv.org/abs/2504.05185
10 Apr, VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning, https://arxiv.org/abs/2504.08837
11 Apr, Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning, https://arxiv.org/abs/2504.08672
13 Apr, Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability, https://arxiv.org/abs/2504.09639
21 Apr, Learning to Reason under Off-Policy Guidance, https://arxiv.org/abs/2504.14945
22 Apr, Tina: Tiny Reasoning Models via LoRA, https://arxiv.org/abs/2504.15777
29 Apr, Reinforcement Learning for Reasoning in Large Language Models with One Training Example, https://arxiv.org/abs/2504.20571
30 Apr, Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math, https://arxiv.org/abs/2504.21233
2 May, Llama-Nemotron: Efficient Reasoning Models, https://arxiv.org/abs/2505.00949
5 May, RM-R1: Reward Modeling as Reasoning, https://arxiv.org/abs/2505.02387
6 May, Absolute Zero: Reinforced Self-play Reasoning with Zero Data, https://arxiv.org/abs/2505.03335
12 May, INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning, https://arxiv.org/abs/2505.07291
12 May, MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining, https://arxiv.org/abs/2505.07608
14 May, Qwen3 Technical Report, https://arxiv.org/abs/2505.09388
15 May, Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models, https://arxiv.org/abs/2505.10554
19 May, AdaptThink: Reasoning Models Can Learn When to Think, https://arxiv.org/abs/2505.13417
19 May, Thinkless: LLM Learns When to Think, https://arxiv.org/abs/2505.13379
20 May, General-Reasoner: Advancing LLM Reasoning Across All Domains, https://arxiv.org/abs/2505.14652
21 May, Learning to Reason via Mixture-of-Thought for Logical Reasoning, https://arxiv.org/abs/2505.15817
21 May, RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning, https://arxiv.org/abs/2505.15034
23 May, QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning, https://www.arxiv.org/abs/2505.17667
26 May, Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles, https://arxiv.org/abs/2505.19914
26 May, Learning to Reason without External Rewards, https://arxiv.org/abs/2505.19590
29 May, Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, https://arxiv.org/abs/2505.22954
30 May, Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning, https://arxiv.org/abs/2505.24726
30 May, ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, https://arxiv.org/abs/2505.24864
2 Jun, Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning, https://arxiv.org/abs/2506.01939
3 Jun, Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening, https://www.arxiv.org/abs/2506.02355
9 Jun, Reinforcement Pre-Training, https://arxiv.org/abs/2506.08007
10 Jun, RuleReasoner: Reinforced Rule-based Reasoning via Domain-aware Dynamic Sampling, https://arxiv.org/abs/2506.08672
10 Jun, Reinforcement Learning Teachers of Test Time Scaling, https://www.arxiv.org/abs/2506.08388
12 Jun, Magistral, https://arxiv.org/abs/2506.10910
12 Jun, Spurious Rewards: Rethinking Training Signals in RLVR, https://arxiv.org/abs/2506.10947
16 Jun, AlphaEvolve: A coding agent for scientific and algorithmic discovery, https://arxiv.org/abs/2506.13131
17 Jun, Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs, https://arxiv.org/abs/2506.14245
23 Jun, Programming by Backprop: LLMs Acquire Reusable Algorithmic Abstractions During Code Training, https://arxiv.org/abs/2506.18777
26 Jun, Bridging Offline and Online Reinforcement Learning for LLMs, https://arxiv.org/abs/2506.21495
1b. Inference-Time Reasoning Strategies
This part of the list covers methods that improve reasoning dynamically at test time, without requiring retraining. Often, these papers are focused on trading of computational performance for modeling performance.
This post is for paid subscribers
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み